【Hadoop入门】Hadoop生态之Flume简介
1 什么是Flume?
Flume是Hadoop生态系统中的一个高可靠、高性能的日志收集、聚合和传输系统。它支持在系统中定制各类数据发送方(Source)、接收方(Sink)和数据收集器(Channel),从而能够高效地处理不同来源和格式的数据流。Flume的设计目标是将数据从多个数据源收集并传输到集中的数据存储系统中,如HDFS、HBase或Kafka等,以便进行后续的分析和处理。
2 Flume的核心特点
- 分布式架构:能够水平扩展以处理大规模数据流
- 高可靠性:确保数据在传输过程中不丢失
- 高容错性:自动处理节点故障,保证系统持续运行
- 灵活可扩展:支持自定义数据源、数据处理和目标存储
- 简单易用:通过配置文件即可实现复杂的数据流管道
3 Flume的核心概念
3.1 基本组件
Source(数据源):
- 负责接收或收集数据
- Flume支持多种数据源类型,如Avro Source(接收Avro格式的数据)、Exec Source(执行命令并收集输出)、Spooling Directory Source(监控目录并收集新文件)等
Channel(数据通道):
- 作为数据的缓冲区,连接Source和Sink
- 支持多种Channel类型,如Memory Channel(内存通道,速度快但数据可能丢失)、File Channel(文件通道,数据持久化但速度较慢)等
Sink(数据接收方):
- 负责将Channel中的数据发送到目的地
- Flume支持多种Sink类型,如HDFS Sink(将数据写入HDFS)、Logger Sink(将数据输出到日志)、Kafka Sink(将数据发送到Kafka集群)等
3.2 工作流程
- 数据收集:Source从数据源收集数据,并将其发送到Channel中
- 数据缓存:Channel作为缓冲区,暂时存储数据,直到Sink准备好接收
- 数据传输:Sink从Channel中读取数据,并将其发送到目的地
4 Flume的典型应用场景
- 日志收集与聚合:从多台服务器收集日志到中央存储
- 实时数据管道:构建实时数据传输通道
- 事件数据采集:收集用户行为等事件数据
- 数据预处理:在数据传输过程中进行简单的数据清洗和转换
5 Flume的优势
- 多种数据源支持:可以接收来自文件、syslog、HTTP等多种来源的数据
- 灵活的目标存储:支持写入HDFS、HBase、Kafka等多种存储系统
- 可靠的传输机制:通过事务机制保证数据不丢失
- 水平扩展能力:可以通过增加节点来提高吞吐量
- 丰富的插件生态:社区提供了大量现成的组件
6 Flume的简单示例
# 以下是一个基本的Flume配置示例:
# 定义Agent组件名称
agent.sources = spool-source
agent.channels = file-channel
agent.sinks = hdfs-sink# 配置Spooling Directory Source
agent.sources.spool-source.type = spooldir
agent.sources.spool-source.spoolDir = /data/logs/flume_spool # 监控的本地目录
agent.sources.spool-source.fileHeader = true
agent.sources.spool-source.deserializer.maxLineLength = 51200 # 单行最大长度(字节)# 配置File Channel(持久化通道)
agent.channels.file-channel.type = file
agent.channels.file-channel.checkpointDir = /data/flume/checkpoint # 检查点目录
agent.channels.file-channel.dataDirs = /data/flume/data # 数据存储目录
agent.channels.file-channel.capacity = 1000000 # 通道最大事件数
agent.channels.file-channel.transactionCapacity = 1000 # 事务处理量# 配置HDFS Sink
agent.sinks.hdfs-sink.type = hdfs
agent.sinks.hdfs-sink.hdfs.path = hdfs://namenode:8020/flume/events/%Y-%m-%d/%H # HDFS存储路径
agent.sinks.hdfs-sink.hdfs.filePrefix = logs- # 文件前缀
agent.sinks.hdfs-sink.hdfs.fileSuffix = .log # 文件后缀
agent.sinks.hdfs-sink.hdfs.rollInterval = 3600 # 文件滚动间隔(秒)
agent.sinks.hdfs-sink.hdfs.rollSize = 128MB # 文件滚动大小
agent.sinks.hdfs-sink.hdfs.rollCount = 0 # 基于事件数的滚动(0表示禁用)
agent.sinks.hdfs-sink.hdfs.fileType = DataStream # 文件存储格式
agent.sinks.hdfs-sink.hdfs.writeFormat = Text # 写入格式# 组件连接关系
agent.sources.spool-source.channels = file-channel
agent.sinks.hdfs-sink.channel = file-channel7 Flume的进阶功能
- 多级流动:可以构建多级Flume代理,实现数据的层次化收集
- 负载均衡:支持在多个sink之间进行负载均衡
- 故障转移:当主sink不可用时自动切换到备用sink
- 拦截器链:可以串联多个拦截器实现复杂的数据处理逻辑
8 总结
Flume作为大数据生态系统中的重要组件,为海量数据收集提供了可靠的解决方案。其分布式、高可靠的特性使其特别适合企业级的大规模日志收集场景。通过灵活的配置和扩展能力,Flume可以适应各种复杂的数据采集需求,是大数据管道中不可或缺的一环。随着大数据技术的不断发展,Flume也在持续进化,与Kafka、Spark等新一代大数据技术的集成越来越紧密,在未来仍将发挥重要作用。
相关文章:

【Hadoop入门】Hadoop生态之Flume简介
1 什么是Flume? Flume是Hadoop生态系统中的一个高可靠、高性能的日志收集、聚合和传输系统。它支持在系统中定制各类数据发送方(Source)、接收方(Sink)和数据收集器(Channel),从而能…...
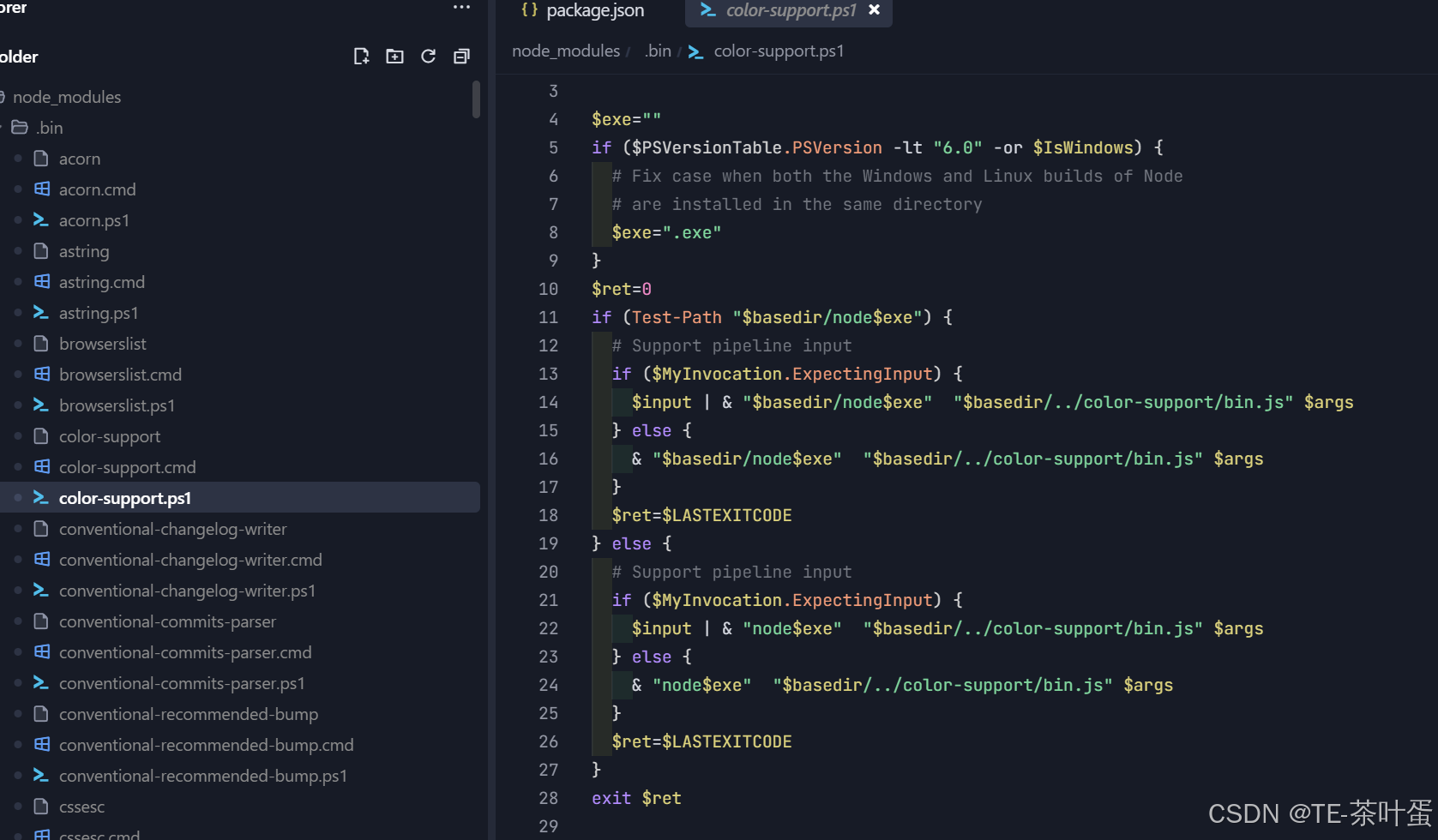
npx 的作用以及延伸知识(.bin目录,npm run xx 执行)
文章目录 前言原理解析1. npx 的作用2. 为什么会有 node_modules/.bin/lerna3. npx 的查找顺序4. 执行流程总结1: 1. .bin 机制什么是 node_modules/.bin?例子 2. npx 的底层实现npx 是如何工作的?为什么推荐用 npx?npx 的特殊能力…...

本地部署DeepSeek-R1(Dify升级最新版本、新增插件功能、过滤推理思考过程)
下载最新版本Dify Dify1.0版本之前不支持插件功能,先升级DIfy 下载最新版本,目前1.0.1 Git地址:https://github.com/langgenius/dify/releases/tag/1.0.1 我这里下载到老版本同一个目录并解压 拷贝老数据 需先停用老版本Dify PS D:\D…...
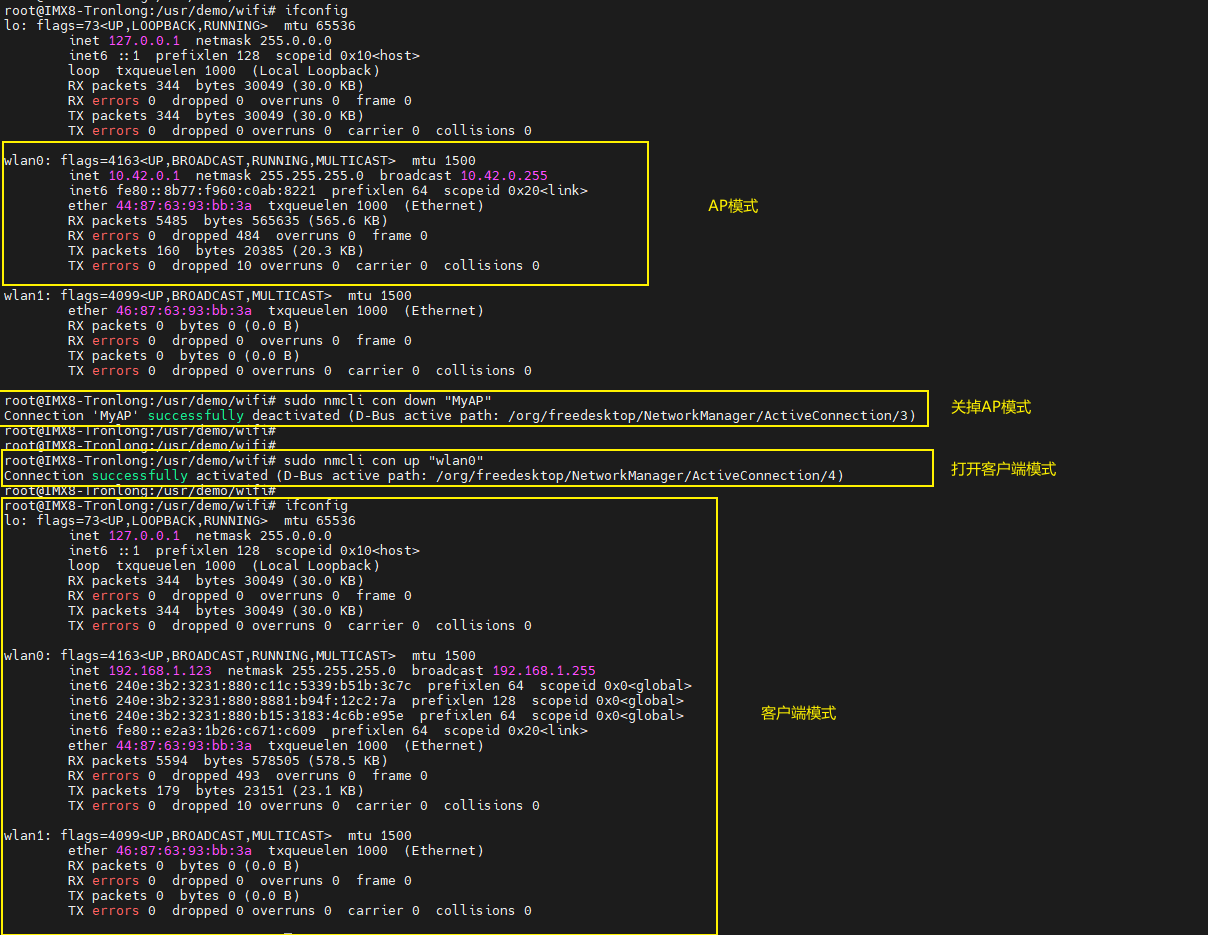
【ubuntu】在Linux Yocto的基础上去适配Ubuntu的wifi模块
一、修改wifi的节点名 1.找到wifi模块的PID和VID ifconfig查看wifi模块网络节点的名字,发现是wlx44876393bb3a(wlxmac地址) 通过udevadm info -a /sys/class/net/wlx44876393bba路径的命令去查看wlx44876393bba的总线号,端口号…...

25软考新版系统分析师怎么备考?重点考哪些?(附新版备考资源)
软考系统分析师(高级资格)考试涉及知识面广、难度较大,需要系统化的复习策略。以下是结合考试大纲和历年真题整理的复习重点及方法: 一、明确考试结构与分值分布 1.综合知识(选择题,75分) 2…...
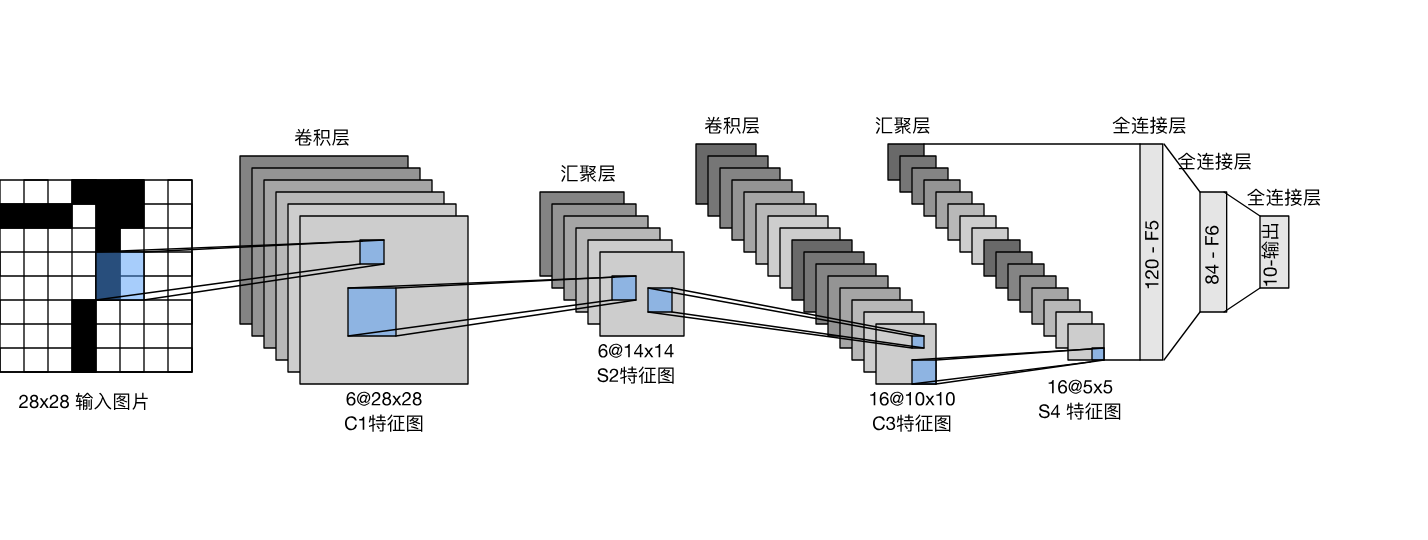
PyTorch入门------卷积神经网络
前言 参考:神经网络 — PyTorch Tutorials 2.6.0cu124 文档 - PyTorch 深度学习库 一个典型的神经网络训练过程如下: 定义一个包含可学习参数(或权重)的神经网络 遍历输入数据集 将输入通过神经网络处理 计算损失(即…...

Edge浏览器安卓版流畅度与广告拦截功能评测【不卡还净】
安卓设备上使用浏览器的体验,很大程度取决于两个方面。一个是滑动和页面切换时的反应速度,另一个是广告干扰的多少。Edge浏览器的安卓版本在这两方面的表现比较稳定,适合日常使用和内容浏览。 先看流畅度。Edge在中端和高端机型上启动速度快&…...

Docker 和 Docker Compose 使用指南
Docker 和 Docker Compose 使用指南 一、Docker 核心概念 镜像(Image) :应用的静态模板(如 nginx:latest)。容器(Container) :镜像的运行实例。仓库(Registry…...

【设计模式】观察者
观察者模式 1 简介 观察者模式是观察者对象们通过注册到被观察者对象中,从而使被观察者发生变化时能通知到观察者,避免硬编码,使用写死的代码逻辑调用通知,从而实现解耦效果。 2 基本代码逻辑 观察者 class IObserver { publ…...
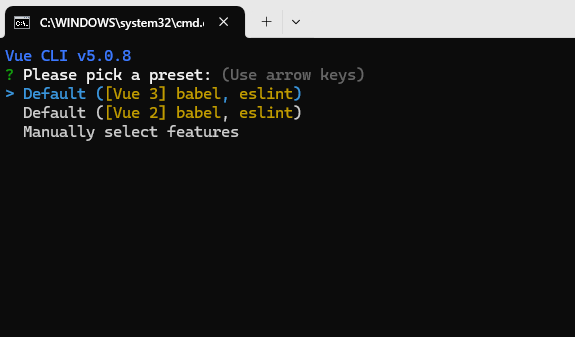
vue3环境搭建、nodejs22.x安装、yarn 1全局安装、npm切换yarn 1、yarn 1 切换npm
vue3环境搭建 node.js 安装 验证nodejs是否安装成功 # 检测node.js 是否安装成功----cmd命令提示符中执行 node -v npm -v 设置全局安装包保存路径、全局装包缓存路径 在node.js 安装路径下 创建 node_global 和 node_cache # 设置npm全局安装包保存路径(新版本…...
安卓开发一个完整的登录页面-支持密码登录和手机验证码登录)
(二十五)安卓开发一个完整的登录页面-支持密码登录和手机验证码登录
下面将详细讲解如何在 Android 中开发一个完整的登录页面,支持密码登录和手机验证码登录。以下是实现过程的详细步骤,从布局设计到逻辑实现,再到用户体验优化,逐步展开。 1. 设计登录页面布局 首先,我们需要设计一个用…...

【java 13天进阶Day05】数据结构,List,Set ,TreeSet集合,Collections工具类
常见的数据结构种类 集合是基于数据结构做出来的,不同的集合底层会采用不同的数据结构。不同的数据结构,功能和作用是不一样的。数据结构: 数据结构指的是数据以什么方式组织在一起。不同的数据结构,增删查的性能是不一样的。不同…...
)
水污染治理(生物膜+机器学习)
文章目录 **1. 水质监测与污染预测****2. 植物-微生物群落优化****3. 系统设计与运行调控****4. 维护与风险预警****5. 社区参与与政策模拟****挑战与解决思路****未来趋势** 前言: 将机器学习(ML)等人工智能技术融入植树生物膜系统ÿ…...
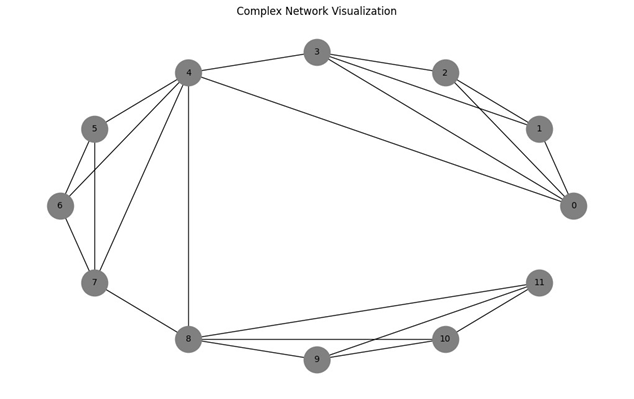
Python人工智能 使用可视图方法转换时间序列为复杂网络
基于可视图方法的时间序列复杂网络转换实践 引言 在人工智能与数据科学领域,时间序列分析是一项基础且重要的技术。本文将介绍一种创新的时间序列分析方法——可视图方法,该方法能将时间序列转换为复杂网络,从而利用复杂网络理论进行更深入…...
spring:加载配置类
在前面的学习中,通过读取xml文件将类加载,或他通过xml扫描包,将包中的类加载。无论如何都需要通过读取xml才能够进行后续操作。 在此创建配置类。通过对配置类的读取替代xml的功能。 配置类就是Java类,有以下内容需要执行&#…...

使用Pydantic优雅处理几何数据结构 - 前端输入验证实践
使用Pydantic优雅处理几何数据结构 - 前端输入验证实践 一、应用场景解析 在视频分析类项目中,前端常需要传递几何坐标数据。例如智能安防系统中,需要接收: 视频流地址(rtsp_video)检测区域坐标点(point…...

从零搭建一套前端开发环境
一、基础环境搭建 1.NVM(Node Version Manager)安装 简介 nvm(Node Version Manager) 是一个用于管理多个 Node.js 版本的工具,允许开发者在同一台机器上轻松安装、切换和使用不同版本的 Node.js。它特别适合需要同时维护多个项目ÿ…...

金融数据库转型实战读后感
荣幸收到老友太保科技有限公司数智研究院首席专家林春的签名赠书。 这是国内第一本关于OceanBase数据库实际替换过程总结的的实战书。打个比方可以说是从战场上下来分享战斗经验。读后感受颇深。我在这里讲讲我的感受。 第三章中提到的应用改造如何降本。应用改造是国产化替换…...

代码审计系列2:小众cms oldcms
目录 sql注入 1. admin/admin.php Login_check 2. admin/application/label/index.php 3. admin/application/hr/index.php 4. admin/application/feedback/index.php 5. admin/application/article/index.php sql注入 1. admin/admin.php Login_check 先看一下p…...

Cursor + MCP,实现自然语言操作 GitLab 仓库
本分分享如何使用 cursor mcp 来操作极狐GitLab 仓库,体验用自然语言在不接触极狐GitLab 的情况下来完成一些仓库操作。 极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitL…...
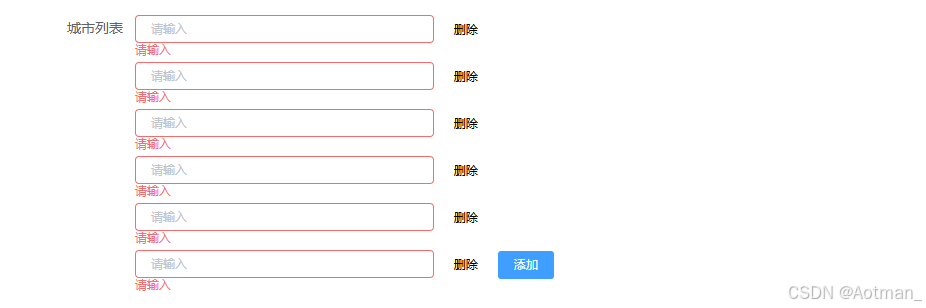
Vue el-from的el-form-item v-for循环表单如何校验rules(一)
实际业务需求场景: 新增或编辑页面(基础信息表单,一个数据列表的表单),数据列表里面的表单数是动态添加的。数据可新增、可删除,在表单保存前,常常需要做表单必填项的校验,校验通过以…...

C#集合List<T>与HashSet<T>的区别
在C#中,List和HashSet都是用于存储元素的集合,但它们在内部实现、用途、性能特性以及使用场景上存在一些关键区别。 内部实现 List:基于数组实现的,可以包含重复的元素,并且元素是按照添加的顺序存储的。 HashSet&…...
【Reading Notes】(8.3)Favorite Articles from 2025 March
【March】 雷军一度登顶中国首富,太厉害了(2025年03月02日) 早盘,小米港股一路高歌猛进,暴涨4%,股价直接飙到52港元的历史新高。这一波猛如虎的操作,直接把雷军的身家拉到了2980亿元,…...

Spring Boot 项目里设置默认国区时区,Jave中Date时区配置
在 Spring Boot 项目里设置国区时区(也就是中国标准时间,即 Asia/Shanghai),可通过以下几种方式实现: 方式一:在application.properties或application.yml里设置 application.properties properties sp…...

从PDF到播客:MIT开发的超越NotebookLM的工具
NotebookLM是谷歌推出的更具创意的AI产品之一,几个月前刚刚推出。 许多人对它的能力感到惊叹——尤其是将长文本转化为两位播客主持人之间有趣对话的功能。 NotebookLM提供的不仅仅是这些,还包括聊天(问答)甚至生成思维导图。 如果你还没有尝试过NotebookLM,我强烈建议…...
Kotlin协程Semaphore withPermit约束并发任务数量
Kotlin协程Semaphore withPermit约束并发任务数量 import kotlinx.coroutines.* import kotlinx.coroutines.sync.Semaphore import kotlinx.coroutines.sync.withPermit import kotlinx.coroutines.launch import kotlinx.coroutines.runBlockingfun main() {val permits 1 /…...
Redis的下载安装和使用(超详细)
目录 一、所需的安装包资源小编放下述网盘了,提取码:wshf 二、双击打开文件redis.desktop.manager.exe 三、点击next后,再点击i agree 四、点击箭头指向,选择安装路径,然后点击Install进行安装 五、安装完后依次点…...

Springboot 学习 之 logback-spring.xml 日志打印
文章目录 1. property2. springProperty3. appender4. logger4.1. 通过包路径控制日志4.2. 通过类名控制日志4.3. 按自定义 Logger 名称控制日志 5. root6. springProfile SpringBoot 项目中可以通过自定义 logback-spring.xml 中各项配置,实现日志的打印控制 1. p…...

从游戏显卡到AI引擎:NVIDIA CUDA如何重构计算世界的底层逻辑
当GPU不再是"显卡" 2025年,当ChatGPT-5的万亿参数模型在0.1秒内完成推理时,人们很少意识到,支撑这场智能革命的不仅是算法突破,更是一场持续20年的架构革命。NVIDIA CUDA技术,这个最初被游戏玩家视为"…...

无线网络入侵检测系统实战 | 基于React+Python的可视化安全平台开发详解
随着无线网络的普及,网络攻击风险也日益严峻。本项目旨在构建一个实时监测、智能识别、高效防护的无线网络安全平台,通过结合前后端技术与安全算法,实现对常见攻击行为的有效监控和防御。 一、项目简介与功能目的 本系统是一款基于 React 前…...