从游戏显卡到AI引擎:NVIDIA CUDA如何重构计算世界的底层逻辑
当GPU不再是"显卡"
2025年,当ChatGPT-5的万亿参数模型在0.1秒内完成推理时,人们很少意识到,支撑这场智能革命的不仅是算法突破,更是一场持续20年的架构革命。NVIDIA CUDA技术,这个最初被游戏玩家视为"显卡驱动"的存在,如今已成为全球90%AI算力的基石。本文将带您穿透技术迷雾,揭示CUDA如何将GPU从图形处理器重塑为通用计算引擎,并正在改写人类文明的算力格局。
一、算力进化论:CPU的黄昏与GPU的黎明
1.1 摩尔定律失效下的生存博弈
当Intel在2004年无奈放弃4GHz奔腾4处理器时,半导体行业首次感受到"频率墙"的寒意。CPU单核性能年均提升从90年代的52%骤降至2010年的3%,这迫使计算架构转向新维度——并行化。此时,NVIDIA工程师发现:游戏显卡中闲置的128个流处理器,其浮点算力竟是顶级CPU的10倍。
颠覆性洞察:
- CPU困境:4核处理器处理100个任务需要25轮调度,如同银行4个窗口服务100位客户
- GPU突破:1000个微型核心同步处理简单指令,如同春运期间1000个自动检票闸机
1.2 CUDA的降维打击
2006年CUDA 1.0的发布,标志着GPU通用计算的正式起航。其革命性在于:
- 编程范式转换:将图形API的"顶点-像素"抽象转换为"线程-内存"模型,使C语言直接操控GPU
- 硬件接口重构:在G80架构中预留10%晶体管用于通用计算单元,埋下算力爆发的伏笔
- 生态卡位策略:免费开发生态与学术推广,使CUDA在2012年AlexNet引爆AI革命时已占据先机
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wSqnYUEr-1744907550424)(https://via.placeholder.com/600x400)]
(图示:CPU仅20%晶体管用于计算单元,GPU则高达80%)
二、解剖CUDA:超越硬件的计算哲学
2.1 三维时空观:网格-块-线程的量子世界
CUDA的线程模型如同分形几何:
- 网格(Grid):宏观任务空间,对应整个计算域
- 块(Block):中观调度单元,最多1024个线程
- 线程(Thread):微观执行个体,携带唯一ID坐标
__global__ void matrixAdd(float *A, float *B, float *C, int N){int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y;if(i<N && j<N) C[i*N+j] = A[i*N+j] + B[i*N+j];
}
// 调用示例:<<<dim3(N/16,N/16), dim3(16,16)>>>
这段经典矩阵加法代码揭示CUDA的核心哲学:用空间拓扑映射解决并行调度难题。每个线程通过三维坐标精准定位计算任务,如同北斗网格定位系统中的每个坐标点。
2.2 内存金字塔:速度与容量的博弈艺术
CUDA的内存体系呈现精妙的层次结构:
| 内存类型 | 带宽(GB/s) | 容量 | 访问范围 | 使用场景 |
|---|---|---|---|---|
| 寄存器 | 8000+ | 256KB/线程 | 线程私有 | 循环变量 |
| 共享内存 | 1500 | 64KB/块 | 块内共享 | 矩阵分块计算 |
| 全局内存 | 900 | 24GB | 全局可见 | 主数据存储 |
优化案例:矩阵乘法优化中,将数据分块载入共享内存,可使计算性能提升83倍。这种设计哲学源自计算机体系结构大师David Patterson的洞察:“存储器是新的计算前沿”。
三、性能炼金术:从硬件特性到算法魔法
3.1 Warp调度:GPU的"量子纠缠"
SM(流多处理器)以32线程为Warp单位进行调度,这种设计带来:
- SIMT(单指令多线程):如同合唱团指挥,1条指令同时控制32个线程
- 隐式同步:Warp内线程天然同步,避免锁机制开销
- 分支惩罚:当Warp内线程执行不同路径时,性能可能下降32倍
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Pjkyu3ld-1744907550426)(https://via.placeholder.com/600x300)]
(图示:Warp在遇到分支时的串行化执行)
3.2 Tensor Core:算力核爆的密码
2017年Volta架构引入的Tensor Core,标志着CUDA进入混合精度计算时代:
- 4x4矩阵乘法:单指令完成FP16矩阵乘累加到FP32
- 性能飞跃:A100的Tensor Core相比V100的CUDA Core,AI训练速度提升20倍
- 架构创新:专用电路实现脉动阵列,数据流如水闸般规律流动
数学表达:
D 16 × 16 = ∑ k = 1 K A 16 × 8 ( k ) ⋅ B 8 × 16 ( k ) 吞吐量 = 312 TFLOPS (FP16) (H100 GPU) \begin{aligned} D_{16\times16} &= \sum_{k=1}^K A_{16\times8}^{(k)} \cdot B_{8\times16}^{(k)} \\ \text{吞吐量} &= 312 \text{ TFLOPS (FP16)} \quad \text{(H100 GPU)} \end{aligned} D16×16吞吐量=k=1∑KA16×8(k)⋅B8×16(k)=312 TFLOPS (FP16)(H100 GPU)
四、超越计算:CUDA构建的生态帝国
4.1 软件栈的降维打击
NVIDIA构建了覆盖全栈的加速库:
- 基础层:cuBLAS(线性代数)、cuFFT(傅里叶变换)
- AI层:cuDNN(深度学习)、TensorRT(推理优化)
- 科学层:NPP(图像处理)、CUDA Math(数学函数)
这种"硬件-编译器-库"三位一体模式,使PyTorch等框架仅需数行代码即可调用GPU算力。
4.2 跨学科革命
- 生物医学:HOOMD-Blue实现艾滋病毒衣壳模拟,速度比CPU快1000倍
- 金融计算:蒙特卡洛期权定价在A100上达到1毫秒级响应
- 气候预测:欧洲中期天气预报中心使用CUDA将台风路径预测提速40倍
五、未来之战:CUDA的挑战与进化
5.1 三大技术挑战
- 内存墙:HBM3e显存带宽虽达3TB/s,仍滞后于算力增长
- 能效比:每瓦性能提升速率从每年1.5倍降至1.1倍
- 异构竞争:AMD ROCm与Intel oneAPI正在蚕食生态
5.2 量子融合架构
2024年Blackwell架构的创新值得关注:
- Transformer引擎:专用硬件加速注意力机制
- 光追算力复用:将RT Core用于科学可视化计算
- Chiplet设计:通过3D封装突破芯片面积限制
结语:站在算力奇点的门槛上
当CUDA悄然成为AI时代的"电力系统",开发者们正站在历史性拐点:一方面要警惕技术垄断带来的生态风险,另一方面需以更开放的心态拥抱异构计算。
相关文章:

从游戏显卡到AI引擎:NVIDIA CUDA如何重构计算世界的底层逻辑
当GPU不再是"显卡" 2025年,当ChatGPT-5的万亿参数模型在0.1秒内完成推理时,人们很少意识到,支撑这场智能革命的不仅是算法突破,更是一场持续20年的架构革命。NVIDIA CUDA技术,这个最初被游戏玩家视为"…...

无线网络入侵检测系统实战 | 基于React+Python的可视化安全平台开发详解
随着无线网络的普及,网络攻击风险也日益严峻。本项目旨在构建一个实时监测、智能识别、高效防护的无线网络安全平台,通过结合前后端技术与安全算法,实现对常见攻击行为的有效监控和防御。 一、项目简介与功能目的 本系统是一款基于 React 前…...
)
前端 实现文字打字效果(仿AI)
DOM结构 <scroll-view class"scroll-view" scroll-y"true" :scroll-top"scrollTop" :style"{height: contentHeight px}"scroll-with-animation show-scrollbar"false" id"report-scroll-view"><view …...
练手小项目:飞机大战)
C#核心(25)练手小项目:飞机大战
简介 通过核心部分的学习,我们已经可以做一些复杂的项目了。 我们这次会用我们学到的面向对象知识写一个飞机大战(性能可能不太好,因为毕竟是控制台项目) 如果你有所不懂,建议多查多思考多问。 因为这次的项目比较难,博主会稍微讲仔细一点。 基类设计:GameObject 抽…...
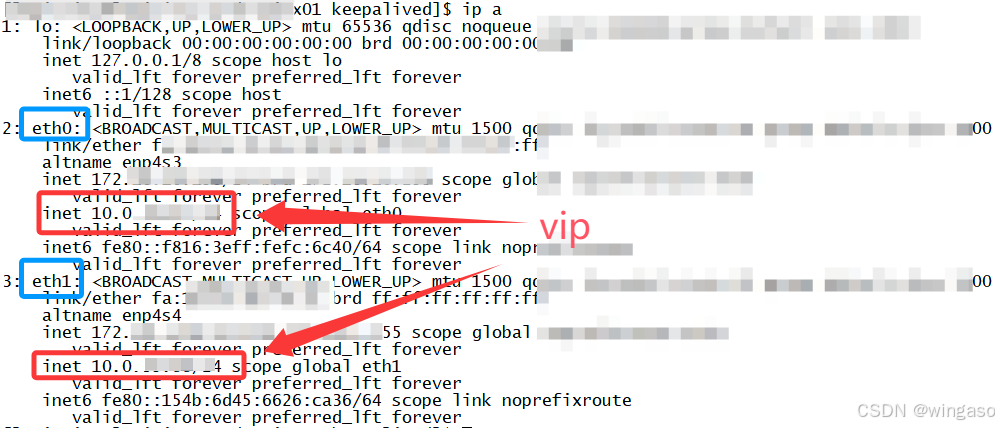
[经验总结]Linux双机双网卡Keepalived高可用配置及验证细节
1. 前言 这种配置需求比较少见,在网上也很少有相关文章,于是记录在此,供有需要的朋友参考。 本篇重点介绍配置的关键点,基础部分简单提及,不赘述。 2. 需求描述 如上图,即给两个主机配置两对高可用主从配…...

Go语言入门到入土——三、处理并返回异常
Go语言入门到入土——三、处理并返回异常 文章目录 Go语言入门到入土——三、处理并返回异常1. 在greetings.go中添加异常处理代码2. 在hello.go中添加日志记录代码3. 运行 1. 在greetings.go中添加异常处理代码 处理空输入的异常,代码如下: package g…...
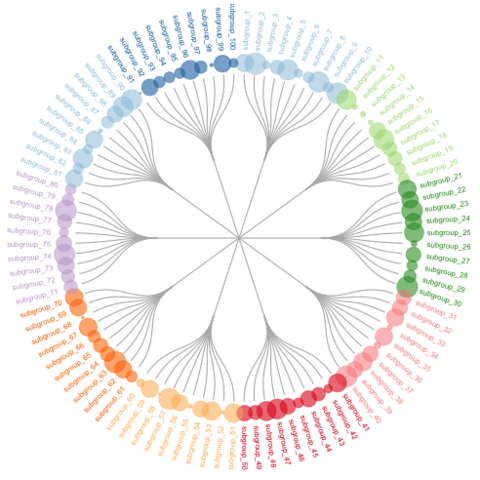
2025.04.17【Dendrogram】生信数据可视化:Dendrogram图表详解
Dendrogram customization Go further with ggraph: edge style, general layout, node features, adding labels, and more. Customized circular dendrogram Learn how to build a circular dendrogram with proper labels. 文章目录 Dendrogram customizationCustomized c…...

Linux下的网络管理
一、ipv4原理 网络接口是指网络中的计算机或网络设备与其他设备实现通讯的进出口,一般是指计算机的网络接口即网卡设备 从RHEL7开始引入了一种新的“一致网络设备命名”的方式为网络接口命名,该方式可以根据固件、设备拓扑、设备类型和位置信息分配固…...

GPT-4o Image Generation Capabilities: An Empirical Study
GPT-4o 图像生成能力:一项实证研究 目录 介绍研究背景方法论文本到图像生成图像到图像转换图像到 3D 能力主要优势局限性与挑战对比性能影响与未来方向结论介绍 近年来,图像生成领域发生了巨大的变化,从生成对抗网络 (GAN) 发展到扩散模型,再到可以处理多种模态的统一生成架…...
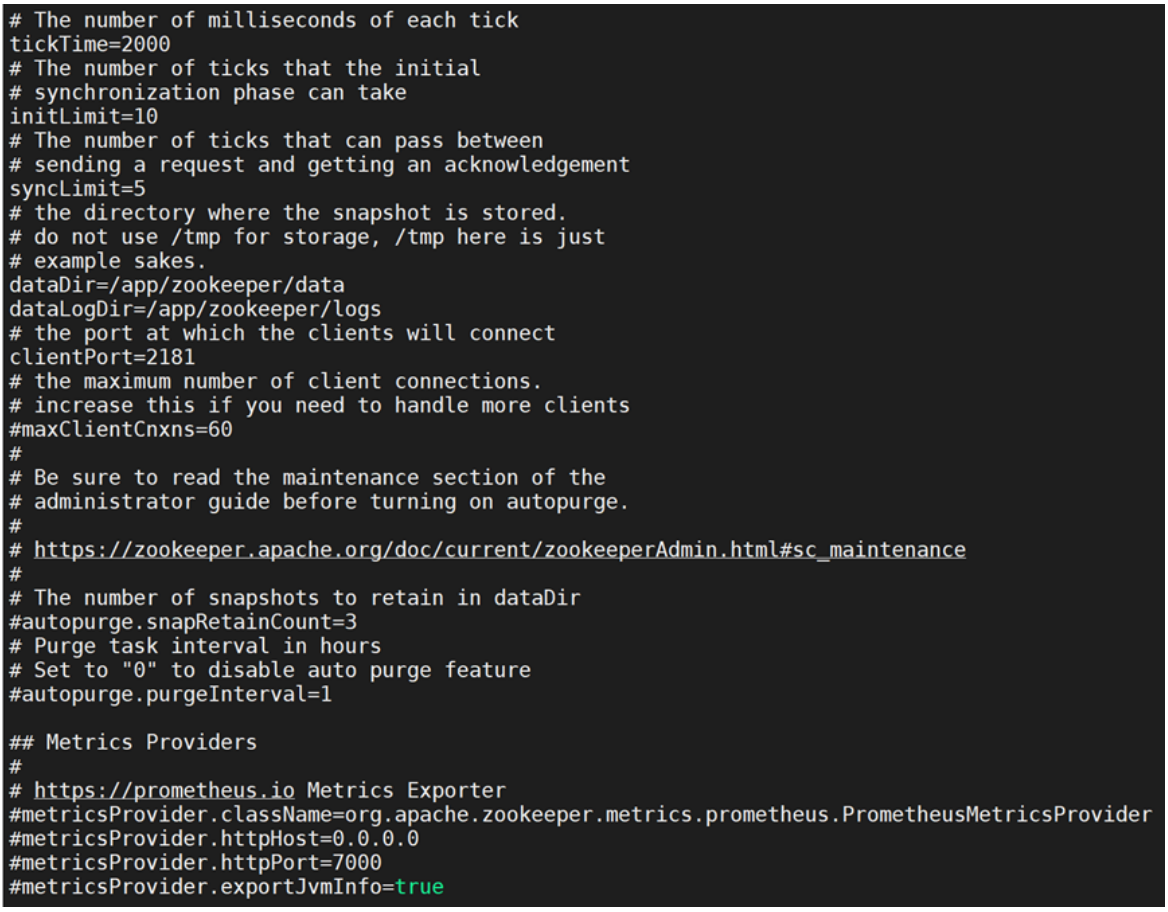
Zookeeper介绍与安装配置
1.综述 1.1.Zookeeper介绍 Zookeeper 是一个分布式协调服务,由 Apache 开发,主要用于管理分布式应用中的配置信息、命名服务、分布式同步和组服务。它通过简单的接口提供高性能、高可用性和严格的顺序访问控制,广泛应用于分布式系统的协调与…...

提示词阶段总结
经过这些天的提示词学习,总结了一下提示词示例,可以直接拿来使用,规范大模型的输出。 CoT(适用于算术题) {问题},让我们一步一步思考。 Auto-CoT(自动思维链,适合回答多个问题一起…...
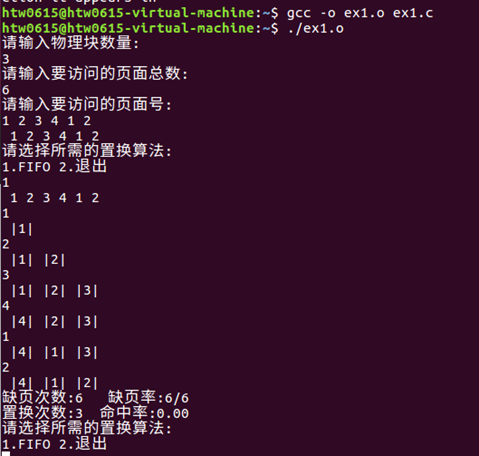
实验五 内存管理实验
实验五 内存管理实验 一、实验目的 1、了解操作系统动态分区存储管理过程和方法。 2、掌握动态分区存储管理的主要数据结构--空闲表区。 3、加深理解动态分区存储管理中内存的分配和回收。 4、掌握空闲区表中空闲区3种不同放置策略的基本思想和实现过程。 5、通过模拟程…...

用Webpack 基础配置快速搭建项目开发环境
Webpack 是一个现代 JavaScript 应用程序的静态模块打包工具,但是Webpack有大量的配置项,对新手不太友好,但是我们可以根据webpack-cli的init命令根据项目需求快速生成webpack的配置文件,本文将手把手教你如何用 Webpack 和 npm 快…...
Axios 介绍及使用指南
本文将基于 Axios 原理,安装及封装方面展开描述,话不多说,现在发车! 一、原理 Axios 中文文档:起步 | Axios中文文档 | Axios中文网 赛前科普: 下文将涉及到三个关键词:Axios,Ajax…...

接口自动化测试(二)
一、接口测试流程:接口文档、用例编写 拿到接口文档——编写接口用例以及评审——进行接口测试——工具/自动化框架进行自动化用例覆盖(70%)——输出测试报告 自动化的目的一般是为了回归 第一件事情:理解需求,学会看接口文档 只需要找到我…...

Arduino+ESP826601s模块连接阿里云并实现温湿度数据上报
ArduinoESP826601s模块连接阿里云并实现温湿度数据上报 一、前言二、准备工作三、程序代码1. Arduino的程序2. ESP826601的程序3. 上面程序需要注意的地方 四、运行结果五、结束语 一、前言 看完我这三篇文章,相信各位朋友对于阿里云物联网平台的使用都有了一定的认…...
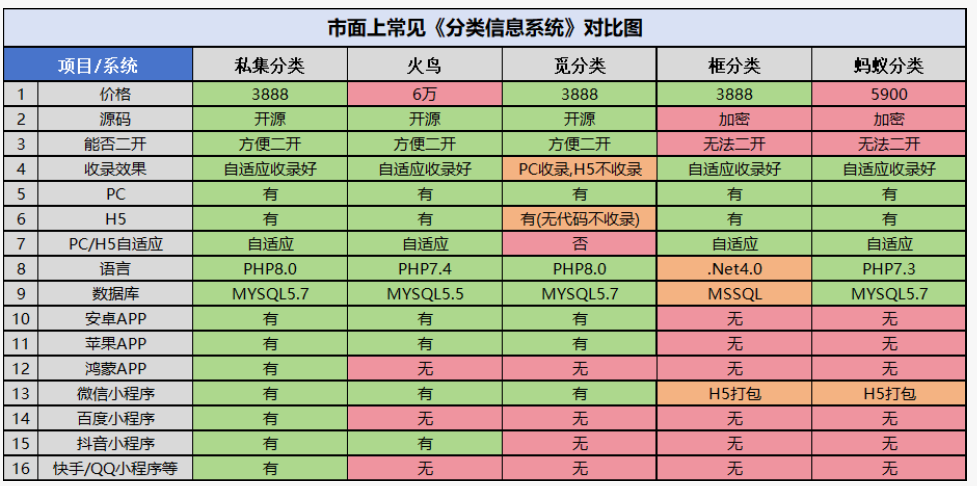
本地生活服务信息分类信息系统
最近在找分类信息系统,看了很多市面上常见的分类信息系统: 1,私集分类信息系统 2,火鸟分类信息系统 3,觅分类信息系统 4,框分类信息系统 5,蚂蚁分类信息系统 发现很多分类信息系统,…...

React Native 0.79 稳定版发布,更快的工具、更多改进
React Native 0.79 已发布。此版本在多个方面进行了性能改进,并修复了一些漏洞。首先,得益于延迟哈希技术,Metro 的启动速度变快了,并且对包导出提供了稳定支持。由于 JS 包压缩方式的改变等原因,Android 的启动时间也…...

【Dify应用】连接数据库生成Echarts图表
这里写自定义目录标题 需求文档内容测试环境实际效果工作流内容工具安装B工作流详解A工作流详解优化建议 需求 甲方要求。根据自然语言生成对应Echarts图表,并且数据来源于私有数据库。 文档内容 本文档内容主要展示使用Dify(本地源码)进行…...

无刷电机槽数相同、转子极数不同的核心区别
一、基础原理差异 无刷电机的核心参数: 槽数(定子槽数,记为 ( Z )):定子铁芯上的绕组槽数量,决定绕组布局。极数(转子磁极数,记为 ( 2p )):转子上的永磁体磁极对数(总极数为 ( 2p ),如 ( p=4 ) 表示 8 极)。核心关系:槽极配合(( Z/2p ))决定电机电磁结构,相同…...

RAG 实战|用 StarRocks + DeepSeek 构建智能问答与企业知识库
文章作者: 石强,镜舟科技解决方案架构师 赵恒,StarRocks TSC Member 👉 加入 StarRocks x AI 技术讨论社区 https://mp.weixin.qq.com/s/61WKxjHiB-pIwdItbRPnPA RAG 和向量索引简介 RAG(Retrieval-Augmented Gen…...

JavaScript 性能优化实战
一、代码执行效率优化 1. 减少全局变量的使用 全局变量在 JavaScript 中会挂载在全局对象(浏览器环境下是window,Node.js 环境下是global)上,频繁访问全局变量会增加作用域链的查找时间。 // 反例:使用全局变量 var globalVar = example; function someFunction() {con…...
ubuntu 22.04 使用ssh-keygen创建ssh互信账户
现有两台ubuntu 22.04服务器,ip分别为192.168.66.88和192.168.88.66。需要将两台服务器创建新用户并将新用户做互信。 创建账户 adduser user1 # 如果此用户不想使用密码,直接一直回车就行,创建的用户是没法使用用户密码进行登陆的 su - …...
【Linux网络】Socket 编程TCP
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 TCP socket API 详解 socket(): bind(): listen(): accept(): connect V0…...

C++指针与内存管理深度解析
前言: 在C开发的道路上,指针和内存管理就像是两个既强大又危险的朋友。掌握它们就如同学会驾驭一辆高性能跑车,稍有不慎可能导致灾难,但一旦熟练掌握,便能发挥出惊人的性能和灵活性。今天就让我们一起深入探讨C中的指…...

ESP32-idf学习(二)esp32C3作服务端与电脑蓝牙数据交互
一、当前需求 目前是想利用蓝牙来传输命令,或者一些数据,包括电脑、手机与板子的数据传输,板子与板子之间的数据传输。构思是一个板子是数据接收终端,在电脑或手机下发指令后,再给其他板子相应指令,也需要…...
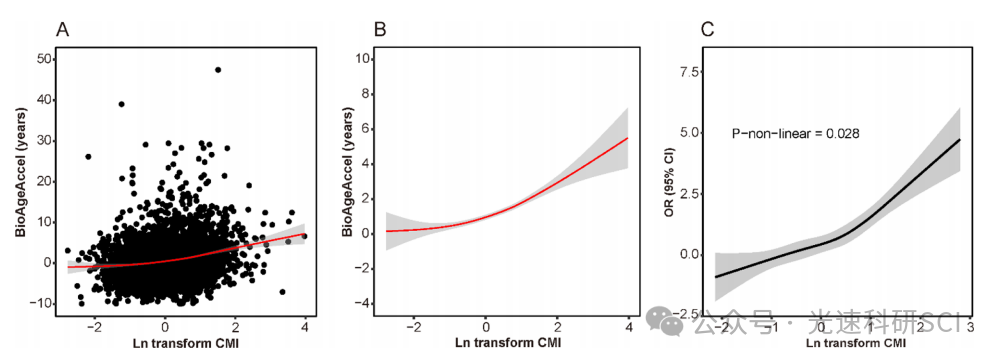
NHANES指标推荐:CMI
文章题目:Association between cardiometabolic index and biological ageing among adults: a population-based study DOI:10.1186/s12889-025-22053-3 中文标题:成年人心脏代谢指数与生物衰老之间的关系:一项基于人群的研究 发…...
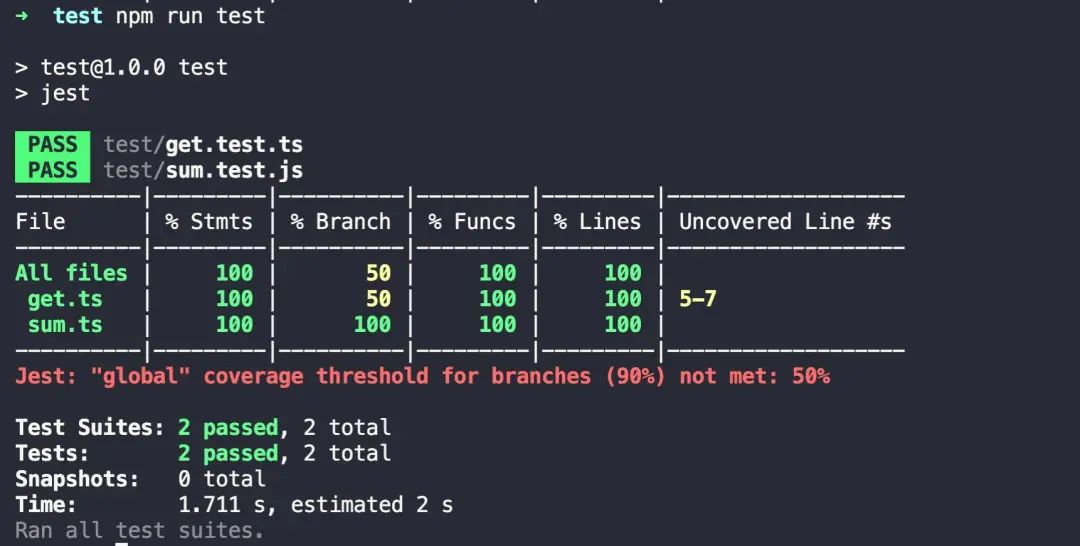
前端单元测试实战:如何开始?
实战:如何开始单元测试 1.安装依赖 npm install --save-dev jest2.简单的例子 首先,创建一个 sum.js 文件 ./sum.js function sum(a, b) {return a b; }module.exports sum;创建一个名为 sum.test.js 的文件,这个文件包含了实际测试内…...

react-native搭建开发环境过程记录
主要参考:官网的教程 https://reactnative.cn/docs/environment-setup 环境介绍:macos ios npm - 已装node18 - 已装,通过nvm进行版本控制Homebrew- 已装yarn - 已装ruby - macos系统自带的2.2版本。watchman - 正常安装Xcode - 正常安装和…...
视图(超详细))
【数据库系统概论】第3章 SQL(四)视图(超详细)
视图(View)是数据库中的虚拟表 通过执行查询定义并存储在数据库中,可以像普通表一样被查询和使用。 视图本身并不存储数据,而是基于一个或多个表的查询结果动态生成。 视图的概念 视图( View )是由其它表或视图上的查询所定义…...