Zookeeper介绍与安装配置
1.综述
1.1.Zookeeper介绍
Zookeeper 是一个分布式协调服务,由 Apache 开发,主要用于管理分布式应用中的配置信息、命名服务、分布式同步和组服务。它通过简单的接口提供高性能、高可用性和严格的顺序访问控制,广泛应用于分布式系统的协调与管理,帮助开发者处理分布式环境中的复杂问题
ZooKeeper集群原理:Zookeeper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供一项基本服务:分布式锁服务。
分布式应用可以基于它实现更高级的服务,实现诸如同步服务、配置维护和集群管理或者命名的服务。Zookeeper服务自身组成一个集群,2n+1个(奇数)服务允许n个失效,集群内一半以上机器可用,Zookeeper就可用。
1.2.架构图
下图是 Zookeeper 的架构图,ZooKeeper 集群中包含 Leader、Follower 以及 Observer 三个角色:
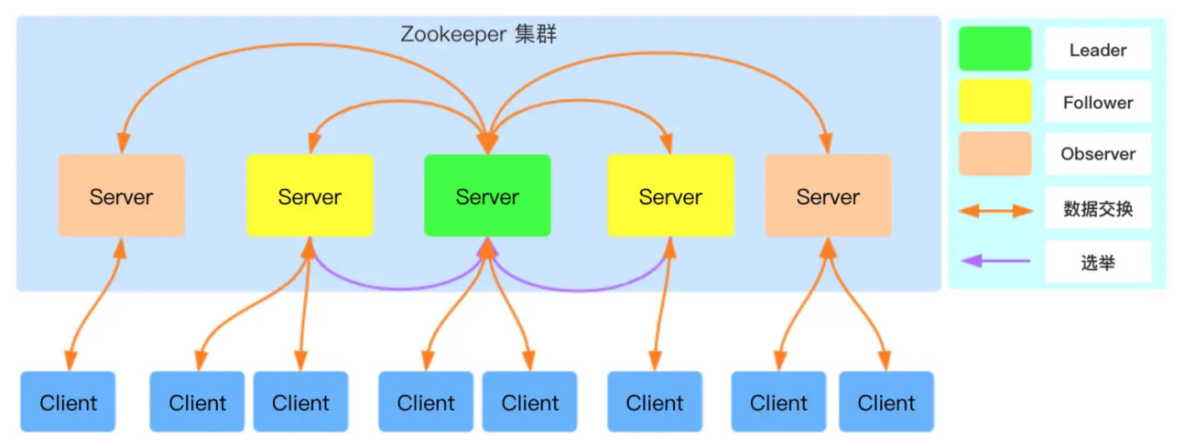
Leader:负责进行投票的发起和决议,更新系统状态,Leader 是由选举产生;
Follower: 用于接受客户端请求并向客户端返回结果,在选主过程中参与投票;
Observer:可以接受客户端连接,接受读写请求,写请求转发给 Leader,但 Observer 不参加投票过程,只同步 Leader 的状态,Observer 的目的是为了扩展系统,提高读取速度。
Client 是 Zookeeper 的客户端,请求发起方
1.3.集群架构原理
Leader主要有三个功能:
1.恢复数据;
2.维持与follower的心跳,接收follower请求并判断follower的请求消息类型;
3.follower的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
Follower主要有四个功能:
1.向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2.接收Leader消息并进行处理;
3.接收Client的请求,如果为写请求,发送给Leader进行投票;
4.返回Client结果。
读操作分析:
ZooKeeper集群中所有的server节点都拥有相同的数据,所以读的时候可以在任意一台server节点上,客户端连接到集群中某一节点,读请求,然后直接返回。当然因为ZooKeeper协议的原因(一半以上的server节点都成功写入了数据,这次写请求便算是成功),读数据的时候可能会读到数据不是最新的server节点,所以比较推荐使用watch机制,在数据改变时,及时感应到。
写操作分析:
当一个客户端进行写数据请求时,会指定ZooKeeper集群中的一个server节点,如果该节点为Follower,则该节点会把写请求转发给Leader,Leader通过内部的协议进行原子广播,直到一半以上的server节点都成功写入了数据,这次写请求便算是成功,然后Leader便会通知相应Follower节点写请求成功,该节点向client返回写入成功响应
zookeeper 的三个端口作用:
2181 : 对 client 端提供服务
2888 : 集群内机器通信使用
3888:选举 leader 使用
2. 安装Zookeeper
2.1.适用版本
版本号:3.8.0(最新stale版本)
JDK版本:jdk1.8.0_341
Zookeeper 需要 Java 运行环境JDK 1.8 或以上
关于新版本的新特性请查阅如下官方:https://zookeeper.apache.org/
2.2.环境准备
操作系统:Linux
Java 环境:Zookeeper 需要 Java 运行环境(JDK 1.8 或以上)。
检查 Java 是否安装:java -version

2.3. 下载Zookeeper
zookeeper官网下载地址:Apache ZooKeeper
Jdk 官网源码包下载地址:Java Archive Downloads - Java SE 8u211 and later (oracle.com)
2.4 安装Zookeeper
2.4.1 解压安装包
下载安装包后上传至服务器。
解压安装包:tar -xf apache-zookeeper-3.9.3-bin.tar.gz

2.4.2 创建数据目录和日志目录
mkdir -p /app/zookeeper/data
mkdir -p /app/zookeeper/logs
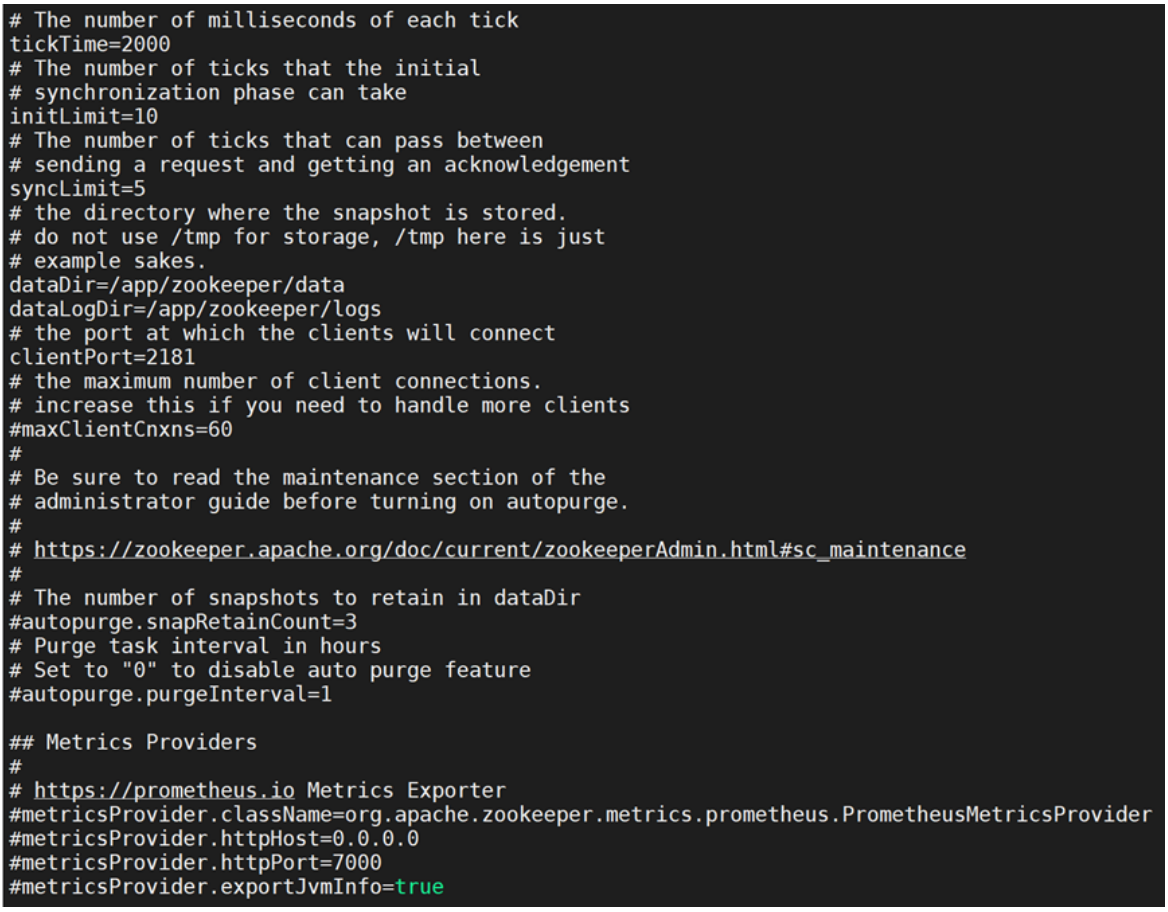
2.4.3 配置Zookeeper
cp conf/zoo_sample.cfg conf/zoo.cfg
vi conf/zoo.cfg 文件,修改以下内容:
dataDir=/app/zookeeper/data
dataLogDir=/app/zookeeper/logs
clientPort=2181
集群配置
如果是集群模式,添加以下配置(以 3 节点为例):
| server.1=192.168.1.101:2888:3888 server.2=192.168.1.102:2888:3888 server.3=192.168.1.103:2888:3888 其中 server.x:x 是节点的唯一 ID。 IP:2888:用于节点间通信。 IP:3888:用于 Leader 选举。 |
配置节点 ID:
在每个节点的 dataDir 目录下创建 myid 文件,并写入对应的节点 ID。
| echo 1 > /data/zookeeper/data/myid # 节点 1 echo 2 > /data/zookeeper/data/myid # 节点 2 echo 3 > /data/zookeeper/data/myid # 节点 3 |
2.4.4 启动Zookeeper
启动zookeeper:/app/zookeeper/bin/zkServer.sh start
# /app/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
# /app/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Client port found: 9090. Client address: localhost. Client SSL: false.
Mode: standalone(单机模式)
集群模式:
在每个节点上启动 Zookeeper:
bin/zkServer.sh start
查看集群状态:
bin/zkServer.sh status
3. Zookeeper集群部署
过程、目录与单机部署一致,集群数量以奇数为准如(3、5、7…)偶数会导致脑裂。
以三台zookeeper服务器为例,均需配置
3.1 配置hosts
#cat >>/etc/hosts << EOF
IP1 zookeeper01
IP2 zookeeper02
IP3 zookeeper03
EOF
3.2 配置myid
| Zookeeper01 #echo 0 >>/app/zookeeper/data/myid |
| Zookeeper02 #echo 1 >>/app/zookeeper/data/myid |
| Zookeeper03 #echo 2 >>/app/zookeeper/data/myid |
3.3 修改配置文件
| #cat >>/app/zookeeper/conf/zoo.cfg <<EOF tickTime=6000 initLimit=15 syncLimit=15 dataDir=/app/zk-data/data dataLogDir=/app/zk-data/logs clientPort=2181 clientPortAddress=0.0.0.0 maxClientCnxns=3000 maxSessionTimeout=120000 minSessionTimeout=4000 autopurge.snapRetainCount=3 autopurge.purgeInterval=1 server.1=0.0.0.1:2888:3888 server.2=0.0.0.2:2888:3888 server.3=0.0.0.3:2888:3888 4lw.commands.whitelist=mntr.conf.ruok EOF |
| tickTime=6000 #ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。例如,session的最小超时时间是2*tickTime。 initLimit=15 #Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许F在 initLimit时间内完成这个工作。通常情况下,我们不用太在意这个参数的设置。如果ZK集群的数据量确实很大了,F在启动的时候,从Leader上同步数据的时间也会相应变长,因此在这种情况下,有必要适当调大这个参数了。(No Java system property) syncLimit=15 #在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果L发出心跳包在syncLimit之后,还没有从F那里收到响应,那么就认为这个F已经不在线了。注意:不要把这个参数设置得过大,否则可能会掩盖一些问题。 dataDir=/app/zk-data/data #存储快照文件 snapshot 的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能。 dataLogDir=/app/zk-data/logs #事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能。(No Java system property) clientPort=2181 #客户端连接server的端口,即对外服务端口,一般设置为 2181 clientPortAddress=0.0.0.0 #对于多网卡的机器,可以为每个IP指定不同的监听端口。默认情况是所有IP都监听 clientPort指定的端口。 New in 3.3.0 maxClientCnxns=3000 #单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60,如果设置为0,那么表明不作任何限制。请注意这个限制的使用范围,仅仅是单台客户端机器与单台ZK服务器之间的连接数限制,不是针对指定客户端IP,也不是ZK集群的连接数限制,也不是单台ZK对所有客户端的连接数限制。 maxSessionTimeout=120000 #Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。默认的Session超时时间是在2 * tickTime ~ 20 * tickTime 这个范围 New in 3.3.0 minSessionTimeout=4000 #Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。默认的Session超时时间是在2 * tickTime ~ 20 * tickTime 这个范围 New in 3.3.0 autopurge.snapRetainCount=3 #这个参数指定了需要保留的文件数目。默认是保留3个 autopurge.purgeInterval=1 #ZK提供了自动清理事务日志和快照文件的功能,这个参数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是0,表示不开启自动清理功 server.1=0.0.0.1:2888:388 #zookeeper 集群监听地址 server.2=0.0.0.2:2888:3888 #zookeeper 集群监听地址 server.3=0.0.0.3:2888:3888 #zookeeper 集群监听地址 4lw.commands.whitelist=mntr.conf.ruok #是为了对 ZooKeeper 可以执行的命令集提供细粒度的控制 |
3.4 启动Zookeeper
#/app/zookeeper/bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
三台ZK,两台是follower,一台是leader。集群启动成功
# /app/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
# /app/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /app/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
3.5 Zookeeper添加系统启动
| #cat >>/etc/systemd/system/zookeeper.service <<EOF [Unit] Description=Zookeeper Service unit Configuration After=network.target [Service] Type=forking Environment=JAVA_HOME=/usr/java/jdk1.8.0_331 CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH ExecStartPost=/bin/sleep 2 ExecStart=/app/zookeeper/bin/zkServer.sh start /app/zookeeper/conf/zoo.cfg ExecStop=/app/zookeeper/bin/zkServer.sh stop PIDFile=/app/zk-data/data/zookeeper_server.pid KillMode=none User=zookeeper Group= zookeeper Restart=on-failure [Install] WantedBy=multi-user.target EOF |
| 添加开启自启 #systemctl enable zookeeper.service |
| 停止ZK #systemctl stop zookeeper.service 启动zk #systemctl start zookeeper.service |
3.6 ZK配置
1. 配置snapshot文件清理策略
autopurge.purgeInterval=1
autopurge.purgeInterval:开启清理事务日志和快照文件的功能,单位是小时。默认是0,表示不开启自动清理功能。
autopurge.snapRetainCount=10
autopurge.snapRetainCount:指定了需要保留的文件数目。默认是保留3个。
2. 限制snapshot数量
snapCount=3000000
每snapCount次事务日志输出后,触发一次快照(snapshot)。 ZooKeeper会生成一个snapshot文件和事务日志文件。 默认是100000。
3. log和data数据分磁盘存储
dataDir:存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里。
dataLogDir:事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能。
4. 调整JVM大小
ZooKeeper的JVM内存默认是根据操作系统本身内存大小的一个百分比预先分配的,所以这不是我们所需要的。
在./bin/zkEnv.sh文件中,有如下配置项:
if [ -f "$ZOOCFGDIR/java.env" ]
then
. "$ZOOCFGDIR/java.env"
fi
我们在./conf/java.env文件中配置JVM的内存,增加如下配置:
export JAVA_HOME=/app/jdk
export JVMFLAGS="-Xms10240m -Xmx20480m $JVMFLAGS"
修改完成使用jmap -heap $pid来验证内存修改情况。
5. ZNode中可以存储数据星的最大值,默认值是1M。
jute.maxbuffer
修改jvm内存参数jute.maxbuffer大小调整到10M=10240KB=10485760Bytes
修改bin/zkServer.sh或者zkEnv.sh
JVMFLAGS="$JVMFLAGS -Djute.maxbuffer=10485760"
4. zookeeper开启ssl
4.1 使用keytool生成客户端和服务端证书
生成含有一个私钥的keystore文件
keytool -genkeypair -alias certificatekey -keyalg RSA -validity 3650 -keystore keystore.jks
查看生成的keystore文件
keytool -list -v -keystore keystore.jks
导出证书
keytool -export -alias certificatekey -keystore keystore.jks -rfc -file selfsignedcert.cer
导入证书到truststore文件中
keytool -import -alias certificatekey -file selfsignedcert.cer -keystore truststore.jks
查看生成的truststore文件
keytool -list -v -keystore truststore.jks
4.2 Zookeeper服务端添加ssl
方案一:添加到配置文件
在zoo.cfg里面添加
serverCnxnFactory=org.apache.zookeeper.server.NettyServerCnxnFactory
ssl.keyStore.location=/app/zookeeper/cert/keystore.jks
ssl.keyStore.password=123456
ssl.trustStore.location=/app/zookeeper/cert/truststore.jks
ssl.trustStore.password=123456
方案二:以变量的形式添加
在zkServer.sh开头添加
export SERVER_JVMFLAGS="
-Dzookeeper.serverCnxnFactory=org.apache.zookeeper.server.NettyServerCnxnFactory
-Dzookeeper.ssl.keyStore.location=/app/zookeeper/cert/keystore.jks
-Dzookeeper.ssl.keyStore.password=123456
-Dzookeeper.ssl.trustStore.location=/app/zookeeper/cert/truststore.jks
-Dzookeeper.ssl.trustStore.password=123456"
配置文件添加安全端口
zoo.cfg需要额外添加安全端口
secureClientPort=2183
为了防止全网监听
secureClientPortAddress=192.168.10.133 注:修改为本机ip地址
启动服务
./zkServer.sh start或systemctl start zookeeper.service
5. 配置Zookeeper ACL权限
ZooKeeper的ACL权限控制, 可以控制节点的读写操作, 保证数据的安全性,ZookeeperACL权限设置分为3部分组成, 分别是:权限模式(Scheme ) 、授权对象I(ID) 、权限信息(Permission ) 。最终组成一条例如“scheme:id:permission"格式的ACL请求信息
ZookeeperACL权限设置分为3部分组成, 分别是:权限模式(Scheme ) 、授权对象I(ID) 、权限信息(Permission ) 。最终组成一条例如“scheme:id:permission"格式的ACL请求信息
(1)权限模式(scheme):授权的策略。
(2)权限对象(id):授权的对象。
(3)权限(permission):授予的权限。
5.1 权限模式(Scheme)
权限模式(scheme):授权的策略
| 模式 | 描述 |
| world | 这种模式方法的授权对象只有一个anyone,代表登录到服务器的所有客户端都能对该节点执行某种权限 |
| ip | 对连接的客户端使用IP地址认证方式进行认证 |
| auth | 使用以添加认证的用户进行认证 |
| digest | 使用 用户:密码方式验证 |
5.2 权限类型(permission)
权限(permission):授予的权限:
| 类型 | ACL简写 | 描述 |
| read | r | 读取节点及显示子节点列表的权限 |
| write | w | 设置节点数据的权限 |
| create | c | 创建子节点的权限 |
| delete | d | 删除子节点的权限 |
| admin | a | 设置该节点ACL权限的权限 |
5.3 授权的命令
授权的命令:
| 命令 | 用法 | 描述 |
| getAcl | getAcl path | 读取节点的ACL |
| setAcl | setAcl path acl | 设置节点的ACL |
| create | create path data acl | 创建节点时设置acl |
| addAuth | addAuth scheme auth | 添加认证用户,类似于登录操作 |
生成授权ID
在xshell中生成
echo -n <user>:<password> | openssl dgst -binary -sha1 | openssl base64
示例:
echo -n angel:123456 | openssl dgst -binary -sha1 | openssl base64
返回的结果是:5qPtfHTjrZrZ4DGSxBY8+G6AhiM=
5.4 设置ACL(两种方式)
方案一:
创建设置ACL
create [-s] [-e] [-c] path [data] [acl]
示例
./zkCli.sh
create /test1 'hello' digest:angel:5qPtfHTjrZrZ4DGSxBY8+G6AhiM=:cdrwa
方案二:
或者直接使用setAcl 设置(属于另一种方案)
setAcl /test1 digest:angel:5qPtfHTjrZrZ4DGSxBY8+G6AhiM=:cdrwa
访问 /test1,会出现权限不足
[zk: localhost:2181(CONNECTED) 1] get /test1
Insufficient permission : /test1
访问前需要添加授权信息
| addauth digest angel:123456 |
| [zk: localhost:2181(CONNECTED) 2] addauth digest angel:123456 [zk: localhost:2181(CONNECTED) 3] get /test1 hello |
5.4.1 明文授权
另一种授权模式: auth 明文授权
使用之前需要先注册用户信息
addauth digest username:password
注册用户信息,后续可以直接用明文授权
| [zk: localhost:2181(CONNECTED) 4] addauth digest wuqian:123456 |
| [zk: localhost:2181(CONNECTED) 5] create /test2 'hello2' auth:wuqian:123456:cdwra Created /test2 |
| [zk: localhost:2181(CONNECTED) 6] get /test2 |
5.4.2 IP授权模式
方式1:setAcl /test3 ip:192.168.0.106:cdwra
方式2:create /test data ip:192.168.0.106:cdwra
5.5关闭ACL
可以通过系统参数zookeeper.skipACL=yes进行配置,默认是no,可以配置为true, 则配置过的ACL将不再进行权限检测
编辑配置启动文件 vim bin/zkServer.sh,然后添加启动参数-D:
53 ZOOMAIN="-Dzookeeper.skipACL=yes -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=$JMXLOCALONLY org.apache.zookeeper.server.quor um.QuorumPeerMain"
重启zkServer,关闭ACL访问控制
./zkServer.sh restart
相关文章:
Zookeeper介绍与安装配置
1.综述 1.1.Zookeeper介绍 Zookeeper 是一个分布式协调服务,由 Apache 开发,主要用于管理分布式应用中的配置信息、命名服务、分布式同步和组服务。它通过简单的接口提供高性能、高可用性和严格的顺序访问控制,广泛应用于分布式系统的协调与…...

提示词阶段总结
经过这些天的提示词学习,总结了一下提示词示例,可以直接拿来使用,规范大模型的输出。 CoT(适用于算术题) {问题},让我们一步一步思考。 Auto-CoT(自动思维链,适合回答多个问题一起…...
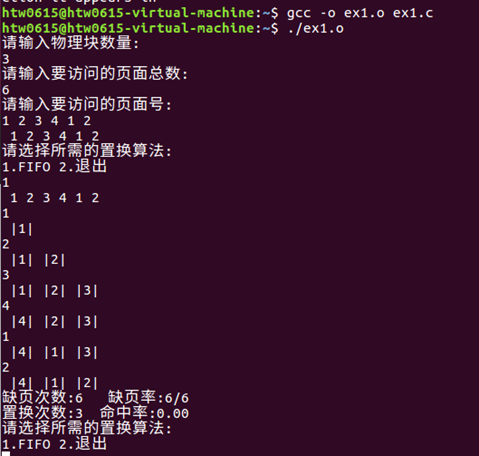
实验五 内存管理实验
实验五 内存管理实验 一、实验目的 1、了解操作系统动态分区存储管理过程和方法。 2、掌握动态分区存储管理的主要数据结构--空闲表区。 3、加深理解动态分区存储管理中内存的分配和回收。 4、掌握空闲区表中空闲区3种不同放置策略的基本思想和实现过程。 5、通过模拟程…...

用Webpack 基础配置快速搭建项目开发环境
Webpack 是一个现代 JavaScript 应用程序的静态模块打包工具,但是Webpack有大量的配置项,对新手不太友好,但是我们可以根据webpack-cli的init命令根据项目需求快速生成webpack的配置文件,本文将手把手教你如何用 Webpack 和 npm 快…...
Axios 介绍及使用指南
本文将基于 Axios 原理,安装及封装方面展开描述,话不多说,现在发车! 一、原理 Axios 中文文档:起步 | Axios中文文档 | Axios中文网 赛前科普: 下文将涉及到三个关键词:Axios,Ajax…...

接口自动化测试(二)
一、接口测试流程:接口文档、用例编写 拿到接口文档——编写接口用例以及评审——进行接口测试——工具/自动化框架进行自动化用例覆盖(70%)——输出测试报告 自动化的目的一般是为了回归 第一件事情:理解需求,学会看接口文档 只需要找到我…...

Arduino+ESP826601s模块连接阿里云并实现温湿度数据上报
ArduinoESP826601s模块连接阿里云并实现温湿度数据上报 一、前言二、准备工作三、程序代码1. Arduino的程序2. ESP826601的程序3. 上面程序需要注意的地方 四、运行结果五、结束语 一、前言 看完我这三篇文章,相信各位朋友对于阿里云物联网平台的使用都有了一定的认…...
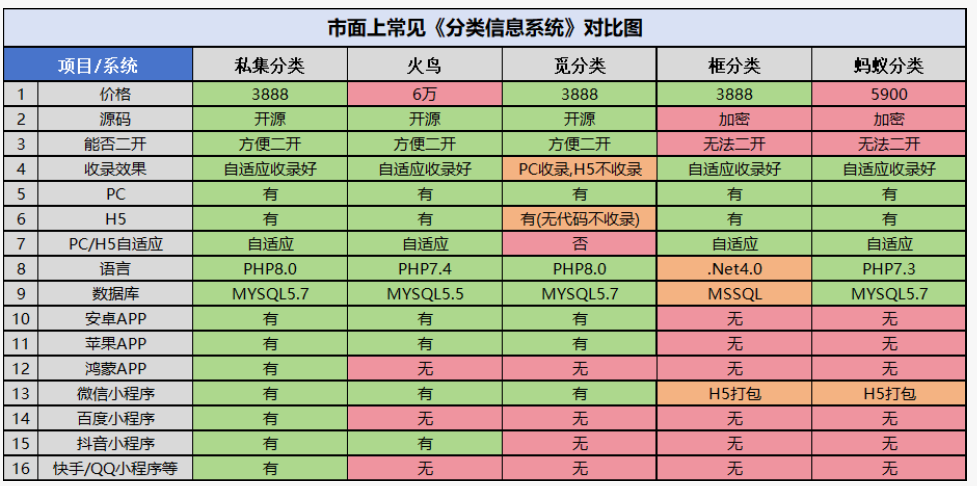
本地生活服务信息分类信息系统
最近在找分类信息系统,看了很多市面上常见的分类信息系统: 1,私集分类信息系统 2,火鸟分类信息系统 3,觅分类信息系统 4,框分类信息系统 5,蚂蚁分类信息系统 发现很多分类信息系统,…...

React Native 0.79 稳定版发布,更快的工具、更多改进
React Native 0.79 已发布。此版本在多个方面进行了性能改进,并修复了一些漏洞。首先,得益于延迟哈希技术,Metro 的启动速度变快了,并且对包导出提供了稳定支持。由于 JS 包压缩方式的改变等原因,Android 的启动时间也…...

【Dify应用】连接数据库生成Echarts图表
这里写自定义目录标题 需求文档内容测试环境实际效果工作流内容工具安装B工作流详解A工作流详解优化建议 需求 甲方要求。根据自然语言生成对应Echarts图表,并且数据来源于私有数据库。 文档内容 本文档内容主要展示使用Dify(本地源码)进行…...

无刷电机槽数相同、转子极数不同的核心区别
一、基础原理差异 无刷电机的核心参数: 槽数(定子槽数,记为 ( Z )):定子铁芯上的绕组槽数量,决定绕组布局。极数(转子磁极数,记为 ( 2p )):转子上的永磁体磁极对数(总极数为 ( 2p ),如 ( p=4 ) 表示 8 极)。核心关系:槽极配合(( Z/2p ))决定电机电磁结构,相同…...

RAG 实战|用 StarRocks + DeepSeek 构建智能问答与企业知识库
文章作者: 石强,镜舟科技解决方案架构师 赵恒,StarRocks TSC Member 👉 加入 StarRocks x AI 技术讨论社区 https://mp.weixin.qq.com/s/61WKxjHiB-pIwdItbRPnPA RAG 和向量索引简介 RAG(Retrieval-Augmented Gen…...

JavaScript 性能优化实战
一、代码执行效率优化 1. 减少全局变量的使用 全局变量在 JavaScript 中会挂载在全局对象(浏览器环境下是window,Node.js 环境下是global)上,频繁访问全局变量会增加作用域链的查找时间。 // 反例:使用全局变量 var globalVar = example; function someFunction() {con…...
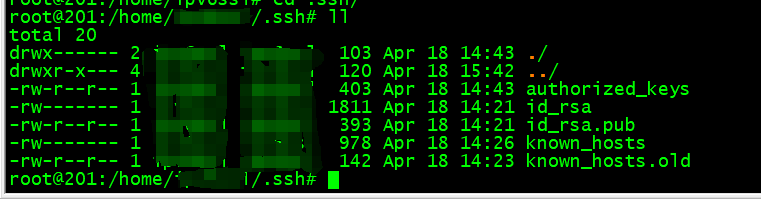
ubuntu 22.04 使用ssh-keygen创建ssh互信账户
现有两台ubuntu 22.04服务器,ip分别为192.168.66.88和192.168.88.66。需要将两台服务器创建新用户并将新用户做互信。 创建账户 adduser user1 # 如果此用户不想使用密码,直接一直回车就行,创建的用户是没法使用用户密码进行登陆的 su - …...
【Linux网络】Socket 编程TCP
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 TCP socket API 详解 socket(): bind(): listen(): accept(): connect V0…...

C++指针与内存管理深度解析
前言: 在C开发的道路上,指针和内存管理就像是两个既强大又危险的朋友。掌握它们就如同学会驾驭一辆高性能跑车,稍有不慎可能导致灾难,但一旦熟练掌握,便能发挥出惊人的性能和灵活性。今天就让我们一起深入探讨C中的指…...

ESP32-idf学习(二)esp32C3作服务端与电脑蓝牙数据交互
一、当前需求 目前是想利用蓝牙来传输命令,或者一些数据,包括电脑、手机与板子的数据传输,板子与板子之间的数据传输。构思是一个板子是数据接收终端,在电脑或手机下发指令后,再给其他板子相应指令,也需要…...
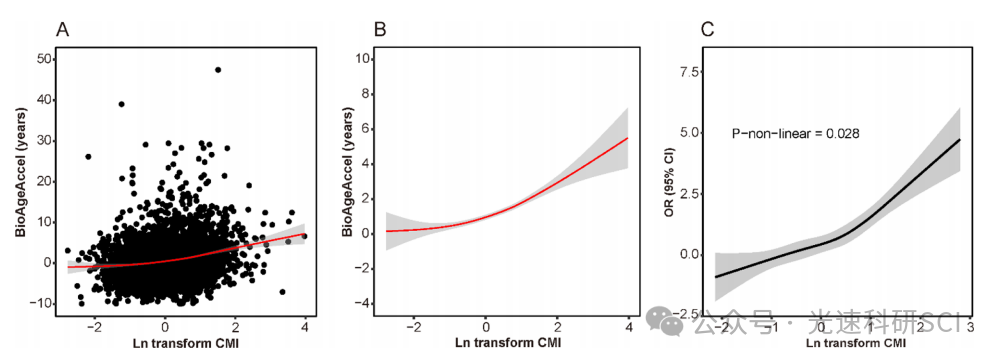
NHANES指标推荐:CMI
文章题目:Association between cardiometabolic index and biological ageing among adults: a population-based study DOI:10.1186/s12889-025-22053-3 中文标题:成年人心脏代谢指数与生物衰老之间的关系:一项基于人群的研究 发…...
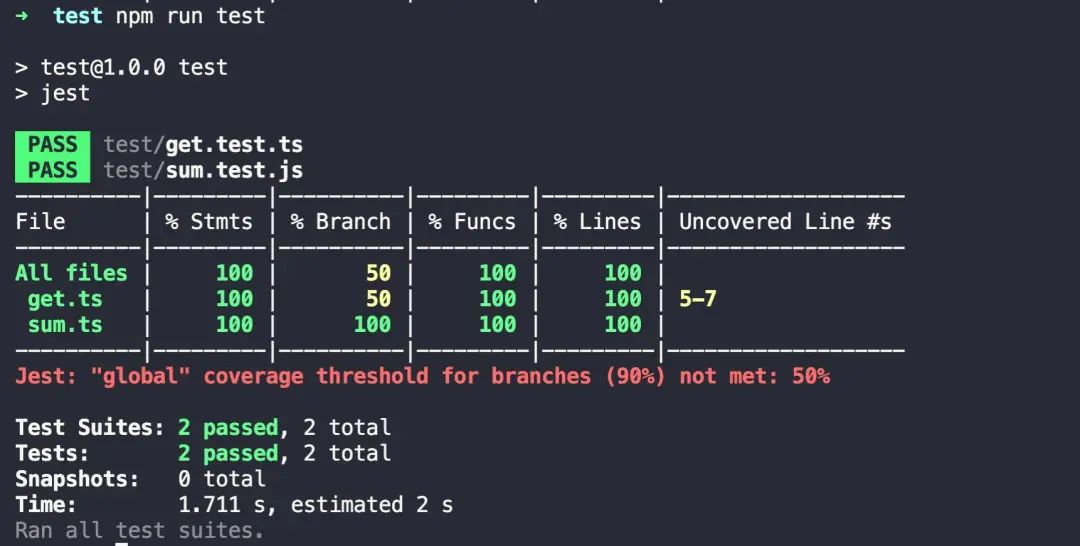
前端单元测试实战:如何开始?
实战:如何开始单元测试 1.安装依赖 npm install --save-dev jest2.简单的例子 首先,创建一个 sum.js 文件 ./sum.js function sum(a, b) {return a b; }module.exports sum;创建一个名为 sum.test.js 的文件,这个文件包含了实际测试内…...

react-native搭建开发环境过程记录
主要参考:官网的教程 https://reactnative.cn/docs/environment-setup 环境介绍:macos ios npm - 已装node18 - 已装,通过nvm进行版本控制Homebrew- 已装yarn - 已装ruby - macos系统自带的2.2版本。watchman - 正常安装Xcode - 正常安装和…...
视图(超详细))
【数据库系统概论】第3章 SQL(四)视图(超详细)
视图(View)是数据库中的虚拟表 通过执行查询定义并存储在数据库中,可以像普通表一样被查询和使用。 视图本身并不存储数据,而是基于一个或多个表的查询结果动态生成。 视图的概念 视图( View )是由其它表或视图上的查询所定义…...
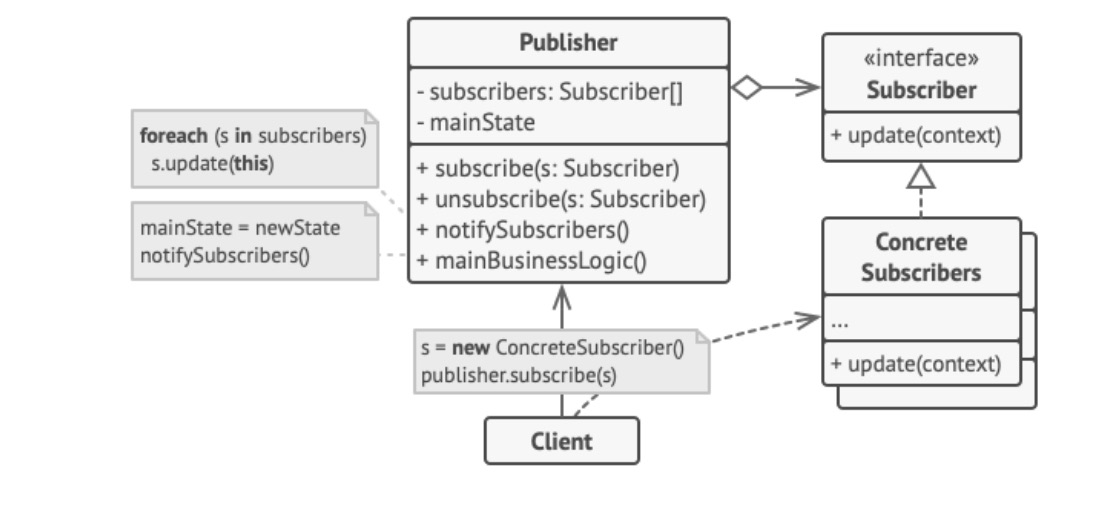
观察者模式详解与C++实现
1. 模式定义 观察者模式(Observer Pattern)是一种行为型设计模式,定义了对象间的一对多依赖关系。当一个对象(被观察者/主题)状态改变时,所有依赖它的对象(观察者)都会自动收到通知…...

空调制冷量和功率有什么关系?
空调的制冷量和功率是衡量空调性能的两个核心参数,二者既有区别又紧密相关,以下是具体解析: 1. 基本定义 制冷量(Cooling Capacity)指空调在单位时间内从室内环境中移除的热量,单位为 瓦特(W) 或 千卡/小时(kcal/h)。它直接反映空调的制冷能力,数值越大,制冷效果越…...

【python报错解决训练】
在编程开发中,正确解读报错信息是解决问题的关键技能。以下是系统学习解读报错信息的方法指南: 一、理解报错信息的核心结构 典型的报错信息包含以下要素(以Python为例): Traceback (most recent call last):File &q…...
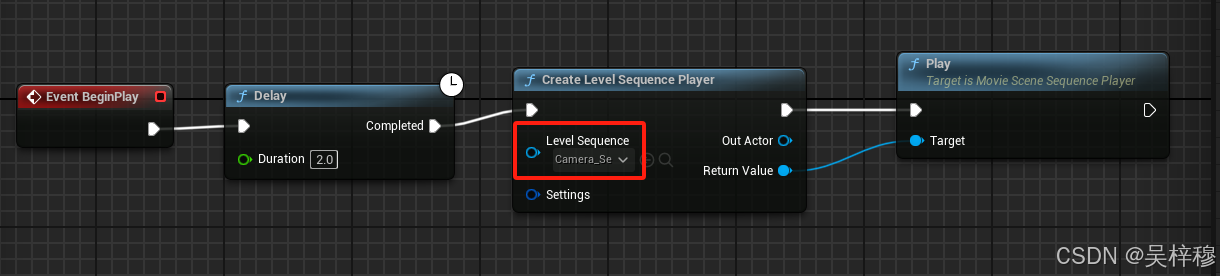
UE5 关卡序列
文章目录 介绍创建一个关卡序列编辑动画添加一个物体编辑动画时间轴显示秒而不是帧时间轴跳转到一个确定的时间时间轴的显示范围更改关键帧的动画插值方式操作多个关键帧 播放动画 介绍 类似于Unity的Animation动画,可以用来录制场景中物体的动画 创建一个关卡序列…...

AI测试用例生成平台
AI测试用例生成平台 项目背景技术栈业务描述项目展示项目重难点 项目背景 针对传统接口测试用例设计高度依赖人工经验、重复工作量大、覆盖场景有限等行业痛点,基于大语言模型技术实现接口测试用例智能生成系统。 技术栈 LangChain框架GLM-4模型Prompt Engineeri…...
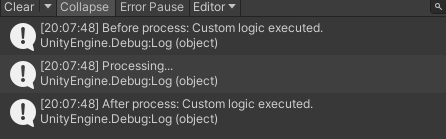
C#中扩展方法和钩子机制使用
1.扩展方法: 扩展方法允许向现有类型 “添加” 方法,而无需创建新的派生类型、重新编译或以其他方式修改原始类型。扩展方法是一种特殊的静态方法,但可以像实例方法一样进行调用。 使用场景: 1.当无法修改某个类的源代码&#…...

大语言模型减少幻觉的常见方案
什么是大语言模型的幻觉 大语言模型的幻觉(Hallucination)是指模型在生成文本时,输出与输入无关、不符合事实、逻辑错误或完全虚构的内容。这种现象主要源于模型基于概率生成文本的本质,其目标是生成语法合理、上下文连贯的文本&…...
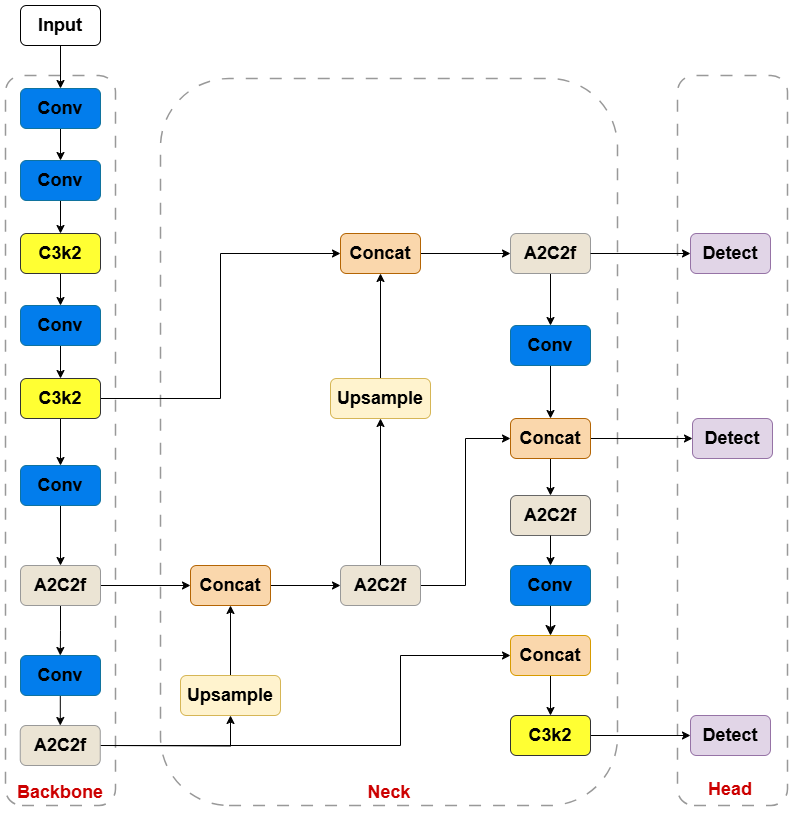
YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOv9、YOLOv10、YOLOv11、YOLOv12的网络结构图
文章目录 一、YOLOv5二、YOLOv6三、YOLOv7四、YOLOv8五、YOLOv9六、YOLOv10七、YOLOv11八、YOLOv12九、目标检测系列文章 本文将给出YOLO各版本(YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOv9、YOLOv10、YOLOv11、YOLOv12)网络结构图的绘制方法及图。本文所展…...
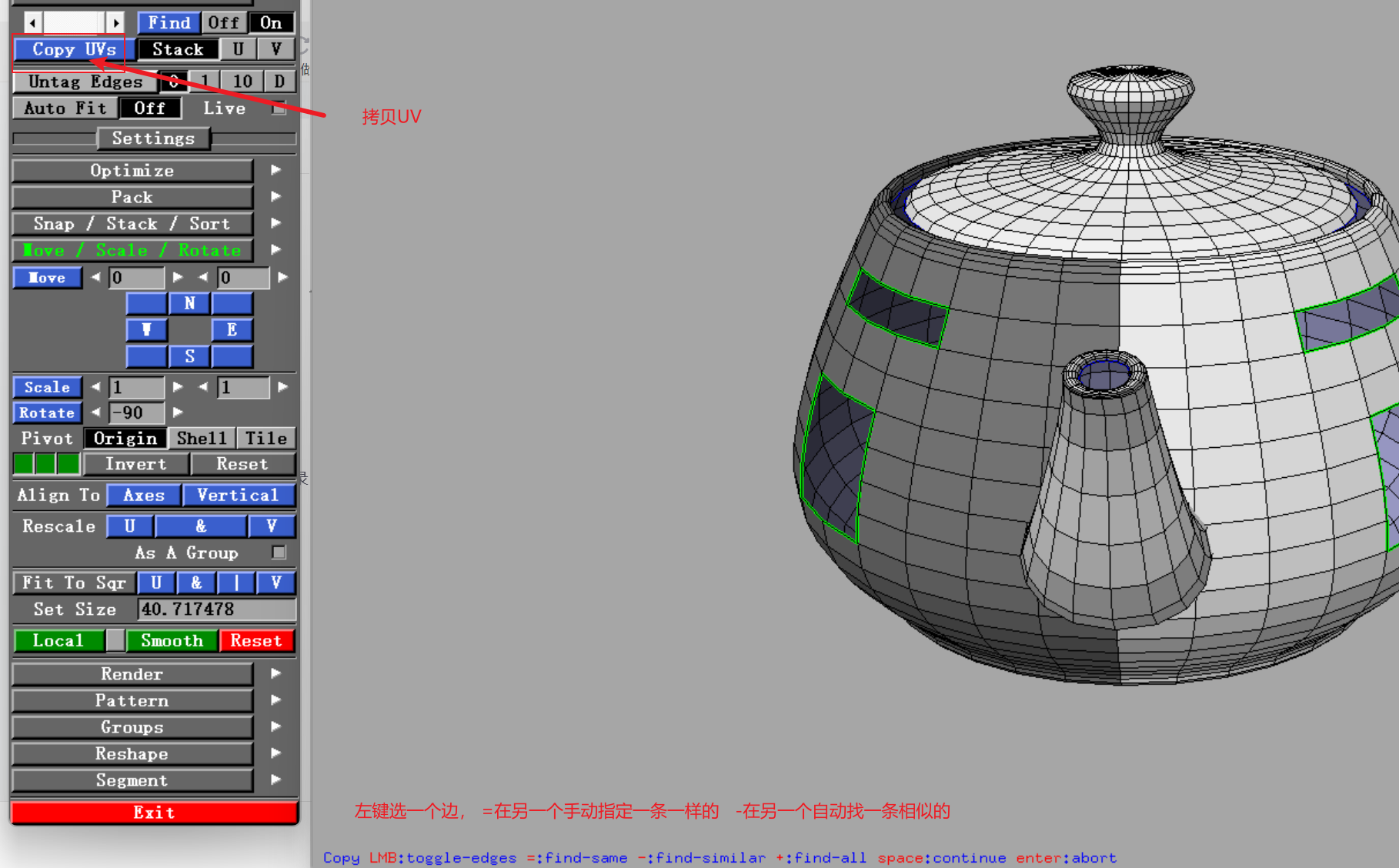
03 UV
04 Display工具栏_哔哩哔哩_bilibili 讲的很棒 ctrlMMB 移动点 s 打针 ss 批量打针...