RAG 实战|用 StarRocks + DeepSeek 构建智能问答与企业知识库

文章作者:
石强,镜舟科技解决方案架构师
赵恒,StarRocks TSC Member
👉 加入 StarRocks x AI 技术讨论社区 https://mp.weixin.qq.com/s/61WKxjHiB-pIwdItbRPnPA
RAG 和向量索引简介
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合外部知识检索与 AI 生成的技术,弥补了传统大模型知识静态、易编造信息的缺陷,使回答更加准确且基于实时信息。
RAG 的核心流程
检索(Retrieval)
-
用户输入问题后,RAG 从外部数据库(如维基百科、企业文档、科研论文等)检索相关内容。
-
检索工具可以是向量数据库、搜索引擎或传统数据库。
生成(Generation)
-
将检索到的相关信息与用户输入一起输入生成模型(如 GPT、LLaMA 等),生成更准确的回答。
-
模型基于检索内容“增强”输出,而非仅依赖内部参数化知识。
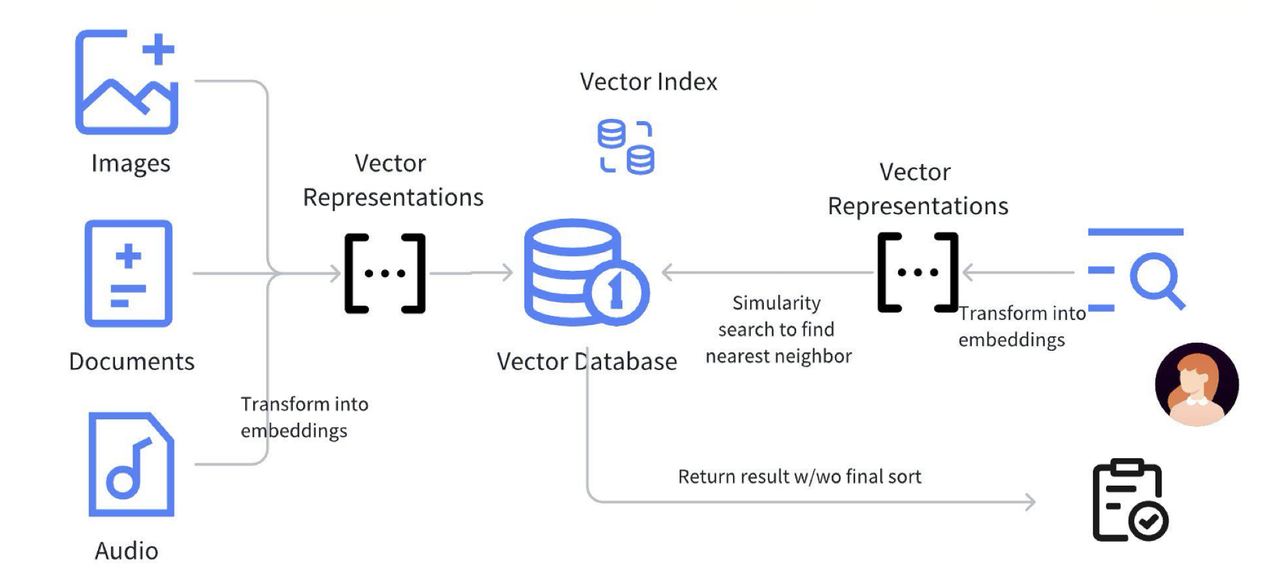
上图展示了 RAG 的标准流程。首先,图片、文档、视频和音频等数据经过预处理,转换为 Embedding 并存入向量数据库。Embedding 通常是高维 float 数组,借助向量索引(如 HNSW、IVF)进行相似性搜索,加速高效检索。
向量索引通过近似最近邻(ANN)算法优化查询效率,减少高维计算负担。语义搜索匹配用户问题与知识库中的相关内容,使回答基于真实信息,从而降低大模型的“幻觉”风险,提升回答的自然性和可靠性。
关于向量检索的更多介绍,可以参考 腾讯大数据基于 StarRocks 的向量检索探索 这篇文章。这里不再展开说明。
StarRocks + DeepSeek 的典型 RAG 应用场景
DeepSeek 负责生成高质量 Embedding 和回答,StarRocks 提供实时高效的向量检索,二者结合可构建更智能、更精准的 AI 解决方案。
企业级知识库
适用场景:
-
企业内部知识库(文档搜索、FAQ)
-
法律、金融、医药等专业领域问答
-
代码搜索、软件开发文档查询
方案:
-
文档嵌入(DeepSeek 负责): 将企业知识库、FAQ、技术文档等数据转换为向量。
-
存储+索引(StarRocks 负责): 使用 HNSW 或 IVFPQ 存储向量存储在 StarRocks 中,支持高效检索。
-
检索增强生成(RAG 负责): 用户输入问题 → DeepSeek 生成查询向量 → StarRocks 进行向量匹配 → 返回相关文档 → DeepSeek 结合文档生成最终回答。
AI 客服与智能问答
适用场景:
-
智能客服(银行、证券、电商)
-
法律、医疗等专业咨询
-
技术支持自动问答
方案:
-
客户对话日志嵌入(DeepSeek 负责): 训练 LLM 处理用户意图,转换历史聊天记录为向量。
-
存储+索引(StarRocks 负责): 采用向量索引让客服系统能够高效查找相似案例。
-
检索增强(RAG 负责): 结合历史客服对话 + 知识库 + DeepSeek LLM 生成答案。
示例流程:
-
用户问:“我如何更改银行卡预留手机号?”
-
StarRocks 检索到 3 个最相似的客户服务记录
-
DeepSeek 结合这 3 条历史记录 + 预设 FAQ,生成精准回答
操作演示
系统组成
-
DeepSeek:提供文本向量化(embedding)和答案生成能力
-
StarRocks:高效存储和检索向量数据(3.4+版本支持向量索引)
实现流程:
| 步骤 | 负责组件 | 具体实现 |
| 1.环境准备 | Ollama StarRocks | 用 Ollama 在本地机器上便捷地部署和运行大型语言模型 |
| 2.数据向量化 | DeepSeek-Embedding | 文本 → 3584 维向量 |
| 3.存储向量 | StarRocks | 创建表,存入向量 |
| 4.近似最近邻搜索 | StarRocks 向量索引 | IVFPQ / HNSW 检索 |
| 5.检索增强 | 模拟 RAG 逻辑 | 结合检索数据 |
| 6.生成答案 | DeepSeek LLM | 生成基于真实数据的回答 |
1.环境准备
1.1 DeepSeek 本地部署
Tips: 以下内容使用的是 macbook 进行 demo 演示
1.1.1 使用 ollama 安装本地模型
在本地部署 DeepSeek 时,Ollama 主要起到模型管理和提供推理接口的作用,支持运行多个不同的 LLM,并允许用户在本地切换和管理不同的模型。
-
下载 ollama:https://ollama.com/
-
安装 deepseek-r1:7b
# 该命令会自动下载并加载模型ollama run deepseek-r1:7b

Tips: 如果想使用云端 LLM(如 DeepSeek 的官方 API),需要获取并填写 API Key
访问 DeepSeek 官网(https://platform.deepseek.com)后注册账号并登录;在仪表盘中创建 API Key(通常在 “API Keys” 或 “Developer” 部分),复制生成的密钥(如 sk-xxxxxxxxxxxxxxxx)。
1.1.2 Deepseek 初步使用
启动 deepseek
执行 ollama run deepseek-r1:7b 直接进入交互模式1.1.3 Deepseek 性能优化
直接在命令行设置参数:(参数单次生效)
OLLAMA_GPU_LAYERS=35 \OLLAMA_CPU_THREADS=6 \OLLAMA_BATCH_SIZE=128 \OLLAMA_CONTEXT_SIZE=4096 \ollama run deepseek-r1:7b
1.1.4 deepseek 使用

显而易见:直接使用 deepseek 进行问答,返回的答案是不符合预期的,需要对知识进行修正
1.2 StarRocks 准备工作
1.2.1 集群部署
版本需求:3.4 及以上
1.2.2 配置设置
打开 vector index
ADMIN SET FRONTEND CONFIG ("enable_experimental_vector" = "true");1.2.3 建库建表
建库:
create database knowledge_base;建表:存储知识库向量
CREATE TABLE enterprise_knowledge (id BIGINT AUTO_INCREMENT,content TEXT NOT NULL,embedding ARRAY<FLOAT> NOT NULL,INDEX vec_idx (embedding) USING VECTOR ("index_type" = "hnsw","dim" = "3584","metric_type" = "l2_distance","M" = "16","efconstruction" = "40")
) ENGINE=OLAP
PRIMARY KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES ("replication_num" = "1");Tips: DeepSeek 的 deepseek-r1:7b 模型(7B 参数版本)默认生成高维嵌入向量,通常是 3584 维
2.将文本转成向量
测试通过 deepseek 将文本转为 3584 维向量
curl -X POST http://localhost:11434/api/embeddings -d '{"model": "deepseek-r1:7b", "prompt": "产品保修期是一年。"}'下面将转化的向量数据保存在 StarRocks 中
3.知识存储 (存储向量到 StarRocks)
import pymysql
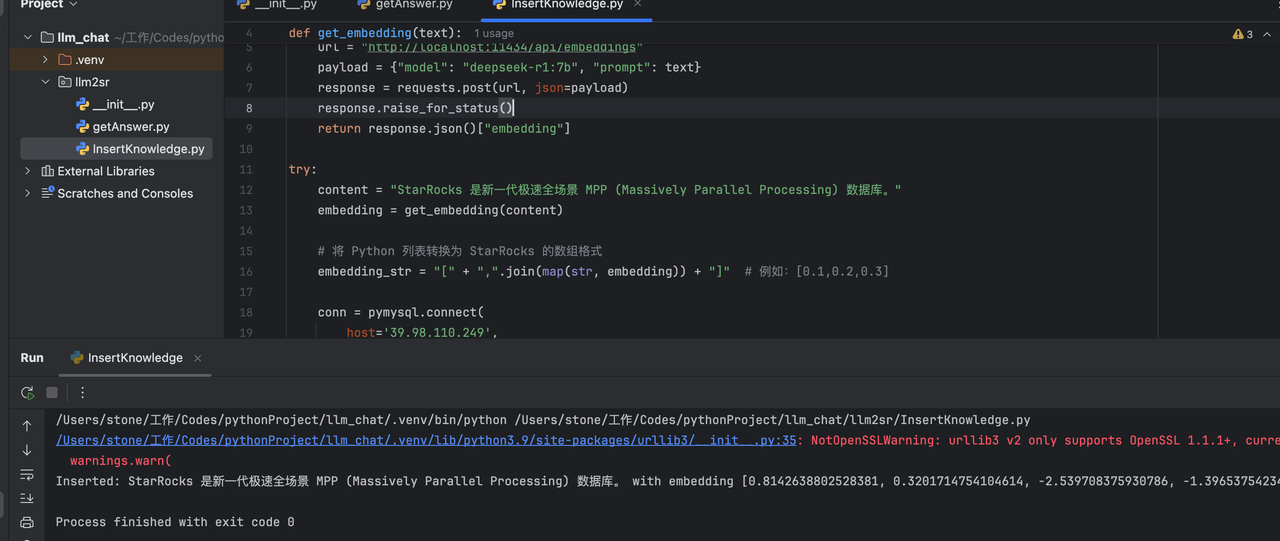
import requestsdef get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]try:content = "StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。"embedding = get_embedding(content)# 将 Python 列表转换为 StarRocks 的数组格式embedding_str = "[" + ",".join(map(str, embedding)) + "]" # 例如:[0.1,0.2,0.3]conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()# 使用格式化的数组字符串sql = "INSERT INTO enterprise_knowledge (content, embedding) VALUES (%s, %s)"cursor.execute(sql, (content, embedding_str))conn.commit()print(f"Inserted: {content} with embedding {embedding[:5]}...")except requests.RequestException as e:print(f"Embedding API error: {e}")
except pymysql.Error as db_err:print(f"Database error: {db_err}")
finally:if 'cursor' in locals():cursor.close()if 'conn' in locals():conn.close()操作演示
4.知识提取 (检索向量 & 输出结果)
import pymysql
import requests# 获取嵌入向量的函数
def get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]# 从 StarRocks 查询相似内容的函数
def search_knowledge_base(query_embedding):try:conn = pymysql.connect(host='39.98.110.249',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()# 将查询向量转换为 StarRocks 的数组格式embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"# 使用 L2 距离搜索最相似的记录sql = """SELECT content, l2_distance(embedding, %s) AS distanceFROM enterprise_knowledgeORDER BY distance ASCLIMIT 1"""cursor.execute(sql, (embedding_str,))result = cursor.fetchone()if result:return result[0] # 返回最匹配的 contentelse:return "未找到相关信息。"except pymysql.Error as db_err:print(f"Database error: {db_err}")return "查询失败。"finally:if 'cursor' in locals():cursor.close()if 'conn' in locals():conn.close()# 主流程
try:query = "StarRocks 的愿景是什么?"query_embedding = get_embedding(query) # 将查询转化为向量answer = search_knowledge_base(query_embedding) # 从知识库检索答案print(f"问题: {query}")print(f"回答: {answer}")except requests.RequestException as e:print(f"Embedding API error: {e}")
except Exception as e:print(f"Error: {e}")执行效果

补充说明:到目前为止的流程仅依赖 StarRocks 进行向量检索,未利用 DeepSeek LLM 进行生成,导致回答生硬且缺乏上下文整合,影响自然性和准确性。为提升效果,应引入 RAG 机制,使检索结果与生成模型深度融合,从而优化回答质量并减少幻觉问题。
5.加入 RAG 增强
5.1 将查询知识库的结果,返回给 DeepSeek LLM ,优化回答质量
构造 RAG Prompt
def build_rag_prompt(query, retrieved_content):prompt = f"""[系统指令] 你是企业智能客服,基于以下知识回答用户问题:[知识上下文] {retrieved_content}[用户问题] {query}"""return prompt# 调用 DeepSeek 生成回答
def generate_answer(prompt):url = "http://localhost:11434/api/generate"payload = {"model": "deepseek-r1:7b", "prompt": prompt}try:response = requests.post(url, json=payload)response.raise_for_status()full_response = ""for line in response.text.splitlines():if line.strip(): # 过滤空行try:json_obj = json.loads(line)if "response" in json_obj:full_response += json_obj["response"] # 只提取答案if json_obj.get("done", False):breakexcept json.JSONDecodeError as e:print(f"JSON 解析错误: {e}, line: {line}")return clean_response(full_response.strip()) # 处理并去掉 <think>XXX</think>except requests.exceptions.RequestException as e:print(f"请求失败: {e}")return "生成失败。"5.2 创建 RAG 过程表:
用于记录用户问题、检索结果和生成回答,保存上下文,方便进行长对话,至于长对话,用户可自行探索。
customer_service_log 表建表语句如下:
CREATE TABLE customer_service_log (id BIGINT AUTO_INCREMENT,user_id VARCHAR(50),question TEXT NOT NULL,question_embedding ARRAY<FLOAT> NOT NULL,retrieved_content TEXT,generated_answer TEXT,timestamp DATETIME NOT NULL,feedback TINYINT DEFAULT NULL
) ENGINE=OLAP
PRIMARY KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES ("replication_num" = "1"
);6.优化后的版本
6.1 知识提取代码
6.1.1 知识提取
import pymysql
import requests
import json
from datetime import datetime
import logging
import re# 获取嵌入向量
def get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text,"stream": "true"}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]# 从 StarRocks 检索知识
def search_knowledge_base(query_embedding):try:conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"sql = """SELECT content, l2_distance(embedding, %s) AS distanceFROM enterprise_knowledgeORDER BY distance ASCLIMIT 3"""cursor.execute(sql, (embedding_str,))results=cursor.fetchall()content=""for result in results:content+=result[0]return contentexcept pymysql.Error as db_err:print(f"Database error: {db_err}")return "查询失败。"finally:cursor.close()conn.close()def build_rag_prompt(query, retrieved_content):prompt = f"""[系统指令] 你是企业智能客服,基于以下知识回答用户问题:[知识上下文] {retrieved_content}[用户问题] {query}"""return prompt# 调用 DeepSeek 生成回答
def generate_answer(prompt):url = "http://localhost:11434/api/generate"payload = {"model": "deepseek-r1:7b", "prompt": prompt}try:response = requests.post(url, json=payload)response.raise_for_status()full_response = ""for line in response.text.splitlines():if line.strip(): # 过滤空行try:json_obj = json.loads(line)if "response" in json_obj:full_response += json_obj["response"] # 只提取答案if json_obj.get("done", False):breakexcept json.JSONDecodeError as e:print(f"JSON 解析错误: {e}, line: {line}")return clean_response(full_response.strip()) # 处理并去掉 <think>XXX</think>except requests.exceptions.RequestException as e:print(f"请求失败: {e}")return "生成失败。"# 记录对话日志
def log_conversation(user_id, question, question_embedding, retrieved_content, generated_answer):try:conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()embedding_str = "[" + ",".join(map(str, question_embedding)) + "]"sql = """INSERT INTO customer_service_log (user_id, question, question_embedding, retrieved_content, generated_answer, timestamp)VALUES (%s, %s, %s, %s, %s, NOW())"""cursor.execute(sql, (user_id, question, embedding_str, retrieved_content, generated_answer))conn.commit()except pymysql.Error as db_err:print(f"Database error: {db_err}")finally:cursor.close()conn.close()def clean_response(text):# 去掉所有 <think>xxx</think> 结构return re.sub(r"<think>.*?</think>", "", text, flags=re.DOTALL).strip()# 主流程
def rag_pipeline(user_id, query):try:logging.info(f"开始处理查询: {query}")query_embedding = get_embedding(query)logging.info("获取嵌入向量成功")retrieved_content = search_knowledge_base(query_embedding)logging.info(f"检索到内容: {retrieved_content[:50]}...") # 只展示前50字符prompt = build_rag_prompt(query, retrieved_content)generated_answer = generate_answer(prompt)logging.info(f"生成回答: {generated_answer[:50]}...")log_conversation(user_id, query, query_embedding, retrieved_content, generated_answer)logging.info("日志记录完成")return generated_answerexcept Exception as e:logging.error(f"发生错误: {e}", exc_info=True)return "处理失败。"# 测试
if __name__ == '__main__':logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")user_id = "user123"query = "StarRocks 的愿景是什么?"answer = rag_pipeline(user_id, query)print(f"问题: {query}")print(f"回答: {answer}")6.1.2 操作演示

总结一下 RAG 增强后的执行流程:
输入:用户输入问题
数据向量化:DeepSeek Embedding
StarRocks 向量索引,在 enterprise_knowledge 表中检索最相似的知识
增强(Augmentation):将检索结果与问题组合成 Prompt,传递给 DeepSeek
生成回答:调用 DeepSeek 生成增强后的回答
记录日志:将问题、检索结果和生成回答存入 customer_service_log
返回结果:将生成的回答返回给用户
6.2 加上 web 可视化界面
<!DOCTYPE html>
<html lang="zh">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>智能问答客服系统</title><script>async function askQuestion() {let question = document.getElementById("question").value;let response = await fetch("/ask", {method: "POST",headers: {"Content-Type": "application/json"},body: JSON.stringify({ question: question })});let data = await response.json();document.getElementById("answer").innerText = data.answer;}</script>
</head>
<body><h1>智能问答客服系统</h1><input type="text" id="question" placeholder="请输入您的问题"><button onclick="askQuestion()">提问</button><p id="answer"></p>
</body>
</html>6.3 完整问答后台服务代码
6.3.1 代码结构如下
6.3.2 知识存储代码
import pymysql
import requestsdef get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]try:content = "StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。"embedding = get_embedding(content)# 将 Python 列表转换为 StarRocks 的数组格式embedding_str = "[" + ",".join(map(str, embedding)) + "]" # 例如:[0.1,0.2,0.3]conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()# 使用格式化的数组字符串sql = "INSERT INTO enterprise_knowledge (content, embedding) VALUES (%s, %s)"cursor.execute(sql, (content, embedding_str))conn.commit()print(f"Inserted: {content} with embedding {embedding[:5]}...")except requests.RequestException as e:print(f"Embedding API error: {e}")
except pymysql.Error as db_err:print(f"Database error: {db_err}")
finally:if 'cursor' in locals():cursor.close()if 'conn' in locals():conn.close()6.3.3 知识提取
import pymysql
import requests
import json
import logging
import re
from flask import Flask, request, jsonify, render_templateapp = Flask(__name__)# 配置日志
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")# 获取嵌入向量
def get_embedding(text):url = "http://localhost:11434/api/embeddings"payload = {"model": "deepseek-r1:7b", "prompt": text, "stream": "true"}response = requests.post(url, json=payload)response.raise_for_status()return response.json()["embedding"]# 从 StarRocks 检索知识
def search_knowledge_base(query_embedding):try:conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()embedding_str = "[" + ",".join(map(str, query_embedding)) + "]"sql = """SELECT content, l2_distance(embedding, %s) AS distanceFROM enterprise_knowledgeORDER BY distance ASCLIMIT 3"""cursor.execute(sql, (embedding_str,))results=cursor.fetchall()content=""for result in results:content+=result[0]# result = cursor.fetchone()return contentexcept pymysql.Error as db_err:print(f"Database error: {db_err}")return "查询失败。"finally:cursor.close()conn.close()# 构造 RAG Prompt
def build_rag_prompt(query, retrieved_content):return f"""[系统指令] 你是企业智能客服,基于以下知识回答用户问题:[知识上下文] {retrieved_content}[用户问题] {query}"""# 调用 DeepSeek 生成回答
def generate_answer(prompt):url = "http://localhost:11434/api/generate"payload = {"model": "deepseek-r1:7b", "prompt": prompt}try:response = requests.post(url, json=payload)response.raise_for_status()full_response = ""for line in response.text.splitlines():if line.strip():try:json_obj = json.loads(line)if "response" in json_obj:full_response += json_obj["response"]if json_obj.get("done", False):breakexcept json.JSONDecodeError as e:logging.warning(f"JSON 解析错误: {e}, line: {line}")return clean_response(full_response.strip()) # 处理并去掉 <think>XXX</think>except requests.exceptions.RequestException as e:logging.error(f"请求失败: {e}")return "生成失败。"# 记录对话日志
def log_conversation(user_id, question, question_embedding, retrieved_content, generated_answer):try:conn = pymysql.connect(host='X.X.X.X',port=9030,user='root',password='sr123456',database='knowledge_base')cursor = conn.cursor()embedding_str = "[" + ",".join(map(str, question_embedding)) + "]"sql = """INSERT INTO customer_service_log (user_id, question, question_embedding, retrieved_content, generated_answer, timestamp)VALUES (%s, %s, %s, %s, %s, NOW())"""cursor.execute(sql, (user_id, question, embedding_str, retrieved_content, generated_answer))conn.commit()except pymysql.Error as db_err:logging.error(f"数据库错误: {db_err}")finally:cursor.close()conn.close()# 清理回答内容,去掉 <think>XXX</think>
def clean_response(text):return re.sub(r"<think>.*?</think>", "", text, flags=re.DOTALL).strip()# RAG 处理流程
def rag_pipeline(user_id,query):try:logging.info(f"开始处理查询: {query}")query_embedding = get_embedding(query)logging.info("获取嵌入向量成功")retrieved_content = search_knowledge_base(query_embedding)logging.info(f"检索到内容: {retrieved_content[:50]}...") # 只展示前50字符prompt = build_rag_prompt(query, retrieved_content)generated_answer = generate_answer(prompt)logging.info(f"生成回答: {generated_answer[:50]}...")log_conversation(user_id, query, query_embedding, retrieved_content, generated_answer)logging.info("日志记录完成")return generated_answerexcept Exception as e:logging.error(f"发生错误: {e}", exc_info=True)return "处理失败。"# Flask API
@app.route("/")
def index():return render_template("index.html") # 渲染前端页面@app.route("/ask", methods=["POST"])
def ask():user_id="sr_01"data = request.jsonquestion = data.get("question", "")result=rag_pipeline(user_id,question)answer = f"问题:{question}。\n 回答:{result}"return jsonify({"answer": answer})if __name__ == "__main__":user_id = "sr"app.run(host="0.0.0.0", port=9033, debug=True)6.3.4 效果演示


参考文档:
Deepseek 搭建:https://zhuanlan.zhihu.com/p/20803691410
Vector index 资料:https://docs.starrocks.io/zh/docs/table_design/indexes/vector_index/
StarRocks AI 共创计划:让数据分析更智能!
AI 时代已来,StarRocks 正在加速进化!我们诚邀社区开发者、数据工程师和 AI 爱好者一起探索 “AI + 数据分析” 的无限可能。无论你是擅长算法优化、应用落地,还是热爱技术布道,这里都有你的舞台!
🌟 你的贡献,能让 StarRocks 更强大!我们期待你在以下方向大展身手:
AI 增强分析:用 LLM、RAG 优化查询、智能 SQL 生成、自然语言交互
工具 & 插件:开发 AI 扩展、模型集成、自动化运维方案
实战案例:分享你的 AI+StarRocks 应用 Demo(附代码/视频更佳!)
🎁 丰厚奖励
Top 10 优秀贡献者将获得 StarRocks 社区荣誉 + 2000 积分奖励(详情参考 StarRocks 布道师计划)
优秀项目有机会被官方推荐,并整合进 StarRocks 生态
📢 立即行动!👉 在社区论坛分享你的创意或 AI 实践:https://forum.mirrorship.cn/
相关文章:
RAG 实战|用 StarRocks + DeepSeek 构建智能问答与企业知识库
文章作者: 石强,镜舟科技解决方案架构师 赵恒,StarRocks TSC Member 👉 加入 StarRocks x AI 技术讨论社区 https://mp.weixin.qq.com/s/61WKxjHiB-pIwdItbRPnPA RAG 和向量索引简介 RAG(Retrieval-Augmented Gen…...

JavaScript 性能优化实战
一、代码执行效率优化 1. 减少全局变量的使用 全局变量在 JavaScript 中会挂载在全局对象(浏览器环境下是window,Node.js 环境下是global)上,频繁访问全局变量会增加作用域链的查找时间。 // 反例:使用全局变量 var globalVar = example; function someFunction() {con…...
ubuntu 22.04 使用ssh-keygen创建ssh互信账户
现有两台ubuntu 22.04服务器,ip分别为192.168.66.88和192.168.88.66。需要将两台服务器创建新用户并将新用户做互信。 创建账户 adduser user1 # 如果此用户不想使用密码,直接一直回车就行,创建的用户是没法使用用户密码进行登陆的 su - …...
【Linux网络】Socket 编程TCP
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 TCP socket API 详解 socket(): bind(): listen(): accept(): connect V0…...

C++指针与内存管理深度解析
前言: 在C开发的道路上,指针和内存管理就像是两个既强大又危险的朋友。掌握它们就如同学会驾驭一辆高性能跑车,稍有不慎可能导致灾难,但一旦熟练掌握,便能发挥出惊人的性能和灵活性。今天就让我们一起深入探讨C中的指…...

ESP32-idf学习(二)esp32C3作服务端与电脑蓝牙数据交互
一、当前需求 目前是想利用蓝牙来传输命令,或者一些数据,包括电脑、手机与板子的数据传输,板子与板子之间的数据传输。构思是一个板子是数据接收终端,在电脑或手机下发指令后,再给其他板子相应指令,也需要…...
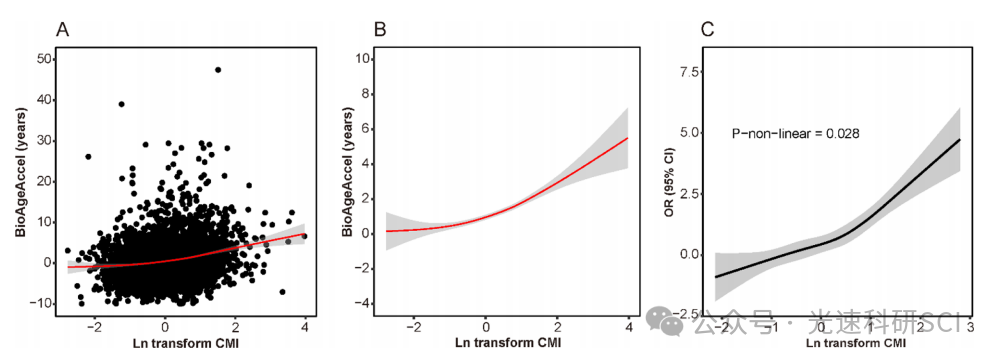
NHANES指标推荐:CMI
文章题目:Association between cardiometabolic index and biological ageing among adults: a population-based study DOI:10.1186/s12889-025-22053-3 中文标题:成年人心脏代谢指数与生物衰老之间的关系:一项基于人群的研究 发…...
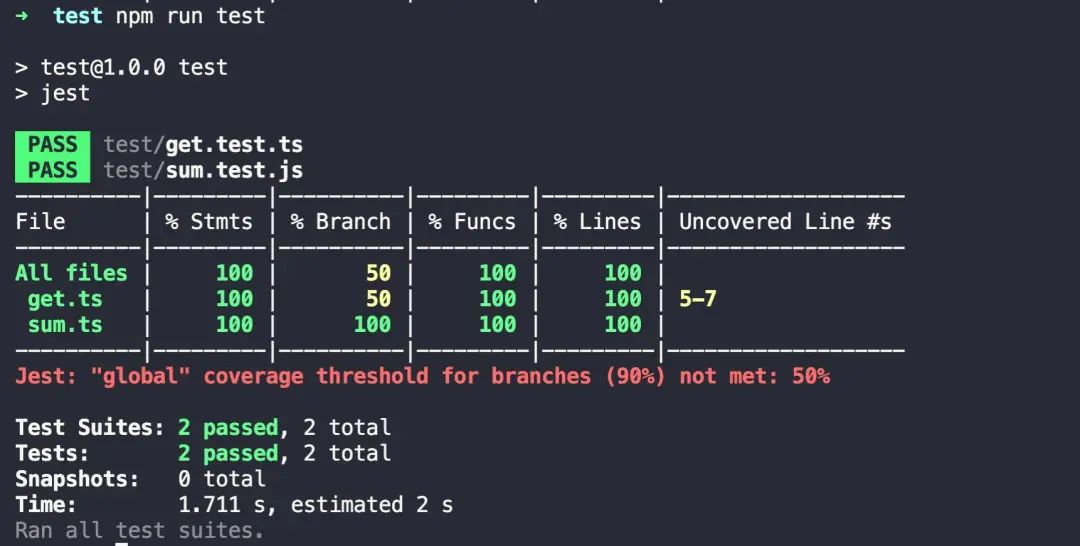
前端单元测试实战:如何开始?
实战:如何开始单元测试 1.安装依赖 npm install --save-dev jest2.简单的例子 首先,创建一个 sum.js 文件 ./sum.js function sum(a, b) {return a b; }module.exports sum;创建一个名为 sum.test.js 的文件,这个文件包含了实际测试内…...

react-native搭建开发环境过程记录
主要参考:官网的教程 https://reactnative.cn/docs/environment-setup 环境介绍:macos ios npm - 已装node18 - 已装,通过nvm进行版本控制Homebrew- 已装yarn - 已装ruby - macos系统自带的2.2版本。watchman - 正常安装Xcode - 正常安装和…...
视图(超详细))
【数据库系统概论】第3章 SQL(四)视图(超详细)
视图(View)是数据库中的虚拟表 通过执行查询定义并存储在数据库中,可以像普通表一样被查询和使用。 视图本身并不存储数据,而是基于一个或多个表的查询结果动态生成。 视图的概念 视图( View )是由其它表或视图上的查询所定义…...
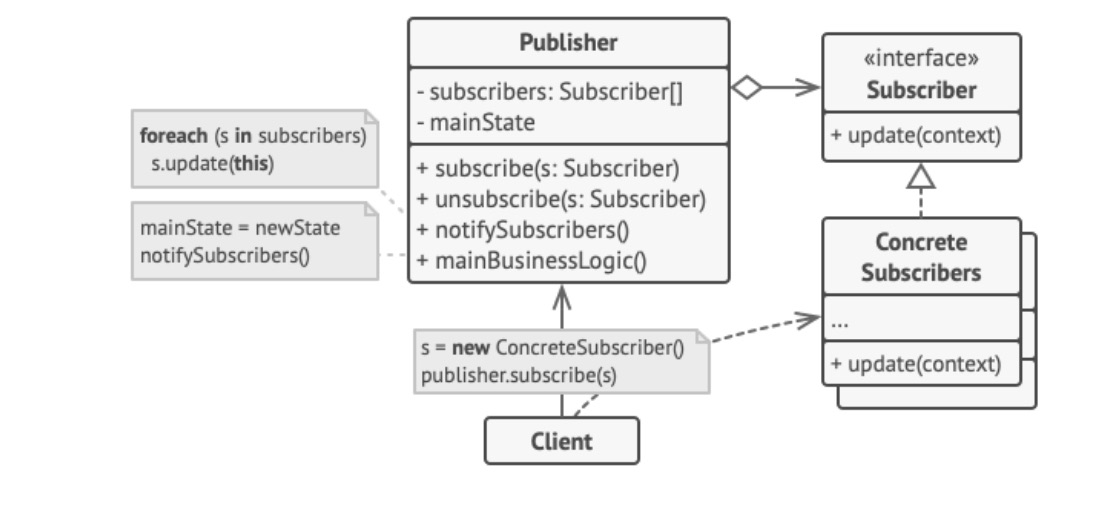
观察者模式详解与C++实现
1. 模式定义 观察者模式(Observer Pattern)是一种行为型设计模式,定义了对象间的一对多依赖关系。当一个对象(被观察者/主题)状态改变时,所有依赖它的对象(观察者)都会自动收到通知…...

空调制冷量和功率有什么关系?
空调的制冷量和功率是衡量空调性能的两个核心参数,二者既有区别又紧密相关,以下是具体解析: 1. 基本定义 制冷量(Cooling Capacity)指空调在单位时间内从室内环境中移除的热量,单位为 瓦特(W) 或 千卡/小时(kcal/h)。它直接反映空调的制冷能力,数值越大,制冷效果越…...

【python报错解决训练】
在编程开发中,正确解读报错信息是解决问题的关键技能。以下是系统学习解读报错信息的方法指南: 一、理解报错信息的核心结构 典型的报错信息包含以下要素(以Python为例): Traceback (most recent call last):File &q…...
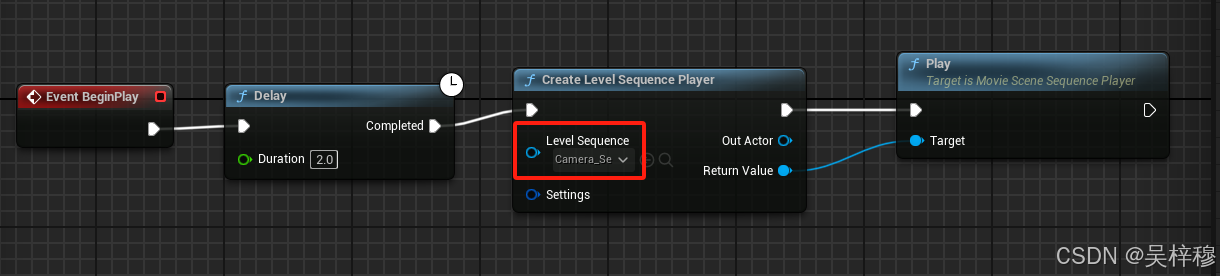
UE5 关卡序列
文章目录 介绍创建一个关卡序列编辑动画添加一个物体编辑动画时间轴显示秒而不是帧时间轴跳转到一个确定的时间时间轴的显示范围更改关键帧的动画插值方式操作多个关键帧 播放动画 介绍 类似于Unity的Animation动画,可以用来录制场景中物体的动画 创建一个关卡序列…...

AI测试用例生成平台
AI测试用例生成平台 项目背景技术栈业务描述项目展示项目重难点 项目背景 针对传统接口测试用例设计高度依赖人工经验、重复工作量大、覆盖场景有限等行业痛点,基于大语言模型技术实现接口测试用例智能生成系统。 技术栈 LangChain框架GLM-4模型Prompt Engineeri…...
C#中扩展方法和钩子机制使用
1.扩展方法: 扩展方法允许向现有类型 “添加” 方法,而无需创建新的派生类型、重新编译或以其他方式修改原始类型。扩展方法是一种特殊的静态方法,但可以像实例方法一样进行调用。 使用场景: 1.当无法修改某个类的源代码&#…...

大语言模型减少幻觉的常见方案
什么是大语言模型的幻觉 大语言模型的幻觉(Hallucination)是指模型在生成文本时,输出与输入无关、不符合事实、逻辑错误或完全虚构的内容。这种现象主要源于模型基于概率生成文本的本质,其目标是生成语法合理、上下文连贯的文本&…...
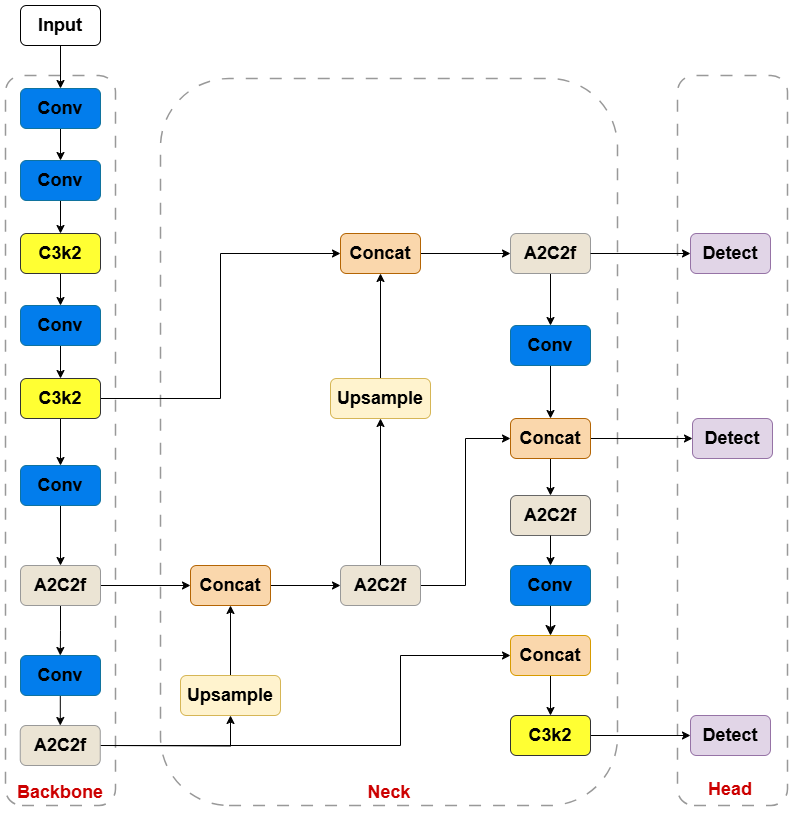
YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOv9、YOLOv10、YOLOv11、YOLOv12的网络结构图
文章目录 一、YOLOv5二、YOLOv6三、YOLOv7四、YOLOv8五、YOLOv9六、YOLOv10七、YOLOv11八、YOLOv12九、目标检测系列文章 本文将给出YOLO各版本(YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOv9、YOLOv10、YOLOv11、YOLOv12)网络结构图的绘制方法及图。本文所展…...
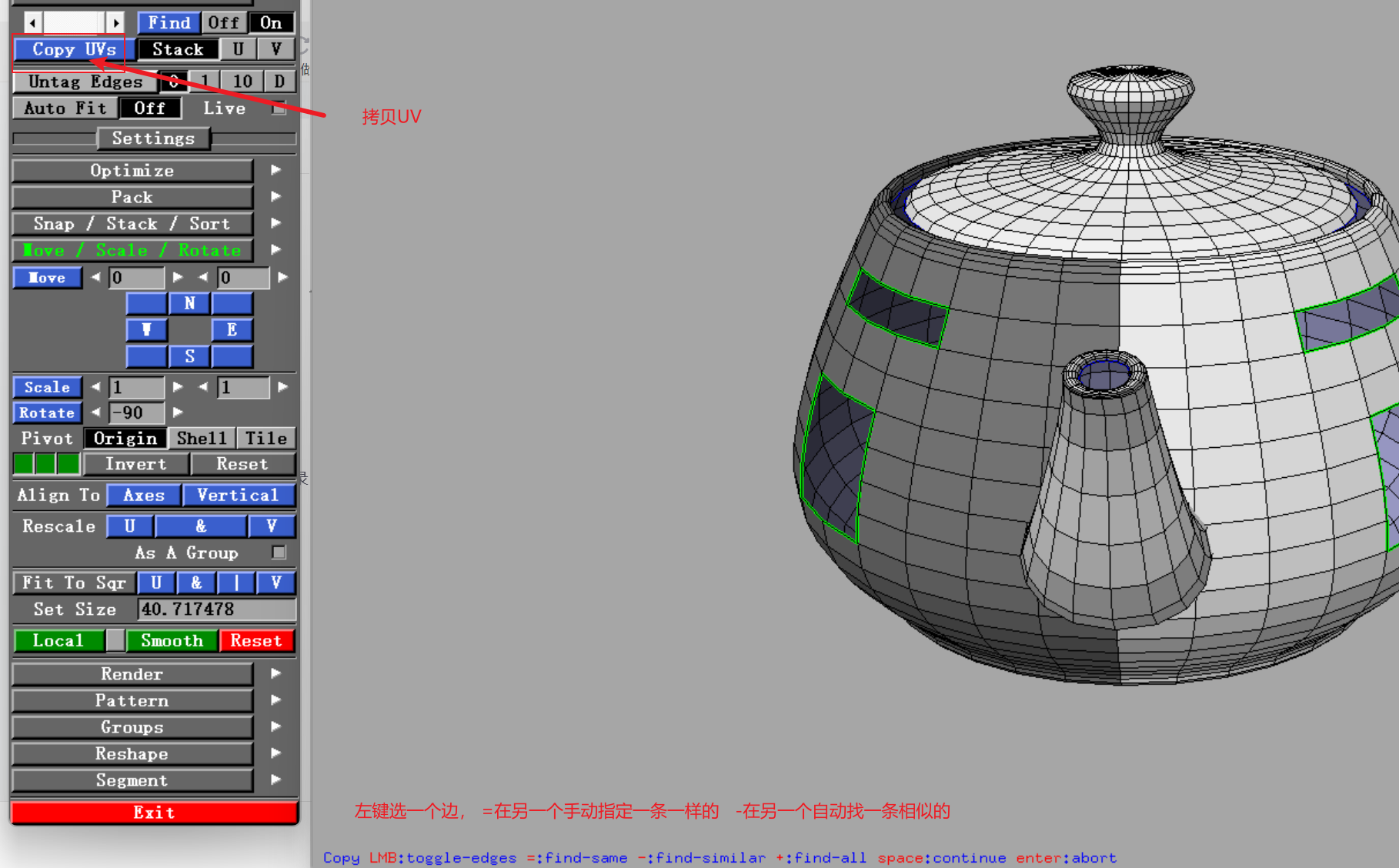
03 UV
04 Display工具栏_哔哩哔哩_bilibili 讲的很棒 ctrlMMB 移动点 s 打针 ss 批量打针...
AIGC-几款本地生活服务智能体完整指令直接用(DeepSeek,豆包,千问,Kimi,GPT)
Unity3D特效百例案例项目实战源码Android-Unity实战问题汇总游戏脚本-辅助自动化Android控件全解手册再战Android系列Scratch编程案例软考全系列Unity3D学习专栏蓝桥系列AIGC(GPT、DeepSeek、豆包、千问、Kimi)👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资…...

Django ORM 定义模型
提示:定义模型字段的类型 文章目录 一、字段类型二、字段属性三、元信息 一、字段类型 常用字段 字段名描述备注AutoFieldint 自增必填参数 primary_keyTrue,无该字段时,django自动创建一个 BigAutoField,一个model不能有两个Au…...
)
4.18---缓存相关问题(操作原子性,击穿,穿透,雪崩,redis优势)
为什么要用redis做一层缓存,相比直接查mysql有什么优势? 首先介绍Mysql自带缓存机制的问题: MySQL 的缓存机制存在一些限制和问题,它自身带的缓存功能Query Cache只能缓存完全相同的查询语句,对于稍有不同的查询语句,…...

java八股之并发编程
1.java线程和操作系统线程之间的区别? 现在java线程本质上是操作系统线程,java中采用的是一对一的线程模型(一个用户线程对应一个内核进程) 2.什么是进程和线程? 1.进程是操作系统一次执行,资源分配和调度的…...

C#/.NET/.NET Core拾遗补漏合集(25年4月更新)
前言 在这个快速发展的技术世界中,时常会有一些重要的知识点、信息或细节被忽略或遗漏。《C#/.NET/.NET Core拾遗补漏》专栏我们将探讨一些可能被忽略或遗漏的重要知识点、信息或细节,以帮助大家更全面地了解这些技术栈的特性和发展方向。 ✍C#/.NET/.N…...

层次式架构核心:中间层的功能、优势与技术选型全解析
层次式架构中的中间层是整个架构的核心枢纽,承担着多种重要职责,在功能实现、优势体现以及技术选型等方面都有丰富的内容,以下为你详细介绍: 一、功能 1.业务逻辑处理 复杂规则运算:在许多企业级应用中,…...

PDF.js 生态中如何处理“添加注释\添加批注”以及 annotations.contents 属性
我们来详细解释一下在 PDF.js 生态中如何处理“添加注释”以及 annotations.contents 属性。 核心要点:PDF.js 本身主要是阅读器,不是编辑器 首先,最重要的一点是:PDF.js 的核心库 (pdfjs-dist) 主要设计用于解析和渲染…...
MySQL性能调优(三):MySQL中的系统库(简介、performance_schema)
文章目录 MySQL性能调优数据库设计优化查询优化配置参数调整硬件优化 1.MySQL中的系统库1.1.系统库简介1.2.performance_schema1.2.1.什么是performance_schema1.2.2.performance_schema使用1.2.3.检查当前数据库版本是否支持1.2.4.performance_schema表的分类1.2.5.performanc…...

【Python语言基础】22、异常处理
文章目录 1. 异常1.1 简介1.2 为什么需要异常处理 2. 基本语法2.1 各部分详解 3. 异常处理流程3.1 执行try代码块3.2 异常发生检查3.3 异常捕获与匹配3.4 执行匹配的 except 代码块3.5 执行 else 代码块(可选)3.6 执行 finally 代码块(可选&a…...

印度zj游戏出海代投本土网盟广告核心优势
印度游戏出海代投本土网盟广告的核心优势包括: 本土化广告策略:针对印度市场的特点,定制本土化的广告策略,吸引更多印度用户的关注和参与。 深度了解印度市场:对印度文化、消费习惯、网络使用习惯等有深入了解&#x…...

NO.97十六届蓝桥杯备战|数论板块-最大公约数和最小公倍数|欧几里得算法|秦九韶算法|小红的gcd(C++)
约数和倍数 如果a 除以b 没有余数,那么a 就是b 的倍数,b 就是a 的约数,记作b ∣ a 。 约数,也称因数。 最⼤公约数和最⼩公倍数 最⼤公约数Greatest Common Divisor,常缩写为gcd。 ⼀组整数的公约数,是…...