使用Service发布应用程序
使用Service发布应用程序
文章目录
- 使用Service发布应用程序
- @[toc]
- 一、什么是Service
- 二、通过Endpoints理解Service的工作机制
- 1.什么是Endpoints
- 2.创建Service以验证Endpoints
- 三、Service的负载均衡机制
- 四、Service的服务发现机制
- 五、定义Service
- 六、Service类型
- 七、无头Service
- 八、多端口Service
文章目录
- 使用Service发布应用程序
- @[toc]
- 一、什么是Service
- 二、通过Endpoints理解Service的工作机制
- 1.什么是Endpoints
- 2.创建Service以验证Endpoints
- 三、Service的负载均衡机制
- 四、Service的服务发现机制
- 五、定义Service
- 六、Service类型
- 七、无头Service
- 八、多端口Service
一、什么是Service
Kubernetes 中的 Service 就像一个智能的“服务导航员”,它帮助用户和其他服务找到并访问一组动态变化的 Pod(容器组)。
- 为什么需要 Service?
想象你有一个餐厅,后厨有多个厨师(Pod)在做菜,但厨师可能随时请假或换班(Pod 被销毁或新建)。如果顾客每次都要记住每个厨师的名字和位置(Pod 的 IP 地址),那会非常麻烦。
Service 的作用就是充当餐厅的“前台”,顾客只需要找前台(Service)点餐,前台会自动分配顾客到可用的厨师那里,无论厨师怎么变动,顾客的体验始终流畅。
- Service 的核心功能
- 稳定访问点:Service 会分配一个固定的“虚拟 IP”(ClusterIP),用户只需记住这个 IP 和端口,无需关心背后 Pod 的变化。
- 负载均衡:如果后台有多个 Pod(比如 3 个处理请求的服务器),Service 会自动将流量平均分配给它们,避免某个 Pod 过载。
- 动态感知:当 Pod 因故障重启或扩容时,Service 能自动更新后端列表,确保流量只发给健康的 Pod。
- Service 的工作原理
- 标签匹配:创建 Service 时,你需要指定一个“标签选择器”(比如
app: nginx),Service 会自动找到所有带有这个标签的 Pod。 - Endpoints 列表:Service 背后有一个动态更新的列表(Endpoints),记录所有符合条件的 Pod 的 IP 和端口。Pod 变化时,列表自动更新。
- 流量转发:每个节点上的
kube-proxy组件会监听 Service 的变化,并通过 iptables 或 IPVS 规则将流量从 Service 的虚拟 IP 转发到实际 Pod。
- Service 的常见类型
- ClusterIP(默认):只能在集群内部访问,适合内部服务之间的通信(比如前端调用后端 API)。
- NodePort:在每个节点上开一个固定端口(如 30080),外部用户通过
节点IP:端口访问服务。 - LoadBalancer:在云平台(如 AWS)自动创建负载均衡器,外部流量通过这个均衡器访问服务。
- ExternalName:将 Service 映射到一个外部域名(如数据库服务),让集群内部像访问本地服务一样访问外部资源。
- 举个实际例子
假设你运行了 3 个 Nginx 容器(Pod),它们的 IP 可能随时变化。创建一个 ClusterIP 类型的 Service 后:
- Service 会分配一个固定 IP(如
10.96.148.206)。 - 用户访问
10.96.148.206:80,Service 自动将请求轮询转发到 3 个 Nginx Pod。 - 即使某个 Pod 崩溃,Service 会剔除它,并将流量导向剩余的健康 Pod。
Service 是 Kubernetes 中解决服务发现、负载均衡和稳定访问的核心机制。它像一座桥梁,连接了动态变化的 Pod 和需要稳定访问的用户或服务,让整个系统更健壮、更易管理。
二、通过Endpoints理解Service的工作机制
1.什么是Endpoints
Kubernetes 中的 Endpoints 可以理解为 Service 的“实时通讯录”,它动态记录了哪些 Pod 是真正在干活的后端实例,以及它们的具体位置(IP 和端口)。用生活中的例子来比喻:
- Endpoints 是什么?
想象你有一家快递公司(Service),客户打电话下单时,客服(Service)需要知道当前有哪些快递员(Pod)在值班,才能分配订单。
Endpoints 就是这个快递公司的“值班表”,实时记录所有在岗快递员的姓名、位置和联系方式(Pod 的 IP 和端口)。即使快递员轮班、请假或新增人手(Pod 扩缩容),值班表都会自动更新,确保客服永远知道该联系谁。
- Endpoints 的作用
- 动态更新:当 Pod 被创建、销毁或故障时,Endpoints 会自动刷新列表,确保 Service 只将流量转发到健康的 Pod。
- 负载均衡基础:Service 根据 Endpoints 中的列表,将请求平均分配给多个 Pod(比如轮询),避免某个 Pod 过载。
- 服务发现:其他服务只需访问 Service 的固定地址(如
my-service:80),无需关心背后具体是哪些 Pod 在工作,Endpoints 会默默完成地址翻译。
- 举个具体例子
假设你运行了 3 个 Nginx 服务器(Pod),它们的 IP 可能是临时的。创建一个 Service 后:
- Endpoints 自动生成:Kubernetes 会生成一个与 Service 同名的 Endpoints,记录这 3 个 Pod 的 IP 和端口(如
10.1.2.3:80)。 - 流量分配:当用户访问 Service 时,请求会被转发到 Endpoints 列表中的任意一个 Pod。如果某个 Pod 崩溃,Endpoints 会立刻剔除它,确保用户不受影响。
- 手动管理的特殊场景
大多数情况下 Endpoints 是自动管理的,但有时需要手动维护:
- 连接外部服务:比如使用非 Kubernetes 管理的数据库,可以手动创建一个 Endpoints,指定数据库的 IP 和端口,让 Service 像管理内部 Pod 一样代理外部服务。
Endpoints 是 Kubernetes 中默默支撑 Service 的“幕后英雄”。它像一张实时更新的地图,确保 Service 总能找到正确的 Pod,让整个系统在动态变化中保持稳定和高效。
2.创建Service以验证Endpoints
(1)编辑YAML文件
[root@master ~]# vi nginx-deploy.yaml
[root@master ~]# cat nginx-deploy.yaml
apiVersion: apps/v1 # 版本号
kind: Deployment # 类型为Deployment
metadata: # 元数据name: nginx-deploy labels: # 标签app: nginx-deploy
spec: # 详细信息replicas: 2 # 副本数量selector: # 选择器,指定该控制器管理哪些PodmatchLabels: # 匹配规则app: nginx-podtemplate: # 定义模板,当副本数量不足时会根据模板定义创建Pod副本metadata:labels:app: nginx-pod # Pod的标签spec:containers: # 容器列表(本例仅定义一个容器)- name: nginx # 容器的名称image: nginx:1.14.2 # 容器所用的镜像ports:- name: nginx-portcontainerPort: 80 # 容器需要暴露的端口
[root@master ~]#
containerPort是Pod内部容器的端口,仅起到标记作用,并不能改变容器本身的端口,可以省略。
(2)基于配置文件创建Deployment
[root@master ~]# kubectl apply -f nginx-deploy.yaml
deployment.apps/nginx-deploy created
(3)查看每个pod的IP
[root@master ~]# kubectl get pod -l app=nginx-pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deploy-59c566bbbb-nbdrn 1/1 Running 0 17s 10.244.104.55 node2 <none> <none>
nginx-deploy-59c566bbbb-tq9ts 1/1 Running 0 17s 10.244.166.131 node1 <none> <none>
(4)测试pod的访问
[root@master ~]# curl 10.244.166.131
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>body {width: 35em;margin: 0 auto;font-family: Tahoma, Verdana, Arial, sans-serif;}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p><p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p><p><em>Thank you for using nginx.</em></p>
</body>
</html>
结果表示可正常访问
(5)创建service文件发布该应用程序
[root@master ~]# vim nginx-service.yaml
[root@master ~]# cat nginx-service.yaml
apiVersion: v1
kind: Service
metadata:name: nginx-svc # 为Service对象命名
spec:selector:app: nginx-pod #指定Pod的标签ports:- port: 8080 # Service绑定的端口targetPort: 80 # 目标Pod的端口
这里标签选择器设置的标签名称需要和Deployment中Pod模板中的标签名称保持一致才能匹配。
(6)创建service
[root@master ~]# kubectl apply -f nginx-service.yaml
service/nginx-svc created
(7)查看该service的ClusterIP地址和绑定端口
[root@master ~]# kubectl get service nginx-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-svc ClusterIP 10.111.142.214 <none> 8080/TCP 18s
ClusterIP地址就是集群的IP地址,由K8S管理和分配给Service的虚拟IP地址。只能在集群内部访问,既不会分配给Pod,也不会分配给节点主机,不具备网络通信能力,无法被ping通,因为没有一个实体网络对象会相应它。
(8)测试通过集群IP地址和service端口访问后端Pod承载的应用程序
[root@master ~]# curl 10.111.142.214:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>body {width: 35em;margin: 0 auto;font-family: Tahoma, Verdana, Arial, sans-serif;}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p><p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p><p><em>Thank you for using nginx.</em></p>
</body>
</html>
(9)查看service详细信息
[root@master ~]# kubectl describe service nginx-svc
Name: nginx-svc
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.111.142.214 # ClusterIP地址
IPs: 10.111.142.214
Port: <unset> 8080/TCP # Service端口
TargetPort: 80/TCP
Endpoints: 10.244.104.55:80,10.244.166.131:80
Session Affinity: None
Events: <none>
Service生成的Endpoints是一组由后端Pod的IP地址和容器端口组成的端点集合。
(10)进一步查看Endpoints的列表
[root@master ~]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.10.30:6443 26d
nginx-svc 10.244.104.55:80,10.244.166.131:80 6m18s
K8S自动创建与service同名的Endpoints
接下来考察pod副本的变更对Endpoints的影响
(11)扩容deployment副本数至3
[root@master ~]# kubectl scale deployment nginx-deploy --replicas=3
deployment.apps/nginx-deploy scaled
(12)再次查看service详细信息,可以发现ClusterIP和端口没有改变,新增加的pod副本的IP地址自动加入Endpoints中,目前为3个pod
[root@master ~]# kubectl describe service nginx-svc
Name: nginx-svc
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.111.142.214
IPs: 10.111.142.214
Port: <unset> 8080/TCP
TargetPort: 80/TCP
Endpoints: 10.244.104.55:80,10.244.104.56:80,10.244.166.131:80
Session Affinity: None
Events: <none>
(13)将pod副本减少到1,查看service详细信息,可以发现被终止的pod副本自动从Endpoints中移除
[root@master ~]# kubectl scale deployment nginx-deploy --replicas=1
deployment.apps/nginx-deploy scaled
[root@master ~]# kubectl describe service nginx-svc
Name: nginx-svc
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=nginx-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.111.142.214
IPs: 10.111.142.214
Port: <unset> 8080/TCP
TargetPort: 80/TCP
Endpoints: 10.244.166.131:80
Session Affinity: None
Events: <none>
(14)依次删除service和deployment
[root@master ~]# kubectl delete -f nginx-service.yaml
service "nginx-svc" deleted
[root@master ~]# kubectl delete -f nginx-deploy.yaml
deployment.apps "nginx-deploy" deleted
简单的Service也可以使用kubectl expose命令创建,本例基于配置文件创建Service的等价命令为kubectl expose deploy nginx-deploy --port=8080 --target-port=80 --name=nginx-svc。也可以将Deployment配置文件与Service配置文件合并为一个多文档的YAML配置文件,基于该配置文件一次性创建Deployment和Service。
三、Service的负载均衡机制
Kubernetes 中的 Service 负载均衡机制,可以想象成一个“智能调度中心”,它负责将用户请求合理分配给后端的多个 Pod(容器实例),确保流量均匀分发且不遗漏任何一个实例。
- Service 的核心作用
Service 是 Kubernetes 的“流量调度员”,它通过以下方式实现负载均衡:
- 稳定入口:为动态变化的 Pod 提供一个固定的虚拟 IP(ClusterIP)或外部访问地址(如 NodePort、LoadBalancer),用户无需关心 Pod 的具体位置。
- 动态感知:通过标签(Label)自动筛选出符合条件的 Pod,并实时更新这些 Pod 的地址列表(Endpoints)。
- 流量分发:将请求按规则(如轮询、随机)转发到健康的 Pod,避免某些 Pod 过载。
- 负载均衡的实现过程
(1)匹配 Pod:标签选择器
Service 通过标签(例如 app: nginx)找到所有对应的 Pod,就像快递公司通过“区域编号”筛选出所有负责某片区域的快递员。
(2)维护实时列表:Endpoints
Service 背后有一个动态更新的“值班表”(Endpoints),记录所有可用 Pod 的 IP 和端口。当 Pod 发生扩缩容或故障时,列表自动更新,确保流量只发给健康的实例。
(3)转发规则:kube-proxy 的作用
每个节点上的 kube-proxy 组件是实际的“调度员”:
-
监听变化:实时监控 Service 和 Pod 的状态变化。
-
设置规则
:通过 iptables 或 IPVS(高效的内核级负载均衡工具)创建转发规则。例如:
- 轮询:依次将请求分给每个 Pod,像轮流给快递员分配订单。
- 随机:随机选一个 Pod 处理请求,避免顺序固定导致负载不均。
- 最少连接:优先选择当前任务最少的 Pod,类似给最闲的快递员派单。
- 不同 Service 类型的负载均衡
- ClusterIP(内部访问):默认类型,通过虚拟 IP 在集群内部转发流量,适合微服务间的通信。
- NodePort(外部访问):在每个节点上开一个固定端口(如 30080),外部用户通过节点 IP 和端口访问,流量最终由 Service 分发给 Pod。
- LoadBalancer(云环境):自动调用云平台(如 AWS、阿里云)的负载均衡器,将外部流量均匀分发到集群内的 Pod。
- 举个生活例子
假设你开了一家网红奶茶店,有 3 台奶茶机(Pod)制作饮品:
- Service 的作用:顾客只需记住店铺地址(Service 的 ClusterIP),不用知道每台奶茶机的位置。
- 负载均衡:前台(kube-proxy)根据订单量,轮流将顾客请求分给不同的奶茶机。如果某台机器坏了,前台自动跳过它,确保其他机器继续工作。
- 动态扩展:高峰期新增 2 台奶茶机,前台立即将它们加入“可用列表”,顾客无感知。
Service 的负载均衡机制就像一个“智能调度系统”,通过动态感知 Pod、维护实时列表、按规则分发请求,确保流量高效、稳定地分配到后端实例。无论是内部微服务还是外部用户请求,Service 都能灵活应对动态变化。
四、Service的服务发现机制
Kubernetes 中的 Service 服务发现机制就像一个“智能电话簿”,它帮助应用程序在动态变化的集群环境中快速找到其他服务的位置,无需手动记录或更新地址。
- 为什么需要服务发现?
想象你住在一个小区里,邻居们经常搬家(Pod 动态扩缩容)。如果每次想找邻居借东西,都要挨家挨户敲门询问地址(Pod 的 IP),效率会很低。
服务发现的作用就是自动维护一个“邻居通讯录”(Service),你只需记住邻居的名字(服务名称),就能随时找到他们的最新住址(Pod 的 IP)。
- 服务发现的核心机制
(1)静态“电话簿”:环境变量
当一个新的住户(Pod)搬进小区时,物业(Kubernetes)会给他一本“通讯录”(环境变量),里面记录了所有邻居(Service)的固定电话(ClusterIP)和门牌号(端口)。例如:
MY_SERVICE_SERVICE_HOST=10.96.148.206
MY_SERVICE_SERVICE_PORT=80
这本通讯录的问题是:如果邻居搬家(Pod 重启或更换),电话簿不会自动更新,只能重新找物业要一本(重启 Pod)。
(2)动态“查询系统”:DNS 解析
Kubernetes 还提供了一个“智能查询热线”(DNS)。你只需记住邻居的名字(服务名称),比如 my-service.default.svc.cluster.local,拨通这条热线(发起 DNS 查询),它会告诉你邻居的最新电话(Service 的 ClusterIP)和门牌号(端口)。
即使邻居频繁搬家,热线总能提供最新地址。例如,curl my-service:80 就能访问后端 Pod。
(3)自动维护的“值班表”:Endpoints
Service 背后有一个“实时值班表”(Endpoints),记录所有当前在岗的邻居(健康 Pod)的地址和联系方式(IP:端口)。当邻居请假(Pod 下线)或新邻居加入(扩容 Pod),值班表会自动更新。Service 通过这张表确保请求只会发给在岗的邻居。
(4)精准匹配的“标签系统”
每个邻居(Pod)都会在门口贴标签(如 app=nginx),Service 像一个“管家”,负责收集所有符合标签的邻居信息(通过标签选择器筛选 Pod)。例如,只要贴有 app=nginx 标签的 Pod 都能被 Service 发现并加入通讯录。
-
服务发现的实际流程
-
创建 Service:通过标签选择器(如
app=nginx)关联一组 Pod。 -
生成 Endpoints:Kubernetes 自动维护这些 Pod 的地址列表(Endpoints)。
-
DNS 注册:Service 的名称和 ClusterIP 被注册到集群的 DNS 系统中(如 CoreDNS)。
-
流量转发:当请求到达 Service 的 ClusterIP 时,
kube-proxy根据 Endpoints 列表,通过 iptables 或 IPVS 规则将流量转发到具体 Pod。
- 特殊场景:无头服务(Headless Service)
如果不需要统一的入口(如数据库集群),可以创建一个“无头服务”(Headless Service)。它会直接返回所有 Pod 的 IP 列表,让调用方自行决定如何访问(比如按需选择主节点)。
Service 的服务发现机制通过 动态维护地址列表(Endpoints)、DNS 自动解析 和 标签匹配,解决了集群中服务地址动态变化的问题。它就像一个全能的“社区管家”,让应用程序无需关心后端实例的变化,只需记住服务名称,即可稳定通信。
五、定义Service
apiVersion: v1 # Kubernetes API 版本
kind: Service # 资源类型为 Service
metadata:name: my-service # Service 名称
spec:selector: # 标签选择器,用于关联 Podapp: my-app # 选择具有标签 app=my-app 的 Podports:- protocol: TCP # 协议类型(TCP/UDP)port: 80 # Service 对外暴露的端口targetPort: 9376 # Pod 实际监听的端口(如容器端口)type: ClusterIP # Service 类型(默认为 ClusterIP)
六、Service类型
Kubernetes 的 Service 类型 可以理解为不同的“服务入口模式”,决定了如何让用户或应用访问到后端的 Pod。
- ClusterIP(默认类型)
通俗比喻:就像公司内部的“分机电话”,只能在内网使用。
-
作用:为集群内部提供一个固定的虚拟 IP(VIP),其他服务(如前端调用后端 API)通过这个 IP 访问 Pod。
-
特点:无法从集群外直接访问,适合内部服务通信。
-
示例
type: ClusterIP # 默认类型,可省略
- NodePort
通俗比喻:在每栋大楼(节点)上挂一个“统一门牌号”,外人都能通过这个门牌号找到入口。
-
作用:在每个节点上开放一个固定端口(如 30000-32767),外部用户通过
<节点IP>:<端口>访问服务。 -
特点:可从集群外访问,适合开发测试或简单的外部访问需求。
-
示例
type: NodePort ports:- nodePort: 31000 # 手动指定端口(可选)
- LoadBalancer
通俗比喻:雇佣一个“云平台快递员”,自动把外部流量分发到多个节点。
-
作用:在云平台(如 AWS、阿里云)自动创建负载均衡器,将外部流量均匀分发到集群内的 Pod。
-
特点:提供高可用性和扩展性,适合生产环境对外暴露服务。
-
示例
type: LoadBalancer
- ExternalName
通俗比喻:给外部服务贴一个“内部别名”,像通讯录里的快捷方式。
-
作用:将 Service 映射到外部服务的 DNS 名称(如数据库),集群内部通过 Service 名称访问外部资源。
-
特点:不代理流量,仅通过 DNS 别名简化访问,适合集成外部服务(如云数据库)。
-
示例
type: ExternalName externalName: my-database.example.com # 外部服务地址
如何选择类型?
- 内部通信:用
ClusterIP(默认)。 - 临时外部访问:用
NodePort(如测试环境)。 - 生产环境外部访问:用
LoadBalancer(需云平台支持)。 - 访问外部服务:用
ExternalName(如对接旧系统或数据库)。
Service 类型是 Kubernetes 中控制服务访问范围的“开关”,通过不同模式灵活应对内部通信、外部访问或跨平台集成等需求。
七、无头Service
Kubernetes 中的 无头 Service(Headless Service) 就像一个“没有统一前台”的服务入口,它的设计目的是让客户端绕过负载均衡,直接访问具体的 Pod 实例。
- 无头 Service 的特点
- 没有固定 IP:普通 Service 会分配一个虚拟 IP(ClusterIP)作为统一入口,而无头 Service 直接跳过这一步,不分配 ClusterIP,就像快递公司没有总机电话,客户需要直接联系快递员。
- 直连 Pod:客户端通过 DNS 查询无头 Service 的名称时,会拿到所有关联 Pod 的真实 IP 列表,而不是一个虚拟 IP。这类似于快递公司直接给你所有快递员的联系方式,你可以自行选择联系谁。
- 工作原理
- 动态 DNS 列表:当创建一个无头 Service 时,Kubernetes 会为每个 Pod 生成一条 DNS 记录(例如
web-0.my-service.default.svc.cluster.local),客户端查询服务名称时,会返回所有 Pod 的 IP 地址列表。 - 无负载均衡:流量不经过
kube-proxy转发,也没有负载均衡规则,客户端需要自己决定如何分配请求(比如轮询、随机选择 Pod)。
- 适用场景
- 有状态应用:比如数据库集群(如 MySQL、MongoDB),每个 Pod 需要稳定的网络身份,便于其他节点通过固定名称访问主节点或副本。
- 分布式系统:如分布式缓存(Redis Cluster)、消息队列(Kafka),需要节点间直接通信,而不是通过统一的代理。
- 调试与测试:直接访问特定 Pod 的 IP 进行问题排查,无需经过中间层。
- 如何创建无头 Service
在 YAML 文件中设置 clusterIP: None,并关联 Pod 的标签:
apiVersion: v1
kind: Service
metadata:name: my-headless-service
spec:clusterIP: None # 关键配置selector:app: my-app # 关联的 Pod 标签ports:- port: 80targetPort: 8080
此时,查询 my-headless-service 的 DNS 会返回所有匹配 Pod 的 IP(如 10.0.0.1, 10.0.0.2)。
- 对比普通 Service
| 普通 Service | 无头 Service |
|---|---|
| 有 ClusterIP,统一入口 | 无 ClusterIP,直接暴露 Pod IP |
| 自动负载均衡到 Pod | 客户端自行处理负载均衡 |
| 适用于无状态应用(如 Web 服务) | 适用于有状态应用(如数据库集群) |
无头 Service 是 Kubernetes 中一种“去中心化”的服务发现机制,适合需要直接访问 Pod 或维护稳定网络身份的场景。它通过放弃负载均衡和统一入口,换取了更高的灵活性和对分布式系统的支持。
八、多端口Service
Kubernetes 中的 多端口 Service 就像一个“多功能插座”,允许通过一个服务入口同时暴露多个端口,每个端口对应不同的功能或协议。
- 为什么需要多端口 Service?
假设你有一个快递柜(Pod),既能收快递(HTTP 端口 80),又能发快递(HTTPS 端口 443),或者还需要监控快递状态(管理端口 8080)。
如果每次新增功能都要单独开一个快递柜(Service),管理会变得复杂。
多端口 Service 的作用就是在一个服务中定义多个端口,统一管理这些不同功能。
- 核心机制
-
多端口定义:在 Service 的配置中,通过
ports字段定义多个端口,每个端口需有唯一名称(如http、https),避免歧义。 -
端口映射
:每个端口需指定三个关键参数:
port:Service 对外暴露的端口(用户访问的入口)。targetPort:Pod 内实际监听的端口(容器端口)。protocol:协议类型(如 TCP 或 UDP)。
示例配置:
apiVersion: v1
kind: Service
metadata:name: web-service
spec:selector:app: webports:- name: http # 端口名称protocol: TCPport: 80 # 用户访问的端口targetPort: 80 # Pod 实际端口- name: httpsprotocol: TCPport: 443targetPort: 443
- 实际应用场景
(1)混合协议服务
- 例如,一个服务同时处理 HTTP(端口 80)和 WebSocket(端口 8080),通过多端口 Service 统一暴露。
(2)分层功能管理
- 比如 Web 服务器(端口 80)和监控接口(端口 8080)共用同一组 Pod,但通过不同端口区分功能。
(3)外部访问优化
- 若使用
NodePort类型,可为每个端口分配不同的节点端口(如 30001 和 30002),避免单端口过载。
- 注意事项
- 端口命名必须唯一:避免配置冲突(如两个端口都叫
http)。 - 协议一致性:不同端口可使用不同协议(如 TCP 和 UDP),但需确保后端 Pod 支持。
- 负载均衡独立:每个端口的流量会独立进行负载均衡,互不影响。
- 对比单端口 Service
| 单端口 Service | 多端口 Service |
|---|---|
| 一个功能对应一个 Service | 多个功能共享一个 Service |
| 配置简单,适合单一场景 | 配置稍复杂,适合多功能聚合场景 |
| 管理多个 Service 需更多资源 | 统一管理,减少资源开销 |
多端口 Service 是 Kubernetes 中简化服务管理的利器,通过一个入口支持多种功能,既节省资源又提升灵活性。就像一台支持 USB、HDMI、电源的多接口扩展坞,让复杂需求变得简洁高效。
相关文章:

使用Service发布应用程序
使用Service发布应用程序 文章目录 使用Service发布应用程序[toc]一、什么是Service二、通过Endpoints理解Service的工作机制1.什么是Endpoints2.创建Service以验证Endpoints 三、Service的负载均衡机制四、Service的服务发现机制五、定义Service六、Service类型七、无头Servic…...
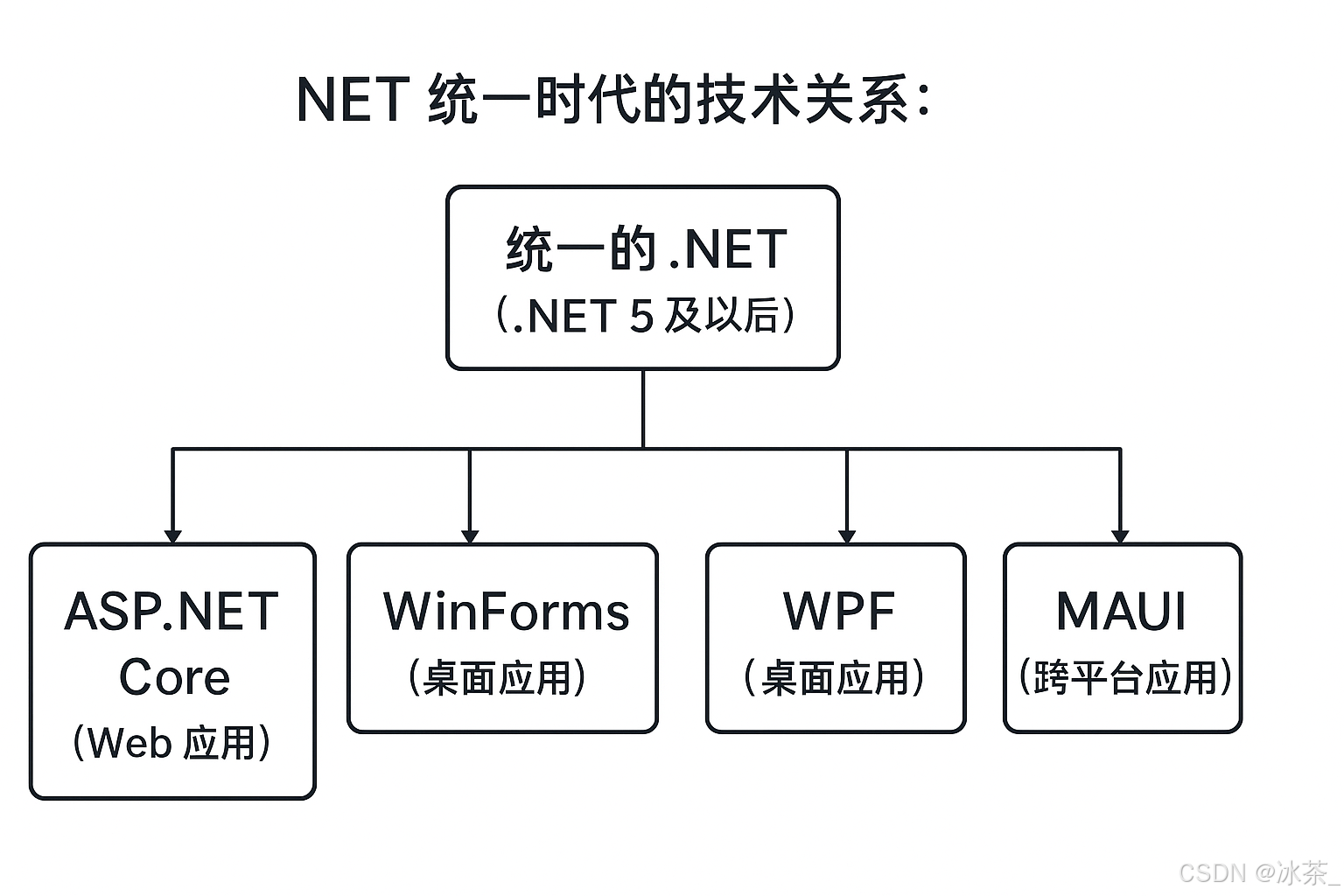
Winform发展历程
Windows Forms (WinForms) 发展历程 起源与背景(1998-2002) Windows Forms(简称WinForms)是微软公司推出的基于.NET Framework的GUI(图形用户界面)开发框架,于2002年随着.NET Framework 1.0的…...

【Hadoop入门】Hadoop生态之Flume简介
1 什么是Flume? Flume是Hadoop生态系统中的一个高可靠、高性能的日志收集、聚合和传输系统。它支持在系统中定制各类数据发送方(Source)、接收方(Sink)和数据收集器(Channel),从而能…...
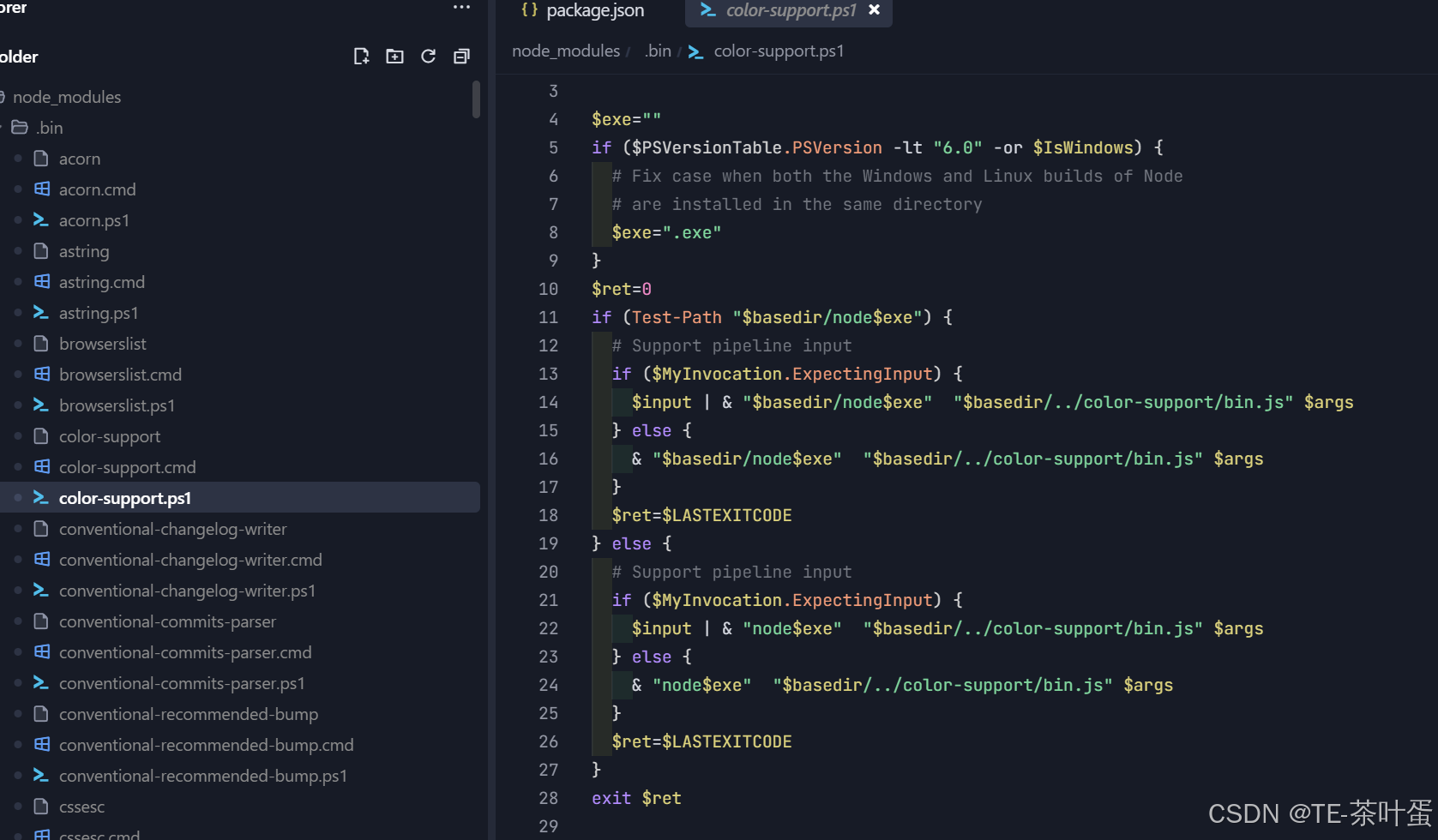
npx 的作用以及延伸知识(.bin目录,npm run xx 执行)
文章目录 前言原理解析1. npx 的作用2. 为什么会有 node_modules/.bin/lerna3. npx 的查找顺序4. 执行流程总结1: 1. .bin 机制什么是 node_modules/.bin?例子 2. npx 的底层实现npx 是如何工作的?为什么推荐用 npx?npx 的特殊能力…...

本地部署DeepSeek-R1(Dify升级最新版本、新增插件功能、过滤推理思考过程)
下载最新版本Dify Dify1.0版本之前不支持插件功能,先升级DIfy 下载最新版本,目前1.0.1 Git地址:https://github.com/langgenius/dify/releases/tag/1.0.1 我这里下载到老版本同一个目录并解压 拷贝老数据 需先停用老版本Dify PS D:\D…...
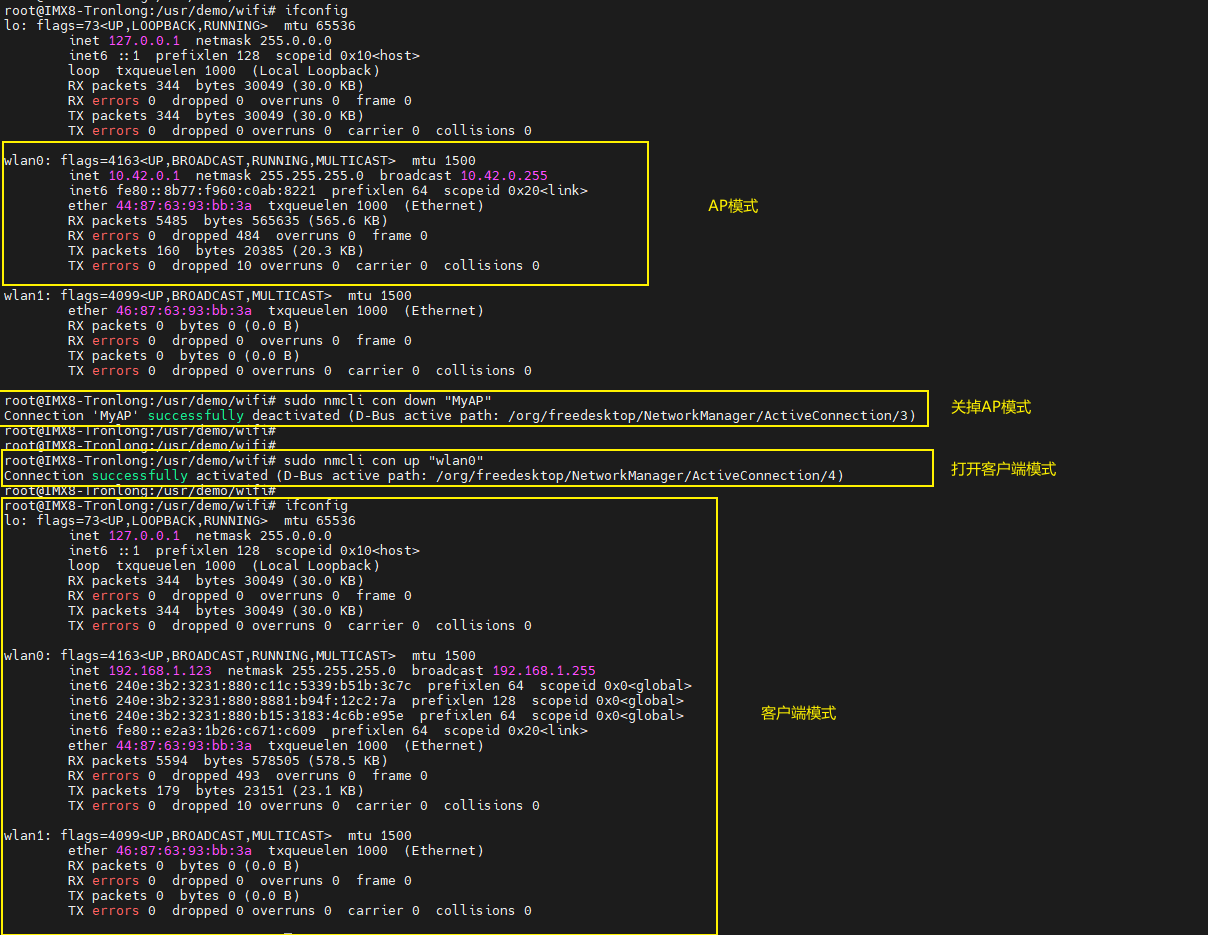
【ubuntu】在Linux Yocto的基础上去适配Ubuntu的wifi模块
一、修改wifi的节点名 1.找到wifi模块的PID和VID ifconfig查看wifi模块网络节点的名字,发现是wlx44876393bb3a(wlxmac地址) 通过udevadm info -a /sys/class/net/wlx44876393bba路径的命令去查看wlx44876393bba的总线号,端口号…...

25软考新版系统分析师怎么备考?重点考哪些?(附新版备考资源)
软考系统分析师(高级资格)考试涉及知识面广、难度较大,需要系统化的复习策略。以下是结合考试大纲和历年真题整理的复习重点及方法: 一、明确考试结构与分值分布 1.综合知识(选择题,75分) 2…...
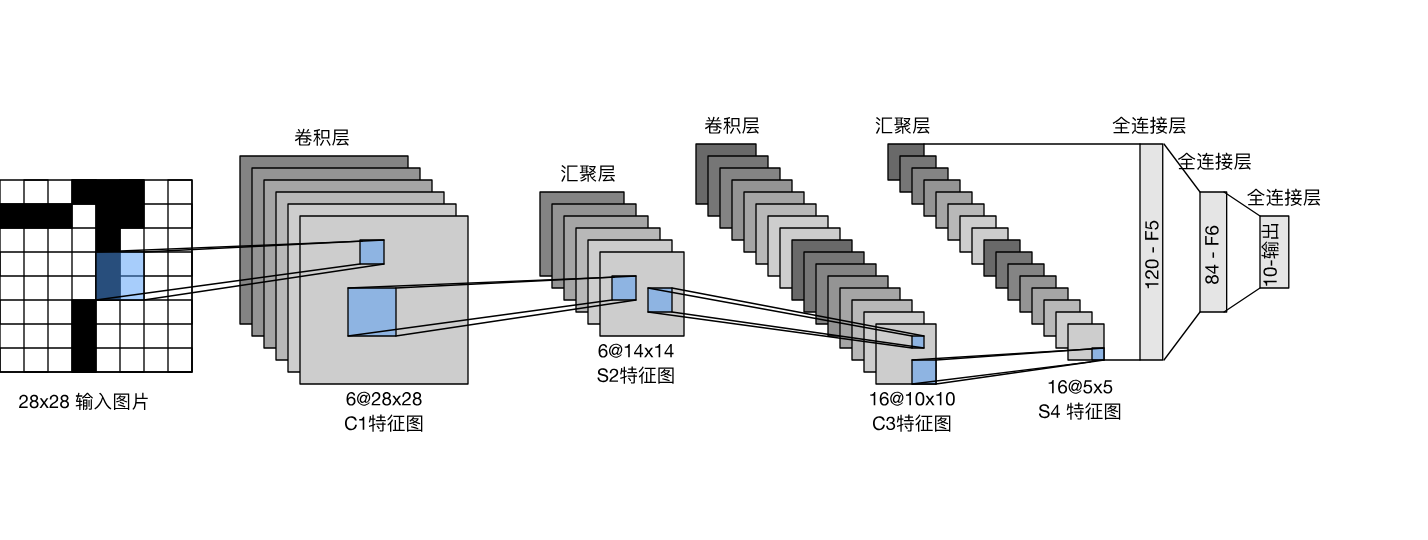
PyTorch入门------卷积神经网络
前言 参考:神经网络 — PyTorch Tutorials 2.6.0cu124 文档 - PyTorch 深度学习库 一个典型的神经网络训练过程如下: 定义一个包含可学习参数(或权重)的神经网络 遍历输入数据集 将输入通过神经网络处理 计算损失(即…...

Edge浏览器安卓版流畅度与广告拦截功能评测【不卡还净】
安卓设备上使用浏览器的体验,很大程度取决于两个方面。一个是滑动和页面切换时的反应速度,另一个是广告干扰的多少。Edge浏览器的安卓版本在这两方面的表现比较稳定,适合日常使用和内容浏览。 先看流畅度。Edge在中端和高端机型上启动速度快&…...

Docker 和 Docker Compose 使用指南
Docker 和 Docker Compose 使用指南 一、Docker 核心概念 镜像(Image) :应用的静态模板(如 nginx:latest)。容器(Container) :镜像的运行实例。仓库(Registry…...

【设计模式】观察者
观察者模式 1 简介 观察者模式是观察者对象们通过注册到被观察者对象中,从而使被观察者发生变化时能通知到观察者,避免硬编码,使用写死的代码逻辑调用通知,从而实现解耦效果。 2 基本代码逻辑 观察者 class IObserver { publ…...
vue3环境搭建、nodejs22.x安装、yarn 1全局安装、npm切换yarn 1、yarn 1 切换npm
vue3环境搭建 node.js 安装 验证nodejs是否安装成功 # 检测node.js 是否安装成功----cmd命令提示符中执行 node -v npm -v 设置全局安装包保存路径、全局装包缓存路径 在node.js 安装路径下 创建 node_global 和 node_cache # 设置npm全局安装包保存路径(新版本…...
安卓开发一个完整的登录页面-支持密码登录和手机验证码登录)
(二十五)安卓开发一个完整的登录页面-支持密码登录和手机验证码登录
下面将详细讲解如何在 Android 中开发一个完整的登录页面,支持密码登录和手机验证码登录。以下是实现过程的详细步骤,从布局设计到逻辑实现,再到用户体验优化,逐步展开。 1. 设计登录页面布局 首先,我们需要设计一个用…...

【java 13天进阶Day05】数据结构,List,Set ,TreeSet集合,Collections工具类
常见的数据结构种类 集合是基于数据结构做出来的,不同的集合底层会采用不同的数据结构。不同的数据结构,功能和作用是不一样的。数据结构: 数据结构指的是数据以什么方式组织在一起。不同的数据结构,增删查的性能是不一样的。不同…...
)
水污染治理(生物膜+机器学习)
文章目录 **1. 水质监测与污染预测****2. 植物-微生物群落优化****3. 系统设计与运行调控****4. 维护与风险预警****5. 社区参与与政策模拟****挑战与解决思路****未来趋势** 前言: 将机器学习(ML)等人工智能技术融入植树生物膜系统ÿ…...
Python人工智能 使用可视图方法转换时间序列为复杂网络
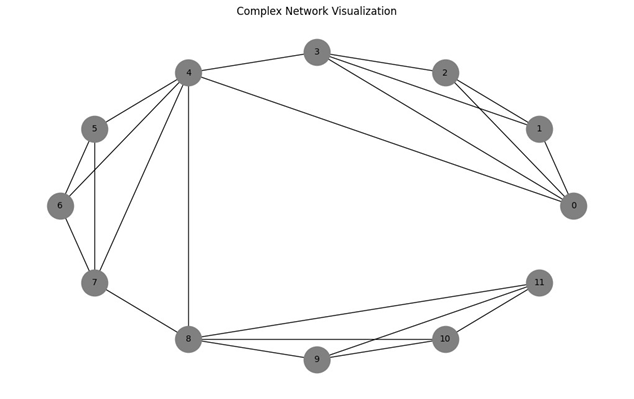
基于可视图方法的时间序列复杂网络转换实践 引言 在人工智能与数据科学领域,时间序列分析是一项基础且重要的技术。本文将介绍一种创新的时间序列分析方法——可视图方法,该方法能将时间序列转换为复杂网络,从而利用复杂网络理论进行更深入…...
spring:加载配置类
在前面的学习中,通过读取xml文件将类加载,或他通过xml扫描包,将包中的类加载。无论如何都需要通过读取xml才能够进行后续操作。 在此创建配置类。通过对配置类的读取替代xml的功能。 配置类就是Java类,有以下内容需要执行&#…...

使用Pydantic优雅处理几何数据结构 - 前端输入验证实践
使用Pydantic优雅处理几何数据结构 - 前端输入验证实践 一、应用场景解析 在视频分析类项目中,前端常需要传递几何坐标数据。例如智能安防系统中,需要接收: 视频流地址(rtsp_video)检测区域坐标点(point…...

从零搭建一套前端开发环境
一、基础环境搭建 1.NVM(Node Version Manager)安装 简介 nvm(Node Version Manager) 是一个用于管理多个 Node.js 版本的工具,允许开发者在同一台机器上轻松安装、切换和使用不同版本的 Node.js。它特别适合需要同时维护多个项目ÿ…...

金融数据库转型实战读后感
荣幸收到老友太保科技有限公司数智研究院首席专家林春的签名赠书。 这是国内第一本关于OceanBase数据库实际替换过程总结的的实战书。打个比方可以说是从战场上下来分享战斗经验。读后感受颇深。我在这里讲讲我的感受。 第三章中提到的应用改造如何降本。应用改造是国产化替换…...

代码审计系列2:小众cms oldcms
目录 sql注入 1. admin/admin.php Login_check 2. admin/application/label/index.php 3. admin/application/hr/index.php 4. admin/application/feedback/index.php 5. admin/application/article/index.php sql注入 1. admin/admin.php Login_check 先看一下p…...

Cursor + MCP,实现自然语言操作 GitLab 仓库
本分分享如何使用 cursor mcp 来操作极狐GitLab 仓库,体验用自然语言在不接触极狐GitLab 的情况下来完成一些仓库操作。 极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitL…...
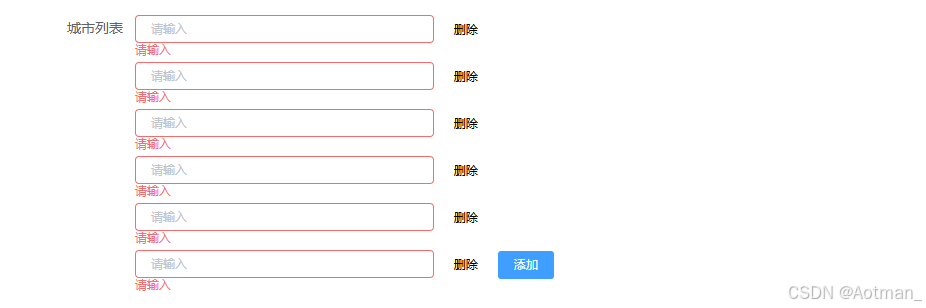
Vue el-from的el-form-item v-for循环表单如何校验rules(一)
实际业务需求场景: 新增或编辑页面(基础信息表单,一个数据列表的表单),数据列表里面的表单数是动态添加的。数据可新增、可删除,在表单保存前,常常需要做表单必填项的校验,校验通过以…...

C#集合List<T>与HashSet<T>的区别
在C#中,List和HashSet都是用于存储元素的集合,但它们在内部实现、用途、性能特性以及使用场景上存在一些关键区别。 内部实现 List:基于数组实现的,可以包含重复的元素,并且元素是按照添加的顺序存储的。 HashSet&…...
【Reading Notes】(8.3)Favorite Articles from 2025 March
【March】 雷军一度登顶中国首富,太厉害了(2025年03月02日) 早盘,小米港股一路高歌猛进,暴涨4%,股价直接飙到52港元的历史新高。这一波猛如虎的操作,直接把雷军的身家拉到了2980亿元,…...

Spring Boot 项目里设置默认国区时区,Jave中Date时区配置
在 Spring Boot 项目里设置国区时区(也就是中国标准时间,即 Asia/Shanghai),可通过以下几种方式实现: 方式一:在application.properties或application.yml里设置 application.properties properties sp…...

从PDF到播客:MIT开发的超越NotebookLM的工具
NotebookLM是谷歌推出的更具创意的AI产品之一,几个月前刚刚推出。 许多人对它的能力感到惊叹——尤其是将长文本转化为两位播客主持人之间有趣对话的功能。 NotebookLM提供的不仅仅是这些,还包括聊天(问答)甚至生成思维导图。 如果你还没有尝试过NotebookLM,我强烈建议…...
Kotlin协程Semaphore withPermit约束并发任务数量
Kotlin协程Semaphore withPermit约束并发任务数量 import kotlinx.coroutines.* import kotlinx.coroutines.sync.Semaphore import kotlinx.coroutines.sync.withPermit import kotlinx.coroutines.launch import kotlinx.coroutines.runBlockingfun main() {val permits 1 /…...
Redis的下载安装和使用(超详细)
目录 一、所需的安装包资源小编放下述网盘了,提取码:wshf 二、双击打开文件redis.desktop.manager.exe 三、点击next后,再点击i agree 四、点击箭头指向,选择安装路径,然后点击Install进行安装 五、安装完后依次点…...

Springboot 学习 之 logback-spring.xml 日志打印
文章目录 1. property2. springProperty3. appender4. logger4.1. 通过包路径控制日志4.2. 通过类名控制日志4.3. 按自定义 Logger 名称控制日志 5. root6. springProfile SpringBoot 项目中可以通过自定义 logback-spring.xml 中各项配置,实现日志的打印控制 1. p…...