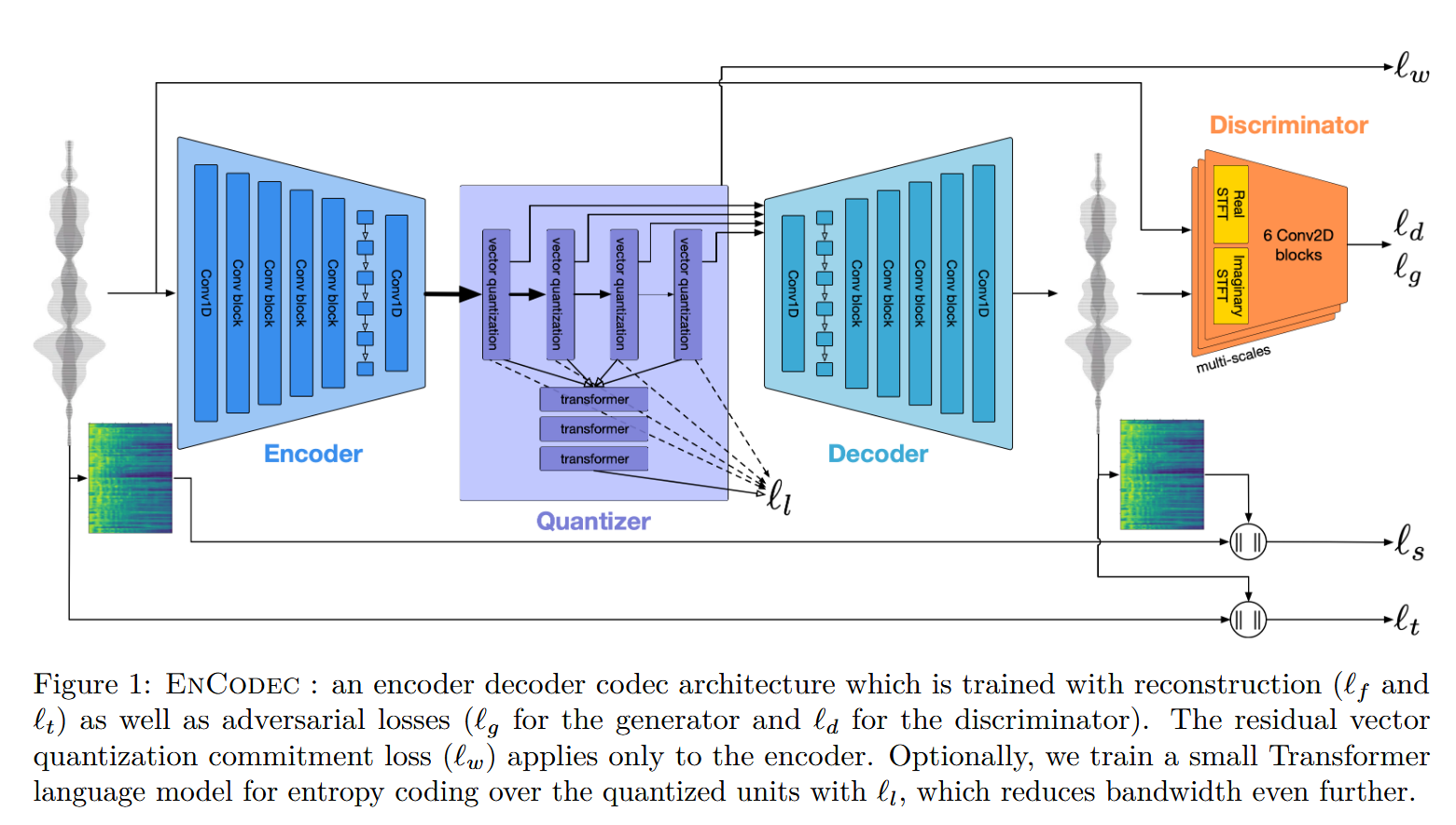
[文献阅读] EnCodec - High Fidelity Neural Audio Compression
[文献信息]:[2210.13438] High Fidelity Neural Audio Compression facebook团队提出的一个用于高质量音频高效压缩的模型,称为EnCodec。Encodec是VALL-E的重要前置工作,正是Encodec的压缩量化使得VALL-E能够出现,把语音领域带向大模型时代。
摘要
随着互联网流量的增长,音频压缩是一个越来越重要的问题。传统上,这是通过用信号处理变换分解输入并权衡不太可能影响感知的分量的质量来实现的。
该文介绍了一个最先进的实时,高保真,音频编解码器,Encodec。它包括一个流编码器-解码器(streaming encoder-decoder)架构,具有以端到端方式训练的量化潜在空间。
在结构上,Encodec在编码器和解码器之间加入了残差量化层RVQ,使得中间离散特征进一步量化,并且不损失大部分信息。为了加快解码速度,还设计了一个轻量级的Transformer模型来进一步预测下一步的量化特征,从而加快量化的速度。
训练上引入了一种新的损失平衡器机制来稳定训练:损失的权重现在定义了它应该代表的整体梯度的分数,从而将这个超参数的选择与损失的典型规模解耦。
Encodec结构
论文的核心思想是使用神经网络来实现数据的压缩、音频数据的压缩。当遇到这种压缩问题的时候,我们最先想到的模型是AutoEncoder(自编码器)。AutoEncoder包含两个部分:Encoder和Decoder。Encoder负责将原始数据映射到低维度的潜空间,Decoder负责将潜空间中的变量映射成原始的数据。
为了进一步减少音频数据的大小,有利于数字存储和传输,模型中还需要包含量化的过程,将连续的音频信号转换为离散的数值。当然,量化过程也会导致一部分的信息损失。因此,设计的量化算法在减小文件大小的同时也要尽量减少对音质的影响。
基于上述两点的考虑,论文中设计的神经网络采样了典型的编解码器架构,带有一个Encoder和一个Decoder。为了实现量化的过程,Encoder和Decoder之间插入了一个Quantizer(量化器)。
持续时间为d的音频信号可以由序列 $x∈[−1,1]^{C_a×T} $表示,其中Ca是音频通道的数量, T = d ⋅ f s r T=d⋅f_{sr} T=d⋅fsr 是给定采样率 f s r f_{sr} fsr 下的音频样本的数量。
EnCodec模型由三个主要组成部分组成:
- 编码器网络E输入音频提取并输出潜在表示 z ;
- 量化层Q使用矢量量化产生压缩表示 z q z_q zq ;
- 最后,解码器网络G从压缩的潜在表示 z q z_q zq 重建时域信号 x ^ \hat x x^。
Encoder和Decoder
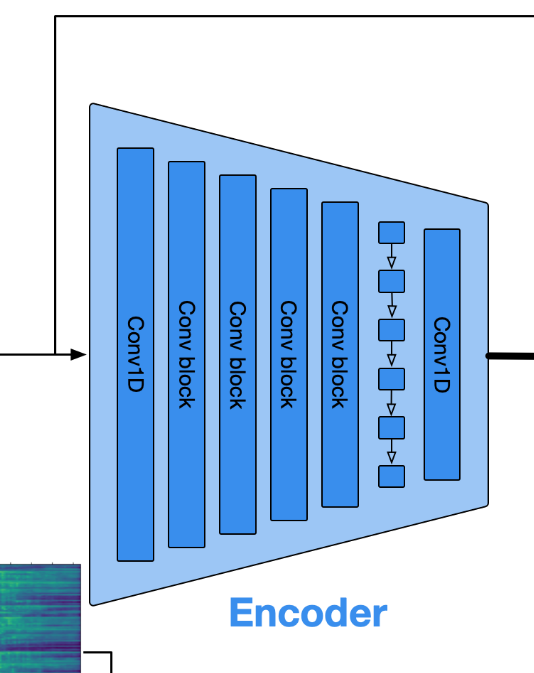
编码器模型E包括具有C个通道,kernel_size=7的1D卷积,其后是B个卷积块。 每个卷积块由单个残差单元组成,该残差单元之后是下采样层,该下采样层由步长卷积组成,其核大小K是步长S的两倍。 剩余单元包含两个核大小为3的卷积和一个跳跃连接。 每当发生下采样时,通道的数量就会加倍。 卷积块之后是用于序列建模的两层LSTM和具有7个核大小和D个输出通道的最终1D卷积层。
Encoder模型由1D卷积层和B个卷积块组成。1D卷积层的核大小为7,通道数为C。每个卷积块包含一个残差单元(residual unit)和一个步幅卷积的下采样层(downsampling layer consisting in a strided convolution)。核的大小是步幅的两倍。残差单元包括两个核大小为3的卷积和一个skip connection。每次下采样,通道数都会翻倍。卷积块后还会接一个两层LSTM进行序列建模。最后还会接一个1D卷积层。这个卷积层的核大小也是7,输出通道数为D。参照SoundStream的参数设置,1D卷积层的通道数C=32,卷积块的个数B=4,这4个卷积块的步幅(stride)分别是2、4、5、8。
Decoder与Encoder是对称的设计,将Encoder中卷积下采样改为上采样就可以了。
Non-streamable 在不可流处理的设置中,我们为每个卷积使用一个总的填充K − S,在第一个时间步长之前和最后一个时间步长之后平均分配(如果K − S是奇数,则在之前再分配一个)。 我们进一步将输入分割为1秒的块,重叠10 ms以避免点击,并在将每个块馈送到模型之前对其进行归一化,在解码器的输出上应用逆运算,增加可忽略的带宽开销以传输比例。 我们使用层标准化(Ba等人, 2016),计算还包括时间维度的统计量,以便保持相对尺度信息。
Streamable 对于流式设置,所有填充都放在第一个时间步长之前。 对于步长为s的转置卷积,我们输出s个第一个时间步,并将剩余的s个步骤保存在内存中,以便在下一帧可用时完成,或者在流结束时丢弃它。 由于这种填充方案,一旦接收到前320个样本(13 ms),模型就可以输出320个样本(13 ms)。 我们将层归一化替换为在时间维度上计算的统计数据,并使用权重归一化(Salimans & Kingma,2016),因为前者不适合流媒体设置。 我们注意到,通过保持一种形式的标准化,客观指标会有一个小的增益,如表A.3所示
考虑到音频流式实时传输的需求,模型有两种变体:流式变体和非流式变体。二者的区别仅仅在于填充的位置和归一化的方式。在流式变体中,所有的填充都会放在第一个时间步之前。模型可以在接收到第一批320个样本(13毫秒)后立即输出。除了这个,流式变体还使用weight normalization(权重归一化)来代替对时间维度进行统计的layer normalization(层归一化)。
在这里,我们需要解释一下为什么说第一批样本是320个,为什么它的持续时间是13ms?
解答:编码器中包含四个卷积块,这四个卷积块的步幅分别为2、4、5、8。也就是说,通过这四个卷积块后生成的一个数据点原来实际对应的是: 2×4×5×8=320 个数据点。所以说,流式变体的模型接收到了320个样本之后,就可以开始输出了。持续时间是13ms这个结论,是针对24kHz的音频来说的。对于24kHz的音频,一秒有24k个样本点。那如果数据仅有320个样本点的话,对应的时间就应该是: 秒毫秒320/24000=0.0133秒=13.3毫秒 。13.3毫秒其实就是一帧的持续时间。
残差向量量化RVQ
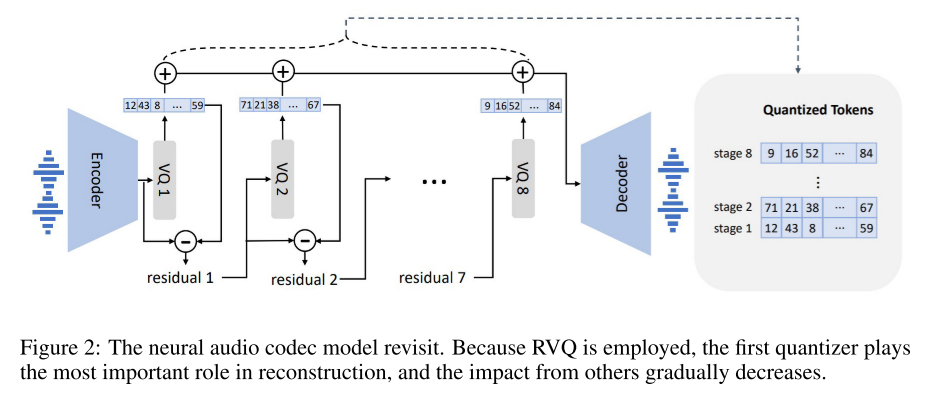
图来自VALL-E https://arxiv.org/abs/2301.02111。
对于一层量化,从Encoder输出的向量会与码本codebook中的向量进行对比,找到最相似的那个向量,记录它的下标。
**残差量化:**但是一层的量化损失太多信息,于是将原始向量与量化向量做差,对差值向量进一步量化,通过8层的残差量化,既能减少codebook的大小,又能减少信息的损失。
第一个block包含最重要的信息,后续的block则负责精确还原语音时的细节信息
同时,多层的残差量化让模型有了更多的选择性,训练时可以随机采样出前面k个block进行训练,保证在丢弃后若干个不重要的block时,模型仍然能够保持一定的精度。此时,模型可以在低比特率时选择性地丢弃后面的blocks,实现了对比特率的动态适应。
RVQ的训练策略:
- codebook的更新策略:在训练过程中,每当codebook中的一个entry被选中用来代表一个输入向量时,这个entry就会根据输入数据进行更新。更新是通过计算entry的新值和旧值的指数移动平均来实现的。指数移动平均的衰减系数 β=0.99 。如果某个codebook的entry在当前批次数据中没有被任何输入向量选择,那么它可能被替换。替换通常是通过在当前批次数据中随机选择一个输入向量来完成的。
- 梯度计算:使用Straight-Through Estimator(直通估计器)计算量化步骤对应的梯度。在STE中,即便量化步骤是不可微的(选择最近的codebook entry),我们仍然可以“假装”这个步骤是恒等操作,从而可以通过它传递梯度。
- 损失函数:quantizer的输入与输出之间的均方误差,梯度只对其输入计算,这个损失会被添加到总的训练损失中
训练
总损失由以下构成:
重建损失项(Reconstruction Loss),感知损失项(Discriminative Loss)(通过鉴别器)和RVQ commitment 损失(RVQ commitment Loss)
重构损失包含时域重构损失和频域重构损失。
频域重构损失计算的是mel-spectrogram之间的差异。损失函数采用的是重构语音和目标语音在多个时间尺度上计算出的L1损失和L2损失的线性组合。
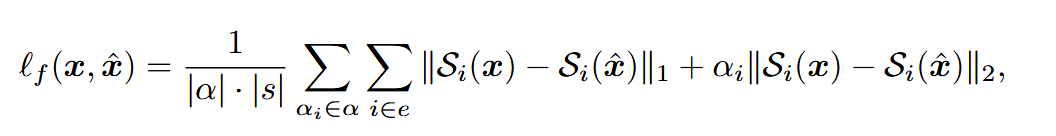
为了进一步提高所生成样本的质量,引入了一个基于多尺度STFT(MS-STFT)鉴别器的感知损失项
生成器的对抗性损失(adversarial loss)构造如下:
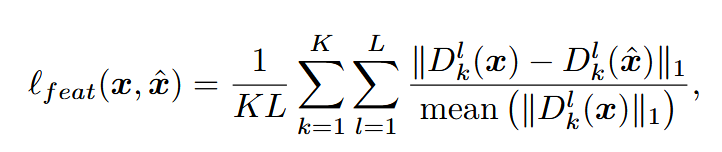
残差量化器损失
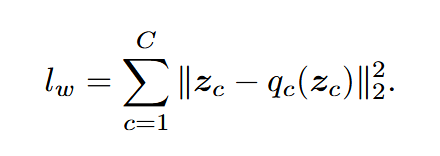
为了稳定训练,特别是来自鉴别器的梯度的变化尺度,引入了损失平衡器
结果
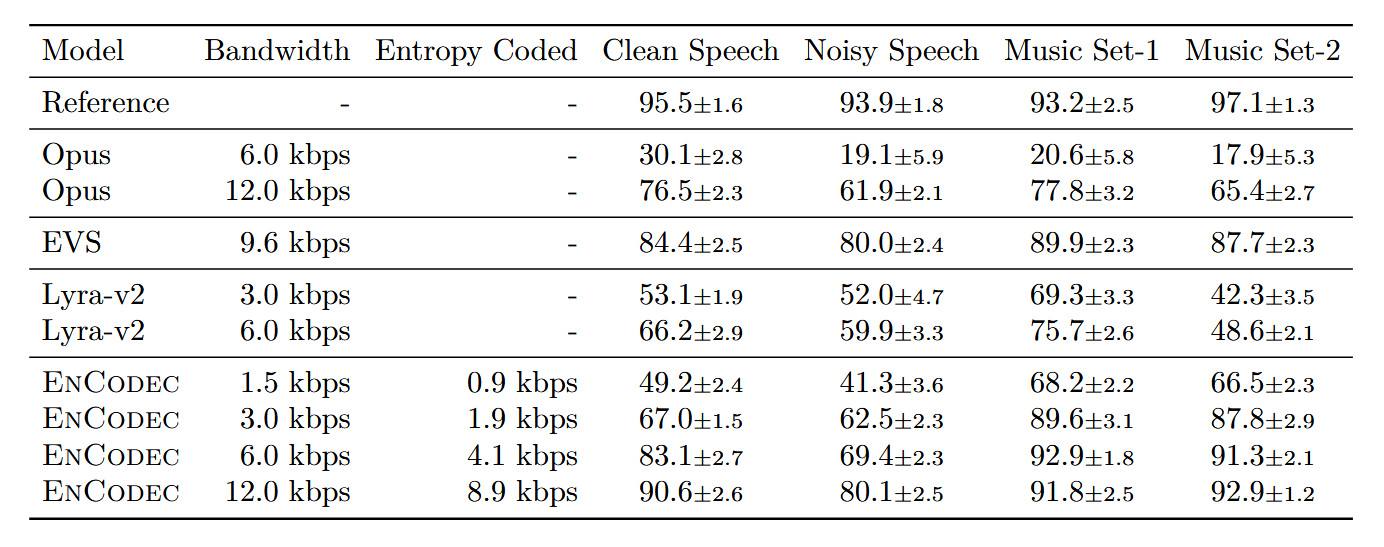
实验
huggingface上用于音频编码解码模型Encodec的官方示例 Encodec (编码) — EnCodec
加载模型,和预处理器processor。
processor 对音频数据进行预处理。将音频数据的采样率设置为与处理器一致(24kHz)。
选取一个样本。
from datasets import load_dataset, Audio
from transformers import EncodecModel, AutoProcessor
librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")model = EncodecModel.from_pretrained("facebook/encodec_24khz")
processor = AutoProcessor.from_pretrained("facebook/encodec_24khz")librispeech_dummy = librispeech_dummy.cast_column("audio", Audio(sampling_rate=processor.sampling_rate))
audio_sample = librispeech_dummy[-1]["audio"]["array"]
inputs = processor(raw_audio=audio_sample, sampling_rate=processor.sampling_rate, return_tensors="pt")对inputs编码,编码为离散特征
# 编码
encoder_outputs = model.encode(inputs["input_values"], inputs["padding_mask"])print(encoder_outputs)
对编码的中间特征解码,还原回音频数据。
# 解码
audio_values = model.decode(encoder_outputs.audio_codes, encoder_outputs.audio_scales, inputs["padding_mask"])[0]print(audio_values)
相关文章:
[文献阅读] EnCodec - High Fidelity Neural Audio Compression
[文献信息]:[2210.13438] High Fidelity Neural Audio Compression facebook团队提出的一个用于高质量音频高效压缩的模型,称为EnCodec。Encodec是VALL-E的重要前置工作,正是Encodec的压缩量化使得VALL-E能够出现,把语音领域带向大…...

【操作系统原理01】操作系统引论
文章目录 大纲一、中断与异常0.大纲1. 中断的作用2. 中断类型2.1 内中断2.2 外中断2.3 判断内外中断 3. 中断机制原理 二、系统调用0. 大纲1.什么是系统调用2.系统调用分类 三、操作性系统内核(了解)0.大纲1.内核2.各种操作系统结构特性 四、操作系统引论0.大纲1.磁盘存储 图片…...

http请求和websocket区别和使用场景
这个问题问得很好,下面我分几部分来详细讲解 WebSocket 的传输能力、适用场景,以及为什么即使用了 WebSocket,我们仍然会用 HTTP 接口👇 ✅ 一、WebSocket 可以传输多少内容? 理论上: WebSocket 协议本身…...

动态规划经典例题:最长单调递增子序列、完全背包、二维背包、数字三角形硬币找零
一.最长单调递增子序列 设计一个O(n^2)时间的算法,找出由n个数组成的序列的最长单调递增子序列。 实验原理 状态转移方程(递推公式): 对于每个 i,遍历之前的元素 j,如果 nums[j] < nums[i]࿰…...

最新得物小程序sign签名加密,请求参数解密,响应数据解密逆向分析
点击精选,出现https://app.dewu.com/api/v1/h5/index/fire/index 这个请求 直接搜索sign的话不容易定位 直接搜newAdvForH5就一个,进去再搜sign,打上断点 可以看到t.params就是没有sign的请求参数, 经过Object(a.default)该函数…...

Day2—3:前端项目uniapp壁纸实战
接下来我们做一个专题精选 <view class"theme"><common-title><template #name>专题精选</template><template #custom><navigator url"" class"more">More</navigator></template></common…...

SQL系列:常用函数
1、【MySQL】合并字段函数(列转行) 它可以将两个字段中的数据合并到一个字段中。 1)CONCAT函数 CONCAT函数可以将多个字段中的数据合并到一个字段中。它的语法格式如下: SELECT CONCAT(字段1,字段2,...字段N) FROM 表名;SELEC…...

Python基于知识图谱的医疗问答系统【附源码、文档说明】
博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇&…...

yarn的三个资源调度策略
1. 容量调度器(Capacity Scheduler) 策略原理:将集群资源划分为多个队列,每个队列有固定的资源容量,且可以设置资源的最大和最小使用量。不同的用户或应用程序可以被分配到不同的队列中,在队列内部&#x…...

股指期货跨期套利是如何赚取价差利润的?
股指期货跨期套利,简单来说,就是在同一交易所内,针对同一股指期货品种的不同交割月份合约进行的套利交易。投资者会同时买入某一月份的股指期货合约,并卖出另一月份的股指期货合约,待未来某个时间点,再将这…...
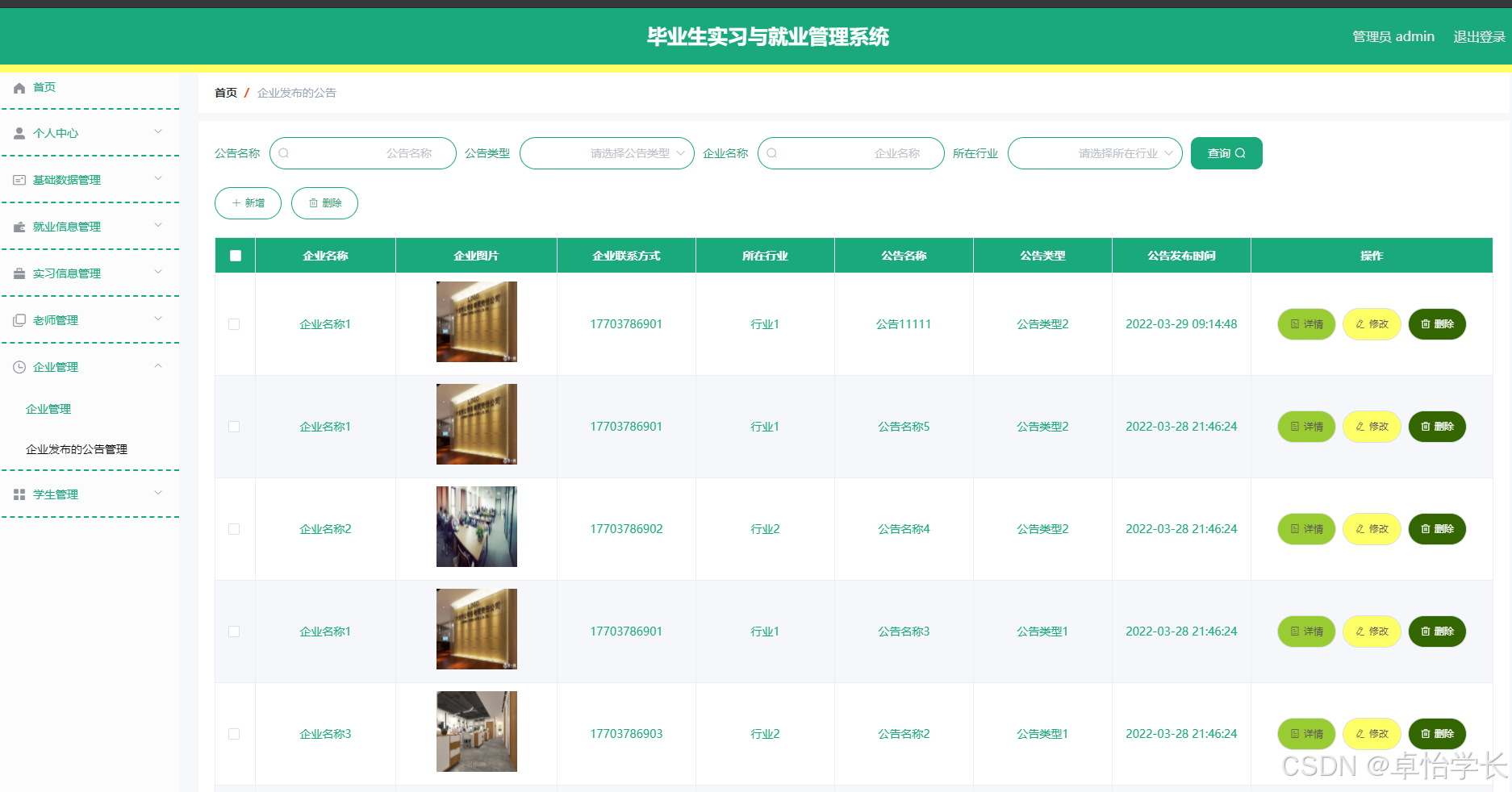
w297毕业生实习与就业管理系统
🙊作者简介:多年一线开发工作经验,原创团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹赠送计算机毕业设计600个选题excel文…...
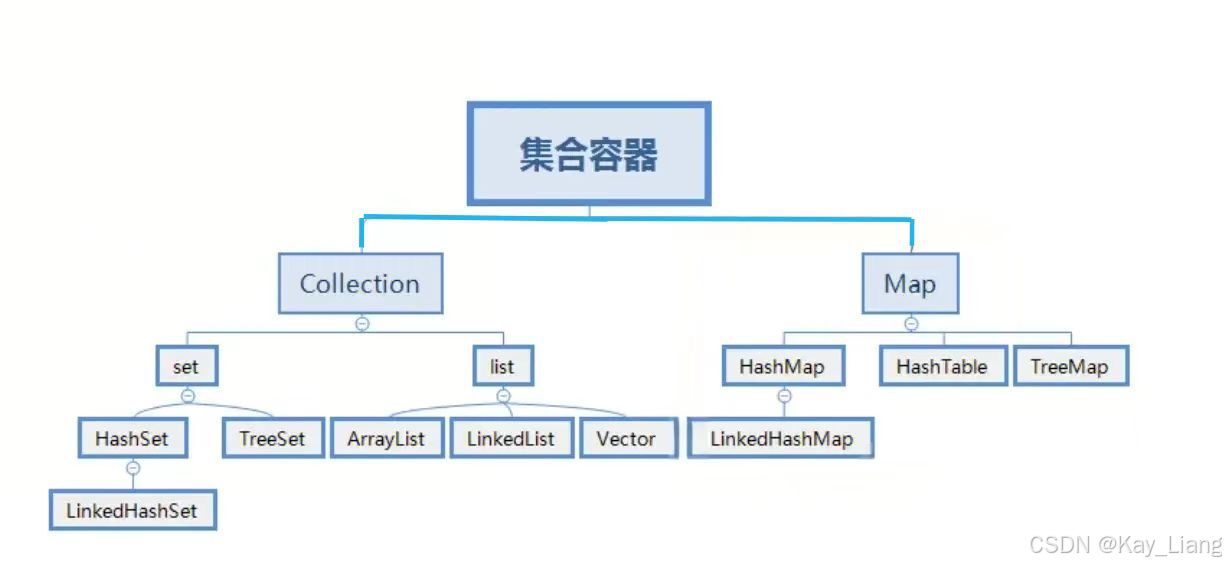
Java集合框架中的List、Map、Set详解
在Java开发中,集合框架是处理数据时不可或缺的工具之一。今天,我们来深入了解一下Java集合框架中的List、Map和Set,并探讨它们的常见方法操作。 目录 一、List集合 1.1 List集合介绍 1.2 List集合的常见方法 添加元素 获取元素 修改元素…...

让机器学习更透明:使用 Python 开发可解释性模型工具包
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...
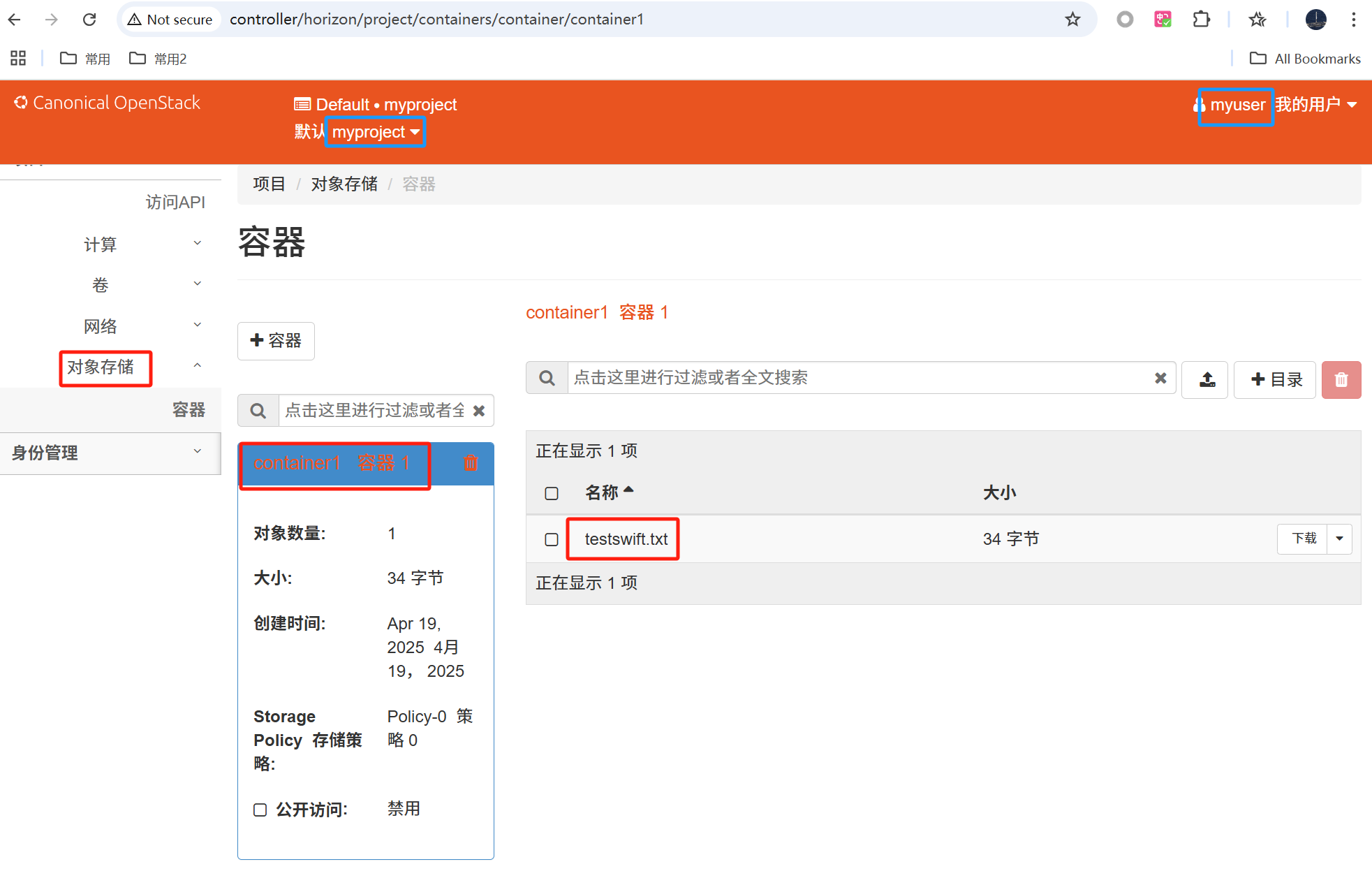
OpenStack Yoga版安装笔记(23)Swift安装
一、官方文档 Object Storage Install Guide — Swift 2.29.3.dev5 documentation 二、环境准备 之前的实验,已经有controller, compute1, block1节点,并已经完成Keystone、Glance、Nova、Neutron、Cinder等主要OpenStack Service的安装。 此处新增…...

MRO 工业品电商系统:智能精准匹配,快速满足采购需求
在竞争激烈的工业领域,企业对 MRO 工业品的采购需求越来越多。但传统 MRO 采购存在信息不透明、客户选型困难,流程复杂处理周期长、库存信息不明确、成本高和客户价格管理混乱等诸多问题。随着电商发展,MRO 工业品电商系统出现,给…...

2025年Q1数据安全政策、规范、标准以及报告汇总共92份(附下载)
一、政策演进趋势分析 (一)国家级政策新动向 数据要素市场建设 数据流通安全治理方案(重点解析数据确权与交易规则) 公共数据授权运营规范(创新性提出分级授权机制) 新兴技术安全规范 人工智能安全标准…...
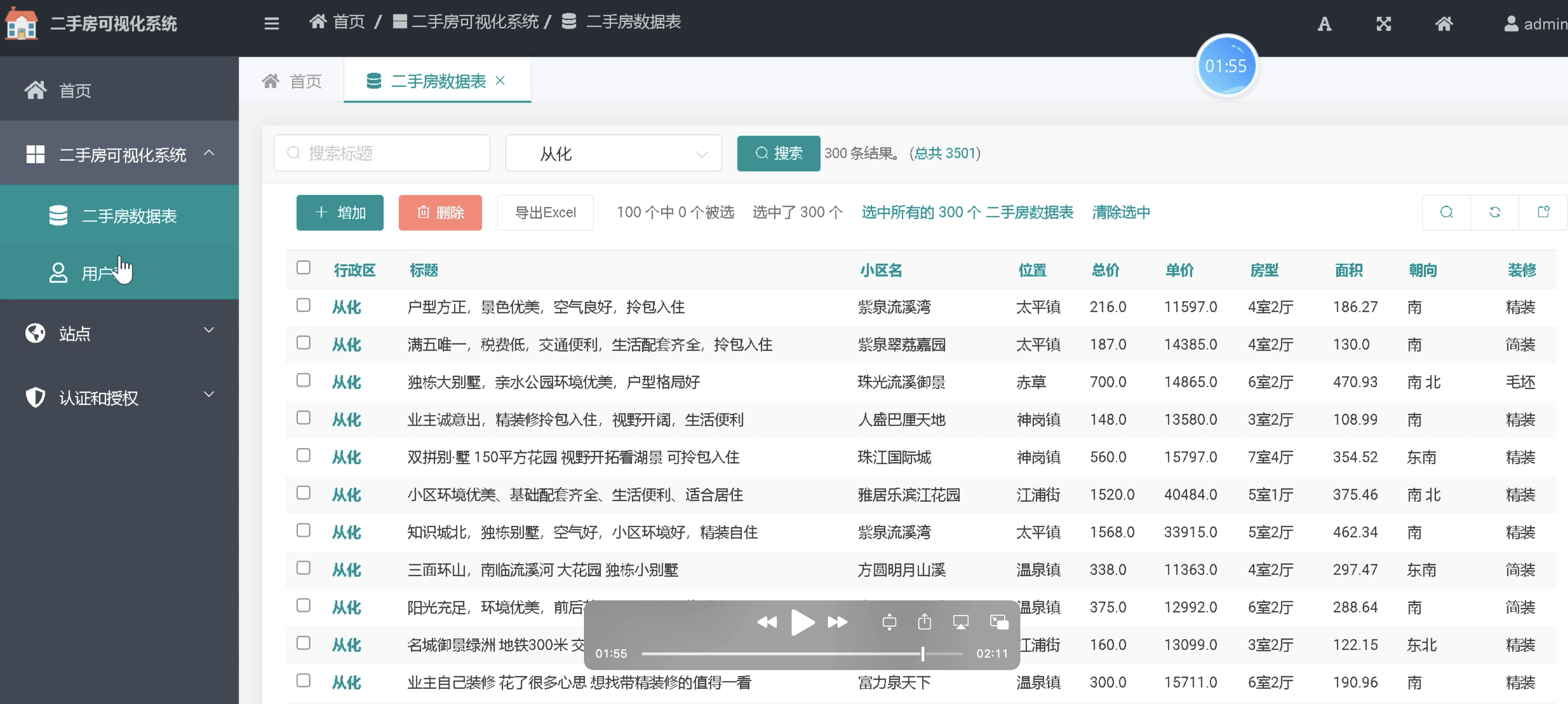
基于Python Django 的全国房价大数据可视化系统(附源码,部署)
博主介绍:✌程序员徐师兄,7年大厂开发经验。全网粉丝12w,CSDN博客专家,同时活跃在掘金、华为云、阿里云、InfoQ等平台,专注Java技术和毕业项目实战分享✌ 🍅文末获取源码联系🍅 👇&a…...
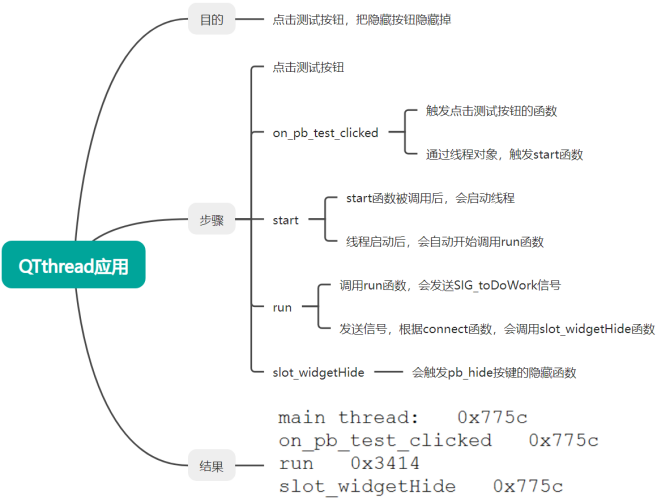
项目班——0408——qt的多线程开发
目录 一、并发、并行的概念 1. 并发 例子 2. 并行 二、qt的多线程开发 三、Qt多线程开发方法 1、可以使用QTthread 创建线程 来执行线程函数 2、可以借助moveToThread将对象转移到另一个线程中,然后执行 一、并发、并行的概念 1. 并发 多个任务在同一时间…...

每天学一个 Linux 命令(25):more
可访问网站查看,视觉品味拉满: http://www.616vip.cn/25/index.html 每天学一个 Linux 命令(25):more 命令简介 more 是一个经典的分页显示文本文件内容的命令行工具,适用于逐页浏览长文本文件。它简单易用,适合快速查看内容,但功能比 less 更为基础(不支持向后翻…...

那就聊一聊mysql的锁
MySQL 的锁机制是数据库并发控制的核心,作为 Java 架构师需要深入理解其实现原理和适用场景。以下是 MySQL 锁机制的详细解析: 一、锁的分类维度 1. 按锁粒度划分 锁粒度特点适用场景全局锁锁定整个数据库(FLUSH TABLES WITH READ LOC…...
-数据类型转换)
python(八)-数据类型转换
#数据类型转换 #转换为整型int #字符串str--》整数int #纯数字的字符串可以转换,否则会报错 s 2025 n int(s) print(type(s),type(n)) print(n)#浮点数float--》整数int s1 2.23 print(int(s1))#bool-->整数int s2,s3 True,False print(int(s2),int(s3))#转…...

Python语法系列博客 · 第7期[特殊字符] 列表推导式与字典推导式:更优雅地处理数据结构
上一期小练习解答(第6期回顾) ✅ 练习1:统计文件行数 with open("data.txt", "r", encoding"utf-8") as f:lines f.readlines()print(f"总行数:{len(lines)}")✅ 练习2:反…...

如何0基础学stm32?
如何0基础学stm32? 作为一个混迹嵌入式领域十余年的老兵,每次看到"0基础学STM32"这样的提问,我都忍不住想笑,又有些无奈。这就像问"如何0基础学开飞机"一样—虽然理论上可行,但过程恐怕没那么愉快…...
)
Cesium 加载 本地 b3dm 格式文件 并且 获取鼠标点击处经纬度 (亲测可用)
很奇怪cesium 里面只支持 相对路径 不支持绝对路径 我把 模型放在 /***/Cesium-1.128/Apps/SampleData/Cesium3DTiles/Tilesets 下面 "../../SampleData/Cesium3DTiles/Tilesets/terra_b3dms/tileset.json",所有源码 const viewer new Cesium.Viewer("cesiu…...

新能源汽车动力电池热管理方案全解析:开启电车续航与安全的密码
热管理:新能源汽车的隐形守护者 在新能源汽车飞速发展的今天,热管理系统作为保障车辆核心部件稳定运行的关键,正逐渐成为行业关注的焦点。据市场研究机构的数据显示,近年来新能源汽车的销量持续攀升,而与之相伴的是热…...

无需训练的具身导航探索!TRAVEL:零样本视觉语言导航中的检索与对齐
作者: Navid Rajabi, Jana Kosecka 单位:乔治梅森大学计算机科学系 论文标题:TRAVEL: Training-Free Retrieval and Alignment for Vision-and-Language Navigation 论文链接:https://arxiv.org/pdf/2502.07306 主要贡献 提出…...
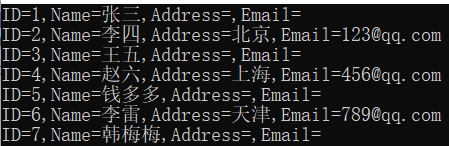
C#测试linq中的左连接的基本用法
使用linq联表或者连接两个对象集合查询时一般使用的是join关键字,返回结果中包含两个表或两个对象集合中连接字段相等的数据记录,如果要实现sql语句中的左连接效果,并没有现成的left join关键字,此时可以使用DefaultIfEmpty 实现左…...
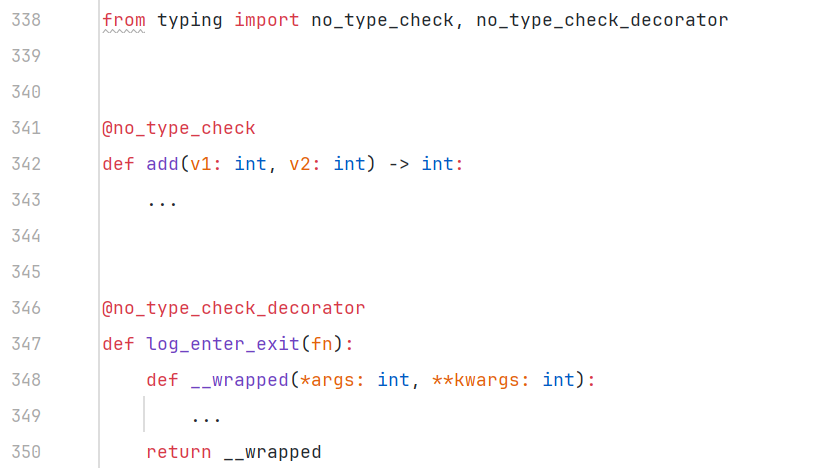
2025-04-19 Python 强类型编程
文章目录 1 方法标注1.1 参数与返回值1.2 变参类型1.3 函数类型 2 数据类型2.1 内置类型2.2 复杂数据结构2.3 类别选择2.4 泛型 3 标注方式3.1 注释标注3.2 文件标注 4 特殊情形4.1 前置引用4.2 函数标注扩展4.3 协变与逆变4.4 dataclass 5 高级内容5.1 接口5.2 泛型的协变/逆变…...
)
Java大模型MCP服务端开发-数据库查询与数据分析(附源码)
Java大模型MCP服务端开发-数据库查询 MCP服务器概述安装依赖服务端对象服务器传输服务器功能客户端测试源码地址MCP服务器概述 MCP服务器是模型上下文协议(MCP)架构中的基础组件,为客户端提供工具、资源和功能。它实现了协议的服务器端,负责: 暴露客户端可以发现和执行的工…...
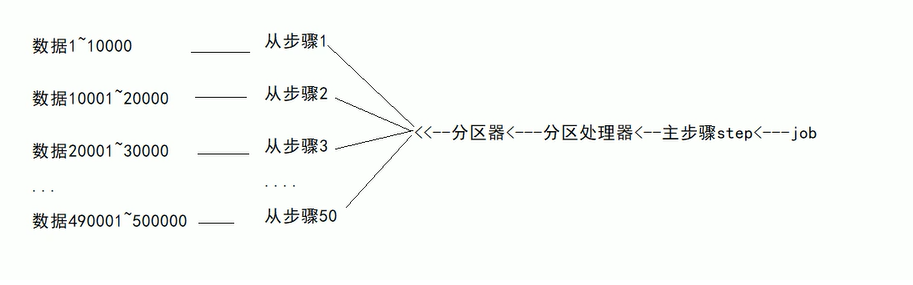
spring-batch批处理框架(2)
文章目录 八、作业控制8.1 作业启动8.1.1 SpringBoot 启动8.1.2 Spring 单元测试启动8.1.3 RESTful API 启动 8.2 作业停止方案1:Step 步骤监听器方式方案2:StepExecution停止标记 8.3 作业重启8.3.1 禁止重启8.3.2 限制重启次数8.3.3 无限重启 九、Item…...