TensorFlow 实现 Mixture Density Network (MDN) 的完整说明
本文档详细解释了一段使用 TensorFlow 构建和训练混合密度网络(Mixture Density Network, MDN)的代码,涵盖数据生成、模型构建、自定义损失函数与预测可视化等各个环节。
1. 导入库与设置超参数
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import math
说明:
- 引入用于数值运算(NumPy)、构建深度学习模型(TensorFlow/Keras)和绘图(Matplotlib)的基础工具包。
超参数定义
N_HIDDEN = 15 # 隐藏层神经元数量
N_MIXES = 10 # GMM 中混合成分数量
OUTPUT_DIMS = 1 # 输出维度(目标变量维度)
2. 自定义 MDN 层
class MDN(layers.Layer):def __init__(self, output_dims, num_mixtures, **kwargs):super(MDN, self).__init__(**kwargs)self.output_dims = output_dimsself.num_mixtures = num_mixturesself.params = self.num_mixtures * (2 * self.output_dims + 1) # pi, mu, sigmaself.dense = layers.Dense(self.params)def call(self, inputs):output = self.dense(inputs)return output
说明:
params表示 GMM 每个分量包含mu(均值)、sigma(标准差)和pi(权重),共2*D + 1个参数。- 输出维度为
(batch_size, num_mixtures * (2*output_dims + 1))。
3. 自定义 MDN 损失函数
def get_mixture_loss_func(output_dims, num_mixtures):def mdn_loss(y_true, y_pred):y_true = tf.reshape(y_true, [-1, 1])out_mu = y_pred[:, :num_mixtures * output_dims]out_sigma = y_pred[:, num_mixtures * output_dims:2 * num_mixtures * output_dims]out_pi = y_pred[:, -num_mixtures:]mu = tf.reshape(out_mu, [-1, num_mixtures, output_dims])sigma = tf.exp(tf.reshape(out_sigma, [-1, num_mixtures, output_dims]))pi = tf.nn.softmax(out_pi)y_true = tf.tile(y_true[:, tf.newaxis, :], [1, num_mixtures, 1])normal_dist = tf.exp(-0.5 * tf.square((y_true - mu) / sigma)) / (sigma * tf.sqrt(2.0 * np.pi))prob = tf.reduce_prod(normal_dist, axis=2)weighted_prob = prob * piloss = -tf.math.log(tf.reduce_sum(weighted_prob, axis=1) + 1e-8)return tf.reduce_mean(loss)return mdn_loss
说明:
- 通过概率密度函数计算目标值属于 GMM 各个分布的概率,并取加权平均。
- 对数似然函数取负作为损失。
4. 从输出分布中采样
def sample_from_output(y_pred, output_dims, num_mixtures, temp=1.0):out_mu = y_pred[:num_mixtures * output_dims]out_sigma = y_pred[num_mixtures * output_dims:2 * num_mixtures * output_dims]out_pi = y_pred[-num_mixtures:]out_sigma = np.exp(out_sigma)out_pi = np.exp(out_pi / temp)out_pi /= np.sum(out_pi)mixture_idx = np.random.choice(np.arange(num_mixtures), p=out_pi)mu = out_mu[mixture_idx * output_dims:(mixture_idx + 1) * output_dims]sigma = out_sigma[mixture_idx * output_dims:(mixture_idx + 1) * output_dims]sample = np.random.normal(mu, sigma)return sample
说明:
- 使用 softmax 处理
pi,选择一个分布后按对应的mu和sigma采样。 temp控制采样温度(温度越高分布越平坦)。
5. 生成训练数据
NSAMPLE = 3000
y_data = np.float32(np.random.uniform(-10.5, 10.5, NSAMPLE))
r_data = np.random.normal(size=NSAMPLE)
x_data = np.sin(0.75 * y_data) * 7.0 + y_data * 0.5 + r_data * 1.0
x_data = x_data.reshape((NSAMPLE, 1))
y_data = y_data.reshape((NSAMPLE, 1))
说明:
- 构造非线性映射关系的合成数据:
x = sin(0.75y)*7 + 0.5y + 噪声。 x是输入,y是目标。
6. 构建模型
model = keras.Sequential([layers.Dense(N_HIDDEN, input_shape=(1,), activation='relu'),layers.Dense(N_HIDDEN, activation='relu'),MDN(OUTPUT_DIMS, N_MIXES)
])
model.compile(loss=get_mixture_loss_func(OUTPUT_DIMS, N_MIXES), optimizer=keras.optimizers.Adam())
model.summary()
说明:
- 构建一个两层隐层的前馈神经网络,输出 MDN 层。
- 使用自定义的 MDN 损失函数训练模型。
7. 模型训练
model.fit(x_data, y_data, batch_size=128, epochs=200, validation_split=0.15, verbose=1)
- 批量大小 128,训练 200 个 epoch,保留 15% 数据用于验证。
8. 模型测试与预测可视化
x_test = np.linspace(-15, 15, 1000).astype(np.float32).reshape(-1, 1)
y_pred = model.predict(x_test)
y_samples = np.array([sample_from_output(p, OUTPUT_DIMS, N_MIXES) for p in y_pred])
- 对连续输入进行预测并从预测的 GMM 中采样。
可视化预测结果
plt.figure()
plt.scatter(x_test, y_samples, alpha=0.3, s=10)
plt.title("MDN Predictions")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
原始数据与预测对比
plt.figure(figsize=(8, 5))
plt.scatter(x_data, y_data, label="Original Data", alpha=0.2, s=10)
plt.scatter(x_test, y_samples, label="MDN Samples", alpha=0.5, s=10, color='r')
plt.title("MDN Prediction vs Training Data")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.grid(True)
plt.show()
总代码如下
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import math# 超参数
N_HIDDEN = 15
N_MIXES = 10
OUTPUT_DIMS = 1# === 1. 自定义 MDN 层 ===
class MDN(layers.Layer):def __init__(self, output_dims, num_mixtures, **kwargs):super(MDN, self).__init__(**kwargs)self.output_dims = output_dimsself.num_mixtures = num_mixturesself.params = self.num_mixtures * (2 * self.output_dims + 1) # pi, mu, sigmaself.dense = layers.Dense(self.params)def call(self, inputs):output = self.dense(inputs)return output# === 2. 自定义损失函数 ===
def get_mixture_loss_func(output_dims, num_mixtures):def mdn_loss(y_true, y_pred):y_true = tf.reshape(y_true, [-1, 1])out_mu = y_pred[:, :num_mixtures * output_dims]out_sigma = y_pred[:, num_mixtures * output_dims:2 * num_mixtures * output_dims]out_pi = y_pred[:, -num_mixtures:]mu = tf.reshape(out_mu, [-1, num_mixtures, output_dims])sigma = tf.exp(tf.reshape(out_sigma, [-1, num_mixtures, output_dims]))pi = tf.nn.softmax(out_pi)y_true = tf.tile(y_true[:, tf.newaxis, :], [1, num_mixtures, 1])normal_dist = tf.exp(-0.5 * tf.square((y_true - mu) / sigma)) / (sigma * tf.sqrt(2.0 * np.pi))prob = tf.reduce_prod(normal_dist, axis=2)weighted_prob = prob * piloss = -tf.math.log(tf.reduce_sum(weighted_prob, axis=1) + 1e-8)return tf.reduce_mean(loss)return mdn_loss# === 3. 从输出采样函数 ===
def sample_from_output(y_pred, output_dims, num_mixtures, temp=1.0):out_mu = y_pred[:num_mixtures * output_dims]out_sigma = y_pred[num_mixtures * output_dims:2 * num_mixtures * output_dims]out_pi = y_pred[-num_mixtures:]out_sigma = np.exp(out_sigma)out_pi = np.exp(out_pi / temp)out_pi /= np.sum(out_pi)mixture_idx = np.random.choice(np.arange(num_mixtures), p=out_pi)mu = out_mu[mixture_idx * output_dims:(mixture_idx + 1) * output_dims]sigma = out_sigma[mixture_idx * output_dims:(mixture_idx + 1) * output_dims]sample = np.random.normal(mu, sigma)return sample# === 4. 生成训练数据 ===
NSAMPLE = 3000
y_data = np.float32(np.random.uniform(-10.5, 10.5, NSAMPLE))
r_data = np.random.normal(size=NSAMPLE)
x_data = np.sin(0.75 * y_data) * 7.0 + y_data * 0.5 + r_data * 1.0
x_data = x_data.reshape((NSAMPLE, 1))
y_data = y_data.reshape((NSAMPLE, 1))plt.figure()
plt.scatter(x_data, y_data, alpha=0.3)
plt.title("Training Data")
plt.show()# === 5. 构建模型 ===
model = keras.Sequential([layers.Dense(N_HIDDEN, input_shape=(1,), activation='relu'),layers.Dense(N_HIDDEN, activation='relu'),MDN(OUTPUT_DIMS, N_MIXES)
])
model.compile(loss=get_mixture_loss_func(OUTPUT_DIMS, N_MIXES), optimizer=keras.optimizers.Adam())
model.summary()# === 6. 模型训练 ===
model.fit(x_data, y_data, batch_size=128, epochs=200, validation_split=0.15, verbose=1)# === 7. 测试与可视化 ===
x_test = np.linspace(-15, 15, 1000).astype(np.float32).reshape(-1, 1)
y_pred = model.predict(x_test)
y_samples = np.array([sample_from_output(p, OUTPUT_DIMS, N_MIXES) for p in y_pred])plt.figure()
plt.scatter(x_test, y_samples, alpha=0.3, s=10)
plt.title("MDN Predictions")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
# === 8. 测试数据与预测对比图 ===plt.figure(figsize=(8, 5))
plt.scatter(x_data, y_data, label="Original Data", alpha=0.2, s=10)
plt.scatter(x_test, y_samples, label="MDN Samples", alpha=0.5, s=10, color='r')
plt.title("MDN Prediction vs Training Data")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.grid(True)
plt.show()总结
本项目展示了如何使用 TensorFlow 构建混合密度网络,用以建模复杂的条件分布。相比传统回归模型,MDN 能够生成多峰预测结果,适用于不确定性高、输出存在多解的场景。
相关文章:
 的完整说明)
TensorFlow 实现 Mixture Density Network (MDN) 的完整说明
本文档详细解释了一段使用 TensorFlow 构建和训练混合密度网络(Mixture Density Network, MDN)的代码,涵盖数据生成、模型构建、自定义损失函数与预测可视化等各个环节。 1. 导入库与设置超参数 import numpy as np import tensorflow as t…...

xml+html 概述
1.什么是xml xml 是可扩展标记语言的缩写: Extensible Markup Language。 <root><h1> text 1</h1> </root> web 应用开发,需要配置 web.xml,就是个典型的 xml文件 <web-app><servlet><servlet-name&…...

混合精度训练中的算力浪费分析:FP16/FP8/BF16的隐藏成本
在大模型训练场景中,混合精度训练已成为降低显存占用的标准方案。然而,通过NVIDIA Nsight Compute深度剖析发现,精度转换的隐藏成本可能使理论算力利用率下降40%以上。本文基于真实硬件测试数据,揭示不同精度格式的计算陷阱。…...

Python语法系列博客 · 第5期[特殊字符] 模块与包的导入:构建更大的程序结构
上一期小练习解答(第4期回顾) ✅ 练习1:判断偶数函数 def is_even(num):return num % 2 0print(is_even(4)) # True print(is_even(5)) # False✅ 练习2:求平均值 def avg(*scores):return sum(scores) / len(scores)print(…...

Sleuth+Zipkin 服务链路追踪
微服务架构中,为了更好追踪服务之间调用,实现时间分析,性能瓶颈分析,故障排查,因此有必要搭建链路追踪。下面简单介绍下实现的过程。 一.引入依赖 <!-- 链路追踪 zipkin已经集成有sleuth,不需要再单独…...
)
意志力的源头——AMCC(前部中扣带皮层)
AMCC(前部中扣带皮层)在面对痛苦需要坚持的事情时会被激活。它的存在能够使人类个体在面临困难的事、本能感到不愿意的麻烦事情时,能够自愿地去做这些事——这些事必须是局部痛苦或宏观的痛苦,即微小的痛苦micro-sucks。 AMCC更多…...

[Jenkins]pnpm install ‘pnpm‘ 不是内部或外部命令,也不是可运行的程序或批处理文件。
这个错误提示再次说明:你的系统(CMD 或 Jenkins 环境)找不到 pnpm 命令的位置。虽然你可能已经用 npm install -g pnpm 安装过,但系统不知道它装在哪里,也就无法执行 pnpm 命令。 ✅ 快速解决方法:直接用完…...

Java从入门到“放弃”(精通)之旅——数组的定义与使用⑥
Java从入门到“放弃”(精通)之旅🚀——数组⑥ 前言——什么是数组? 数组:可以看成是相同类型元素的一个集合,在内存中是一段连续的空间。比如现实中的车库,在java中,包含6个整形类…...

部署rocketmq集群
容器化部署RocketMQ5.3.1集群 背景: 生产环境单机的MQ不具有高可用,所以我们应该部署成集群模式,这里给大家部署一个双主双从异步复制的Broker集群 一、安装docker yum install -y docker systemctl enable docker --now # 单机部署参考: https://www.cnblogs.com/hsyw/p/1…...
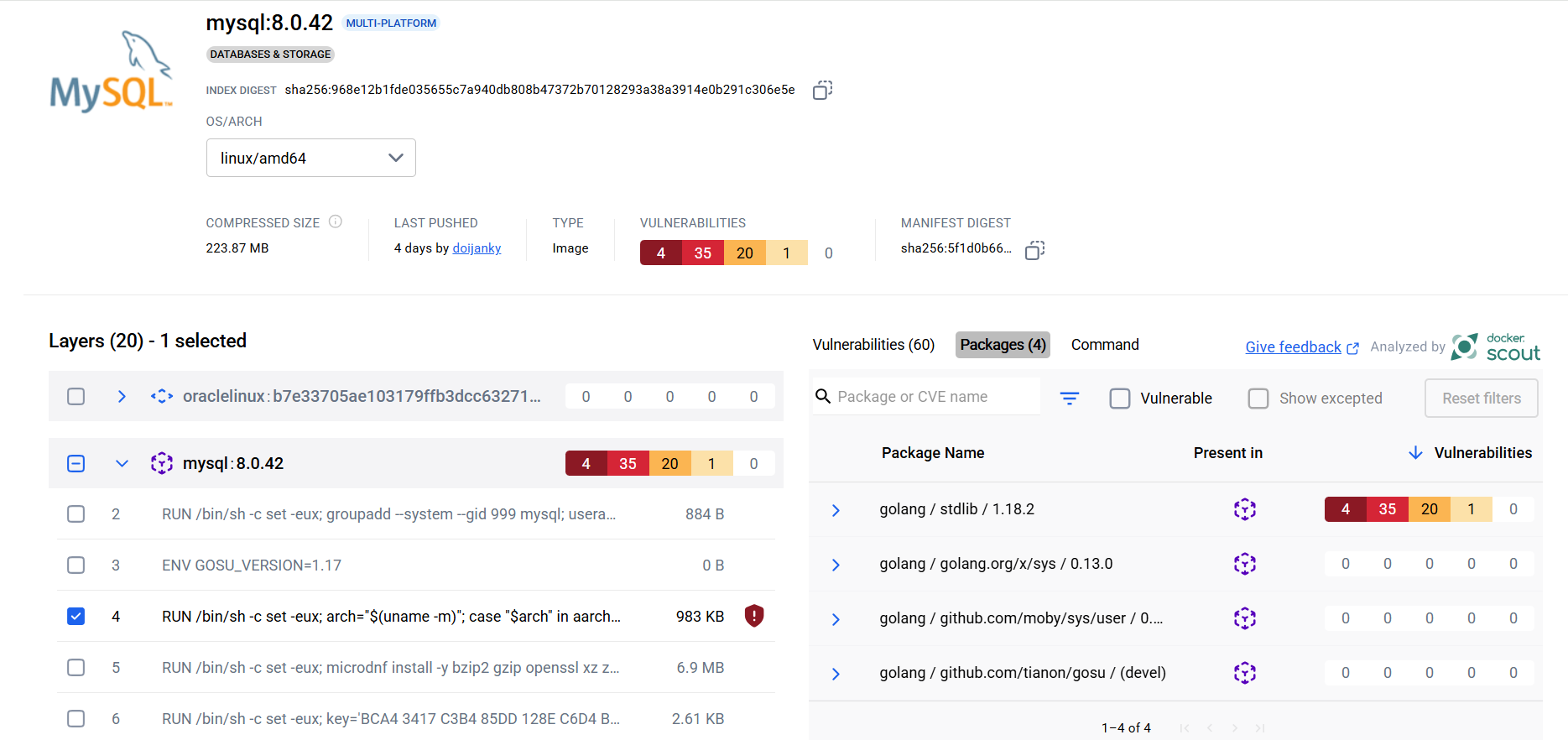
如何对docker镜像存在的gosu安全漏洞进行修复——筑梦之路
这里以mysql的官方镜像为例进行说明,主要流程为: 1. 分析镜像存在的安全漏洞具体是什么 2. 根据分析结果有针对性地进行修复处理 3. 基于当前镜像进行修复安全漏洞并复核验证 # 镜像地址mysql:8.0.42 安全漏洞现状分析 dockerhub网站上获取该镜像的…...

Ubuntu 安装WPS Office
文章目录 Ubuntu 安装WPS Office下载安装文件安装WPS问题1.下载缺失字体文件2.安装缺失字体 Ubuntu 安装WPS Office 下载安装文件 需要到 WPS官网 下载最新软件,比如wps-office_12.1.0.17900_amd64.deb 安装WPS 执行命令进行安装 sudo dpkg -i wps-office_12.1…...
基于springboot的老年医疗保健系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...

使用Ollama本地运行deepseek模型
Ollama 是一个用于管理 AI 模型的工具 下载 Ollama Ollama 选择版本 下载模型 安装好后,下载模型 选择模型 选择模型大小,复制对应命令(越大越聪明,但是内存要求越高) 打开控制台运行命令,第一次运行会自动…...
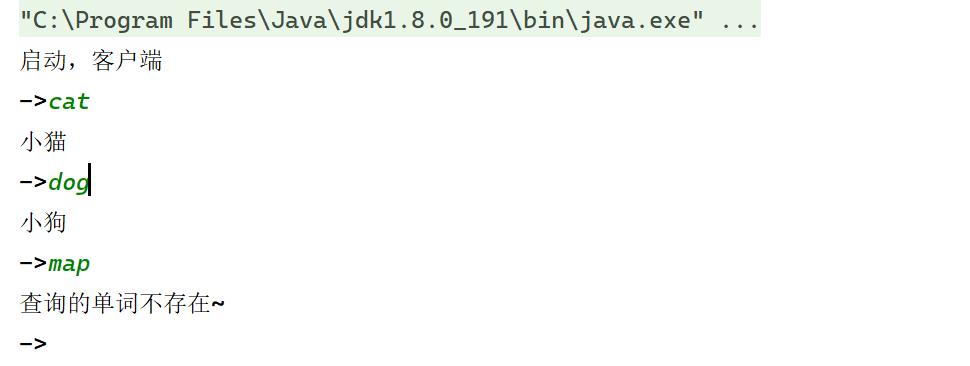
网络编程 - 3
目录 UDP 连接拓展(业务逻辑) 词典服务器实现 完 UDP 连接拓展(业务逻辑) 我们上一篇文章实现了一个回显服务器,在服务端中业务方法 process 中,只是单纯的将客户端输入的东西 return 了一下࿰…...

rebase和merge的区别
目录 1. 合并机制与提交历史 2. 冲突处理方式 3. 历史追溯与团队协作 4. 推荐实践 5. 撤销难度 git rebase和git merge是Git中两种不同的分支合并策略,核心区别在于提交历史的处理方式:merge保留原始分支结构并生成合并提交&am…...
5G 毫米波滤波器的最优选择是什么?
新的选择有很多,但到目前为止还没有明确的赢家。 蜂窝电话技术利用大量的带带,为移动用途提供不断增加的带宽。 其中的每一个频带都需要透过滤波器将信号与其他频带分开,但目前用于手机的滤波器技术可能无法扩展到5G所规划的全部毫米波&#…...

【HDFS入门】HDFS性能调优实战:压缩与编码技术深度解析
目录 1 HDFS性能调优概述 2 HDFS压缩技术原理与应用 2.1 常见压缩算法比较 2.2 压缩流程架构 2.3 压缩配置实践 3 列式存储编码技术 3.1 ORC与Parquet对比 3.2 ORC文件结构 3.3 Parquet编码流程 4 性能调优实战建议 4.1 压缩选择策略 4.2 编码优化技巧 5 性能测试…...
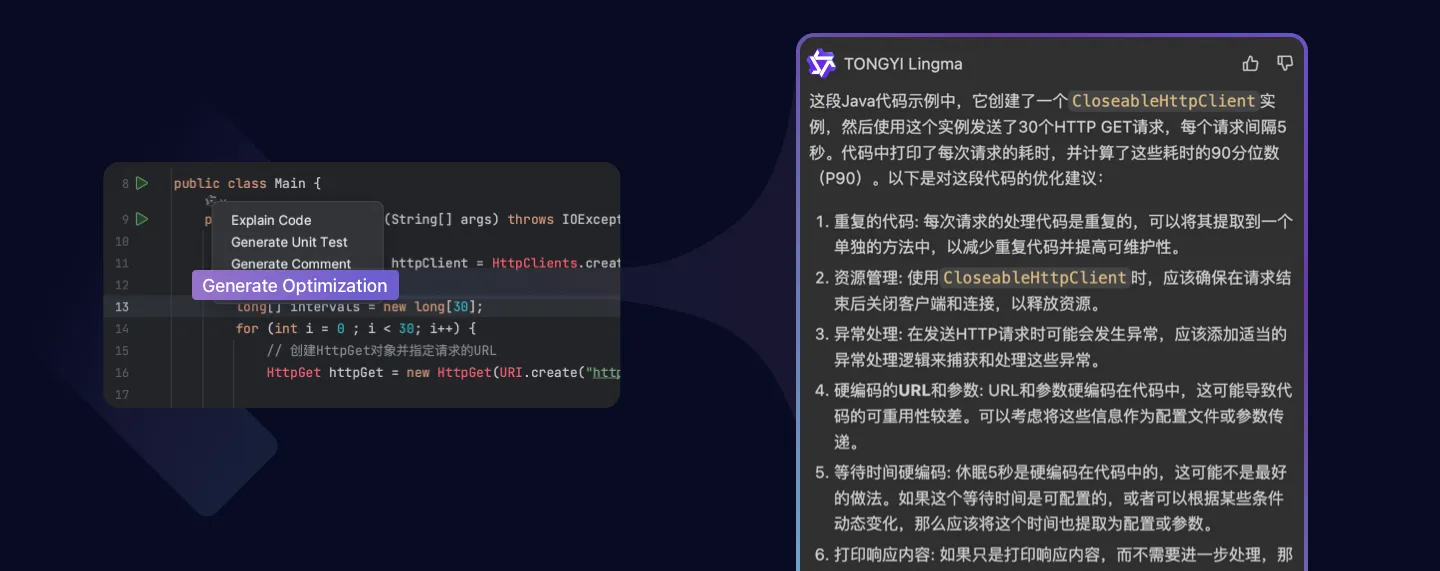
如何在 IntelliJ IDEA 中安装通义灵码 - AI编程助手提升开发效率
随着人工智能技术的飞速发展,AI 编程助手已成为提升开发效率和代码质量的强大工具。在众多 AI 编程助手之中,阿里云推出的通义灵码凭借其智能代码补全、代码解释、生成单元测试等丰富功能,脱颖而出,为开发者带来了全新的编程体验。…...
从零到一:管理系统设计新手如何快速上手?
管理系统设计是一项复杂而富有挑战性的任务,它要求设计者具备多方面的知识和技能,包括需求分析、架构设计、数据管理、用户界面设计等。对于初次接触这一领域的新手而言,如何快速上手并成为一名合格的管理系统设计者呢?本文将从管…...
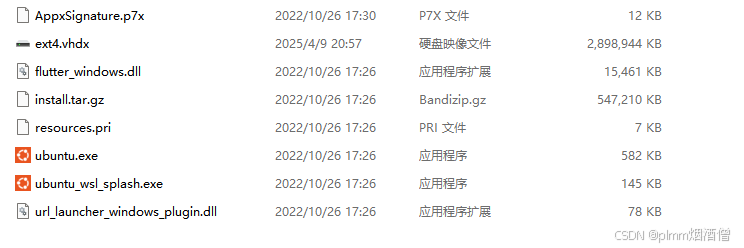
WSL (ext4.vhdx文件)占用空间过大,清理方式记录,同时更改 WSL 保存位置
一、问题 之前使用 WSL Ubuntu 进行过开发板的 Yocto 项目编译,占用空间达到了 70GB 多的空间。后来进行了项目迁移,删除了 WSL 中的所有文件,但是从 Windows 查看空间占用却没有减少: 占用依然是 70 多,查阅发现 vhdx…...

深入解析Java日志框架Logback:从原理到最佳实践
Logback作为Java领域最主流的日志框架之一,由Log4j创始人Ceki Glc设计开发,凭借其卓越的性能、灵活的配置以及与SLF4J的无缝集成,成为企业级应用开发的首选日志组件。本文将从架构设计、核心机制、配置优化等维度全面剖析Logback的技术细节。 一、Logback的架构设计与核心模…...

PCI总线和PCIe总线
本文来源:腾讯元宝 PCI(Peripheral Component Interconnect,外围组件互连) 是一种由 Intel 在 1991年 提出的 并行总线标准,用于连接计算机主板上的各种外设(如显卡、网卡、声…...
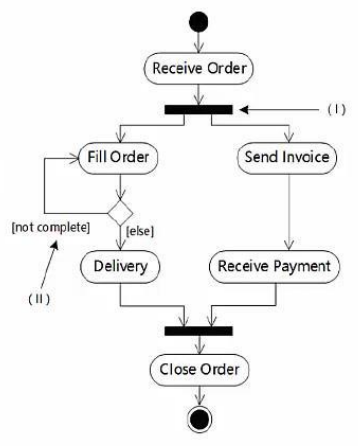
《软件设计师》复习笔记(14.2)——统一建模语言UML、事务关系图
目录 1. UML概述 2. UML构造块 (1) 事物(Things) (2) 关系(Relationships) 真题示例: 3. UML图分类 (1) 结构图(静态) (2) 行为图(动态) 4. 核心UML图详解 5.…...
:eMMC与UFS协议标准)
Flash存储器(三):eMMC与UFS协议标准
目录 一.协议介绍 1.1 eMMC协议标准 1.1.1 设计背景 1.1.2 协议演进 1.2 UFS协议标准 1.2.1 设计背景 1.2.2 协议演进 二.特性对比 三.应用场景 在嵌入式存储领域,eMMC(嵌入式多媒体卡)和UFS(通用闪存存储ÿ…...

在RK3588上使用哪个流媒体服务器合适
在RK3588平台上选择合适的流媒体服务器时,需考虑其ARM Cortex-A76/A55架构、硬件编解码能力(如支持H.264/H.265/AV1解码)以及Linux/Android系统支持。以下是推荐的方案: 1. 轻量级方案:GStreamer RTSP 适用场景&…...

PHP8.2.9NTS版本使用composer报错,扩展找不到的问题处理
使用composer install时报错: The openssl extension is required for SSL/TLS protection but is not available. If you can not enable the openssl extension, you can disable this error, at y our own risk, by setting the ‘disable-tls’ option to true.…...
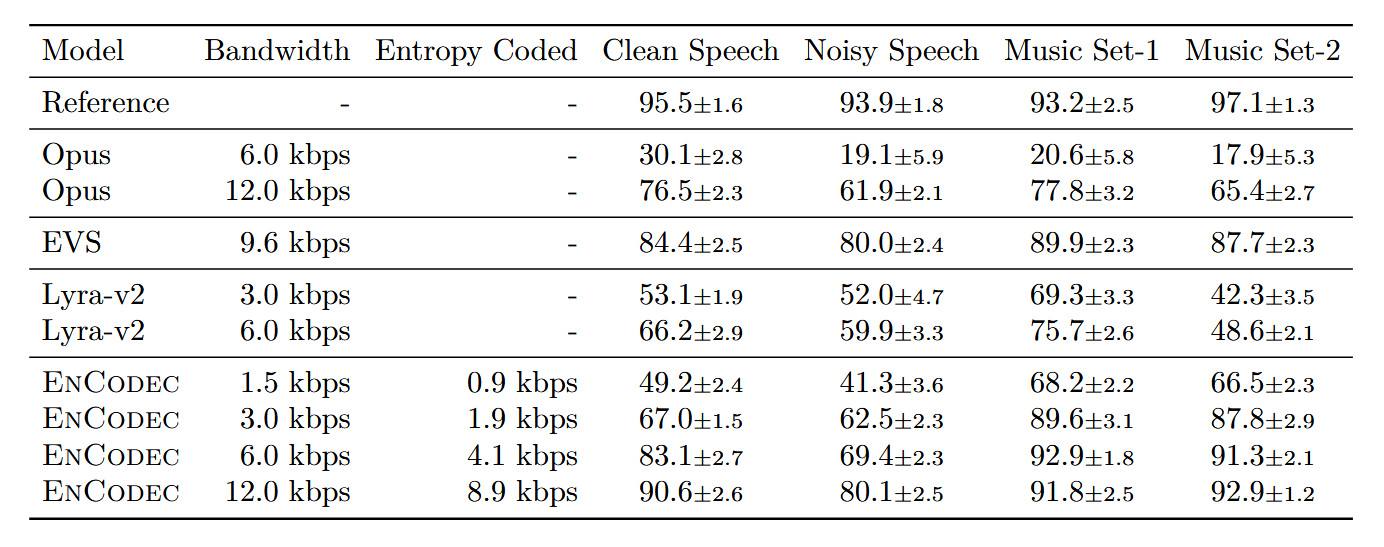
[文献阅读] EnCodec - High Fidelity Neural Audio Compression
[文献信息]:[2210.13438] High Fidelity Neural Audio Compression facebook团队提出的一个用于高质量音频高效压缩的模型,称为EnCodec。Encodec是VALL-E的重要前置工作,正是Encodec的压缩量化使得VALL-E能够出现,把语音领域带向大…...

【操作系统原理01】操作系统引论
文章目录 大纲一、中断与异常0.大纲1. 中断的作用2. 中断类型2.1 内中断2.2 外中断2.3 判断内外中断 3. 中断机制原理 二、系统调用0. 大纲1.什么是系统调用2.系统调用分类 三、操作性系统内核(了解)0.大纲1.内核2.各种操作系统结构特性 四、操作系统引论0.大纲1.磁盘存储 图片…...

http请求和websocket区别和使用场景
这个问题问得很好,下面我分几部分来详细讲解 WebSocket 的传输能力、适用场景,以及为什么即使用了 WebSocket,我们仍然会用 HTTP 接口👇 ✅ 一、WebSocket 可以传输多少内容? 理论上: WebSocket 协议本身…...

动态规划经典例题:最长单调递增子序列、完全背包、二维背包、数字三角形硬币找零
一.最长单调递增子序列 设计一个O(n^2)时间的算法,找出由n个数组成的序列的最长单调递增子序列。 实验原理 状态转移方程(递推公式): 对于每个 i,遍历之前的元素 j,如果 nums[j] < nums[i]࿰…...