如何增加 Elasticsearch 中的 primary shard 数量
作者:来自 Elastic Kofi Bartlett

探索增加 Elasticsearch 中 primary shard 数量的方法。
更多阅读:
-
Elasticsearch:Split index API - 把一个大的索引分拆成更多分片
-
Elasticsearch:通过 shrink API 减少 shard 数量来缩小 Elasticsearch 索引
-
Elasticsearch: Reindex 接口
无法增加已有索引的 primary shard 数量,这意味着如果你想增加 primary shard 数量,必须重新创建索引。在这种情况下通常有两种方法可用: _reindex API 和 _split API。
_split API 通常比 _reindex API 更快。在执行这两种操作之前必须停止写入索引,否则 source_index 和 target_index 的文档数量会不一致。
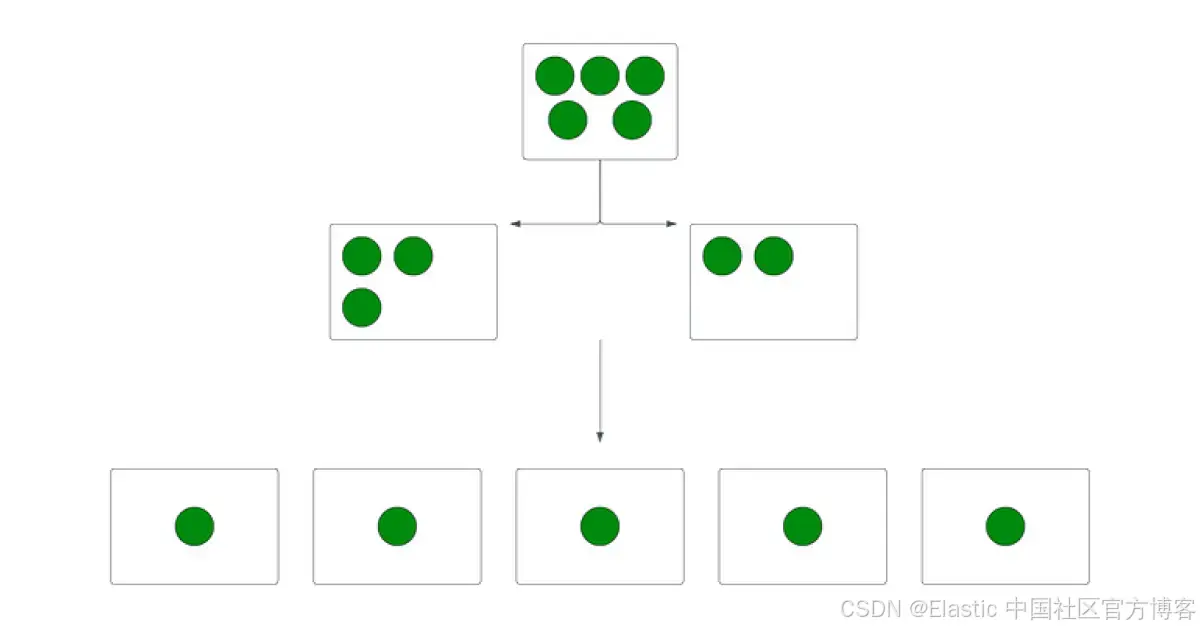
方法 1 – 使用 split API
split API 用于通过复制现有索引的设置和映射,创建一个具有所需 primary shard 数量的新索引。可以在创建过程中设置所需的 primary shard 数量。在使用 split API 之前应检查以下设置:
-
源索引必须是只读的。这意味着需要停止写入过程。
-
目标索引的 primary shard 数量必须是源索引 primary shard 数量的倍数。例如,如果源索引有 5 个 primary shard,目标索引可以设置为 10、15、20 等。
注意:如果只需要更改 primary shard 数量,建议使用 split API,因为它比 Reindex API 快得多。
实现 split API
创建一个测试索引:
POST test_split_source/_doc
{"test": "test"
}我们可以使用如下的命令来查看这个索引的设置:
GET test_split_source/_settings{"test_split_source": {"settings": {"index": {"routing": {"allocation": {"include": {"_tier_preference": "data_content"}}},"number_of_shards": "1","provided_name": "test_split_source","creation_date": "1744934104333","number_of_replicas": "1","uuid": "Ixn7Y6gdTaOnuW9x9AbEjg","version": {"created": "9009000"}}}}
}我们可以看到 number_of_shards 为 1。
源索引必须是只读的才能进行 split:
PUT test_split_source/_settings
{"index.blocks.write": true
}设置和映射会自动从源索引复制:
POST /test_split_source/_split/test_split_target
{"settings": {"index.number_of_shards": 3}
}在上面,我们可以看到 number_of_shards 是 3。它是我们之前的 1 的整数倍。
你可以使用以下命令检查进度:
GET _cat/recovery/test_split_target?v&h=index,shard,time,stage,files_percent,files_total由于设置和映射是从源索引复制的,目标索引是只读的。现在让我们为目标索引启用写入操作:
PUT test_split_target/_settings
{"index.blocks.write": null
}在删除原始索引之前,检查源索引和目标索引的 docs.count:
GET _cat/indices/test_split*?v&h=index,pri,rep,docs.count索引名称和别名名称不能相同。你需要删除源索引,并将源索引名称作为别名添加到目标索引:
DELETE test_split_source
PUT /test_split_target/_alias/test_split_source在将 test_split_source 别名添加到 test_split_target 索引后,你应该使用以下命令进行测试:
GET test_split_source
POST test_split_source/_doc
{"test": "test"
}方法 2 – 使用 reindex API
通过使用 Reindex API 创建新索引,可以设置任何数量的 primary shard 数量。在使用所需的 primary shard 数量创建新索引后,源索引中的所有数据可以重新索引到该新索引。
除了 split API 的功能外,还可以使用 reindex API 中的 ingest_pipeline 对数据进行处理。通过 ingest_pipeline,只有符合筛选条件的指定字段会使用查询索引到目标索引中。数据内容可以通过 painless 脚本进行修改,并且可以将多个索引合并为一个索引。
实现 reindex API
创建一个测试 reindex:
POST test_reindex_source/_doc
{"test": "test"
}从源索引复制设置和映射:
GET test_reindex_source使用设置、映射和所需的 shard 数量创建目标索引:
PUT test_reindex_target
{"mappings" : {},"settings": {"number_of_shards": 10,"number_of_replicas": 0,"refresh_interval": -1}
}*注意:设置 number_of_replicas: 0 和 refresh_interval: -1 将提高 reindex 速度。
启动 reindex 过程。设置 requests_per_second=-1 和 slices=auto 将调整 reindex 速度。
POST _reindex?requests_per_second=-1&slices=auto&wait_for_completion=false
{"source": {"index": "test_reindex_source"},"dest": {"index": "test_reindex_target"}
}当你运行 reindex API 时,系统会显示 task_id。复制该 task_id 并使用 _tasks API 检查进度:
GET _tasks/<task_id>在 reindex 完成后,更新设置:
PUT test_reindex_target/_settings
{"number_of_replicas": 1,"refresh_interval": "1s"
}在删除原始索引之前,检查源索引和目标索引的 docs.count,应该是相同的:
GET _cat/indices/test_reindex_*?v&h=index,pri,rep,docs.count索引名称和别名名称不能相同。删除源索引,并将源索引名称作为别名添加到目标索引:
DELETE test_reindex_source
PUT /test_reindex_target/_alias/test_reindex_source在将 test_split_source 别名添加到 test_split_target 索引后,使用以下命令进行测试:
GET test_reindex_source总结
如果你想增加已有索引的 primary shard 数量,需要将设置和映射重新创建到一个新索引中。实现这一点有两种主要方法:reindex API 和 split API。在使用这两种方法之前,必须停止当前的索引操作。
想获得 Elastic 认证吗?了解下一期 Elasticsearch 工程师培训的时间!
Elasticsearch 拥有许多新特性,帮助你为你的用例构建最佳的搜索解决方案。深入了解我们的示例笔记本,开始免费的云试用,或现在就尝试在本地机器上使用 Elastic。
原文:How to increase primary shard count in Elasticsearch - Elasticsearch Labs
相关文章:
如何增加 Elasticsearch 中的 primary shard 数量
作者:来自 Elastic Kofi Bartlett 探索增加 Elasticsearch 中 primary shard 数量的方法。 更多阅读: Elasticsearch:Split index API - 把一个大的索引分拆成更多分片 Elasticsearch:通过 shrink API 减少 shard 数量来缩小 El…...

Java 并发性能优化:线程池的最佳实践
Java 并发性能优化:线程池的最佳实践 在 Java 并发编程的世界里,线程池堪称提高应用性能与稳定性的神器。恰如其分地运用线程池,能让我们在多线程任务调度时游刃有余,既能避免线程频繁创建销毁带来的开销,又能合理管控…...

【综述】一文读懂卷积神经网络(CNN)
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。本文旨在介绍CN…...

Python爬虫实战:获取网易新闻数据
一、引言 随着互联网的飞速发展,网络上蕴含着海量的信息资源。新闻数据作为其中的重要组成部分,对于舆情分析、市场研究、信息传播等多个领域具有重要价值。网易新闻作为国内知名的新闻平台,拥有丰富多样的新闻内容。使用 Python 的 Scrapy 框架进行网易新闻数据的爬取,可…...

YOLO学习笔记 | 基于COCO Stuff数据集与YOLOv11的多类别物体检测与分割
基于COCO Stuff数据集与YOLOv11的多类别物体检测与分割技术解析 一、技术背景与YOLOv11核心改进 YOLOv11是Ultralytics推出的新一代目标检测与分割模型,在YOLOv8的基础上进一步优化了架构设计与训练流程。其核心改进包括: 自适应特征增强(AFE)模块:通过空间上下文模块(…...

ICS丨Chapter 1 Introduction to Computer System
Chapter 1 Introduction to Computer System Courses About Systems: DBMSDistributed SystemsCompilersArchitectureOperating Systemse.t.c. 1. Brief Introduction 1.1. What’s about CSAPP?1.2. Power of Abstraction1.3. Importance of understanding HOW things wor…...
阿里云集群开启debug
1、安装 kubectl Macos brew install kubectl Windows: https://kubernetes.io/zh-cn/docs/tasks/tools/install-kubectl-windows/ 下载后,放到任意目录 2、配置连接信息 mac 将以下内容复制到计算机 $HOME/.kube/config 文件下: windows 不同集…...

Flink Hive Catalog最佳实践
Flink Hive Catalog 最佳实践 一、配置与初始化 依赖管理 Hive Connector 版本对齐:需确保 flink-sql-connector-hive 版本与 Hive 版本严格匹配(如 Hive 3.1.3 对应 flink-sql-connector-hive-3.1.3_2.12),同时添加 Hadoop 遮蔽…...
Unity之如何实现RenderStreaming视频推流
文章目录 前言引入 UnityRenderStreaming 的好处教程步骤 1:设置环境步骤 2: 创建项目步骤 3:安装软件包步骤 5:下载示例步骤 6:检查配置环境步骤 7:打开推流场景步骤 8: 准备用于流式传输的WebServer应用程序步骤 9: 运行 示例场景步骤 10:检查视频是否在浏览器中显示…...

【java实现+4种变体完整例子】排序算法中【桶排序】的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格
以下是桶排序的详细解析,包含基础实现、常见变体的完整代码示例,以及各变体的对比表格: 一、桶排序基础实现 原理 将数据分到有限数量的桶中,每个桶内部使用其他排序算法(如插入排序或快速排序)…...
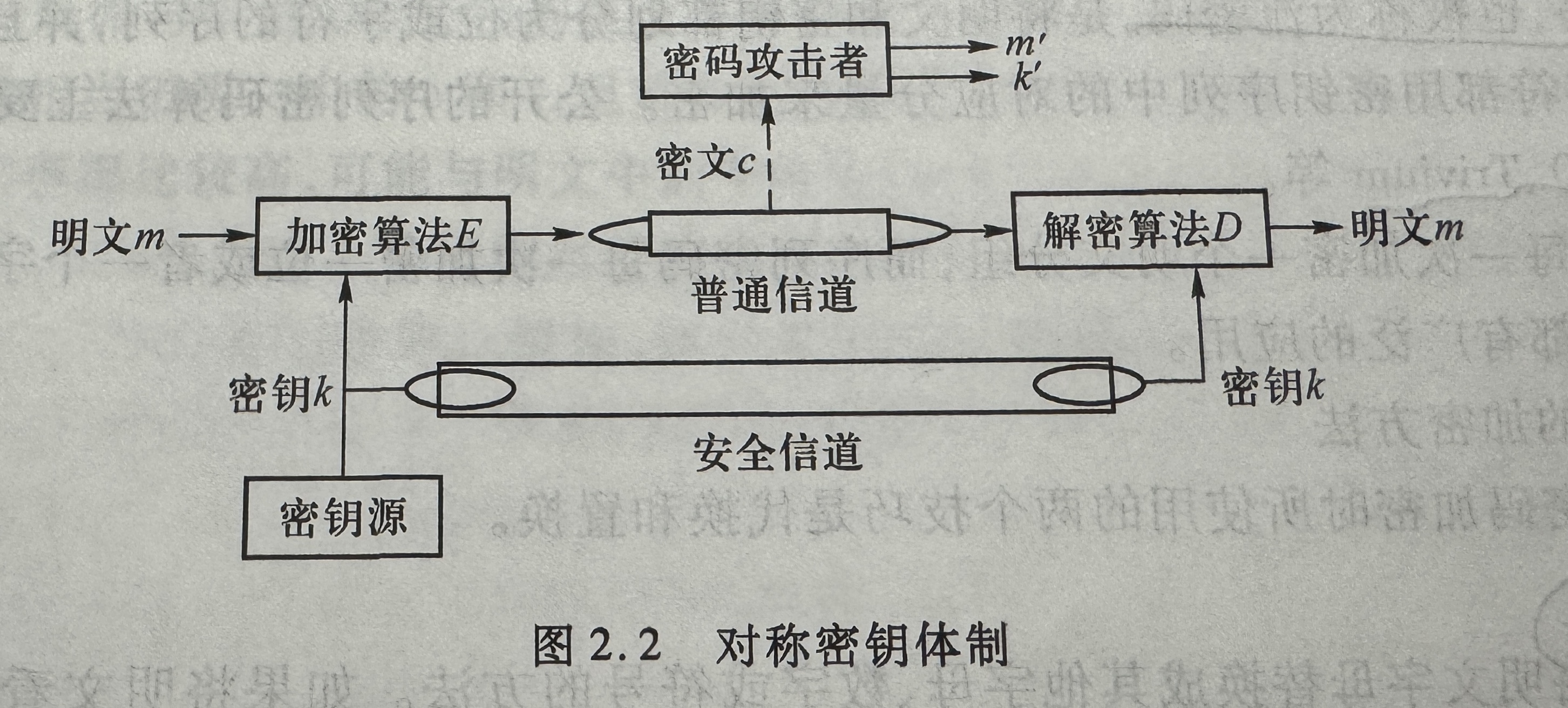
计算机三级:信息安全基础技术与原理(2.1密码技术简单梳理)
以下是密码学发展历程的表格归纳: 发展阶段时间范围关键节点与标志性技术技术突破与核心贡献古典密码时期古代至19世纪• 公元前17世纪 克里特岛Phaistos圆盘(未知符号加密) • 中国西周“阴符”、北宋五言诗密码 • 1466年 艾伯蒂多表代替密码 • 1883年 克尔克霍…...

基于CNN与VGG16的图像识别快速实现指南
基于CNN与VGG16的图像识别快速实现指南 以下是从零实现代码到原理剖析的完整流程,包含TensorFlow/Keras框架的代码示例与关键优化技巧,满足快速实验需求。 一、核心原理对比 特性CNN(基础模型)VGG16结构深度5-10层(如…...

【内置函数】84个Python内置函数全整理
Python 内置函数全集(完整分类 参数详解 示例) 文章目录 Python 内置函数全集(完整分类 参数详解 示例)一、数值与数学函数abs(x)divmod(a, b)pow(x, y, modNone)round(number[, ndigits])sum(iterable, /, start0)hash(obj) …...
【每天一个知识点】模式识别
“模式识别”是一种从数据中识别出规律、结构或趋势的技术,它广泛应用于人工智能、机器学习、图像处理、语音识别、自然语言处理等领域。简单来说,就是让计算机学会“看出”数据中的规律,比如: 从图像中识别人脸(人脸识…...

Codeforces Educational Round 177 Div. 2 【B题,C待补
B 二分 题意 样例 5 3 10 3 4 2 1 512 找最右边的L下标即可 思路 二分最靠右的L端点,R端点取最右端(n*k处),找到后,答案就是L的位置(pos),(因为如果pos满足,则pos左边的所有下标都满足 代码 const in…...

哈夫曼编码和哈夫曼树
哈夫曼编码(Huffman Coding) 是一种基于字符出现频率的无损数据压缩算法,通过构建哈夫曼树(Huffman Tree) 来生成最优前缀编码,使得高频字符用短编码,低频字符用长编码,从而实现高效…...

中西面点实训室虚拟仿真操作平台
在餐饮行业蓬勃发展的当下,中西面点作为其中极具特色与市场需求的重要分支,对于专业人才的渴望愈发强烈。一个功能完备、设施先进的中西面点实训室,已然成为培养高素质面点专业人才的关键阵地。凯禾瑞华——实训室建设 一、中西面点实训室建设…...

Python字典深度解析:高效键值对数据管理指南
一、字典核心概念解析 1. 字典定义与特征 字典(Dictionary)是Python中基于哈希表实现的无序可变容器,通过键值对存储数据,具有以下核心特性: 键值对结构:{key: value}形式存储数据快…...
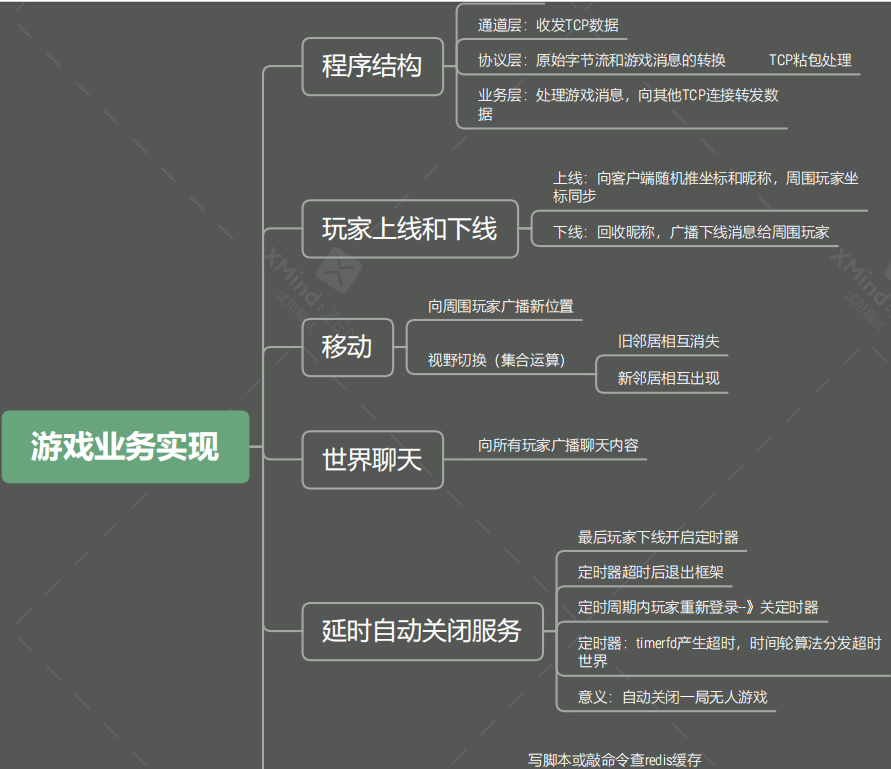
C++游戏服务器开发之⑦redis的使用
目录 1.当前进度 2.守护进程 3.进程监控 4.玩家姓名添加文件 5.文件删除玩家姓名 6.redis安装 7.redis存取命令 8.redis链表存取 9.redis程序结构 10.hiredisAPI使用 11.基于redis查找玩家姓名 12.MAKEFILE编写 13.游戏业务实现总结 1.当前进度 2.守护进程 3.进程监…...
模拟投资大师思维:AI对冲基金开源项目详解
这里写目录标题 引言项目概述核心功能详解多样化的AI投资智能体灵活的运行模式透明的决策过程 安装和使用教程环境要求安装步骤基本使用方法运行对冲基金模式运行回测模式 应用场景和实际价值教育和研究价值潜在的商业应用与现有解决方案的对比局限性与发展方向 结论 引言 随着…...
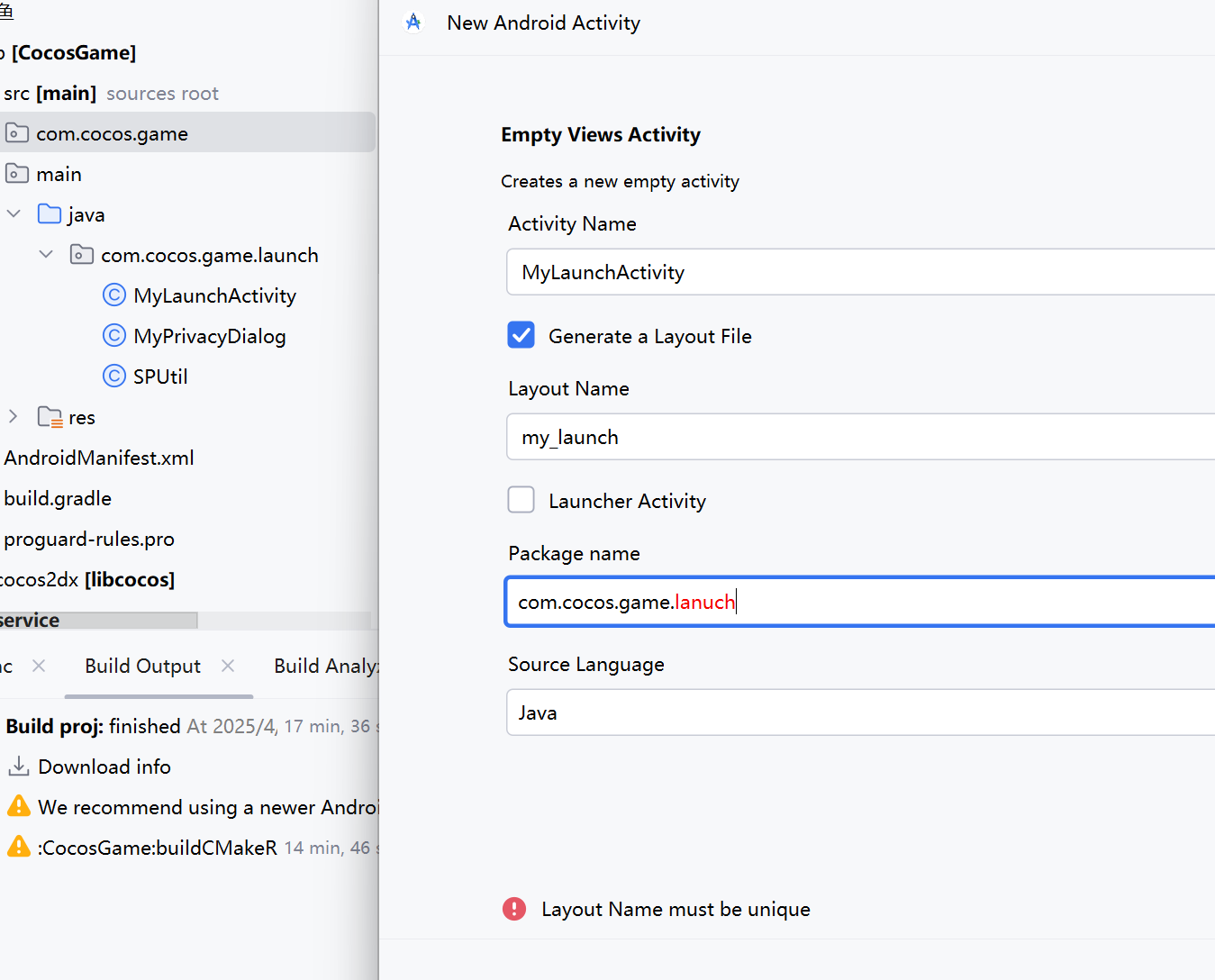
Cocos Creater打包安卓App添加隐私弹窗详细步骤+常见问题处理
最终演示效果,包含所有代码内容 + 常见错误问题处理 点击服务协议、隐私政策,跳转到相关网页, 点击同意进入游戏,不同意关闭应用 一,添加Activity,命名为MyLaunchActivity 二,编写MyLaunchActivity.java的内容 package com.cocos.game.launch;import android.os.Bund…...

Android 热点二维码简单示例
Android 热点二维码简单示例 一、前言 Android 原生设置有热点二维码分享功能,有些系统应用也会有这个需求。 下面看看是如何实现的。 本文是一个比较简单的内容。 二、热点二维码生成实现 1、效果 整个应用就一个普通的Activity,显示一个按钮和二维…...

探秘Python 工匠:案例、技巧与工程实践:解锁Python进阶的通关秘籍
重要的放前面 Python 工匠:案例、技巧与工程实践 探秘Python 工匠:案例、技巧与工程实践:解锁Python进阶的通关秘籍 在Python的编程世界中,从入门小白到技术大牛的进阶之路往往充满挑战。Python工匠:案例、技巧与工…...
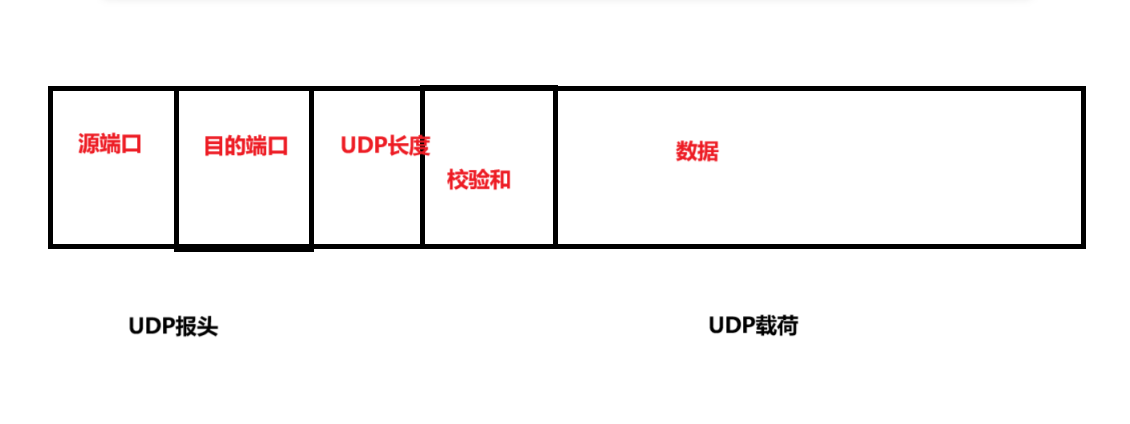
JAVAEE(网络原理—UDP报头结构)
我们本篇文章要讲的是UDP的报头结构以及注意事项。 下面呢,我先说一下UDP是什么? 1.UDP是什么? UDP是一种网络协议。网络协议是计算机网络中,为了使不同设备之间能够准确、高效地进行数据交换和通信,而预先制定的一…...

通过docker create与export来分析诊断故障镜像
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...
LINUX419 更换仓库(没换成)find命令
NAT模式下虚拟机需与网卡处在同一个网段中吗 和VM1同个网段 会不会影响 这个很重要 是2 改成点2 倒是Ping通了 为啥ping百度 ping到别的地方 4399 倒是ping通了 准备下载httpd包 下不下来 正在替换为新版本仓库 报错 failure: repodata/repomd.xml from local: [Er…...
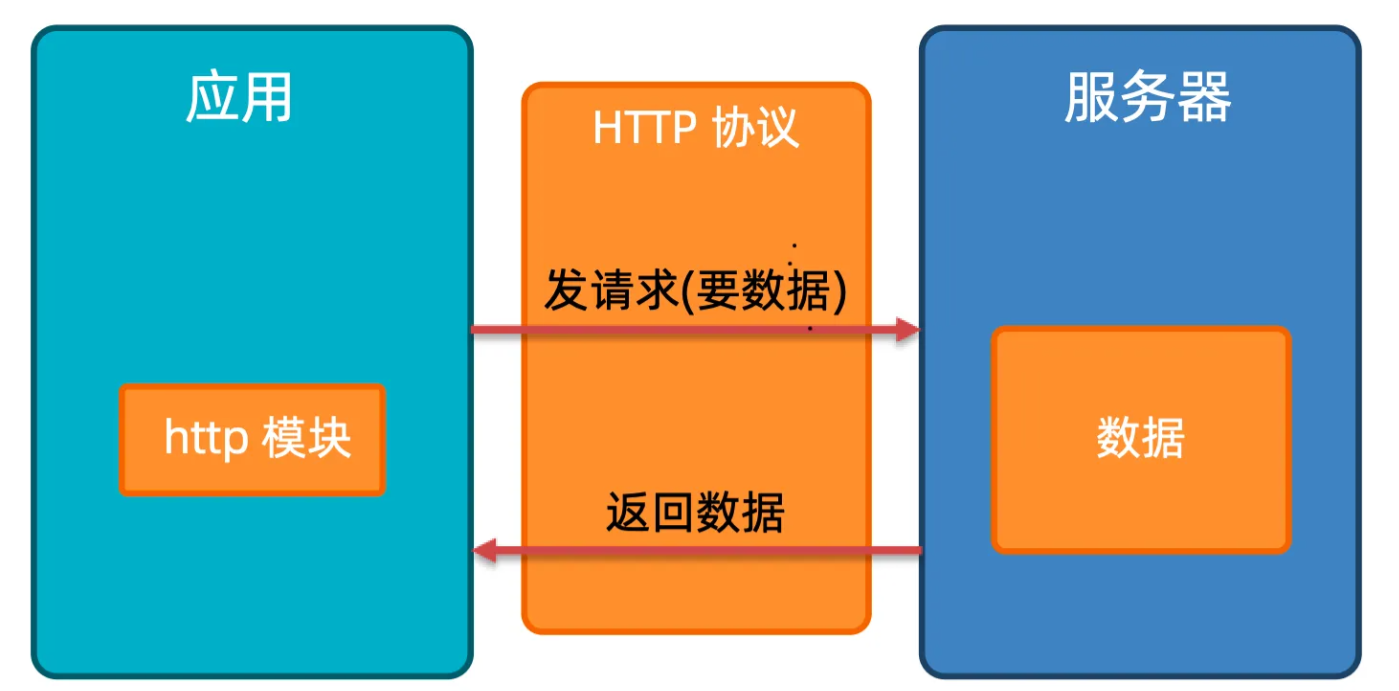
鸿蒙学习笔记(5)-HTTP请求数据
一、Http请求数据 http模块是鸿蒙内置的一个模块,提供了网络请求的能力。不需要再写比较原始的AJAS代码。 ps:在项目中如果要访问网络资源,不管是图片文件还是网络请求,必须给项目开放权限。 (1)网络连接方式 HTTP数…...

AI文生图工具推荐
一、AI文生图技术实现原理 AI文生图(Text-to-Image)基于生成对抗网络(GAN)或扩散模型(Diffusion Model)实现,通过深度学习将文本描述转化为图像。其核心流程包括: 文本编码…...

Spark-SQL核心编程
Spark-SQL核心编程 数据加载与保存 加载数据 spark.read.load 是加载数据的通用方法。如果读取不同格式的数据,可以对不同的数据格式进行设定 保存数据 df.write.save 是保存数据的通用方法。如果保存不同格式的数据,可以对不同的数据格式进行设定 …...

github 项目迁移到 gitee
1. 查看远程仓库地址 git remote -v 2. 修改远程仓库地址 确保 origin 指向你的 Gitee 仓库,如果不是,修改远程地址。 git remote set-url origin https://gitee.com/***/project.git 3. 查看本地分支 git branch 4. 推送所有本地分支 git p…...