在 Amazon Graviton 上运行大语言模型:CPU 推理性能实测与调优指南

引言
在生成式 AI 浪潮中,GPU 常被视为大模型推理的唯一选择。然而,随着 ARM 架构的崛起和量化技术的成熟,CPU 推理的性价比逐渐凸显。本文基于 Amazon Graviton 系列实例与 llama.cpp 工具链,实测了 Llama 3、DeepSeek 等模型的推理性能,揭示 CPU 在大模型推理中的潜力。
CPU 运行大模型的核心场景
在以下场景中,CPU 可作为经济高效的解决方案:
-
边缘推理与实时交互:低延迟需求的场景(如客服机器人、轻量化 AI 助手)中,CPU 无需复杂硬件部署即可满足实时响应。
-
成本敏感型业务:通过量化技术压缩模型后,CPU 可降低硬件采购与运维成本。
-
混合架构补充:在 GPU 资源受限时,CPU 可作为弹性资源池处理突发请求。
-
隐私合规场景:部分场景需避免使用外部加速卡以简化数据流安全管控。
-
数据预处理和特征工程:文本处理,特征提取,数据清洗,这种依赖单线程库的,CPU 更合适。
-
无高频调用或高吞吐算力要求场景:CPU 更适合小吞吐但是高延迟敏感、或者虽然高吞吐但是使用频率低的任务。
CPU 与 GPU 的架构差异及性能影响
1. 硬件特性对比
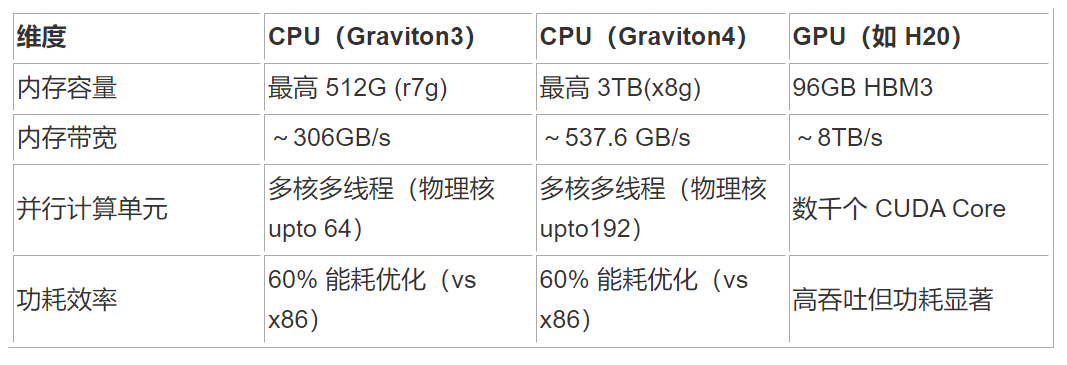
2. 模型加载与推理差异
-
模型加载:CPU 将模型权重加载到主存(RAM)中,而 GPU 则是将模型权重加载至显存(VRAM)中。
-
Prompt Token 处理:CPU 会将输入 token 从内存加载到 CPU 缓存中,然后逐步执行推理过程,CPU 能够并行利用多个内核,推理速度与计算核心数量密切相关,但相较 GPU 并行能力有限;GPU 会通过 CUDA 将输入数据加载到显存中,然后并行执行模型推理。
-
Token 生成:CPU 在生成 token 时需要访问大量的 KV 缓存,在流式推理(Streaming Inference) 场景下,每个 token 需要不断访问已有缓存,因此容易受到内存带宽影响,相比较 GPU 内存带宽来讲,CPU 内存带宽瓶颈往往限制 token 生成速度。
总结:GPU 依赖并行计算单元实现高吞吐,而 CPU 需通过批处理与线程绑定提升效率,所以 CPU 更适合低并行度任务或小型模型。
Graviton 运行大模型的架构优化
1. 硬件架构特性
Graviton3 和 Graviton4 的核心改进:
-
Graviton3 拥有 15 条宽发射通道和两倍更大的指令窗口, 相比较 Graviton2 显著提升了指令级并行度。
-
Graviton3 采用了优化的分支预测器,为更大型的模型提供了更准确的分支预测。它还配备了 16 位 BFloat 支持和 256 位 SVE 矢量计算能力,针对 AI/ML 工作负载进行了专门加速。
-
存储子系统方面,Graviton3 也做出了重大改进。与 Graviton2 相比,它的 SIMD 带宽提升了一倍,内存访问带宽提高了 50%。同时,它还支持 2 倍内存预取增强,TLS 指令提速约一倍,确保数据高效流动。
-
Graviton4 也对内存子系统进行了强化,内存带宽比 Graviton3 提升了 75%,确保数据能够高效流动,满足 AI/ML 对存储带宽的旺盛需求。
2. 软件栈优化措施
-
量化支持:基于 ARM NEON 指令的 8-bit/4-bit 量化算子优化(如 GGML 库)。
-
线程调度:绑定物理核心避免超线程争抢,NUMA-aware 内存分配。
-
编译优化:使用 GCC 11 + 或 Clang 14 + 开启 -mcpu=native 与 -O3 优化。
3. Graviton 社区持续活跃
-
主流的机器学习框架都已经为 Graviton3 的特性做好了充分适配,包括 PyTorch 2.0 及更高版本、TensorFlow 1.9.1 及更高版本,以及 OnnxRuntime 1.17.0 及更高版本、Scikit-learn 1.0 及更高版本等。
-
llama.cpp 这种创新的开源框架,也已针对 Graviton3 进行了优化。
-
亚马逊云科技还提供了预装这些优化框架的 Python Wheel 文件和深度学习容器镜像,用户可以一键启动,免去手动配置的麻烦。
性能实测与对比分析
以下数据基于 llama.cpp 测试框架。
1. 典型模型吞吐表现(量化模型)
*下图测试数据针对模型 meta-llama-3-8b-instruct.Q4_0.gguf 和 meta-llama-3-70b-instruct.Q4_0.gguf。
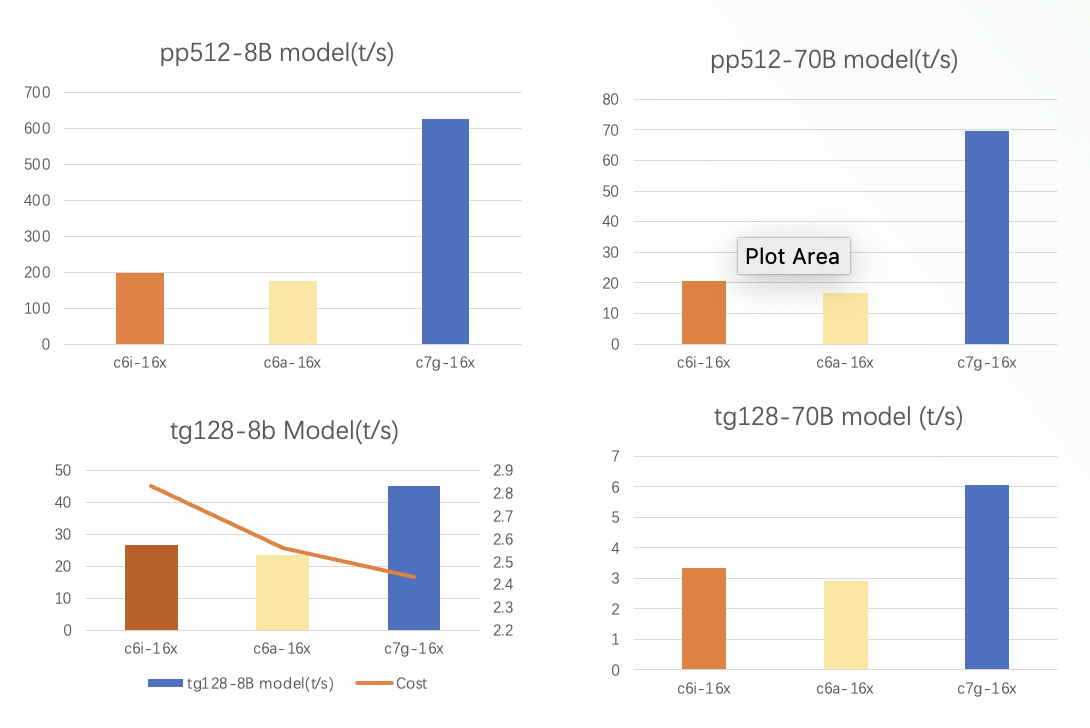
*pp512 指标为 prompt processing 512 个 token,tg128 为生成 128 个 token。
从图中我们可以看出:
与同等规格的 x86 实例相比,Graviton3/4 实例提供了卓越的性价比表现。对于相同的 llama 模型和测试用例,亚马逊云科技新一代 Graviton4 实例始终拥有明显更高的推理吞吐能力,较上一代 Graviton3 实例的性能提升是显著的。对于相同实例类型和线程数量,8B 规模的较小模型通常会比 70B 的大规模模型拥有更高的吞吐量表现。
2. DeepSeek 相关蒸馏模型表现(无量化模型)
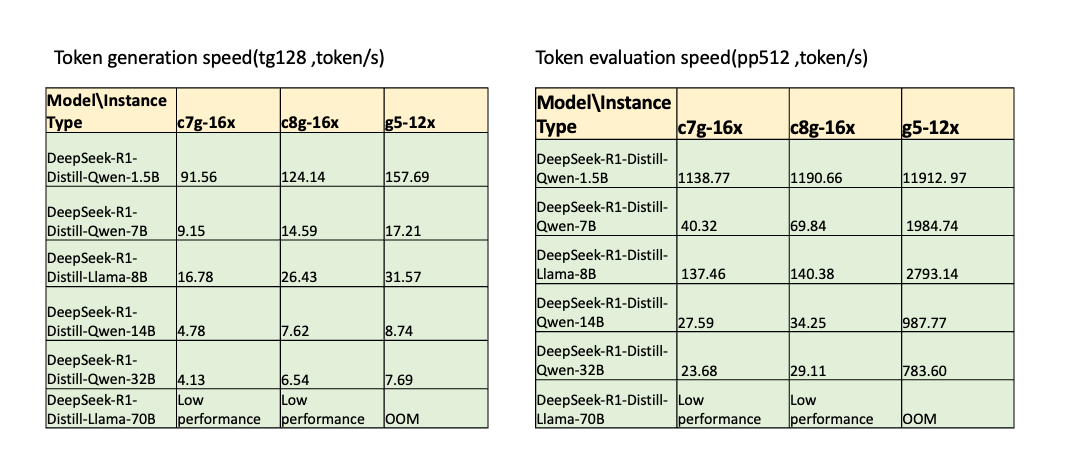
从图中我们可以看出,Graviton3 实例在 8B 及以下无量化模型表现基本可以满足人眼阅读速度, Graviton4 实例在 32B 及以下都能够达到或者接近人眼阅读速度,对于 prompt 相对较短的场景,Graviton 效价比还是比较可观。
3. 不同实例规格性能
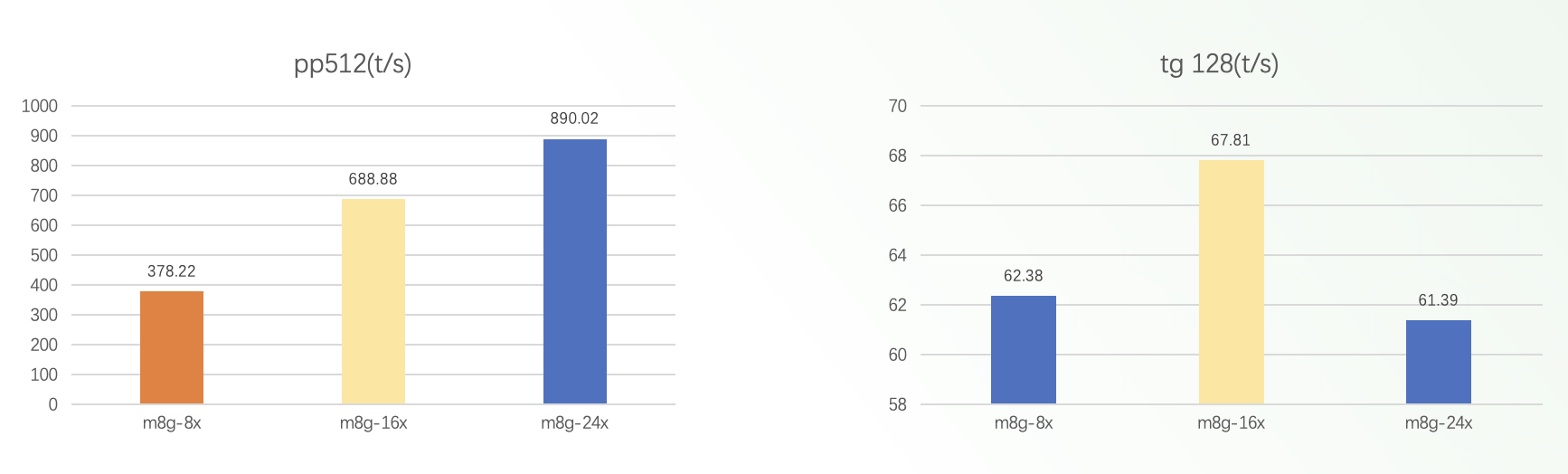
从图中我们可以看到:
-
随着 vCPU 核心数从 8 核增加到 16 核,再到 24 核,pp512 的吞吐量也呈现出近乎线性的增长趋势,说明对于这类计算密集型的工作负载,增加更多的计算资源能够有效提升系统的 prompt token 处理能力。
-
另一方面,tg128 模拟了生成 128 个 token 的场景,可以对应文本续写或对话生成等应用。但是,与 pp512 不同的是,tg128 的吞吐量随着 vCPU 核心数的增加,提升空间并不太大。从 8 核到 16 核,吞吐量仅有小幅提升,进一步增加到 24 核时,性能提升也相当有限。
这种现象主要是由于语言模型生成任务本身的特殊性质所决定的。生成过程需要模型在每个时间步都捕捉上下文语义,并根据条件概率预测下一个 token,这种高度串行化的计算模式使得单个请求的延迟降低了对并行化的需求。因此,对于像 tg128 这样的生成任务,单纯增加 vCPU 核心数不太可能带来理想的线性加速比,还需要结合其他的优化手段,比如通过模型剪枝减小参数量、利用更高带宽的内存等来进一步提升生成效率。
4. 不同实例类型性能
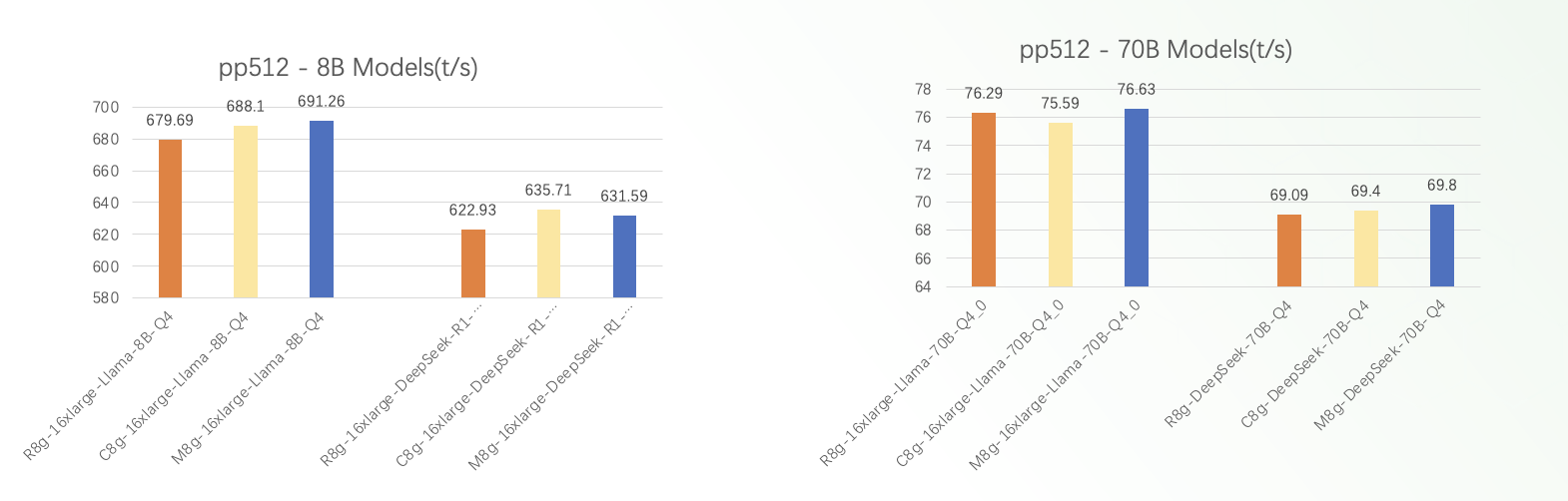
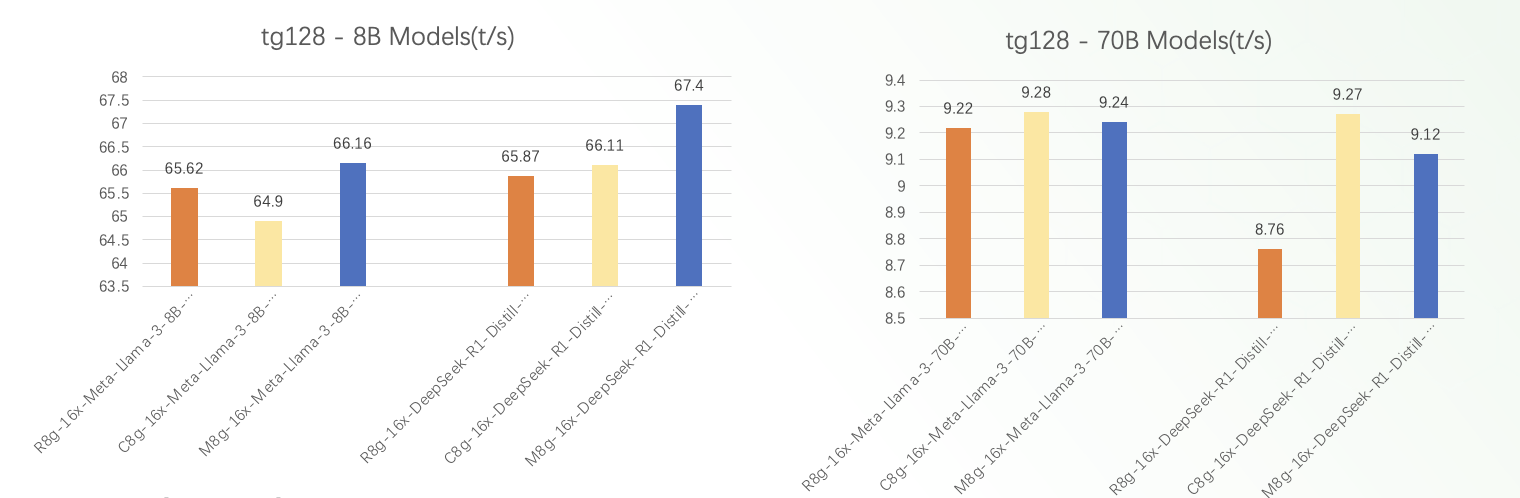
从图中可以看出:
-
较小的 8B 模型由于参数体积更小,对计算资源的利用率更高,因此对实例硬件配置的差异会表现出更明显的性能差异。而对于 70B 这种大规模模型来说,由于计算和内存带宽长期处于饱和状态,不同实例类型之间的性能变化就相对不太显著了。
在部署 Llama/DeepSeek 等大规模语言模型时,我们不仅需要根据具体的应用场景来选择合适的实例规格,还要平衡参数量和硬件资源之间的匹配关系。只有做到有机结合,才能充分释放语言模型的潜能,实现最优的性价比。
5. 关键场景性能
a. 批处理场景测试(model: DeepSeek-R1-Distill-Llama-8B-Q4_0.gguf,instance: c8g-16x)
第一组 prompt 64 token, generate 128 token


第二组 prompt 128 token, generate 128 token

第三组 prompt 256 token,generate 128 token
![]()

第四组 prompt 512 token, generate 128 token
![]()

所以在生成 128token 的场景测试中,生成 token 的速度可以在 16 个 batch 场景下达到 296 t/s。
b. 首 Token 延迟
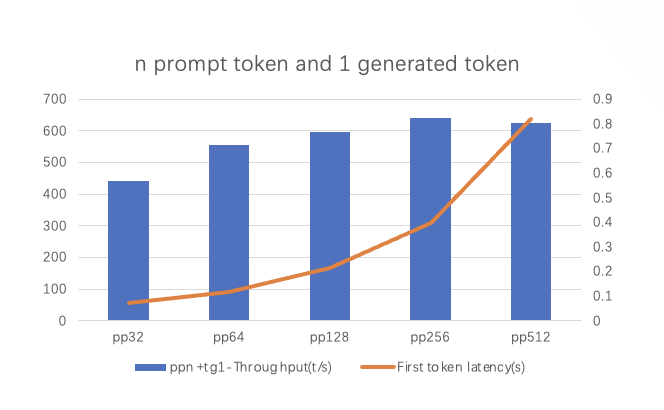
从图中我们可以看出:
-
吞吐量随 Prompt Token 增加先升后降:当 Prompt Token 增加到 pp256 或 pp512 时,吞吐量接近峰值,随后略有下降,即 Prompt Token 的数量对吞吐量的影响存在一个最佳区间。
-
首 Token 延迟随 Prompt Token 增加而增加:随着 Prompt Token 数量从 pp32 增加到 pp512,首 Token 延迟显著上升。在 pp512 时,延迟达到最大(约 8 秒)。
吞吐量变化原因包括以下几个方面:
-
Prompt Token 数量少时(如 pp32):初始化开销较大,资源利用率较低,吞吐量较低。
-
Prompt Token 数量适中时(如 pp256):计算单元和硬件资源达到较优的并行处理效率,吞吐量达到峰值。
-
Prompt Token 数量过多时(如 pp512 重复情况):数据传输开销增加,硬件资源的带宽限制和缓存效率下降,吞吐量略微下降。
6. TCO 表现(model: DeepSeek-R1-Distill-Llama-8B-Q4_0.gguf,pp=128token tg=128token)
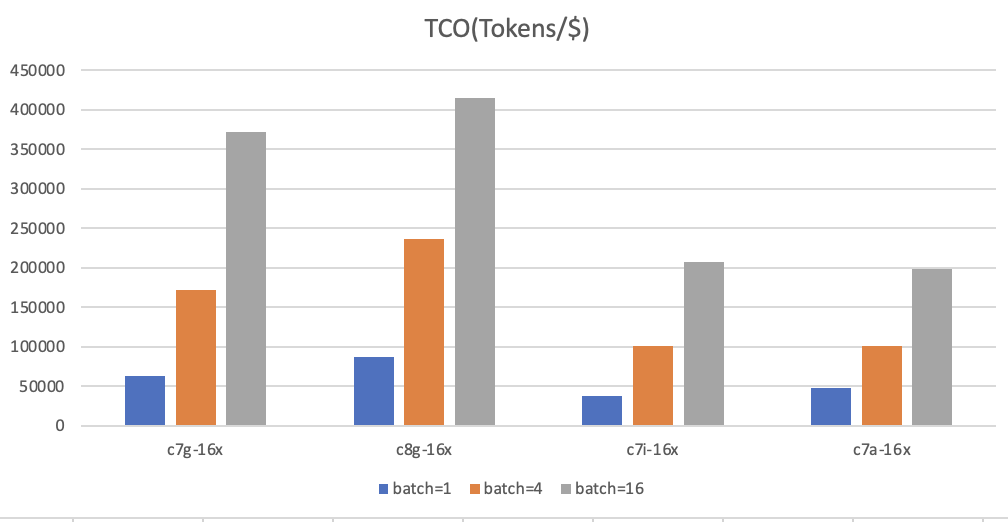
由图中可以看出,Graviton3 可以在 1 美元 cost 下生成 360000 token,而 Graviton4 可以生成多达 420000+ 的 token。这不仅说明 Graviton4 在 CPU 领域处于领先地位,而且对于那些希望从小规模开始,并在 LLM 应用之路上逐步扩展的用户来说,也提供了一个极具吸引力的优势。
调优实践指南
1. 参数调优策略
-
在本地编译 llama.cpp 并使用-DCMAKE_CXX_FLAGS=”-mcpu=native” -DCMAKE_C_FLAGS=”-mcpu=native”编译参数,可以让 llama.cpp 基于本地 CPU 参数编译,从而达到理想性能。
-
llama.cpp 支持多种模型量化格式,在实际生产中,在保证模型可以确保 SLA 的前提下可以通过减少权重精度降低内存占用和计算量,从而提高整体性能。
-
合理设置线程数,通常设置为物理核心数,从而充分利用实例的多核能力。
-
绑定 CPU 核心,减少跨 NUMA 节点的内存访问延迟。
-
减少上下文长度(使用合适的 context 长度),调整批处理策略(例如使用合理的 batch-size),简化生成参数等,都可以从不同层面使得 CPU 达到最佳性能。
2. 部署建议
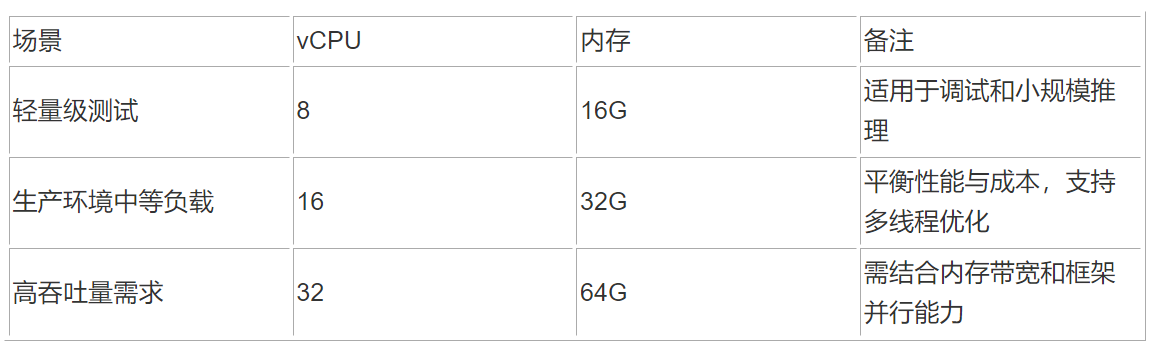
以模型 DeepSeek-R1-Distill-Llama-8B-Q4_0.gguf 为例,在确定运行 4bit 量化的 8B 参数模型所需的虚拟机 vCPU 和内存配置时,需综合考虑模型存储、计算需求和系统开销:
-
内存需求
-
参数数量:8B(80亿)个参数
-
量化存储:4bit/参数 = 0.5 字节/参数
-
总共参数量内存:
-
推理内存需求:激活值和中间缓存,通常为参数内存的 1-3 倍(8~12GB),取决于输入序列长度和模型结构。
-
系统与框架开销:操作系统和推理框架本身需要额外内存(约 1-2GB)。
-
总内存估算约 4+8+2=14GB
-
vCPU 配置
-
由上面测试 3 的图可以看出因为推理框架支持多线程,增加 vCPU 可以提升 prompt 处理的吞吐量。但随着 vCPU 核心数增加,token 生成的速度仅有小幅提升,进一步增加到 24 核,系统提升也相当有限。所以我们可以以 8 个 vCPU 进行初始实测,然后逐步调整力争达到客户需求的 SLA。
综上所述,我们可以按照以下配置来测试:
结语
Amazon Graviton 实例通过硬件架构创新与软件生态优化,为 CPU 推理场景提供了高性价比的选择。在 8B~70B 参数规模的模型中,Graviton4 可达到 10-60 t/s 的吞吐表现,结合量化技术与参数调优,可满足生产级 AI 应用的性能与成本需求。未来随着 ARM 指令集与模型编译器的进一步优化,CPU 在大模型推理领域的潜力将持续释放。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
本篇作者

本期最新实验为《创新基石 —— 基于 Graviton 构建差异化生成式AI向量数据库》
✨ 在本次实验中,你可以在基于 Graviton 的 EC2 实例上轻松启动 Milvus 向量数据库,加速您的生成式 AI 应用。基于 Graviton 的 EC2 实例为您提供极佳性价比的向量数据库部署选项。
📱 即刻在云上探索实验室,开启构建开发者探索之旅吧!
⏩[点击进入实验] 构建无限, 探索启程!
相关文章:
在 Amazon Graviton 上运行大语言模型:CPU 推理性能实测与调优指南
引言 在生成式 AI 浪潮中,GPU 常被视为大模型推理的唯一选择。然而,随着 ARM 架构的崛起和量化技术的成熟,CPU 推理的性价比逐渐凸显。本文基于 Amazon Graviton 系列实例与 llama.cpp 工具链,实测了 Llama 3、DeepSeek 等模型的…...
每日定投40刀BTC(14)20250409 - 20250419
定投 坚持 《磨剑篇》浮生多坎壈,志业久盘桓。松柏凌霜易,骅骝涉险难。砺锋临刃缺,淬火取金残。但使精魂在,重开万象端。...

详解反射型 XSS 的后续利用方式:从基础窃取到高级组合拳攻击链
在网络安全领域,反射型跨站脚本攻击(Reflected Cross-Site Scripting,简称反射型 XSS)因其短暂的生命周期和临时性,常被视为“低危”漏洞,威胁性不如存储型或 DOM 型 XSS。然而,这种看法低估了它…...
服务治理-服务注册
一个服务在真实项目部署的时候,如果压力较大,会做多实例部署。 在IDEA里面做多实例部署的话,只需要配置多个启动项。...

NestJS——多环境配置方案(dotenv、config、@nestjs/config、joi配置校验)
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...
MongoDB导出和导入数据
安装mongodump工具 参考文章mongodump工具安装及使用详解_mongodump安装-CSDN博客 MongoDB导入导出和备份的命令工具从4.4版本开始不再自动跟随数据库一起安装,而是需要自己手动安装。 官方网站下载链接:Download MongoDB Command Line Database Tools …...

数据从辅存调入主存,页表中一定存在
在虚拟内存系统中,数据从辅存调入主存时,页表中一定存在对应的页表项,但页表项的「存在状态」会发生变化。以下是详细分析: 关键逻辑 页表的作用 页表是虚拟内存的核心数据结构,记录了虚拟地址到物理地址的映射关系…...
Serving入门
ServingHelloWorld Serverless 一个核心思想就是按需分配,那么 Knative 是如何实现按需分配的呢?另外在前面已经了解到 Knative Serving 在没有流量的时候是可以把Pod 缩容到零的。接下来就通过一些例子体验一下 Knative 缩容到零和按需自动扩缩容的能力…...

硬件操作指南——ATK-MD0430 V20
使用CC2530控制正点原子ATK-MD0430 V20显示的完整指南 本文将详细介绍如何使用CC2530单片机控制正点原子ATK-MD0430 V20显示屏,包括IAR开发环境的配置、硬件连接、程序编写和调试等完整步骤。 一、开发环境准备 1. IAR开发环境安装与配置 首先需要安装IAR Embed…...

【HDFS入门】HDFS数据冗余与容错机制解析:如何保障大数据高可靠存储?
目录 1 HDFS冗余机制设计哲学 1.1 多副本存储策略的工程权衡 1.2 机架感知的智能拓扑算法 2 容错机制实现原理 2.1 故障检测的三重保障 2.2 数据恢复的智能调度 3 关键场景容错分析 3.1 数据中心级故障应对 3.2 数据损坏的校验机制 4 进阶优化方案 4.1 纠删码技术实…...
UE学习记录part19
231 insect: insect enemy type 创建dead动画资源 往insect head上添加socket 创建攻击root motion动画。motion warping需要与root motion合作使用 为buff_blue创建物理资产 设置simulate physic使sinsect死亡后能落到地板上而不是漂浮在空中,要将die函数设置为 -…...

运行后allure报告没有自动更新(已解决)
pycharm直接运行run.py文件, allure生成的报告都没有更新,需要手动删除旧报告后再次运行才可以 pytest.ini [pytest]testpaths testcases/ addopts --alluredir ./report/result --clean-alluredir run.py主要代码 if __name__ "__main__&qu…...

深度学习在语音识别中的应用
引言 语音识别技术是人工智能领域中的一个重要分支,它使得机器能够理解和转换人类的语音为文本。深度学习的出现极大地推动了语音识别技术的发展。本文将介绍如何使用深度学习构建一个基本的语音识别系统,并提供一个实践案例。 环境准备 在开始之前&a…...
)
CUDA Tools 常用命令总结与记录 (需要细化)
以下是对 CUDA Toolkit 中常用工具和命令的详细总结,涵盖编译器、调试器、性能分析工具、GPU管理工具等核心组件: 一、编译器工具:nvcc nvcc 是 NVIDIA CUDA 编译器,用于编译 .cu 文件生成可执行文件或中间代码。 常用命令与参数…...
微信小程序 时间戳与日期格式的转换
1. 微信小程序 时间戳与日期格式的转换 微信小程序中的时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数。例如现在北京时间2015-12-31 17:00:00的时间戳是1451552400,就是指从北京时间1970-01-01 08:00:00到…...
【深度学习—李宏毅教程笔记】Transformer
目录 一、序列到序列(Seq2Seq)模型 1、Seq2Seq基本原理 2、Seq2Seq模型的应用 3、Seq2Seq模型还能做什么? 二、Encoder 三、Decoder 1、Decoder 的输入与输出 2、Decoder 的结构 3、Non-autoregressive Decoder 四、Encoder 和 De…...
【人工智能学习-01-01】20250419《数字图像处理》复习材料的word合并PDF,添加页码
前情提要 20250419今天是上师大继续教育人工智能专升本第一学期的第一次线下课。 三位老师把视频课的内容提炼重点再面授。(我先看了一遍视频,但是算法和图像都看不懂,后来就直接挂分刷满时间,不看了) 今天是面对面授…...

如何从 GitHub 镜像仓库到极狐GitLab?
最近 GitHub 封禁中国用户的事情闹得沸沸扬扬,虽然官方发布的报道说中国用户被限制登录是因为配置错误导致,已经撤回了更新,中国用户已经可以正常使用。但是这就像横在国内开发者和企业头上的“达摩克利斯之剑”。为了避免 GitHub 不可用而带来的影响,国内开发者和企业可以…...

【云馨AI-大模型】2025年4月第三周AI领域全景观察:硬件革命、生态博弈与国产化突围
一、硬件算力突破点燃多智能体时代 谷歌在4月12日Cloud Next大会发布第七代TPU Ironwood,单芯片算力达4614 TFLOPs,较前代内存提升6倍,专为AI推理场景优化。配合发布的Gemini 2.5 Flash模型通过"思考"功能实现成本优化,…...

ETL数据集成平台在交通运输行业的五大应用场景
在智能交通与数字物流时代,交通运输企业每天产生海量数据——车辆轨迹、货物状态、乘客流量、设备日志……但这些数据往往被困在分散的系统中:GPS定位数据躺在车载终端里,物流订单卡在Excel表中,地铁客流统计锁在本地服务器内。如…...
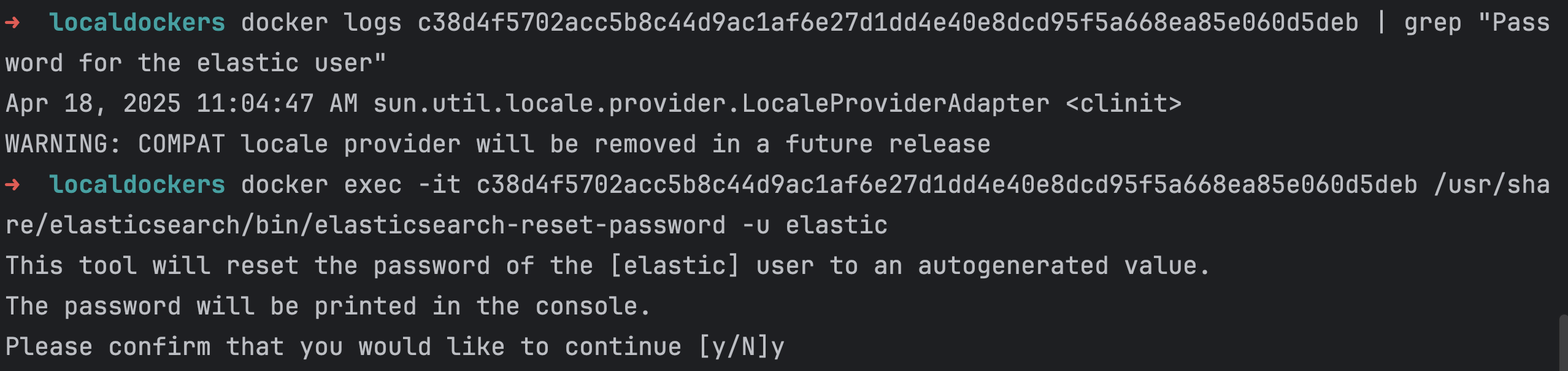
使用 Docker 安装 Elastic Stack 并重置本地密码
Elastic Stack(也被称为 ELK Stack)是一个非常强大的工具套件,用于实时搜索、分析和可视化大量数据。Elastic Stack 包括 Elasticsearch、Logstash、Kibana 等组件。本文将展示如何使用 Docker 安装 Elasticsearch 并重置本地用户密码。 ###…...
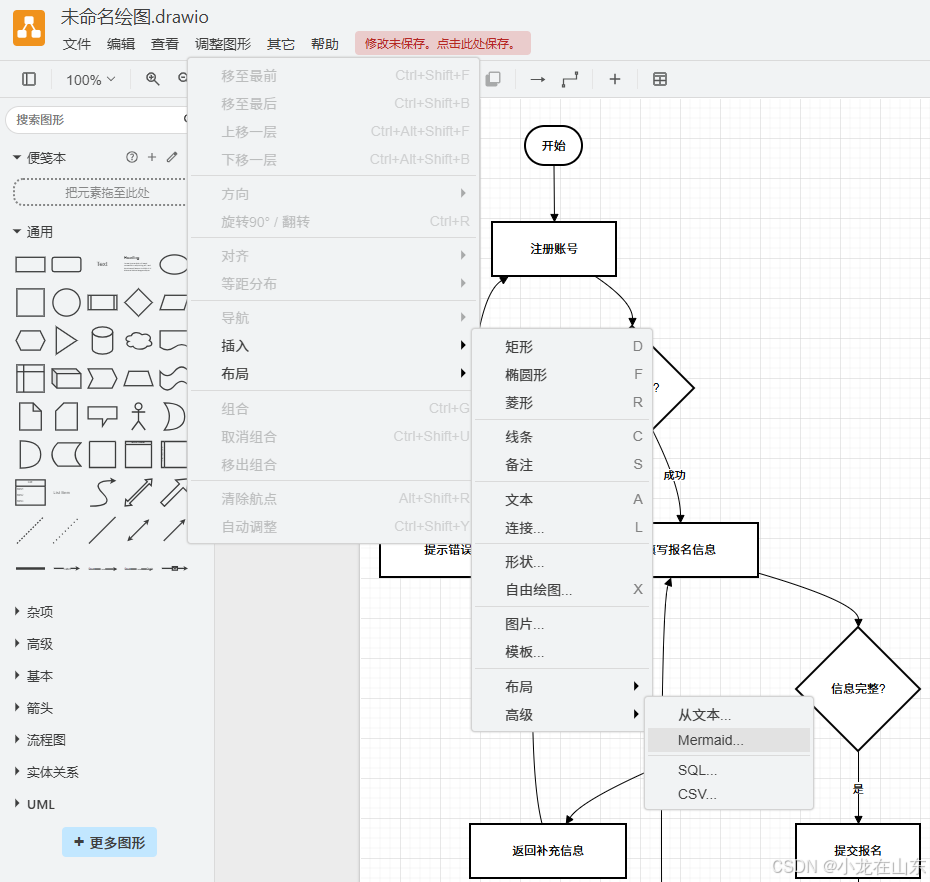
利用 Deepseek 和 Mermaid 画流程图
提示词 你是一个产品经理,请绘制一个报名比赛的流程图,要求生成符合Mermaid语法的代码,具体要求如下: 1.注册账号 2.填写报名信息 3.参加比赛 4.查看比赛结果 生成的结果 flowchart TDA([开始]) --> B[注册账号]B --> C{账…...

系统架构设计师:系统架构概述案例分析与简答题、详细解析与评分要点
10道系统架构概述知识体系案例分析与简答题,涵盖架构设计原则、质量属性、演化过程、评估方法等核心考点,并附详细解析与评分要点: 一、案例分析题(5题) 1. 电商系统高并发场景下的架构设计 背景:某电商平…...

学习笔记: Mach-O 文件
“结构决定性质,性质决定用途”。如果不了解结构,是很难真正理解的。 通过一个示例的可执行文件了解Mach-O文件的结构 Mach-O基本结构 Header: :文件类型、目标架构类型等Load Commands:描述文件在虚拟内存中的逻辑结构、布局Data: 在Load commands中…...

图论-BFS搜索图/树-最短路径问题的解决
续上篇~图论--DFS搜索图/树-CSDN博客 先看第一次学习的博客!!👇👇👇👇 👉 有一些问题是广搜 和 深搜都可以解决的,例如岛屿问题,这里我们记dfs的写法就好啦,…...

【uniapp】vue2 使用 Vuex 状态管理
创建store文件夹:store/index.js // index.js import Vue from vue import Vuex from vuex import address from ./modules/address.jsVue.use(Vuex)const store new Vuex.Store({modules: {address} })export default store 创建modules文件夹:modul…...

vcpkg缓存问题研究
vcpkg缓存问题研究 问题描述解决方案官网给出的方案其实并不是大多数人语境中的“清除缓存”实际解决方案 问题描述 使用vcpkg管理c的库的时候,vcpkg会在c盘某些地方缓存下载的库,如果安装的库过多,这个缓存文件夹会过大占用磁盘空间&#x…...

个人自用-导入安装Hexo
因为本人原来就有备份好的资料,所以重新安装起来会很方便,这个教程也只适合我自己用 但是所有的命令行都要在Git的命令行里面使用(因为我就是这样操作的) 1 安装Git Git的官网 Git git --version 这个是查看Git的版本 git --…...

《AI大模型应知应会100篇》第26篇:Chain-of-Thought:引导大模型进行步骤推理
第26篇:Chain-of-Thought:引导大模型进行步骤推理 摘要 在自然语言处理(NLP)和人工智能领域,如何让大模型像人类一样进行逐步推理是一个核心挑战。Chain-of-Thought (思维链) 技术的出现为这一问题提供了强有力的解决…...

大模型API中转平台选择指南:如何找到优质稳定的服务
在人工智能快速发展的今天,大模型的应用已经渗透到各个领域。无论是开发智能应用的技术团队,还是希望通过AI提升效率的企业,都离不开大模型API的支持。然而,市场上的大模型API中转服务良莠不齐,层层转包的中间商模式不…...