Day10【基于encoder- decoder架构实现新闻文本摘要的提取】
实现新闻文本摘要的提取
- 1. 概述与背景
- 2.参数配置
- 3.数据准备
- 4.数据加载
- 5.主程序
- 6.预测评估
- 7.生成效果
- 8.总结
1. 概述与背景
新闻摘要生成是自然语言处理(NLP)中的一个重要任务,其目标是自动从长篇的新闻文章中提取出简洁、准确的摘要。近年来,基于深度学习的摘要生成方法已成为主流,尤其是采用 Encoder-Decoder 架构的模型。这个架构在机器翻译、文本摘要、文档标注、多模态交互等领域取得了显著的效果。
本文基于现有数据集,先将输入的新闻文本数据和对应的标题摘要在已知词表上序列化,然后将序列化后的输入索引数据(作为输入文本数据)和标签索引数据(作为生成式文本摘要标签)共同输入到Encoder-Decoder模型架构中得到输出预测的文本摘要数据,之后将输出的预测文本摘要数据以及另一份标签索引数据(作为真实的文本标签)两者使用交叉熵损失函数计算loss,最后反向传播更新梯度。
2.参数配置
config.py
# -*- coding: utf-8 -*-"""
配置参数信息
"""
import os
import torchConfig = {"model_path": "output","input_max_length": 120,"output_max_length": 30,"epoch": 200,"batch_size": 32,"optimizer": "adam","learning_rate":1e-3,"seed":42,"vocab_size":6219,"vocab_path":"vocab.txt","train_data_path": r"sample_data.json","valid_data_path": r"sample_data.json","beam_size":5}3.数据准备
词表文件vocab.txt词表文件
新闻文本数据训练和验证数据
4.数据加载
loader.py
# -*- coding: utf-8 -*-import json
import torch
from torch.utils.data import DataLoader
"""
数据加载
"""class DataGenerator:def __init__(self, data_path, config, logger):self.config = configself.logger = loggerself.path = data_pathself.vocab = load_vocab(config["vocab_path"])self.config["vocab_size"] = len(self.vocab)self.config["pad_idx"] = self.vocab["[PAD]"]self.config["start_idx"] = self.vocab["[CLS]"]self.config["end_idx"] = self.vocab["[SEP]"]self.load()def load(self):self.data = []with open(self.path, encoding="utf8") as f:for i, line in enumerate(f):line = json.loads(line)title = line["title"]content = line["content"]self.prepare_data(title, content)return#文本到对应的index#头尾分别加入[cls]和[sep]def encode_sentence(self, text, max_length, with_cls_token=True, with_sep_token=True):input_id = []if with_cls_token:input_id.append(self.vocab["[CLS]"])for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))if with_sep_token:input_id.append(self.vocab["[SEP]"])input_id = self.padding(input_id, max_length)return input_id#补齐或截断输入的序列,使其可以在一个batch内运算def padding(self, input_id, length):input_id = input_id[:length]input_id += [self.vocab["[PAD]"]] * (length - len(input_id))return input_id#输入输出转化成序列def prepare_data(self, title, content):input_seq = self.encode_sentence(content, self.config["input_max_length"], False, False) #输入序列output_seq = self.encode_sentence(title, self.config["output_max_length"], True, False) #输出序列gold = self.encode_sentence(title, self.config["output_max_length"], False, True) #不进入模型,用于计算lossself.data.append([torch.LongTensor(input_seq),torch.LongTensor(output_seq),torch.LongTensor(gold)])returndef __len__(self):return len(self.data)def __getitem__(self, index):return self.data[index]def load_vocab(vocab_path):token_dict = {}with open(vocab_path, encoding="utf8") as f:for index, line in enumerate(f):token = line.strip()token_dict[token] = indexreturn token_dict#用torch自带的DataLoader类封装数据
def load_data(data_path, config, logger, shuffle=True):dg = DataGenerator(data_path, config, logger)dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)return dl
输入数据和标签的编码主要通过 encode_sentence 方法实现。具体来说,输入数据(如新闻内容)和标签(如新闻标题)都需要转化为对应的索引序列,以便供模型进行训练。编码过程如下:
-
输入数据(
content)编码:encode_sentence方法将新闻内容转换为词汇表中的索引序列。首先,如果需要,添加[CLS]标记作为序列的开始,然后遍历文本中的每个字符,将其映射为词汇表中的索引,如果词汇表中没有该字符,则使用[UNK](未知词)表示。最后,如果需要,添加[SEP]标记作为序列的结束。生成的索引序列会通过padding方法填充或截断至预设的最大长度。 -
标签数据(
title)编码:标签(即标题)也会通过encode_sentence方法进行编码,步骤与输入数据类似,因为标题是需要预测生成表示要输出的序列,因此会包含[CLS]标记作为开头,不包含[SEP],以区分输入和输出。 -
计算损失的
gold序列:在训练中,为了计算损失,gold序列会与输出序列相似,作为真实的标签,在它后面包含[SEP]标记和输出序列对齐,作为模型训练时的目标序列。 -
生成解码过程:模型训练完毕后,
Decoder会根据输入的Encoder编码向量及输出序列的第一个标记CLS输出第一个预测的token,根据输入的Encoder编码向量及输出序列(第一个标记CLS+生成的前一个token)输出第二个预测token,之后再根据输入的Encoder编码向量及输出序列(第一个标记CLS+生成的前2个token)输出第三个预测token,以此类推。直到输出最后一个预测的token为SEP时,生成解码过程结束。 -
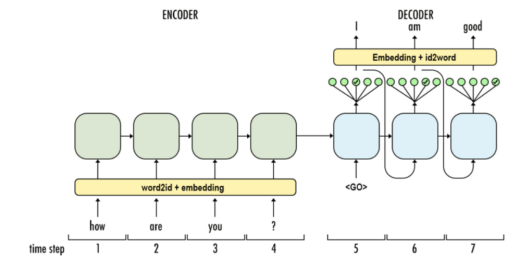
通过这样的编码方式,输入数据和标签数据被转化为整数索引序列,并进行填充或截断,以确保它们具有相同的长度,从而可以批量处理并输入到模型进行训练。
5.主程序
# -*- coding: utf-8 -*-
import sys
import torch
import random
import os
import numpy as np
import time
import logging
import json
from config import Config
from evaluate import Evaluator
from loader import load_data#这个transformer是本文件夹下的代码,和我们之前用来调用bert的transformers第三方库是两回事
from transformer.Models import Transformerlogging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型训练主程序
"""# seed = Config["seed"]
# random.seed(seed)
# np.random.seed(seed)
# torch.manual_seed(seed)
# torch.cuda.manual_seed_all(seed)def choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["learning_rate"]if optimizer == "adam":return torch.optim.Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return torch.optim.SGD(model.parameters(), lr=learning_rate)def main(config):#创建保存模型的目录if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])#加载模型logger.info(json.dumps(config, ensure_ascii=False, indent=2))model = Transformer(config["vocab_size"], config["vocab_size"], 0, 0,d_word_vec=128, d_model=128, d_inner=256,n_layers=1, n_head=2, d_k=64, d_v=64,)# 标识是否使用gpucuda_flag = torch.cuda.is_available()if cuda_flag:logger.info("gpu可以使用,迁移模型至gpu")model = model.cuda()#加载优化器optimizer = choose_optimizer(config, model)# 加载训练数据train_data = load_data(config["train_data_path"], config, logger)#加载效果测试类evaluator = Evaluator(config, model, logger)#加载lossloss_func = torch.nn.CrossEntropyLoss(ignore_index=0)#训练for epoch in range(config["epoch"]):epoch += 1model.train()if cuda_flag:model.cuda()logger.info("epoch %d begin" % epoch)train_loss = []for index, batch_data in enumerate(train_data):if cuda_flag:batch_data = [d.cuda() for d in batch_data]input_seq, target_seq, gold = batch_datapred = model(input_seq, target_seq)loss = loss_func(pred, gold.view(-1))train_loss.append(float(loss))loss.backward()optimizer.step()optimizer.zero_grad()logger.info("epoch average loss: %f" % np.mean(train_loss))evaluator.eval(epoch)model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)torch.save(model.state_dict(), model_path)returnif __name__ == "__main__":main(Config)
主程序主要实现了基于Transformer架构的模型训练过程。在训练过程中,首先通过配置文件Config获取相关参数,并根据配置创建一个Transformer模型。训练过程在指定的轮次(epoch)内进行,每一轮开始时,首先设定模型为训练模式。接着,对于每个训练批次,输入数据(input_seq)、目标序列(target_seq)和真实标签(gold)被送入模型中进行前向传播,计算出模型预测值(pred)。通过交叉熵损失函数(CrossEntropyLoss)与真实标签进行对比,得到当前批次的损失。损失值会被累积并进行反向传播(loss.backward()),优化器更新参数(optimizer.step()),并清空梯度缓存(optimizer.zero_grad())。每一轮训练结束后,打印出平均损失值并进行模型效果评估。
6.预测评估
evaluate.py
# -*- coding: utf-8 -*-
from loader import load_data
from collections import defaultdict
from transformer.Translator import Translator"""
模型效果测试
"""class Evaluator:def __init__(self, config, model, logger):self.config = configself.model = modelself.logger = loggerself.valid_data = load_data(config["valid_data_path"], config, logger, shuffle=False)self.reverse_vocab = dict([(y, x) for x, y in self.valid_data.dataset.vocab.items()])self.translator = Translator(self.model,config["beam_size"],config["output_max_length"],config["pad_idx"],config["pad_idx"],config["start_idx"],config["end_idx"])def eval(self, epoch):self.logger.info("开始测试第%d轮模型效果:" % epoch)self.model.eval()self.model.cpu()self.stats_dict = defaultdict(int) # 用于存储测试结果for index, batch_data in enumerate(self.valid_data):input_seqs, target_seqs, gold = batch_datafor input_seq in input_seqs:generate = self.translator.translate_sentence(input_seq.unsqueeze(0))print("输入:", self.decode_seq(input_seq))print("输出:", self.decode_seq(generate))breakreturndef decode_seq(self, seq):pre_seq = []for idx in seq:if idx < 6 :continuechar = self.reverse_vocab[int(idx)]pre_seq.append(char)return "".join(pre_seq)在模型的评估过程中,验证集数据被加载并逐批传入模型进行推理。每一批数据中的输入序列通过 Translator 进行翻译,生成相应的预测输出。预测过程通常涉及使用模型的前向传播,将输入序列转化为目标语言的输出。为了评估模型效果,生成的输出是通过索引序列的方式进行表示,而这些索引随后会被映射回具体的词汇,通过反向词汇表解码为可读的文本。每次翻译后,模型的输入和生成的输出都会被打印出来,以便进行直观的对比。通过反复的测试与评估,能够逐步提高模型的准确性和生成质量。
7.生成效果
训练200轮效果:
2025-04-19 12:44:56,206 - __main__ - INFO - epoch 200 begin
2025-04-19 12:44:57,086 - __main__ - INFO - epoch average loss: 0.416101
2025-04-19 12:44:57,086 - __main__ - INFO - 开始测试第200轮模型效果:
输入: 阿根廷布宜诺斯艾利斯省奇尔梅斯市一服装店,8个月内被抢了三次。最后被抢劫的经历,更是直接让老板心理崩溃:歹徒在抢完不久后发现衣服“抢错了尺码”,理直气壮地拿着衣服到店里换,老板又不敢声张,只好忍气吞声。(中国新闻网)
输出: 阿根廷歹徒抢服装尺码不对拿回店里换
输入: 就俄罗斯免费医疗话题,国家卫生计生委国际司司长任明辉表示,真正的免费医疗制度不存在。或由税收支持,或个人和企业支付的医疗保险社会保险解决。免费医疗国家的患者看病不花钱,费用在各种税收或缴纳的保险中体现了。(网图)
输出: 卫生计生委国际司司长:真正的免费医疗不存在
输入: 6月合格境外机构投资者(QFII)加快入市步伐。据中登公司发布的2013年6月份统计月报显示,QFII基金6月份在沪深两市分别新增开户14、15个A股股票账户,这29个账户让QFII在沪深两市的总账户数达到465个。
输出: 6月QFII积极入市新增开户户9户
输入: 路透社消息,一艘从利比亚横渡地中海开往意大利的偷渡船倾覆,约400人身亡。船上载有550多名偷渡客,许多是年轻人和儿童,大部分来自撒哈拉以南非洲地区。事发后意大利海防部队展开搜救,获救的150人被送往意大利南部港口。
输出: 从利比亚开往意大利:400偷渡客沉船身亡
8.总结
本文实现了一个基于 Transformer Encoder-Decoder 架构的新闻摘要生成系统。通过使用词汇表将输入数据和目标输出数据转化为索引序列,并通过交叉熵损失函数训练模型,模型通过 Beam Search 解码生成摘要。训练过程中使用了多轮的模型评估和优化,使得最终模型能够生成简洁、准确的新闻摘要。
相关文章:
Day10【基于encoder- decoder架构实现新闻文本摘要的提取】
实现新闻文本摘要的提取 1. 概述与背景2.参数配置3.数据准备4.数据加载5.主程序6.预测评估7.生成效果8.总结 1. 概述与背景 新闻摘要生成是自然语言处理(NLP)中的一个重要任务,其目标是自动从长篇的新闻文章中提取出简洁、准确的摘要。近年来…...

【blender小技巧】使用blender的Cats Blender Plugin插件将3D人物模型快速绑定或者修复为标准的人形骨骼
文章目录 前言绑定或者修复人形骨骼1、下载模型2、导入模型到blender中3、删除无用的相机和灯光3、导出模型并在unity中使用 专栏推荐完结 前言 有时候我们下载的3D人物模型,可能不带骨骼信息,或者带一些错乱的骨骼信息。这时候我们就可以使用blender将…...
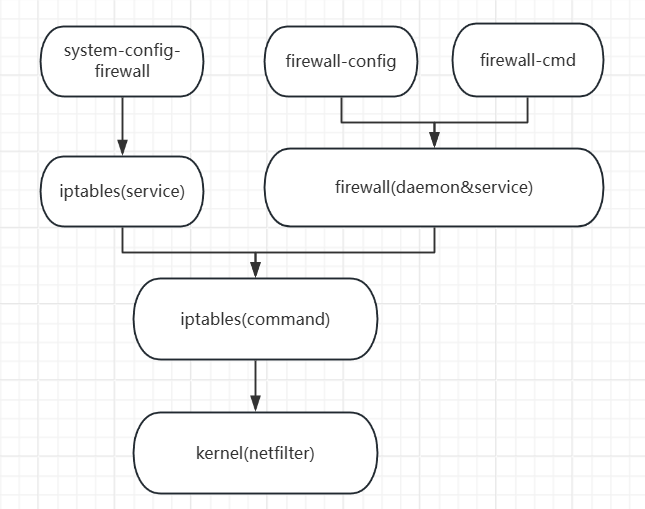
Linux——firewalld防火墙(笔记)
目录 一:Firewalld防火墙的概述 (1)firewalld简介 (2)firewalld&iptables的关系 (3)firewalld与iptables service的区别 1. 规则管理方式 2. 默认策略与设计逻辑 3. 配置文…...

《分布式软总线赋能老旧设备高效通信》
在数字化转型的浪潮中,分布式软总线技术成为实现设备互联互通的关键力量。然而,当面对大量老旧设备时,其性能受限的现状对分布式软总线提出了严峻挑战。如何在这些性能瓶颈下,让老旧设备实现高效连接与通信,是亟待解决…...
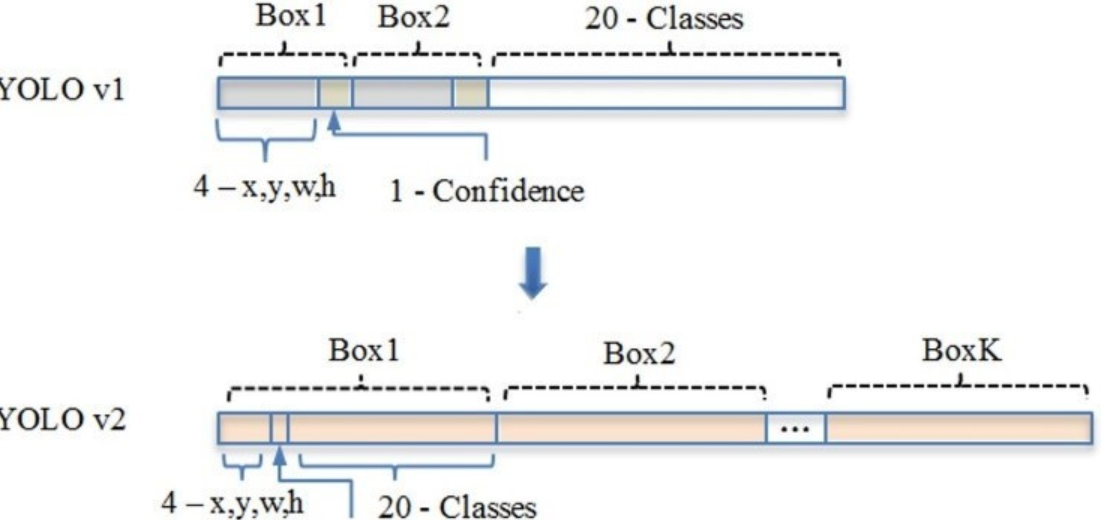
YOLO拓展-锚框(anchor box)详解
一.锚框(anchor box)概述 1.1什么是锚框 锚框就是一种进行预测的像素框,通过遍历输入图像上所有可能的像素框,然后选出正确的目标框,并对位置和大小进行调整就可以完成目标检测任务。 对于yolo锚框的建设须基于实际…...

GPU渲染阶段介绍+Shader基础结构实现
GPU是什么 (CPU)Center Processing Unit:逻辑编程 (GPU)Graphics Processing Unit:图形处理(矩阵运算,数据公式运算,光栅化) 渲染管线 渲染管线也称为渲染流水线&#x…...

第32讲:卫星遥感与深度学习融合 —— 让地球“读懂”算法的语言
目录 🔍 一、讲讲“遥感+深度学习”到底是干啥的? ✅ 能解决什么问题? 🧠 二、基础原理串讲:深度学习如何“看懂”遥感图? 🛰 遥感图像数据类型: 🧠 CNN的基本思路: 🧪 三、实战案例:用CNN对遥感图像做地类分类 📦 所需R包: 🗂️ 步骤一:构建训…...
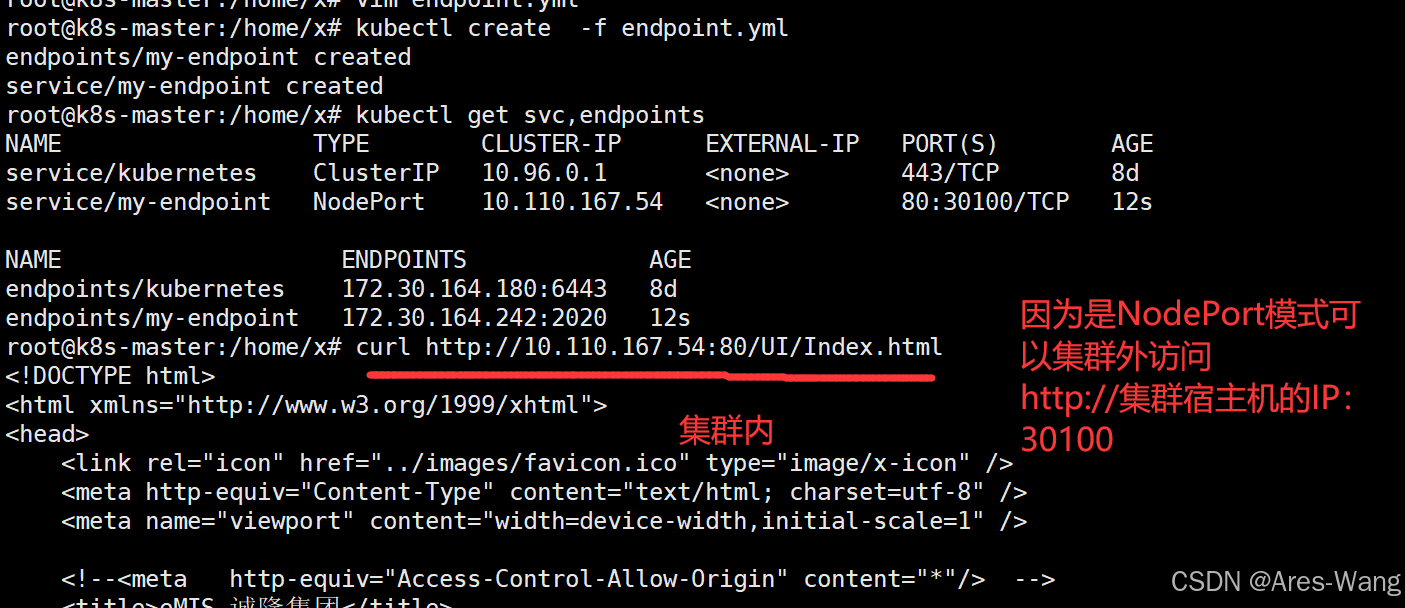
kubernetes》》k8s》》Service
Kubernetes 中的 Service 是用于暴露应用服务的核心抽象,为 Pod 提供稳定的访问入口、负载均衡和服务发现机制。Service在Kubernetes中代表了一组Pod的逻辑集合,通过创建一个Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址…...

多道程序和多任务操作系统区别
多道程序 vs. 多道任务:对比分析 ✅ 共同点 方面共同特征核心机制都依赖于进程/任务切换执行需求实现多个程序或任务"并发"执行系统支持都需要操作系统的支持(如调度算法、内存管理)本质目标提高资源利用率(CPU不空转…...

CMFA在自动驾驶中的应用案例
CMFA在自动驾驶中的典型应用案例 CMFA(Cross-Modal Feature Alignment)方法在自动驾驶领域有多个成功的应用场景,以下是几个典型案例: 1. 多模态3D目标检测 应用场景:车辆、行人、骑行者等交通参与者的精确检测 …...

已注册商标如何防止被不使用撤销!
近年来已注册商标被撤销越来越多,不乏著名企业或机构,普推知产商标老杨看到前一阵看到央视和百度等申请的商标也被申请撤销,连续三年不使用撤销也是正常的商标流程。 已注册商标被撤销普推老杨看到案例主要是集中在一些早期申请注册的好记的商…...

android 打包内容 安卓打包工具有哪些
Android ROM打包工具与技巧分享 eMMC存储与Android文件系统 eMMC作为手机和平板电脑的内嵌式存储器,因其集成了控制器并提供标准接口等优势,受到Android厂商青睐。采用eMMC存储的Android手机,其文件系统(system、data分区)通常采用ext4格式…...
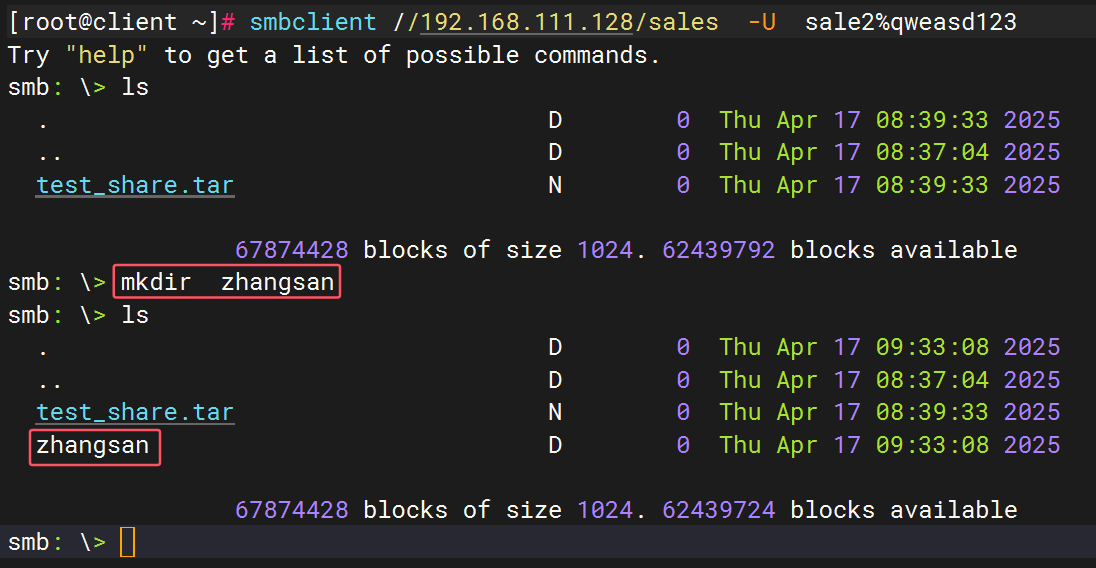
管理与维护samba服务器
允许 Linux、Unix 系统与 Windows 系统之间进行文件和打印机共享,使得不同操作系统的用户能够方便地访问和共享资源,就像在同一局域网中的 Windows 计算机之间共享资源一样。 server01安装Samba服务器 [rootserver ~]# rpm -qa | grep samba [rootserver…...
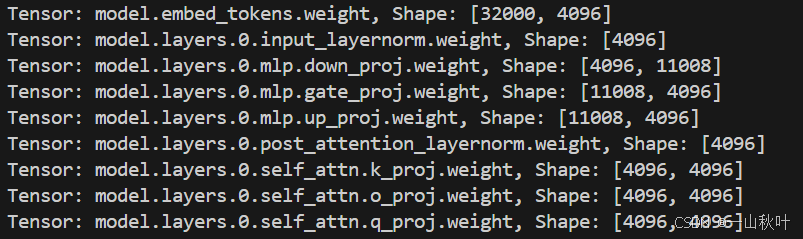
EAGLE代码研读+模型复现
要对代码下手了,加油(ง •_•)ง 作者在他们自己的设备上展现了推理的评估结果,受第三方评估认证,EAGLE为目前最快的投机方法(虽然加速度是评估投机解码方法的主要指标,但其他点也值得关注。比如PLD和Lookahead无需额…...
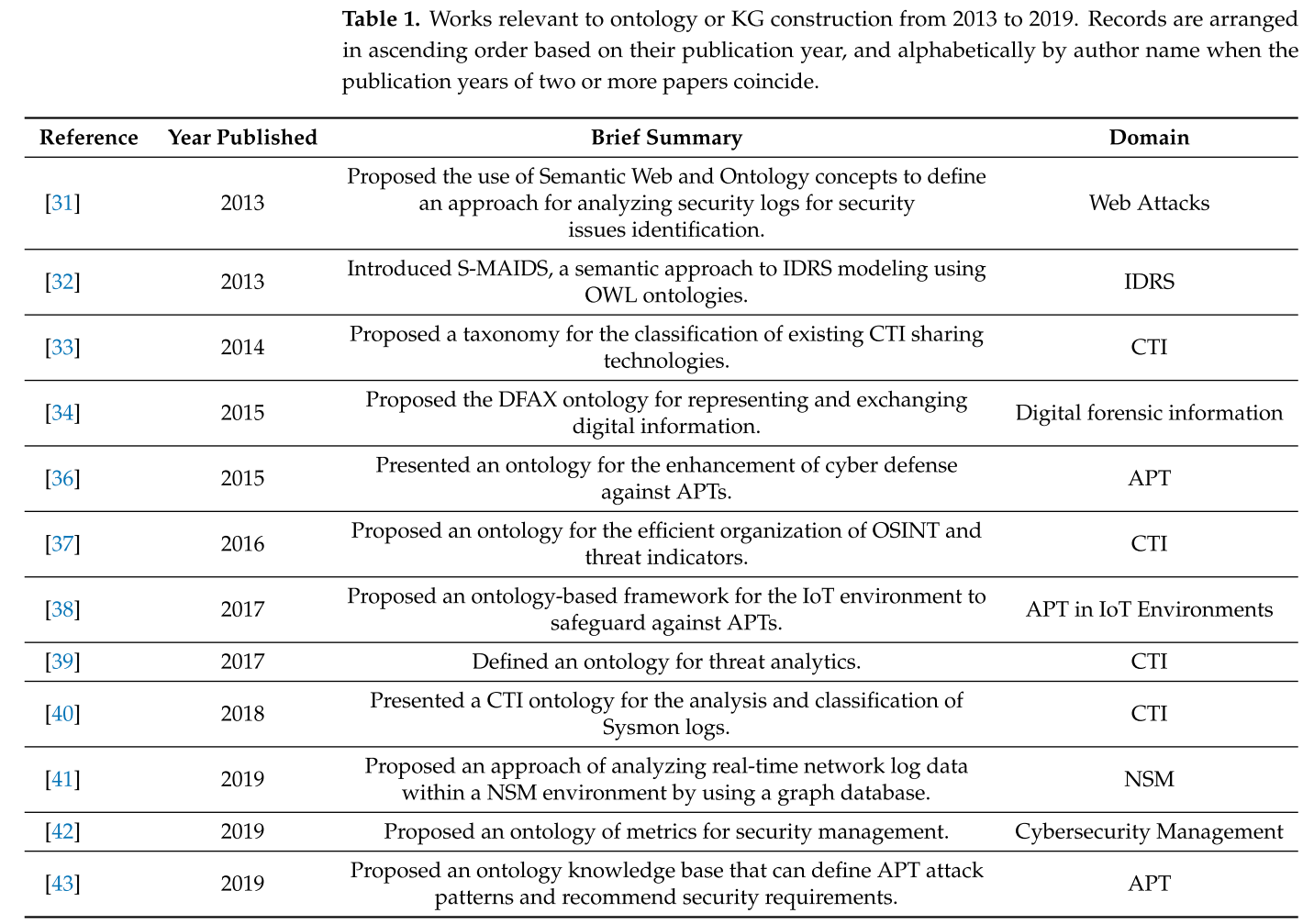
2024期刊综述论文 Knowledge Graphs and Semantic Web Tools in Cyber Threat Intelligence
发表在期刊Journal of Cybersecurity and Privacy上,专门讲知识图谱技术和语义Web工具在网络威胁情报领域的作用,还把本体和知识图谱放在相同的地位上讨论。 此处可以明确一点:本体和知识图谱都可以用于网络威胁情报的应用,当然也…...

vue3+vite 多个环境配置
同一套代码 再也不用在不同的环境里来回切换请求地址了 然后踩了一个坑 就是env的文件路径是在当前项目下 不是在views内 因为公司项目需求只有dev和pro两个环境 虽然我新增了3个 但是只在这两个里面配置了 .env是可以配置一些公共配置的 目前需求来说不需要 所以我也懒得配了。…...

秒杀系统解决两个核心问题的思路方法总结:1.库存超卖问题;2.用户重复抢购问题。
秒杀系统解决两个核心问题 秒杀系统解决两个核心问题:一、解决库存超卖的核心逻辑:解释:原子性保证: 二、如何避免重复抢购:使用 Redis 做唯一标识判断优点: 三、流程完整梳理:四、通过数据库建…...
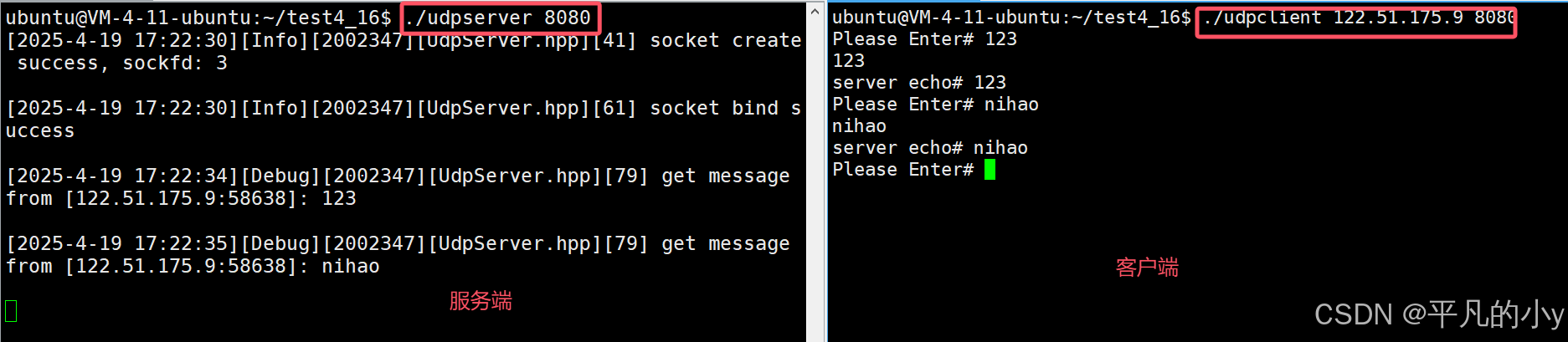
linux socket编程之udp(实现客户端和服务端消息的发送和接收)
目录 一.创建socket套接字(服务器端) 二.bind将prot与端口号进行绑定(服务器端) 2.1填充sockaddr_in结构 2.2bind绑定端口 三.直接通信(服务器端) 3.1接收客户端发送的消息 3.2给客户端发送消息 四.客户端通信 4.1创建socket套接字 4.2客户端bind问题 4.3直接通信即可…...

SAP HANA使用命令行快速导出导入
楔子 今天折腾了接近一下午,就为了使用SAP HANA自带的命令行工具来导出数据备份。 SAP HANA(后续简称Hana)是内存数据库,性能这一方面上还真没怕过谁。 由于SAP HANA提供了Hana Studio这个桌面工具来方便运维和DBA使用…...

goland做验证码识别时报“undefined: gosseract.NewClient”
gosseract 应该有 和 c 相关的配置库因此需要安装 cgo 并且启用 CGO_ENABLED 在cmd下面输入这个 go env -w CGO_ENABLED1 接着输入 go env 验证是否设置成功 解决了这个问题后 “undefined: gosseract.NewClient” 又出现了 # runtime/cgo …...
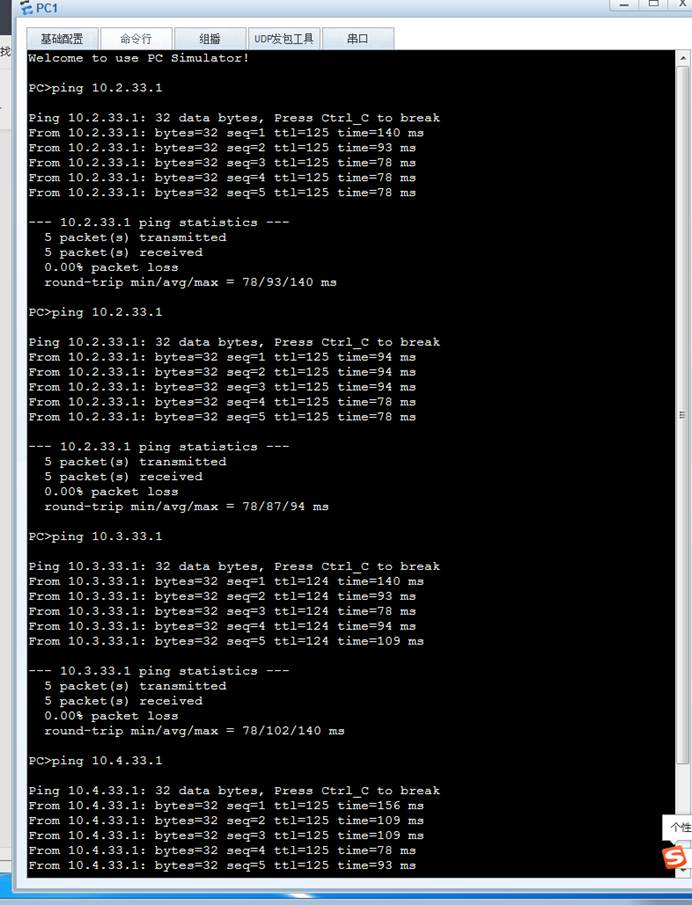
计算机网络 实验四 静态路由的配置与应用
一、实验目的 掌握路由器基础工作原理及静态路由协议机制熟练使用华为ENSP网络模拟器进行拓扑设计与设备配置建立系统化的网络故障排除思维通过实践验证静态路由在中小型网络中的部署优势 二、实验环境 硬件配置:标准PC终端软件工具:华为企业网络模拟…...

Vue自定义指令-防抖节流
Vue2版本 // 防抖 // <el-button v-debounce"[reset,click,300]" ></el-button> // <el-button v-debounce"[reset]" ></el-button> Vue.directive(debounce, { inserted: function (el, binding) { let [fn, event "cl…...

[每周一更]-(第140期):sync.Pool 使用详解:性能优化的利器
文章目录 一、什么是 sync.Pool?二、sync.Pool 的基本作用三、sync.Pool 的主要方法四、sync.Pool 的内部工作原理五、sync.Pool 适用场景六、使用示例示例 1:基本使用输出示例:示例 2:并发使用 七、一个基于 sync.Pool 的 **Benc…...

3.QT-信号和槽|自定义槽函数|自定义信号}自定义的语法}带参数的信号和槽(C++)
信号和槽 Linux信号 Signal 系统内部的通知机制. 进程间通信的方式. 信号源:谁发的信号.信号的类型:哪种类别的信号信号的处理方式:注册信号处理函数,在信号被触发的时候自动调用执行. Qt中的信号和Linux中的信号,虽…...

健康养生之道
在快节奏的现代生活中,健康养生不再是中老年人的专属话题,越来越多的人开始意识到,合理的养生方式是保持良好身体状态和生活质量的关键。 饮食养生是健康的基石。遵循 “食物多样、谷类为主” 的原则,保证每天摄入足够的蔬菜、…...
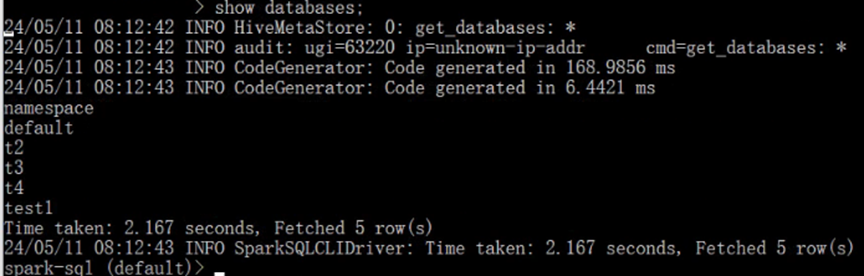
Spark-SQL核心编程3
数据加载与保存 通用方式: SparkSQL 提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL 默认读取和保存的文件格式为parquet 数据加载方法: spark.read.lo…...
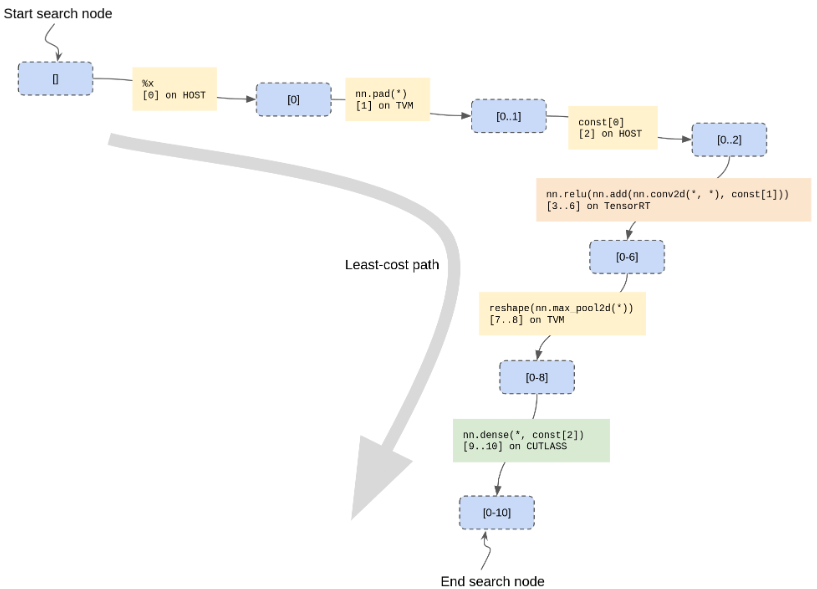
TVM计算图分割--Collage
1 背景 为满足高效部署的需要,整合大量优化的tensor代数库和运行时做为后端成为必要之举。现在的深度学习后端可以分为两类:1)算子库(operator kernel libraries),为每个DL算子单独提供高效地低阶kernel实现。这些库一般也支持算…...
默认不聚焦问题处理)
elementUI中MessageBox.confirm()默认不聚焦问题处理
在项目中使用elementUI的MessageBox.confirm()出现了默认不聚焦的问题,默认确认按钮是浅色的,需要点击一下才会变成正常。面对这种问题,创建新组件,实现聚焦。替换默认的MessageBox.confirm() 解决 创建components/MessageBoxCo…...
)
【刷题Day20】TCP和UDP(浅)
TCP 和 UDP 有什么区别? TCP提供了可靠、面向连接的传输,适用于需要数据完整性和顺序的场景。 UDP提供了更轻量、面向报文的传输,适用于实时性要求高的场景。 特性TCPUDP连接方式面向连接无连接可靠性提供可靠性,保证数据按顺序…...

sql server 预估索引大小
使用deepseek工具预估如下: 问题: 如果建立一个数据类型是datetime的索引,需要多大的空间? 回答: 如果建立一个数据类型是 datetime 的索引,索引的大小取决于以下因素: 索引键的大小&#…...