Spark-SQL核心编程3
数据加载与保存
通用方式:
SparkSQL 提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL 默认读取和保存的文件格式为parquet
数据加载方法:
spark.read.load 是加载数据的通用方法。如果读取不同格式的数据,可以对不同的数据格式进行设定。
spark.read.format("…")[.option("…")].load("…")
三种加载数据的方法:
使用 option 参数加载数据,在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
(适用于需要传入数据库连接信息的情况。)
使用 load方法加载数据,在"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"格式下需要传入加载数据的路径。
(适用于指定数据路径和类型的情况。)
使用format 加载数据,指定加载的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和
"textFile"。
前面都是使用 read API 先把文件加载到 DataFrame 然后再查询,其实,我们也可以直接在文件上进行查询: 文件格式.'文件路径'
spark.sql("select * from json.’ Spark-SQL/input/user.json’").show
数据保存方法:
主要介绍了两种保存数据的方法,一种是df write.save的通用方法,另一种是通过指定format、option和save(需要指定数据格式和保存路径的情况)路径来保存。
format("…"):指定保存的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"。
save ("…"):在"csv"、"orc"、"parquet"和"textFile"格式下需要传入保存数据的路径。
option("…"):在"jdbc"格式下需要传入 JDBC 相应参数,url、user、password 和 dbta
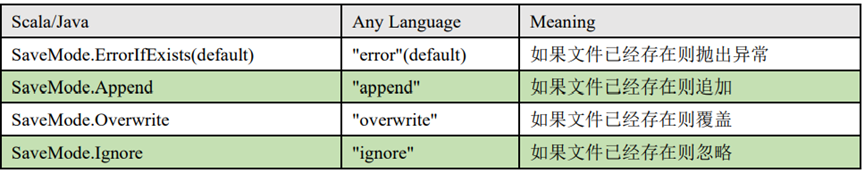
save mode的不同选项,如append、error、overwrite和ignore,以及它们在文件已存在时的处理方式。
Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式
存储格式。
加载数据:
val df = spark.read.load("examples/src/main/resources/users.parquet")
保存数据:
var df = spark.read.json("/opt/module/data/input/people.json")
df.write.mode("append").save("/opt/module/data/output")
数据格式与数据源
默认数据源介绍了 Spark 的默认数据源,能够存储嵌套数据,简化了数据操作。强调了默认数据源的便利性,通常不需要修改配置。
JSON
JSON数据处理:
spark SQL自动检测JSON数据集的结构,并将其加载为dataset。
可以通过 SparkSession.read.json()去加载 JSON 文件。
强调了spark中读取的JSON文件每一行应为一个json串。
加载json文件
val path = "/opt/module/spark-local/people.json"
val peopleDF = spark.read.json(path)
创建临时表
peopleDF.createOrReplaceTempView("people")
数据查询
val resDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
CSV 数据
CSV 文件的读取方法,通常用于简单的数据导入。
Spark SQL 可以配置 CSV 文件的列表信息,读取 CSV 文件,CSV 文件的第一行设置为
数据列。
spark.read.format("csv").option("sep",";").option("inferSchema","true")
.option("header", "true").load("data/user.csv")
MySQL 数据操作
连接与加载
通过 JDBC 连接 MySQL 数据库并加载数据的方法。
强调:驱动版本与 MySQL 版本匹配的重要性。
介绍了三种加载数据的方式:使用 option 参数逐个设置连接信息。使用 options 参数在 URL 中融合连接信息。使用 spark.read.jdbc 方法直接传入 JDBC 参数。
写入数据
通过 JDBC 将数据写入 MySQL 数据库的方法。
举例说明了如何创建 RDD 并将其转换为 DataFrame 进行写入操作。
强调了 save mode 在写入操作中的应用。
1) 导入依赖
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.27</version>
</dependency>
MySQL8 <version>8.0.11</version>2) 读取数据
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SQL")
val spark:SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()import spark.implicits._
//通用的load方式读取spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/system").option("driver","com.mysql.jdbc.Driver")//com.mysql.cj.jdbc.Driver.option("user","root").option("password","123456").option("dbtable","user").load().show()spark.stop()//通用的load方法的另一种形式
spark.read.format("jdbc").options(Map("url"->"jdbc:mysql://localhost:3306/system?user=root&password=123456","dbtable"->"user","driver"->"com.mysql.jdbc.Driver")).load().show()//通过JDBC
val pros :Properties = new Properties()
pros.setProperty("user","root")
pros.setProperty("password","123456")
val df :DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/system","user",pros)
df.show()3) 写入数据
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SQL")
val spark:SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()import spark.implicits._
val rdd: RDD[Stu] = spark.sparkContext.makeRDD(List(Stu("lisi", 20),Stu("zs", 30)))
val ds:Dataset[Stu] = rdd.toDS()ds.write.format("jdbc").option("url","jdbc:mysql://localhost:3306/system").option("driver","com.mysql.jdbc.Driver").option("user","root").option("password","123456").option("dbtable","user2").mode(SaveMode.Append).save()spark.stop()
Spark-SQL连接Hive
连接方式:内嵌Hive、外部Hive、Spark-SQL CLI、Spark beeline 以及代码操作。
内嵌HIVE:在生产环境中几乎不使用内嵌Hive模式。
外部HIVE:需要与虚拟机中的Hive相连,需下载并配置PS ML、CORE杠set SML、HDFS等文件,并修改配置文件以指向虚拟机的Have。
在虚拟机中下载以下配置文件

如果想在spark-shell中连接外部已经部署好的 Hive,需要通过以下几个步骤:
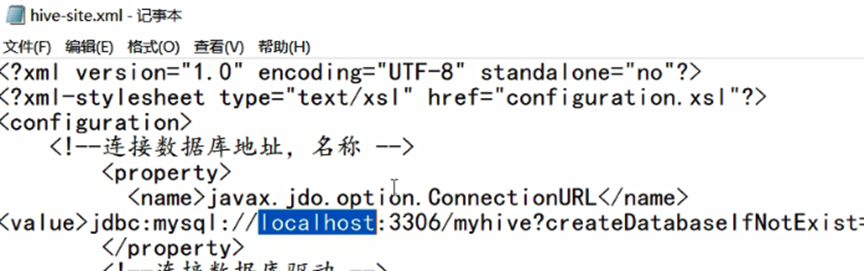
Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下,并将url中的localhost改为node01

驱动放置:MySQL驱动 copy 需要放到 jars/目录下

把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
重启 spark-shell
运行Spark-SQL CLI
Spark SQL CLI 可以很方便的在本地运行 Hive 元数据服务以及从命令行执行查询任务。在 Spark 目录下执行如下命令启动 Spark SQL CLI,直接执行 SQL 语句,类似于 Hive 窗口。
操作步骤:
- 将mysql的驱动放入jars/当中;
- 将hive-site.xml文件放入conf/当中;
- 运行bin/目录下的spark-sql.cmd 或者打开cmd,在
D:\spark\spark-3.0.0-bin-hadoop3.2\bin当中直接运行spark-sql

可以直接运行SQL语句,如下所示:
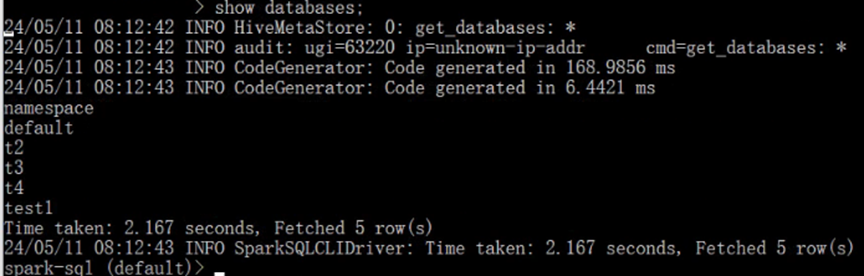
运行Spark-SQL CLI的使用:
通过spark-sql. cmd运行,可以直接输入MySQL语句,不需要SQL括号和双引号。
驱动和配置文件的放置位置与外部Hive相同。
导入依赖:需要导入与Spark版本一致的依赖包(如3.0.0版本),并与Hive版本保持一致。
虚拟机运行:强调所有操作需要在虚拟机运行的情况下进行,除非使用IDEA。
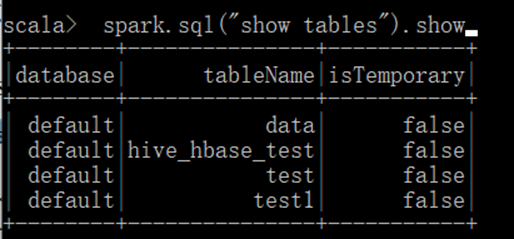
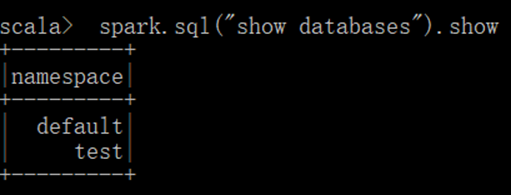
代码实现:导入必要的包。创建配置对象和SQL对象,输入SQL语句以展示数据库和数据表。
相关文章:
Spark-SQL核心编程3
数据加载与保存 通用方式: SparkSQL 提供了通用的保存数据和数据加载的方式。这里的通用指的是使用相同的API,根据不同的参数读取和保存不同格式的数据,SparkSQL 默认读取和保存的文件格式为parquet 数据加载方法: spark.read.lo…...
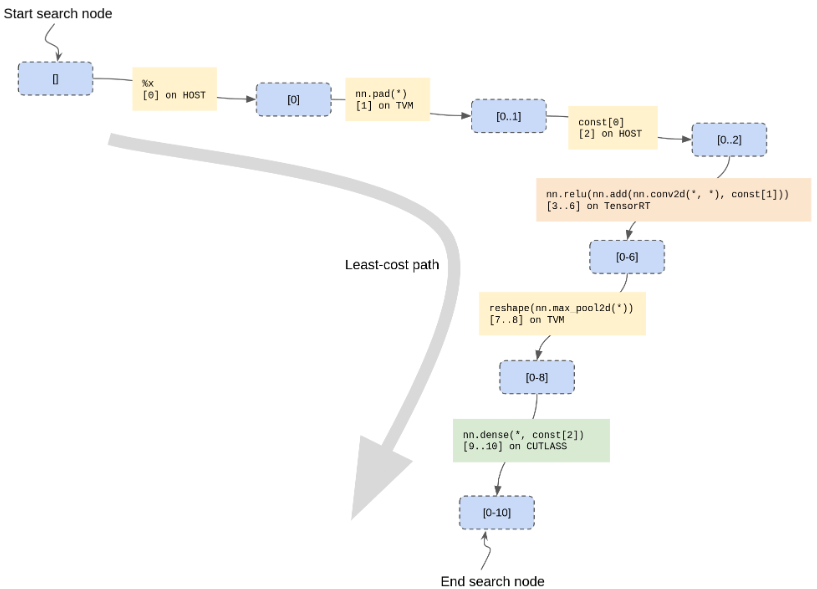
TVM计算图分割--Collage
1 背景 为满足高效部署的需要,整合大量优化的tensor代数库和运行时做为后端成为必要之举。现在的深度学习后端可以分为两类:1)算子库(operator kernel libraries),为每个DL算子单独提供高效地低阶kernel实现。这些库一般也支持算…...
默认不聚焦问题处理)
elementUI中MessageBox.confirm()默认不聚焦问题处理
在项目中使用elementUI的MessageBox.confirm()出现了默认不聚焦的问题,默认确认按钮是浅色的,需要点击一下才会变成正常。面对这种问题,创建新组件,实现聚焦。替换默认的MessageBox.confirm() 解决 创建components/MessageBoxCo…...
)
【刷题Day20】TCP和UDP(浅)
TCP 和 UDP 有什么区别? TCP提供了可靠、面向连接的传输,适用于需要数据完整性和顺序的场景。 UDP提供了更轻量、面向报文的传输,适用于实时性要求高的场景。 特性TCPUDP连接方式面向连接无连接可靠性提供可靠性,保证数据按顺序…...

sql server 预估索引大小
使用deepseek工具预估如下: 问题: 如果建立一个数据类型是datetime的索引,需要多大的空间? 回答: 如果建立一个数据类型是 datetime 的索引,索引的大小取决于以下因素: 索引键的大小&#…...

利用 i2c 快速从 Interface 生成 Class
利用 i2c 快速从 Interface 生成 Class(支持 TS & ArkTS) 在日常 TypeScript 或 ArkTS 开发中,需要根据 interface 定义手动实现对应的 class,这既重复又容易出错。分享一个命令行工具 —— interface2class,简称…...
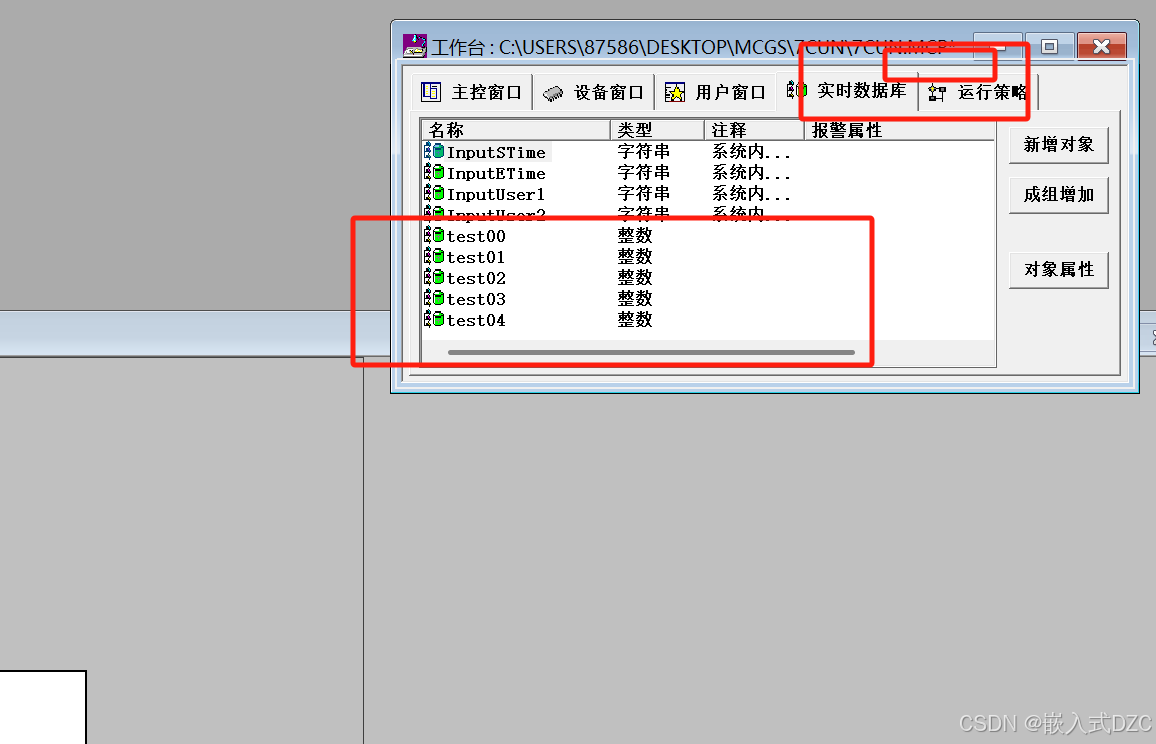
MCGS昆仑通太屏笔记
4.3寸:4013ef/e1 7寸:7032kw 特点: 如果是使用组态屏进行调试使用,选择com1如果是实际项目使用,选择com2 操作步骤: 先创建设备窗口,再创建用户界面 在设备窗口界面,依次设置如下…...
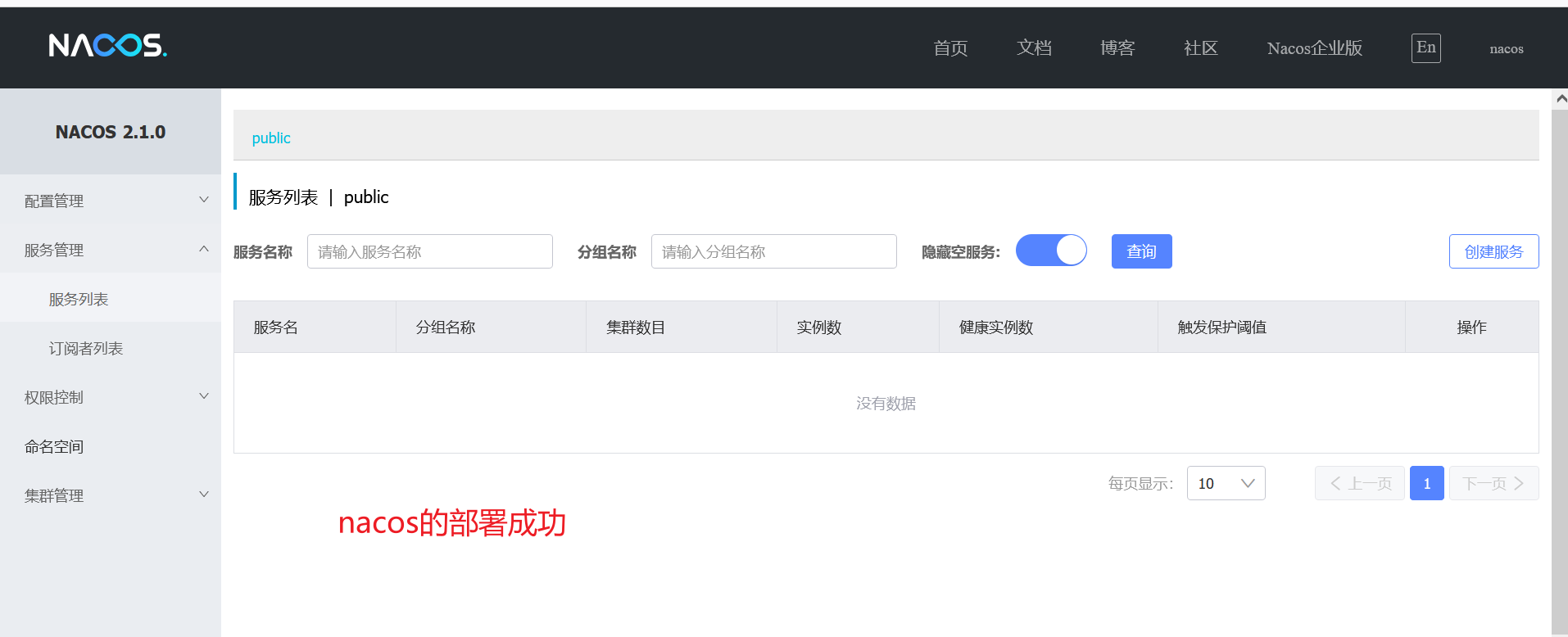
服务治理-搭建Nacos注册中心
运行nacos.sql文件。 将准备好的nacos目录和nacos.tar包上传。 192.168.59.101是我的虚拟机ip,8848是我们设置的访问端口号。...

网络--socket编程(2)
Socket 编程 TCP TCP 网络程序 和刚才 UDP 类似 . 实现一个简单的英译汉的功能 TCP socket API 详解 下面介绍程序中用到的 socket API, 这些函数都在 sys/socket.h 中。 socket(): • socket() 打开一个网络通讯端口 , 如果成功的话 , 就像 open() 一样返回一个…...

【FreeRTOS进阶】优先级翻转现象详解及解决方案
【FreeRTOS进阶】优先级翻转现象详解及解决方案 接下来我们聊聊优先级翻转这个经典问题。这个问题在实时系统中经常出现,尤其是在任务较多的场景下,而且问题定位起来比较麻烦。 什么是优先级翻转? 优先级翻转的核心定义很简单:…...

结合建筑业务讲述TOGAF标准处理哪种架构
TOGAF标准处理哪种架构 内容介绍业务架构业务策略,治理,组织和关键业务流程数据架构组织的逻辑和物理数据资产以及数据管理资源的结构应用架构待部署的各个应用程序,它们之间的交互以及与组织核心业务流程的关系的蓝图技术架构支持业务&#…...

C++入门小馆: 深入string类(一)
嘿,各位技术潮人!好久不见甚是想念。生活就像一场奇妙冒险,而编程就是那把超酷的万能钥匙。此刻,阳光洒在键盘上,灵感在指尖跳跃,让我们抛开一切束缚,给平淡日子加点料,注入满满的pa…...
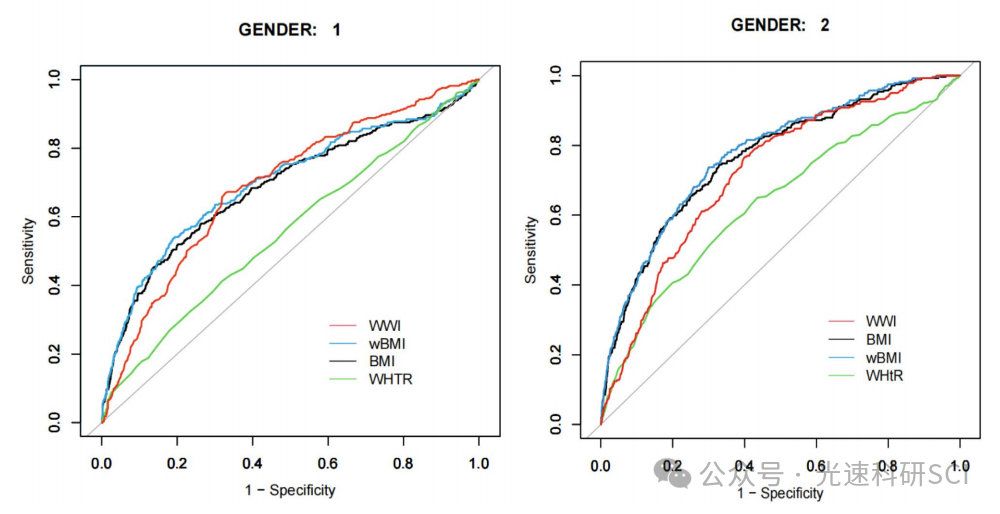
NHANES指标推荐:WWI
文章题目:Weight-adjusted waist circumference index with hepatic steatosis and fibrosis in adult females: a cross-sectional, nationally representative study (NHANES 2017-2020) DOI:10.1186/s12876-025-03706-4 中文标题:体重调整…...
2025.04.18|【Map】地图绘图技巧全解
Add circles Add circles on a Leaflet map Change tile Several background tiles are offered by leaflet. Learn how to load them, and check the possibilities. 文章目录 Add circlesChange tile 2025.04.18【Map】| 地图绘图技巧全解1. 准备工作2. 地理区域着色图&…...
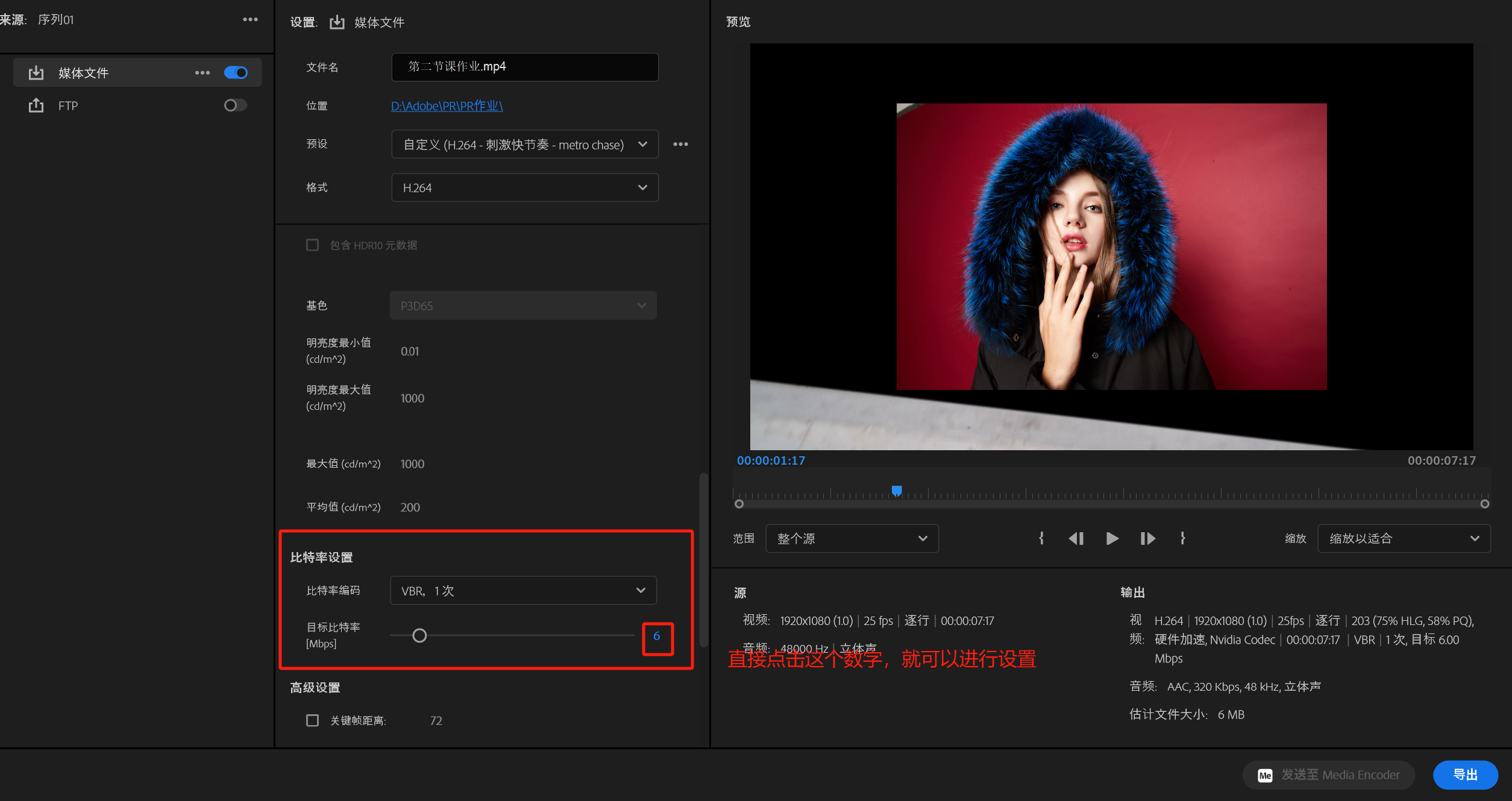
PR第一课
目录 1.新建 2.PR内部设置 3.导入素材 4.关于素材窗口 5.关于编辑窗口 6.序列的创建 7.视频、图片、音乐 7.1 带有透明通道的素材 8.导出作品 8.1 打开方法 8.2 导出时,需要修改的参数 1.新建 2.PR内部设置 随意点开 编辑->首选项 中的任意内容&a…...

C# 预定义类型全解析
在 C# 编程中,预定义类型是基础且重要的概念。下面我们来详细了解 C# 的预定义类型。 预定义类型概述 C# 提供了 16 种预定义类型,包含 13 种简单类型和 3 种非简单类型。所有预定义类型的名称都由全小写字母组成。 预定义简单类型 预定义简单类型表…...

@EnableAsync+@Async源码学习笔记之六
接上文,我们本文分析 AsyncExecutionAspectSupport 的源码: package org.springframework.aop.interceptor;import java.lang.reflect.Method; import java.util.Map; import java.util.concurrent.Callable; import java.util.concurrent.CompletableFu…...

Java CMS和G1垃圾回收器
举个真带劲的例子:把JVM内存比作你家的祖传旱厕 想象你有个祖传旱厕,分三个坑: 新坑区(年轻代):刚拉的屎热乎着(新对象)陈年坑(老年代):风干的屎…...
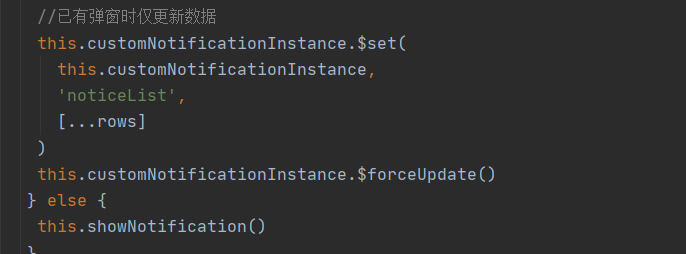
Vue+Notification 自定义消息通知组件 支持数据分页 实时更新
效果图: message.vue 消息组件 子组件 <template><div class"custom-notification"><div class"content"><span click"gotoMessageList(currentMessage.split()[1])">{{ currentMessage.split()[0] }}</…...
不规则曲面上两点距离求取
背景 在CT中求皮肤上两点间的弧长。由于人体表面并不是规则的曲面,不可能用圆的弧长求取方法来计算出两点间的弧长。 而在不规则的曲面上求两点的距离,都可以用类似测地线距离求取的方式来求取(积分),而转化为搜索路…...

Redis面试问题缓存相关详解
Redis面试问题缓存相关详解 一、缓存三兄弟(穿透、击穿、雪崩) 1. 穿透 问题描述: 缓存穿透是指查询一个数据库中不存在的数据,由于缓存不会保存这样的数据,每次都会穿透到数据库,导致数据库压力增大。例…...
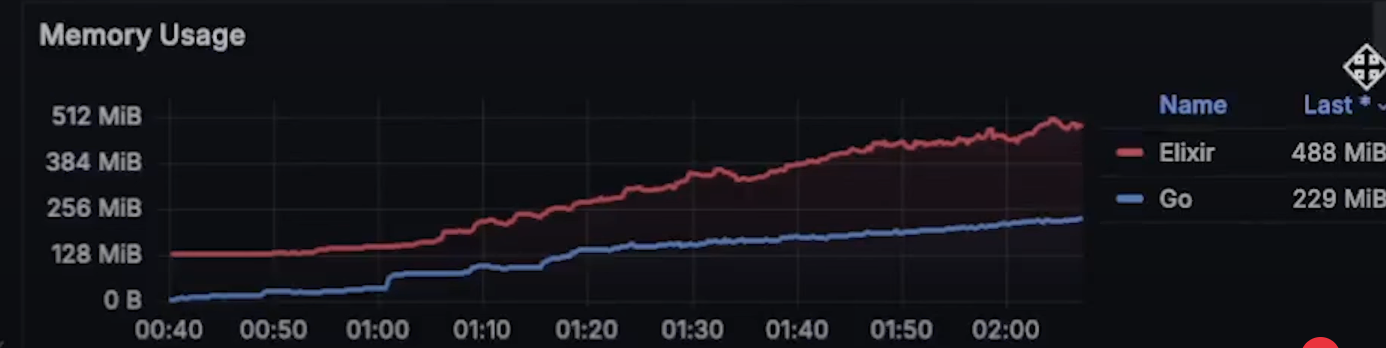
性能比拼: Elixir vs Go
本内容是对知名性能评测博主 Anton Putra Elixir vs Go (Golang) Performance (Latency - Throughput - Saturation - Availability) 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 对比 Elixir 和 Go 简介 许多人长期以来一直要求我对比 Elixir 和 Go。在本视频…...
:深入理解精益分析的核心要点)
精益数据分析(6/126):深入理解精益分析的核心要点
精益数据分析(6/126):深入理解精益分析的核心要点 在创业和数据驱动的时代浪潮中,我们都在不断探索如何更好地利用数据推动业务发展。我希望通过和大家分享对《精益数据分析》的学习心得,一起在这个充满挑战和机遇的领…...
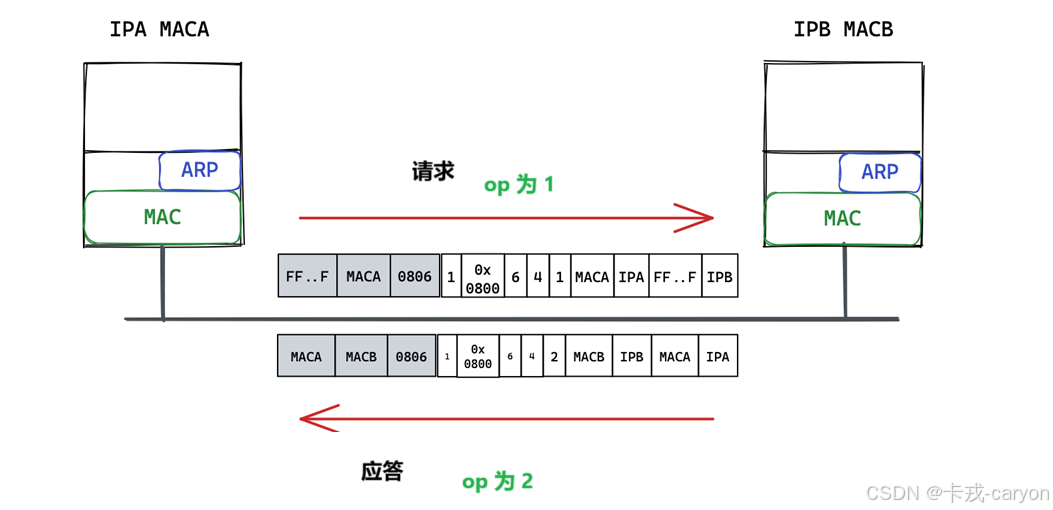
【Linux网络与网络编程】11.数据链路层mac帧协议ARP协议
前面在介绍网络层时我们提出来过一个问题:主机是怎么把数据交给路由器的?那里我们说这是由数据链路层来做的。 网络上的报文在物理结构上是以mac帧的形式流动的,但在逻辑上是以IP流动的,IP的流动是需要mac帧支持的。 数据链路层解…...

JAVA设计模式:注解+模板+接口
1.基础组件 1.1注解类控制代码执行启动、停止、顺序 /*** author : test* description : 数据同步注解* date : 2025/4/18*/ Target({ElementType.TYPE}) Retention(RetentionPolicy.RUNTIME) Documented public interface SyncMeta {/*** 执行服务名称* return*/String name…...

Linux系统编程 day6 进程间通信mmap
父子共享的信息:文件描述符,mmap建立的共享映射区(MAP_SHARED) mmap父子间进程通信 var的时候 :读时共享,写时复制 父进程先创建映射区,指定共享MAP_SHARED权限 , fork创建子进程…...

【MySQL】MySQL建立索引不知道注意什么?
基本原则: 1.选择性原则: 选择高选择性的列建立索引(该列有大量不同的值) 2.适度原则:不是越多越好,每个索引都会增加写入开销 列选择注意事项: 1.常用查询条件列:WHERE字句中频繁使用的列 2.连接操作列…...
:SM4 对称加密算法)
定制一款国密浏览器(9):SM4 对称加密算法
上一章介绍了 SM3 算法的移植要点,本章介绍对称加密算法 SM4 的移植要点。 SM4 算法相对 SM3 算法来说复杂一些,但还是比较简单的算法,详细算法说明参考《GMT 0002-2012 SM4分组密码算法》这份文档。铜锁开源项目的实现代码在 sm4.c 文件中,直接拿过来编译就可以。 但需要…...
对微服务的数据一致性和恢复性有何影响?如何选择?)
Redis 的持久化机制(RDB, AOF)对微服务的数据一致性和恢复性有何影响?如何选择?
Redis 的持久化机制(RDB 和 AOF)对于保证 Redis 服务重启或崩溃后数据的恢复至关重要,这直接影响到依赖 Redis 的微服务的数据一致性和恢复能力。 1. RDB (Redis Database Backup) 机制: 在指定的时间间隔内,将 Redis 在内存中的…...
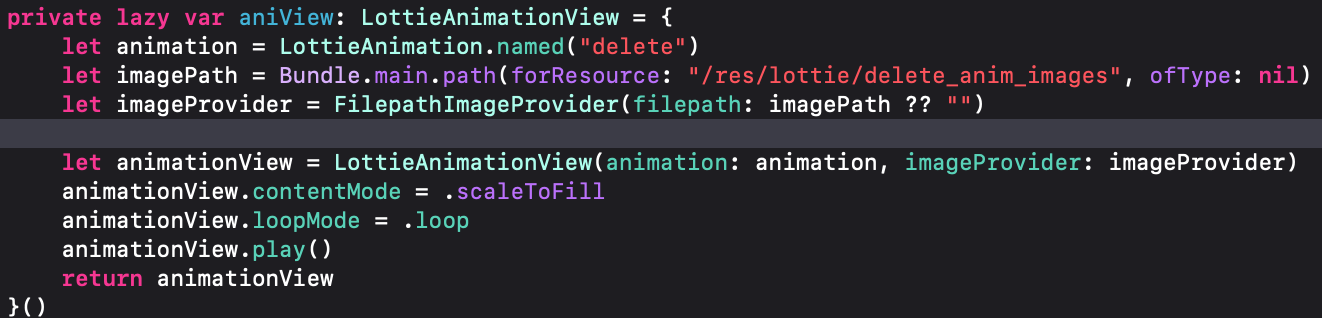
lottie深入玩法
A、json文件和图片资源分开 delete 是json资源名字 /res/lottie/delete_anim_images是图片资源文件夹路径 JSON 中引用的图片名,必须与实际图片文件名一致 B、json文件和图片资源分开,并且图片加载不固定 比如我有7张图片,分别命名1~7&…...