游戏引擎学习第233天
原地归并排序地方很蒙圈
game_render_group.cpp:注意当前的SortEntries函数是O(n^2),并引入一个提前退出的条件
其实我们不太讨论这些话题,因为我并没有深入研究过计算机科学,所以我也没有太多内容可以分享。但希望在过去几天里,大家对计算机科学领域有了基本的了解,如果大家有兴趣,可以自己去深入查找相关资料。更重要的是,我希望大家能够理解大O表示法的实际应用,知道当我说“这个是O(n^2)”或者“这是O(n log n)”时,能明白这对代码有什么实际意义,以及为什么我们会关注这些方面。至于计算机科学的其他内容,我是一个非常注重实践的程序员,对计算机科学的知识并不多,所以可能这就是你们听到的最后一次相关的讨论。
话虽如此,基于一些计算机科学的知识,我们仍然有一些实际的编程工作要做。举个例子,我们现在讨论的是一个O(n^2)的排序算法,具体来说,这是一个经典的冒泡排序(bubble sort)。在这个算法中,我们已经有了一个待办事项,就是引入一个提前退出的条件。我们之前讨论过,实际上在冒泡排序中,如果我们发现列表已经排好序了,就不需要继续进行所有的N次遍历。我们可以通过一个标志变量来标识列表是否已经排序,如果在某次遍历中没有发生交换,我们就可以知道列表已经排序好了,然后就可以提前退出排序。
具体来说,我们可以创建一个变量,比如叫做ListIsSorted,它在排序之前设为true,然后在遍历过程中每当发生交换时,就将它设为false,这样我们就知道列表可能没有完全排序。在每次遍历结束后,如果ListIsSorted仍然为true,就表示列表已经排好序了,我们可以提前结束排序,避免进行不必要的遍历。
这是冒泡排序的一个传统实现,很多人都会加入这个提前退出的条件,因为它相对来说计算开销不大。当然,我们还可以做一些更极端的事情,比如在没有发生交换时,直接设定一个计数器或者其他一些变量,来标识列表是否已经排序。但总体来说,使用一个简单的标志来标识排序状态,是冒泡排序的标准做法。
这也是我们在实际编程中可能遇到的一种优化,利用大O表示法可以帮助我们理解算法的时间复杂度,进而帮助我们做出一些有用的优化。

引入这个条件将“预期运行时间”从O(n^2)改为更少的时间复杂度
加入提前退出条件后,这并不会改变最坏情况下的时间复杂度,它依然是O(n2)。那么它究竟做了什么呢?它将期望的运行时间从O(n2)改变为某个较小的值,但具体减少多少时间是无法确定的,因为它完全取决于输入列表的排序情况。
如果输入的列表已经是排好序的,通常情况下,这样的优化能大幅度减少运行时间,可能变成接近O(n)的情况。但如果列表中的元素顺序很乱,特别是那些应该排在前面的元素出现在后面,最坏情况下仍然会保持O(n^2)。
因此,加入提前退出条件并不能保证始终减少运行时间,它的效果取决于初始数据的排序情况。在一般情况下,它只是优化了程序的预期运行时间,使其在某些情况下能更快完成。
game_render_group.cpp:引入MergeSort
现在来讨论另一种排序方法——归并排序。归并排序的工作原理是将数据拆分成多个小块,然后对每个小块进行排序,最后将已排序的小块合并成一个完整的有序数组。具体来说,归并排序会将一个数组不断拆分成两半,直到每个小块只有一个或两个元素,然后对这些小块进行合并。
我们开始时会有一个包含元素的数组,目标是将这个数组拆分成两部分。实现归并排序的方式通常是递归的,这也是最简单的一种方法。我们不需要手动实现栈,因为程序本身的调用栈就能处理这个问题,尽管稍后根据不同的排序算法,可能会考虑使用其他方式来实现。
为了实现归并排序,首先我们需要检查数组的元素数量。如果数组中只有一个元素,那么它已经是有序的,因此无需做任何操作。如果数组中有两个元素,我们只需要检查这两个元素,并在它们的顺序不正确时交换它们。对于这两种情况,我们已经实现了排序的基本操作。
当数组的元素超过两个时,归并排序的关键在于将数组分割成两个更小的部分。为了做到这一点,我们需要计算出数组的一半,创建两个新的子数组:第一个子数组包含前一半元素,第二个子数组包含剩下的元素。需要注意的是,如果原数组的元素数量是奇数,两个子数组的大小可能会不同。
接下来,我们对这两个子数组分别递归地调用归并排序,使得每个子数组都变成有序的。然而,尽管每个子数组内部已经是有序的,两个子数组之间仍然需要进行合并操作。在合并的过程中,我们需要逐步比较两个子数组的元素,将它们按顺序合并到一个新的数组中,这个过程叫做“归并”。
这个过程涉及遍历两个子数组并将它们的元素逐一插入到新数组中,直到所有元素都被合并在一起。
归并排序的核心是分治思想,即通过将大问题分解成小问题来逐步解决。通过递归地将数组拆分成小块,直到每个小块都有序,再将这些有序的小块合并成最终的有序数组。

我们可以通过一个简单的例子来理解归并排序是如何工作的。假设我们有一个无序的数组:
原始数组:[38, 27, 43, 3, 9, 82, 10]
步骤 1:将数组分割成两半
首先,我们将数组分成两个部分:
- 左半部分:[38, 27, 43]
- 右半部分:[3, 9, 82, 10]
步骤 2:继续递归分割
对每个部分再进行递归拆分,直到每个子数组只有一个元素:
-
左半部分:[38, 27, 43] 继续分割成:
- [38] 和 [27, 43] (左边单独成一组,右边继续分割)
- [27] 和 [43](继续分割)
-
右半部分:[3, 9, 82, 10] 继续分割成:
- [3, 9] 和 [82, 10]
- [3] 和 [9] 以及 [82] 和 [10]
现在每个子数组都有单个元素了:
- [38], [27], [43], [3], [9], [82], [10]
步骤 3:开始合并
从最小的子数组开始,逐步合并它们为有序的数组。
-
合并 [27] 和 [43]:
- [27] 和 [43] 比较,结果是:[27, 43]
-
合并 [38] 和 [27, 43]:
- [38] 和 [27] 比较,38 比 27 大,所以 [27, 38] 然后与 [43] 比较,结果是:[27, 38, 43]
-
合并 [3] 和 [9]:
- [3] 和 [9] 比较,结果是:[3, 9]
-
合并 [82] 和 [10]:
- [82] 和 [10] 比较,结果是:[10, 82]
-
合并 [3, 9] 和 [10, 82]:
- 先比较 [3] 和 [10],选择较小的 [3]。
- 接着比较 [9] 和 [10],选择较小的 [9],然后是 [10] 和 [82],最后是 [82],结果是:[3, 9, 10, 82]
步骤 4:合并剩下的部分
接下来合并已排序的部分:
- 合并 [27, 38, 43] 和 [3, 9, 10, 82]:
- 比较最小的元素 [27] 和 [3],选择 [3]。
- 然后比较 [27] 和 [9],选择 [9],接着比较 [27] 和 [10],选择 [10],再比较 [27] 和 [27],选择 [27],然后是 [38] 和 [43],结果是:[3, 9, 10, 27, 38, 43, 82]
最终结果
经过归并排序后,整个数组被排序为:
排序后的数组:[3, 9, 10, 27, 38, 43, 82]
总结
通过这个例子,可以看到归并排序的过程:通过递归将数组分割成越来越小的部分,直到每个子数组只有一个元素。然后,通过逐步合并这些子数组,最终得到一个有序的数组。
Blackboard:我们能在原地进行Merge Sort吗?
我们在讨论一个在原地(in-place)实现归并排序的问题。归并排序通常需要额外的存储空间来合并两个已排序的部分,然而我们在思考是否有可能通过不使用额外的存储空间来实现这一点。通常情况下,如果使用额外的存储空间,归并操作会变得更高效,因为我们知道所需的空间量不会超过原始列表的大小。
但是我们想要挑战自己,看看是否能在原地完成这个归并操作。归并排序的基本思想是将一个大的列表分成两个已排序的小部分,然后将这两个部分合并为一个大的排序列表。这个过程的关键是每次从两个已排序的部分中选取较小的元素,逐步将它们插入到最终的合并结果中。
在原地合并时,我们面临的问题是:我们无法简单地将合并结果放到一个新的列表中,而必须直接修改原始数据。这时的挑战是,如果我们从其中一个子列表取出一个元素,如何确保它被正确插入到目标位置,而不会丢失其他元素的信息。
具体来说,假设我们有两个已排序的子列表(即半部分),我们需要从这两个子列表中各取一个元素,然后比较它们并选择较小的一个放到结果中。当我们放入一个元素时,问题就来了:如果我们直接交换元素,那么原本应该在第一个子列表中的元素会被移到另一个位置,这样就破坏了它原本的位置。为了处理这个问题,我们可以设置一个标记,记录交换操作的状态,并确保下一次访问该元素时,能够将其恢复到正确的位置。
此外,当我们交换两个元素时,需要更新指向这些元素的指针。假设我们从第二个子列表取出一个元素并放入当前列表中,那么我们就需要更新第二个子列表的指针,指向下一个元素。同时,我们需要设置一个标记,表示下次访问时该元素已经被交换,应该按照正确的顺序进行访问。这种处理方式使得我们可以在原地完成归并排序。
总的来说,虽然通过这种方法可以实现原地归并排序,但操作起来相对复杂,需要管理指针和标记,确保每一步都能正确处理元素。实现这种方法的好处是节省了额外的空间,但也带来了实现上的复杂性。如果不特别要求原地排序,使用额外的存储空间可能会更为高效和简便。
在合并操作中,我们使用一个“输出指针”来指示当前合并结果的位置。每次合并后,我们都会更新该指针,直到所有元素都被合并进结果中。为了确保合并过程的正确性,我们可以在最后检查输出指针是否与预期的值相等,即是否所有元素都被正确合并。
这种方法理论上是可行的,但由于它的复杂性,实际应用中可能会选择更简单的方式,例如使用额外的存储空间进行合并。

game_render_group.cpp:为排序函数引入一个验证器
在处理排序算法时,为了确保排序正确性,应该在代码中加入一个验证机制,特别是在编写复杂的排序算法时,验证变得尤为重要。虽然冒泡排序(Bubble Sort)可能出错的概率较低,但归并排序(Merge Sort)由于其更复杂的结构,出错的可能性相对较高。因此,在进行实际操作前,应该加入一个验证步骤,确保所有排序结果都符合预期。
在这段代码中,我们通过一个验证函数来检查排序结果是否正确。验证的过程很简单:对于排序后的列表,检查每一对相邻元素,确保每个元素都不大于它后面的元素。具体来说,就是遍历列表中的每一对相邻元素,如果前一个元素大于后一个元素,则表明排序存在错误。
为了实现这一点,我们可以在排序逻辑中加入一个条件判断,检查是否处于验证模式。处于验证模式时,我们会对排序结果进行逐一检查。通过这种方式,我们能够在排序过程中发现潜在的问题,及时纠正。
这种验证机制非常有用,因为它能够帮助我们确保排序算法在复杂的情况下仍然能够按预期工作,尤其是在面对复杂的排序算法(如归并排序)时。通过这种方式,我们可以有效地避免假设排序结果是正确的,而不进行实际验证,从而提高代码的可靠性。




Debugger:运行游戏并触发断言,在修复测试之前
我们在进行排序验证时,发现代码有一个小问题,就是在验证排序时,需要修改一个条件:不能直接读取数组的最后一个元素。因为数组的索引是从0开始的,所以在遍历数组时,如果访问超出了最后一个有效元素的位置,就会发生越界错误。为了解决这个问题,我们需要在进行排序验证时,确保数组索引不越界。具体来说,在验证排序结果时,应该使用 count - 1,以避免访问到数组的结束部分。
另外,为了确保验证机制的有效性,可以暂时关闭排序代码部分,目的是检查如果传入一个未排序的数组,验证是否能正确触发错误提示。这样就可以确认验证功能是否能够有效地捕捉到未排序的情况,确保代码在排序过程中能够正确地检查和处理数组。
最终,通过这种方式,我们不仅能够验证排序算法的正确性,还能确保在出现错误时,能够及时捕捉并提示错误,从而为代码提供了额外的安全保障。这种方法提供了一种可靠的检测机制,帮助我们在开发和调试过程中避免潜在的错误,确保排序算法在不同情况下都能够正确执行。


game_render_group.cpp:继续处理MergeSort,交替进行测试
在实现归并排序时,遇到了一个问题,即如何正确地处理两个已经排序的数组(或数组的部分),并将它们合并为一个排序后的数组。归并操作的核心是不断比较两个数组的当前元素,将较小的元素放入结果数组中,并且更新相应的指针,以确保顺序正确。
首先,在归并操作中,我们需要处理两个已排序的数组——称之为half 0和half 1。每当需要从这两个数组中选择一个元素时,我们比较它们的当前元素,选择较小的一个放入结果数组中,并移动相应的指针。如果一个数组中的元素已经被全部处理完,另一个数组的剩余元素可以直接复制到结果数组中。
然而,在实现过程中会遇到以下几个问题:
-
指针越界问题:在读取两个数组的元素时,如果一个数组的元素已经被消耗完,我们不能继续从该数组读取数据。这要求我们在合并时要知道每个数组的结束位置,并在合并过程中避免越界读取。
-
处理剩余元素:当一个数组中的元素已全部消耗时,另一个数组的元素可以直接复制到结果数组。为了正确处理这一情况,我们需要确保程序能够检查某一数组是否已完全处理,并且不再尝试从已空的数组中读取数据。
为了实现这些,我们可以通过显式地追踪每个数组的结束位置来处理。我们引入了read_half变量,来跟踪当前读取位置。每当读取完一个数组中的元素,就更新该数组的指针,直到所有元素都被处理完。
此外,为了避免覆盖已经排序的元素,我们可能需要一个额外的缓冲区或者栈来存储中间结果。这是因为,如果我们从half 1读取元素并将其写入half 0,就会覆盖half 0中的数据。所以,需要确保在操作时,half 0中的数据不会被覆盖,直到合并操作完成。
接下来,为了避免在处理过程中产生错误,我们还可以引入一些断言(assertions)来验证是否存在越界访问或未处理的元素。例如,在合并时可以检查指针是否已越界,确保操作的正确性。
这种思考方式有助于理解如何处理两个已排序数组的合并,同时保持操作的正确性和效率。在实现时,虽然我们暂时没有使用额外的内存(即希望尽量做到“原地排序”),但为了调试和验证,暂时使用一些辅助缓冲区来简化逻辑,是一种常见的做法。最终,随着算法的完成和测试,我们可以逐步优化和简化代码,使其既高效又易于理解。
总的来说,这个过程中最重要的部分是确保合并操作中不会越界读取或写入数据,并且合理管理每个数组的读取指针,避免覆盖已经排序好的数据。通过这些策略,能够有效地完成归并排序,并确保算法的正确性。

Blackboard:绘制出这个场景
我们设想一个最简单的归并场景,有两个已经排好序的数组片段(也可以理解为两段有序的区域)。现在我们假设总是从其中一个区域(比如 half 1)中读取元素,并不断将这些元素写入最终合并结果的位置上。问题在于:这些写入位置恰好是原先另一个区域(half 0)中的数据所在的位置。
这就引出了一个关键点——我们每次从 half 1 中取出一个元素写入目标位置时,实际上是把 half 0 中尚未处理的数据“压”了下去。换句话说,half 0 的数据会被覆盖掉。为了避免数据丢失,我们必须把这些被“挤下去”的元素保存起来,相当于模拟一个“栈”的结构,这些元素会在稍后仍然被访问,因此不能直接丢弃。
所以我们做的事情就像这样:
- 一开始目标数组的写入指针从起始位置开始。
- 每次比较两个 half 的当前值,决定哪个值写入目标位置。
- 假设从 half 1 中选出一个元素写入目标位置:
- 这时目标位置上可能是 half 0 中还没处理的有效元素,为了不丢失这个值,我们将其保存下来,像是“推入一个临时栈”中。
- 然后继续处理后续元素。
接下来我们要面对的问题是读取的时候:
- 由于部分元素原本在 half 0 中的顺序位置已经被覆盖(它们被临时“压栈”了),当我们要继续读取 half 0 时,需要从这个“栈”中把值拿回来,而不是从原始位置去读取。
换句话说,整个过程类似于“延迟访问 + 值的搬移”,在原地排序的限制下,我们通过临时的逻辑结构(如一个可视化的栈)保存被覆盖的值,从而避免使用额外内存的前提下完成正确排序。
这个“最简单版本”的尝试目的是为了验证这种策略在最基础的情况下是否可行,以及理解值如何在内存中被移动、保存、重用的细节。一步步建立起这套逻辑后,再推广到更复杂的情况,从而实现完整的、原地的归并排序。
game_render_group.cpp:引入Half0StackCount,并明确列出所有的情况
我们这里正在思考如何实现一个原地归并排序,即在不使用额外内存缓冲区的前提下完成合并操作。之前的思路已经建立了半区 half 0 和 half 1 的指针,并尝试实现归并排序的逻辑。接下来我们针对「处理被覆盖数据」这一关键点引入了一个“栈式结构”的想法。
以下是详细的逻辑思路梳理:
-
half0_stack_count 初始化为 0:
- 表示我们当前从 half 0 区域中“被压下去”的元素数量,也就是那些被 half 1 写入目标位置时覆盖掉的元素。
-
栈的存储位置:
- 我们意识到这些被“推入栈”的元素实际上就保存在 half 1 原来的位置区域内(也就是还未写入合并目标的空间),所以我们并不需要为栈开辟单独的内存,只需要一个栈计数器来追踪压入了多少个元素。
-
处理逻辑:
-
情况一:read_half1 达到末尾
- 说明 half 1 中的数据已经用完。
- 这时如果栈(half0_stack_count)是 0,说明 half 0 还有剩余,就继续从 half 0 中读取元素合并。
- 如果栈不为 0,那么说明我们之前已经将 half 0 中的部分元素“推”到了 half 1 区域,现在就应该从栈中弹出数据继续写入目标位置。
- 这些元素是之前按顺序被压入的,因此它们本身是有序的,不需要重新比较,直接按顺序写入即可。
- 因为我们是按顺序处理的,栈中内容的顺序也一定符合归并排序的顺序。
-
结论:
- 如果 half 1 用完了,只要把 half 0 的剩余部分(包括压入栈中的)写完即可,排序就完成了。
- 所以真正需要处理的是栈中是否有数据,有就继续写;没有就继续从 half 0 读取正常内容。
-
-
逻辑校验和认知修正:
- 起初我们以为如果 half0_stack_count > 0 就可以直接完成剩下的排序,其实不然。我们必须继续将 half 0 中的剩余数据也合并进去,确保整个序列是完整的有序输出。
- 最终我们认识到:我们需要同时处理栈和 read_half0 的两个来源,直到所有数据都被写入合并区域。
总结概念与结构:
- half 1 是优先写入的来源区域,如果写入 half 1 的过程中会覆盖 half 0 的数据,则把被覆盖的 half 0 数据“推入栈”中。
- 栈的存储空间就是 half 1 原区域,我们只需用一个计数器维护它。
- 当 half 1 耗尽时,就检查栈中是否有被保存的 half 0 元素,有就弹出写入;否则就继续从 half 0 正常读取数据。
- 全过程保持了元素的有序性,且不依赖额外内存,实现了原地归并排序的初步结构。
这个结构和思路为实现完全原地归并排序打下了坚实的基础,虽然逻辑复杂,但清晰掌握“栈式保存”和“指针推进”这两个核心,就能逐步构造出完整正确的实现。

Blackboard:走一遍问题的流程
我们现在面临的问题是,当我们进行归并排序并尝试原地进行数据交换时,会出现一些非常棘手的情况,特别是在合并过程涉及到覆盖并保存原数据时。
我们设想了一个具体的例子来说明这个难题:
情景构造:
- 假设原来的缓冲区(half 1)比较短,里面只有两个元素,例如
a和b。 - 在 half 0 中有若干个数字,例如
1、2、3、4。 - 我们要对这些元素进行合并排序,目标是输出一个从小到大的有序序列。
操作过程:
-
比较 first(指向 half 0)和 second(指向 half 1)中的元素。
-
假设 a 和 b 的排序位置在整个合并中应该靠前:
- 我们先将 half 0 的第一个元素(如
1)写到目标位置,同时把 half 1 的第一个元素a存到 half 0 中暂存(类似入栈); - 然后将
2写出,同时把b也保存起来; - 现在,原来的 half 1 已经被“消耗完”,但真正的问题来了。
- 我们先将 half 0 的第一个元素(如
当前的问题:
现在我们到了一个非常微妙的情况:
- 剩下的 half 0 中的值
3、4本该在a和b之后,但由于我们之前把a和b存在了 half 0 中的“栈空间”中。 - 现在排序的顺序反而变成了
3(还没被处理)→a→b,打乱了我们原有的数据顺序。 - 换句话说,现在有一组新的数据也需要参与归并,而这些数据的来源位置发生了转换和混淆。
我们的推测与思路转变:
这个现象启发了我们一个新的想法:
- 整个合并的过程其实就像是在两个缓冲区之间反复交换数据。
- 每次我们把一部分数据从 one buffer 拷贝到另一个 buffer,并同时保留某些数据。
- 如果我们可以把这个模型推广成“始终在两个缓冲区之间做归并,只是每次归并的角色发生变化”——那我们是否可以构造一个逻辑缓冲对调机制?
初步总结:
- 我们正面临一个非常典型的原地归并排序中的“覆盖+顺序错乱”问题;
- 为了解决它,我们尝试模拟实际的值交换,并提出了是否可以以两个缓冲区为单位来处理归并的策略;
- 这个思路可以让我们摆脱之前复杂的“栈结构”管理,并可能为实现更干净的 in-place merge sort带来突破;
- 接下来我们将探索是否可以构造一个抽象模型,使得归并总是在“当前源缓冲区”和“目标缓冲区”之间进行,动态切换角色,从而避免逻辑混乱和覆盖错误。
这个阶段非常关键,因为我们正在从一个复杂的状态管理方案过渡到可能更普适的“缓冲区视角”模型,这种转变可能会简化整个算法实现的复杂度。
game_render_group.cpp:引入Swap
我们现在决定放开手脚,打破思路,尝试更大胆的方法来解决归并排序中的原地合并问题。
初始思路:
我们最开始的设想是,在排序过程中,我们需要从两个有序子数组中读取元素,进行比较,然后将较小的那个放入正确的位置。通常这会涉及到频繁的比较、指针前移等操作。
面临的问题:
随着我们开始进行原地归并,我们不得不开始交换两个区域中的元素。问题在于,这种交换可能造成“覆盖”,也就是说我们在处理一个元素时,可能会覆盖掉还未处理的另一个子序列中的值。
解决方式的转变:
为了让代码更清晰也更安全,我们决定封装一个“交换操作”函数。我们不再直接进行值赋值,而是通过:
swap(entry_a, entry_b);
的形式来进行统一的交换。
这有几个好处:
- 简化逻辑:不需要每次都手写赋值,容易出错。
- 便于调试:每个交换都可以统一记录或打印,方便追踪。
- 代码整洁:逻辑更加明确,交换的目的和行为直观可见。
下一步操作:
在具体实现上:
- 我们将读取两个子序列的指针(
ReadHalf0,ReadHalf1); - 然后根据比较结果,选择其中一个进行交换;
- 使用我们封装好的
swap(ReadHalf0, ReadHalf1),统一处理逻辑; - 同时,也可以将这个交换函数运用在归并排序的各个位置上,不仅让代码更易读,也减少错误的几率。
总结:
我们正在从“手动数据操作”向“结构化操作流程”转变——通过封装交换逻辑来提升代码的健壮性、可维护性和可读性。这种方式不仅让实现更简洁清晰,也为我们之后处理复杂情况(例如多层递归归并)打下更好的基础。
接下来我们将继续扩展这个思路,利用统一的交换机制来处理原地排序中复杂的交错合并问题。

game_render_group.cpp:第一步 - 找到第一个无序的元素对
我们现在进入归并排序中最核心、也最具挑战性的部分:原地合并两个有序子数组。此时我们采用的是一种更高效的策略,避免不必要的数据移动。
当前核心思想:
我们维护一个结构(或指针)来追踪“当前排序键”,如果我们即将“退休”的元素已经处于正确位置,那我们无需做任何处理。也就是说,如果当前位置已经是排序后该有的值,就跳过它,不做任何修改。
操作逻辑详解:
-
判断是否需要跳过当前元素:
- 如果当前
ReadHalf0指向的元素已经在正确位置(即小于ReadHalf1指向的元素),那就不需要交换; - 我们仅仅将
ReadHalf0向前推进一位,跳过这个已经在位的值。
- 如果当前
-
需要交换的情况:
- 如果
ReadHalf1的排序键更小,说明这个值必须放到前面来,那我们就要进行交换; - 使用封装好的
swap(ReadHalf0, ReadHalf1),交换两个指针所指的数据。
- 如果
-
连续交换:
- 一旦开始交换,就意味着后续可能还需要继续交换;
- 因此,我们进入一个循环,持续比较、交换,直到
ReadHalf1的指针到达末尾,或者当前的排序顺序不再要求交换为止。
特殊优化点:
- 实际上我们在做的是一边遍历、一边“处理错位的值”;
- 只处理确实乱序的值,不动那些本来就在正确位置的元素;
- 这样一来,我们有效减少了内存访问和写操作,提升整体性能。
结论:
这种策略本质上是让归并过程更智能、更节省资源:
我们并不是机械地复制所有数据,而是仅在“确实需要”的情况下才进行交换处理。同时,我们可以连续处理多个需要调整的位置,避免重复判断和冗余步骤。
后续我们将继续基于这个思路,逐步完成整个原地归并排序过程。目标是既保持排序稳定性,又尽可能节省内存和提高速度。

Blackboard:这个Merge Sort算法的两个阶段
目前我们设计的归并排序逻辑可以分为两个主要阶段:
第一阶段:寻找需要排序的起始位置
我们首先要做的是确定真正“需要排序”的起点。具体来说:
- 我们从两个已经排好序的子数组开始。
- 遍历第一个子数组(通常是
ReadHalf0)的指针,只要当前的排序键小于第二个子数组(ReadHalf1)中当前元素的排序键,说明该元素已经处于正确的位置,不需要任何操作。 - 这部分元素我们直接跳过,无需交换,也无需复制,极大地节省了操作开销。
这个阶段的目标是 快速跳过那些已经有序、无需处理的部分,减少无谓的处理。
第二阶段:进行实际的归并处理
一旦找到了需要处理的位置,也就是出现 ReadHalf1 中的元素排序键小于当前 ReadHalf0 元素的情况,就开始归并处理:
- 从当前指针开始,对两个子数组进行比较;
- 把排序键更小的元素移动到目标位置;
- 如果移动发生在同一块内存区域(原地归并),还需要考虑避免覆盖问题;
- 所有参与交换的元素将被逐步写入最终排序完成的位置。
阶段设计的意义
- 第一阶段让我们可以跳过大量“已经排序好”的元素;
- 第二阶段才是对剩余真正无序部分的处理;
- 这种设计既提升了性能,也让整个归并逻辑更加清晰可控;
- 有助于后续实现“原地归并”或“部分内存复用”等高级优化策略。
通过这样的两阶段结构,我们能够更高效地处理大型数据集中的排序任务,避免无谓地打乱已有顺序,并为最终完成高效、正确的归并排序打下基础。
game_render_group.cpp:标注步骤
我们现在已经将归并排序的逻辑进一步拆解并明确化,可以分为两个清晰的步骤,并加以注释说明,以便理清整个算法的核心操作。
步骤一:寻找第一个乱序对
我们做的第一件事是:
- 从两个已经排好序的子序列中,第一个子序列的起始位置(
ReadHalf0)开始; - 依次比较
ReadHalf0和ReadHalf1所指向元素的SortKey; - 如果
ReadHalf0->SortKey < ReadHalf1->SortKey,说明该元素无需处理,已处于正确位置; - 此时可以将
ReadHalf0向前移动,继续对比下一个; - 这个过程会持续到找到第一个乱序的情况(即
ReadHalf0->SortKey > ReadHalf1->SortKey); - 如果在扫描过程中两个指针最终相遇(即
ReadHalf0 == ReadHalf1),说明两个子序列本身已经完全有序,归并完成,无需任何操作。
这个阶段的目的就是快速跳过前面已经排好序的部分,找到真正需要归并处理的起点。
步骤二:准备进行归并操作
在完成步骤一后,如果 ReadHalf0 和 ReadHalf1 没有相遇(说明仍有乱序段存在),则说明:
- 接下来的元素存在交错顺序,需要通过归并重新组织;
- 理论上此时我们应该处理
ReadHalf1所在的部分,将它们正确插入到ReadHalf0的区域; - 不过我们先不着急实施具体的插入或交换操作,因为还要进一步分析子数组的边界情况,以及交换后的稳定性和排序正确性。
在继续前,我们还知道:
- 当前算法设计下,两段子数组长度均大于1(至少为3个元素总数),因此不会出现某个子数组为空的特殊情况;
- 所以我们不需要对“空数组”或“未定义指针”做特殊保护逻辑;
- 可以专注于处理那些确实处于乱序关系的子元素。
通过这两个步骤的明确划分,我们在逻辑上实现了:
- 跳过无序部分,节省不必要的处理;
- 只处理真正需要归并的元素区域;
- 为接下来的原地归并和优化打好基础。
这种分阶段推进的方式,不仅提升了效率,也让整个算法的控制逻辑变得更清晰、可验证和可调试。后续可以在此基础上进一步补全“交换操作”的详细流程。

Blackboard:继续讲解下一个阶段
我们此时已经处理完了前段已排好序的部分,现在进入了关键阶段:需要对乱序段进行交换与归并操作。当前的逻辑和状态可以详细总结如下:
当前状态概述:
我们处于一个关键位置,满足以下条件:
- 前面的元素已经是正确顺序,无需再处理;
- 当前指针所指的
ReadHalf0和ReadHalf1所指元素出现乱序,即ReadHalf1->SortKey < ReadHalf0->SortKey; - 我们将执行一些“交换”操作,把
ReadHalf1中的元素依序插入ReadHalf0的位置,使整体重新恢复有序状态; - 会有一段连续的
ReadHalf1区域被插入进来,插入完成后,这些已经交换过来的值就是完全正确的顺序,不再需要处理。
缓冲区状态划分:
现在我们可以将整个数据缓冲区(buffer)逻辑上划分为三块:
- 第一区域:我们已经处理好的前半段,它们处于正确位置;
- 第二区域:经过交换操作后,从
ReadHalf1移动过来的部分,这些数据也是正确顺序; - 第三区域:剩下的还未处理的部分,即
ReadHalf1剩余数据和可能残余的ReadHalf0数据(如在插入过程中未能全部移动时留下的部分)。
这三部分的关系明确:
- 第一块在最前;
- 第二块是由
ReadHalf1向ReadHalf0插入后的数据; - 第三块是新的归并区域;
而新的“归并范围”就是我们当前的第二区域和第三区域之间——即我们下一步要继续做同样归并处理的目标区域。
栈的可能性与迭代归并:
当前的感觉是,我们可能需要用一个栈来追踪这些分段或交换区间,目的是记录处理过程中的“中间缓冲区状态”,便于递归或迭代地执行归并逻辑。
但实际上,也可能根本不需要显式栈。因为:
- 每一次归并后,新的“剩余段”依然是有序的两个段的组合;
- 所以我们完全可以只需更新指针,切换“当前归并缓冲区”指向新的两个子段;
- 接着重复上一个“查找乱序点+交换归并”的操作。
也就是说:我们只要不断地更新指针范围,重复同样的逻辑,每一步都把一部分“处理正确”,最终整段都会被逐步归并到正确顺序。
总结要点:
- 每一轮归并操作完成后,我们会留下一个处理完的块,以及两个新块;
- 这两个新块之间的相对顺序是已知的,仍可复用已有逻辑;
- 不需要递归、不需要复杂数据结构,只要不断切换当前归并段指针;
- 整个过程是逐步推进、原地处理的,每次都只处理当前最前端的无序部分;
- 所有“交换”过来的元素,顺序已经保证,不需重复检查或处理。
这是一种分段式、增量式的原地归并策略,思路清晰,结构紧凑,处理逻辑复用性强,同时具备良好的可维护性与执行效率。下一步可以具体实现循环逻辑与指针推进条件。
game_render_group.cpp:第二步 - 交换尽可能多的元素
我们现在进入了具体的交换和比较阶段,目标是将两个缓冲区中的数据原地归并为一个有序序列。下面是这一部分的详细逻辑与处理方式总结:
总体目标:
我们有两个正在读取的指针,分别是 ReadHalf0 和 ReadHalf1,当前要完成的任务是在保证顺序的前提下,将 ReadHalf1 中应排在 ReadHalf0 前的元素“插入”进来,实现原地归并。
关键点分析:
-
三段结构的背景
当前逻辑中我们正在归并处理的,是处于两个有序段之间的部分数据。这两段可以看作是两个“缓冲区”或“子数组”。 -
比较对象的选择
- 我们需要一个“当前比较目标”,即
compare_with,用来确定当前ReadHalf1指向的元素是否应该移动到ReadHalf0的位置。 - 这个比较目标最开始是当前的
ReadHalf0所指的元素。
- 我们需要一个“当前比较目标”,即
-
首次交换逻辑
- 一旦发现
ReadHalf1中的元素比compare_with小(说明顺序错了),就执行交换; - 完成第一次交换后,原来的
ReadHalf1值已被置入正确位置,compare_with也应更新为该位置新的值。
- 一旦发现
-
后续循环推进
- 只要
ReadHalf1还没到末尾,并且继续存在满足条件(顺序错位)的数据,就不断地推进ReadHalf1; - 每次推进都意味着一个更小的元素被“放入”前面,构建起了一个新的有序段;
- 在这个过程中,
ReadHalf0也跟着前进,因为被写入了新值。
- 只要
写指针与读指针分离的必要性:
虽然从逻辑上我们是“交换”了两个位置的值,但为了避免在原地修改时破坏数据顺序,这里引入了“写指针”概念。也就是说:
ReadHalf1是读取插入值的指针;write_half_0(也就是新的ReadHalf0)是我们实际写入的目标位置;- 同时,我们维护一个
compare_with元素,作为接下来所有比较的基准。
替代思路:比较值缓存,避免频繁交换
在进一步思考后,发现可以优化逻辑为:
- 将
compare_with的值缓存; - 不用每次都交换数据,而是通过缓存值进行一次性判断,直接决定哪些值应写入;
- 因此,可以实现更加流畅的、线性推进式的归并处理。
特殊情况处理:
- 当
ReadHalf1遇到数组末尾:说明没有更多数据需要处理,可以直接退出; - 是否需要稳定排序:
- 在目前讨论中,排序是否稳定并不重要;
- 即对于
SortKey相同的情况,不强求原始顺序保持。
总结:
这一部分的归并过程核心是:
- 用缓存的方式记录当前比较值;
- 双指针同步推进;
- 原地归并无需复杂的数据结构;
- 如果提前遇到顺序正确的段,跳过;
- 若顺序错位则通过“逻辑交换”实现前插。
整个归并过程,是自适应推进、比较驱动、以写为主导的过程。我们通过灵活地推进两个指针,实现了一种无需开辟额外内存空间的原地有序归并策略。这种方法不仅高效,而且结构简洁,适合在数据交换与合并操作中复用。

Blackboard:绘制当前的情况
我们当前所处的位置,是对一段数据进行原地编号排序(numbered sort in-place)的过程中,进入了更复杂但也更有趣的一步。以下是这一部分内容的详细中文总结:
背景回顾:
我们前面完成了以下几个阶段:
- 跳过已排序部分:先找出数组中前面已经按顺序排列好的部分,直接跳过,不做处理;
- 处理乱序起点:接下来遇到乱序元素,我们开始对两个子序列进行原地归并。
现在进入到如下的更复杂情形:
当前处理状态:
我们现在手头上有以下几个部分:
- half0 的前半部分:已经在正确的位置上,无需变动;
- 当前交换产生的部分(称为“中间已交换部分”):
- 为了让部分元素归位,我们将 half1 中的一些较小元素插入到了 half0 的后面;
- 这些位置上的原始元素被交换了出去,形成了一小段新的有序序列;
- half0 的剩余部分:还未参与归并、仍需处理的元素;
- half1 的剩余部分:在归并过程中未被插入的元素。
操作逻辑:
- 暂存交换前的值:当我们决定开始归并某个位置的值时,首先将当前值暂存起来;
- 循环交换推进归并:
- 每次比较后发现需要归并,就执行交换操作;
- 即:当前 half1 的值插入前面,half0 原来的值被挤出,后续将被继续处理;
- 判断终止条件:
- 一旦 half1 中的值不再小于比较目标(compare_with),说明归并阶段到此为止;
- 或者 half1 数据用尽,同样意味着当前归并阶段结束。
当前的新挑战:
由于归并过程中插入了 half1 的一部分元素,原始的 half0 后段数据被挤出,整个数据结构现在变成了如下几个逻辑“缓冲区”:
- half0 原本的前段(不动)
- half1 插入后形成的新段(已交换区)
- half0 的剩余段
- half1 的剩余段
以上四段数据中,第1段、第2段已经有序,第3段、第4段也各自有序,但它们之间尚未完成归并。
下一步思考:
现在的任务是将 第3段和第2段+第4段进行合并,具体操作步骤包括:
- 把第3段的数据“覆盖性写入”第2段区域;
- 后面第4段的数据则随着归并过程向后推移;
- 重要的是,我们希望不借助额外内存,完成整个过程的原地排序。
难点与不确定性:
- 这种多段数据的原地归并存在指针操作和数据覆盖的问题;
- 要实现这种“边合并边覆盖边推移”的逻辑,需要特别细致地管理读写指针和中间缓存;
- 目前我们并不确定能否完成,但希望通过推导而不是直接查找答案,尽力找出是否存在一种可行的算法路径。
总结:
当前阶段,我们面对的是一种典型的归并排序中的“原地处理”问题,已经进入较复杂的多段有序数据合并阶段。我们目前采取的策略是:
- 将每一步推进的交换暂存;
- 多段缓冲区之间通过指针推进实现归并;
- 在不借助额外内存的情况下,尝试找出一种合理的推进合并方式;
- 此外,也在探索是否需要额外的栈结构来记录归并推进状态。
这一过程本质上是对**原地归并排序(in-place merge sort)**可行性的深度实验。我们目前并不确定该算法是否存在或高效,但会继续尝试推理和构造,直到确认是否可行。
game_render_group.cpp:第三步 - 将交换的Half0元素重新交换回去
我们当前已经完成了前两个步骤:
- 跳过已排序的前缀;
- 对发现的乱序片段尽可能多地进行交换操作,确保前面尽量恢复有序状态。
接下来进入的是 第 3 步:处理交换后留下的“三个缓冲区”的复杂局面,以下是对该部分内容的详细中文总结:
当前状态概览:
经过之前的操作,现在我们的数组被逻辑划分成了三个缓冲区(buffer):
- 已排序缓冲区:这是原始 half0 前部,完全有序,不需要再处理;
- 中间交换缓冲区:这部分由 half1 中较小的元素插入原 half0 中形成,之前的 half0 元素被“挤出”到了后方。它是从 half1 “借入”元素到 half0 所产生的新段;
- 待归并缓冲区:由 half0 和 half1 的剩余部分组成,两部分仍需归并,当前归并目标是把这两部分数据合并到中间交换缓冲区的位置上。
这些缓冲区的结构大致如下:
[ 已排序段 ] [ 中间交换段 ] [ half0 剩余部分 ] [ half1 剩余部分 ]
关键推理与目标:
- 中间交换段的插入操作是对 half0 的一次“替换性”归并,现在我们必须将原 half0 剩余的部分“归并回去”;
- 此操作必须在原地完成,不能借助额外内存空间;
- 当前指针
read_half0,read_half1,swap_read,swap_end等需要被重新组织,以在这个复杂状态下协调数据归位; - 最终目标:让中间交换段、half0 剩余段、half1 剩余段之间合并成一个有序段。
实际操作逻辑:
我们将要执行如下几步:
- 定义范围:
swap_read指向中间交换段的起始(来自 half1 的交换元素);swap_end是该段的终止位置(read_half1指针所在位置);
- 归并处理:
- 用
swap_read遍历原 half1 中被交换到中间缓冲区的段; - 将它们逐个归并回 half0 的剩余部分中,归并后再写入中间缓冲区;
- 用
- 条件判断:
- 如果
read_half1已到达末尾,说明 half1 的数据已处理完,此时只需逆向地将中间交换段和 half0 剩余段进行归并; - 否则还需继续考虑 read_half1 的数据并做出判断是否继续归并。
- 如果
辅助措施与建议:
- 在这个阶段,我们建议构造一个明确的测试数据(例如 1 到 8 的数字),可视化调试排序过程;
- 在调试中观察每一步指针的推进与交换,验证逻辑是否符合预期;
- 把当前归并逻辑抽象成函数有助于递归调用和局部调试,后续可能需要反复进入类似阶段。
下一步展望:
我们接下来要进行的是:
- 将 swap_read 到 swap_end 之间的部分(即交换段),根据 half0 剩余和 half1 剩余继续合并;
- 最终形成一个连续、排序良好的段落,作为整体归并排序中的一部分;
- 由于每一步都可能会再次产生新的“交换段”,整个过程极有可能是递归调用的,因此后续代码架构也需要支持递归处理。
总结:
本阶段我们面对的是归并排序中最复杂的环节之一 —— 在原地进行多段数据归并,且需要处理数据结构“交换后再归并”的非对称性。
我们已经完成了将 half1 中较小部分插入 half0 的操作,当前任务是:
- 理清缓冲段的逻辑结构;
- 使用指针操作完成下一步的归并;
- 保证整个操作始终在原数组空间内完成。
接下来的挑战是把剩余数据继续合并进交换段,逐步推进整体排序的完成。这是原地归并排序能否成功实现的关键一环。

Blackboard:重新排列条目
我们当前面临的局面是,我们已经完成了一个从 half1 中提取元素并将其插入 half0 的过程。原本 half0 的那部分内容被“挤出”并移动到了数组的某个后部位置。
当前数组状态分析:
- 原先在 half0 中的一段元素,已经被 half1 中的新元素替换了;
- 被替换出来的 half0 段目前临时存放在数组的后部;
- half1 中参与替换的部分已移动到前部;
- 也就是说:原 half0 中的一段内容被转移出去了,取而代之的是 half1 中的一段数据。
接下来要做的事情:
- 将被挤出去的 half0 段放回原来的位置;
- 同时,需要将替换它的 half1 内容移动到后方;
- 整体是一个复杂的“互换段落”操作,两个区域需要在内存中交换位置;
- 这操作不仅复杂,还必须做到“原地”完成,即不使用额外的缓冲区。
这就相当于一个比较棘手的内存块互换操作,我们必须将某段元素放到前面,同时将另一段元素往后“冒泡式”移动。
操作难点与策略:
- 这是归并排序中最棘手的部分,尤其是在不允许额外空间的条件下;
- 好消息是:这种类型的操作通常在实现阶段会看起来非常混乱,但一旦弄清楚之后,它的逻辑可以显著简化;
- 所以尽管当前状态令人头大,但我们不应该过早放弃,因为很可能再推进一点,就能看到清晰的合并结构;
- 经常会出现一种情况:当你写完并跑通一个复杂逻辑后,突然发现其中的一些路径是可以合并、提取甚至彻底去掉的。
特殊情况优化判断:
- 如果此时
read_half1 == end,说明 half1 中的数据已经处理完毕; - 这种情况下,我们只需要把之前挤出去的 half0 内容再移回原来的区域;
- 不需要再做三段合并,仅仅是把半段挪动回来即可;
- 所以这一种情况的逻辑明显更简单。
正常情况的三段合并策略:
当 half1 还有剩余数据时,我们会有如下三段需要处理:
- 从 half0 被替换出去的那段;
- half0 剩余尚未处理的段;
- half1 中剩余的段。
我们需要把这三段数据,合并成一个新的有序区间,并原地写入原先 half0 的位置。
实际合并策略推演:
- 初始时我们需要使用多个指针分别指向三个缓冲区的开始;
- 比较三个位置上的数据,每次选择最小的一个写入目标位置;
- 然后推进对应的指针;
- 重复此过程直到所有三段都被完全合并进目标区域;
- 在这过程中要特别小心指针之间的边界判断,防止越界;
- 一旦某个缓冲段的数据处理完,就只需要继续归并剩余的两段,直到全部完成。
后续的思考:
- 目前我们正处于归并排序实现中的“最难”阶段;
- 但不要因此沮丧,因为一旦我们理清这三段如何合并、如何交换、如何平衡指针关系之后,整个排序逻辑就会趋于简化;
- 此外,通过构造适当的测试样例(例如升序数组 1-8),我们可以更清晰地观察指针移动与合并过程;
- 未来甚至可能优化 swap 策略,使得整个过程更高效、更容易实现。
总结:
我们现在的任务是执行一个复杂的“原地区块互换 + 三段合并”操作,用以还原并完成 half0 的合并过程。这个过程困难且容易混淆,但并非不可行。通过清晰地划分数据区段、合理管理指针与边界条件,我们可以完成这一最复杂的排序阶段。同时,一旦实现成功,未来有机会进一步简化并优化整个流程。

Blackboard:考虑如何交换这些块的顺序
我们当前遇到的难题是需要对已经交换的两个数据块进行位置上的整体调换,以还原出正确的排序顺序。以下是对当前问题的详细整理与深入分析:
当前状态
我们处理的是归并排序中的中间阶段,具体是在两个半段 half0 和 half1 之间进行就地合并(不借助额外空间):
- 假设我们有一个缓冲区,
half marker标记了一半的位置; - 我们已将 half0 的一部分全部交换了出去;
- 此时处于数组前部的是 half1 中被提前交换出来的部分;
- 被挤出去的 half0 的部分现在处在数组较后的位置。
换句话说,我们此时的数据状态是:
[ half1的一段 | half0剩余部分 ]
但我们真正想要的是:
[ half0剩余部分 | half1的一段 ]
这两个段需要整体对调顺序。
面临的问题
为了实现顺序调换,我们需要将这两个段的位置整体互换,但问题随之而来:
- 若两个段长度不同(这是普遍情况),在实际交换过程中:
- 每一次把前段的一项交换到后段的正确位置时;
- 后段的一项也会被交换出来,但它却被错误地放到了前段;
- 最终导致我们陷入“不断修复被破坏结构”的循环。
这就意味着:每一次交换都会带来新的不一致,导致整体需要 O(n) 次交换才能完成重组,这是比较昂贵的。
推演例子(抽象):
假设我们有两个区间 A 和 B,要将它们顺序对调:
当前: [ AAAAA | BBB ]
目标: [ BBB | AAAAA ]
哪怕我们从后往前挪动,或者试图“就地旋转”,都需要频繁交换两段的元素,而且每次交换都涉及到中间缓冲(临时存放),在没有辅助空间的前提下:
- 把 A 挪到后面,每次都要牺牲掉一个 B;
- 把 B 挪到前面,又会破坏 A 的剩余排列;
- 除非完全“旋转整个中间区域”,否则无法避免每次交换所带来的中间污染;
- 而“就地旋转”恰恰就是 O(n) 操作,避免不了。
对策略的反思与取舍:
虽然这是 O(n) 的操作,但我们已经无法回避。除非提前在交换过程中,使用更复杂的策略(例如循环旋转、缓冲优化、反复逆转等)提前处理好次序,否则就得接受这种开销。
不过有几点思考也提了出来:
-
是否可以 smarter 地选择什么时候交换、怎么交换?
比如我们是不是在 earlier stage 时就能发现这种对调的需求,提前避免? -
是否可以用更 clever 的方式合并结构?
比如利用逆序拼接,然后反转? -
是否每次归并都一定要处理这么复杂的结构?
如果能在初期就确定部分顺序无需调整,也许可以跳过?
最终决定:
目前,我们采取最直接的方案:接受 O(n) 的就地对调开销,将 half1 提前交换出来的部分移动回去,将原本被挤出的 half0 部分移回来,完成整体顺序修复。
具体方式如下:
- 设立两个指针:一个指向 half1(交换后在前面的位置),一个指向 half0(被推到后面的位置);
- 持续执行 swap 操作,直到两个段完全调换位置;
- 代价虽高,但在当前结构下已是最直接、最实用的方式;
- 后续如果能通过算法优化减少这种情况发生频率,就可以整体提升效率。
总结:
我们遇到了归并排序中最麻烦的一种结构:两个不同大小的区间,需要在数组中交换其整体顺序。在不使用额外空间的限制下,这个过程不可避免是 O(n) 的复杂度。虽然当下方案显得“笨重”,但它是可行且必要的。我们也在探索是否有更聪明的预处理方式或合并策略,从而降低后续的代价。这是就地归并中的关键难点之一,也是真正需要深挖与测试的实现细节。

Blackboard:考虑这两种情况
我们当前的问题越来越复杂,进入了归并排序中最棘手的一种情况:两段不同大小的区域需要交换顺序,并且这种交换因为没有额外缓冲空间,导致处理过程非常“恶心”和低效。以下是这部分内容的详细中文总结:
问题本质
我们面对的是两块不等长的数据块需要整体交换位置的情况:
- 比如现在数组中有两个区域,分别是 A 和 B;
- 我们的目标是将 A 和 B 的顺序颠倒成 B、A;
- 但 A 和 B 的长度不相等,所以不能一次性“平移”;
- 而每次交换一个块的内容时,会不断引入新“未对齐”的区域,导致整个过程变成类似递归式的嵌套交换。
复杂性分析
- 如果我们先处理较大的块,比如先把较大的那段数据块搬到正确的位置;
- 然后再回过头去处理剩余的两块较小区域;
- 这就会变成递归式的数据交换:第一次搬动之后剩下两段错位的区域,又需要再交换顺序,依此类推。
每次“局部对调”都不可避免引入新问题,导致整个过程成本非常高——我们基本上会把所有时间都花在交换数据上。
实际上的困扰
- 这种交换非常不划算,尤其是在数组内部进行时,内存写操作频繁;
- 对于性能来说,这种情况是非常不优的;
- 换句话说:明明只是为了重排顺序,结果搞成了交换地狱;
- 我们甚至开始怀疑这是否“值得做”,因为处理时间远超其他操作的占比。
可能的出路
我们开始思考是否可以从更早的阶段入手,提前避免陷入这种多次交换的结构。设想:
- 如果我们在更早的时候,就选择“更聪明的交换顺序”;
- 比如在初次处理数据段落时,就避免生成需要后期大规模重新调整顺序的布局;
- 那么我们是否可以从根源上避免陷入递归式的交换逻辑?
思维发散
我们甚至产生了自我怀疑:是不是有些关键点我们漏掉了?比如:
- 如果我们在之前处理 half0 和 half1 时,
- 在“交换数据的位置”和“写入目标”之间做了更聪明的决策,
- 是否就不会在现在这个位置上需要如此费力地去交换这两个块?
这是非常关键的问题。
实际限制
- 虽然我们希望能找到更好的解决方式;
- 但由于当前已经陷入了这种“结构错位”的状态,哪怕回退重做也可能面临同样的问题;
- 除非我们能系统性地重新设计合并策略,否则这个递归交换的操作仍然是最直接且必须面对的步骤。
当前结论
目前看,我们只能暂时接受这种做法,哪怕它效率不高:
- 如果两个段落需要交换,且长度不同;
- 那么我们就按“先搬动大的”策略;
- 然后对剩下的部分递归执行“交换顺序”的操作;
- 尽管它会造成大量重复的写操作,但逻辑上是可行的。
未来如果有机会,可以进一步优化算法本身,从“根部”避免出现这种错位结构。
总结
当前问题本质是归并时两段不同长度数据的就地交换,它带来了递归嵌套式的复杂交换流程。我们尝试从逻辑上最小化交换次数,但目前仍未找到更优策略。当前策略虽然低效但逻辑清晰,是在限制条件下的无奈选择。进一步优化的方向在于:前期阶段更聪明地布局数据,避免陷入这种必须大量交换的困局。
Blackboard:走一遍发生的过程
我们尝试换一个角度重新思考这个问题,并推导出一个可能的优化策略,下面是详细中文总结:
当前的合并逻辑回顾
- 假设我们当前正在合并两个排序过的半区(两个有序的段),比如说
half0和half1; - 我们从左往右遍历;
- 如果当前元素已经在正确的位置(如第一个是
A),我们就跳过不处理; - 接着如果接下来的几个元素(例如
D、E、F)来自half1,而它们在排序中应该先于当前的B、C,那么就需要交换; - 我们执行交换,把
B、C放到后面,把D、E、F提前;
问题转折点
但当我们交换了之后,比如:
- 当前有两个区域:
- 一块是新换进来的
D、E、F; - 一块是原先还没换完的
G、H、I;
- 一块是新换进来的
- 然后我们遇到下一个
F,而它其实应该在G之前; - 这时候如果我们继续和
G比较,会发现顺序是合理的; - 但如果继续向后走,可能会再遇到问题。
于是,我们提出一个关键思路:
核心新思路:重置比较指针
我们意识到,在经历一次批量交换之后,我们可以将当前“比较目标”的指针回退到之前那个刚刚被交换的点,然后重新比较当前新换入的值和老的值。
举例:
- 初始比较目标是
D; - 我们从
half0中交换出B、C,换进D、E; - 接着遇到
F,这个值应该再次和D比较,而不是继续向前; - 因为我们知道:之前换进来的
D、E一定是比我们停止点F更早排序; - 所以我们只需要把比较指针 reset(重置)回停止交换的位置,然后继续比较。
判断是否成立
我们发现这个逻辑是合理的:
- 我们已经知道先前换进的值全部是比当前停止点小的;
- 所以当前停止点以后若继续换入,新的比较就应该从停止点重新开始;
- 换句话说:我们可以将交换作为一个独立阶段,然后重置指针回交换起始点,再继续合并;
- 这样既保留了排序逻辑,又避免了无意义的额外交换。
新流程总结
- 遍历两个有序段;
- 当某个元素顺序不对时:
- 执行一段批量交换;
- 交换完成后;
- 重置比较指针回交换开始的位置;
- 继续比较当前元素和新的目标,重复步骤;
- 最终完成排序合并。
优点
- 不再陷入复杂的“递归式区域交换”;
- 避免了大量无用的 swap 操作;
- 合并逻辑保持清晰;
- 实现起来简单而直观。
最终结论
我们发现,通过重置比较指针回先前交换的起点,我们可以大大简化排序合并过程,避免复杂又低效的递归交换结构。这是一次关键性思路突破,可能让整个合并逻辑更高效、更可控,是当前方案中非常值得采纳的优化策略。
game_render_group.cpp:直接将ReadHalf1设为InHalf1
我们正在读取指针的一半内容。从“read half one”来看,它只是再次等于“half one”,也就是说我们只是简单地赋值,没有做复杂的操作。

Blackboard:构建一个情况并查看会发生什么
我们正在仔细检查代码逻辑,反复确认实现方式是否正确。如果这个方案可行,那效果会非常惊人。于是我们构造了一个测试用例来验证思路的准确性。
我们设置了一串字符作为模拟输入,比如:a、b、c、d、e、f、g、h、i、j、k、l。我们跳过第一个元素 a,然后将 a 和 b 进行比较。a 更小,所以保留 a,指针向下移动到下一个位置。接着我们比较 d 和 b,发现 b 更小,因此执行替换操作,把 b 放到当前位置。
继续进行,我们用 c 和 d 比较,c 更小,同样进行替换,把 c 放到当前位置,d 往后移。然后我们比较 d 和 g,发现 d 更优,所以停止替换过程,并把指针回退到 d 的位置。
这时候我们的位置还在 f,我们接下来要比较的是 f 和 d。我们有一个假设是,在 d 之前的元素都已经被处理过,所以可以确定将 d 换回来是对的,但我们并不确定接下来的元素是否比当前的更小。也就是说,我们知道 d 是正确的选择,但无法确定下一个元素是否也比某个之前的元素更劣,这才是问题的关键。
由此我们意识到,我们确实能够确认某些元素是排在后面的,比如 d,但是无法对其它还未遍历的元素做出准确判断。因此我们在某个节点做了替换操作之后,后续操作可能因为缺乏上下文而出现逻辑问题。
所以我们进一步思考,在处理当前位置时,必须比较两个关键的对象:一个是当前元素,另一个是最近交换过来的元素。只要我们知道需要交换谁进来,那么就能继续推进算法。
打个比方,如果我们在当前位置把 d 换进来,把 f 放到 d 原来的位置,然后继续向下扫描,我们能确认在再次遇到之前交换过的元素前,会先处理所有后续的新元素。也就是说,我们不会提前回头,除非已经完成了所有向后的遍历。
所以从逻辑上讲,我们只需要一个“交换基准指针”的栈结构,记录每一次交换的起点,来追踪交换路径和依赖关系。只要有这个栈,我们就能继续操作而不迷失位置。
最终我们决定下一步行动是构建这个栈结构并验证整体逻辑的正确性,以解决当前的问题并确保遍历的准确性。
Blackboard:关于需要存储那些回指针的观点
计划在周一再尝试这个方案。我们认为我们所需要的只是记住当前的栈指针,并且仅需要为此分配空间来存储它。虽然我们只需要存储这个回溯指针,但是有人可能会觉得这是“作弊”,因为这意味着在某种程度上我们已经在使用额外的存储空间。
我们也考虑过,如果能找到一种巧妙的方式,避免显式地存储这个回溯指针,那就能避免使用额外的空间。然而,目前还没有想到如何做到这一点,因为无法预知我们需要放入多少个元素。
因此,我们认为如果总是需要在某个地方存储回溯指针,可能就无法做到原地操作了。每次切换时,我们必须记住这个回溯指针的位置,所以如果能构造出一个完美的“乒乓”结构,还是存在问题。换句话说,原地操作似乎是行不通的。
基于目前的分析,我们推测可能没有办法原地解决问题,虽然这个预测并不十分有力,因为我们没有深入探讨过,也没有做出严格的证明。因此,可能我们还缺少某个巧妙的思路,能够让我们找到更高效的解决方案。不过,至少目前我们无法想到这种方法。
前面部分看的一脸懵逼
game_render_group.cpp:让MergeSort使用一些临时存储,并重写SortEntries以使用该存储
我们决定在做归并排序时需要一些临时存储空间。为了简单起见,我们可以采用一种比较简陋的方法,直接创建一个临时指针 temp 来存储数据。由于时间有限,我们选择按照最基础的方式来实现,虽然这不是最优的方案。
我们先定义一个临时存储空间 temp,然后在归并排序过程中使用它。具体实现如下:我们创建两个循环,并使用两个输入数据流(如 half0 和 half1),我们比较这两个数据流中的元素,将较小的元素存放在输出位置 out。如果一个数据流已经为空,我们会直接从另一个数据流中取值,直到所有数据都被处理完毕。最终,我们将所有元素存放到 temp 中,然后将它们复制回原始的排序数组中。
这种方法虽然简单,但在理论上是可行的。我们可以先完成这一最简单的版本,然后再考虑更优化的方案。如果采用更聪明的缓冲策略,例如“乒乓式”交换(ping-pong buffering),就可以避免将数据复制回原数组,从而减少不必要的操作。
接下来,我们要确认是否有足够的空间来执行排序。我们检查了之前的代码,发现实际上我们并不再需要“排序空间”(sort space),因此不需要再为临时数据分配额外的空间。我们只需在调用排序函数之前,为 temp 分配合适大小的空间。
我们通过调用 SortEntries 函数来进行排序,这时只需要传入合适的临时存储空间即可,不再需要之前的 sort space 处理。为了确保一切顺利进行,我们会在代码中加入一些断言,确保 temp 和输入数据流的内容正确。
总之,当前的解决方案是通过创建临时存储来实现归并排序,后续我们可以根据需要进一步优化和调整。


Debugger:在修复测试并查看排序正确性之前触发断言
我们再次运行代码并观察其行为,按理说如果排序出错,应该会触发断言。起初我们遇到了一个断言条件的问题,原本设置成“必须大于1”,后来意识到其实只需要“大于等于1”即可,修正后程序正常运行,没有出现断言错误,说明当前逻辑没有问题。
虽然我们最终未能找到原地完成归并排序的方法,感到有些遗憾,但当前的实现是合理的。我们暂时没有更好的思路,也还不确定是否想去查阅资料得到“剧透”,希望能自己思考出解决方案。与此同时也意识到,可能有人已经查过了相关信息,因此我们决定先不去看外部反馈。
基于目前的分析,我们猜测归并排序无法真正原地完成。后来查阅资料,发现我们猜测大致正确:如果想在不使用额外空间的情况下实现归并排序,确实需要更多复杂的操作。
例如,看到某些学校教材或技术资料中提到的“原地归并排序”方案,通常都涉及到复杂的区块复制(如整块数据上移等操作)。这类方法基本都涉及到临时空间的处理,并不是纯粹意义上的原地操作。也就是说,确实没有一个简单又彻底“就地完成”的解决方法。
因此,得出结论:如果不能非常清晰地做到原地操作,那么使用额外的临时存储空间是更现实的选择。而且,从性能角度来看,使用额外内存来执行“乒乓式”交换其实会更快,也能使整个排序过程更简洁。
虽然未能设计出一个彻底原地的方案,但考虑到已有的方法都需要进行块级数据移动,我们对现有的设计和推理结果感到满意。接下来可以安心使用更高效的带临时空间的排序方式,完全避免那些复杂的原地处理逻辑。
总的来说,虽然略有遗憾,但现有方案简单、清晰、性能更佳,已经是一个很不错的解决方式。


Q&A
我没有查过,所以可能不行,但我想到的解决方案是:每当从上半部分选择一个元素时,将其放置在下半部分的合适位置,并将上半部分的元素下移以填补选择的元素占据的位置,然后将未选择的下半部分元素存储在上半部分的末尾空位,设置下半部分的读取指针指向该末尾部分。对此有何看法?
我们思考了一种可能的做法:每当从上半部分选择了一个元素时,就把它插入到下半部分相应的位置,然后将上半部分整体向下移动,以填补这个元素离开后留下的空位,同时将被替换出来的下半部分元素移动到上半部分的末尾。
虽然这个思路在理论上看起来有可能实现归并排序的“原地”处理,但我们的直觉是:这太麻烦了。原因在于这个方法涉及大量的区块复制操作(block copy),每次调整都要对整个上半部分做移动操作,开销非常大。
与其进行这种高代价的数据搬移,不如直接使用额外的临时空间。因为当操作复杂度已经上升到这种程度时,我们就已经付出了比使用临时空间更多的处理成本,效率反而更低。
因此我们认为,这种策略虽然在概念上是一种原地思路的尝试,但实际执行中代价过高,不具备实用性。相比之下,使用临时空间进行缓冲、交换和拷贝,反而更加清晰、高效、易于实现,是更值得采用的方案。
离题了,不过我在论坛发了一篇关于TSP中2(2n)论证的帖子,如果你有兴趣可以看看
我们提到一个题外话,有人在论坛上发布了关于旅行商问题(TSP)中“2 的 2 的 N 次方”复杂度相关的讨论帖,我们表示了兴趣,并打算在周末抽时间去看一下这个帖子。
这其中提到的问题可能涉及到对 TSP 算法复杂度的分析,尤其是当状态空间呈指数级增长时的行为,例如在处理所有路径组合时,状态可能达到 2(2N) 级别。我们对这种指数爆炸的问题产生了兴趣,准备稍后深入研究。
虽然不是当前正在做的事情的主题,但这个问题引发了我们对组合优化、算法极限和复杂度理论的关注,未来可能会继续跟进这个方向。
维基百科上的一个variants称只需要一个槽位+O(1)的额外指针
我们讨论了 Wikipedia 中关于归并排序的一种变体实现,据说这种实现只需要一个额外槽位加上一行额外的指针即可完成原地排序。
我们分析认为,确实,如果使用块复制(block copy)技术,将上半部分整体下移,就可以实现原地归并操作。比如说,我们不进行常规的元素交换,而是查找当前元素应该插入的位置,然后将该位置之后的所有元素整体向后移动一个位置,再插入目标元素。这种做法本质上类似于“插入排序”。
从理论上讲,这样的做法可以原地完成归并排序,不需要额外空间,但其代价是操作代价极高。每一次插入都可能导致整个数组的部分元素移动,带来 O(n²) 级别的最坏情况性能。这就导致虽然空间上满足“原地”,但时间复杂度和效率极差,实际上非常不实用。
我们原本希望能找到一种更聪明的做法,在不牺牲太多性能的前提下完成原地归并,但目前看起来暂时没有想到更好的方式。当然,也不排除未来能找到某种巧妙的方法,只是目前还没有明确的理论证明或实证方案表明这种做法是可行而且高效的。
如果之后突然想到某种更巧妙、节省空间和效率兼顾的方法,未来有机会还会继续尝试和实现。我们仍然对这个问题保持开放和探索的态度。
相关文章:
游戏引擎学习第233天
原地归并排序地方很蒙圈 game_render_group.cpp:注意当前的SortEntries函数是O(n^2),并引入一个提前退出的条件 其实我们不太讨论这些话题,因为我并没有深入研究过计算机科学,所以我也没有太多内容可以分享。但希望在过去几天里…...
卷积神经网络基础(二)
停更好久的卷积神经网络基础知识终于开始更新了哈哈,今天主要介绍的是误差反向传播法。 目录 一、计算图 1.1 用计算图求解 1.2 局部计算 1.3 为什么采用计算图 二、链式法则 2.1 计算图的反向传播 2.2 链式法则 2.3 链式法则和计算图 三、反向传播 3.1 …...
探索大语言模型(LLM):定义、发展、构建与应用
文章目录 引言大规模语言模型的基本概念大规模语言模型的发展历程1. 基础模型阶段(2018年至2021年)2. 能力探索阶段(2019年至2022年)3. 突破发展阶段(以2022年11月ChatGPT的发布为起点) 大规模语言模型的构…...

树莓派超全系列教程文档--(33)树莓派启动选项
树莓派启动选项 启动选项start_file ,fixup_filecmdlinekernelarm_64bitramfsfileramfsaddrinitramfsauto_initramfsdisable_poe_fandisable_splashenable_uartforce_eeprom_reados_prefixotg_mode (仅限Raspberry Pi 4)overlay_prefix配置属…...

PTA:模拟EXCEL排序
Excel可以对一组纪录按任意指定列排序。现请编写程序实现类似功能。 输入格式: 输入的第一行包含两个正整数 n (≤105) 和 c,其中 n 是纪录的条数,c 是指定排序的列号。之后有 n 行,每行包含一条学生纪录。每条学生纪录由学号(6…...

Python 爬虫解决 GBK乱码问题
文章目录 前言爬取初尝试与乱码问题编码知识科普UTF - 8GBKUnicode Python中的编码转换其他编码补充知识GBKGB18030GB2312UTF(UCS Transfer Format)Unicode 总结 前言 在Python爬虫的过程中,我尝试爬取一本小说,遇到GBK乱码问题&a…...

Scala与人工智能:融合多范式编程的AI开发利器
在人工智能(AI)技术飞速发展的今天,编程语言的选择直接影响着算法实现效率与系统可扩展性。Scala,作为一门融合面向对象(OOP)与函数式编程(FP)的多范式语言,凭借其独特的…...

解决echarts饼图label显示不全的问题
解决办法 添加如下配置: labelLayout: {hideOverlap: false},...

JCST 2025年 区块链论文 录用汇总
Conference:Journal of Computer Science and Technology (JCST) CCF level:CCF B Categories:交叉/综合/新兴 Year:2025(截止4.19) JCST 2024年 区块链论文 录用汇总 1 Title: An Understandable Cro…...
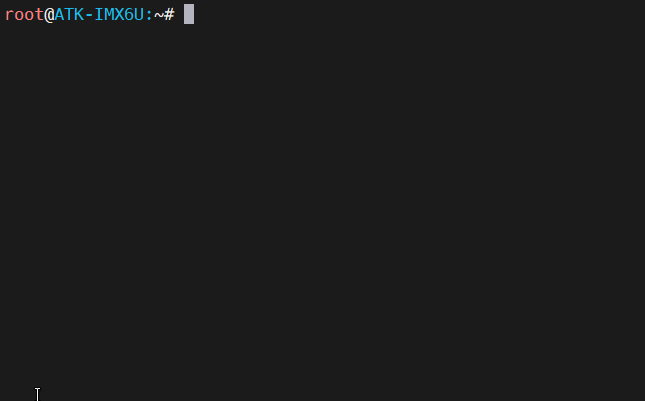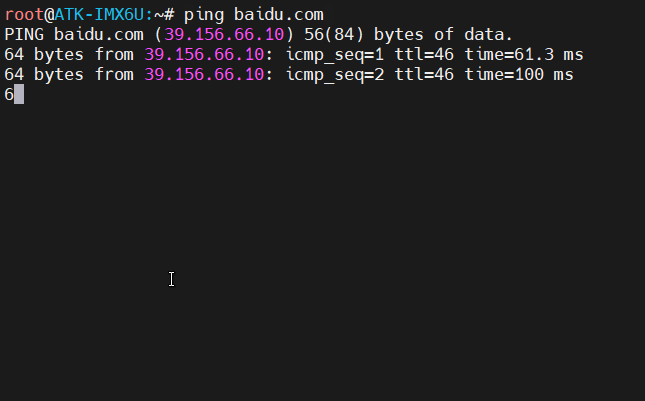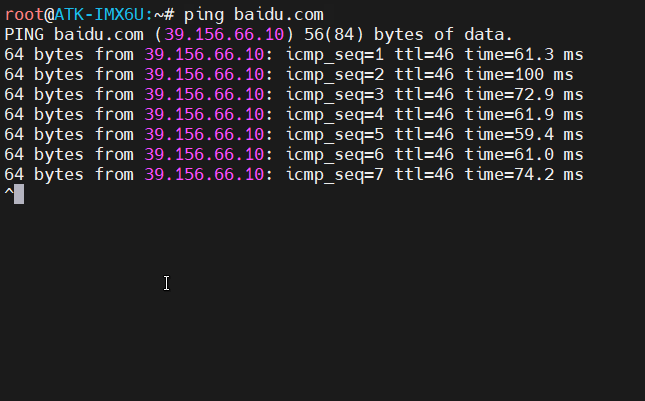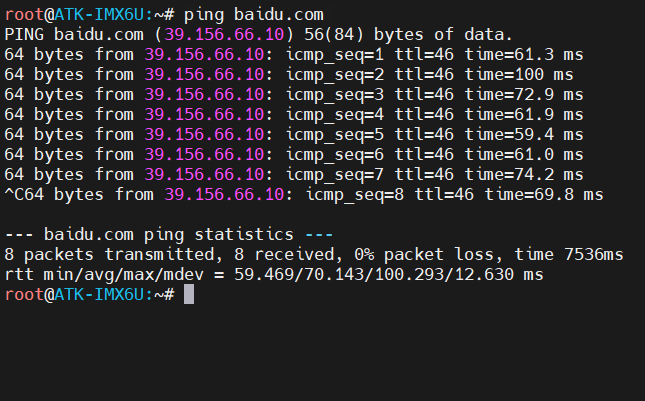
不带无线网卡的Linux开发板上网方法
I.MX6ULL通过网线上网 设置WLAN共享修改开发板的IP 在使用I.MX6ULL-MINI开发板学习Linux的时候,有时需要更新或者下载一些资源包,但是开发板本身是不带无线网卡或者WIFI芯片的,尝试使用网口连接笔记本,笔记本通过无线网卡连接WIFI…...
选择排序(简单选择排序、堆排序)
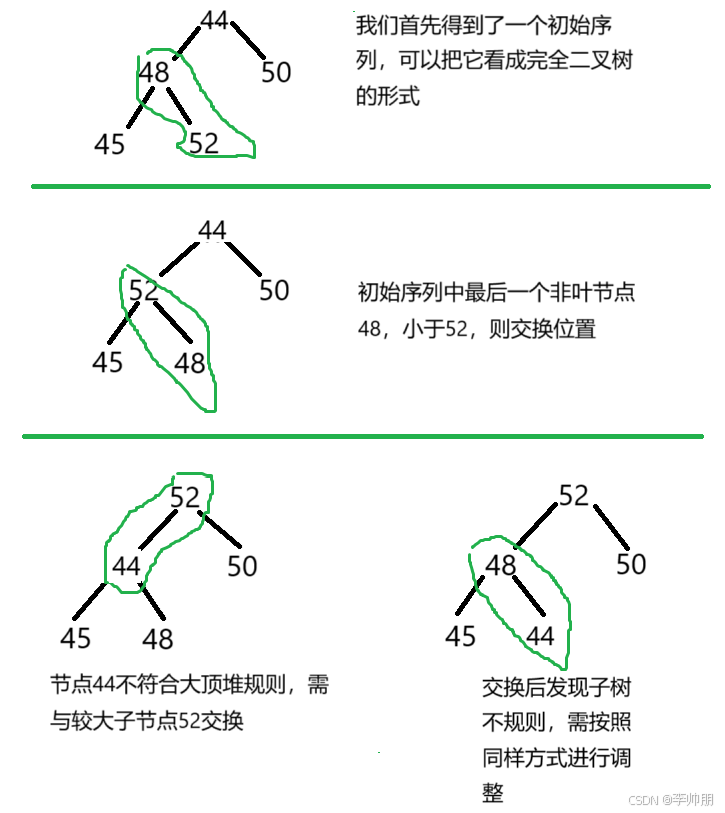
简单选择排序(Selection Sort) 1. 算法思想 它通过多次遍历数组,每次从未排序部分中选择最小(或最大)的元素,将其放到已排序部分的末尾(或开头),直到整个数组有序。 2.…...

velocity模板引擎
文章目录 学习链接一. velocity简介1. velocity简介2. 应用场景3. velocity 组成结构 二. 快速入门1. 需求分析2. 步骤分析3. 代码实现3.1 创建工程3.2 引入坐标3.3 编写模板3.4 输出结果示例1编写模板测试 示例2 4. 运行原理 三. 基础语法3.1 VTL介绍3.2 VTL注释3.2.1 语法3.2…...

word选中所有的表格——宏
Sub 选中所有表格()Dim aTable As TableApplication.ScreenUpdating FalseActiveDocument.DeleteAllEditableRanges wdEditorEveryoneFor Each aTable In ActiveDocument.TablesaTable.Range.Editors.Add wdEditorEveryoneNextActiveDocument.SelectAllEditableRanges wdEdito…...

13.第二阶段x64游戏实战-分析人物等级和升级经验
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 上一个内容:12.第二阶段x64游戏实战-远程调试 效果图: 如下图红框,…...

容器化-Docker-基础
一、Docker 核心概念 1、容器化技术的本质 Docker 是基于 Linux 内核的轻量级容器化技术,通过 Namespace 和 Cgroups 实现资源隔离与限制,将应用及其依赖封装成可移植的容器。与传统虚拟机(需模拟完整硬件层)不同,Docker 容器共享宿主机内核,启动时间以秒级计算,资源占…...
六边形棋盘格(Hexagonal Grids)的坐标
1. 二位坐标转六边形棋盘的方式 1-1这是“波动式”的 这种就是把【方格子坐标】“左右各错开半个格子”做到的 具体来说有如下几种情况 具体到庙算平台上,是很巧妙的用一个4位整数,前两位为x、后两位为y来进行表示 附上计算距离的代码 def get_hex_di…...

SICAR 标准 安全门锁操作箱 按钮和指示灯说明
1、安全门锁操作箱 2、按钮和指示灯说明 一、指示灯说明 红灯: 常亮:表示安全门已解锁;闪烁:表示安全门未复位;熄灭:表示安全门已复位。 黄灯: 常亮:表示处于维修模式。 绿灯&…...
Day10【基于encoder- decoder架构实现新闻文本摘要的提取】
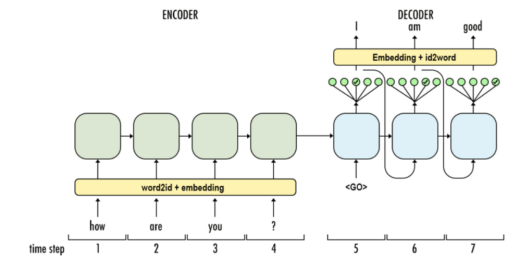
实现新闻文本摘要的提取 1. 概述与背景2.参数配置3.数据准备4.数据加载5.主程序6.预测评估7.生成效果8.总结 1. 概述与背景 新闻摘要生成是自然语言处理(NLP)中的一个重要任务,其目标是自动从长篇的新闻文章中提取出简洁、准确的摘要。近年来…...

【blender小技巧】使用blender的Cats Blender Plugin插件将3D人物模型快速绑定或者修复为标准的人形骨骼
文章目录 前言绑定或者修复人形骨骼1、下载模型2、导入模型到blender中3、删除无用的相机和灯光3、导出模型并在unity中使用 专栏推荐完结 前言 有时候我们下载的3D人物模型,可能不带骨骼信息,或者带一些错乱的骨骼信息。这时候我们就可以使用blender将…...
Linux——firewalld防火墙(笔记)
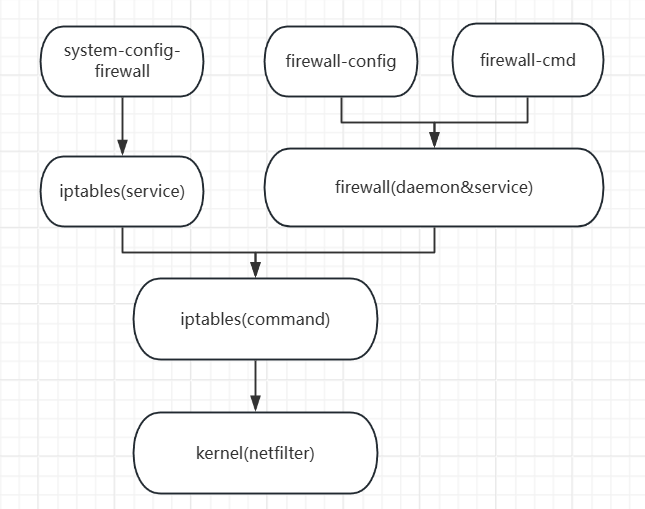
目录 一:Firewalld防火墙的概述 (1)firewalld简介 (2)firewalld&iptables的关系 (3)firewalld与iptables service的区别 1. 规则管理方式 2. 默认策略与设计逻辑 3. 配置文…...

《分布式软总线赋能老旧设备高效通信》
在数字化转型的浪潮中,分布式软总线技术成为实现设备互联互通的关键力量。然而,当面对大量老旧设备时,其性能受限的现状对分布式软总线提出了严峻挑战。如何在这些性能瓶颈下,让老旧设备实现高效连接与通信,是亟待解决…...
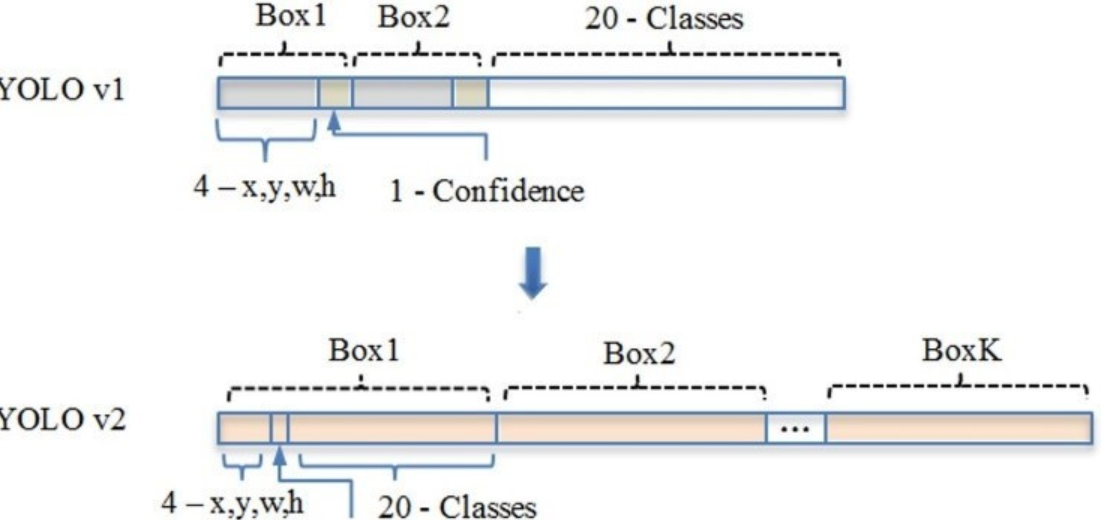
YOLO拓展-锚框(anchor box)详解
一.锚框(anchor box)概述 1.1什么是锚框 锚框就是一种进行预测的像素框,通过遍历输入图像上所有可能的像素框,然后选出正确的目标框,并对位置和大小进行调整就可以完成目标检测任务。 对于yolo锚框的建设须基于实际…...

GPU渲染阶段介绍+Shader基础结构实现
GPU是什么 (CPU)Center Processing Unit:逻辑编程 (GPU)Graphics Processing Unit:图形处理(矩阵运算,数据公式运算,光栅化) 渲染管线 渲染管线也称为渲染流水线&#x…...

第32讲:卫星遥感与深度学习融合 —— 让地球“读懂”算法的语言
目录 🔍 一、讲讲“遥感+深度学习”到底是干啥的? ✅ 能解决什么问题? 🧠 二、基础原理串讲:深度学习如何“看懂”遥感图? 🛰 遥感图像数据类型: 🧠 CNN的基本思路: 🧪 三、实战案例:用CNN对遥感图像做地类分类 📦 所需R包: 🗂️ 步骤一:构建训…...
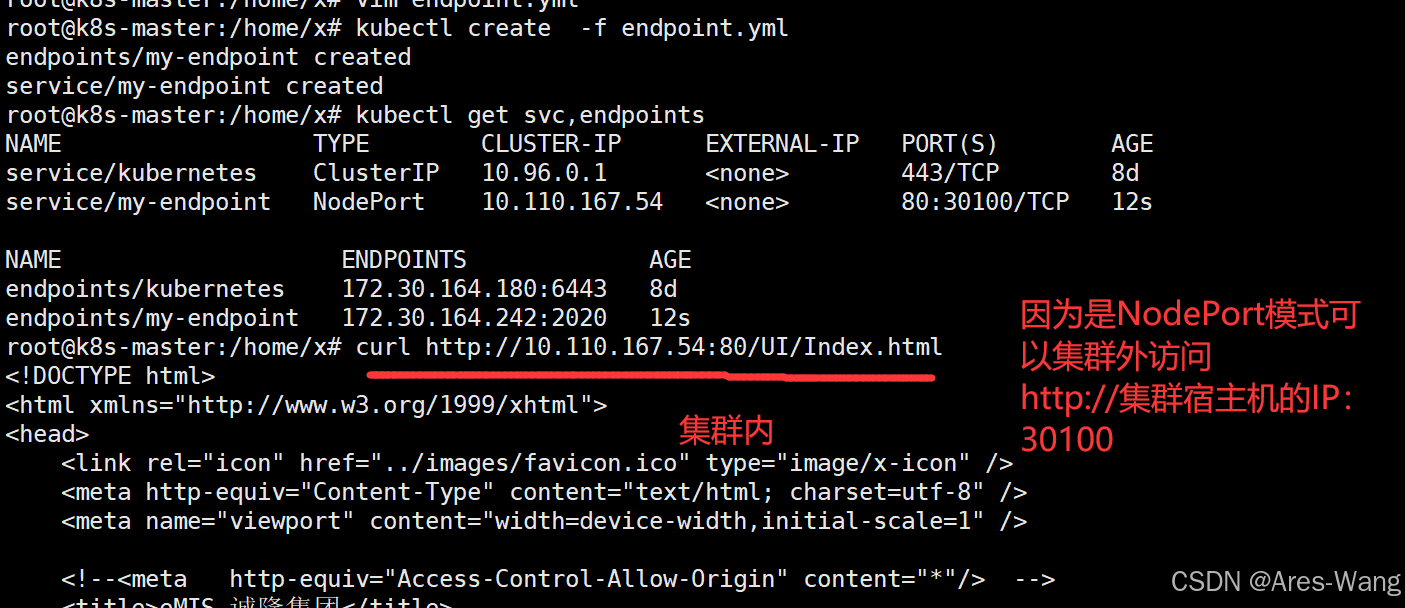
kubernetes》》k8s》》Service
Kubernetes 中的 Service 是用于暴露应用服务的核心抽象,为 Pod 提供稳定的访问入口、负载均衡和服务发现机制。Service在Kubernetes中代表了一组Pod的逻辑集合,通过创建一个Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址…...

多道程序和多任务操作系统区别
多道程序 vs. 多道任务:对比分析 ✅ 共同点 方面共同特征核心机制都依赖于进程/任务切换执行需求实现多个程序或任务"并发"执行系统支持都需要操作系统的支持(如调度算法、内存管理)本质目标提高资源利用率(CPU不空转…...

CMFA在自动驾驶中的应用案例
CMFA在自动驾驶中的典型应用案例 CMFA(Cross-Modal Feature Alignment)方法在自动驾驶领域有多个成功的应用场景,以下是几个典型案例: 1. 多模态3D目标检测 应用场景:车辆、行人、骑行者等交通参与者的精确检测 …...

已注册商标如何防止被不使用撤销!
近年来已注册商标被撤销越来越多,不乏著名企业或机构,普推知产商标老杨看到前一阵看到央视和百度等申请的商标也被申请撤销,连续三年不使用撤销也是正常的商标流程。 已注册商标被撤销普推老杨看到案例主要是集中在一些早期申请注册的好记的商…...

android 打包内容 安卓打包工具有哪些
Android ROM打包工具与技巧分享 eMMC存储与Android文件系统 eMMC作为手机和平板电脑的内嵌式存储器,因其集成了控制器并提供标准接口等优势,受到Android厂商青睐。采用eMMC存储的Android手机,其文件系统(system、data分区)通常采用ext4格式…...
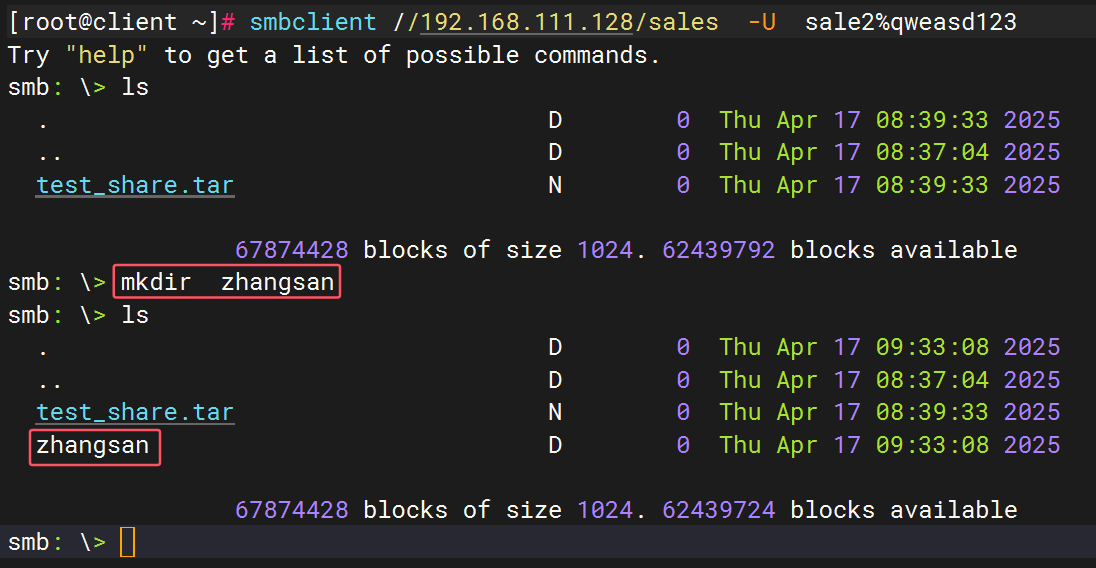
管理与维护samba服务器
允许 Linux、Unix 系统与 Windows 系统之间进行文件和打印机共享,使得不同操作系统的用户能够方便地访问和共享资源,就像在同一局域网中的 Windows 计算机之间共享资源一样。 server01安装Samba服务器 [rootserver ~]# rpm -qa | grep samba [rootserver…...