GPT-SoVITS 使用指南
一、简介
TTS(Text-to-Speech,文本转语音):是一种将文字转换为自然语音的技术,通过算法生成人类可听的语音输出,广泛应用于语音助手、无障碍服务、导航系统等场景。类似的还有SVC(歌声转换)、SVS(歌声合成)等。
GPT-SoVITS:是一个开源的TTS(文本到语音)项目,它是基于生成式预训练模型GPT(Generative Pre-trained Transformer)与语音克隆技术SoVITS(Speech-to-Video Voice Transformation System)结合的语音合成工具。这个项目允许用户仅通过少量的样本数据,例如1分钟的音频文件,就可以克隆声音。它支持将汉语、英语、日语三种语言的文本转为克隆声音,并且部署方便,训练速度快,效果显著。
项目地址:https://github.com/RVC-Boss/GPT-SoVITS
在线试用地址(各种游戏600多个角色):AI Hobbyist TTS
官方教程:GPT-SoVITS指南 · 语雀
二、入门指南
详细见官方教程:整合包教程 · 语雀
下载GPT-SoVITS:访问整合包及模型下载链接 · 语雀,下载整合包
解压缩:使用7-Zip解压缩压缩包
运行Web UI:双击go-webui.bat打开,不要以管理员身份运行!打开的bat不可以关闭!这个黑色的bat框就是控制台。
如下图所示,小黑框会显示网址并弹出网页,如果没有弹出网页可以复制http://localhost:9874/到浏览器打开

素材准备:我这里是从喜马拉雅下载的邓紫棋的声音日记。将其保存到本地目录。喜马拉雅-国内专业音频分享平台,随时随地,听我想听!
人声伴奏分离&去混响去延迟:使用UVR5工具处理原音频,如下图一点击“开启人声分离WebUI”后,会弹出下图二网页。
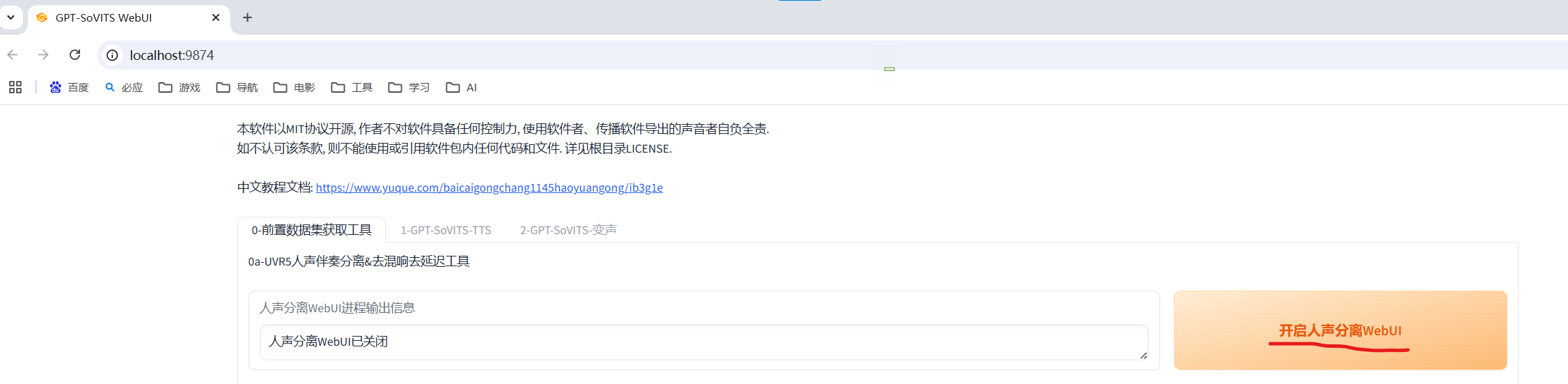
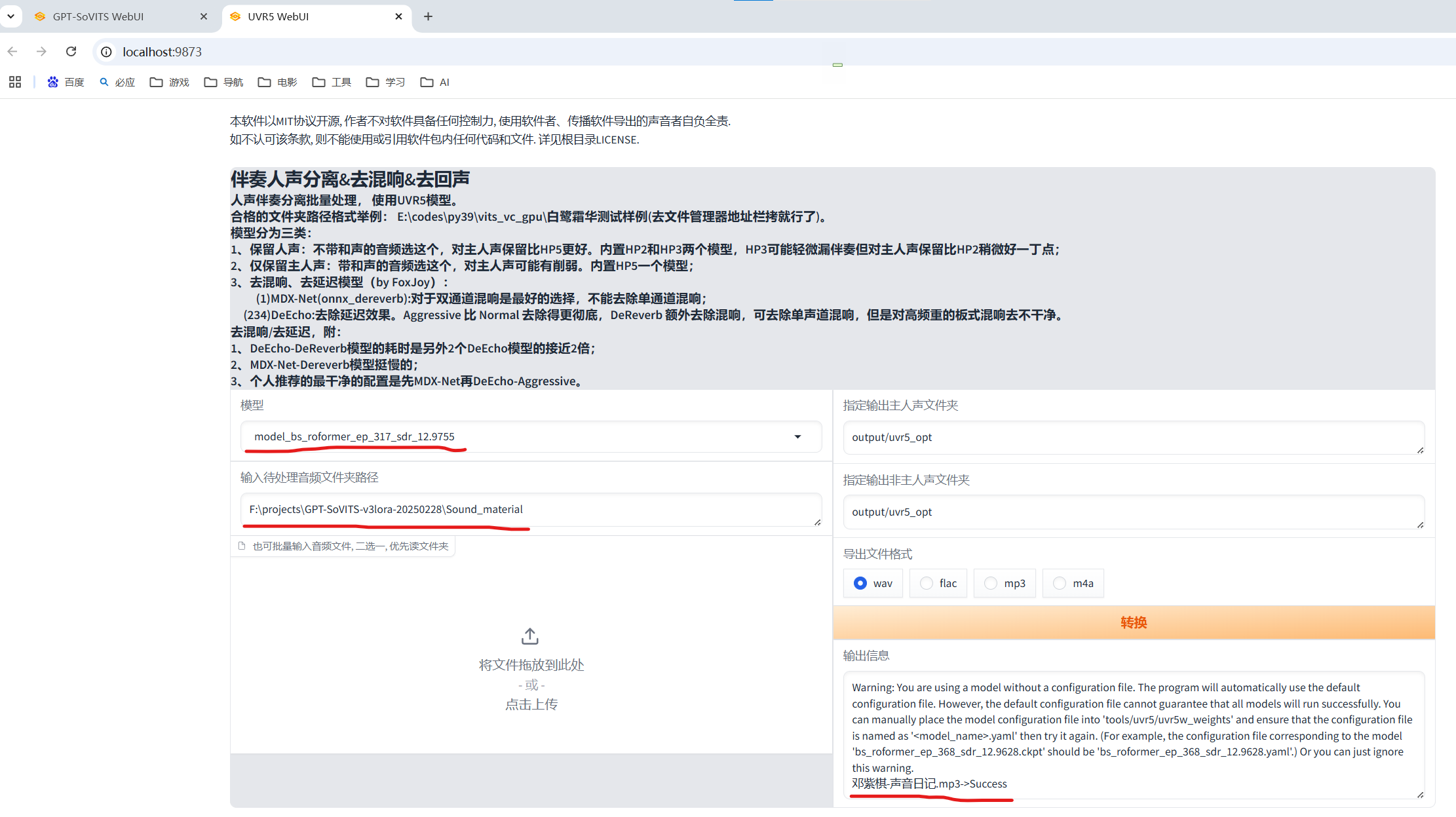
先用model_bs_roformer_ep_317_sdr_12.9755模型(已经是目前最好的模型)处理一遍(提取人声),然后将输出的干声音频再用onnx_dereverb最后用DeEcho-Aggressive(去混响),输出格式选wav。输出的文件默认在GPT-SoVITS-beta\output\uvr5_opt这个文件夹下。处理完的音频(vocal)的是人声,(instrument)是伴奏,(_vocal_main_vocal)的没混响的,(others)的是混响。(vocal)(_vocal_main_vocal)才是要用的文件,其他都可以删除。结束后记得到WebUI关闭UVR5节省显存。
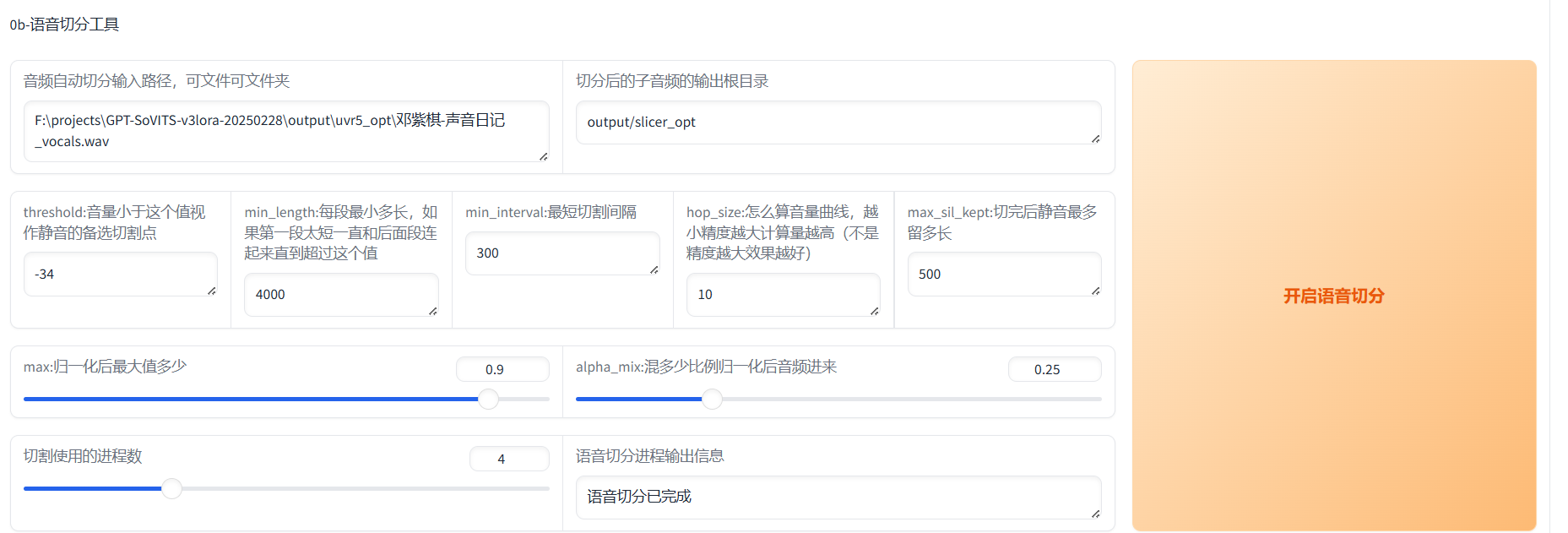
音频切割:作用是去除冗余部分(如静音、背景杂音),保留有效人声;分割语音段落,便于模型学习发音、语调等细节特征。
首先输入原音频的文件夹路径(不要有中文),如果刚刚经过了UVR5处理那么就是uvr5_opt这个文件夹。然后建议可以调整的参数有min_length、min_interval和max_sil_kept单位都是ms。min_length根据显存大小调整,显存越小调越小。min_interval根据音频的平均间隔调整,如果音频太密集可以适当调低。max_sil_kept会影响句子的连贯性,不同音频不同调整,不会调的话保持默认。其他参数不建议调整。点击开启语音切割,马上就切割好了。默认输出路径在output/slicer_opt。
音频降噪:可消除背景噪声(如杂音、电流声、环境音),保留纯净人声,并增强语音的清晰度。
如果你觉得你的音频足够清晰可以跳过这步(我这里下载的音频没杂音,跳过),降噪对音质的破坏挺大的,谨慎使用。输入刚才切割完音频的文件夹,默认是output/slicer_opt文件夹。然后点击开启语音降噪。默认输出路径在output/denoise_opt。

打标:打标就是给每个音频配上文字,这样才能让AI学习到每个字该怎么读。这里的标指的是标注。
如果你上一步切分了或者降噪了,那么已经自动帮你填充好路径了。然后选择达摩ASR或者fast whisper。达摩ASR只能用于识别汉语和粤语,效果也最好。fast whisper可以标注99种语言,是目前最好的英语和日语识别,模型尺寸选large,语种选auto自动。whisper可以选择精度,建议选float16,float16比float32快。然后点开始语音识别就好了,默认输出是output/asr_opt这个路径。
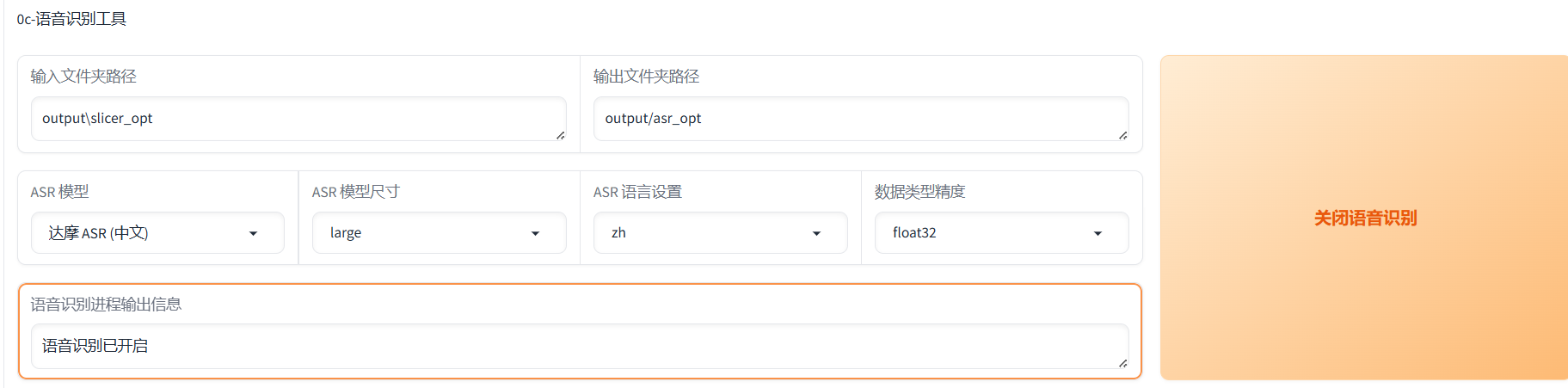
控制台的log如下,显示ASR任务完成就是成功了
校对标注:语音识别完成后,点击“开启音频标注WebUI”。这里会弹出SubFix操作界面(是一个专为轻松编辑与修改音频字幕而设计的Web工具。它使用户能够实时查看更改,并方便地合并、分割、删除和编辑音频的字幕。)

如下图所示,对语音识别出来的字幕进行手工校验修改
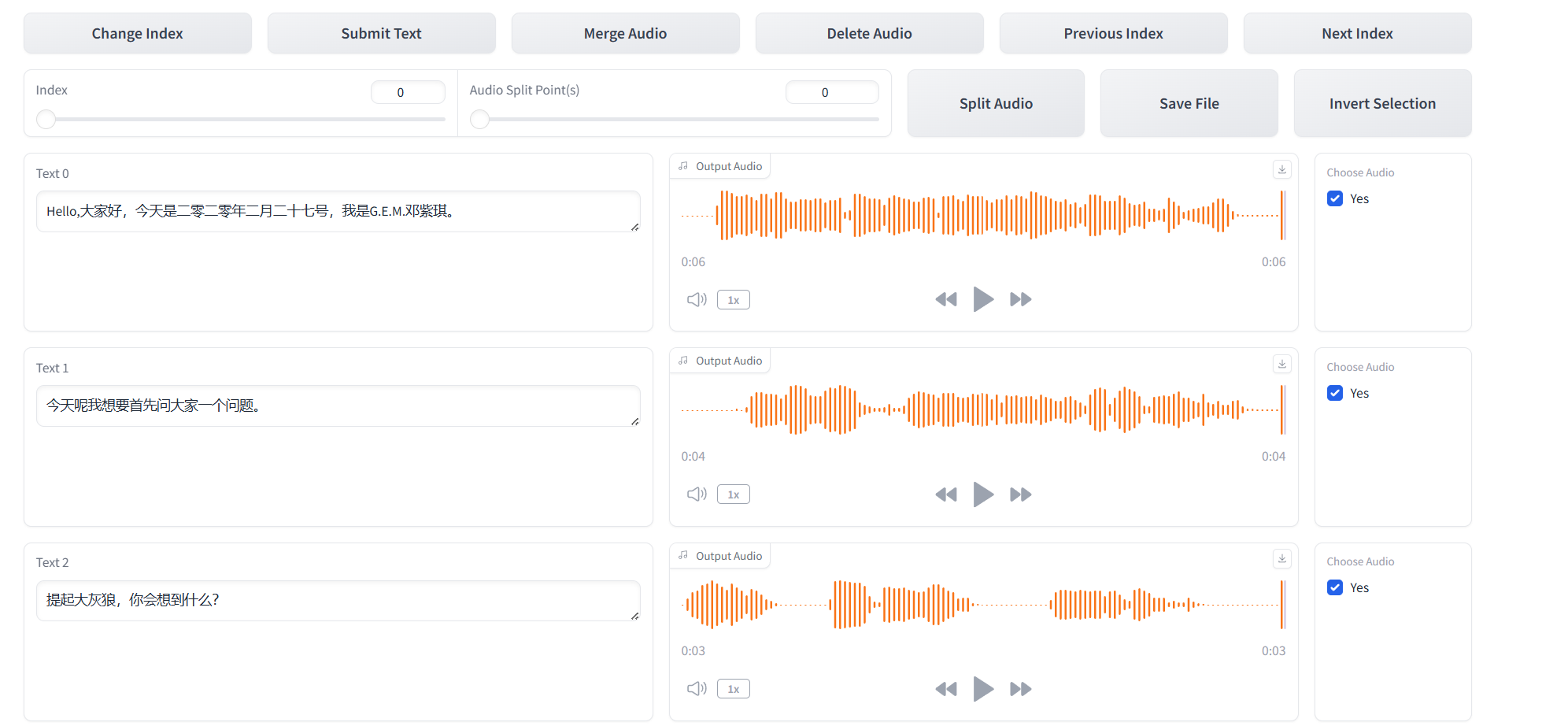
修改完没问题的话,在“Choose Audio”那里打个勾,整页校验完后,点“Submit Text”保存。
然后点“Next Index”跳转到下一页进行校验。直到全部校验完成。
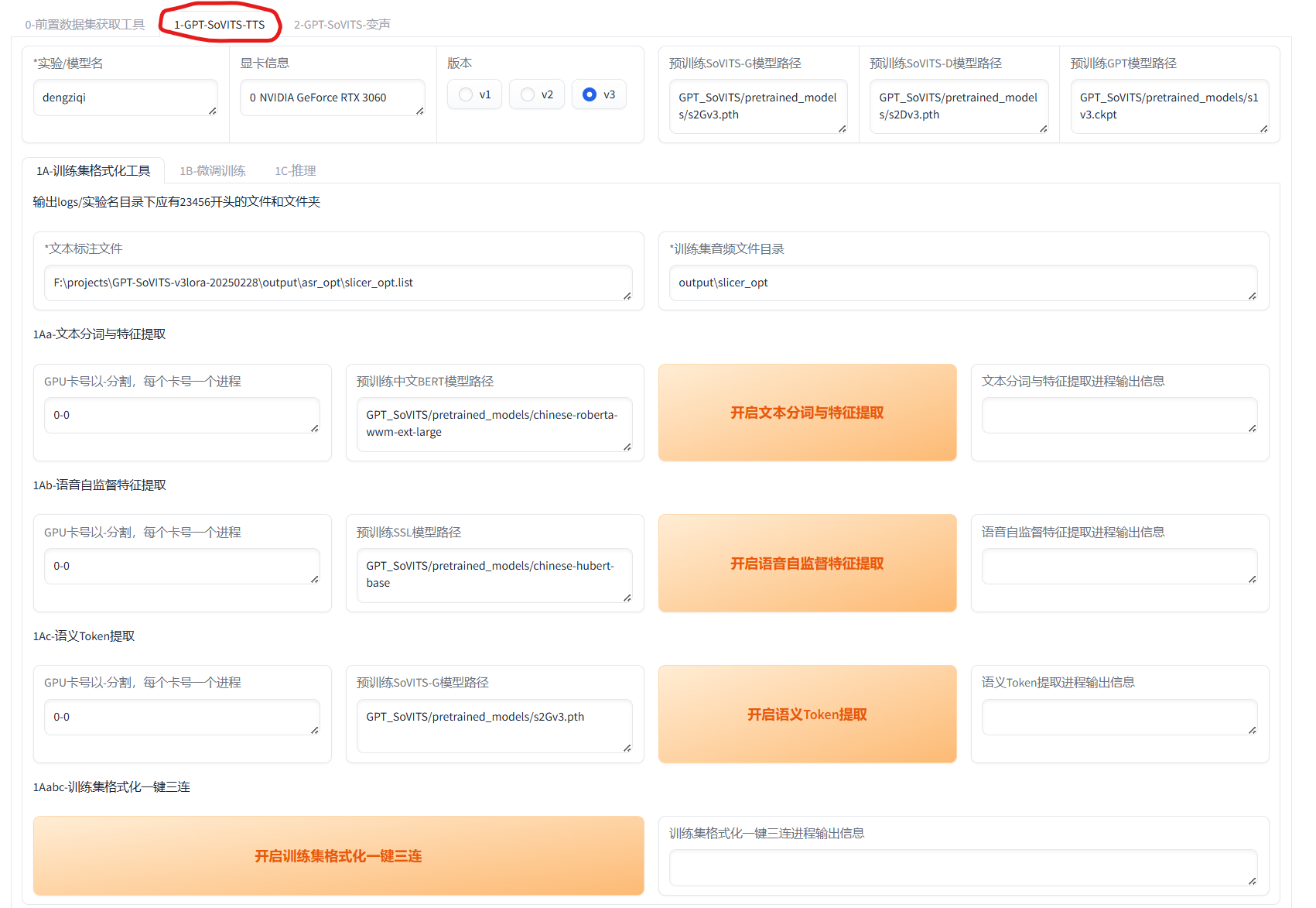
模型训练:来到第二个界面,输入模型名称,然后点击“开启训练集格式化一键三连”(这个会将原始音频及标注数据转化为模型训练所需的标准化格式,确保数据的高效利用与模型稳定学习)
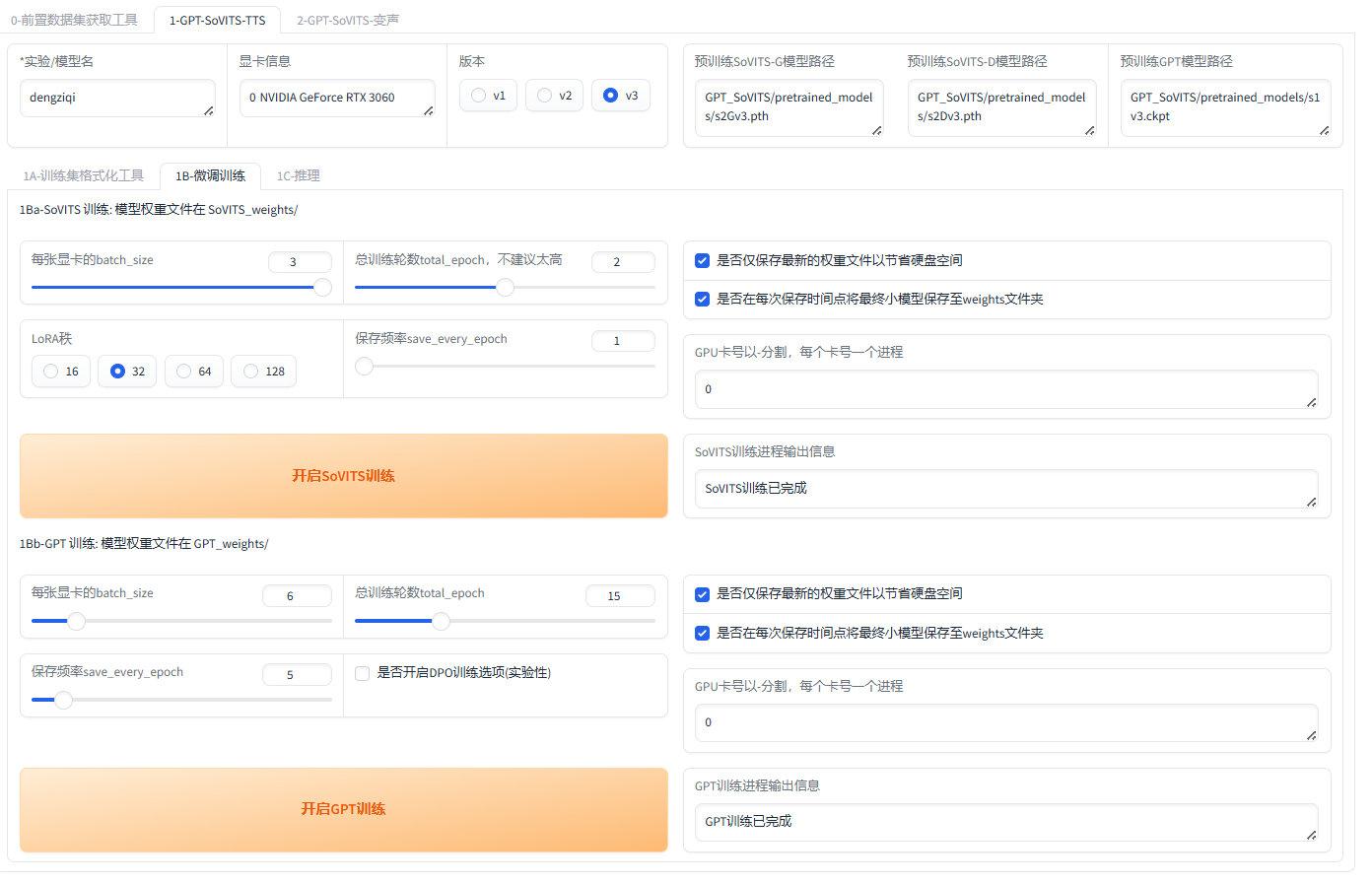
微调训练:如下图开启SoVITS及GPT训练,并等待训练完成。
我这里是用的V3,所以等训练完成后可以在两个V3目录看到已经训练好的模型。
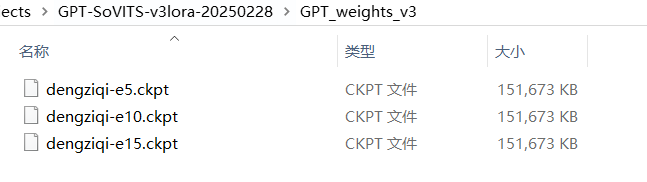

注意:模型这里的e代表轮数,s代表步数。解释如下:
轮数(Epoch):模型完整遍历整个训练数据集的次数。
-
轮数越多,模型对数据的学习越充分,但过度增加可能导致过拟合(训练集表现好,泛化能力差)。
-
通常需结合验证集效果(如损失值、语音质量)动态调整,选择最佳轮数。
步数(Steps):每轮(Epoch)中模型参数更新的次数,由批次大小(Batch Size)决定。
-
计算公式:
Steps per Epoch = 训练集样本总数 / Batch Size -
步数反映单轮训练中模型参数优化的粒度,与计算资源消耗直接相关。
-
Batch Size较小时,单轮步数增多,训练更精细但耗时更长;Batch Size较大时,步数减少,但需更高显存。
在线推理:如下图所示,先点击“刷新模型路径”,然后下拉选择模型。
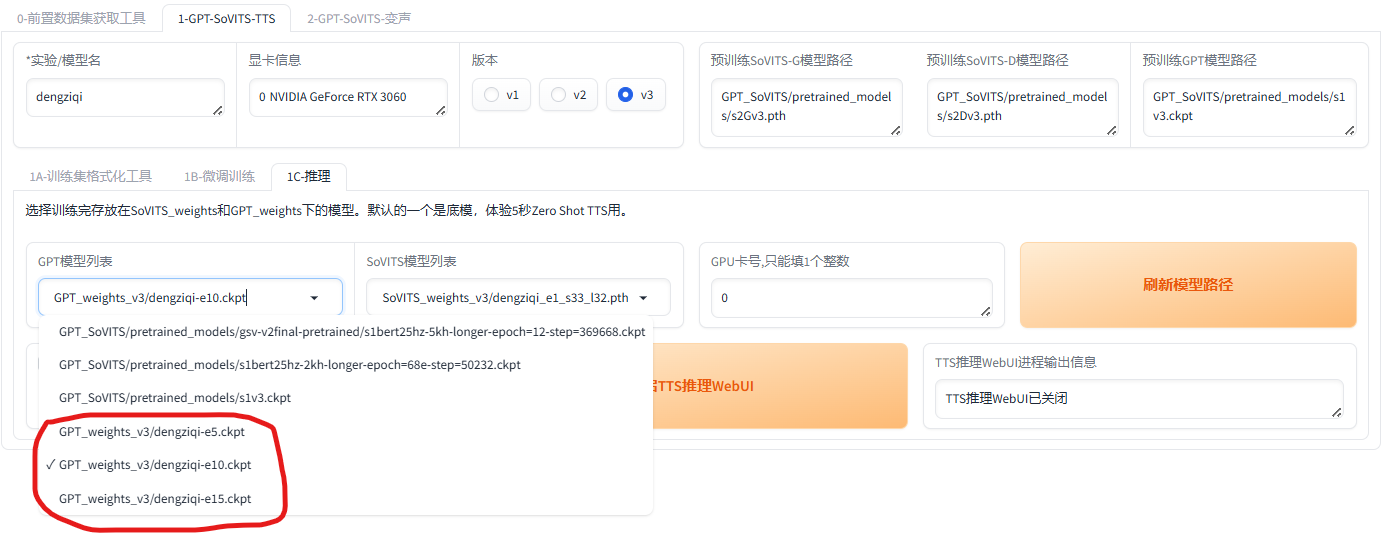
模型选择好后,点击“开启TTS推理WebUI”,过一会会自动打开在线推理的界面。如果没跳出来的话, 复制http://localhost:9872/到浏览器打开。
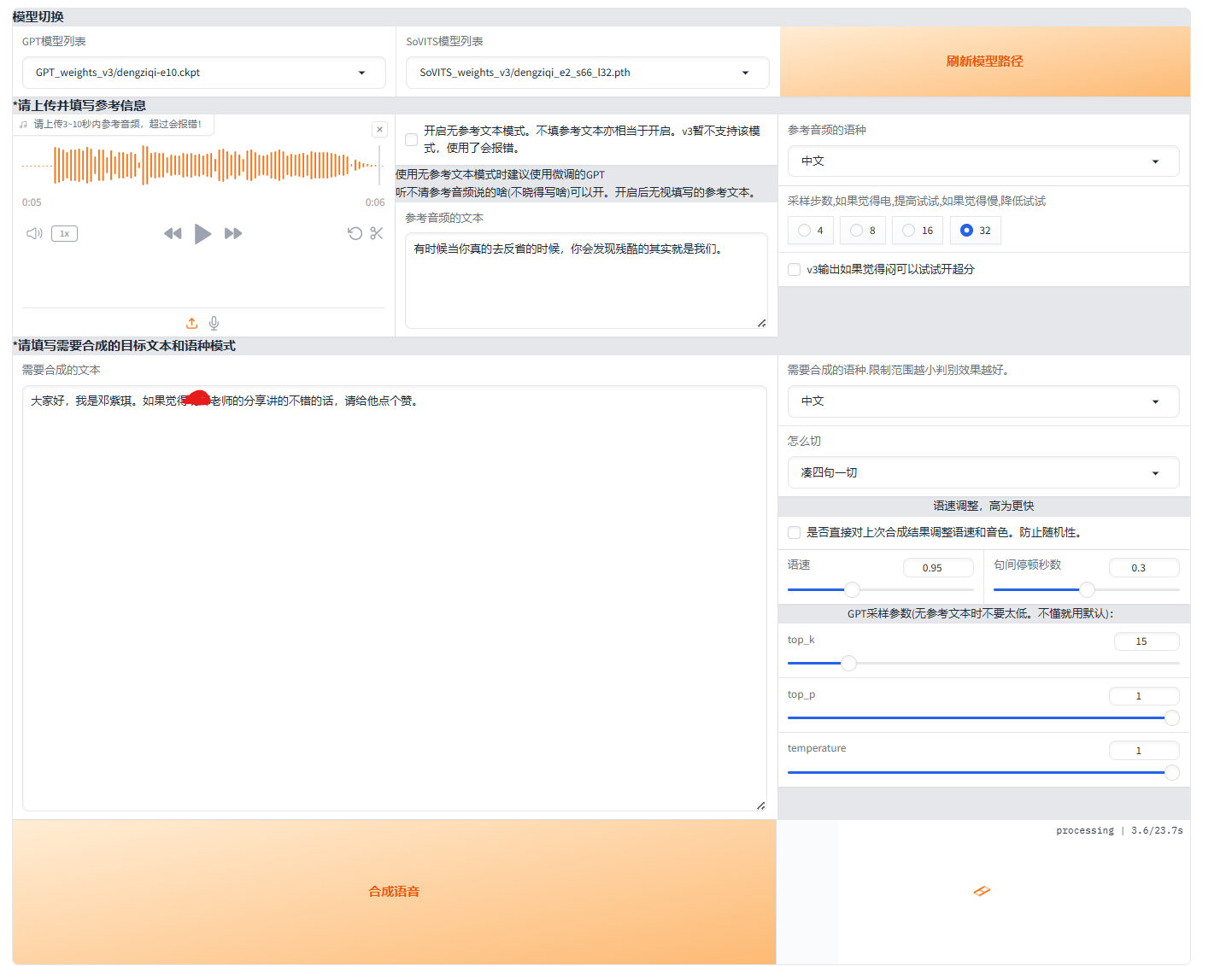
如上图所示,上传一段参考音频及对应的文本信息(会学习语速和语气,建议是数据集中的音频),然后输入要合成的文本,点击“合成语音”,过几秒右下角输出的语音就会生成出来了。
至此,我们的语音模型就完成并可以在线调用了。
top_k、top_p 和 temperature参数讲解
(1) temperature(温度)
-
作用:控制生成结果的随机性。
-
值越大(>1):概率分布更平滑,生成结果更多样、随机,可能出现意想不到的语调或发音(适合需要创造性的场景)。
-
值越小(<1):概率分布更尖锐,生成结果更保守、稳定,贴近训练数据分布(适合追求自然度和一致性的场景)。
-
默认值:通常为
1.0。
-
(2) top_k
-
作用:限制采样范围,仅从概率最高的前
k个候选 token 中选择。-
值越大(如100):采样范围广,生成多样性高,但可能引入不合理的发音。
-
值越小(如5):采样范围窄,生成更保守,但可能导致语音单调。
-
默认值:通常为
5。
-
(3) top_p(核采样)
-
作用:动态选择累积概率达到
p的候选 token 集合。-
值越大(如0.9):允许更多低概率 token 参与采样,生成多样性高。
-
值越小(如0.5):仅保留高概率 token,生成更稳定。
-
默认值:通常为
1.0(即不启用,若设为<1会覆盖top_k)。
-
三、其他的TTS项目分享
Spark-TTS
ChatTTS
相关文章:
GPT-SoVITS 使用指南
一、简介 TTS(Text-to-Speech,文本转语音):是一种将文字转换为自然语音的技术,通过算法生成人类可听的语音输出,广泛应用于语音助手、无障碍服务、导航系统等场景。类似的还有SVC(歌声转换&…...

美信监控易:数据采集与整合的卓越之选
在当今复杂多变的运维环境中,一款具备强大数据采集与整合能力的运维管理软件对于企业的稳定运行和高效决策至关重要。美信监控易正是这样一款在数据采集与整合方面展现出显著优势的软件,以下是它的一些关键技术优势,值得每一个运维团队深入了…...

基于Redis的3种分布式ID生成策略
在分布式系统设计中,全局唯一ID是一个基础而关键的组件。随着业务规模扩大和系统架构向微服务演进,传统的单机自增ID已无法满足需求。高并发、高可用的分布式ID生成方案成为构建可靠分布式系统的必要条件。 Redis具备高性能、原子操作及简单易用的特性&…...

OCR技术与视觉模型技术的区别、应用及展望
在计算机视觉技术飞速发展的当下,OCR技术与视觉模型技术成为推动各行业智能化变革的重要力量。它们在原理、应用等方面存在诸多差异,在自动化测试领域也展现出不同的表现与潜力,下面将为你详细剖析。 一、技术区别 (一ÿ…...
End-to-End从混沌到秩序:基于LLM的Pipeline将非结构化数据转化为知识图谱
摘要:本文介绍了一种将非结构化数据转换为知识图谱的端到端方法。通过使用大型语言模型(LLM)和一系列数据处理技术,我们能够从原始文本中自动提取结构化的知识。这一过程包括文本分块、LLM 提示设计、三元组提取、归一化与去重,最终利用 NetworkX 和 ipycytoscape 构建并可…...
)
比特币的跨输入签名聚合(Cross-Input Signature Aggregation,CISA)
1. 引言 2024 年,人权基金会(Human Rights Foundation,简称 HRF)启动了一项研究奖学金计划,旨在探讨“跨输入签名聚合”(Cross-Input Signature Aggregation,简称 CISA)的潜在影响。…...
)
洛谷P1177【模板】排序:十种排序算法全解(2)
我们接着上一篇继续讲【洛谷P1177【模板】排序:十种排序算法全解(1)】 三、计数排序(Counting Sort) 仅适用于数据范围较小的情况 // Java import java.io.*; public class Main {static final int OFFSET 100000;public static void…...
MySql 三大日志(redolog、undolog、binlog)详解

Docker使用、容器迁移
Docker 简介 Docker 是一个开源的容器化平台,用于打包、部署和运行应用程序及其依赖环境。Docker 容器是轻量级的虚拟化单元,运行在宿主机操作系统上,通过隔离机制(如命名空间和控制组)确保应用运行环境的一致性和可移…...
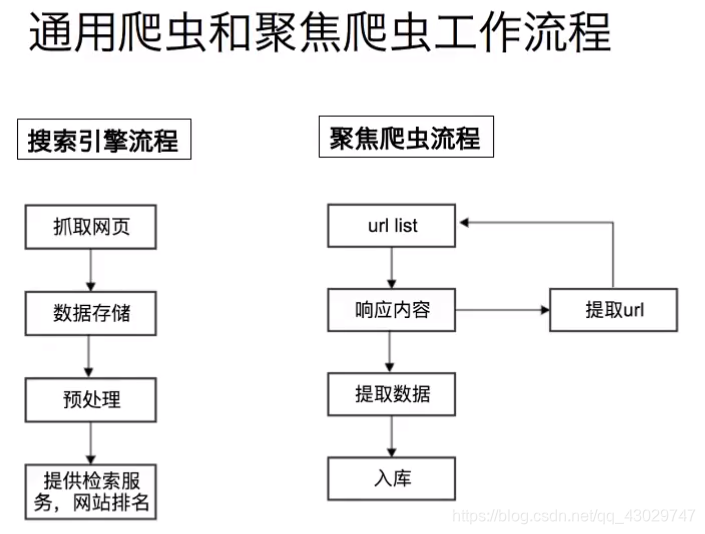
HTTP:九.WEB机器人
概念 Web机器人是能够在无需人类干预的情况下自动进行一系列Web事务处理的软件程序。人们根据这些机器人探查web站点的方式,形象的给它们取了一个饱含特色的名字,比如“爬虫”、“蜘蛛”、“蠕虫”以及“机器人”等!爬虫概述 网络爬虫(英语:web crawler),也叫网络蜘蛛(…...
2025妈妈杯数学建模C题完整分析论文(共36页)(含模型建立、可运行代码、数据)
2025 年第十五届 MathorCup 数学建模C题完整分析论文 目录 摘 要 一、问题分析 二、问题重述 三、模型假设 四、 模型建立与求解 4.1问题1 4.1.1问题1思路分析 4.1.2问题1模型建立 4.1.3问题1代码(仅供参考) 4.1.4问题1求解结果(仅…...
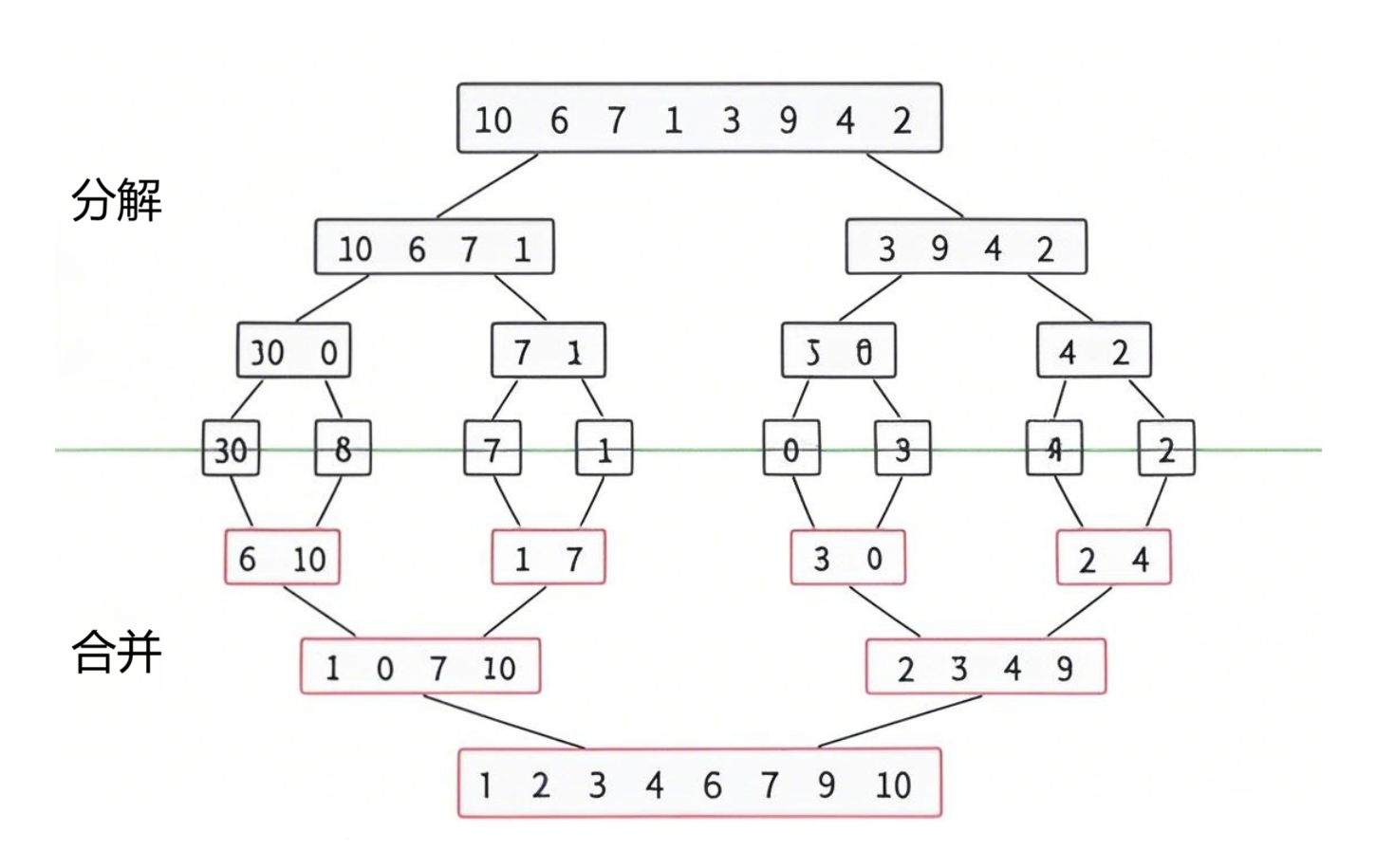
数据结构排序算法全解析:从基础原理到实战应用
在计算机科学领域,排序算法是数据处理的核心技术之一。无论是小规模数据的简单整理,还是大规模数据的高效处理,选择合适的排序算法直接影响着程序的性能。本文将深入解析常见排序算法的核心思想、实现细节、特性对比及适用场景,帮…...

UMG:ListView
1.创建WBP_ListView,添加Border和ListView。 2.创建Object,命名为Item(数据载体,可以是其他类型)。新增变量name。 3.创建User Widget,命名为Entry(循环使用的UI载体).添加Border和Text。 4.设置Entry继承UserObjectListEntry接口。 5.Entry中对象生成时…...

每天学一个 Linux 命令(18):mv
可访问网站查看,视觉品味拉满: http://www.616vip.cn/18/index.html 每天学一个 Linux 命令(18):mv 命令功能 mv(全称:move)用于移动文件/目录或重命名文件/目录,是…...
ubuntu24.04上使用qemu和buildroot模拟vexpress-ca9开发板构建嵌入式arm linux环境
1 准备工作 1.1 安装qemu 在ubuntu系统中使用以下命令安装qemu。 sudo apt install qemu-system-arm 安装完毕后,在终端输入: qemu- 后按TAB键,弹出下列命令证明安装成功。 1.2 安装arm交叉编译工具链 sudo apt install gcc-arm-linux-gnueabihf 安装之…...
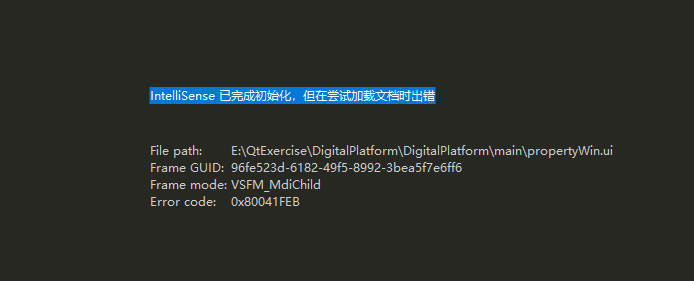
IntelliSense 已完成初始化,但在尝试加载文档时出错
系列文章目录 文章目录 系列文章目录前言一、原因二、使用步骤 前言 IntelliSense 已完成初始化,但在尝试加载文档时出错 File path: E:\QtExercise\DigitalPlatform\DigitalPlatform\main\propertyWin.ui Frame GUID:96fe523d-6182-49f5-8992-3bea5f7e6ff6 Frame …...

dumpsys--音频服务状态信息
Audio相关的信息获取指令: dumpsys media.audio_flinger dumpsys media.audio_policy dumpsys audio media.audio_flinger dumpsys media.audio_flinger 用于获取 AudioFlinger 服务的详细状态信息。 1. 命令作用 该命令输出当前系统的 音频设备状态、活跃音频流…...
【更新完毕】2025泰迪杯数据挖掘竞赛A题数学建模思路代码文章教学:竞赛论文初步筛选系统
完整内容请看文末最后的推广群 基于自然语言处理的竞赛论文初步筛选系统 基于多模态分析的竞赛论文自动筛选与重复检测模型 摘要 随着大学生竞赛规模的不断扩大,参赛论文的数量激增,传统的人工筛选方法面临着工作量大、效率低且容易出错的问题。因此&…...

服务器内存规格详解
服务器内存规格详解 一、内存安装原则与配置规范 1. 内存槽位安装规则 规则描述CPU1对应的内存槽位至少需配置一根内存禁止混用不同规格(容量/位宽/rank/高度)内存条,需保持相同Part No.推荐完全平衡的内存配置,避免通道/处理器…...

kafka集群认证
1、安装Kerberos(10.10.10.168) yum install krb5-server krb5-workstation krb5-libs -y 查看版本 klist -V Kerberos 5 version 1.20.1 编辑/etc/hosts 10.10.10.168 ms1 10.10.10.150 ms2 10.10.10.110 ms3 vim /etc/krb5.conf # Configuration snippets ma…...

数据要素市场化核心概念解析与产业实践路径
在数字经济成为全球经济增长新引擎的背景下,数据要素市场化配置改革正推动着生产关系的深刻变革。本文基于数据要素价值化全生命周期,系统梳理关键概念体系,为数据资产化实践提供方法论支撑。 一、数据资源的价值演进路径 1.基础资源层 原…...
Vue3+Vite+TypeScript+Element Plus开发-22.客制Table组件
系列文档目录 Vue3ViteTypeScript安装 Element Plus安装与配置 主页设计与router配置 静态菜单设计 Pinia引入 Header响应式菜单缩展 Mockjs引用与Axios封装 登录设计 登录成功跳转主页 多用户动态加载菜单 Pinia持久化 动态路由 -动态增加路由 动态路由-动态删除…...

QT 文件和文件夹操作
文件操作 1. 文件读写 QFile - 基本文件操作 // 只写模式创建文件(如果文件已存在会清空内容) file.open(QIODevice::WriteOnly);// 读写模式创建文件 file.open(QIODevice::ReadWrite);// 追加模式(如果文件不存在则创建) fil…...

confluent-kafka入门教程
文章目录 官方文档与kafka-python的对比配置文档配置项 Producer代码示例Consumer代码示例 官方文档 confluent_kafka API — confluent-kafka 2.8.0 documentation Quick Start for Confluent Cloud | Confluent Documentation 与kafka-python的对比 对比维度confluent-ka…...

江苏广电HC2910-创维代工-Hi3798cv200-2+8G-海美迪安卓7.0-强刷包
江苏广电HC2910-创维代工-Hi3798cv200-28G-海美迪安卓7.0-强刷包 说明 1、由于原机的融合网关路由不能设置,原网口无法使用,需要用usb2.0的RJ45usb网卡接入。 通过usb接口网卡联网可以实现百兆网口连接。原机usb3.0的接口可以以接入硬盘,播放…...

如何提高前端应用的性能?
如何提高前端应用的性能? 提高前端应用性能的方法可以从以下几个方面入手: 1. **代码优化** - 使用代码分割(Code Splitting)按需加载资源 - 减少DOM操作,使用虚拟DOM技术 - 避免深层嵌套的数据结构 - 使用Web Worker…...

python 库 下载 ,整合在一个小程序 UIUIUI
上图 import os import time import threading import requests import subprocess import importlib import tkinter as tk from tkinter import ttk, messagebox, scrolledtext from concurrent.futures import ThreadPoolExecutor, as_completed from urllib.parse import…...

Python爬虫-爬取猫眼演出数据
前言 本文是该专栏的第53篇,后面会持续分享python爬虫干货知识,记得关注。 猫眼平台除了有影院信息之外,它还涵盖了演出信息,比如说“演唱会,音乐节,话剧音乐剧,脱口秀,音乐会,戏曲艺术,相声”等等各种演出相关信息。 而本文,笔者将以猫眼平台为例,基于Python爬虫…...
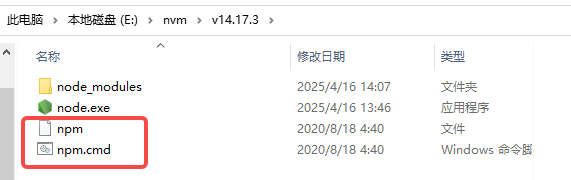
nvm切换node版本后,解决npm找不到的问题
解决方法如下 命令行查看node版本 node -v找到node版本所对应的npm版本 点击进入node版本 npm对应版本下载 点击进入npm版本 下载Windows 压缩包 下载完成后,解压,文件改名为npm 复制到你nvm对应版本的node_modules 下面 将下载的npm /bin 目录…...

Windows系统安装MySQL安装实战分享
以下是在 Windows 系统上安装 MySQL 的详细实战步骤,涵盖下载、安装、配置及常见问题处理。 一、准备工作 下载 MySQL 安装包 访问 MySQL 官网。选择 MySQL Community Server(免费版本)。根据系统位数(32/64位)下载 …...