python课堂随记
11.15
连接符
name='mcl'
print('我叫',name)
print('我叫'+name)#连接符
age=18
print('我叫'+name+'年龄'+str(age))
#连接符需要数据类型相同11.17随记
除法运算神奇
8/5 #1.6
8//5 #1
-8/5 #-1.6
-8//5 #-2##次方表示—两个**
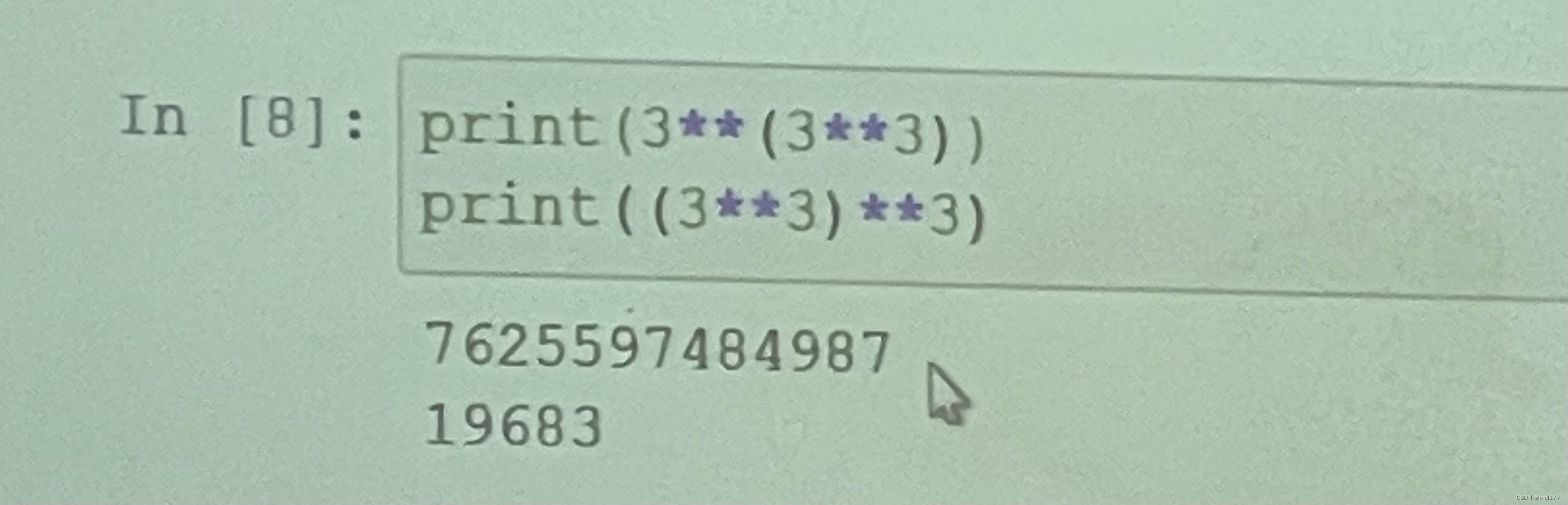
3的27次方
27的3次方
小结
程序的书写,包括代码缩进、注释、语句续行、关键字区分大小写等
内容
Python的数值类型数据和字符类型数据
Python的运算符包括算术运算符、比较运算符、逻辑运算符、赋值运算符等
Python不要求在使用变量之前声明其数据类型,但数据集类型决定了数的存储和操作的方式不同
3个函数:bool(),type(),len()
12.8随记
二分查找法
#ex0518.py
list1 = [1,42,3,-7,8,9,-10,5]
#二分查找要求查找的序列时有序的,假设是升序列表
list1.sort()
print(list1)
find=eval(input("请输入要查看的数据:"))low = 0
high = len(list1)-1
flag=False
while low <= high :mid = int((low + high) / 2)if list1[mid] == find :flag=Truebreak#左半边elif list1[mid] > find :high = mid -1#右半边else :low = mid + 1if flag==True:print("您查找的数据{},是第{}个元素".format(find,mid+1))
else:print("没有您要查找的数据")统计单词出现的次数
#ex0517.py
sentence='Beautiful is better than ugly.Explicit is better than implicit.\
Simple is better than complex.Complex is better than complicated.'
#将文本中涉及标点用空格替换
for ch in ",.?!":sentence=sentence.replace(ch," ")
#利用字典统计词频
words=sentence.split()
map1={}
for word in words:if word in map1:map1[word]+=1else:map1[word]=1
#对统计结果排序
items=list(map1.items())
items.sort(key=lambda x:x[1],reverse=True)
#打印控制
for item in items:word,count=itemprint("{:<12}{:>5}".format(word,count))12.13随记
6.1函数的定义和调用

def getarea(x,y):return x*y
print(getarea(3,2))
print(getarea("hello",2))
函数嵌套调用
def sum(n):def fact(a):t = 1for i in range(1,a+1):t*=ireturn ts = 0for i in range(1,n+1):s+=fact(i)return s
n = 5
print("{}以内的阶乘之和为{}".format(n,sum(n)))

6.2函数的参数和返回值

def getscore(pe,eng,math,phy,chem):return pe*0.5+eng*1+math*1.2+phy*1+chem*1
getscore(93,89,78,89,72) #按位置传递
getscore(pe=93,math=78,chem=72,eng=89,phy=89) #赋值传递 直接指定
参数数据类型:数值型 字符串型
组合数据类型:列表 元组 字典 集合 #传递地址
数值型
a = 10
def func(num):num += 1print("形参的地址 {}".format(id(num)))print("形参的值 {}".format(num))a = 1func(a)
a,id(a)组合数据类型
tup =(1,5,7,8,12,9)
ls = []
def getOdd(tup1,ls1):for i in tup1:if i%2:ls1.append(i)return ls1getOdd(tup,ls)
print(ls)
#ex0608.pydef showmessage(name,age=18):"打印任何传入的字符串"print ("姓名: ",name)print ("年龄: ",age)return#调用showmessage函数
showmessage(age=19,name="Kate" )
print ("------------------------")
showmessage(name="John")#program0510.py
def showmessage(name,*p_info,**scores):print ("姓名: ",name)for e in p_info:print(e,end=" ")for item in scores.items():print(item,end=" ")print() return#调用showmessage函数
showmessage("Kate","male",18,"Dalian");
print("------------------------------")
showmessage("Kate","male",18,"Dalian",math=86,pe=92,eng=88)def compare( arg1, arg2 ):result = arg1 >arg2return result # 函数体内result值
btest= compare(10,9.99) # 调用sum函数
print ("函数的返回值: ",btest)#ex0612.py
def findwords(sentence):"统计参数中含有字符e的单词,保存到列表中,并返回"result=[]words=sentence.split()for word in words:if word.find("e")!=-1:result.append(word)return resultss="Return the lowest index in S where substring sub is found,"
print(findwords(ss))12.15

闭包


print("okllll");
print("终于好了 姐要吐了")
def getarea(x,y):return x*y
print(getarea(3,2))
print(getarea("hello",2)乱七八糟
#判断奇偶
def isodd(x):if type(x) != int:print("{}不是整数,退出程序!".format(x))returnelif x%2==0:print("{}is even!".format(x))return Falseelif x%2==1:print("{}is odd!".format(x))return Trueprint(isodd(1))
print(isodd(2))
a=[1,2,3]
print(isodd(a))练习
编写函数,计算某班级学生考试的平均分。
要求:
(1)班级共 10 人,计算平均分时可以根据全部人数或者实际参加考试人数计算。
(2)完成 avgScore()函数。
提示:
(1)定义函数 avgScore()时,参数 n 为默认参数,其默认值为 10。在调用函数 avgScore() 时,如果没有传入 n 的实参,则 n 取默认值;如果传入 n 的实参,则函数会使用传递给 n 的新值。
(2)函数 avgScore()用于计算考试成绩的平均分,接收列表类型的参数 scores。
12.20
python文件操作
主要考虑文件的读写

文件的打开和关闭


rb二进制读模式,wb二进制写模式

python文件读写的常用方法
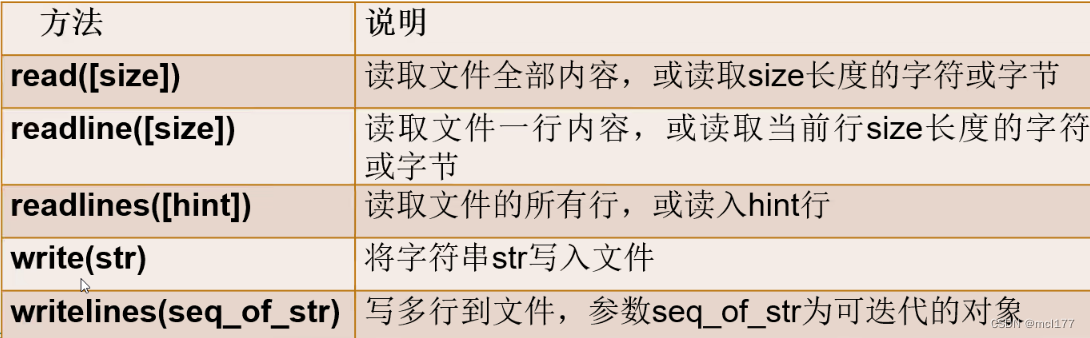
read
f=open("test.txt","r")
str1=f.read(13)
print(str1)
str2=f.read()
print(str2)
f.close()
程序和文件需要放在同一个文件夹
#ex0903.py
f=open("test.txt","r")
flist=f.readlines() # flist是包含文件内容的列表
print(flist)
for line in flist:print(line) #使用print(line,end="")将不显示文件中的空行。
f.close()#ex0904.py
f=open("test.txt","r")
str1=f.readline()while str1!="": #判断文件是否结束print(str1)str1=f.readline()
f.close()
write
fname = input("请输入追加数据的文件名:")
f1 = open(fname,"w+")
f1.write("向文件中写入字符串\n")
f1.write("继续写入")
f1.close()跟指针相关,tell,seek

file = open("d:\\shiyan\\test.txt","r+")
str1 = file.read(6)
str1
file.tell()
file.readline()
file.tell()
file.readlines()
file.tell()
file.close()file = open("d:\\shiyan\\test.txt","r+")
file.seek(6)
str1 = file.read(8)
str1
file.tell()
file.seek(6)
file.write("@@@@@@@")
file.seek(0)
file.readline()#以'wb'方式打开二进制文件
fileb = open(r"d:\\shiyan\\mydata.dat","wb")
fileb.write(b"Hello Python")
n = 123
fileb.write(bytes(str(n),encoding='utf-8'))
fileb.write(b"\n3.14")
fileb.close()
#以'rb'方式打开二进制文件
file = open(r"d:\\shiyan\\mydata.dat","rb")
print(file.read())
file.close()
#以'r'方式打开二进制文件
filec = open(r"d:\\shiyan\\mydata.dat","r")
print(filec.read())
filec.close()
12.27随记
#ex0911.py
lst1 = ["read","write","tell","seek"]
dict1 = {"type1":"TextFile","type2":"BinaryFile"}
fileb = open(r"d:\\shiyan\\mydata.dat","wb")
#写入数据
import pickle
pickle.dump(lst1,fileb)
pickle.dump(dict1,fileb)
fileb.close()
#读取数据
fileb = open(r"d:\\shiyan\\mydata.dat","rb")
fileb.read()
fileb.seek(0)
x = pickle.load(fileb)
y = pickle.load(fileb)
x,y
fileb.close()#ex0912.py
import shutil
shutil.copyfile("d:\\shiyan\\test.txt","d:\\shiyan\\testb.py")#ex0913.py
import os,os.path
fname = input("请输入需要删除的文件名:")
if os.path.exists(fname):os.remove(fname)
else:print("{}文件不存在".format(fname))#program0714.py
import os,os.path,sys
fname=input("请输入需要更名的文件:")
gname=input("请输入更名后的文件名:")
if not os.path.exists(fname):print("{}文件不存在".format(fname))sys.exit(0)
elif os.path.exists(gname):print("{}文件已存在".format(gname))sys.exit(0)
else:os.rename(fname,gname)
print("rename success")#ex0915.py
import os
os.getcwd()
os.listdir()
os.mkdir('myforder')
os.removedirs('yourforder\f1\f2')
os.makedirs('aforder\\ff1\\ff2')
import shutil
shutil.rmtree('yourforder')#ex0916.py
# 向CSV文件中写入一维数据并读取
lst1 = ["name","age","school","address"]
filew= open('d:\\shiyan\\asheet.csv','w')
filew.write(",".join(lst1))
filew.close()filer= open('d:\\shiyan\\asheet.csv','r')
line=filer.read()
print(line)
filer.close()#ex0917.py
# 使用内置csv模块写入和读取二维数据datas = [['Name', 'DEP', 'Eng','Math', 'Chinese'],
['Rose', '法学', 89, 78, 65],
['Mike', '历史', 56,'', 44],
['John', '数学', 45, 65, 67]
]import csv
filename = 'd:\\shiyan\\bsheet.csv'
with open(filename, 'w',newline="") as f:writer = csv.writer(f)for row in datas:writer.writerow(row) ls=[]
with open(filename,'r') as f:reader = csv.reader(f)#print(reader)for row in reader:print(reader.line_num, row) # 行号从1开始ls.append(row)print(ls)#ex0919.py
filename=input("请输入要添加行号的文件名:")
filename2=input("请输入新生成的文件名:")
sourcefile=open(filename,'r',encoding="utf-8")
targetfile=open(filename2,'w',encoding="utf-8")
linenumber=""
for (num,value) in enumerate(sourcefile):if num<9:linenumber='0'+str(num+1)else:linenumber=str(num+1)str1=linenumber+" "+valueprint(str1)targetfile.write(str1)
sourcefile.close()
targetfile.close()#ex0920.py
from datetime import datetime
filename=input("请输入日志文件名:")
file=open(filename,'a')
print("请输入日志,exit结束")
s=input("log:")
while s.lower()!="exit":file.write("\n"+s)file.write("\n----------------------\n")file.flush()s=input("log:")
file.write("\n====="+str(datetime.now())+"=====\n")
file.close()
12.29 模块和库编程
from datetime import datetime
aday = datetime.now()
aday
print(aday)
dt1 = datetime(2021,9,10,13,59)
dt1
type(dt1)
print("当前时间是{}:{}:{}".format(dt1.hour,dt1.minute,dt1.second))筛选key words
# program0617.py
'''
使用jieba库分解中文文本,并使用字典实现词频统计
'''
# encoding=utf-8
import jieba
# read need analyse file
article = open("shuihu70.txt",encoding='utf-8').read()
words = jieba.lcut(article)
# count word freq
word_freq = {}
for word in words:if len(word)==1:continueelse:word_freq[word]= word_freq.get(word,0)+1
# sorted
freq_word = []
for word, freq in word_freq.items():freq_word.append((word, freq))
freq_word.sort(key = lambda x:x[1], reverse=True)
max_number = eval(input("显示前多少位高频词? "))
# display
for word, freq in freq_word[:max_number]:print(word, freq)
# program0618.py
'''
使用jieba库分解中文文本,并使用字典实现词频统计,统计结果中排除
部分单词,被排除单词保存在文件stopwords.txt中
'''
import jieba
stopwords = [line.strip() for line in open('stopwords.txt', 'r', \encoding='utf-8').readlines()]
# add extra stopword
stopwords.append('')
# read need analyse file
article = open("sanguo60.txt",encoding='utf-8').read()
words = jieba.cut(article, cut_all = False)
# count word freq
word_freq = {}
for word in words:if (word in stopwords) or len(word)==1:continueif word in word_freq:word_freq[word] += 1else:word_freq[word] = 1
# sorted
freq_word = []
for word, freq in word_freq.items():freq_word.append((word, freq))
freq_word.sort(key = lambda x:x[1], reverse=True)
max_number = eval(input("需要前多少位高频词? "))
# display
for word, freq in freq_word[:max_number]:print(word, freq)# program0619.py
'''
使用jieba库分解中文文本,并使用字典实现词频统计,统计结果中排除
部分单词,被排除单词保存在文件stopwords.txt中,合并了部分同义词
'''
import jieba
stopwords=[line.strip() for line in open('stopwords.txt',\encoding='utf-8').readlines()]
# add extra stopword
stopwords.append('')
# read need analyse file
article = open("sanguo60.txt",encoding='utf-8').read()
words = jieba.lcut(article)
# count word freq
word_freq = {}
for word in words:if (word in stopwords) or len(word)==1:continueelif word=='玄德' or word=='玄德曰':newword='刘备'elif word=='关公' or word=='云长':newword='关羽'elif word=='丞相':newword='曹操'elif word=='孔明' or word=='孔明曰':newword='诸葛亮'else:newword=wordif newword in word_freq:word_freq[newword] += 1else:word_freq[newword] = 1
# sorted
freq_word = []
for word, freq in word_freq.items():freq_word.append((word, freq))
freq_word.sort(key = lambda x:x[1], reverse=True)
max_number = eval(input("需要前多少位高频词? "))
# display
for word, freq in freq_word[:max_number]:print(word, freq)
相关文章:
python课堂随记
11.15 连接符 namemcl print(我叫,name) print(我叫name)#连接符 age18 print(我叫name年龄str(age)) #连接符需要数据类型相同 11.17随记 除法运算神奇 8/5 #1.6 8//5 #1 -8/5 #-1.6 -8//5 #-2 ##次方表示—两个** 3的27次方 27的3次方 小结 程序的书写&…...

Agent安装-Beszel 轻量级服务器监控平台
docker-compose安装 beszel-agent 安装 docker-compose 配置文件 services:beszel-agent:image: henrygd/beszel-agent:latestcontainer_name: beszel-agentrestart: unless-stoppednetwork_mode: hostvolumes:- ./beszel_socket:/beszel_socket- /var/run/docker.sock:/var…...
算法—选择排序—js(场景:简单实现,不关心稳定性)
选择排序原理:(简单但低效) 每次从未排序部分选择最小元素,放到已排序部分的末尾。 特点: 时间复杂度:O(n) 空间复杂度:O(1) 不稳定排序 // 选择排序 function selectionSort(arr) {for (let …...

websocket和SSE学习记录
websocket学习记录 websocket使用场景 即时聊天在线文档协同编辑实施地图位置 从开发角度来学习websocket开发 即使通信项目 通过node建立简单的后端接口,利用fs, path, express app.get(*, (req, res) > {const assetsType req.url.split(/)[…...

【统计分析120】统计分析120题分享
1-30 判断题 数学模型 指的是通过抽象、简化现实世界的某些现象,利用数学语言来描述他们的结构和行为,做出一些必要的假设,运用适当的数学工具,得到一个数学结论 数学模型:指的是通过抽象、简化现实世界的某些现象&am…...
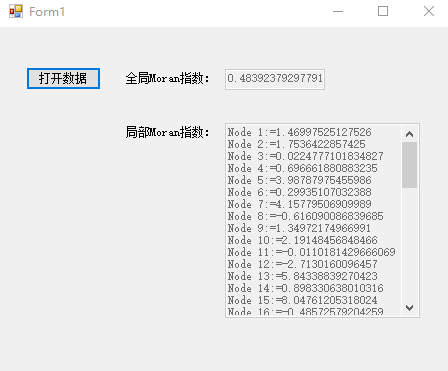
【计量地理学】实验四 主成分分析与莫兰指数
一、实验内容 (一) 某地区35个城市2004年的7项经济统计指标数据见(数据中的“题目1”sheet)。 (1)试用最短距离聚类法对35个城市综合实力进行系统聚类分析,并画出聚类谱系图: 在此次实验内容…...

手写call,bind,apply
foo.Mycall(obj,1,2,3) Function.prototype.Mycallfunction(target,...args){if(typeof this!function){throw new TypeError(this is not a function)}// 判断target是否是对象if(targetnull||targetundefined){targetwindow}if(typeof target!object){targetObject(target)}/…...

【读书笔记·VLSI电路设计方法解密】问题64:什么是芯片的功耗分析
低功耗设计是一种针对VLSI芯片功耗持续攀升问题的设计策略。随着工艺尺寸微缩,单颗芯片可集成更多元件,导致功耗相应增长。更严峻的是,现代芯片工作频率较二十年前大幅提升,而功耗与频率呈正比关系。因此,芯片功耗突破…...
Ubuntu18.04安装Qt5.12
本文介绍了在Ubuntu18.04环境下安装QT QT5.12相关安装包下载地址 https://download.qt.io/archive/qt/5.12/ Linux系统下Qt的离线安装包以.run结尾 (sudo apt-get install open-vm-tools open-vm-tools-desktop解决无法paste的问题) 安装 1.cd命令 终端进入对应的文件夹下面 2.…...

【SpringBoot】99、SpringBoot中整合RabbitMQ实现重试功能
最近在做一个项目,需要使用 MQ 实现重试功能,在这里给各位分享一下。 1、整合 RabbitMQ <!-- rabbitmq消息队列 --> <dependency><groupId>org.springframework.boot</groupId><...
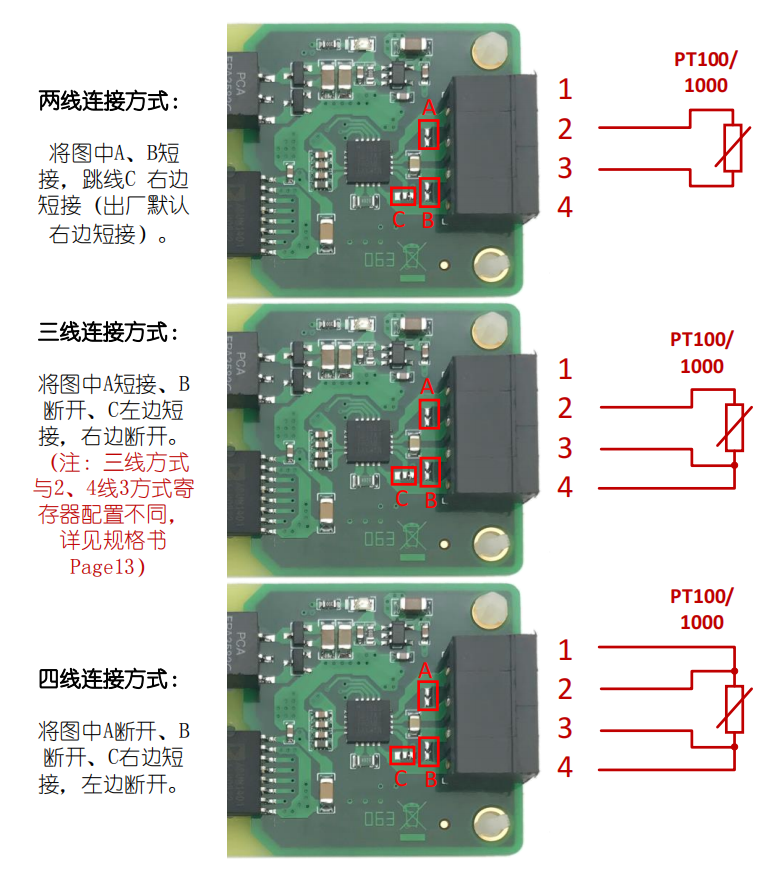
max31865典型电路
PT100读取有很多种方案,常用的惠斯通电桥,和专用IC max31865 。 电阻温度检测器(RTD)是一种阻值随温度变化的电阻。铂是最常见、精度最高的测温金属丝材料。铂RTD称为PT-RTD,镍、铜和其它金属亦可用来制造RTD。RTD具有较宽的测温范围&#x…...
)
每日一道leetcode(补充版)
1004. 最大连续1的个数 III - 力扣(LeetCode) 题目 给定一个二进制数组 nums 和一个整数 k,假设最多可以翻转 k 个 0 ,则返回执行操作后 数组中连续 1 的最大个数 。 示例 1: 输入:nums [1,1,1,0,0,0,1…...
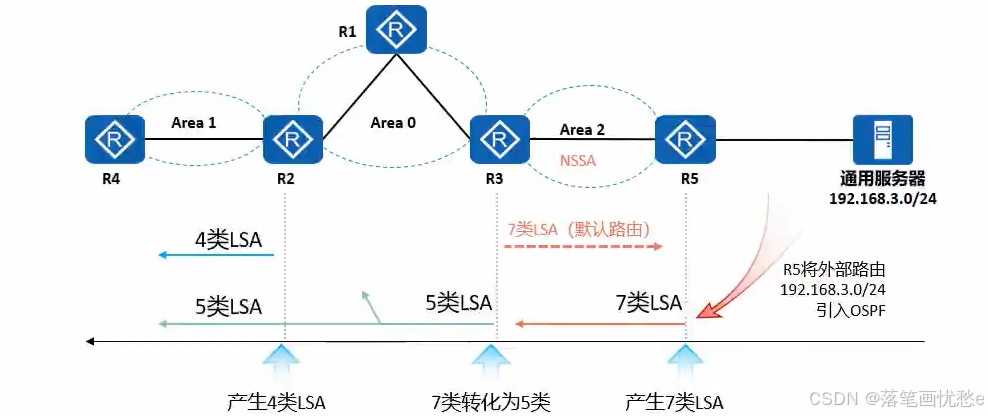
数据通信学习笔记之OSPF的区域
OSPFArea 用于标识一个 OSPF 的区域 区域是从逻辑上将设备划分为不同的组,每个组用区域号 (Area ID)来标识 OSPF 的区域 ID 是一个 32bit 的非负整数,按点分十进制的形式(与 IPV4 地址的格式一样)呈现,例如 Area0.0.0.1。 为了简便起见&#…...

5 提示词工程指南-计划与行动
5 提示词工程指南-计划与行动 计划与行动 Cline 有两种模式: Plan 描述目标和需求、提问与回答、讨论、抽象项目的各个方面、确定技术路线、确定计划 计划与确认相当于架构师,不编写代码Act 按计划编写代码 按照计划编码Plan 模式的本质是构建实际编码前的上下文,Act 的本…...
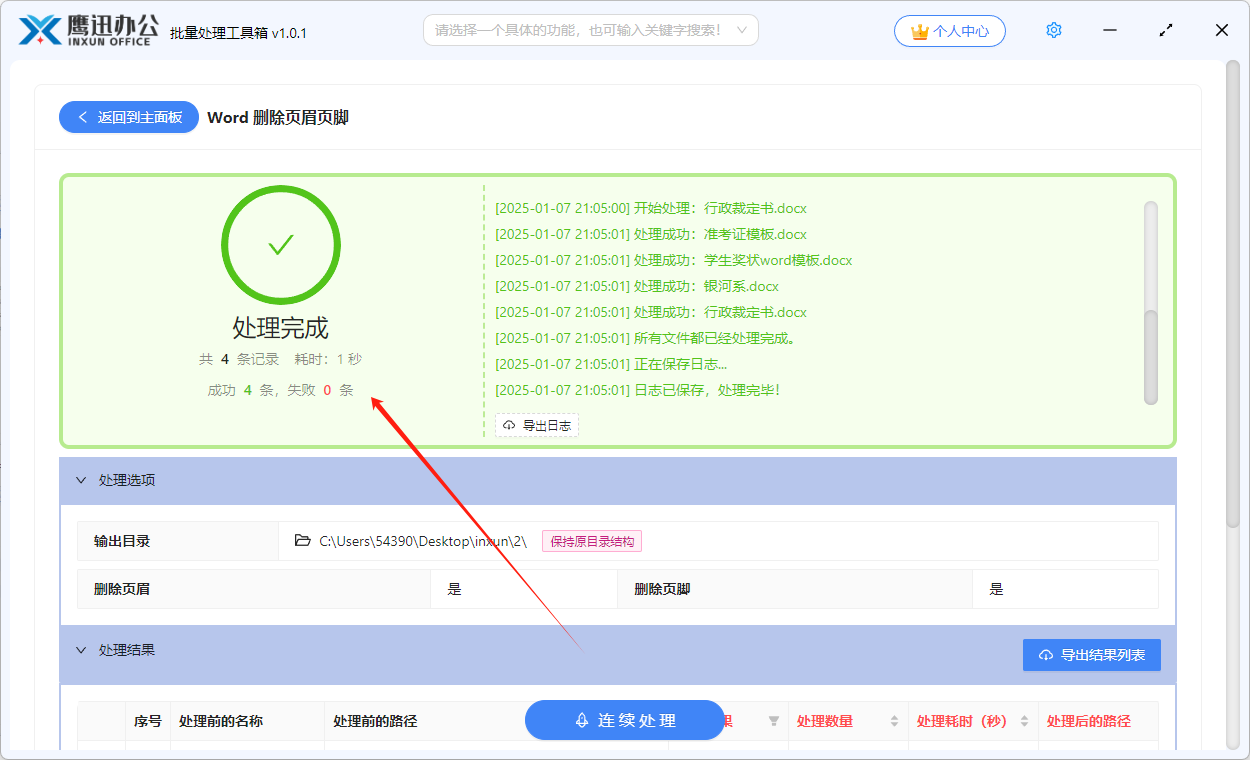
如何一键批量删除多个 Word 文档中的页眉和页脚
在工作中,许多 Word 文档的页眉页脚中包含公司名称、Logo、电话等信息,用于对外宣传。但有时我们需要批量删除这些页眉页脚信息,尤其当信息有误时,手动逐个删除会增加工作量,导致效率低下。本文将介绍一种便捷的方法&a…...
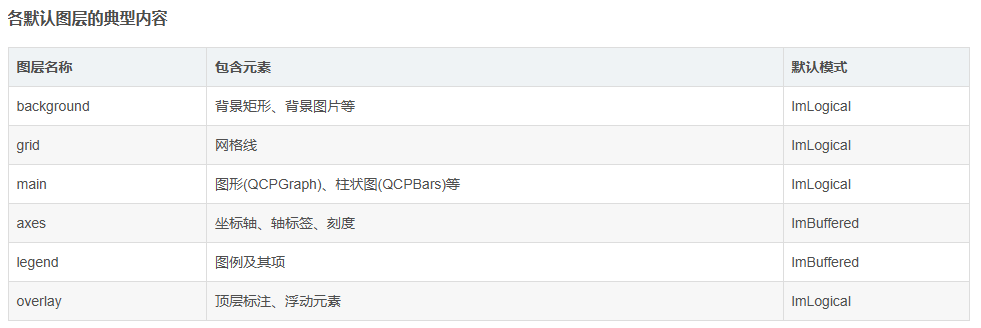
QCustomPlot中自定义图层
QCustomPlot 使用图层(QCPLayer)系统来组织绘图元素的绘制顺序和可见性。下面详细介绍如何自定义图层并将可绘制对象关联到特定图层。 1. 理解 QCustomPlot 的图层系统 QCustomPlot 的图层系统具有以下特点: 图层按顺序排列,后绘制的图层会覆盖前面的图…...

Dubbo QoS操作手册
QOS 操作手册 QoS概述 启动参数 参数说明默认值qos-enable是否启动Qostrueqos-port启动Qos绑定的端口22222qos-accept-foreign-ip是否运行远程访问falseqos-accept-foreign-whitelist支持的远端地址ip地址(段)无qos-anonymous-access-permission-lefe…...
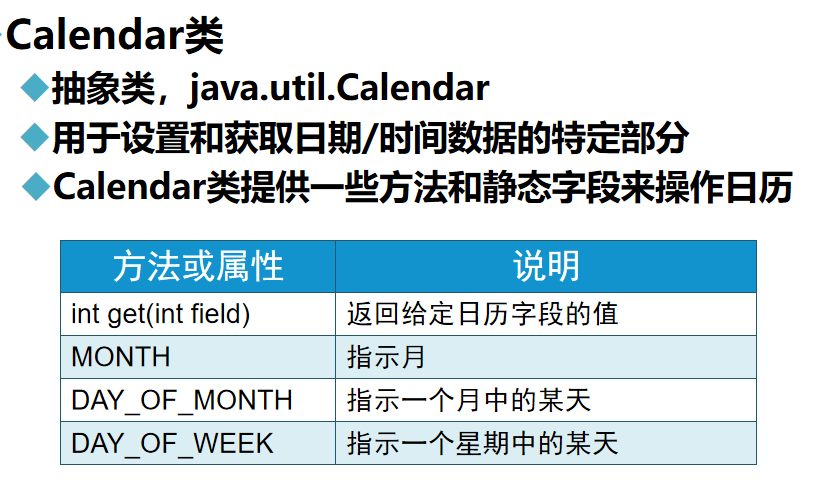
-实用类-
1. API是什么 2.什么是枚举 !有点类似封装! 2.包装类 注意: 1.Boolean类构造方法参数为String类型时,若该字符串内容为true(不考虑大小写),则该Boolean对象表示true,否则表示false 2.当包装类构造方法参…...

Apache Parquet 文件组织结构
简要概述 Apache Parquet 是一个开源、列式存储文件格式,最初由 Twitter 与 Cloudera 联合开发,旨在提供高效的压缩与编码方案以支持大规模复杂数据的快速分析与处理。Parquet 文件采用分离式元数据设计 —— 在数据写入完成后,再追加文件级…...
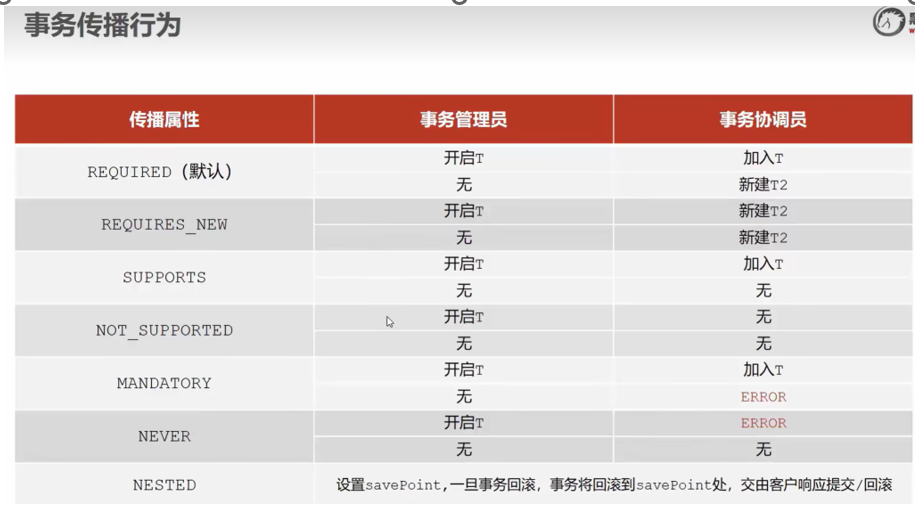
Spring 事务管理核心机制与传播行为应用
Spring 事务详解 一、Spring 事务简介 Spring 事务管理基于 AOP(面向切面编程)实现,通过 声明式事务(注解或 XML 配置)统一管理数据库操作,确保数据一致性。核心目标:保证多个数据库操作的原子…...

从零开始解剖Spring Boot启动流程:一个Java小白的奇幻冒险之旅
大家好呀!今天我们要一起探索一个神奇的话题——Spring Boot的启动流程。我知道很多小伙伴一听到"启动流程"四个字就开始头疼,别担心!我会用最通俗易懂的方式,带你从main()方法开始,一步步揭开Spring Boot的…...

集合框架(重点)
1. 什么是集合框架 List有序插入对象,对象可重复 Set无序插入对象,对象不可重复(重复对象插入只会算一个) Map无序插入键值对象,键只唯一,值可多样 (这里的有序无序指的是下标,可…...
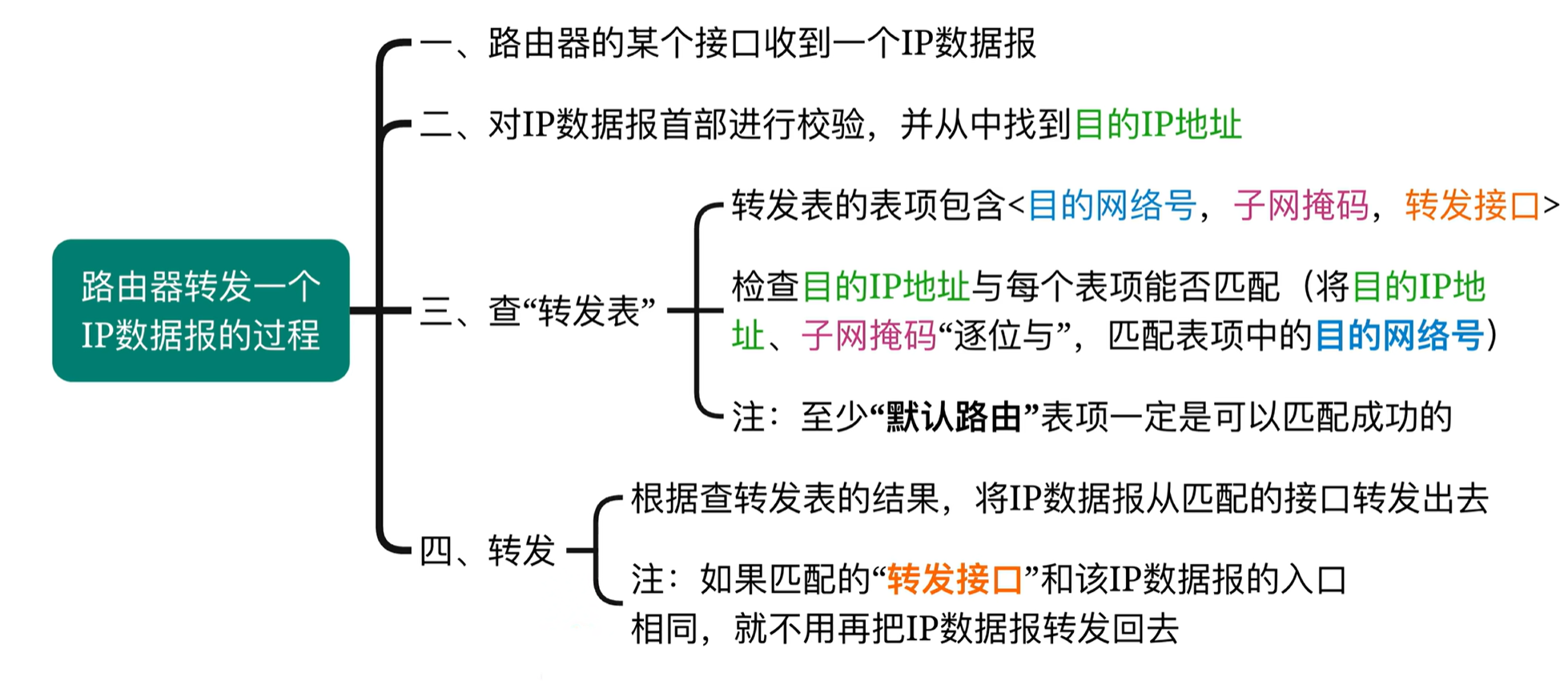
IPv4地址分类与常用网络地址详解
常见的 IPv4 地址分类: 1. A 类地址(Class A) 范围:0.0.0.0 到 127.255.255.255 默认子网掩码:255.0.0.0 或 /8 用途:通常用于大型网络,例如大型公司、组织。 特点: 网络地址范围…...
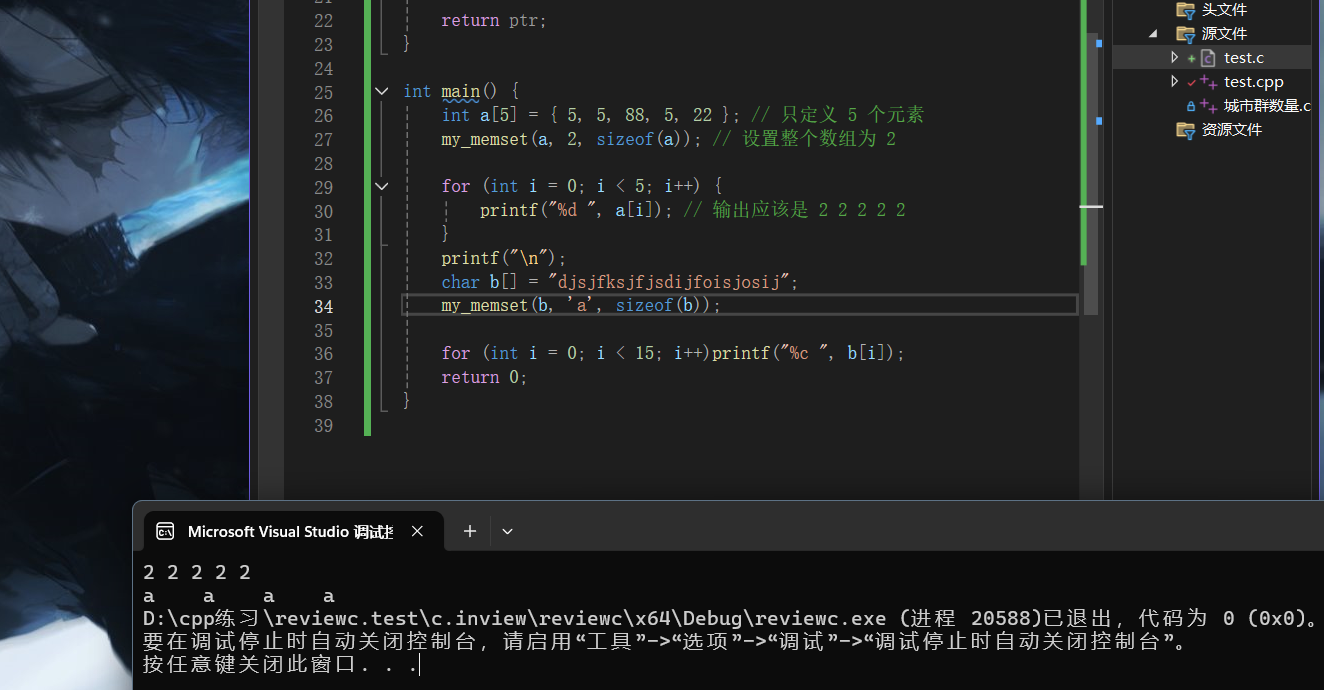
模拟实现memmove,memcpy,memset
目录 前言 一、模拟实现memmove 代码演示: 二、模拟实现memcpy 代码演示: 三、模拟实现memset 代码演示: 总结 前言 这篇文章主要讲解了库函数的模拟实现,包含memmove,memcpy,memset 一、模拟实现m…...
等权限,未同步告知权限申请的使用目的,不符合相关法律法规要求)
uni-app 开发安卓 您的应用在运行时,向用户索取(定位、相机、存储)等权限,未同步告知权限申请的使用目的,不符合相关法律法规要求
您的应用在运行时,向用户索取(定位、相机、存储)等权限,未同步告知权限申请的使用目的,不符合相关法律法规要求。 测试步骤:1、 工作台 -打卡,申请定位权限;2、工作台-设置-编辑资料-更换头像,申请相机、存 储权限。 修改建议:APP在申请敏感权限时,应同步说明权限申…...

RHCSA Linux 系统文件内容显示2
6. 过滤文件内容显示 grep (1)功能:在指定普通文件中查找并显示含指定字符串的行,也可与管道符连用。 (2)格式:grep 选项... 关键字字符串 文件名... (3)常用选项及说…...

C语言状态字与库函数详解:概念辨析与应用实践
C语言状态字与库函数详解:概念辨析与应用实践 一、状态字与库函数的核心概念区分 在C语言系统编程中,"状态字"和"库函数"是两个经常被混淆但本质完全不同的概念,理解它们的区别是掌握系统编程的基础。 1. 状态字&…...
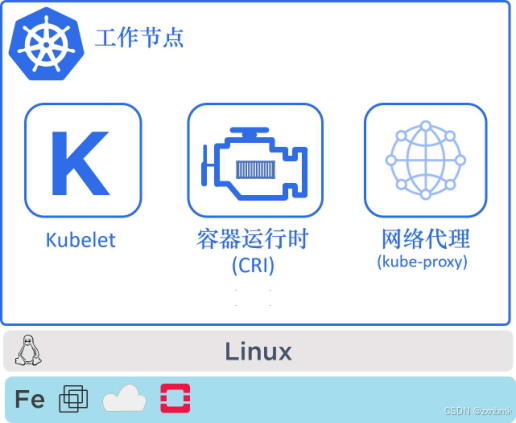
【2】Kubernetes 架构总览
Kubernetes 架构总览 主节点与工作节点 主节点 Kubernetes 的主节点(Master)是组成集群控制平面的关键部分,负责整个集群的调度、状态管理和决策。控制平面由多个核心组件构成,包括: kube-apiserver:集…...

Redis下载
目录 安装包 1、使用.msi方式安装 2.使用zip方式安装【推荐方式】 添加环境变量 配置后台运行 启动: 1.startup.cmd的文件 2.cmd窗口运行 3.linux源码安装 (1)准备安装环境 (2)上传安装文件 (3&…...

React 文章 分页
删除功能 携带路由参数跳转到新的路由项 const navigate useNavigate() 根据文章ID条件渲染...