Python 深度学习实战 第11章 自然语言处理(NLP)实例
Python 深度学习实战 第11章 自然语言处理(NLP)实例
内容概要
第11章深入探讨了自然语言处理(NLP)的深度学习应用,涵盖了从文本预处理到序列到序列学习的多种技术。本章通过IMDB电影评论情感分类和英西翻译任务,详细介绍了如何使用循环神经网络(RNN)、卷积神经网络(CNN)和Transformer架构来处理文本数据。读者将掌握如何使用深度学习解决文本分类和序列到序列问题,并理解Transformer的工作原理。

主要内容
-
文本预处理
- 文本标准化:将文本转换为小写、去除标点等。
- 分词(Tokenization):将文本分割为单词或短语。
- 词汇索引:将每个词转换为数值表示。
- TextVectorization层:使用Keras的TextVectorization层进行高效文本预处理。
-
文本表示方法
- 词袋模型(Bag-of-Words):将文本视为单词集合,忽略顺序。
- 序列模型:处理单词顺序,适用于RNN、CNN和Transformer。
-
词嵌入(Word Embeddings)
- 学习词嵌入:使用Embedding层学习词向量。
- 预训练词嵌入:加载如GloVe等预训练词嵌入。
-
Transformer架构
- 自注意力机制(Self-Attention):通过计算词之间的相关性生成上下文感知的词表示。
- 多头注意力(Multi-Head Attention):将自注意力机制分解为多个独立的子空间。
- Transformer编码器(TransformerEncoder):结合自注意力和前馈网络。
- 位置编码(Positional Encoding):向模型注入词序信息。
-
序列到序列学习
- RNN序列到序列模型:使用GRU或LSTM进行序列到序列任务。
- Transformer序列到序列模型:结合Transformer编码器和解码器进行机器翻译。
关键代码和算法
1.1 文本标准化和分词
import string
import tensorflow as tfdef custom_standardization_fn(string_tensor):lowercase_string = tf.strings.lower(string_tensor)return tf.strings.regex_replace(lowercase_string, f"[{re.escape(string.punctuation)}]", "")def custom_split_fn(string_tensor):return tf.strings.split(string_tensor)text_vectorization = tf.keras.layers.TextVectorization(output_mode="int",standardize=custom_standardization_fn,split=custom_split_fn
)dataset = ["I write, erase, rewrite","Erase again, and then","A poppy blooms.",
]text_vectorization.adapt(dataset)
1.2 词袋模型(二元编码)
text_vectorization = tf.keras.layers.TextVectorization(max_tokens=20000,output_mode="multi_hot"
)text_only_train_ds = train_ds.map(lambda x, y: x)
text_vectorization.adapt(text_only_train_ds)
binary_1gram_train_ds = train_ds.map(lambda x, y: (text_vectorization(x), y))def get_model(max_tokens=20000, hidden_dim=16):inputs = tf.keras.Input(shape=(max_tokens,))x = tf.keras.layers.Dense(hidden_dim, activation="relu")(inputs)x = tf.keras.layers.Dropout(0.5)(x)outputs = tf.keras.layers.Dense(1, activation="sigmoid")(x)model = tf.keras.Model(inputs, outputs)model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"])return modelmodel = get_model()
model.fit(binary_1gram_train_ds.cache(), validation_data=val_ds, epochs=10)
1.3 序列模型(嵌入层和双向LSTM)
max_length = 600
max_tokens = 20000
text_vectorization = tf.keras.layers.TextVectorization(max_tokens=max_tokens,output_mode="int",output_sequence_length=max_length
)
text_vectorization.adapt(text_only_train_ds)inputs = tf.keras.Input(shape=(None,), dtype="int64")
embedded = tf.keras.layers.Embedding(input_dim=max_tokens, output_dim=256)(inputs)
x = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32))(embedded)
x = tf.keras.layers.Dropout(0.5)(x)
outputs = tf.keras.layers.Dense(1, activation="sigmoid")(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"])model.fit(int_train_ds, validation_data=int_val_ds, epochs=10)
1.4 Transformer编码器
class TransformerEncoder(tf.keras.layers.Layer):def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):super().__init__(**kwargs)self.embed_dim = embed_dimself.dense_dim = dense_dimself.num_heads = num_headsself.attention = tf.keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)self.dense_proj = tf.keras.Sequential([tf.keras.layers.Dense(dense_dim, activation="relu"), tf.keras.layers.Dense(embed_dim)])self.layernorm_1 = tf.keras.layers.LayerNormalization()self.layernorm_2 = tf.keras.layers.LayerNormalization()def call(self, inputs, mask=None):if mask is not None:mask = mask[:, tf.newaxis, :]attention_output = self.attention(inputs, inputs, attention_mask=mask)proj_input = self.layernorm_1(inputs + attention_output)proj_output = self.dense_proj(proj_input)return self.layernorm_2(proj_input + proj_output)vocab_size = 20000
embed_dim = 256
num_heads = 2
dense_dim = 32
inputs = tf.keras.Input(shape=(None,), dtype="int64")
x = tf.keras.layers.Embedding(vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = tf.keras.layers.GlobalMaxPooling1D()(x)
x = tf.keras.layers.Dropout(0.5)(x)
outputs = tf.keras.layers.Dense(1, activation="sigmoid")(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"])model.fit(int_train_ds, validation_data=int_val_ds, epochs=20)
1.5 Transformer序列到序列模型
class TransformerDecoder(tf.keras.layers.Layer):def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):super().__init__(**kwargs)self.embed_dim = embed_dimself.dense_dim = dense_dimself.num_heads = num_headsself.attention_1 = tf.keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)self.attention_2 = tf.keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)self.dense_proj = tf.keras.Sequential([tf.keras.layers.Dense(dense_dim, activation="relu"), tf.keras.layers.Dense(embed_dim)])self.layernorm_1 = tf.keras.layers.LayerNormalization()self.layernorm_2 = tf.keras.layers.LayerNormalization()self.layernorm_3 = tf.keras.layers.LayerNormalization()self.supports_masking = Truedef get_causal_attention_mask(self, inputs):input_shape = tf.shape(inputs)batch_size, sequence_length = input_shape[0], input_shape[1]i = tf.range(sequence_length)[:, tf.newaxis]j = tf.range(sequence_length)mask = tf.cast(i >= j, dtype="int32")mask = tf.reshape(mask, (1, input_shape[1], input_shape[1]))mult = tf.concat([tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)], axis=0)return tf.tile(mask, mult)def call(self, inputs, encoder_outputs, mask=None):causal_mask = self.get_causal_attention_mask(inputs)if mask is not None:padding_mask = tf.cast(mask[:, tf.newaxis, :], dtype="int32")padding_mask = tf.minimum(padding_mask, causal_mask)attention_output_1 = self.attention_1(query=inputs, value=inputs, key=inputs, attention_mask=causal_mask)attention_output_1 = self.layernorm_1(inputs + attention_output_1)attention_output_2 = self.attention_2(query=attention_output_1, value=encoder_outputs, key=encoder_outputs, attention_mask=padding_mask)attention_output_2 = self.layernorm_2(attention_output_1 + attention_output_2)proj_output = self.dense_proj(attention_output_2)return self.layernorm_3(attention_output_2 + proj_output)embed_dim = 256
dense_dim = 2048
num_heads = 8
encoder_inputs = tf.keras.Input(shape=(None,), dtype="int64", name="english")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(encoder_inputs)
encoder_outputs = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
decoder_inputs = tf.keras.Input(shape=(None,), dtype="int64", name="spanish")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(decoder_inputs)
x = TransformerDecoder(embed_dim, dense_dim, num_heads)(x, encoder_outputs)
x = tf.keras.layers.Dropout(0.5)(x)
decoder_outputs = tf.keras.layers.Dense(vocab_size, activation="softmax")(x)
transformer = tf.keras.Model([encoder_inputs, decoder_inputs], decoder_outputs)
transformer.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
transformer.fit(train_ds, epochs=30, validation_data=val_ds)
精彩语录
-
中文:自然语言的“规则”是在事实之后才形成的,这使得它与机器语言不同。
英文原文:Natural language was shaped by an evolution process, much like biological organisms—that’s what makes it “natural.” Its “rules,” like the grammar of English, were formalized after the fact and are often ignored or broken by its users.
解释:这句话强调了自然语言的动态特性和与机器语言的区别。 -
中文:机器学习的目标是让模型从数据中学习有用特征,而不是手动设计规则。
英文原文:When you find yourself building systems that are big piles of ad hoc rules, as a clever engineer, you’re likely to start asking: “Could I use a corpus of data to automate the process of finding these rules? Could I search for the rules within some kind of rule space, instead of having to come up with them myself?”
解释:这句话介绍了机器学习在自然语言处理中的重要性。 -
中文:Transformer架构通过注意力机制实现了序列到序列任务的革命性进展。
英文原文:The Transformer architecture, which consists of a TransformerEncoder and a TransformerDecoder, yields excellent results on sequence-to-sequence tasks.
解释:这句话总结了Transformer架构的核心优势。 -
中文:词嵌入将单词的语义关系建模为向量空间中的距离关系。
英文原文:Word embeddings are vector spaces where semantic relationships between words are modeled as distance relationships between vectors that represent those words.
解释:这句话介绍了词嵌入的基本概念。 -
中文:序列到序列学习是一个强大的框架,适用于多种NLP任务。
英文原文:Sequence-to-sequence learning is a generic, powerful learning framework that can be applied to solve many NLP problems, including machine translation.
解释:这句话强调了序列到序列学习的广泛适用性。
总结
通过本章的学习,读者将掌握文本的深度学习处理方法,包括如何使用词袋模型、序列模型和Transformer架构进行文本分类和序列到序列任务。这些知识将为解决实际问题提供强大的工具。
相关文章:
Python 深度学习实战 第11章 自然语言处理(NLP)实例
Python 深度学习实战 第11章 自然语言处理(NLP)实例 内容概要 第11章深入探讨了自然语言处理(NLP)的深度学习应用,涵盖了从文本预处理到序列到序列学习的多种技术。本章通过IMDB电影评论情感分类和英西翻译任务,详细介绍了如何使…...
:Matplotlib 高级图表定制 - 精雕细琢,让你的图表脱颖而出!)
零基础上手Python数据分析 (19):Matplotlib 高级图表定制 - 精雕细琢,让你的图表脱颖而出!
写在前面 —— 超越默认样式,掌握 Matplotlib 精细控制,打造专业级可视化图表 上一篇博客,我们学习了 Matplotlib 的基础绘图功能,掌握了如何绘制常见的折线图、柱状图、散点图和饼图,并进行了基本的图表元素定制,例如添加标题、标签、图例等。 这些基础技能已经能让我…...
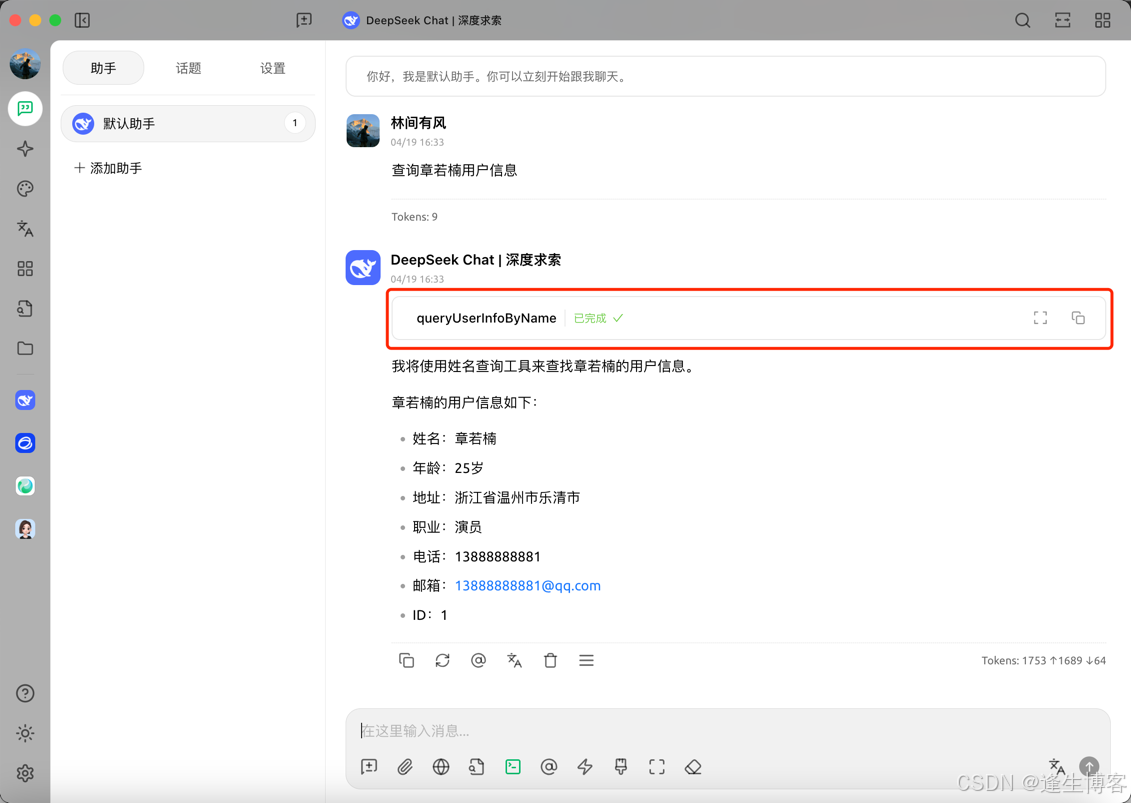
将 DeepSeek 集成到 Spring Boot 项目实现通过 AI 对话方式操作后台数据
文章目录 项目简介本项目分两大模块 GiteeMCP 简介环境要求项目代码核心实现代码MCP 服务端MCP 客户端 DeepSeek APIDockersse 连接ws 连接(推荐)http 连接 vue2-chat-windowCherry Studio配置模型配置 MCP调用 MCP 项目简介 在本项目中,我们…...
《前端面试题之 Vue 篇(第三集)》
目录 1、 nvm的常用命令①.Node.js 版本与 npm 版本的对应关系②Vue2 与 Vue3 项目的 Node.js 版本分界线③版本管理实践建议 2、Vue2 项目搭建(基于 vue-cli Webpack)① 环境准备② 安装 Vue CLI(脚手架)③.创建项目(…...

PHP实现图片自动添加水印效果
<?php // 设置原始图片路径和水印图片路径 $original_image original.jpg; $watermark_image watermark.png;// 创建图片资源 $original imagecreatefromjpeg($original_image); $watermark imagecreatefrompng($watermark_image);// 获取图片尺寸 $original_width im…...

嵌入式C语言位操作的几种常见用法
作为一名老单片机工程师,我承认,当年刚入行的时候,最怕的就是看那些密密麻麻的寄存器定义,以及那些让人眼花缭乱的位操作。 尤其是遇到那种“明明改了寄存器,硬件就是不听话”的情况,简直想把示波器砸了&am…...
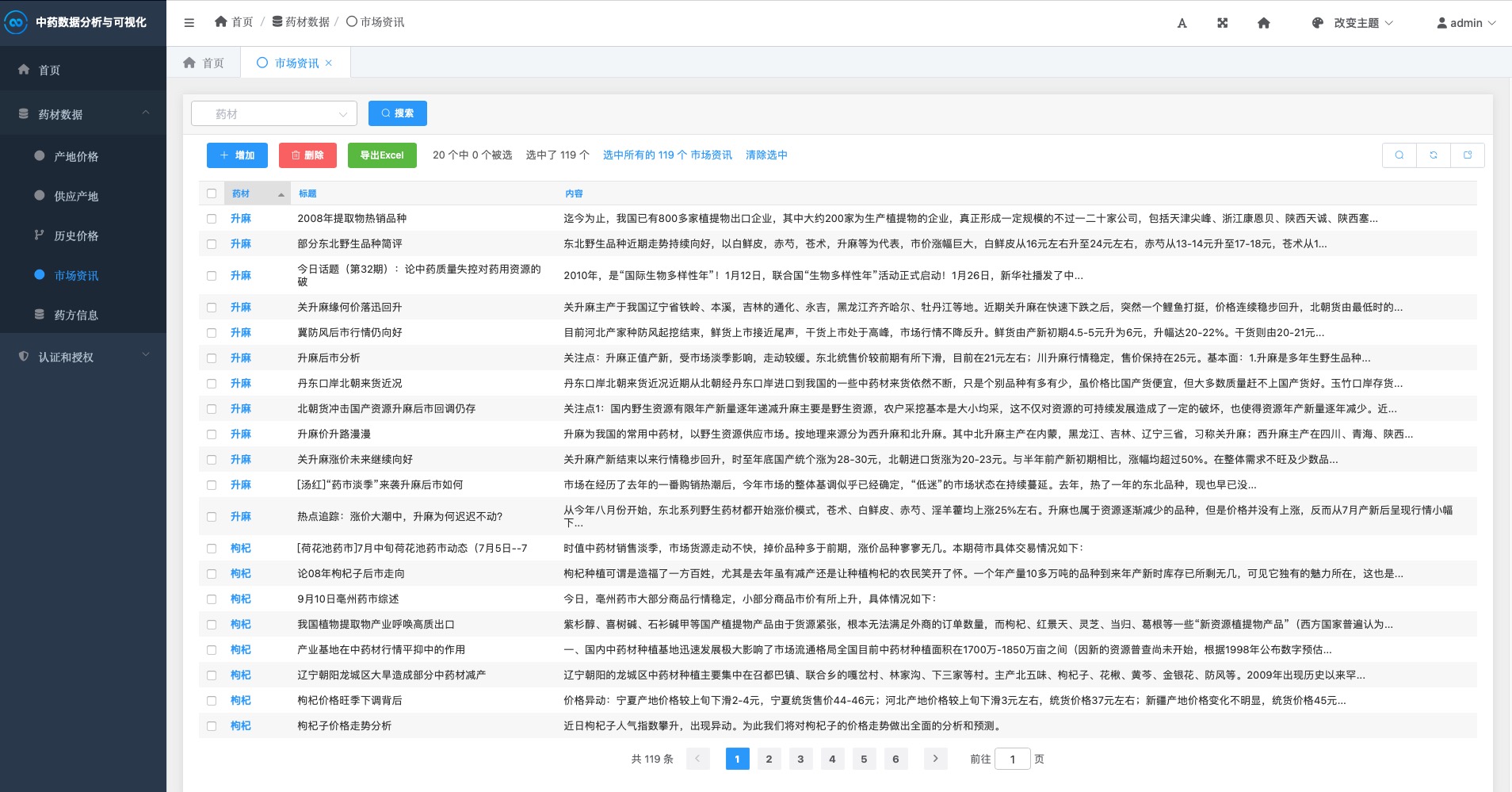
基于Djiango实现中药材数据分析与可视化系统
中药材数据分析与可视化系统 项目截图 登录 注册 首页 药材Top20 药材价格 产地占比 历史价格 新闻资讯 后台管理 一、项目概述 中药材数据分析与可视化系统是一个基于Django框架开发的专业Web应用,致力于对各类中药材数据进行全面、系统的采集、分析和可视化展示…...
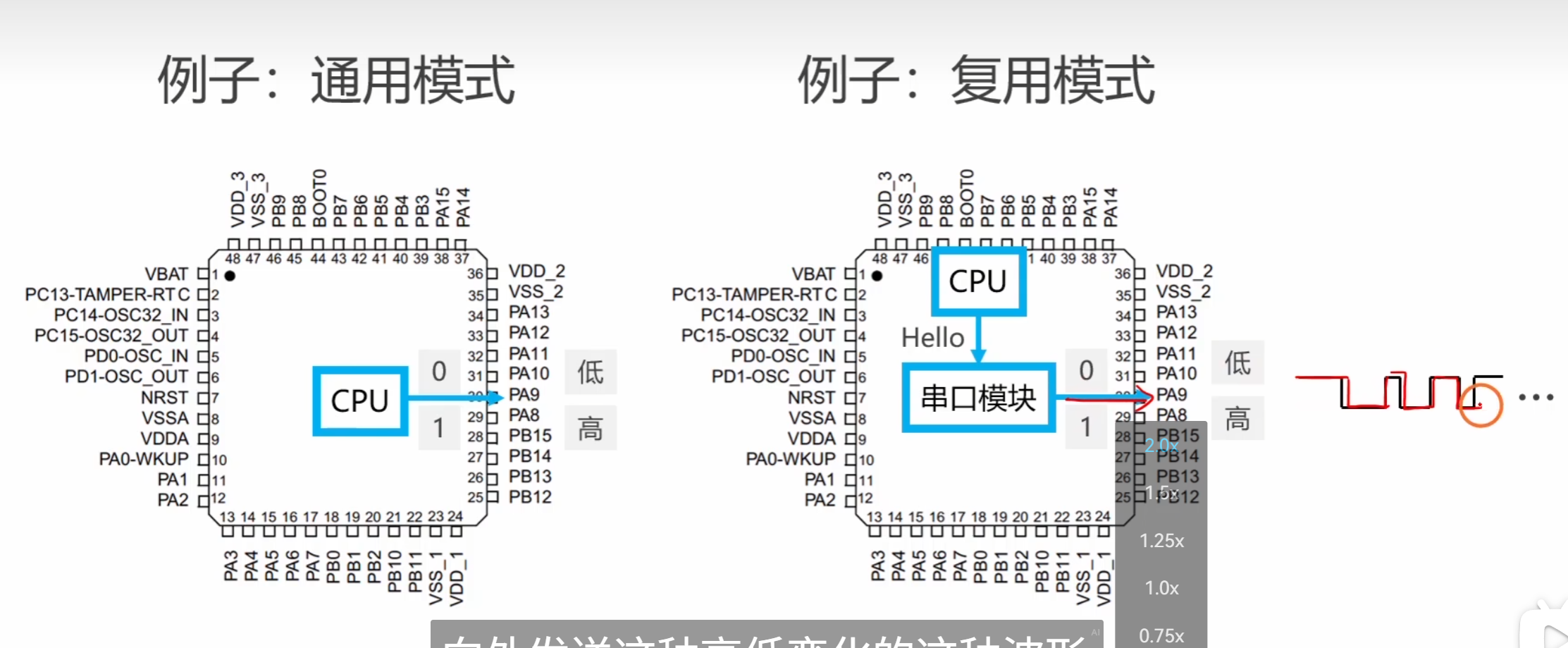
stm32(gpio的四种输出)
其实GPIO这个片上外设的功能: 用于控制IO引脚。 CPU就如同大脑,而这些片上外设就如同四肢一样的关系 如图 —————————————————————————————— OK类比了以上 其实GPIO是有 八种工作模式的 这八种工作模式 因为GPIO是面向IO…...
案例分析与简答题、详细解析与评分要点)
系统架构设计师:计算机组成与体系结构(如CPU、存储系统、I/O系统)案例分析与简答题、详细解析与评分要点
计算机组成与体系结构 10道案例分析与简答题 案例分析题(5道) 1. Cache映射与主存编址计算 场景:某计算机系统采用32位地址总线,主存容量为4GB,Cache容量为512KB,块大小为64B,使用4路组相联映射…...
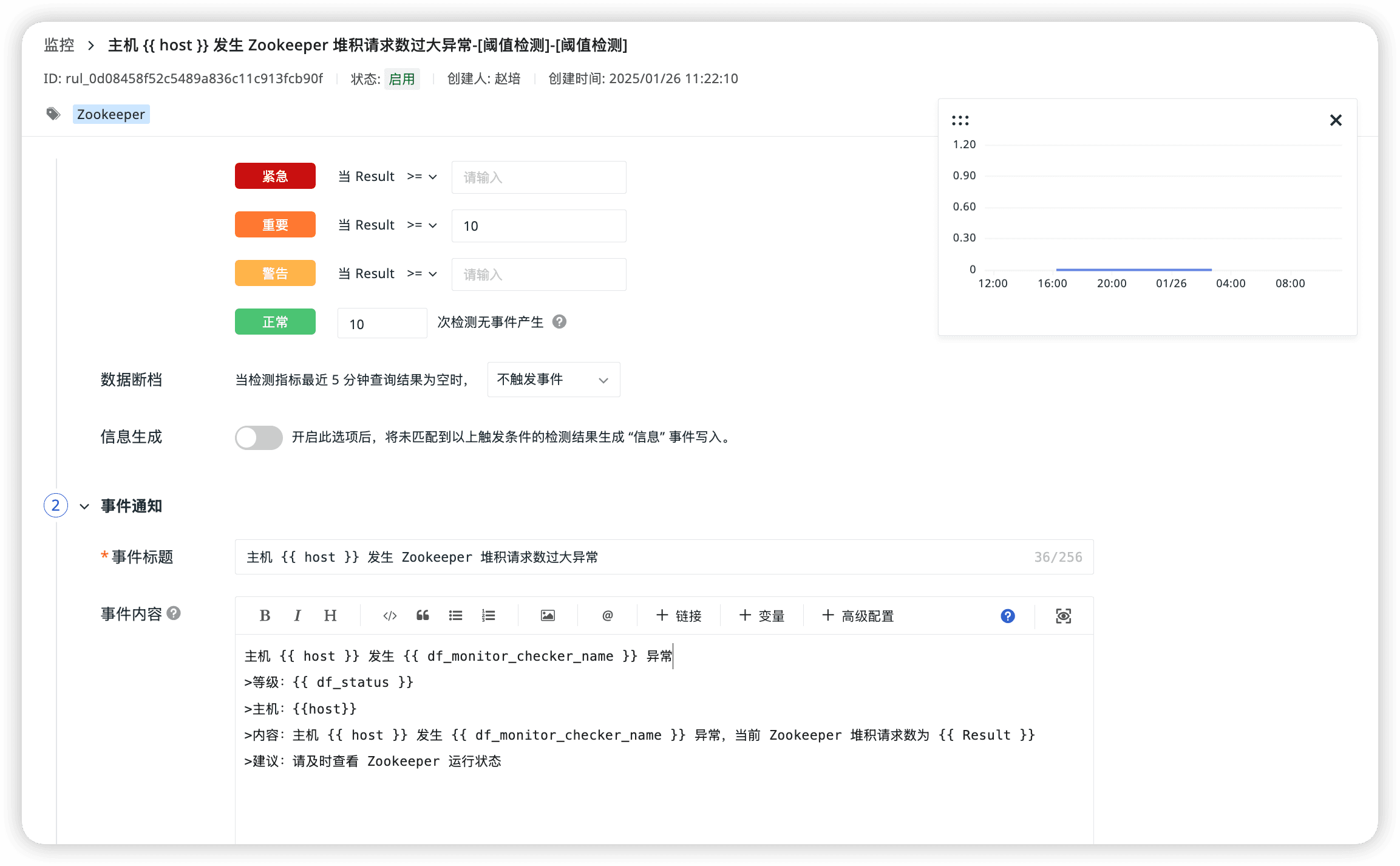
Zookeeper 可观测性最佳实践
Zookeeper 介绍 ZooKeeper 是一个开源的分布式协调服务,用于管理和协调分布式系统中的节点。它提供了一种高效、可靠的方式来解决分布式系统中的常见问题,如数据同步、配置管理、命名服务和集群管理等。本文介绍通过 DataKit 采集 Zookeeper 指标&#…...

位运算---总结
位运算 基础 1. & 运算符 : 有 0 就是 0 2. | 运算符 : 有 1 就是 1 3. ^ 运算符 : 相同为0 相异为1 and 无进位相加位运算的优选级 不用在意优先级,能加括号就加括号给一个数 n ,确定它的二进制位中第 x 位是 0 还是 1? 规定: 题中所说的第x位指:int 在32位机器下4个…...

2. 什么是最普通的自动化“裸奔状态”?
什么是最普通的自动化"裸奔状态"?从大厂案例看测试代码的生存困境 一个典型的"裸奔代码"示例 # 打开目标网站 driver.get(http://test-site.com/login-page)# 登录操作 driver.find_element_by_id(user).send_keys(tester) driver.find_eleme…...
)
头歌java课程实验(函数式接口及lambda表达式)
第1关:利用lambda表达式对Book数组按多个字段进行排序 任务描述 本关任务:利用Comparator接口完成对Book数组同时按多个字段进行排序。 编程要求 1、本任务共有三个文件,可查看各文件的内容 2、无需修改SortBy.java枚举文件及Book.java类文…...

微信小程序三种裁剪动画有效果图
效果图 .wxml <image class"img inset {{status?action1:}}" src"{{src}}" /> <image class"img circle {{status?action2:}}" src"{{src}}" /> <image class"img polygon {{status?action3:}}" src&quo…...
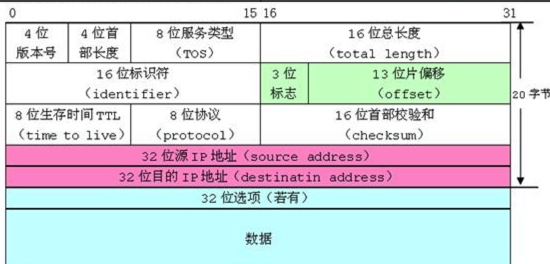
C语言笔记(鹏哥)上课板书+课件汇总(结构体)-----数据结构常用
结构体 目录: 1、结构体类型声明 2、结构体变量的创建和初始化 3、结构体成员访问操作符 4、结构体内存对齐*****(重要指数五颗星) 5、结构体传参 6、结构体实现位段 一、结构体类型声明 其实在指针中我们已经讲解了一些结构体内容了&…...
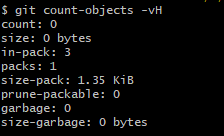
git清理--解决.git文件过大问题
背景:为什么.git比我仓库中的文件大很多 为什么我的git中只有一个1KB的README,但是.git却又1G多?当我想把这个git库push到gitee时,还会报错: 根据报错信息,可看出失败的原因是:有文件的大小超过…...

Jetson Orin NX 部署YOLOv12笔记
步骤一.创建虚拟环境 conda create -n yolov12 python3.8.20 注意:YOLOv12/YOLOv11/YOLOv10/YOLOv9/YOLOv8/YOLOv7a/YOLOv5 环境通用 步骤二.激活虚拟环境 conda activate yolov12 #激活环境 步骤三.查询Jetpack出厂版本 Jetson系列平台各型号支持的最高Jetp…...
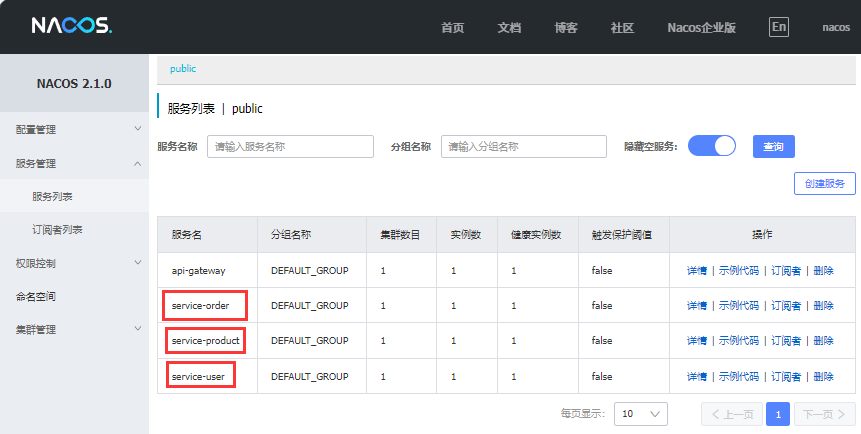
微服务2--服务治理与服务调用
前言 :本文主要阐述微服务架构中的服务治理,以及Nacos环境搭建、服务注册、服务调用,负载均衡以及Feign实现服务调用。 服务治理 服务治理是微服务架构中最核心最基本的模块。用于实现各个微服务的自动化注册与发现。 服务注册:在…...

Arduino示例代码讲解:Project 08 - Digital Hourglass 数字沙漏
Arduino示例代码讲解:Project 08 - Digital Hourglass 数字沙漏 Project 08 - Digital Hourglass 数字沙漏程序功能概述功能:硬件要求:输出:代码结构全局变量`setup()` 函数`loop()` 函数计时和点亮LED:读取倾斜开关状态:重置LED和计时器:运行过程注意事项Project 08 - …...

python生成项目依赖文件requirements.txt
文章目录 通过pip freeze去生成通过pipreqs去生成 通过pip freeze去生成 pip freeze > requirements.txt会将整个python的Interceptor的环境下lib包下所有的依赖都生成到这个文件当中,取决于我们使用的python的版本下所有的安装包。不建议使用这种方式ÿ…...
C语言之高校学生信息快速查询系统的实现
🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 C语言之高校学生信息快速查询系统的实现 目录 任务陈述与分析 问题陈述问题分析 数据结构设…...
:打破创业幻想,拥抱数据驱动)
精益数据分析(7/126):打破创业幻想,拥抱数据驱动
精益数据分析(7/126):打破创业幻想,拥抱数据驱动 在创业的道路上,我们都怀揣着梦想,但往往容易陷入自我编织的幻想中。我希望通过和大家一起学习《精益数据分析》,能帮助我们更清醒地认识创业过…...
Spring Boot 项目中发布流式接口支持实时数据向客户端推送
1、pom依赖添加 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency>2、事例代码 package com.pojo.prj.controller;import com.pojo.common.core.utils.String…...

Ubuntu安装MySQL步骤及注意事项
一、安装前准备 1. 系统更新:在安装 MySQL 之前,确保你的 Ubuntu 系统软件包是最新的,这能避免因软件包版本问题导致的安装错误,并获取最新的安全补丁。打开终端,执行以下两条命令: sudo apt update sudo …...

【网络篇】从零写UDP客户端/服务器:回显程序源码解析
大家好呀 我是浪前 今天讲解的是网络篇的第四章:从零写UDP客户端/服务器:回显程序源码解析 从零写UDP客户端/服务器:回显程序源码解析 UDP 协议特性核心类介绍 UDP的socket应该如何使用:1: DatagramSocket2: DatagramPacket回…...
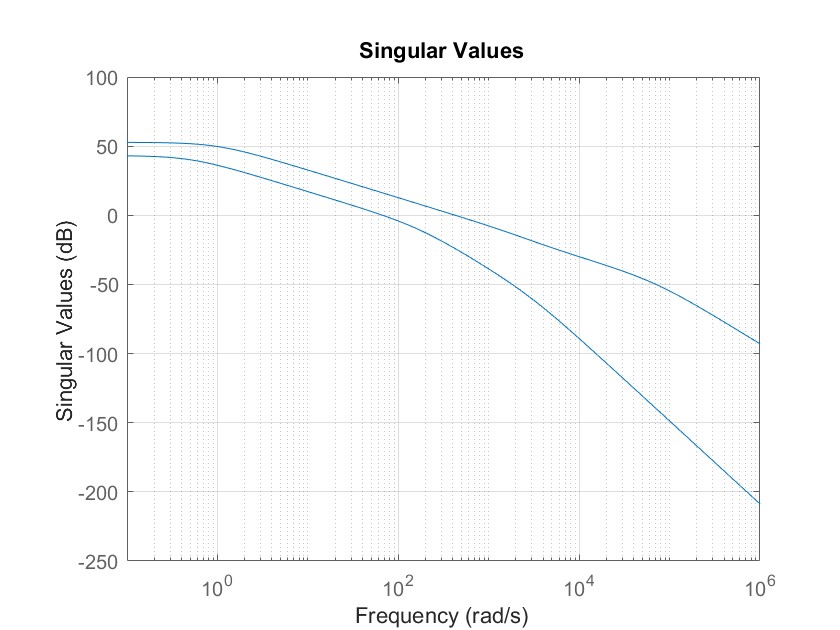
MATLAB 控制系统设计与仿真 - 38
多变量系统控制器设计实例1 考虑如下给出的多变量系统模型: 考虑混合灵敏度问题,引入加权矩阵: 设计鲁棒控制器,并绘制闭环系统的阶跃响应曲线及开环系统的奇异值曲线。 MATLAB代码如下: clear all;clc; stf(s); g1…...

轻量化高精度的视频语义分割
Video semantic segmentation (VSS)视频语义分割 Compact Models(紧凑模型) 在深度学习中,相对于传统模型具有更小尺寸和更少参数数量的模型。这些模型的设计旨在在保持合理性能的同时,减少模型的计算和存储成本。 紧凑模型的设计可以涉及以下一些技术: 深度剪枝(Deep…...

Spring Boot 版本与对应 JDK 版本兼容性
Spring Boot 版本与对应 JDK 版本兼容性 以下是 Spring Boot 主要版本与所需 JDK 版本的对应关系,以及长期支持(LTS)信息: 最新版本对应关系 (截至2024年) Spring Boot 版本发布日期支持的 JDK 版本备注3.2.x (最新)2023-11JDK 17-21推荐使用 JDK 173…...

[密码学实战]详解gmssl库与第三方工具兼容性问题及解决方案
[密码学实战]详解gmssl库与第三方工具兼容性问题及解决方案 引言 国密算法(SM2/SM3/SM4)在金融、政务等领域广泛应用,但开发者在集成gmssl库实现SM2签名时,常遇到与第三方工具(如OpenSSL、国密网关)验证不…...

JavaScript模块化开发:CommonJS、AMD到ES模块
引言 在Web开发的早期阶段,JavaScript代码通常被编写在一个庞大的文件中或分散在多个脚本标签里,这种方式导致了全局变量污染、依赖关系难以管理、代码复用困难等问题。随着Web应用日益复杂,模块化编程成为了解决这些问题的关键。本文将带您…...