基于Canal+Spring Boot+Kafka的MySQL数据变更实时监听实战指南
前期知识背景
binlog
什么是binlog
它记录了所有的DDL和DML(除 了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的。一般来说开启二进制日志大概会有1%的性能损耗。
binlog分类
MySQL Binlog的格式有三种,分别是STATEMENT,MIXED,ROW。在配置文件可以选择配置:binlog_format= statement|mixed|row
statement
binlog 会记录每次一执行写操作的语句。相对row模式节省空间,但是可能产生不一致性,比如“update tt set create_date=now()”, 如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点:节省空间。
缺点:有可能造成数据不一致。
row
binlog会记录每次操作前后每行记录的变化。
优点:保持数据的绝对一致性。
缺点:占用较大空间。
mixed
以上两种结合
综合上面对比,Canal想做监控分析,选择row格式比较合适。
binlog查看命令
#查看binlog日志是否开启
SHOW VARIABLES LIKE 'log_bin';#查看binlog模式
SHOW VARIABLES LIKE 'binlog_format';#查看binlog写入的二进制日志文件的名称和偏移量(Position)
SHOW MASTER STATUS;


canal
介绍
Canal,译意为水道/管道/沟渠,主要用途是基于M小ySQL数据库增量日志解析,提供增量数据订阅和消费。同步增量数据的一个工具
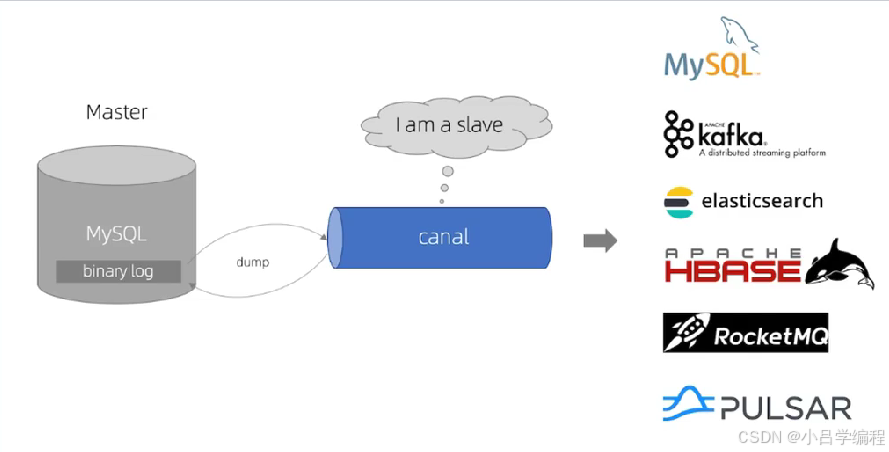
应用场景
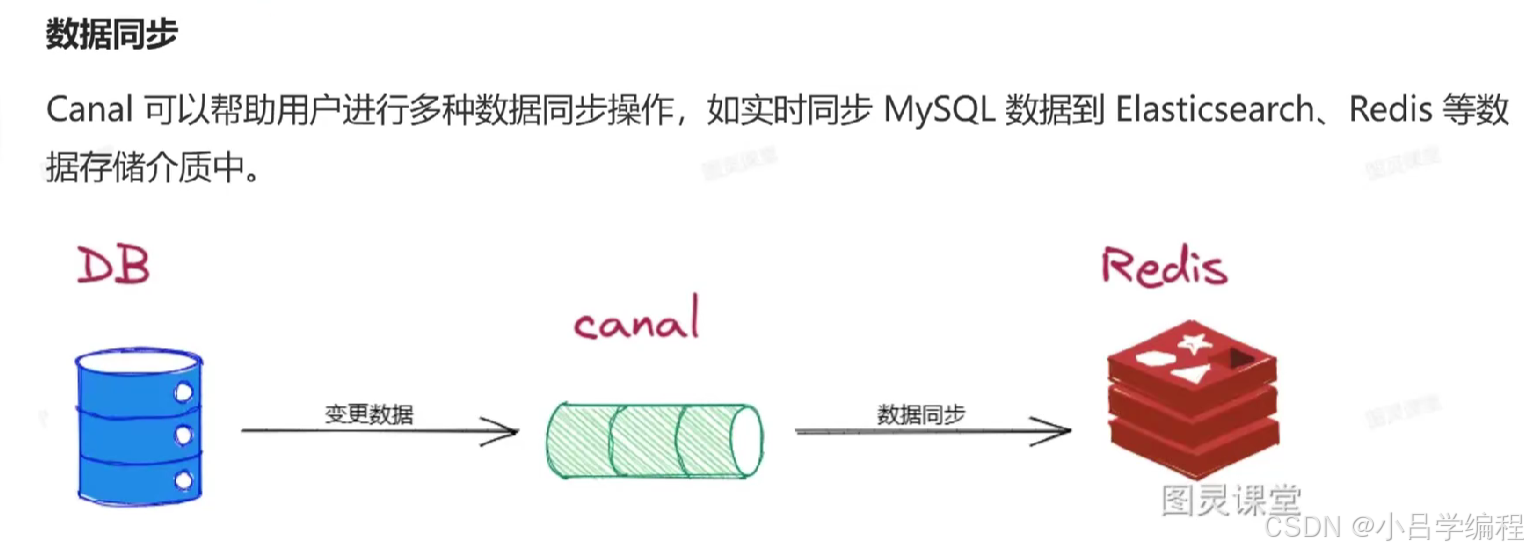
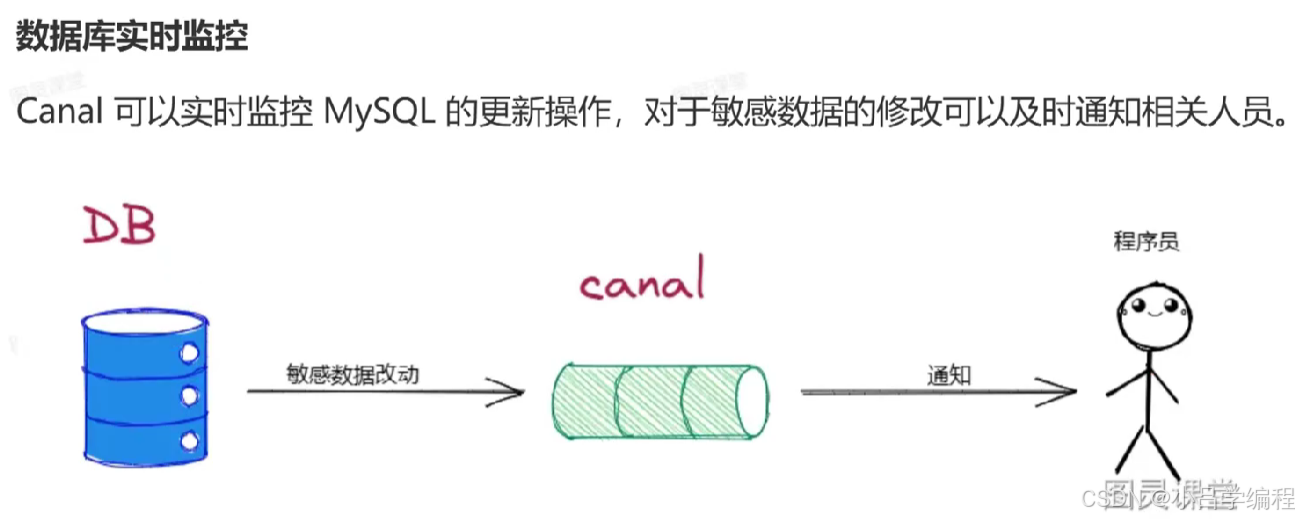
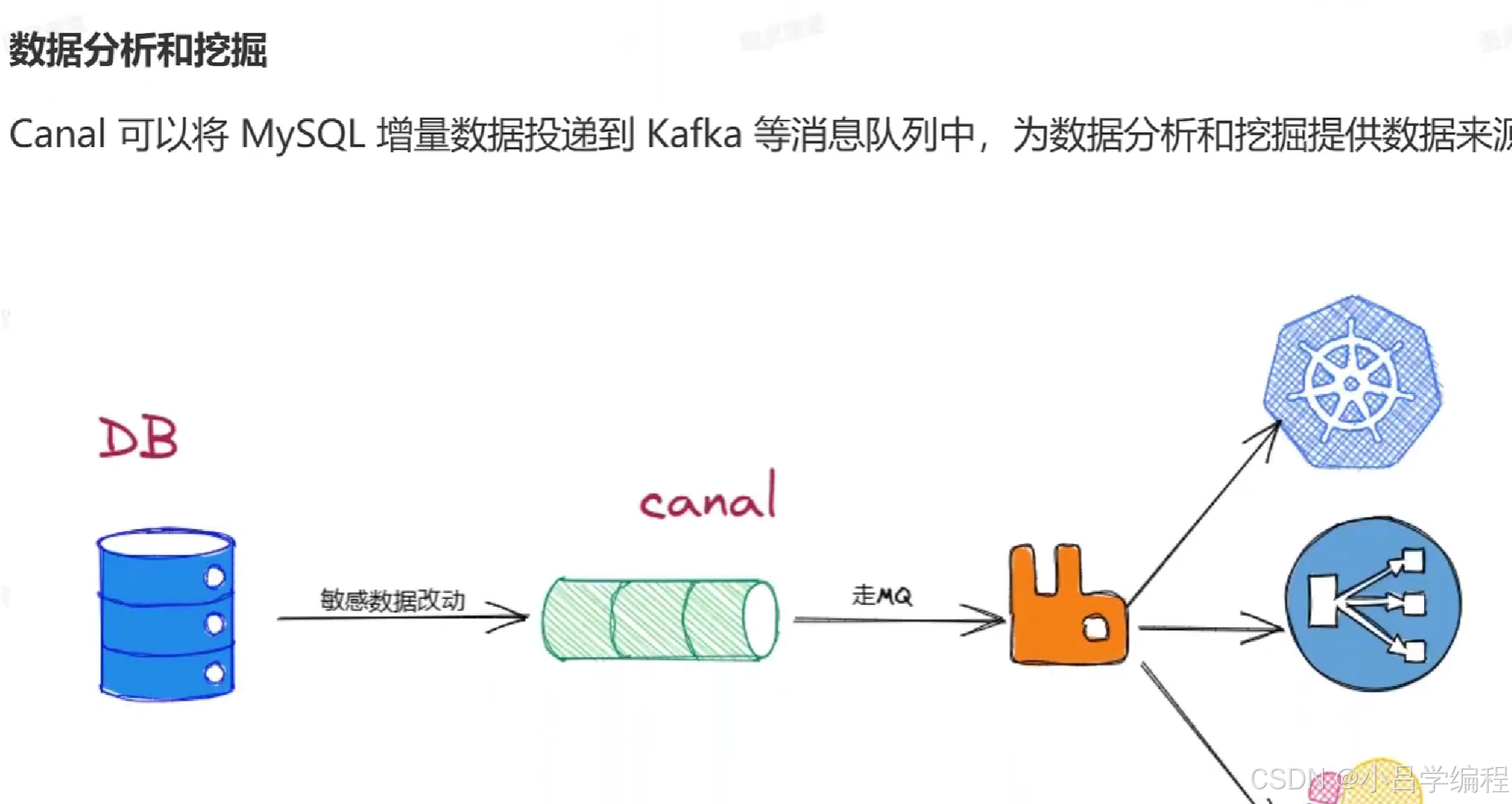
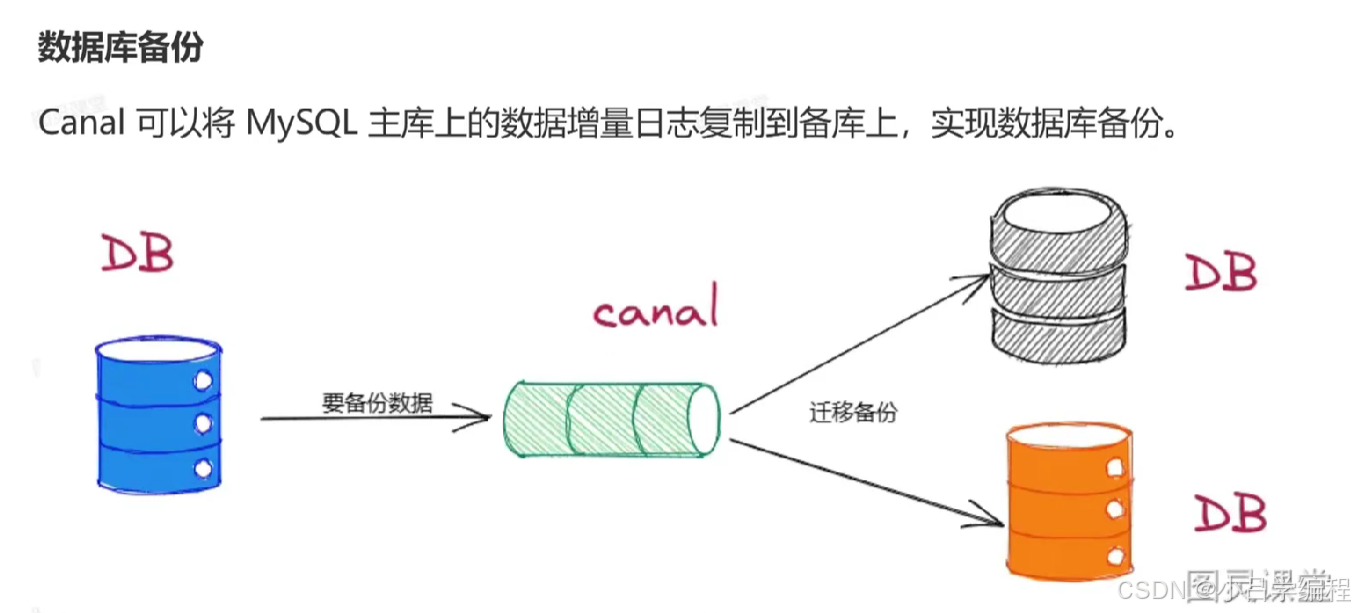
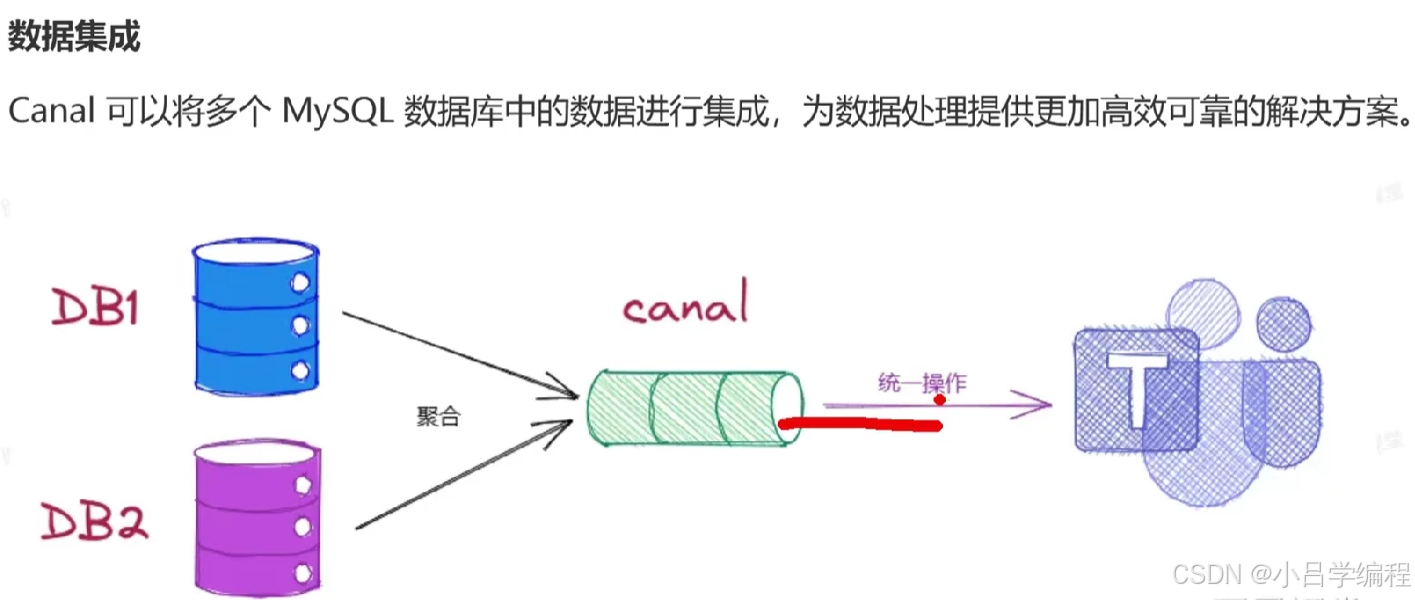
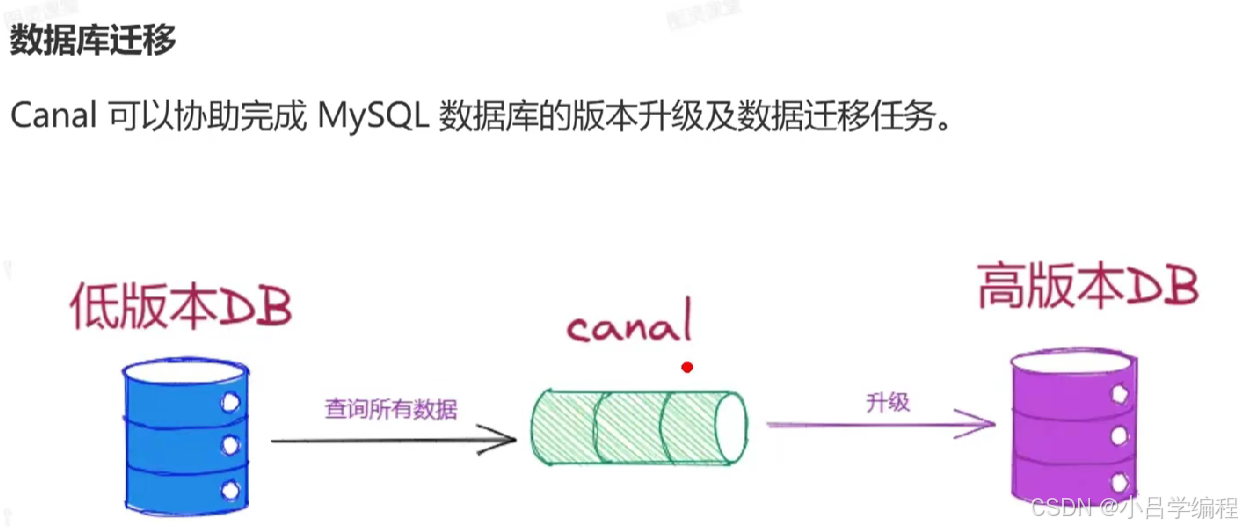
安装
windows版本
kafka和zookepeer安装和配置
这几篇文章有着安装详细步骤和安装中问题的解决方案,写的很棒!!
【Zookeeper】Windows下安装Zookeeper(图文记录详细步骤,手把手包安装成功)-CSDN博客文章浏览阅读3.5w次,点赞119次,收藏375次。Windows下安装Zookeeper(图文记录每一个步骤,手把手包安装成功)https://blog.csdn.net/tttzzzqqq2018/article/details/132093374
【Kafka】Windows下安装Kafka(图文记录详细步骤)_windows安装kafka-CSDN博客文章浏览阅读6w次,点赞196次,收藏805次。(一)、Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。(二)、Kafka 本质上是⼀个消息队列。与zeromq不同的是,Kafka是一个独立的框架而不是一个库。通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。高吞吐量 :即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。_windows安装kafkahttps://blog.csdn.net/tttzzzqqq2018/article/details/132127105
ZooKeeper启动时报错:JAVA_HOME is not set_zkserver 设置java home-CSDN博客文章浏览阅读6.4k次,点赞2次,收藏9次。情景再现:win7系统,jdk1.8,安装完成后启动Zookeeper很明显,就是说我得jdk路径没有设置,这个的确,jdk1.8已经不需要设置路径了。java -version当然是存在的。1.最直接的方式就是去环境变量中添加JAVA_HOME2.另一种方式,在zkServer.cmd启动的时候,会找%JAVA_HOME%\bin\java.jar 进行java基础环境的启动。所以,zk..._zkserver 设置java homehttps://blog.csdn.net/Ocean_tu/article/details/85703092
Windows下启动单机kafka出现:系统找不到指定路径_kafka为什么找不到路径-CSDN博客文章浏览阅读6.4k次,点赞7次,收藏16次。在博主进行window下安装单机的kafka_2.11-1.0.0时,下载后解压后什么也不用做,直接去启动,出现:系统找不到指定路径解决:是kafka不能识别本机的java环境(JVM),故需要指定java路径,进入kafka路径下的\bin\windows,找到:kafka-run-class.bat,右键编辑它找到下面修改成你本机的java路径,如我的是在D:\Haigui\java\jdk,改成下面:然后保存退出。重新运行成功!!!..._kafka为什么找不到路径https://blog.csdn.net/guihua55/article/details/112199854
这里着重讲一下配置和创建所需的topic步骤~
windows中:(都使用管理员cmd)1.运行zoopker执行:zkserver2.运行kafka进入:
cd D:\QT\canal\kafka运行:
.\bin\windows\kafka-server-start.bat .\config\server.properties创建topic进入:
D:\QT\canal\kafka\bin\windows执行命令:创建canal-test主题
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic canal-test查看:
kafka-topics.bat --bootstrap-server localhost:9092 --listcanal安装和配置
提供安装包需要可以拿去(注意:版本是1.1.4的,对应的mysql版本是5.7的),版本不匹配大家可以去官网安装
链接: https://pan.baidu.com/s/12ryIoh0YTuiYAF5YRsVy9g?pwd=pd8b
提取码: pd8b
第一步:解压缩
第二步:配置文件
D:\QT\canal\canal.deployer-1.1.4\conf\canal.properties
修改这几个配置:
#支持rocketmq、tcp、kafka三种模式
canal.serverMode = kafka
#kafka的topic名称
canal.destinations = canal-test
#kafka的端口地址
canal.mq.servers = localhost:9092
D:\QT\canal\canal.deployer-1.1.4\conf\example\instance.properties
修改这几个配置:
#binlog监听文件
canal.instance.master.journal.name=mysql-bin.000010
#用户名(可以自己创建用户,我这里使用默认的)
canal.instance.dbUsername=root
#密码
canal.instance.dbPassword=lyt123456@
#监听表库
canal.instance.filter.regex=.*\\..*
#kafka的topic名称
canal.mq.topic=canal-test
docker版本
compose安装mysq、kafka、zookepeer
参考文档
使用docker-compose 部署 MySQL(所有版本通用)_docker compose mysql-CSDN博客
编写docker-compose.yml
使用 vim docker-compose.yml 将以下数据添加进去
version: '3'
services:mysql:image: mysql:5.7container_name: mysql5environment:- MYSQL_ROOT_PASSWORD=lyt123456@volumes:- /home/docker/mysql8/log:/var/log/mysql- /home/docker/mysql8/data:/var/lib/mysql- /home/docker/mysql8/conf.d:/etc/mysql/conf.d- /etc/localtime:/etc/localtime:roports:- 3306:3306restart: alwayszookeeper:image: zookeeper:3.4.14 container_name: zookeeperports:- "2181:2181"volumes:- ./zookeeper/data:/data environment:ZOO_MY_ID: 1ZOO_SERVERS: server.1=zookeeper:2888:3888kafka:image: wurstmeister/kafka:2.13-2.8.1container_name: kafkaports:- "9092:9092"environment:KAFKA_BROKER_ID: 1KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://47.108.199.244:9092 # 替换为实际IP:cite[8]:cite[6]KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true' # 自动创建Topic:cite[8]volumes:- /var/run/docker.sock:/var/run/docker.sock # 容器管理权限:cite[7]- ./kafka/logs:/kafkadepends_on:- zookeeper
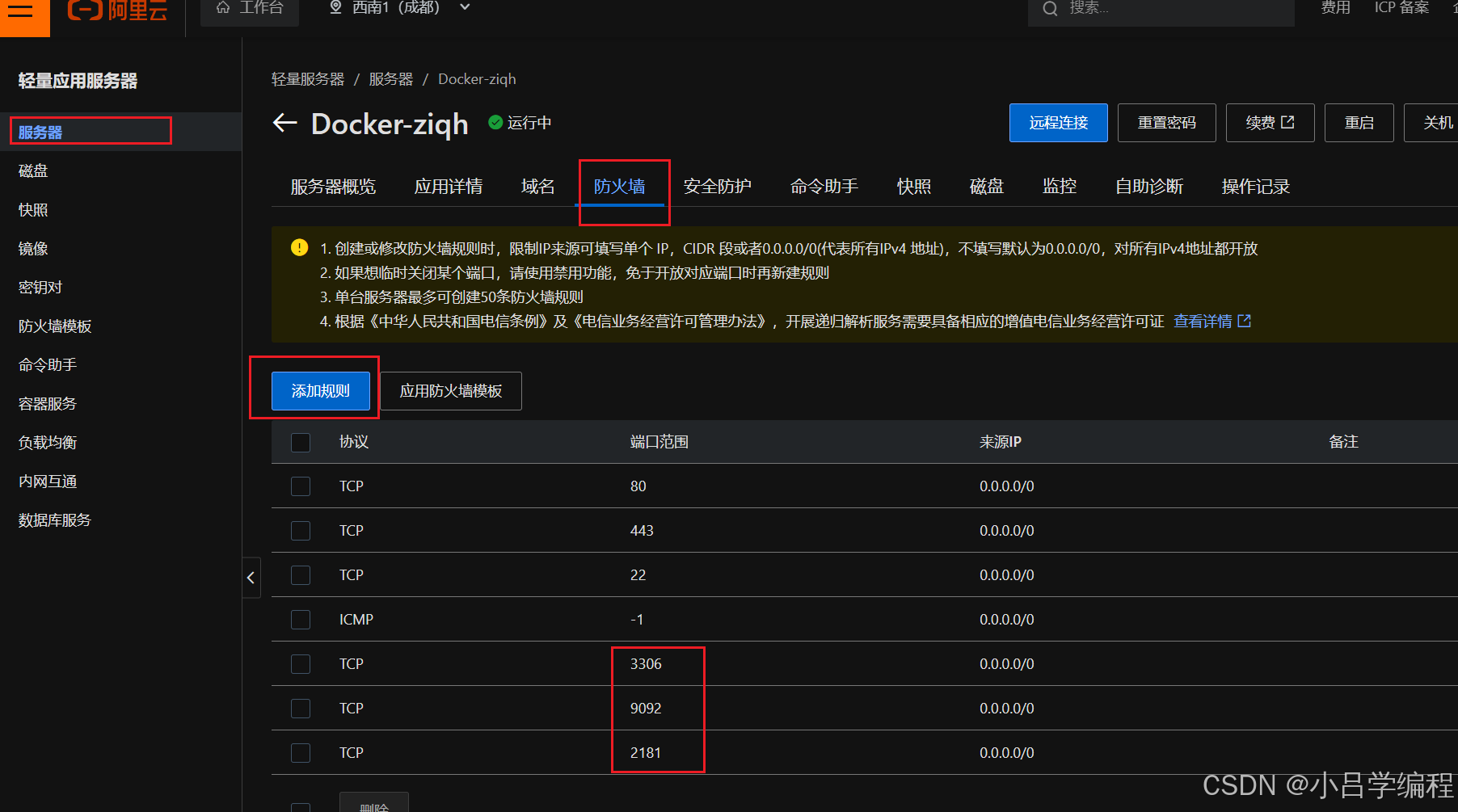
防火墙开启端口访问权限
docker pull拉取失败使用阿里镜像
获取阿里云镜像加速器地址:
-
登录 阿里云容器镜像服务控制台
-
左侧菜单选择「镜像工具」→「镜像加速器」
-
复制专属加速器地址(需阿里云账号)
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors": ["https://[你的镜像地址].aliyuncs.com"]
}
EOF启动
docker-compose -f docker-compose.yml up -d
查看
docker ps

canal安装
注意:canal依赖jdk,先下载jdk
链接: https://pan.baidu.com/s/1uiJXmGQsTT_lxLyDajj6DQ?pwd=vuha
提取码: vuha
注意:mysql5.7版本使用百度网盘提供的canal版本,其余的官网自行下载
第一步:下载并解压 Canal
tar -zxvf canal.deployer-1.1.7.tar.gz第二步:修改 Canal 配置
上面有配置修改信息哦,直接进入修改就ok啦~~~~
第三步:启动 Canal
# 进入 Canal 部署目录
cd /path/to/canal
sh bin/startup.sh第四步:查看是否启动
如果输出包含 CanalLauncher,说明 Canal 已启动
jps -l | grep canalSpringboot项目实战
第一步:创建springboot项目
第二步:添加配置文件
#数据库配置
spring:datasource:url: jdbc:mysql://47.108.199.244:3306/canal?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTCusername: rootpassword: lyt123456@driver-class-name: com.mysql.jdbc.Driverkafka:bootstrap-servers: 127.0.0.1:9092producer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializerconsumer:group-id: cache-groupkey-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializer第三步:导入依赖
<dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.66</version></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.3.1</version></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.9.0</version></dependency><dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.4</version></dependency>第四步:消费者定义
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;@Service
public class KafkaMsg {@KafkaListener(topics = "canal-test", groupId = "cache-group")public void handleMessage(ConsumerRecord<?, ?> cus) {try {System.out.println(cus);} catch (Exception e) {e.printStackTrace();}}
}第五步:验证
执行:
UPDATE user SET name = 'name6' WHERE id = 1;
打断点后会进入到消费者中消费信息啦~~~
输出数据格式:
{"data": [{"id": "1","name": "name6"}],"database": "canal","es": 1744815531000,"id": 2,"isDdl": false,"mysqlType": {"id": "bigint(20)","name": "varchar(255)"},"old": [{"name": "name8"}],"pkNames": ["id"],"sql": "","sqlType": {"id": -5,"name": 12},"table": "user","ts": 1744815532842,"type": "UPDATE"
}如果到这个时候依旧不能成功监听到数据表中变化的数据,那就拆分检查一下
binlog -> canal -> kafka
1.首先检查一下 binlog -> canal 链路是否通
- binlog日志是否开启
- 模式是否为ROW
- 如果还不行就拆开跑这一个链路是否成功(更改 canal.serverMode 为 tcp,使用下面的代码验证)
2.kafka
- 自己写个生产者和消费者看是否可以触发
bug得靠自己去解决啦!!!!程序员只有自己救自己~~~~~
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Component;import java.net.InetSocketAddress;
import java.util.List;@Component
public class CannalClient implements InitializingBean {private final static int BATCH_SIZE = 1000;@Overridepublic void afterPropertiesSet() throws Exception {// 创建链接CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("127.0.0.1", 11111), "example", "", "");try {//打开连接connector.connect();//订阅数据库表,全部表connector.subscribe(".*\\..*");//回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿connector.rollback();while (true) {// 获取指定数量的数据Message message = connector.getWithoutAck(BATCH_SIZE);//获取批量IDlong batchId = message.getId();//获取批量的数量int size = message.getEntries().size();//如果没有数据if (batchId == -1 || size == 0) {try {//线程休眠2秒Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}} else {//如果有数据,处理数据printEntry(message.getEntries());}//进行 batch id 的确认。确认之后,小于等于此 batchId 的 Message 都会被确认。connector.ack(batchId);}} catch (Exception e) {e.printStackTrace();} finally {connector.disconnect();}}/*** 打印canal server解析binlog获得的实体类信息*/private static void printEntry(List<Entry> entrys) {for (Entry entry : entrys) {if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {//开启/关闭事务的实体类型,跳过continue;}//RowChange对象,包含了一行数据变化的所有特征//比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等RowChange rowChage;try {rowChage = RowChange.parseFrom(entry.getStoreValue());} catch (Exception e) {throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e);}//获取操作类型:insert/update/delete类型EventType eventType = rowChage.getEventType();//打印Header信息System.out.println(String.format("================》; binlog[%s:%s] , name[%s,%s] , eventType : %s",entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),eventType));//判断是否是DDL语句if (rowChage.getIsDdl()) {System.out.println("================》;isDdl: true,sql:" + rowChage.getSql());}//获取RowChange对象里的每一行数据,打印出来for (RowData rowData : rowChage.getRowDatasList()) {//如果是删除语句if (eventType == EventType.DELETE) {printColumn(rowData.getBeforeColumnsList());//如果是新增语句} else if (eventType == EventType.INSERT) {printColumn(rowData.getAfterColumnsList());//如果是更新的语句} else {//变更前的数据System.out.println("------->; before");printColumn(rowData.getBeforeColumnsList());//变更后的数据System.out.println("------->; after");printColumn(rowData.getAfterColumnsList());}}}}private static void printColumn(List<CanalEntry.Column> columns) {for (CanalEntry.Column column : columns) {System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());}}
}补充
这是我在写这个demo的时候用的命令,大家可以看看有没有可以用的
#更新数据
UPDATE user SET name = 'name6' WHERE id = 1;
#查看开关是否打开
SHOW VARIABLES LIKE 'log_bin';
#binlog模式
SHOW VARIABLES LIKE 'binlog_format';
#文件位置
SHOW MASTER STATUS;#创建用户
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'47.108.199.244' IDENTIFIED BY 'lyt123456@' WITH GRANT OPTION;
FLUSH PRIVILEGES;-- 查看用户权限
SHOW GRANTS FOR 'canal'@'%';-- 使用命令登录:mysql -u root -p
-- 创建用户 用户名:canal 密码:Canal@123456
create user 'canal'@'%' identified by 'Canal@123456';
-- 授权 *.*表示所有库
grant SELECT, REPLICATION SLAVE, REPLICATION CLIENT on *.* to 'canal'@'%' identified by 'Canal@123456';cd /home/canal/binsh stop.shsh startup.shjps -l | grep canalcd /home/canal/logs/canaltail -f canal.logdocker-compose -f docker-compose.yml up -ddocker psdocker exec -it 515cfc22985a bashmysql -u root -pSELECT User, Host FROM mysql.user;DROP USER 'test1'@'localhost';47.108.199.244CREATE USER 'root'@'%' IDENTIFIED BY '你的新密码'; -- 替换 '你的新密码' 为实际密码
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;dockerkafka-topics.sh --create \--bootstrap-server 47.108.199.244:9092 \--replication-factor 1 \--partitions 1 \--topic canal-topic-2kafka-topics.sh --list --bootstrap-server 47.108.199.244:9092windows:运行zoopkerzkserver运行kafkacd D:\QT\canal\kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties创建topicD:\QT\canal\kafka\bin\windowskafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic canal-testkafka-topics.bat --bootstrap-server localhost:9092 --list
相关文章:
基于Canal+Spring Boot+Kafka的MySQL数据变更实时监听实战指南
前期知识背景 binlog 什么是binlog 它记录了所有的DDL和DML(除 了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL 的二进制日志是事务安全型的。一般来说开启二进制日志大概会有1%的性能损耗。 binlog分类 MySQL Bi…...

MySQL运维三部曲初级篇:从零开始打造稳定高效的数据库环境
文章目录 一、服务器选型——给数据库一个舒适的家二、系统调优——打造高性能跑道三、MySQL配置——让数据库火力全开四、监控体系——数据库的体检中心五、备份恢复——数据安全的最后防线六、主从复制——数据同步的艺术七、安全加固——守护数据长城 引言:从小白…...

golang context源码
解析 context结构 Deadline:返回 context 的过期时间; Done:返回 context 中的 channel; Err:返回错误; Value:返回 context 中的对应 key 的值. type Context interface {Deadline() (deadl…...

【MySQL】MySQL的基础语法及其语句的介绍
1、基础语法 mysql -h【主机名】 -u【用户名】 -p //登录MySQL exit或quit; //退出MySQL show database; //查看MySQL下的所有数据库 use 【数据库名】; //进入数据库 show tables; //查看数据库下的所有表名 *MySQL的启动和关闭 &am…...

大模型应用开发自学笔记
理论学习地址: https://zh.d2l.ai/chapter_linear-networks/index.html autodl学术加速: source /etc/network_turboconda常见操作: 删除: conda remove --name myenv --all -y导出: conda env export > environment.yml…...

Spring能够有效地解决单例Bean之间的循环依赖问题
在Spring框架中,earlySingletonObjects和singletonObjects是两个与Bean实例化过程密切相关的概念,它们都存储在DefaultSingletonBeanRegistry类中。这两个概念主要用于Spring的依赖注入机制,特别是针对单例Bean的创建过程。 singletonObject…...

【计算机视觉】三维视觉项目 - Colmap二维图像重建三维场景
COLMAP 3D重建 项目概述项目功能项目运行方式1. 环境准备2. 编译 COLMAP3. 数据准备4. 运行 COLMAP 常见问题及解决方法1. **编译问题**2. **运行问题**3. **数据问题** 项目实战建议项目参考文献 项目概述 COLMAP 是一个开源的三维重建软件,专注于 Structure-from…...
)
Linux 离线部署 Docker 18.06.3 终极指南(附一键安装卸载脚本)
Linux 离线部署 Docker 18.06.3 终极指南(附一键安装/卸载脚本) 摘要:本文针对无外网环境的 Linux 服务器,提供基于二进制包的 Docker 18.06.3 离线安装全流程指南。包含自动化脚本设计、服务配置优化及安全卸载方案,…...
ALSA架构学习2(驱动MAX98357A)
1 前言和环境 之前其实写过两篇,一篇是讲ALSA,一篇是I2S。 ALSA架构学习1(框架)_alsa框架学习-CSDN博客 总线学习5--I2S_max98357接喇叭教程-CSDN博客 在ALSA那篇的结尾,也提了几个小练习。比如: ### 4…...
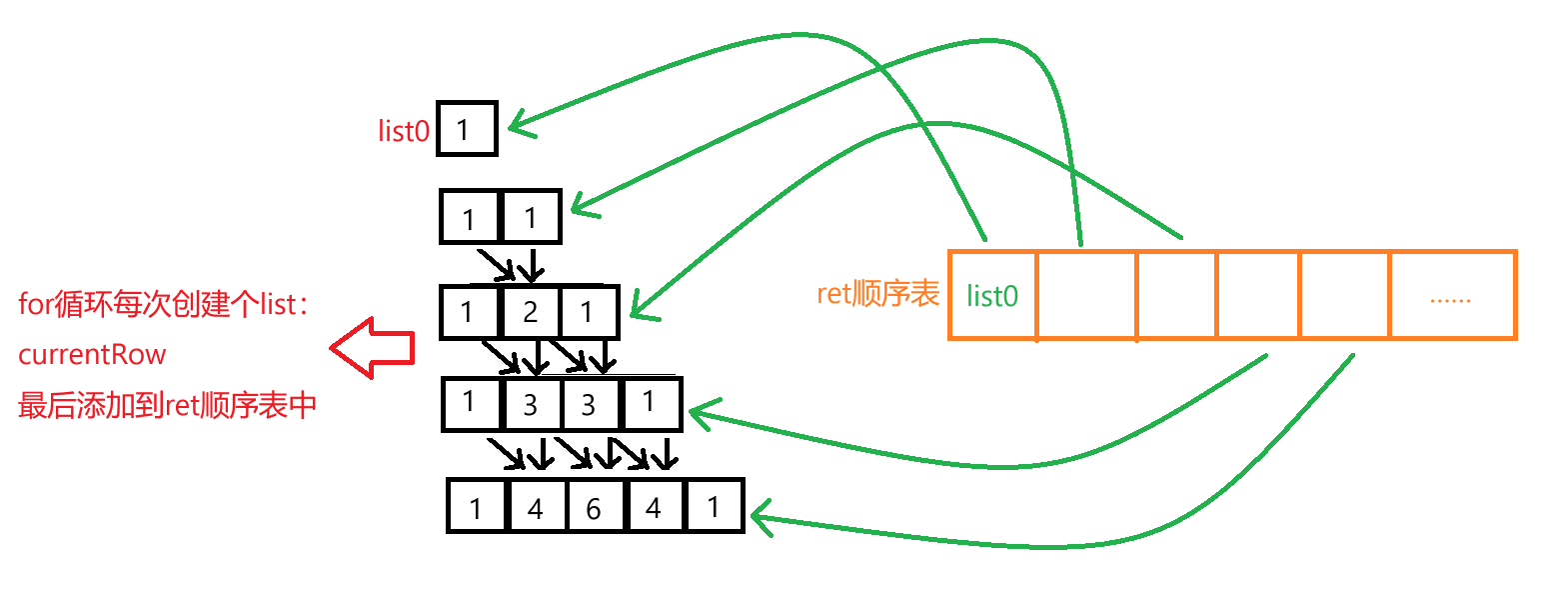
数据结构*集合框架顺序表-ArrayList
集合框架 常见的集合框架 什么是顺序表 顺序表是一种线性表数据结构,它借助一组连续的存储单元来依次存储线性表中的数据元素。一般情况下采用数组存储。 在数组上完成数据的增删查改。 自定义简易版的顺序表 代码展示: public interface IArray…...
VMware Workstation 保姆级 Linux(CentOS) 创建教程(附 iso)
文章目录 一、下载二、创建 一、下载 CentOS-7.9-x86_64-DVD-2009.iso 二、创建 VMware Workstation 保姆级安装教程(附安装包) VMware Workstation 保姆级安装教程(附安装包) VMware Workstation 保姆级安装教程(附安装包)...

51、项⽬中的权限管理怎么实现的
答:权限管理有三个很重要的模块; (1)⽤⼾模块:可以给⽤⼾分配不同的⻆⾊ (2)⻆⾊模块:可以授于⽤⼾不同的⻆⾊,不同的⻆⾊有不同权限 (3)权限模块:⽤于管理系统中的权限接⼝,为⻆⾊提供对…...
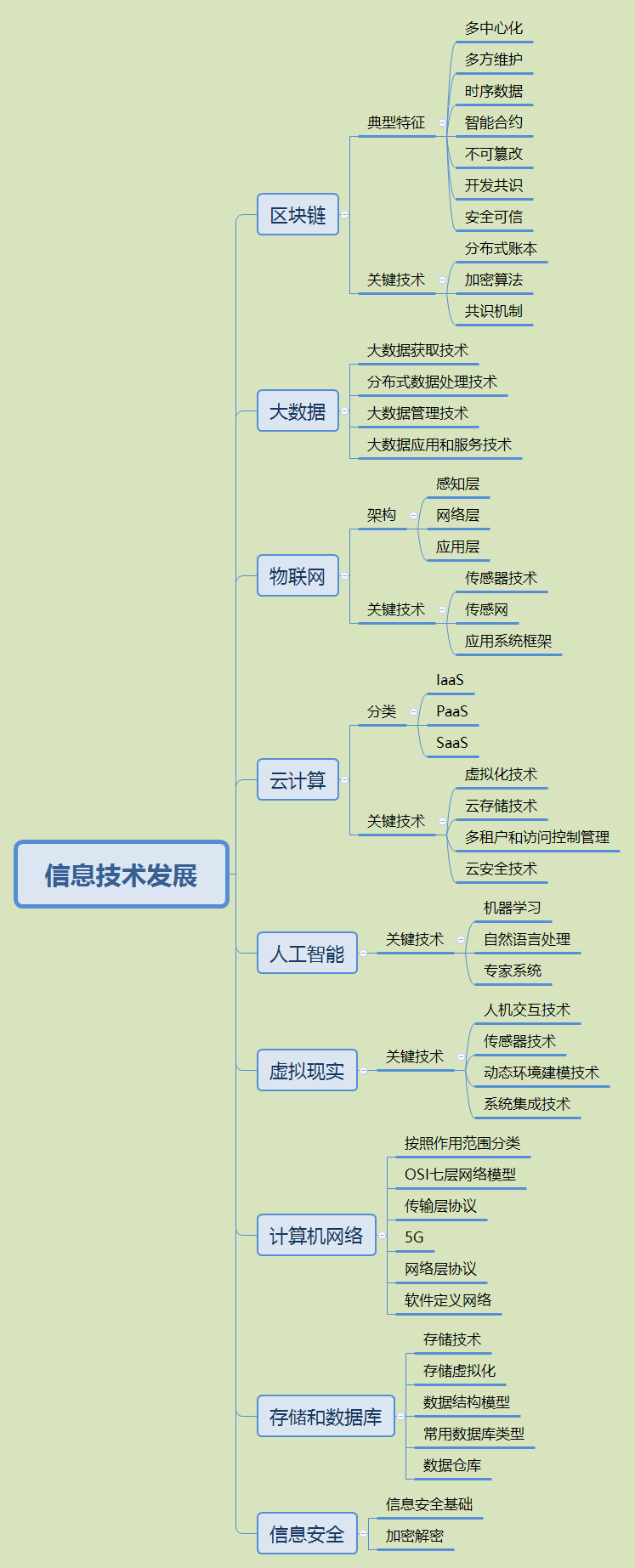
软考-信息系统项目管理师-2 信息技术发展
总结思维导图 云计算(掌握) (3)多租户和访问控制管理访问控制管理是云计算应用的核心问题之一云计算访问控制的研究主要集中在云计算访问控制模型、基于ABE密码体制的云计算访问控制、云中多租户及虚拟化访问控制研究云中多租户及虚拟化访问控制是云计算的典型特征。 大数据(…...

Spring Boot JPA 开发之Not an entity血案
项目状况介绍 项目环境 JDK 21Spring Boot 3.4.3Hibernate: 6.6.13.Final项目描述 因为是微服务架构,项目层级如下 project-parent project-com project-A … project-X 其中: project-parent定义依赖库的版本project-com 定义了一些公用的方法和配置,包括持久层的配置。…...
HTMLCSS实现轮播图效果
这段代码实现了一个具有自动轮播、手动切换功能的图片轮播图,并且配有指示器(小圆点)来显示当前图片位置。轮播图可通过左右箭头按钮进行手动切换,也能自动定时切换,当鼠标悬停在轮播图上时,自动轮播会暂停…...

嵌入式学习——opencv图像库编程
环境配置 OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和图像处理库,广泛用于各种计算机视觉任务,如图像处理、视频分析、人脸识别、物体检测、机器学习等。它提供了丰富的函数和工具,用于处理…...

【每日八股】复习 MySQL Day1:事务
文章目录 复习 MySQL Day1:事务MySQL 事务的四大特性?并发事务会出现什么问题?MySQL 事务的隔离级别?不同事务隔离级别下会发生什么问题?MVCC 的实现原理?核心数据结构版本链构建示例可见性判断算法MVCC 可…...

java 设计模式之代理模式
简介 代理模式:使用代理类来增强目标类的功能。在代码结构上,代理对象持有目标对象,通过代理对象访问目标对象,这样可以在不改变目标对象的前提下增加额外的功能,如权限校验、缓存等 代理模式内部的角色:…...

外接键盘与笔记本命令键键位不同解决方案(MacOS)
文章目录 修改键位第一步:打开设置第二步:进入键盘快捷键第三步:修改修饰键设置第四步:调整键位第五步:保存设置tips ikbc c87键盘win键盘没反应的解决亲测的方法这是百度的答案标题常规组合键尝试:型号差…...

python爬虫复习
requests模块 爬虫的分类 通用爬虫:将一整张页面进行数据采集聚焦爬虫:可以将页面中局部或指定的数据进行采集 聚焦爬虫是需要建立在通用的基础上来实现 功能爬虫:基于selenium实现的浏览器自动化的操作分布式爬虫:使用分布式机群…...

kotlin知识体系(五) :Android 协程全解析,从作用域到异常处理的全面指南
1. 什么是协程 协程(Coroutine)是轻量级的线程,支持挂起和恢复,从而避免阻塞线程。 2. 协程的优势 协程通过结构化并发和简洁的语法,显著提升了异步编程的效率与代码质量。 2.1 资源占用低(一个线程可运行多个协程)…...
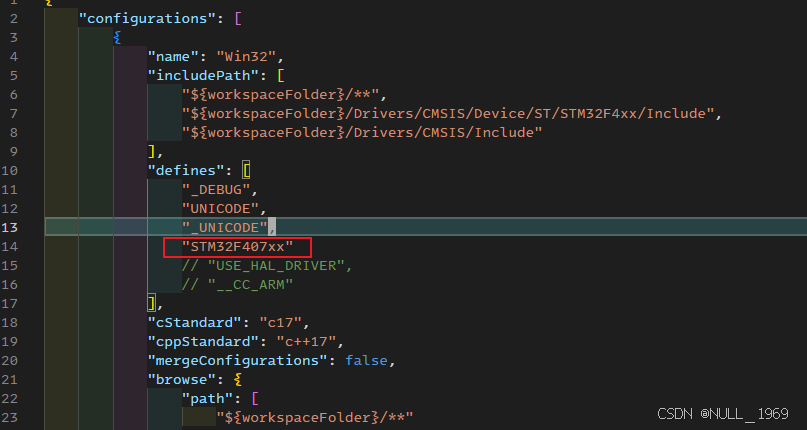
vscode stm32 variable uint32_t is not a type name 问题修复
问题 在使用vscodekeil开发stm32程序时,发现有时候vscode的自动补全功能失效,且problem窗口一直在报错。variable “uint32_t” is not a type name uint32_t 定义位置 uint32_t 实际是在D:/Keil_v5/ARM/ARMCC/include/stdint.h中定义的。将D:/Keil_v5…...
Formality:Bug记录
相关阅读 Formalityhttps://blog.csdn.net/weixin_45791458/category_12841971.html?spm1001.2014.3001.5482 本文记录博主在使用Synopsys的形式验证工具Formality中遇到的一个Bug。 Bug复现 情况一 // 例1 module dff (input clk, input d_in, output d_out …...

在ubuntu20.04+系统部署VUE及Django项目的过程记录——以腾讯云为例
目录 1. 需求2. 项目准备3. VUE CLI项目部署3.1 部署前的准备3.1.1 后端通信路由修改3.1.2 导航修改 3.2 构建项目3.3 配置nginx代理 4. 后端配置4.1 其他依赖项4.2 单次执行测试4.3 创建Systemd 服务文件4.4 配置 Nginx 作为反向代理 5. 其他注意事项 1. 需求 近期做一些简单…...

回归,git 分支开发操作命令
核心分支说明 主分支(master/production)存放随时可部署到生产环境的稳定代码,仅接受通过测试的合并请求。 开发分支(develop)集成所有功能开发的稳定版本,日常开发的基础分支,从该分支创建特性…...
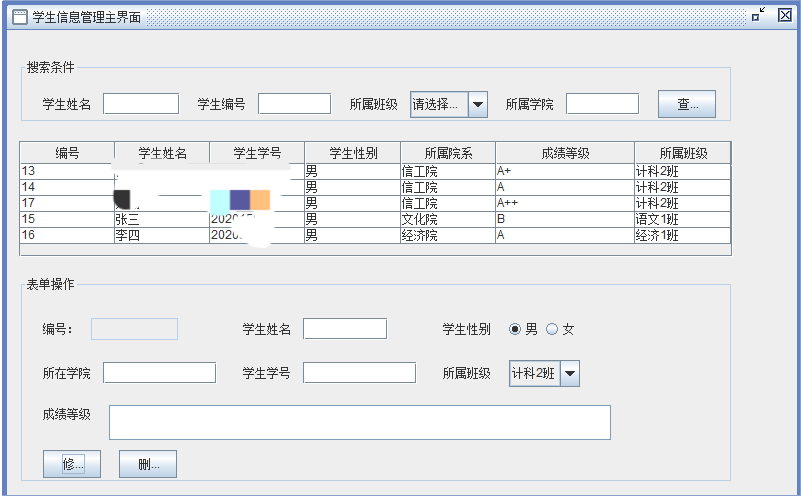
【java+Mysql】学生信息管理系统
学生信息管理系统是一种用于管理学生信息的软件系统,旨在提高学校管理效率和服务质量。本课程设计报告旨在介绍设计和实现学生信息管理系统的过程。报告首先分析了系统的需求,包括学生基本信息管理、成绩管理等功能。接着介绍了系统的设计方案࿰…...

小白从0学习网站搭建的关键事项和避坑指南(2)
以下是针对小白从零学习网站搭建的 进阶注意事项和避坑指南(第二期),覆盖开发中的高阶技巧、常见陷阱及解决方案,帮助你在实战中提升效率和质量: 一、进阶技术选型避坑 1. 前端框架选择 误区:盲目追求最新…...
Windows 10 上安装 Spring Boot CLI详细步骤
在 Windows 10 上安装 Spring Boot CLI 可以通过以下几种方式完成。以下是详细的步骤说明: 1. 手动安装(推荐) 步骤 1:下载 Spring Boot CLI 访问 Spring Boot CLI 官方发布页面。下载最新版本的 .zip 文件(例如 sp…...

spring boot -- 配置文件application.properties 换成 application.yml
在Spring Boot项目中,application.properties和application.yml是两种常用的配置文件格式,它们各自具有不同的特点和适用场景2。以下是它们之间的主要差异2: 性能差异 4: 加载机制 2: application.properties文件会被加载到内存中,并且只加载一次,之后直接从内存中读取…...

Spring Boot实战:基于策略模式+代理模式手写幂等性注解组件
一、为什么需要幂等性? 核心定义:在分布式系统中,一个操作无论执行一次还是多次,最终结果都保持一致。 典型场景: 用户重复点击提交按钮网络抖动导致的请求重试消息队列的重复消费支付系统的回调通知 不处理幂等的风…...