消息队列知识点详解
消息队列场景
什么是消息队列
可以把消息队列理解一个使用队列来通信的组件,它的本质是交换机+队列的模式,实现发送消息,存储消息,消费消息的过程。
我们通常说的消息队列,MQ其实就是消息中间件,业界中比较常用的消息中间件有:RabbiyMQ、RockMQ、Kafka等
消息队列的选型
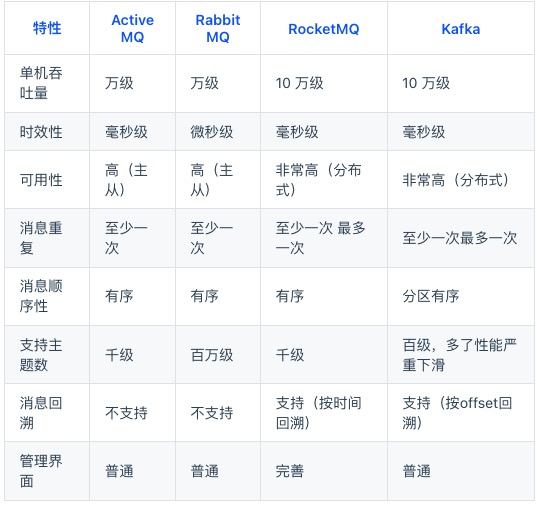
选型的时候我们需要根据业务的场景,结合上述特性来进行选型。
消息队列的使用场景
- 解耦:在分布式系统中,可以通过消息队列进行异步通信,不再使用OpenFeign等HTTP的网络之间进行通信,这样项目中就不会存在耦合,系统也不会有太大的影响,即使一个系统挂了,请求消息也只是堆积在消息队列中,不会对其他系统造成影响。
- 异步:加入一个操作涉及到了好几个不同的步骤或者是分布式系统,这些不需要同步执行,那么可以考虑消息队列进行异步操作。假设用于有一个创建订单操作,其中涉及到客户轨迹添加,更新库存,创建订单,拉起支付等功能。那么如果我们使用OpenFeign等网络调用链进行调用,那么此时会产生大量的时间,客户是无法接受的。并且其中像客户轨迹添加这样的操作是不需要同步的,如果使用MQ将客户创建订单时,将后面的所有操作全部放到MQ进行异步操作,随后返回成功信息,这样就可以加快系统的访问速度。
- 削峰:一个系统访问有流量高峰期,也有流量低峰期,假设12306的购票活动,需要用户创建订单->锁定余票库存->拉起支付->更新记录等,但是此时如果有几千万人次进行抢票,我们的支付服务可能受不了这么大的并发,可能会直接挂掉,所以这里可以加一个MQ,将微服务调用链发给支付服务的所有请求堆在MQ中,在支付服务的最大限度内进行处理,这样就会避免服务崩溃的问题。
消息重复的消费怎么做
生产端为了保证数据的发送成功,可能会重复推送消息直到收到成功ACK(网络、消息队列异常),这样就会在队列内产生重复的消息,一个成熟的MQ框架会有自己的解决方案,比如用空间换时间,存储已经处理过的message_id,给生产者提供一个可靠的发送消息的接口。
但是消费者段却无法根本的解决这个问题,在不高并发的要求下,拉取消息+处理业务逻辑+提交消费者偏移量需要事务做处理,且消费者端可能会挂掉,很可能导致拉取到重复的消息。
这种解决办法也就只有在业务层面做控制,对于已经成功的消息,本地数据库或者缓存来存储业务标识,每次处理前先进行校验,保证幂等性。
消息丢失怎么解决
使用一个消息队列,其实就分为三大块:生产者,中间件,消费者,如果要保证数据的不丢失,就要保证这三个部分不会出问题。
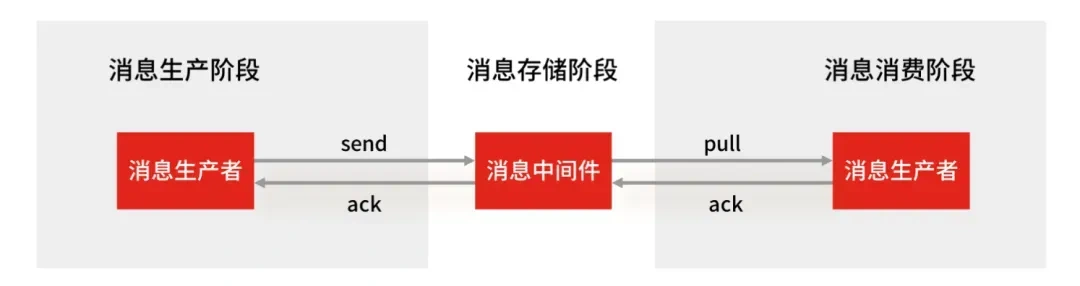
- 消息生产阶段:生产者会不会丢失消息,取决于消息生产者对异常的处理是否合理。丛消息被生产出来,然后提交给MQ的过程中,只要能正常收到MQ消息队列的ack确认消息,就表示发送成功,所以只要处理好返回值和异常,如果返回错误,就进行重发,那么这个阶段是不会出现问题的。
- 消息存储阶段:这里使用kafka为例,kafka一般是使用集群部署的,生产者在发送消息时,消息队列一般会写多个节点,一般是多个节点,可以理解为多个备份,即便一个节点挂了,也会保证数据不丢失。
- 消息消费阶段:消费者接受到消息+处理完毕后,并回复ack的话,那么消息消费阶段就不会消失,这样一来即使其中一个节点挂了,也可以保证数据不丢失
以上三点只要有一个疏漏就会导致消息的丢失
消息队列的可靠性是怎么保证的
- 消息持久化:确保消息能够持久化是非常关键的,在系统掉点、系统崩溃重启后仍然可以读取持久化的消息并放到消息队列中
- 消息确认机制:消费者在成功消费消息后,应该向消息队列发送确认,消息队列只有收到确认后才会将消息丛队列中移除。如果没有收到确认,则会在一定时间内重发该消息。在kafka中,消费者通过commitasync提交便宜量,从而确认消息。
- 消息重试策略:当消费者处理消息失败时,需要有合理的重试策略,可以设置重试次数以及重试间隔时间。
消息队列的顺序性怎么保证的
以kafka为例,可以将顺序的消息发送到同一个主题的同一个分区来保证消息是有序的,但是这个可能会影响消费者的并行处理速度,并且消费者进行消费的时候必须单线程处理顺序消息。
如何保证幂等性写
幂等性写指的是同一操作的多次执行的结果和一次执行的结果相同。假设支付宝付款操作,多次执行但是只会扣一次钱。
- 唯一标识:为每一个请求生成全局唯一的id,服务端校验该id是否已处理,适用于场景接口调用,消息消费等。
- 乐观锁:通过版本号或者时间戳等方式控制并发更新,确保多次更新等同于单次操作,适用于场景数据库记录的更新
- 数据库唯一约束:使用数据库的唯一索引来限制重复的插入,适用于插入的场景
- 分布式锁:通过锁机制保证一个时刻只有一个请求执行关键操作,适用于高并发场景下的资源争夺。
如何保证数据的一致性,事务消息如何实现。
这里直接举一个用户发起创建订单的例子
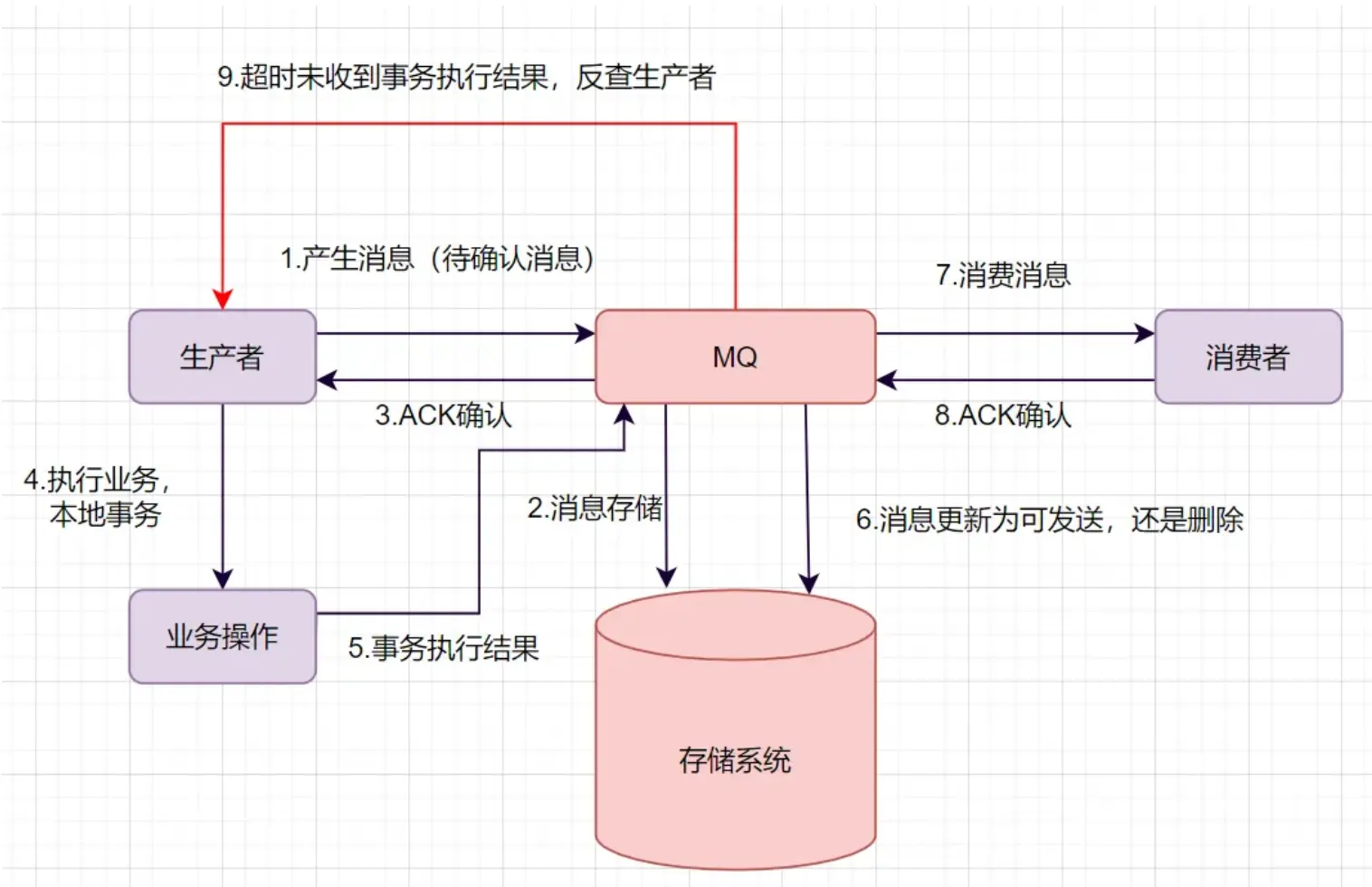
假设用户点击支付后,首先创建订单(包含订单表写入、库存表更新等数数据库更新操作),事务完成后拉起支付服务(下游服务),此时我们的需求是,当事务执行出错(发生rollback),不再调用下游服务,当事务执行成功并commit,必须拉起下游服务执行支付操作,但是此时万一发送消息不成功,下游操作就无法感知这个操作,出现数据不一致。
- 生产者产生消息,发送一条半事务消息到MQ服务器
- MQ收到消息后,将消息持久化道存储系统,这条消息是待发送的状态
- MQ服务器返回ACK给生产者,将消息持久化到存储系统,这条消息不会触发推送事件
- 生产者执行本地事务
- 如果本地事务执行成功,即commit执行结果到MQ服务器,如果执行失败,发送rollback
- 如果是正常的commit,MQ服务器更新消息状态为可发送,如果是rollback则删除消息
- 如果消息更新为可推送,则MQ服务器直接将消息push给消费者,消费者消费完返回ACK
- 如果MQ服务器长时间收不到生产者的commit或者rollback,他会反查生产者。
kafka
kafka的特点
- 高吞吐量,低延迟:kafka每秒可以处理几十万条消息,他的最低延迟也只有几毫米,每个topic可以分为对歌partition,consumer group对partition进行consumer操作
- 可扩展性:kafka集群支持扩展
- 持久性:消息被持久化到本地磁盘,并且支持数据备份
- 容错性:允许集群中及节点失败
- 高并发:数千个客户端同时读写
kafka为什么这么快?
- 顺序写入优化:kafka将消息顺序写入磁盘,减少了磁盘的寻道时间,这种方式比随机读写效率更高
- 批处理技术:kafka支持批量发送消息,这意味着生产者在发送消息的时候可以等待到有足够数据量囤积的时候再发送,这种方法减少了网络和磁盘的开销
- 零拷贝技术:kafka使用零拷贝技术,可以直接将数据从磁盘里发送到网络套接字,避免了再用户空间和内核空间之间相互转换
- 压缩技术:kafka支持消息压缩,这不仅减少了网络的传输的数据量,提高整体的吞吐量
介绍下Kafka的模型,kafka是推送还是拉取
消费者模型
推送模型(push)
- 基于推送模型的消息系统,由消息代理记录消费者的状态
- 消息代理在将消息推送到消费者后,标记这条消息已经消费,但是这种方法无法很好的保证数据被处理
- 如果要保证数据被处理,需要消息代理记录消息的所有状态,这种太消耗资源,不可取
- push模式是设置MQ中的,他无法适应消费者的速率,过快会导致消费者拒绝服务,过慢会导致队列内消息积压
拉取模型(pull)
kafka采用的是拉取模型,由消费者自己记录消费的状态,每个消费者顺序的拉取每个分区的消息
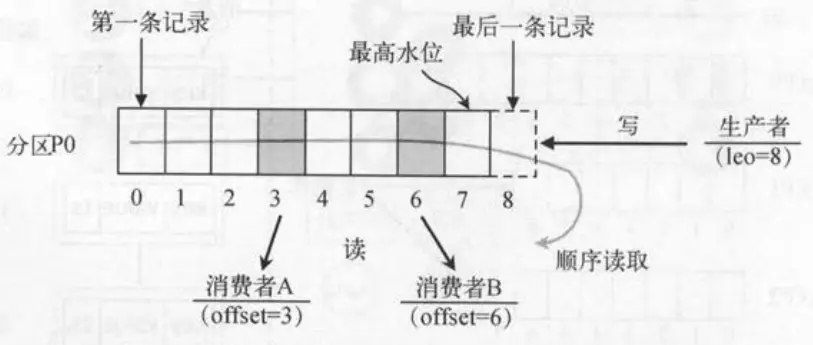
- 两个消费者拉取同一主题的消息,消费者A的消费进度是3,B的进度为6,也叫偏移量
- 消费者拉取的最大上限称为最高水位,生产者最新写入的消息如果还没有到达备份的数量,那么这个消息对消费者不可见
- 这种优点是:消费者可以任意控制偏移量来消费任意时刻的消息。
消费者组
kafka中的消费者是以消费者组的形式工作,由一个或者多个消费者构成消费者组,共同消费一个topic,但是每一个分区在同一时刻只能被同一消费者组中的一个消费者消费,但是不同消费者组可以在同一时刻消费一个分区。
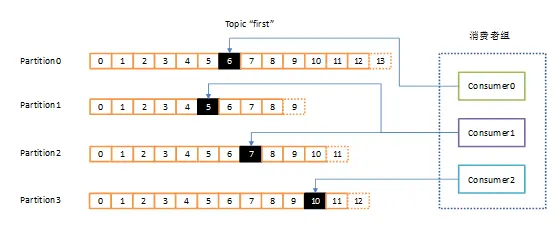
消费方式
kafka采用拉取pull的方式从broker中读取数据
优点是pull模式可以根据consumer的消费能力进行拉取
缺点是如果此时kafka中没有数据,消费者可能会陷入循环,一致在拉取null数据,针对这一点kafka的消费者在消费数据时会传入一个时常参数,如果没有数据,consumer会等待一段时间返回,时常为timeout
kafka为什么一个分区只能由消费者组的一个消费者消费
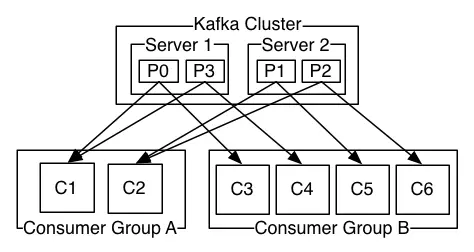
如果两个消费者负责同一个分区,那么就意味着两个消费者同时读取分区的消息,由于消费者自己可以控制读取消息的offset,可能c1才读到2,c2读到1,那么当c1没读完的时候,c2已经读到3了,这样会造成消息浪费,相当于多线程同时读取一个消息,这是没意义的
消息中间件是如何做到高可用的
消息中间件如何保证高可用呢,单机是没有高可用可言的,高可用都是对集群来说的。
kafka的基础架构,由多个broker组成,每个broker都是一个节点,当你创建一个topic时,他可以划分为partion,而每个partion只放一部分数据,分别存在不同的broker上,也就是说,一个topic数据是分散在不同的broker上的,每个及其存放一部分数据
那么是不是broker挂了partion就挂了?其实在kafka0.8之后提供了副本机制来保证高可用,即每个partion的数据会同步到其他的机器上,形成副本,然后所有副本会选取一个leader出来,让leader和生产者和消费者打交道,其他副本都是follower。写数据时,leader负责把数据同步给所有的follower,读消息时,直接读leader上的数据即可。如果某个broker挂掉了,那么这个broker的partion在其他机器上都有副本的,如果挂的是leader,那么会从follower会重新选择一个leader
相关文章:
消息队列知识点详解
消息队列场景 什么是消息队列 可以把消息队列理解一个使用队列来通信的组件,它的本质是交换机队列的模式,实现发送消息,存储消息,消费消息的过程。 我们通常说的消息队列,MQ其实就是消息中间件,业界中比较…...
序列号绑定的SD卡坏了怎么办?
在给SD卡烧录程序的时候,大家发现有的卡是无法烧录的,如:复印机的SD卡不能被复制通常涉及以下几个技术原因,可能与序列号绑定、加密保护或硬件限制有关: 一、我们以复印机的系统卡为例来简单讲述一下 序列号或硬件绑定…...

使用SystemWeaver生成SOME/IP ETS ARXML的完整实战指南
使用SystemWeaver生成SOME/IP ETS ARXML的完整实战指南 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,可以分享一下给大家。点击跳转到网站。 https://www.captainbed.cn/ccc 一、SystemWeaver与SOME/IP基础认知 1.1 SystemWe…...

基于单片机的BMS热管理功能设计
标题:基于单片机的BMS热管理功能设计 内容:1.摘要 摘要:在电动汽车和储能系统中,电池管理系统(BMS)的热管理功能至关重要,它直接影响电池的性能、寿命和安全性。本文的目的是设计一种基于单片机的BMS热管理功能。采用…...
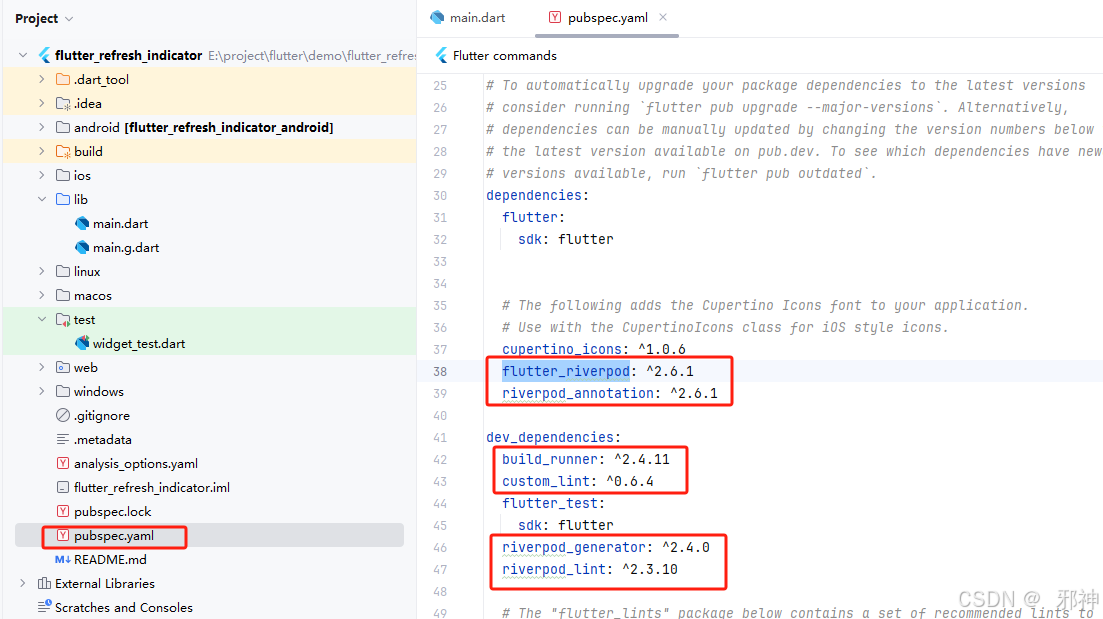
Flutter 状态管理 Riverpod
Android Studio版本 Flutter SDK 版本 将依赖项添加到您的应用 flutter pub add flutter_riverpod flutter pub add riverpod_annotation flutter pub add dev:riverpod_generator flutter pub add dev:build_runner flutter pub add dev:custom_lint flutter pub add dev:riv…...
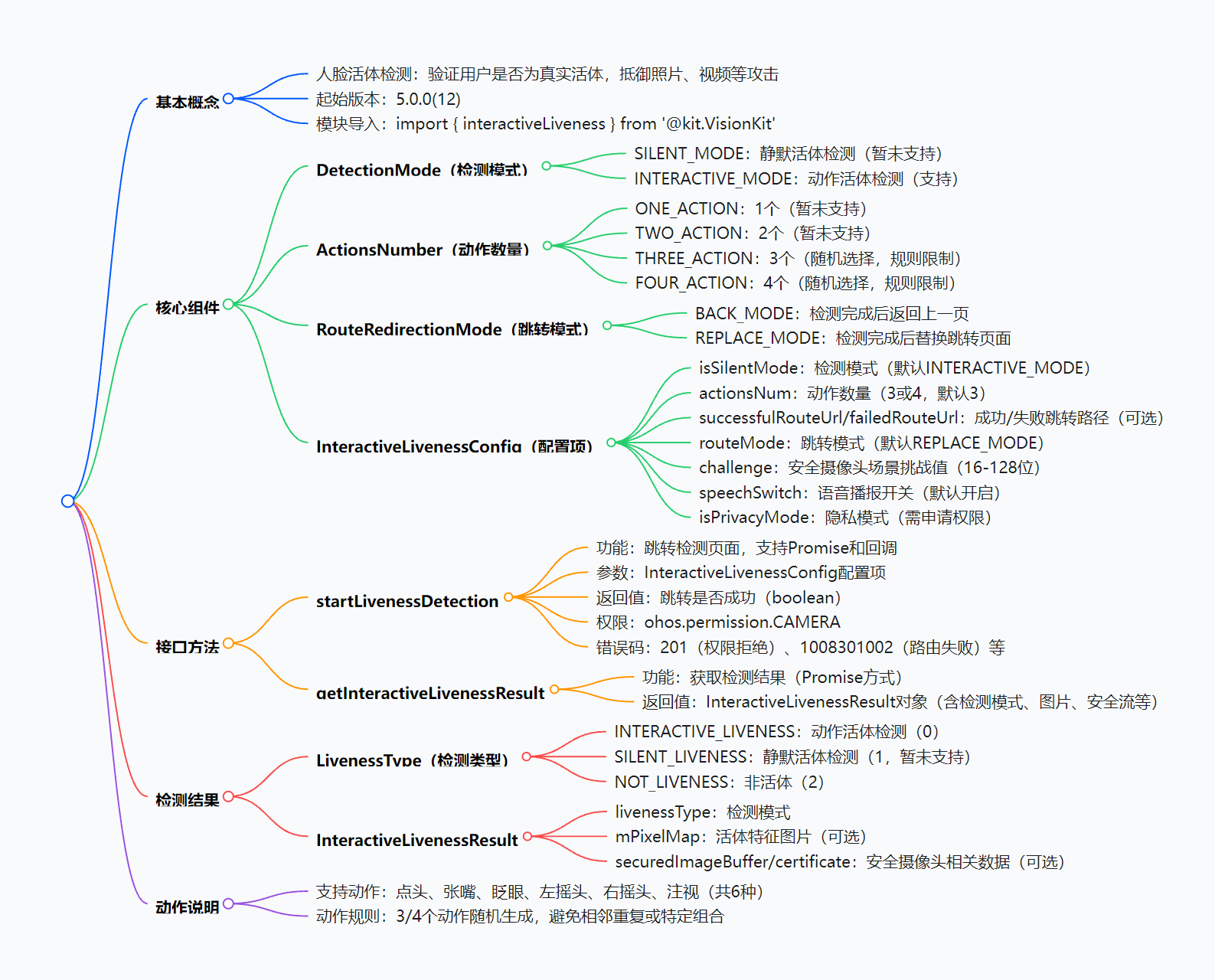
【HarmonyOS 5】VisionKit人脸活体检测详解
【HarmonyOS 5】VisionKit人脸活体检测详解 一、VisionKit人脸活体检测是什么? VisionKit是HamronyOS提供的场景化视觉服务工具包。 华为将常见的解决方案,通常需要三方应用使用SDK进行集成。华为以Kit的形式集成在HarmoyOS系统中,方便三方…...

Pycharm(九)函数的闭包、装饰器
目录 一、函数参数 二、闭包 三、装饰器 一、函数参数 def func01():print("func01 shows as follows") func01() # 函数名存放的是函数所在空间的地址 print(func01)#<function func01 at 0x0000023BA9FC04A0> func02func01 print(func02)#<function f…...

【深度学习】详解矩阵乘法、点积,内积,外积、哈达玛积极其应用|tensor系列02
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【深度学习】你真的理解张量了吗?|标量、向量、矩阵、张量的秩|01每日一言🌼: “脑袋想不明白的,就用脚想”…...
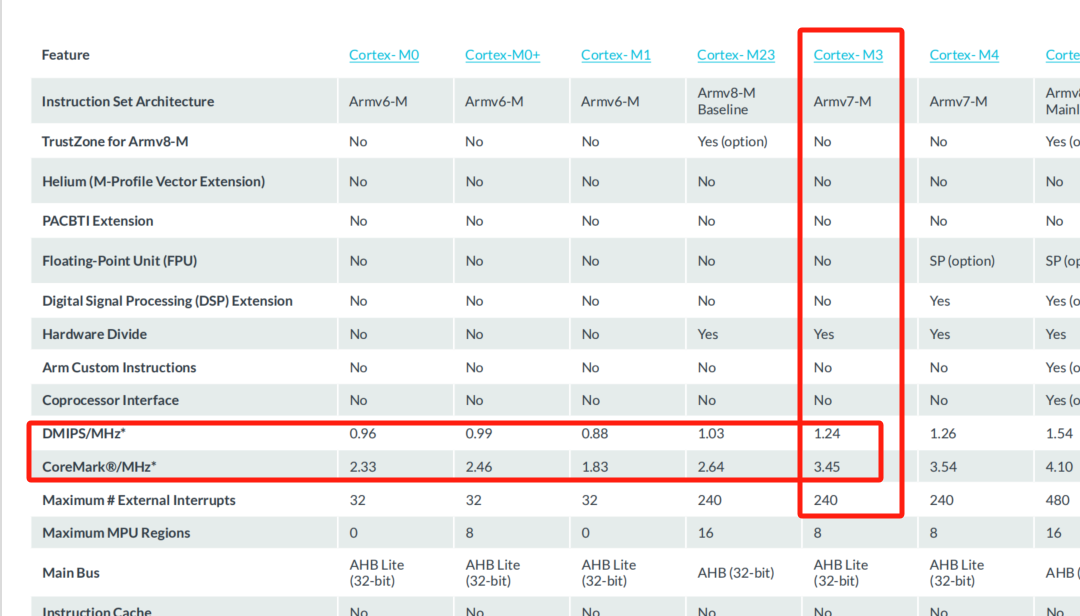
MH2103系列coremark1.0跑分数据和优化,及基于arm2d的优化应用
CoreMark 1.0 介绍 CoreMark 是由 EEMBC(Embedded Microprocessor Benchmark Consortium)组织于 2009 年推出的一款用于衡量嵌入式系统 CPU 或 MCU 性能的标准基准测试工具。它旨在替代陈旧的 Dhrystone 标准(Dhrystone 容易受到各种libc不同…...
Flowith AI,解锁下一代「知识交易市场」
前言 最近几周自媒体号都在疯狂推Manus,看了几篇测评后,突然在某个时间节点,在特工的文章下,发现了很小众的Flowith。 被这段评论给心动到,于是先去注册了下账号。一翻探索过后,发现比我想象中要有趣的多&…...

策略模式:优雅应对多变的业务需求
一、策略模式基础概念 策略模式(Strategy Pattern) 是一种行为型设计模式,它通过定义一系列可互换的算法族,并将每个算法封装成独立的策略类,使得算法可以独立于使用它的客户端变化。策略模式的核心思想是 “将算法的…...
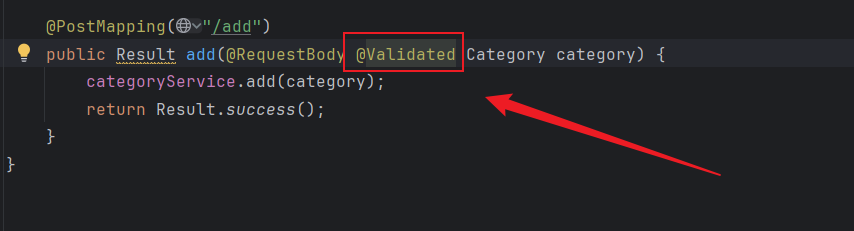
SpringBoot企业级开发之【文章分类-新增文章分类】
看一下新增文章的需求: 接口文档: 开发思路: 先在controller下去创建add方法,方法内导入Service类获取add的结果;再在Service接口下去创建add的方法;然后在Service实现类下去实现方法的作用,且导…...
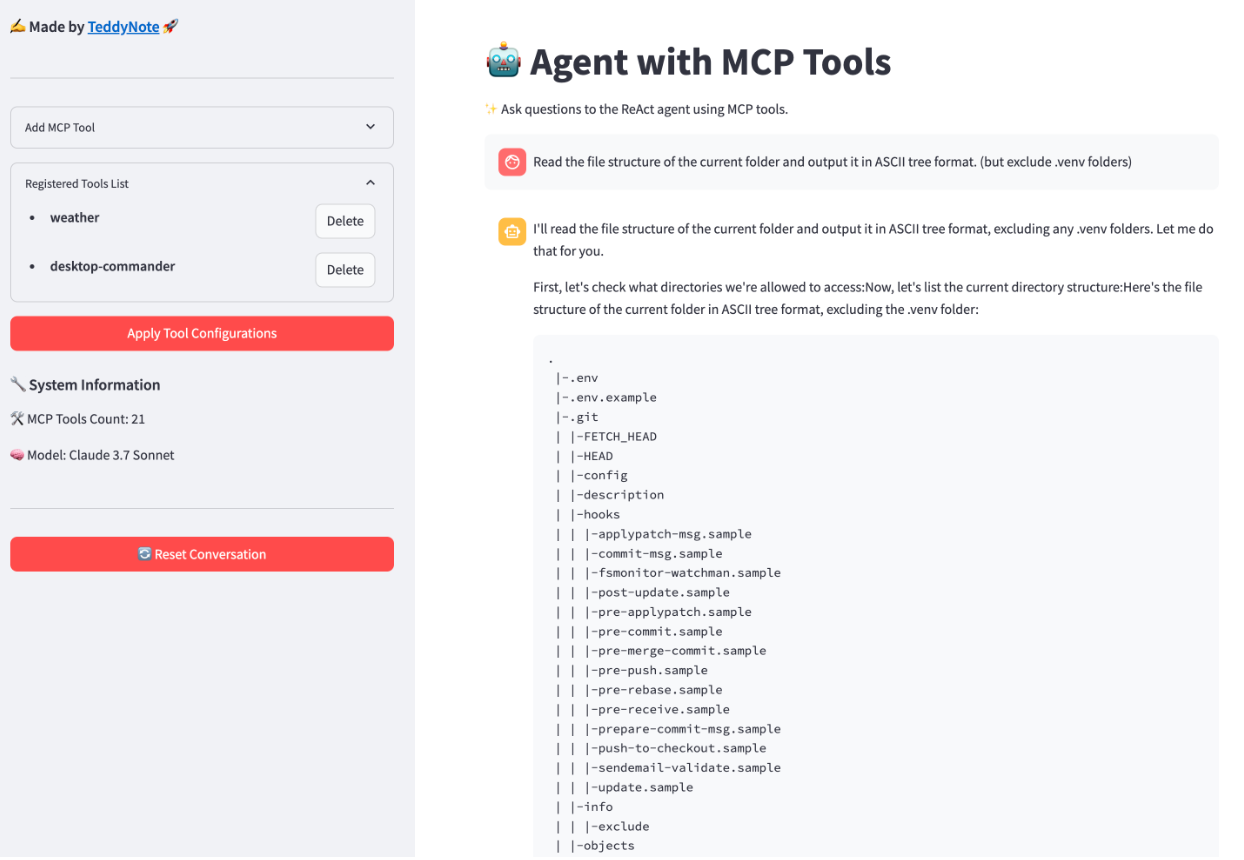
【AI News | 20250421】每日AI进展
AI Repos 1、langgraph-mcp-agents 基于LangGraph的AI智能体系统,集成了MCP,使AI助手能访问各种数据源和API。提供了Streamlit网页界面,方便与LangGraph和MCP工具交互。可以通过界面动态添加、删除以及配置MCP工具,无需重启应用&…...

牛客 | OJ在线编程常见输入输出练习
1.只有输出 言归正传,本张试卷总共包括18个题目,包括了笔试情况下的各种输入输出。 第一题不需要输入,仅需输出字符串 Hello Nowcoder! 即可通过。 #include <iostream> using namespace std; int main(){string s "Hello Nowco…...
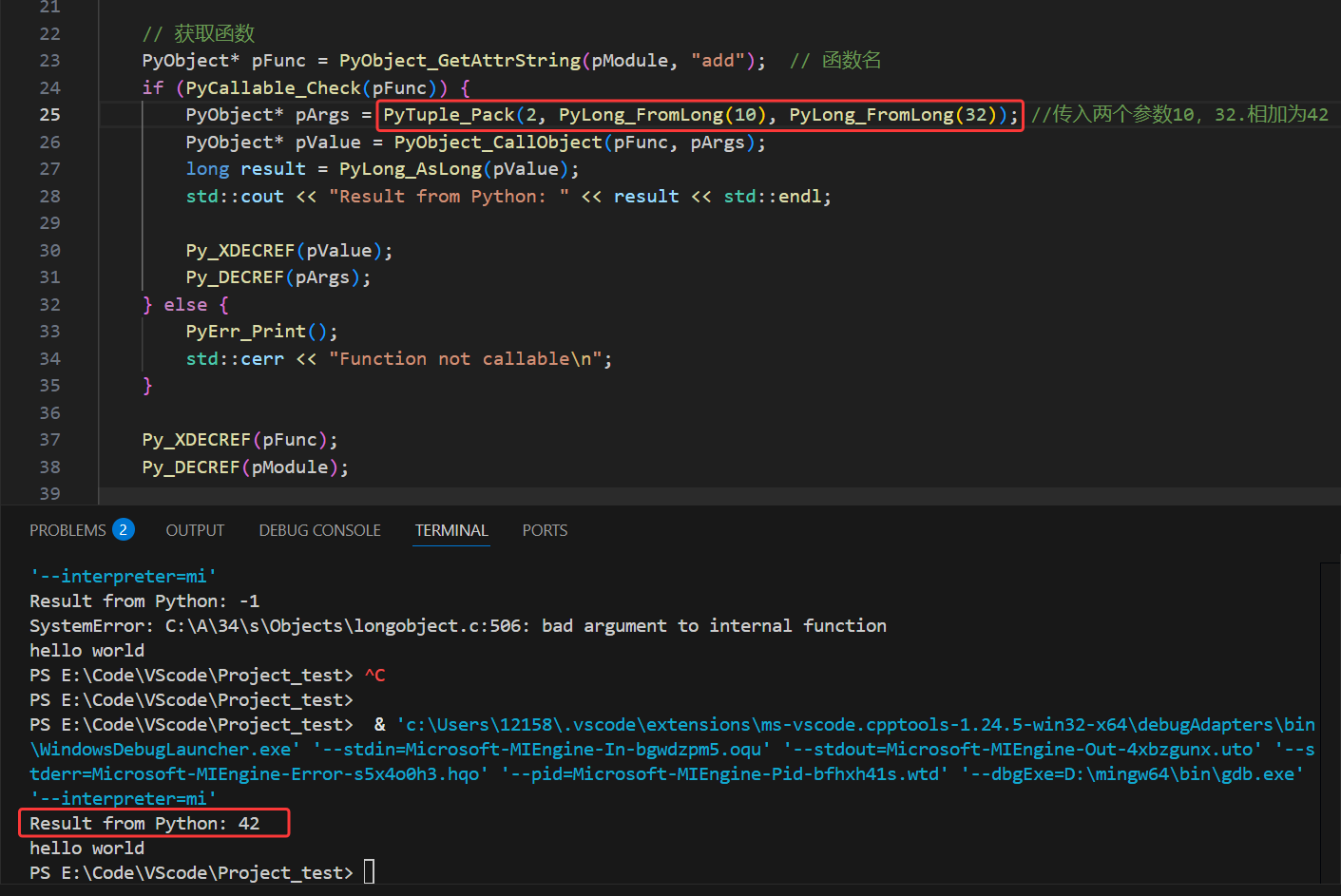
python生成动态库在c++中调用
一.Windows下生成动态库.pyd 在setup.py的同目录下使用python setup.py build_ext --inplace 二.在vscode的c中使用.pyd文件(动态库) 1)配置python的环境 python -c "import sys; print(sys.executable)" #确定python安装位置 2…...

程序员学商务英文之Terms of Payment Packing
Dia-3: Packing 1 包装-1 1. I’m here to improve my communication skill of English. 我来这里是为了提升我的英文沟通技能。 2. What a co-incidence! Fancy meeting you here. 这么巧!真没想到在这见到你。 3. Some birds aren’t meant to be caged…...
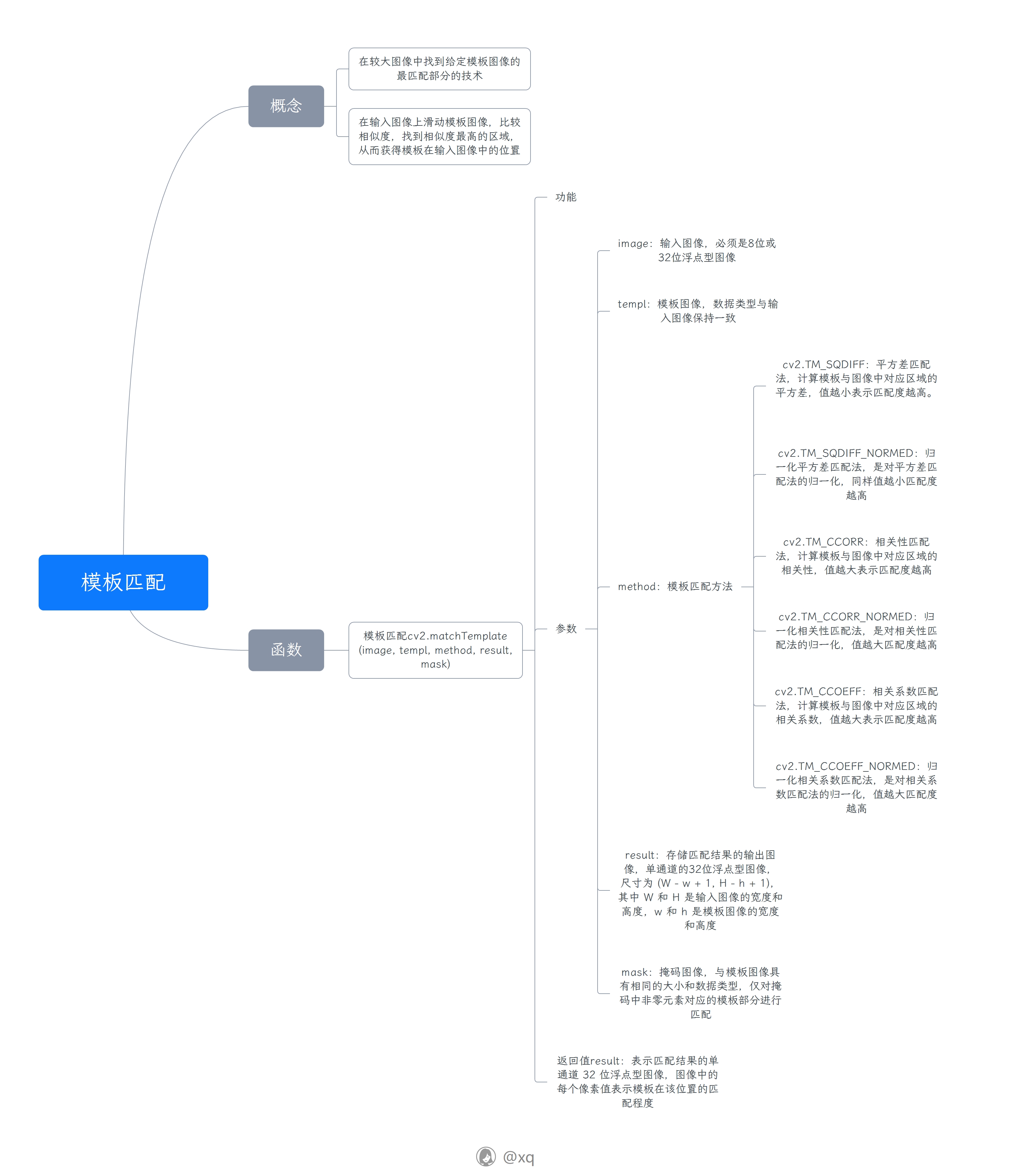
OpenCV基础函数学习4
【大纲笔记见附件pdf】 目录 一、基于OpenCV的形态学操作 二、基于OpenCV的直方图处理 三、基于OpenCV霍夫变换 四、基于OpenCV模板匹配 一、基于OpenCV的形态学操作 二、基于OpenCV的直方图处理 三、基于OpenCV霍夫变换 四、基于OpenCV模板匹配...
Nginx反向代理用自定义Header参数
【啰嗦两句】 也不知道为啥,我仅仅想在Nginx的反向代理中使用自己定义的“x-api-key”做Header参数,却发现会被忽略,网上搜的资料都是说用“proxy_set_header”,却只愿意介绍最基本的几个参数,你懂的,那些资…...
详解机器学习各算法的优缺点!!
在机器学习这个 “工具库” 里,算法就像各种各样的工具,每一种都有自己的 “脾气” 和 “特长”。有些算法擅长找规律,有些算法能快速分类,还有些在处理复杂数据时特别厉害。 而且,就像锤子适合敲钉子、螺丝刀适合拧螺…...

Manus AI与多语言手写识别
一、手写识别技术的发展历程 1.1 早期的手写识别技术 手写识别技术起源很早,1929年德国人Tausheck就取得了相关专利。早期主要采用模板匹配等方法,该方法需准备字符模板库,提取待识别字符特征后进行匹配。但其局限性明显,对字符…...

C++23 让 Lambda 表达式中的 () 更可选:P1102R2 提案深度解析
文章目录 一、背景与动机:Lambda 表达式中的痛点1.1 问题的根源 二、P1102R2 提案:让 () 可选2.1 提案的核心内容2.2 语法调整的细节2.3 提案的合理性 三、编译器支持:主流编译器的跟进四、对 C 编程的影响:简化语法与提升一致性4…...

规则引擎 - Easy Rules
Easy Rules 依赖demodemo1demo2 总结 Easy Rules 是一个轻量级的 Java 规则引擎,使用简单,适合快速开发和简单的规则场景,适合对于一些判断,是否属于白名单,是否有特殊权限,是否属于当前区域,调…...

3步拆解Linux内核源码的思维模型
3步拆解Linux内核源码的思维模型 ——从“不敢碰”到“庖丁解牛” 一、第一步:资料收集与框架搭建——像拼图一样找到“地图” 初看Linux内核源码的人,往往会被其千万行代码淹没。但正如登山前需要地形图,阅读内核前必须构建认知框架。 1…...

MyBatis与MyBatis-Plus:字段自动填充的两种实现方式
目录 1. 使用 MyBatis 拦截器实现字段自动填充 2. 使用 MyBatis-Plus 实现字段自动填充 1. 使用 MyBatis 拦截器实现字段自动填充 实现步骤 创建拦截器 实现 MyBatis 的 Interceptor 接口,通过拦截 MyBatis 执行的 SQL 操作来自动填充公共字段 Intercepts({Signa…...

深度学习:人工智能的核心驱动力
深度学习 在当今科技飞速发展的时代,人工智能(AI)无疑是最具影响力和变革性的技术之一。而深度学习,作为人工智能领域的核心技术,正以其强大的能力和广泛的应用,深刻地改变着我们的生活和世界。深度学习究竟…...

Java学习路线--自用--带链接
1.Java基础 黑马:黑马程序员Java零基础视频教程_下部 2.MySQL 尚硅谷:MySQL数据库入门到大牛,mysql安装到优化,百科全书级,全网天花板 3.Redis 黑马:黑马程序员Redis入门到实战教程,深度透…...

在Qt中验证LDAP账户(Windows平台)
一、前言 原本以为在Qt(Windows平台)中验证 LDAP 账户很简单:集成Open LDAP的开发库即可。结果临了才发现,Open LDAP压根儿不支持Windows平台。沿着重用的原则,考虑迁移Open LDAP的源代码,却发现工作量不小…...
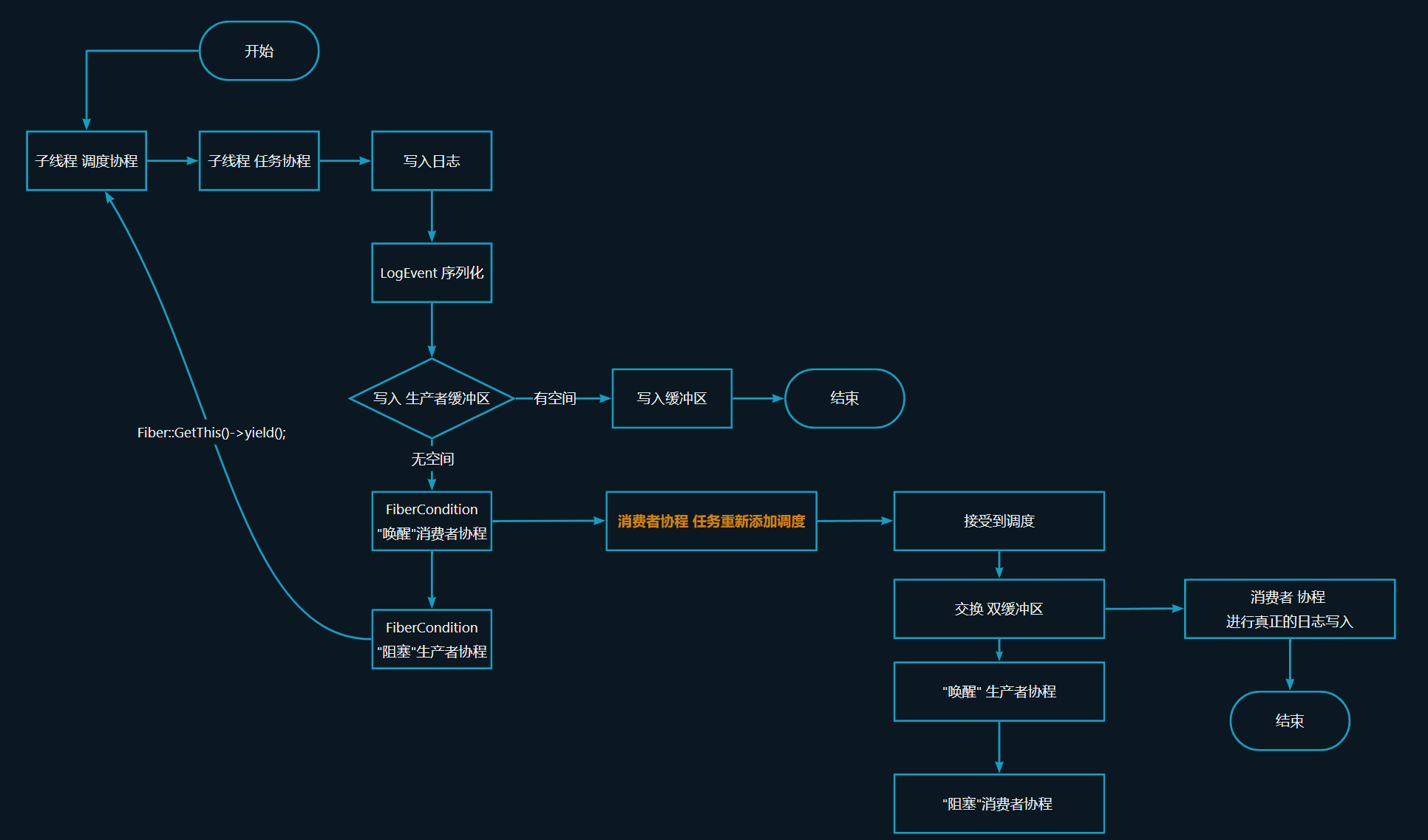
【sylar-webserver】重构日志系统
文章目录 主要工作流程图FiberConditionBufferBufferManagerLogEvent 序列化 & 反序列化LoggerRotatingFileLogAppender 主要工作 实现, LogEvent 序列化和反序列化 (使用序列化是为了更标准,如果转成最终的日志格式再存储(确…...

树莓派超全系列教程文档--(38)config.txt视频配置
config.txt视频配置 视频选项HDMI模式树莓派4-系列的HDMI树莓派5-系列的HDMI 复合视频模式enable_tvout LCD显示器和触摸屏ignore_lcddisable_touchscreen 通用显示选项disable_fw_kms_setup 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 视频选…...

线性DP:最短编辑距离
Dp 状态表示 f(i,j) 集合所有将A[1~i]变成B[1~j]的操作方式属性min 状态计算 (划分) 增f(i,j)f(i,j-1)1//A[i]元素要增加,说明A前i位置与B前j-1相同删f(i,j)f(i-1,j)1//A[i]元素要删除,说明A前i…...