[langchain教程]langchain03——用langchain构建RAG应用
RAG
RAG过程
离线过程:
- 加载文档
- 将文档按一定条件切割成片段
- 将切割的文本片段转为向量,存入检索引擎(向量库)
在线过程:
- 用户输入Query,将Query转为向量
- 从向量库检索,获得相似度TopN信息
- 将检索结果和用户输入,共同组成Prompt
- 将Prompt 输入大模型,获取LLM的回复
用langchian构建RAG
1. 加载文档
LangChain中的文档对象Document有两个属性:
page_content: str类型,记录此文档的内容。metadata: dict类型,保存与此文档相关的元数据,包括文档ID、文件名等。
在langchain中,加载文档使用 文档加载器DocumentLoader 来实现,它从源文档加载数据并返回文档列表。每个DocumentLoader都有其特定的参数,但它们都可以通过.load()方法以相同的方式调用。
加载pdf
需要先安装pypdf库
pip install pypdf
用PyPDFLoader加载pdf,输入是文件路径,输出提取出的内容列表:
from langchain_community.document_loaders import PyPDFLoaderloader = PyPDFLoader(file_path)
pages = []
for page in loader.load():pages.append(page)
返回的文档列表如下所示:
[
Document(metadata={'source': 'D:\\桌面\\RAG分析.pdf', 'page': 0}, page_content='11111111111111111111111111111111111111111111111111111111'),
Document(metadata={'source': 'D:\\桌面\\RAG分析.pdf', 'page': 1}, page_content='2222222222222222222222222222222222222222222222222222222')
]
加载网页
简单快速的文本提取
对于“简单快速”解析,需要 langchain-community 和 beautifulsoup4 库:
pip install langchain-community beautifulsoup4
使用WebBaseLoader,输入是url的列表,返回一个 Document 对象的列表,列表里的内容是一系列包含页面文本的字符串。在底层,它使用的是 beautifulsoup4 库。
import bs4
from langchain_community.document_loaders import WebBaseLoaderpage_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"loader = WebBaseLoader(web_paths=[page_url])
docs = loader.load()assert len(docs) == 1
print(docs)
这样提取出的基本上是页面 HTML 中文本的转储,可能包含多余的信息,提取的信息如下所示(截取了首部)
[Document(metadata={'source': 'https://python.langchain.com/', 'title': 'How to add memory to chatbots | 🦜️🔗 LangChain',},page_content='\n\n\n\n\nHow to add memory to chatbots | 🦜️🔗 LangChain\n\n\n\n\n\n\nSkip to main contentJoin us at ')
]
如果了解底层 HTML 中主体文本的表示,可以通过 BeautifulSoup 指定所需的 <div> 类和其他参数。
下面仅解析文章的主体文本:
loader = WebBaseLoader(web_paths=[page_url],bs_kwargs={"parse_only": bs4.SoupStrainer(class_="theme-doc-markdown markdown"),},bs_get_text_kwargs={"separator": " | ", "strip": True},
)docs = []
async for doc in loader.alazy_load():docs.append(doc)assert len(docs) == 1
doc = docs[0]
提取出的内容如下所示:
[Document(metadata={'source': 'https://python.langchain.com/docs/how_to/chatbots_memory/'}, page_content='How to add memory to chatbots | A key feature of chatbots is their ability to use the content of previous conversational turns as context. ')
]
可以使用各种设置对 WebBaseLoader 进行参数化,允许指定请求头、速率限制、解析器和其他 BeautifulSoup 的关键字参数。详细信息参见 API 参考。
高级解析
如果想对页面内容进行更细粒度的控制或处理,可以用langchain-unstructured进行高级解析。
pip install langchain-unstructuredpip install unstructured
注意: 如果不安装unstructured会报错!
下面的代码不是为每个页面生成一个 Document 并通过 BeautifulSoup 控制其内容,而是生成多个 Document 对象,表示页面上的不同结构。这些结构包括章节标题及其对应的主体文本、列表或枚举、表格等。
from langchain_unstructured import UnstructuredLoaderpage_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = UnstructuredLoader(web_url=page_url)docs = []
for doc in loader.load():docs.append(doc)print(docs[:5])
输出如下所示(太长了,截取了部分):
[Document(metadata={'image_url': 'https://colab.research.google.com/assets/colab-badge.svg', 'link_texts': ['Open In Colab'], 'link_urls': ['https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/how_to/chatbots_memory.ipynb'], 'languages': ['eng'], 'filetype': 'text/html', 'url': 'https://python.langchain.com/docs/how_to/chatbots_memory/', 'category': 'Image', 'element_id': '76f10732f139a03f24ecf55613a5116a'}, page_content='Open In Colab'), Document(metadata={'category_depth': 0, 'languages': ['eng'], 'filetype': 'text/html', 'url': 'https://python.langchain.com/docs/how_to/chatbots_memory/','category': 'Title', 'element_id': 'b6bfe64119578f39e0dd7d0287b2964a'}, page_content='How to add memory to chatbots'), Document(metadata={'languages': ['eng'], 'filetype': 'text/html', 'parent_id': 'b6bfe64119578f39e0dd7d0287b2964a', 'url': 'https://python.langchain.com/docs/how_to/chatbots_memory/', 'category': 'NarrativeText', 'element_id': 'ac3524f3e30afbdf096b186a665188ef'},page_content='A key feature of chatbots is their ability to use the content of previous conversational turns as context. This state management can take several forms, including:'), Document(metadata={'category_depth': 1, 'languages': ['eng'], 'filetype': 'text/html', 'parent_id': 'b6bfe64119578f39e0dd7d0287b2964a', 'url': 'https://python.langchain.com/docs/how_to/chatbots_memory/', 'category': 'ListItem', 'element_id': '0c9193e450bacf9a4d716208b2e7b1ee'}, page_content='Simply stuffing previous messages into a chat model prompt.'),
]
可以用doc.page_content来输出正文文本:
for doc in docs[:5]:print(doc.page_content)
输出如下所示:
Open In Colab
Open on GitHub
How to add memory to chatbots
A key feature of chatbots is their ability to use the content of previous conversational turns as context. This state management can take several forms, including:
Simply stuffing previous messages into a chat model prompt.
2. 切割文档
当文档过长时,模型存在两方面问题:一是可能无法完整加载至上下文窗口,二是即便能加载,从中提取有用信息也较为困难。
为破解此困境,可将文档拆分成多个块来进行嵌入与存储,如此一来,分块后还能快速精准地定位到与查询最相关的部分。
在具体操作中,可以把文档按照每块 1000 个字符的规格进行拆分,同时在块之间设置 200 个字符的重叠。之所以设置重叠,是为了降低将某块有效信息与其关联的重要上下文被人为割裂开的风险,保证内容的连贯性与完整性。
以下代码采用的文本分割器是 RecursiveCharacterTextSplitter,它会利用常见分隔符对文档进行递归拆分,直至各块大小满足既定要求。此外,代码还启用了 add_start_index=True 的设置,使每个分割后的文档块在初始文档中的字符起始位置得以保留,这一位置信息将以元数据属性 “start_index” 的形式呈现。
from langchain_text_splitters import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)
3. 将块转为向量存储到数据库
为了在运行时能够对文本块进行高效搜索,我们通常需要对文本块进行索引,而嵌入内容是实现这一目标的常见方法。
我们将每个文档分割后的文本块进行嵌入处理,并将这些嵌入插入到向量数据库中。当要搜索这些分割后的文本块时,可以将文本搜索查询进行嵌入,然后执行“相似性”度量,以识别出与查询嵌入最相似的存储文本块。其中,余弦相似性是一种简单且常用的相似性度量方法,它通过测量每对嵌入(高维向量)之间的角度的余弦值,来评估它们的相似程度。
我们可以通过Chroma 向量存储和 Ollama嵌入模型,完成对所有文档分割后的文本块的嵌入和存储工作。
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddingsembedding = OllamaEmbeddings(model_url="http://localhost:11434")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=embedding)
4. 检索
创建一个简单的应用程序,接受用户问题,搜索相关文档,并将检索到的文档和初始问题传递给模型以返回答案,具体步骤如下:
-
定义搜索文档的逻辑:LangChain 定义了一个检索器接口,它封装了一个可以根据字符串返回相关文档的索引查询。检索器的唯一要求是能够接受查询并返回文档,具体的底层逻辑由检索器指定。
-
使用向量存储检索器:最常见的检索器类型是向量存储检索器,它利用向量存储的相似性搜索能力来促进检索。任何
VectorStore都可以轻松转换为一个Retriever,使用VectorStore.as_retriever()方法。
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 6})retrieved_docs = retriever.invoke("What are the approaches to Task Decomposition?")print(retrieved_docs[0].page_content)
输出如下所示:
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.
Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.
5. 生成
生成时,将所有内容整合到一个链中,该链接受一个问题,检索相关文档,构建提示,将其传递给模型,并解析输出。
from langchain_community.document_loaders import UnstructuredURLLoader
from langchain_community.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.retrievers import VectorStoreRetriever
from langchain_community.prompts import PromptTemplate
from langchain_community.chains import RetrievalQA# 加载文档
page_url = "https://python.langchain.com/docs/how_to/chatbots_memory/"
loader = UnstructuredURLLoader(urls=[page_url])# 拆分文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200, add_start_index=True
)
all_splits = text_splitter.split_documents(loader.load())# 创建向量存储和嵌入
embedding = OllamaEmbeddings(model_url="http://localhost:11434")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=embedding)
retriever = VectorStoreRetriever(vectorstore=vectorstore)# 构建提示和生成链
prompt_template = """Use the following context to answer the question at the end. If the answer isn't found in the context, just say that you don't know.{context}Question: {question}"""
PROMPT = PromptTemplate.from_template(prompt_template)# 创建 RAG 链
rag_chain = RetrievalQA.from_chain_type(retriever=retriever,chain_type="stuff",prompt=PROMPT
)# 执行查询
result = rag_chain.invoke("What are the approaches to Task Decomposition?")
print(result['result'])
相关文章:

[langchain教程]langchain03——用langchain构建RAG应用
RAG RAG过程 离线过程: 加载文档将文档按一定条件切割成片段将切割的文本片段转为向量,存入检索引擎(向量库) 在线过程: 用户输入Query,将Query转为向量从向量库检索,获得相似度TopN信息将…...

Web 前端包管理工具深度解析:npm、yarn、pnpm 全面对比与实战建议
引言: 在现代web前端开发中,包管理工具的重要性不言而喻,无论是构建项目脚手架,安装ui库,管理依赖版本,还是实现monorepo项目结构,一个高效稳定的包管理工具都会大幅提升开发体验和协作效率 作为一名前端工程师,深入了解这些工具背后的机制与差异,对于提升项目可维护性和团队…...
【springsecurity oauth2授权中心】简单案例跑通流程 P1
项目被拆分开,需要一个授权中心使得每个项目都去授权中心登录获取用户权限。而单一项目里权限使用的是spring-security来控制的,每个controller方法上都有 PreAuthorize("hasAuthority(hello)") 注解来控制权限,想以最小的改动来实…...
spark—SQL3
连接方式 内嵌Hive: 使用时无需额外操作,但实际生产中很少使用。 外部Hive: 在虚拟机下载相关配置文件,在spark-shell中连接需将hive-site.xml拷贝到conf/目录并修改url、将MySQL驱动copy到jars/目录、把core-site.xml和hdfs-sit…...

Linux-scp命令
scp(Secure Copy Protocol)是基于 SSH 的安全文件传输命令,用于在本地和远程主机之间加密传输文件或目录。以下是详细用法和示例: 基本语法 scp [选项] 源文件 目标路径常用选项 选项描述-P 端口号指定 SSH 端口(默认…...
的作用)
【PyQt5】@QtCore.pyqtSlot()的作用
在 PyQt5 中,QtCore.pyqtSlot() 是一个装饰器,用于将普通的 Python 方法标记为 可被信号连接的槽函数。它的主要作用是: 1. 标识槽函数 核心作用:告诉 PyQt 这个方法是一个槽(Slot),可以被信号…...

Go语言中的Context
目录 Go语言中的Context 1. Context的基本概念 1.1 Context的核心作用 2. Context的基本用法 2.1 创建Context 背景Context 可取消的Context 带有超时的Context 2.2 在Goroutine间传递Context 2.3 获取Context的值 为Context添加自定义数据 访问Context中的值 3. C…...

小刚说C语言刷题——1039 求三个数的最大数
1.题目描述 已知有三个不等的数,将其中的最大数找出来。 输入 输入只有一行,包括3个整数。之间用一个空格分开。 输出 输出只有一行(这意味着末尾有一个回车符号),包括1个整数。 样例 输入 1 5 8 输出 8 2.…...

一文了解相位阵列天线中的真时延
本文要点 真时延是宽带带相位阵列天线的关键元素之一。 真时延透过在整个信号频谱上应用可变相移来消除波束斜视现象。 在相位阵列中使用时延单元或电路板,以提供波束控制和相移。 市场越来越需要更快、更可靠的通讯网络,而宽带通信系统正在努力满…...

在 UE5 编辑器中,由于游戏设置 -> EV100 设置,点击播放前后的光照不同。如何保持点击播放前后的光照一致?
In Unreal Engine 5 (UE5), discrepancies in lighting between the editor and play modes are often due to auto exposure settings, particularly when using the EV100 system. To maintain consistent lighting across both modes, follow these steps:YouTube1Epic …...

Git 配置 GPG 提交签名
使用 GPG 对 Git 提交进行签名,可以证明该提交确实是你本人提交的。这在团队协作和代码审核中非常有用,GitHub/GitLab 等平台也会显示 “Verified” 标签。 🧩 一、检查是否已安装 GPG gpg --version 如果未安装,可使用以下命令…...

linux学习 5 正则表达式及通配符
重心应该放在通配符的使用上 正则表达式 正则表达式是用于 文本匹配和替换 的强大工具 介绍两个交互式的网站来学习正则表达式 regexlearn 支持中文 regexone 还有一个在线测试的网址 regex101 基本规则 符号作用示例.匹配任何字符除了换行a.b -> axb/a,b[abc]匹配字符…...

eplan许可证与版本兼容性问题
在使用EPLAN电气设计软件时,确保许可证与软件版本之间的兼容性至关重要。不兼容的许可证可能导致软件无法正常运行,影响工作效率。本文将为您深入解析EPLAN许可证与版本兼容性问题,并提供解决方案,确保您的软件始终处于最佳状态。…...

【Easylive】AdminFilter 详细解析
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 AdminFilter 详细解析 AdminFilter 是一个 Spring Cloud Gateway 的过滤器,用于在请求到达微服务之前进行 权限校验(如管理员 Token 验证)。以下是逐行解…...

纷析云开源财务软件:助力企业实现数字化自主权
在数字化转型浪潮中,企业财务管理面临高成本、低灵活性、数据孤岛等痛点。纷析云开源财务软件(项目地址:https://gitee.com/shenxji/fxy)凭借其开源基因与模块化设计,为企业提供了一条“低成本、高可控”的数字化路径。…...
基于超启发鲸鱼优化算法的混合神经网络多输入单输出回归预测模型 HHWOA-CNN-LSTM-Attention
基于超启发鲸鱼优化算法的混合神经网络多输入单输出回归预测模型 HHWOA-CNN-LSTM-Attention 随着人工智能技术的飞速发展,回归预测任务在很多领域得到了广泛的应用。尤其在金融、气象、医疗等领域,精确的回归预测模型能够为决策者提供宝贵的参考信息。为…...

解决使用hc595驱动LED数码管亮度低的问题
不知道大家在做项目的时候有没有遇到使用hc595驱动LED数码管亮度低的问题(数码管位数较多),如果大佬们有好的方法的可以评论区留言 当时我们解决是换成了天微的驱动芯片,现在还在寻找新的解决办法(主要软件不花钱&…...

【Linux】轻量级命令解释器minishell
Minishell 一、项目背景 在linux操作系统中,用户对操作系统进行的一系列操作都不能直接操作内核,而是通过shell间接对内核进行操作。 Shell 是操作系统中的一种程序,它为用户提供了一种与操作系统内核和计算机硬件进行交互的界面。用户可以通…...

Android RK356X TVSettings USB调试开关
Android RK356X TVSettings USB调试开关 平台概述操作-打开USB调试实现源码补充说明 平台 RK3568 Android 11 概述 RK3568 是瑞芯微(Rockchip)推出的一款高性能处理器,支持 USB OTG(On-The-Go)和 USB Host 功能。US…...
)
CGAL 计算直线之间的距离(3D)
文章目录 一、简介二、实现代码三、实现效果一、简介 这里的计算思路很简单: 1、首先将两个三维直线均平移至过原点处,这里两条直线可以构成一个平面normal。 2、如果两个直线平行,那么两条直线之间的距离就转换为直线上一点到另一直线的距离。 3、如果两个直线不平行,则可…...
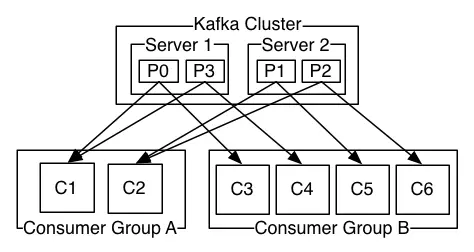
消息队列知识点详解
消息队列场景 什么是消息队列 可以把消息队列理解一个使用队列来通信的组件,它的本质是交换机队列的模式,实现发送消息,存储消息,消费消息的过程。 我们通常说的消息队列,MQ其实就是消息中间件,业界中比较…...
序列号绑定的SD卡坏了怎么办?
在给SD卡烧录程序的时候,大家发现有的卡是无法烧录的,如:复印机的SD卡不能被复制通常涉及以下几个技术原因,可能与序列号绑定、加密保护或硬件限制有关: 一、我们以复印机的系统卡为例来简单讲述一下 序列号或硬件绑定…...

使用SystemWeaver生成SOME/IP ETS ARXML的完整实战指南
使用SystemWeaver生成SOME/IP ETS ARXML的完整实战指南 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,可以分享一下给大家。点击跳转到网站。 https://www.captainbed.cn/ccc 一、SystemWeaver与SOME/IP基础认知 1.1 SystemWe…...

基于单片机的BMS热管理功能设计
标题:基于单片机的BMS热管理功能设计 内容:1.摘要 摘要:在电动汽车和储能系统中,电池管理系统(BMS)的热管理功能至关重要,它直接影响电池的性能、寿命和安全性。本文的目的是设计一种基于单片机的BMS热管理功能。采用…...
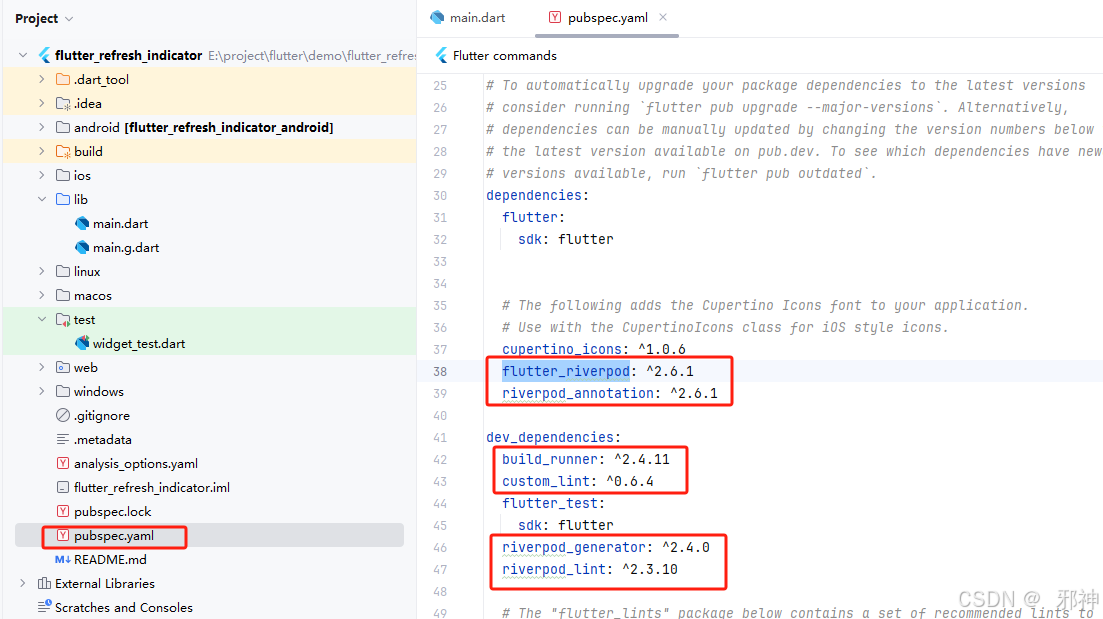
Flutter 状态管理 Riverpod
Android Studio版本 Flutter SDK 版本 将依赖项添加到您的应用 flutter pub add flutter_riverpod flutter pub add riverpod_annotation flutter pub add dev:riverpod_generator flutter pub add dev:build_runner flutter pub add dev:custom_lint flutter pub add dev:riv…...
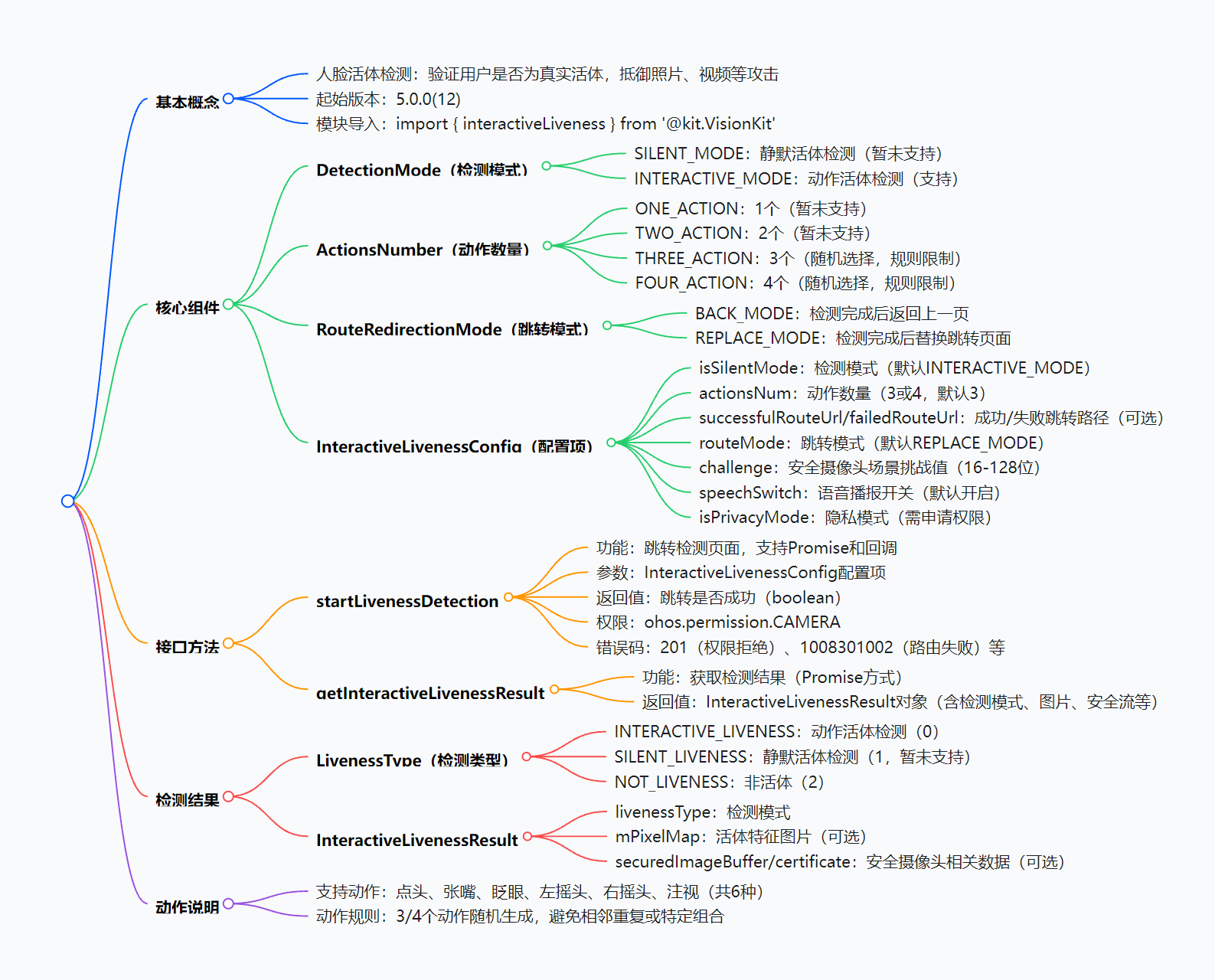
【HarmonyOS 5】VisionKit人脸活体检测详解
【HarmonyOS 5】VisionKit人脸活体检测详解 一、VisionKit人脸活体检测是什么? VisionKit是HamronyOS提供的场景化视觉服务工具包。 华为将常见的解决方案,通常需要三方应用使用SDK进行集成。华为以Kit的形式集成在HarmoyOS系统中,方便三方…...

Pycharm(九)函数的闭包、装饰器
目录 一、函数参数 二、闭包 三、装饰器 一、函数参数 def func01():print("func01 shows as follows") func01() # 函数名存放的是函数所在空间的地址 print(func01)#<function func01 at 0x0000023BA9FC04A0> func02func01 print(func02)#<function f…...

【深度学习】详解矩阵乘法、点积,内积,外积、哈达玛积极其应用|tensor系列02
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【深度学习】你真的理解张量了吗?|标量、向量、矩阵、张量的秩|01每日一言🌼: “脑袋想不明白的,就用脚想”…...
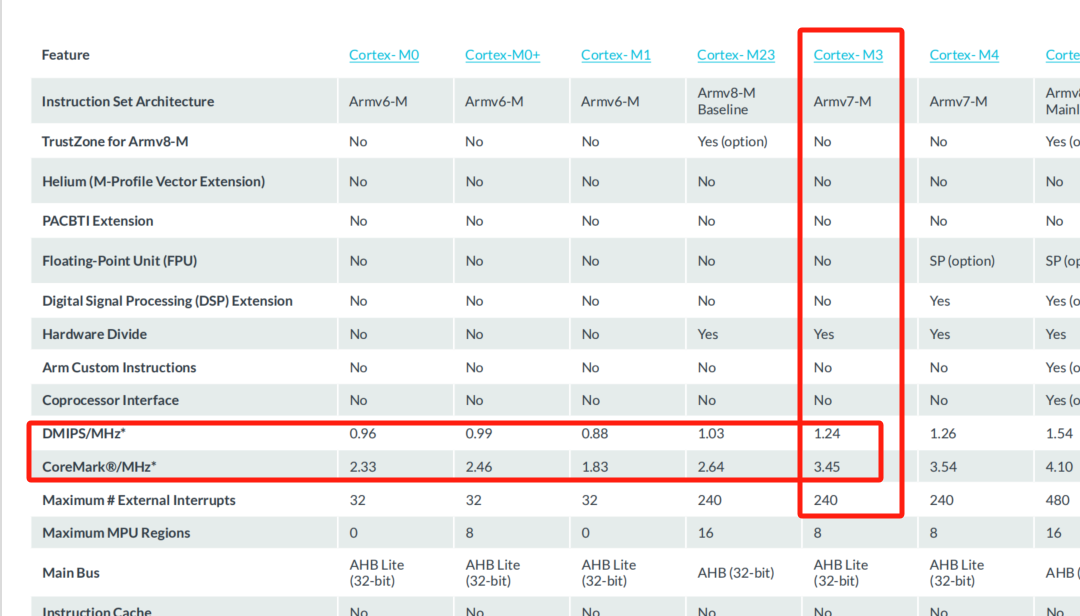
MH2103系列coremark1.0跑分数据和优化,及基于arm2d的优化应用
CoreMark 1.0 介绍 CoreMark 是由 EEMBC(Embedded Microprocessor Benchmark Consortium)组织于 2009 年推出的一款用于衡量嵌入式系统 CPU 或 MCU 性能的标准基准测试工具。它旨在替代陈旧的 Dhrystone 标准(Dhrystone 容易受到各种libc不同…...
Flowith AI,解锁下一代「知识交易市场」
前言 最近几周自媒体号都在疯狂推Manus,看了几篇测评后,突然在某个时间节点,在特工的文章下,发现了很小众的Flowith。 被这段评论给心动到,于是先去注册了下账号。一翻探索过后,发现比我想象中要有趣的多&…...