B+树节点与插入操作
B+树节点与插入操作
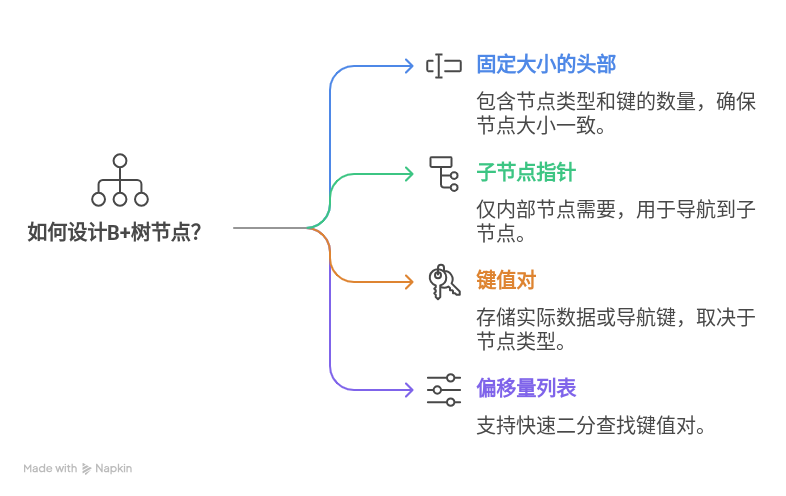
设计B+树节点
在设计B+树的数据结构时,我们首先需要定义节点的格式,这将帮助我们理解如何进行插入、删除以及分裂和合并操作。以下是对B+树节点设计的详细说明。
节点格式概述
所有的B+树节点大小相同,这是为了后续使用自由列表机制。即使当前阶段不处理磁盘数据,一个具体的节点格式仍然是必要的,因为它决定了节点的字节大小以及何时应该分裂一个节点。
节点组成部分
-
固定大小的头部(Header):
- 包含节点类型(叶节点或内部节点)。
- 包含键的数量(nkeys)。
-
子节点指针列表(仅内部节点有):
- 每个内部节点包含指向其子节点的指针列表。
-
KV对列表:
- 包含键值对(key-value pairs),对于叶节点是实际数据,对于内部节点则是用于导航的键。
-
到KV对的偏移量列表:
- 用于支持KV对的二分查找,通过记录每个KV对在节点中的位置来加速查找过程。
节点格式示例:
| type | nkeys | pointers | offsets | key-values | unused |
|---|---|---|---|---|---|
| 2B | 2B | nkeys * 8B | nkeys * 2B | … | … |
每个KV对的格式如下:
| klen | vlen | key | val |
|---|---|---|---|
| 2B | 2B | … | … |
简化与限制
为了专注于学习基础知识,而不是创建一个真实的数据库系统,这里做出了一些简化:
- 叶节点和内部节点使用相同的格式,尽管这会导致一些空间浪费(例如,叶节点不需要指针,内部节点不需要存储值)。
- 内部节点的分支数为𝑛时,包含𝑛个键,每个键都是从相应子树的最小键复制而来。实际上,对于𝑛个分支只需要𝑛−1个键。额外的键主要是为了简化可视化。
- 设置节点大小为4KB,这是典型的操作系统页面大小。然而,键和值可能非常大,超过单个节点的容量。解决这个问题的方法包括外部存储大型KVs或使节点大小可变,但这些不是基础问题的核心部分,因此我们将通过限制KV大小来避免这些问题,确保它们总是能适应于一个节点内。
这种设计使得我们可以集中精力于理解和实现B+树的基本操作,如插入、删除、分裂和合并,同时保持代码的简洁性和易理解性。
const HEADER = 4
const BTREE_PAGE_SIZE = 4096
const BTREE_MAX_KEY_SIZE = 1000
const BTREE_MAX_VAL_SIZE = 3000
func init() {node1max := HEADER + 8 + 2 + 4 + BTREE_MAX_KEY_SIZE + BTREE_MAX_VAL_SIZEassert(node1max <= BTREE_PAGE_SIZE) // maximum KV
}
键大小限制
键大小的限制也确保了内部节点总是能够容纳至少2个键。这对于维持B+树的结构完整性非常重要。
内存中的数据类型
在我们的代码中,一个节点只是一个按这种格式解释的字节块。从内存移动数据到磁盘时,没有序列化步骤会更简单。
type BNode []byte // 可以直接写入磁盘
解耦数据结构与IO
在设计B+树时,无论是内存中的还是磁盘上的数据结构,都需要进行空间的分配和释放。通过使用回调函数,我们可以将这些操作抽象出来,形成数据结构与其他数据库组件之间的边界。
回调机制的设计
以下是Go语言中定义的BTree结构示例,它展示了如何通过回调来管理磁盘页面:
type BTree struct {// 指针(非零页号)root uint64// 管理磁盘页面的回调函数get func(uint64) []byte // 解引用一个指针new func([]byte) uint64 // 分配一个新的页面(写时复制)del func(uint64) // 释放一个页面
}
对于磁盘上的B+树,数据库文件是一个由页号(指针)引用的页面(节点)数组。我们将按照以下方式实现这些回调:
get:从磁盘读取一个页面。new:分配并写入一个新的页面(采用写时复制的方式)。del:释放一个页面。
这种方法允许我们以统一的方式处理内存和磁盘上的数据结构,同时保持代码的清晰和模块化。
为了操作B+树节点的字节格式,我们需要定义一些辅助函数来解析和访问节点中的数据。以下是基于节点格式的详细实现。
节点格式回顾
因为Node的类型就是[]byte,我们可以定义一些辅助函数来解析和访问节点中的数据。
| type | nkeys | pointers | offsets | key-values | unused |
|---|---|---|---|---|---|
| 2B | 2B | nkeys * 8B | nkeys * 2B | … | … |
每个键值对(key-value pair)的格式为:
| klen | vlen | key | val |
|---|---|---|---|
| 2B | 2B | … | … |
辅助函数的实现
我们将为节点定义以下辅助函数:
- 解析头部信息:获取节点类型和键的数量。
- 访问指针列表:用于内部节点的子节点指针。
- 访问偏移量列表:用于快速定位键值对。
- 解析键值对:从偏移量中提取键和值。
解析头部信息
节点头部包含两部分:
type(2字节):节点类型(叶节点或内部节点)。nkeys(2字节):键的数量。
const (BNODE_NODE = 1 // internal nodes without values BNODE_LEAF = 2 // leaf nodes with values
)
func (node BNode) btype() uint16 {return binary.LittleEndian.Uint16(node[0:2])
}
func (node BNode) nkeys() uint16 {return binary.LittleEndian.Uint16(node[2:4])
}func (node BNode) setHeader(btype uint16, nkeys uint16) {binary.LittleEndian.PutUint16(node[0:2], btype)binary.LittleEndian.PutUint16(node[2:4], nkeys)
}
子节点
// pointers
func (node BNode) getPtr(idx uint16) uint64 {//assert(idx < node.nkeys())pos := HEADER + 8*idxreturn binary.LittleEndian.Uint64(node[pos:])
}
func (node BNode) setPtr(idx uint16, val uint64) {
//assert(idx < node.nkeys())pos := HEADER + 8*idxbinary.LittleEndian.PutUint64(node[pos:], val)
}
解析节点中的键值对与偏移量
在B+树的节点中,键值对(KV pairs)是紧密排列存储的。为了高效地访问第n个键值对,我们引入了偏移量列表,以实现O(1)的时间复杂度来定位键值对,并支持节点内的二分查找。
以下是相关代码和解释:
1. 偏移量列表
偏移量列表用于快速定位键值对的位置。每个偏移量表示相对于第一个键值对起点的字节位置(即键值对的结束位置)。通过偏移量列表,我们可以直接跳到指定的键值对,而无需逐一遍历整个节点。
// 计算偏移量列表中第idx个偏移量的位置
func offsetPos(node BNode, idx uint16) uint16 {assert(1 <= idx && idx <= node.nkeys()) // 确保索引有效return HEADER + 8*node.nkeys() + 2*(idx-1)
}// 获取第idx个偏移量
func (node BNode) getOffset(idx uint16) uint16 {if idx == 0 {return 0 // 第一个键值对的起始偏移量为0}return binary.LittleEndian.Uint16(node[offsetPos(node, idx):])
}// 设置第idx个偏移量
func (node BNode) setOffset(idx uint16, offset uint16) {pos := offsetPos(node, idx)binary.LittleEndian.PutUint16(node[pos:], offset)
}
2. 键值对的位置计算
kvPos函数返回第n个键值对相对于整个节点的字节偏移量。它结合了偏移量列表的信息,使得可以直接定位键值对。
// 返回第idx个键值对的位置
func (node BNode) kvPos(idx uint16) uint16 {assert(idx <= node.nkeys()) // 确保索引有效return HEADER + 8*node.nkeys() + 2*node.nkeys() + node.getOffset(idx)
}
3. 获取键和值
通过kvPos函数,我们可以轻松提取键值对中的键和值。
// 获取第idx个键
func (node BNode) getKey(idx uint16) []byte {assert(idx < node.nkeys()) // 确保索引有效pos := node.kvPos(idx)klen := binary.LittleEndian.Uint16(node[pos:]) // 键长度return node[pos+4 : pos+4+uint16(klen)] // 跳过klen和vlen字段
}// 获取第idx个值
func (node BNode) getVal(idx uint16) []byte {assert(idx < node.nkeys()) // 确保索引有效pos := node.kvPos(idx)klen := binary.LittleEndian.Uint16(node[pos:]) // 键长度vlen := binary.LittleEndian.Uint16(node[pos+2:]) // 值长度return node[pos+4+uint16(klen) : pos+4+uint16(klen)+uint16(vlen)]
}
4. 节点大小
nbytes函数通过访问最后一个键值对的结束位置,可以方便地计算节点中已使用的字节数。
// 返回节点的大小(已使用字节数)
func (node BNode) nbytes() uint16 {return node.kvPos(node.nkeys())
}
5. 节点内查找操作
节点内的查找操作是B+树的核心功能之一,既支持范围查询也支持点查询。以下是一个基于线性扫描的实现,未来可以替换为二分查找以提高效率。
// 返回第一个满足 kid[i] <= key 的子节点索引
func nodeLookupLE(node BNode, key []byte) uint16 {nkeys := node.nkeys()found := uint16(0)// 第一个键是从父节点复制来的,因此总是小于等于keyfor i := uint16(1); i < nkeys; i++ {cmp := bytes.Compare(node.getKey(i), key)if cmp <= 0 {found = i // 更新找到的索引}if cmp >= 0 {break // 找到大于等于key的键时停止}}return found
}
这种设计不仅提高了节点操作的效率,还为后续扩展(如二分查找和插入删除操作)奠定了坚实的基础。
更新 B+ 树节点
在 B+ 树中,更新节点的操作涉及插入键值对、复制节点(Copy-on-Write)、以及处理内部节点的链接更新。以下是详细的设计和实现。
1. 插入到叶节点
插入键值对到叶节点的过程包括以下步骤:
- 使用
nodeLookupLE找到插入位置。 - 创建一个新节点,并将旧节点的内容复制到新节点中,同时插入新的键值对。
// 向叶节点插入一个新的键值对
func leafInsert(new BNode, old BNode, idx uint16,key []byte, val []byte,
) {// 设置新节点的头部信息(类型为叶节点,键的数量增加1)new.setHeader(BNODE_LEAF, old.nkeys()+1)// 复制旧节点中 [0, idx) 范围内的键值对到新节点nodeAppendRange(new, old, 0, 0, idx)// 在新节点的 idx 位置插入新的键值对nodeAppendKV(new, idx, 0, key, val)// 复制旧节点中 [idx, nkeys) 范围内的键值对到新节点nodeAppendRange(new, old, idx+1, idx, old.nkeys()-idx)
}
2. 节点复制函数
为了支持高效的节点复制操作,我们定义了两个辅助函数:
nodeAppendKV:将单个键值对插入到指定位置。nodeAppendRange:将多个键值对从旧节点复制到新节点。
2.1 插入单个键值对
// 将一个键值对插入到指定位置
func nodeAppendKV(new BNode, idx uint16, ptr uint64, key []byte, val []byte) {// 设置指针(仅内部节点需要)new.setPtr(idx, ptr)// 获取当前键值对的位置pos := new.kvPos(idx)// 写入键长度binary.LittleEndian.PutUint16(new[pos+0:], uint16(len(key)))// 写入值长度binary.LittleEndian.PutUint16(new[pos+2:], uint16(len(val)))// 写入键copy(new[pos+4:], key)// 写入值copy(new[pos+4+uint16(len(key)):], val)// 更新下一个键的偏移量new.setOffset(idx+1, new.getOffset(idx)+4+uint16(len(key)+len(val)))
}
2.2 复制多个键值对
// 将多个键值对从旧节点复制到新节点
func nodeAppendRange(new BNode, old BNode,dstNew uint16, srcOld uint16, n uint16,
) {for i := uint16(0); i < n; i++ {srcIdx := srcOld + idstIdx := dstNew + i// 复制键值对key := old.getKey(srcIdx)val := old.getVal(srcIdx)nodeAppendKV(new, dstIdx, old.getPtr(srcIdx), key, val)}
}
3. 更新内部节点
对于内部节点,当子节点被分裂时,可能需要更新多个链接。我们使用 nodeReplaceKidN 函数来替换一个子节点链接为多个链接。
// 替换一个子节点链接为多个链接
func nodeReplaceKidN(tree *BTree, new BNode, old BNode, idx uint16,kids ...BNode,
) {inc := uint16(len(kids)) // 新增的子节点数量// 设置新节点的头部信息(类型为内部节点,键的数量增加 inc-1)new.setHeader(BNODE_NODE, old.nkeys()+inc-1)// 复制旧节点中 [0, idx) 范围内的键值对到新节点nodeAppendRange(new, old, 0, 0, idx)// 插入新的子节点链接for i, node := range kids {// 为每个子节点分配页号,并插入其第一个键作为边界键nodeAppendKV(new, idx+uint16(i), tree.new(node), node.getKey(0), nil)}// 复制旧节点中 [idx+1, nkeys) 范围内的键值对到新节点nodeAppendRange(new, old, idx+inc, idx+1, old.nkeys()-(idx+1))
}
4. 关键点总结
-
Copy-on-Write:
- 每次修改节点时,都会创建一个新节点并复制旧节点的内容。这种设计确保了数据的一致性和持久性。
-
插入逻辑:
- 叶节点的插入通过
leafInsert实现,而内部节点的更新通过nodeReplaceKidN实现。 - 在插入过程中,键值对的顺序必须保持一致,因为偏移量列表依赖于前一个键值对的位置。
- 叶节点的插入通过
-
回调机制:
tree.new回调用于分配新的子节点页号,这使得我们可以灵活地支持内存和磁盘上的存储。
-
扩展性:
- 当前实现基于线性扫描,未来可以通过二分查找优化查找效率。
- 支持多链接更新,方便处理子节点分裂的情况。
示例用法
以下是一个简单的例子,展示如何向叶节点插入键值对:
func ExampleLeafInsert() {// 创建一个旧节点old := make(BNode, 4096)old.setHeader(BNODE_LEAF, 0)// 创建一个新节点new := make(BNode, 4096)// 插入键值对leafInsert(new, old, 0, []byte("key1"), []byte("value1"))// 验证插入结果fmt.Printf("Key: %s, Value: %s\n", new.getKey(0), new.getVal(0))
}
分裂 B+ 树节点
在 B+ 树中,由于每个节点的大小受到页面限制(BTREE_PAGE_SIZE),当一个节点变得过大时,我们需要将其分裂为多个节点。最坏情况下,一个超大的节点可能需要被分裂为 3 个节点。
以下是详细的设计和实现。
1. 分裂逻辑概述
1.1 节点分裂的基本规则
- 如果节点的大小小于等于
BTREE_PAGE_SIZE,则无需分裂。 - 如果节点的大小超过
BTREE_PAGE_SIZE,我们首先尝试将其分裂为两个节点:- 左节点:包含前半部分数据。
- 右节点:包含后半部分数据。
- 如果左节点仍然过大,则需要进一步分裂为三个节点:
- 左左节点:包含左节点的前半部分数据。
- 中间节点:包含左节点的后半部分数据。
- 右节点:保持不变。
1.2 返回值
- 函数返回分裂后的节点数量(1、2 或 3)以及对应的节点数组。
2. 实现细节
2.1 nodeSplit2 函数
该函数将一个超大的节点分裂为两个节点,确保右节点始终适合一个页面。
// 将超大的节点分裂为两个节点
func nodeSplit2(left BNode, right BNode, old BNode) {nkeys := old.nkeys()half := nkeys / 2// 复制前半部分到左节点left.setHeader(old.NodeType(), half)nodeAppendRange(left, old, 0, 0, half)// 复制后半部分到右节点right.setHeader(old.NodeType(), nkeys-half)nodeAppendRange(right, old, 0, half, nkeys-half)
}
2.2 nodeSplit3 函数
该函数处理节点的完整分裂逻辑,返回 1 至 3 个节点。
// 分裂一个过大的节点,结果是 1~3 个节点
func nodeSplit3(old BNode) (uint16, [3]BNode) {if old.nbytes() <= BTREE_PAGE_SIZE {// 如果节点大小符合限制,则无需分裂old = old[:BTREE_PAGE_SIZE]return 1, [3]BNode{old, nil, nil} // 返回单个节点}// 创建临时节点left := BNode(make([]byte, 2*BTREE_PAGE_SIZE)) // 左节点可能需要再次分裂right := BNode(make([]byte, BTREE_PAGE_SIZE))// 第一次分裂:将旧节点分裂为左节点和右节点nodeSplit2(left, right, old)if left.nbytes() <= BTREE_PAGE_SIZE {// 如果左节点大小符合限制,则返回两个节点left = left[:BTREE_PAGE_SIZE]return 2, [3]BNode{left, right, nil}}// 如果左节点仍然过大,则需要第二次分裂leftleft := BNode(make([]byte, BTREE_PAGE_SIZE))middle := BNode(make([]byte, BTREE_PAGE_SIZE))// 第二次分裂:将左节点分裂为左左节点和中间节点nodeSplit2(leftleft, middle, left)// 验证分裂结果assert(leftleft.nbytes() <= BTREE_PAGE_SIZE)// 返回三个节点return 3, [3]BNode{leftleft, middle, right}
}
3. 关键点分析
-
分裂条件:
- 如果节点的大小小于等于
BTREE_PAGE_SIZE,则无需分裂。 - 如果节点的大小超过限制,则需要进行一次或两次分裂。
- 如果节点的大小小于等于
-
分裂策略:
- 每次分裂都将节点分为两部分,确保右节点始终适合一个页面。
- 如果左节点仍然过大,则需要进一步分裂。
-
临时节点:
- 分裂过程中创建的节点是临时分配在内存中的。
- 这些节点只有在调用
nodeReplaceKidN时才会真正分配到磁盘上。
-
边界情况:
- 确保左节点和右节点的大小始终符合限制。
- 使用断言(
assert)验证分裂结果的正确性。
这种分裂机制为构建高效的 B+ 树奠定了基础,同时也为后续优化(如动态调整页面大小)提供了良好的起点。
B+ 树插入操作
在 B+ 树中,插入操作是核心功能之一。我们已经实现了以下三个节点操作:
leafInsert:更新叶节点。nodeReplaceKidN:更新内部节点。nodeSplit3:分裂超大的节点。
现在,我们将这些操作组合起来,实现完整的 B+ 树插入逻辑。插入操作从根节点开始,通过键查找直到到达目标叶节点,然后执行插入操作。
1. 插入逻辑概述
1.1 插入流程
- 从根节点开始递归查找,找到目标叶节点。
- 如果找到的键已存在,则更新其值(
leafUpdate)。 - 如果键不存在,则插入新键值对(
leafInsert)。 - 如果节点过大,则进行分裂(
nodeSplit3)。 - 更新父节点以反映子节点的变化(
nodeReplaceKidN)。
1.2 递归处理
- 内部节点的插入是递归的,每次插入完成后返回更新后的节点。
- 如果返回的节点过大,则需要分裂,并更新父节点的链接。
2. 实现细节
2.1 treeInsert 函数
该函数是 B+ 树插入的核心入口,负责处理递归插入和分裂逻辑。
// 插入一个键值对到节点中,结果可能需要分裂。
// 调用者负责释放输入节点并分配分裂后的结果节点。
func treeInsert(tree *BTree, node BNode, key []byte, val []byte) BNode {// 创建一个新的临时节点,允许其大小超过一页new := BNode{data: make([]byte, 2*BTREE_PAGE_SIZE)}// 查找插入位置idx := nodeLookupLE(node, key)// 根据节点类型执行不同的操作switch node.btype() {case BNODE_LEAF:// 叶节点if bytes.Equal(key, node.getKey(idx)) {// 键已存在,更新其值leafUpdate(new, node, idx, key, val)} else {// 插入新键值对leafInsert(new, node, idx+1, key, val)}case BNODE_NODE:// 内部节点nodeInsert(tree, new, node, idx, key, val)default:panic("bad node!")}return new
}
2.2 leafUpdate 函数
leafUpdate 类似于 leafInsert,但它用于更新已存在的键值对,而不是插入重复的键。
// 更新叶节点中的现有键值对
func leafUpdate(new BNode, old BNode, idx uint16,key []byte, val []byte,
) {// 设置新节点的头部信息new.setHeader(BNODE_LEAF, old.nkeys())// 复制旧节点的内容到新节点nodeAppendRange(new, old, 0, 0, old.nkeys())// 更新指定位置的键值对pos := new.kvPos(idx)binary.LittleEndian.PutUint16(new[pos+2:], uint16(len(val))) // 更新值长度copy(new[pos+4+uint16(len(key)):], val) // 更新值内容
}
2.3 nodeInsert 函数
对于内部节点,插入操作是递归的。插入完成后,需要检查子节点是否过大,并进行分裂。
// 向内部节点插入键值对
func nodeInsert(tree *BTree, new BNode, node BNode, idx uint16,key []byte, val []byte,
) {// 获取子节点的指针kptr := node.getPtr(idx)// 递归插入到子节点knode := treeInsert(tree, tree.get(kptr), key, val)// 分裂子节点nsplit, split := nodeSplit3(knode)// 释放旧的子节点tree.del(kptr)// 更新父节点的链接nodeReplaceKidN(tree, new, node, idx, split[:nsplit]...)
}
3. 关键点分析
-
递归与分裂:
- 插入操作是递归的,从根节点开始,直到找到目标叶节点。
- 每次插入完成后,如果节点过大,则需要分裂,并更新父节点的链接。
-
内存管理:
- 插入过程中创建的临时节点需要由调用者负责释放。
- 使用回调函数(如
tree.new和tree.del)管理页面的分配和释放。
-
分裂策略:
- 使用
nodeSplit3处理节点分裂,确保分裂后的节点始终符合页面大小限制。 - 分裂后的节点数量可能是 1、2 或 3。
- 使用
-
边界情况:
- 如果键已存在,则直接更新其值。
- 如果插入导致根节点分裂,则需要创建新的根节点。
4. 示例用法
以下是一个简单的例子,展示如何向 B+ 树中插入键值对:
func ExampleTreeInsert() {// 初始化 B+ 树tree := &BTree{root: 1, // 假设根节点页号为 1get: func(pageNum uint64) []byte {// 模拟从磁盘读取节点return loadFromDisk(pageNum)},new: func(data []byte) uint64 {// 模拟分配新页面return allocatePage(data)},del: func(pageNum uint64) {// 模拟释放页面deallocatePage(pageNum)},}// 插入键值对key := []byte("example_key")value := []byte("example_value")// 获取根节点rootNode := tree.get(tree.root)// 执行插入操作updatedRoot := treeInsert(tree, rootNode, key, value)// 更新根节点tree.root = tree.new(updatedRoot)
}
5. 总结
通过上述设计和实现,我们能够高效地完成 B+ 树的插入操作。关键点包括:
- 递归插入:从根节点开始,递归查找目标叶节点。
- 分裂机制:使用
nodeSplit3确保节点大小始终符合限制。 - 内存管理:通过回调函数管理页面的分配和释放。
- 灵活性:支持动态调整树的结构,适应不同大小的数据。
这种插入机制为构建高效的 B+ 树奠定了基础,同时也为后续优化(如批量插入、并发控制)提供了良好的起点。
代码仓库地址:database-go
相关文章:
B+树节点与插入操作
B树节点与插入操作 设计B树节点 在设计B树的数据结构时,我们首先需要定义节点的格式,这将帮助我们理解如何进行插入、删除以及分裂和合并操作。以下是对B树节点设计的详细说明。 节点格式概述 所有的B树节点大小相同,这是为了后续使用自由…...
)
4.20刷题记录(单调栈)
第一部分:简单介绍 单调栈我的理解是在栈中存储数字出现的位置,然后通过遍历比较当前栈顶元素与当前元素的大小关系,从而确定逻辑相关顺序。 第二部分:真题讲解 (1)739. 每日温度 - 力扣(Lee…...
线性回归之多项式升维
文章目录 多项式升维简介简单案例实战案例多项式升维优缺点 多项式升维简介 多项式升维(Polynomial Expansion)是线性回归中一种常用的特征工程方法,它通过将原始特征进行多项式组合来扩展特征空间,从而让线性模型能够拟合非线性关…...

【上位机——MFC】运行时类信息机制
运行时类信息机制的使用 类必须派生自CObject类内必须添加声明宏DECLARE_DYNAMIC(theClass)3.类外必须添加实现宏 IMPLEMENT_DYNAMIC(theClass,baseClass) 具备上述三个条件后,CObject::IsKindOf函数就可以正确判断对象是否属于某个类。 代码示例 #include <…...

POSIX多线程,解锁高性能编程
在计算机编程的广阔领域中,POSIX 标准就像是一把通用的钥匙,开启了跨平台编程的大门。POSIX,即 Portable Operating System Interface(可移植操作系统接口) ,是 IEEE 为了规范各种 UNIX 操作系统提供的 API…...

利用TCP+多进程技术实现私聊信息
服务器: import socket from multiprocessing import Process from threading import Threaduser_dic {}def send_recv(client_conn, client_addr):while 1:# 接收客户端发送的消息res client_conn.recv(1024).decode("utf-8")print("客户端发送…...
颠覆传统!毫秒级响应的跨平台文件同步革命,远程访问如本地操作般丝滑
文章目录 前言1. 安装Docker2. Go File使用演示3. 安装cpolar内网穿透4. 配置Go File公网地址5. 配置Go File固定公网地址 前言 在这个信息爆炸的时代,谁不曾遭遇过类似的窘境呢?试想,当你正于办公室中埋首案牍时,手机突然弹出一…...
CrewAI Community Version(一)——初步了解以及QuickStart样例
目录 1. CrewAI简介1.1 CrewAI Crews1.2 CrewAI Flows1.3 Crews和Flows的使用情景 2. CrewAI安装2.1 安装uv2.2 安装CrewAI CLI 3. 官网QuickStart样例3.1 创建CrewAI Crews项目3.2 项目结构3.3 .env3.4 智能体角色及其任务3.4.1 agents.yaml3.4.2 tasks.yaml 3.5 crew.py3.6 m…...

蓝桥杯 18.分考场
分考场 原题目链接 题目描述 有 n 个人参加某项特殊考试。 为了公平,要求任何两个认识的人不能分在同一个考场。 你的任务是求出最少需要分几个考场才能满足这个条件。 输入描述 第一行:一个整数 n,表示参加考试的人数(1 ≤…...
)
1. ubuntu20.04 终端实现 ros的输出 (C++,Python)
本节对应赵虚左ROS书籍的1.3.1-->1.3.3 1)创建一个工作空间 2)创建一个功能包和导入依赖 3)编辑源文件 4)编辑配置文件 5)编译和执行 1)创建一个工作空间 mkdir -p catkin_ws/src cd catkin_ws ca…...
Nginx下搭建rtmp流媒体服务 并使用HLS或者OBS测试
所需下载地址: 通过网盘分享的文件:rtmp 链接: https://pan.baidu.com/s/1t21J7cOzQR1ASLrsmrYshA?pwd0000 提取码: 0000 window: 解压 win目录下的 nginx-rtmp-module-1.2.2.zip和nginx 1.7.11.3 Gryphon.zip安装包,解压时选…...

vue vite打完包后依然想保留某个文件夹下的console.log方便以后的观察的详细做法
首先需要安装包 npm i terser rollup/plugin-strip 具体的包如下: "rollup/plugin-strip": "^3.0.4","terser": "^5.39.0", // 这个不用也行 如果不用则需要将build中的minify和terserOptions一并删除了然后在vite.co…...

Lateral 查询详解:概念、适用场景与普通 JOIN 的区别
1. 什么是Lateral查询? Lateral查询(也称为横向关联查询)是一种特殊的子查询,允许子查询中引用外层查询的列(即关联引用),并在执行时逐行对外层查询的每一行数据执行子查询。 语法上通常使用关…...

[langchain教程]langchain03——用langchain构建RAG应用
RAG RAG过程 离线过程: 加载文档将文档按一定条件切割成片段将切割的文本片段转为向量,存入检索引擎(向量库) 在线过程: 用户输入Query,将Query转为向量从向量库检索,获得相似度TopN信息将…...

Web 前端包管理工具深度解析:npm、yarn、pnpm 全面对比与实战建议
引言: 在现代web前端开发中,包管理工具的重要性不言而喻,无论是构建项目脚手架,安装ui库,管理依赖版本,还是实现monorepo项目结构,一个高效稳定的包管理工具都会大幅提升开发体验和协作效率 作为一名前端工程师,深入了解这些工具背后的机制与差异,对于提升项目可维护性和团队…...
【springsecurity oauth2授权中心】简单案例跑通流程 P1
项目被拆分开,需要一个授权中心使得每个项目都去授权中心登录获取用户权限。而单一项目里权限使用的是spring-security来控制的,每个controller方法上都有 PreAuthorize("hasAuthority(hello)") 注解来控制权限,想以最小的改动来实…...
spark—SQL3
连接方式 内嵌Hive: 使用时无需额外操作,但实际生产中很少使用。 外部Hive: 在虚拟机下载相关配置文件,在spark-shell中连接需将hive-site.xml拷贝到conf/目录并修改url、将MySQL驱动copy到jars/目录、把core-site.xml和hdfs-sit…...

Linux-scp命令
scp(Secure Copy Protocol)是基于 SSH 的安全文件传输命令,用于在本地和远程主机之间加密传输文件或目录。以下是详细用法和示例: 基本语法 scp [选项] 源文件 目标路径常用选项 选项描述-P 端口号指定 SSH 端口(默认…...
的作用)
【PyQt5】@QtCore.pyqtSlot()的作用
在 PyQt5 中,QtCore.pyqtSlot() 是一个装饰器,用于将普通的 Python 方法标记为 可被信号连接的槽函数。它的主要作用是: 1. 标识槽函数 核心作用:告诉 PyQt 这个方法是一个槽(Slot),可以被信号…...

Go语言中的Context
目录 Go语言中的Context 1. Context的基本概念 1.1 Context的核心作用 2. Context的基本用法 2.1 创建Context 背景Context 可取消的Context 带有超时的Context 2.2 在Goroutine间传递Context 2.3 获取Context的值 为Context添加自定义数据 访问Context中的值 3. C…...

小刚说C语言刷题——1039 求三个数的最大数
1.题目描述 已知有三个不等的数,将其中的最大数找出来。 输入 输入只有一行,包括3个整数。之间用一个空格分开。 输出 输出只有一行(这意味着末尾有一个回车符号),包括1个整数。 样例 输入 1 5 8 输出 8 2.…...

一文了解相位阵列天线中的真时延
本文要点 真时延是宽带带相位阵列天线的关键元素之一。 真时延透过在整个信号频谱上应用可变相移来消除波束斜视现象。 在相位阵列中使用时延单元或电路板,以提供波束控制和相移。 市场越来越需要更快、更可靠的通讯网络,而宽带通信系统正在努力满…...

在 UE5 编辑器中,由于游戏设置 -> EV100 设置,点击播放前后的光照不同。如何保持点击播放前后的光照一致?
In Unreal Engine 5 (UE5), discrepancies in lighting between the editor and play modes are often due to auto exposure settings, particularly when using the EV100 system. To maintain consistent lighting across both modes, follow these steps:YouTube1Epic …...

Git 配置 GPG 提交签名
使用 GPG 对 Git 提交进行签名,可以证明该提交确实是你本人提交的。这在团队协作和代码审核中非常有用,GitHub/GitLab 等平台也会显示 “Verified” 标签。 🧩 一、检查是否已安装 GPG gpg --version 如果未安装,可使用以下命令…...

linux学习 5 正则表达式及通配符
重心应该放在通配符的使用上 正则表达式 正则表达式是用于 文本匹配和替换 的强大工具 介绍两个交互式的网站来学习正则表达式 regexlearn 支持中文 regexone 还有一个在线测试的网址 regex101 基本规则 符号作用示例.匹配任何字符除了换行a.b -> axb/a,b[abc]匹配字符…...

eplan许可证与版本兼容性问题
在使用EPLAN电气设计软件时,确保许可证与软件版本之间的兼容性至关重要。不兼容的许可证可能导致软件无法正常运行,影响工作效率。本文将为您深入解析EPLAN许可证与版本兼容性问题,并提供解决方案,确保您的软件始终处于最佳状态。…...

【Easylive】AdminFilter 详细解析
【Easylive】项目常见问题解答(自用&持续更新中…) 汇总版 AdminFilter 详细解析 AdminFilter 是一个 Spring Cloud Gateway 的过滤器,用于在请求到达微服务之前进行 权限校验(如管理员 Token 验证)。以下是逐行解…...

纷析云开源财务软件:助力企业实现数字化自主权
在数字化转型浪潮中,企业财务管理面临高成本、低灵活性、数据孤岛等痛点。纷析云开源财务软件(项目地址:https://gitee.com/shenxji/fxy)凭借其开源基因与模块化设计,为企业提供了一条“低成本、高可控”的数字化路径。…...
基于超启发鲸鱼优化算法的混合神经网络多输入单输出回归预测模型 HHWOA-CNN-LSTM-Attention
基于超启发鲸鱼优化算法的混合神经网络多输入单输出回归预测模型 HHWOA-CNN-LSTM-Attention 随着人工智能技术的飞速发展,回归预测任务在很多领域得到了广泛的应用。尤其在金融、气象、医疗等领域,精确的回归预测模型能够为决策者提供宝贵的参考信息。为…...

解决使用hc595驱动LED数码管亮度低的问题
不知道大家在做项目的时候有没有遇到使用hc595驱动LED数码管亮度低的问题(数码管位数较多),如果大佬们有好的方法的可以评论区留言 当时我们解决是换成了天微的驱动芯片,现在还在寻找新的解决办法(主要软件不花钱&…...