《MySQL:MySQL表的基本查询操作CRUD》
CRUD:Create(创建)、Retrieve(读取)、Update(更新)、Delete(删除)。
Create
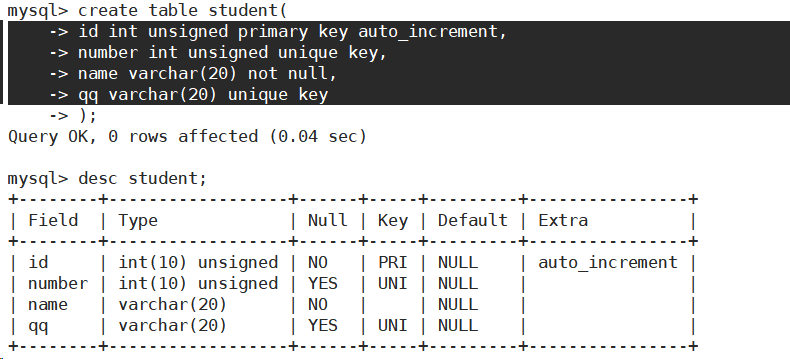

into 可以省略。
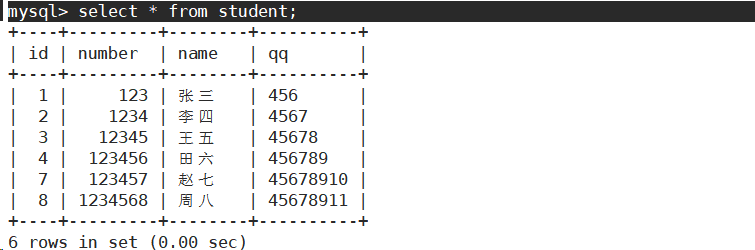
插入否则更新
由于主键或唯一键冲突而导致插入失败。

可以选择性的进行同步更新操作语法:
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...
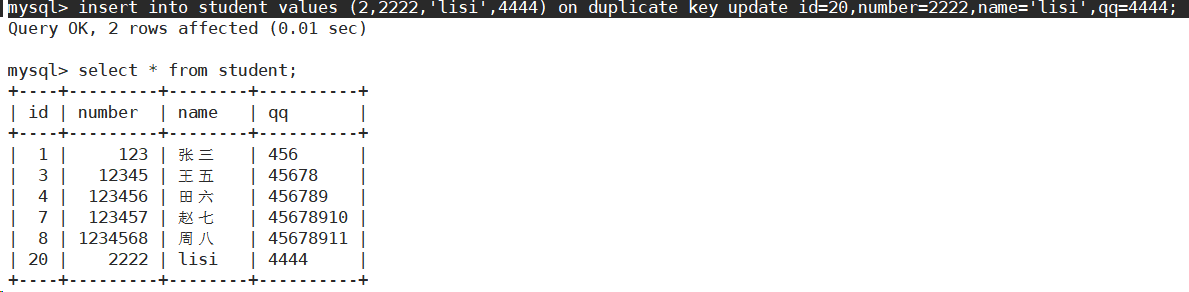
2 rows affected (0.01 sec):表示表中有数据冲突,并且数据已经被更新。
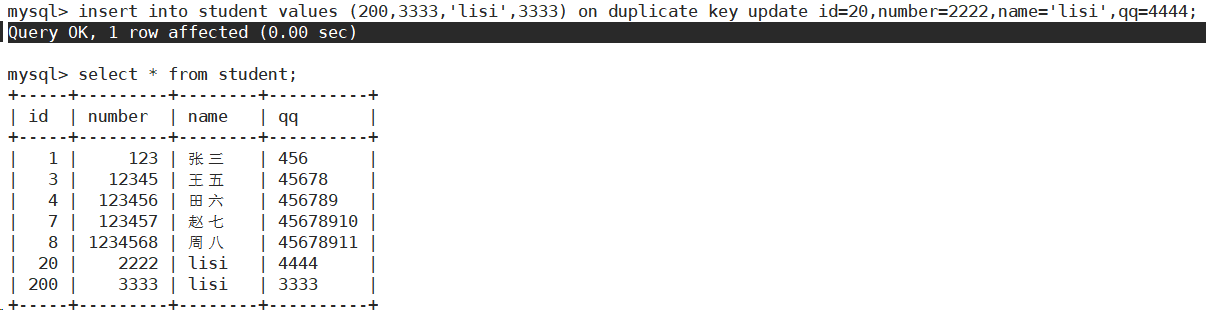
1 row affected (0.00 sec):表示表中没有数据冲突,数据被插入。
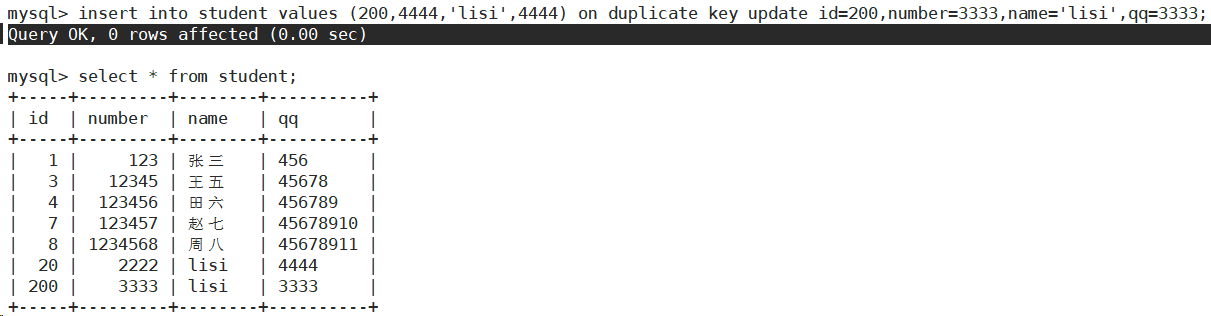
0 rows affected (0.00 sec):表示表中有数据冲突,但是冲突的值跟update的值相等。
替换
主键或唯一键没有冲突,则直接插入;如果有冲突,则删除后再插入。
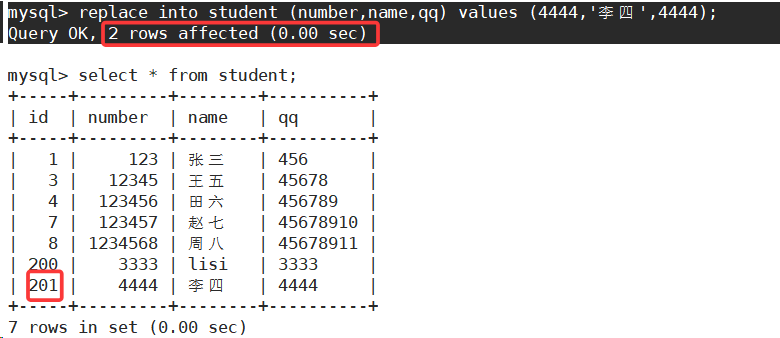
2 rows affected (0.00 sec):表示表中有冲突数据,删除后重新插入。
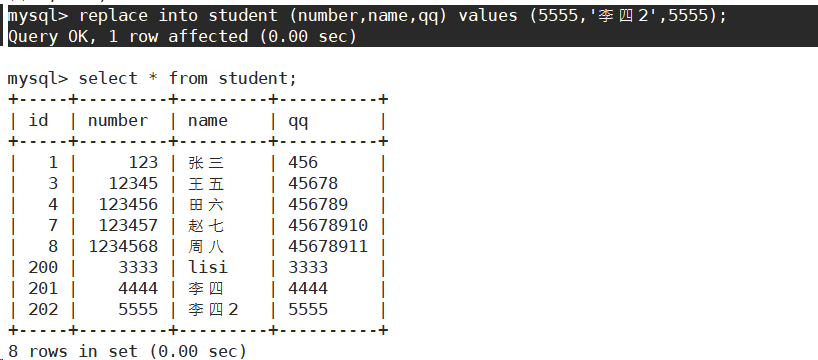
1 row affected (0.00 sec):表示表中没有冲突数据,直接插入。
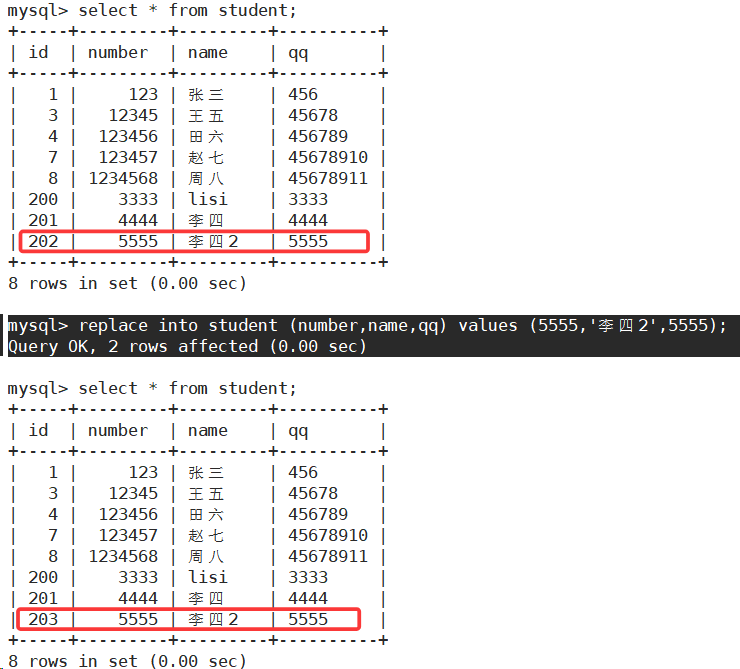
可以看到,如果表中有数据冲突,是删除后再插入的。
Retrieve
- 建立一张表结构。
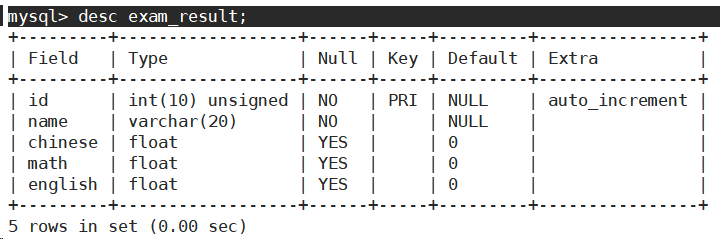
- 插入以下数据。

SELECT列
全列查询
通常情况下使用*进行全列查询。
- 查询的列越多,意味着数据量越大
- 可能影响索引的使用
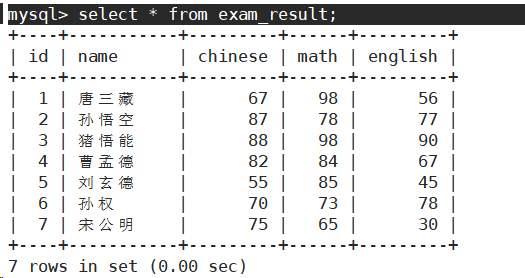
指定列查询

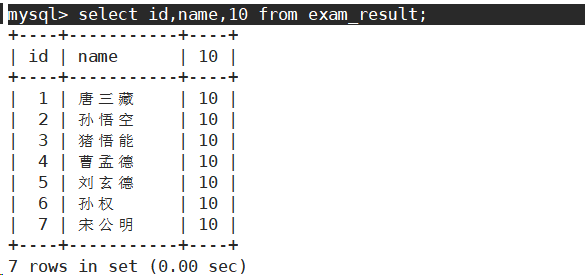
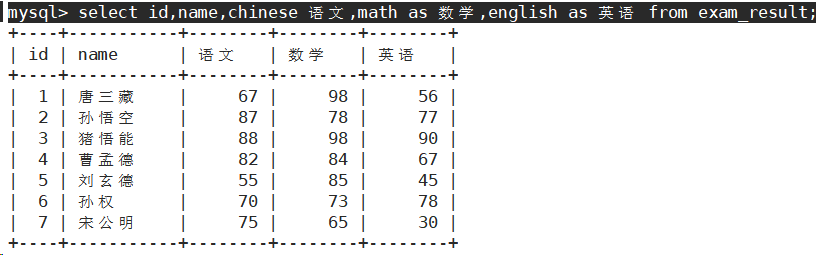
查询字段为表达式
- 表达式不包含字段。
- 表达式包含一个字段。
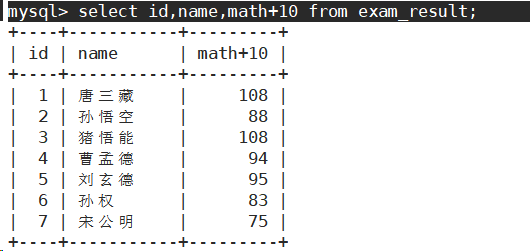
- 表达式包含多个字段。
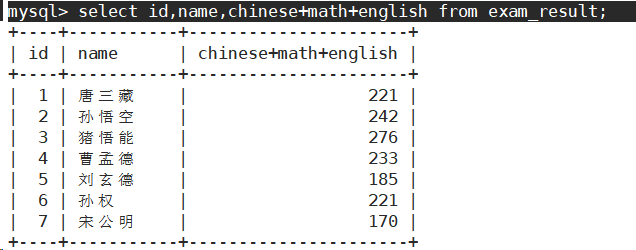
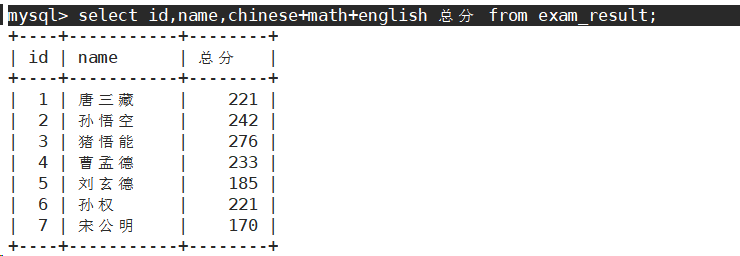
为查询结果指定别名
SELECT column [AS] alias_name [...] FROM table_name;
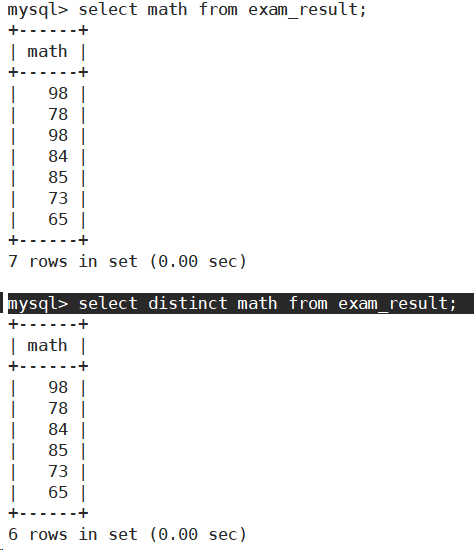
结果去重
where条件
一列有多行,实际我们可能需要查询符合某些条件的记录。
比较运算符
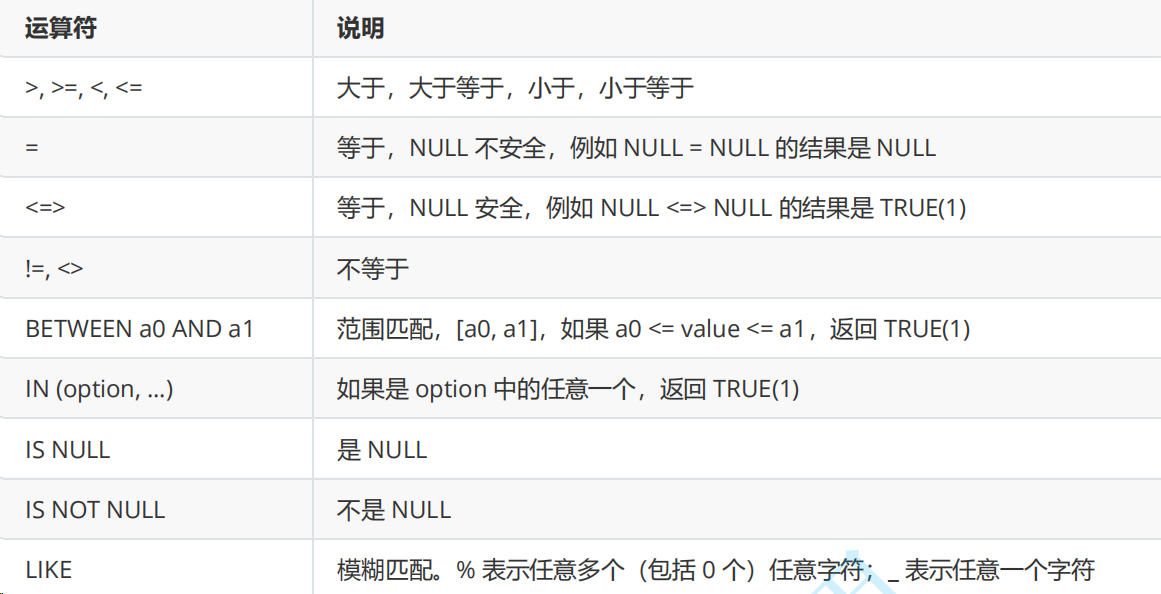
逻辑运算符
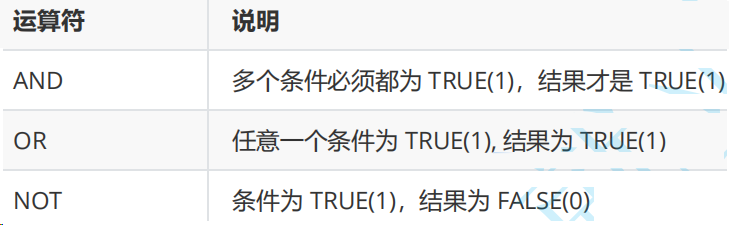
基本比较
- 英语不及格的同学及英语成绩
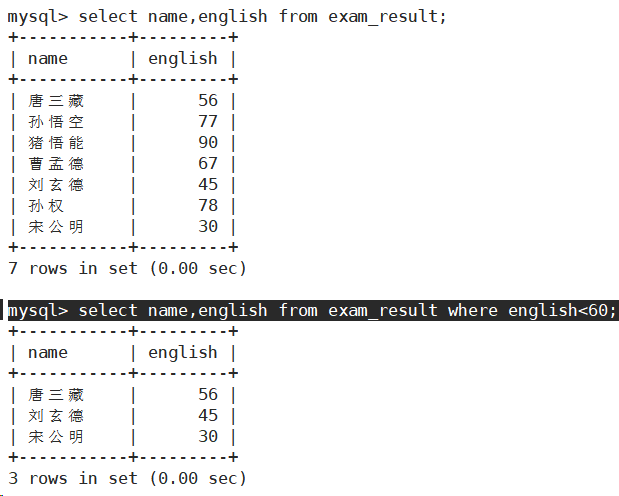
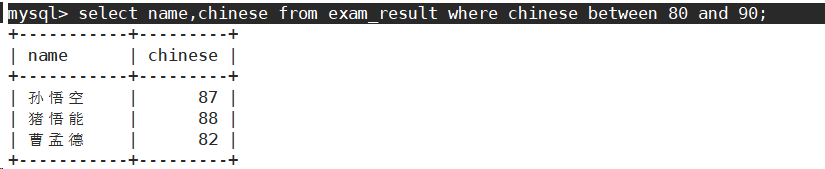
- 语文成绩在 [80, 90] 分的同学及语文成绩
使用and进行条件连接。
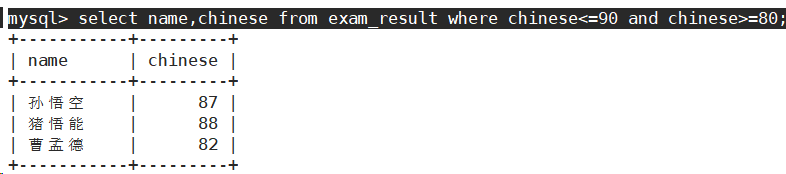
使用between and进行条件连接。
- 数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
使用or条件进行连接。

使用in条件。

- 姓孙的同学 及 孙某同学
模糊匹配 like:
- like % 匹配任意(包含0个)多个字符
- like _ 严格匹配任意一个字符
姓孙的同学。
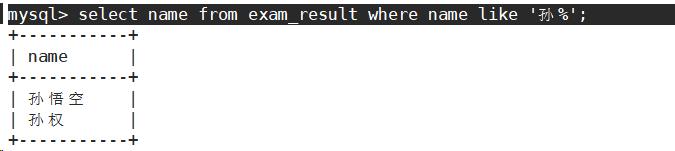
孙某同学。
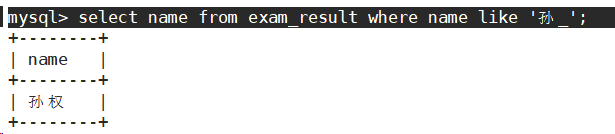
- 语文成绩好于英语成绩的同学
- 总分在 200 分以上的同学

注意:别名不能在where条件中使用。因为select的查询顺序是先查询表再看限制条件再筛选字段。

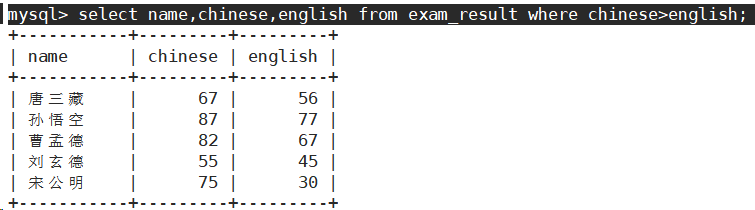
- 语文成绩 > 80 并且不姓孙的同学

- 孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80

有如下表结构。
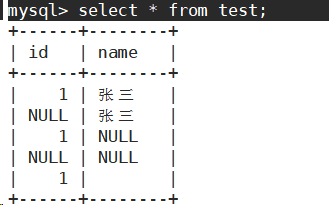
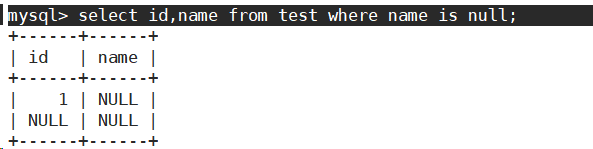
- 查询名字为空的同学。
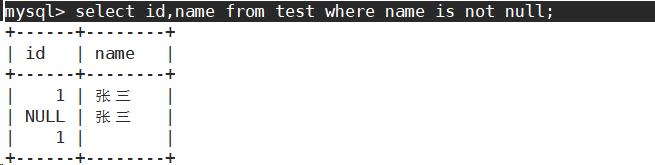
- 查询名字不为空的同学。
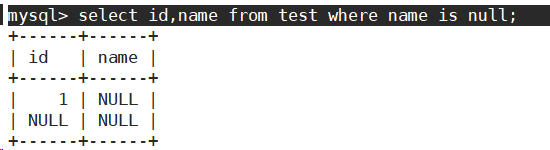
- 查询名字等于空串的同学。
结果排序
- ASC:升序,从小到大
- DESC:降序,从大到小
- 默认为ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
- 同学及数学成绩,按数学成绩升序显示
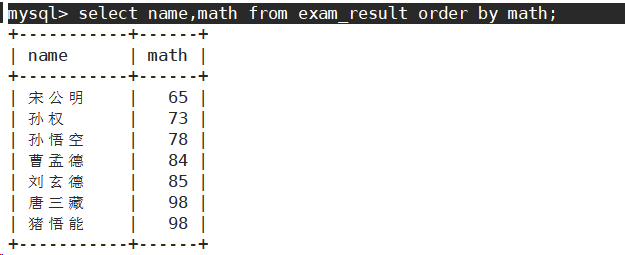
order by默认为升序。
- 同学及数学成绩,按数学成绩降序显示
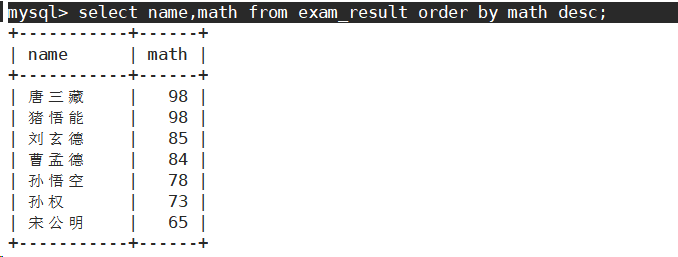
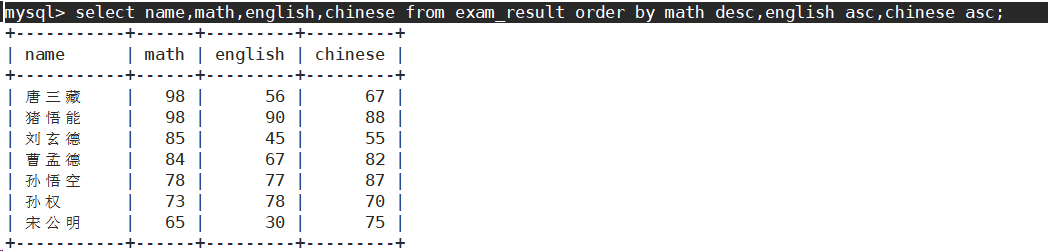
- 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
意思就是,如果数学成绩相同,则英语成绩按升序排序;如果数学、英语成绩都相同,则语文成绩按升序排列。
- 查询同学及总分,由高到低
order by中可以有表达式。
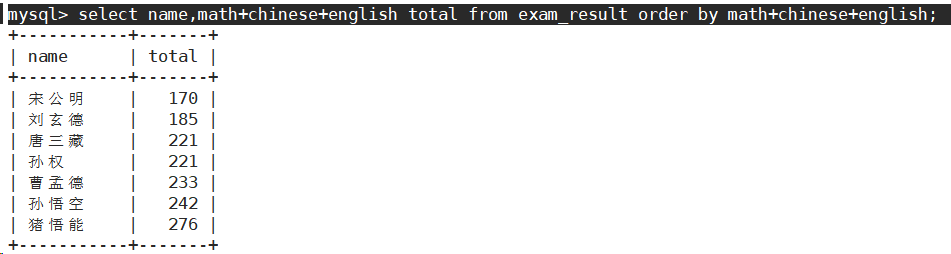
order by中可以使用别名。
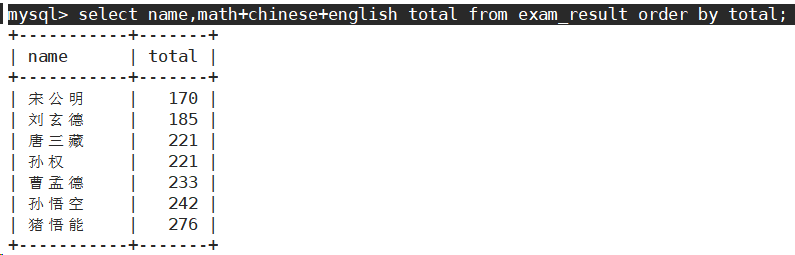
这里order by为什么能用别名呢?因为排序一定是先有数据,再排序,所以,select的执行顺序是先要有表结构,再筛选数据,再对数据做排序。
- 查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示

- 查询姓孙的同学或者姓宋的同学的总分,结果按总分由高到低显示

select执行顺序。

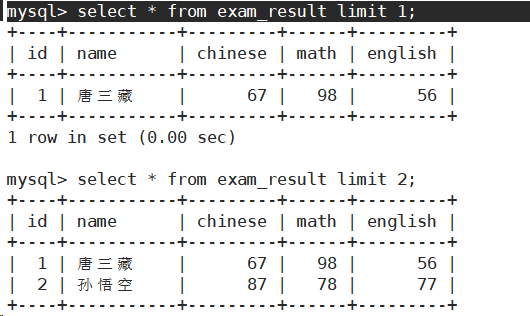
筛选分页结果
起始下标为0
从0开始,筛选n条结果
- SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
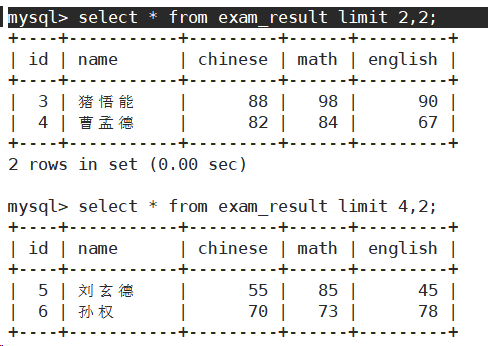
从s开始,筛选n条结果
- SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s,n;
从s开始,筛选n条结果
- SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n,offset s;
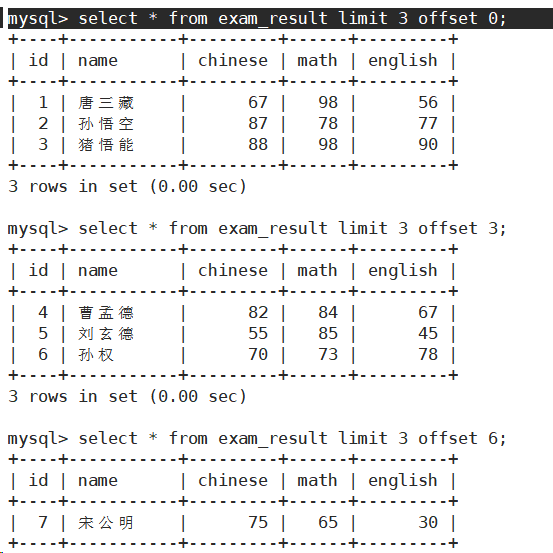
-
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
- 查询姓孙的同学或者姓宋的同学的总分,结果按总分由高到低显示,并只显示两条记录
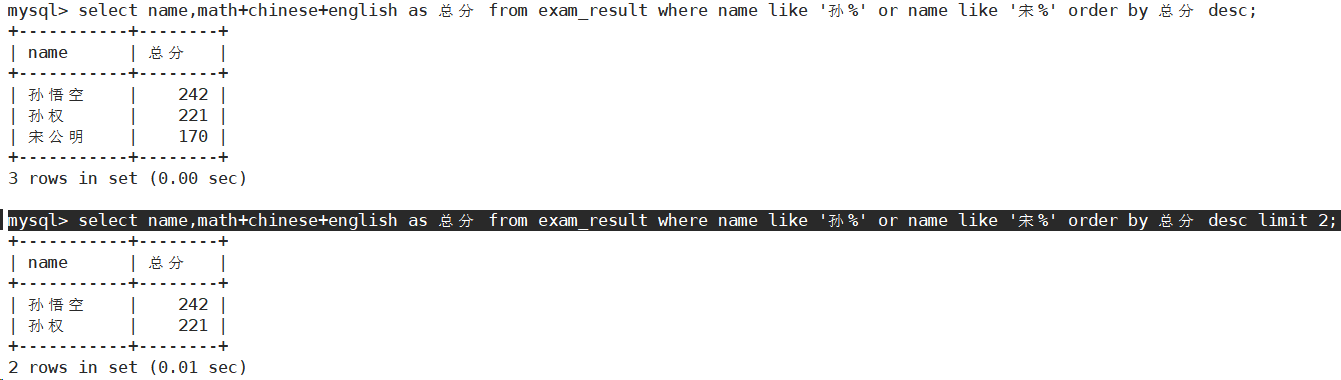
limit的本质是“显示”,只有筛选数据的工作全都准备好了,最后才显示。此时,select的执行顺序为:

Update
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
-
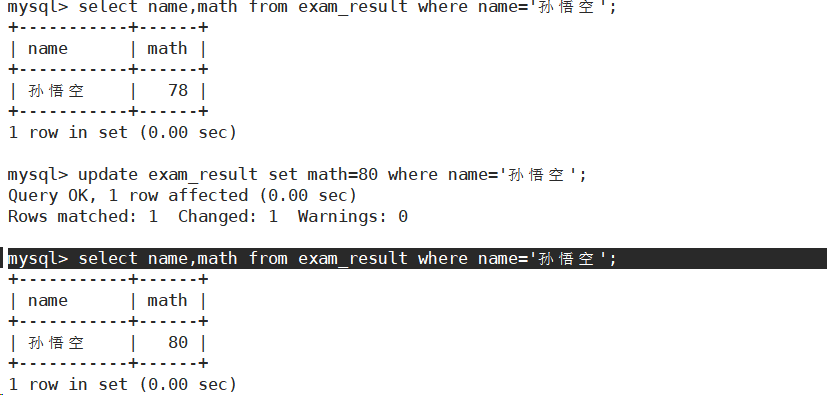
将孙悟空同学的数学成绩变更为 80 分
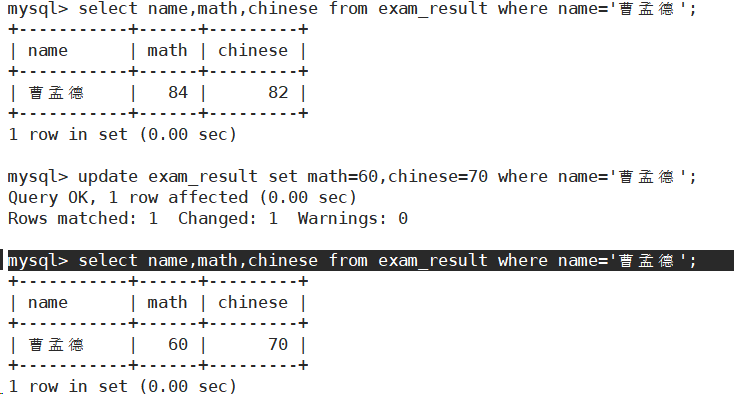
- 将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
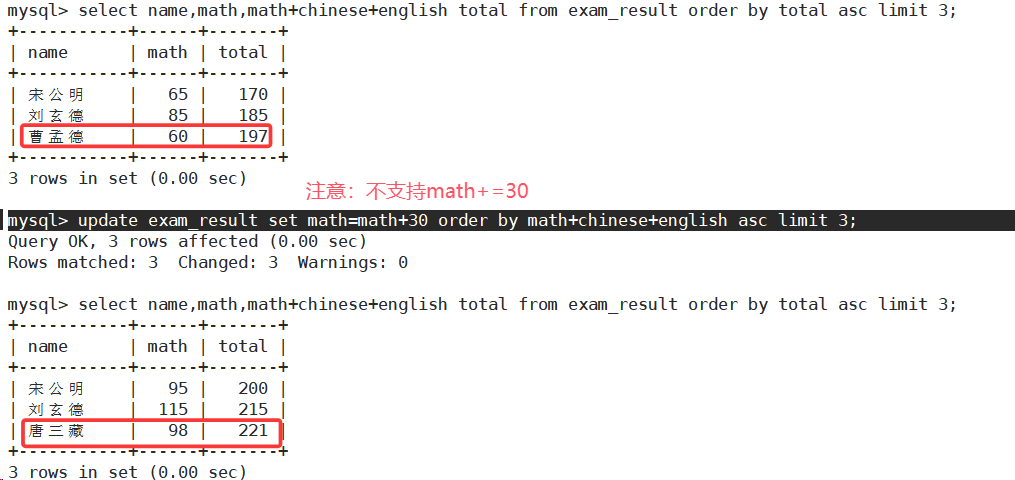
-
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
-
将所有同学的语文成绩更新为原来的 2 倍
更新全表的语句慎用!
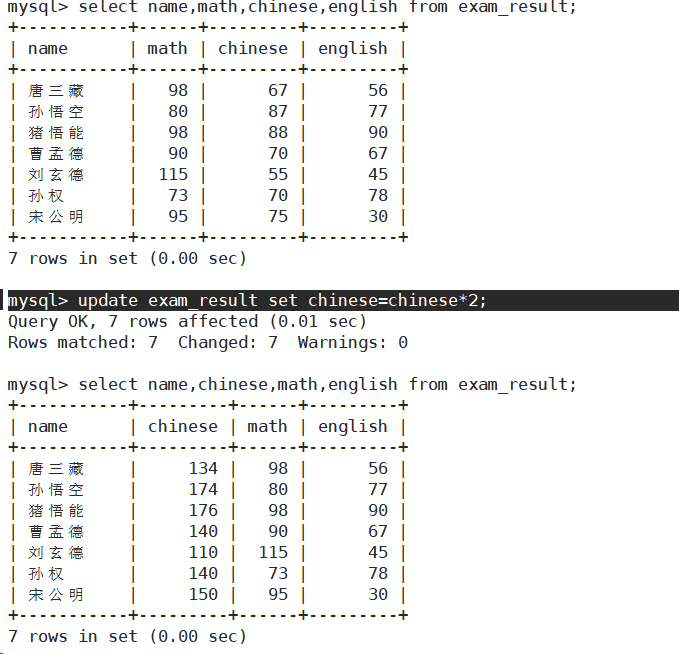
Delete
删除数据
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
- 删除孙悟空同学的考试成绩
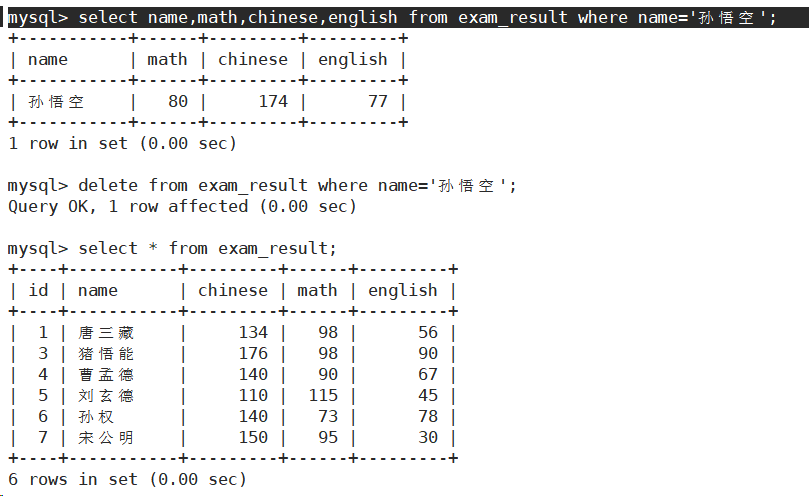
删除整表数据
注意:删除整表操作要慎用!
- 建立如下表结构。
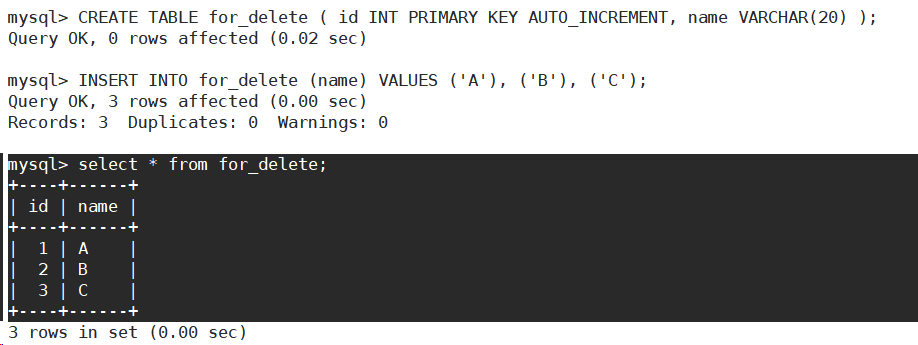
- 删除整张表中的数据。
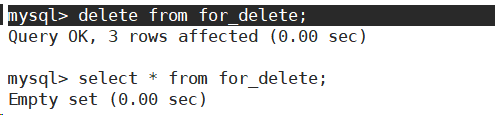

注意:只是删除了整张表中的数据,表还存在。
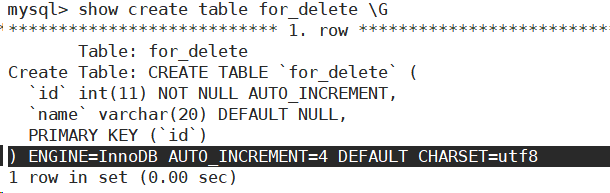
- 再插入一条数据。发现自增id在原值上增长。
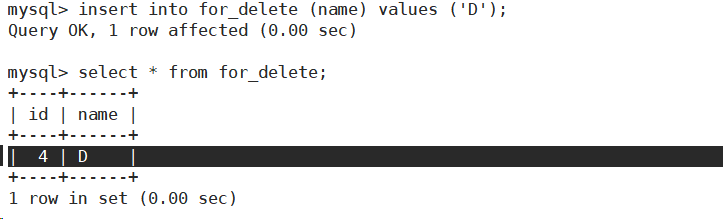
delete 删除整表中的数据,并没有删除auto_increment项。
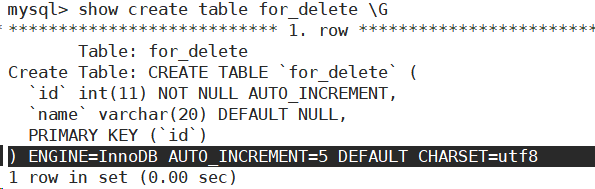
截断表
TRUNCATE [TABLE] table_name
- 只能对整表操作,不能像 DELETE 一样针对部分数据操作;
- 实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
- 会重置 AUTO_INCREMENT 项
- 建立如下表结构并插入数据。
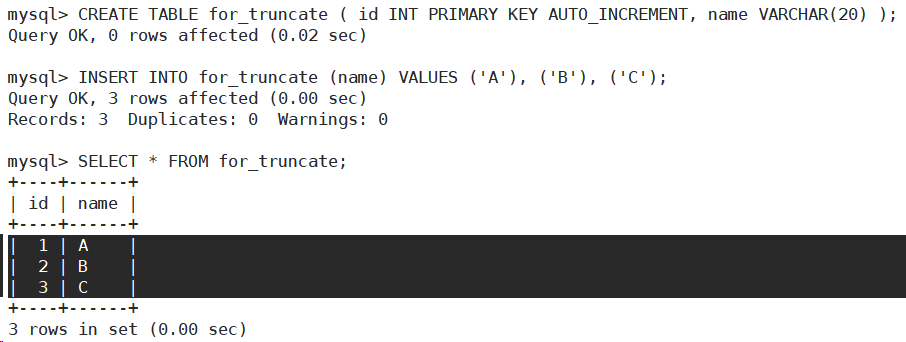
- 截断表。
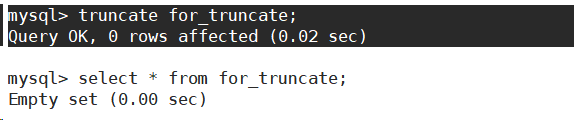
可以看到影响行数是0,实际并没有对数据进行操作。
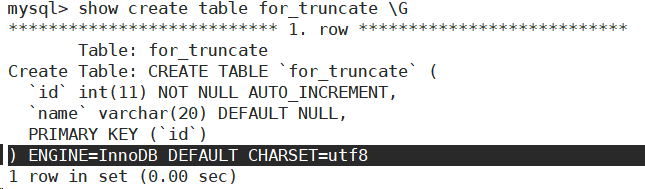
截断表,会删除auto_increment项。
- 再插入一条数据。自增id重新在增长。
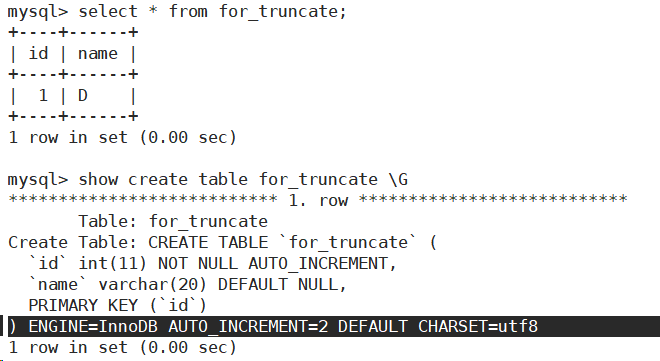
插入查询结果
INSERT INTO table_name [(column [, column ...])] SELECT ...
例:删除表中的的重复复记录,重复的数据只能有一份。
- 创建表结构并插入数据。
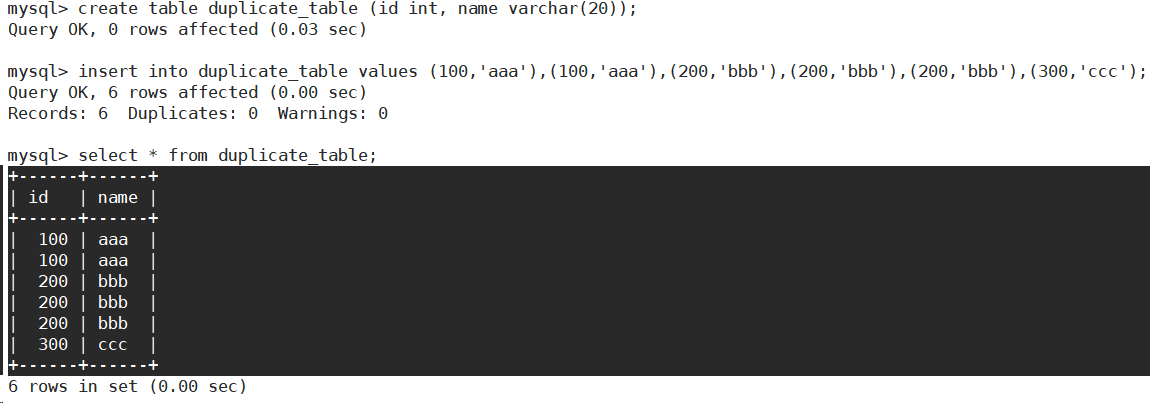
如何去掉重复的数据?
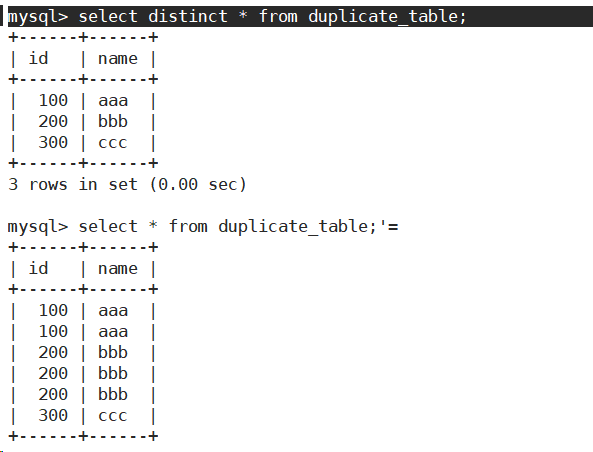
查询的时候使用distinct确实可以查到去重之后的结果,但是原表数据没有更改。也不能使用delete 加where限制,会把相同的数据全部删除完。可以这样做:
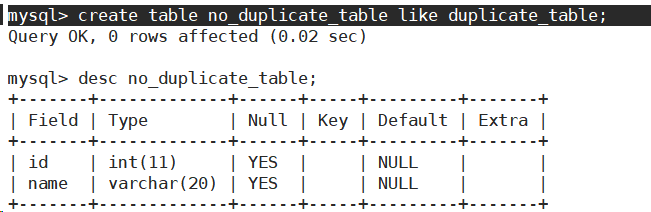
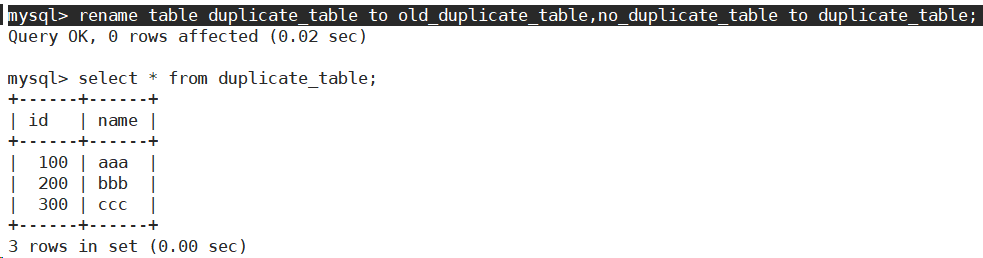
- 创建一张空表no_duplicate_table,结构和duplicate_table一样。
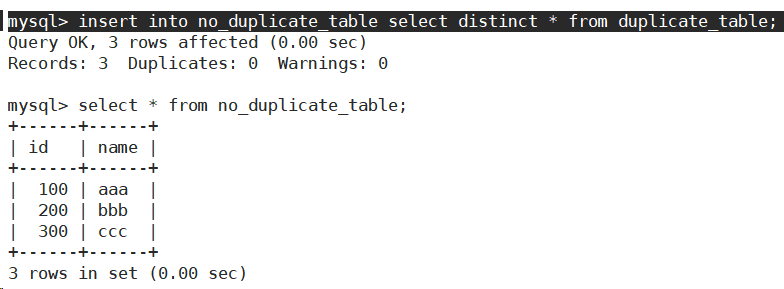
- 将duplicate_table去重之后的数据插入到no_duplicate_table
-
通过重命名表,实现原子的去重操作。将no_duplicate_table重命名为duplicate_tabe,将duplicate_table重命名为其他名字
聚合函数

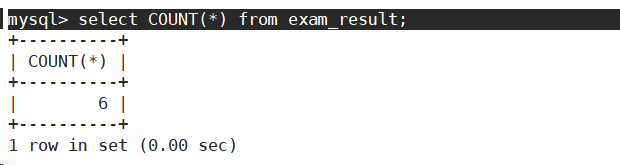
- 统计班级共有多少同学
使用*做统计,不受null的影响。

使用表达式做统计。
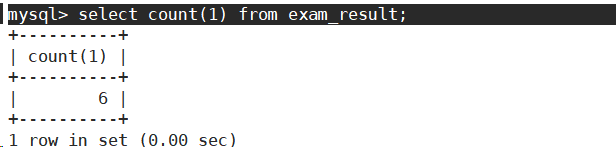
- 统计数学成绩分数个数
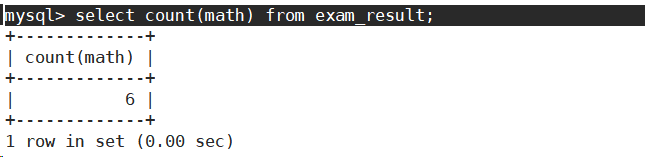
统计的是全部数学成绩的个数。不符合题意。

统计的是去重之后的数学成绩的个数。符合题意。
- 统计数学成绩的总分。
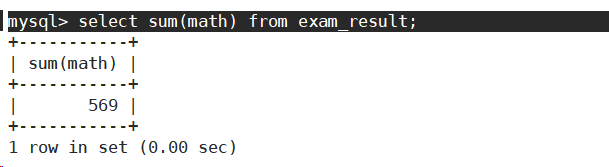
- 统计数学成绩小于100分的分数总分。
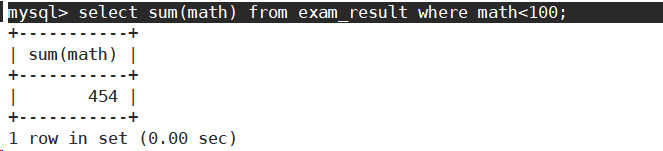
- 统计平均总分。
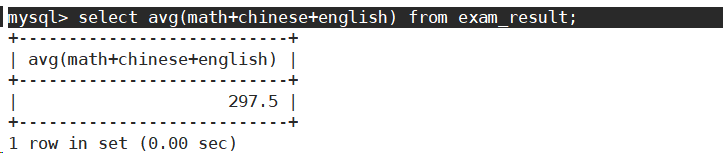
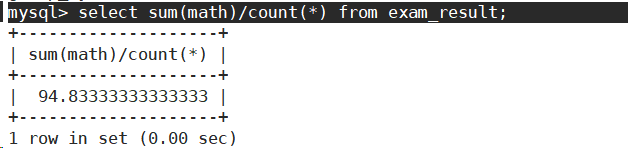
- 统计数学成绩的平均分。
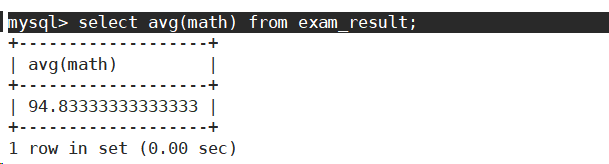
-
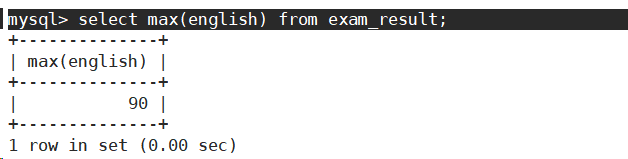
返回英语最高分。
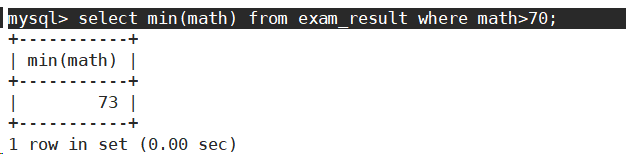
- 返回 > 70 分以上的数学最低分。
一定要可聚合,也就是有多个数据才能聚合。


group by子句的使用
select column1, column2, .. from table group by column;
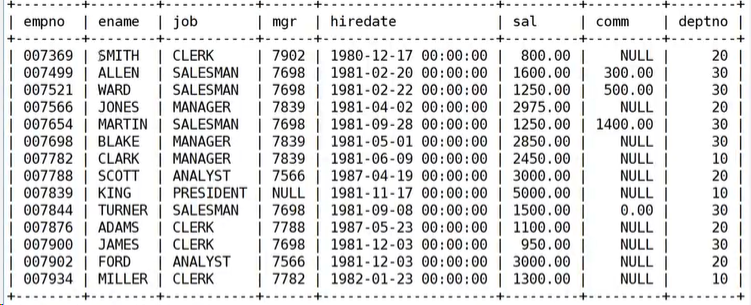
- 如何显示每个部门的平均工资和最高工资
select deptno,avg(sal),max(sal) from EMP group by deptno;
- 显示每个部门的每种岗位的平均工资和最低工资
select avg(sal),min(sal),job, deptno from EMP group by deptno, job;
- 显示平均工资低于2000的部门和它的平均工资
- 统计各个部门的平均工资
select avg(sal) from EMP group by deptno;
- having和group by配合使用,对group by结果进行过滤
select avg(sal) as myavg from EMP group by deptno having myavg<2000;
having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where。区别是什么?条件筛选的阶段不同。

相关文章:
《MySQL:MySQL表的基本查询操作CRUD》
CRUD:Create(创建)、Retrieve(读取)、Update(更新)、Delete(删除)。 Create into 可以省略。 插入否则更新 由于主键或唯一键冲突而导致插入失败。 可以选择性的进行同步…...

CF2096F Wonderful Impostors
题解 看到题意很容易想到用双指针来维护所有可行的区间,但是显然不能对所有的 1 区间来维护所有的可行区间,这样的区间数量会太多,我们无法快速进行判断。 所以只能对满足答案的所有区间进行双指针,这就要求我们如何快速插入和删…...

多维度信息捕捉:利用向量、稀疏向量、全文搜索及张量实现RAG的极致性能
开源 AI 原生数据库 Infinity 0.2 release 正式发布,提供了 2 种新数据类型:稀疏向量Sparse Vector 和 张量Tensor,在此前的全文搜索和向量搜索之外, Infinity 提供了更多的召回手段,如下图所示,用户可以采…...
vscode使用remote ssh插件连接服务器的问题
本人今天发现自己的vscode使用remote ssh连接不上服务器了,表现是:始终在初始化 解决方法: 参考链接:vscode remote-ssh 连接失败的基本原理和优雅的解决方案 原因 vscode 的 SSH 之所以能够拥有比传统 SSH 更加强大的功能&a…...

基础版-图书管理系统
现在我们用面向对象编程,首先我们要明确这个图书管理系统的对象有哪些? 图书管理需要管理图书(对象1),在哪管理图书呢?书架(对象2)上 然后由谁来管呢?有两类人…...
)
【单片机 C语言】单片机学习过程中常见C库函数(学习笔记)
memset() C 标准库 - <string.h> string .h 头文件定义了一个变量类型、一个宏和各种操作字符数组的函数。 <string.h> 是 C 标准库中的一个头文件,提供了一组用于处理字符串和内存块的函数。这些函数涵盖了字符串复制、连接、比较、搜索和内存操作…...
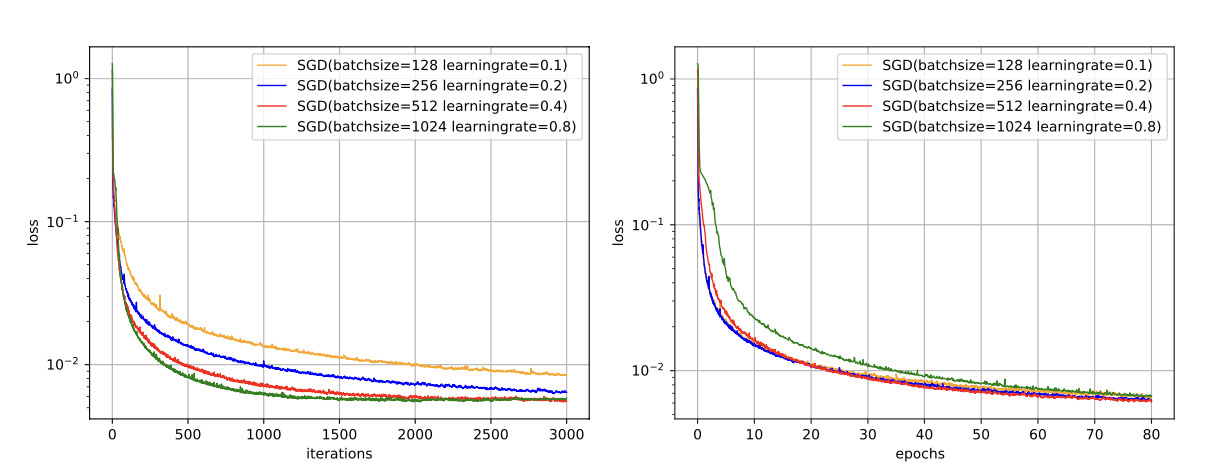
神经网络优化 - 小批量梯度下降之批量大小的选择
上一博文学习了小批量梯度下降在神经网络优化中的应用: 神经网络优化 - 小批量梯度下降-CSDN博客 在小批量梯度下降法中,批量大小(Batch Size)对网络优化的影响也非常大,本文我们来学习如何选择小批量梯度下降的批量大小。 一、批量大小的…...

Novartis诺华制药社招入职综合能力测评真题SHL题库考什么?
一、综合能力测试 诺华制药的入职测评中,综合能力测试是重要的一部分,主要考察应聘者的问题解决能力、数值计算能力和逻辑推理能力。测试总时长为46分钟,实际作答时间为36分钟,共24题。题型丰富多样,包括图形变换题、分…...

文件的物理结构和逻辑结构的区分
文件的物理结构和逻辑结构是文件系统中两个重要的概念,它们分别描述了文件在存储设备上的实际存储方式以及用户在编程或操作文件时所看到的抽象组织形式。理解这两者的区别和联系对于深入掌握文件系统的设计和实现至关重要。 一、文件的逻辑结构 定义 文件的逻…...

C语言学习记录(16)文件操作7
前面学的东西感觉都跟写代码有关系,怎么突然就开始说文件了,有什么用呢? 其实,文件是另一种数据存储的方式,学会使用文件就可以让我们的数据持久的保存。 一、文件是什么 就算没有学过相关的知识,在这么…...

Coze平台 创建AI智能体的详细步骤指南
一、创建智能体的基础流程 注册与登录 访问Coze官网(www.coze.cn),使用邮箱或手机号注册账号并登录。 创建智能体 在控制台点击左侧“”按钮,选择“创建智能体”,输入名称(如“职场鼓励师”&…...

《作用域大冒险:从闭包到内存泄漏的终极探索》
“爱自有天意,天有道自不会让有情人分离” 大家好,关于闭包问题其实实际上是js作用域的问题,那么js有几种作用域呢? 作用域类型关键字/场景作用域范围示例全局作用域var(无声明)整个程序var x 10;函数作用…...

android Stagefright框架
作为Android音视频开发人员,学习Stagefright框架需要结合理论、源码分析和实践验证。以下是系统化的学习路径: 1. 基础准备 熟悉Android多媒体体系 掌握MediaPlayer、MediaCodec、MediaExtractor等核心API的用法。 理解Android的OpenMAX IL(…...

Shell脚本-变量的分类
在Shell脚本编程中,变量是存储数据的基本单位。它们可以用来保存字符串、数字甚至是命令的输出结果。正确地定义和使用变量能够极大地提高脚本的灵活性与可维护性。本文将详细介绍Shell脚本中变量的不同分类及其应用场景,帮助你编写更高效、简洁的Shell脚…...

<C#>.NET WebAPI 的 FromBody ,FromForm ,FromServices等详细解释
在 .NET 8 Web API 中,[FromBody]、[FromForm]、[FromHeader]、[FromKeyedServices]、[FromQuery]、[FromRoute] 和 [FromServices] 这些都是用于绑定控制器动作方法参数的特性,下面为你详细解释这些特性。 1. [FromBody] 作用:从 HTTP 请求…...

让数据应用更简单:Streamlit与Gradio的比较与联系
在数据科学与机器学习的快速发展中,如何快速构建可视化应用成为了许多工程师和数据科学家的一个重要需求。Streamlit和Gradio是两款备受欢迎的开源库,它们各自提供了便捷的方式来构建基于Web的应用。虽然二者在功能上有许多相似之处,但它们的…...

LlamaIndex 生成的本地索引文件和文件夹详解
LlamaIndex 生成的本地索引文件和文件夹详解 LlamaIndex 在生成本地索引时会创建一个 storage 文件夹,并在其中生成多个 JSON 文件。以下是每个文件的详细解释: 1. storage 文件夹结构 1.1 docstore.json 功能:存储文档内容及其相关信息。…...
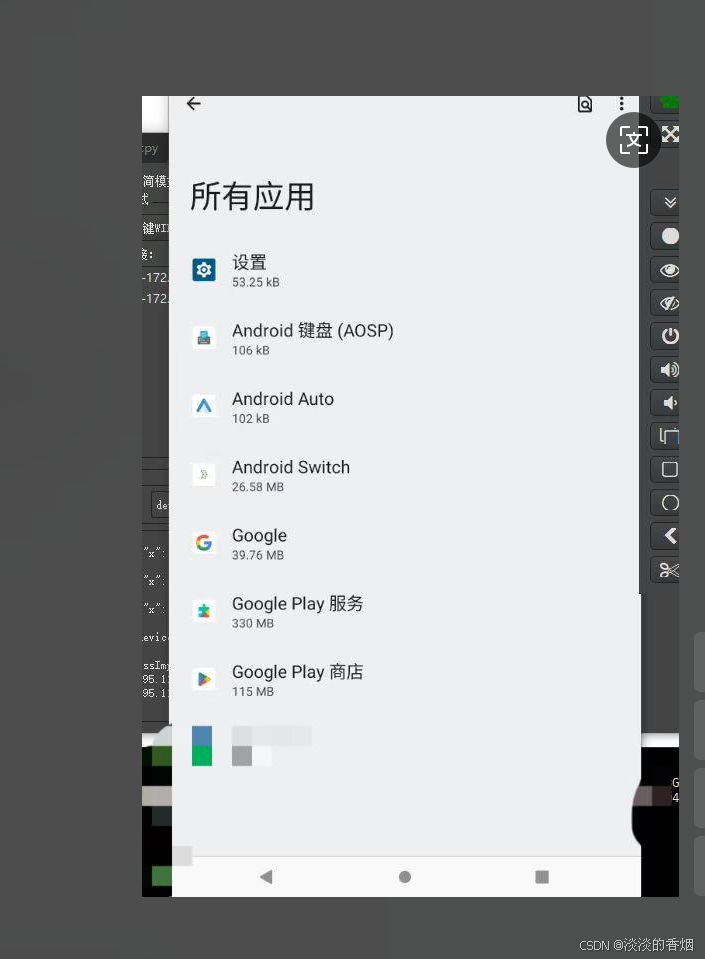
AndroidRom定制删除Settings某些菜单选项
AndroidRom定制删除Settings某些菜单选项 1.前言. 最近在Rom开发中需要隐藏设置中的某些菜单,launcher3中的定制开发,这个属于很基本的定制需求,和隐藏google搜素栏一样简单,这里我就不展开了,直接上代码. 2.隐藏网络…...

Mysql相关知识2:Mysql隔离级别、MVCC、锁
文章目录 MySQL的隔离级别可重复读的实现原理Mysql锁按锁的粒度分类按锁的使用方式分类按锁的状态分类 MySQL的隔离级别 在 MySQL 中,隔离级别定义了事务之间相互隔离的程度,用于控制一个事务对数据的修改在何时以及如何被其他事务可见。MySQL 支持四种…...

Python爬虫实战:获取海口最近2周天气数据,为出行做参考
一、引言 天气状况对人们的出行计划影响重大。获取准确的天气信息并进行分析,能助力用户更好地规划出行。天气网虽提供丰富的天气数据,但因网站存在反爬机制,直接获取数据存在一定难度。本研究借助 Python 的 Scrapy 框架,结合多种技术手段,实现对海口最近两周天气数据的…...

并发设计模式之双缓冲系统
双缓冲的本质是 通过空间换时间,通过冗余的缓冲区解决生产者和消费者的速度差异问题,同时提升系统的并发性和稳定性。 双缓冲的核心优势 优势具体表现解耦生产与消费生产者和消费者可以独立工作,无需直接同步。提高并发性生产者和消…...

linux sysfs的使用
在Linux内核驱动开发中,device_create_file 和 device_remove_file 用于动态创建/删除设备的 sysfs 属性文件,常用于暴露设备信息或控制参数。以下是完整示例及详细说明: 1. 头文件引入 #include <linux/module.h> #include <linux/…...
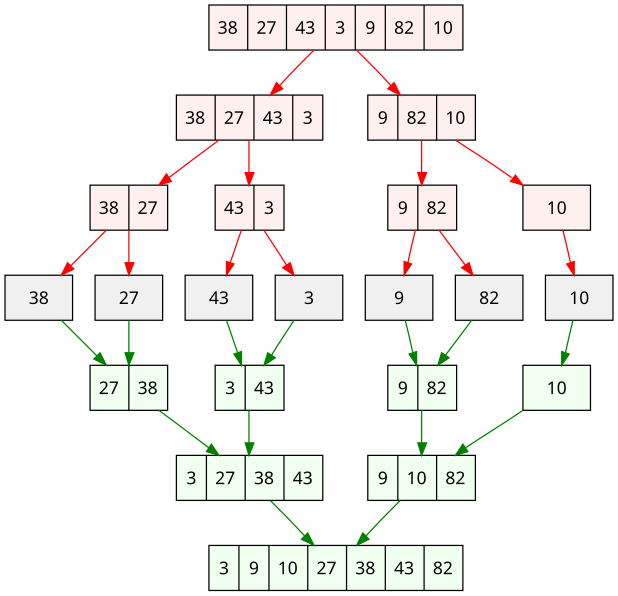
【数据结构和算法】3. 排序算法
本文根据 数据结构和算法入门 视频记录 文章目录 1. 排序算法2. 插入排序 Insertion Sort2.1 概念2.2 具体步骤2.3 Java 实现2.4 复杂度分析 3. 快排 QuickSort3.1 概念3.2 具体步骤3.3 Java实现3.4 复杂度分析 4. 归并排序 MergeSort4.1 概念4.2 递归具体步骤4.3 Java实现4.4…...

LintCode第192题-通配符匹配
描述 给定一个字符串 s 和一个字符模式 p ,实现一个支持 ? 和 * 的通配符匹配。匹配规则如下: ? 可以匹配任何单个字符。* 可以匹配任意字符串(包括空字符串)。 两个串完全匹配才算匹配成功。 样例 样例1 输入: "aa&q…...

redis常用的五种数据类型
redis常用的五种数据类型 文档 redis单机安装redis数据类型-位图bitmap 说明 官网操作命令指南页面:https://redis.io/docs/latest/commands/?nameget&groupstring 常用命令 keys *:查看所有键exists k1 k2:键存在个数type k1&…...

Linux 进程与线程间通信方式及应用分析
Linux 进程与线程间通信方式及应用分析 文章目录 Linux 进程与线程间通信方式及应用分析 1. 管道(Pipe)1.1 匿名管道(Anonymous Pipe)示例代码:结果: 1.2 命名管道(FIFO)示例代码&am…...

AI日报 - 2024年04月22日
🌟 今日概览(60秒速览) ▎🤖 模型进展 | Google发布Gemini 2.5 Flash,强调低延迟与成本效益;Kling AI 2.0展示多轴运动视频生成;研究揭示SLM在知识图谱上优于LLM,RLHF在推理提升上存局限。 ▎💼…...

FreeRTos学习记录--2.内存管理
后续的章节涉及这些内核对象:task、queue、semaphores和event group等。为了让FreeRTOS更容易使用,这些内核对象一般都是动态分配:用到时分配,不使用时释放。使用内存的动态管理功能,简化了程序设计:不再需…...
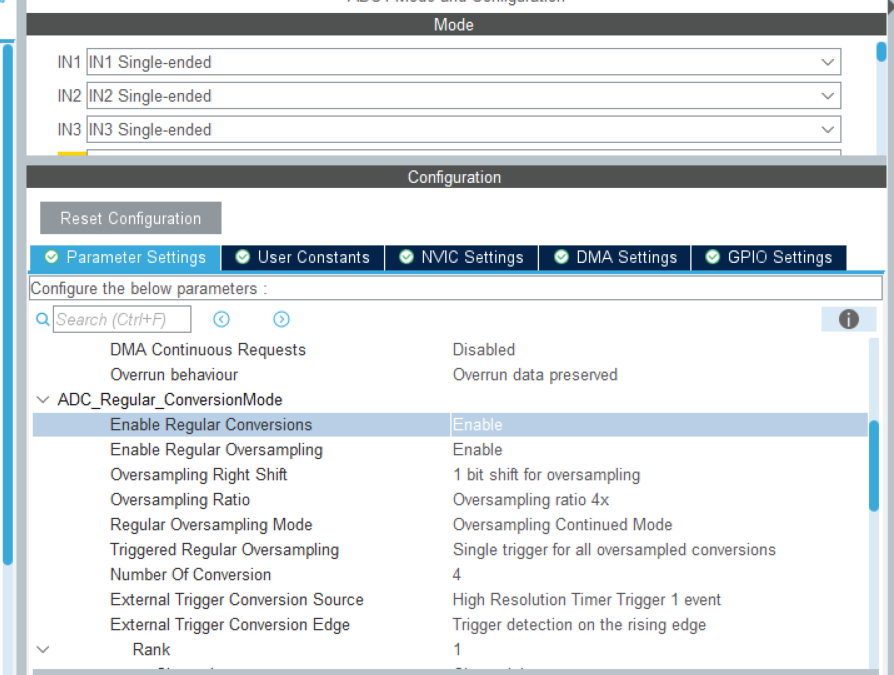
HAL库(STM32CubeMX)——高级ADC学习、HRTIM(STM32G474RBT6)
系列文章目录 文章目录 系列文章目录前言存在的问题HRTIMcubemx配置前言 对cubemx的ADC的设置进行补充 ADCs_Common_Settings Mode:ADC 模式 Independent mod 独立 ADC 模式,当使用一个 ADC 时是独立模式,使用两个 ADC 时是双模式,在双模式下还有很多细分模式可选 ADC_Se…...
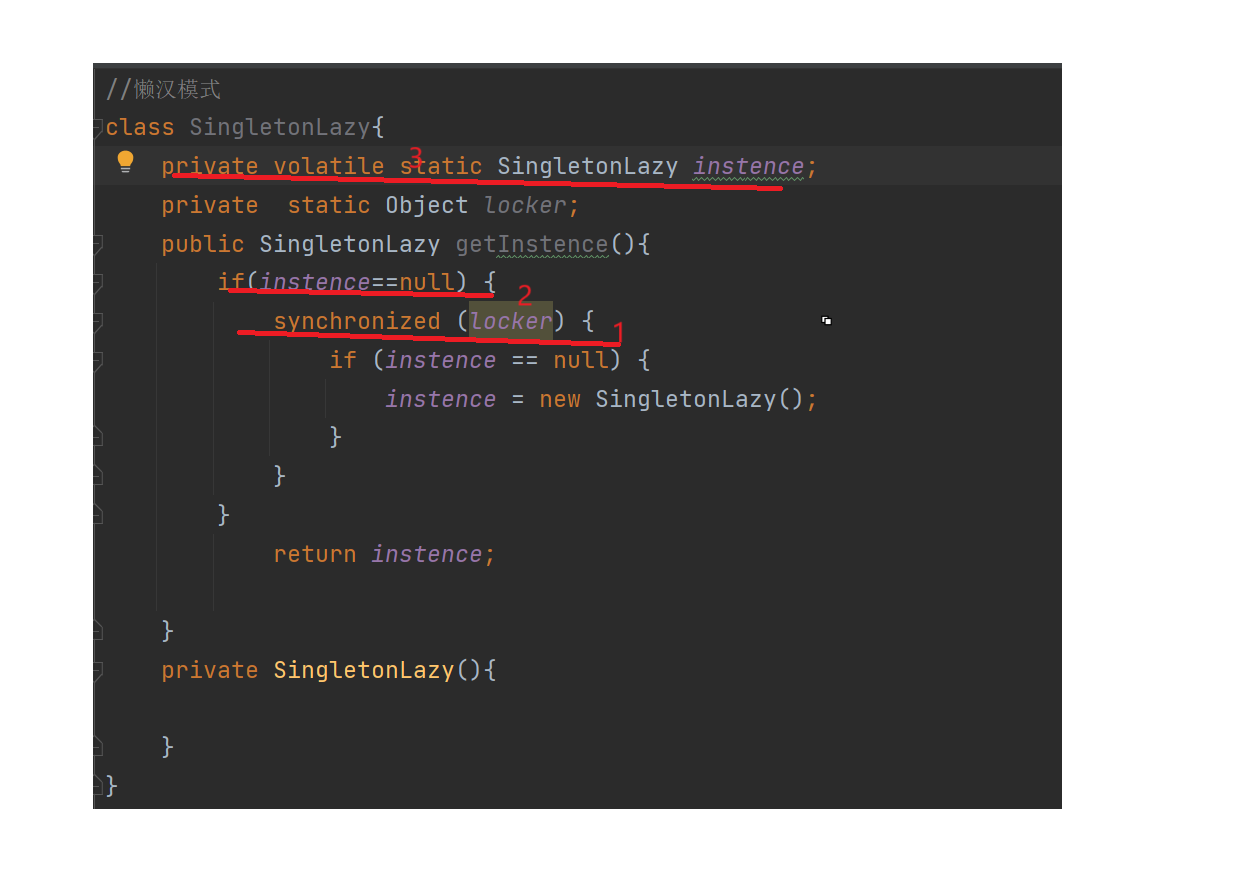
单例模式(线程安全)
1.什么是单例模式 单例模式(Singleton Pattern)是一种创建型设计模式,旨在确保一个类只有一个实例,并提供一个全局访问点来访问该实例。这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单…...