第 4 篇:平稳性 - 时间序列分析的基石
第 4 篇:平稳性 - 时间序列分析的基石
在上一篇中,我们学习了如何将时间序列分解为趋势、季节性和残差。我们看到,很多真实世界的时间序列(比如 CO2 浓度)都包含明显的趋势(长期向上或向下)和/或季节性(固定周期的波动)。
这些成分虽然揭示了数据的内在模式,但也带来了一个“问题”:它们使得序列的统计特性随时间而变化。例如,带有上升趋势的序列,其均值(平均水平)会随着时间推移而增加。这种“不稳定”的特性,在时间序列分析中被称为非平稳性 (Non-stationarity)。
为什么我们要关心这个?因为许多经典且强大的时间序列预测模型(如 ARIMA 模型家族)都建立在一个关键假设之上:数据是平稳的 (Stationary)。
本篇我们就来深入探讨这个时间序列分析的基石——平稳性。我们将了解:
- 什么是平稳性?
- 为什么平稳性如此重要?
- 如何判断一个序列是否平稳?
- 如果序列不平稳,最常用的处理方法是什么?
什么是平稳性 (Stationarity)?
想象一条平静的湖面(Stationary)和一条奔腾的河流(Non-stationary)。
- 平静的湖面: 在任何位置取一瓢水,它的平均深度、水面的波动程度(方差)看起来都差不多。
- 奔腾的河流: 在上游和下游取水,平均深度可能截然不同;在急流和缓滩处,水流的湍急程度(方差)也相差甚远。
平稳性 就是时间序列数据拥有类似“平静湖面”的特性。更严谨地说,一个时间序列是**(弱)平稳**的,如果它的:
- 均值 (Mean) 不随时间
t变化。 - 方差 (Variance) 不随时间
t变化。 - 自协方差 (Autocovariance) 只依赖于时间的间隔
k,而不依赖于具体的时间点t。(这保证了序列内部的相关性结构是稳定的,我们暂时不用深究数学细节,理解前两点更重要)。
看图说话:
- 平稳序列 (Stationary): 数据点围绕一个固定的水平线上下波动,且波动的幅度大致稳定。典型的例子是白噪声 (White Noise),即纯粹的随机波动。

- 非平稳序列 (Non-stationary):
- 含趋势: 数据明显呈现长期上升或下降。 (例如我们上一篇分解出的 CO2 趋势部分)
- 含季节性: 数据存在固定的周期性波动。 (例如 CO2 的季节性部分)
- 方差变化: 数据的波动幅度随时间变化(例如,早期波动小,后期波动剧烈)。
- 随机游走 (Random Walk): 一个典型的非平稳过程,下一步的位置是当前位置加上一个随机步长。股价有时被建模为类似随机游走。

为什么平稳性如此重要?
- 模型假设: 很多经典时间序列模型(如 ARMA, ARIMA)明确要求输入数据是平稳的。如果用非平稳数据直接建模,可能会导致模型参数估计不准、预测结果不可靠。
- 可预测性基础: 平稳序列意味着其统计特性在未来可能保持不变。这为我们基于历史模式进行预测提供了更坚实的基础。如果一个序列的均值和方差都在不断变化,预测其未来将非常困难。
- 简化分析: 处理平稳序列通常比处理非平稳序列更简单。我们可以专注于分析其内部的相关性结构(自相关性),而不用同时处理变化的趋势和季节性。
如何判断平稳性?
主要有两种方法:
-
视觉检查 (Visual Inspection):
- 直接绘制时间序列图: 观察是否存在明显的趋势或季节性模式?数据的均值线是否大致水平?数据的波动幅度是否大致恒定?
- 查看分解图 (来自上一篇):
seasonal_decompose的结果可以帮助我们。如果趋势 (Trend) 成分不是水平的,或者季节性 (Seasonal) 成分很明显,那么原始序列很可能不是平稳的。
-
统计检验 (Statistical Tests):
-
肉眼观察有时会骗人,我们需要更客观的统计方法。最常用的检验之一是 ADF 检验 (Augmented Dickey-Fuller Test)。
-
ADF 检验的目的: 它的“原假设 (Null Hypothesis)”是序列存在单位根 (Unit Root),即序列是非平稳的。它的“备择假设 (Alternative Hypothesis)”是序列没有单位根,即序列是平稳的。
-
如何解读结果? 我们主要关心检验输出的 p-value:
- 如果 p-value > 0.05 (常用的显著性水平): 我们没有足够证据拒绝原假设。也就是说,我们倾向于认为序列是非平稳的。
- 如果 p-value <= 0.05: 我们拒绝原假设。也就是说,我们倾向于认为序列是平稳的。
-
Python 实现 (使用
statsmodels):
from statsmodels.tsa.stattools import adfuller import statsmodels.api as sm import pandas as pd# 仍然使用上一篇的月度 CO2 数据 data = sm.datasets.co2.load_pandas().data data['co2'].interpolate(inplace=True) monthly_data = data.resample('M').mean()print("对原始月度 CO2 数据进行 ADF 检验:") result = adfuller(monthly_data['co2'])print('ADF Statistic: %f' % result[0]) print('p-value: %f' % result[1]) print('Critical Values:') for key, value in result[4].items():print('\t%s: %.3f' % (key, value))# 解释 p-value if result[1] > 0.05:print("\n结论:p-value > 0.05,未能拒绝原假设,数据很可能非平稳。") else:print("\n结论:p-value <= 0.05,拒绝原假设,数据很可能平稳。")运行上述代码,你会发现 CO2 数据的 p-value 远大于 0.05,印证了我们视觉观察到的非平稳性。
-
如何让序列平稳?—— 差分 (Differencing)
如果我们的序列被判断为非平稳,怎么办?最常用、最简单的处理方法就是差分 (Differencing)。
差分的思想很简单:计算相邻时间点数据之间的差值。
-
一阶差分 (First Difference):
Y'(t) = Y(t) - Y(t-1)- 目的: 主要用于消除序列中的线性趋势。
- 效果: 如果原序列有稳定增长或下降的趋势,差分后的序列通常会围绕 0 值上下波动。
-
季节性差分 (Seasonal Difference):
Y'(t) = Y(t) - Y(t-s),其中s是季节性周期长度(例如,对于月度数据年度季节性,s=12)。- 目的: 主要用于消除序列中的季节性。
-
高阶差分: 有时需要进行多次差分(例如,对一阶差分后的序列再做一次差分,称为二阶差分),或者结合使用普通差分和季节性差分,来达到平稳。但通常一阶或二阶差分就足够了。过度差分可能会引入不必要的模式。
Python 实现一阶差分 (.diff()):
import matplotlib.pyplot as plt
import seaborn as sns# 对 CO2 数据进行一阶差分
monthly_data['co2_diff'] = monthly_data['co2'].diff()# 差分后第一个值是 NaN,需要去掉或填充
monthly_data_diff = monthly_data.dropna() # 去掉 NaN 值print("\n差分后的数据 (前几行):")
print(monthly_data_diff.head())# 绘制差分后的序列图
plt.figure(figsize=(12, 6))
sns.lineplot(data=monthly_data_diff, x=monthly_data_diff.index, y='co2_diff')
plt.title('First Difference of Monthly CO2 Data')
plt.xlabel('Date')
plt.ylabel('First Difference')
plt.axhline(0, color='red', linestyle='--') # 添加 0 值参考线
plt.show()# 对差分后的序列再次进行 ADF 检验
print("\n对一阶差分后的 CO2 数据进行 ADF 检验:")
result_diff = adfuller(monthly_data_diff['co2_diff'])
print('ADF Statistic: %f' % result_diff[0])
print('p-value: %f' % result_diff[1])
print('Critical Values:')
for key, value in result_diff[4].items():print('\t%s: %.3f' % (key, value))if result_diff[1] > 0.05:print("\n结论:p-value > 0.05,差分后数据仍可能非平稳 (可能需要进一步处理,如季节性差分)。")
else:print("\n结论:p-value <= 0.05,拒绝原假设,差分后数据很可能平稳。")# 注意:CO2 数据同时有强趋势和强季节性,仅一阶差分可能不足以完全平稳,
# ADF检验的 p-value 可能会显著降低,但仍可能大于 0.05 或略小于 0.05。
# 完全平稳化可能需要再做季节性差分: .diff(12)
# monthly_data['co2_diff_seasonal'] = monthly_data['co2'].diff().diff(12).dropna()
# 但我们这里主要演示一阶差分的效果。

解读结果:
- 差分后的图形: 你会看到,原始 CO2 数据那个明显的上升趋势消失了!差分后的序列现在看起来更像是在 0 附近波动,尽管可能还保留着一些季节性模式。
- 差分后的 ADF 检验: 运行 ADF 检验,你会发现差分后序列的 p-value 显著降低了(可能已经小于 0.05,或者非常接近)。这表明一阶差分有效地移除了大部分非平稳性(主要是趋势)。如果 p-value 仍然偏高,可能意味着还需要处理季节性(进行季节性差分)。
重要提醒: 我们的目标是使用尽可能少的差分次数来使序列平稳。过度差分会丢失信息。
小结
今天我们学习了时间序列分析中一个至关重要的概念——平稳性:
- 定义: 平稳序列的均值、方差和自协方差结构不随时间改变。
- 重要性: 是许多经典时间序列模型的基础假设。
- 判断方法:
- 视觉检查: 观察时间序列图和分解图中的趋势、季节性及波动幅度。
- 统计检验: 使用 ADF 检验,通过 P-value 判断是否存在单位根(非平稳)。
- 处理方法: 最常用的使序列平稳的方法是差分(一阶差分消除趋势,季节性差分消除季节性)。
理解并能够处理数据的平稳性,是进行有效时间序列建模的关键一步。
下一篇预告
到目前为止,我们已经掌握了如何加载、可视化、分解时间序列,以及如何处理非平稳性。现在,我们终于可以开始尝试做一些简单的预测 (Forecasting) 了!
下一篇,我们将学习几种最基础、最直观的预测方法,比如朴素预测、平均法、移动平均法等。它们虽然简单,但有时效果惊人,并且是理解更复杂模型的重要起点。
准备好迎接你的第一个时间序列预测模型了吗?敬请期待!
(对你的数据进行 ADF 检验和差分,结果如何?差分后的序列看起来平稳了吗?欢迎在评论区分享你的实践!)
相关文章:
第 4 篇:平稳性 - 时间序列分析的基石
第 4 篇:平稳性 - 时间序列分析的基石 在上一篇中,我们学习了如何将时间序列分解为趋势、季节性和残差。我们看到,很多真实世界的时间序列(比如 CO2 浓度)都包含明显的趋势(长期向上或向下)和/…...
DeepSeek赋能Nuclei:打造网络安全检测的“超级助手”
引言 各位少侠,周末快乐,幸会幸会! 今天唠一个超酷的技术组合——用AI大模型给Nuclei开挂,提升漏洞检测能力! 想象一下,当出现新漏洞时,少侠们经常需要根据Nuclei模板,手动扒漏洞文章…...
)
分享一个python启动文件脚本(django示例)
今天给大家分享一个python启动文件脚本 在日常开发中,我们常常需要运行多条命令来完成“静态收集”“数据库迁移”“启动服务”……如果把这些命令整合到一个脚本里就好了 一、整体流程概览 #mermaid-svg-wA6UnfATaUOfJoPn {font-family:"trebuchet ms"…...

从0到1彻底掌握Trae:手把手带你实战开发AI Chatbot,提升开发效率的必备指南!
我正在参加Trae「超级体验官」创意实践征文, 本文所使用的 Trae 免费下载链接: www.trae.ai/?utm_source… 前言 大家好,我是小Q,字节跳动近期推出了一款 AI IDE—— Trae,由国人团队开发,并且限时免费体…...

3200温控板电路解析
提示:文章 文章目录 前言一、背景二、2.12.2 三、3.1 总结 前言 前期疑问: 本文目标: 一、背景 最近重温3200温控板电路设计和芯片选型 3200代码仓 二、 2.1 按照顺序整理,主要是依靠自己想到的来整理 1、传感器是pt1000&…...

opencv图片颜色识别,颜色的替换
图片颜色识别 1. RGB颜色空间2. 颜色加法2.1使用numpy对图像进行加法2.2使用opencv加法(cv2.add) 3 颜色加权加法(cv2.addWeighted())4. HSV颜色空间5. 制作掩膜4. 与运算(cv2.bitwise_and)5.颜色的替换7 R…...
B实验-12
需要注意版本、页面源代码 两个文件一个目录:phpinfo robots phpmyadmin 实验12 靶机1 一个key在phpmyadmin,一个key在回收站 用两个扫描目录的工具扫,nmap给python版 情况1:弱口令 root root root 123456 …...

Python多技术融合在生态参量估算中的创新应用—以蒸散发与植被GPP估算为例
在全球气候变化背景下,精确估算陆地生态系统水碳通量成为生态研究的关键命题。本研究创新性地整合Python编程、遥感数据处理、机器学习算法及生态过程模型,构建了一套高效可靠的蒸散发(ET)与植被总初级生产力(GPP&…...

文件有几十个T,需要做rag,用ragFlow能否快速落地呢?
一、RAGFlow的优势 1、RAGFlow处理大规模数据性能: (1)、RAGFlow支持分布式索引构建,采用分片技术,能够处理TB级数据。 (2)、它结合向量搜索和关键词搜索,提高检索效率。 …...
【网工第6版】第5章 网络互联②
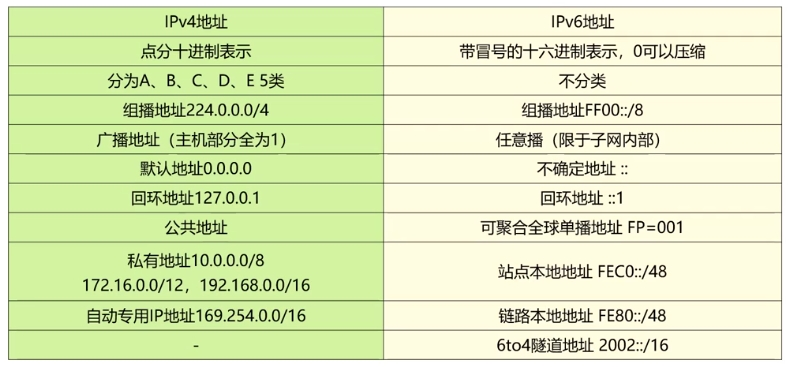
目录 ■ IPV6 ▲ IPV6报文格式 ◎ IPV6扩展报头(RFC2460) ◎ IPv6相关协议 ▲ IPV6地址分类 ◎ IPv6地址基础 ◎ IPv6地址举例 ◎ IPv6地址分类 ◎ 特殊地址对比IPv4 vs IPv6 ▲ 过渡技术 本章重要程度:☆☆☆☆☆ ■ IPV6 与IPv4…...

为什么Makefile中的clean需要.PHONY
原因一:避免Makefile检查时间戳 前置知识:makefile在依赖文件没有改变时不会执行编译命令 #第一次执行,OK [rootVM-16-14-centos ~]# make g -E main.cc -o main.i g -S main.i -o main.s g -c main.s -o main.o g main.o -o main#第二…...

Vue组件库开发实战:从0到1构建可复用的微前端模块
🔥 随着前端项目越来越复杂,如何开发一个可以随处使用的组件库变得尤为重要。本文将带你从0开始,实现一个完全独立的Vue组件库,包含样式隔离、主题定制等核心功能。 前言 在日常开发中,我们经常需要在不同项目间复用组…...
)
相机标定(输出相机内参和畸变参数)
相机标定 这里我用笔记本电脑自带的摄像头进行相机标定 仅作示例,实际工程中要用对应的摄像头进行标定 同时代码也要相应的修改,不过修改的主要是相机的初始化 粗略的说就是打开相机那部分要修改(依据实际情况相应修改) 最终的结果…...

单页面应用的特点,什么是路由,VueRouter的下载,安装和使用,路由的封装抽离,声明式导航的介绍和使用
文章目录 一.什么是单页面应用?二.什么是路由?生活中的路由和Vue中的路由 三.VueRouter(重点)0.引出1.介绍2.下载与使用(5个基本步骤2个核心步骤)2.1 五个基本步骤2.2 两个核心步骤 四.路由的封装抽离五.声明式导航1.导航链接特点一:能跳转特点二:能高亮 2.两个高亮类名2.1.区…...
)
数字ic后端设计从入门到精通2(含fusion compiler, tcl教学)
上篇回顾 上一篇文章需要讨论了net,pin的基础用法,让我们来看一下高级一点的用法 instance current_instance current_instance 是 Synopsys 工具(如 Fusion Compiler 或 Design Compiler)中用于在设计层次结构中导航的关键命令。它允许用…...
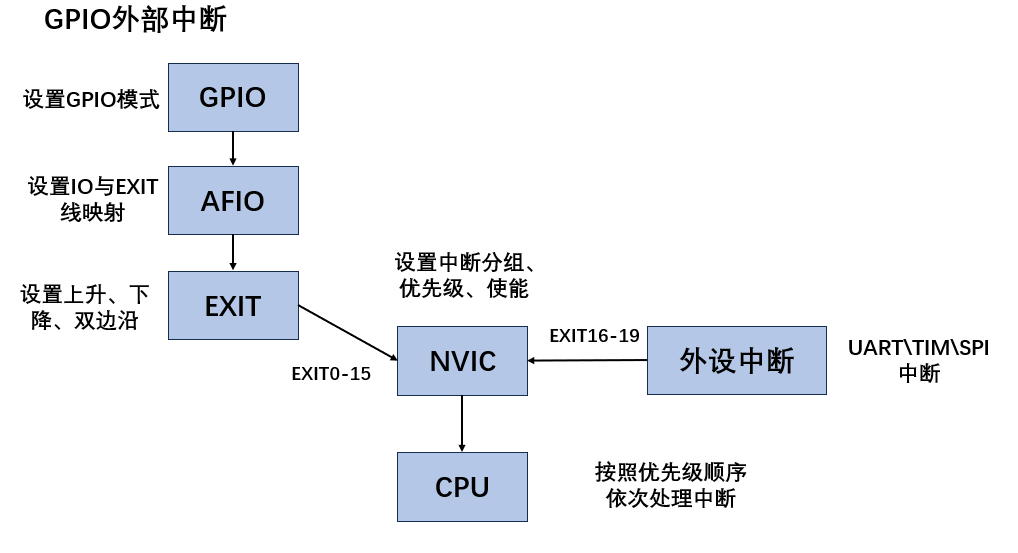
STM32---外部中断EXTI
目录 一、中断向量表 二、EXTI工作原理图 三、NVIC模块 四、GPIO设置为EXTI的结构 五、C语言示例代码 在STM32中,中断是一个非常重要的结构,他能让我们在执行主函数的时候,由硬件检测一些外部或内部产生的中断信号,跳转到中断…...

Itext进行PDF的编辑开发
这周写了一周的需求,是制作一个PDF生成功能,其中用到了Itext来制作PDF的视觉效果。其中一些功能不是很懂,仅作记录,若要学习请仔细甄别正确与否。 开始之前,我还是想说,这傻福需求怎么想出来的,…...
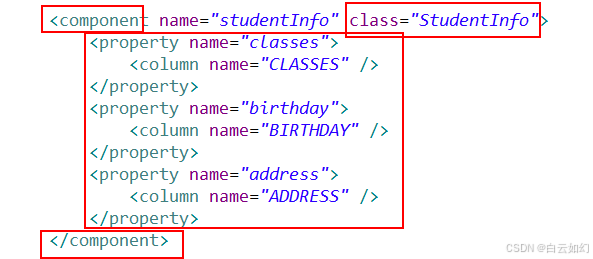
Hibernate的组件映射
在实际的开发中,使用的是非常多的,还有几种比较特殊的关系映射: 组件映射继承映射 先看一下组件映射: 组件映射中, 组件也是一个类, 但是这个类它不独立称为一个实体, 也就是说, 数据库中没有一个表格单独的和它对应, 具体情况呢, 看演示:...
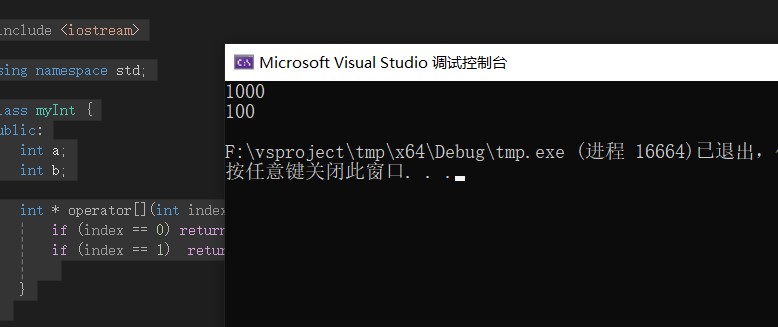
C++ 操作符重载Operator
C可以重载大多数操作符,如算术运算符号,-号。 位操作符<<,>> 下标符号[]等都可以重载。 重载的意思,是让这些符号,按你定义的行为来执行代码,但是这种自定义,是有限制的,必须有一…...
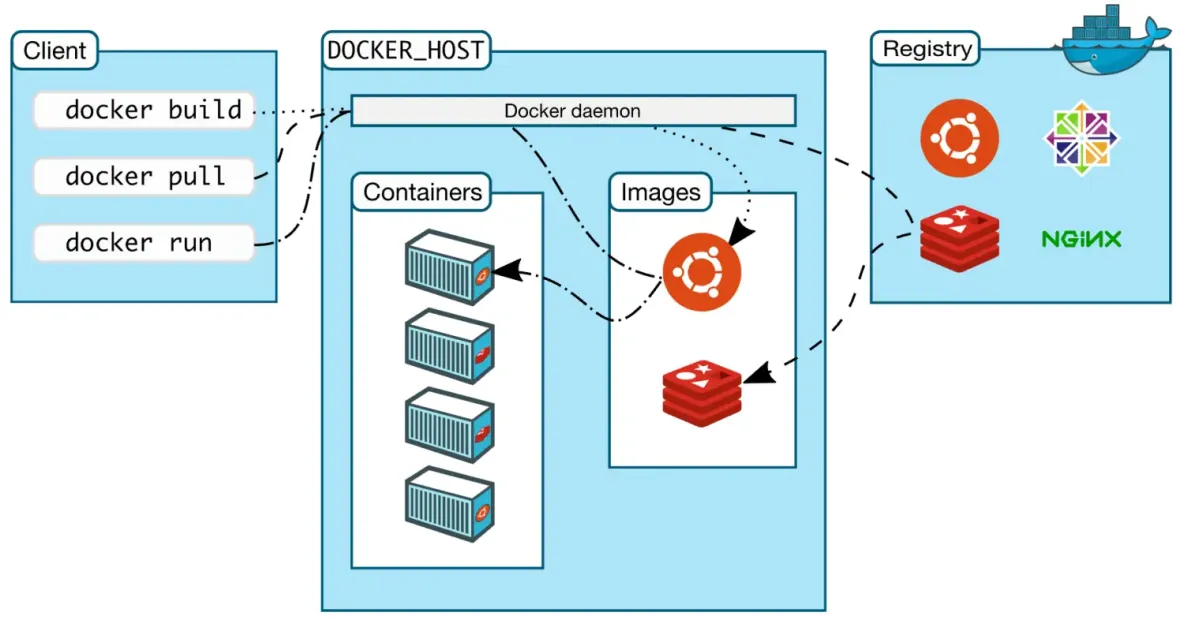
Docker 镜像、容器和 Docker Compose的区别
前言:Docker 的镜像、容器和 Docker Compose 是容器化技术的核心组件,以下是对它们的详细解析及使用场景说明。 1、Docker 镜像(Image) 定义: 镜像是只读模板,包含运行应用程序所需的代码、…...

Linux深度探索:进程管理与系统架构
1.冯诺依曼体系结构 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。 截至目前,我们所认识的计算机,都是由⼀个个的硬件组件组成。 输入设备:键盘,鼠标…...
一段式端到端自动驾驶:VAD:Vectorized Scene Representation for Efficient Autonomous Driving
论文地址:https://github.com/hustvl/VAD 代码地址:https://arxiv.org/pdf/2303.12077 1. 摘要 自动驾驶需要对周围环境进行全面理解,以实现可靠的轨迹规划。以往的方法依赖于密集的栅格化场景表示(如:占据图、语义…...

17.整体代码讲解
从入门AI到手写Transformer-17.整体代码讲解 17.整体代码讲解代码 整理自视频 老袁不说话 。 17.整体代码讲解 代码 import collectionsimport math import torch from torch import nn import os import time import numpy as np from matplotlib import pyplot as plt fro…...

把dll模块注入到游戏进程的方法_基于文件修改的注入方式
1、概述 本文主要是介绍两种基于文件修改的注入方式,一种是“DLL劫持”,另一种是“修改导入表”。这两种注入方式都是利用操作系统加载PE时的特点来实现的,我们在实现这两种注入方式时只需专注于注入dll的实现,而不用花费额外的精力去关注注入器的实现。要想深入了解这两种…...

4月21日星期一今日早报简报微语报早读
4月21日星期一,农历三月廿四,早报#微语早读。 1、女子伸腿阻止列车关门等待同行人员,被深圳铁路警方行政拘留; 2、北理工再通报:开除宫某党籍,免去行政职务,解除聘用关系; 3、澳门…...
spark和Hadoop的区别)
Spark(20)spark和Hadoop的区别
Apache Spark 和 Apache Hadoop 都是广泛使用的开源大数据处理框架,但它们在设计理念、架构、性能和适用场景等方面存在显著区别。以下是它们的主要区别: ### **1. 架构设计** - **Hadoop**: - **HDFS(Hadoop Distributed File…...
Kubeflow 快速入门实战(二) - Pipelines / Katib / KServer
承接前文博客 Kubeflow 快速入门实战(一) Kubeflow 快速入门实战(一) - 简介 / Notebooks-CSDN博客文章浏览阅读441次,点赞19次,收藏6次。本文主要介绍了 Kubeflow 的主要功能和能力,适用场景,基本用法。以及Notebook,…...

【JavaEE初阶】多线程重点知识以及常考的面试题-多线程进阶(一)
本篇博客给大家带来的是多线程中常见的所策略和CAS知识点. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅🚀 要开心要快…...

ECA 注意力机制:让你的卷积神经网络更上一层楼
ECA 注意力机制:让你的卷积神经网络更上一层楼 在深度学习领域,注意力机制已经成为提升模型性能的重要手段。从自注意力(Self-Attention)到各种变体,研究人员不断探索更高效、更有效的注意方法。今天我们要介绍一种轻…...
)
基于定时器查询模式的LED闪烁(STC89C52单片机)
#include <reg52.h> sbit LED P0^0; sbit ADDR0 P1^0; sbit ADDR1 P1^1; sbit ADDR2 P1^2; sbit ADDR3 P1^3; sbit ENLED P1^4; void main() { unsigned char cnt 0; //定义一个计数变量,记录T0溢出次数 ENLED 0; //使能U3,选择…...