维度建模工具箱 提纲与总结
这里写自定义目录标题
- 基本概念
- 事实表和维度表
- BI(Business Intelligence) 产品
- 事实表
- 事实表的粒度
- 事实表的种类
- 维度表建模技术
- 基本原则
- 避免用自然键作为维度表的主键,而要使用类似自增的整数键
- 避免过度规范化
- 避免变成形同事实表的维度表
- SCD(Slowly Changed Dimension)建模
- 其它常见规则
- 结语
这是一本数据仓库、维度建模领域的经典著作,但是也让我觉得枯燥至极。我好久没看到这么枯燥的书了——尤其是这蹩脚的翻译,为阅读增添了不少难度。这本书枯燥的原因(除了垃圾的翻译之外),可能是它太像一本工具书了,前十章都在用一个“尽量简单”的建模例子,引申出建模所要使用的一些技术。然而一般来说这种例子都非常枯燥,不知所云。其次是作者基本没有介绍书中出现的术语,比如“无事实的事实表”,“自然键”等,因此看到这些术语即觉得拗口,也很难快速吸收文字里的知识。如今已经读完这本书一月有余,希望用脑子里还剩下的东西来写一篇博文,说说这本书带给了我什么知识,必要的时候辅以工作中的实际例子来讲解一些术语。这篇文章先会进行背景介绍和基础术语介绍,然后讲解书中提到的基本建模方法。
基本概念
事实表和维度表
数据仓库中的表分为事实表和维度表。事实表一般存储了一系列事件,通常带有一些用以分析的度量(比如金额等数字),而维度表一般存储着一些相互关联的属性。举个最简单的例子,一个订单表是事实表,每一行存储着一次购物行为。而一个订单通常和以下这些“维度”都有关系,比如用户信息,比如物流信息,比如时间信息。
我们知道大数据领域,一般不太遵循SQL那一套规范化,也就是允许行与行之间有很多重复的字段。那为什么数仓里不直接把各种维度直接展开,全放到事实表里,而是要费劲地整一套维度建模理论?
首先,这里讨论的数仓并不只是数据的仓库,而是通常有一些实时查询的需求,下游可以直接从数仓的数据来构建BI报表。也就是整本书讨论的是可以支持BI下游的数仓,而不是一些基于HDFS之类的数仓。有了这一条件,数仓就有性能要求,因此抽取维度表的好处就有:
- 降低事实表的列数量,从而大大降低事实表的大小
- BI软件通常可以较好地执行一级JOIN,尤其是JOIN KEY为int时。也就是说正常情况下,JOIN维度表的性能较好
- 提高列值的标准化程度,在列值转化为维度键的时候会先看维度表中是否已有类似的值,从而避免创建相似但类似的维度(比方说大小写不一样等)
通过上面的一大段阐述,就是为了说明维度建模是很重要、很实用的技术。只有技术有其实用性,接下来才有必要讨论如何更好地进行建模。
BI(Business Intelligence) 产品
经典的BI产品有微软的PowerBI等。BI产品可以方便地搭建动态的可视化报表。比如我们都用Excel画过柱状图、饼图等,这些就是可视化的图形。把这些图形放在一个页面里,可以叫它一个报表。比方说某个商店的报表里可以包含:
- 最近卖出最多的十件商品
- 卖的最好的十件新品
- 退货率最高的十件商品
这样,管理者可以一目了然他/她最关心的一些指标,方便他做出决策。
那什么叫动态报表呢?从我使用BI的经验来看,动态主要体现在两个方面
- BI可以定时从数据库里获取最新的数据,从而自动更新报表展示的数值和统计图等
- BI支持实时聚合计算,比方说一个大公司的产品会在多个区域进行售卖,管理者可能希望分析四川和浙江畅销商品的差别;产品也分为入门级和高端产品,管理者希望分别看到入门级和高端产品中哪些产品卖的比较好。如此繁多的分析需求,人工一个一个做出报表是费时费力的。而BI产品可以自动地根据某些维度过滤或聚合数据,得到用户想要的答案。这样用户分析的自由度也大大提升了,只要是原始数据里有的维度,都可以进行自助的分类分析。那原始数据里没有的维度该怎么办?让上游提供呗:)
事实表
事实表的粒度
介绍过事实表,和数仓在BI侧的应用,接下来可以讲解事实表的粒度设计。粒度在本书中被通篇强调,因为粒度决定了下游可以进行分析的精细程度。
比方说我们有一个原始订单表,记录了用户的每一个订单,那么订单表可以有两种设计方式,这两种设计方式的粒度不同:
- 以订单作为粒度,好比我们在淘宝购物车里一次性买了好几件商品,那么这一次下单,只会在订单表里产生一行事件
- 以每个订单的每种商品作为粒度,也就是假如一个订单买了商品1和商品2,那事实表里就会有两条记录
这两种设计的最大区别是什么?从下游应用(下游应用包含BI场景,或者其它分析场景)来看,如果下游希望进行商品维度的分析,那么只有第2种方式能满足。那你可能会说,我把每个订单购买的商品信息存下来不就行了吗?这样会增加分析的复杂程度,毕竟订单和商品是一对多的关系,最终需要一个数组或者更复杂的结构(想想我们不仅关心商品种类,还关心商品购买的数量)来存储。作者虽然不建议在数仓维度建模时进行规范化,但是作者觉得第一范式(也就是每个列不要存储复杂结构如数组、对象等)的底线还是要守住的。
OK,那你可能还会问,如果我要以订单作为分析对象该怎么办?有的分析只能以订单为粒度进行,比方说满减优惠。这时可以给商品订单加上订单维度,用以保存订单的相关信息,比如订单总金额,订单收货地址,订单优惠等。然后订单维度和商品订单事实表以外键关联。
不过一切设计在没有说清楚场景的时候,都很难比较。刚刚的分析是假定需要有很多基于商品的分析,假如情况并非如此,可能结果也不一样。
事实表的种类
事实表有三种基本种类
- 事务事实表:也就是通常所说的事实表,每次事件发生时会记录一行(或多行)。比如订单表,每个订单会多一行
- 周期快照事实表:通常是将事务事实表以某一周期汇总后进行分析。比如工作中常见的以日为周期、周为周期或者月为周期。按周期汇总可以去除时间不同带来的影响,比方说周末的商品销售量和工作日的一般有很大不同;还可以减少数据量,提高分析的性能。
- 累积快照事实表:这一名称非常令人困惑,我觉得叫多步骤事实表可能更直观一些。它通常记录了一系列事件的状态流转过程,比方说一个商品采购事实表,可能需要记录某批次采购的状态,包括合同签订、供应商发货、分发到子仓库等步骤,每个步骤有一些关键维度(比如接收人是谁,接收商品数量、接收金额等)和关键日期。这个表就很适合存储这样的多步骤事实。
那么可能有人会问了,3#看起来就像是把几类不同的事实粘合在一起,能用多个1#类事实表替代吗?
作者提到,SQL的跨行分析能力很差。假如我们希望找出第一阶段和第二阶段之间的时间差大于5天的慢流程,那就需要做一次多事实表JOIN得到临时表,然后再在临时表上做进一步分析。如果某些事实本身就具有3#可应用的模式,那何必强行用1#呢?
事实表还有一些特殊形式,比如
- 无事实的事实表:我觉得称它为无度量的事实表更好。这样的事实表中可能没有数字,比如一个用户使用数据表,只记录用户某时某刻使用了App的某一功能。这样的表虽然没有数字,但还属于事实表——或者可以将其看成度量为“1”的事实表,即用户某时某刻使用了某一功能,一次。这个“1”也是可加的,比方说可以用于统计用户当天使用了各个功能次数的分布,找到用户最常使用的功能,因此不要觉得没有度量就不是事实表。
- 聚集事实表:我觉得叫聚合事实表更合适。聚集事实表通常在原始表上选择某些维度进行聚合,以达到提高性能的目的。比方说周期快照事实表相当于是在时间维度聚合的聚集事实表。
维度表建模技术
基本原则
避免用自然键作为维度表的主键,而要使用类似自增的整数键
自然键通常指的是维度信息中具有现实意义的某些列,它们能唯一指定维度表中的一行(或者某些行,在需要保留更改记录的情况下)。自然键非常直观,比方说用产品SKU作为商品表的主键,事实表都通过SKU与商品表关联。那么为什么作者建议不要使用自然键作为维度表主键呢?主要原因大概有:
- 自然键是从特定的业务背景产生的,使用自然键带来的假设很可能会在未来被违背。比如说商品的SKU可能会被重复利用,当某一商品下架后一段时间,这个SKU就可能代表另一个商品。这样的维度表会给使用者带来很大困惑。
- 方便从多个数据源中集成数据,不用考虑多个数据源中自然键的定义是否相同,是否会重复等
- 整数的JOIN操作性能很好
避免过度规范化
我们知道在SQL数据库建模领域有第一范式、第二范式、第三范式等。而在数仓建模领域,通常只遵循第一范式,只要每个列都存储基础类型就可以。换个术语来说,数仓领域通常是星型模型(事实表在中央,与一系列维度表关联,就像从一个点发出多条射线一样),而不是雪花模型(事实表在中央与多个维度表关联,维度表还和一系列维度表关联,就像雪花,每个子结构都相似)。
为什么需要避免过度规范化?主要从性能和简单性出发考虑:
- 一层JOIN的性能还不错,多层JOIN性能差,不方便进行实时分析
- 星型模型只有一层,方便使用者理解
如果有的使用者担心非规范化存储了很多重复值,浪费了很多空间,作者的意见是,维度表的容量相对于事实表少了几个数量级,因此无需在意空间的浪费。
作者在本书中还反复提到了支架表。支架表的想法和雪花模型比较类似,大概就是把维度表中一些重复的属性抽成单独的维度表,并与主维度表关联。作者强调支架表可以用,但是尽量不要用,否则可能是走在过度规范化的路上——作者既然叫它“支架”而不是雪花,说明一般来说主维度也就和另一个副维度相关联。如果关联了好几个副维度,那可就不是支架而是真雪花了。
避免变成形同事实表的维度表
什么时候维度表会形同事实表呢?通常是事实表和维度表都使用了同一主键的时候。比方说一个订单表存储了用户的一次购买行为(以订单为粒度),而设计者觉得应该把订单信息(比如订单号、订单日期、订单金额等我就瞎说一通了)单独放到一个订单维度表里,而事实表里存放订单维度键、用户维度键等。这时会发现,事实表和维度表的行数是相同的。
也就是说,当看到维度表和事实表一样大时,就要觉得有点不对劲了。这两个表实际上是同一个表,因此解决方法是把两个表的字段合一(因为它们粒度相同,主键相同,因此合一不会有任何问题),然后再考虑抽取维度。可以参考第11章-电信中的评审例子来理解这一原则
SCD(Slowly Changed Dimension)建模
第五章主要讲解了SCD建模问题。书中称之为缓慢变化维度,但实际上只关注维度变化的问题,而不只是“缓慢”变化维度。从这一章之后,书中会时不时提到“第二类变化维度”这种词,指的就是第五章介绍的这些SCD建模方法
事件表的修改通常是追加新的事件来增加行数,修改一般也是订正错误的事件,所以一般来说,修改历史事件不太需要很多讨论。但维度表通常会被多个事实表、多行关联,因此维度表的修改要考虑的问题更多。比如说
- 当维度表更新时,所有关联事件的维度都会被更新,这是预期的吗?比方说需要让历史数据的维度保持原样,新修改的维度只影响新数据吗?
- 维度表更新速度有多快?比方说用户维度表中,包含了一个更新频率很高的字段:“用户积分”,但是其它字段比如用户姓名、城市等几乎不变化。在这种情况下,如果需要记录历史变更记录,那整个维度会因为“用户积分”维度,导致变化很频繁,甚至变化频率都要和事实表不相上下了——这样导致的问题是维度表会记录太多历史数据,过分庞大,而且大部分变化都只针对一个维度,无效存储太多。这时候就要考虑将快速变化的部分从缓慢变化维度中抽离出来
上面大致介绍了变化维度建模需要考虑的事项,接下来介绍具体的建模方法。需要注意从这一章开始
- 不变化维度:这算是缓慢变化维度的一种特例:只追加新值,但从不变化。比方说日期表
- 直接修改原来的维度行:最暴力,但是会造成所有与之关联的事件,维度都更新,无法保留变更记录
- 为每一行加上有效的起止时间,若修改已有的维度行,则会插入新行,并将旧行的截止时间设为新行开始时间(end-time exclusive)。
- 添加新列,表示最近几次修改记录:比如一个员工信息表,可以用“上个部门”和“当前部门”两个列来记录变化,通常在只关心最近几次变动的场景下比较实用
- 将快速变化部分从缓慢变化维度中抽取出来,同时使用范围值替代确定值:比如刚刚说的用户积分,可以使用用户消费等级这样的维度替代,比如消费0-5000元的为初级用户,10w+的为忠实用户等,避免维度快速变化给维度表带来太多更新。如果需要计算用户的真实积分数值,可以使用周期快照表等方式实现。
- 混合以上维度的方法:通常一个维度表中的属性很多,每个属性的特点也不同,因此可以混合以上的处理方法来处理某个维度表。比方说,为了方便起见,有的属性虽然需要保留历史数据,但我们希望还可以快速获取它当前的值,比方说对于员工信息表,我们希望每一行都有当前员工所在部门,和历史时期员工所在部门,我们就可以混合类型1和2建立维度表。每次员工部门变化时,我们既要运用类型2方法插入一行表明当前员工部门变化的数据(并设置旧数据的结束时间),还要把“当前部门”这一列全都刷成最新值。除此之外还有一些混合建模技术,可以通过书来查看。
其它常见规则
这些可以直接看11.2节“设计评审的一般性考虑”和16.9节 “需要避免的常见维度建模错误”,作者做了比较好的总结。
- 避免使用原始操作代码或者缩写作为维度属性,要使用人类可读的文本。比方说要用Yes/No(或者True/False,是/否等)来代表是否,而不要使用0/1,或者T/F这样摸棱两可的符号来节约空间。这样是为了让维度值有更好的可读性,而且也方便用户在BI应用上自主地分析数据,而不用跑去问数据源团队这个符号到底是什么意思
- 不论事实表或维度表,它们粒度要一致,比方说不要在日精度的表里塞入周汇总或月汇总数据,这样很容易造成统计错误(比如求和、计数)并且让使用者迷惑
结语
工作之后也没有太多时间看书或者写总结,这篇笔记也写得比较粗糙。如果有什么说得不对的或者希望讨论的也可以直接提出来
相关文章:

维度建模工具箱 提纲与总结
这里写自定义目录标题 基本概念事实表和维度表BI(Business Intelligence) 产品 事实表事实表的粒度事实表的种类 维度表建模技术基本原则避免用自然键作为维度表的主键,而要使用类似自增的整数键避免过度规范化避免变成形同事实表的维度表 SCD(Slowly Changed Dimen…...

【沉浸式求职学习day21】【常用类分享,完结!】
沉浸式求职学习 String类(完结) 和 equals的区别 StringBuffer日期类DateCalendar File类 String类(完结) 上次讲了一些创建String类实例的方法。 今天要分享的第一个点是常考的关于String的面试题 和 equals的区别 首先是&…...

国防科大清华城市空间无人机导航推理!GeoNav:赋予多模态大模型地理空间推理能力,实现语言指令导向的空中目标导航
作者: Haotian Xu 1 ^{1} 1, Yue Hu 1 ^{1} 1, Chen Gao 2 ^{2} 2, Zhengqiu Zhu 1 ^{1} 1, Yong Zhao 1 ^{1} 1, Yong Li 2 ^{2} 2, Quanjun Yin 1 ^{1} 1单位: 1 ^{1} 1国防科技大学系统工程学院, 2 ^{2} 2清华大学论文标题:Geo…...

uniapp打ios包
uniapp在windows电脑下申请证书并打包上架 前言 该开发笔记记录了在window系统下,在苹果开发者网站生成不同证书,进行uniapp打包调试和上线发布,对window用户友好 注:苹果打包涉及到两种证书:开发证书 和 分发证书 …...

Redis 的指令执行方式:Pipeline、事务与 Lua 脚本的对比
Pipeline 客户端将多条命令打包发送,服务器顺序执行并一次性返回所有结果。可以减少网络往返延迟(RTT)以提升吞吐量。 需要注意的是,Pipeline 中的命令按顺序执行,但中间可能被其他客户端的命令打断。 典型场景&…...
VTK C++开发示例 --- 将点投影到平面上)
(14)VTK C++开发示例 --- 将点投影到平面上
文章目录 1. 概述2. CMake链接VTK3. main.cpp文件4. 演示效果 更多精彩内容👉内容导航 👈👉VTK开发 👈 1. 概述 计算一个点在一个平面上的投影。 vtkPlane 是 VTK(Visualization Toolkit)库中的一个类&…...
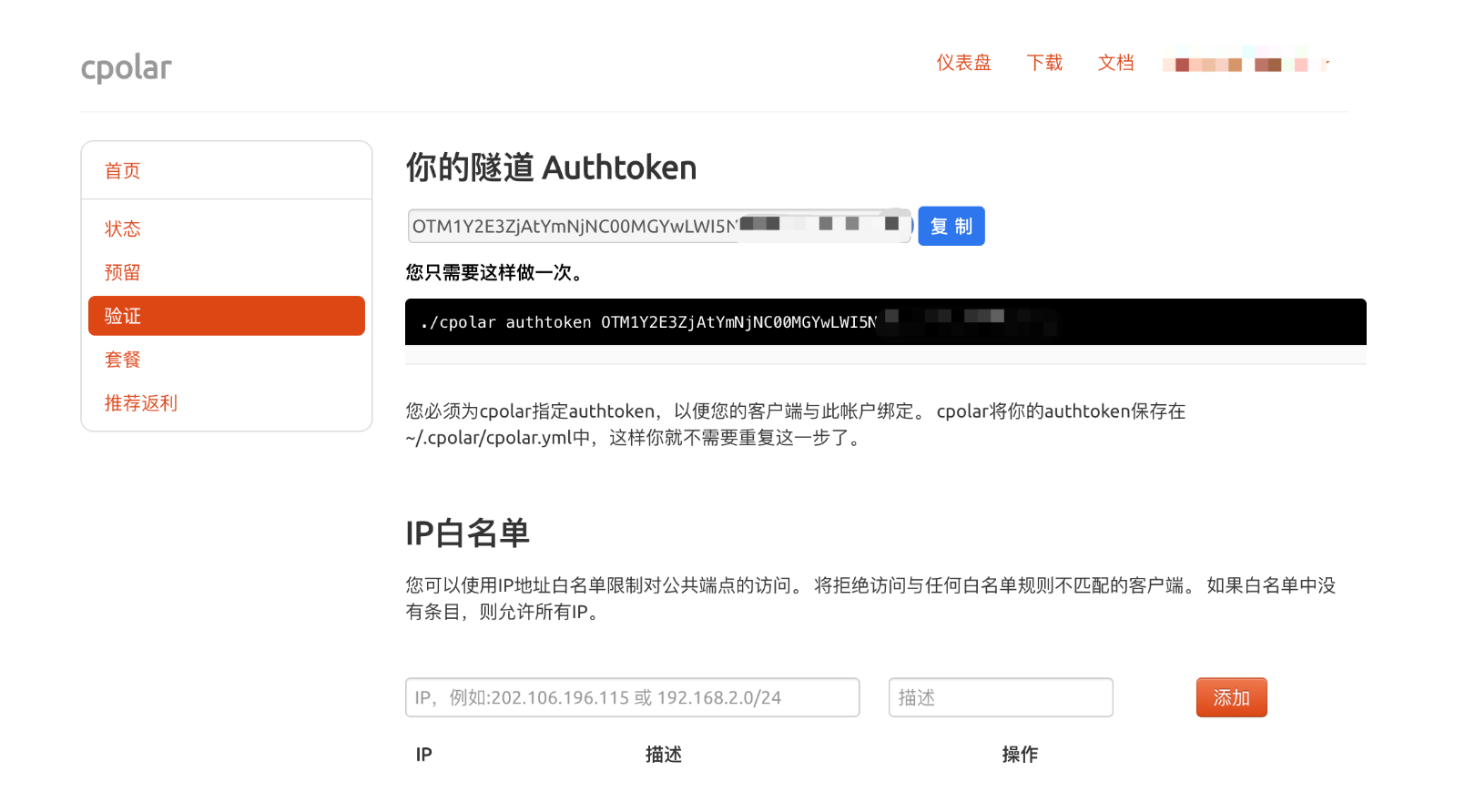
快速搭建 Cpolar 内网穿透(Mac 系统)
1、Cpolar快速入门教程(官方) 链接地址:Cpolar 快速入门 2、官方教程详解 本地安装homebrew /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"这个是从 git 上拉取的&#x…...

【Flink SQL实战】 UTC 时区格式的 ISO 时间转东八区时间
文章目录 一、原始数据格式二、解决方案三、其他要求 在实际开发中,我们常常会遇到此类情况:数据源里的时间格式是类似 2025-04-21T09:23:16.025Z 这种带 TimeZone 标识的 ISO 8601 格式,而我们需要在 Flink SQL 中将其转换成北京时间显示。 …...

动态监控进程
1.介绍: top和ps命令很相似,它们都是用来显示正在执行的进程,top和ps最大的不同之处,在于top在执行中可以更新正在执行的进程. 2.基本语法: top [选项] 选项说明 ⭐️僵死进程:内存没有释放,但是进程已经停止工作了,需要及时清理 交互操作说明 应用案…...
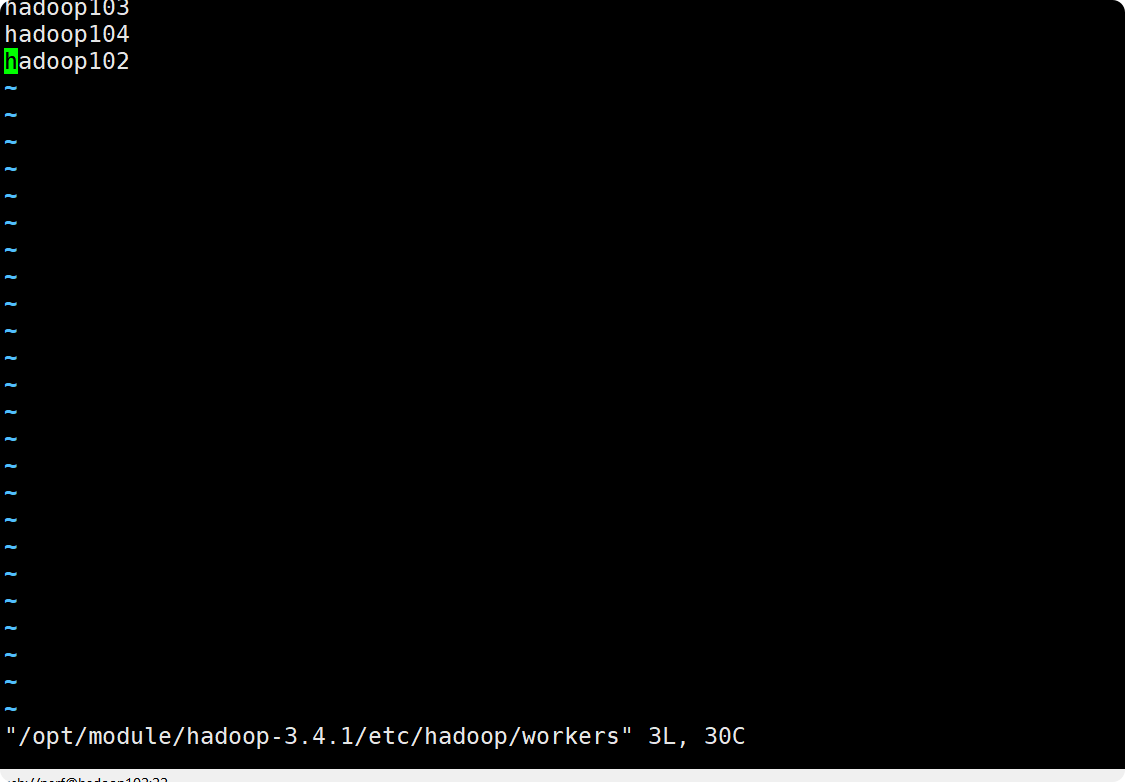
HADOOP 3.4.1安装和搭建(尚硅谷版~)
目录 1.配置模版虚拟机 2.克隆虚拟机 3.在hadoop102安装JDK 4.完全分布式运行模式 1.配置模版虚拟机 1.安装模板虚拟机,IP地址192.168.10.100、主机名称hadoop100、内存2G、硬盘20G(有需求的可以配置4G内存,50G硬盘) 2.hado…...

第 4 篇:平稳性 - 时间序列分析的基石
第 4 篇:平稳性 - 时间序列分析的基石 在上一篇中,我们学习了如何将时间序列分解为趋势、季节性和残差。我们看到,很多真实世界的时间序列(比如 CO2 浓度)都包含明显的趋势(长期向上或向下)和/…...
DeepSeek赋能Nuclei:打造网络安全检测的“超级助手”
引言 各位少侠,周末快乐,幸会幸会! 今天唠一个超酷的技术组合——用AI大模型给Nuclei开挂,提升漏洞检测能力! 想象一下,当出现新漏洞时,少侠们经常需要根据Nuclei模板,手动扒漏洞文章…...
)
分享一个python启动文件脚本(django示例)
今天给大家分享一个python启动文件脚本 在日常开发中,我们常常需要运行多条命令来完成“静态收集”“数据库迁移”“启动服务”……如果把这些命令整合到一个脚本里就好了 一、整体流程概览 #mermaid-svg-wA6UnfATaUOfJoPn {font-family:"trebuchet ms"…...

从0到1彻底掌握Trae:手把手带你实战开发AI Chatbot,提升开发效率的必备指南!
我正在参加Trae「超级体验官」创意实践征文, 本文所使用的 Trae 免费下载链接: www.trae.ai/?utm_source… 前言 大家好,我是小Q,字节跳动近期推出了一款 AI IDE—— Trae,由国人团队开发,并且限时免费体…...

3200温控板电路解析
提示:文章 文章目录 前言一、背景二、2.12.2 三、3.1 总结 前言 前期疑问: 本文目标: 一、背景 最近重温3200温控板电路设计和芯片选型 3200代码仓 二、 2.1 按照顺序整理,主要是依靠自己想到的来整理 1、传感器是pt1000&…...

opencv图片颜色识别,颜色的替换
图片颜色识别 1. RGB颜色空间2. 颜色加法2.1使用numpy对图像进行加法2.2使用opencv加法(cv2.add) 3 颜色加权加法(cv2.addWeighted())4. HSV颜色空间5. 制作掩膜4. 与运算(cv2.bitwise_and)5.颜色的替换7 R…...
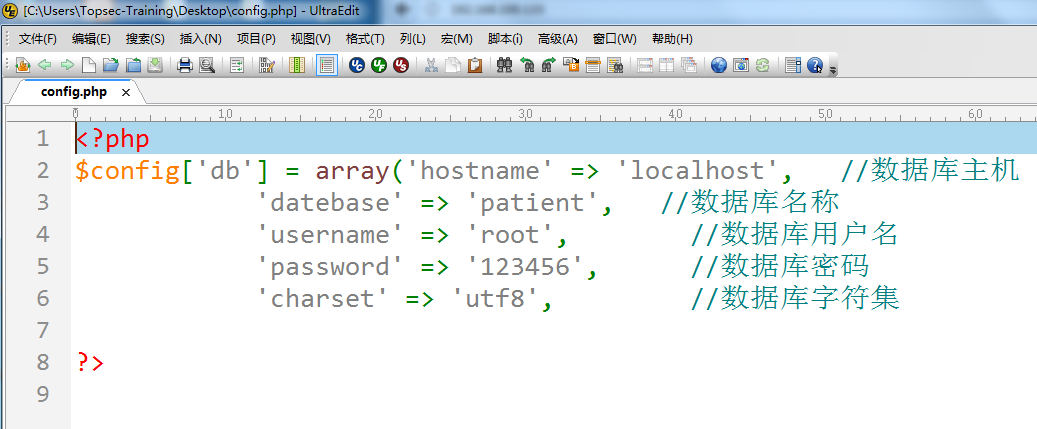
B实验-12
需要注意版本、页面源代码 两个文件一个目录:phpinfo robots phpmyadmin 实验12 靶机1 一个key在phpmyadmin,一个key在回收站 用两个扫描目录的工具扫,nmap给python版 情况1:弱口令 root root root 123456 …...

Python多技术融合在生态参量估算中的创新应用—以蒸散发与植被GPP估算为例
在全球气候变化背景下,精确估算陆地生态系统水碳通量成为生态研究的关键命题。本研究创新性地整合Python编程、遥感数据处理、机器学习算法及生态过程模型,构建了一套高效可靠的蒸散发(ET)与植被总初级生产力(GPP&…...

文件有几十个T,需要做rag,用ragFlow能否快速落地呢?
一、RAGFlow的优势 1、RAGFlow处理大规模数据性能: (1)、RAGFlow支持分布式索引构建,采用分片技术,能够处理TB级数据。 (2)、它结合向量搜索和关键词搜索,提高检索效率。 …...
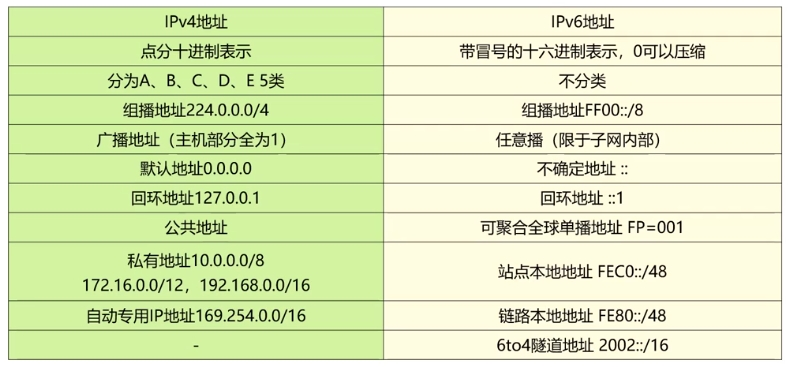
【网工第6版】第5章 网络互联②
目录 ■ IPV6 ▲ IPV6报文格式 ◎ IPV6扩展报头(RFC2460) ◎ IPv6相关协议 ▲ IPV6地址分类 ◎ IPv6地址基础 ◎ IPv6地址举例 ◎ IPv6地址分类 ◎ 特殊地址对比IPv4 vs IPv6 ▲ 过渡技术 本章重要程度:☆☆☆☆☆ ■ IPV6 与IPv4…...

为什么Makefile中的clean需要.PHONY
原因一:避免Makefile检查时间戳 前置知识:makefile在依赖文件没有改变时不会执行编译命令 #第一次执行,OK [rootVM-16-14-centos ~]# make g -E main.cc -o main.i g -S main.i -o main.s g -c main.s -o main.o g main.o -o main#第二…...

Vue组件库开发实战:从0到1构建可复用的微前端模块
🔥 随着前端项目越来越复杂,如何开发一个可以随处使用的组件库变得尤为重要。本文将带你从0开始,实现一个完全独立的Vue组件库,包含样式隔离、主题定制等核心功能。 前言 在日常开发中,我们经常需要在不同项目间复用组…...
)
相机标定(输出相机内参和畸变参数)
相机标定 这里我用笔记本电脑自带的摄像头进行相机标定 仅作示例,实际工程中要用对应的摄像头进行标定 同时代码也要相应的修改,不过修改的主要是相机的初始化 粗略的说就是打开相机那部分要修改(依据实际情况相应修改) 最终的结果…...

单页面应用的特点,什么是路由,VueRouter的下载,安装和使用,路由的封装抽离,声明式导航的介绍和使用
文章目录 一.什么是单页面应用?二.什么是路由?生活中的路由和Vue中的路由 三.VueRouter(重点)0.引出1.介绍2.下载与使用(5个基本步骤2个核心步骤)2.1 五个基本步骤2.2 两个核心步骤 四.路由的封装抽离五.声明式导航1.导航链接特点一:能跳转特点二:能高亮 2.两个高亮类名2.1.区…...
)
数字ic后端设计从入门到精通2(含fusion compiler, tcl教学)
上篇回顾 上一篇文章需要讨论了net,pin的基础用法,让我们来看一下高级一点的用法 instance current_instance current_instance 是 Synopsys 工具(如 Fusion Compiler 或 Design Compiler)中用于在设计层次结构中导航的关键命令。它允许用…...
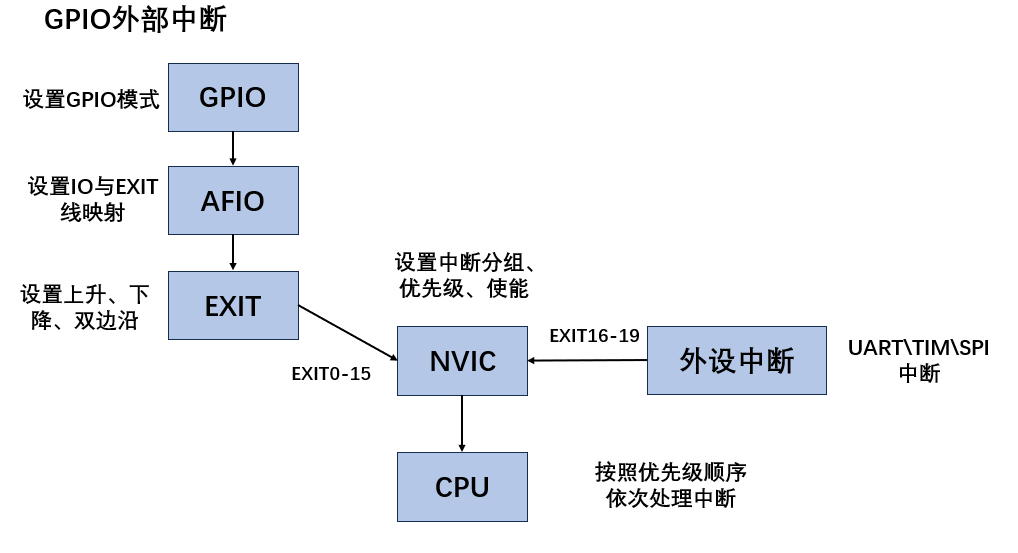
STM32---外部中断EXTI
目录 一、中断向量表 二、EXTI工作原理图 三、NVIC模块 四、GPIO设置为EXTI的结构 五、C语言示例代码 在STM32中,中断是一个非常重要的结构,他能让我们在执行主函数的时候,由硬件检测一些外部或内部产生的中断信号,跳转到中断…...

Itext进行PDF的编辑开发
这周写了一周的需求,是制作一个PDF生成功能,其中用到了Itext来制作PDF的视觉效果。其中一些功能不是很懂,仅作记录,若要学习请仔细甄别正确与否。 开始之前,我还是想说,这傻福需求怎么想出来的,…...
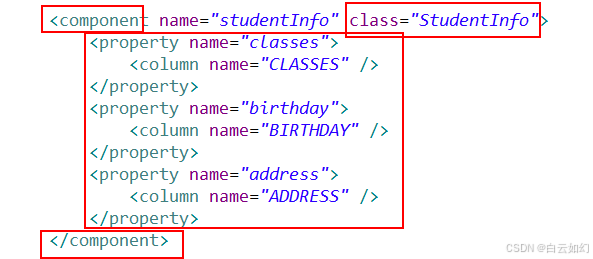
Hibernate的组件映射
在实际的开发中,使用的是非常多的,还有几种比较特殊的关系映射: 组件映射继承映射 先看一下组件映射: 组件映射中, 组件也是一个类, 但是这个类它不独立称为一个实体, 也就是说, 数据库中没有一个表格单独的和它对应, 具体情况呢, 看演示:...
C++ 操作符重载Operator
C可以重载大多数操作符,如算术运算符号,-号。 位操作符<<,>> 下标符号[]等都可以重载。 重载的意思,是让这些符号,按你定义的行为来执行代码,但是这种自定义,是有限制的,必须有一…...
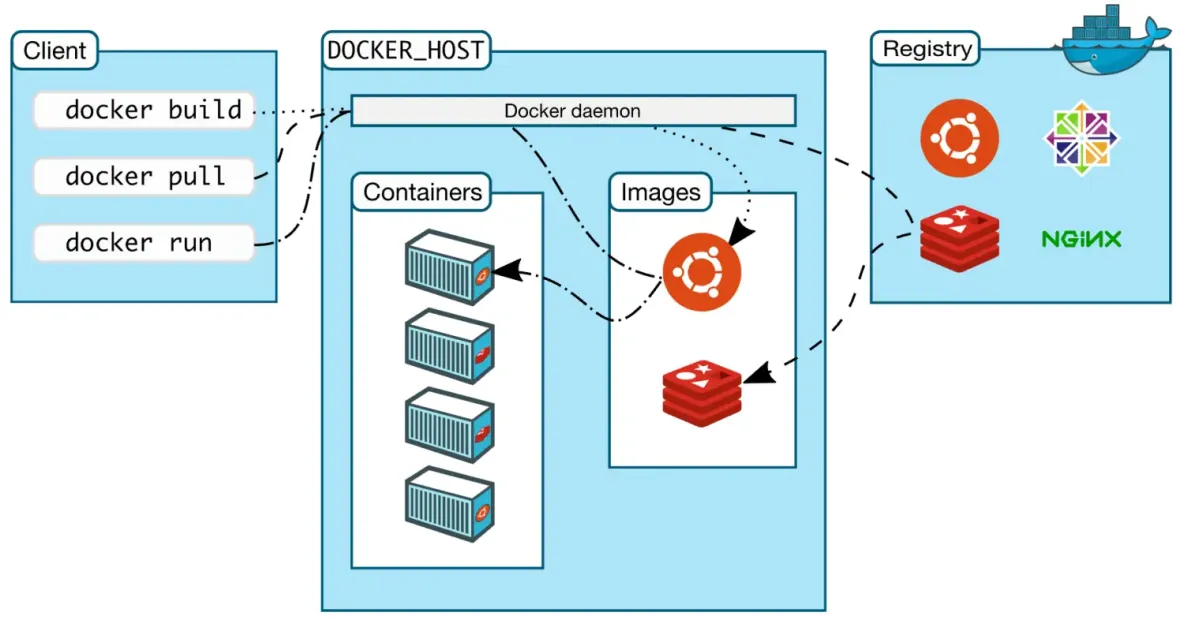
Docker 镜像、容器和 Docker Compose的区别
前言:Docker 的镜像、容器和 Docker Compose 是容器化技术的核心组件,以下是对它们的详细解析及使用场景说明。 1、Docker 镜像(Image) 定义: 镜像是只读模板,包含运行应用程序所需的代码、…...