数据处理: 亲和聚类
Affinity Propagation(亲和传播)是一种基于"消息传递"概念的聚类算法,由Brendan Frey和Delbert Dueck于2007年提出。与K-Means等需要预先指定簇数量的算法不同,Affinity Propagation能够自动确定最佳簇的数量,这使得它在许多实际应用中非常有用。
1. 原理
通过数据点之间交换两种消息来进行聚类:
-
责任度(Responsibility)消息(r(i,k)):
-
表示数据点i适合选择数据点k作为其"代表点"(exemplar)的程度
-
从点i发送到候选代表点k
-
-
可用度(Availability)消息(a(i,k)):
-
表示数据点k适合作为数据点i的"代表点"的程度
-
从候选代表点k发送回点i
-
算法步骤
-
初始化相似度矩阵:计算所有数据点之间的相似度(通常使用负欧氏距离)
-
设置偏向参数:对角线元素设置为相同的值(控制产生多少聚类)
-
迭代更新消息:
-
更新责任度消息
-
更新可用度消息
-
-
确定代表点:当消息收敛后,选择代表点并分配聚类
数学表达
-
相似度矩阵:s(i,k) = -||xᵢ - xₖ||²
-
责任度更新:r(i,k) = s(i,k) - max{a(i,k') + s(i,k')} (k'≠k)
-
可用度更新:
-
对于k≠i:a(i,k) = min{0, r(k,k) + Σmax{0,r(i',k)}} (i'∉{i,k})
-
对角线元素:a(k,k) = Σmax{0,r(i',k)} (i'≠k)
-
2. 特点
优点
-
不需要预先指定簇的数量
-
能够发现数据中自然存在的簇结构
-
对初始条件不敏感
-
可以处理非球形簇
缺点
-
时间复杂度较高(O(N²T),N是样本数,T是迭代次数)
-
内存消耗大(需要存储N×N的相似度矩阵)
-
对偏向参数(Preference)的选择敏感
3. Python实现
from sklearn.cluster import AffinityPropagation
from sklearn import metrics
from sklearn.datasets import make_blobs
import numpy as np
import matplotlib.pyplot as plt# 生成样本数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=300, centers=centers, cluster_std=0.5, random_state=0)# 计算相似度矩阵(负欧氏距离)
similarities = -np.sum((X[:, np.newaxis, :] - X[np.newaxis, :, :]) ** 2, axis=2)# 运行Affinity Propagation
af = AffinityPropagation(affinity='precomputed', random_state=0).fit(similarities)
cluster_centers_indices = af.cluster_centers_indices_
labels = af.labels_n_clusters_ = len(cluster_centers_indices)print('Estimated number of clusters:', n_clusters_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))# 绘制结果
plt.figure(figsize=(10, 6))
colors = plt.cm.Spectral(np.linspace(0, 1, len(set(labels))))for k, col in zip(range(n_clusters_), colors):class_members = labels == kcluster_center = X[cluster_centers_indices[k]]plt.plot(X[class_members, 0], X[class_members, 1], 'o', markerfacecolor=col,markeredgecolor='k', markersize=8)plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,markeredgecolor='k', markersize=14)plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()关键参数说明
-
damping (阻尼系数,默认0.5):
-
控制消息传递的阻尼程度(0.5-1)
-
较高的值可以防止数值振荡,但会减慢收敛速度
-
-
preference (偏向参数):
-
控制产生多少聚类
-
通常设置为相似度的中位数
-
值越大,产生的聚类越多
-
-
affinity (相似度计算方式):
-
'euclidean':使用负欧氏距离
-
'precomputed':使用预先计算的相似度矩阵
-
-
max_iter (最大迭代次数,默认200):
-
算法运行的最大迭代次数
-
-
convergence_iter (收敛迭代次数,默认15):
-
连续多少次迭代没有变化就认为收敛
-
4. 实际应用案例
案例1:文档聚类
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import AffinityPropagation
import pandas as pd# 示例文档
documents = ["机器学习是人工智能的一个分支","深度学习使用神经网络","Python是一种编程语言","Java也是一种编程语言","监督学习需要标签数据","无监督学习发现数据中的模式"
]# 将文档转换为TF-IDF特征向量
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(documents)# 运行Affinity Propagation
af = AffinityPropagation(affinity='cosine', damping=0.7).fit(X.toarray())# 输出聚类结果
df = pd.DataFrame({'Document': documents,'Cluster': af.labels_
})
print(df.sort_values('Cluster'))案例2:图像聚类
from sklearn.cluster import AffinityPropagation
from sklearn.datasets import load_sample_image
from sklearn.feature_extraction.image import extract_patches_2d
import numpy as np# 加载示例图像
china = load_sample_image("china.jpg")# 将图像转换为2D数组(高度×宽度, RGB)
X = china.reshape((-1, 3))# 随机采样部分像素点(减少计算量)
np.random.seed(0)
indices = np.random.choice(X.shape[0], 1000, replace=False)
X_sample = X[indices]# 运行Affinity Propagation
af = AffinityPropagation(damping=0.75, preference=-20000).fit(X_sample)# 可视化聚类中心(代表颜色)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
for i, color in enumerate(af.cluster_centers_):plt.subplot(1, len(af.cluster_centers_), i+1)plt.imshow(color.reshape(1, 1, 3))plt.axis('off')
plt.show()5. 参数调优
- 通过网格搜索寻找最佳damping和preference参数
- 使用轮廓系数等指标评估聚类质量
- 对于高维数据,考虑使用余弦相似度
- 可以稀疏化相似度矩阵(只保留每个点的最近邻)
6. 总结
与其他聚类算法的比较
| 特性 | Affinity Propagation | K-Means | DBSCAN | 层次聚类 |
|---|---|---|---|---|
| 需要指定簇数 | 否 | 是 | 否 | 是/否 |
| 簇形状适应性 | 任意 | 球形 | 任意 | 任意 |
| 处理噪声数据 | 中等 | 差 | 好 | 中等 |
| 时间复杂度 | O(N²) | O(NKT) | O(N²) | O(N³) |
| 内存消耗 | 高 | 低 | 中等 | 高 |
| 适合数据规模 | 小到中等 | 大 | 中等 | 小 |
Affinity Propagation是一种强大的聚类算法,对于中小规模数据集能够提供非常有价值的聚类结果。特别适用于以下场景:
-
不知道数据中应该有多少个簇
-
数据中存在非球形的簇结构
-
需要找到最具代表性的数据点(exemplars)
在实际应用中的建议:
-
对数据进行适当的预处理和标准化
-
尝试不同的preference和damping参数
-
使用评估指标验证聚类质量
-
对于大规模数据,考虑使用近似算法或降维技术
相关文章:

数据处理: 亲和聚类
Affinity Propagation(亲和传播)是一种基于"消息传递"概念的聚类算法,由Brendan Frey和Delbert Dueck于2007年提出。与K-Means等需要预先指定簇数量的算法不同,Affinity Propagation能够自动确定最佳簇的数量࿰…...
LabVIEW液压系统远程监控与故障诊断
开发了一种基于LabVIEW的远程液压系统监控解决方案,通过先进的数据采集与分析技术,有效提升工程机械的运作效率和故障响应速度。该系统结合现场硬件设备和远程监控软件,实现了液压系统状态的实时检测和故障诊断,极大地提升了维护效…...

Idea中实用设置和插件
目录 一、Idea使用插件 1.Fitten Code智能提示 2.MyBatisCodeHelperPro 3.HighlightBracketPair 4.Rainbow Brackets Lite 5.GitToolBox(存在付费) 6.MavenHelperPro 7.Search In Repository 8.VisualGC(存在付费) 9.vo2dto 10.Key Promoter X 11.CodeGlance…...

安卓处理登录权限问题
在安卓应用中实现登录权限控制,需确保用户登录后才能访问特定功能。以下是分步骤的解决方案: 1. 保存和检查登录状态 使用安全存储保存登录凭证: 推荐使用 EncryptedSharedPreferences 存储敏感信息(如Token、用户ID)…...
Java写数据结构:栈
1.概念: 一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。 压栈:栈的插…...

使用Unity Cache Server提高效率
2021年1月20日19:04:28 1 简介 Unity Cache Server,翻译过来就是Unity缓存服务器 1.1 缓存服务器の官方介绍 Unity 有一个完全自动的资源管线。每当修改 .psd 或 .fbx 文件等源资源时,Unity 都会检测到更改并自动将其重新导入。随后,Unity 以内部格式存储从文件导入的数…...

29个常见的Terraform 面试问题
问题 1:假设您使用 Terraform 创建了一个 EC2 实例,创建完成后,您从状态文件中删除了该条目,那么运行 Terraform Apply 命令时会发生什么? 由于我们已从该状态文件中删除了该条目,因此 Terraform 将不再管…...

机器学习-08-推荐算法-案例
总结 本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则 参考 机器学习(三):Apriori算法(算法精讲) Apriori 算法 理论 重点 MovieLens:一个常用的电影推荐系统领域的数据集 23张图&#x…...
LLM中的N-Gram、TF-IDF和Word embedding
文章目录 1. N-Gram和TF-IDF:通俗易懂的解析1.1 N-Gram:让AI学会"猜词"的技术1.1.1 基本概念1.1.2 工作原理1.1.3 常见类型1.1.4 应用场景1.1.5 优缺点 1.2 TF-IDF:衡量词语重要性的尺子1.2.1 基本概念1.2.2 计算公式1.2.3 为什么需…...

uniapp APP端 DOM生成图片保存到相册
<template> <view class"container" style"padding-bottom: 30rpx;"> <view class"hdbg pr w100 " style"height: 150rpx;"> <top-bar content分享 Back"Back"></top-b…...

Office文件内容提取 | 获取Word文件内容 |Javascript提取PDF文字内容 |PPT文档文字内容提取
关于Office系列文件文字内容的提取 本文主要通过接口的方式获取Office文件和PDF、OFD文件的文字内容。适用于需要获取Word、OFD、PDF、PPT等文件内容的提取实现。例如在线文字统计以及论文文字内容的提取。 一、提取Word及WPS文档的文字内容。 支持以下文件格式: …...
)
算法——背包问题(分类)
背包问题(Knapsack Problem)是一类经典的组合优化问题,广泛应用于资源分配、投资决策、货物装载等领域。根据约束条件和问题设定的不同,背包问题主要分为以下几种类型: 1. 0-1 背包问题(0-1 Knapsack Probl…...
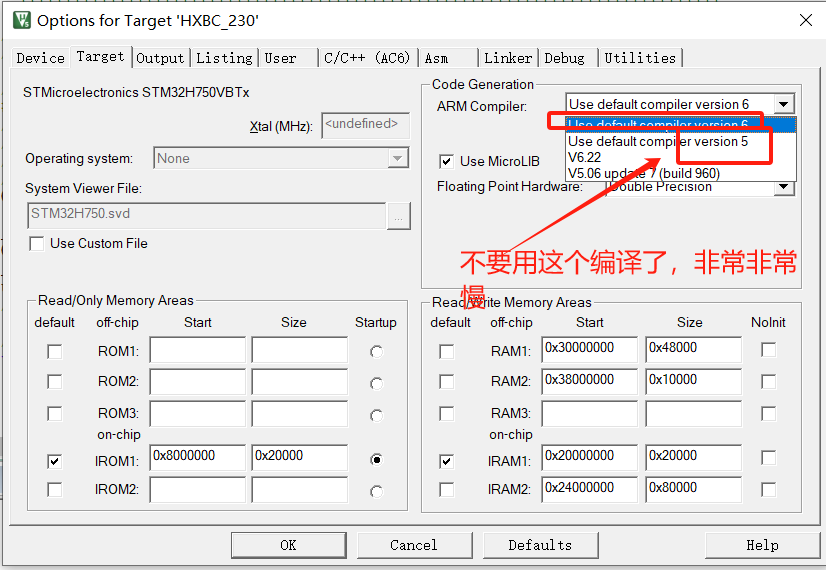
HXBC编译相关错误
0、Keil MDK报错:Browse information of one or more files is not available----解决方法: 1、使用cubemax生成的工程中,某些引脚自定义了的,是在main.h中,要记得移植。 注意:cubemax生成的spi.c后,在移植的时候,注意hal_driver下面要对应增加hal_stm32H7xxxspi.c …...

Windows 环境下 Apache 配置 WebSocket 支持
目录 前言1. 基本知识2. 实战前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 爬虫神器,无代码爬取,就来:bright.cn 原先写过apache的http配置:Apache httpd-vhosts.conf 配置详解(附Demo) 1. 基本知识 🔁 WebSocket 是 HTTP 的升级协议 客户…...
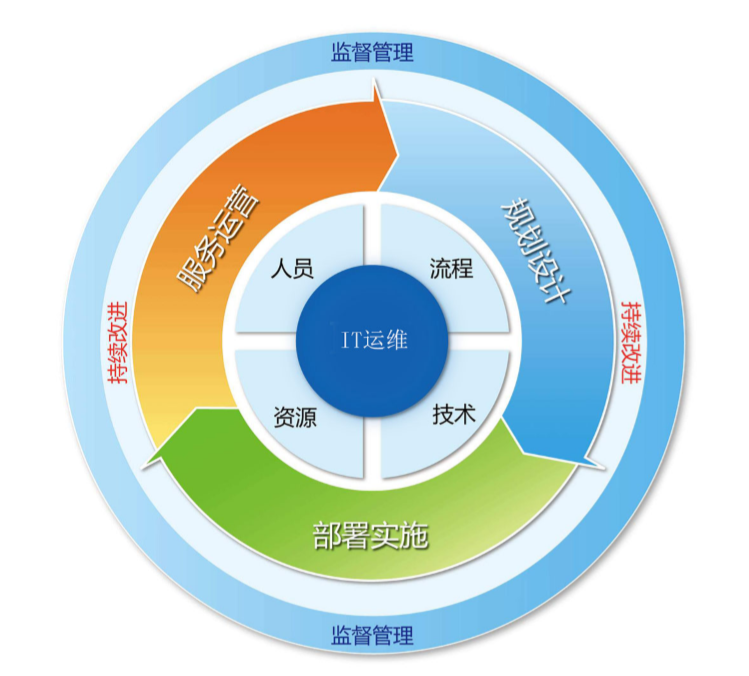
运维概述(linux 系统)
1、运维的基本概念 2、企业的运行模式 3、计算机硬件 运维概述 运维岗位的定义 在技术人员(写代码的)之间,一致对运维有一个开玩笑的认知:运维就是修电脑的、装网线的、背锅的岗位。 IT运维管理是指为了保障企业IT系统及网络…...

C语言 数据结构 【堆】动态模拟实现,堆排序,TOP-K问题
引言 堆的各个接口的实现(以代码注释为主),实现堆排序,解决经典问题:TOP-K问题 一、堆的概念与结构 堆 具有以下性质 • 堆中某个结点的值总是不大于或不小于其父结点的值; • 堆总是一棵完全二叉树。 二…...

MFC文件-写MP4
下载本文件 本文件将创作MP4视频文件代码整合到两个文件中(Mp4Writer.h和Mp4Writer.cpp),将IYUV视频流编码为H264,PCM音频流编码为AAC,写入MP4文件。本文件仅适用于MFC程序。 使用方法 1.创建MFC项目。 2.将Mp4Writer.h和Mp4Wri…...

8.观察者模式:思考与解读
原文地址:观察者模式:思考与解读 更多内容请关注:7.深入思考与解读设计模式 引言 在开发软件时,系统的某些状态可能会发生变化,而你希望这些变化能够自动通知到依赖它们的其他模块。你是否曾经遇到过,系统中某个对象…...

CMake execute_process用法详解
execute_process 是 CMake 中的一个命令,用于在 CMake 配置阶段(即运行 cmake 命令时)执行外部进程。它与 add_custom_command 或 add_custom_target 不同,后者是在构建阶段(如 make 或 ninja)执行命令。ex…...

模型加载常见问题
safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge 问题代码: model AutoModelForVision2Seq.from_pretrained( "/data-nvme/yang/Qwen2.5-VL-32B-Instruct", trust_remote_codeTrue, torch_dtypetorc…...
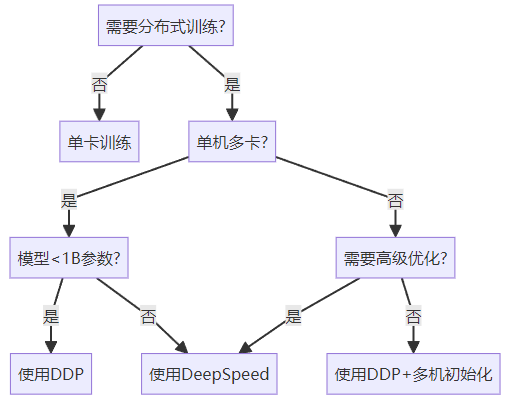
PyTorch 深度学习实战(37):分布式训练(DP/DDP/Deepspeed)实战
在上一篇文章中,我们探讨了混合精度训练与梯度缩放技术。本文将深入介绍分布式训练的三种主流方法:Data Parallel (DP)、Distributed Data Parallel (DDP) 和 DeepSpeed,帮助您掌握大规模模型训练的关键技术。我们将使用PyTorch在CIFAR-10分类…...
微信小程序通过mqtt控制esp32
目录 1.注册巴法云 2.设备连接mqtt 3.微信小程序 备注 本文esp32用的是MicroPython固件,MQTT服务用的是巴法云。 本文参考巴法云官方教程:https://bemfa.blog.csdn.net/article/details/115282152 1.注册巴法云 注册登陆并新建一个topicÿ…...
1.Vue3 - 创建Vue3工程
目录 一、 基于vue-cli 脚手架二、基于vite 推荐2.1 介绍2.2 创建项目2.3 文件介绍2.3.1 extensions.json2.3.2 脚手架的根目录2.3.3 主要文件 src2.3.3.1 main.js2.3.3.2 App.vue 组件2.3.3.3 conponents 2.3.4 env.d.ts2.3.5 index.html 入口文件2.3.6 package2.3.7 tsconfig…...

AI编写的“黑科技风格、自动刷新”的看板页面
以下的 index.html 、 script.js 和 styles.css 文件,实现一个具有黑科技风格、自动刷新的能源管理系统实时监控看板。 html页面 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name&q…...
11-DevOps-Jenkins Pipeline流水线作业
前面已经完成了,通过在Jenkins中创建自由风格的工程,在界面上的配置,完成了发布、构建的过程。 这种方式的缺点就是如果要在另一台机器上进行同样的配置,需要一项一项去填写,不方便迁移,操作比较麻烦。 解…...
)
23种设计模式-结构型模式之外观模式(Java版本)
Java 外观模式(Facade Pattern)详解 🧭 什么是外观模式? 外观模式是结构型设计模式之一,为子系统中的一组接口提供一个统一的高层接口,使得子系统更易使用。 就像是酒店前台,帮你处理入住、叫…...

【JavaWeb后端开发03】MySQL入门
文章目录 1. 前言1.1 引言1.2 相关概念 2. MySQL概述2.1 安装2.2 连接2.2.1 介绍2.2.2 企业使用方式(了解) 2.3 数据模型2.3.1 **关系型数据库(RDBMS)**2.3.2 数据模型 3. SQL语句3.1 DDL语句3.1.1 数据库操作3.1.1.1 查询数据库3.1.1.2 创建数据库3.1.1…...

Github 热点项目 Jumpserver开源堡垒机让服务器管理效率翻倍
Jumpserver今日喜提160星,总星飙至2.6万!这个开源堡垒机有三大亮点:① 像哆啦A梦的口袋,支持多云服务器一站式管理;② 安全审计功能超硬核,操作记录随时可回放;③ 网页终端无需装插件࿰…...

第七届传智杯全国IT技能大赛程序设计赛道 国赛(总决赛)—— (B组)题解
1.小苯的木棍切割 【解析】首先我们先对数列排序,找到其中最小的数,那么我们就保证了对于任意一个第i1个的值都会大于第i个的值那么第i2个的值也比第i个大,那么我们第i1次切木棍的时候一定会当第i个的值就变为了0的,第i1减去的应该…...
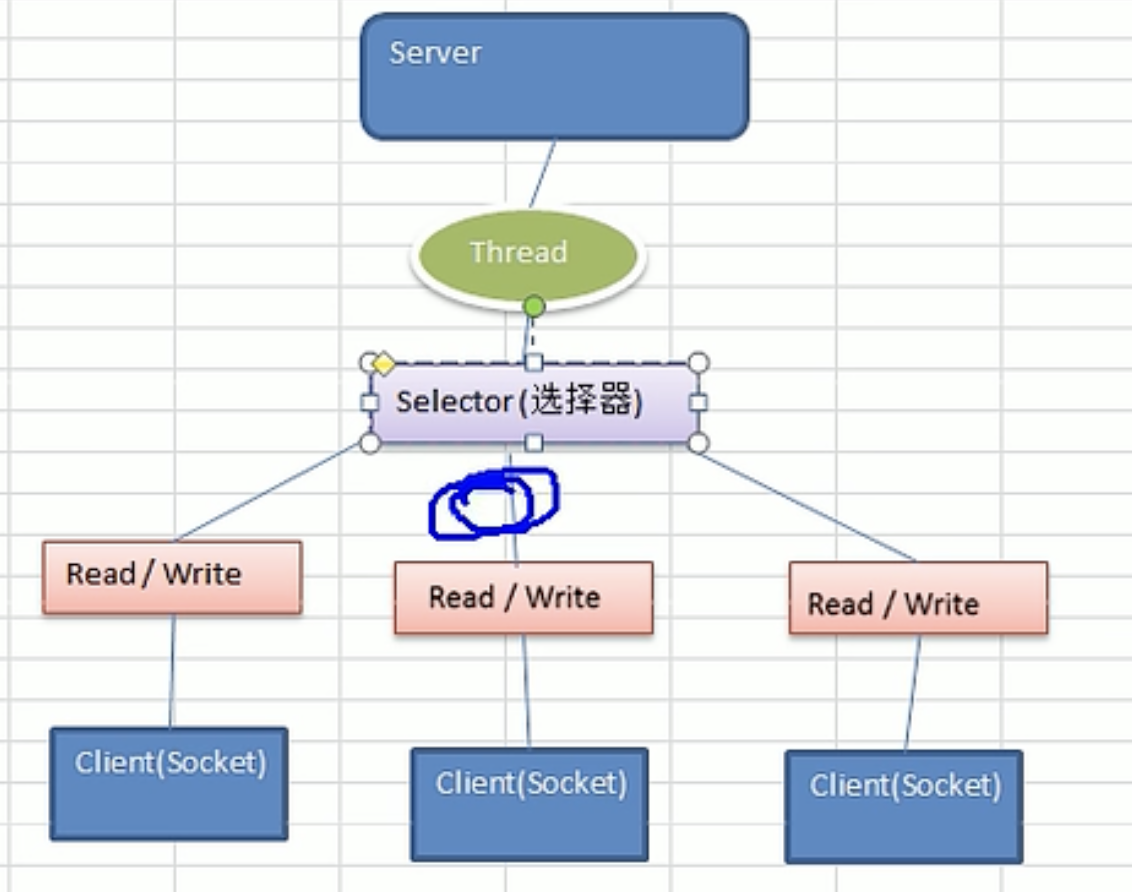
Netty前置基础知识之BIO、NIO以及AIO理论详细解析和实战案例
前言 Netty是什么? Netty 是一个基于 Java 的 高性能异步事件驱动网络应用框架,主要用于快速开发可维护的协议服务器和客户端。它简化了网络编程的复杂性,特别适合构建需要处理海量并发连接、低延迟和高吞吐量的分布式系统。 1)Netty 是…...