机器学习-08-推荐算法-案例
总结
本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则
参考
机器学习(三):Apriori算法(算法精讲)
Apriori 算法 理论 重点
MovieLens:一个常用的电影推荐系统领域的数据集
23张图,带你入门推荐系统
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用:
对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。

要构建一个包含用户、商品和评分的数据集,并基于 Python 实现基于用户的商品推荐,我们可以使用协同过滤算法(Collaborative Filtering)。以下是实现的步骤:
基于用户的协同过滤推荐案例
在真实的推荐系统场景中,用户通常只会对少量商品进行评分,而大部分商品的评分为 0(表示未评分)。为了模拟这种稀疏性,我们可以调整数据生成逻辑,使得每个用户的评分矩阵中有更多的 0 值。
以下是如何生成稀疏评分矩阵的完整代码实现:
1. 构建稀疏评分矩阵
我们将通过随机生成的方式,确保每个用户只对少量商品评分(例如每个用户平均评分 3-5 个商品),其余商品的评分为 0。
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 设置随机种子以确保结果可复现
np.random.seed(42)# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))# 随机生成稀疏评分数据
for i in range(num_users):# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)num_rated_items = np.random.randint(1, max_ratings_per_user + 1)# 随机选择该用户评分的商品索引rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)# 随机生成评分(1 到 5)ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)# 打印评分矩阵
print("用户-商品评分矩阵:")
print(df)
输出示例:

2. 计算用户相似度并预测评分
接下来,我们基于稀疏评分矩阵计算用户相似度,并为目标用户预测未评分商品的评分。
# 计算用户之间的相似度
user_similarity = cosine_similarity(df)
user_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)print("\n用户相似度矩阵:")
print(user_similarity_df)# 预测目标用户对未评分商品的评分
def predict_ratings(target_user, df, user_similarity_df):# 获取目标用户的评分target_ratings = df.loc[target_user]# 修改这里:初始化预测评分为float类型predicted_ratings = pd.Series(0.0, index=df.columns, dtype='float64')for item in df.columns:if target_ratings[item] == 0: # 只预测未评分的商品# 获取对该商品评分过的用户users_who_rated = df[df[item] > 0].index# 计算加权平均评分weighted_sum = 0.0similarity_sum = 0.0for user in users_who_rated:rating = df.loc[user, item]similarity = user_similarity_df.loc[target_user, user]weighted_sum += rating * similaritysimilarity_sum += similarityif similarity_sum > 0:predicted_ratings[item] = weighted_sum / similarity_sumreturn predicted_ratings# 目标用户
target_user = '用户1'# 预测评分
predicted_ratings = predict_ratings(target_user, df, user_similarity_df)print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
3. 运行结果解释
假设运行上述代码后,输出如下:
用户相似度矩阵(部分):
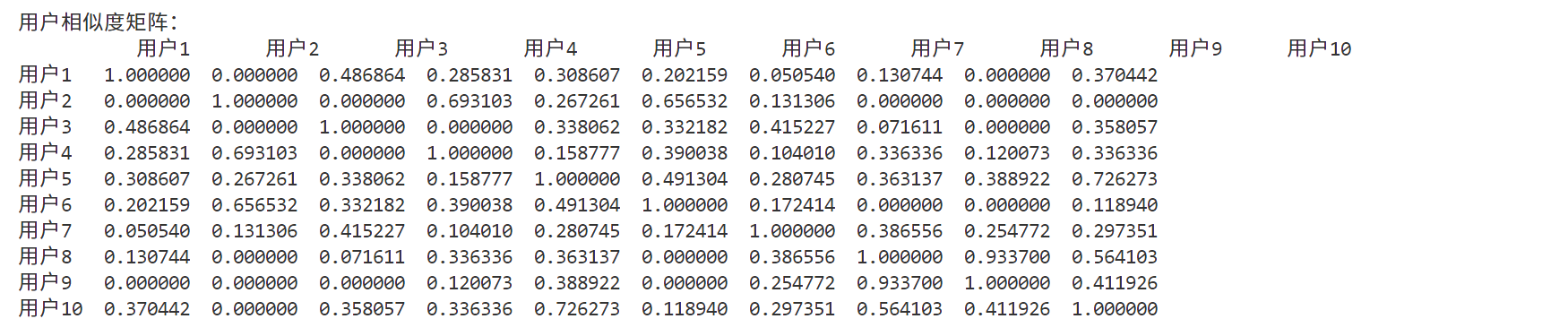
为目标用户 用户1 预测的评分:

推荐给用户 用户1 的商品:

4. 总结
通过引入稀疏评分矩阵,我们更贴近真实场景,其中大多数商品的评分为 0。对于目标用户 用户1,我们预测了其对未评分商品的评分,并推荐了预测评分最高的商品(如 商品3、商品10 等)。
你可以根据需要进一步优化算法,例如:
- 调整评分稀疏度(例如减少评分的商品数量)。
- 使用其他相似度计算方法(如皮尔逊相关系数)。
- 引入隐式反馈数据(如点击、浏览等行为)。
5.代码改进方法
在计算用户相似度时,如果用户评分数据过于稀疏(比如某些用户没有共同评分的商品),可能会导致计算相似度时出现问题。以下是改进后的代码,增加了数据预处理和异常处理:
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 设置随机种子以确保结果可复现
np.random.seed(42)# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))# 随机生成稀疏评分数据
for i in range(num_users):# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)num_rated_items = np.random.randint(1, max_ratings_per_user + 1)# 随机选择该用户评分的商品索引rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)# 随机生成评分(1 到 5)ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)# 打印评分矩阵
print("用户-商品评分矩阵:")
print(df)# 计算用户之间的相似度(改进版)
def calculate_user_similarity(df):# 填充缺失值为0(如果还没有填充)df_filled = df.fillna(0)# 计算余弦相似度user_similarity = cosine_similarity(df_filled)# 将对角线设置为0(避免用户与自己比较)np.fill_diagonal(user_similarity, 0)# 转换为DataFrameuser_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)return user_similarity_dfuser_similarity_df = calculate_user_similarity(df)# 计算用户之间的相似度
# user_similarity = cosine_similarity(df)
# user_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)print("\n用户相似度矩阵:")
print(user_similarity_df)# 预测目标用户对未评分商品的评分
# def predict_ratings(target_user, df, user_similarity_df):
# # 获取目标用户的评分
# target_ratings = df.loc[target_user]# # 修改这里:初始化预测评分为float类型
# predicted_ratings = pd.Series(0.0, index=df.columns, dtype='float64')# for item in df.columns:
# if target_ratings[item] == 0: # 只预测未评分的商品
# # 获取对该商品评分过的用户
# users_who_rated = df[df[item] > 0].index# # 计算加权平均评分
# weighted_sum = 0.0
# similarity_sum = 0.0
# for user in users_who_rated:
# rating = df.loc[user, item]
# similarity = user_similarity_df.loc[target_user, user]
# weighted_sum += rating * similarity
# similarity_sum += similarity# if similarity_sum > 0:
# predicted_ratings[item] = weighted_sum / similarity_sum# return predicted_ratings# 预测目标用户对未评分商品的评分(改进版)
def predict_ratings(target_user, df, user_similarity_df, min_similar_users=1):target_ratings = df.loc[target_user]predicted_ratings = pd.Series(0.0, index=df.columns,dtype='float64')for item in df.columns:if target_ratings[item] == 0:users_who_rated = df[df[item] > 0].indexweighted_sum = 0similarity_sum = 0valid_users = 0for user in users_who_rated:similarity = user_similarity_df.loc[target_user, user]# 只考虑正相似度的用户if similarity > 0:rating = df.loc[user, item]weighted_sum += rating * similaritysimilarity_sum += similarityvalid_users += 1# 至少有min_similar_users个相似用户才进行预测if valid_users >= min_similar_users and similarity_sum > 0:predicted_ratings[item] = weighted_sum / similarity_sumreturn predicted_ratings# 目标用户
target_user = '用户1'# 预测评分
predicted_ratings = predict_ratings(target_user, df, user_similarity_df)print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
输出如下:
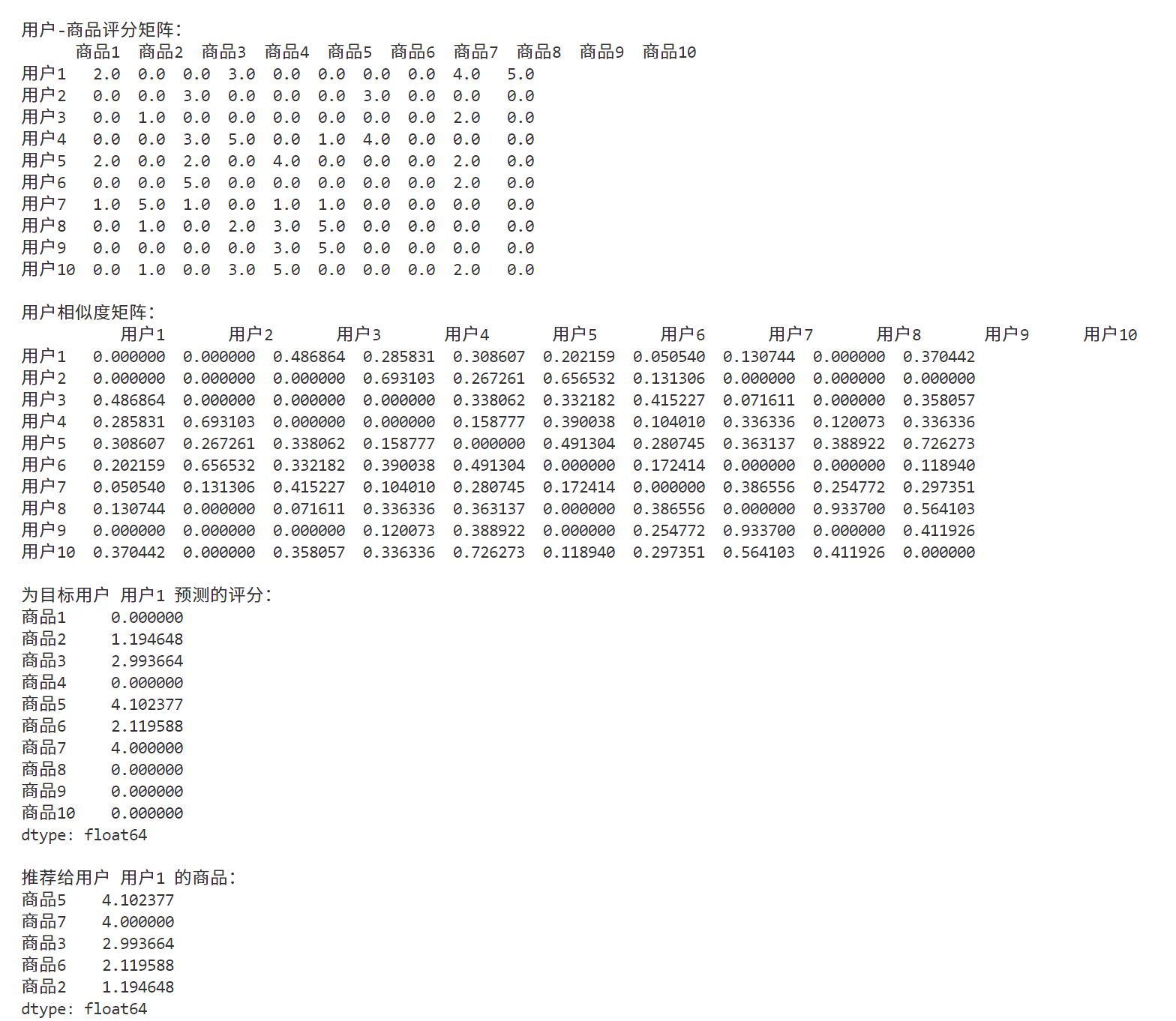
主要改进点:
增加了calculate_user_similarity函数来封装相似度计算逻辑
在计算相似度前确保数据已填充缺失值
将对角线相似度设为0(避免用户与自己比较)
在预测评分时增加了min_similar_users参数,确保有足够多的相似用户才进行预测
只考虑正相似度的用户参与预测
这些改进可以解决以下潜在问题:
处理缺失值问题
避免用户与自己的相似度影响结果
确保预测时有足够的参考用户
提高预测结果的可靠性
基于物品的协同过滤推荐案例
基于物品的协同过滤(Item-Based Collaborative Filtering)是一种推荐算法,其核心思想是:如果两个商品被相似的用户评分,那么这两个商品可能是相似的。我们可以根据商品之间的相似性,为目标用户推荐他们未评分但可能感兴趣的商品。
以下是基于上述稀疏评分矩阵实现基于物品的协同过滤的完整代码:
1. 数据准备
我们使用之前生成的稀疏评分矩阵 df,其中包含 10 个用户和 10 个商品。
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 设置随机种子以确保结果可复现
np.random.seed(42)# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))# 随机生成稀疏评分数据
for i in range(num_users):# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)num_rated_items = np.random.randint(1, max_ratings_per_user + 1)# 随机选择该用户评分的商品索引rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)# 随机生成评分(1 到 5)ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)print("用户-商品评分矩阵:")
print(df)
输出如下:
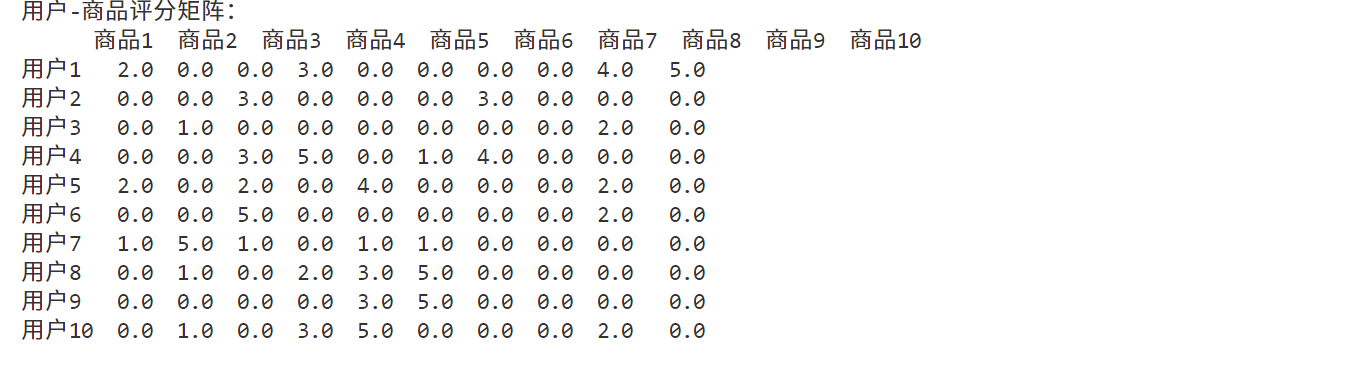
2. 计算商品相似度
在基于物品的协同过滤中,我们需要计算商品之间的相似度。可以使用余弦相似度来衡量商品之间的相似性。
# 转置评分矩阵,使得行表示商品,列表示用户
item_similarity = cosine_similarity(df.T) # 对转置后的矩阵计算相似度
item_similarity_df = pd.DataFrame(item_similarity, index=df.columns, columns=df.columns)print("\n商品相似度矩阵:")
print(item_similarity_df)
输出示例:
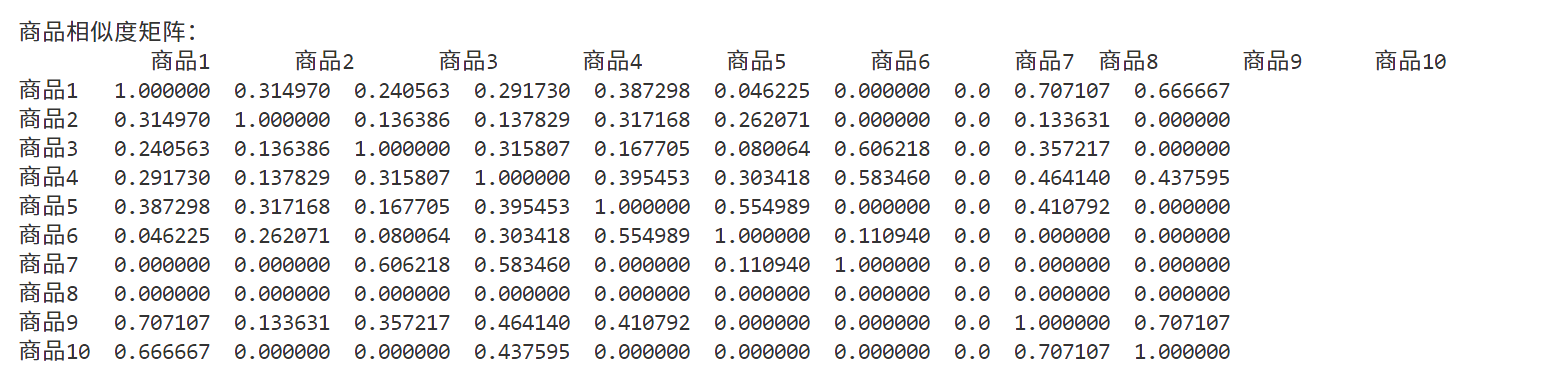
3. 基于商品相似度预测评分
对于目标用户未评分的商品,我们可以利用商品相似度和用户已评分的商品来预测评分。
def predict_item_based(target_user, df, item_similarity_df):# 获取目标用户的评分target_ratings = df.loc[target_user]# 初始化预测评分predicted_ratings = pd.Series(0, index=df.columns)for item in df.columns:if target_ratings[item] == 0: # 只预测未评分的商品# 获取与当前商品相似的商品similar_items = item_similarity_df[item]# 计算加权平均评分weighted_sum = 0similarity_sum = 0for other_item in df.columns:if target_ratings[other_item] > 0 and similar_items[other_item] > 0:rating = target_ratings[other_item]similarity = similar_items[other_item]weighted_sum += rating * similaritysimilarity_sum += similarityif similarity_sum > 0:predicted_ratings[item] = weighted_sum / similarity_sumreturn predicted_ratings# 目标用户
target_user = '用户1'# 预测评分
predicted_ratings = predict_item_based(target_user, df, item_similarity_df)print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)
输出如下:
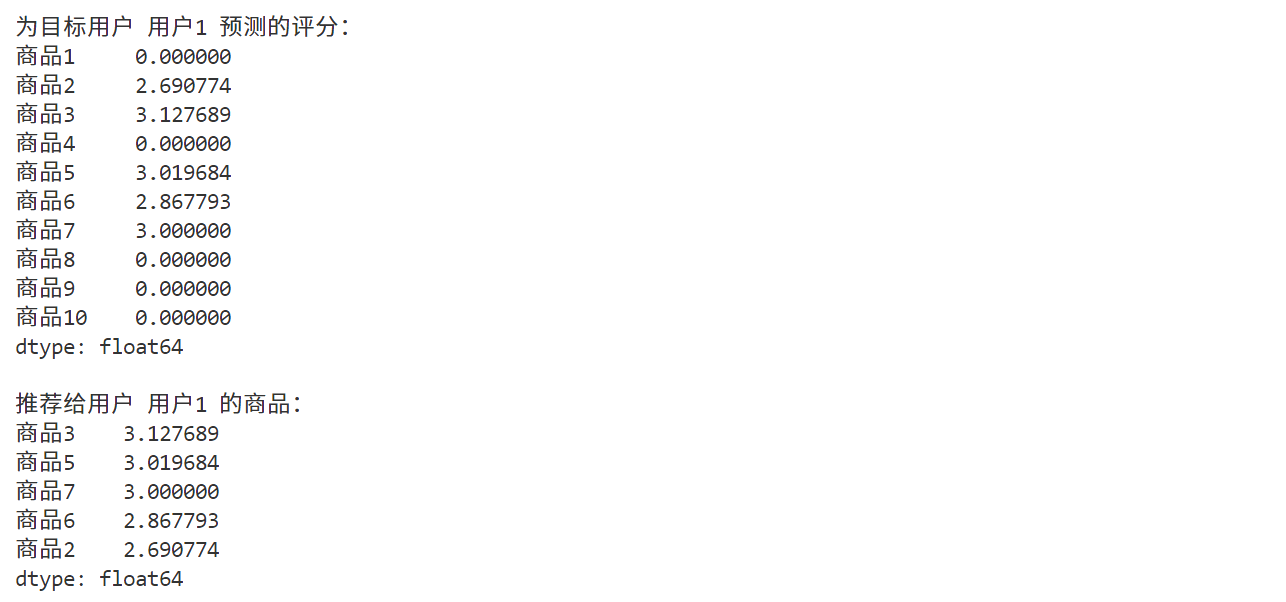
4. 总结
通过基于物品的协同过滤算法,我们成功为目标用户 用户1 推荐了未评分但可能感兴趣的商品(如 商品3、商品10 等)。这种算法的核心在于计算商品之间的相似性,并利用相似商品的评分来预测目标用户对未评分商品的兴趣。
你可以根据需要进一步优化算法,例如:
- 使用其他相似度计算方法(如皮尔逊相关系数)。
- 引入隐式反馈数据(如点击、浏览等行为)。
- 结合基于用户的协同过滤和基于物品的协同过滤,形成混合推荐系统。
推荐算法流程优化版本-召回过滤精排混排强规则
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 设置随机种子以确保结果可复现
np.random.seed(42)# 参数设置
num_users = 10 # 用户数量
num_items = 10 # 商品数量
max_ratings_per_user = 5 # 每个用户最多评分的商品数量# 初始化评分矩阵 (初始值为 0)
ratings = np.zeros((num_users, num_items))# 随机生成稀疏评分数据
for i in range(num_users):# 随机选择该用户评分的商品数量(1 到 max_ratings_per_user)num_rated_items = np.random.randint(1, max_ratings_per_user + 1)# 随机选择该用户评分的商品索引rated_items = np.random.choice(num_items, size=num_rated_items, replace=False)# 随机生成评分(1 到 5)ratings[i, rated_items] = np.random.randint(1, 6, size=num_rated_items)# 构建 DataFrame
user_ids = [f"用户{i+1}" for i in range(num_users)]
item_ids = [f"商品{j+1}" for j in range(num_items)]
df = pd.DataFrame(ratings, index=user_ids, columns=item_ids)# 打印评分矩阵
print("用户-商品评分矩阵:")
print(df)# 计算用户之间的相似度(改进版)
def calculate_user_similarity(df):# 填充缺失值为0(如果还没有填充)df_filled = df.fillna(0)# 计算余弦相似度user_similarity = cosine_similarity(df_filled)# 将对角线设置为0(避免用户与自己比较)np.fill_diagonal(user_similarity, 0)# 转换为DataFrameuser_similarity_df = pd.DataFrame(user_similarity, index=df.index, columns=df.index)return user_similarity_dfuser_similarity_df = calculate_user_similarity(df)print("\n用户相似度矩阵:")
print(user_similarity_df)# 预测目标用户对未评分商品的评分(改进版)
def predict_ratings(target_user, df, user_similarity_df, min_similar_users=1):target_ratings = df.loc[target_user]predicted_ratings = pd.Series(0.0, index=df.columns,dtype='float64')for item in df.columns:if target_ratings[item] == 0:users_who_rated = df[df[item] > 0].indexweighted_sum = 0similarity_sum = 0valid_users = 0for user in users_who_rated:similarity = user_similarity_df.loc[target_user, user]# 只考虑正相似度的用户if similarity > 0:rating = df.loc[user, item]weighted_sum += rating * similaritysimilarity_sum += similarityvalid_users += 1# 至少有min_similar_users个相似用户才进行预测if valid_users >= min_similar_users and similarity_sum > 0:predicted_ratings[item] = weighted_sum / similarity_sumreturn predicted_ratings# 目标用户
target_user = '用户1'# 预测评分
predicted_ratings = predict_ratings(target_user, df, user_similarity_df)print(f"\n为目标用户 {target_user} 预测的评分:")
print(predicted_ratings)# 推荐商品
recommended_items = predicted_ratings[predicted_ratings > 0].sort_values(ascending=False)
print(f"\n推荐给用户 {target_user} 的商品:")
print(recommended_items)# 评估推荐系统
def evaluate_recommendation(df, user_similarity_df, test_ratio=0.2):from sklearn.model_selection import train_test_split# 转换为长格式melted_df = df.reset_index().melt(id_vars='index', var_name='item', value_name='rating')melted_df.columns = ['user', 'item', 'rating']# 分割训练集和测试集train_df, test_df = train_test_split(melted_df[melted_df['rating'] > 0], test_size=test_ratio)# 重建训练矩阵train_matrix = pd.pivot_table(train_df, values='rating', index='user', columns='item').fillna(0)# 计算用户相似度train_similarity = calculate_user_similarity(train_matrix)# 评估每个测试用户mae = 0test_users = test_df['user'].unique()for user in test_users:# 获取测试用户的实际评分actual_ratings = test_df[test_df['user'] == user].set_index('item')['rating']# 预测评分predicted = predict_ratings(user, train_matrix, train_similarity)# 计算MAEcommon_items = actual_ratings.index.intersection(predicted.index)if len(common_items) > 0:mae += np.mean(np.abs(actual_ratings[common_items] - predicted[common_items]))mae /= len(test_users)print(f"\n推荐系统评估结果(MAE): {mae:.4f}")# 运行评估
evaluate_recommendation(df, user_similarity_df)# ... 已有代码保持不变 ...# 1. 召回阶段 - 多种召回策略
def recall_strategies(target_user, df, user_similarity_df):# 策略1: 基于用户的协同过滤召回cf_recall = predict_ratings(target_user, df, user_similarity_df)cf_items = cf_recall[cf_recall > 0].index.tolist()# 策略2: 热门商品召回popular_items = df.sum().sort_values(ascending=False).head(5).index.tolist()# 策略3: 新商品召回new_items = df.columns[-3:].tolist() # 假设最后3个是新商品# 合并召回结果并去重recalled_items = list(set(cf_items + popular_items + new_items))return recalled_items# 2. 过滤阶段 - 过滤掉不合适的商品
def filter_items(target_user, recalled_items, df):# 获取用户已购买/已评价的商品rated_items = df.loc[target_user][df.loc[target_user] > 0].index.tolist()# 过滤掉用户已经购买/评价过的商品filtered_items = [item for item in recalled_items if item not in rated_items]# 强规则过滤示例:过滤掉特定商品blacklist = ['商品5'] # 假设商品5被列入黑名单filtered_items = [item for item in filtered_items if item not in blacklist]return filtered_items# 3. 精排阶段 - 对过滤后的商品进行精细排序
def ranking(target_user, filtered_items, df, user_similarity_df):# 计算每个商品的预测评分predicted_ratings = predict_ratings(target_user, df, user_similarity_df)# 计算商品热度item_popularity = df.sum()# 综合评分 = 预测评分 * 0.7 + 热度 * 0.3 (加权得分)ranked_items = {}for item in filtered_items:score = predicted_ratings[item] * 0.7 + item_popularity[item] * 0.3ranked_items[item] = score# 按得分排序ranked_items = sorted(ranked_items.items(), key=lambda x: x[1], reverse=True)return ranked_items# 4. 混排阶段 - 结合多种策略生成最终推荐列表
def mixed_sorting(ranked_items):final_list = []# 强规则:确保特定商品排在前面promoted_item = '商品2' # 假设商品2是推广商品for i, (item, score) in enumerate(ranked_items):if item == promoted_item:final_list.insert(0, (item, score)) # 推广商品置顶else:final_list.append((item, score))# 多样性控制:避免同类型商品扎堆# 这里简化为限制连续出现相似商品diversified_list = []prev_item_type = Nonefor item, score in final_list:current_type = item[-1] # 假设商品类型由商品ID最后一位决定if current_type == prev_item_type:score *= 0.9 # 相似类型商品降权diversified_list.append((item, score))prev_item_type = current_typereturn sorted(diversified_list, key=lambda x: x[1], reverse=True)# 5. 完整推荐流程
def full_recommendation_pipeline(target_user, df, user_similarity_df):print(f"\n开始为用户 {target_user} 生成推荐...")# 召回recalled_items = recall_strategies(target_user, df, user_similarity_df)print(f"\n召回阶段结果: {recalled_items}")# 过滤filtered_items = filter_items(target_user, recalled_items, df)print(f"过滤后结果: {filtered_items}")# 精排ranked_items = ranking(target_user, filtered_items, df, user_similarity_df)print(f"精排后结果: {ranked_items}")# 混排final_recommendations = mixed_sorting(ranked_items)print(f"最终推荐列表: {final_recommendations}")return final_recommendations# 运行完整推荐流程
final_recommendations = full_recommendation_pipeline(target_user, df, user_similarity_df)# 输出最终推荐结果
print("\n=== 最终推荐结果 ===")
for item, score in final_recommendations:print(f"{item}: {score:.2f}")输出如下:



基于scikit-surprise实现推荐
scikit-surprise 是一个用于构建推荐系统的 Python 库,专注于协同过滤(Collaborative Filtering)算法。以下是基于 scikit-surprise 实现一个简单的推荐系统的完整代码示例。
1. 安装依赖
首先,确保你已经安装了 scikit-surprise:
pip install scikit-surprise==1.1.4
2. 数据准备
我们使用 scikit-surprise 提供的内置数据集(例如 MovieLens 数据集),或者自定义数据集。
示例:加载 MovieLens 数据集
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import train_test_split# 加载内置的 MovieLens 数据集
data = Dataset.load_builtin('ml-100k')# 将数据划分为训练集和测试集
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)
如果你有自己的数据集(例如用户、物品、评分),可以按照以下方式加载:
import pandas as pd
from surprise import Dataset, Reader# 假设你的数据是一个 Pandas DataFrame
ratings_dict = {"user_id": [1, 1, 1, 2, 2, 3, 3, 3],"item_id": [101, 102, 103, 101, 104, 102, 103, 104],"rating": [5, 3, 4, 4, 2, 5, 3, 1],
}
df = pd.DataFrame(ratings_dict)# 定义评分范围
reader = Reader(rating_scale=(1, 5))# 加载自定义数据集
data = Dataset.load_from_df(df[["user_id", "item_id", "rating"]], reader)# 划分训练集和测试集
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)
3. 构建推荐模型
scikit-surprise 提供了多种协同过滤算法,例如 SVD(奇异值分解)、KNN(最近邻算法)等。以下以 SVD 为例:
from surprise import SVD
from surprise import accuracy# 初始化 SVD 模型
model = SVD()# 在训练集上训练模型
model.fit(trainset)# 在测试集上进行预测
predictions = model.test(testset)# 计算 RMSE(均方根误差)
rmse = accuracy.rmse(predictions)
print(f"RMSE: {rmse}")
4. 推荐物品
我们可以为特定用户生成推荐物品列表。以下是一个示例函数,用于获取某个用户的前 N 个推荐物品:
def get_top_n_recommendations(model, user_id, items, n=5):# 预测用户对所有物品的评分predictions = [(item, model.predict(user_id, item).est) for item in items]# 按评分排序predictions.sort(key=lambda x: x[1], reverse=True)# 返回前 N 个推荐物品return predictions[:n]# 获取所有物品 ID
items = df["item_id"].unique()# 为用户 1 生成推荐
user_id = 1
top_n_recommendations = get_top_n_recommendations(model, user_id, items, n=5)
print(f"为用户 {user_id} 推荐的物品:")
for item, score in top_n_recommendations:print(f"物品 ID: {item}, 预测评分: {score:.2f}")
5. 使用 KNN 算法
如果你想使用 KNN 算法(基于用户的协同过滤或基于物品的协同过滤),可以按照以下方式实现:
from surprise import KNNBasic# 初始化 KNN 模型(基于用户的协同过滤)
sim_options = {"name": "cosine", # 相似度计算方法"user_based": True # 基于用户(True)还是基于物品(False)
}
model = KNNBasic(sim_options=sim_options)# 在训练集上训练模型
model.fit(trainset)# 在测试集上进行预测
predictions = model.test(testset)# 计算 RMSE
rmse = accuracy.rmse(predictions)
print(f"RMSE: {rmse}")
6. 完整代码整合
以下是完整的代码示例,包含数据加载、模型训练、评估和推荐:
import pandas as pd
from surprise import Dataset, Reader, SVD, accuracy
from surprise.model_selection import train_test_split# 自定义数据集
ratings_dict = {"user_id": [1, 1, 1, 2, 2, 3, 3, 3],"item_id": [101, 102, 103, 101, 104, 102, 103, 104],"rating": [5, 3, 4, 4, 2, 5, 3, 1],
}
df = pd.DataFrame(ratings_dict)# 定义评分范围
reader = Reader(rating_scale=(1, 5))# 加载数据集
data = Dataset.load_from_df(df[["user_id", "item_id", "rating"]], reader)# 划分训练集和测试集
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)# 初始化 SVD 模型
model = SVD()# 在训练集上训练模型
model.fit(trainset)# 在测试集上进行预测
predictions = model.test(testset)# 计算 RMSE
rmse = accuracy.rmse(predictions)
print(f"RMSE: {rmse}")# 获取所有物品 ID
items = df["item_id"].unique()# 为用户生成推荐
def get_top_n_recommendations(model, user_id, items, n=5):predictions = [(item, model.predict(user_id, item).est) for item in items]predictions.sort(key=lambda x: x[1], reverse=True)return predictions[:n]# 为用户 1 生成推荐
user_id = 1
top_n_recommendations = get_top_n_recommendations(model, user_id, items, n=5)
print(f"为用户 {user_id} 推荐的物品:")
for item, score in top_n_recommendations:print(f"物品 ID: {item}, 预测评分: {score:.2f}")
7. 输出结果
运行上述代码后,你会得到以下输出:
- RMSE:模型在测试集上的均方根误差。
- 推荐列表:为指定用户生成的前 N 个推荐物品及其预测评分。
8. 扩展功能
-
超参数调优:
- 使用
GridSearchCV或手动调整模型参数(如n_factors、lr_all等)来优化模型性能。
- 使用
-
交叉验证:
- 使用
cross_validate函数评估模型的稳定性和泛化能力。
- 使用
-
其他算法:
- 尝试其他算法(如 NMF、SlopeOne 或 CoClustering)并比较效果。
通过上述代码,你可以快速构建一个基于协同过滤的推荐系统!
相关文章:

机器学习-08-推荐算法-案例
总结 本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则 参考 机器学习(三):Apriori算法(算法精讲) Apriori 算法 理论 重点 MovieLens:一个常用的电影推荐系统领域的数据集 23张图&#x…...
LLM中的N-Gram、TF-IDF和Word embedding
文章目录 1. N-Gram和TF-IDF:通俗易懂的解析1.1 N-Gram:让AI学会"猜词"的技术1.1.1 基本概念1.1.2 工作原理1.1.3 常见类型1.1.4 应用场景1.1.5 优缺点 1.2 TF-IDF:衡量词语重要性的尺子1.2.1 基本概念1.2.2 计算公式1.2.3 为什么需…...

uniapp APP端 DOM生成图片保存到相册
<template> <view class"container" style"padding-bottom: 30rpx;"> <view class"hdbg pr w100 " style"height: 150rpx;"> <top-bar content分享 Back"Back"></top-b…...

Office文件内容提取 | 获取Word文件内容 |Javascript提取PDF文字内容 |PPT文档文字内容提取
关于Office系列文件文字内容的提取 本文主要通过接口的方式获取Office文件和PDF、OFD文件的文字内容。适用于需要获取Word、OFD、PDF、PPT等文件内容的提取实现。例如在线文字统计以及论文文字内容的提取。 一、提取Word及WPS文档的文字内容。 支持以下文件格式: …...
)
算法——背包问题(分类)
背包问题(Knapsack Problem)是一类经典的组合优化问题,广泛应用于资源分配、投资决策、货物装载等领域。根据约束条件和问题设定的不同,背包问题主要分为以下几种类型: 1. 0-1 背包问题(0-1 Knapsack Probl…...
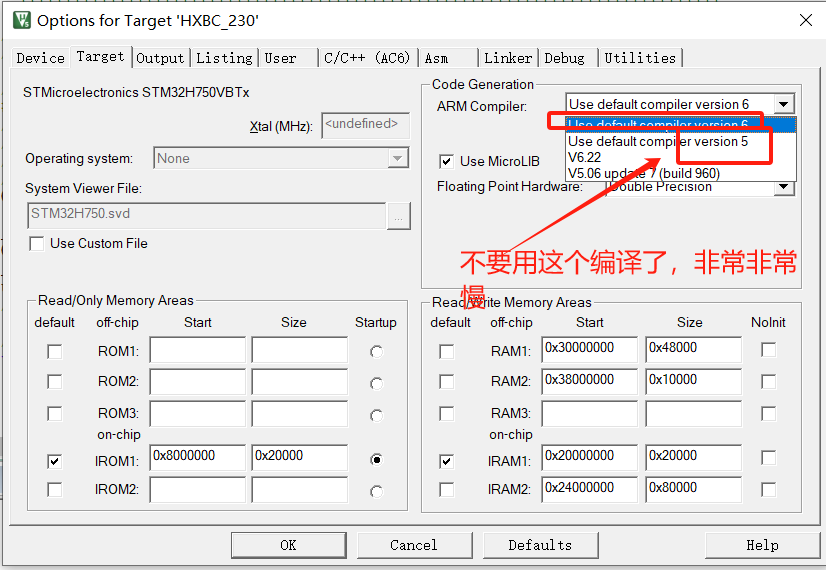
HXBC编译相关错误
0、Keil MDK报错:Browse information of one or more files is not available----解决方法: 1、使用cubemax生成的工程中,某些引脚自定义了的,是在main.h中,要记得移植。 注意:cubemax生成的spi.c后,在移植的时候,注意hal_driver下面要对应增加hal_stm32H7xxxspi.c …...

Windows 环境下 Apache 配置 WebSocket 支持
目录 前言1. 基本知识2. 实战前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 爬虫神器,无代码爬取,就来:bright.cn 原先写过apache的http配置:Apache httpd-vhosts.conf 配置详解(附Demo) 1. 基本知识 🔁 WebSocket 是 HTTP 的升级协议 客户…...
运维概述(linux 系统)
1、运维的基本概念 2、企业的运行模式 3、计算机硬件 运维概述 运维岗位的定义 在技术人员(写代码的)之间,一致对运维有一个开玩笑的认知:运维就是修电脑的、装网线的、背锅的岗位。 IT运维管理是指为了保障企业IT系统及网络…...

C语言 数据结构 【堆】动态模拟实现,堆排序,TOP-K问题
引言 堆的各个接口的实现(以代码注释为主),实现堆排序,解决经典问题:TOP-K问题 一、堆的概念与结构 堆 具有以下性质 • 堆中某个结点的值总是不大于或不小于其父结点的值; • 堆总是一棵完全二叉树。 二…...

MFC文件-写MP4
下载本文件 本文件将创作MP4视频文件代码整合到两个文件中(Mp4Writer.h和Mp4Writer.cpp),将IYUV视频流编码为H264,PCM音频流编码为AAC,写入MP4文件。本文件仅适用于MFC程序。 使用方法 1.创建MFC项目。 2.将Mp4Writer.h和Mp4Wri…...

8.观察者模式:思考与解读
原文地址:观察者模式:思考与解读 更多内容请关注:7.深入思考与解读设计模式 引言 在开发软件时,系统的某些状态可能会发生变化,而你希望这些变化能够自动通知到依赖它们的其他模块。你是否曾经遇到过,系统中某个对象…...

CMake execute_process用法详解
execute_process 是 CMake 中的一个命令,用于在 CMake 配置阶段(即运行 cmake 命令时)执行外部进程。它与 add_custom_command 或 add_custom_target 不同,后者是在构建阶段(如 make 或 ninja)执行命令。ex…...

模型加载常见问题
safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge 问题代码: model AutoModelForVision2Seq.from_pretrained( "/data-nvme/yang/Qwen2.5-VL-32B-Instruct", trust_remote_codeTrue, torch_dtypetorc…...
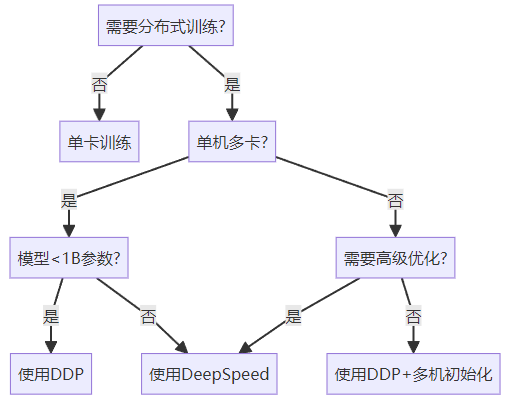
PyTorch 深度学习实战(37):分布式训练(DP/DDP/Deepspeed)实战
在上一篇文章中,我们探讨了混合精度训练与梯度缩放技术。本文将深入介绍分布式训练的三种主流方法:Data Parallel (DP)、Distributed Data Parallel (DDP) 和 DeepSpeed,帮助您掌握大规模模型训练的关键技术。我们将使用PyTorch在CIFAR-10分类…...
微信小程序通过mqtt控制esp32
目录 1.注册巴法云 2.设备连接mqtt 3.微信小程序 备注 本文esp32用的是MicroPython固件,MQTT服务用的是巴法云。 本文参考巴法云官方教程:https://bemfa.blog.csdn.net/article/details/115282152 1.注册巴法云 注册登陆并新建一个topicÿ…...
1.Vue3 - 创建Vue3工程
目录 一、 基于vue-cli 脚手架二、基于vite 推荐2.1 介绍2.2 创建项目2.3 文件介绍2.3.1 extensions.json2.3.2 脚手架的根目录2.3.3 主要文件 src2.3.3.1 main.js2.3.3.2 App.vue 组件2.3.3.3 conponents 2.3.4 env.d.ts2.3.5 index.html 入口文件2.3.6 package2.3.7 tsconfig…...

AI编写的“黑科技风格、自动刷新”的看板页面
以下的 index.html 、 script.js 和 styles.css 文件,实现一个具有黑科技风格、自动刷新的能源管理系统实时监控看板。 html页面 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name&q…...
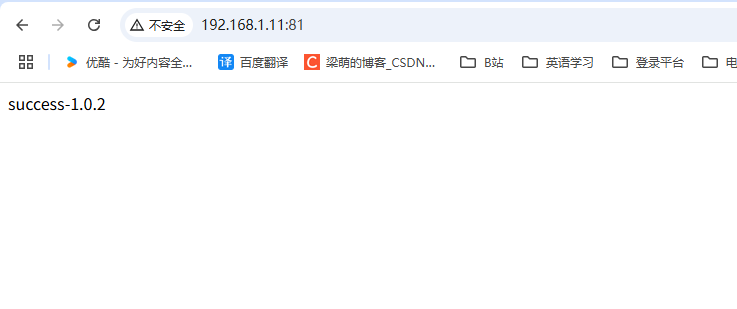
11-DevOps-Jenkins Pipeline流水线作业
前面已经完成了,通过在Jenkins中创建自由风格的工程,在界面上的配置,完成了发布、构建的过程。 这种方式的缺点就是如果要在另一台机器上进行同样的配置,需要一项一项去填写,不方便迁移,操作比较麻烦。 解…...
)
23种设计模式-结构型模式之外观模式(Java版本)
Java 外观模式(Facade Pattern)详解 🧭 什么是外观模式? 外观模式是结构型设计模式之一,为子系统中的一组接口提供一个统一的高层接口,使得子系统更易使用。 就像是酒店前台,帮你处理入住、叫…...

【JavaWeb后端开发03】MySQL入门
文章目录 1. 前言1.1 引言1.2 相关概念 2. MySQL概述2.1 安装2.2 连接2.2.1 介绍2.2.2 企业使用方式(了解) 2.3 数据模型2.3.1 **关系型数据库(RDBMS)**2.3.2 数据模型 3. SQL语句3.1 DDL语句3.1.1 数据库操作3.1.1.1 查询数据库3.1.1.2 创建数据库3.1.1…...

Github 热点项目 Jumpserver开源堡垒机让服务器管理效率翻倍
Jumpserver今日喜提160星,总星飙至2.6万!这个开源堡垒机有三大亮点:① 像哆啦A梦的口袋,支持多云服务器一站式管理;② 安全审计功能超硬核,操作记录随时可回放;③ 网页终端无需装插件࿰…...

第七届传智杯全国IT技能大赛程序设计赛道 国赛(总决赛)—— (B组)题解
1.小苯的木棍切割 【解析】首先我们先对数列排序,找到其中最小的数,那么我们就保证了对于任意一个第i1个的值都会大于第i个的值那么第i2个的值也比第i个大,那么我们第i1次切木棍的时候一定会当第i个的值就变为了0的,第i1减去的应该…...
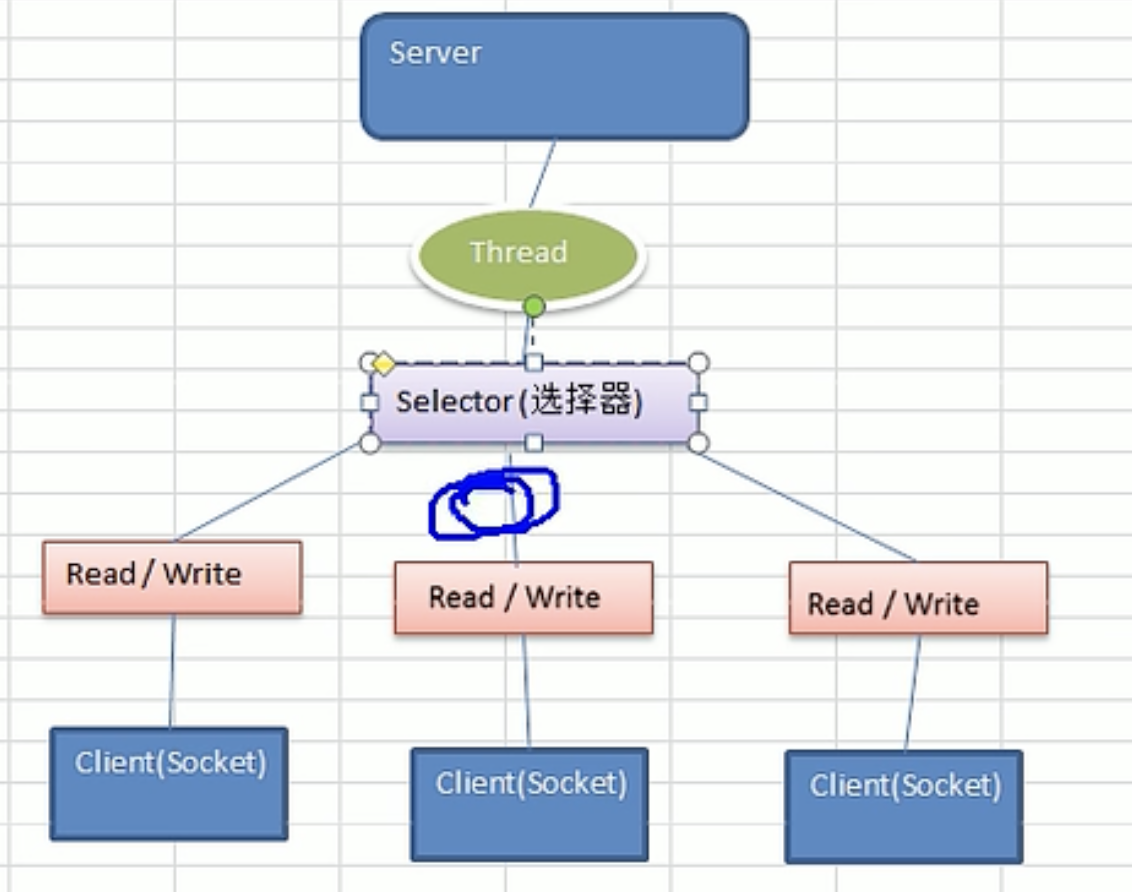
Netty前置基础知识之BIO、NIO以及AIO理论详细解析和实战案例
前言 Netty是什么? Netty 是一个基于 Java 的 高性能异步事件驱动网络应用框架,主要用于快速开发可维护的协议服务器和客户端。它简化了网络编程的复杂性,特别适合构建需要处理海量并发连接、低延迟和高吞吐量的分布式系统。 1)Netty 是…...
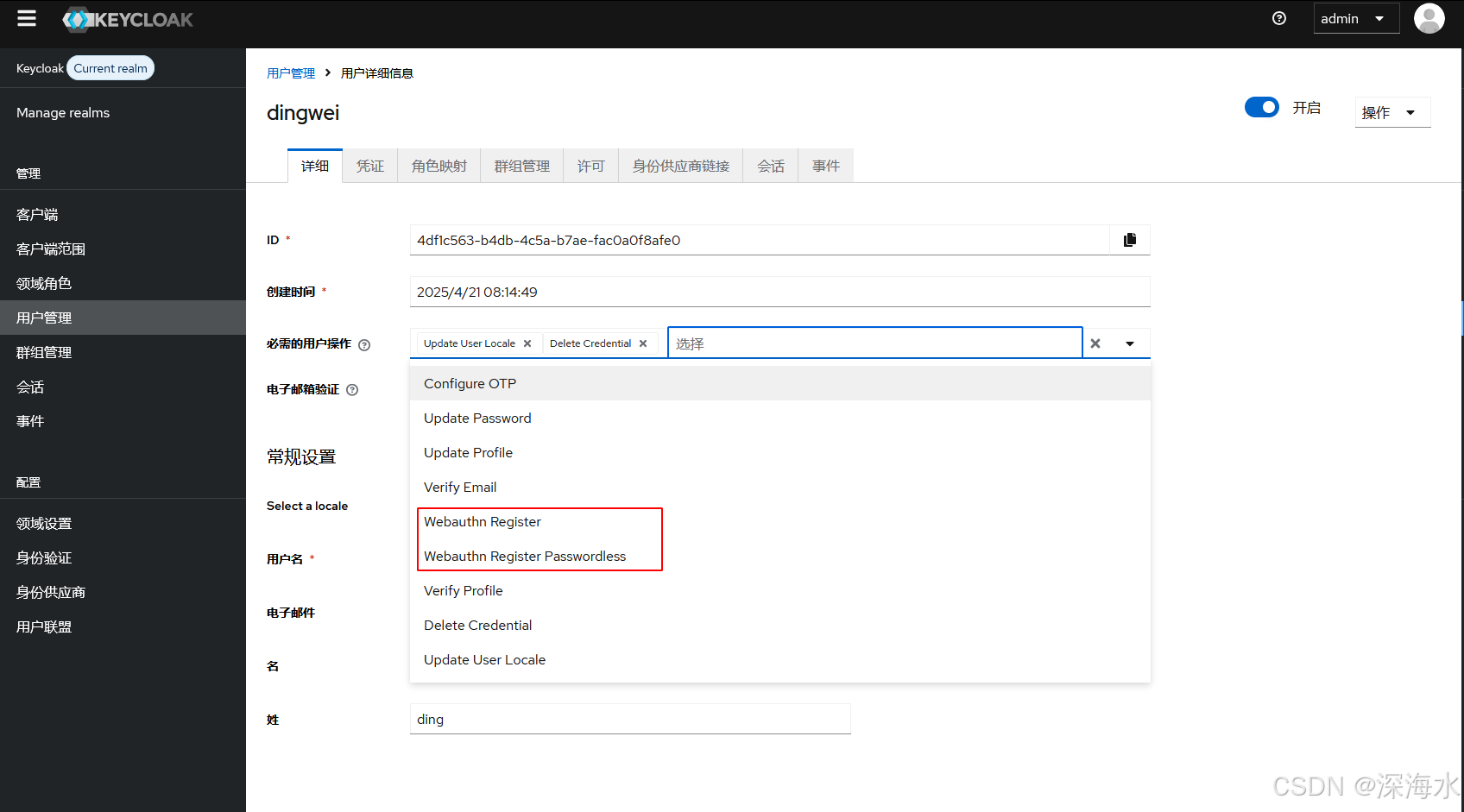
开源身份和访问管理(IAM)解决方案:Keycloak
一、Keycloak介绍 1、什么是 Keycloak? Keycloak 是一个开源的身份和访问管理(Identity and Access Management - IAM)解决方案。它旨在为现代应用程序和服务提供安全保障,简化身份验证和授权过程。Keycloak 提供了集中式的用户…...
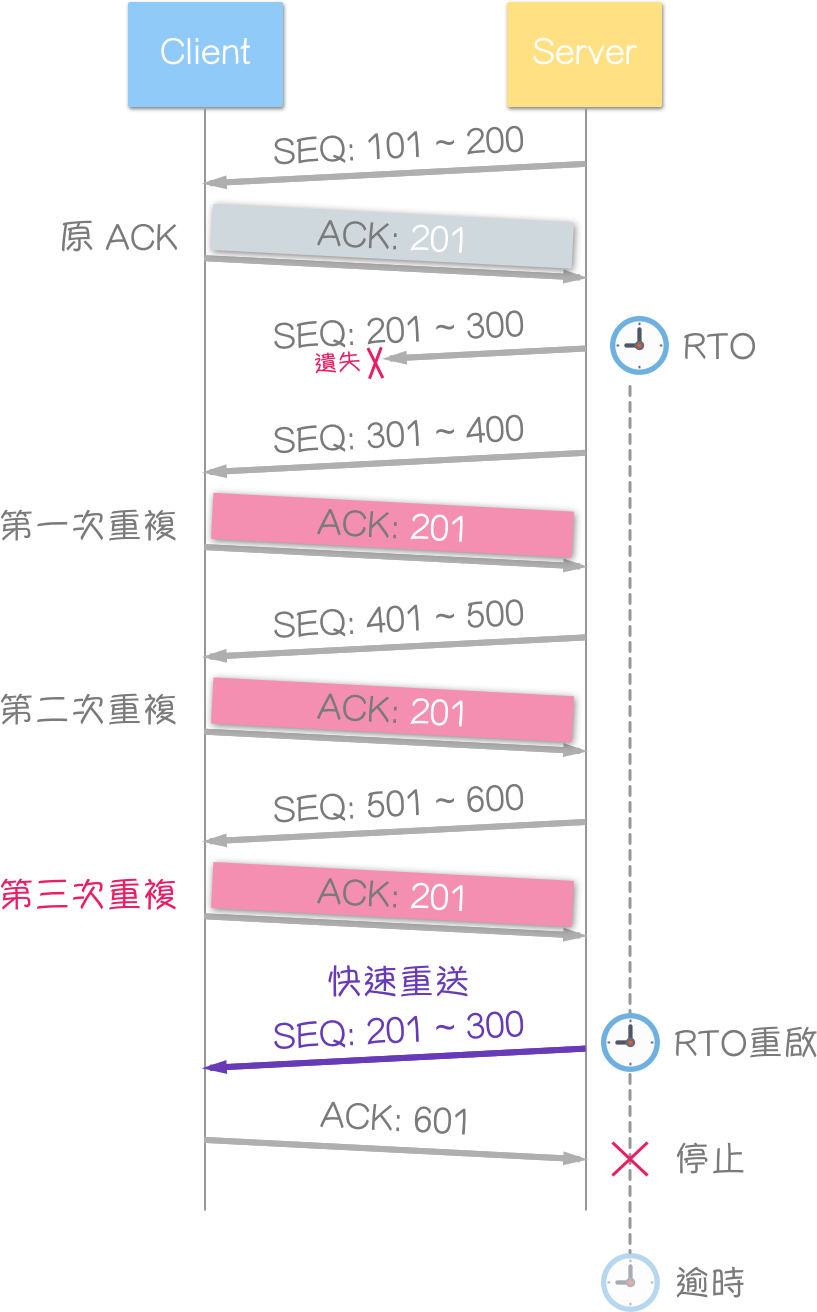
深入理解 TCP 协议 | 流量、拥塞及错误控制机制
注:本文为 “TCP 协议” 相关文章合辑。 原文为繁体,注意术语描述差异。 略作重排,如有内容异常,请看原文。 作者在不同的文章中互相引用其不同文章,一并汇总于此。 可从本文右侧目录直达本文主题相关的部分ÿ…...
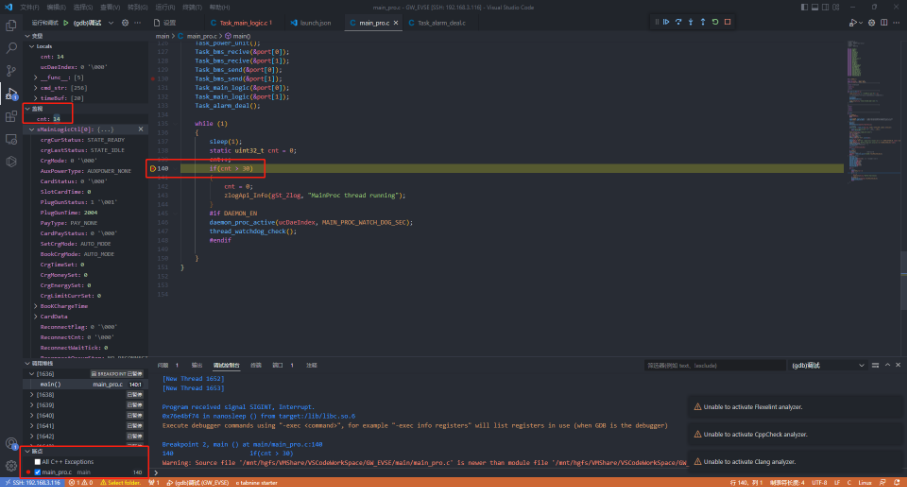
VSCode远程图形化GDB
VSCode远程图形化GDB 摘要一、安装VSCode1、使用.exe安装包安装VSCode2、VSCode 插件安装3、VSCode建立远程连接 二、core dump找bug1、开启core文件2、永久生效的方法3、编写测试程序4、运行结果5、查看core段错误位置6、在程序中开启core dump并二者core文件大小 三、gdbserv…...
软件工程师中级考试-上午知识点总结(上)
我总结的这些都是每年的考点,必须要记下来的。 1. 计算机系统基础 1.1 码 符号位0表示正数,符号位1表示负数。补码:简化运算部件的设计,最适合进行数字加减运算。移码:与前几种不同,1表示,0表…...

Python+CoppeliaSim+ZMQ remote API控制机器人跳舞
这是一个使用Python和CoppeliaSim(V-REP)控制ASTI人型机器人进行舞蹈动作的演示项目。 项目描述 本项目展示了如何使用Python通过ZeroMQ远程API与CoppeliaSim仿真环境进行交互,控制ASTI人型机器人执行预定义的舞蹈动作序列。项目包含完整的机…...

基于FreeRTOS和STM32的微波炉
一、项目简介 使用STM32F103C8T6、舵机、继电器、加热片、蜂鸣器、两个按键、LCD及DHT11传感器等硬件。进一步,结合FreeRTOS和状态机等软件实现了一个微波炉系统;实现的功能包含:人机交互、时间及功率设置、异常情况处理及固件升级等。 二、…...

维度建模工具箱 提纲与总结
这里写自定义目录标题 基本概念事实表和维度表BI(Business Intelligence) 产品 事实表事实表的粒度事实表的种类 维度表建模技术基本原则避免用自然键作为维度表的主键,而要使用类似自增的整数键避免过度规范化避免变成形同事实表的维度表 SCD(Slowly Changed Dimen…...