Pytorch分布式训练(DDP)(记录)
为什么要分布式训练?
随着深度学习模型参数量和数据量不断增大,单卡显存和计算能力有限,单机单卡训练难以满足大模型/大数据集训练需求,因此我们需要:
单机多卡并行:利用一台机器上多张 GPU 加速训练。
多机多卡并行:多台机器协同训练,实现大规模分布式计算。
分布式训练的常见方式
数据并行(Data Parallelism):每个 GPU 拷贝一份相同模型,划分不同 batch 数据独立计算,再同步梯度更新。
模型并行(Model Parallelism):将模型拆分到不同 GPU,适合单卡放不下的超大模型。
本文聚焦 数据并行 中的 PyTorch 官方实现:DistributedDataParallel (DDP)。
1. 相关参数设置
# distribution training
parser.add_argument('--world-size', default=-1, type=int,help='number of nodes for distributed training')
parser.add_argument('--rank', default=-1, type=int,help='node rank for distributed training')
parser.add_argument('--dist-url', default='env://', type=str,help='url used to set up distributed training')
parser.add_argument('--seed', default=None, type=int,help='seed for initializing training. ')
parser.add_argument("--local_rank", type=int, help='local rank for DistributedDataParallel')
–world-size: 总的进程数(所有节点上的进程数之和)1台机器×8卡 → 8, 2台×8卡 → 16
–rank: 当前进程所在的“节点”编号,从0开始
–dist-url: 分布式进程通信的初始化地址’env://’ 用环境变量,或者 ‘tcp://ip:port’
–seed: 随机种子,保证可复现
–local_rank: 当前进程在本节点内的GPU编号,launch 或 torchrun 自动传
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=2 --node_rank=0 --master_addr="x.x.x.x" --master_port=12345 main.py --world-size 2 --rank 0
–nproc_per_node:单个节点启动多少个进程(等于单机的 GPU 数)
比如:
2台机器,每台8张GPU
每台跑 8 个进程(–nproc_per_node=8)
world_size = nnodes × nproc_per_node = 2 × 8 = 16
rank 是全局进程编号
节点0的8个进程 → rank 0~7
节点1的8个进程 → rank 8~15
🔸 local_rank 是节点内GPU编号
节点0内 rank=0 的进程 → local_rank=0
节点0内 rank=1 的进程 → local_rank=1
…
节点1内 rank=8 的进程 → local_rank=0
节点1内 rank=9 的进程 → local_rank=1
🔸 dist_url 是所有进程用来连线通信的地址
通常是 env://,或者 tcp://192.168.1.1:12345
🔸现在推荐 torchrun(后续补充)更简洁
torchrun --nnodes=2 --nproc_per_node=8 --node_rank=0 --master_addr=192.168.1.1 --master_port=12345 main.py --seed 42
不用你 main.py 里写 --world-size 和 --rank,torchrun 自动算好放进环境变量 RANK、WORLD_SIZE、LOCAL_RANK,然后你可以直接在代码里:
local_rank = int(os.environ[“LOCAL_RANK”])
rank = int(os.environ[“RANK”])
world_size = int(os.environ[“WORLD_SIZE”])
2. 判断是否进行分布式
if 'WORLD_SIZE' in os.environ:assert args.world_size > 0, 'please set --world-size and --rank in the command line'# launch by torch.distributed.launch# Single node# python -m torch.distributed.launch --nproc_per_node=8 main.py --world-size 1 --rank 0 ...# Multi nodes# python -m torch.distributed.launch --nproc_per_node=8 main.py --world-size 2 --rank 0 --dist-url 'tcp://IP_OF_NODE0:FREEPORT' ...# python -m torch.distributed.launch --nproc_per_node=8 main.py --world-size 2 --rank 1 --dist-url 'tcp://IP_OF_NODE0:FREEPORT' ...local_world_size = int(os.environ['WORLD_SIZE'])args.world_size = args.world_size * local_world_sizeargs.rank = args.rank * local_world_size + args.local_rankprint('world size: {}, world rank: {}, local rank: {}'.format(args.world_size, args.rank, args.local_rank))print('os.environ:', os.environ)else:# single process, useful for debugging# python main.py ...args.world_size = 1args.rank = 0args.local_rank = 0if args.seed is not None:random.seed(args.seed)torch.manual_seed(args.seed)np.random.seed(args.seed)
torch.distributed.launch 或 torchrun 启动的时候,会自动往 os.environ 里塞环境变量:
WORLD_SIZE:总进程数(一般 = GPU 数)
RANK:当前进程的全局 rank 编号
LOCAL_RANK:当前进程在本机内的 GPU 编号
- 获取GPU数
local_world_size = int(os.environ['WORLD_SIZE'])# --nproc_per_node=8 即8个
- 计算全局 world_size 和 rank
args.world_size = args.world_size * local_world_size
args.rank = args.rank * local_world_size + args.local_rank
3. 环境变量与 rank/world_size 设置
- 分布式环境下,每个进程代表一个 GPU,需要知道:
- local_rank → 当前机器内 GPU 编号
- rank → 全局唯一进程编号
- world_size → 全局进程数量(= 总 GPU 数)
torch.cuda.set_device(args.local_rank)
print('| distributed init (local_rank {}): {}'.format(args.local_rank, args.dist_url), flush=True)
torch.distributed.init_process_group(backend='nccl', init_method=args.dist_url, world_size=args.world_size, rank=args.rank)
cudnn.benchmark = True
后续记录一些logger,代码省略。。。
4. 加载模型
# build model
model = build_model(args)
model = model.cuda()
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], broadcast_buffers=False)# loss
...# optimizer
...# Data loading code
train_dataset, val_dataset = get_datasets(args)train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
assert args.batch_size // dist.get_world_size() == args.batch_size / dist.get_world_size(), 'Batch size is not divisible by num of gpus.'
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size // dist.get_world_size(), shuffle=(train_sampler is None),num_workers=args.workers, pin_memory=True, sampler=train_sampler, drop_last=True)val_sampler = torch.utils.data.distributed.DistributedSampler(val_dataset, shuffle=False)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=args.batch_size // dist.get_world_size(), shuffle=False,num_workers=args.workers, pin_memory=True, sampler=val_sampler)
总结
先整理到这里,后续在实践中不断完善相关内容。
相关文章:
(记录))
Pytorch分布式训练(DDP)(记录)
为什么要分布式训练? 随着深度学习模型参数量和数据量不断增大,单卡显存和计算能力有限,单机单卡训练难以满足大模型/大数据集训练需求,因此我们需要: 单机多卡并行:利用一台机器上多张 GPU 加速训练。 …...

爆肝整理!Stable Diffusion的完全使用手册(二)
继续介绍Stable Diffusion的文生图界面功能。 往期文章详见: 爆肝整理!Stable Diffusion的完全使用手册(一) 下面接着对SD的文生图界面的进行详细的介绍。本期介绍文生图界面的截图2,主要包含生成模块下的采用方法、调度类型、迭…...

Redis 键管理
Redis 键管理 以下从键重命名、随机返回键、键过期机制和键迁移四个维度展开详细说明,结合 Redis 核心命令与底层逻辑进行深入分析: 一、键重命名 1. RENAME 与 RENAMENX **RENAME key newkey**: 功能:强制重命名…...

OpenCV day5
函数内容接上文:OpenCV day4-CSDN博客 目录 9.cv2.adaptiveThreshold(): 10.cv2.split(): 11.cv2.merge(): 12.cv2.add(): 13.cv2.subtract(): 14.cv2.multiply(): 15.cv2.divide(): 1…...
基于Spring Boot+微信小程序的智慧农蔬微团购平台-项目分享
基于Spring Boot微信小程序的智慧农蔬微团购平台-项目分享 项目介绍项目摘要目录系统功能图管理员E-R图用户E-R图项目预览登录页面商品管理统计分析用户地址添加 最后 项目介绍 使用者:管理员、用户 开发技术:MySQLSpringBoot微信小程序 项目摘要 随着…...
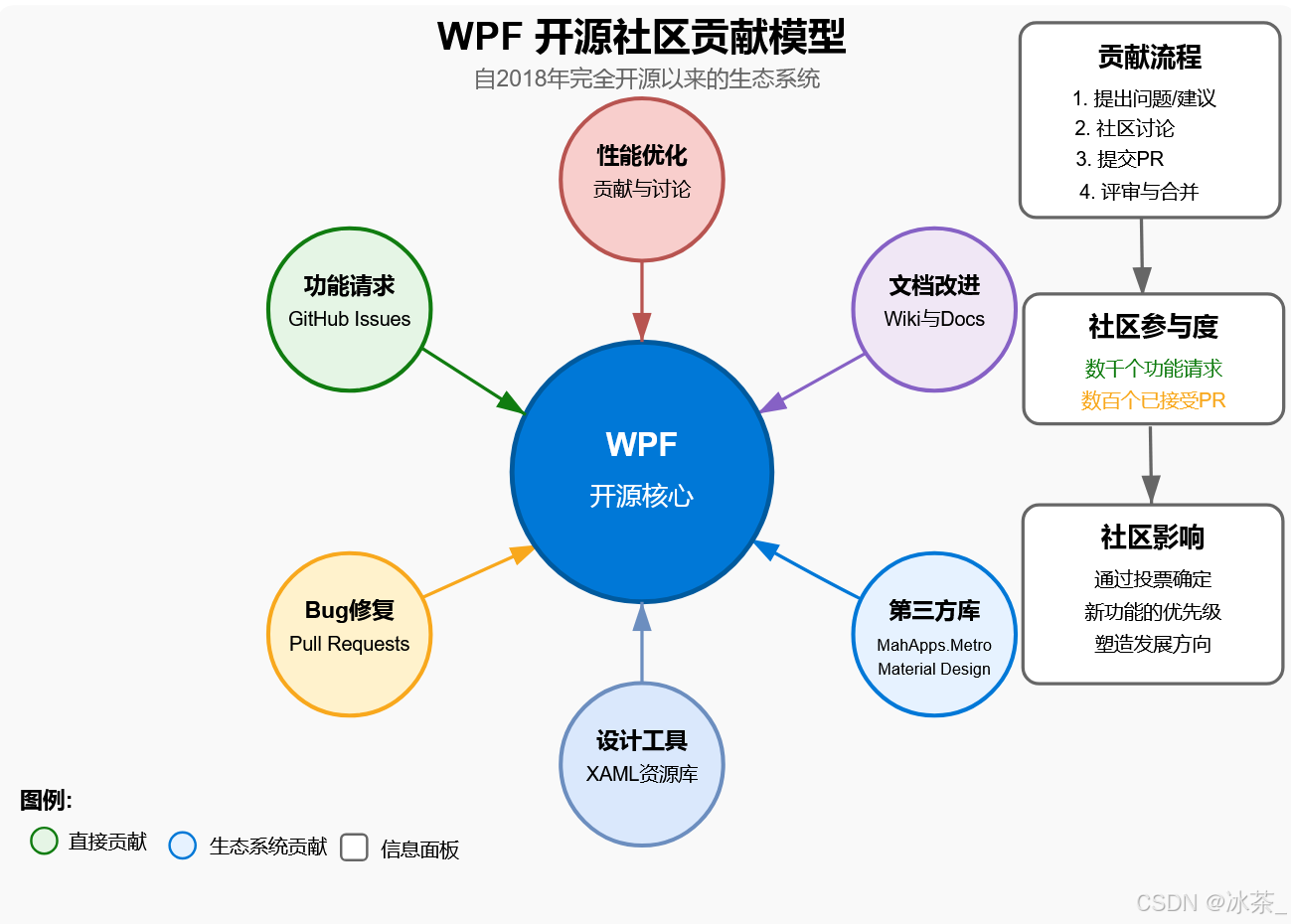
WPF的发展历程
文章目录 WPF的发展历程引言起源与背景(2001-2006)从Avalon到WPF设计目标与创新理念 WPF核心技术特点与架构基础架构与渲染模型关键技术特点MVVM架构模式 WPF在现代Windows开发中的地位与前景当前市场定位与其他微软UI技术的关系未来发展前景 社区贡献与…...
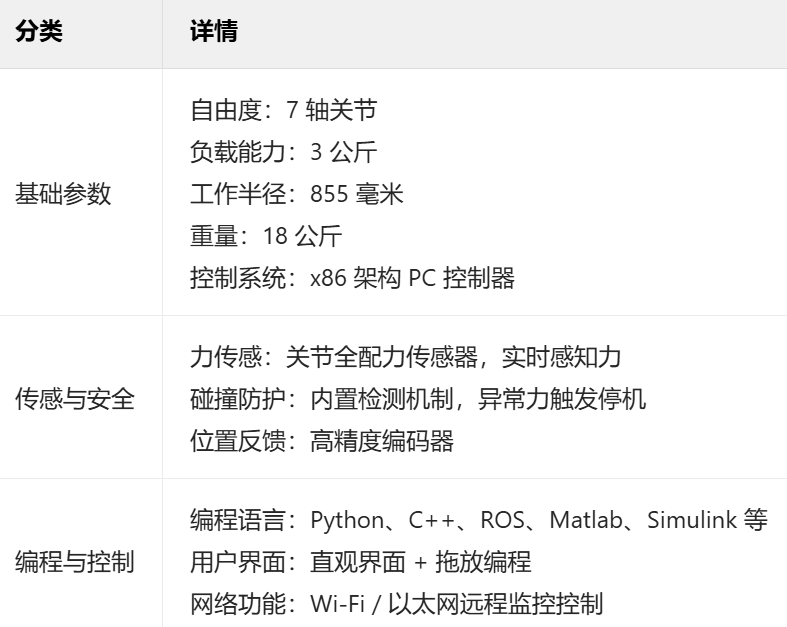
Franka机器人ROS 2来袭:解锁机器人多元应用新可能
前言: 在机器人技术蓬勃发展的当下,每一次创新都可能为行业带来新的变革。2025年3月12日,Franka Robotics发布的Franka ROS 2软件包首次版本0.1.0,将著名的franka_ros软件包引入当前的ROS 2 LTS Humble Hawksbill,这一…...
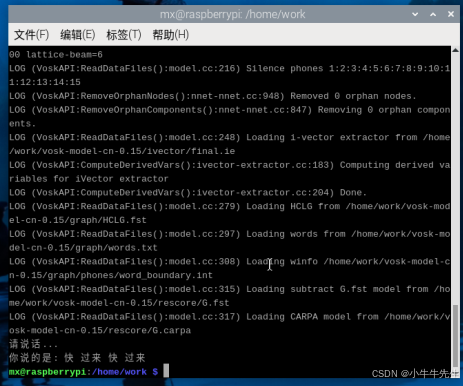
树莓派5+Vosk+python实现语音识别
简介 Vosk是语音识别开源框架,支持二十种语言 - 中文,英语,印度英语,德语,法语,西班牙语,葡萄牙语,俄语,土耳其语,越南语,意大利语,荷…...

系统分析师知识点:访问控制模型OBAC、RBAC、TBAC与ABAC的对比与应用
在信息安全领域,访问控制是确保数据和资源安全的关键技术。随着信息系统复杂度的提高,访问控制技术也在不断演进,从早期简单的访问控制列表(ACL)发展到如今多种精细化的控制模型。本文将深入剖析四种主流的访问控制模型:基于对象的…...

Golang errors 包快速上手
文章目录 1.变量2.类型3.函数3.1 New3.2 Is简介函数签名核心功能示例代码使用场景注意事项小结 3.3 As简介函数签名核心功能示例代码使用场景注意事项小结 3.4 Unwrap简介函数签名核心功能使用示例使用场景注意事项小结 3.5 Join简介函数签名核心功能使用场景注意事项小结 4.小…...

数据结构——顺序表(C语言实现)
1.顺序表的概述 1.1 顺序表的概念及结构 在了解顺序表之前,我们要先知道线性表的概念,线性表,顾名思义,就是一个线性的且具有n个相同类型的数据元素的有限序列,常见的线性表有顺序表、链表、栈、队列、字符串等等。线…...

Qt Multimedia 库总结
Qt Multimedia 库总结 Qt Multimedia 库是 Qt 框架中用于处理多媒体内容的模块,支持音频、视频、摄像头和录音功能。它为开发者提供了跨平台的 API,适用于桌面、移动和嵌入式设备。本文将从入门到精通,逐步解析 Qt Multimedia 的核心功能、使…...
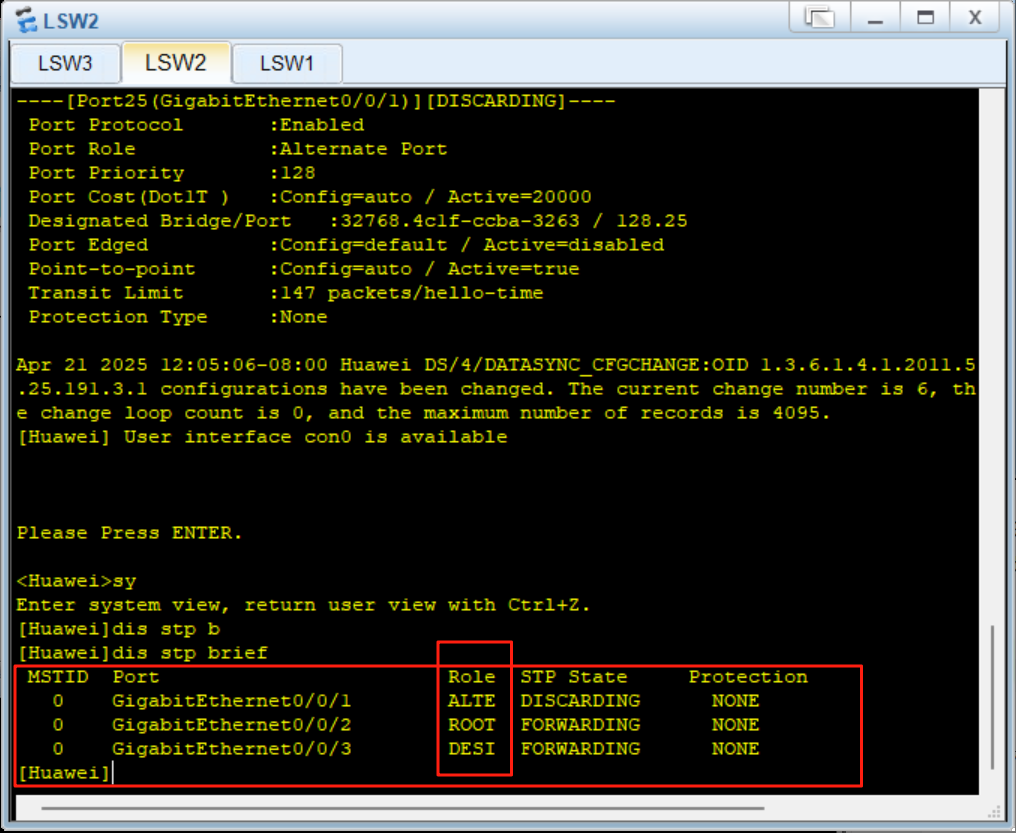
STP原理与配置以及广播风暴实验STP实验
学习目标 环路引起的问题 掌握STP的工作原理 掌握STP的基本配置 STP的配置 环路引起的问题 一、广播风暴(Broadcast Storm) 问题原理: 交换机对广播帧(如 ARP 请求、DHCP 发现报文)的处理方式是洪泛࿰…...
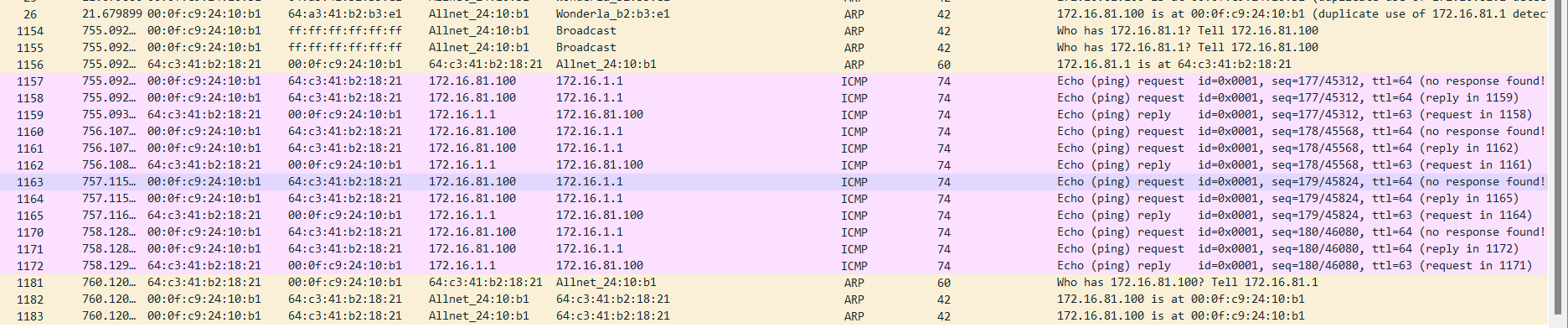
网络不可达network unreachable问题解决过程
问题:访问一个环境中的路由器172.16.1.1,发现ssh无法访问,ping发现回网络不可达 C:\Windows\System32>ping 172.16.1.1 正在 Ping 172.16.1.1 具有 32 字节的数据: 来自 172.16.81.1 的回复: 无法访问目标网。 来自 172.16.81.1 的回复:…...
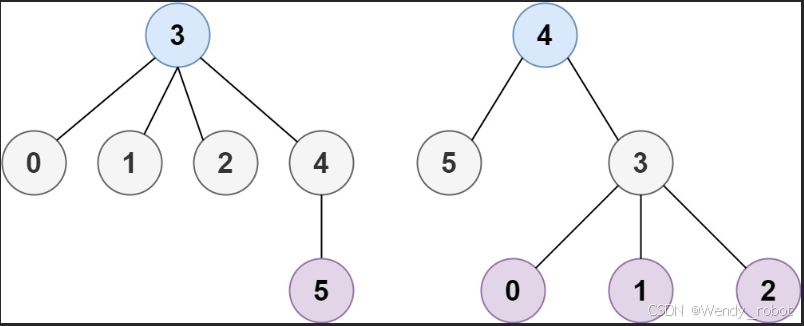
力扣经典拓扑排序
207. 课程表(Course Schedule) 你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。 在选修某些课程之前需要一些先修课程。先修课程按数组 prerequisites 给出,其中 prerequisites[i] [ai, bi] ,表…...

Session与Cookie的核心机制、用法及区别
Python中Session与Cookie的核心机制、用法及区别 在Web开发中,Session和Cookie是两种常用的用于跟踪用户状态的技术。它们在实现机制、用途和安全性方面都有显著区别。本文将详细介绍它们的核心机制、用法以及它们之间的主要区别。 一、Cookie的核心机制与用法 1…...
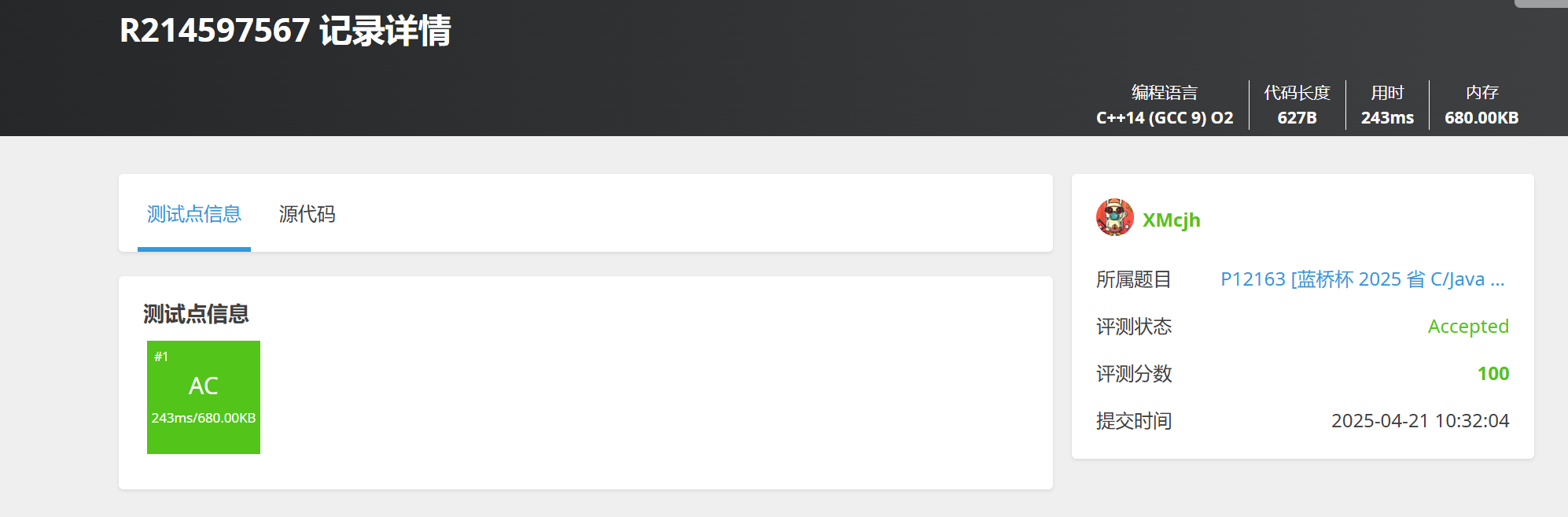
【第16届蓝桥杯C++C组】--- 2025
hello呀,小伙伴们,这是第16届蓝桥杯第二道填空题,和第一道填空题一样也是十分基础的题目,有C语言基础基本都可以解,下面我讲讲我当时自己的思路和想法,如果你们有更优化的代码和思路,也可以分享…...
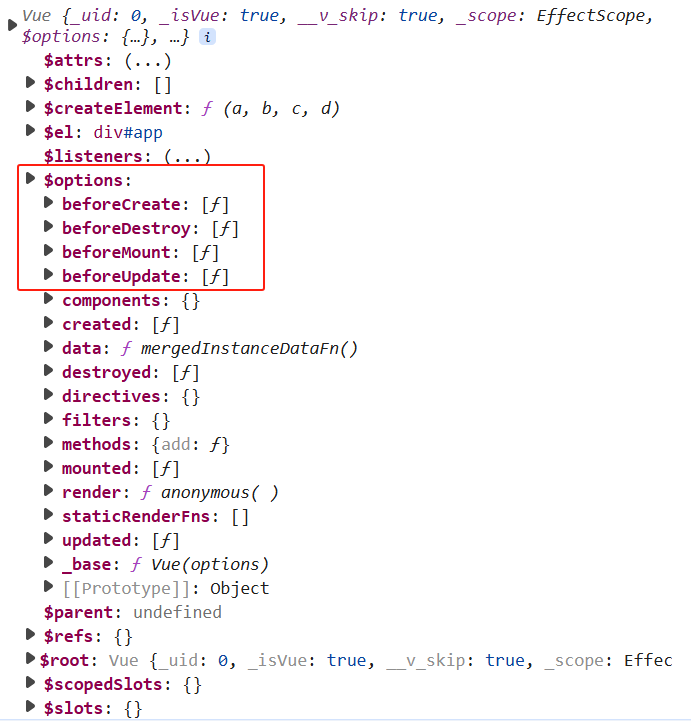
前端基础之《Vue(7)—生命周期》
一、什么是生命周期 1、生命周期 组件从“生”到“死”的全过程。 每一个组件都有生命周期。 2、生命周期四大阶段 创建阶段:beforeCreate、created 挂载阶段:beforeMount、mounted 更新阶段:beforeUpdate、updated 销毁阶段:be…...

C语言高频面试题——指针数组和数组指针
指针数组和数组指针是 C/C 中容易混淆的两个概念,以下是详细对比: 1. 指针数组(Array of Pointers) 定义:一个数组,其元素是 指针类型。语法:type* arr[元素个数]; 例如:int* ptr_a…...

Linux服务器配置Anaconda环境、Pytorch库(图文并茂的教程)
引言:为了方便后续新进组的 师弟/师妹 使用课题组的服务器,特此编文(ps:我导从教至今四年,还未招师妹) ✅ NLP 研 2 选手的学习笔记 笔者简介:Wang Linyong,NPU,2023级&a…...
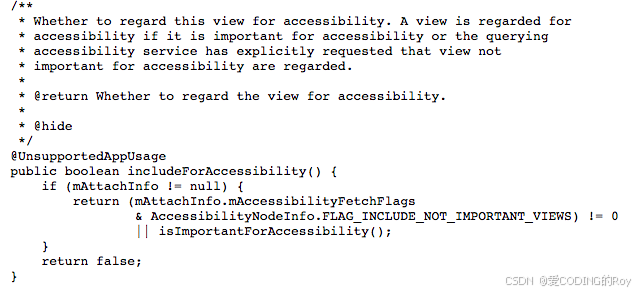
Android端使用无障碍服务实现远程、自动刷短视频
最近在做一个基于无障碍自动刷短视频的APP,需要支持用任意蓝牙遥控器远程控制, 把无障碍服务流程大致研究了一下,从下面3个部分做一下小结。 1、需要可调整自动上滑距离和速度以适配不同的屏幕和应用 智能适配99%机型,滑动参数可…...

搭建用友U9Cloud ERP及UAP IDE环境
应用环境 Microsoft Windows 10.0.19045.5487 x64 专业工作站版 22H2Internet Information Services - 10.0.19041.4522Microsoft SQL Server 2019 - 15.0.2130.3 (X64)Microsoft SQL Server Reporing Services 2019 - 15.0.9218.715SQL Server Management Studio -18.6 laster…...

多模态大语言模型arxiv论文略读(二十九)
Temporal Insight Enhancement: Mitigating Temporal Hallucination in Multimodal Large Language Models ➡️ 论文标题:Temporal Insight Enhancement: Mitigating Temporal Hallucination in Multimodal Large Language Models ➡️ 论文作者:Li Su…...

Java开发中的设计模式之观察者模式详细讲解
观察者模式(Observer Pattern)是一种行为型设计模式,它定义了对象之间的一种一对多的依赖关系。当一个对象的状态发生改变时,所有依赖于它的对象都会自动收到通知并更新。这种模式在Java开发中非常常见,尤其是在事件驱…...

基于SpringAI Alibaba实现RAG架构的深度解析与实践指南
一、RAG技术概述 1.1 什么是RAG技术 RAG(Retrieval-Augmented Generation)检索增强生成是一种将信息检索技术与生成式AI相结合的创新架构。它通过以下方式实现智能化内容生成: 知识检索阶段:从结构化/非结构化数据源中检索相关…...

卷积神经网络(CNN)详解
文章目录 引言1.卷积神经网络(CNN)的诞生背景2.卷积神经网络(CNN)介绍2.1 什么是卷积神经网络?2.2 卷积神经网络(CNN)的基本特征2.2.1 局部感知(Local Connectivity)2.2.…...

element-plus添加暗黑模式
main.ts文件 //引入暗黑模式样式 import "element-plus/theme-chalk/dark/css-vars.css"; style.scss文件 // 设置默认主题色 :root {--base-menu-min-width: 80px;--el-color-primary-light-5: green !important;--route--view--background-color: #fff !import…...
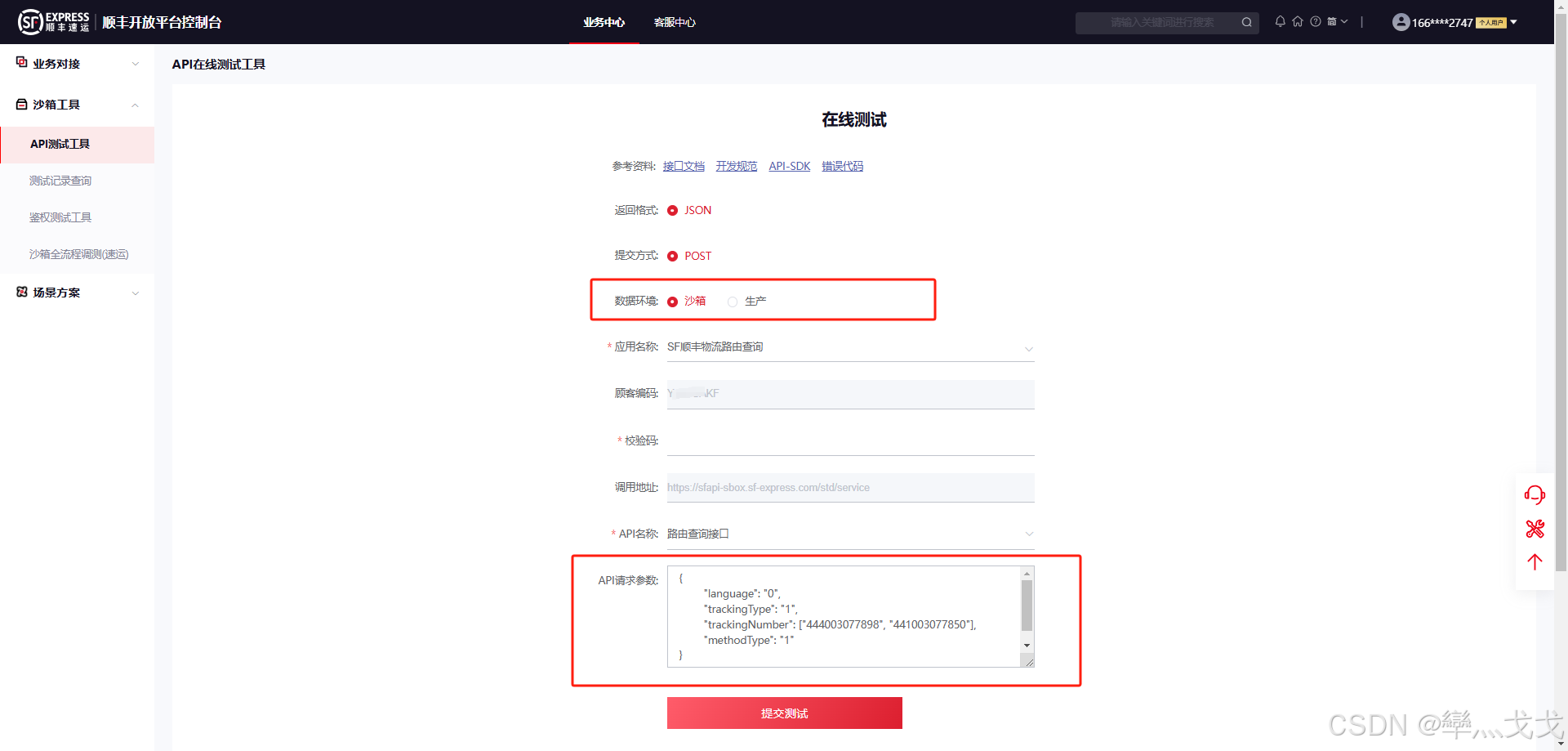
【SF顺丰】顺丰开放平台API对接(注册、API测试篇)
1.注册开发者账号 注册地址:顺丰企业账户中心 2.登录开发平台 登录地址:顺丰开放平台 3.开发者对接 点击开发者对接 4.创建开发对接应用 开发者应用中“新建应用”创建应用,最多创建应用限制数量5个 注意:需要先复制保存生产校验…...
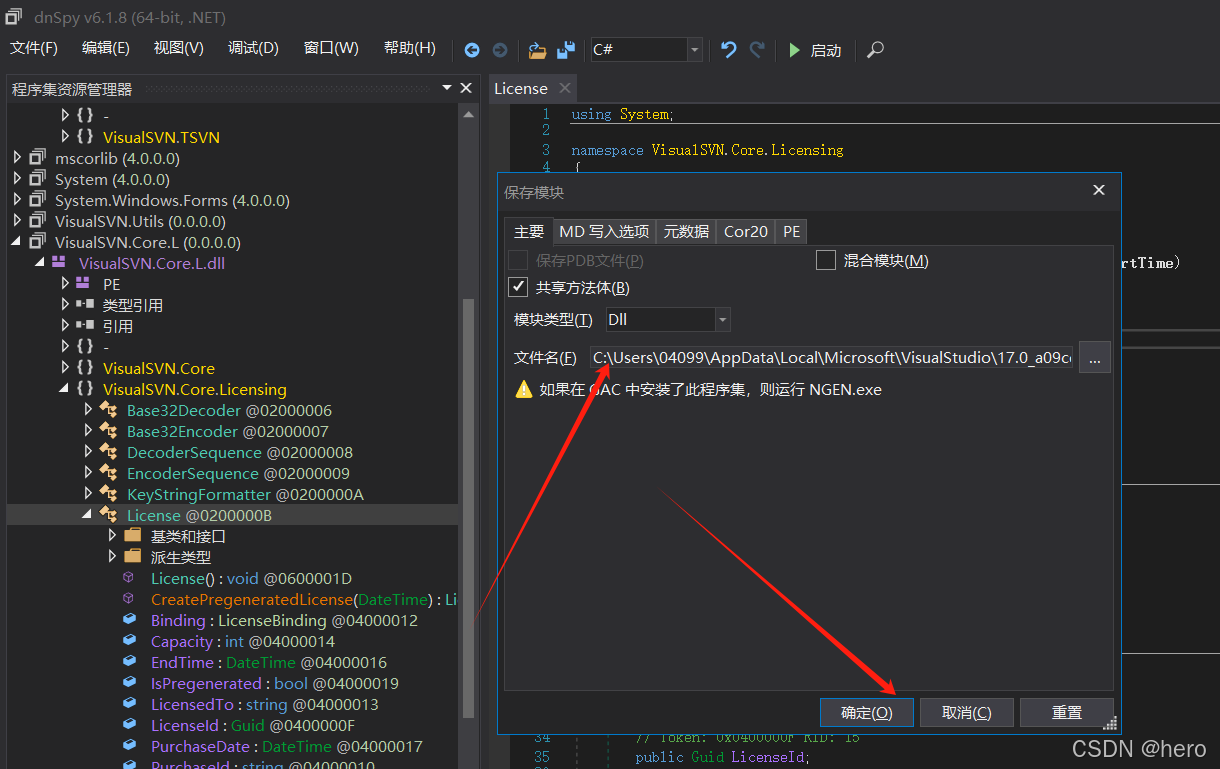
VisualSVN过期后的解决方法
作为一款不错的源代码管理软件,svn还是有很多公司使用的。在vs中使用svn,大家一般用的都是VisualSVN插件。在30天试用期过后,它就不能被免费使用了。下面给大家讲如何免费延长过期时间(自定义天数,可以设定一个很大的值…...

代码随想录算法训练营第二十一天
LeetCode题目: 93. 复原 IP 地址78. 子集90. 子集 II2364. 统计坏数对的数目 其他: 今日总结 往期打卡 93. 复原 IP 地址 跳转: 93. 复原 IP 地址 学习: 代码随想录公开讲解 问题: 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能…...