3、排序算法1---按考研大纲做的
一、插入排序
1、直接插入排序
推荐先看这个视频
1.1、原理
- 第一步,索引0的位置是有序区(有序区就是有序的部分,刚开始就只有第一个数据是有序的)。
- 第二步,将第2个位置到最后一个位置的元素,依次进行排序,而这个排序的过程,类似于扑克牌。(我们将后面的2~n个元素一个一个的与有序区对比,将它插入到有序区里面的适当位置)。
我们采用顺序查找的方式,来找到要插入位置,进行插入------>这就是直接插入排序。

1.2、代码实现(C语言)
- while和for来实现
#include <stdio.h>
void insertionSort1(int arr[], int n) {for (int i = 1; i < n; i++) {int temp = arr[i];int j = i - 1;// 从后向前扫描,移动大于key的元素while (j >= 0 && arr[j] > temp) {arr[j + 1] = arr[j];j--;}arr[j + 1] = temp;}
}
- 2个for实现
#include <stdio.h>
void insertSort2(int arr[],int n){for(int i =1;i<n;i++){int temp = arr[i];int j;for(j = i;j>0&&temp<arr[j-1];--j){arr[j]=arr[j-1];}arr[j]=temp;}
}
2、折半插入排序
折半插入排序视频。
2.1、原理
- 在直接插入排序基础上,使用二分查找确定插入位置,减少比较次数。
- 算法步骤
- 从第一个元素开始,该元素可认为已排序
- 取出下一个元素,在已排序序列中使用二分查找找到插入位置
- 将插入位置后的所有元素后移一位
- 将新元素插入到找到的位置
- 重复步骤2~4
2.2、代码实现(C语言)
#include <stdio.h>
void insert(int arr[],int n){for(int i =1;i<n;i++){int temp = arr[i];int j = i-1;while(j>-1&&temp<arr[j]){arr[j+1]=arr[j];--j;}arr[j+1]=temp;}
}
void binaryInsert(int arr[],int n){for(int i = 1;i<n;i++){int left=0;int right=i-1;int temp = arr[i];//二分查找待插入位置while(left<=right){int mid = (left+right)/2;if(arr[mid]>temp){right = mid-1;}else{left = mid+1;}}for(int j = i;j>left;j--){arr[j]=arr[j-1];}//插入元素arr[left]=temp;}
}
int main(int argc, char const *argv[])
{int arr[]={36,27,20,60,55,7,28,36,67,44,16};int n = sizeof(arr)/sizeof(arr[0]);binaryInsert(arr,n);for(int i =0;i<n;++i){printf("%d ",arr[i]);}printf("\n");return 0;
}
二、希尔排序
1、原理
- 希尔排序也是插入排序的升级版。
- 希尔排序的第一步是设计增量(一般默认为序列长度的一半)。
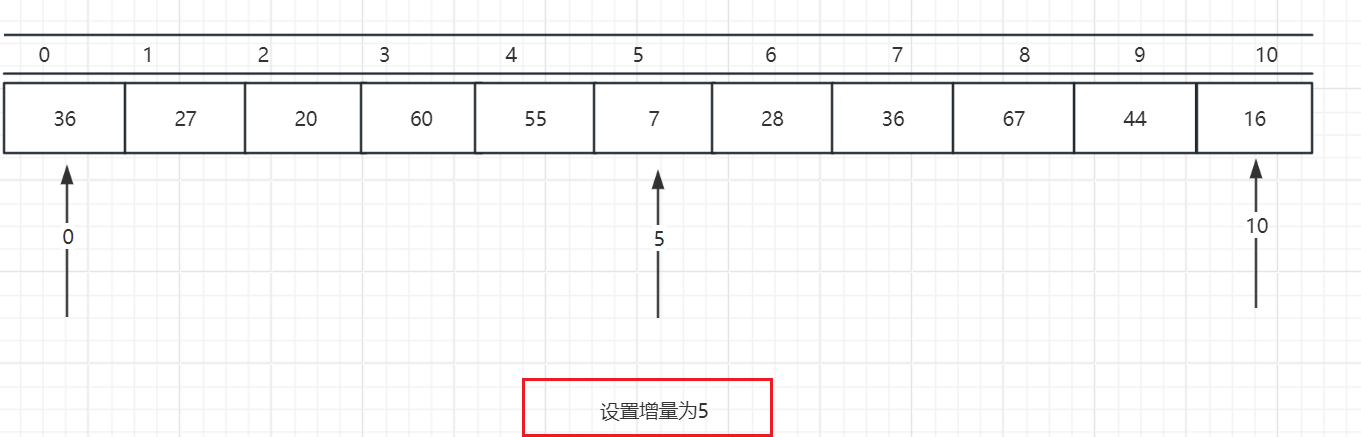
- 开始分组,第一组从0 开始,以增量5为例,我们需要 0 ,5,10位置的数据进行交换(这里是用直接插入排序来进行的交换)。
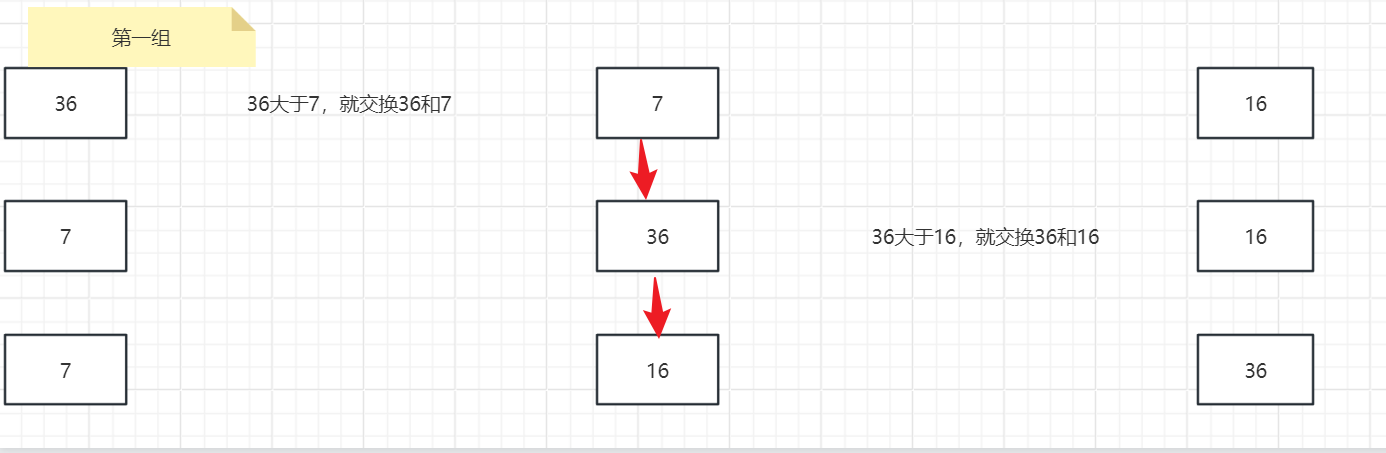
- 那么第2组就是从1开始,以增量5为例,我们需要1,6位置的数据进行交换。依次下去,直到最后一个元素。
- 增量就需要进行再次改变,设置为之前的一半,向下取整。例如 5/2=2 。
- 继续分组交换数据(这里是用直接插入排序来进行的交换)。
增量会不断减小的,为了得到最终结果,我们的最后一个增量是1的大小,只有这样才能得到最终结果。
2、代码实现(C语言)
void shellSort(int arr[],int n){int gap;for(gap=n/2;gap>0;gap/=2){//确定增量for(int i = 0;i<gap;++i){//每一个增量的分组个数for(int j = i+gap;j<n;j+=gap){//直接插入排序int temp = arr[j];int k = j-gap;while(k>-1&&temp<arr[k]){arr[k+gap]=arr[k];k-=gap;}arr[k+gap]=temp;}}}
}
int main(int argc, char const *argv[])
{int arr[]={36,27,20,60,55,7,28,36,67,44,16};shellSort(arr,11);for(int i =0;i<11;++i){printf("%d ",arr[i]);}printf("\n");return 0;
}
三、冒泡排序
冒泡排序视频。
1、原理
- 每一轮的相邻元素进行比较,这2个元素,如果逆序,就交换数据。
- 每轮可以排好1个元素,总共n-1轮,每轮都会少比较一对数据。
由此我们可知:
n是元素个数。
轮数是n-1次。
比较是n-i-1次。i 是第几轮。
2、代码实现(C语言)
- 第1种方法----经典写法
void bubbleSort(int arr[],int n){for(int i =0;i<n-1;i++){//要进行的轮数,写成n也可以for(int j =0;j<n-i-1;j++){//比较的次数if(arr[j+1]<arr[j]){int temp = arr[j];arr[j]=arr[j+1];arr[j+1]=temp;}}}
}
int main(int argc, char const *argv[])
{int arr[]={36,27,20,60,55,7,28,36,67,44,16};bubbleSort(arr,11);for(int i =0;i<11;++i){printf("%d ",arr[i]);}printf("\n");return 0;
}
- 第2种方法-----标记交换
- 有的时候,并不是每一轮都需要交换,flag标记上一轮是否交换了,就可以减少比较次数。
void bubbleSort(int arr[],int n){for(int i =0;i<n-1;i++){//要进行的轮数,写成n也可以int flag = 1;for(int j =0;j<n-i-1;j++){//比较的次数if(arr[j+1]<arr[j]){int temp = arr[j];arr[j]=arr[j+1];arr[j+1]=temp;flag = 0;//交换了,flag改为0}}if(flag==1){break;}}
}
int main(int argc, char const *argv[])
{int arr[]={36,27,20,60,55,7,28,36,67,44,16};bubbleSort(arr,11);for(int i =0;i<11;++i){printf("%d ",arr[i]);}printf("\n");return 0;
}
- 第3种方法----do while优化(推荐这种写法)
- 先把newIndex设置为0,只要交换数据了,newIndex就改变。
- newIndex来保存交换的元素位置
- 下一次就只需要进行0到newIndex之间的比较,后面的元素不用比较了,因为它们是有序的。
- 如果newIndex 没有变化,还是0,就说明不需要排序了。直接结束排序了。
- 先把newIndex设置为0,只要交换数据了,newIndex就改变。
void bubbleSort(int arr[],int n){int newIndex;int temp_length=n;do{newIndex = 0;for(int i =0;i<n-1;i++){if(arr[i]>arr[i+1]){int temp = arr[i];arr[i]=arr[i+1];arr[i+1]=temp;newIndex = i+1;}}n=newIndex;}while(newIndex>0);
}
四、简单选择排序
简单选择排序
1、原理
- 每次从待排序序列中选择最小(或最大)的元素,放到已排序序列的末尾(或前面),直到全部元素有序。
2、代码实现(Cpp语言和c语言)
- cpp版本
void selectionSort(vector<int>& arr) {int n = arr.size();for (int i = 0; i < n - 1; i++) {int minIndex = i; // 记录最小元素的索引for (int j = i + 1; j < n; j++) {if (arr[j] < arr[minIndex]) {minIndex = j;}}swap(arr[i], arr[minIndex]); // 将最小值放到已排序区间末尾}
}
- c语言版本
void selectSort(int arr[],int n){for(int i =0;i<n;i++){int minIndex = i;for(int j =i+1;j<n;j++){if(arr[j]<arr[minIndex]){minIndex=j;}}swap(arr[minIndex],arr[i]);}
}
五、快速排序
1、原理
- 第一步:确定枢轴(pivot),枢轴可以是任意位置。
- 第二步:设置left、right指针来寻找第一个比pivot大的元素和第一个比pivot小的元素,然后交换这2个元素。【注意:先移动right,避免left越界,超过right】
- 递归处理,直到空或只剩下一个为止。
2、代码实现(C语言)
- 第1种:双边循环
#include <stdio.h>
#include <vector>
#include <iostream>
#include <cmath>
#include <algorithm>
#include <ctime>
using namespace std;int quickDoubleSort(int arr[], int startIndex, int endIndex) {srand(time(NULL));int randomIndex = rand() % (endIndex - startIndex + 1) + startIndex;swap(arr[startIndex], arr[randomIndex]); // 随机选择基准并交换到开头int pivot = arr[startIndex]; // 现在再取基准值int left = startIndex;int right = endIndex;while (left < right) {while (left < right && arr[right] > pivot) { // 先移动 right,避免 left 越界right--;}while (left < right && arr[left] <= pivot) { // 再移动 leftleft++;}if (left < right) {swap(arr[left], arr[right]);}}swap(arr[left], arr[startIndex]); // 把基准值放到正确位置return left;
}void quickSort(int arr[], int startIndex, int endIndex) {if (startIndex >= endIndex) return;int pivot = quickDoubleSort(arr, startIndex, endIndex);quickSort(arr, startIndex, pivot - 1);quickSort(arr, pivot + 1, endIndex);
}int main() {int arr[] = {36, 27, 20, 60, 55, 7, 28, 36, 67, 44, 16};int n = sizeof(arr) / sizeof(arr[0]);quickSort(arr, 0, n - 1);for (int i = 0; i < n; ++i) {printf("%d ", arr[i]);}printf("\n");return 0;
}- 第2种:单边循环
int singleQuickSort(int arr[],int startIndex,int endIndex){int tmp = arr[startIndex];int mark = startIndex;for(int i = startIndex+1;i<=endIndex;++i){if(arr[i]<tmp){mark++;swap(arr[mark],arr[i]);}}swap(arr[mark],arr[startIndex]);return mark;
}
void singleQuick(int arr[],int startIndex,int endIndex){if(startIndex>=endIndex)return;int pivot= singleQuickSort(arr,startIndex,endIndex);singleQuick(arr,startIndex,pivot-1);singleQuick(arr,pivot+1,endIndex);
}
int main(int argc,char*const argv[]){int arr[]={36,27,20,60,55,7,28,36,67,44,16};int n = sizeof(arr) / sizeof(arr[0]);singleQuick(arr,0,n-1);for(int i =0;i<n;i++){printf("%d ",arr[i]);}printf("\n");
}
- 第3种:算法常用的写法—ACWing里面的写法。(c++)
- 可以发现到,它没有swap( arr [ mark ] , q[ i ] )这一步,所以它是把这一步放入到了quick_sort( q , l , j ) 。
#include <algorithm>
#include <vector>
#include<iostream>
using namespace std;
const int N = 1e5+10;
int q[N];
int n;
void quick_sort(int q[],int l,int r){if(l>=r)return;int x = q[l];int i = l-1;int j = r+1;while(i<j){do i++;while(q[i]<x);do j--;while(q[j]>x);if(i<j)swap(q[i],q[j]);}quick_sort(q,l,j);quick_sort(q,j+1,r);
}
int main(int argc,char*const argv[]){cin>>n;for(int i =0;i<n;i++){cin>>q[i];}quick_sort(q,0,n-1);for(int i=0;i<n;i++){cout<<q[i]<<" ";}cout<<endl;
}
六、堆排序
堆排序视频
1、原理可以看这篇文章了解堆。
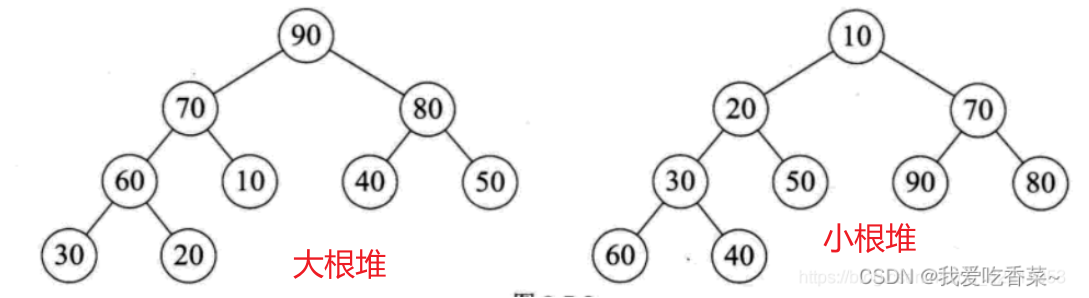
1.1、大根堆
- 大根堆(完全二叉树)
- 任一节点大于等于左右孩子
- 第i节点的左孩子是2i,右孩子是2i+1,而它的父亲是i/2的绝对值。【下标1开始存储的规律】
- 虽然是完全二叉树的理想结构,实际上是用数组来存储数据,进行操作。
步骤
- 1、插入节点
- 是插入到完全二叉树的最后一个位置。然后开始上移操作。
- 2、获取/移除最小元素
- 获取和删除的是堆顶节点。
- 删除后,就需要把最后一个节点临时补充到原本堆顶的位置。再判断堆顶的顺序进行交换。
1.2、小根堆
- 小根堆(完全二叉树)
- 任一节点小于等于左右孩子
- 第i节点的左孩子是2i,右孩子是2i+1,而它的父亲是i/2的绝对值。【下标1开始存储的规律】
- 虽然是完全二叉树的理想结构,实际上是用数组来存储数据,进行操作。
步骤
- 1、插入节点
- 是插入到完全二叉树的最后一个位置。然后开始上移操作。
- 2、获取/移除最小元素
- 获取和删除的是堆顶节点。
- 删除后,就需要把最后一个节点临时补充到原本堆顶的位置。再判断堆顶的顺序进行交换。

- 时间复杂度
- 插入 (push):O(log n)
- 删除 (pop):O(log n)
- 获取堆顶 (top):O(1)
2、代码实现(Cpp语言)
- 大根堆
#include <algorithm>
#include <vector>
#include<iostream>
using namespace std;
class MaxHeap{
private:vector<int> heap;// i/2 (j-1)/4// i => (j-1)/2//2i 2i+1 j-1 j//上浮调整(插入时,使用)void shiftUp(int index){//index是插入的位置while(index>0){int parent = (index-1)/2;if(heap[parent]>=heap[index]){break;}swap(heap[parent],heap[index]);index = parent;}}//下浮调整(删除时,使用)void shiftDown(int index){int size = heap.size();int leftChild = 2*index+1;while(leftChild<size){int rightChild = leftChild+1;int maxChild = leftChild;//假设左节点是最大值if(rightChild<size&&heap[rightChild]>heap[leftChild]){maxChild = rightChild;}if(heap[index]>=heap[maxChild]){break;//当前节点是最大}swap(heap[index],heap[maxChild]);index = maxChild;leftChild=2*index +1;}}
public:void push(int val){heap.push_back(val);shiftUp(heap.size()-1);}void pop(){if(heap.empty())return;//为空就不进行了swap(heap[0],heap.back());heap.pop_back();shiftDown(0);}int top()const{if(!heap.empty())return heap[0];throw runtime_error("Heap is empty");}bool empty()const{return heap.empty();}
};
int main(int argc,char*const argv[]){// 大根堆测试MaxHeap maxHeap;maxHeap.push(3);maxHeap.push(1);maxHeap.push(4);std::cout << "MaxHeap Top: " << maxHeap.top() << std::endl; // 4maxHeap.pop();std::cout << "After pop, MaxHeap Top: " << maxHeap.top() << std::endl; // 3cout<<endl;
}
- 小根堆
class MinHeap {
private:std::vector<int> heap;void siftUp(int idx) {while (idx > 0) {int parent = (idx - 1) / 2;if (heap[parent] <= heap[idx]) break; // 父节点更小,无需调整std::swap(heap[parent], heap[idx]);idx = parent;}}void siftDown(int idx) {int size = heap.size();int leftChild = 2 * idx + 1;while (leftChild < size) {int rightChild = leftChild + 1;int minChild = leftChild; // 假设左子节点是最小值if (rightChild < size && heap[rightChild] < heap[leftChild]) {minChild = rightChild; // 右子节点更小}if (heap[idx] <= heap[minChild]) break; // 当前节点已满足小根堆性质std::swap(heap[idx], heap[minChild]);idx = minChild;leftChild = 2 * idx + 1;}}public:void push(int val) {heap.push_back(val);siftUp(heap.size() - 1);}void pop() {if (heap.empty()) return;std::swap(heap[0], heap.back());heap.pop_back();siftDown(0);}int top() const {if (!heap.empty()) return heap[0];throw std::runtime_error("Heap is empty");}bool empty() const {return heap.empty();}
};
#include <iostream>
#include <vector>
int main() {// 小根堆测试MinHeap minHeap;minHeap.push(3);minHeap.push(1);minHeap.push(4);std::cout << "MinHeap Top: " << minHeap.top() << std::endl; // 1minHeap.pop();std::cout << "After pop, MinHeap Top: " << minHeap.top() << std::endl; // 3return 0;
}
七、归并排序
归并排序视频
1、原理
- 分治思想
- 将数组递归地二分,直到子数组长度为1(天然有序)
- 合并两个已排序的子数组
- 合并操作
- 用双指针比较两个子数组的元素
- 每次选择较小者放入新数组
- 剩余元素直接追加
2、代码实现(C语言)
static void merge(int arr[],int left,int right,int mid){const int n1 = mid - left+1;//左边空间的个数const int n2 = right - mid;//右边空间的个数int arr1[n1];//暂时存储左边的值int arr2[n2];//暂时存储右边的值for(int i =0;i<n1;++i){arr1[i]=arr[left+i];}for(int i =0;i<n2;++i){arr2[i]=arr[mid+1+i];}int i =0;int j =0;int k =left;while(i<n1&&j<n2){if(arr1[i]<=arr2[j]){arr[k]=arr1[i++];}else if(arr1[i]>arr2[j]){arr[k]=arr2[j++];}++k;}//不一定全部arr数据都重新传入了,可能还剩一些while(i<n1){arr[k++]=arr1[i++];}while(j<n2){arr[k++]=arr2[j++];}
}
void mergeLoop(int arr[],int left,int right){if(left==right){return;}int mid = (left+right)/2;mergeLoop(arr,left,mid);mergeLoop(arr,mid+1,right);//拆分完后进行归并merge(arr,left,right,mid);
}
int main(int argc,char*const argv[]){int arr[] = {36 ,27 ,20 ,60 ,55 ,7 ,28 ,36, 67 ,44 ,16};int n =sizeof(arr)/sizeof(arr[0]);mergeLoop(arr,0,n-1);for(int i =0;i<n;++i){printf("%d ",arr[i]);}
}
八、基数排序
基数排序视频。
1、原理
- 基数排序的核心:
- 将整数按每一位(从低位到高位,或高位到低位)依次排序。由于每个位的排序必须稳定(相同值的元素顺序不变),多次排序后整体数组有序。
- 具体步骤(以 LSD 为例):
- 确定最大数的位数(决定排序轮次)。
- 从最低位开始(个位 → 十位 → 百位…):
- 将数字按当前位的数值分到 10 个桶(0~9)。
- 按桶顺序(0→9)合并所有元素,形成新数组。
- 重复步骤 2 直到所有位处理完毕。

2、代码实现(Cpp语言)(支持非负整数)
#include <vector>
#include<iostream>
#include<cmath>
#include<algorithm>
using namespace std;
void radixSort(vector<int>&arr){if(arr.empty())return ;//找到最大数的位数int maxVal = *max_element(arr.begin(),arr.end());//获取最大数int maxDigit = 0;//记录位数while(maxVal>0){maxVal/=10;maxDigit++;}//从低到高位排序vector<vector<int>>buckets(10);//设置10个桶for(int i =0;i<maxDigit;i++){//将元素按当前位分到桶中for(int num:arr){int digit = (num/static_cast<int>(pow(10,i)))%10;//digit的作用是 从整数 num 中提取第 i 位的数字(从右往左数,最低位为第0位)//pow计算 10 的 i 次方//static_cast<int>强制转换,避免浮点数影响//num/pow(10,i)将num右移i位,例如num=1234->1234/100 = 12//%10:得到最右边的数字 12%10=2buckets[digit].push_back(num);}//合并桶,形成新的数组int index =0;for(auto & bucket:buckets){for(int num:bucket){arr[index++]=num;}bucket.clear();}}
}int main() {std::vector<int> arr = {170, 45, 75, 90, 802, 24, 2, 66};radixSort(arr);std::cout << "Sorted Array: ";for (int num : arr) {std::cout << num << " ";}// 输出:2 24 45 66 75 90 170 802return 0;
}- 例子
原数组:[170, 45, 75, 90, 802, 24, 2, 66]
最大数 802 → 3 位第一轮(个位)分桶:
0: 170, 90
2: 802, 2
4: 24
5: 45, 75
6: 66
合并后:[170, 90, 802, 2, 24, 45, 75, 66]第二轮(十位)分桶:
0: 802, 2
2: 24
6: 66
7: 170, 75
9: 90
5: 45
合并后:[802, 2, 24, 45, 66, 170, 75, 90]第三轮(百位)分桶:
0: 2, 24, 45, 66, 75, 90
8: 802
合并后:[2, 24, 45, 66, 75, 90, 802]相关文章:
3、排序算法1---按考研大纲做的
一、插入排序 1、直接插入排序 推荐先看这个视频 1.1、原理 第一步,索引0的位置是有序区(有序区就是有序的部分,刚开始就只有第一个数据是有序的)。第二步,将第2个位置到最后一个位置的元素,依次进行排…...
llama-webui docker实现界面部署
1. 启动ollama服务 [nlp server]$ ollama serve 2025/04/21 14:18:23 routes.go:1007: INFO server config env"map[OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST: OLLAMA_KEEP_ALIVE:24h OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:4 OLLAMA_MAX_…...

jinjia2将后端传至前端的字典变量转换为JS变量
后端 country_dict {AE: .amazon.ae, AU: .amazon.com.au} 前端 const country_list JSON.parse({{ country_list | tojson | safe }});...

如何深入理解引用监视器,安全标识以及访问控制模型与资产安全之间的关系
一、核心概念总结 安全标识(策略决策的 “信息载体) 是主体(如用户、进程)和客体(如文件、数据库、设备)的安全属性,用于标记其安全等级、权限、访问能力或受保护级别,即用于标识其安全等级、权限范围或约束…...

Linux的Socket开发补充
是listen函数阻塞等待连接,还是accept函数阻塞等待连接? 这两个函数的名字,听起来像listen一直在阻塞监听,有连接了就accept,但其实不是的。 调用listen()后,程序会立即返回,继续执行后续代码&a…...

Flutter异常Couldn‘t find dynamic library in default locations
Flutter项目在Windows系统使用ffigen生成代码时报下面的错误: [SEVERE] : Couldnt find dynamic library in default locations. [SEVERE] : Please supply one or more path/to/llvm in ffigens config under the key llvm-path. Unhandled exception: Exception: …...

Spring-AOP分析
Spring分析-AOP 1.案例引入 在上一篇文章中,【Spring–IOC】【https://www.cnblogs.com/jackjavacpp/p/18829545】,我们了解到了IOC容器的创建过程,在文末也提到了AOP相关,但是没有作细致分析,这篇文章就结合示例&am…...

[特殊字符] Prompt如何驱动大模型对本地文件实现自主变更:Cline技术深度解析
在AI技术快速发展的今天,编程方式正在经历一场革命性的变革。从传统的"人写代码"到"AI辅助编程",再到"AI自主编程",开发效率得到了质的提升。Cline作为一款基于VSCode的AI编程助手,通过其独特的pro…...
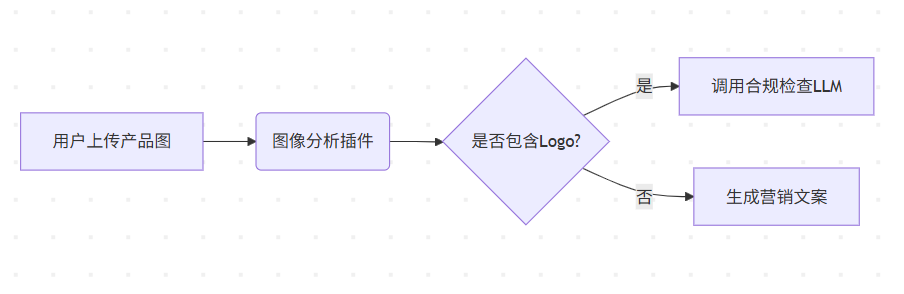
【专业解读:Semantic Kernel(SK)】大语言模型与传统编程的桥梁
目录 Start:什么是Semantic Kernel? 一、Semantic Kernel的本质:AI时代的操作系统内核 1.1 重新定义LLM的应用边界 1.2 技术定位对比 二、SK框架的六大核心组件与技术实现 2.1 内核(Kernel):智能任务调度中心 2…...

PHP 8 中的 Swow:高性能纯协程网络通信引擎
一、什么是 Swow? Swow 是一个高性能的纯协程网络通信引擎,专为 PHP 设计。它结合了最小化的 C 核心和 PHP 代码,旨在提供高性能的网络编程支持。Swow 的核心目标是释放 PHP 在高并发场景下的真正潜力,同时保持代码的简洁和易用性…...
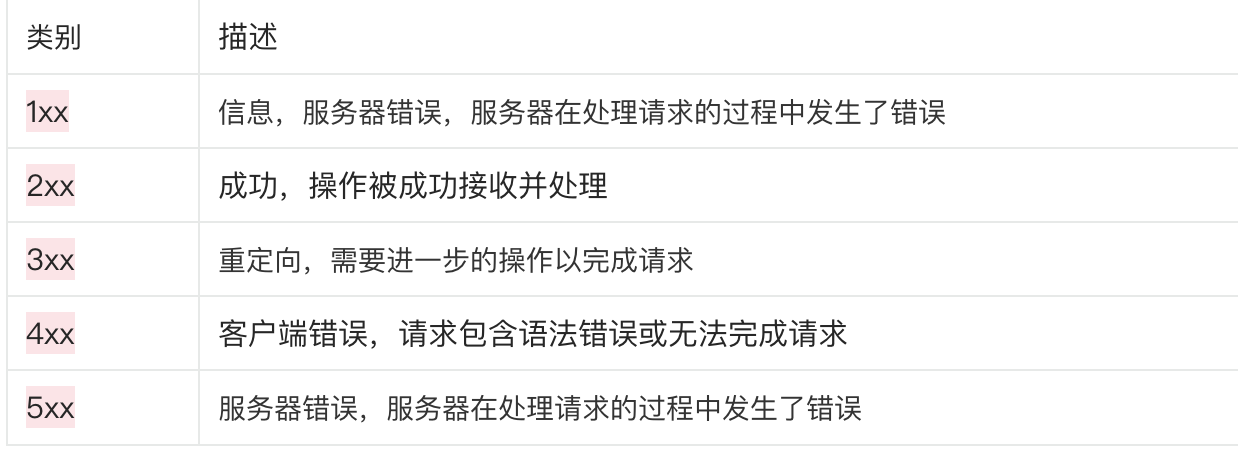
你学会了些什么211201?--http基础知识
概念 HTTP–Hyper Text Transfer Protocol,超文本传输协议;是一种建立在TCP上的无状态连接(短连接)。 整个基本的工作流程是:客户端发送一个HTTP请求(Request ),这个请求说明了客户端…...

每天学一个 Linux 命令(29):tail
可访问网站查看,视觉品味拉满: http://www.616vip.cn/29/index.html tail 命令用于显示文件的末尾内容,默认显示最后 10 行。它常用于实时监控日志文件或查看文件的尾部数据。以下是详细说明和示例: 命令格式 tail [选项] [文件...]常用选项 选项描述-n <NUM> …...

【形式化验证基础】活跃属性Liveness Property和安全性质(Safety Property)介绍
文章目录 一、Liveness Property1、概念介绍2、形式化定义二、Safety Property1. 定义回顾2. 核心概念解析3. 为什么强调“有限前缀”4. 示例说明4.1 示例1:交通信号灯系统4.2 示例2:银行账户管理系统5. 实际应用的意义三. 总结一、Liveness Property 1、概念介绍 在系统的…...

技工院校无人机专业工学一体化人才培养方案
随着无人机技术在农业植保、地理测绘、应急救援等领域的深度应用,行业复合型人才缺口持续扩大。技工院校作为技能型人才培养主阵地,亟需构建与行业发展同步的无人机专业人才培养体系。本文基于"工学一体化"教育理念,从课程体系、实…...

PI0 Openpi 部署(仅测试虚拟环境)
https://github.com/Physical-Intelligence/openpi/tree/main 我使用4070tisuper, 14900k,完全使用官方默认设置,没有出现其他问题。 目前只对examples/aloha_sim进行测试,使用docker进行部署, 默认使用pi0_aloha_sim模型(但是文档上没找到对应的&…...

计算机视觉——利用AI幻觉检测图像是否是生成式算生成的图像
概述 俄罗斯的新研究提出了一种非常规方法,用于检测不真实的AI生成图像——不是通过提高大型视觉-语言模型(LVLMs)的准确性,而是故意利用它们的幻觉倾向。 这种新方法使用LVLMs提取图像的多个“原子事实”,然后应用自…...

性能测试工具和JMeter功能概要
主流性能测试工具 LoadRunner JMeter [本阶段学习] 1.1 LoadRunner HP LoadRunner是一种工业级标准性能测试负载工具,可以模拟上万用户实施测试,并在测试时可实时检测应用服务器及服务器硬件各种数据,来确认和查找存在的瓶颈支持多协议&am…...

《理解 Java 泛型中的通配符:extends 与 super 的使用场景》
大家好呀!👋 今天我们要聊一个让很多Java初学者头疼的话题——泛型通配符。别担心,我会用最通俗易懂的方式,带你彻底搞懂这个看似复杂的概念。准备好了吗?Let’s go! 🚀 一、为什么我们需要泛型通配符&…...

C#学习第17天:序列化和反序列化
什么是序列化? 定义:序列化是指把对象转换为一种可以轻松存储或传输的格式,如JSON、XML或二进制格式。这个过程需要捕获对象的类型信息和数据内容。用途:使得对象可以持久化到文件、发送至网络、或存储在数据库中。 什么是反序列…...
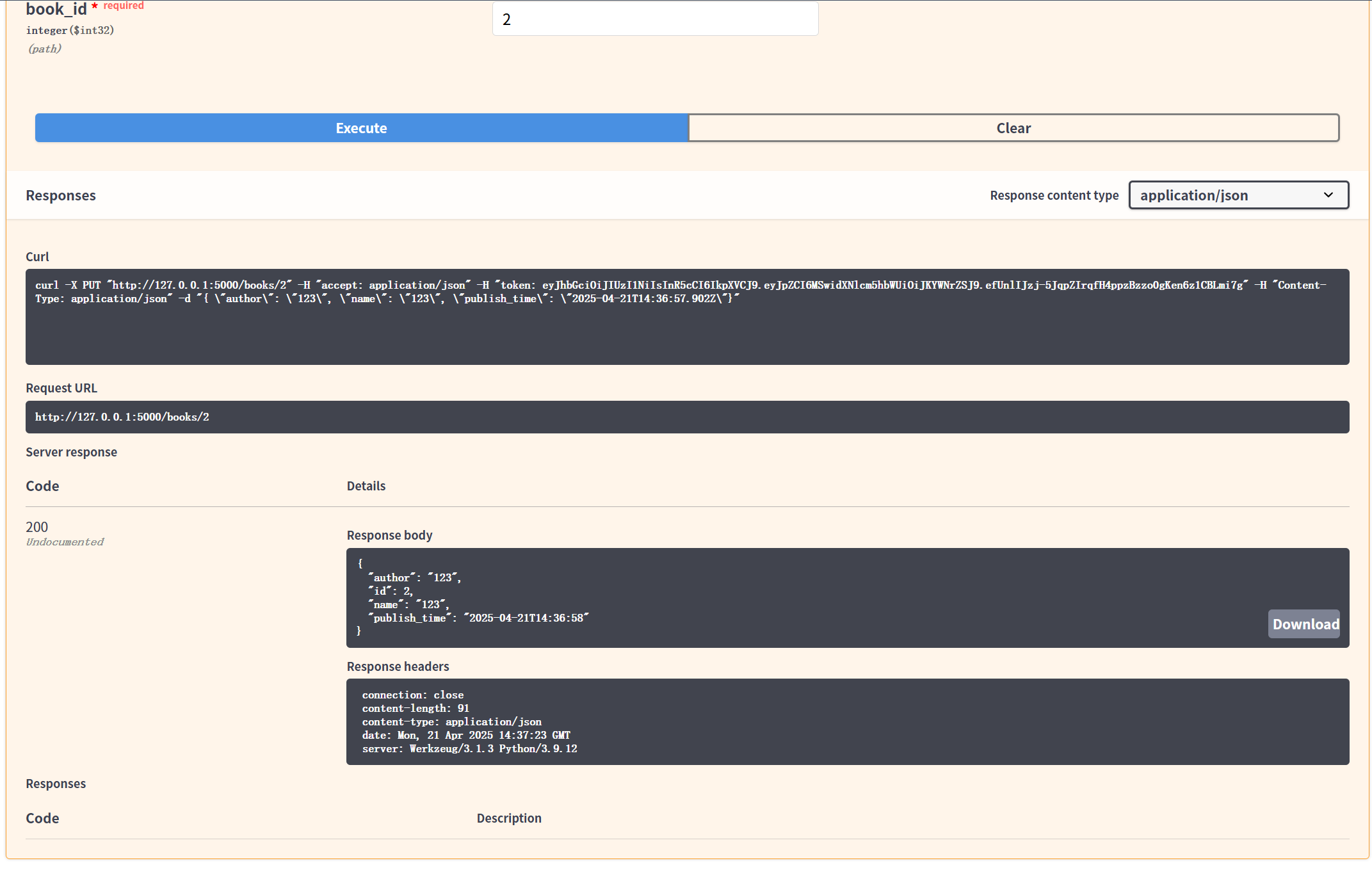
FlaskRestfulAPI接口的初步认识
FlaskRestfulAPI 介绍 记录学习 Flask Restful API 开发的过程 项目来源:【Flask Restful API教程-01.Restful API介绍】 我的代码仓库:https://gitee.com/giteechaozhi/flask-restful-api.git 后端API接口实现功能:数据库访问控制…...
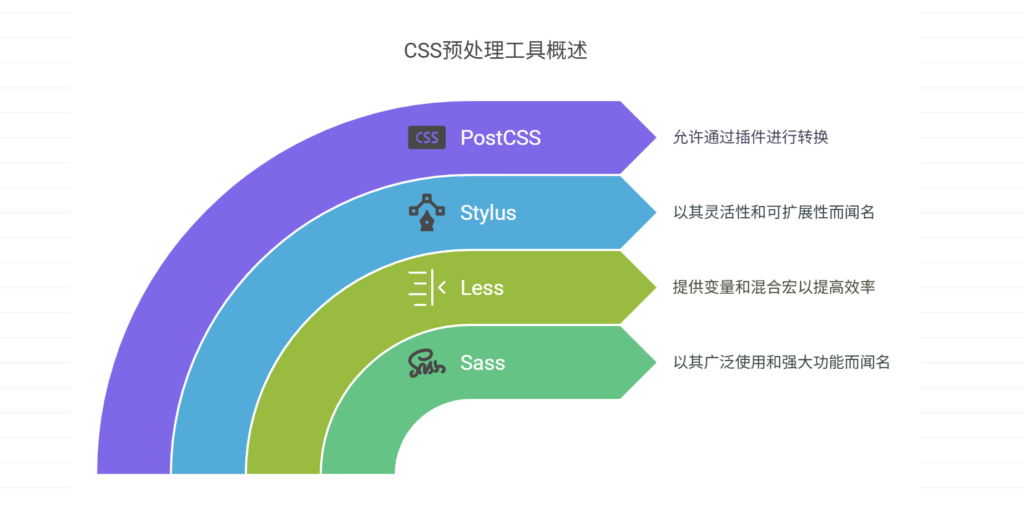
CSS预处理工具有哪些?分享主流产品
目前主流的CSS预处理工具包括:Sass、Less、Stylus、PostCSS等。其中,Sass是全球使用最广泛的CSS预处理工具之一,以强大的功能、灵活的扩展性以及完善的社区生态闻名。Sass通过增加变量、嵌套、混合宏(mixin)等功能&…...
可以通过 自定义事件 或 页面引用 实现)
微信小程序中,将搜索组件获取的值传递给父页面(如 index 页面)可以通过 自定义事件 或 页面引用 实现
将搜索组件获取的值传递给父页面(如 index 页面)可以通过 自定义事件 或 页面引用 实现 方法 1:自定义事件(推荐) 步骤 1:搜索组件内触发事件 在搜索组件的 JS 中,当获取到搜索值时,…...

深度学习预训练和微调
目录 1. 预训练(Pre-training)是什么? 2. 微调(Fine-tuning)是什么? 3. 预训练和微调的对象 4. 特征提取如何实现? 预训练阶段: 微调阶段: 5. 这样做的作用和意义 …...
AI 速读 SpecReason:让思考又快又准!
在大模型推理的世界里,速度与精度往往难以兼得。但今天要介绍的这篇论文带来了名为SpecReason的创新系统,它打破常规,能让大模型推理既快速又准确,大幅提升性能。想知道它是如何做到的吗?快来一探究竟! 论…...
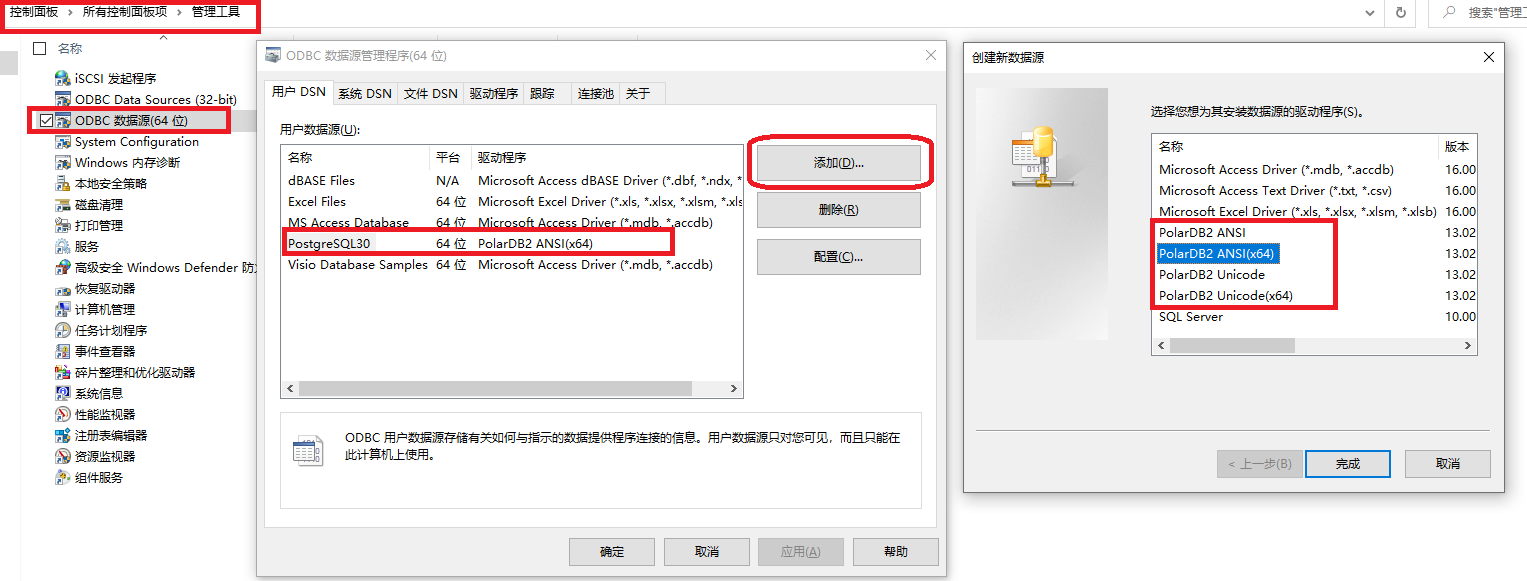
Qt通过ODBC和QPSQL两种方式连接PostgreSQL或PolarDB PostgreSQL版
一、概述 以下主要在Windows下验证连接PolarDB PostgreSQL版(阿里云兼容 PostgreSQL的PolarDB版本)。Linux下类似,ODBC方式则需要配置odbcinst.ini和odbc.ini。 二、代码 以下为完整代码,包含两种方式连接数据库,并…...
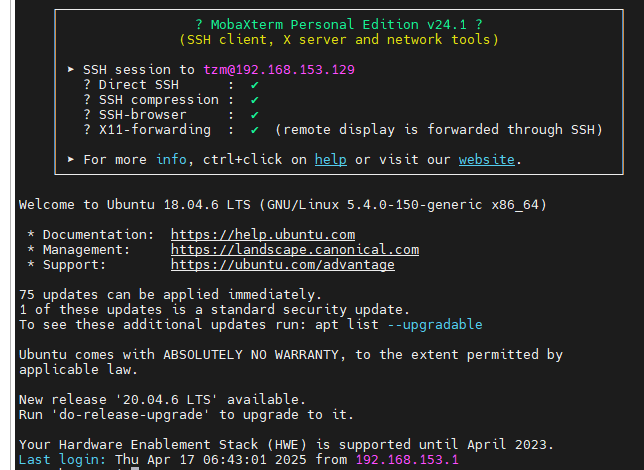
MobaXterm连接Ubuntu(SSH)
1.查看Ubuntu ip 打开终端,使用指令 ifconfig 由图可知ip地址 2.MobaXterm进行SSH连接 点击session,然后点击ssh,最后输入ubuntu IP地址以及用户名...

Lambda 函数与 peek 操作的使用案例
Lambda 函数和 peek 操作是 Java 8 Stream API 中非常有用的特性,下面我将介绍它们的使用案例。 Lambda 函数使用案例 Lambda 表达式是 Java 8 引入的一种简洁的匿名函数表示方式。 集合操作 List<String> names Arrays.asList("Alice", "B…...
 和 逐字字符串(@) 功能)
C# 的 字符串插值($) 和 逐字字符串(@) 功能
这段代码使用了 C# 的 字符串插值($) 和 逐字字符串() 功能,并在 SQL 语句中动态拼接变量。下面详细解释它们的用法: 1. $(字符串插值) $ 是 C# 的 字符串插值 符号,允许…...

软考 中级软件设计师 考点知识点笔记总结 day13 数据库系统基础知识 数据库模式映像 数据模型
文章目录 数据库系统基础知识6.1 基本概念6.1.1 DBMS的特征与分类 6.2 数据库三级模式两级映像6.3 数据库的分析与设计过程6.4 数据模型6.4.1 ER模型6.4.2 关系模型 数据库系统基础知识 基本概念 数据库三级模式两级映像 数据库的分析与设计过程 数据模型 关系代数 数据库完整…...

蓝桥杯2024省A.成绩统计
蓝桥杯2024省A.成绩统计 题目 题目解析与思路 题目要求返回至少要检查多少个人的成绩,才有可能选出k名同学,他们的方差小于一个给定的值 T 二分枚举答案位置,将答案位置以前的数组单独取出并排序,然后用k长滑窗O(1)计算方差 问…...