机器学习-08-关联规则更新
总结
本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则和协同过滤。
参考
机器学习(三):Apriori算法(算法精讲)
Apriori 算法 理论 重点
【手撕算法】【Apriori】关联规则Apriori原理、代码实现
FPGROWTH算法详解
MovieLens:一个常用的电影推荐系统领域的数据集
23张图,带你入门推荐系统
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合
+算法评估+持续调优+工程化接口实现
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用:
对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。

关联规则
啤酒与尿布
“啤酒与尿布” 的故事相信很多人都听过,年轻爸爸去超市购买尿布时,经常会买点啤酒犒劳自己。因此,沃尔玛将这两种商品进行了捆绑销售,最终获得了更好的销量。
“啤酒与尿布”的故事


这个故事背后的理论依据就是 “推荐算法”,因为尿布和啤酒经常出现在同一个购物车中,那么向购买尿布的年轻爸爸推荐啤酒确实有一定道理。
关联规则算法
获得啤酒与尿布的关系的一种算法就是关联规则算法:
1.关联规则推荐算法:这种算法基于关联规则挖掘的技术。它通过分析用户行为数据中的项集之间的关联关系,找出频繁项集和关联规则,然后根据这些规则进行推荐。比如,根据用户购买商品的历史记录,可以挖掘出购买商品之间的关联规则,然后根据规则推荐其他相关商品给用户。
关联规则算法最开始是面向购物篮分析问题:
如何在消费者购买了特定商品,比如PC机和一台数码相机后,作为销售人员的你针对该消费者已购买的商品进行分析(购物篮分析),可以继续给该消费者推荐什么产品,该消费者才能更感兴趣。

关联规则算法可以帮助我们在大量历史销售数字中发现“已有的多数客户在购买PC机和数码相机后,还经常购买哪些产品”这样的一个规律。
关联规则就是通过发现顾客放入“购物篮”中的不同商品之间的关联,分析顾客的购物习惯,而物品见的某种联系我们称为关联。
这种关联的发现可以帮助零售商了解哪些商品频繁的被顾客同时购买,从而帮助他们开发更好的营销策略。
关联规则 (Association Rules,又称 Basket Analysis) 是形如X→Y的蕴涵式,
其中, X和Y分别称为关联规则的先导(antecedent或left-hand-side, LHS)和后继(consequent或right-hand-side, RHS) 。
在这当中,关联规则X→Y,利用其支持度和置信度从大量数据中挖掘出有价值的数据项之间的相关关系。
关联规则解决的常见问题如:“如果一个消费者购买了产品A,那么他有多大机会购买产品B?”以及“如果他购买了产品C和D,那么他还将购买什么产品?”
关联规则定义:
假设
I = {I1,I2,。。。Im}是包含所有商品(item)的集合,
包含k个项的项集称为k项集(k-itemset)。
给定一个交易数据库D,其中每个事务(Transaction)T是I的非空子集,即每一个交易都与一个唯一的标识符TID(Transaction ID)对应。
关联规则挖掘的目的即通过已发生的事务数据,找到其中有效关联性较高的项集所构成的规则。
那么,如何度量关联规则的有效性及关联性呢?
首先,该关联规则本身所对应的商品应当具有一定的普遍推荐价值,即支持度较高;关联规则在D中的支持度(support)是D中事务同时包含X、Y的百分比,即概率;
其次该规则的发生应当具有一定的可能性,即置信度较高。置信度(confidence)是D中事务已经包含X的情况下,包含Y的百分比,即条件概率。
如果满足最小支持度阈值min_support和最小置信度阈值min_confidence,则认为关联规则是重要的。
当一个项集(XY)的支持度大于等于min_support,这个项集就被称为频繁项集(Frequent Itemset)。
当以频繁项集(XY)构成的关联规则(X→Y)的置信度大于等于min_confidence,这个关联规则就被称为强关联规则。强关联规则也是关联规则挖掘的最终产出。

关联规则挖掘过程主要包含两个阶段:
第一阶段必须先从资料集合中找出所有的频繁项集(Frequent Itemsets),
第二阶段再由这些高频项目组中产生强关联规则(Association Rules)。
举个栗子🌰说明下
| TID | 牛奶 | 面包 | 尿布 | 啤酒 | 鸡蛋 | 可乐 |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1 | 1 | 1 | 1 | 0 |
| 3 | 1 | 0 | 1 | 1 | 0 | 1 |
| 4 | 1 | 1 | 1 | 1 | 0 | 0 |
| 5 | 1 | 1 | 1 | 0 | 0 | 1 |
上表格是顾客购买记录的数据库D,包含
5个事务, 即D=5,有5个订单。
项集I={牛奶,面包,尿布,啤酒,鸡蛋}。
若给定最小支持度in_support=0.5,最小置信度min_confidence=0.6,
考虑一个二项集:{牛奶,面包},
事务1,4,5同时包含牛奶和面包,那么说明包含牛奶和面包的有3个事务,即X∩Y=3,支持度(X∩Y)/D=3/5=0.6>min_support,则{牛奶,面包}是一个频繁项集。
对于关联规则(牛奶→面包),在数据库D中4个事务是包含牛奶的,即X=4, 因而置信度(X∩Y)/X=3/4=0.75>min_confidence,则认为购买牛奶和购买面包之间存在强关联。
关联规则算法Apriori实现
Apriori算法实现原理
R.Agrawal 和 R. Srikant于1994年在文献中提出了Apriori算法,该算法的描述如下图所示:
candidate itemsets候选项集合
frequent itemsets频繁项集合
1)令k = 1
2)统计每个k项集的支持度,并找出频繁k项集
3)利用频繁k项集生成候选k+1项集
4)令k=k+1,重复第 2)步

// 尺寸为k的候选项目集
C_k:Candidate itemsets of size k
//大小为k的频繁项目集
L_k:frequent itemsets of size k
L1={frequent 1-itemsets}; // 大小为1的频繁项目集
// k从1开始,频繁项目集不为0
for (k=1;L_k≠0;k++) // 从 L_k频繁项目集 中生成 C_k+1候选项目集C_k+1=GenerateCandidates(L_k) // 对于每一个数据库D中的事务t for each transaction t in database do // 包含在t中的C_k+1中的候选者的增量计数increment count of candidates in C_k+1 that are contained in t endfor // 在 C_k+1中的候选集中找到大于最小支持度的作为L_K+1频繁候选项集 L_k+1=candidates in C_k+i with support >= min_sup
endfor
return U_kL_k;
举例🌰:说明下
Apriori算法实例—产生频繁项集
Apriori算法实例—产生关联规则
Apriori算法思想总结





FPGROWTH算法
Apriori的挑战及改进方案
挑战
多次数据库扫描
巨大数量的候补项集
繁琐的支持度计算
改善Apriori: 基本想法
减少扫描数据库的次数
减少候选项集的数量
简化候选项集的支持度计算
具体参考这个:
FPGROWTH算法详解
手写完整代码
# 1.构建候选1项集C1
def createC1(dataSet):# 获取数据集中所有不重复的项c1 = list(set([y for x in dataSet for y in x]))c1.sort() # 排序# 将每个项转换为集合形式c2 = [[x] for x in c1]# 使用frozenset以便作为字典键使用return list(map(frozenset, c2))# 将候选集Ck转换为频繁项集Lk
# D:原始数据集
# Cn: 候选集项Ck
# minSupport:支持度的最小值
def scanD(D, Ck, minSupport):# 候选集计数字典ssCnt = {}# 遍历每条交易记录for tid in D:# 遍历每个候选项集for can in Ck:# 如果候选项集是当前交易记录的子集if can.issubset(tid):# 统计候选项集出现次数if can not in ssCnt.keys(): ssCnt[can] = 1else: ssCnt[can] += 1# 计算总交易数numItems = float(len(D))Lk = [] # 候选集项Cn生成的频繁项集LksupportData = {} # 候选集项Cn的支持度字典# 计算候选项集的支持度for key in ssCnt:support = ssCnt[key] / numItems# 如果支持度大于等于最小支持度,加入频繁项集if support >= minSupport:Lk.append(key)# 记录所有候选项集的支持度supportData[key] = supportreturn Lk, supportData# 连接操作,将频繁Lk-1项集通过拼接转换为候选k项集
def aprioriGen(Lk_1, k):Ck = []lenLk = len(Lk_1)for i in range(lenLk):# 获取前k-2个项L1_list = list(Lk_1[i])L1 = L1_list[:k - 2]L1.sort()for j in range(i + 1, lenLk):# 获取另一个项集的前k-2个项L2_list = list(Lk_1[j])L2 = list(Lk_1[j])[:k - 2]L2.sort()# 前k-2个项相同时,将两个集合合并if L1 == L2:Ck.append(Lk_1[i] | Lk_1[j])return Ck# Apriori算法主函数
def apriori(dataSet, minSupport=0.5):# 生成候选1项集C1 = createC1(dataSet)# 扫描数据集,生成频繁1项集L1, supportData = scanD(dataSet, C1, minSupport)L = [L1] # 存储所有频繁项集k = 2# 循环生成更高阶的频繁项集while (len(L[k-2]) > 0):Lk_1 = L[k-2]# 生成候选k项集Ck = aprioriGen(Lk_1, k)print("ck:", Ck)# 扫描数据集,生成频繁k项集Lk, supK = scanD(dataSet, Ck, minSupport)supportData.update(supK)print("lk:", Lk)L.append(Lk)k += 1return L, supportData# 生成关联规则
# L: 频繁项集列表
# supportData: 包含频繁项集支持数据的字典
# minConf 最小置信度
def generateRules(L, supportData, minConf=0.7):# 包含置信度的规则列表bigRuleList = []# 从频繁二项集开始遍历for i in range(1, len(L)):for freqSet in L[i]:# 拆分项集为单个项的后件集合H1 = [frozenset([item]) for item in freqSet]if (i > 1):# 处理高阶频繁项集rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)else:# 处理频繁二项集calcConf(freqSet, H1, supportData, bigRuleList, minConf)return bigRuleList# 计算是否满足最小可信度
def calcConf(freqSet, H, supportData, brl, minConf=0.7):prunedH = [] # 满足最小置信度的后件集合# 用每个conseq作为后件for conseq in H:# 计算前件支持度P_A = supportData[freqSet.difference(conseq)]# 计算置信度conf = supportData[freqSet] / P_Aif conf >= minConf:print(freqSet - conseq, '-->', conseq, 'conf:', conf)# 将规则加入结果列表(前件, 后件, 置信度)brl.append((freqSet - conseq, conseq, conf))prunedH.append(conseq)return prunedH# 对规则进行评估
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):m = len(H[0]) # 后件长度if (len(freqSet) > (m + 1)):# 生成更高阶的后件候选集Hmp1 = aprioriGen(H, m + 1)# 计算置信度Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)if (len(Hmp1) > 0):# 递归处理更高阶后件rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)# 测试数据集
dataset = [['土豆', '尿不湿', '啤酒'], ['巧克力', '牛奶', '土豆', '啤酒'], ['牛奶', '尿不湿', '啤酒'],['巧克力', '尿不湿', '啤酒'], ['巧克力', '啤酒']]
# 运行Apriori算法
L, supportData = apriori(dataset, minSupport=0.5)
# 生成关联规则
rules = generateRules(L, supportData, minConf=0.7)
# 打印所有关联规则
for e in rules:print(e)运行输出如下:
ck: [frozenset({‘尿不湿’, ‘啤酒’}), frozenset({‘巧克力’, ‘啤酒’}), frozenset({‘尿不湿’, ‘巧克力’})]
lk: [frozenset({‘尿不湿’, ‘啤酒’}), frozenset({‘巧克力’, ‘啤酒’})]
ck: []
lk: []
frozenset({‘尿不湿’}) --> frozenset({‘啤酒’}) conf: 1.0
frozenset({‘巧克力’}) --> frozenset({‘啤酒’}) conf: 1.0
(frozenset({‘尿不湿’}), frozenset({‘啤酒’}), 1.0)
(frozenset({‘巧克力’}), frozenset({‘啤酒’}), 1.0)
调包完成关联规则
efficient_apriori 包实现
# 安装:pip install efficient-apriori==2.0.5
from efficient_apriori import apriori
# 测试数据集
dataset = [['土豆', '尿不湿', '啤酒'], ['巧克力', '牛奶', '土豆', '啤酒'], ['牛奶', '尿不湿', '啤酒'],['巧克力', '尿不湿', '啤酒'], ['巧克力', '啤酒']]
freqItemSet, rules = apriori(dataset, 0.5, 0.7)
print(freqItemSet)
print(rules)
输出如下:
{1: {(‘尿不湿’,): 3, (‘啤酒’,): 5, (‘巧克力’,): 3}, 2: {(‘啤酒’, ‘尿不湿’): 3, (‘啤酒’, ‘巧克力’): 3}}
[{尿不湿} -> {啤酒}, {巧克力} -> {啤酒}]
fpgrowth_py 包实现
Apriori算法效率比较低,建议在使用的时候直接使用基于Apriori算法开发的FP-growth算法,fpgrowth_py 实现代码如下:
# 安装:pip install fpgrowth_py==1.0.0
from fpgrowth_py import fpgrowth
dataset = [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
freqItemSet, rules = fpgrowth(dataset, 0.5, 0.7)
print(freqItemSet)
print(rules) dataset = [['土豆', '尿不湿', '啤酒'], ['巧克力', '牛奶', '土豆', '啤酒'], ['牛奶', '尿不湿', '啤酒'],['巧克力', '尿不湿', '啤酒'], ['巧克力', '啤酒']]freqItemSet, rules = fpgrowth(dataset, 0.5, 0.7)
print(freqItemSet)
print(rules) 输出如下:
[{1}, {1, 3}, {3}, {2, 3}, {2}, {5}, {3, 5}, {2, 3, 5}, {2, 5}]
[[{1}, {3}, 1.0], [{2, 3}, {5}, 1.0], [{3, 5}, {2}, 1.0], [{2}, {5}, 1.0], [{5}, {2}, 1.0]][{‘尿不湿’}, {‘啤酒’, ‘尿不湿’}, {‘巧克力’}, {‘啤酒’, ‘巧克力’}, {‘啤酒’}]
[[{‘尿不湿’}, {‘啤酒’}, 1.0], [{‘巧克力’}, {‘啤酒’}, 1.0]]
相关文章:

机器学习-08-关联规则更新
总结 本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则和协同过滤。 参考 机器学习(三):Apriori算法(算法精讲) Apriori 算法 理论 重点 【手撕算法】【Apriori】关联规则Apriori原理、代码…...
Flutter与FastAPI的OSS系统实现
作者:孙嘉成 目录 一、对象存储 二、FastAPI与对象存储 2.1 缤纷云S4服务API对接与鉴权实现 2.2 RESTful接口设计与异步路由优化 三、Flutter界面与数据交互开发 3.1 应用的创建 3.2页面的搭建 3.3 文件的上传 关键词:对象存储、FastAPI、Flutte…...

Kubernetes控制平面组件:API Server详解(二)
云原生学习路线导航页(持续更新中) kubernetes学习系列快捷链接 Kubernetes架构原则和对象设计(一)Kubernetes架构原则和对象设计(二)Kubernetes架构原则和对象设计(三)Kubernetes控…...

MySQL-锁机制3-意向共享锁与意向排它锁、死锁
文章目录 一、意向锁二、死锁应该如何避免死锁问题? 总结 一、意向锁 在表获取共享锁或者排它锁时,需要先检查该表有没有被其它事务获取过X锁,通过意向锁可以避免大量的行锁扫描,提升表获取锁的效率。意向锁是一种表级锁…...
报告系统状态的连续日期 mysql + pandas(连续值判断)
本题用到知识点:row_number(), union, date_sub(), to_timedelta()…… 目录 思路 pandas Mysql 思路 链接:报告系统状态的连续日期 思路: 判断连续性常用的一个方法,增量相同的两个列的差值是固定的。 让日期与行号 * 天数…...

pytest自动化中关于使用fixture是否影响用例的独立性
第一个问题:难道使用fixture 会影响用例独立吗? ✅ 简单回答: 使用 fixture ≠ 不独立。 只要你的 fixture 是每次测试都能自己运行、自己产生数据的,那么测试用例依然是“逻辑独立”的。 ✅ 怎么判断 fixture 是否影响独立性&a…...

Token与axios拦截器
目录 一、Token 详解 1. Token 的定义与作用 2. Token 的工作流程 3. Token 的优势 4. Token 的安全实践 5. JWT 结构示例 二、Axios 拦截器详解 1. 拦截器的作用 2. 请求拦截器 3. 响应拦截器 4. 拦截器常见场景 5. 移除拦截器 三、完整代码示例 四、总结 五、…...

unity3d实现物体闪烁
unity3d实现物体闪烁,代码如下: using UnityEngine;public class Test : MonoBehaviour {//创建一个常量,用来接收时间的变化值private float shake;//通过控制物体的MeshRenderer组件的开关来实现物体闪烁的效果private MeshRenderer BoxColliderClick…...
)
C#—Lazy<T> 类型(延迟初始化/懒加载模式)
C# 的 Lazy<T> 类型 Lazy<T> 是 C# 中的一个类,用于实现延迟初始化(懒加载)模式。它提供了一种线程安全的方式来延迟创建大型或资源密集型对象,直到第一次实际需要时才进行初始化。 主要特点 延迟初始化:…...

Spring Boot 项目启动命令解析
Spring Boot 项目启动命令参数 一、启动命令基础格式 java [JVM参数] [Spring Boot参数] -jar your-project.jar必选部分:java -jar your-project.jar 启动可执行 JAR 包。 可选部分: JVM 参数:控制 Java 虚拟机行为(如内存、垃…...
?及 `docker run` 详细执行过程)
为什么 Docker 容器中有额外的目录(如 `/dev`、`/proc`、`/sys`)?及 `docker run` 详细执行过程
、当你使用 docker run 启动一个基于极简镜像(如 scratch 或手动构建的镜像)的容器时,发现容器内出现了 /dev、/proc、/sys 等目录,即使你的镜像中并未包含这些目录。这是因为 Docker 在启动容器时,会自动挂载一些必要…...

Tailwind 武林奇谈:bg-blue-400 失效,如何重拾蓝衣神功?
前言 江湖有云,Tailwind CSS,乃前端武林中的轻功秘籍。习得此技,排版如行云流水,配色似御风随形,收放自如,随心所欲。 某日,小侠你奋笔敲码,正欲施展“蓝衣神功”(bg-blue-400),让按钮怒气冲冠、蓝光满面,怎料一招使出,画面竟一片白茫茫大地真干净,毫无半点杀气…...

【Docker 运维】Java 应用在 Docker 容器中启动报错:`unable to allocate file descriptor table`
文章目录 一、根本原因二、判断与排查方法三、解决方法1、限制 Docker 容器的文件描述符上限2、在执行脚本中动态设置ulimit的值3、升级至 Java 11 四、总结 容器内执行脚本时报错如下,Java 进程异常退出: library initialization failed - unable to a…...

开始放飞之先搞个VSCode
文章目录 开始放飞之先搞个VSCode重要提醒安装VSCode下载MinGW-w64回到VSCode中去VSCode原生调试键盘问题遗留问题参考文献 开始放飞之先搞个VSCode 突然发现自己的新台式机上面连个像样的编程环境都没有,全是游戏了!!!ÿ…...
基于SA模拟退火算法的车间调度优化matlab仿真,输出甘特图和优化收敛曲线
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 基于SA模拟退火算法的车间调度优化matlab仿真,输出甘特图和优化收敛曲线。输出指标包括最小平均流动时间,最大完工时间,最小间隙时间。 2…...

【仿Mudou库one thread per loop式并发服务器实现】SERVER服务器模块实现
SERVER服务器模块实现 1. Buffer模块2. Socket模块3. Channel模块4. Poller模块5. EventLoop模块5.1 TimerQueue模块5.2 TimeWheel整合到EventLoop5.1 EventLoop与线程结合5.2 EventLoop线程池 6. Connection模块7. Acceptor模块8. TcpServer模块 1. Buffer模块 Buffer模块&…...

基于Redis实现高并发抢券系统的数据同步方案详解
在高并发抢券系统中,我们通常会将用户的抢券结果优先写入 Redis,以保证系统响应速度和并发处理能力。但数据的最终一致性要求我们必须将这些结果最终同步到 MySQL 的持久化库中。本文将详细介绍一种基于线程池 Redis Hash 扫描的异步数据同步方案&#…...

SPL 量化 序言
序言 量化交易是通过数学模型、统计学方法和计算机技术,将市场行为转化为可执行的交易策略的自动化投资方式。其核心是通过大数据分析、机器学习和金融工程等技术,从历史数据中挖掘市场规律,预测价格趋势并生成交易信号。 量化交易的实现通…...

【LLM Prompt】CoT vs.ToT
CoT(Chain of Thought) Definition: CoT refers to the method of prompting a language model to generate responses in a step-by-step manner, explicitly showing the reasoning process leading to the final answer.定义: CoT 是一种提示语言模型…...
uniapp h5接入地图选点组件
uniapp h5接入地图选点组件 1、申请腾讯地图key2、代码接入2.1入口页面 (pages/map/map)templatescript 2.2选点页面(pages/map/mapselect/mapselect)templatescript 该内容只针对uniapp 打包h5接入地图选点组件做详细说明&#x…...
)
【Rust 精进之路之第13篇-生命周期·进阶】省略规则与静态生命周期 (`‘static`)
系列: Rust 精进之路:构建可靠、高效软件的底层逻辑 作者: 码觉客 发布日期: 2025年4月20日 引言:让编译器“读懂”你的意图——省略的艺术 在上一篇【生命周期入门】中,我们理解了生命周期的必要性——它是 Rust 编译器用来确保引用有效性、防止悬垂引用的关键机制。我…...

OSI模型和传输过程
OSI模型概述 OSI(Open Systems Interconnection)模型是由国际标准化组织(ISO)提出的一个概念性框架,用于标准化网络通信功能。它将网络通信分为七层,每一层负责特定的功能,并通过接口与相邻层交…...

MySQL-CASE WHEN条件语句
介绍 MySQL 中的一种流程控制语法结构,用于在 SQL 查询中实现条件逻辑。它允许你根据一个或多个条件的真假来返回不同的值。可以根据某些条件对数据进行分类或者转换。 使用方式 简单 CASE 表达式 CASE input_expressionWHEN when_expression THEN result_expre…...

【随缘更新,免积分下载】Selenium chromedriver驱动下载(最新版135.0.7049.42)
目录 一、chromedriver概述 二、chromedriver使用方式 三、chromedriver新版本下载🔥🔥🔥 四、Selenium与Chrome参数设置🔥🔥 五、Selenium直接操控已打开的Chrome浏览器🔥🔥🔥…...
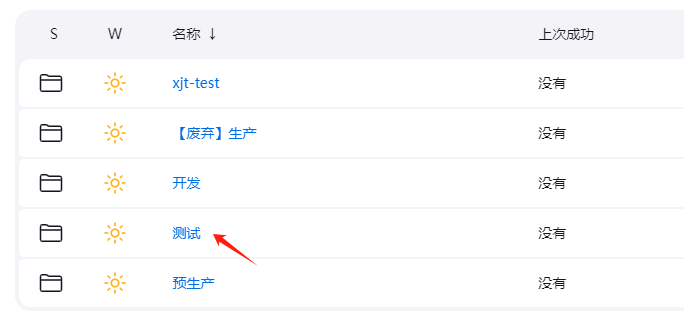
jenkins批量复制Job项目的shell脚本实现
背景 现在需要将“测试” 目录中的所有job全部复制到 一个新目录中 test2。可以结合jenkins提供的apilinux shell 进行实现。 测试目录的实际文件夹名称是 test。 脚本运行效果如下: [qdevsom5f-dev-hhyl shekk]$ ./copy_jenkins_job.sh 创建文件夹 test2 获取源…...

iOS Google登录
iOS Google登录 SDK下载地址在 Firebase 有下载,要下载整个SDK文件,然后拿其中的Google 登录SDK来使用 Firebase 官方文档 github 下载链接...

嵌入式工程师( C / C++ )笔试面试题汇总
注:本文为 “嵌入式工程师笔试面试题” 相关文章合辑。 未整理去重。 如有内容异常,请看原文。 嵌入式必会 C 语言笔试题汇总 Z 沉浮 嵌入式之旅 2021 年 01 月 19 日 00:00 用预处理指令 #define 声明一个常数,用以表明 1 年中有多少秒&a…...

重构便携钢琴专业边界丨特伦斯便携钢琴V30Pro定义新一代便携电钢琴
在便携电钢琴领域,特伦斯推出的V30Pro折叠钢琴以"技术革新场景适配"的双重升级引发关注。这款产品不仅延续了品牌标志性的折叠结构,更通过声学系统重构与智能交互优化,重新定义了便携乐器的专业边界。 ▶ 核心特点:技术…...
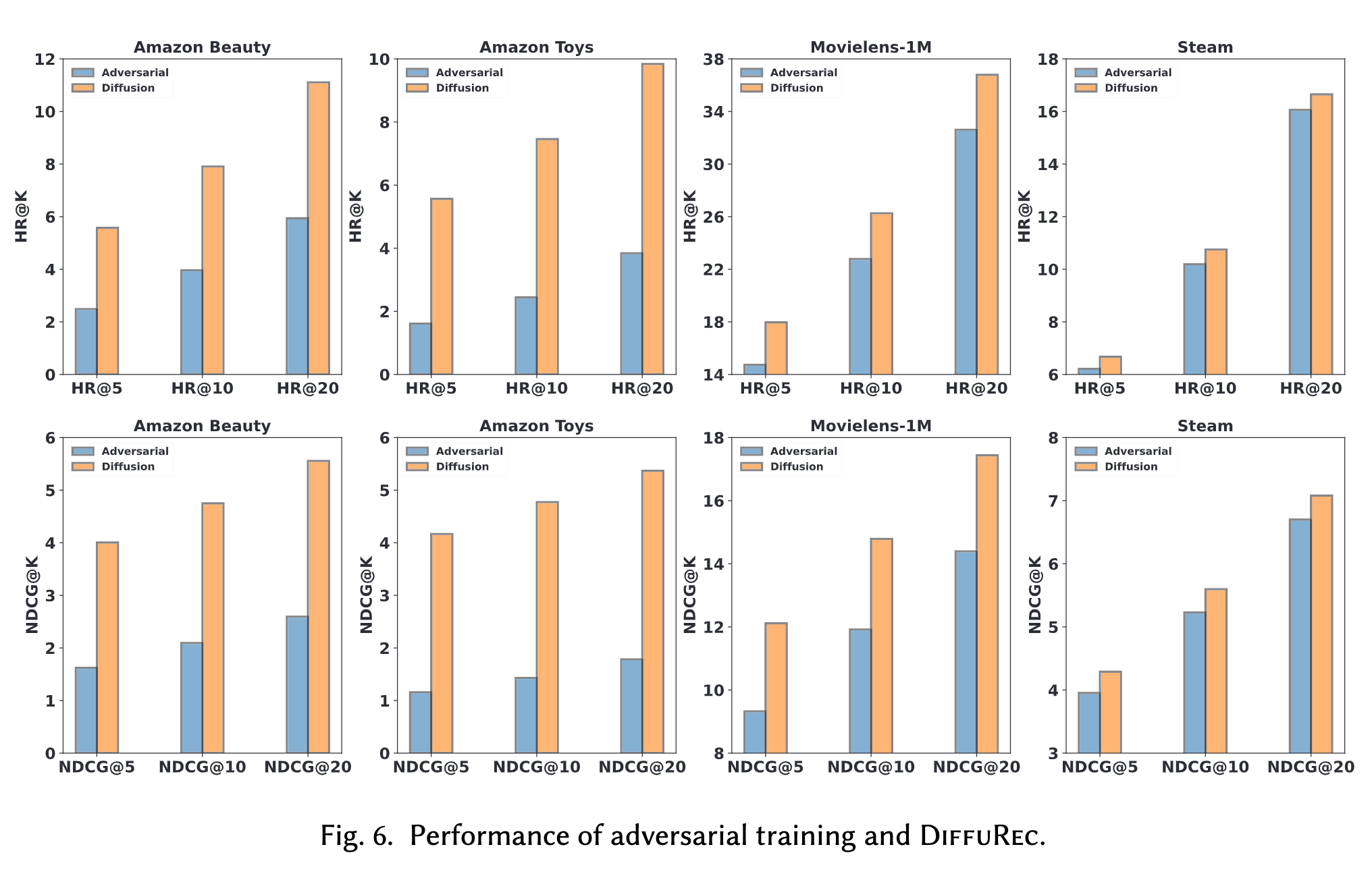
DiffuRec: A Diffusion Model for Sequential Recommendation
DiffuRec: A Diffusion Model for Sequential Recommendation Background 序列推荐(Sequential Recommendation, SR)领域,主流方法是将用户与物品表示为fixed embedding。然而,这种静态向量表达方式难以全面刻画用户多样化的兴趣…...

多模态大语言模型arxiv论文略读(三十三)
Jailbreaking Attack against Multimodal Large Language Model ➡️ 论文标题:Jailbreaking Attack against Multimodal Large Language Model ➡️ 论文作者:Zhenxing Niu, Haodong Ren, Xinbo Gao, Gang Hua, Rong Jin ➡️ 研究机构: Xidian Univer…...