多模态大语言模型arxiv论文略读(三十三)

Jailbreaking Attack against Multimodal Large Language Model
➡️ 论文标题:Jailbreaking Attack against Multimodal Large Language Model
➡️ 论文作者:Zhenxing Niu, Haodong Ren, Xinbo Gao, Gang Hua, Rong Jin
➡️ 研究机构: Xidian University、Wormpex AI Research、Meta
➡️ 问题背景:多模态大型语言模型(MLLMs)如ChatGPT-4V等,因其在多模态任务中的强大能力而受到广泛关注。然而,这些模型的安全性问题也日益凸显,尤其是通过特定的攻击手段(如“越狱攻击”)可以绕过模型的对齐防护,使其生成有害内容。传统的越狱攻击主要针对纯文本的大型语言模型(LLMs),而针对MLLMs的越狱攻击研究相对较少。
➡️ 研究动机:研究团队旨在探索针对MLLMs的越狱攻击,特别是通过图像越狱提示(imgJP)来绕过模型的对齐防护。此外,研究还探讨了MLLMs越狱攻击与LLMs越狱攻击之间的联系,以及如何利用MLLMs越狱攻击来提高LLMs越狱攻击的效率。
➡️ 方法简介:研究团队提出了一种基于最大似然的方法,通过修改对抗攻击的目标函数,生成能够使MLLMs生成有害内容的imgJP。该方法不仅具有数据通用性(即生成的imgJP可以用于多种未见过的提示和图像),还具有模型迁移性(即生成的imgJP可以用于攻击多种不同的MLLMs)。此外,研究团队还提出了一种基于构造的方法,将MLLMs越狱攻击转化为LLMs越狱攻击,显著提高了LLMs越狱攻击的效率。
➡️ 实验设计:研究团队在自建的多模态数据集AdvBench-M上进行了实验,该数据集包含500个有害行为,每个行为由一条指令和一个目标句子组成。实验评估了imgJP和deltaJP在不同条件下的攻击成功率(ASR),包括不同类型的有害行为和不同模型的响应类型。实验结果表明,所提出的方法在数据通用性和模型迁移性方面表现出色,能够有效越狱多种MLLMs,并显著提高了LLMs越狱攻击的效率。
GeReA: Question-Aware Prompt Captions for Knowledge-based Visual Question Answering
➡️ 论文标题:GeReA: Question-Aware Prompt Captions for Knowledge-based Visual Question Answering
➡️ 论文作者:Ziyu Ma, Shutao Li, Bin Sun, Jianfei Cai, Zuxiang Long, Fuyan Ma
➡️ 研究机构: 湖南大学、莫纳什大学、中国军事科学院
➡️ 问题背景:基于知识的视觉问答(Knowledge-based Visual Question Answering, VQA)任务需要机器在给定图像的情况下回答开放领域的问题,这通常需要超出图像本身的世界知识。早期的研究依赖于预定义的知识库(KBs)来获取知识,而最近的研究则利用大型语言模型(LLMs)作为隐式知识引擎,通过将图像转换为文本信息(如标题和答案候选)来获取和推理相关知识。然而,这种转换可能会引入无关信息,导致LLM误解图像并忽略对准确回答至关重要的视觉细节。
➡️ 研究动机:现有的方法,如基于检索的方法和基于GPT-3的方法,存在知识获取不准确和引入无关信息的问题。为了克服这些问题,研究团队提出了一种新的框架GeReA,通过提示多模态大型语言模型(MLLMs)来生成与问题相关的提示标题(question-aware prompt captions),并学习一个强大的联合知识-图像-问题表示,以预测最终答案。
➡️ 方法简介:GeReA框架分为两个阶段:1) 问题相关提示标题生成,2) 问题相关提示标题推理。在第一阶段,通过将问题相关的图像区域和问题特定的手动提示输入到冻结的MLLM中,生成问题相关的提示标题。在第二阶段,这些提示标题、图像-问题对和相似样本被输入到多模态推理模型中,以学习一个强大的联合知识-图像-问题表示,从而预测最终答案。
➡️ 实验设计:研究团队在OK-VQA和A-OKVQA数据集上进行了实验,评估了GeReA在不同条件下的表现。实验结果表明,GeReA在OK-VQA数据集上取得了66.5%的测试准确率,在A-OKVQA数据集上取得了63.3%的测试准确率,显著优于现有的最先进方法。
LHRS-Bot: Empowering Remote Sensing with VGI-Enhanced Large Multimodal Language Model
➡️ 论文标题:LHRS-Bot: Empowering Remote Sensing with VGI-Enhanced Large Multimodal Language Model
➡️ 论文作者:Dilxat Muhtar, Zhenshi Li, Feng Gu, Xueliang Zhang, Pengfeng Xiao
➡️ 研究机构: 南京大学 (Nanjing University)
➡️ 问题背景:大型语言模型(LLMs)在信息交流和解决复杂问题方面展现了卓越的能力。为了扩展LLMs的感知能力,多模态大型语言模型(MLLMs)通过视觉表示和视觉指令调优,展示了强大的多模态指令跟随能力,可以作为多种任务的通用接口。然而,在遥感(RS)领域,现有的MLLMs未能充分考虑多样化的地理景观和RS图像中的不同对象,导致在RS图像理解方面存在显著挑战。
➡️ 研究动机:为了弥补这一差距,研究团队构建了一个大规模的RS图像-文本数据集(LHRS-Align)和一个信息丰富的RS特定指令数据集(LHRS-Instruct),并提出了一个专门针对RS领域的MLLM——LHRS-Bot。LHRS-Bot通过新颖的多级视觉-语言对齐策略和课程学习方法,旨在提高RS图像理解的性能。
➡️ 方法简介:研究团队通过将RS图像与开放街图(OSM)中的地理特征对齐,生成了LHRS-Align数据集。该数据集包含115万对高质量的RS图像-文本对。此外,通过重新组织多个开源RS数据集并使用GPT-4生成复杂指令数据,构建了LHRS-Instruct数据集。LHRS-Bot利用这些数据集,通过多级视觉特征总结和课程学习策略,实现了对RS图像的深入理解和复杂指令的执行。
➡️ 实验设计:研究团队在多个RS数据集上进行了实验,包括图像分类、视觉问答(VQA)和视觉定位任务。实验设计了不同任务的评估,以全面验证LHRS-Bot的多任务解决能力。此外,还使用LHRS-Bench基准对不同LLMs在RS领域的性能进行了评估。实验结果表明,LHRS-Bot在RS图像理解任务中表现出色,特别是在检测复杂对象、参与人类对话和从视觉信息中提取见解方面。
Unified Hallucination Detection for Multimodal Large Language Models
➡️ 论文标题:Unified Hallucination Detection for Multimodal Large Language Models
➡️ 论文作者:Xiang Chen, Chenxi Wang, Yida Xue, Ningyu Zhang, Xiaoyan Yang, Qiang Li, Yue Shen, Lei Liang, Jinjie Gu, Huajun Chen
➡️ 研究机构: 浙江大学计算机科学与技术学院、浙江大学软件技术学院、浙江大学-蚂蚁集团知识图谱联合实验室、蚂蚁集团
➡️ 问题背景:尽管多模态大语言模型(Multimodal Large Language Models, MLLMs)在多模态任务中取得了显著进展,但它们面临着生成内容与输入数据或已知世界知识相矛盾的问题,即“幻觉”(hallucination)。这种幻觉现象阻碍了MLLMs的实际应用,并可能导致错误信息的传播。
➡️ 研究动机:现有的幻觉检测研究主要集中在特定任务上,如图像描述,而忽略了文本到图像生成等任务。此外,这些研究在幻觉类别和评估粒度方面也存在局限性。为了克服这些限制,研究团队提出了一种统一的多模态幻觉检测框架,旨在涵盖更广泛的多模态任务和幻觉类别,提供更细粒度的评估。
➡️ 方法简介:研究团队构建了一个多模态幻觉检测基准(MHaluBench),该基准涵盖了多种幻觉类别和多模态任务,并具备细粒度的分析功能。此外,团队还提出了一种统一的幻觉检测框架(UNIHD),该框架通过提取核心声明、自主选择工具、并行执行工具和幻觉验证等步骤,利用多种辅助工具来检测MLLMs生成内容中的幻觉。
➡️ 实验设计:研究团队在MHaluBench基准上进行了实验,评估了UNIHD框架的有效性。实验设计了多种任务,包括图像到文本生成和文本到图像生成,通过细粒度的声明提取和工具辅助验证,全面评估了模型在不同任务中的幻觉检测能力。实验结果表明,UNIHD框架在检测幻觉方面表现出色,但多模态幻觉检测仍然是一个具有挑战性的任务。
The Instinctive Bias: Spurious Images lead to Illusion in MLLMs
➡️ 论文标题:The Instinctive Bias: Spurious Images lead to Illusion in MLLMs
➡️ 论文作者:Tianyang Han, Qing Lian, Rui Pan, Renjie Pi, Jipeng Zhang, Shizhe Diao, Yong Lin, Tong Zhang
➡️ 研究机构: The Hong Kong University of Science and Technology (HKUST), University of Illinois at Urbana-Champaign (UIUC), The Hong Kong Polytechnic University (PolyU), NVIDIA
➡️ 问题背景:大型语言模型(LLMs)近年来取得了显著进展,尤其是多模态大型语言模型(MLLMs)的出现,赋予了LLMs视觉处理能力,从而在多种多模态任务中表现出色。然而,当这些模型面对某些图像和文本输入时,表现却大打折扣。研究发现,当输入的图像与问题相关但不一致时,MLLMs会受到视觉幻觉的影响,导致错误的输出。
➡️ 研究动机:现有的研究主要集中在简单的视觉问答任务上,而忽略了复杂视觉推理场景中MLLMs的表现。研究团队发现,MLLMs在处理复杂视觉问题时,倾向于忽略问题的语义信息,直接根据图像中的对象进行回答,而不是利用其推理能力。为了量化这一问题,研究团队设计了一个新的基准测试CorrelationQA,以评估MLLMs在面对误导性图像时的视觉幻觉程度。
➡️ 方法简介:研究团队提出了一个系统的方法,通过构建CorrelationQA基准测试,评估MLLMs在面对误导性图像时的表现。CorrelationQA包含7,308个文本-图像对,涵盖13个类别。每个问题-答案对包含多个与答案相关的图像,这些图像可能会误导MLLMs。研究团队首先使用GPT-4生成有意义的问题-答案对,然后利用先进的扩散模型生成相应的误导性图像,包括自然图像和OCR图像。
➡️ 实验设计:研究团队在CorrelationQA基准测试上评估了9个主流的MLLMs,包括LLaVA-13B、LLaVA-7B、CogVLM、InstructBlip、Idefics、mPLUG-Owl2、Qwen-VL、GPT4-V和Mini-GPT4。实验设计了不同的图像类型(如事实图像、误导性图像、随机图像和OCR图像),以及不同的评估指标(如成功回答率和准确率下降),以全面评估MLLMs在不同条件下的表现。实验结果表明,所有测试的MLLMs在面对误导性图像时都表现出不同程度的视觉幻觉,尤其是在OCR图像上表现更为明显。
相关文章:
多模态大语言模型arxiv论文略读(三十三)
Jailbreaking Attack against Multimodal Large Language Model ➡️ 论文标题:Jailbreaking Attack against Multimodal Large Language Model ➡️ 论文作者:Zhenxing Niu, Haodong Ren, Xinbo Gao, Gang Hua, Rong Jin ➡️ 研究机构: Xidian Univer…...
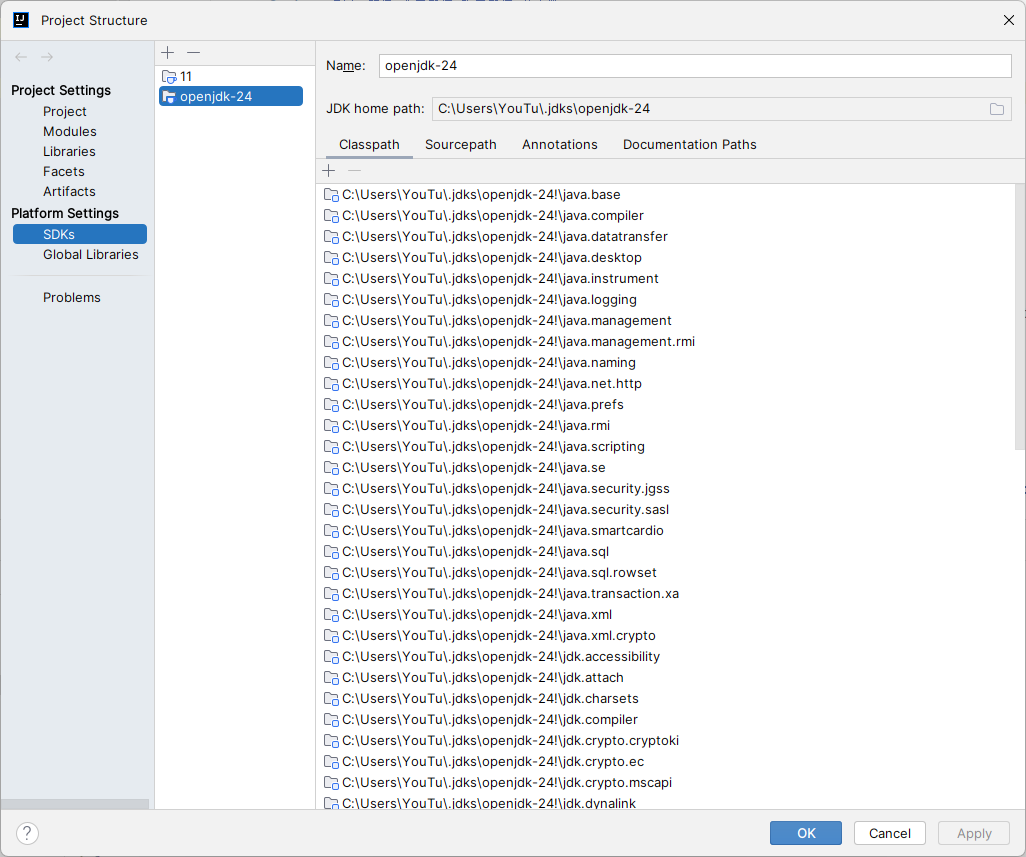
IntelliJ IDEA download JDK
IntelliJ IDEA download JDK 自动下载各个版本JDK,步骤 File - Project Structure (快捷键 Ctrl Shift Alt S) 如果下载失败,换个下载站点吧。一般选择Oracle版本,因为java被Oracle收购了 好了。 花里胡哨&#…...
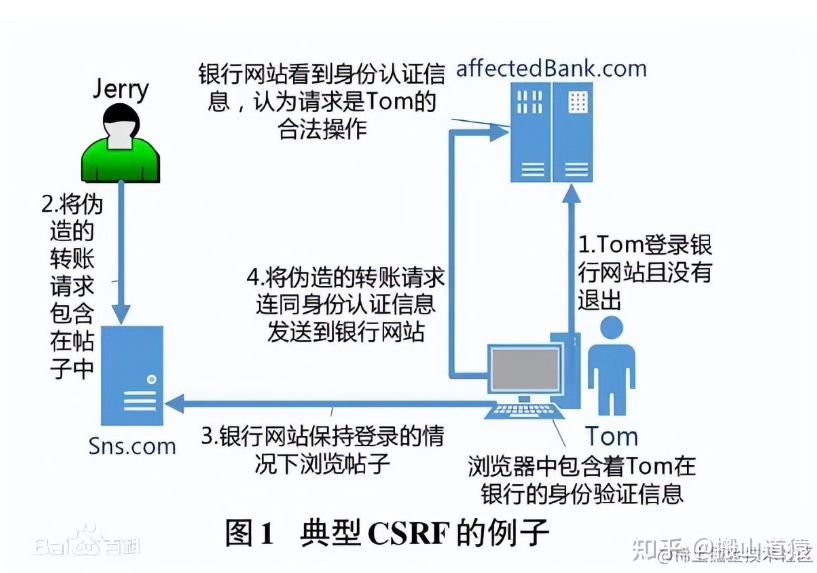
计算机网络——常见的网络攻击手段
什么是XSS攻击,如何避免? XSS 攻击,全称跨站脚本攻击(Cross-Site Scripting),这会与层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,因此有人将跨站脚本攻击缩写为XSS。它指的是恶意攻击者往Web页面…...

Android动态化技术优化
Android动态化技术优化 一、WebView优化基础 1.1 WebView性能瓶颈 初始化耗时内存占用高页面加载慢白屏问题1.2 WebView基本配置 class OptimizedWebView : WebView {init {// 开启硬件加速setLayerType(LAYER_TYPE_HARDWARE, null...
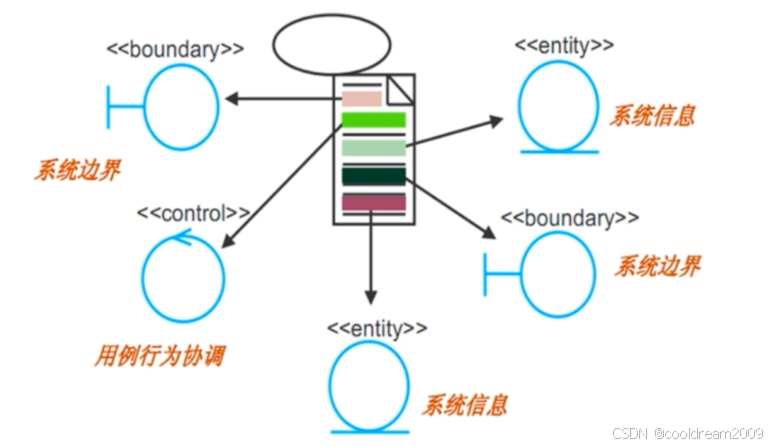
面向对象设计中的类的分类:实体类、控制类和边界类
目录 前言1. 实体类(Entity Class)1.1 定义和作用1.2 实体类的特点1.3 实体类的示例 2. 控制类(Control Class)2.1 定义和作用2.2 控制类的特点2.3 控制类的示例 3. 边界类(Boundary Class)3.1 定义和作用3…...
鸿蒙ArkUI实战之TextArea组件、RichEditor组件、RichText组件、Search组件的使用
本文接上篇继续更新ArkUI中组件的使用,本文介绍的组件有TextArea组件、RichEditor组件、RichText组件、Search组件,这几个组件的使用对应特定场景,使用时更加需要注意根据需求去使用 TextArea组件 官方文档: TextArea-文本与输…...
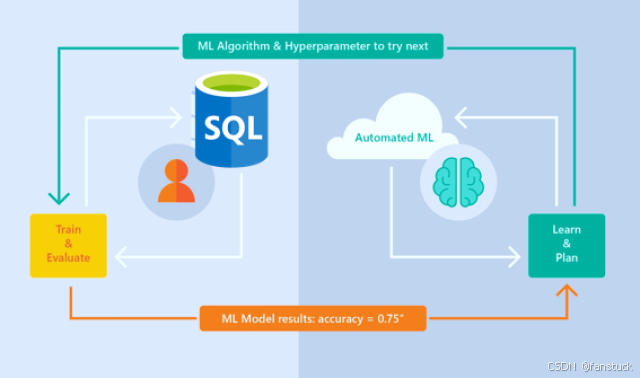
初创企业机器学习训练:云服务器配置对效率、成本与可扩展性的影响
在当今的初创企业中,机器学习模型训练已成为驱动创新和智能产品的核心环节。然而,深度学习模型的训练通常需要大量的计算资源,如何高效利用云服务器的基础配置成为初创团队关注的重点。云服务器的基础配置通常包括 vCPU(虚拟CPU&a…...

【“星瑞” O6 评测】—NPU 部署 face parser 模型
前言 瑞莎星睿 O6 (Radxa Orion O6) 拥有高达 28.8TOPs NPU (Neural Processing Unit) 算力,支持 INT4 / INT8 / INT16 / FP16 / BF16 和 TF32 类型的加速。这里通过通过官方的工具链进行FaceParsingBiSeNet的部署 1. FaceParsingBiSeNet onnx 推理 首先从百度网盘…...

56、如何快速让⼀个盒⼦⽔平垂直居中
在网页开发中,有多种方式能让一个盒子实现水平垂直居中。下面为你介绍几种常见且快速的方法。 1. 使用 Flexbox 布局 Flexbox 是一种非常便捷的布局模型,能够轻松实现元素的水平和垂直居中。 html <!DOCTYPE html> <html lang"en"&…...

互联网大厂Java面试:Spring Cloud与微服务的奇妙之旅
互联网大厂Java面试:Spring Cloud与微服务的奇妙之旅 在一家知名的互联网公司,一位严肃且专业的面试官正准备对求职者进行技术考察。而这次的应聘者,是自称拥有丰富经验但实际上却是个搞笑的水货程序员——马飞机。接下来,我们将…...

BDO分厂积极开展“五个一”安全活动
BDO分厂为规范化学习“五个一”活动主题,按照“上下联动、分头准备 、差异管理、资源共享”的原则,全面激活班组安全活动管理新模式,正在积极开展班组安全活动,以单元班组形式对每个班组每周组织一次“五个一”安全活动。 丁二醇单…...
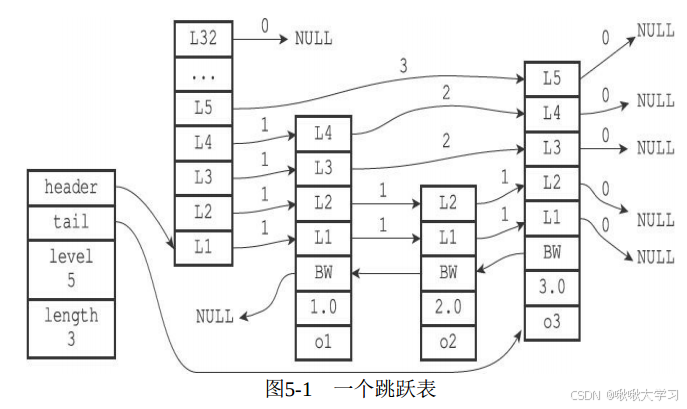
[Redis]1-高效的数据结构P2-Set
按照惯例,先丢一个官网文档链接。 上篇我们已经了解了高效的数据结构P1-String与Hash。 这篇,我们继续来了解Redis的 Set 与 Sorted set。 目录 有序集合 Sorted set底层实现 集合 Set总结资料引用 有序集合 Sorted set Redis 有序集合是一组唯一的字符…...

在ubuntu20.04上安装ros2
1,更新系统并安装依赖 sudo apt update sudo apt upgrade sudo apt install curl gnupg2 lsb-release2,增加ROS2仓库配置 echo "deb [archamd64] https://packages.ros.org/ros2/ubuntu focal main" | sudo tee /etc/apt/sources.list.d/ros…...
用ffmpeg 实现拉取h265的flv视频转存成264的mp4 实现方案
参考文章 支持 flvh265 的ffmpeg编译安装_demuxer flvhevc异常-CSDN博客 windwos有别人编译好的 支持HEVC/H265 RTMP播放的FFMPEG/FFPLAY WINDOWS版本 但是linux没有所以得自己编译 1.需要对ffmpeg进行源码修改 这里使用 https://github.com/numberwolf/FFmpeg-QuQi-H265-…...
加密与 SQL Server 建立安全连接“问题)
解决“驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接“问题
参考链接: https://blog.csdn.net/yyj12138/article/details/123073146...

[密码学实战]基于Python的国密算法与通用密码学工具箱
引言 在当今数字化浪潮中,信息安全已成为个人隐私保护与商业机密守护的核心议题。作为一位在密码学领域深耕多年的技术实践者,我深谙密码学工具在构建数字安全防线中的关键作用。正是基于这份认知与责任,我倾力打造了一款全方位、高性能的密码学工具,专为满足广大用户在日…...

论文降重GPT指令-实侧有效从98%降低到8%
步骤1:文本接收 指令: 请用户提供需要优化的文本内容。 对文本进行初步分析,识别文本的基本结构和风格。 操作: 接收并分析用户提交的文本。 步骤2:文本优化 2.1 连接词处理 指令: 删除或替换连接词&#x…...
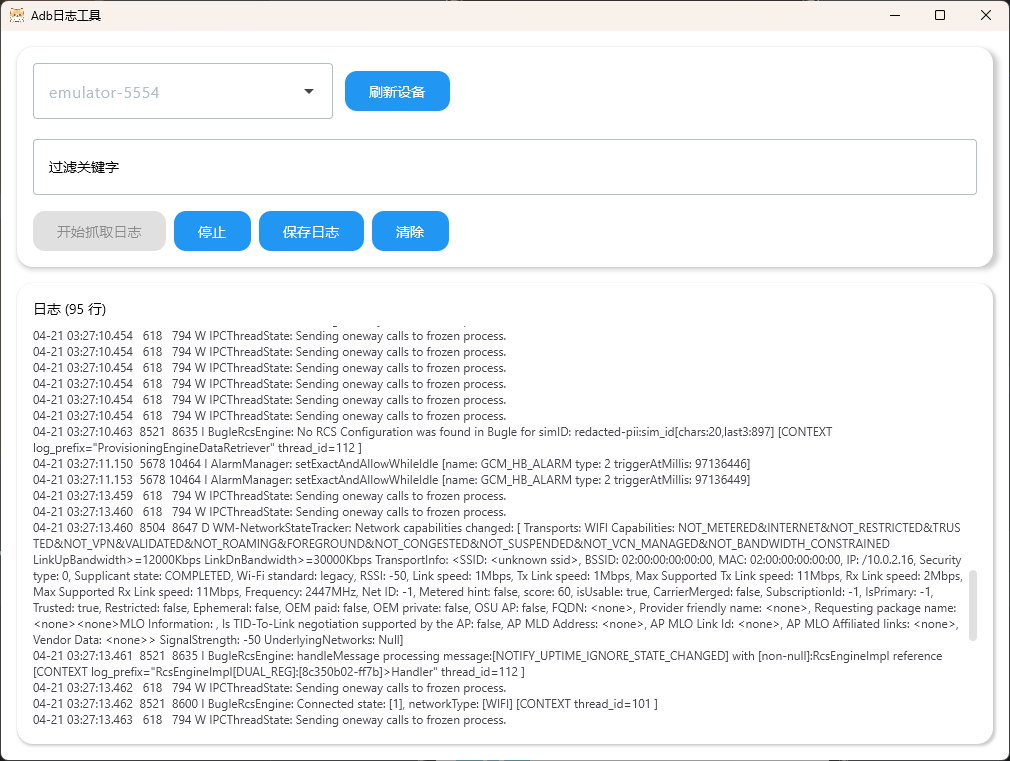
Compose Multiplatform Android Logcat工具
一、通过adb发送指令,收集设备日志并保存 二、UI 三、代码 /*** 获取设备列表*/fun getDevices(): List<String> {val process ProcessBuilder("adb", "devices").redirectErrorStream(true).start()val output process.inputStream.…...
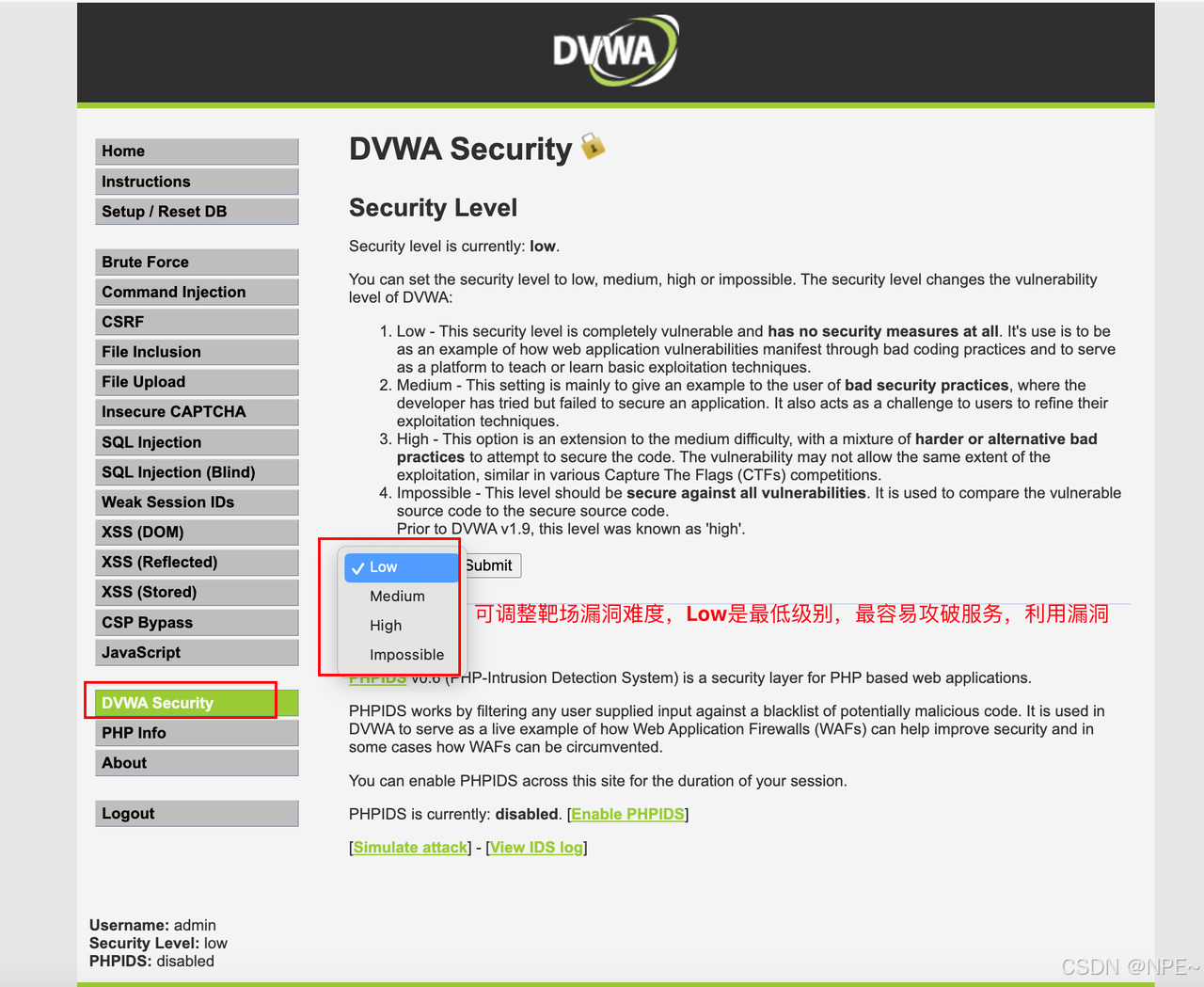
[渗透测试]渗透测试靶场docker搭建 — —全集
[渗透测试]渗透测试靶场docker搭建 — —全集 对于初学者来说,仅仅了解漏洞原理是不够的,还需要进行实操。对于公网上的服务我们肯定不能轻易验证某些漏洞,否则可能触犯法律。这是就需要用到靶场。 本文主要给大家介绍几种常见漏洞对应的靶场…...

JavaScript 渲染内容爬取:Puppeteer 入门
在现代网络应用中,许多网页内容是通过 JavaScript 渲染生成的,传统的爬虫工具往往难以获取这些动态内容。Puppeteer 作为一种强大的浏览器自动化工具,为这一问题提供了优雅的解决方案。本文将带你入门 Puppeteer,介绍如何安装、启…...

Ubuntu 系统下安装和使用性能分析工具 perf
在 Ubuntu 系统下安装和使用性能分析工具 perf 的步骤如下: 1. 安装 perf perf 是 Linux 内核的一部分,通常通过安装 linux-tools 包获取: # 更新软件包列表 sudo apt update# 安装 perf(根据当前内核版本自动匹配) …...

神经网络:从基础到应用,开启智能时代的大门
在当今数字化时代,神经网络已经成为人工智能领域最热门的技术之一。从语音识别到图像分类,从自然语言处理到自动驾驶,神经网络的应用无处不在。它不仅改变了我们的生活方式,还为各个行业带来了前所未有的变革。本文将带你深入了解…...
人工智能-机器学习(线性回归,逻辑回归,聚类)
人工智能概述 人工智能分为:符号学习,机器学习。 机器学习是实现人工智能的一种方法,深度学习是实现机器学习的一种技术。 机器学习:使用算法来解析数据,从中学习,然后对真实世界中是事务进行决策和预测。如垃圾邮件检…...

密码明文放在请求体是否有安全隐患?
明文密码放在请求体中是有安全隐患的,但这个问题可以被控制和缓解,关键在于是否采取了正确的安全措施。 ⚠️ 为什么明文密码有风险? 中间人攻击(MitM): 如果使用 HTTP 明文传输,攻击者可以在数…...

EMQX学习笔记
MQTT简介 MQTT是一种基于发布订阅模式的消息传输协议 消息:设备和设备之间传输的数据,或者服务和服务之间传输的数据 协议:传输数据时所遵循的规则 轻量级:MQTT协议占用的请求源较少,数据报文较小 可靠较强ÿ…...
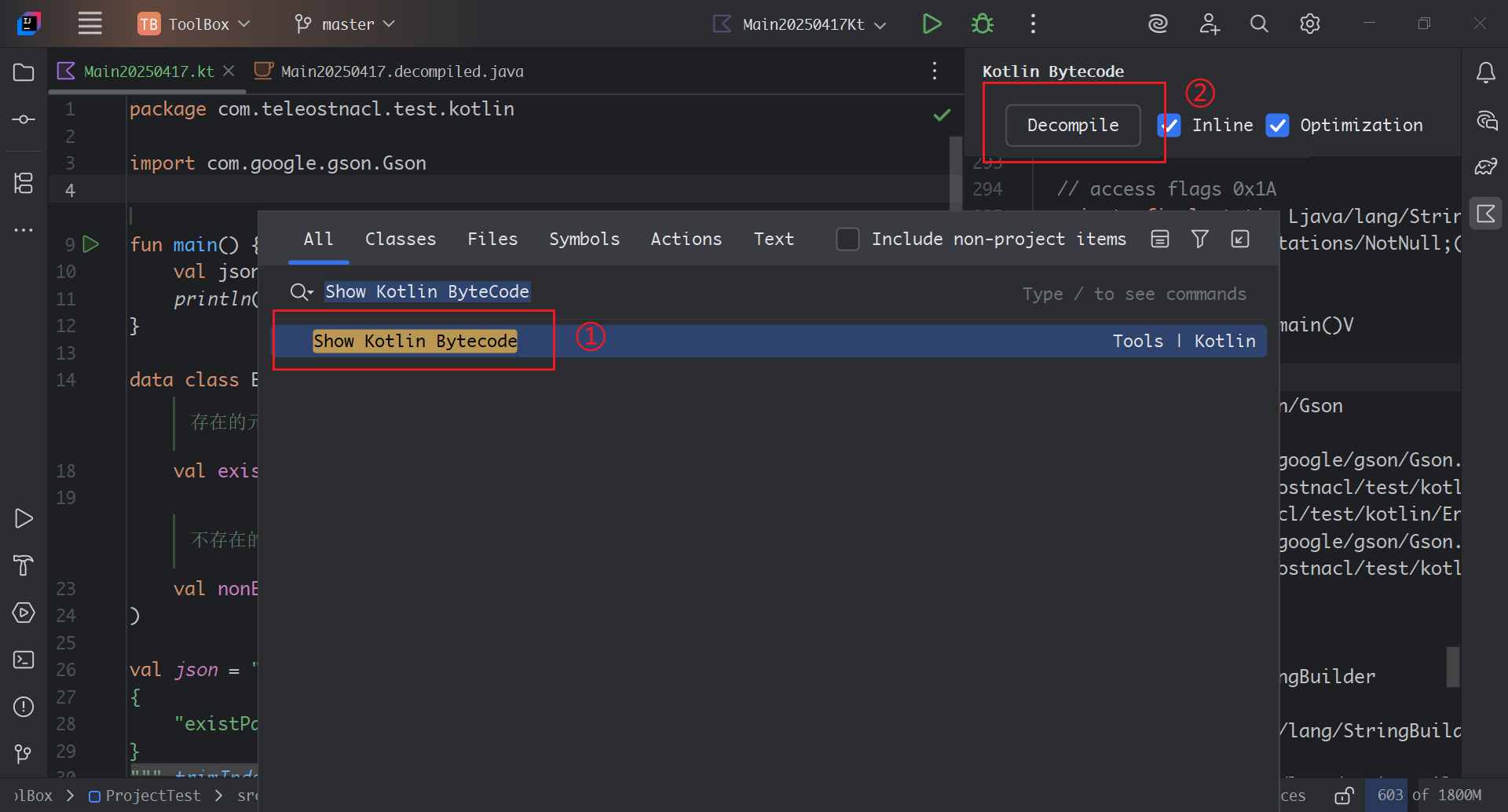
探寻Gson解析遇到不存在键值时引发的Kotlin的空指针异常的原因
文章目录 一、问题背景二、问题原因三、问题探析Kotlin空指针校验Gson.fromJson(String json, Class<T> classOfT)TypeTokenGson.fromJson(JsonReader reader, TypeToken<T> typeOfT)TypeAdapter 和 TypeAdapterFactoryReflectiveTypeAdapterFactoryRecordAdapter …...
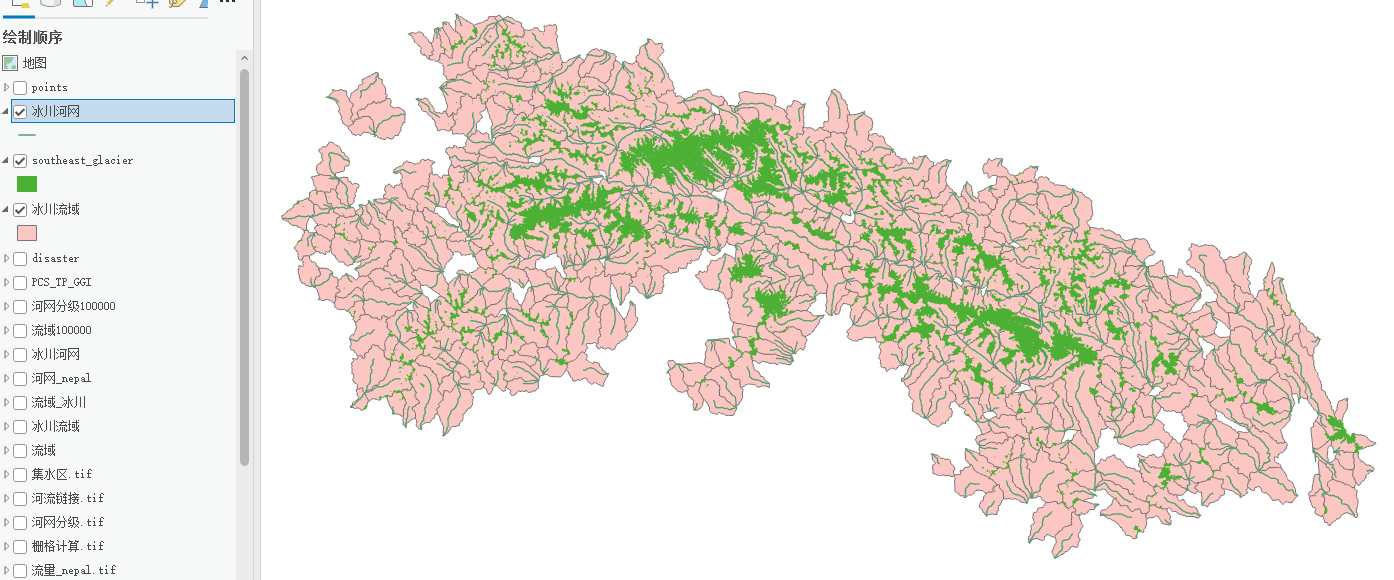
冰川流域提取分析——ArcGIS pro
一、河网提取和流域提取视频详细GIS小熊 || 6分钟学会水文分析—河网提取(以宜宾市为例)_哔哩哔哩_bilibili 首先你要生成研究区域DEM,然后依次是填洼→流向→流量→栅格计算器→河网分级→栅格河网矢量化(得到河网.shpÿ…...

wordpress 垂直越权(CVE=2021-21389)漏洞复现详细教程
关于本地化搭建vulfocus靶场的师傅可以参考我置顶文章 KALI搭建log4j2靶场及漏洞复现全流程-CSDN博客https://blog.csdn.net/2301_78255681/article/details/147286844 描述: BuddyPress 是一个用于构建社区站点的开源 WordPress 插件。在 7.2.1 之前的 5.0.0 版本的 BuddyP…...
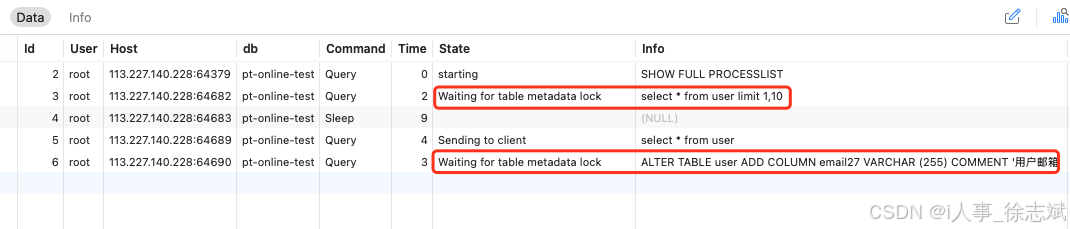
MySQL 线上大表 DDL 如何避免锁表(pt-online-schema-change)
文章目录 1、锁表问题2、pt-online-schema-change 原理3、pt-online-schema-change 实战3.1、准备数据3.2、安装工具3.3、模拟锁表3.4、解决锁表 1、锁表问题 在系统研发过程中,随着业务需求千变万化,避免不了调整线上MySQL DDL数据表的操作,…...

uni-app 状态管理深度解析:Vuex 与全局方案实战指南
uni-app 状态管理深度解析:Vuex 与全局方案实战指南 一、Vuex 使用示例 1. 基础 Vuex 配置 1.1 项目结构 src/ ├── store/ │ ├── index.js # 主入口文件 │ └── modules/ │ └── counter.js # 计数器模块 └── main.js …...