人工智能-机器学习(线性回归,逻辑回归,聚类)
人工智能概述
人工智能分为:符号学习,机器学习。
机器学习是实现人工智能的一种方法,深度学习是实现机器学习的一种技术。
机器学习:使用算法来解析数据,从中学习,然后对真实世界中是事务进行决策和预测。如垃圾邮件检测,楼房价格预测。
深度学习:模仿人类神经网络,建立模型,进行数据分析。如,人脸识别,语义理解,无人驾驶。
工具
Anaconda
Anaconda是一个方便的python包管理和环境管理的软件
可以跨平台,多python版本并存,部署方便
Jupyter Notebook
Jupyter notebook是一个开源的web应用程序,允许开发者方便的创建和共享代码文档
允许吧代码写入独立的cell中,单独执行。用户可以单独测试特定代码块,无需从头开始执行代码。
基础工具包
Panda
强大的分析结构化数据的工具集,可用于快速实现数据导入/出,索引
www.pypandas.cn
Numpy
使用Python进行科学计算的基础软件包。核心:基于N维数组对象ndarray的数组运算。
www.numpy.org.cn
Matplolib
Python基础绘图库,几行代码即可生成绘图
www.matplotlib.org.cn
机器学习的类别
监督学习(Supervised Learning)
-训练数据包括正确的结果
无监督学习(Unsupervised Learning)
-训练数据不包括正确的结果
半监督学习(Semi-supervised Learning)
-训练数据包括少量正确的结果
强化学习(Reinforcement Learning)
-根据每次结果收获的奖惩进行学习,实现优化
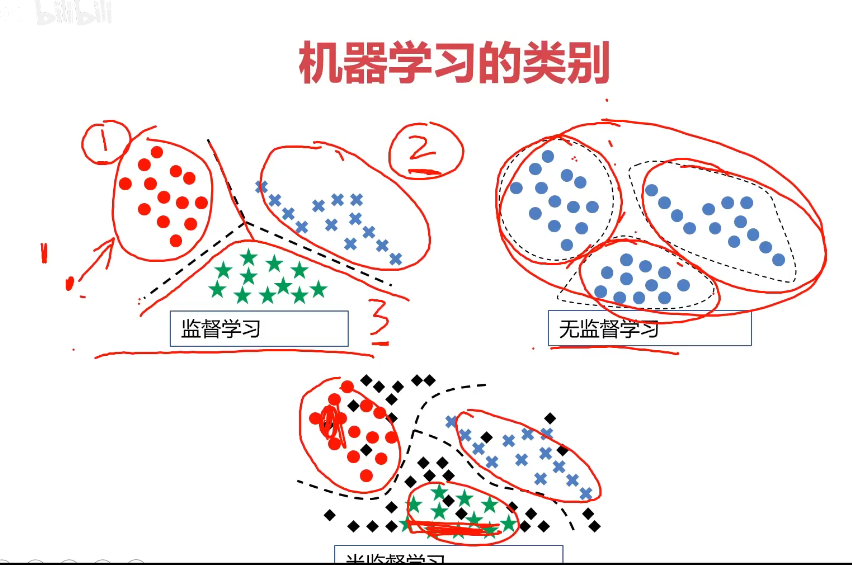
监督学习:线性回归,逻辑回归,决策树,神经网络,卷积神经网络,循环神经网络。
无监督学习:聚类算法
混合学习:监督学习+无监督学习
什么是回归分析?
回归分析:根据数据,确定两种或两种以上变量间相互依赖的定量关系
线性回归:回归分析中,变量与因变量存在线性关系
梯度下降法:
寻找极小值的一种方法。通过向函数上当前点对应梯度的反方向的规定步长距离点进行迭代搜索,直到在极小点收敛。

Scikit-learn
Python语言中专门针对机器学习应用而发展起来的一款开源框架(算法库),可以实现数据预处理,分类,回归,降维,模型选择等常用的机器学习算法
集成了机器学习中各类成熟的算法,不支持深度学习和强化学习。
https://scikit-learn.org/stable/index.html
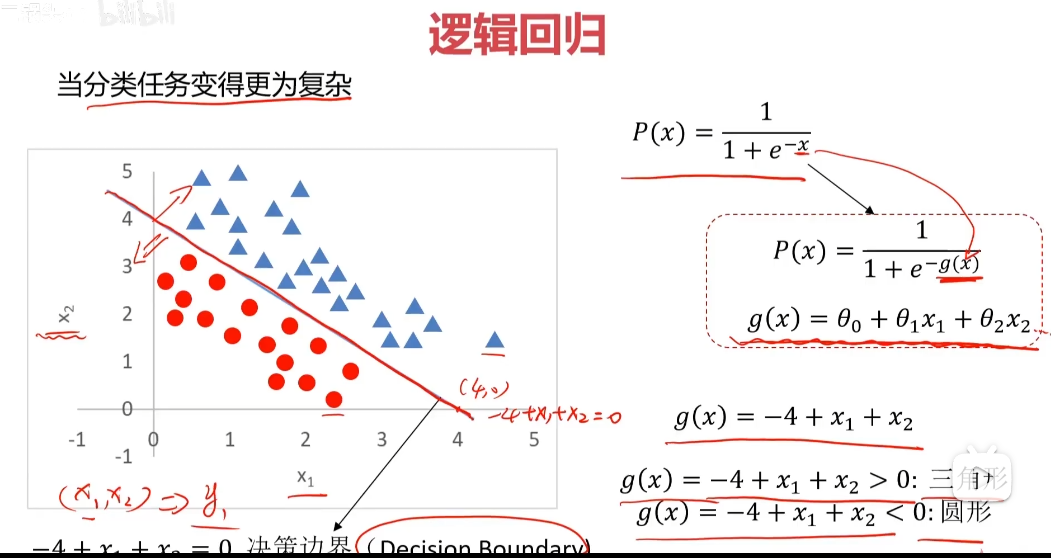
分类问题
分类:根据已知样本的某些特征,判断一个显得样本属于那种已知的样本类
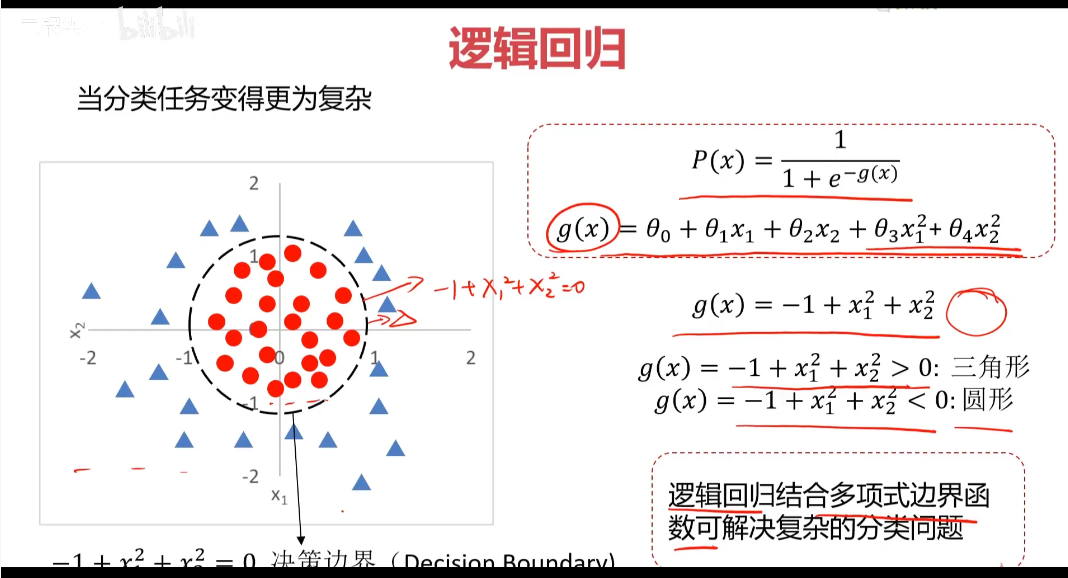
使用逻辑回归拟合数据,可以很好的完成分类任务
线性:y=ax+b
逻辑:y=1/(1+e^(-x)) sigmoid方程 通用公式:P(x)=1/(1+e^(-g(x)))
找到决策边界(Decision Boundary)很关键
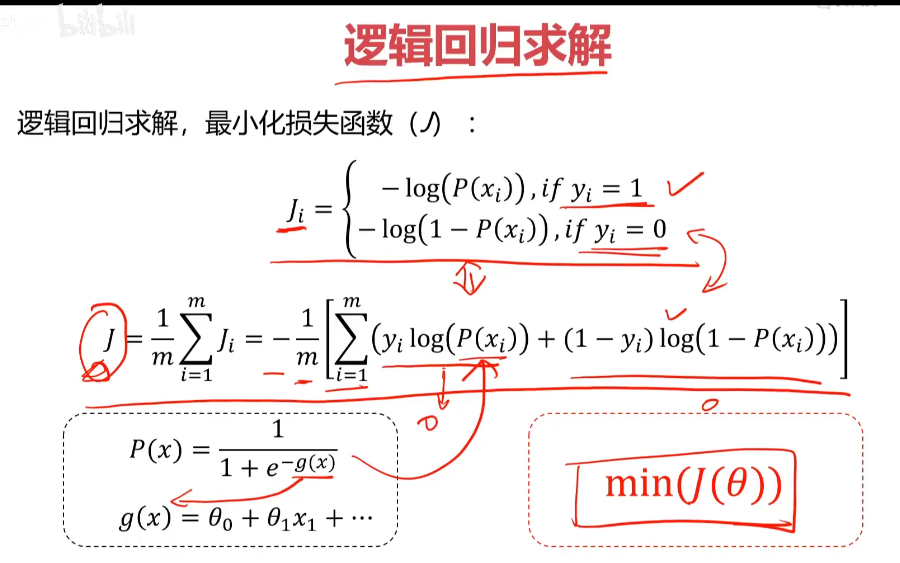
分类任务的损失函数:

逻辑回归实战
实战1考试通过预测
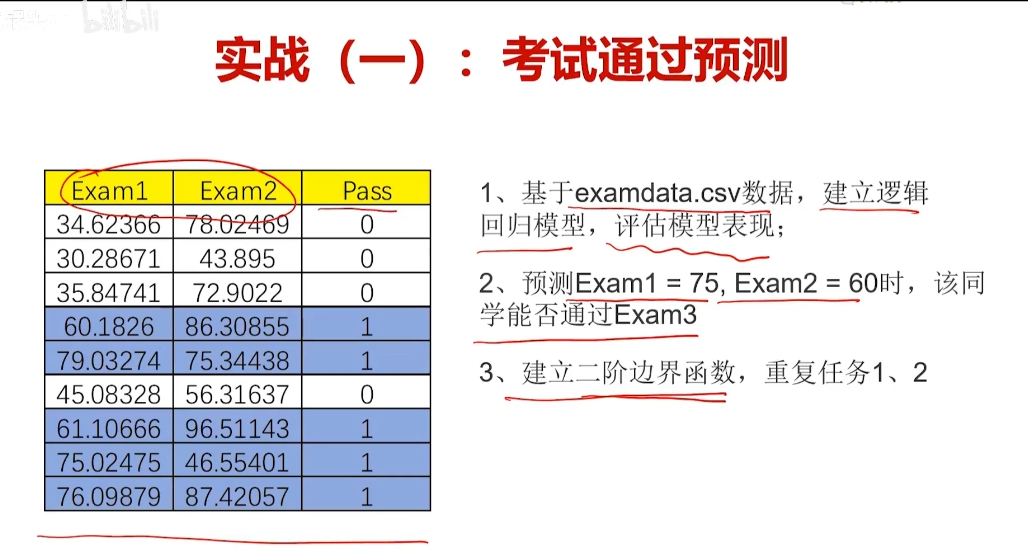
无监督学习
机器学习的一种方法,没有给定先标记过的训练示例,自动对输入的数据进行分类或分群
聚类分析
聚类分析又称为群分析,根据对象某些属性的相似度,将其自动划分为不同的类别。
应用场景:客户划分,基因聚类,新闻关联
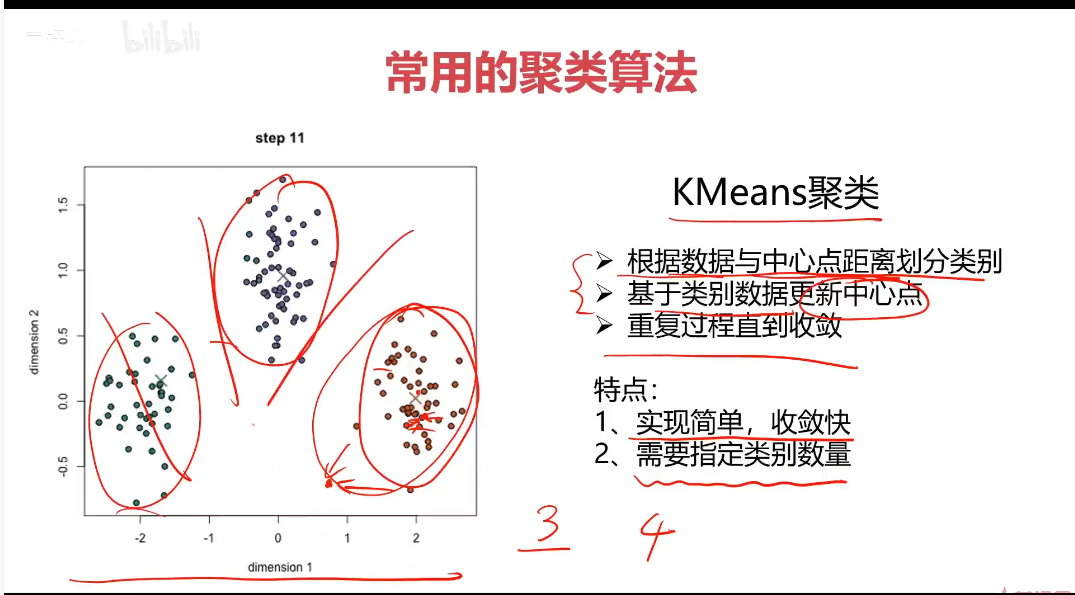
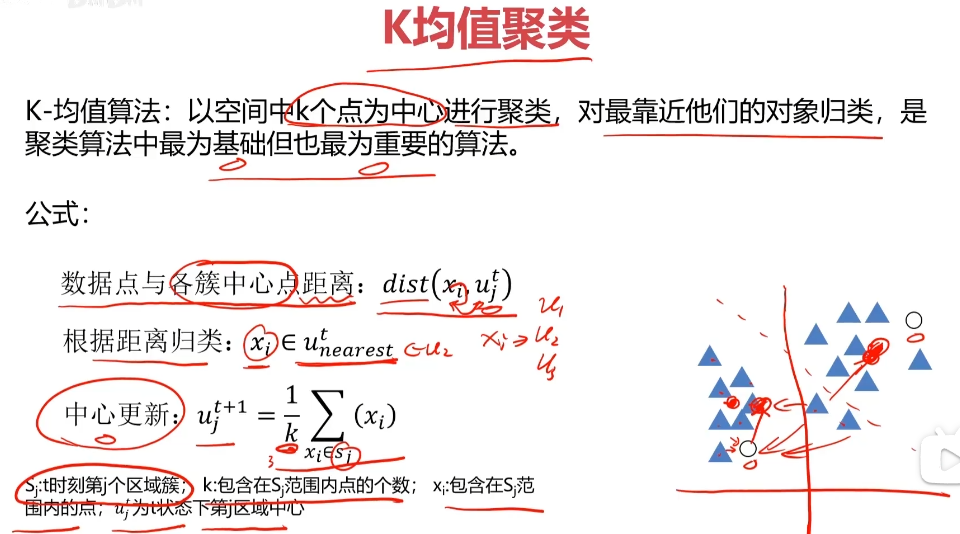
KMeans
K-均值算法:以空间中k个点为中心进行聚类,对最靠近他们的对象归类,是聚类算法中最为基础但也最为重要的算法。
算法流程:
1.选择聚类的个数k
2.确定聚类的中心
3.根据点道聚类中心聚类确定各个点所属类别
4.根据各个类别数据更新聚类中心
5.重复以上步骤直到收敛(中心点不再变化)
优点:
1.简单易实现,收敛速度快
2.参数少
缺点:
1.必须设置簇的数量
2.随机选择初始聚类中心,结果可能缺乏一致性
KNN
K近邻分类模型
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中

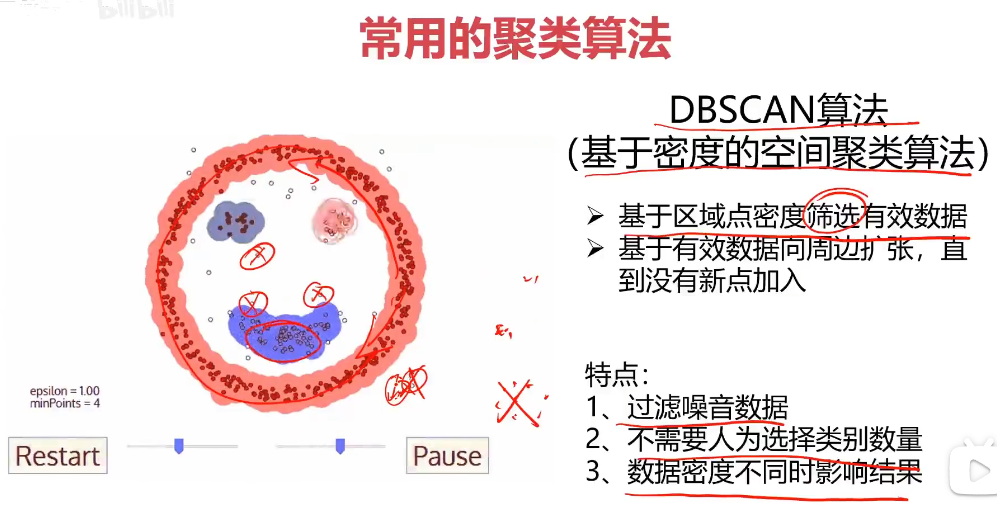
Mean-shift



聚类实战
KMeans实现聚类
模型训练
form sklearn.cluster import KMeans
KM = KMeans(n_clusters=3,random_state=0)
KM.fit(X)
获取中心点:
centers = KM.cluster_centers_
准确率计算:
form sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
预测结果矫正(比如原始数据是0,1,2但是KNN预测的乱序了,如2,0,1):
y_cal = []
for i in y_predict:if i == 0:y_cla.append(2)elif i == 1:y_cal.append(0)else:y_cal.append(1)print(y_predict, y_cal0
Meanshift实现聚类
自动计算带宽(区域半径)
from sklearn.cluster import MeanShift,estimate_bandwidth
#detect bandwidth
bandwidth = estimate_bandwidth(X,n_samples=500)
#X样本数量,n_samples采样的样本数量
模型建立于训练
ms = MeanShift(bandwidth=bandwidth)
ms.fit(X)
KNN实现分类
模型训练
form sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X,y)
实战:2D数据类别划分
1.采用Kmeans算法实现2D数据自动聚类,预测V1=80,V2=60数据类别;
2.计算预测准确率,完成结果矫正
3.采用KNN,Meanshift算法,重复步骤1-2
KMeans算法实现
#load the data
import pandas as pd
import numpy as np
data = pd.read_csv('data.csv')
data.head()
#define X and y
X = data.drop(['labels'],axis=1)
y = data.loc[:,'labels']
y.head()
pd.value_counts(y)
%matplotlib inline
from matplotlib import pyplot as plt
plt.scatter(X.loc[:,'V1'],X.loc[:'V2'])
plt.title("un-labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.show()fig1 = plt.figure()
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:'V2'][y==2])plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.show()
print(X.shape, y.shape)
#set the model
from sklearn.cluster import KMeans
KM = KMeans(n_cluster=3,random_sate=0)
KM.fit(X)centers = KM.cluster_centers_
fig3 = plt.figure()
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:'V2'][y==2])plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
#test data: V1=80,V2=60
y_predict_test = KM.predict([[80, 60]])
print(y_predict_test )#predict based on training data
y_predict = KM.predict(X)
print(pd.value_counts(y_predict), pd.value_counts(y))from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
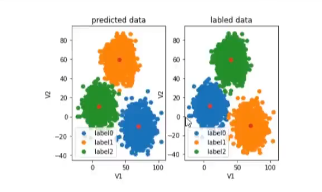
#visualize the data and results
fig4 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_predict==0],X.loc[:'V2'][y_predict==0])
label1 = plt.scatter(X.loc[:,'V1'][y_predict==1],X.loc[:'V2'][y_predict==1])
label2 = plt.scatter(X.loc[:,'V1'][y_predict==2],X.loc[:'V2'][y_predict==2])plt.title("predict data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])fig5 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:'V2'][y==2])plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])plt.show()
#correct the resultsy_corrected = []for i in y_predict:if i == 0:y_corrected.append(1)elif i == 1:y_corrected.append(2) else:y_corrected.append(0) print(pd.value_counts(y_corrected), pd.value_counts(y))
print(accuracy_score(y, y_corrected))
y_corrected = np.array(y_corrected)
print(type(y_corrected))
#visualize the data and results
fig6 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_corrected==0],X.loc[:'V2'][y_corrected==0])
label1 = plt.scatter(X.loc[:,'V1'][y_corrected==1],X.loc[:'V2'][y_corrected==1])
label2 = plt.scatter(X.loc[:,'V1'][y_corrected==2],X.loc[:'V2'][y_corrected==2])plt.title("predict data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])fig7 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:'V2'][y==2])plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])plt.show()
KNN算法实现
查看数据
X.head()
y.head()
#establish a KNN model
from sklearn.neighbors import KNeighborsClassifier
KNN = KNeighborsClassifier(n_neighbors=3)
KNN.fit(X,y)
#predict based on the test data V1=80, V2=60
y_predict_knn_test = KNN.predict([[80, 60]])
y_predict_knn = KNN.predict(X)
print(y_predict_knn_test)
print('knn accuracy:', accuracy_score(y, y_predict_knn))
fig6 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_predict_knn==0],X.loc[:'V2'][y_predict_knn==0])
label1 = plt.scatter(X.loc[:,'V1'][y_predict_knn==1],X.loc[:'V2'][y_predict_knn==1])
label2 = plt.scatter(X.loc[:,'V1'][y_predict_knn==2],X.loc[:'V2'][y_predict_knn==2])plt.title("knn results")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])fig7 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:'V2'][y==2])plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])plt.show()
MeanShift
#meanshift
form sklearn.cluster import MeanShift,estimate_bandwidth
#obtain the bandwidth
bw = estimate_bandwidth(X,n_samples=500)
print(bw)
#establish the meanshift model-un-supervised model
ms = MeanShift(bandwidth=bw)
ms.fit(X)
y_predict_ms = ms.predict(X)
print(pd.value_counts(y_predict_ms), pd.value_counts(y))
fig6 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_predict_knn_ms==0],X.loc[:'V2'][y_predict_knn_ms==0])
label1 = plt.scatter(X.loc[:,'V1'][y_predict_knn_ms==1],X.loc[:'V2'][y_predict_knn_ms==1])
label2 = plt.scatter(X.loc[:,'V1'][y_predict_knn_ms==2],X.loc[:'V2'][y_predict_knn_ms==2])plt.title("kmeanshift results")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])fig7 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:'V2'][y==2])plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])plt.show()
#correct the resultsy_corrected_ms = []for i in y_predict_ms:if i == 0:y_corrected_ms .append(2)elif i == 1:y_corrected_ms .append(1) else:y_corrected_ms .append(0) print(pd.value_counts(y_corrected_ms), pd.value_counts(y))
#convert the results to numpy array
y_corrected = np.array(y_corrected_ms)
print(type(y_corrected_ms)
fig6 = plt.subplot(121)
label0 = plt.scatter(X.loc[:,'V1'][y_predict_knn_ms==0],X.loc[:'V2'][y_predict_knn_ms==0])
label1 = plt.scatter(X.loc[:,'V1'][y_predict_knn_ms==1],X.loc[:'V2'][y_predict_knn_ms==1])
label2 = plt.scatter(X.loc[:,'V1'][y_predict_knn_ms==2],X.loc[:'V2'][y_predict_knn_ms==2])plt.title("ms correct results")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])fig7 = plt.subplot(122)
label0 = plt.scatter(X.loc[:,'V1'][y==0],X.loc[:'V2'][y==0])
label1 = plt.scatter(X.loc[:,'V1'][y==1],X.loc[:'V2'][y==1])
label2 = plt.scatter(X.loc[:,'V1'][y==2],X.loc[:'V2'][y==2])plt.title("labled data")
plt.xlabel('V1')
plt.ylabel('V2')
plt.legend((label0,label1,label2),('label0','label1','label2'))
plt.scatter(centers[:,0],centers[:,1])
plt.show()
##总结
kmeans\knn\meanshift
kmeans\meanshift: un-supervised, training data: X; kmeans: category number; meanshift: calculate the bandwidth
knn: supervised; training data: X\y
相关文章:
人工智能-机器学习(线性回归,逻辑回归,聚类)
人工智能概述 人工智能分为:符号学习,机器学习。 机器学习是实现人工智能的一种方法,深度学习是实现机器学习的一种技术。 机器学习:使用算法来解析数据,从中学习,然后对真实世界中是事务进行决策和预测。如垃圾邮件检…...

密码明文放在请求体是否有安全隐患?
明文密码放在请求体中是有安全隐患的,但这个问题可以被控制和缓解,关键在于是否采取了正确的安全措施。 ⚠️ 为什么明文密码有风险? 中间人攻击(MitM): 如果使用 HTTP 明文传输,攻击者可以在数…...

EMQX学习笔记
MQTT简介 MQTT是一种基于发布订阅模式的消息传输协议 消息:设备和设备之间传输的数据,或者服务和服务之间传输的数据 协议:传输数据时所遵循的规则 轻量级:MQTT协议占用的请求源较少,数据报文较小 可靠较强ÿ…...
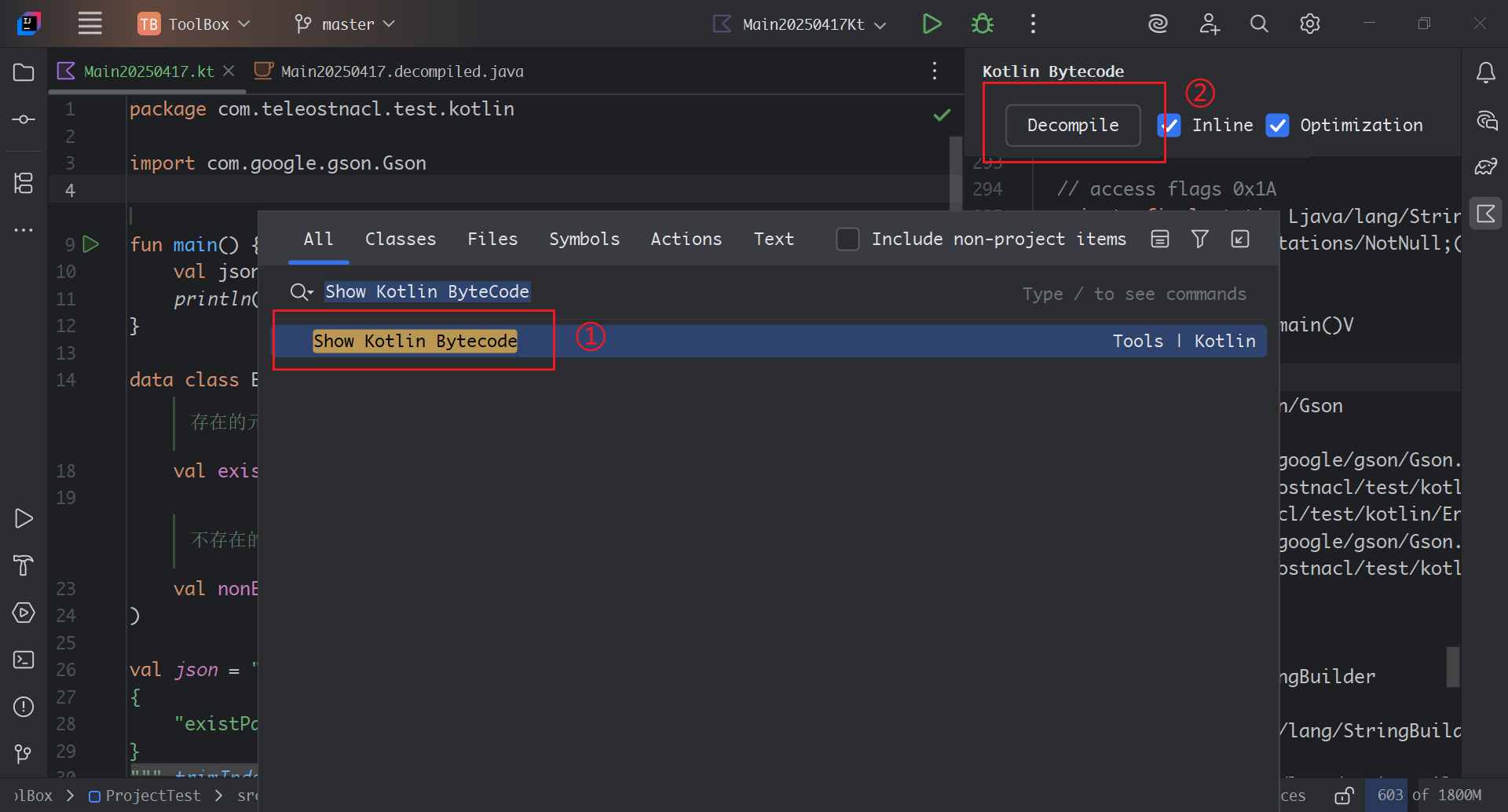
探寻Gson解析遇到不存在键值时引发的Kotlin的空指针异常的原因
文章目录 一、问题背景二、问题原因三、问题探析Kotlin空指针校验Gson.fromJson(String json, Class<T> classOfT)TypeTokenGson.fromJson(JsonReader reader, TypeToken<T> typeOfT)TypeAdapter 和 TypeAdapterFactoryReflectiveTypeAdapterFactoryRecordAdapter …...
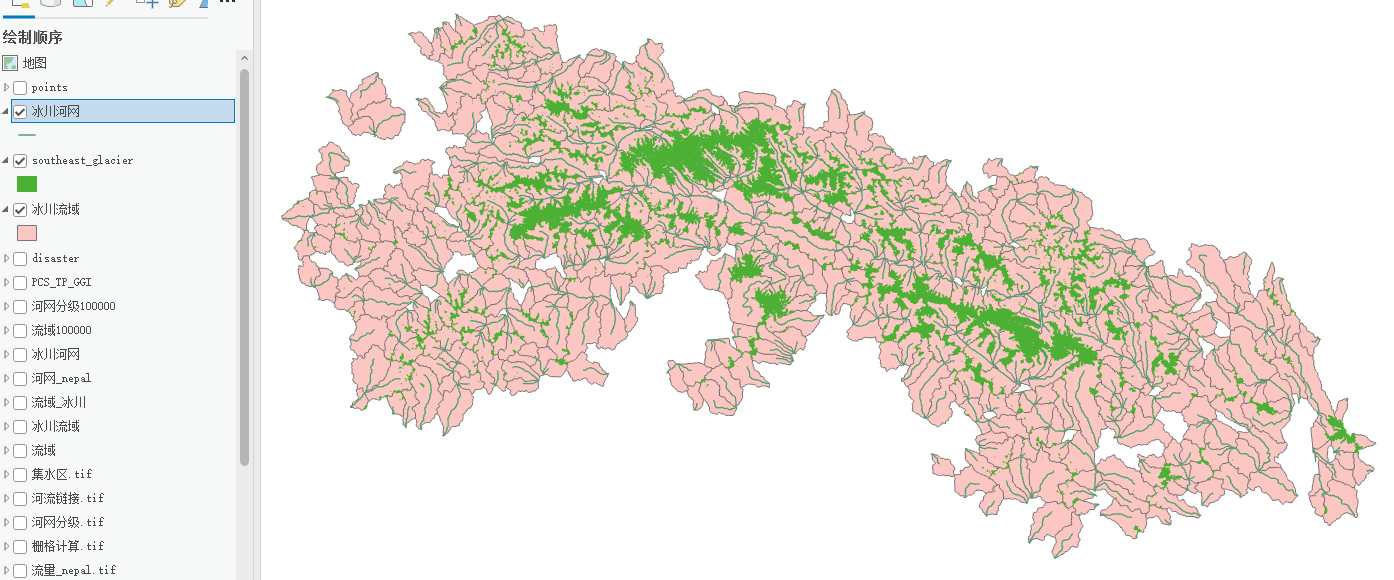
冰川流域提取分析——ArcGIS pro
一、河网提取和流域提取视频详细GIS小熊 || 6分钟学会水文分析—河网提取(以宜宾市为例)_哔哩哔哩_bilibili 首先你要生成研究区域DEM,然后依次是填洼→流向→流量→栅格计算器→河网分级→栅格河网矢量化(得到河网.shpÿ…...

wordpress 垂直越权(CVE=2021-21389)漏洞复现详细教程
关于本地化搭建vulfocus靶场的师傅可以参考我置顶文章 KALI搭建log4j2靶场及漏洞复现全流程-CSDN博客https://blog.csdn.net/2301_78255681/article/details/147286844 描述: BuddyPress 是一个用于构建社区站点的开源 WordPress 插件。在 7.2.1 之前的 5.0.0 版本的 BuddyP…...
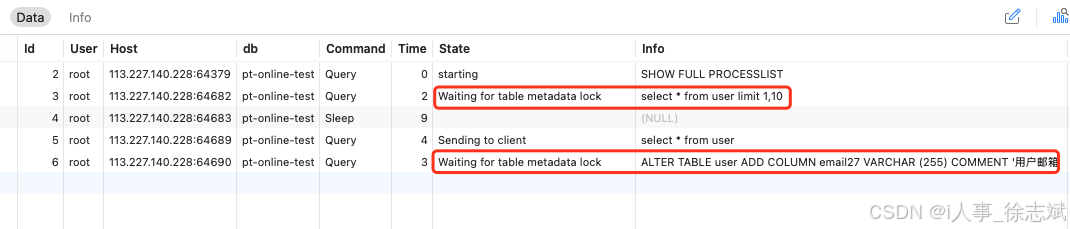
MySQL 线上大表 DDL 如何避免锁表(pt-online-schema-change)
文章目录 1、锁表问题2、pt-online-schema-change 原理3、pt-online-schema-change 实战3.1、准备数据3.2、安装工具3.3、模拟锁表3.4、解决锁表 1、锁表问题 在系统研发过程中,随着业务需求千变万化,避免不了调整线上MySQL DDL数据表的操作,…...

uni-app 状态管理深度解析:Vuex 与全局方案实战指南
uni-app 状态管理深度解析:Vuex 与全局方案实战指南 一、Vuex 使用示例 1. 基础 Vuex 配置 1.1 项目结构 src/ ├── store/ │ ├── index.js # 主入口文件 │ └── modules/ │ └── counter.js # 计数器模块 └── main.js …...
剑指offer经典题目(五)
目录 栈相关 二叉树相关 栈相关 题目一:定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的 min 函数,输入操作时保证 pop、top 和 min 函数操作时,栈中一定有元素。OJ地址 图示如下。 主要思想:我们…...

3、排序算法1---按考研大纲做的
一、插入排序 1、直接插入排序 推荐先看这个视频 1.1、原理 第一步,索引0的位置是有序区(有序区就是有序的部分,刚开始就只有第一个数据是有序的)。第二步,将第2个位置到最后一个位置的元素,依次进行排…...
llama-webui docker实现界面部署
1. 启动ollama服务 [nlp server]$ ollama serve 2025/04/21 14:18:23 routes.go:1007: INFO server config env"map[OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST: OLLAMA_KEEP_ALIVE:24h OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:4 OLLAMA_MAX_…...

jinjia2将后端传至前端的字典变量转换为JS变量
后端 country_dict {AE: .amazon.ae, AU: .amazon.com.au} 前端 const country_list JSON.parse({{ country_list | tojson | safe }});...

如何深入理解引用监视器,安全标识以及访问控制模型与资产安全之间的关系
一、核心概念总结 安全标识(策略决策的 “信息载体) 是主体(如用户、进程)和客体(如文件、数据库、设备)的安全属性,用于标记其安全等级、权限、访问能力或受保护级别,即用于标识其安全等级、权限范围或约束…...

Linux的Socket开发补充
是listen函数阻塞等待连接,还是accept函数阻塞等待连接? 这两个函数的名字,听起来像listen一直在阻塞监听,有连接了就accept,但其实不是的。 调用listen()后,程序会立即返回,继续执行后续代码&a…...

Flutter异常Couldn‘t find dynamic library in default locations
Flutter项目在Windows系统使用ffigen生成代码时报下面的错误: [SEVERE] : Couldnt find dynamic library in default locations. [SEVERE] : Please supply one or more path/to/llvm in ffigens config under the key llvm-path. Unhandled exception: Exception: …...

Spring-AOP分析
Spring分析-AOP 1.案例引入 在上一篇文章中,【Spring–IOC】【https://www.cnblogs.com/jackjavacpp/p/18829545】,我们了解到了IOC容器的创建过程,在文末也提到了AOP相关,但是没有作细致分析,这篇文章就结合示例&am…...

[特殊字符] Prompt如何驱动大模型对本地文件实现自主变更:Cline技术深度解析
在AI技术快速发展的今天,编程方式正在经历一场革命性的变革。从传统的"人写代码"到"AI辅助编程",再到"AI自主编程",开发效率得到了质的提升。Cline作为一款基于VSCode的AI编程助手,通过其独特的pro…...
【专业解读:Semantic Kernel(SK)】大语言模型与传统编程的桥梁
目录 Start:什么是Semantic Kernel? 一、Semantic Kernel的本质:AI时代的操作系统内核 1.1 重新定义LLM的应用边界 1.2 技术定位对比 二、SK框架的六大核心组件与技术实现 2.1 内核(Kernel):智能任务调度中心 2…...

PHP 8 中的 Swow:高性能纯协程网络通信引擎
一、什么是 Swow? Swow 是一个高性能的纯协程网络通信引擎,专为 PHP 设计。它结合了最小化的 C 核心和 PHP 代码,旨在提供高性能的网络编程支持。Swow 的核心目标是释放 PHP 在高并发场景下的真正潜力,同时保持代码的简洁和易用性…...
你学会了些什么211201?--http基础知识
概念 HTTP–Hyper Text Transfer Protocol,超文本传输协议;是一种建立在TCP上的无状态连接(短连接)。 整个基本的工作流程是:客户端发送一个HTTP请求(Request ),这个请求说明了客户端…...

每天学一个 Linux 命令(29):tail
可访问网站查看,视觉品味拉满: http://www.616vip.cn/29/index.html tail 命令用于显示文件的末尾内容,默认显示最后 10 行。它常用于实时监控日志文件或查看文件的尾部数据。以下是详细说明和示例: 命令格式 tail [选项] [文件...]常用选项 选项描述-n <NUM> …...

【形式化验证基础】活跃属性Liveness Property和安全性质(Safety Property)介绍
文章目录 一、Liveness Property1、概念介绍2、形式化定义二、Safety Property1. 定义回顾2. 核心概念解析3. 为什么强调“有限前缀”4. 示例说明4.1 示例1:交通信号灯系统4.2 示例2:银行账户管理系统5. 实际应用的意义三. 总结一、Liveness Property 1、概念介绍 在系统的…...

技工院校无人机专业工学一体化人才培养方案
随着无人机技术在农业植保、地理测绘、应急救援等领域的深度应用,行业复合型人才缺口持续扩大。技工院校作为技能型人才培养主阵地,亟需构建与行业发展同步的无人机专业人才培养体系。本文基于"工学一体化"教育理念,从课程体系、实…...

PI0 Openpi 部署(仅测试虚拟环境)
https://github.com/Physical-Intelligence/openpi/tree/main 我使用4070tisuper, 14900k,完全使用官方默认设置,没有出现其他问题。 目前只对examples/aloha_sim进行测试,使用docker进行部署, 默认使用pi0_aloha_sim模型(但是文档上没找到对应的&…...

计算机视觉——利用AI幻觉检测图像是否是生成式算生成的图像
概述 俄罗斯的新研究提出了一种非常规方法,用于检测不真实的AI生成图像——不是通过提高大型视觉-语言模型(LVLMs)的准确性,而是故意利用它们的幻觉倾向。 这种新方法使用LVLMs提取图像的多个“原子事实”,然后应用自…...

性能测试工具和JMeter功能概要
主流性能测试工具 LoadRunner JMeter [本阶段学习] 1.1 LoadRunner HP LoadRunner是一种工业级标准性能测试负载工具,可以模拟上万用户实施测试,并在测试时可实时检测应用服务器及服务器硬件各种数据,来确认和查找存在的瓶颈支持多协议&am…...

《理解 Java 泛型中的通配符:extends 与 super 的使用场景》
大家好呀!👋 今天我们要聊一个让很多Java初学者头疼的话题——泛型通配符。别担心,我会用最通俗易懂的方式,带你彻底搞懂这个看似复杂的概念。准备好了吗?Let’s go! 🚀 一、为什么我们需要泛型通配符&…...

C#学习第17天:序列化和反序列化
什么是序列化? 定义:序列化是指把对象转换为一种可以轻松存储或传输的格式,如JSON、XML或二进制格式。这个过程需要捕获对象的类型信息和数据内容。用途:使得对象可以持久化到文件、发送至网络、或存储在数据库中。 什么是反序列…...
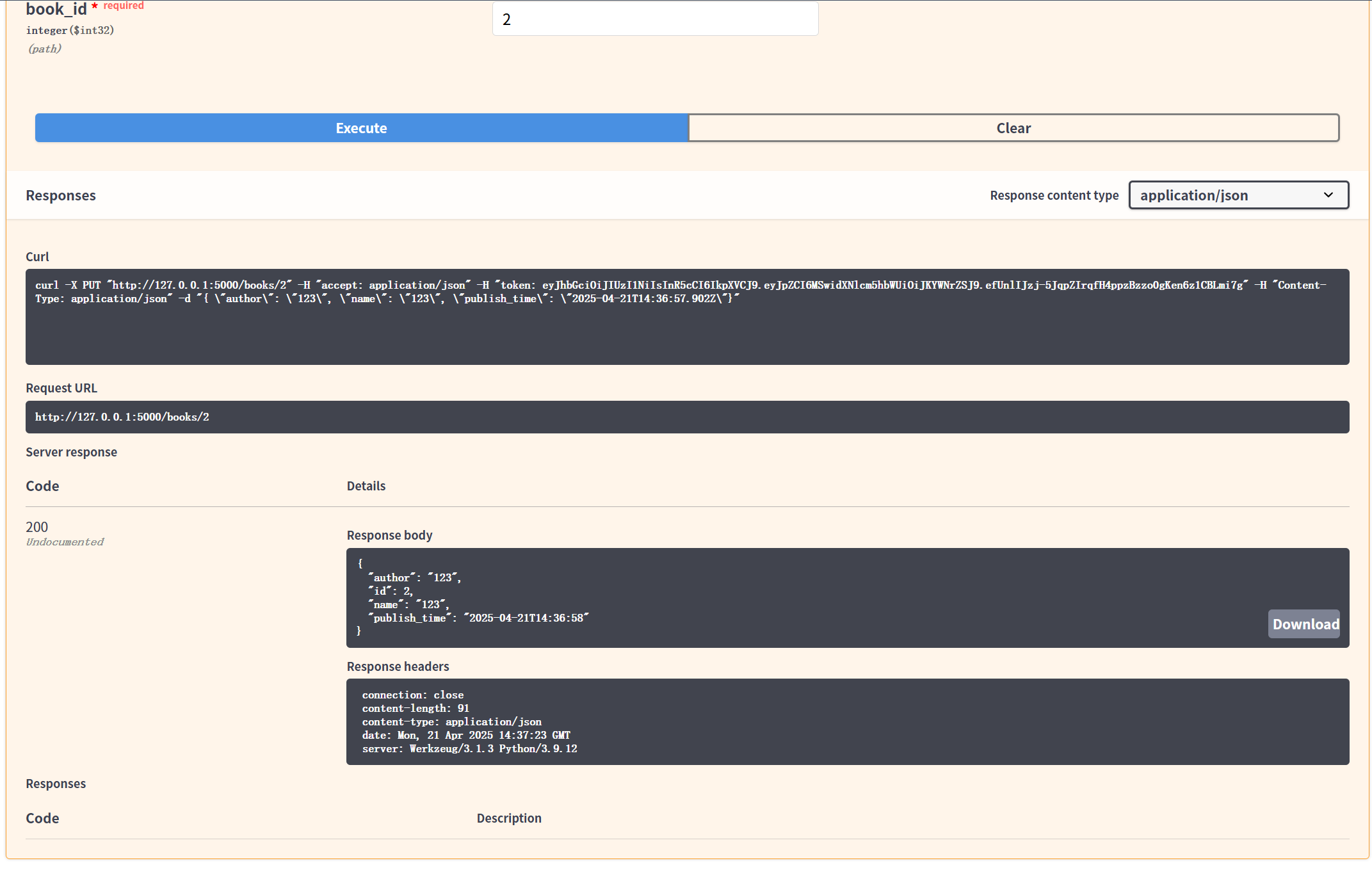
FlaskRestfulAPI接口的初步认识
FlaskRestfulAPI 介绍 记录学习 Flask Restful API 开发的过程 项目来源:【Flask Restful API教程-01.Restful API介绍】 我的代码仓库:https://gitee.com/giteechaozhi/flask-restful-api.git 后端API接口实现功能:数据库访问控制…...
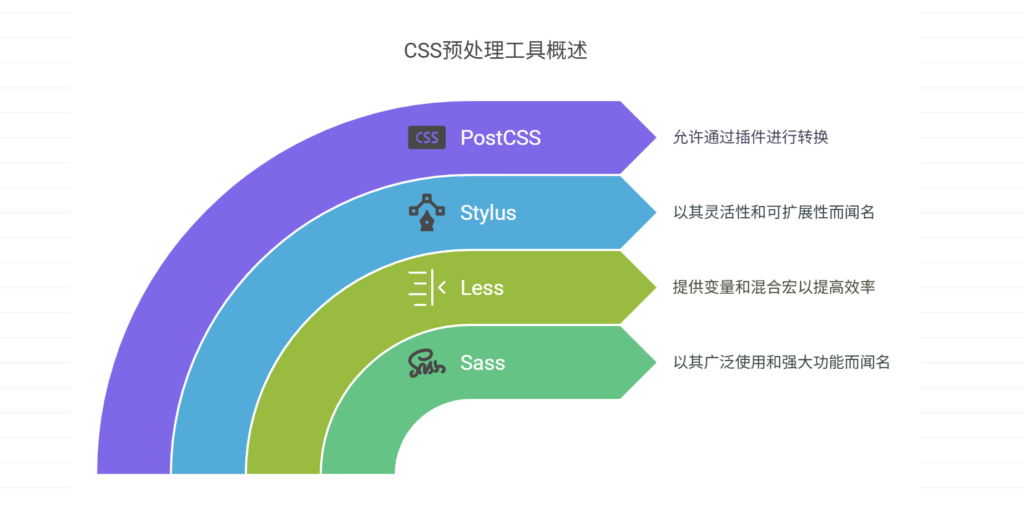
CSS预处理工具有哪些?分享主流产品
目前主流的CSS预处理工具包括:Sass、Less、Stylus、PostCSS等。其中,Sass是全球使用最广泛的CSS预处理工具之一,以强大的功能、灵活的扩展性以及完善的社区生态闻名。Sass通过增加变量、嵌套、混合宏(mixin)等功能&…...