Self-Ask:LLM Agent架构的思考模式 | 智能体推理框架与工具调用实践
作为程序员,我们习惯将复杂问题分解为可管理的子任务,这正是递归和分治算法的核心思想。那么,如何让AI模型也具备这种结构化思考能力?本文深入剖析Self-Ask推理模式的工作原理、实现方法与最佳实践,帮助你构建具有清晰推理链路的AI系统,就像调试一个递归函数一样追踪AI的"思考过程"。
Self-Ask:AI 推理的"侦探模式"
什么是 Self-Ask 模式?
Self-Ask(自问自答)是一种AI推理策略,通过问题分解和逐步解答来处理复杂问题。2022年由斯坦福大学研究者提出,旨在提升大语言模型的多步骤推理能力。核心机制是将一个复杂问题拆分为多个简单子问题,逐一解答后整合结果。值得注意的是,Self-Ask不只是agent的设计模式,更是一种提示词工程模式,以及大模型微调的一种设计模式,体现了AI系统设计的多层次应用价值。
Self-Ask与其他推理方法比较
推理方法 | 核心特点 | 与Self-Ask区别 |
Chain-of-Thought | 连续思考流 | Self-Ask更结构化 |
ReAct | 环境交互 | Self-Ask专注内部推理 |
Reflection | 自我反思 | Self-Ask侧重问题分解 |
Self-Ask可与外部工具自然结合,当需要最新信息时可调用搜索工具获取答案。
Self-Ask的优缺点
从工程实现角度看,Self-Ask类似于软件架构中的分层设计模式,其核心优势在于将复杂推理转化为可追踪的线性执行路径,实现了类似日志系统的调试便利性和模块化架构的可维护性。这种结构化思考方式遵循单一职责原则,使每个子问题独立求解,有效降低了系统复杂度(从潜在的指数级降至O(n)线性复杂度)。然而,这种递归式推理也带来了类似函数调用栈的性能开销,增加了token消耗;同时,整体效果高度依赖于初始问题分解的质量,这与系统设计中接口定义的重要性类似。在简单任务上,Self-Ask可能违反YAGNI原则,引入不必要的复杂性;而在复杂推理链上,则可能面临类似大型应用中的状态管理挑战,导致上下文信息丢失。
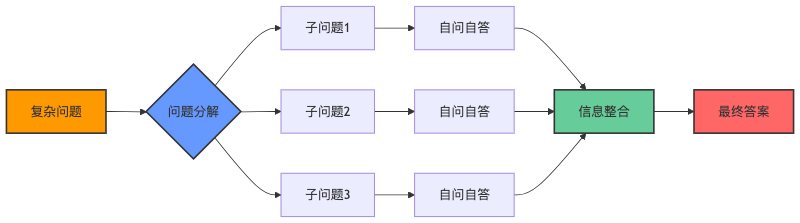
Self-Ask 的工作原理
Self-Ask通过三步法解决复杂问题:
问题分解
复杂问题→简单子问题
自问自答循环
| 问题 :谁是第一个登上月球的宇航员的妻子? 自问:谁是第一个登上月球的宇航员? 自问:尼尔·阿姆斯特朗的妻子是谁? 最终答案:珍妮特·希顿。 |
信息整合
子问题答案→最终解答
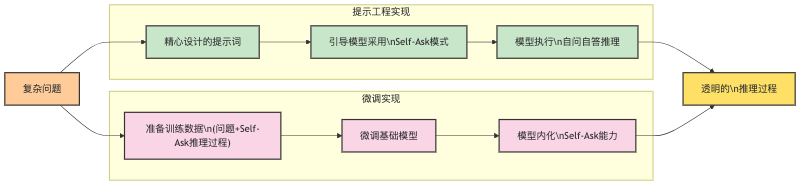
Self-Ask 实现方法
Self-Ask有三种实现路径:提示工程、Agent和模型微调。
提示工程实现
# 核心提示模板
问题:[用户问题]自问:[子问题]
自答:[答案]最终答案:[结论]提升效果技巧:通过添加示例引导、使用领域特定提示和整合外部工具调用,可显著提升Self-Ask的表现质量。
如下是论文 Measuring and Narrowing the Compositionality Gap in Language Models[1] 中的例子:
Agent实现
Self-Ask在Agent系统中的应用尤为强大,特别是与搜索工具结合时。 langchain 框架中也集成了开箱即用的 self-ask-search agent 工具。

Self-Ask Agent工作流程:问题处理、自问自答循环与结果整合三阶段
实际应用示例:
问题:2024年奥运会在哪个城市举办,这个城市有什么著名景点? 自问:2024年奥运会在哪个城市举办? 自问:巴黎有哪些著名景点? 最终答案:2024年奥运会将在法国巴黎举办。巴黎的著名景点包括埃菲尔铁塔、卢浮宫、凯旋门、巴黎圣母院、蒙马特高地、塞纳河和香榭丽舍大街等世界闻名的旅游胜地。 |
这个例子展示了Self-Ask如何与搜索工具结合,处理需要实时信息的复杂问题。Agent通过自问自答的方式,将问题分解为两个子问题,并利用搜索工具获取最新信息,最终整合成完整答案。这种方法特别适合处理需要多步骤推理且涉及外部知识的问题。
模型微调实现
微调模型在表现一致性、领域特定优化和token消耗减少方面具有明显优势。
简单微调实现例子:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, Trainer# 1. 准备训练数据
train_data = [{"input": "问题:谁是美国第一位登月宇航员的妻子?","output": "自问:谁是美国第一位登月宇航员?\n自答:尼尔·阿姆斯特朗。\n\n自问:尼尔·阿姆斯特朗的妻子是谁?\n自答:珍妮特·希顿。\n\n最终答案:珍妮特·希顿。"},{"input": "问题:法国的首都是哪个城市,这个城市的人口有多少?","output": "自问:法国的首都是哪个城市?\n自答:巴黎。\n\n自问:巴黎的人口有多少?\n自答:巴黎市区人口约220万,大巴黎地区人口约1200万。\n\n最终答案:法国的首都是巴黎,巴黎市区人口约220万,大巴黎地区人口约1200万。"}# 更多训练样本...
]# 2. 数据预处理
defpreprocess_function(examples):inputs = [ex["input"] for ex in examples]targets = [ex["output"] for ex in examples]model_inputs = tokenizer(inputs, max_length=512)labels = tokenizer(targets, max_length=512,")model_inputs["labels"] = labels["input_ids"]return model_inputs# 3. 加载预训练模型和tokenizer
model_name = "Qwen/Qwen-7B" # 使用阿里云的Qwen模型
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="auto")# 4. 设置训练参数
training_args = TrainingArguments(output_dir="./self-ask-model",num_train_epochs=3,per_device_train_batch_size=4,save_steps=500,save_total_limit=2,logging_dir="./logs",
)# 5. 训练模型
trainer = Trainer(model=model,args=training_args,train_dataset=preprocess_function(train_data),
)
trainer.train()# 6. 保存微调后的模型
model.save_pretrained("./self-ask-model-final")
tokenizer.save_pretrained("./self-ask-model-final")# 7. 使用微调后的模型
def generate_self_ask_response(question):input_text = f"问题:{question}"inputs = tokenizer(input_text, return_tensors="pt")outputs = model.generate(inputs.input_ids,max_length=512,temperature=0.7,top_p=0.9,do_sample=True)return tokenizer.decode(outputs[0], skip_special_tokens=True)# 测试微调后的模型
test_question = "谁发明了电话,他是哪国人?"
response = generate_self_ask_response(test_question)
print(response)这个例子展示了如何使用Transformers库微调一个基础语言模型来执行Self-Ask推理。通过准备包含问题和自问自答格式回答的训练数据,模型学会了这种推理模式,可以自动将复杂问题分解并逐步解答。微调后的模型无需每次都提供详细的提示,就能生成结构化的自问自答推理过程。
总结与实践建议
从工程角度看,Self-Ask本质上是一种递归问题解决模式,类似于我们编写的分治算法。它通过"问题分解→子问题求解→结果合并"这个经典流程提升AI推理能力。实践中,建议从简单场景入手调试,关注整个推理链路而非仅关注输出结果,就像我们debug代码时需要跟踪完整执行路径一样。在实际项目中,可以灵活组合工具调用API、CoT等技术,构建更强大的推理系统。正如福尔摩斯的名言:"排除不可能后,剩下的即是真相"—Self-Ask正是这种逐步缩小解空间的编程思维在AI领域的应用。
引用链接
[1]Measuring and Narrowing the Compositionality Gap in Language Models:https://arxiv.org/pdf/2210.03350
相关文章:
Self-Ask:LLM Agent架构的思考模式 | 智能体推理框架与工具调用实践
作为程序员,我们习惯将复杂问题分解为可管理的子任务,这正是递归和分治算法的核心思想。那么,如何让AI模型也具备这种结构化思考能力?本文深入剖析Self-Ask推理模式的工作原理、实现方法与最佳实践,帮助你构建具有清晰…...

【前端】【业务场景】【面试】在网页开发中,如何优化图片以提高页面加载速度?解决不同设备屏幕适配问题
📌 问题 1:在网页开发中,如何优化图片以提高页面加载速度? 🔍 一、关键词总结 关键词说明图片压缩借助 TinyPNG、ImageOptim 等工具,无损减小图片文件大小格式选择JPEG(照片类)、P…...

Git Flow分支模型
经典分支模型(Git Flow) 由 Vincent Driessen 提出的 Git Flow 模型,是管理 main(或 master)和 dev 分支的经典方案: main 用于生产发布,保持稳定; dev 用于日常开发,合并功能分支(feature/*); 功能开发在 feature 分支进行,完成后合并回 dev; 预发布分支(rele…...

安装 vmtools
第2章 安装 vmtools 1.安装 vmtools 的准备工作 1)现在查看是否安装了 gcc 查看是否安装gcc 打开终端 输入 gcc - v 安装 gcc 链接:https://blog.csdn.net/qq_45316173/article/details/122018354?ops_request_misc&request_id&biz_id10…...
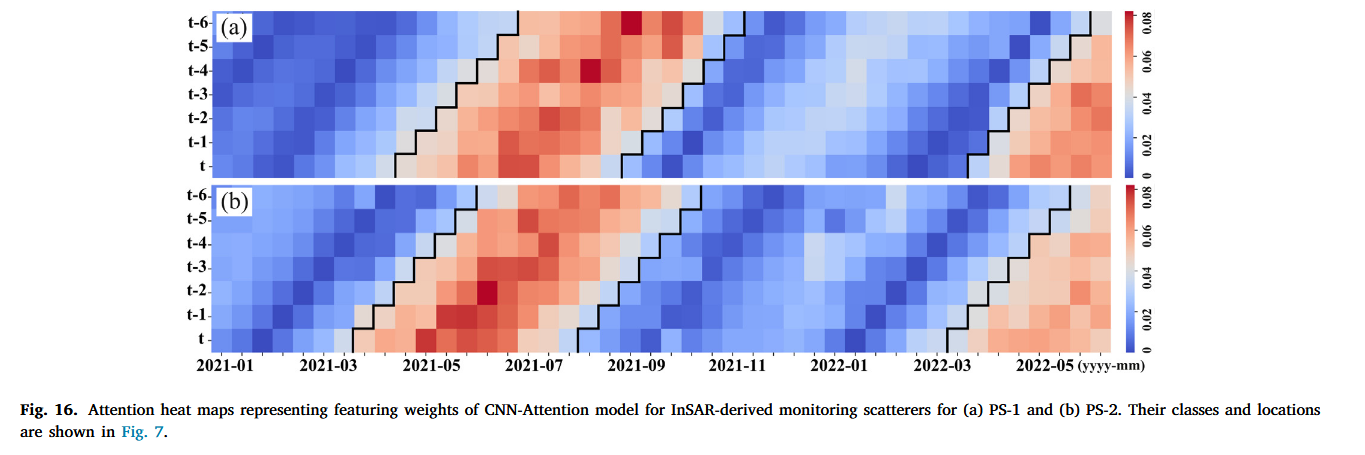
【论文阅读20】-CNN-Attention-BiGRU-滑坡预测(2025-03)
这篇论文主要探讨了基于深度学习的滑坡位移预测模型,结合了MT-InSAR(多时相合成孔径雷达干涉测量)观测数据,提出了一种具有可解释性的滑坡位移预测方法。 [1] Zhou C, Ye M, Xia Z, et al. An interpretable attention-based deep…...

滑动窗口学习
2090. 半径为 k 的子数组平均值 题目 问题分析 给定一个数组 nums 和一个整数 k,需要构建一个新的数组 avgs,其中 avgs[i] 表示以 nums[i] 为中心且半径为 k 的子数组的平均值。如果在 i 前或后不足 k 个元素,则 avgs[i] 的值为 -1。 思路…...

用户需求报告、系统需求规格说明书、软件需求规格说明的对比分析
用户需求报告、系统需求规格说明书(SyRS)和软件需求规格说明书(SRS)是需求工程中的关键文档,分别对应不同层次和视角的需求描述。以下是它们的核心区别对比: 1. 用户需求报告(User Requirem…...

# 基于PyTorch的食品图像分类系统:从训练到部署全流程指南
基于PyTorch的食品图像分类系统:从训练到部署全流程指南 本文将详细介绍如何使用PyTorch框架构建一个完整的食品图像分类系统,涵盖数据预处理、模型构建、训练优化以及模型保存与加载的全过程。 1. 系统概述 本系统实现了一个基于卷积神经网络(CNN)的…...
v-html 显示富文本内容
返回数据格式: 只有图片名称 显示不出完整路径 解决方法:在接收数据后手动给img格式的拼接vite.config中的服务器地址 页面: <el-button click"">获取信息<el-button><!-- 弹出层 --> <el-dialog v-model&…...

【数学建模】孤立森林算法:异常检测的高效利器
孤立森林算法:异常检测的高效利器 文章目录 孤立森林算法:异常检测的高效利器1 引言2 孤立森林算法原理2.1 核心思想2.2 算法流程步骤一:构建孤立树(iTree)步骤二:构建孤立森林(iForest)步骤三:计算异常分数 3 代码实现…...

<项目代码>YOLO小船识别<目标检测>
项目代码下载链接 YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN)࿰…...

Crawl4AI:打破数据孤岛,开启大语言模型的实时智能新时代
当大语言模型遇见数据饥渴症 在人工智能的竞技场上,大语言模型(LLMs)正以惊人的速度进化,但其认知能力的跃升始终面临一个根本性挑战——如何持续获取新鲜、结构化、高相关性的数据。传统数据供给方式如同输血式营养支持ÿ…...

AI 技术发展:从起源到未来的深度剖析
一、AI 的起源与早期发展 人工智能(AI)作为计算机科学的重要分支,其诞生可以追溯到 20 世纪中叶。1943 年,艾伦・图灵提出图灵机的概念,为计算机科学和 AI 理论奠定了基础。1950 年,图灵又提出著名的图灵…...

jsconfig.json文件的作用
jsconfig.json文件的作用 为什么今天会谈到这个呢?有这么一个场景:我们每次开发项目时都会给路径配置别名,配完别名之后可以简化我们的开发,但是随之而来的就有一个问题,一般来说,当我们使用相对路径时…...

nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包
nodejs的包管理工具介绍,npm的介绍和安装,npm的初始化包 ,搜索包,下载安装包 🧰 一、Node.js 的包管理工具有哪些? 工具简介是否默认特点npmNode.js 官方的包管理工具(Node Package Manager&am…...

常见的raid有哪些,使用场景是什么?
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)是一种将多个物理硬盘组合成一个逻辑硬盘的技术,目的是通过数据冗余和/或并行访问提高性能、容错能力和存储容量。不同的 RAID 级别有不同的实现方式和应用场景。以下…...

【Spring Boot】MyBatis多表查询的操作:注解和XML实现SQL语句
1.准备工作 1.1创建数据库 (1)创建数据库: CREATE DATABASE mybatis_test DEFAULT CHARACTER SET utf8mb4;(2)使用数据库 -- 使⽤数据数据 USE mybatis_test;1.2 创建用户表和实体类 创建用户表 -- 创建表[⽤⼾表…...
个人学习笔记(12):网络爬虫)
金融数据分析(Python)个人学习笔记(12):网络爬虫
一、导入模块和函数 from bs4 import BeautifulSoup from urllib.request import urlopen import re from urllib.error import HTTPError from time import timebs4:用于解析HTML和XML文档的Python库。 BeautifulSoup:方便地从网页内容中提取和处理数据…...
[Android]豆包爱学v4.5.0小学到研究生 题目Ai解析
拍照解析答案 【应用名称】豆包爱学 【应用版本】4.5.0 【软件大小】95mb 【适用平台】安卓 【应用简介】豆包爱学,一般又称河马爱学教育平台app,河马爱学。 关于学习,你可能也需要一个“豆包爱学”这样的AI伙伴,它将为你提供全方位的学习帮助…...
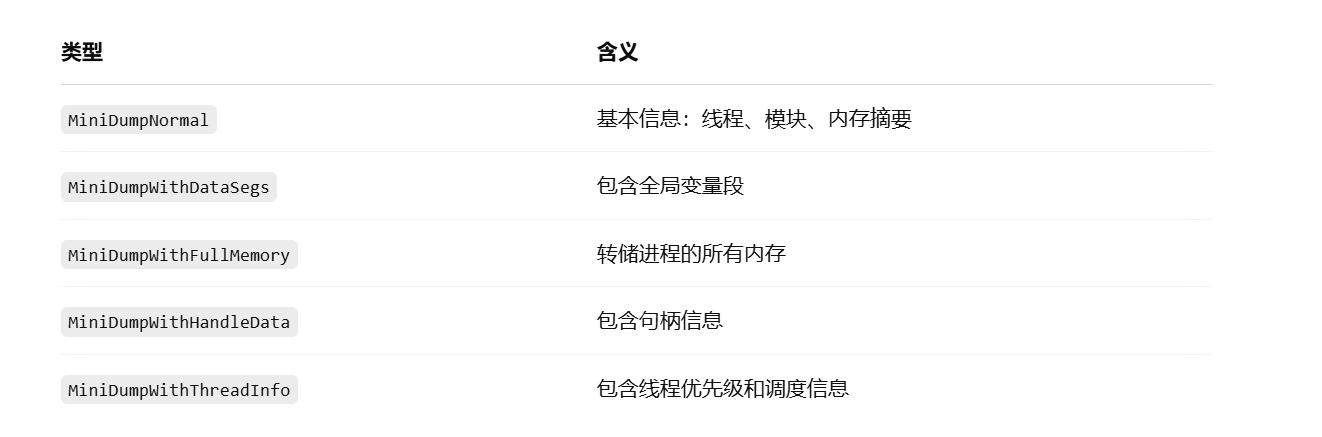
Qt开发:软件崩溃时,如何生成dump文件
文章目录 一、程序崩溃时如何自动生成 Dump 文件二、支持多线程中的异常捕获三、在 DLL 中使用 Dump 捕获四、封装成可复用类五、MiniDumpWriteDump函数详解 一、程序崩溃时如何自动生成 Dump 文件 步骤一:包含必要的头文件 #include <Windows.h> #include …...

普罗米修斯Prometheus监控安装(mac)
普罗米修斯是后端数据监控平台,通过Node_exporter/mysql_exporter等收集数据,Grafana将数据用图形的方式展示出来 官网各平台下载 Prometheus安装(mac) (1)通过brew安装 brew install prometheus &…...

Python SQL 工具包:SQLAlchemy介绍
SQLAlchemy 是一个功能强大且灵活的 Python SQL 工具包和对象关系映射(ORM)库。它被广泛用于与关系型数据库进行交互,提供了从低级 SQL 表达式到高级 ORM 的完整工具链。SQLAlchemy 的设计目标是让开发者能够以 Pythonic 的方式操作数据库&am…...

Shader属性讲解+Cg语言讲解
CPU调用GPU传递数据 修改Render组件的material属性 在脚本中更改游戏物体材质颜色代码示例: using System.Collections; using System.Collections.Generic; using UnityEngine;public class TestFixedColor : MonoBehaviour {void Start(){//创建预制体GameObjec…...
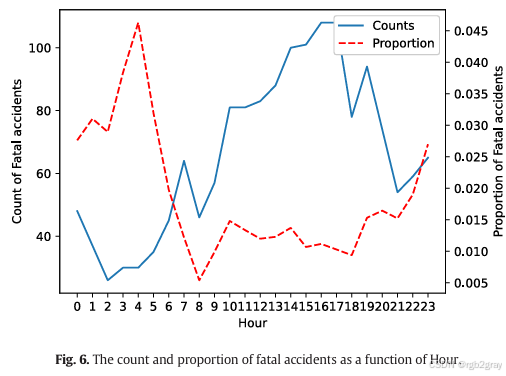
基于LightGBM-TPE算法对交通事故严重程度的分析与可视化
基于LightGBM-TPE算法对交通事故严重程度的分析与可视化 原文: Analysis and visualization of accidents severity based on LightGBM-TPE 1. 引言部分 文章开篇强调了道路交通事故作为意外死亡的主要原因,引起了多学科领域的关注。分析事故严重性特…...

什么是CRM系统,它的作用是什么?CRM全面指南
CRM(Customer Relationship Management,客户关系管理)系统是一种专门用于集中管理客户信息、优化销售流程、提升客户满意度、支持精准营销、驱动数据分析决策、加强跨部门协同、提升客户生命周期价值的业务系统工具。其中,优化销售…...

MySQL 启动报错:InnoDB 表空间丢失问题及解决方法
MySQL 启动报错:InnoDB 表空间丢失问题及解决方法 在启动 MySQL 时,遇到了如下错误: 2025-01-16T12:43:28.341240Z 0 [ERROR] InnoDB: Tablespace 5975 was not found at ./my_jspt/sw_rtu_message_202408.ibd. 2025-01-16T12:43:28.341244…...
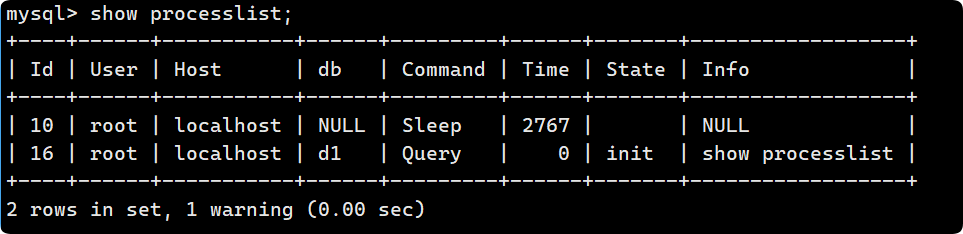
MYSQL之库的操作
创建数据库 语法很简单, 主要是看看选项(与编码相关的): CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...] create_specification: [DEFAULT] CHARACTER SET charset_name [DEFAULT] COLLATE collation_name 1. 语句中大写的是…...

笔记本电脑研发笔记:BIOS,Driver,Preloader详记
在笔记本电脑的研发过程中,Driver(驱动程序)、BIOS(基本输入输出系统)和 Preloader(预加载程序)之间存在着密切的相互关系和影响,具体如下: 相互关系 BIOS 与 Preload…...

同样的html标记,不同语言的文本,显示的字体和粗细会不一样吗
同样的 HTML 标记,在不同语言的文本下,显示出来的字体和粗细确实可能会不一样,原因如下: 🌍 不同语言默认字体不同 浏览器字体回退机制 CSS 里写的字体如果当前系统不支持,就会回退到下一个,比如…...
)
JavaScript 笔记 --- part 5 --- Web API (part 3)
(webAPI part3) BOM 操作 JS 执行机制 javascript 是单线程的, 也就是说, 只能同时执行一个任务。 为了解决这个问题, 利用多核 CPU 的计算能力, HTML5 提出 Web Worker API, 允许 JavaScript 脚本创建多个线程, 并将任务分配给这些线程。 于是, JS 出现了同步和异步的概念。…...