人工智能02-深度学习中的不确定性测量
🔬 深度学习中的不确定性测量详解
Uncertainty Measurement in Deep Learning
🧠 一、什么是不确定性(Uncertainty)?
在深度学习中,不确定性是指模型对其预测结果的“信心程度”。一个模型不仅要输出预测,还要知道自己有多确定这个预测是对的。特别在如下任务中尤为重要:
-
图像分类(Image Classification)
-
图像分割(Semantic Segmentation)
-
医疗影像分析、自动驾驶、金融风险评估等关键应用场景
简单理解:预测是“猫”的概率是 0.95,模型很有信心;如果是 0.51,那说明模型不太确定,存在不确定性。
🎯 二、不确定性的分类
不确定性主要分为以下三种类型:
1. Predictive Uncertainty(预测不确定性)
-
指模型最终对预测结果整体的不确定性。
-
是以下两种不确定性的叠加:
Predictive Uncertainty=Aleatoric+Epistemic\text{Predictive Uncertainty} = \text{Aleatoric} + \text{Epistemic}
2. Aleatoric Uncertainty(数据不确定性)
-
来源:输入数据中固有的噪声或模糊性
-
示例:
-
医学图像模糊不清,无法判断器官边界
-
拍摄条件差,图像中信息不足
-
-
特点:
-
无法通过增加数据或改善模型来完全消除
-
可以通过最大概率或**熵(entropy)**来度量
-
3. Epistemic Uncertainty(模型不确定性)
-
来源:模型自身的未知性或知识盲区
-
示例:
-
模型训练集中从未见过某类输入
-
模型容量不足或过拟合
-
-
特点:
-
可以通过增加训练数据、优化模型结构来减小
-
常用MC Dropout 与 预测方差(Predictive Variance) 来估算
-
📊 三、Aleatoric 不确定性测量方法
✅ 方法一:1 - Maximum Probability(1 - MP)
-
模型的输出为一组类别概率 [p1,p2,...,pC][p_1, p_2, ..., p_C]
-
最大概率值表示模型最信心的预测:
pmax=max(p1,...,pC)p_{\text{max}} = \max(p_1, ..., p_C) -
不确定性定义为:
Uncertainty=1−pmax\text{Uncertainty} = 1 - p_{\text{max}}
🔎 理解:
-
最大概率接近 1 → 模型很有信心 → 不确定性低
-
最大概率接近 0.5 → 模型犹豫不决 → 不确定性高
✅ 方法二:熵(Entropy)
熵衡量整个概率分布的混乱程度:
H=−∑i=1Cpilog(pi)H = - \sum_{i=1}^{C} p_i \log(p_i)
-
如果模型集中在某个类别上(例如 [0.99, 0.005, 0.005]),熵很低 → 确信
-
如果模型预测均衡(如 [0.33, 0.33, 0.34]),熵很高 → 很困惑
📈 最大熵出现在所有类别概率接近均匀分布的时候。
🧠 四、Epistemic 不确定性测量方法
Epistemic 不确定性是模型对自身的预测能力没有信心,尤其是面对未知输入或训练集覆盖不足时。
✅ 核心方法:MC Dropout + 多次预测 + 方差估计
✳️ 步骤解析:
Step 1:启用 Dropout
-
正常测试阶段关闭 Dropout
-
这里需要打开 Dropout以引入模型结构的随机性
在 PyTorch 中通过
model.train()来启用 Dropout
Step 2:对同一个输入进行 N 次前向传播(Forward Passes)
-
每次由于 Dropout 结构不同 → 预测结果略有差异
-
得到 N 个概率预测集合:
{pi1,pi2,...,piN}\{p_{i1}, p_{i2}, ..., p_{iN}\}
Step 3:计算预测方差(Predictive Variance)
对于第 ii 类别的概率,计算方差如下:
Var(pi)=1N∑k=1Npik2−(1N∑k=1Npik)2\text{Var}(p_i) = \frac{1}{N} \sum_{k=1}^{N} p_{ik}^2 - \left( \frac{1}{N} \sum_{k=1}^{N} p_{ik} \right)^2
-
第一项:平方的平均值
-
第二项:平均值的平方
方差越大 → 模型每次预测结果波动大 → 不确定性高
Step 4:所有类别平均 → 得到整体不确定性
Uncertainty=1C∑i=1CVar(pi)\text{Uncertainty} = \frac{1}{C} \sum_{i=1}^{C} \text{Var}(p_i)
最终得到每个输入样本的整体模型不确定性。
💻 五、代码实现(PyTorch)
def compute_epistemic_uncertainty(model, input_tensor, num_passes=20):model.train() # 打开 Dropoutsoftmax_outputs = []with torch.no_grad():for _ in range(num_passes):outputs = model(input_tensor) # 模型输出 logitsprobs = F.softmax(outputs, dim=1)softmax_outputs.append(probs.unsqueeze(0)) # shape: [1, B, C]stacked = torch.cat(softmax_outputs, dim=0) # shape: [N, B, C]mean_probs = stacked.mean(dim=0) # shape: [B, C]var_probs = stacked.var(dim=0) # shape: [B, C]epistemic_uncertainty = var_probs.mean(dim=1) # shape: [B]return mean_probs, epistemic_uncertainty
🔁 六、Aleatoric 与 Epistemic 不确定性的对比
| 属性 | Aleatoric | Epistemic |
|---|---|---|
| 来源 | 数据噪声、模糊性 | 模型对知识掌握不足 |
| 是否可被学习降低 | ❌ 否 | ✅ 是 |
| 常用方法 | 1 - MP, 熵 | MC Dropout, 预测方差 |
| 举例 | 图像模糊,听不清语音 | 新类别输入、训练不足 |
🧪 七、实际案例与应用场景
| 应用场景 | 推荐评估方法 | 原因 |
|---|---|---|
| 医疗图像分类 | 熵 + MC Dropout | 风险高、需可信预测 |
| 自动驾驶 | MC Dropout | 安全性极高需求 |
| 文本情感分析 | 熵 | 多分类概率分布解释性强 |
| 零样本学习 | MC Dropout | 检测 unseen 类别更有效 |
✅ 八、总复习:核心公式与重点记忆
Aleatoric:
-
1 - MP:
Uncertainty=1−max(p1,...,pC)\text{Uncertainty} = 1 - \max(p_1, ..., p_C) -
熵:
H=−∑pilog(pi)H = - \sum p_i \log(p_i)
Epistemic:
-
预测方差:
Var(pi)=1N∑pik2−(1N∑pik)2\text{Var}(p_i) = \frac{1}{N} \sum p_{ik}^2 - \left( \frac{1}{N} \sum p_{ik} \right)^2 -
总不确定性:
Uncertainty=1C∑i=1CVar(pi)\text{Uncertainty} = \frac{1}{C} \sum_{i=1}^{C} \text{Var}(p_i)
📦 模型设置与优化配置
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
✅ 解释:
-
nn.CrossEntropyLoss():用于多分类任务的损失函数,衡量模型预测与真实标签的差距。 -
optim.Adam(...):优化器,采用自适应学习率算法,能够有效更新模型参数。 -
lr=0.0001:设置较小学习率以确保训练稳定。
🎯 Practice 0: 混淆矩阵评估模型预测准确性
from sklearn.metrics import confusion_matrixmodel.eval()
all_predictions = []
all_labels = []with torch.no_grad():for images, labels in tqdm(test_loader, desc="Evaluating"):images, labels = images.to(device), labels.to(device)outputs = model(images)_, predicted = torch.max(outputs, 1)all_predictions.extend(predicted.cpu().numpy())all_labels.extend(labels.cpu().numpy())conf_matrix = confusion_matrix(all_labels, all_predictions)
print("Confusion Matrix:")
print(conf_matrix)
✅ 分析:
-
模型设为 eval 模式,关闭 Dropout、BatchNorm 训练特性。
-
遍历测试集,记录预测结果与真实标签。
-
使用 sklearn 生成 混淆矩阵,评估每类分类效果,发现模型在哪些类别上容易混淆。
🔎 Practice 1: 查看模型输出(logits & 概率)
model.eval()
for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)print(outputs.shape)print(outputs)probabilities = torch.softmax(outputs, dim=1)print(probabilities)break
✅ 分析:
-
查看模型对一批样本的输出:
-
outputs是 logits,未归一化的类别得分。 -
softmax(outputs)转换为概率分布。 -
每个样本的输出维度为
[num_classes],用于多分类预测。
-
📊 Practice 2: Aleatoric 不确定性评估 —— 最大概率法
# 1 - max probability
all_mp = []with torch.no_grad():for images, labels in tqdm(test_loader, desc="Evaluating"):images, labels = images.to(device), labels.to(device)outputs = model(images)probabilities = torch.softmax(outputs, dim=1)max_prob, _ = torch.max(probabilities, dim=1)max_prob = 1 - max_proball_mp.extend(max_prob.cpu().numpy())all_mp = np.array(all_mp)
data_uncertainty = np.mean(all_mp)
print(f"Data Uncertainty: {data_uncertainty}")
✅ 分析:
-
对每个样本,找出模型预测的最大类别概率 pmaxp_{\text{max}}。
-
计算 1−pmax1 - p_{\text{max}} 作为不确定性得分。
-
所有样本的平均值即为数据不确定性(Aleatoric)。
📈 Practice 3: Aleatoric 不确定性评估 —— 熵方法
# Entropy
all_entropy = []with torch.no_grad():for images, labels in tqdm(test_loader, desc="Evaluating"):images, labels = images.to(device), labels.to(device)outputs = model(images)probabilities = torch.softmax(outputs, dim=1)entropy = -torch.sum(probabilities * torch.log(probabilities + 1e-8), dim=1)all_entropy.extend(entropy.cpu().numpy())all_entropy = np.array(all_entropy)
data_uncertainty = np.mean(all_entropy)
print(f"Data Uncertainty: {data_uncertainty}")
✅ 分析:
-
使用信息熵公式:
H=−∑pilog(pi)H = -\sum p_i \log(p_i) -
熵越大,模型越“困惑”;熵越小,模型越“自信”。
-
这是更细腻的 Aleatoric 估计方法。
🎛️ Practice 4: 模型结构修改 —— 添加 Dropout(用于 Epistemic 不确定性)
model.fc2 = nn.Sequential(nn.Dropout(p=0.5),nn.Linear(in_features=84, out_features=10)
)
✅ 分析:
-
替换输出层为
Dropout + Linear,用于支持 MC Dropout。 -
Dropout 增加模型在推理时的随机性(前提是测试阶段强制开启 Dropout)。
🧩 Practice 5: 启用 Dropout 层(仅用于推理阶段)
def enable_dropout(model):"""Function to enable dropout during inference."""for module in model.modules():if module.__class__.__name__.startswith('Dropout'):module.train()
✅ 分析:
-
通常测试阶段 Dropout 是关闭的。
-
为了做 MC Dropout,只开启 Dropout 层而不影响 BatchNorm 等其他模块。
-
模拟“多个模型预测”,以计算 Epistemic 不确定性。
🔁 Practice 6: Epistemic Uncertainty via MC Dropout
model.eval()
enable_dropout(model)num_mc_passes = 20
all_mean_probs = []
all_var_probs = []with torch.no_grad():for images, labels in tqdm(test_loader, desc="MC Dropout Inference"):images = images.to(device)mc_probs = []for _ in range(num_mc_passes):outputs = model(images)probs = torch.softmax(outputs, dim=1)mc_probs.append(probs.unsqueeze(0))stacked_probs = torch.cat(mc_probs, dim=0)mean_probs = stacked_probs.mean(dim=0)var_probs = stacked_probs.var(dim=0)epistemic_uncertainty = var_probs.mean(dim=1)all_mean_probs.extend(mean_probs.cpu().numpy())all_var_probs.extend(epistemic_uncertainty.cpu().numpy())all_mean_probs = np.array(all_mean_probs)
all_var_probs = np.array(all_var_probs)
mean_uncertainty = np.mean(all_var_probs)
print(f"Epistemic Uncertainty (average): {mean_uncertainty:.6f}")
✅ 分析:
-
启用 Dropout,在推理阶段对每个样本预测多次。
-
堆叠预测 → 计算每个类别的均值和方差。
-
平均方差 = 样本的不确定性评分。
-
全体样本平均值即为模型整体的 Epistemic 不确定性。
🧠 结语:总结模型不确定性三种评估方式
| 方法 | 类型 | 特点 |
|---|---|---|
| 1 - Max Prob | Aleatoric | 快速、粗略估计 |
| Entropy | Aleatoric | 更细腻,考虑整体分布 |
| MC Dropout + 方差 | Epistemic | 测试阶段多次推理,评估模型知识盲区 |
相关文章:

人工智能02-深度学习中的不确定性测量
🔬 深度学习中的不确定性测量详解 Uncertainty Measurement in Deep Learning 🧠 一、什么是不确定性(Uncertainty)? 在深度学习中,不确定性是指模型对其预测结果的“信心程度”。一个模型不仅要输出预测…...
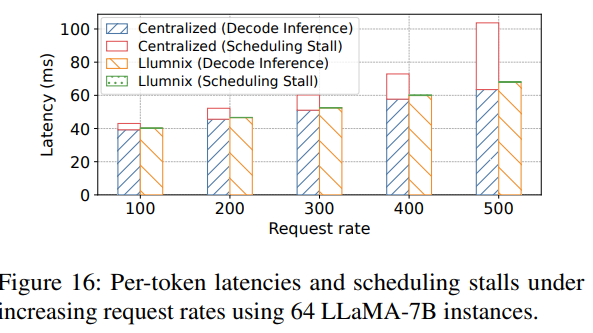
【DeepSeek 学习推理】Llumnix: Dynamic Scheduling for Large Language Model Serving实验部分
6.1 实验设置 测试平台。我们使用阿里云上的16-GPU集群(包含4个GPU虚拟机,类型为ecs.gn7i-c32g1.32xlarge)。每台虚拟机配备4个NVIDIA A10(24 GB)GPU(通过PCI-e 4.0连接)、128个vCPU、752 GB内…...

Kubernetes相关的名词解释kubeadm(19)
kubeadm是什么? kubeadm 是 Kubernetes 官方提供的一个用于快速部署和管理 Kubernetes 集群的命令行工具。它简化了集群的初始化、节点加入和升级过程,特别适合在生产环境或学习环境中快速搭建符合最佳实践的 Kubernetes 集群。 kubeadm 的定位 不是完整…...

什么是负载均衡?NGINX是如何实现负载均衡的?
大家好,我是锋哥。今天分享关于【什么是负载均衡?NGINX是如何实现负载均衡的?】面试题。希望对大家有帮助; 什么是负载均衡?NGINX是如何实现负载均衡的? 1000道 互联网大厂Java工程师 精选面试题-Java资源…...

docker容器,mysql的日志文件怎么清理
访问问题 你的问题是因为在当前路径 /home/ictrek/data/ragflow-mysql 下没有名为 data 的子目录。以下是详细分析和解决方法: 错误原因 路径不存在 当前目录 /home/ictrek/data/ragflow-mysql 下没有名为 data 的子目录,执行 cd data/ 时会报错 No suc…...
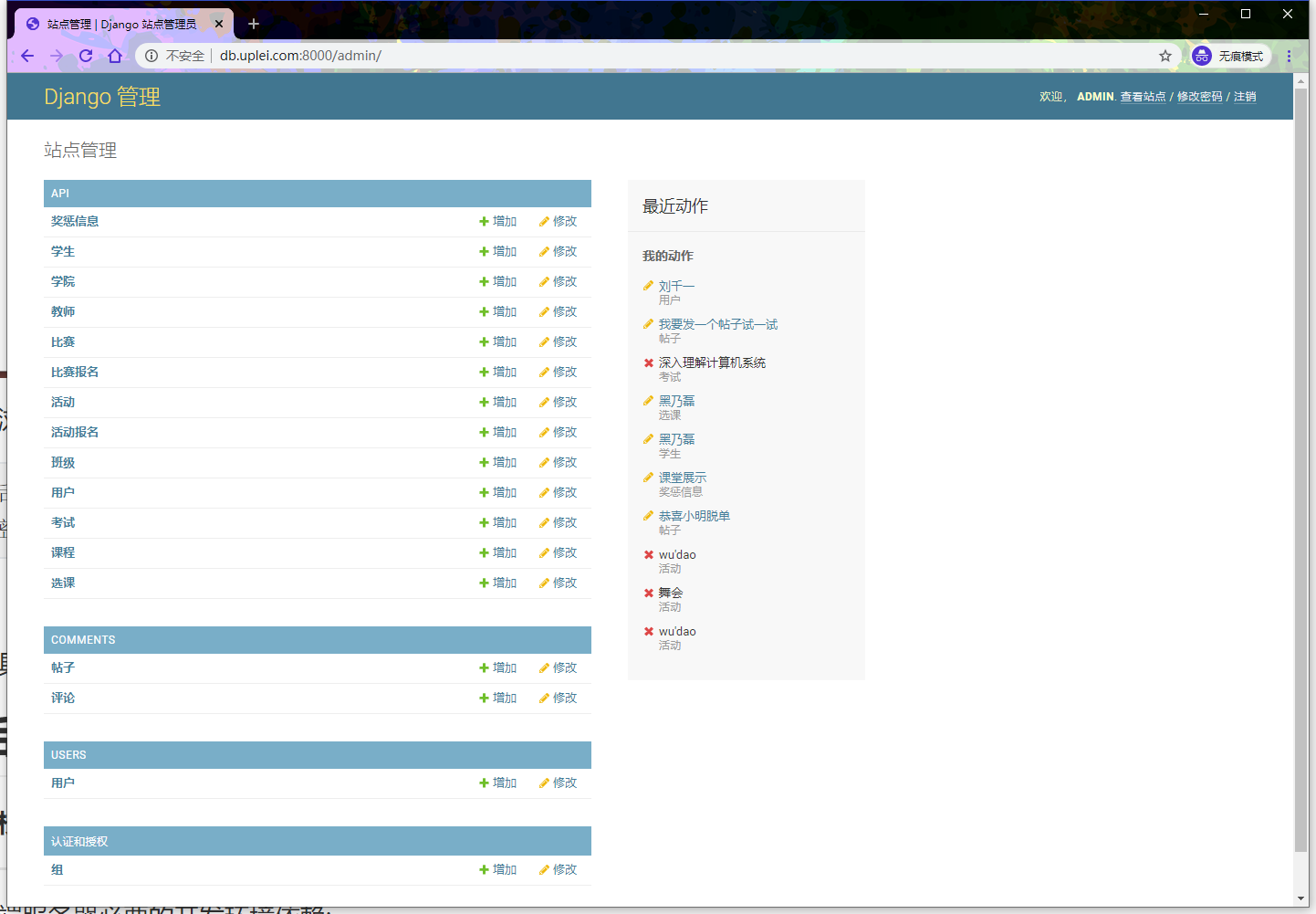
基于Python(Django)+SQLite实现(Web)校园助手
校园助手 本校园助手采用 B/S 架构。并已将其部署到服务器上。在网址上输入 db.uplei.com 即可访问。 使用说明 可使用如下账号体验: 学生界面: 账号1:123 密码1:123 账户2:201805301348 密码2:1 # --------------…...

Python 列表与元组深度解析:从基础概念到函数实现全攻略
在 Python 编程的广袤天地中,列表(List)和元组(Tuple)是两种不可或缺的数据结构。它们如同程序员手中的瑞士军刀,能高效地处理各类数据。从简单的数值存储到复杂的数据组织,列表和元组都发挥着关…...

从零开始搭建Django博客②--Django的服务器内容搭建
本文主要在Ubuntu环境上搭建,为便于研究理解,采用SSH连接在虚拟机里的ubuntu-24.04.2-desktop系统搭建,当涉及一些文件操作部分便于通过桌面化进行理解,通过Nginx代理绑定域名,对外发布。 此为从零开始搭建Django博客…...
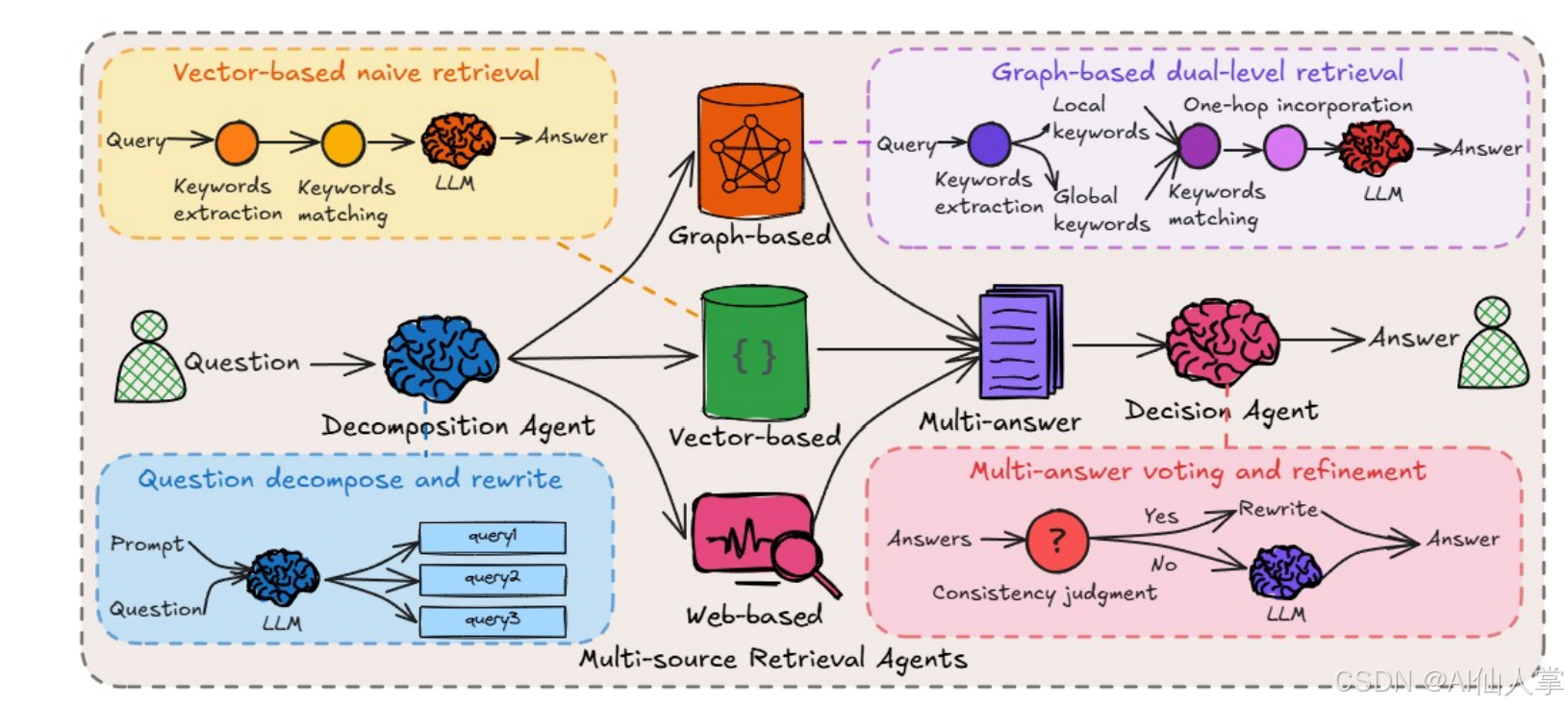
【读论文】HM-RAG:分层多智能体多模态检索增强生成
如何在多模态信息检索和生成中,通过协作式多智能体系统来处理复杂的多模态查询。传统的单代理RAG系统在处理需要跨异构数据生态系统进行协调推理的复杂查询时存在根本性限制:处理多种查询类型、数据格式异质性和检索任务目标的多样性;在视觉内容和文本内…...

mysql日常巡检
1.查看mysql服务是否异常 systemctl status mysql_3306 查看MySQL进程是否存在 ps -ef | grep mysql 2.连接异常检查 (1)查看是否异常连接 show processlist; #或 show full processlist; (2)查看当前失败连接数 show global status like aborted_connects; (3)查看试…...

【Git】branch合并分支
在 Git 中,将分支合并到 main 分支是一个常见的操作。以下是详细的步骤和说明,帮助你完成这个过程。 1. 确保你在正确的分支上 首先,你需要确保当前所在的分支是 main 分支(或者你要合并到的目标分支)。 检查当前分支…...
文件操作和IO(上)
绝对路径和相对路径 文件按照层级结构进行组织(类似于数据结构中的树型结构),将专门用来存放管理信息的特殊文件称为文件夹或目录。对于文件系统中文件的定位有两种方式,一种是绝对路径,另一种是相对路径。 绝对路径…...

7.6 GitHub Sentinel后端API实战:FastAPI高效集成与性能优化全解析
GitHub Sentinel Agent 用户界面设计与实现:后端 API 集成 关键词:前后端分离架构、RESTful API 设计、数据序列化、命令行工具开发、集成测试 后端 API 集成关键技术实现 本阶段需要完成前端界面与后端服务的无缝对接,实现以下核心功能: #mermaid-svg-FFnzT13beWV52dtx …...

JavaFX深度实践:从零构建高级打地鼠游戏(含多物品与反馈机制)
大家好!经典的“打地鼠”游戏是许多人童年的回忆,也是学习 GUI 编程一个非常好的切入点。但仅仅是“地鼠出来就打”未免有些单调。今天,我们来点不一样的——用 JavaFX 打造一个高级版的打地鼠游戏!在这个版本中,洞里钻…...
Python 简介与入门
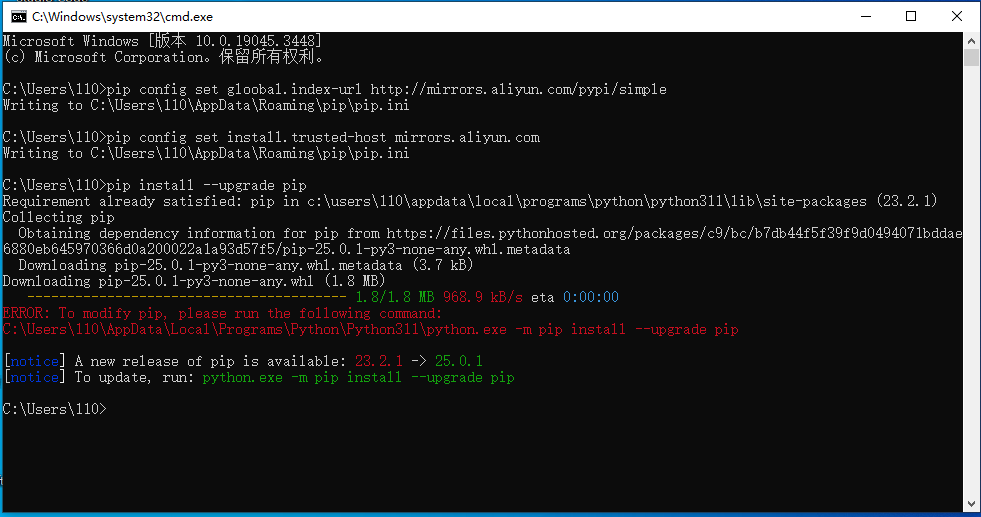
目录 一、Python 初识 1、Python 的优势 2、Python 的特性 3、Python 的应用领域 二、Linux 环境中安装 Python 1、下载 Python3.11.6 2、安装依赖包 3、解压 Python 压缩包 4、安装 Python 5、编译及安装 6、建立软链接 7、测试 Python3 运行 8、设置国内 pip 更…...

理解RAG第六部分:有效的检索优化
在RAG系统中,识别相关上下文的检索器组件的性能与语言模型在生成有效响应方面的性能同样重要,甚至更为重要。因此,一些改进RAG系统的努力将重点放在优化检索过程上。 从检索方面提高RAG系统性能的一些常见方法。通过实施高级检索技术&#x…...

实训Day-2 流量分析与安全杂项
目录 实训Day-2-1流量分析实战 实训目的 实训任务1 SYN半链接攻击流量分析 实训任务2 SQL注入攻击流量分析一 实训任务3 SQL注入攻击流量分析二 实训任务4 Web入侵溯源一 实训任务5 Web入侵溯源二 编辑 实训Day-2-1安全杂项实战 实训目的 实训任务1 流量分析 FTP…...
几种电气绝缘类型
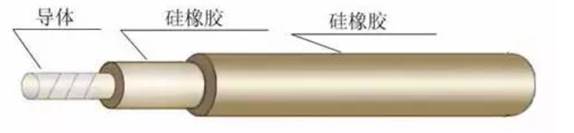
1. 基本绝缘 1.1 绝缘等级 1.2 I类设备 2. 附加绝缘 3. 双重绝缘 4. 加强绝缘 5. 功能性绝缘 1. 基本绝缘 用于防止触及带电部件的初级保护,该防护是由绝缘材料完成的 基本绝缘的目的在于为防电击提供一个基本的保护,以避免触电的危险,不过此类绝缘只能保证正常状态下…...

char32_t、char16_t、wchar_t 用于 c++ 语言里存储 unicode 编码的字符,给出它们的具体定义
(1) #include <iostream> #include <string>int main() { std::u16string s u"C11 引入 char16_t"; // 定义 UTF-16 字符串for (char16_t c : s) // 遍历输出每个 char16_t 的值std::cout << std::hex << (…...

Java Set/List 知识点 Java面试 基础面试题
Java Set/List 知识点 Set与List区别 List 有序、值可重复,内部数据结构 Obejct[ ] 数组Set 无序、值不重复,内部数据结构 HashMap keyobject value固定new Object() ArrayList 有序存储元素允许元素重复,允许存储 null 值支持动态扩容非线程安全 HashSet、LinkedHa…...
Oracle Database Resident Connection Pooling (DRCP) 白皮书阅读笔记
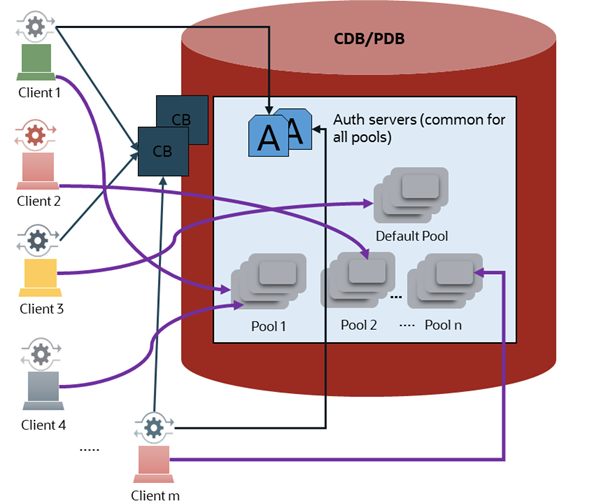
本文为“Extreme Oracle Database Connection Scalability with Database Resident Connection Pooling (DRCP)”的中文翻译加阅读笔记。觉得是重点的就用粗体表示了。 白皮书版本为March 2025, Version 3.3,副标题为:Optimizing Oracle Database resou…...
FastAPI WebSocket 聊天应用详细教程
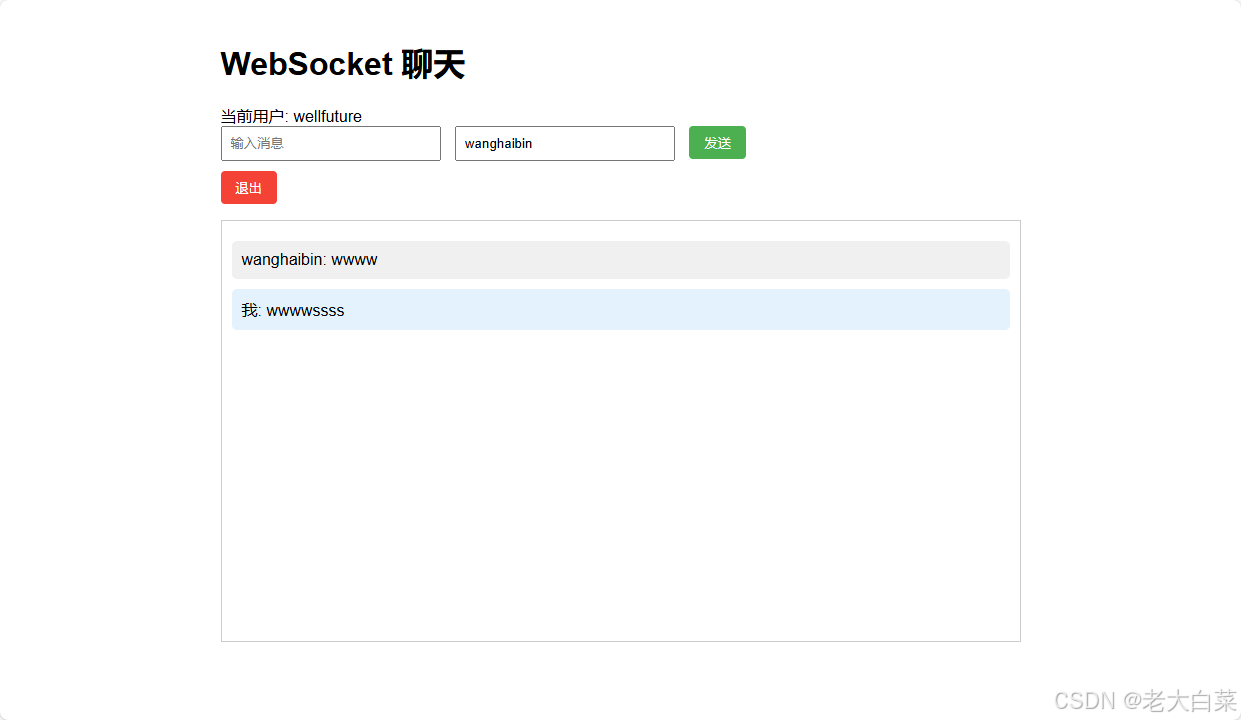
项目简介 这是一个基于 FastAPI 和 WebSocket 实现的实时聊天应用,支持一对一聊天、离线消息存储等功能。 技术栈 后端:FastAPI (Python)前端:HTML、JavaScript、CSS通信:WebSocket认证:简单的 token 认证 项目结构…...
洛谷 P6879 JOI2020 Collecting Stamps 3 题解)
(区间 dp)洛谷 P6879 JOI2020 Collecting Stamps 3 题解
题意 给定一个周长为 L L L 的圆,从一个点出发,有 N N N 个黑白熊雕像,编号为 1 1 1 到 N N N,第 i i i 个雕像在顺时针 X i X_i Xi 米处,如果你没有在 T i T_i Ti 秒内收集到这个黑白熊雕像,那…...

vue3+canvas裁剪框样式【前端】
目录 canvas绘制裁剪框:拖拽改变框的大小:圆圈样式:方块样式: canvas绘制裁剪框: // 绘制裁剪框 const drawCropRect (ctx: CanvasRenderingContext2D): void > {if (cropRect.value.width > 0 && crop…...

【Vue3 / TypeScript】 项目兼容低版本浏览器的全面指南
在当今前端开发领域,Vue3 和 TypeScript 已成为主流技术栈。然而,随着 JavaScript 语言的快速演进,许多现代特性在低版本浏览器中无法运行。本文将详细介绍如何使 Vue3 TypeScript 项目完美兼容 IE11 等低版本浏览器。 一、理解兼容性挑战 …...

软件功能测试和非功能测试有什么区别和联系?
软件测试是保障软件质量的核心环节,而软件功能测试和非功能测试作为测试领域的两大重要组成部分,承担着不同但又相互关联的职责。 软件功能测试指的是通过验证软件系统的各项功能是否按照需求规格说明书来正确实现,确保软件的功能和业务流程…...
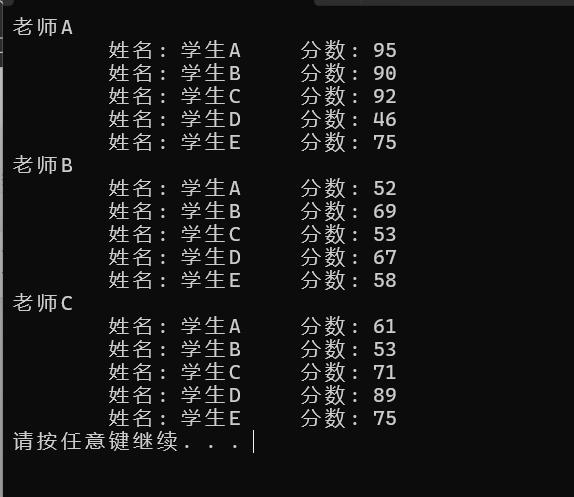
10_C++入门案例习题: 结构体案例
案例描述 学校正在做毕设项目,每名老师带领5个学生,总共有3名老师,需求如下 设计学生和老师的结构体,其中在老师的结构体中,有老师姓名和一个存放5名学生的数组作为成员 学生的成员有姓名、考试分数, 创建…...

快速定位达梦缓存的执行计划并清理
开发告诉你一个sql慢,你想看看缓存中执行计划时,怎么精准快速定位? 可能一般人通过文本内容模糊搜索 select cache_item, substr(sqlstr,1,60)stmt from v$cachepln where sqlstr like %YOUR SQL STRING%; 搜出来的内容比较多,研…...

Spring中配置 Bean 的两种方式:XML 配置 和 Java 配置类
在 Spring 框架中,配置 Bean 的方式主要有两种:XML 配置 和 Java 配置类。这两种方式都可以实现将对象注册到 Spring 容器中,并通过依赖注入进行管理。本文将详细介绍这两种配置方式的步骤,并提供相应的代码示例。 1. 使用 XML 配置的方式 步骤 创建 Spring 配置文件 创建…...

AI算子开发是什么
AI算子开发是指为人工智能(尤其是深度学习)模型中的基础计算单元(如卷积、矩阵乘法、激活函数等)设计并优化其底层实现的过程。这些计算单元被称为“算子”(Operator),它们是构建神经网络的核心…...