并发设计模式实战系列(3):工作队列

🌟 大家好,我是摘星! 🌟
今天为大家带来的是并发设计模式实战系列,第三章工作队列(Work Queue),废话不多说直接开始~
目录
一、核心原理深度拆解
1. 生产者-消费者架构
2. 核心组件
二、生活化类比:餐厅厨房系统
三、Java代码实现(生产级Demo)
1. 完整可运行代码
2. 关键配置解析
四、横向对比表格
1. 多线程模式对比
2. 队列实现对比
五、高级优化技巧
1. 动态线程池调整
2. 优先级任务处理
3. 监控指标埋点
六、扩展设计模式集成
1. 责任链+工作队列(复杂任务处理)
七、高级错误处理机制
1. 重试策略设计
2. 代码实现(带重试的Worker)
八、分布式工作队列扩展
1. 基于Kafka的分布式架构
2. 关键配置参数
九、性能调优实战指南
1. 性能瓶颈定位四步法
2. JVM优化参数建议
十、行业应用案例解析
1. 电商秒杀系统实现
2. 日志处理流水线
十一、虚拟线程(Loom)前瞻
1. 新一代线程模型对比
2. 虚拟线程工作队列示例
十二、设计模式决策树
一、核心原理深度拆解
1. 生产者-消费者架构
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Producers │───> │ Work Queue │───> │ Consumers │
│ (多线程生成) │<─── │ (任务缓冲) │<─── │ (线程池处理) │
└─────────────┘ └─────────────┘ └─────────────┘- 解耦设计:分离任务创建(生产者)与任务执行(消费者)
- 流量削峰:队列缓冲突发流量,防止系统过载
- 资源控制:通过线程池限制最大并发处理数
2. 核心组件
- BlockingQueue:线程安全的任务容器(支持put/take阻塞操作)
- ThreadPool:可配置核心/最大线程数,保持CPU利用率与响应速度平衡
- 任务拒绝策略:定义队列满时的处理方式(丢弃/抛异常/生产者处理)
二、生活化类比:餐厅厨房系统
| 系统组件 | 现实类比 | 核心机制 |
| 生产者 | 服务员接收顾客点单 | 快速记录订单,不参与烹饪 |
| 工作队列 | 悬挂式订单传送带 | 暂存待处理订单,平衡前后台节奏 |
| 消费者 | 厨师团队 | 按订单顺序并行烹饪 |
- 高峰期应对:10个服务员接收订单 → 传送带缓冲50单 → 5个厨师并行处理
三、Java代码实现(生产级Demo)
1. 完整可运行代码
import java.util.concurrent.*;public class WorkQueuePattern {// 任务队列(建议根据内存设置合理容量)private final BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(100);// 线程池配置private final ExecutorService workerPool = new ThreadPoolExecutor(4, // 核心厨师数8, // 最大厨师数(应对高峰期)30, TimeUnit.SECONDS, // 闲置线程存活时间new LinkedBlockingQueue<>(20), // 线程池等待队列new ThreadFactory() { // 定制线程命名private int count = 0;@Overridepublic Thread newThread(Runnable r) {return new Thread(r, "worker-" + count++);}},new ThreadPoolExecutor.AbortPolicy() // 队列满时拒绝任务);// 生产者模拟class OrderProducer implements Runnable {@Overridepublic void run() {int orderNum = 0;while (!Thread.currentThread().isInterrupted()) {try {Runnable task = () -> {System.out.println("处理订单: " + Thread.currentThread().getName());// 模拟处理耗时try { Thread.sleep(500); } catch (InterruptedException e) {}};workQueue.put(task); // 阻塞式提交System.out.println("生成订单: " + (++orderNum));Thread.sleep(200); // 模拟下单间隔} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}}// 启动系统public void start() {// 启动2个生产者线程new Thread(new OrderProducer(), "producer-1").start();new Thread(new OrderProducer(), "producer-2").start();// 消费者自动从队列取任务new Thread(() -> {while (!Thread.currentThread().isInterrupted()) {try {Runnable task = workQueue.take();workerPool.execute(task);} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}).start();}public static void main(String[] args) {WorkQueuePattern kitchen = new WorkQueuePattern();kitchen.start();// 模拟运行后关闭try { Thread.sleep(5000); } catch (InterruptedException e) {}kitchen.shutdown();}// 优雅关闭public void shutdown() {workerPool.shutdown();try {if (!workerPool.awaitTermination(3, TimeUnit.SECONDS)) {workerPool.shutdownNow();}} catch (InterruptedException e) {workerPool.shutdownNow();}}
}2. 关键配置解析
// 线程池参数调优公式(参考)
最佳线程数 = CPU核心数 * (1 + 平均等待时间/平均计算时间)// 四种拒绝策略对比:
- AbortPolicy:直接抛出RejectedExecutionException(默认)
- CallerRunsPolicy:由提交任务的线程自己执行
- DiscardPolicy:静默丢弃新任务
- DiscardOldestPolicy:丢弃队列最旧任务四、横向对比表格
1. 多线程模式对比
| 模式 | 任务调度方式 | 资源管理 | 适用场景 |
| Work Queue | 集中队列分配 | 精确控制线程数 | 通用任务处理 |
| Thread-Per-Task | 直接创建线程 | 容易资源耗尽 | 简单低并发场景 |
| ForkJoin Pool | 工作窃取算法 | 自动负载均衡 | 计算密集型任务 |
| Event Loop | 单线程事件循环 | 极低资源消耗 | IO密集型任务 |
2. 队列实现对比
| 队列类型 | 排序方式 | 阻塞特性 | 适用场景 |
| LinkedBlockingQueue | FIFO | 可选有界/无界 | 通用任务排队 |
| PriorityBlockingQueue | 自定义优先级 | 无界队列 | 紧急任务优先处理 |
| SynchronousQueue | 无缓冲 | 直接传递 | 实时任务处理 |
| DelayQueue | 延迟时间 | 时间触发 | 定时任务调度 |
五、高级优化技巧
1. 动态线程池调整
// 根据队列负载动态扩容
if (workQueue.size() > threshold) {ThreadPoolExecutor pool = (ThreadPoolExecutor) workerPool;pool.setMaximumPoolSize(newMaxSize);
}2. 优先级任务处理
// 使用PriorityBlockingQueue需实现Comparable
class PriorityTask implements Runnable, Comparable<PriorityTask> {private int priority;@Overridepublic int compareTo(PriorityTask other) {return Integer.compare(other.priority, this.priority);}// run()方法实现...
}3. 监控指标埋点
// 监控队列深度
Metrics.gauge("workqueue.size", workQueue::size);// 线程池监控
ThreadPoolExecutor pool = (ThreadPoolExecutor) workerPool;
Metrics.gauge("pool.active.threads", pool::getActiveCount);
Metrics.gauge("pool.queue.size", () -> pool.getQueue().size());六、扩展设计模式集成
1. 责任链+工作队列(复杂任务处理)
┌───────────┐ ┌───────────┐ ┌───────────┐
│ Task │ │ Task │ │ Task │
│ Splitter │───> │ Processor │───> │ Aggregator│
└───────────┘ └───────────┘ └───────────┘↓ ↓ ↓[拆分子任务] [并行处理] [结果合并]- 场景:电商订单处理(拆分子订单→并行校验→合并结果)
- 代码片段:
// 任务拆分器
class OrderSplitter {List<SubOrder> split(MainOrder order) { /* 拆分为N个子订单 */ }
}// 子任务处理器
class OrderValidator implements Runnable {public void run() { /* 库存校验/地址校验等 */ }
}// 结果聚合器
class ResultAggregator {void aggregate(List<SubResult> results) { /* 合并校验结果 */ }
}七、高级错误处理机制
1. 重试策略设计
| 策略类型 | 实现方式 | 适用场景 |
| 立即重试 | 失败后立即重试最多3次 | 网络抖动等临时性问题 |
| 指数退避 | 等待时间=2^n秒(n为失败次数) | 服务过载类错误 |
| 死信队列 | 记录失败任务供人工处理 | 数据错误等需干预问题 |
2. 代码实现(带重试的Worker)
class RetryWorker implements Runnable {private final Runnable task;private int retries = 0;public RetryWorker(Runnable task) {this.task = task;}@Overridepublic void run() {try {task.run();} catch (Exception e) {if (retries++ < MAX_RETRY) {long delay = (long) Math.pow(2, retries);executor.schedule(this, delay, TimeUnit.SECONDS);} else {deadLetterQueue.put(task);}}}
}八、分布式工作队列扩展
1. 基于Kafka的分布式架构
┌────────────┐│ Kafka ││ (Partition)│└─────┬──────┘│
┌───────────┐ ┌───┴────┐ ┌───────────┐
│ Producer ├───orders───> │ │ ──workers─> │ Consumer │
│ Service │ │ Topic │ │ Group │
└───────────┘ └─────────┘ └───────────┘- 特性:
-
- 分区机制实现并行处理
- 消费者组自动负载均衡
- 持久化保证不丢消息
2. 关键配置参数
# 生产者端
acks=all # 确保消息持久化
retries=10 # 发送失败重试次数
max.in.flight=5 # 最大未确认请求数# 消费者端
enable.auto.commit=false # 手动提交offset
max.poll.records=100 # 单次拉取最大记录数
session.timeout.ms=30000 # 心跳检测时间九、性能调优实战指南
1. 性能瓶颈定位四步法
- 监控队列深度:
workQueue.size() > 阈值时报警 - 分析线程状态:
ThreadMXBean bean = ManagementFactory.getThreadMXBean();
for (long tid : bean.getAllThreadIds()) {System.out.println(bean.getThreadInfo(tid));
}- JVM资源检查:
jstat -gcutil <pid> 1000 # GC情况
jstack <pid> # 线程dump- 压测工具验证:
ab -n 10000 -c 500 http://api/endpoint2. JVM优化参数建议
-XX:+UseG1GC # G1垃圾回收器
-XX:MaxGCPauseMillis=200 # 目标暂停时间
-Xms4g -Xmx4g # 固定堆大小
-XX:MetaspaceSize=256m # 元空间初始值
-XX:+ParallelRefProcEnabled # 并行处理引用十、行业应用案例解析
1. 电商秒杀系统实现
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ 请求入口 │ │ 库存预扣 │ │ 订单生成 │
│ (Nginx限流) │───> │ (Redis队列) │───> │ (DB批量写入) │
└───────────────┘ └───────────────┘ └───────────────┘- 关键设计:
-
- 使用Redis List作为分布式队列
- 库存预扣与订单生成解耦
- 数据库批量写入合并操作
2. 日志处理流水线
// 使用Disruptor高性能队列
class LogEventProcessor {void onEvent(LogEvent event, long sequence, boolean endOfBatch) {// 1. 格式清洗// 2. 敏感信息过滤// 3. 批量写入ES}
}- 性能对比:
-
- 传统队列:10万条/秒
- Disruptor:2000万条/秒
十一、虚拟线程(Loom)前瞻
1. 新一代线程模型对比
| 维度 | 平台线程 | 虚拟线程 |
| 内存消耗 | 1MB/线程 | 1KB/线程 |
| 切换成本 | 涉及内核调度 | 用户态轻量级切换 |
| 适用场景 | CPU密集型任务 | IO密集型高并发场景 |
2. 虚拟线程工作队列示例
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();void handleRequest(Request request) {executor.submit(() -> {try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {Future<String> user = scope.fork(() -> queryUser(request));Future<String> order = scope.fork(() -> queryOrder(request));scope.join();return new Response(user.get(), order.get());}});
}十二、设计模式决策树
graph TDA[任务类型?] --> B{CPU密集型}A --> C{IO密集型}B --> D[线程数=CPU核心数+1]C --> E[线程数=CPU核心数*2]E --> F{是否需资源隔离?}F --> |是| G[使用多个独立线程池]F --> |否| H[共享线程池+队列]H --> I{是否需优先级?}I --> |是| J[PriorityBlockingQueue]I --> |否| K[LinkedBlockingQueue]相关文章:
并发设计模式实战系列(3):工作队列
🌟 大家好,我是摘星! 🌟 今天为大家带来的是并发设计模式实战系列,第三章工作队列(Work Queue),废话不多说直接开始~ 目录 一、核心原理深度拆解 1. 生产者-消费者架构 …...
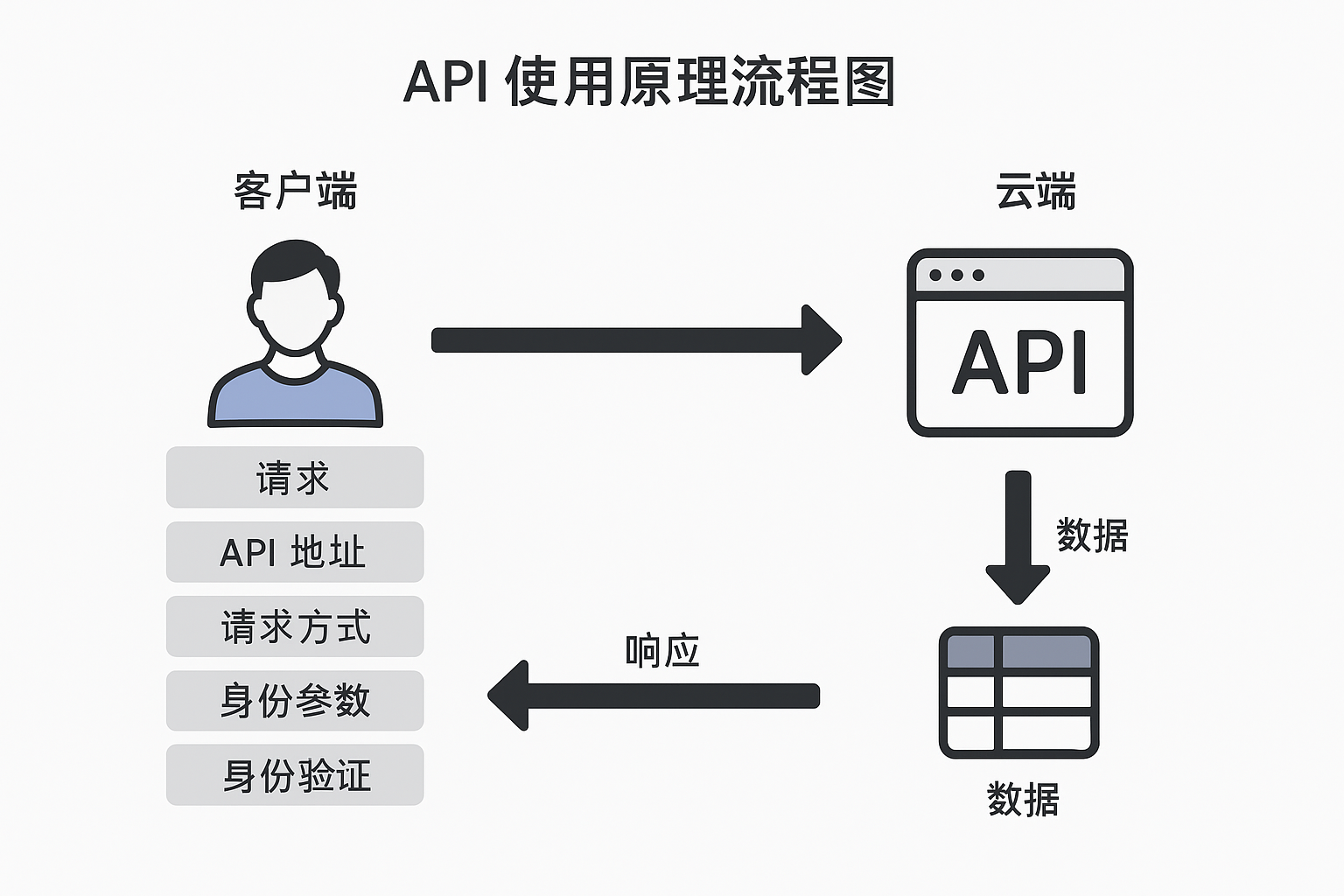
如何理解抽象且不易理解的华为云 API?
API的概念在华为云的使用中非常抽象,且不容易理解,用通俗的语言 形象的比喻来讲清楚——什么是华为云 API,怎么用,背后原理,以及主要元素有哪些,尽量让新手也能明白。 🧠 一句话先理解…...

10分钟二叉树的非递归排序完成
import java.util.Stack;public class test_04_23 {//二叉树的三种遍历static class TreeNode{int data;TreeNode left;TreeNode right;public TreeNode(int data){this.data data;}}//先序遍历public static void test1(TreeNode root){Stack<TreeNode> stack new Sta…...

[特殊字符]fsutil命令用法详解
🔧fsutil命令用法详解 以下是 fsutil 命令的常见用法及功能详解: 1. 基础语法 fsutil [子命令] [参数]2. 核心功能与用法 (1)管理硬链接 fsutil hardlink create <新硬链接路径> <原文件路径>作用:为文…...
详细介绍)
GPIO(通用输入输出端口)详细介绍
一、基本概念 GPIO(General - Purpose Input/Output)即通用输入输出端口,是微控制器(如 STM32 系列)中非常重要的一个外设。它是一种软件可编程的引脚,用户能够通过编程来控制这些引脚的输入或输出状态。在…...
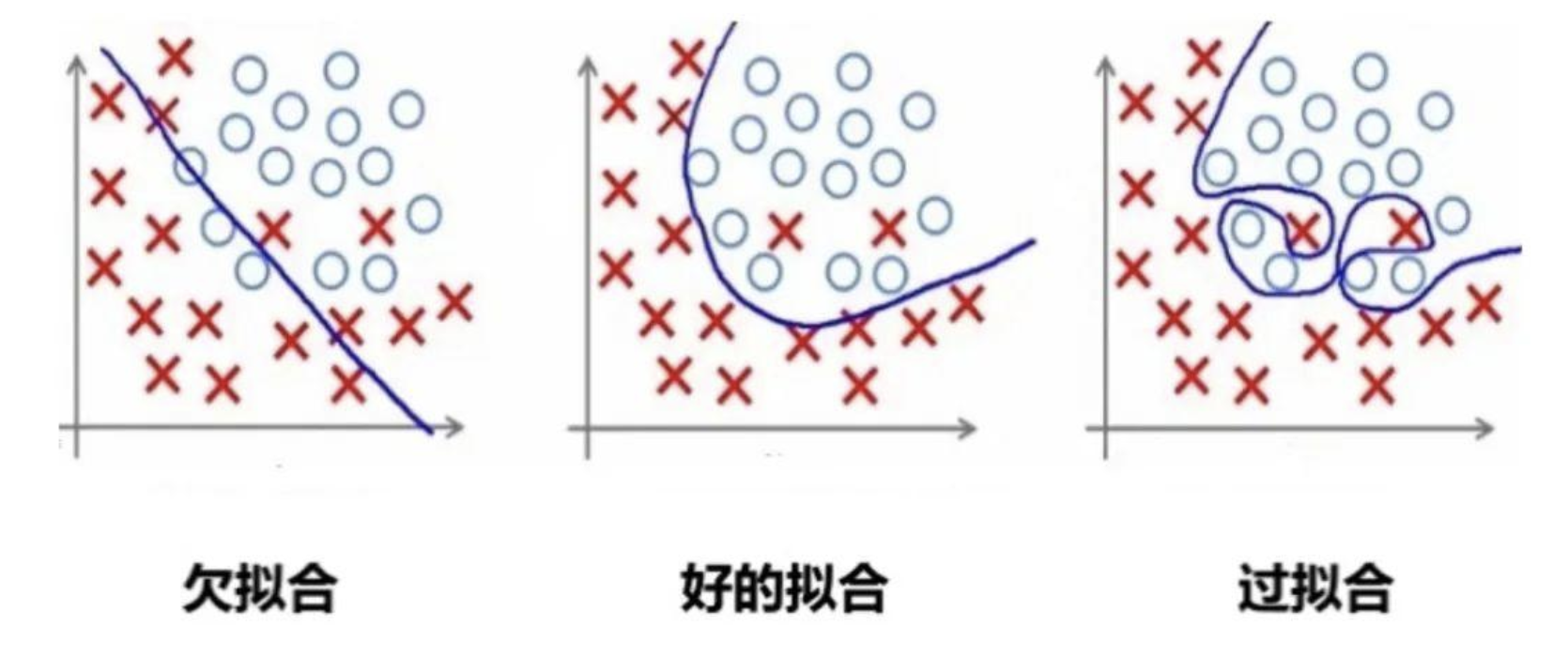
深度学习-全连接神经网络(过拟合,欠拟合。批量标准化)
七、过拟合与欠拟合 在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。 1. 概念认知 …...

Java面向对象的三大特性
## 1. 封装(Encapsulation) 封装是将数据和操作数据的方法绑定在一起,对外部隐藏对象的具体实现细节。通过访问修饰符来实现封装。 示例代码: java public class Student { // 私有属性 private String name; private int age; …...

多路转接select服务器
目录 select函数原型 select服务器 select的缺点 前面介绍过多路转接就是能同时等待多个文件描述符,这篇文章介绍一下多路转接方案中的select的使用 select函数原型 #include <sys/select.h> int select(int nfds, fd_set *readfds, fd_set *writefds, f…...
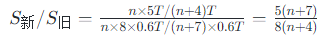
系统架构设计师:流水线技术相关知识点、记忆卡片、多同类型练习题、答案与解析
流水线记忆要点 公式 总时间 (n k - 1)Δt 吞吐率 TP n / 总时间 → 1/Δt(max) 加速比 S nk / (n k - 1) | 效率 E n / (n k - 1) 关键概念 周期:最长段Δt 冲突: 数据冲突(RAW) → 旁路/…...
复刻低成本机械臂 SO-ARM100 3D 打印篇
视频讲解: 复刻低成本机械臂 SO-ARM100 3D 打印篇 清理了下许久不用的3D打印机,挤出机也裂了,更换了喷嘴和挤出机夹具,终于恢复了正常工作的状态,接下来还是要用起来,不然吃灰生锈了,于是乎想起…...

AudioRecord 简单分析
基于AudioRecord简单分析,以下是HeadsetMIC tinymix "TX_CDC_DMA_TX_4 Channels" "One" tinymix "TX_AIF2_CAP Mixer DEC0" "1" tinymix "TX DEC0 MUX" "SWR_MIC" tinymix "TX SMIC MUX0" "SWR_…...
Flutter IOS 真机 Widget 错误。Widget 安装后系统中没有
错误信息: SendProcessControlEvent:toPid: encountered an error: Error Domaincom.apple.dt.deviceprocesscontrolservice Code8 "Failed to show Widget com.xxx.xxx.ServerStatus error: Error DomainFBSOpenApplicationServiceErrorDomain Code1 "T…...
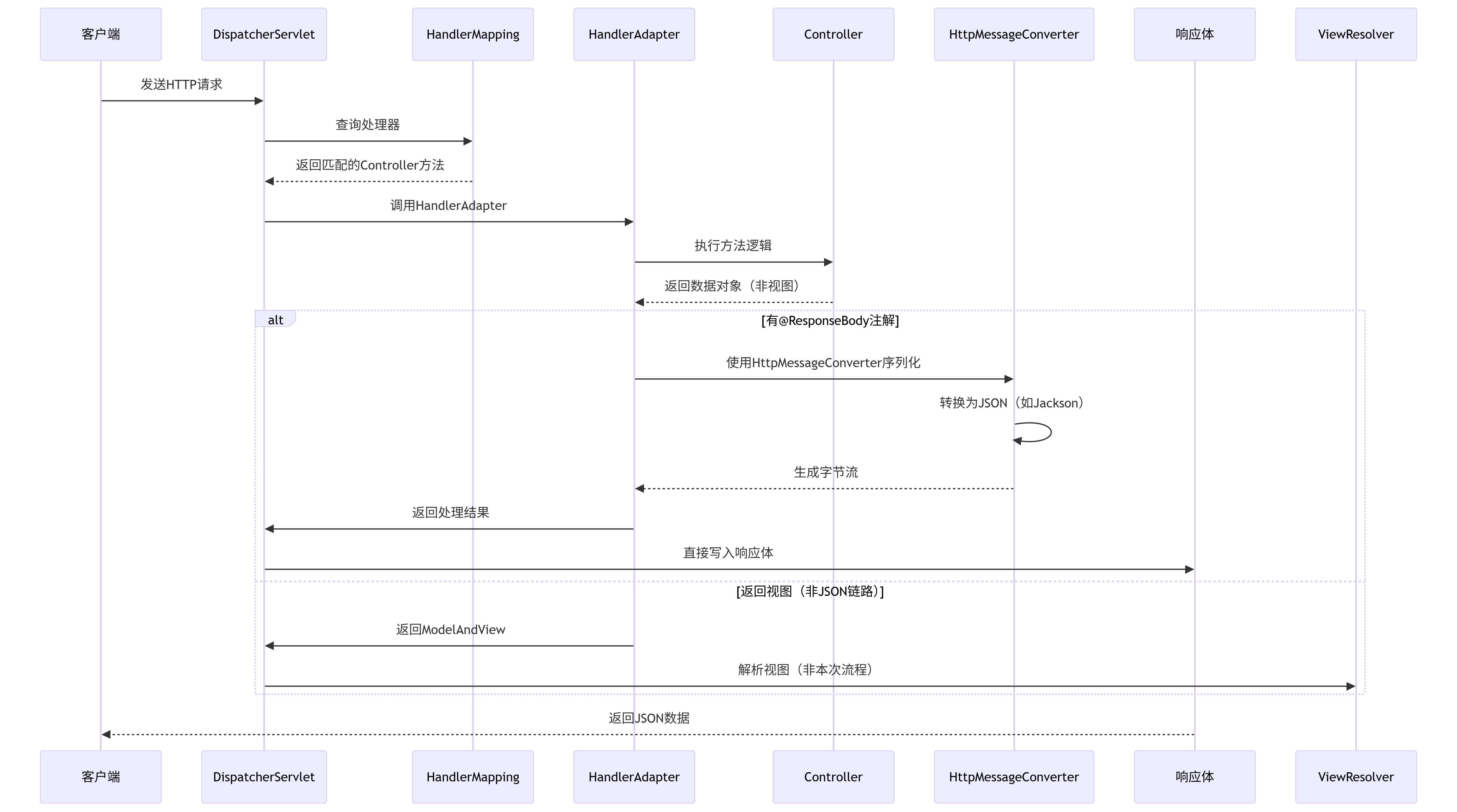
Spring之我见 - Spring MVC重要组件和基本流程
核心组件详解 前端控制器 - DispatcherServlet 作用:所有请求的入口,负责请求分发和协调组件。 public class DispatcherServlet extends HttpServlet {// 核心服务方法protected void doService(HttpServletRequest request, HttpServletResponse re…...

使用 Axios 进行 API 请求与接口封装:打造高效稳定的前端数据交互
引言 在现代前端开发中,与后端 API 进行数据交互是一项核心任务。Axios 作为一个基于 Promise 的 HTTP 客户端,以其简洁易用、功能强大的特点,成为了前端开发者处理 API 请求的首选工具。本文将深入探讨如何使用 Axios 进行 API 请求&#x…...
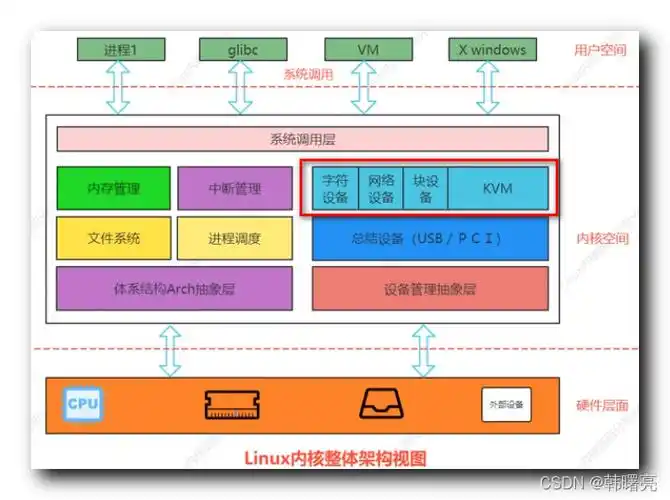
理解字符设备、设备模型与子系统:以 i.MX8MP 平台为例
视频教程请关注 B 站:“嵌入式 Jerry” Linux 内核驱动开发中,很多人在接触字符设备(char device)、设备模型(device model)和各种子系统(subsystem)时,往往会感到概念混…...
鸿蒙Flutter仓库停止更新?
停止更新 熟悉 Flutter 鸿蒙开发的小伙伴应该知道,Flutter 3.7.12 鸿蒙化 SDK 已经在开源鸿蒙社区发布快一年了, Flutter 3.22.x 的鸿蒙化适配一直由鸿蒙突击队仓库提供,最近有小伙伴反馈已经 2 个多月没有停止更新了,不少人以为停…...

vscode使用笔记
文章目录 安装快捷键 vscode是前端开发的一款利器。 安装 快捷键 ctrlp # 查找文件(和idea的双击shift不一样) ctrlshiftf # 搜索内容...

《 C++ 点滴漫谈: 三十四 》从重复到泛型,C++ 函数模板的诞生之路
一、引言 在 C 编程的世界里,类型是一切的基础。我们为 int 写一个求最大值的函数,为 double 写一个相似的函数,为 std::string 又写一个……看似合理的行为,逐渐堆积成了难以维护的 “函数墙”。这些函数逻辑几乎一致࿰…...
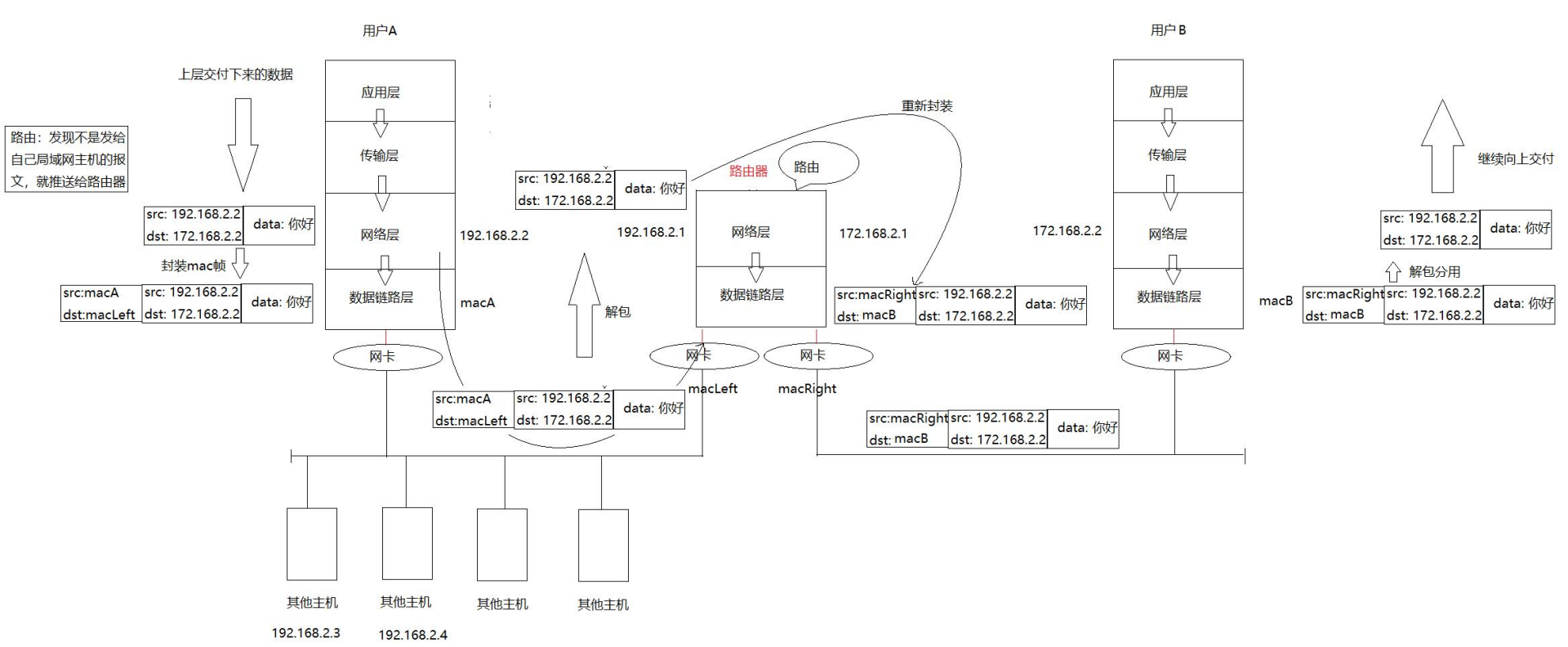
网络基础概念(下)
网络基础概念(上)https://blog.csdn.net/Small_entreprene/article/details/147261091?sharetypeblogdetail&sharerId147261091&sharereferPC&sharesourceSmall_entreprene&sharefrommp_from_link 网络传输的基本流程 局域网网络传输流…...
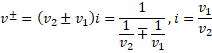
一个关于相对速度的假想的故事-4
回到公式, 正写速度叠加和倒写速度叠加的倒写相等,这就是这个表达式所要表达的意思。但倒写叠加用的是减法,而正写叠加用的是加法。当然是这样,因为正写叠加要的是单位时间上完成更远的距离,而倒写叠加说的是单位距离需…...
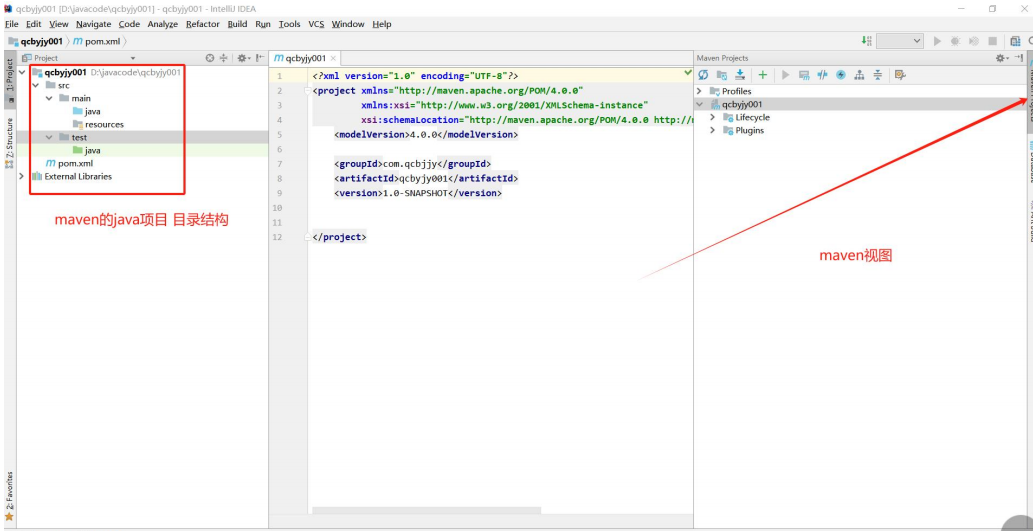
Idea创建项目的搭建方式
目录 一、普通Java项目 二、普通JavaWeb项目 三、maven的JavaWeb项目 四、maven的Java项目 一、普通Java项目 1. 点击 Create New Project 2. 选择Java项目,选择JDK,点击Next 3. 输入项目名称(驼峰式命名法),可选…...

My SQL 索引
核心目标: 理解 mysql 索引的工作原理、类型、优缺点,并掌握创建、管理和优化索引的方法,以显著提升数据库查询性能。 什么是索引? 索引是一种特殊的数据库结构,它包含表中一列或多列的值以及指向这些值所在物理行的指…...

人工智能02-深度学习中的不确定性测量
🔬 深度学习中的不确定性测量详解 Uncertainty Measurement in Deep Learning 🧠 一、什么是不确定性(Uncertainty)? 在深度学习中,不确定性是指模型对其预测结果的“信心程度”。一个模型不仅要输出预测…...
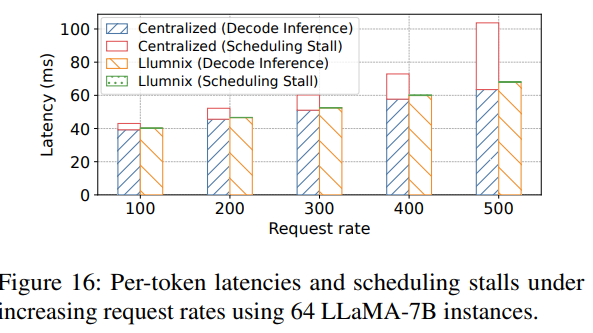
【DeepSeek 学习推理】Llumnix: Dynamic Scheduling for Large Language Model Serving实验部分
6.1 实验设置 测试平台。我们使用阿里云上的16-GPU集群(包含4个GPU虚拟机,类型为ecs.gn7i-c32g1.32xlarge)。每台虚拟机配备4个NVIDIA A10(24 GB)GPU(通过PCI-e 4.0连接)、128个vCPU、752 GB内…...

Kubernetes相关的名词解释kubeadm(19)
kubeadm是什么? kubeadm 是 Kubernetes 官方提供的一个用于快速部署和管理 Kubernetes 集群的命令行工具。它简化了集群的初始化、节点加入和升级过程,特别适合在生产环境或学习环境中快速搭建符合最佳实践的 Kubernetes 集群。 kubeadm 的定位 不是完整…...

什么是负载均衡?NGINX是如何实现负载均衡的?
大家好,我是锋哥。今天分享关于【什么是负载均衡?NGINX是如何实现负载均衡的?】面试题。希望对大家有帮助; 什么是负载均衡?NGINX是如何实现负载均衡的? 1000道 互联网大厂Java工程师 精选面试题-Java资源…...

docker容器,mysql的日志文件怎么清理
访问问题 你的问题是因为在当前路径 /home/ictrek/data/ragflow-mysql 下没有名为 data 的子目录。以下是详细分析和解决方法: 错误原因 路径不存在 当前目录 /home/ictrek/data/ragflow-mysql 下没有名为 data 的子目录,执行 cd data/ 时会报错 No suc…...
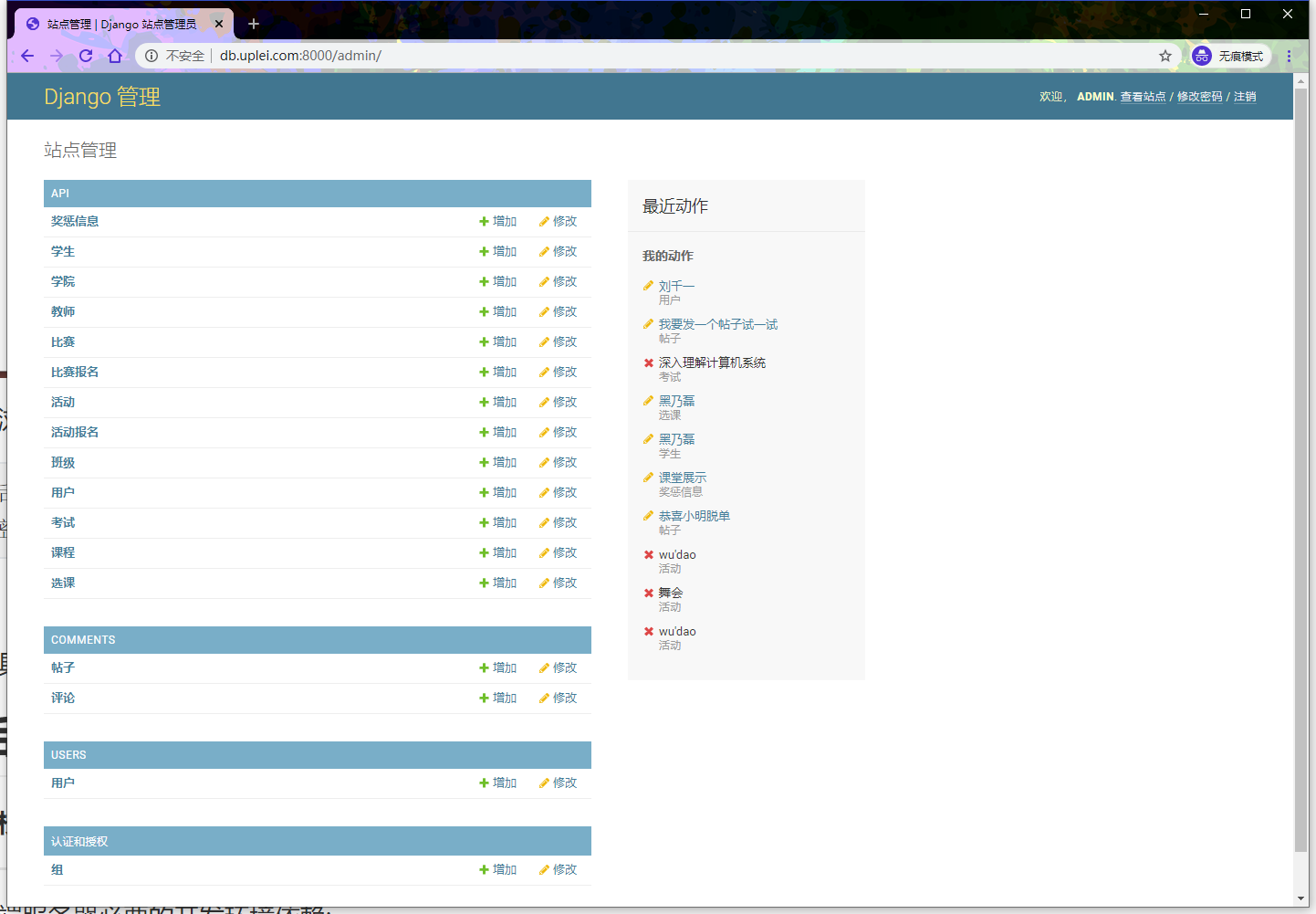
基于Python(Django)+SQLite实现(Web)校园助手
校园助手 本校园助手采用 B/S 架构。并已将其部署到服务器上。在网址上输入 db.uplei.com 即可访问。 使用说明 可使用如下账号体验: 学生界面: 账号1:123 密码1:123 账户2:201805301348 密码2:1 # --------------…...

Python 列表与元组深度解析:从基础概念到函数实现全攻略
在 Python 编程的广袤天地中,列表(List)和元组(Tuple)是两种不可或缺的数据结构。它们如同程序员手中的瑞士军刀,能高效地处理各类数据。从简单的数值存储到复杂的数据组织,列表和元组都发挥着关…...

从零开始搭建Django博客②--Django的服务器内容搭建
本文主要在Ubuntu环境上搭建,为便于研究理解,采用SSH连接在虚拟机里的ubuntu-24.04.2-desktop系统搭建,当涉及一些文件操作部分便于通过桌面化进行理解,通过Nginx代理绑定域名,对外发布。 此为从零开始搭建Django博客…...