【深度学习】#8 循环神经网络
主要参考学习资料:
《动手学深度学习》阿斯顿·张 等 著
【动手学深度学习 PyTorch版】哔哩哔哩@跟李牧学AI
为了进一步提高长线学习的效率,该系列从本章开始将舍弃原始教材的代码部分,专注于理论和思维的提炼,系列名也改为“深度学习”消除误导性。在学习中将理论与实践紧密结合固然有其好处,但在所学知识的广度面前,先铺垫广泛的理论基础,再根据最终实践的目标筛选出需要得到深化的理论知识可能是更有效的策略。
目录
- 序列模型
- 文本预处理
- 语言模型
- 马尔可夫模型与n元语法
- 自然语言统计
- 学习语言模型
- 循环神经网络
- 有隐状态的循环神经网络
- 困惑度
- 通过时间反向传播
- 循环神经网络的梯度分析
- 1.截断时间步
- 2.随机截断
- 通过时间反向传播的细节
- 梯度裁剪
概述
- 序列模型是处理序列信息的模型。
- 处理文本序列信息的语言模型存在其独有的挑战。
- 循环神经网络通过隐状态存储过去的信息。
- 通过时间反向传播是反向传播在循环神经网络中的特定应用。
- 截断时间步和梯度裁剪可以缓解循环神经网络的梯度消失与爆炸问题。
序列模型
卷积神经网络可以有效地处理空间信息,而循环神经网络(RNN)则可以很好地处理序列信息。循环神经网络通过引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。
音乐、语音、文本和视频都是序列信息,如果它们的序列被重排,就会失去原本的意义。
处理序列数据需要统计工具和新的深度神经网络架构。假设对于一组序列数据,在时间步 t ∈ Z + t\in\mathbb Z^+ t∈Z+时观察到的数据为 x t x_t xt,则预测 x t x_t xt的途径为:
x t ∼ P ( x t ∣ x t − 1 , ⋯ , x 1 ) x_t\sim P(x_t|x_{t-1},\cdots,x_1) xt∼P(xt∣xt−1,⋯,x1)
有效估计 P ( x t ∣ x t − 1 , ⋯ , x 1 ) P(x_t|x_{t-1,\cdots,x_1}) P(xt∣xt−1,⋯,x1)的策略归结为以下两种:
第一种,假设现实情况下观测所有之前的序列是不必要的,只需要满足某个长度为 τ \tau τ的时间跨度,即观测序列 x t − 1 , ⋯ , x t − τ x_{t-1},\cdots,x_{t-\tau} xt−1,⋯,xt−τ,至少在 t > τ t>\tau t>τ时。此时输入的数量固定,可以使用之前的深度网络,这种模型被称为自回归模型。
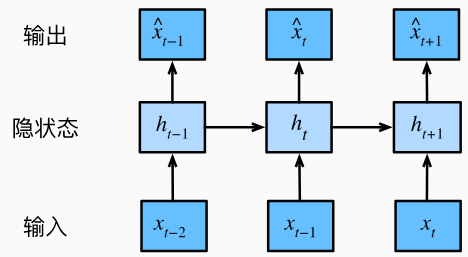
第二种,引入潜变量 h ( t ) h(t) h(t)表示过去的信息,并且同时更新 x ^ t = P ( x t ∣ h t ) \hat x_t=P(x_t|h_t) x^t=P(xt∣ht)和 h t = g ( h t − 1 , x t − 1 ) h_t=g(h_{t-1},x_{t-1}) ht=g(ht−1,xt−1)。由于 h ( t ) h(t) h(t)从未被观测到,这类模型被称为隐变量自回归模型,如下图所示:
文本预处理
文本是最常见的序列数据之一。文本常见的预处理步骤通常包括:
- 将文本作为字符串加载到内存中;
- 将字符串拆分为词元(如单词和字符);
- 建立一个词表,将拆分的词元映射到数字索引;
- 将文本转换为数字索引序列,以便模型操作。
词元是文本的基本单位,可以是单词或字符。但模型需要的输入是数字而不是字符串,因此需要构建一个字典,也称词表,来将字符串类型的词元映射到从0开始的数字索引中。统计一个文本数据集中出现的所有不重复的词元,得到的结果称为语料库。词表根据语料库中每个词元出现的频率为其分配一个数字索引,很少出现的词元则通常被移除以降低复杂度。除此之外,未知词元 ’<unk>’ \texttt{'<unk>'} ’<unk>’用于映射语料库中不存在的词元,填充词元 ’<pad>’ \texttt{'<pad>'} ’<pad>’用于填充长度不足的序列使输入序列具有相同的长度,序列开始词元 ’<bos>’ \texttt{'<bos>'} ’<bos>’和序列结束词元 ’<eos>’ \texttt{'<eos>'} ’<eos>’定义序列的开始与结束。
语言模型
马尔可夫模型与n元语法
在自回归模型中,我们使用 x t − 1 , ⋯ , x t − τ x_{t-1},\cdots,x_{t-\tau} xt−1,⋯,xt−τ而非 x t − 1 , ⋯ , x 1 x_{t-1},\cdots,x_1 xt−1,⋯,x1预测 x t x_t xt。当预测的状态只与其前 n n n个时间步的状态有关,我们称其满足 n n n阶马尔可夫性质,相应的模型被称为 n n n阶马尔可夫模型。阶数越高,对应的依赖关系链就越长。根据马尔可夫性质可以推导出许多应用于序列建模的近似公式:
P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ) P ( x 3 ) P ( x 4 ) P(x_1,x_2,x_3,x_4)=P(x_1)P(x_2)P(x_3)P(x_4) P(x1,x2,x3,x4)=P(x1)P(x2)P(x3)P(x4)
P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 2 ) P ( x 4 ∣ x 3 ) P(x_1,x_2,x_3,x_4)=P(x_1)P(x_2|x_1)P(x_3|x_2)P(x_4|x_3) P(x1,x2,x3,x4)=P(x1)P(x2∣x1)P(x3∣x2)P(x4∣x3)
P ( x 1 , x 2 , x 3 , x 4 ) = P ( x 1 ) P ( x 2 ∣ x 1 ) P ( x 3 ∣ x 1 , x 2 ) P ( x 4 ∣ x 3 , x 2 ) P(x_1,x_2,x_3,x_4)=P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)P(x_4|x_3,x_2) P(x1,x2,x3,x4)=P(x1)P(x2∣x1)P(x3∣x1,x2)P(x4∣x3,x2)
使用 1 1 1阶、 2 2 2阶、 3 3 3阶马尔可夫性质的概率公式被称为一元语法、二元语法和三元语法模型。
自然语言统计
自然语言的统计结果往往符合一些规律。
首先,词频最高的词很多为虚词(the、and、of等),这些词通常被称为停用词,在做文本分析时可以被过滤掉。但它们本身有一定意义,因此模型仍然使用它们。
还有一个问题是词频衰减的速度相当快,以下是H.G.Wells的小说The Time Machine的词频图:
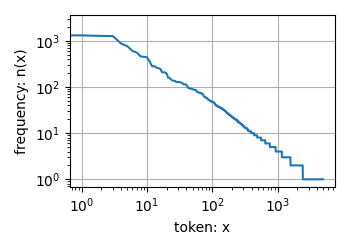
除去前几个单词,剩余的单词与其词频的变化规律大致遵循双对数坐标图上的一条直线。这意味着单词的频率满足齐普夫定律,即第 i i i个最常用单词的频率 n i n_i ni满足
n i ∝ 1 i α n_i\propto\displaystyle\frac1{i^\alpha} ni∝iα1
其等价于
log n i = − α log i + c \log n_i=-\alpha\log i+c logni=−αlogi+c
其中 α \alpha α是描述分布的指数, c c c是常数。这意味着较少的单词拥有极高的词频,而大部分单词的词频与之相比十分地低。
在二元语法(bigram)和三元语法(trigram)的情况下,即两个单词和三个单词构成的序列,它们的分布也在一定程度上遵循齐普夫定律:
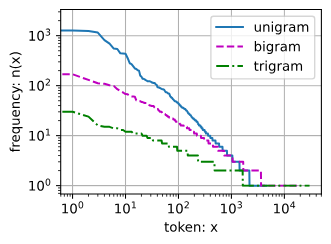
随着 n n n元语法中 n n n的增大, n n n个单词的序列的最高词频的衰减也十分迅速,且越来越多的单词序列只会出现 1 1 1次。
学习语言模型
假设长度为 T T T的文本序列中的词元依次为 x 1 , x 2 , ⋯ , x T x_1,x_2,\cdots,x_T x1,x2,⋯,xT,于是 x t ( 1 ⩽ t ⩽ T ) x_t(1\leqslant t\leqslant T) xt(1⩽t⩽T)可以被认为是文本序列在时间步 t t t处的观测或标签。在给定这样的文本序列时,语言模型的目标是估计序列的联合概率
P ( x 1 , x 2 , ⋯ , x T ) = ∏ t = 1 T P ( x t ∣ x 1 , ⋯ , x t − 1 ) P(x_1,x_2,\cdots,x_T)=\displaystyle\prod^T_{t=1}P(x_t|x_1,\cdots,x_{t-1}) P(x1,x2,⋯,xT)=t=1∏TP(xt∣x1,⋯,xt−1)
例如,包含 4 4 4个单词的一个文本序列是
P ( d e e p , l e a r n i n g , i s , f u n ) = P ( d e e p ) P ( l e a r n i n g ∣ d e e p ) P ( i s ∣ d e e p , l e a r n i n g ) P ( f u n ∣ d e e p , l e a r n i n g , i s ) P(\mathrm{deep},\mathrm{learning},\mathrm{is},\mathrm{fun})=P(\mathrm{deep})P(\mathrm{learning}|\mathrm{deep})P(\mathrm{is}|\mathrm{deep},\mathrm{learning})P(\mathrm{fun}|\mathrm{deep},\mathrm{learning},\mathrm{is}) P(deep,learning,is,fun)=P(deep)P(learning∣deep)P(is∣deep,learning)P(fun∣deep,learning,is)
为了训练语言模型,我们需要计算单词出现的概率以及给定前面几个单词后出现某个单词的条件概率。训练数据集中单词的概率可以根据给定单词的相对词频计算,例如通过统计单词“deep”在数据集中出现的次数,然后除以整个语料库中的单词数来得到估计值 P ^ ( d e e p ) \hat P(\mathrm{deep}) P^(deep)。这对频繁出现的单词效果不错。
接下来我们尝试估计
P ^ ( l e a r n i n g ∣ d e e p ) = n ( d e e p , l e a r n i n g ) n ( d e e p ) \hat P(\mathrm{learning}|\mathrm{deep})=\displaystyle\frac{n(\mathrm{deep},\mathrm{learning})}{n(\mathrm{deep})} P^(learning∣deep)=n(deep)n(deep,learning)
其中 n ( x ) n(x) n(x)和 n ( x , x ′ ) n(x,x') n(x,x′)分别为单个单词和连续单词对出现的次数。但是根据齐普夫定律可想而知,连续单词对“deep learning”出现的频率低得多,要想找到足够的出现次数来获得准确的估计并不容易。而对于 3 3 3个或更多单词的组合,情况会变得更糟。
一种常见的应对小概率和零概率问题的策略是拉普拉斯平滑,它在所有计数中添加一个小常量 ϵ \epsilon ϵ:
P ^ ( x ) = n ( x ) + ϵ 1 / m n + ϵ 1 \hat P(x)=\displaystyle\frac{n(x)+\epsilon_1/m}{n+\epsilon_1} P^(x)=n+ϵ1n(x)+ϵ1/m
P ^ ( x ′ ∣ x ) = n ( x , x ′ ) + ϵ 2 P ^ ( x ) n ( x ) + ϵ 2 \hat P(x'|x)=\displaystyle\frac{n(x,x')+\epsilon_2\hat P(x)}{n(x)+\epsilon_2} P^(x′∣x)=n(x)+ϵ2n(x,x′)+ϵ2P^(x)
其中 m m m为训练集中不重复单词的数量,不同变量数目的条件概率估计所用的 ϵ \epsilon ϵ都是超参数。但这种方法很容易变得无效,原因如下:
- 我们需要存储所有单词和单词序列的计数。
- 该方法忽视了单词的意思和具有跨度的上下文关系。
- 长单词序列中的大部分是没出现过的,因而无法区分它们。
循环神经网络及其变体,和后续介绍的其他序列模型将克服这些问题。
循环神经网络
对于 n n n元语法模型,想要基于更大的时间跨度作出预测,只有增大 n n n,代价是参数将指数级增长,因为每个不重复的单词都需要存储在所有长度小于 n n n的单词序列之后其出现的条件概率。使用隐变量自回归模型则可以对参数进行压缩:
P ( x t ∣ x t − 1 , ⋯ , x 1 ) ≈ P ( x t ∣ h t − 1 ) P(x_t|x_{t-1},\cdots,x_1)\approx P(x_t|h_{t-1}) P(xt∣xt−1,⋯,x1)≈P(xt∣ht−1)
其中 h t − 1 h_{t-1} ht−1是隐状态,也称为隐藏变量,它会在每个时间步以新的输入 x t x_t xt和前一时刻的隐状态 h t − 1 h_{t-1} ht−1更新自己:
h t = f ( x t , h t − 1 ) h_t=f(x_t,h_{t-1}) ht=f(xt,ht−1)
尽管我们不知道隐状态具体存储了怎样的信息,但就公式来看,它在每个时间步确实是由所有之前的输入共同决定的。缺乏直观的可解释性是深度学习的普遍特点。
有隐状态的循环神经网络
循环神经网络(RNN)是具有隐状态的神经网络。
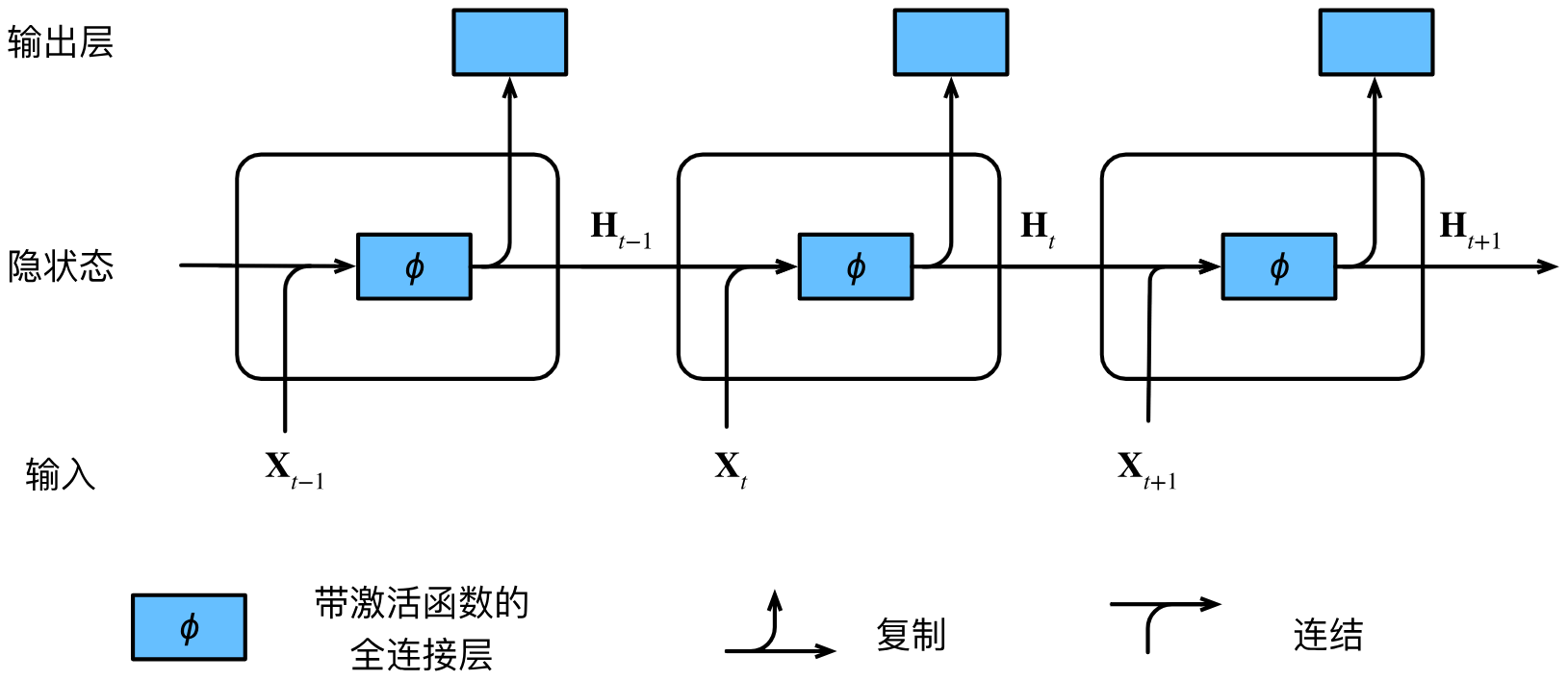
假设有 n n n个序列样本的小批量,在时间步 t t t,小批量输入 X t ∈ R n × d \mathbf X_t\in\mathbb R^{n\times d} Xt∈Rn×d的每一行对应一个序列时间步 t t t处的一个样本。接下来,我们用 H t ∈ R n × h \mathbf H_t\in\mathbb R^{n\times h} Ht∈Rn×h表示时间步 t t t的隐藏变量,并保存了前一个时间步的隐藏变量 H t − 1 \mathbf H_{t-1} Ht−1和利用它更新自身的权重参数 W h h ∈ R h × h \mathbf W_{hh}\in\mathbb R^{h\times h} Whh∈Rh×h。接收到输入时,RNN会先更新隐藏变量:
H t = ϕ ( X t W x h + H t − 1 W h h + b h ) \mathbf H_t=\phi(\mathbf X_t\mathbf W_{xh}+\mathbf H_{t-1}\mathbf W_{hh}+\mathbf b_h) Ht=ϕ(XtWxh+Ht−1Whh+bh)
再根据新的隐藏变量计算输出层的输出:
O t = H t W h q + b q \mathbf O_t=\mathbf H_t\mathbf W_{hq}+\mathbf b_q Ot=HtWhq+bq
可见,隐藏变量类似于多层感知机中隐藏层的输出,但不同的是它在计算时多出了 H t − 1 W h h \mathbf H_{t-1}\mathbf W_{hh} Ht−1Whh一项,不再仅由当前的输入决定。
对于更多的时间步,RNN不会引入新的参数,只会更新已有的参数,以此维持稳定的参数开销。同时,和普通的自回归模型相比,RNN有固定数量的输入,不会因考虑的时间步而改变。
将 X t W x h + H t − 1 W h h \mathbf X_t\mathbf W_{xh}+\mathbf H_{t-1}\mathbf W_{hh} XtWxh+Ht−1Whh写成分块矩阵乘法可得:
X t W x h + H t − 1 W h h = [ X t , H t − 1 ] [ W x h W h h ] \mathbf X_t\mathbf W_{xh}+\mathbf H_{t-1}\mathbf W_{hh}=\begin{bmatrix}\mathbf X_t,\mathbf H_{t-1}\end{bmatrix}\begin{bmatrix}\mathbf W_{xh}\\\mathbf W_{hh}\end{bmatrix} XtWxh+Ht−1Whh=[Xt,Ht−1][WxhWhh]
因此该计算相当于将 X t \mathbf X_t Xt和 H t − 1 \boldsymbol H_{t-1} Ht−1按行连接,将 W x h \mathbf W_{xh} Wxh和 W h h \mathbf W_{hh} Whh按列连接再相乘。由此有隐状态的循环神经网络的计算逻辑如下图所示:
困惑度
由于语言模型和分类模型在本质上有共通之处,输出都是离散的,因此可以引入交叉熵衡量其质量。一个更好的语言模型应该在预测中对序列下一个标签词元给出更高的概率,对序列中所有 n n n个词元的交叉熵损失求平均值得到:
1 n ∑ i = 1 n − log P ( x i ∣ x i − 1 , ⋯ , x 1 ) \displaystyle\frac1n\sum^n_{i=1}-\log P(x_i|x_{i-1},\cdots,x_1) n1i=1∑n−logP(xi∣xi−1,⋯,x1)
由于历史原因,自然语言处理领域更常使用困惑度,它是对上式进行指数运算的结果:
P P = exp ( − 1 n ∑ i = 1 n log P ( x i ∣ x i − 1 , ⋯ , x 1 ) ) PP=\exp\left(-\displaystyle\frac1n\sum^n_{i=1}\log P(x_i|x_{i-1},\cdots,x_1)\right) PP=exp(−n1i=1∑nlogP(xi∣xi−1,⋯,x1))
- 在最好的情况下,模型对标签词元的概率估计总是 1 1 1,此时困惑度为 1 1 1。
- 在最坏的情况下,模型对标签词元的概率估计总是 0 0 0,此时困惑度为正无穷。
- 在基线上,模型对词表中所有不重复词元的概率估计均匀分布,此时困惑度为不重复词元的数量。
通过时间反向传播
通过时间反向传播(BPTT)是循环神经网络中反向传播技术的一个特定应用。
循环神经网络的梯度分析
我们先从循环神经网络的简化模型开始,将时间步 t t t的隐状态表示为 h t h_t ht,输入表示为 x t x_t xt,输出表示为 o t o_t ot,并使用 w h w_h wh和 w o w_o wo表示隐藏层(拼接后)和输出层的权重。则每个时间步的隐状态和输出可写为:
h t = f ( x t , h t − 1 , w h ) h_t=f(x_t,h_{t-1},w_h) ht=f(xt,ht−1,wh)
o t = g ( h t , w o ) o_t=g(h_t,w_o) ot=g(ht,wo)
对于前向传播,我们有目标函数 L L L评估所有 T T T个时间步内输出 o t o_t ot和对应的标签 y t y_t yt之间的差距:
L ( x 1 , ⋯ , x T , y 1 , ⋯ , y T , w h , w o ) = 1 T ∑ t = 1 T l ( y t , o t ) L(x_1,\cdots,x_T,y_1,\cdots,y_T,w_h,w_o)=\displaystyle\frac1T\sum^T_{t=1}l(y_t,o_t) L(x1,⋯,xT,y1,⋯,yT,wh,wo)=T1t=1∑Tl(yt,ot)
对于反向传播,目标函数 L L L对于参数 w h w_h wh的梯度按照链式法则有:
∂ L ∂ w h = 1 T ∑ t = 1 T ∂ l ( y t , o t ) ∂ w h = 1 T ∑ t = 1 T ∂ l ( y t , o t ) ∂ o t ∂ g ( h t , w o ) ∂ h t ∂ h t ∂ w h \begin{equation}\begin{split}\displaystyle\frac{\partial L}{\partial w_h}&=\frac1T\sum^T_{t=1}\frac{\partial l(y_t,o_t)}{\partial w_h}\\&=\frac1T\sum^T_{t=1}\frac{\partial l(y_t,o_t)}{\partial o_t}\frac{\partial g(h_t,w_o)}{\partial h_t}\frac{\partial h_t}{\partial w_h}\end{split}\end{equation} ∂wh∂L=T1t=1∑T∂wh∂l(yt,ot)=T1t=1∑T∂ot∂l(yt,ot)∂ht∂g(ht,wo)∂wh∂ht
乘积的第一项和第二项很容易计算,而第三项 ∂ h t ∂ w h \displaystyle\frac{\partial h_t}{\partial w_h} ∂wh∂ht既依赖 h t − 1 h_{t-1} ht−1又依赖 w h w_h wh,而 h t − 1 h_{t-1} ht−1也依赖 w h w_h wh,需要循环计算参数 w h w_h wh对 h t h_t ht的影响:
∂ h t ∂ w h = ∂ f ( x t , h t − 1 , w h ) ∂ w h + ∂ f ( x t , h t − 1 , w h ) ∂ h t − 1 ∂ h t − 1 ∂ w h = ∂ f ( x t , h t − 1 , w h ) ∂ w h + ∑ i = 1 t − 1 ( ∏ j = i + 1 t ∂ f ( x j , h j − 1 , w h ) ∂ h j − 1 ) ∂ f ( x i , h i − 1 , w h ) ∂ w h \begin{equation}\begin{split}\displaystyle\frac{\partial h_t}{\partial w_h}&=\frac{\partial f(x_t,h_{t-1},w_h)}{\partial w_h}+\frac{\partial f(x_t,h_{t-1},w_h)}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial w_h}\\&=\frac{\partial f(x_t,h_{t-1},w_h)}{\partial w_h}+\sum^{t-1}_{i=1}\left(\prod^t_{j=i+1}\frac{\partial f(x_j,h_{j-1},w_h)}{\partial h_{j-1}}\right)\frac{\partial f(x_i,h_{i-1},w_h)}{\partial w_h}\end{split}\end{equation} ∂wh∂ht=∂wh∂f(xt,ht−1,wh)+∂ht−1∂f(xt,ht−1,wh)∂wh∂ht−1=∂wh∂f(xt,ht−1,wh)+i=1∑t−1(j=i+1∏t∂hj−1∂f(xj,hj−1,wh))∂wh∂f(xi,hi−1,wh)
当 t t t很大时,计算链条会变得很长,需要采取办法解决这一问题。
1.截断时间步
截断时间步在 τ \tau τ步后截断上式的求和运算,只将求和终止到 ∂ h t − τ ∂ w h \displaystyle\frac{\partial h_{t-\tau}}{\partial w_h} ∂wh∂ht−τ来近似实际梯度。这使得模型主要侧重于短期影响而非长期影响,变得更简单但也更稳定。
2.随机截断
随机截断通过随机变量序列 ξ t \xi_t ξt实现在随机时间步后截断。 ξ t \xi_t ξt预先确定好一个值 0 ⩽ π t ⩽ 1 0\leqslant\pi_t\leqslant1 0⩽πt⩽1,再根据如下两点分布生成序列:
P ( ξ t = 0 ) = 1 − π t P(\xi_t=0)=1-\pi_t P(ξt=0)=1−πt
P ( ξ t = π t − 1 ) = π t P(\xi_t=\pi_t^{-1})=\pi_t P(ξt=πt−1)=πt
于是我们用如下式子来替换 ∂ h t ∂ w h \displaystyle\frac{\partial h_t}{\partial w_h} ∂wh∂ht的计算:
z t = ∂ f ( x t , h t − 1 , w h ) ∂ w h + ξ t ∂ f ( x t , h t − 1 , w h ) ∂ h t − 1 ∂ h t − 1 ∂ w h z_t=\displaystyle\frac{\partial f(x_t,h_{t-1},w_h)}{\partial w_h}+\xi_t\frac{\partial f(x_t,h_{t-1},w_h)}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial w_h} zt=∂wh∂f(xt,ht−1,wh)+ξt∂ht−1∂f(xt,ht−1,wh)∂wh∂ht−1
在递归计算的过程中, ξ t \xi_t ξt会随机在某个时间步取到 0 0 0,进而截断后续的计算,同时之前计算的权重会随着递归的次数而增加。最终效果是短序列梯度出现的概率高,而长序列梯度出现的概率低,但长序列得到的权重更高。根据 E [ ξ t ] = 1 \mathbb E[\xi_t]=1 E[ξt]=1和期望的线性性质可以得到 E [ z t ] = ∂ h t ∂ w h \mathbb E[z_t]=\displaystyle\frac{\partial h_t}{\partial w_h} E[zt]=∂wh∂ht,因此该估计是无偏的。
随机截断在实践中可能并不比常规截断好,原因有三:
- 在对过去若干时间步进行反向传播后,观测结果足以捕获实际的依赖关系。
- 随机变量带来的方差抵消了时间步越多梯度越精确的效果。
- 局部性先验的小范围交互模型更匹配数据的本质。
通过时间反向传播的细节
从简化模型扩展到对单个样本的运算,对于时间步 t t t,设单个样本的输入及其对应的标签分别为 x t ∈ R d \boldsymbol x_t\in\mathbb R^d xt∈Rd和 y t y_t yt,计算隐状态 h t ∈ R h \boldsymbol h_t\in\mathbb R^h ht∈Rh和输出 o t ∈ R q o_t\in\mathbb R^q ot∈Rq的公式为:
h t = W h x x t + W h h h t − 1 \boldsymbol h_t=\boldsymbol W_{hx}\boldsymbol x_t+\boldsymbol W_{hh}\boldsymbol h_{t-1} ht=Whxxt+Whhht−1
o t = W q h h t \boldsymbol o_t=\boldsymbol W_{qh}\boldsymbol h_t ot=Wqhht
其中权重参数为 W h t ∈ R h × d \mathbf W_{ht}\in\mathbb R^{h\times d} Wht∈Rh×d、 W h h ∈ R h × h \mathbf W_{hh}\in\mathbb R^{h\times h} Whh∈Rh×h和 W q h ∈ R q × h \mathbf W_{qh}\in\mathbb R^{q\times h} Wqh∈Rq×h。
用 l ( o t , y t ) l(\mathbf o_t,y_t) l(ot,yt)表示时间步 t t t处的损失函数,则目标函数的总体损失为:
L = 1 T ∑ t = 1 T l ( o t , y t ) L=\displaystyle\frac1T\sum^T_{t=1}l(\mathbf o_t,y_t) L=T1t=1∑Tl(ot,yt)
接下来沿箭头所指反方向遍历循环神经网络的计算图:
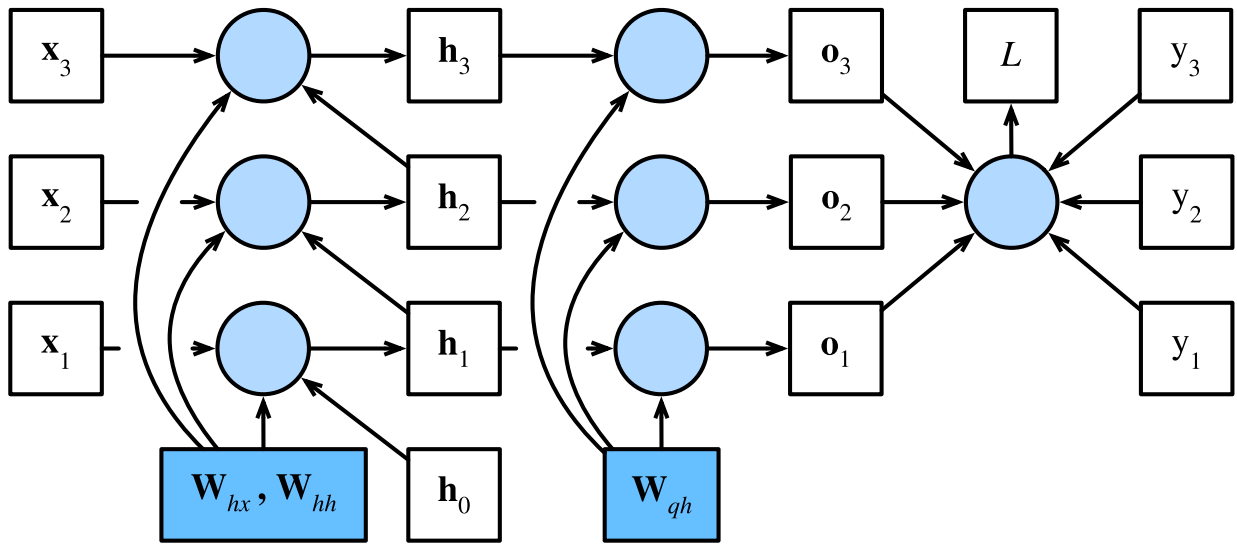
首先,在任意时间步 t t t,目标函数关于模型输出的微分计算为:
∂ L ∂ o t = ∂ l ( o t , y t ) T ⋅ ∂ o t ∈ R q \displaystyle\frac{\partial L}{\partial\boldsymbol o_t}=\frac{\partial l(\boldsymbol o_t,y_t)}{T\cdot\partial\boldsymbol o_t}\in\mathbb R^q ∂ot∂L=T⋅∂ot∂l(ot,yt)∈Rq
目标函数对 W q h \mathbf W_{qh} Wqh的梯度依赖于 o t \boldsymbol o_t ot,根据链式法则有(prod表示链式法则中的乘法运算):
∂ L ∂ W q h = ∑ t = 1 T prod ( ∂ L ∂ o t , ∂ o t ∂ W q h ) = ∑ t = 1 T ∂ L ∂ o t h t ⊤ ∈ R q × h \displaystyle\frac{\partial L}{\partial\mathbf{W}_{qh}}=\sum_{t=1}^T\text{prod}\left(\frac{\partial L}{\partial\mathbf{o}_t},\frac{\partial\mathbf{o}_t}{\partial\mathbf{W}_{qh}}\right)=\sum_{t=1}^T\frac{\partial L}{\partial\mathbf{o}_t}\mathbf{h}_t^\top\in\mathbb R^{q\times h} ∂Wqh∂L=t=1∑Tprod(∂ot∂L,∂Wqh∂ot)=t=1∑T∂ot∂Lht⊤∈Rq×h
在最终时间步 T T T,目标函数对 h T \mathbf h_T hT的梯度仅依赖于 o T \mathbf o_T oT:
∂ L ∂ h T = prod ( ∂ L ∂ o T , ∂ o T ∂ h T ) = W q h ⊤ ∂ L ∂ o T ∈ R h \displaystyle\frac{\partial L}{\partial\mathbf{h}_T}=\text{prod}\left(\frac{\partial L}{\partial\mathbf{o}_T},\frac{\partial\mathbf{o}_T}{\partial\mathbf{h}_T}\right)=\mathbf{W}_{qh}^\top\frac{\partial L}{\partial\mathbf{o}_T}\in\mathbb R^h ∂hT∂L=prod(∂oT∂L,∂hT∂oT)=Wqh⊤∂oT∂L∈Rh
但目标函数对其余时间步下 h t \mathbf h_t ht的梯度依赖于 o t \mathbf o_t ot和 h t + 1 \mathbf h_{t+1} ht+1,此时需要进行递归运算:
∂ L ∂ h t = prod ( ∂ L ∂ h t + 1 , ∂ h t + 1 ∂ h t ) + prod ( ∂ L ∂ o t , ∂ o t ∂ h t ) = W h h ⊤ ∂ L ∂ h t + 1 + W q h ⊤ ∂ L ∂ o t \displaystyle\frac{\partial L}{\partial\mathbf{h}_t}=\text{prod}\left(\frac{\partial L}{\partial\mathbf{h}_{t+1}},\frac{\partial\mathbf{h}_{t+1}}{\partial\mathbf{h}_t}\right)+\text{prod}\left(\frac{\partial L}{\partial\mathbf{o}_t},\frac{\partial\mathbf{o}_t}{\partial\mathbf{h}_t} \right) = \mathbf{W}_{hh}^\top\frac{\partial L}{\partial\mathbf{h}_{t+1}}+\mathbf{W}_{qh}^\top\frac{\partial L}{\partial\mathbf{o}_t} ∂ht∂L=prod(∂ht+1∂L,∂ht∂ht+1)+prod(∂ot∂L,∂ht∂ot)=Whh⊤∂ht+1∂L+Wqh⊤∂ot∂L
将该递归式展开可得:
∂ L ∂ h t = ∑ i = t T ( W h h ⊤ ) T − i W q h ⊤ ∂ L ∂ o T + t − i \displaystyle\frac{\partial L}{\partial\mathbf{h}_t}=\sum_{i=t}^T{\left(\mathbf{W}_{hh}^\top\right)}^{T-i}\mathbf{W}_{qh}^\top\frac{\partial L}{\partial\mathbf{o}_{T+t-i}} ∂ht∂L=i=t∑T(Whh⊤)T−iWqh⊤∂oT+t−i∂L
上式出现了 W h h ⊤ \mathbf W_{hh}^\top Whh⊤的幂运算,当指数非常大时,幂中小于 1 1 1的特征值会消失,大于 1 1 1的特征值会发散,表现形式为梯度消失和梯度爆炸。一种解决方法是截断时间步,下一章将介绍缓解这一问题的更复杂的序列模型。
最后,目标函数对隐藏层模型参数 W x h \mathbf W_{xh} Wxh和 W h h \mathbf W_{hh} Whh的梯度依赖于所有的 h t \mathbf h_t ht,根据链式法则有:
∂ L ∂ W h x = ∑ t = 1 T prod ( ∂ L ∂ h t , ∂ h t ∂ W h x ) ∑ t = 1 T ∂ L ∂ h t x t ⊤ \displaystyle\frac{\partial L}{\partial\mathbf{W}_{hx}}=\sum_{t=1}^T\text{prod}\left(\frac{\partial L}{\partial\mathbf{h}_t},\frac{\partial\mathbf{h}_t}{\partial\mathbf{W}_{hx}}\right)\sum_{t=1}^T \frac{\partial L}{\partial\mathbf{h}_t}\mathbf{x}_t^\top ∂Whx∂L=t=1∑Tprod(∂ht∂L,∂Whx∂ht)t=1∑T∂ht∂Lxt⊤
∂ L ∂ W h h = ∑ t = 1 T prod ( ∂ L ∂ h t , ∂ h t ∂ W h h ) = ∑ t = 1 T ∂ L ∂ h t h t − 1 ⊤ \displaystyle\frac{\partial L}{\partial \mathbf{W}_{hh}}=\sum_{t=1}^T\text{prod}\left(\frac{\partial L}{\partial\mathbf{h}_t}, \frac{\partial\mathbf{h}_t}{\partial \mathbf{W}_{hh}}\right)= \sum_{t=1}^T \frac{\partial L}{\partial \mathbf{h}_t} \mathbf{h}_{t-1}^\top ∂Whh∂L=t=1∑Tprod(∂ht∂L,∂Whh∂ht)=t=1∑T∂ht∂Lht−1⊤
梯度裁剪
除了专门针对BPTT的截断时间步,还有一种更普适的修复梯度爆炸的方法,称为梯度裁剪。
最基本的梯度裁剪在反向传播的过程中对梯度进行限制,在梯度的范数超过某个阈值时,将其按比例缩小,其公式为:
g ← min ( 1 , θ ∣ ∣ g ∣ ∣ ) g \boldsymbol g\leftarrow\min\left(\displaystyle1,\frac\theta{||\boldsymbol g||}\right)\boldsymbol g g←min(1,∣∣g∣∣θ)g
通过这样做,梯度范数将永远不会超过 θ \theta θ。
相关文章:
【深度学习】#8 循环神经网络
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 为了进一步提高长线学习的效率,该系列从本章开始将舍弃原始教材的代码部分,专注于理论和思维的提炼,系列名也改为“深度学习…...

开源状态机引擎,在实战中可以放心使用
### Squirrel-Foundation 状态机开源项目介绍 **Squirrel-Foundation** 是一个轻量级、灵活、可扩展、易于使用且类型安全的 Java 状态机实现,适用于企业级应用。它提供了多种方式来定义状态机,包括注解声明和 Fluent API,并且支持状态转换、…...

机器学习超参数优化全解析
机器学习超参数优化全解析 摘要 本文全面深入地剖析了机器学习模型中的超参数优化策略,涵盖了从参数与超参数的本质区别,到核心超参数(如学习率、批量大小、训练周期)的动态调整方法;从自动化超参数优化技术…...

AI 模型在前端应用中的典型使用场景和限制
典型使用场景 1. 智能表单处理 // 使用TensorFlow.js实现表单自动填充 import * as tf from tensorflow/tfjs; import { loadGraphModel } from tensorflow/tfjs-converter;async function initFormPredictor() {// 加载预训练的表单理解模型const model await loadGraphMod…...
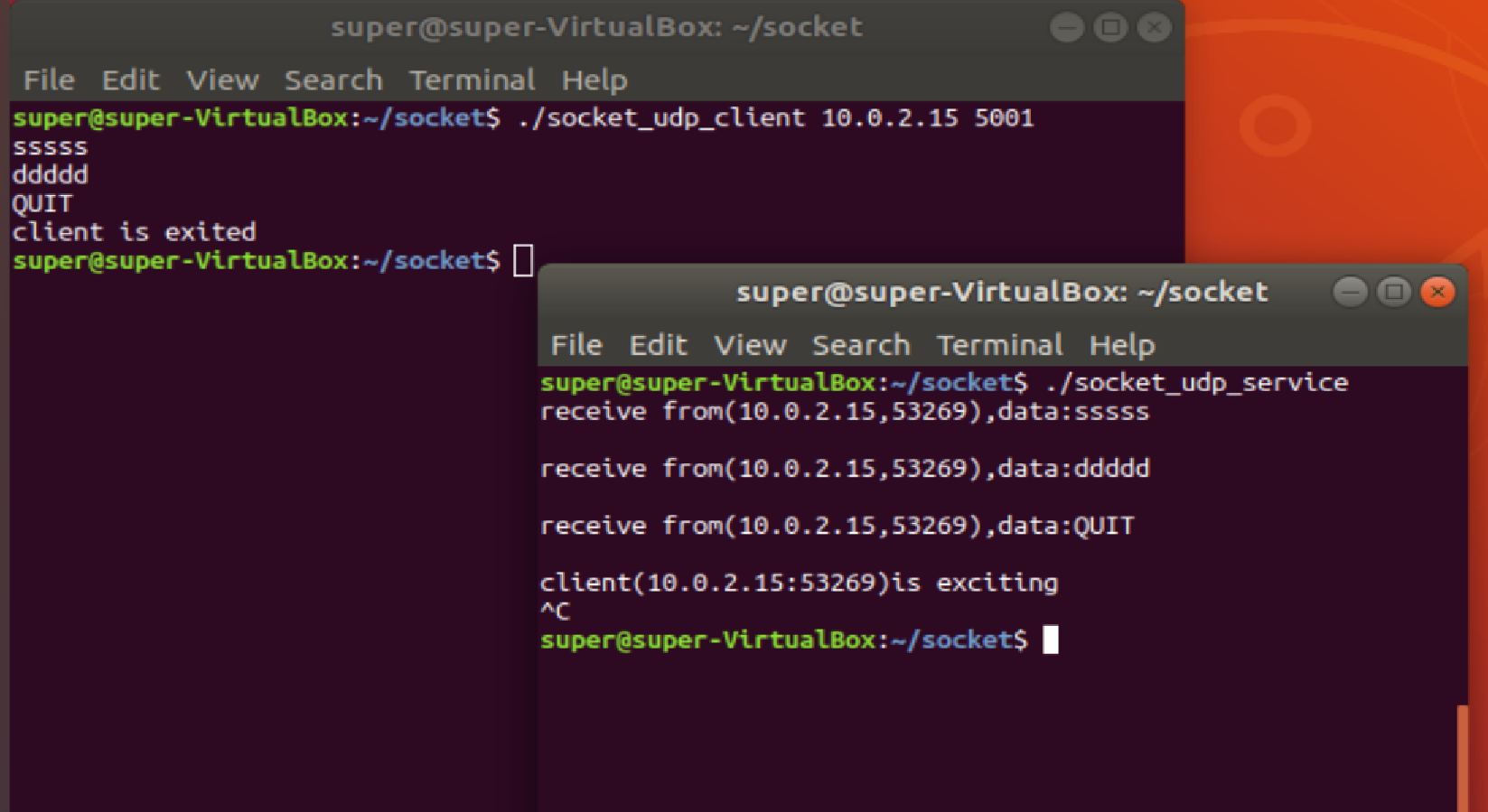
Linux学习——UDP
编程的整体框架 bind:绑定服务器:TCP地址和端口号 receivefrom():阻塞等待客户端数据 sendto():指定服务器的IP地址和端口号,要发送的数据 无连接尽力传输,UDP:是不可靠传输 实时的音视频传输&#x…...

leetcode205.同构字符串
两个哈希表存储字符的映射关系,如果前面字符的映射关系和后面的不一样则返回false class Solution {public boolean isIsomorphic(String s, String t) {if (s.length() ! t.length()) {return false;}int length s.length();Map<Character, Character> s2…...

软考软件设计师考试情况与大纲概述
文章目录 **一、考试科目与形式****二、考试大纲与核心知识点****科目1:计算机与软件工程知识****科目2:软件设计** **三、备考建议****四、参考资料** 这是一个系列文章的开篇 本文对2025年软考软件设计师考试的大纲及核心内容进行了整理,并…...

24. git revert
基本概述 git revert 的作用是:撤销某次的提交。与 git reset 不同的是,git revert 不会修改提交历史,而是创建一个新的提交来反转之前的提交。 基本用法 1.基本语法 git revert <commit-hash>该命令会生成一个新的提交,…...

Redis—内存淘汰策略
记:全体LRU,ttl LRU,全体LFU,ttl LFU,全体随机,ttl随机,最快过期,不淘汰(八种) Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存&…...

Java大厂面试:JUC锁机制的深度探讨 - 从synchronized到StampedLock
Java大厂面试:JUC锁机制的深度探讨 在一个风和日丽的下午,马飞机同学来到了一家互联网大厂参加Java开发岗位的面试。这次他面对的是严肃且专业的面试官李老师,而话题则围绕着Java并发编程中的重要组成部分——JUC(java.util.conc…...
——LSTM详解)
NLP高频面试题(五十一)——LSTM详解
长短期记忆网络(LSTM)相较于传统循环神经网络(RNN)的核心改进在于通过引入记忆单元(cell state)和门机制(gating mechanism)来有效缓解梯度消失与梯度爆炸问题,从而更好地捕捉长距离依赖关系 。在其网络结构中,信息通过输入门(input gate)、遗忘门(forget gate)和…...
Power BI企业运营分析——数据大屏搭建思路
Power BI企业运营分析——数据大屏搭建思路 欢迎来到Powerbi小课堂,在竞争激烈的市场环境中,企业运营分析平台成为提升竞争力的核心工具。 整合多源数据,实时监控关键指标,精准分析业务,快速识别问题机遇。其可视化看…...
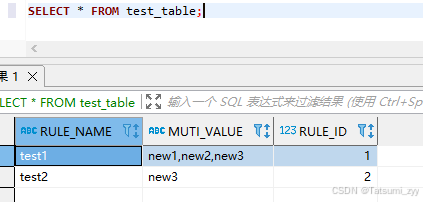
oracle将表字段逗号分隔的值进行拆分,并替换值
需求背景:需要源数据变动,需要对历史表已存的字段值根据源数据进行更新。如果是单字段存值,直接根据映射表关联修改即可。但字段里面若存的值是以逗号分割,比如旧值:‘old1,old2,old3’,要根据映射关系调整…...
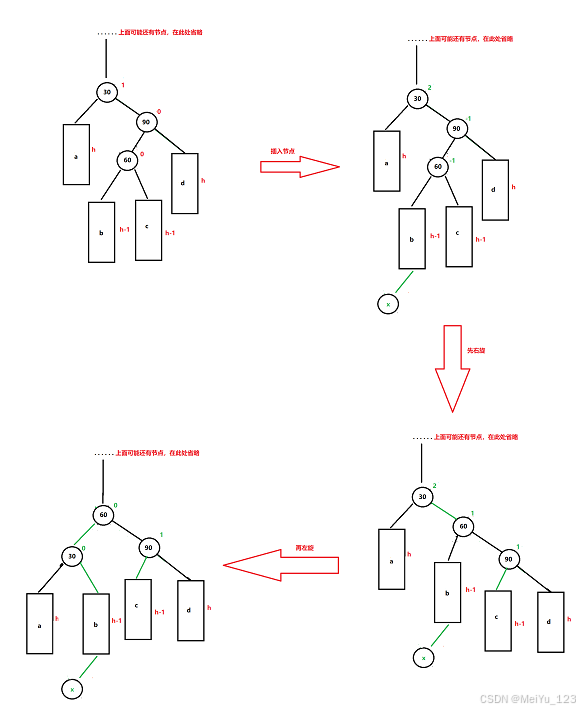
【重走C++学习之路】16、AVL树
目录 一、概念 二、AVL树的模拟实现 2.1 AVL树节点定义 2.2 AVL树的基本结构 2.3 AVL树的插入 1. 插入步骤 2. 调节平衡因子 3. 旋转处理 4. 开始插入 2.4 AVL树的查找 2.5 AVL树的删除 1. 删除步骤 2. 调节平衡因子 3. 旋转处理 4. 开始删除 结语 一、概念 …...

NumPy进阶:广播机制、高级索引与通用函数详解
目录 一、广播机制:不同形状数组间的运算 1. 概念 2. 广播规则 3. 实例 二、高级索引:布尔索引与花式索引 1. 布尔索引 (1)创建布尔索引 (2)布尔索引的应用 2. 花式索引 (1࿰…...

597页PPT丨流程合集:流程梳理方法、流程现状分析,流程管理规范及应用,流程绩效的管理,流程实施与优化,流程责任人的角色认知等
流程梳理是通过系统化分析优化业务流程的管理方法,其核心包含四大步骤:①目标确认,明确业务痛点和改进方向;②现状分析,通过流程图、价值流图还原现有流程全貌,识别冗余环节和瓶颈节点;③优化设…...

[密码学基础]GMT 0029-2014签名验签服务器技术规范深度解析
GMT 0029-2014签名验签服务器技术规范深度解析 引言 在数字化转型和网络安全需求激增的背景下,密码技术成为保障数据完整性与身份认证的核心手段。中国密码管理局发布的GMT 0029-2014《签名验签服务器技术规范》,为签名验签服务器的设计、开发与部署提…...

Kinibi-610a:面向芯片厂商与设备制造商的TEE升级详解
安全之安全(security)博客目录导读 目录 一、TEE内存管理革新 二、TA加载架构优化 三、系统日志(syslog)集成 四、加密日志支持 五、工具链升级至Python3 六、总结与展望 七、参考资料 Trustonic最新发布的可信执行环境(TEE)Kinibi-610a,在前代Kinibi-600多平台支…...
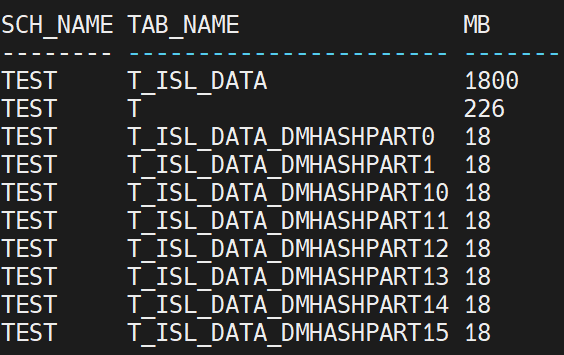
来啦,烫,查询达梦表占用空间
想象一下oracle,可以查dba_segments,但是这个不可靠(达梦官方连说明书都没有) 先拼接一个sql set lineshow off SELECT SELECT ||||OWNER|||| AS OWNER,||||TABLE_NAME|||| AS TABLE_NAME,TABLE_USED_SPACE(||||OWNER||||,||||T…...
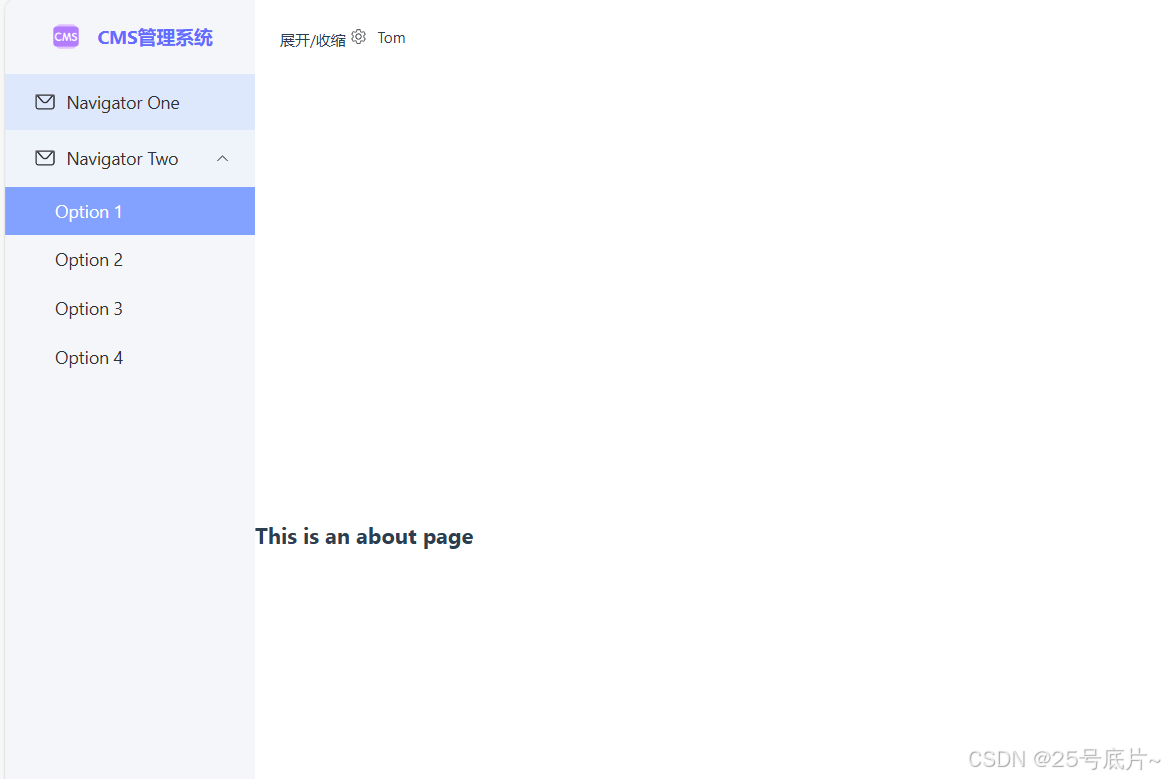
vue3:十一、主页面布局(修改左侧导航条的样式)
一、样式 1、初始样式 2、 左侧导航栏搭建完成样式 二、实现 1、设置左侧导航栏底色 (1)去掉顶部和左侧导航栏的底色 初始页面效果 顶部与左侧底色样式 将代码中与顶部与左侧的样式删掉 移除后页面效果 加入设定背景色 #f4f6f9 加入底色后颜色展示 (2)去除菜单项底色 初…...

开发网页程序时预览时遇到跨域问题解决方法
CocosCreator 开发h5游戏要用接口、开发html程序网页程序在chrome中预览时都会遇到跨域问题,怎么办? 网上有很多方法,主要是通过服务器端去配置,但那个相对来说消弱安全问题,这个不建议,因为是开发,个人行业,我们知道问题所以,简单点就主要是通过chrome的参数来禁用: 关闭 Ch…...

Sentinel源码—7.参数限流和注解的实现二
大纲 1.参数限流的原理和源码 2.SentinelResource注解的使用和实现 2.SentinelResource注解的使用和实现 (1)SentinelResource注解的使用 (2)SentinelResource注解和实现 (1)SentinelResource注解的使用 一.引入Sentinel Spring Boot Starter依赖 <dependency><…...

操作系统原理简要介绍
文章目录 计算机启动的底层流程(从裸机到操作系统)内核用户态与内核态内核分类 进程与线程:操作系统的 “执行者”内存管理:数据的“存储与调度”文件系统:数据的“组织与持久化”设备驱动:硬件的“翻译官”…...
组件)
QML ShaderEffect(着色器效果)组件
ShaderEffect 是 QML 中用于实现自定义着色器效果的组件,允许开发者使用 GLSL 着色器语言创建图形效果。 核心属性 基本属性 属性类型默认值说明fragmentShaderstring""片段着色器代码vertexShaderstring""顶点着色器代码blendingbooltrue是…...

2.6 递归
递归 特性: >.一递一归 >.终止条件 一般为:0 1 -1 #测试函数的返回值为函数 def test_recursion():return test_recursion() print(test_recursion()) RecursionError: maximum recursion depth exceeded #案例:计算 …...

麒麟系统网络连接问题排查
麒麟系统网络连接有红色叹号,不能上外网 了。 首先执行 ping -c4 8.8.8.8 和 nc -zv 8.8.8.8 53,如果 都能正常通信,说明你的网络可以访问公共 DNS 服务器(如 Google DNS 8.8.8.8),但域名解析仍然失败,可能是 DNS 解析配置问题 或 系统 DNS 缓存/代理干扰。以下是进一步…...

opencv(双线性插值原理)
双线性插值是一种图像缩放、旋转或平移时进行像素值估计的插值方法。当需要对图像进行变换时,特别是尺寸变化时,原始图像的某些像素坐标可能不再是新图像中的整数位置,这时就需要使用插值算法来确定这些非整数坐标的像素值。 双线性插值的工…...

从信号处理角度理解图像处理的滤波函数
目录 1、预备知识 1.1 什么是LTI系统? 1.1.1 首先来看什么是线性系统,前提我们要了解什么是齐次性和叠加性。...
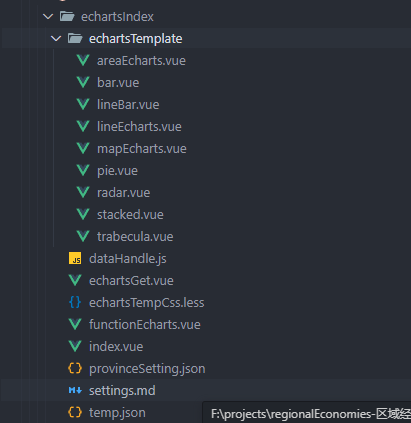
echarts模板化开发,简易版配置大屏组件-根据配置文件输出图形和模板(vue2+echarts5.0)
实现结果 项目结构 根据我的目录和代码 复制到项目中 echartsTemplate-echarts图形 pie实例 <template><div :id"echartsId"></div> </template> <script> export default {name: ,components: {},mixins: [],props: [echartsId,…...

从人工到智能:外呼系统如何重构企业效率新生态
在数字化转型的浪潮中,智能外呼系统正从边缘辅助工具演变为企业效率革命的核心引擎。根据Gartner最新调研数据,部署AI外呼系统的企业客服效率平均提升68%,销售线索转化率增长42%。但在这场技术驱动的变革中,真正决定成败的往往不是…...