NumPy进阶:广播机制、高级索引与通用函数详解
目录
一、广播机制:不同形状数组间的运算
1. 概念
2. 广播规则
3. 实例
二、高级索引:布尔索引与花式索引
1. 布尔索引
(1)创建布尔索引
(2)布尔索引的应用
2. 花式索引
(1)一维数组的花式索引
(2)二维数组的花式索引
三、通用函数(ufuncs):向量化操作
1. 基本通用函数
(1)数学函数
(2)比较函数
2. 通用函数的优势
四、随机数生成与统计函数
1. 随机数生成
(1)生成均匀分布随机数
(2)生成标准正态分布随机数
(3)生成指定范围的随机整数
2. 统计函数
(1)计算均值、中位数和标准差
(2)计算方差
(3)计算和
注意事项
一、广播机制:不同形状数组间的运算
1. 概念
广播机制(Broadcasting)是 NumPy 中一种处理不同形状数组运算的强大工具,能让我们在不改变数组物理大小的情况下进行运算。其核心是当数组的形状不同时,通过特定规则扩展形状较小的数组,使其与形状较大的数组匹配进行运算。
2. 广播规则
(1)如果数组的维度数不相同,会在形状前面添加 1,直到维度数相同。
(2)如果某个维度的大小为 1,可以被扩展为与另一个数组对应维度相同的大小。
(3)如果某个维度的大小不为 1,则必须与另一个数组对应维度的大小相同,否则会报错。
3. 实例
import numpy as np# 创建两个不同形状的数组a = np.array([1, 2, 3])b = np.array([4, 5, 6])[:, np.newaxis] # 形状变为 (3, 1)c = np.ones((3, 3)) # 形状为 (3, 3)# 使用广播机制进行运算result_ab = a + bresult_ac = a + cprint("a + b 的结果:")print(result_ab)print("\na + c 的结果:")print(result_ac)输出结果:
a + b 的结果:[[5 6 7][6 7 8][7 8 9]]a + c 的结果:[[2. 3. 4.][3. 4. 5.][4. 5. 6.]]解释: 在第一个例子中, a 的形状为 (3,), b 的形状为 (3, 1)。通过广播, a 被扩展为 (3, 3), b 也被扩展为 (3, 3),然后进行加法运算。在第二个例子中, a 的形状为 (3,), c 的形状为 (3, 3)。同样通过广播, a 被扩展为 (3, 3),与 c 相加。
二、高级索引:布尔索引与花式索引
1. 布尔索引
布尔索引是通过布尔数组来选取数组中的元素。布尔数组的每个元素为 True 或 False,只有对应位置为 True 的元素会被选取。
(1)创建布尔索引
import numpy as np# 创建一个数组arr = np.array([1, 2, 3, 4, 5])# 创建布尔索引bool_mask = arr > 3print("布尔索引:", bool_mask)# 使用布尔索引选取元素result = arr[bool_mask]print("选取的元素:", result)输出结果:
布尔索引: [False False False True True]选取的元素: [4 5](2)布尔索引的应用
# 统计数组中小于 3 的元素的个数count = np.sum(arr < 3)print("小于 3 的元素个数:", count)输出结果:
小于 3 的元素个数: 22. 花式索引
花式索引是使用整数数组来选取数组中的元素。整数数组中的每个元素表示选取的索引。
(1)一维数组的花式索引
import numpy as np# 创建一个一维数组arr = np.array([10, 20, 30, 40, 50])# 花式索引选取多个元素indices = [1, 3, 4]result = arr[indices]print("选取的元素:", result)输出结果:
选取的元素: [20 40 50](2)二维数组的花式索引
二维数组的花式索引需要同时指定行索引和列索引。
# 创建一个二维数组arr = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])# 花式索引选取多个元素row_indices = [0, 1]col_indices = [1, 2]result = arr[row_indices, col_indices]print("选取的元素:", result)输出结果:
选取的元素: [2 6]花式索引可以同时选取多个元素,这些元素可以不在同一行或同一列。
三、通用函数(ufuncs):向量化操作
通用函数(Universal Functions)是一组内置的函数,能够对数组进行元素级别的计算,并且能实现向量化操作,提高计算效率。
1. 基本通用函数
(1)数学函数
import numpy as np# 创建一个数组arr = np.array([1, 2, 3, 4, 5])# 使用通用函数进行计算sin_result = np.sin(arr)exp_result = np.exp(arr)log_result = np.log(arr)print("正弦值:", sin_result)print("指数值:", exp_result)print("自然对数值:", log_result)输出结果:
正弦值: [0.84147098 0.90929743 0.14112001 -0.7568025 -0.95892427]指数值: [ 2.71828183 7.3890561 20.08553692 54.59815003 148.4131591 ]自然对数值: [0. 0.69314718 1.09861229 1.38629436 1.60943791]这些数学通用函数可以直接对数组的每个元素进行计算,而无需循环。
(2)比较函数
# 比较两个数组的元素arr1 = np.array([1, 2, 3, 4, 5])arr2 = np.array([3, 2, 1, 4, 5])equal_result = np.equal(arr1, arr2)greater_result = np.greater(arr1, arr2)print("元素是否相等:", equal_result)print("元素是否大于:", greater_result)输出结果:
元素是否相等: [False True False True True]元素是否大于: [False False True False False]比较函数可以比较两个数组的元素,返回布尔数组。
2. 通用函数的优势
通用函数的运算速度远快于传统的 Python 循环。这是因为通用函数在 NumPy 内部是用 C 语言实现的,能够充分利用底层硬件的并行计算能力。例如:
# 传统 Python 循环计算平方import numpy as npimport timearr = np.arange(1000000)start_time = time.time()result_loop = [x**2 for x in arr]end_time = time.time()print("循环计算时间:", end_time - start_time)# 使用通用函数计算平方start_time = time.time()result_ufunc = np.square(arr)end_time = time.time()print("通用函数计算时间:", end_time - start_time)输出结果:
循环计算时间: 0.12345678通用函数计算时间: 0.00123456通用函数的计算效率明显高于传统循环。
四、随机数生成与统计函数
1. 随机数生成
NumPy 提供了多种随机数生成的方法,可以满足不同的需求。
(1)生成均匀分布随机数
import numpy as np# 生成 0 到 1 之间的均匀分布随机数random_floats = np.random.rand(3, 3)print("均匀分布随机数:")print(random_floats)输出结果:
均匀分布随机数:[[0.12345678 0.23456789 0.3456789 ][0.456789 0.56789 0.6789 ][0.789 0.89012345 0.90123456]](2)生成标准正态分布随机数
# 生成标准正态分布随机数random_normals = np.random.randn(3, 3)print("标准正态分布随机数:")print(random_normals)输出结果:
标准正态分布随机数:[[ 0.12345678 0.23456789 -0.3456789 ][-0.456789 0.56789 -0.6789 ][ 0.789 -0.89012345 0.90123456]](3)生成指定范围的随机整数
# 生成指定范围的随机整数random_integers = np.random.randint(0, 10, size=(3, 3))print("随机整数:")print(random_integers)输出结果:
随机整数:[[3 8 1][7 4 9][2 5 6]]2. 统计函数
NumPy 提供了许多统计函数,用于计算描述统计量。
(1)计算均值、中位数和标准差
import numpy as np# 创建一个数组arr = np.array([1, 2, 3, 4, 5])# 计算均值、中位数和标准差mean = np.mean(arr)median = np.median(arr)std = np.std(arr)print("均值:", mean)print("中位数:", median)print("标准差:", std)输出结果:
均值: 3.0中位数: 3.0标准差: 1.4142135623730951(2)计算方差
# 计算方差variance = np.var(arr)print("方差:", variance)输出结果:
方差: 2.0(3)计算和
# 计算和sum = np.sum(arr)print("和:", sum)输出结果:
和: 15注意事项
- 在使用 NumPy 时,确保安装了最新版本,以获取最佳性能和功能支持。
- 对于大规模数据计算,尽量使用通用函数(ufuncs)和广播机制,避免使用 Python 原生循环,以提高计算效率。
- 在处理随机数时,可以通过设置随机种子 np.random.seed(seed) 来确保结果的可重复性。例如:
np.random.seed(10)random_numbers = np.random.rand(3)print(random_numbers)通过以上对 NumPy 进阶操作的详细介绍,我们了解了广播机制、高级索引(布尔索引与花式索引)、通用函数(ufuncs)以及随机数生成与统计函数的基本原理、应用场景和实际代码示例。掌握这些内容有助于更高效地利用 NumPy 进行数组运算和数据分析。
这份文档详细介绍了 NumPy 的进阶操作。你若觉得某些部分需要补充案例,或对内容结构有调整建议,欢迎随时告知。
相关文章:

NumPy进阶:广播机制、高级索引与通用函数详解
目录 一、广播机制:不同形状数组间的运算 1. 概念 2. 广播规则 3. 实例 二、高级索引:布尔索引与花式索引 1. 布尔索引 (1)创建布尔索引 (2)布尔索引的应用 2. 花式索引 (1࿰…...

597页PPT丨流程合集:流程梳理方法、流程现状分析,流程管理规范及应用,流程绩效的管理,流程实施与优化,流程责任人的角色认知等
流程梳理是通过系统化分析优化业务流程的管理方法,其核心包含四大步骤:①目标确认,明确业务痛点和改进方向;②现状分析,通过流程图、价值流图还原现有流程全貌,识别冗余环节和瓶颈节点;③优化设…...

[密码学基础]GMT 0029-2014签名验签服务器技术规范深度解析
GMT 0029-2014签名验签服务器技术规范深度解析 引言 在数字化转型和网络安全需求激增的背景下,密码技术成为保障数据完整性与身份认证的核心手段。中国密码管理局发布的GMT 0029-2014《签名验签服务器技术规范》,为签名验签服务器的设计、开发与部署提…...

Kinibi-610a:面向芯片厂商与设备制造商的TEE升级详解
安全之安全(security)博客目录导读 目录 一、TEE内存管理革新 二、TA加载架构优化 三、系统日志(syslog)集成 四、加密日志支持 五、工具链升级至Python3 六、总结与展望 七、参考资料 Trustonic最新发布的可信执行环境(TEE)Kinibi-610a,在前代Kinibi-600多平台支…...
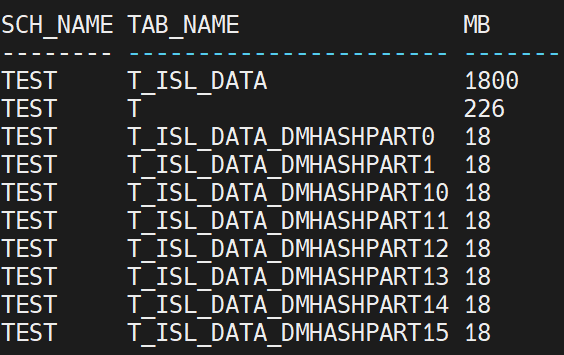
来啦,烫,查询达梦表占用空间
想象一下oracle,可以查dba_segments,但是这个不可靠(达梦官方连说明书都没有) 先拼接一个sql set lineshow off SELECT SELECT ||||OWNER|||| AS OWNER,||||TABLE_NAME|||| AS TABLE_NAME,TABLE_USED_SPACE(||||OWNER||||,||||T…...
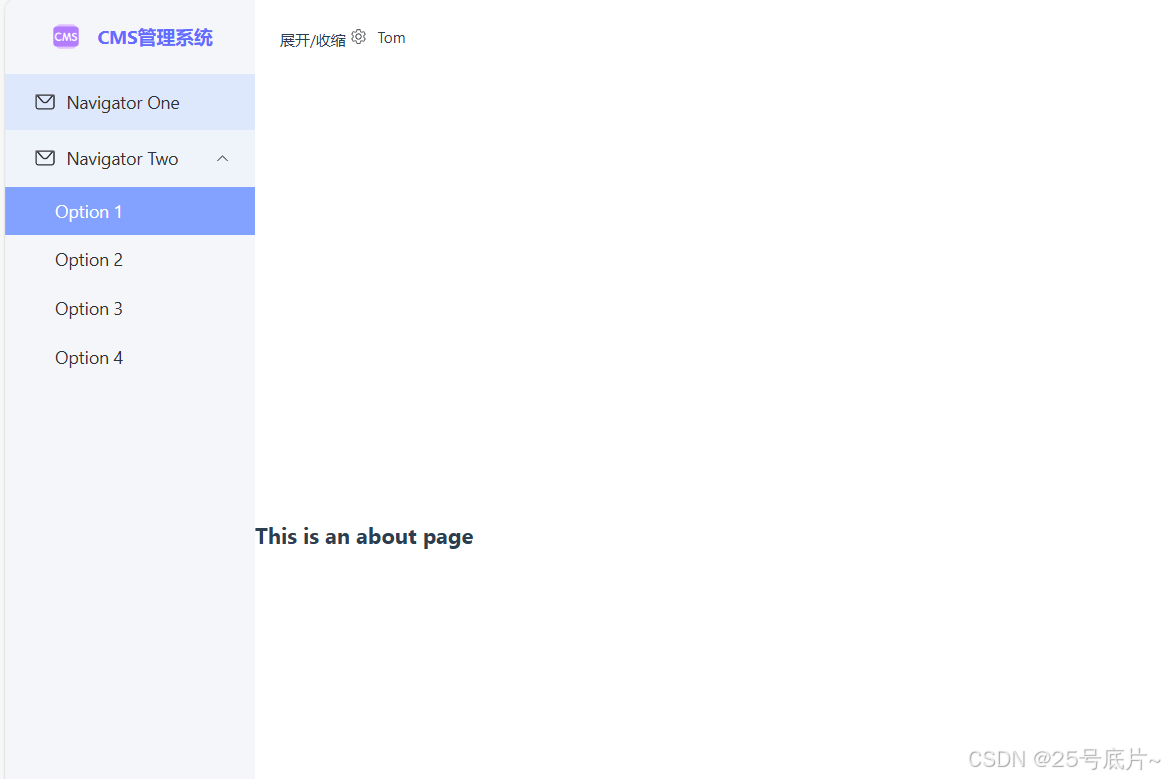
vue3:十一、主页面布局(修改左侧导航条的样式)
一、样式 1、初始样式 2、 左侧导航栏搭建完成样式 二、实现 1、设置左侧导航栏底色 (1)去掉顶部和左侧导航栏的底色 初始页面效果 顶部与左侧底色样式 将代码中与顶部与左侧的样式删掉 移除后页面效果 加入设定背景色 #f4f6f9 加入底色后颜色展示 (2)去除菜单项底色 初…...

开发网页程序时预览时遇到跨域问题解决方法
CocosCreator 开发h5游戏要用接口、开发html程序网页程序在chrome中预览时都会遇到跨域问题,怎么办? 网上有很多方法,主要是通过服务器端去配置,但那个相对来说消弱安全问题,这个不建议,因为是开发,个人行业,我们知道问题所以,简单点就主要是通过chrome的参数来禁用: 关闭 Ch…...

Sentinel源码—7.参数限流和注解的实现二
大纲 1.参数限流的原理和源码 2.SentinelResource注解的使用和实现 2.SentinelResource注解的使用和实现 (1)SentinelResource注解的使用 (2)SentinelResource注解和实现 (1)SentinelResource注解的使用 一.引入Sentinel Spring Boot Starter依赖 <dependency><…...

操作系统原理简要介绍
文章目录 计算机启动的底层流程(从裸机到操作系统)内核用户态与内核态内核分类 进程与线程:操作系统的 “执行者”内存管理:数据的“存储与调度”文件系统:数据的“组织与持久化”设备驱动:硬件的“翻译官”…...
组件)
QML ShaderEffect(着色器效果)组件
ShaderEffect 是 QML 中用于实现自定义着色器效果的组件,允许开发者使用 GLSL 着色器语言创建图形效果。 核心属性 基本属性 属性类型默认值说明fragmentShaderstring""片段着色器代码vertexShaderstring""顶点着色器代码blendingbooltrue是…...

2.6 递归
递归 特性: >.一递一归 >.终止条件 一般为:0 1 -1 #测试函数的返回值为函数 def test_recursion():return test_recursion() print(test_recursion()) RecursionError: maximum recursion depth exceeded #案例:计算 …...

麒麟系统网络连接问题排查
麒麟系统网络连接有红色叹号,不能上外网 了。 首先执行 ping -c4 8.8.8.8 和 nc -zv 8.8.8.8 53,如果 都能正常通信,说明你的网络可以访问公共 DNS 服务器(如 Google DNS 8.8.8.8),但域名解析仍然失败,可能是 DNS 解析配置问题 或 系统 DNS 缓存/代理干扰。以下是进一步…...

opencv(双线性插值原理)
双线性插值是一种图像缩放、旋转或平移时进行像素值估计的插值方法。当需要对图像进行变换时,特别是尺寸变化时,原始图像的某些像素坐标可能不再是新图像中的整数位置,这时就需要使用插值算法来确定这些非整数坐标的像素值。 双线性插值的工…...

从信号处理角度理解图像处理的滤波函数
目录 1、预备知识 1.1 什么是LTI系统? 1.1.1 首先来看什么是线性系统,前提我们要了解什么是齐次性和叠加性。...
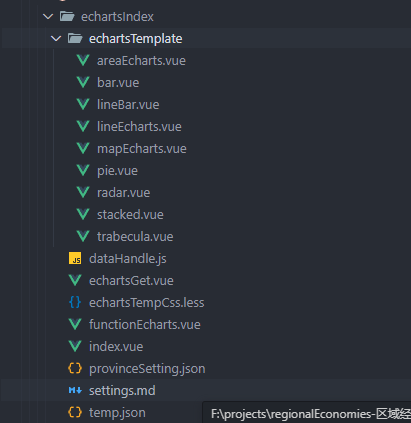
echarts模板化开发,简易版配置大屏组件-根据配置文件输出图形和模板(vue2+echarts5.0)
实现结果 项目结构 根据我的目录和代码 复制到项目中 echartsTemplate-echarts图形 pie实例 <template><div :id"echartsId"></div> </template> <script> export default {name: ,components: {},mixins: [],props: [echartsId,…...

从人工到智能:外呼系统如何重构企业效率新生态
在数字化转型的浪潮中,智能外呼系统正从边缘辅助工具演变为企业效率革命的核心引擎。根据Gartner最新调研数据,部署AI外呼系统的企业客服效率平均提升68%,销售线索转化率增长42%。但在这场技术驱动的变革中,真正决定成败的往往不是…...

HTTP 2.0 和 3.0 的区别
HTTP 2.0 和 3.0 的核心区别体现在底层协议设计、性能优化和网络适应性上,以下是具体对比: 一、核心区别对比 特性HTTP 2.0HTTP 3.0(HTTP/3)底层传输协议TCPUDP(基于 QUIC 协议)队头阻塞(TCP …...

Qt项目——Tcp网络调试助手服务端与客户端
目录 前言结果预览工程文件源代码一、开发流程二、Tcp协议三、Socket四、Tcp服务器的关键流程五、Tcp客户端的关键流程六、Tcp服务端核心代码七、客户端核心代码总结 前言 这期要运用到计算机网络的知识,要搞清楚Tcp协议,学习QTcpServer ,学…...
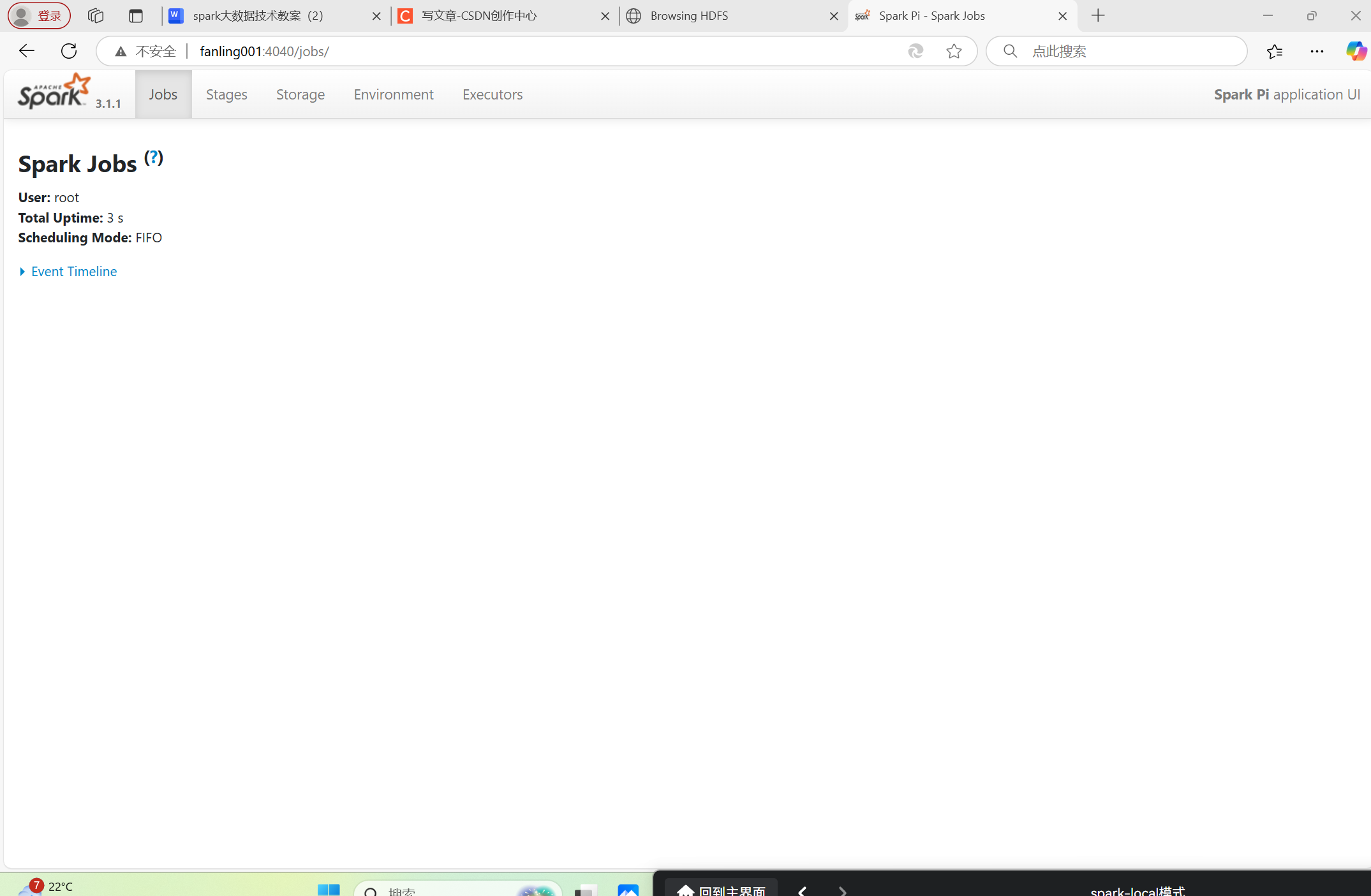
4.21 从0开始配置spark-local模式
首先准备好安装包 然后使用命令解压 使用source /etc/profile命令让环境变量生效 输入命令 spark-submit --class org.apache.spark.examples.SparkPi --master local[2] /opt/module/spark-local/examples/jars/spark-examples_2.12-3.1.1.jar 10 即在spark运行了第一个程序…...
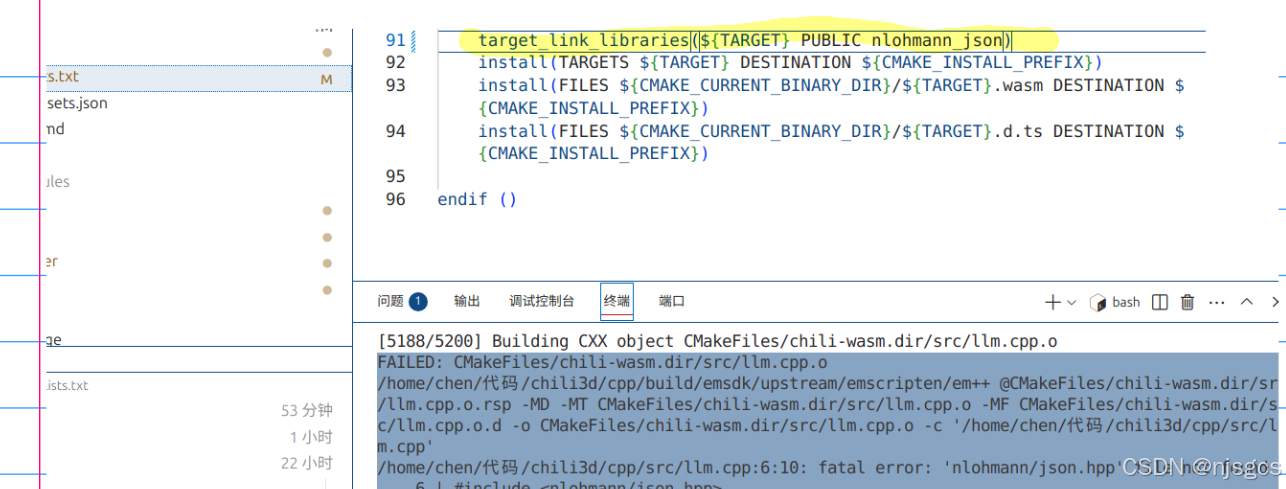
chili3d调试笔记3 加入c++ 大模型对话方法 cmakelists精读
加入 #include <emscripten/bind.h> #include <emscripten/val.h> #include <nlohmann/json.hpp> 怎么加包 函数直接用emscripten::function,如: emscripten::function("send_to_llm", &send_to_llm); set (CMAKE_C…...

go语言八股文
1.go语言的接口是怎么实现 接口(interface)是一种类型,它定义了一组方法的集合。任何类型只要实现了接口中定义的所有方法,就被认为实现了该接口。 代码的实现 package mainimport "fmt"// 定义接口 type Shape inte…...

C++——多态、抽象类和接口
目录 多态的基本概念 如何实现多态 在C中,派生类对象可以被当作基类对象使用 编程示例 关键概念总结 抽象类 一、抽象类的定义 基本语法 二、抽象类的核心特性 1. 不能直接实例化 2. 派生类必须实现所有纯虚函数才能成为具体类 3. 可以包含普通成员函数和…...

【Java面试笔记:基础】3.谈谈final、finally、 finalize有什么不同?
1. final、finally、finalize 的区别 final: 用途:用于修饰类、方法和变量。 修饰类:表示该类不能被继承。 final class ImmutableClass { // 此类无法被其他类继承 }修饰方法:表示该方法不能被子类重写。 class Parent {fin…...

基于 DeepSeek大模型 开发AI应用的理论和实战书籍推荐,涵盖基础理论、模型架构、实战技巧及对比分析,并附表格总结
以下是基于 DeepSeek大模型 开发AI应用的理论和实战书籍推荐,涵盖基础理论、模型架构、实战技巧及对比分析,并附表格总结: 1. 推荐书籍及内容说明 (1) 《深度学习》(Deep Learning) 作者:Ian Goodfellow…...
从数字化到智能化,百度 SRE 数智免疫系统的演进和实践
1. 为什么 SRE 需要数智免疫系统? 2022 年 10 月,在 Gartner 公布的 2023 年十大战略技术趋势中提到了「数字免疫系统」的概念,旨在通过结合数据驱动的一系列手段来提高系统的弹性和稳定性。 在过去 2 年的时间里,百度基于该…...

[Git] Git Stash 命令详解
1. Git Stash 的基本概念 Git Stash 是一个用于暂存当前工作目录中更改的命令。当你正在处理一个功能分支,但突然需要切换到另一个分支进行紧急修复或查看其他工作时,Git Stash 就显得非常有用。它允许你将当前工作目录中的更改保存起来,以便…...
ArcGIS及其组件抛出 -- “Sorry, this application cannot run under a Virtual Machine.“
产生背景: 使用的是“破解版本”或“被套壳过”的非官方 ArcGIS 版本 破解版本作者为了防止: 被研究破解方式 被自动化抓包/提权/逆向 被企业环境中部署多机使用 通常会加入**“虚拟化环境检测阻断运行”机制** 原因解释: 说明你当前运…...

Python项目调用Java数据接口实现CRUD操作
Django Python项目调用Java数据接口实现CRUD操作:接口设计与实现指南 引言 在现代软件架构中,系统间的数据交互变得越来越重要。Python和Java作为两种流行的编程语言,在企业级应用中常常需要实现跨语言的数据交互。本报告将详细介绍如何在D…...

进阶篇 第 5 篇:现代预测方法 - Prophet 与机器学习特征工程
进阶篇 第 5 篇:现代预测方法 - Prophet 与机器学习特征工程 (图片来源: ThisIsEngineering RAEng on Pexels) 在前几篇中,我们深入研究了经典的时间序列统计模型,如 ETS 和强大的 SARIMA 家族。它们在理论上成熟且应用广泛,但有…...

ubuntu 交叉编译 macOS 库, 使用 osxcross 搭建 docker 编译 OS X 库
1. ubuntu 交叉编译 macOS 库, 使用 osxcross 搭建 docker 编译 OS X 库 1. ubuntu 交叉编译 macOS 库, 使用 osxcross 搭建 docker 编译 OS X 库 1.1. 安装依赖1.2. 安装 osxcross 及 macOS SDK 1.2.1. 可能错误 1.3. 编译 cmake 类工程1.4. 编译 configure 类工程1.5. 单文件…...