【数学建模】随机森林算法详解:原理、优缺点及应用
随机森林算法详解:原理、优缺点及应用
文章目录
- 随机森林算法详解:原理、优缺点及应用
- 引言
- 随机森林的基本原理
- 随机森林算法步骤
- 随机森林的优点
- 随机森林的缺点
- 随机森林的应用场景
- Python实现示例
- 超参数调优
- 结论
- 参考文献
引言
随机森林是机器学习领域中一种强大的集成学习算法,由Leo Breiman在2001年提出。它结合了决策树和bagging技术,通过构建多个决策树并将它们的预测结果进行组合,从而提高了模型的准确性和稳定性。本文将详细介绍随机森林的工作原理、优缺点以及实际应用场景。
随机森林的基本原理
(参考资料:机器学习算法系列(十八)-随机森林算法(Random Forest Algorithm)”)
首先介绍机器学习中的一个概念:集成学习(Ensemble learning)。集成学习往往是通过训练学习出多个估计器,当需要预测时通过结合器将多个估计器的结果整合起来当作最后的结果输出。

集成学习的优势是提升了单个估计器的通用性与鲁棒性,比单个估计器拥有更好的预测性能。集成学习的另一个特点是能方便地进行并行化操作。
然后在介绍随机森林算法之前,先来介绍一种集成学习算法——Bagging算法,又称自助聚集算法(Bootstrap aggregating),由自助取样(Bootstrap)与汇总(Aggregating)两部分组成。算法的具体步骤为:假设有一个大小为 N 的训练数据集,每次从该数据集中有放回的取选出大小为 M 的子数据集,一共选 K 次,根据这 K 个子数据集,训练学习出 K 个模型。当要预测的时候,使用这 K 个模型进行预测,再通过取平均值或者多数分类的方式,得到最后的预测结果。

然后来介绍本文的主角——随机森林算法。在上述Bagging算法中,将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,这样的算法即为随机森林算法。随机森林算法是以决策树为估计器的Bagging算法。
随机森林本质上是多个决策树的集合,其中每棵树都是独立训练的。算法的核心思想包括两个随机性:
- 样本随机性:使用bootstrap采样方法从原始训练集中有放回地抽取样本,形成每棵决策树的训练集。
- 特征随机性:在构建每棵决策树的过程中,每次分裂节点时只考虑特征子集(随机选择的特征)。
随机森林算法步骤
- 从原始训练数据集中通过Bootstrap采样选择 n n n个样本
- 对于每个样本集合,构建一个决策树:
- 在节点分裂时,随机选择 m m m个特征, m m m远小于特征总数
- 根据选定的特征,使用信息增益或基尼系数等指标确定最佳分裂点
- 树一直生长到达到停止条件(如叶子节点中的样本数量最小阈值)
- 重复步骤1和2,构建 k k k棵决策树
- 对于分类问题,采用投票方式;对于回归问题,取平均值作为最终预测结果

随机森林的优点
- 高准确性:通过集成多棵决策树的结果,随机森林通常能够获得较高的预测准确率。
- 抗过拟合能力强:随机性的引入有效减少了模型的方差,提高了泛化能力。
- 能处理高维数据:对于特征数量较多的数据集表现良好,无需特征选择。
- 能评估特征重要性:可以计算每个特征对模型预测的贡献度。
- 对缺失值和异常值不敏感:具有较强的鲁棒性。
- 易于并行化:每棵树的训练过程可以独立进行,适合分布式计算。
随机森林的缺点
- 可解释性较差:相比单棵决策树,随机森林的决策过程更难以解释。
- 训练时间较长:需要构建多棵决策树,计算开销较大。
- 对噪声数据敏感:在某些情况下可能会过度拟合噪声。
- 预测时间较长:需要遍历所有决策树才能得出最终结果。
随机森林的应用场景
- 分类与回归问题:适用于各类监督学习任务。
- 特征选择:可以通过特征重要性评分进行特征筛选。
- 异常检测:识别数据集中的异常点。
- 金融领域:风险评估、信用评分、股票预测等。
- 医疗健康:疾病诊断、患者分类等。
- 生物信息学:基因表达分析、蛋白质结构预测等。
- 图像识别:物体检测、人脸识别等。
Python实现示例
下面是使用scikit-learn库实现随机森林的简单示例:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 生成示例数据
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=42)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建随机森林分类器
rf_classifier = RandomForestClassifier(n_estimators=100, max_depth=10,random_state=42)# 训练模型
rf_classifier.fit(X_train, y_train)# 预测
y_pred = rf_classifier.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")# 特征重要性
feature_importances = rf_classifier.feature_importances_
for i, importance in enumerate(feature_importances):print(f"特征 {i}: {importance:.4f}")
超参数调优
随机森林的主要超参数包括:
- n_estimators:决策树的数量,一般越多越好,但会增加计算成本。
- max_depth:树的最大深度,控制模型复杂度。
- min_samples_split:分裂内部节点所需的最小样本数。
- min_samples_leaf:叶节点所需的最小样本数。
- max_features:每次分裂时考虑的最大特征数。
可以使用网格搜索或随机搜索等方法进行超参数优化:
from sklearn.model_selection import GridSearchCVparam_grid = {'n_estimators': [100, 200, 300],'max_depth': [10, 20, 30, None],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]
}grid_search = GridSearchCV(RandomForestClassifier(random_state=42), param_grid=param_grid, cv=5, n_jobs=-1)grid_search.fit(X_train, y_train)
print(f"最佳参数: {grid_search.best_params_}")
print(f"最佳得分: {grid_search.best_score_:.4f}")
结论
随机森林作为一种强大的集成学习方法,在各种机器学习任务中表现出色。它结合了多棵决策树的预测能力,通过引入随机性来提高模型的泛化能力。虽然在可解释性和计算复杂度方面存在一些局限,但其高准确性、抗过拟合能力和处理高维数据的能力使其成为数据科学家和机器学习工程师的重要工具。
随着计算能力的提升和分布式计算技术的发展,随机森林的应用范围将会进一步扩大,尤其是在需要高精度预测且可解释性要求不是特别高的场景中。
参考文献
- Breiman, L. (2001). Random forests. Machine learning, 45(1), 5-32.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: data mining, inference, and prediction. Springer Science & Business Media.
- Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
希望这篇文章能帮助你更好地理解随机森林算法的工作原理、优缺点及应用场景。如有任何问题或建议,欢迎在评论区留言讨论!
相关文章:
【数学建模】随机森林算法详解:原理、优缺点及应用
随机森林算法详解:原理、优缺点及应用 文章目录 随机森林算法详解:原理、优缺点及应用引言随机森林的基本原理随机森林算法步骤随机森林的优点随机森林的缺点随机森林的应用场景Python实现示例超参数调优结论参考文献 引言 随机森林是机器学习领域中一种…...
蓝桥杯 19.合根植物
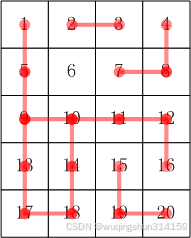
合根植物 原题目链接 题目描述 W 星球的一个种植园被分成 m n 个小格子(东西方向 m 行,南北方向 n 列)。每个格子里种了一株合根植物。 这种植物有个特点,它的根可能会沿着南北或东西方向伸展,从而与另一个格子的…...

Linux环境MySQL出现无法启动的问题解决 [InnoDB] InnoDB initialization has started.
目录 起因 强制启用恢复模式 备份数据 起因 服务器重启了,然后服务器启动完成之后我发现MySQL程序没有启动,错误信息如下: 2025-04-19T12:46:47.648559Z 1 [System] [MY-013576] [InnoDB] InnoDB initialization has started. 2025-04-1…...
高性能服务器配置经验指南1——刚配置好服务器应该做哪些事
文章目录 安装ubuntu安装必要软件设置用户远程连接安全问题ClamAV安装教程步骤 1:更新系统软件源步骤 2:升级系统(可选但推荐)步骤 3:安装 ClamAV步骤 4:更新病毒库步骤 5:验证安装ClamAV 常用命…...

DePIN驱动的分布式AI资源网络
GAEA通过通证经济模型激励全球用户共享闲置带宽、算力、存储资源,构建覆盖150多个国家/地区的分布式AI基础设施网络。相比传统云服务,GAEA具有显著优势: 成本降低70%:通过利用边缘设备资源,避免了集中式数据中心所需…...

徐州服务器租用:虚拟主机的应用场景
虚拟主机也可以被称为网站空间或者是共享主机,主要是通过软硬件技术将一台物理服务器分割成多个逻辑单元的技术,让每一个单元都拥有着独立的IP地址和完整的网络服务功能,那么虚拟主机的应用场景都有哪些呢? 许多中小型企业会选择租…...
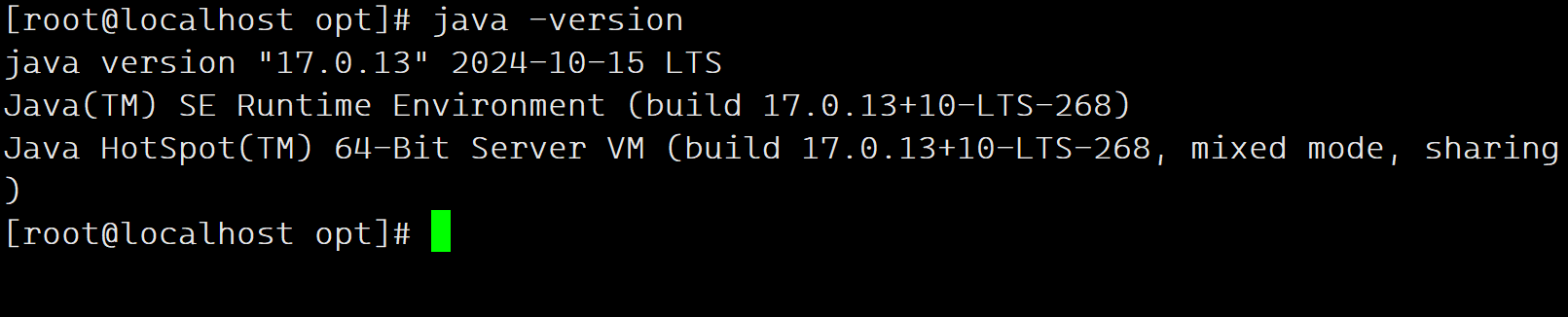
Centos7安装Jenkins(图文教程)
本章教程,主要记录在centos7安装部署Jenkins 的详细过程。 [root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core) 一、基础环境安装 内存大小要求:256 MB 内存以上 硬盘大小要求:10 GB 及以上 安装基础java环境:Java 17 ( JRE 或者 JDK 都可…...

【JAVA】十三、基础知识“接口”精细讲解!(二)(新手友好版~)
哈喽大家好呀qvq,这里是乎里陈,接口这一知识点博主分为三篇博客为大家进行讲解,今天为大家讲解第二篇java中实现多个接口,接口间的继承,抽象类和接口的区别知识点,更适合新手宝宝们阅读~更多内容持续更新中…...

边缘计算盒子是什么?
边缘计算盒子是一种小型的硬件设备,通常集成了处理器、存储器和网络接口等关键组件,具备一定的计算能力和存储资源,并能够连接到网络。它与传统的云计算不同,数据处理和分析直接在设备本地完成,而不是上传到云端&#…...

量子计算在密码学中的应用与挑战:重塑信息安全的未来
在当今数字化时代,信息安全已成为全球关注的焦点。随着量子计算技术的飞速发展,密码学领域正面临着前所未有的机遇与挑战。量子计算的强大计算能力为密码学带来了新的应用场景,同时也对传统密码体系构成了潜在威胁。本文将深入探讨量子计算在…...
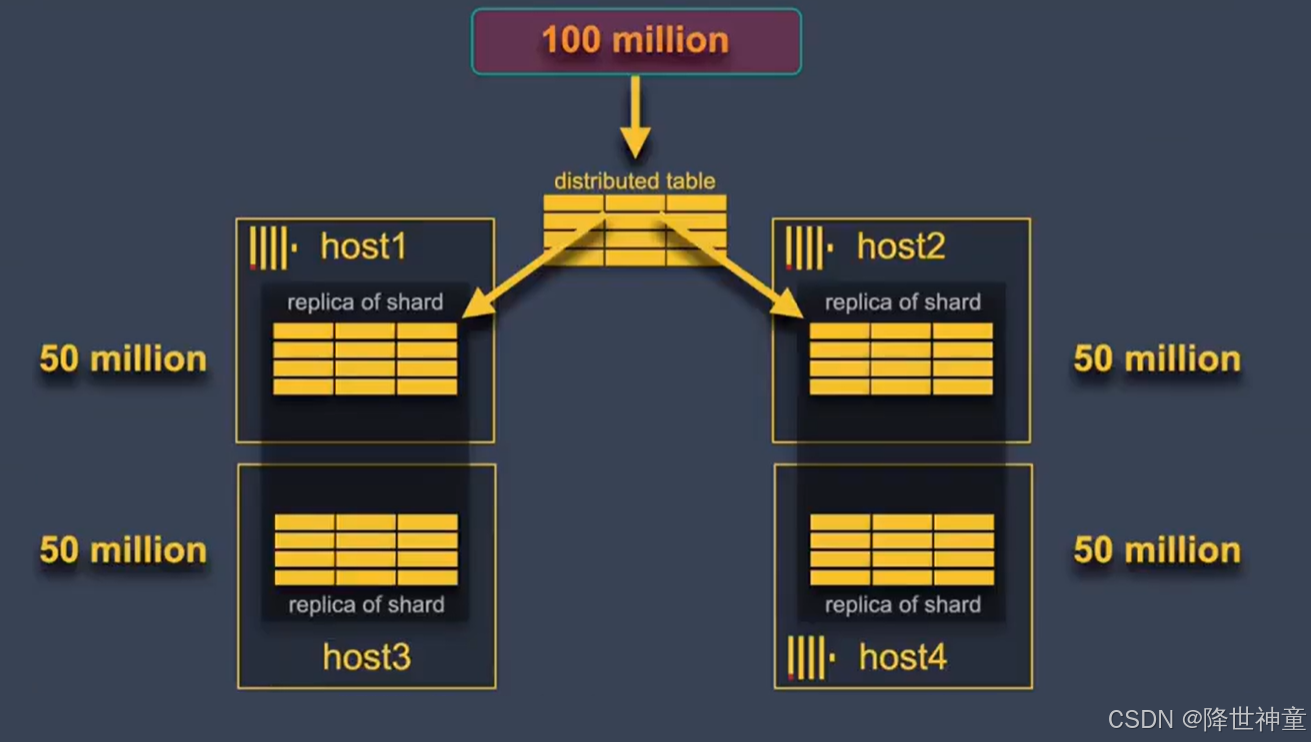
大数据系列 | 详解基于Zookeeper或ClickHouse Keeper的ClickHouse集群部署--完结
大数据系列 | 详解基于Zookeeper或ClickHouse Keeper的ClickHouse集群部署 1. ClickHouse与MySQL的区别2. 在群集的所有机器上安装ClickHouse服务端2.1. 在线安装clickhouse2.2. 离线安装clickhouse 3. ClickHouse Keeper/Zookeeper集群安装4. 在配置文件中设置集群配置5. 在每…...
——辐射度量学)
【C++游戏引擎开发】第20篇:基于物理渲染(PBR)——辐射度量学
引言 在基于物理渲染(PBR)中,辐射度量学是描述光与物质交互的核心数学框架。本文将深入解析辐射度量学的四大基础量,双向反射分布函数(BRDF)的物理本质,以及如何通过积分形式推导出渲染方程。最后,通过OpenGL实践,直观展示辐射率(Radiance)在三维场景中的分布规律。…...
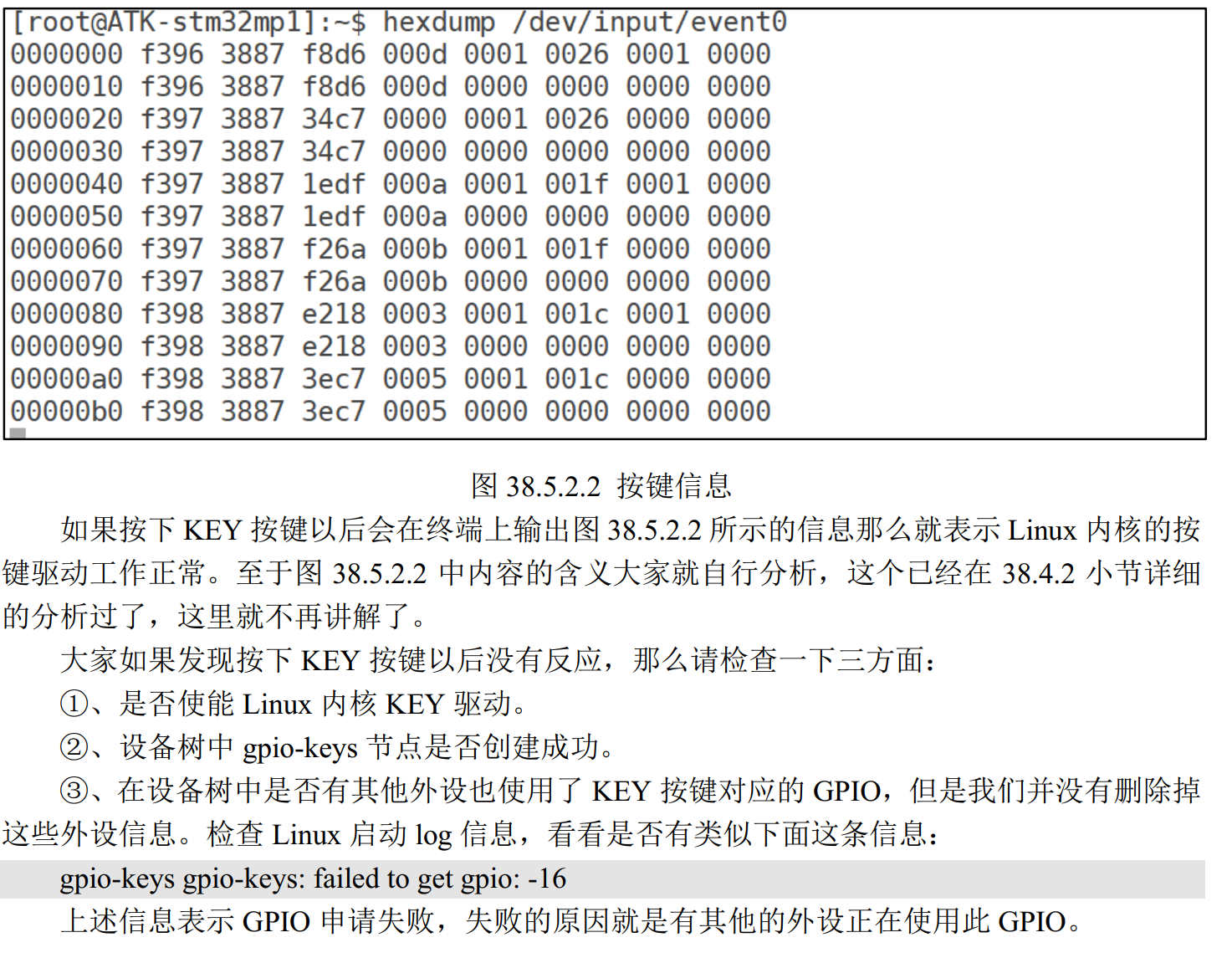
19Linux自带按键驱动程序的使用_csdn
1、自带按键驱动程序源码简析 2、自带按键驱动程序的使用 设备节点信息: gpio-keys {compatible "gpio-keys";pinctrl-names "default";pinctrl-0 <&key_pins_a>;autorepeat;key0 {label "GPIO Key L";linux,code &l…...
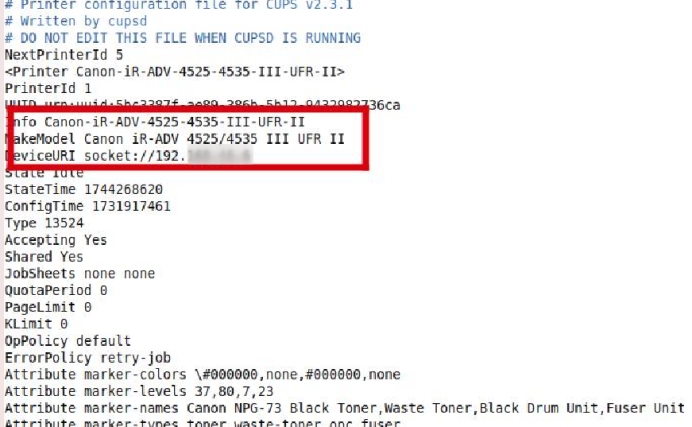
用银河麒麟 LiveCD 快速查看原系统 IP 和打印机配置
原文链接:用银河麒麟 LiveCD 快速查看原系统 IP 和打印机配置 Hello,大家好啊!今天给大家带来一篇在银河麒麟操作系统的 LiveCD 或系统试用镜像环境下,如何查看原系统中电脑的 IP 地址与网络打印机 IP 地址的实用教程。在系统损坏…...
.net core 项目快速接入Coze智能体-开箱即用-第2节
目录 一、Coze智能体的核心价值 二、开箱即用-效果如下 三 流程与交互设计 本节内容调用自有或第三方的服务 实现语音转文字 四:代码实现----自行实现 STT 【语音转文字】 五:代码实现--调用字节API实现语音转文字 .net core 项目快速接入Coze智能…...
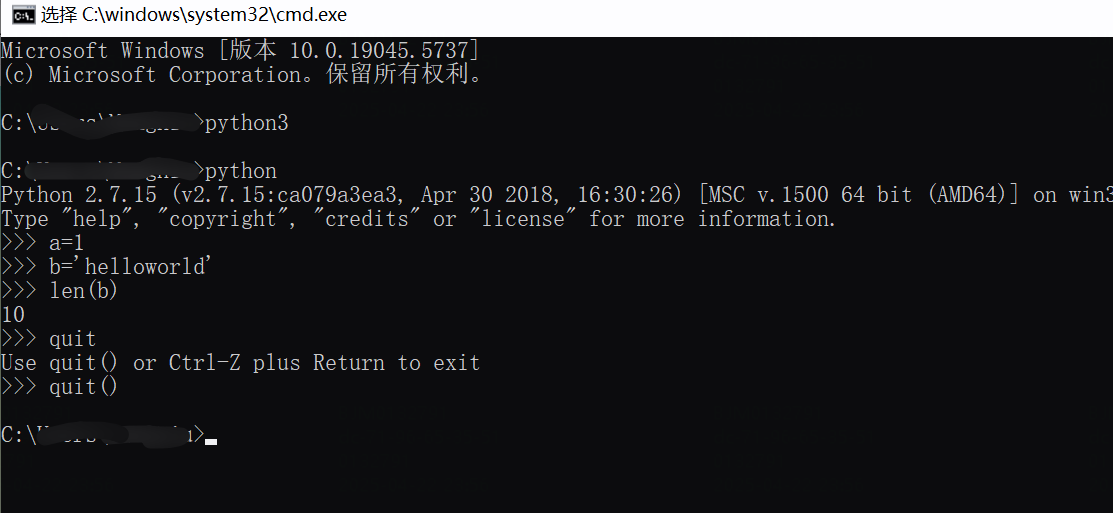
win10中打开python的交互模式
不是输入python3,输入python,不知道和安装python版本有没有关系。做个简单记录,不想记笔记了...
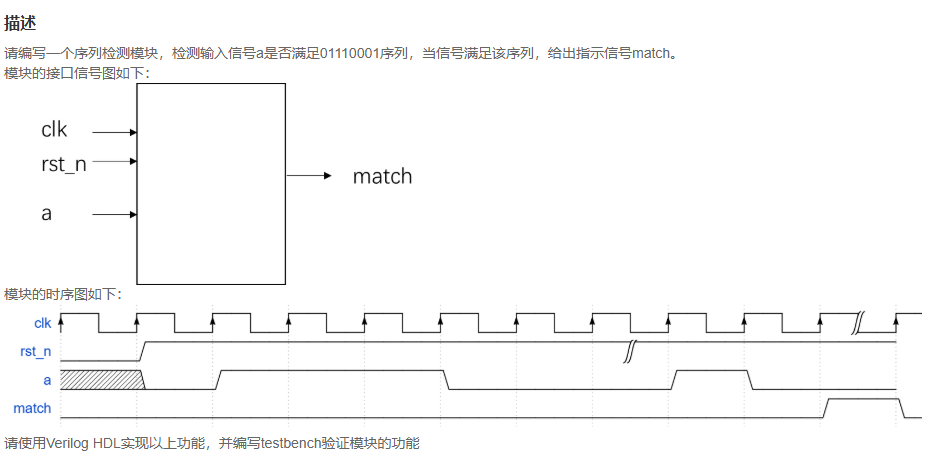
时序逻辑电路——序列检测器
文章目录 一、序列检测二、牛客真题1. 输入序列连续的序列检测(输入连续、重叠、不含无关项、串行输入)写法一:移位寄存器写法二:Moore状态机写法三:Mealy状态机 一、序列检测 序列检测器指的就是将一个指定的序列&…...

SVT-AV1编码器中的模块
一 模块列表 1 svt_input_cmd_creator 2 svt_input_buffer_header_creator 3 svt_input_y8b_creator 4 svt_output_buffer_header_creator 5 svt_output_recon_buffer_header_creator 6 svt_aom_resource_coordination_result_creator 7 svt_aom_picture_analysis_result_creat…...

TikTok X-Gnarly纯算分享
TK核心签名校验:X-Bougs 比较简单 X-Gnarly已经替代了_signature参数(不好校验数据) 主要围绕query body ua进行加密验证 伴随着时间戳 浏览器指纹 随机值 特征值 秘钥转换 自写算法 魔改base64编码 与X-bougs 长a-Bougs流程一致。 视频…...

LPDDR5协议新增特性
文章目录 一、BL/n_min参数含义二、RDQS_t/RDQS_c引脚的功能三、DMI引脚的功能3.1、Write操作时的Data Mask数据掩码操作3.2、Write/Read操作时的Data Bus Inversion操作四、CAS命令针对WR/RD/Mask WR命令的低功耗组合配置4.1、Write/Read操作前的WCK2CK同步操作4.2、Write/Rea…...
:Python Pandas索引技术详解)
python数据分析(二):Python Pandas索引技术详解
Python Pandas索引技术详解:从基础到多层索引 1. 引言 Pandas是Python数据分析的核心库,而索引技术是Pandas高效数据操作的关键。良好的索引使用可以显著提高数据查询和操作的效率。本文将系统介绍Pandas中的各种索引技术,包括基础索引、位…...
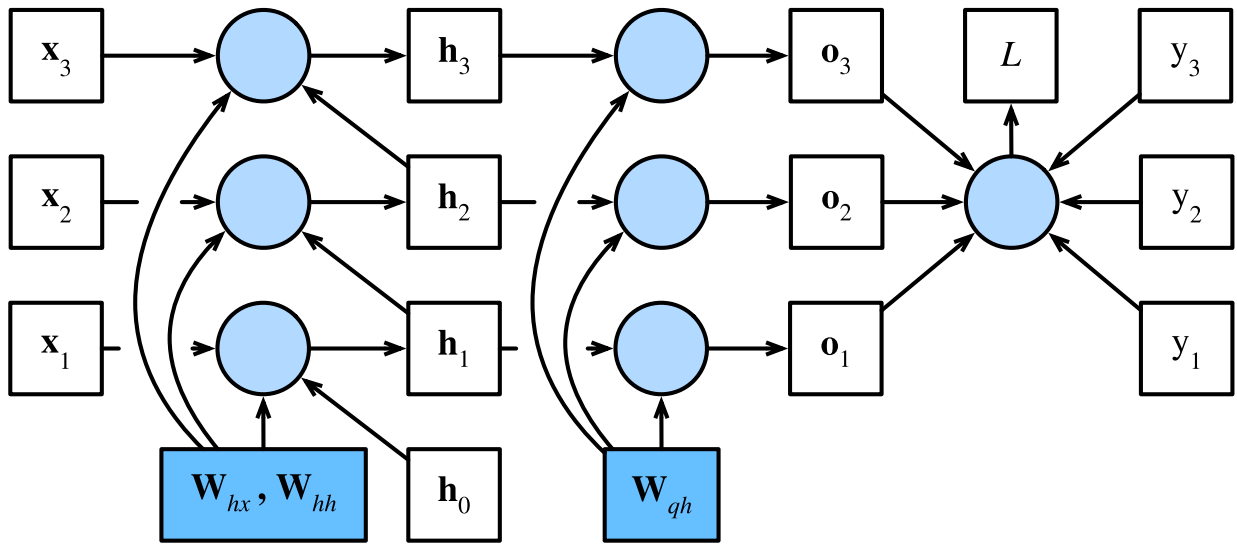
【深度学习】#8 循环神经网络
主要参考学习资料: 《动手学深度学习》阿斯顿张 等 著 【动手学深度学习 PyTorch版】哔哩哔哩跟李牧学AI 为了进一步提高长线学习的效率,该系列从本章开始将舍弃原始教材的代码部分,专注于理论和思维的提炼,系列名也改为“深度学习…...

开源状态机引擎,在实战中可以放心使用
### Squirrel-Foundation 状态机开源项目介绍 **Squirrel-Foundation** 是一个轻量级、灵活、可扩展、易于使用且类型安全的 Java 状态机实现,适用于企业级应用。它提供了多种方式来定义状态机,包括注解声明和 Fluent API,并且支持状态转换、…...

机器学习超参数优化全解析
机器学习超参数优化全解析 摘要 本文全面深入地剖析了机器学习模型中的超参数优化策略,涵盖了从参数与超参数的本质区别,到核心超参数(如学习率、批量大小、训练周期)的动态调整方法;从自动化超参数优化技术…...

AI 模型在前端应用中的典型使用场景和限制
典型使用场景 1. 智能表单处理 // 使用TensorFlow.js实现表单自动填充 import * as tf from tensorflow/tfjs; import { loadGraphModel } from tensorflow/tfjs-converter;async function initFormPredictor() {// 加载预训练的表单理解模型const model await loadGraphMod…...
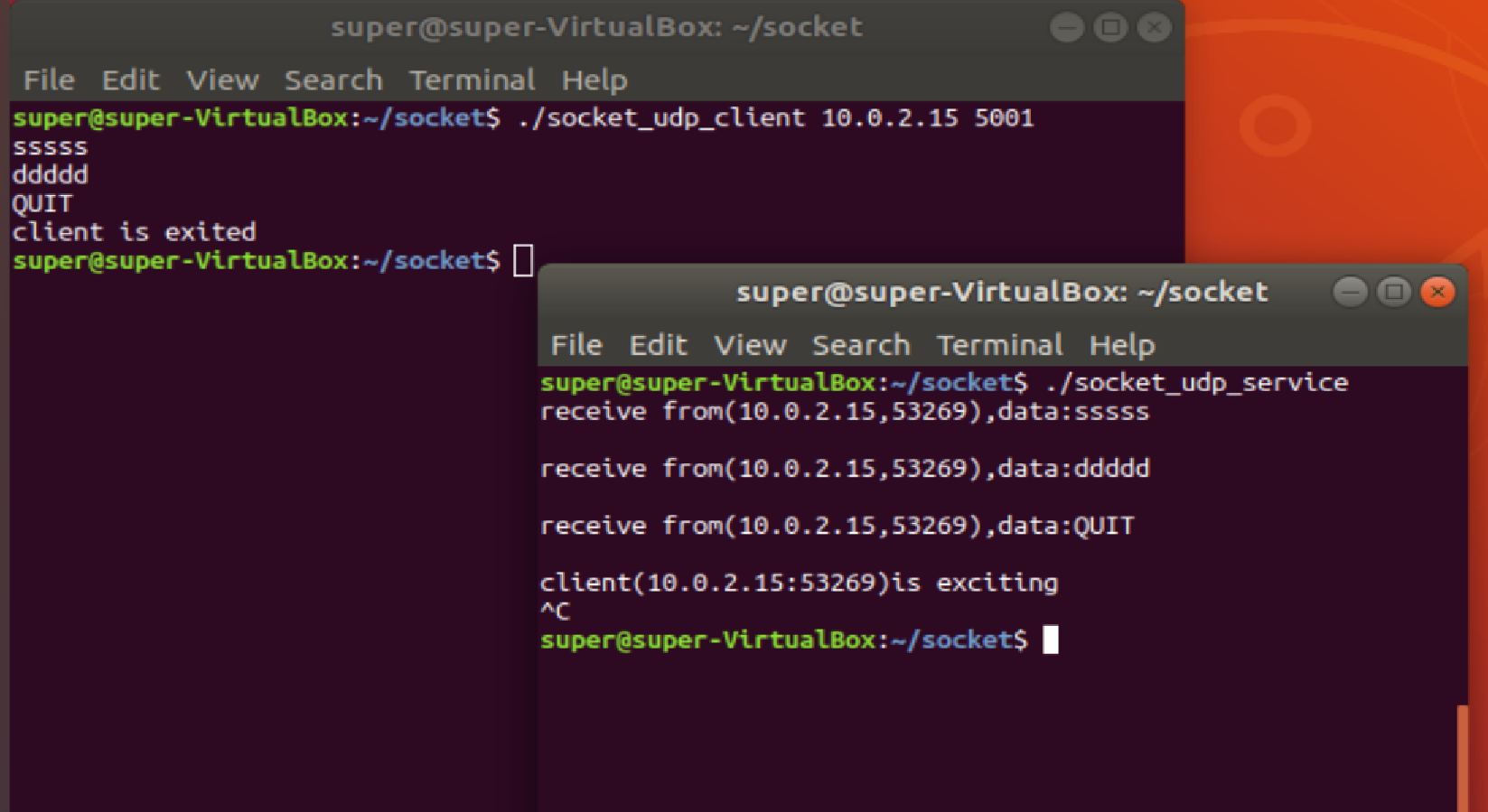
Linux学习——UDP
编程的整体框架 bind:绑定服务器:TCP地址和端口号 receivefrom():阻塞等待客户端数据 sendto():指定服务器的IP地址和端口号,要发送的数据 无连接尽力传输,UDP:是不可靠传输 实时的音视频传输&#x…...

leetcode205.同构字符串
两个哈希表存储字符的映射关系,如果前面字符的映射关系和后面的不一样则返回false class Solution {public boolean isIsomorphic(String s, String t) {if (s.length() ! t.length()) {return false;}int length s.length();Map<Character, Character> s2…...

软考软件设计师考试情况与大纲概述
文章目录 **一、考试科目与形式****二、考试大纲与核心知识点****科目1:计算机与软件工程知识****科目2:软件设计** **三、备考建议****四、参考资料** 这是一个系列文章的开篇 本文对2025年软考软件设计师考试的大纲及核心内容进行了整理,并…...

24. git revert
基本概述 git revert 的作用是:撤销某次的提交。与 git reset 不同的是,git revert 不会修改提交历史,而是创建一个新的提交来反转之前的提交。 基本用法 1.基本语法 git revert <commit-hash>该命令会生成一个新的提交,…...

Redis—内存淘汰策略
记:全体LRU,ttl LRU,全体LFU,ttl LFU,全体随机,ttl随机,最快过期,不淘汰(八种) Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存&…...