CS144 Lab1实战记录:实现TCP重组器
文章目录
- 1 实验背景与要求
- 1.1 TCP的数据分片与重组问题
- 1.2 实验具体任务
- 2 重组器的设计架构
- 2.1 整体架构
- 2.2 数据结构设计
- 3 重组器处理的关键场景分析
- 3.1 按序到达的子串(直接写入)
- 3.2 乱序到达的子串(需要存储)
- 3.3 与已处理区域重叠的子串
- 3.4 与待处理子串重叠的情况
- 3.5 超出容量的子串
- 3.6 结束标记处理
- 4 insert方法的实现流程
- 4.1 入口处理
- 4.2 已处理字节的检查
- 4.3 容量限制检查
- 4.4 直接写入处理
- 4.5 子串存储与合并
- 4.6 结束处理
- 5 count_bytes_pending实现
- 6 调试经验
1 实验背景与要求
在网络传输的过程中,TCP协议必须解决一个关键挑战:如何将不可靠的网络上传输的、可能乱序、丢失、重复或重叠的数据包片段重新组装成连续的字节流?这正是Stanford CS144 Lab1中我们要实现的Reassembler(重组器)组件的核心功能。
1.1 TCP的数据分片与重组问题
TCP协议在发送数据时,会将应用层的字节流划分为多个较小的段(segment),每个段封装在一个IP数据包中进行传输。然而,在网络传输过程中,这些数据包可能会:
- 乱序到达:后发送的数据包可能先到达
- 完全丢失:某些数据包永远不会到达目的地
- 重复到达:同一个数据包可能被网络复制并多次传递
- 部分重叠:重传的包可能与原包内容有部分重叠
接收方必须能够处理这些情况,将所有正确接收的数据按照原始顺序重新组装成连续的字节流,并传递给应用层。这就是重组器(Reassembler)需要解决的问题。
1.2 实验具体任务
在Lab1中,我们需要实现一个Reassembler类,其主要API如下:
// 插入一个新的子字符串,以便重组为一个ByteStream
void insert(uint64_t first_index, std::string data, bool is_last_substring);// 计算重组器内部存储的字节数量
uint64_t count_bytes_pending() const;// 访问输出流的读取器
Reader& reader();
这个重组器要处理以下核心任务:
- 子串的重组:将不同的子串按照它们在原始流中的顺序重新组装
- 对ByteStream的写入:尽快地将重组好的字节写入输出流
- 内部存储管理:对于暂时无法写入(存在空洞)的子串进行存储
- 容量限制:考虑ByteStream容量限制,丢弃超出容量的字节
- 流结束处理:当接收到标记为最后的子串,并且所有数据都已写入时,关闭输出流
Github的实现代码:https://github.com/HeZephyr/minnow
2 重组器的设计架构
2.1 整体架构
重组器的整体架构如下图所示:
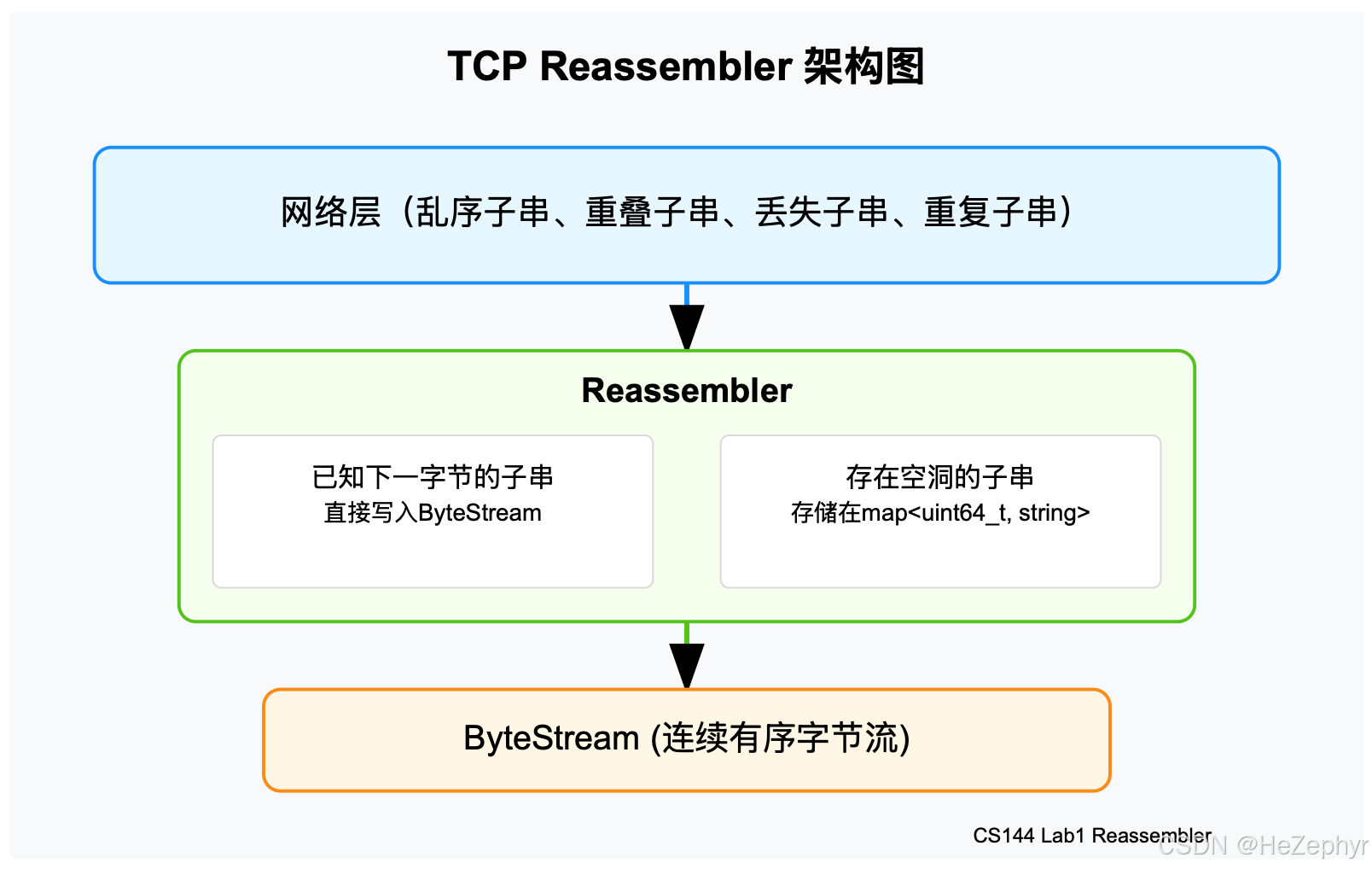
重组器处于网络层和应用层之间,负责将网络传输的不可靠、乱序的数据片段转换为应用层可以使用的可靠、有序的字节流。它的内部需要处理两种情况:
- 可以直接写入ByteStream的子串(下一个期望的字节)
- 需要暂时存储的子串(存在空洞,不能立即写入)
2.2 数据结构设计
为了实现重组器的功能,我们需要设计适当的数据结构。这里我选择了以下成员变量:
ByteStream output_; // 输出流
uint64_t next_index_ = 0; // 下一个要写入的字节索引
bool eof_ = false; // 是否收到了标记为最后的子串
uint64_t eof_index_ = 0; // 流的结束索引位置
std::map<uint64_t, std::string> unassembled_; // 存储未组装的子串
这些数据结构的详细说明:
- ByteStream output_:重组器将重组好的数据写入这个流,应用程序从这个流的读取端获取数据
- uint64_t next_index_:表示下一个期望接收的字节的索引位置,初始值为0,每写入一个字节就增加1。用于判断新到的子串是否可以直接写入
- bool eof_:标记是否已收到流的最后一个子串,当收到
is_last_substring=true的子串时设置为true - uint64_t eof_index_:记录流的总长度(最后一个字节之后的位置),当
next_index_ == eof_index_时,表示所有数据都已处理完毕 - std::map<uint64_t, std::string> unassembled_:存储那些已接收但因为前面有空洞而不能立即写入的子串,键为子串的起始索引,值为子串内容,使用map可以自动按索引排序,便于查找和合并
这种设计的优势在于:
- 使用有序映射(std::map)能够高效地管理乱序到达的子串
- 通过比较
next_index_和子串的起始位置,可以快速判断子串是否可以直接写入 - 当空洞被填补时,能够方便地找到并处理下一个连续的子串
3 重组器处理的关键场景分析
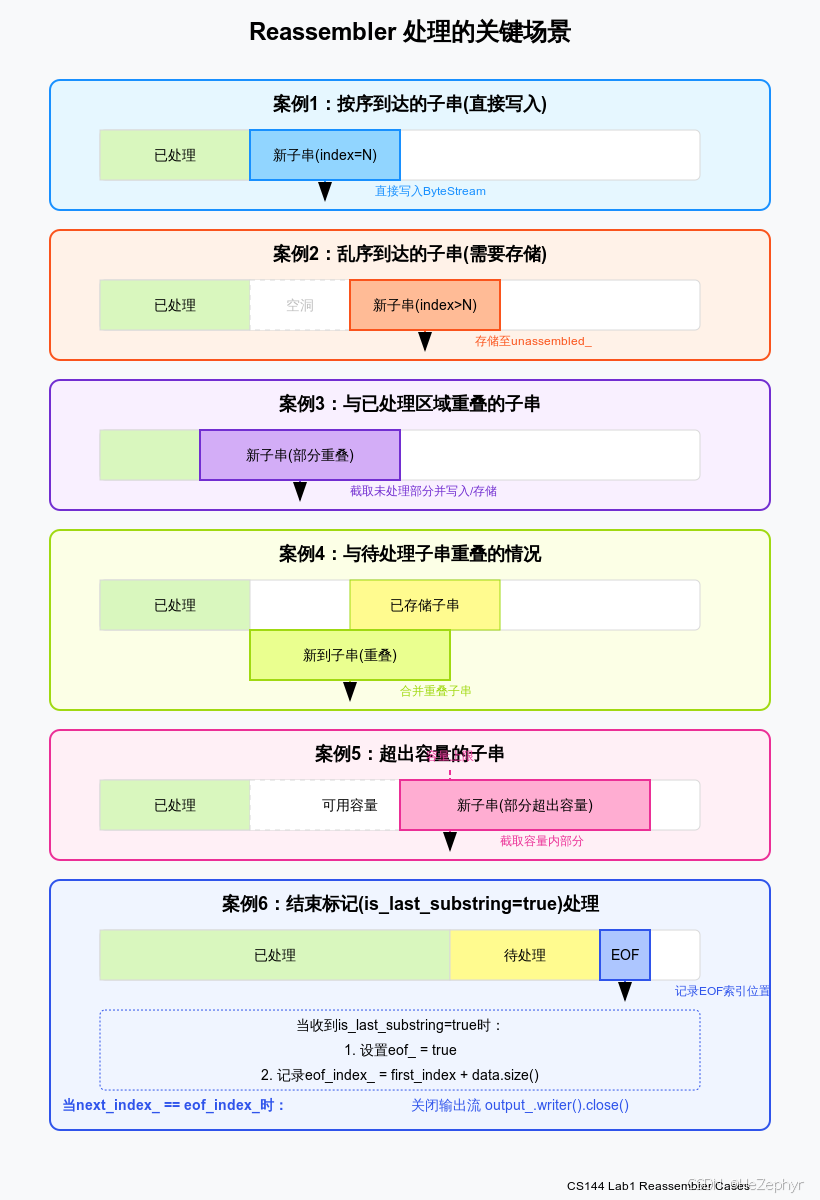
在实现重组器时,需要处理多种不同的子串到达场景。以下通过图解分析重组器需要处理的典型情况:
3.1 按序到达的子串(直接写入)
当接收到的子串的起始索引恰好等于当前期望的下一个字节索引(first_index == next_index_)时,可以直接将该子串写入输出流。这是最简单的情况,不需要任何临时存储。
处理逻辑:
- 将子串内容通过
output_.writer().push(data)直接写入ByteStream - 更新
next_index_ += data.size() - 检查是否有后续已存储的子串现在可以连续写入
示例:假设当前next_index_ = 5,收到子串insert(5, "hello", false),可以直接将"hello"写入ByteStream,并更新next_index_ = 10
3.2 乱序到达的子串(需要存储)
当接收到的子串起始索引大于当前期望的下一个字节索引(first_index > next_index_)时,表示中间存在"空洞"。这种情况下,需要将子串临时存储在unassembled_映射中,等待空洞被填补。
处理逻辑:
- 检查子串是否超出容量限制
- 如果未超出,将子串存储在
unassembled_[first_index] = data - 可能需要处理与已存储子串的重叠情况
示例:假设当前next_index_ = 5,收到子串insert(10, "world", false),由于10 > 5,表示5-9的字节尚未收到,将"world"存储在unassembled_[10] = "world",等待空洞被填补。
3.3 与已处理区域重叠的子串
有时接收到的子串可能与已处理的区域有重叠(first_index < next_index_)。在这种情况下,需要截取未处理的部分进行处理。
处理逻辑:
- 计算重叠部分:
overlap = next_index_ - first_index - 截取未处理部分:
data.substr(overlap) - 按照非重叠子串的处理方式继续处理
示例:假设当前next_index_ = 5,收到子串insert(3, "hello", false),字节3-4已处理,只需要处理"llo",截取后处理:data = data.substr(2) -> “llo”,使用新索引first_index = 5和新数据"llo"继续处理。
3.4 与待处理子串重叠的情况
当新到达的子串与已经存储在unassembled_中的子串有重叠时,需要合并这些子串以避免重复存储。
处理逻辑:
- 查找可能重叠的子串:使用
lower_bound和前向遍历 - 检查前面的子串是否与当前子串重叠
- 检查后面的子串是否与当前子串重叠
- 合并所有重叠的子串,生成一个更大的连续子串
- 更新
unassembled_映射
示例:假设已存储unassembled_[10] = "world",收到新子串insert(8, "hellowr", false),检测到重叠:8+8 > 10,合并为一个更大的子串:“hellowrld”,更新unassembled_[8] = "hellowrld",并删除原来的条目。
3.5 超出容量的子串
ByteStream有固定容量,而重组器应该尊重这个容量限制。对于超出容量的子串部分,应该直接丢弃。
处理逻辑:
- 计算可接受的最大索引:
acceptable_end = next_index_ + output_.writer().available_capacity() - 判断子串是否完全超出:
first_index >= acceptable_end - 对于部分超出的子串,截取有效部分:
actual_end = min(first_index + data.size(), acceptable_end)
示例:假设当前next_index_ = 5,可用容量为10,可接受的最大索引为5 + 10 = 15,收到子串insert(12, "hello world", false),由于"hello world"长度为11,超出了可接受范围,截取前3个字节"hel"进行处理,丢弃后续字节。
3.6 结束标记处理
当收到标记为最后的子串(is_last_substring = true)时,需要记录流的结束位置,并在所有数据都处理完毕时关闭输出流。
处理逻辑:
- 设置
eof_ = true - 计算并记录结束索引:
eof_index_ = first_index + data.size() - 在每次处理完子串后,检查
next_index_ == eof_index_ - 如果条件满足且
eof_ == true,调用output_.writer().close()关闭流
示例:假设已处理到next_index_ = 15,收到子串insert(15, "end", true),设置eof_ = true,eof_index_ = 15 + 3 = 18,处理完"end"后,next_index_ = 18,由于next_index_ == eof_index_且eof_ == true,关闭输出流。
4 insert方法的实现流程
4.1 入口处理
首先,处理一些边界情况:
- 空字符串的特殊处理,特别是当它被标记为最后一个子串时
- 记录EOF信息,包括是否到达EOF以及EOF的确切位置
void Reassembler::insert(uint64_t first_index, string data, bool is_last_substring)
{// 处理空字符串情况if (data.empty()) {if (is_last_substring) {eof_ = true;eof_index_ = first_index;if (next_index_ == eof_index_) {output_.writer().close();}}return;}// 更新EOF信息if (is_last_substring) {eof_ = true;eof_index_ = first_index + data.size();}
4.2 已处理字节的检查
接下来,检查子串是否已经完全处理过,如果子串的结束位置不超过当前已处理的位置,则整个子串都已被处理,可以直接返回。
// 丢弃完全在已处理范围内的子串if (first_index + data.size() <= next_index_) {// 子串完全在已处理的范围内,忽略if (eof_ && next_index_ == eof_index_) {output_.writer().close();}return;}
4.3 容量限制检查
然后,我们需要考虑ByteStream的容量限制:
- 计算ByteStream的可用容量
- 确定可接受的最大索引位置
- 对于超出容量的子串,只保留在容量范围内的部分
- 通过截取得到可用的子串部分
// 计算ByteStream可用容量uint64_t available_capacity = output_.writer().available_capacity();// 计算这个子串在可接受范围内的结束位置uint64_t acceptable_end = next_index_ + available_capacity;// 如果子串起始位置超出可接受范围,丢弃if (first_index >= acceptable_end) {return;}// 截取子串中在可接受范围内的部分uint64_t actual_start = max(first_index, next_index_);uint64_t actual_end = min(first_index + data.size(), acceptable_end);// 子串中有效部分的偏移量和长度uint64_t offset = actual_start - first_index;uint64_t length = actual_end - actual_start;// 截取可用部分string usable_data = data.substr(offset, length);uint64_t usable_index = actual_start;
4.4 直接写入处理
如果子串正好是下一个期望的字节,可以直接写入:
- 将可用的子串直接写入ByteStream
- 更新
next_index_ - 检查
unassembled_中是否有可以继续写入的子串 - 尝试写入尽可能多的连续子串
// 如果可以直接写入输出流if (usable_index == next_index_) {output_.writer().push(usable_data);next_index_ += usable_data.size();// 检查是否有更多可以写入的子串while (!unassembled_.empty()) {auto it = unassembled_.begin();if (it->first > next_index_) {break; // 有空洞,不能继续写入}// 计算这个子串中有多少新的字节uint64_t overlap = next_index_ - it->first;if (overlap < it->second.size()) {string new_data = it->second.substr(overlap);output_.writer().push(new_data);next_index_ += new_data.size();}// 移除已处理的子串unassembled_.erase(it);}
4.5 子串存储与合并
如果子串不能直接写入,需要存储并处理可能的重叠:
- 使用
lower_bound查找可能重叠的子串 - 检查并合并与前面子串的重叠
- 检查并合并与后面子串的重叠
- 存储合并后的子串
} else if (usable_data.size() > 0) {// 将子串添加到未组装的映射中// 首先检查是否有重叠的子串,可能需要合并auto it = unassembled_.lower_bound(usable_index);// 检查前面的子串if (it != unassembled_.begin()) {auto prev = prev(it);uint64_t prev_end = prev->first + prev->second.size();// 如果前面的子串与当前子串重叠或相邻if (prev_end >= usable_index) {// 合并子串if (prev_end < usable_index + usable_data.size()) {uint64_t extend_len = usable_index + usable_data.size() - prev_end;prev->second += usable_data.substr(usable_data.size() - extend_len);}// 如果完全被前面的子串覆盖,则无需存储if (prev_end >= usable_index + usable_data.size()) {// 检查是否已完成if (eof_ && next_index_ == eof_index_) {output_.writer().close();}return;}// 更新待处理的子串信息usable_index = prev->first;usable_data = prev->second;unassembled_.erase(prev);}}// 检查和合并后面的子串while (it != unassembled_.end() && it->first <= usable_index + usable_data.size()) {uint64_t it_end = it->first + it->second.size();// 如果后面的子串延伸超过当前子串if (it_end > usable_index + usable_data.size()) {uint64_t extend_len = it_end - (usable_index + usable_data.size());usable_data += it->second.substr(it->second.size() - extend_len);}auto to_erase = it;++it;unassembled_.erase(to_erase);}// 存储合并后的子串unassembled_[usable_index] = usable_data;}
4.6 结束处理
最后,检查是否需要关闭输出流:当所有预期的数据都已处理完毕,且已收到标记为最后的子串时,关闭输出流。
// 检查是否已经处理完所有数据if (eof_ && next_index_ == eof_index_) {output_.writer().close();}
}
5 count_bytes_pending实现
除了insert方法外,还需要实现count_bytes_pending方法来计算未组装的字节数:
- 只计算未处理的部分(排除与已处理区域重叠的部分)
- 由于子串可能有重叠,需要计算每个子串的有效长度
uint64_t Reassembler::count_bytes_pending() const
{uint64_t total = 0;for (const auto& [index, data] : unassembled_) {// 只计算还未处理的字节if (index + data.size() > next_index_) {uint64_t valid_start = max(index, next_index_);total += (index + data.size()) - valid_start;}}return total;
}
6 调试经验
- 最困难的部分是正确处理子串重叠,考虑子串重叠处理的边界情况。实现之前最好使用纸笔推演各种情况,确保边界处理正确。
- 考虑容量限制。需明确区分ByteStream的容量和Reassembler可以存储的字节数,确保两者之和不超过总容量。
- 确定何时检查并关闭输出流。建议在每次处理子串后都检查是否满足关闭条件,确保不会错过关闭时机。
相关文章:
CS144 Lab1实战记录:实现TCP重组器
文章目录 1 实验背景与要求1.1 TCP的数据分片与重组问题1.2 实验具体任务 2 重组器的设计架构2.1 整体架构2.2 数据结构设计 3 重组器处理的关键场景分析3.1 按序到达的子串(直接写入)3.2 乱序到达的子串(需要存储)3.3 与已处理区…...
Linux安装mysql_exporter
mysqld_exporter 是一个用于监控 MySQL 数据库的 Prometheus exporter。可以从 MySQL 数据库的 metrics_schema 收集指标,相关指标主要包括: MySQL 服务器指标:例如 uptime、version 等数据库指标:例如 schema_name、table_rows 等表指标:例如 table_name、engine、…...

BeautifulSoup 库的使用——python爬虫
文章目录 写在前面python 爬虫BeautifulSoup库是什么BeautifulSoup的安装解析器对比BeautifulSoup的使用BeautifulSoup 库中的4种类获取标签获取指定标签获取标签的的子标签获取标签的的父标签(上行遍历)获取标签的兄弟标签(平行遍历)获取注释根据条件查找标签根据CSS选择器查找…...
HTTP的Header
一、HTTP Header 是什么? HTTP Header 是 HTTP 协议中的头部信息部分,位于请求或响应的起始行之后,用来在客户端(浏览器等)与服务器之间传递元信息(meta-data)(简单理解为传递信息的…...

linux虚拟机网络问题处理
yum install -y yum-utils \ > device-mapper-persistent-data \ > lvm2 --skip-broken 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile Could not retrieve mirrorlist http://mirrorlist.centos.org/?release7&arch…...

unet算法发展历程简介
UNet是一种基于深度学习的图像分割架构,自2015年提出以来经历了多次改进和扩展,逐渐成为医学图像分割和其他精细分割任务的标杆。以下是UNet算法的主要发展历程和关键变体: 1. 原始UNet(2015) 论文: U-Net: Convoluti…...
)
基于华为云 ModelArts 的在线服务应用开发(Requests 模块)
基于华为云 ModelArts 的在线服务应用开发(Requests 模块) 一、本节目标 了解并掌握 Requests 模块的特点与用法学会通过 PythonRequests 访问华为云 ModelArts 在线推理服务熟悉 JSON 模块在 Python 中的数据序列化与反序列化掌握 Python 文件 I/O 的基…...

【Rust】基本概念
目录 第一个 Rust 程序:猜数字基本概念变量和可变性可变性常量变量隐藏 数据类型标量类型整型浮点型数值运算布尔型字符类型 复合类型元组数组 函数参数语句与表达式函数返回值 控制流使用 if 表达式控制条件if 表达式使用 else if 处理多重条件在 let 语句中使用 i…...

AI-Sphere-Butler之如何使用Llama factory LoRA微调Qwen2-1.5B/3B专属管家大模型
环境: AI-Sphere-Butler WSL2 英伟达4070ti 12G Win10 Ubuntu22.04 Qwen2.-1.5B/3B Llama factory llama.cpp 问题描述: AI-Sphere-Butler之如何使用Llama factory LoRA微调Qwen2-1.5B/3B管家大模型 解决方案: 一、准备数据集我这…...

C++学习之游戏服务器开发十四QT登录器实现
目录 1.界面搭建 2.登录客户端步骤分析 3.拼接登录请求实现 4.发送http请求 5.服务器登录请求处理 6.客户端处理服务器回复数据 7.注册页面启动 8.qt启动游戏程序 1.界面搭建 查询程序依赖的动态库 ldd 程序名 do 1 cdocker rm docker ps -aq 静态编译游戏服务程序&a…...
协同推荐算法实现的智能商品推荐系统 - [基于springboot +vue]
🛍️ 智能商品推荐系统 - 基于springboot vue 🚀 项目亮点 欢迎来到未来的购物体验!我们的智能商品推荐系统就像您的私人购物顾问,它能读懂您的心思,了解您的喜好,为您精心挑选最适合的商品。想象一下&am…...

【LLM】Ollama:容器化并加载本地 GGUF 模型
本教程将完整演示如何在支持多 GPU 的环境下,通过 Docker 实现 Ollama 的本地化部署,并深度整合本地 GGUF 模型。我们将构建一个具备生产可用性的容器化 LLM 服务,包含完整的存储映射、GPU 加速配置和模型管理方案。 前提与环境准备 操作系统…...

实践项目开发-hbmV4V20250407-Taro项目构建优化
Taro项目构建优化实践:大幅提升开发效率 项目背景 在开发基于ReactTaro的前端项目时,随着项目规模的增长,构建速度逐渐成为开发效率的瓶颈。通过一系列构建优化措施,成功将开发环境的构建速度提升了30%-50%,显著改善…...

MySQL中根据binlog日志进行恢复
MySQL中根据binlog日志进行恢复 排查 MySQL 的 binlog 日志问题及根据 binlog 日志进行恢复的方法一、引言二、排查 MySQL 的 binlog 日志问题(一)确认 binlog 是否开启(二)查找 binlog 文件位置和文件名模式(三&#…...
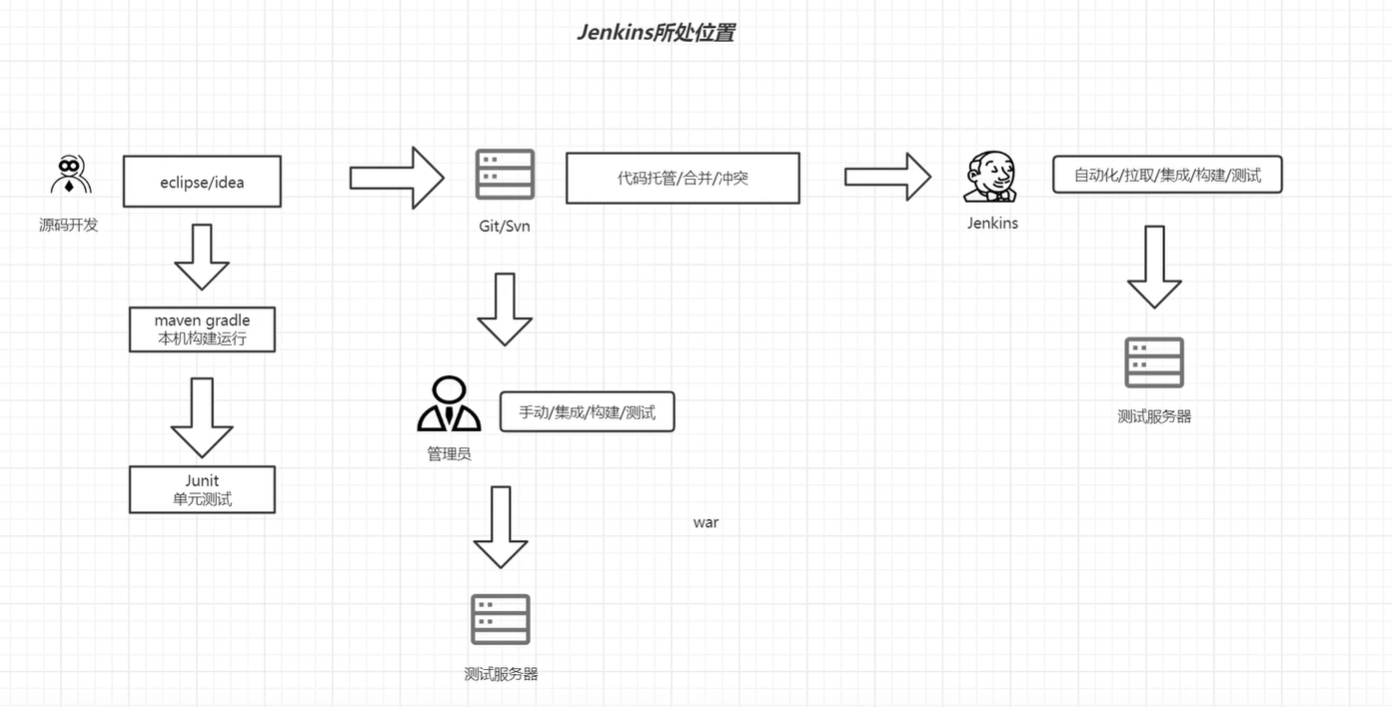
Jenkins的地位和作用
所处位置 Jenkins 是一款开源的自动化服务器,广泛应用于软件开发和测试流程中,主要用于实现持续集成(CI)和持续部署(CD)。它在开发和测试中的位置和作用可以从以下几个方面来理解: 1. 在开发和测…...
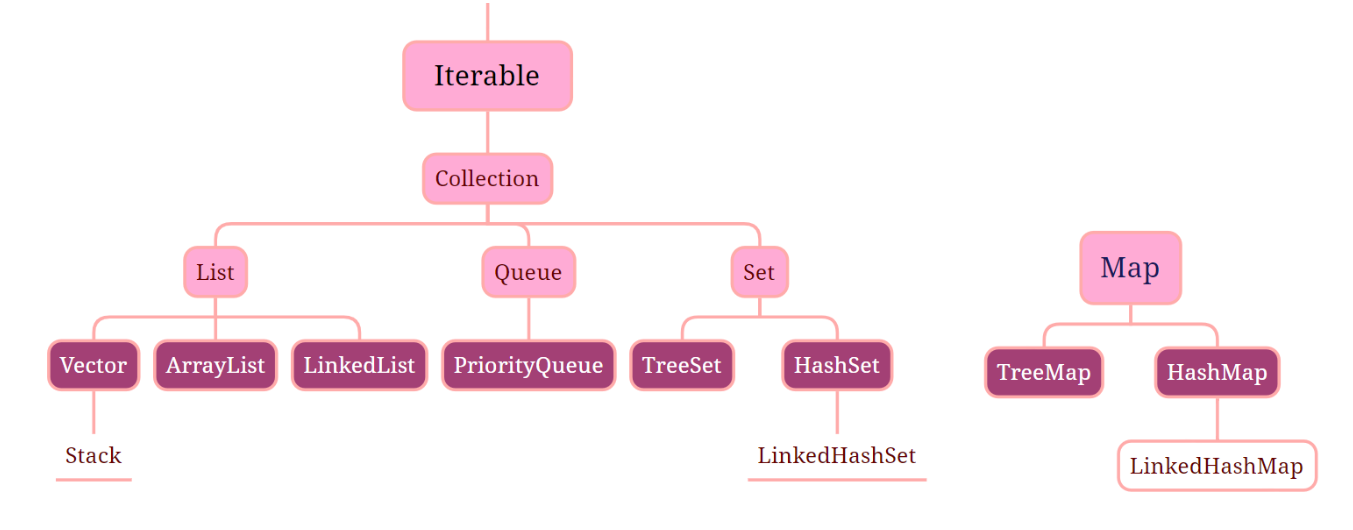
【集合】底层原理实现及各集合之间的区别
文章目录 集合2.1 介绍一下集合2.2 集合遍历的方法2.3 线程安全的集合2.4 数组和集合的区别2.5 ArrayList和LinkedList的区别2.6 ArrayList底层原理2.7 LinkedList底层原理2.8 CopyOnWriteArrayList底层原理2.9 HashSet底层原理2.10 HashMap底层原理2.11 HashTable底层原理2.12…...
)
软考高级-系统架构设计师 论文范文参考(二)
文章目录 论企业应用集成论软件三层结构的设计论软件设计模式的应用论软件维护及软件可维护性论信息系统安全性设计论信息系统的安全性设计(二)论信息系统的架构设计论信息系统架构设计(二) 论企业应用集成 摘要: 2016年9月,我国某省移动通信有限公司决定启动VerisB…...
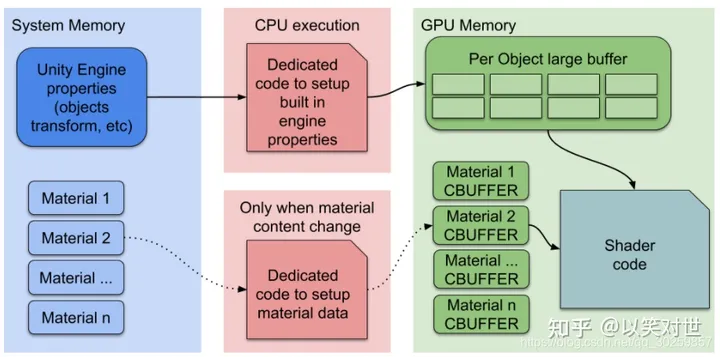
srp batch
参考网址: Unity MaterialPropertyBlock 正确用法(解决无法合批等问题)_unity_define_instanced_prop的变量无法srp合批-CSDN博客 URP | 基础CG和HLSL区别 - 哔哩哔哩 (bilibili.com) 【直播回放】Unity 批处理/GPU Instancing/SRP Batche…...

【Linux运维涉及的基础命令与排查方法大全】
文章目录 前言1、计算机网络常用端口2、Kali Linux中常用的命令3、Kali Linux工具的介绍4、Ubuntu没有网络连接解决方法5、获取路由6、数据库端口 前言 以下介绍计算机常见的端口已经对应的网络协议,Linux中常用命令,以及平时运维中使用的排查网络故障的…...

【2025最新Java八股】redis中io多路复用怎么回事,和多线程的关系
io多路复用 IO 多路复用和多线程是两种不同的技术,他们都是用于改善程序在处理多个任务或多个数据流时的效率和性能的。 但是他俩要解决的问题不一样!IO多路复用主要是提升I/O操作的效率和利用率,所以适合 IO 密集型应用。多线程则是提升CP…...

Webview+Python:用HTML打造跨平台桌面应用的创新方案
目录 一、技术原理与优势分析 1.1 架构原理 1.2 核心优势 二、开发环境搭建 2.1 安装依赖 2.2 验证安装 三、核心功能开发 3.1 基础窗口管理 3.2 HTML↔Python通信 JavaScript调用Python Python调用JavaScript 四、高级功能实现 4.1 系统级集成 4.2 多窗口管理 五…...

Nginx HTTP 414 与“大面积”式洪水攻击联合防御实战
一、引言 在大规模分布式应用中,Nginx 常作为前端负载均衡和反向代理服务器。攻击者若结合超长 URI/头部攻击(触发 HTTP 414)与海量洪水攻击,可在网络层与应用层形成双重打击:一方面耗尽缓冲区和内存,另一…...

Oracle高级语法篇-集合操作
Oracle 集合操作详解 作为数据库领域的佼佼者,Oracle 提供了功能强大的集合操作符,它们能够合并多个查询的结果集,极大提升数据处理效率。接下来,本文将从基础知识点到实战案例,全方位剖析 Oracle 的集合操作。 一、…...

克服储能领域的数据处理瓶颈及AI拓展
对于储能研究人员来说,日常工作中经常围绕着一项核心但有时令人沮丧的任务:处理实验数据。从电池循环仪的嗡嗡声到包含电压和电流读数的大量电子表格,研究人员的大量时间都花在了提取有意义的见解上。长期以来,该领域一直受到对专…...
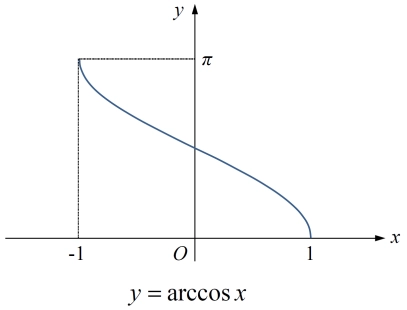
包含物体obj与相机camera的 代数几何代码解释
反余弦函数的值域在 [0, pi] 斜体样式 cam_pose self._cameras[hand_realsense].camera.get_model_matrix() # cam2world# 物体到相机的向量 obj_tcp_vec cam_pose[:3, 3] - self.obj_pose.p dist np.linalg.norm(obj_tcp_vec) # 物体位姿的旋转矩阵 obj_rot_mat self.ob…...

excel解析图片pdf附件不怕
背景 工作中肯定会有导入excel还附带图片附件的下面是我解析的excel,支持图片、pdf、压缩文件实现 依次去解析excel,看看也没有附件,返回的格式是Map,key是第几行,value是附件list附件格式都被解析成pdf格式Reader.jav…...

【Spring】依赖注入的方式:构造方法、setter注入、字段注入
在Spring框架中,除了构造器注入(Constructor Injection)和Setter注入(Setter Injection),还有一种依赖注入方式:字段注入(Field Injection)。字段注入通过在Bean的字段上…...
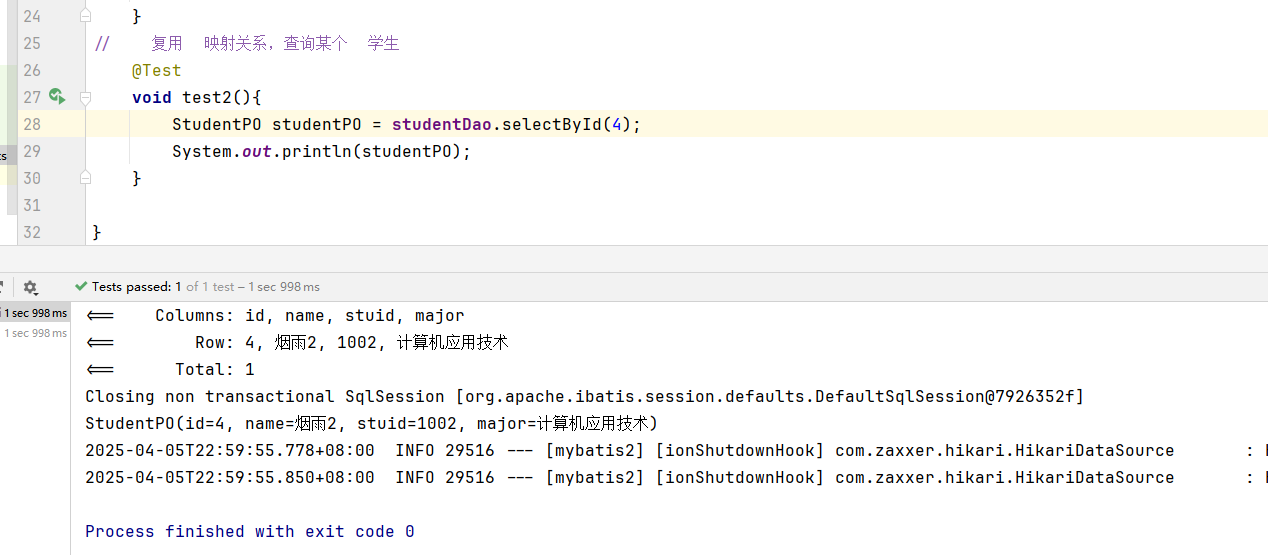
mybatis实现增删改查1
文章目录 19.MyBatis查询单行数据MapperScan 结果映射配置核心文件Results自定义映射到实体的关系 多行数据查询-完整过程插入数据配置mybatis 控制台日志 更新数据删除数据小结通过id复用结果映射模板xml处理结果映射 19.MyBatis 数据库访问 MyBatis,MyBatis-Plus…...
Git,本地上传项目到github
一、Git的安装和下载 https://git-scm.com/ 进入官网,选择合适的版本下载 二、Github仓库创建 点击右上角New新建一个即可 三、本地项目上传 1、进入 要上传的项目目录,右键,选择Git Bash Here,进入终端Git 2、初始化临时仓库…...
基于flask+vue框架的灯饰安装维修系统u49cf(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,工单人员,服务项目,订单记录,服务记录,评价记录 开题报告内容 基于 FlaskVue 框架的灯饰安装维修系统开题报告 一、选题背景与意义 (一)选题背景 随着城市化进程的加速与居民生活品质的显著提升…...