Python 爬虫如何伪装 Referer?从随机生成到动态匹配

一、Referer 的作用与重要性
Referer 是 HTTP 请求头中的一个字段,用于标识请求的来源页面。它在网站的正常运行中扮演着重要角色,例如用于统计流量来源、防止恶意链接等。然而,对于爬虫来说,Referer 也可能成为被识别为爬虫的关键因素之一。许多网站会检查 Referer 字段,如果发现请求头中缺少 Referer 或者 Referer 的值不符合预期,网站可能会拒绝服务或者返回错误信息。
因此,伪装 Referer 成为了爬虫开发者的重要任务。通过合理地设置 Referer,可以降低爬虫被检测到的风险,提高数据采集的成功率。
二、随机生成 Referer
随机生成 Referer 是一种简单但有效的伪装方法。通过生成一些常见的、看似合法的 Referer 值,可以欺骗网站的反爬虫机制。以下是一个使用 Python 实现随机生成 Referer 的示例代码:
import random# 定义一些常见的 Referer 值
referer_list = ["https://www.google.com","https://www.bing.com","https://www.baidu.com","https://www.sogou.com","https://www.yahoo.com","https://www.duckduckgo.com","https://www.yandex.com","https://www.bing.com/search?q=python+爬虫","https://www.google.com/search?q=python+爬虫","https://www.sogou.com/web?query=python+爬虫","https://www.baidu.com/s?wd=python+爬虫","https://www.yandex.com/search/?text=python+爬虫","https://www.duckduckgo.com/?q=python+爬虫"
]# 随机选择一个 Referer
def random_referer():return random.choice(referer_list)# 使用 requests 库发送请求
import requestsdef fetch_with_random_referer(url):headers = {"Referer": random_referer(),"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}response = requests.get(url, headers=headers)return response# 测试
url = "https://example.com"
response = fetch_with_random_referer(url)
print(response.status_code)
print(response.headers)
代码解析
- 定义 Referer 列表:我们定义了一个包含常见搜索引擎和搜索结果页面的 Referer 列表。这些 Referer 值看起来像是用户通过搜索引擎访问目标页面的来源。
- 随机选择 Referer:通过
<font style="color:rgba(0, 0, 0, 0.9);">random.choice()</font>方法从列表中随机选择一个 Referer 值。 - 发送请求:使用
<font style="color:rgba(0, 0, 0, 0.9);">requests</font>库发送 HTTP 请求时,将随机选择的 Referer 添加到请求头中。同时,我们还添加了一个常见的<font style="color:rgba(0, 0, 0, 0.9);">User-Agent</font>,以进一步伪装请求。
优点
- 简单易实现:随机生成 Referer 的方法非常简单,只需要定义一个 Referer 列表并随机选择即可。
- 成本低:不需要复杂的逻辑和额外的资源,适合初学者快速上手。
缺点
- 容易被识别:虽然随机生成的 Referer 可以欺骗一些简单的反爬虫机制,但对于复杂的网站,这种方法可能很容易被识别。因为随机生成的 Referer 可能与实际的用户行为模式不一致。
三、动态匹配 Referer
为了进一步提高伪装效果,我们可以采用动态匹配 Referer 的方法。动态匹配是指根据目标网站的页面结构和链接关系,动态生成合理的 Referer 值。这种方法需要对目标网站的结构进行分析,并根据实际的用户行为路径生成 Referer。
以下是一个动态匹配 Referer 的实现示例:
import requests
from bs4 import BeautifulSoup# 获取目标页面的链接
def get_links(url):headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, "html.parser")links = []for link in soup.find_all("a", href=True):links.append(link["href"])return links# 动态生成 Referer
def dynamic_referer(url, links):# 选择一个与目标页面相关的链接作为 Refererreferer = random.choice(links)if not referer.startswith("http"):referer = url + refererreturn referer# 使用动态 Referer 发送请求
def fetch_with_dynamic_referer(url):links = get_links(url)referer = dynamic_referer(url, links)headers = {"Referer": referer,"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}response = requests.get(url, headers=headers)return response# 测试
url = "https://example.com"
response = fetch_with_dynamic_referer(url)
print(response.status_code)
print(response.headers)
代码解析
- 获取目标页面的链接:使用
<font style="color:rgba(0, 0, 0, 0.9);">requests</font>和<font style="color:rgba(0, 0, 0, 0.9);">BeautifulSoup</font>库获取目标页面的 HTML 内容,并解析出页面中的所有链接。 - 动态生成 Referer:从获取到的链接列表中随机选择一个链接作为 Referer 值。如果链接是相对路径,则将其转换为绝对路径。
- 发送请求:将动态生成的 Referer 添加到请求头中,并发送请求。
优点
- 伪装效果更好:动态生成的 Referer 更符合实际的用户行为模式,因为它是根据目标页面的实际链接关系生成的。
- 适应性强:这种方法可以根据不同的目标网站动态调整 Referer,具有较强的适应性。
缺点
- 实现复杂:需要对目标网站的结构进行分析,并且需要解析 HTML 内容,实现成本较高。
- 性能问题:动态生成 Referer 的过程需要额外的网络请求和解析操作,可能会对爬虫的性能产生一定影响。
四、结合代理和 IP 池
除了伪装 Referer,结合代理和 IP 池可以进一步提高爬虫的伪装效果和稳定性。代理服务器可以隐藏爬虫的真实 IP 地址,而 IP 池可以提供多个代理 IP,避免因频繁访问而被封禁。
以下是一个结合代理和 IP 池的实现示例:
import random
import requests
from requests.auth import HTTPProxyAuth# 定义代理服务器信息
proxyHost = "www.16yun.cn"
proxyPort = "5445"
proxyUser = "16QMSOML"
proxyPass = "280651"# 构造代理地址
proxy_url = f"http://{proxyHost}:{proxyPort}"# 定义代理认证信息
proxy_auth = HTTPProxyAuth(proxyUser, proxyPass)# 动态生成 Referer(假设 get_links 和 dynamic_referer 函数已定义)
def get_links(url):headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}response = requests.get(url, headers=headers, proxies={"http": proxy_url, "https": proxy_url}, auth=proxy_auth)soup = BeautifulSoup(response.text, "html.parser")links = []for link in soup.find_all("a", href=True):links.append(link["href"])return linksdef dynamic_referer(url, links):referer = random.choice(links)if not referer.startswith("http"):referer = url + refererreturn referer# 使用动态 Referer 和代理发送请求
def fetch_with_proxy_and_referer(url):links = get_links(url)referer = dynamic_referer(url, links)headers = {"Referer": referer,"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}proxies = {"http": proxy_url,"https": proxy_url}response = requests.get(url, headers=headers, proxies=proxies, auth=proxy_auth)return response# 测试
url = "https://example.com"
response = fetch_with_proxy_and_referer(url)
print(response.status_code)
print(response.headers)
代码解析
- 定义代理 IP 池:定义一个包含多个代理 IP 的列表。
- 随机选择代理:通过
<font style="color:rgba(0, 0, 0, 0.9);">random.choice()</font>方法从代理 IP 池中随机选择一个代理。 - 发送请求:将动态生成的 Referer 和随机选择的代理添加到请求中,并发送请求。
优点
- 伪装效果更强:结合代理和 IP 池可以同时隐藏爬虫的真实 IP 地址和伪装 Referer,大大提高了伪装效果。
- 稳定性更高:使用 IP 池可以避免因频繁访问而被封禁,提高了爬虫的稳定性。
总结
伪装 Referer 是 Python 爬虫中应对反爬虫机制的重要手段之一。通过随机生成 Referer 和动态匹配 Referer,可以有效降低爬虫被检测到的风险。结合代理和 IP 池,可以进一步提高爬虫的伪装效果和稳定性。在实际应用中,开发者需要根据目标网站的反爬虫机制和自身的需求,选择合适的伪装方法。
相关文章:
Python 爬虫如何伪装 Referer?从随机生成到动态匹配
一、Referer 的作用与重要性 Referer 是 HTTP 请求头中的一个字段,用于标识请求的来源页面。它在网站的正常运行中扮演着重要角色,例如用于统计流量来源、防止恶意链接等。然而,对于爬虫来说,Referer 也可能成为被识别为爬虫的关…...

【MySQL】表的约束(主键、唯一键、外键等约束类型详解)、表的设计
目录 1.数据库约束 1.1 约束类型 1.2 null约束 — not null 1.3 unique — 唯一约束 1.4 default — 设置默认值 1.5 primary key — 主键约束 自增主键 自增主键的局限性:经典面试问题(进阶问题) 1.6 foreign key — 外键约束 1.7…...

基于STC89C52RC和8X8点阵屏、独立按键的小游戏《打砖块》
目录 系列文章目录前言一、效果展示二、原理分析三、各模块代码1、8X8点阵屏2、独立按键3、定时器04、定时器1 四、主函数总结 系列文章目录 前言 用的是普中A2开发板,外设有:8X8LED点阵屏、独立按键。 【单片机】STC89C52RC 【频率】12T11.0592MHz 效…...
数字电子技术基础(五十)——硬件描述语言简介
目录 1 硬件描述语言简介 1.1 硬件描述语言简介 1.2 硬件编程语言的发展历史 1.3 两种硬件描述的比较 1.4 硬件描述语言的应用场景 1.5 基本程序结构 1.5.1 基本程序结构 1.5.2 基本语句和描述方法 1.5.3 仿真 1 硬件描述语言简介 1.1 硬件描述语言简介 硬件描述语…...
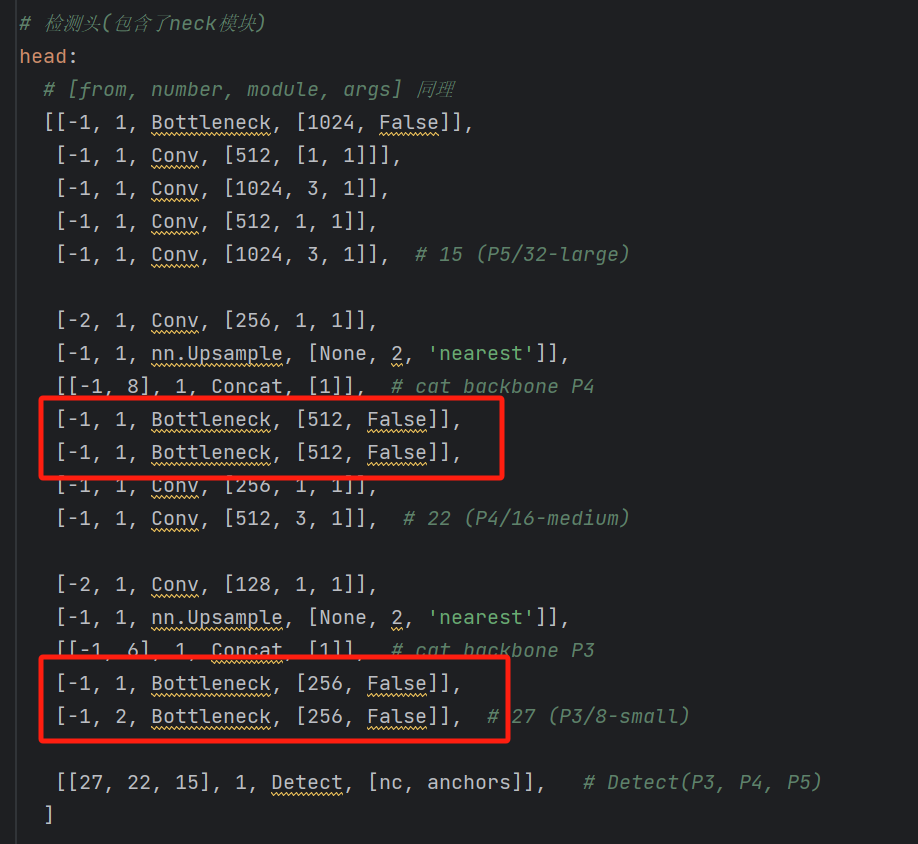
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读
【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读 文章目录 【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3核心文件common.py解读前言autopad函数Conv类__init__成员函数forward成员函数forward_fuse成员函数 Bottleneck类__init__成员…...
16.Chromium指纹浏览器开发教程之WebGPU指纹定制
WebGPU指纹概述 WebGPU是下一代的Web图形和计算API,旨在提供高性能的图形渲染和计算能力。它是WebGL的后继者,旨在利用现代GPU的强大功能,使得Web应用能够实现接近原生应用的图形和计算性能。而且它是一个低级别的API,可以直接与…...

示例:spring 纯xml配置
以下是一个完整的 纯 XML 配置开发示例,涵盖 DAO、Service、Controller 层,通过 Spring XML 配置实现依赖注入和事务管理,无需任何注解。 1. 项目结构 src/main/java ├── com.example.dao │ └── UserDao.java # DAO 接口…...
SQL预编译——预编译真的能完美防御SQL注入吗
SQL注入原理 sql注入是指攻击者拼接恶意SQL语句到接受外部参数的动态SQL查询中,程序本身 未对插入的SQL语句进行过滤,导致SQL语句直接被服务端执行。 拼接的SQL查询例如,通过在id变量后插入or 11这样的条件,来绕过身份验证&#…...

系统架构师2025年论文《论基于UML的需求分析》
论基于构件的软件开发 摘要: 2011 年 3 月,我有幸参加了某市医院预约挂号系统项目的开发工作,并担任系统架构师一职,负责系统的架构设计及核心构件的开发工作。该项目是某市医院为提升患者就医体验、优化挂号流程而委托开发的,项目于 2011 年底验收,满足了医院及患者提…...
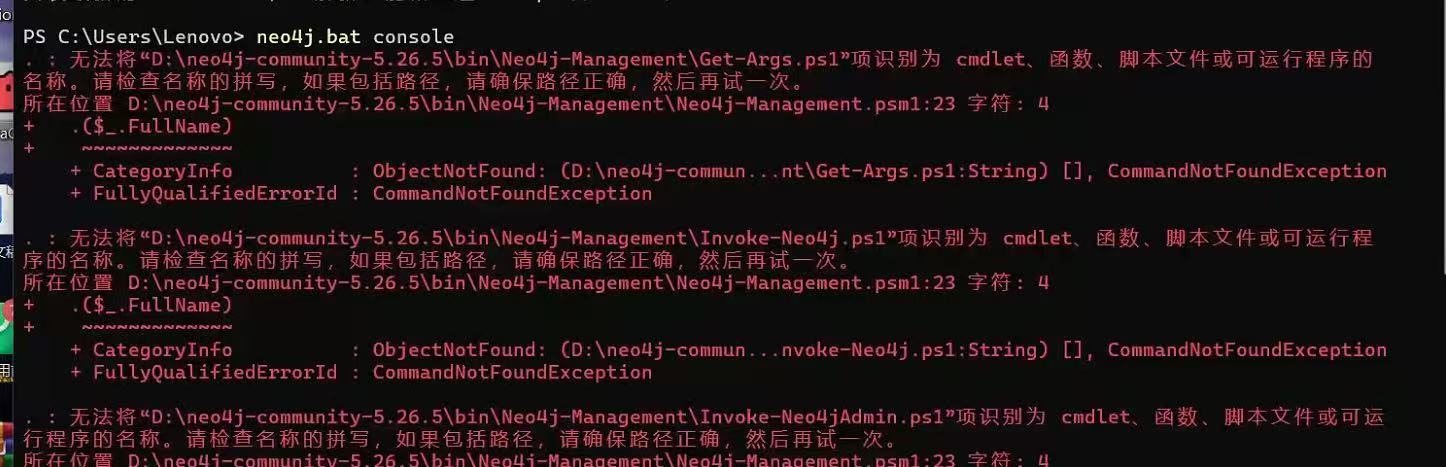
运行neo4j.bat console 报错无法识别为脚本,PowerShell 教程:查看语言模式并通过注册表修改受限模式
无法将“D:\neo4j-community-4.4.38-windows\bin\Neo4j-Management\Get-Args.ps1”项识别为cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再试一次。 前提配置好环境变量之后依然报上面的错…...
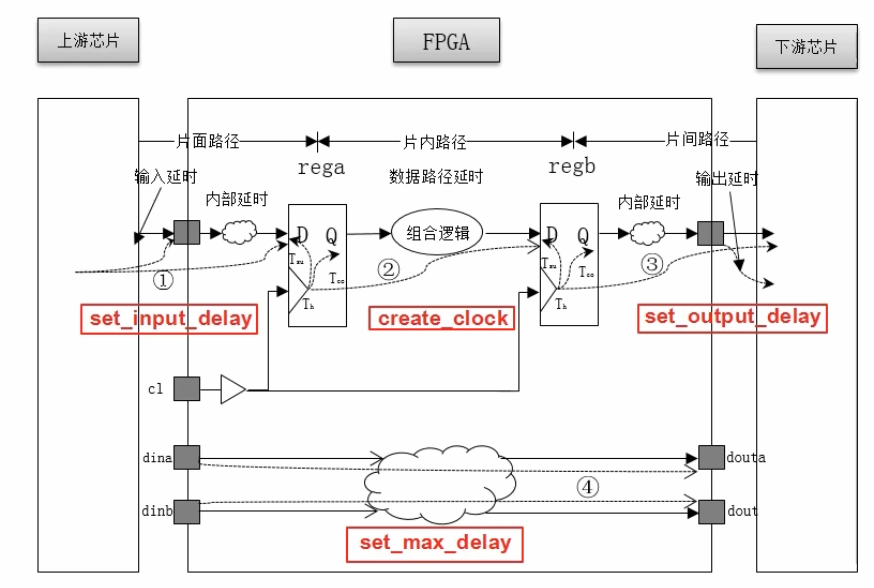
【EDA软件】【设计约束和分析操作方法】
1. 设计约束 设计约束主要分为物理约束和时序约束。 物理约束主要包括I/O接口约束(如引脚分配、电平标准设定等物理属性的约束)、布局约束、布线约束以及配置约束。 时序约束是FPGA内部的各种逻辑或走线的延时,反应系统的频率和速度的约束…...

【Lua】Lua 入门知识点总结
Lua 入门学习笔记 本教程旨在帮助有编程基础的学习者快速入门Lua编程语言。包括Lua中变量的声明与使用,包括全局变量和局部变量的区别,以及nil类型的概念、数值型、字符串和函数的基本操作,包括16进制表示、科学计数法、字符串连接、函数声明…...

Godot学习-关于3D模型选择问题
下面是OBJ、glTF/GLB、BLEND和FBX四种3D模型格式的比较表格,以便更直观地了解它们之间的差异: 特性/格式OBJglTF / GLBBLENDFBX文件类型文本文本/二进制二进制二进制几何数据支持支持支持支持材质支持基础高级(PBR等)完整支持高级…...
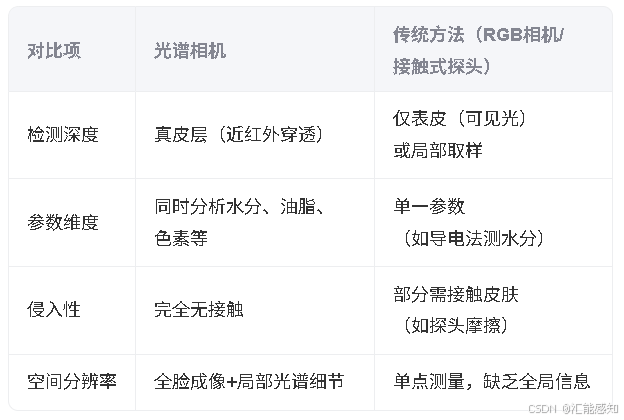
光谱相机在肤质检测中的应用
光谱相机在肤质检测中具有独特优势,能够通过多波段光谱分析皮肤深层成分及生理状态,实现非侵入式、高精度、多维度的皮肤健康评估。以下是其核心应用与技术细节: 一、工作原理 光谱反射与吸收特性: 血红蛋白&a…...
)
IDEA 插件推荐清单(2025)
IDEA 插件推荐清单 精选高效开发必备插件,提升 Java 开发体验与效率。 参考来源:十六款好用的 IDEA 插件,强烈推荐!!!不容错过 代码开发助手类 插件名称功能简介推荐指数CodeGeeX智能代码补全、代码生成、…...

机器学习第一篇 线性回归
数据集:公开的World Happiness Report | Kaggle中的happiness dataset2017. 目标:基于GDP值预测幸福指数。(单特征预测) 代码: 文件一:prepare_for_traning.py """用于科学计算的一个库…...
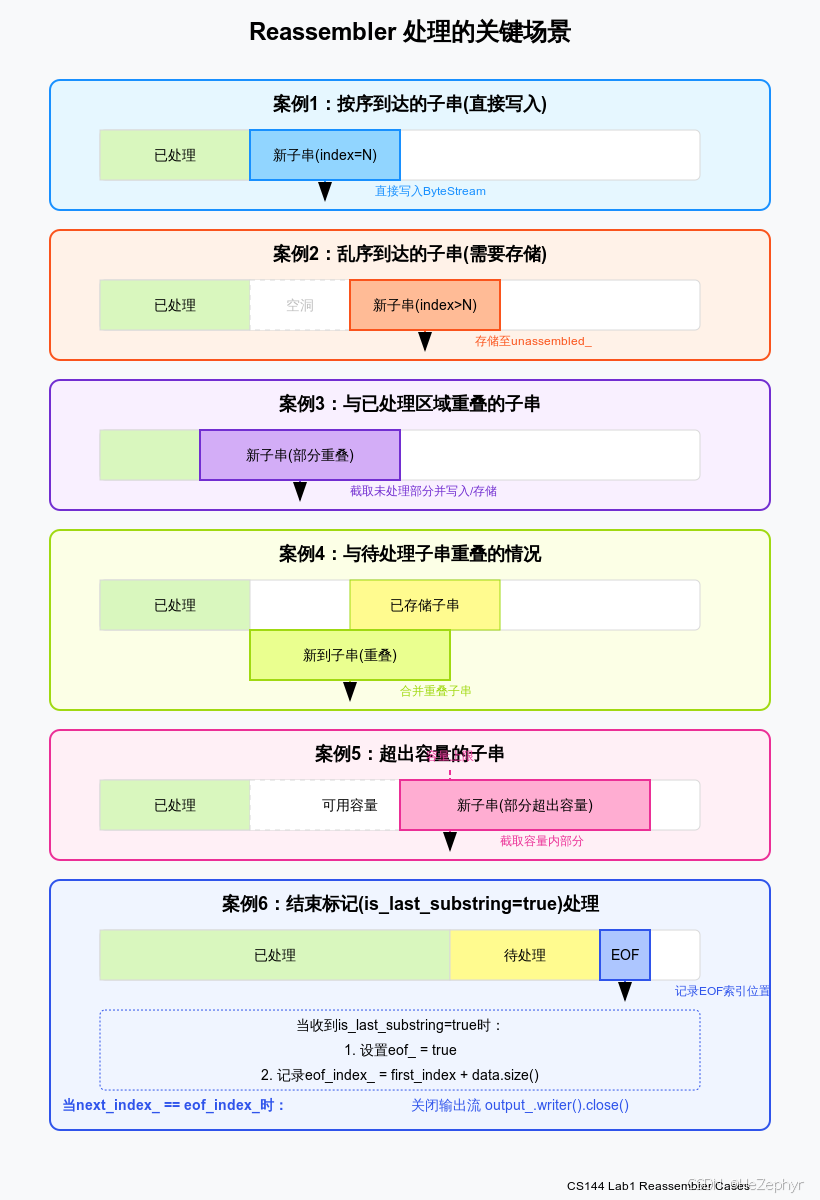
CS144 Lab1实战记录:实现TCP重组器
文章目录 1 实验背景与要求1.1 TCP的数据分片与重组问题1.2 实验具体任务 2 重组器的设计架构2.1 整体架构2.2 数据结构设计 3 重组器处理的关键场景分析3.1 按序到达的子串(直接写入)3.2 乱序到达的子串(需要存储)3.3 与已处理区…...
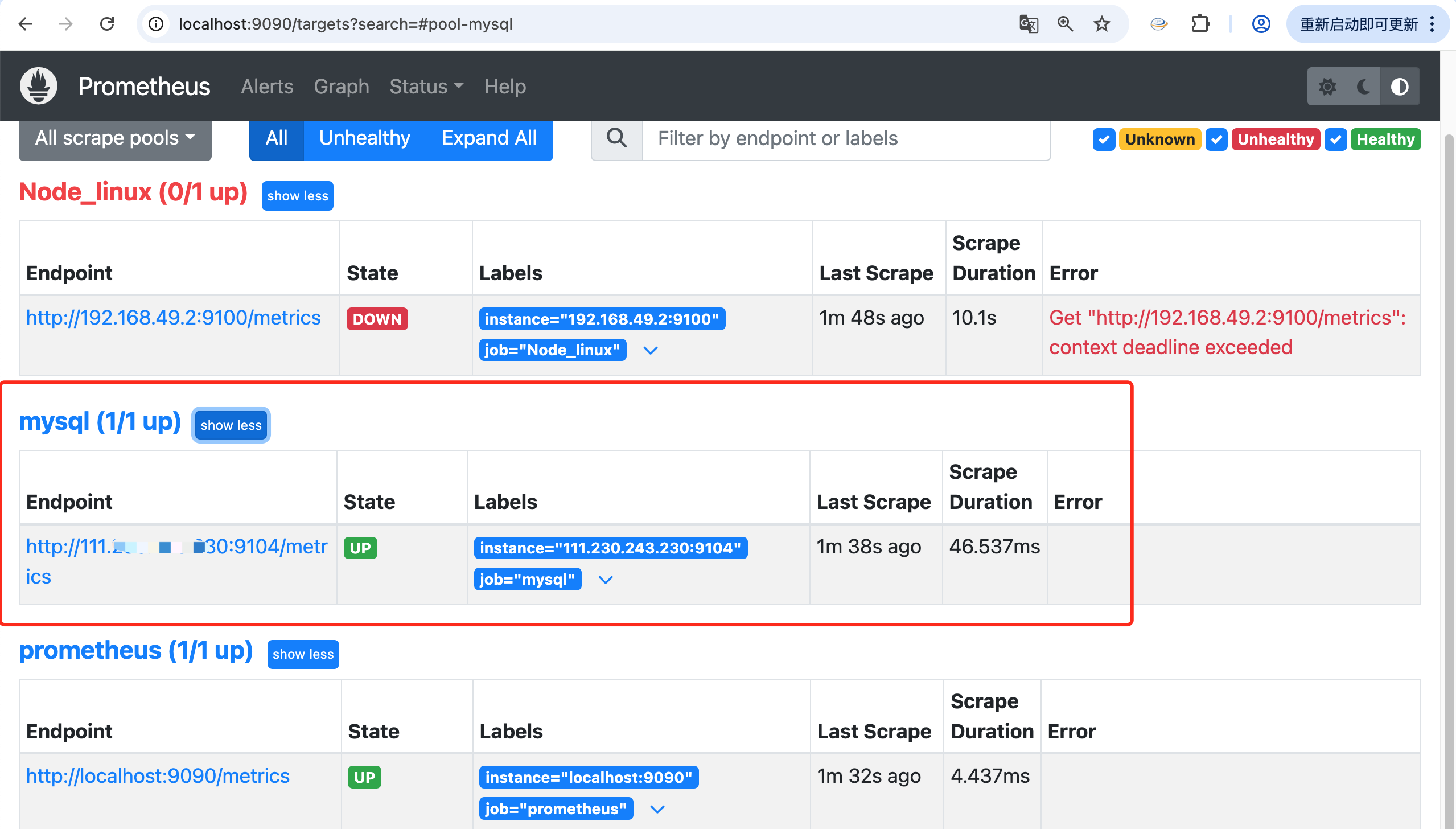
Linux安装mysql_exporter
mysqld_exporter 是一个用于监控 MySQL 数据库的 Prometheus exporter。可以从 MySQL 数据库的 metrics_schema 收集指标,相关指标主要包括: MySQL 服务器指标:例如 uptime、version 等数据库指标:例如 schema_name、table_rows 等表指标:例如 table_name、engine、…...

BeautifulSoup 库的使用——python爬虫
文章目录 写在前面python 爬虫BeautifulSoup库是什么BeautifulSoup的安装解析器对比BeautifulSoup的使用BeautifulSoup 库中的4种类获取标签获取指定标签获取标签的的子标签获取标签的的父标签(上行遍历)获取标签的兄弟标签(平行遍历)获取注释根据条件查找标签根据CSS选择器查找…...
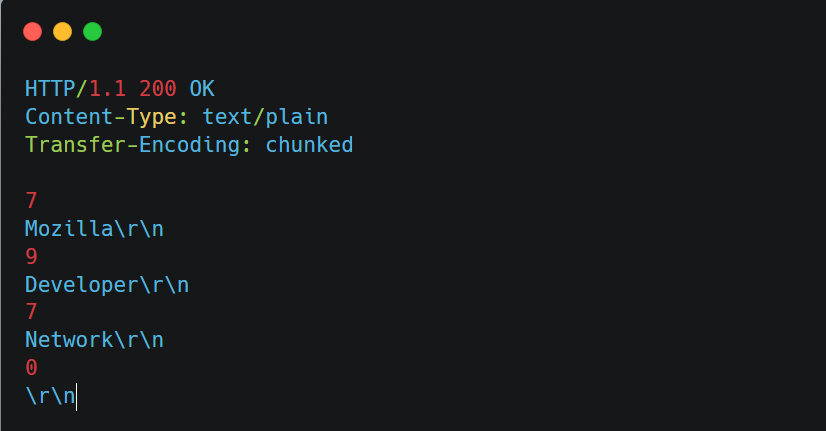
HTTP的Header
一、HTTP Header 是什么? HTTP Header 是 HTTP 协议中的头部信息部分,位于请求或响应的起始行之后,用来在客户端(浏览器等)与服务器之间传递元信息(meta-data)(简单理解为传递信息的…...

linux虚拟机网络问题处理
yum install -y yum-utils \ > device-mapper-persistent-data \ > lvm2 --skip-broken 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile Could not retrieve mirrorlist http://mirrorlist.centos.org/?release7&arch…...

unet算法发展历程简介
UNet是一种基于深度学习的图像分割架构,自2015年提出以来经历了多次改进和扩展,逐渐成为医学图像分割和其他精细分割任务的标杆。以下是UNet算法的主要发展历程和关键变体: 1. 原始UNet(2015) 论文: U-Net: Convoluti…...
)
基于华为云 ModelArts 的在线服务应用开发(Requests 模块)
基于华为云 ModelArts 的在线服务应用开发(Requests 模块) 一、本节目标 了解并掌握 Requests 模块的特点与用法学会通过 PythonRequests 访问华为云 ModelArts 在线推理服务熟悉 JSON 模块在 Python 中的数据序列化与反序列化掌握 Python 文件 I/O 的基…...

【Rust】基本概念
目录 第一个 Rust 程序:猜数字基本概念变量和可变性可变性常量变量隐藏 数据类型标量类型整型浮点型数值运算布尔型字符类型 复合类型元组数组 函数参数语句与表达式函数返回值 控制流使用 if 表达式控制条件if 表达式使用 else if 处理多重条件在 let 语句中使用 i…...

AI-Sphere-Butler之如何使用Llama factory LoRA微调Qwen2-1.5B/3B专属管家大模型
环境: AI-Sphere-Butler WSL2 英伟达4070ti 12G Win10 Ubuntu22.04 Qwen2.-1.5B/3B Llama factory llama.cpp 问题描述: AI-Sphere-Butler之如何使用Llama factory LoRA微调Qwen2-1.5B/3B管家大模型 解决方案: 一、准备数据集我这…...

C++学习之游戏服务器开发十四QT登录器实现
目录 1.界面搭建 2.登录客户端步骤分析 3.拼接登录请求实现 4.发送http请求 5.服务器登录请求处理 6.客户端处理服务器回复数据 7.注册页面启动 8.qt启动游戏程序 1.界面搭建 查询程序依赖的动态库 ldd 程序名 do 1 cdocker rm docker ps -aq 静态编译游戏服务程序&a…...
协同推荐算法实现的智能商品推荐系统 - [基于springboot +vue]
🛍️ 智能商品推荐系统 - 基于springboot vue 🚀 项目亮点 欢迎来到未来的购物体验!我们的智能商品推荐系统就像您的私人购物顾问,它能读懂您的心思,了解您的喜好,为您精心挑选最适合的商品。想象一下&am…...

【LLM】Ollama:容器化并加载本地 GGUF 模型
本教程将完整演示如何在支持多 GPU 的环境下,通过 Docker 实现 Ollama 的本地化部署,并深度整合本地 GGUF 模型。我们将构建一个具备生产可用性的容器化 LLM 服务,包含完整的存储映射、GPU 加速配置和模型管理方案。 前提与环境准备 操作系统…...

实践项目开发-hbmV4V20250407-Taro项目构建优化
Taro项目构建优化实践:大幅提升开发效率 项目背景 在开发基于ReactTaro的前端项目时,随着项目规模的增长,构建速度逐渐成为开发效率的瓶颈。通过一系列构建优化措施,成功将开发环境的构建速度提升了30%-50%,显著改善…...

MySQL中根据binlog日志进行恢复
MySQL中根据binlog日志进行恢复 排查 MySQL 的 binlog 日志问题及根据 binlog 日志进行恢复的方法一、引言二、排查 MySQL 的 binlog 日志问题(一)确认 binlog 是否开启(二)查找 binlog 文件位置和文件名模式(三&#…...