深度学习在DOM解析中的应用:自动识别页面关键内容区块

摘要
本文介绍了如何在爬取东方财富吧(https://www.eastmoney.com)财经新闻时,利用深度学习模型对 DOM 树中的内容区块进行自动识别和过滤,并将新闻标题、时间、正文等关键信息分类存储。文章聚焦爬虫整体性能瓶颈,通过指标对比、优化策略、压测数据及改进结果,展示了从单页耗时约 5 秒优化到约 2 秒的过程,极大提升了工程效率。
一、性能瓶颈点
- 网络请求与代理调度
- 每次 HTTP 请求需经由爬虫代理,存在连接与认证开销。
- DOM 解析与深度学习推理
- 使用 BeautifulSoup 遍历大规模节点;
- 对每个候选区块进行深度学习模型推理(TensorFlow/Keras),推理时间占比高。
- 单线程串行抓取
- 不支持并发,无法充分利用多核 CPU 与网络带宽。
二、指标对比(优化前)
| 指标 | 单页耗时 (秒) | CPU 占用 | 内存占用 |
|---|---|---|---|
| 网络请求 + 代理 | 1.2 | 5% | 50 MB |
| DOM 解析 | 0.8 | 10% | 100 MB |
| 模型推理 (单区块) | 2.5 | 30% | 200 MB |
| 数据存储(本地 SQLite) | 0.5 | 5% | 20 MB |
| 总计 | 5.0 | 50% | 370 MB |
三、优化策略
- 代理连接复用
- 启用
requests.Session并开启 HTTP Keep-Alive,减少握手耗时;
- 启用
- 批量深度学习推理
- 将多个候选区块合并为批次(Batch)输入模型,一次性完成推理,减少启动开销;
- 多线程并发抓取
- 采用
concurrent.futures.ThreadPoolExecutor实现多线程并发请求与解析,提高吞吐量;
- 采用
- 模型量化与 TensorFlow Lite
- 将 Keras 模型导出为 TFLite,并启用浮点16量化,推理更快、占用更低;
- 异步存储
- 异步写入 SQLite 或切换到轻量级 NoSQL(如 TinyDB),降低阻塞;
四、压测数据(优化后)
| 指标 | 单页耗时 (秒) | CPU 占用 | 内存占用 |
|---|---|---|---|
| 网络请求 + 代理复用 | 0.8 | 8% | 55 MB |
| DOM 解析 | 0.6 | 12% | 110 MB |
| 批量模型推理 (TFLite) | 0.4 | 20% | 120 MB |
| 多线程与异步存储 | 0.2 | 10% | 25 MB |
| 总计 | 2.0 | 50% | 310 MB |
五、改进结果
- 平均单页耗时 从 5.0 秒降至 2.0 秒,性能提升 60%+;
- 内存占用 减少 60 MB,推理内存占比降低;
- CPU 利用率 更均衡,多线程并发可支撑更高并发量。
- 整体爬虫更稳定,并可扩展至分布式部署。
代码示例
import time
import requests
from bs4 import BeautifulSoup
import sqlite3
import tensorflow as tf
import numpy as np
from concurrent.futures import ThreadPoolExecutor# -----配置代理 IP(亿牛云爬虫代理示例 www.16yun.cn)-----
PROXY_HOST = "proxy.16yun.cn"
PROXY_PORT = 8100
PROXY_USER = "16YUN"
PROXY_PASS = "16IP"
proxy_meta = f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}"
proxies = {"http": proxy_meta,"https": proxy_meta,
}# --------- HTTP 会话与头部设置 ---------
session = requests.Session()
session.proxies.update(proxies)
session.headers.update({"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ""(KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
})
# 示例 Cookie 设置
session.cookies.set("st_si", "123456789", domain="eastmoney.com")
session.cookies.set("st_asi", "abcdefg", domain="eastmoney.com")# --------- 数据库初始化 ---------
conn = sqlite3.connect("eastmoney_news.db", check_same_thread=False)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS news (id INTEGER PRIMARY KEY AUTOINCREMENT,title TEXT,pub_time TEXT,content TEXT
)
""")
conn.commit()# --------- 加载并量化模型(TFLite) ---------
# 假设已有 Keras 模型 'content_block_model.h5',先转换为 TFLite
def convert_to_tflite(h5_path, tflite_path):model = tf.keras.models.load_model(h5_path)converter = tf.lite.TFLiteConverter.from_keras_model(model)converter.optimizations = [tf.lite.Optimize.DEFAULT]tflite_model = converter.convert()with open(tflite_path, "wb") as f:f.write(tflite_model)# convert_to_tflite("content_block_model.h5", "model_quant.tflite") # 一次性执行# 加载 TFLite 模型
interpreter = tf.lite.Interpreter(model_path="model_quant.tflite")
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()# 模型预测函数(批量)
def predict_blocks(text_list):# 文本预处理示例:截断/填充到固定长度seqs = [[ord(c) for c in text[:200]] + [0] * (200 - len(text[:200])) for text in text_list]inp = np.array(seqs, dtype=np.float32)interpreter.set_tensor(input_details[0]['index'], inp)interpreter.invoke()preds = interpreter.get_tensor(output_details[0]['index'])# 返回布尔列表,True 表示为“关键区块”return [bool(p[1] > 0.5) for p in preds]# --------- 爬取解析函数 ---------
def fetch_and_parse(url):start = time.time()# 1. 获取页面resp = session.get(url, timeout=10)resp.raise_for_status()# 2. 解析 DOMsoup = BeautifulSoup(resp.text, "lxml")# 3. 提取候选区块(示例:所有 <div>)divs = soup.find_all("div")texts = [div.get_text(strip=True) for div in divs]# 4. 批量模型预测is_key = predict_blocks(texts)# 5. 筛选关键区块并抽取新闻字段news_items = []for div, flag in zip(divs, is_key):if not flag:continuetitle_tag = div.find("h1") or div.find("h2") or div.find("h3")time_tag = div.find("span", class_="time") or div.find("em")content = div.get_text(strip=True)if title_tag and time_tag:news_items.append({"title": title_tag.get_text(strip=True),"pub_time": time_tag.get_text(strip=True),"content": content})# 6. 存储到 SQLitefor item in news_items:cursor.execute("INSERT INTO news (title, pub_time, content) VALUES (?, ?, ?)",(item["title"], item["pub_time"], item["content"]))conn.commit()end = time.time()return end - start # 返回耗时# --------- 多线程压测 ---------
if __name__ == "__main__":urls = ["https://www.eastmoney.com/a/20250422XYZ.html",# ... 更多新闻页 URL 列表 ...]with ThreadPoolExecutor(max_workers=5) as executor:times = list(executor.map(fetch_and_parse, urls))print(f"平均单页耗时:{sum(times)/len(times):.2f} 秒")
说明
- 上述代码中,爬虫代理、Cookie、User-Agent 都已配置;
- 将 Keras 模型量化为 TFLite 并启用批量推理,缩短深度学习部分耗时;
- 使用
ThreadPoolExecutor并发抓取与解析;- 最终压测中,多线程 + 模型量化后,平均单页耗时降至约 2 秒。
通过以上性能调优思路和代码实现,可显著提高基于深度学习的 DOM 内容区块识别爬虫的效率,为大规模抓取与分类存储奠定坚实基础。
相关文章:
深度学习在DOM解析中的应用:自动识别页面关键内容区块
摘要 本文介绍了如何在爬取东方财富吧(https://www.eastmoney.com)财经新闻时,利用深度学习模型对 DOM 树中的内容区块进行自动识别和过滤,并将新闻标题、时间、正文等关键信息分类存储。文章聚焦爬虫整体性能瓶颈,通…...
PyQt6实例_pyqtgraph多曲线显示工具_代码分享
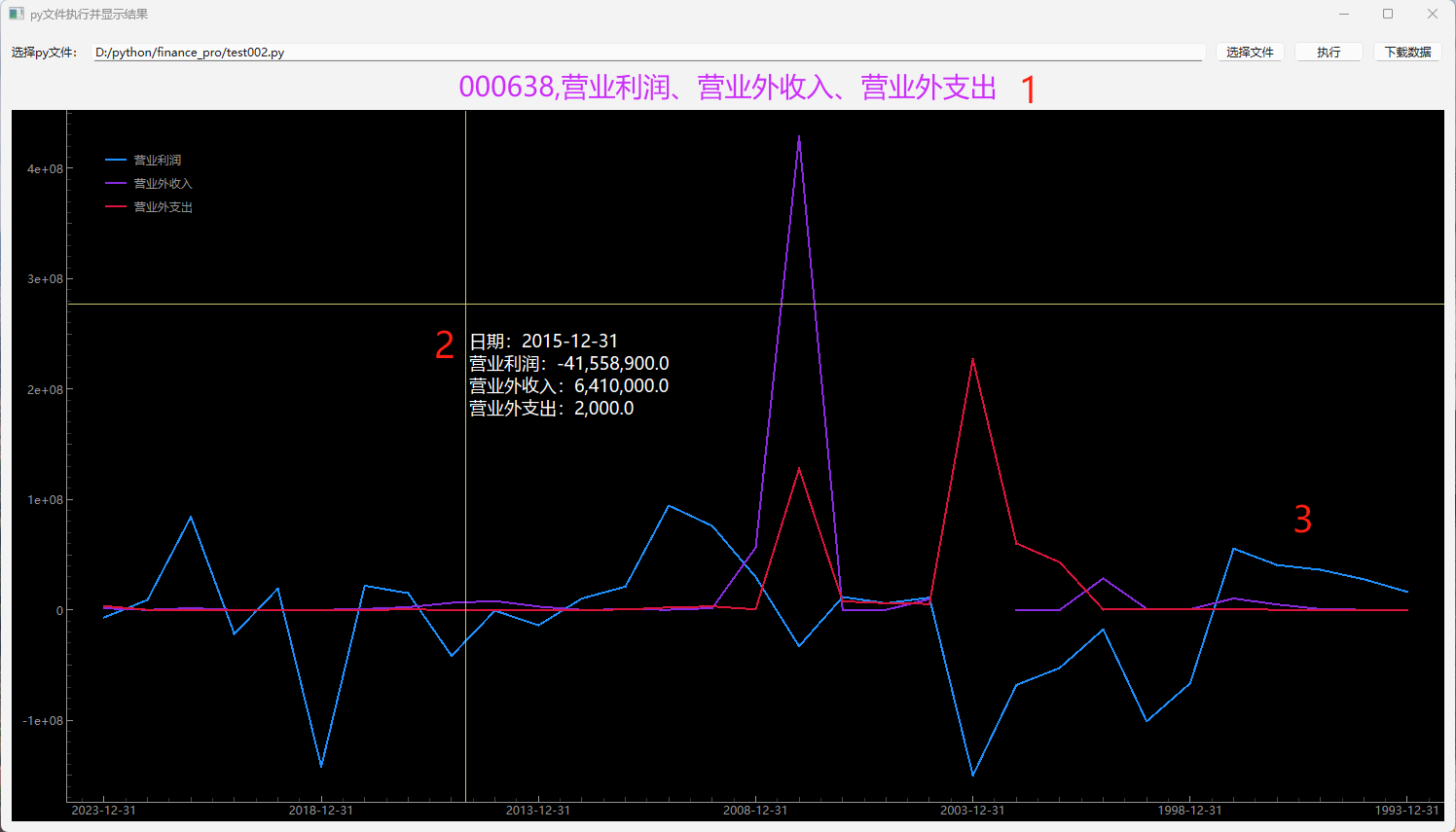
目录 概述 效果 代码 返回结果对象 字符型横坐标 通用折线图工具 工具主界面 使用举例 概述 1 分析数据遇到需要一个股票多个指标对比或一个指标多个股票对比,涉及到同轴多条曲线的显示,所以开发了本工具。 2 多曲线显示部分可以当通用工具使…...
Linux网络编程 多线程Web服务器:HTTP协议与TCP并发实战
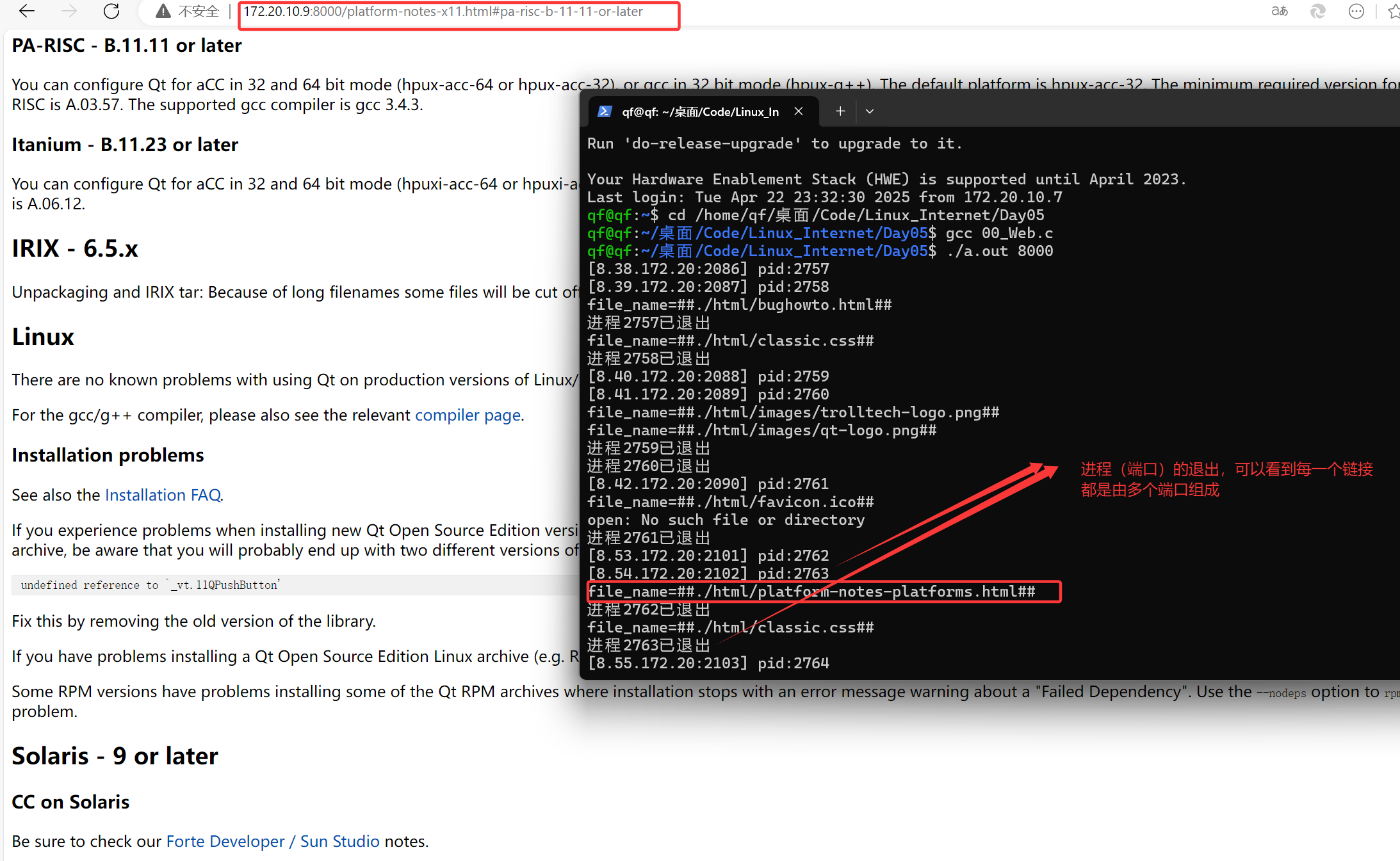
问题解答 TCP是如何防止SYN洪流攻击的? 方式有很多种,我仅举例部分: 1、调整内核参数 我们知道SYN洪流攻击的原理就是发送一系列无法完成三次握手的特殊信号,导致正常的能够完成三次握手的信号因为 连接队列空间不足ÿ…...
)
【Vulkan 入门系列】创建帧缓冲、命令池、命令缓存,和获取图片(六)
这一节主要介绍创建帧缓冲(Framebuffer),创建命令池,创建命令缓存,和从文件加载 PNG 图像数据,解码为 RGBA 格式,并将像素数据暂存到 Vulkan 的 暂存缓冲区中。 一、创建帧缓冲 createFramebu…...

【Git】fork 和 branch 的区别
在 Git 中,“fork” 和 “branch” 是两个不同的概念,它们用于不同的场景并且服务于不同的目的。理解这两者的区别对于有效地使用 Git 进行版本控制非常重要。 1. Fork(分叉) 定义 Fork 是指在 GitHub、GitLab 等代码托管平台上…...
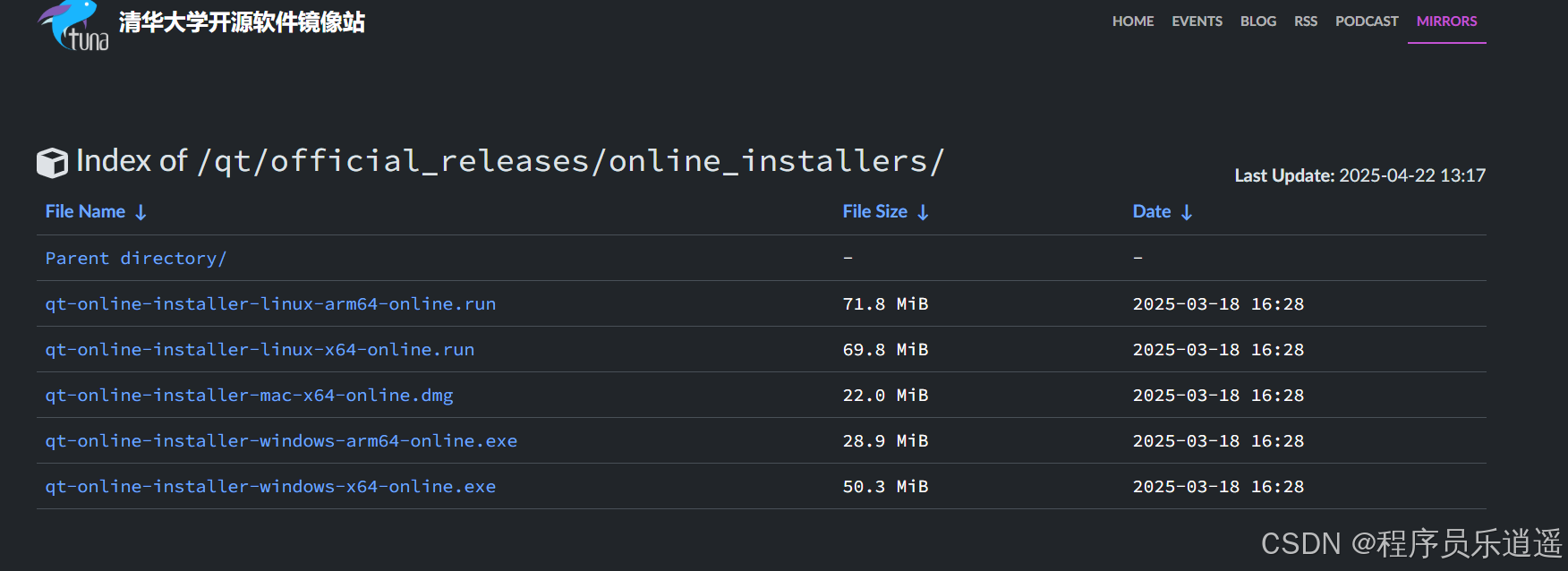
Qt 下载的地址集合
Qt 下载离线安装包 download.qt.io/archive/qt/5.14/5.14.2/ Qt 6 安装下载在线安装包 Index of /qt/official_releases/online_installers/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror...

java将pdf转换成word
1、jar包准备 在项目中新增lib目录,并将如下两个文件放入lib目录下 aspose-words-15.8.0-jdk16.jar aspose-pdf-22.9.jar 2、pom.xml配置 <dependency><groupId>com.aspose</groupId><artifactId>aspose-pdf</artifactId><versi…...
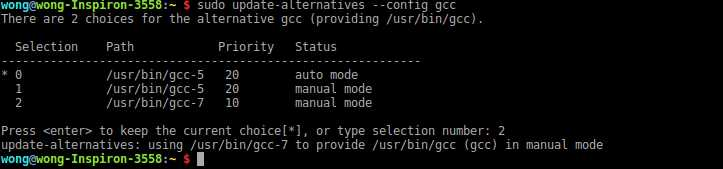
ubuntu下gcc/g++安装及不同版本切换
1. 查看当前gcc版本 $ gcc --version# 查看当前系统中已安装版本 $ ls /usr/bin/gcc*2. 安装新版本gcc $ sudo apt-get update# 这里以版本12为依据(也可以通过源码方式安装,请自行Google!) $ sudo apt-get install -y gcc-12 g…...

缓存与内存;缺页中断;缓存映射:组相联
文章目录 内存(RAM)与缓存(Cache)Memory Management Unit缺页中断 多级缓存缓存替换策略缓存的映射方式 内存(RAM)与缓存(Cache) 缓存: CPU 内部或非常靠近的高速存储&a…...

FPGA入门学习Day1——设计一个DDS信号发生器
目录 一、DDS简介 (一)基本原理 (二)主要优势 (三)与传统技术的对比 二、FPGA存储器 (一)ROM波形存储器 (二)RAM随机存取存储器 (三&…...

微信小程序拖拽排序有效果图
效果图 .wxml <view class"container" style"--w:{{w}}px;" wx:if"{{location.length}}"><view class"container-item" wx:for"{{list}}" wx:key"index" data-index"{{index}}"style"--…...

elasticsearch 查询检索
一、查询方式列举 1、多维度查询 关键词:bool must match {"query": {"bool": {"must": [{"match": {"server_name": "www.test.com"}},{"range": { //时间查询"createTime": …...
WT2000T专业录音芯片:破解普通录音设备信息留存、合规安全与远程协作三大难题
在快节奏的现代商业环境中,会议是企业决策、创意碰撞和战略部署的核心场景。然而,传统会议记录方式常面临效率低、信息遗漏、回溯困难等痛点。如何确保会议内容被精准记录并高效利用?会议室专用录音芯片应运而生,以智能化、高保真…...

【Python 学习笔记】 pip指令使用
系列文章目录 pip指令使用 文章目录 系列文章目录前言安装配置使用pip 管理Python包修改pip下载源 前言 提示:这里可以添加本文要记录的大概内容: 当前文章记录的是我在学习过程的一些笔记和思考,可能存在有误解的地方,仅供大家…...

与Ubuntu相关命令
windows将文件传输到Ubuntu 传输文件夹或文件 scp -r 本地文件夹或文件 ubuntu用户名IP地址:要传输到的文件夹路径 例如: scp -r .\04.py gao192.168.248.129:/home/gao 如果传输文件也可以去掉-r 安装软件 sudo apt-get update 更新软件包列表 sudo apt insta…...

C# 文件读取
文件读取是指使用 C# 程序从计算机文件系统中获取文件内容的过程。将存储在磁盘上的文件内容加载到内存中,供程序处理。主要类型有:文本文件读取(如 .txt, .csv, .json, .xml);二进制文件读取(如 .jpg, .pn…...

leetcode125.验证回文串
class Solution {public boolean isPalindrome(String s) {s s.replaceAll("[^a-zA-Z0-9]", "").toLowerCase();for(int i0,js.length()-1;i<j;i,j--){if(s.charAt(i)!s.charAt(j))return false;}return true;} }...
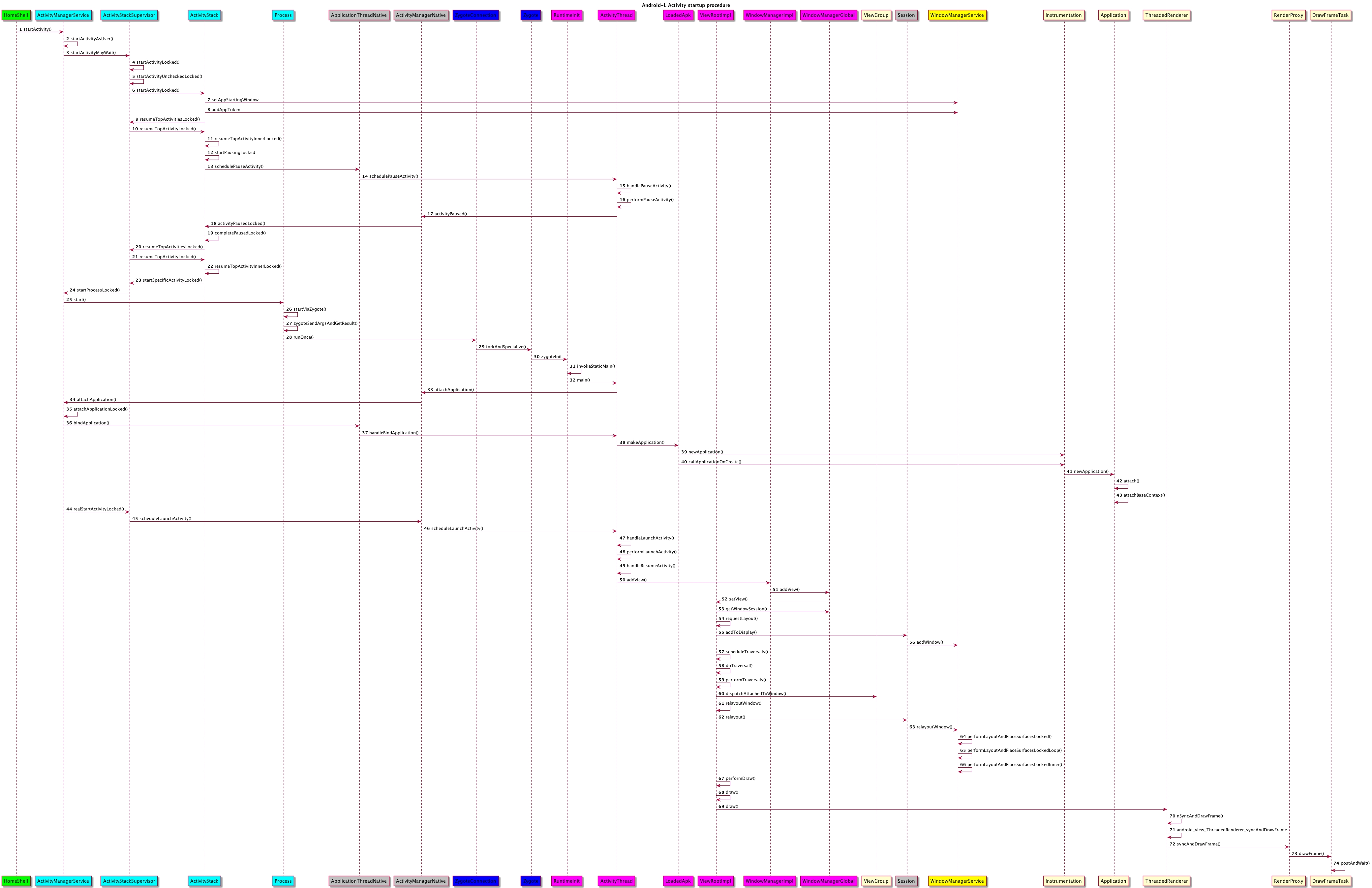
【Android面试八股文】Android系统架构【一】
Android系统架构图 1.1 安卓系统启动 1.设备加电后执行第一段代码:Bootloader 系统引导分三种模式:fastboot,recovery,normal: fastboot模式:用于工厂模式的刷机。在关机状态下,按返回开机 键进…...
——BERT 变体详解)
NLP高频面试题(五十二)——BERT 变体详解
在现代自然语言处理领域,BERT 系列模型不断演进,衍生出多种变体,它们通过改进预训练任务、模型结构和训练策略,在不同应用场景下取得了更优表现。本文首先概览主要 BERT 变体(如 ALBERT、RoBERTa、ELECTRA、SpanBERT、Transformer-XL 等),随后针对以下几个关键问题逐一展…...

【数据可视化-21】水质安全数据可视化:探索化学物质与水质安全的关联
🧑 博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN…...

CSS 选择器介绍
CSS 选择器介绍 1. 基本概念 CSS(层叠样式表)是一种用于描述 HTML 或 XML 文档外观的语言。通过 CSS,可以控制网页中元素的布局、颜色、字体等视觉效果。而 CSS 选择器则是用来指定哪些 HTML 元素应该应用这些样式的工具。 2. 基本选择器 …...
【prometheus+Grafana篇】从零开始:Linux 7.6 上二进制安装 Prometheus、Grafana 和 Node Exporter
💫《博主主页》:奈斯DB-CSDN博客 🔥《擅长领域》:擅长阿里云AnalyticDB for MySQL(分布式数据仓库)、Oracle、MySQL、Linux、prometheus监控;并对SQLserver、NoSQL(MongoDB)有了解 💖如果觉得文章对你有所帮…...
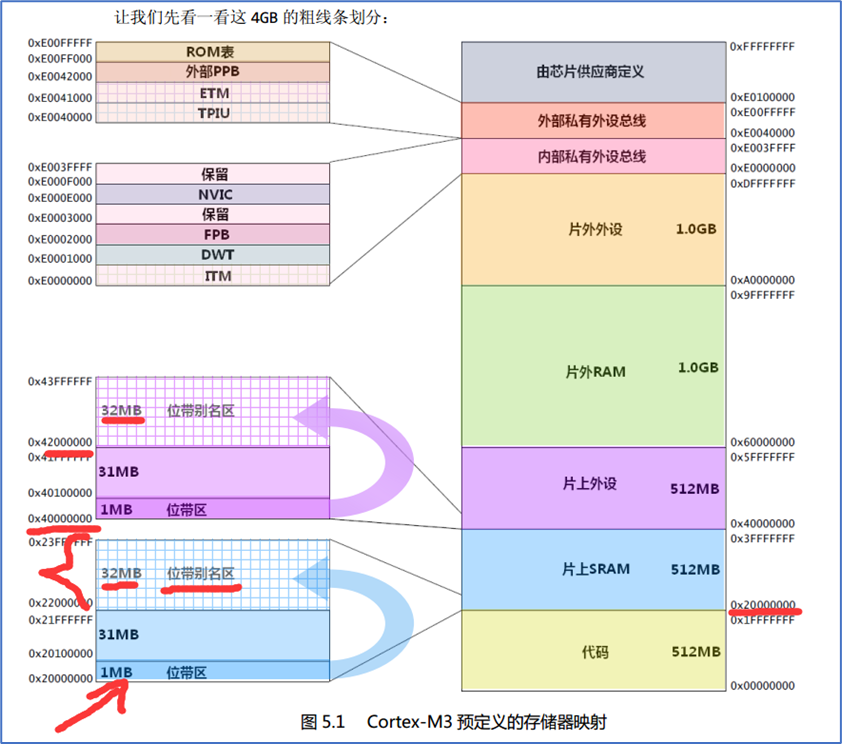
STM32(M4)入门:GPIO与位带操作(价值 3w + 的嵌入式开发指南)
一:GPIO 1.1 了解时钟树(必懂的硬件基础) 在 STM32 开发中,时钟系统是一切外设工作的 “心脏”。理解时钟树的工作原理,是正确配置 GPIO、UART 等外设的核心前提。 1.1.1 为什么必须开启外设时钟? 1. 计…...
树莓派config.txt旧版配置HDMI和杂项选项)
树莓派超全系列教程文档--(42)树莓派config.txt旧版配置HDMI和杂项选项
树莓派config.txt旧版配置HDMI和杂项选项 Raspberry Pi 4 HDMI遗留的杂项选项avoid_warningslogging_level 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 Raspberry Pi 4 HDMI IMPORTANT: 使用VC4 KMS图形驱动程序时,完整的显示管道…...

Linux419 三次握手四次挥手抓包 wireshark
还是Notfound 没连接 可能我在/home 准备配置静态IP vim ctrlr 撤销 u撤销 配置成功 准备关闭防火墙 准备配置 YUM源 df -h 未看到sr0文件 准备排查 准备挂载 还是没连接 计划重启 有了 不重启了 挂载准备 修改配置文件准备 准备清理缓存 ok 重新修改配…...
CSS-跟随图片变化的背景色
CSS-跟随图片变化的背景色 获取图片的主要颜色并用于背景渐变需要安装依赖 colorthief获取图片的主要颜色. 并丢给背景注意 getPalette并不是个异步方法 import styles from ./styles.less; import React, { useState } from react; import Colortheif from colorthief;cons…...
解决Docker 配置 daemon.json文件后无法生效
vim /etc/docker/daemon.json 在daemon中配置一下dns {"registry-mirrors": ["https://docker.m.daocloud.io","https://hub-mirror.c.163.com","https://dockerproxy.com","https://docker.mirrors.ustc.edu.cn","ht…...
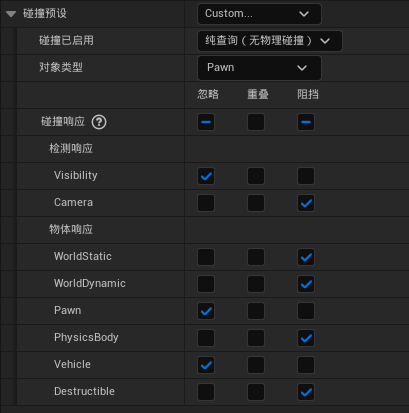
虚幻基础:ue碰撞
文章目录 碰撞:碰撞体 运动后 产生碰撞的行为——碰撞响应由引擎负责,并向各自发送事件忽略重叠阻挡 碰撞响应关系有忽略必是忽略有重叠必是重叠有阻挡不一定阻挡(双方都为阻挡) 碰撞启用:纯查询:开启移动检…...

2025.04.23【探索工具】| STEMNET:高效数据排序与可视化的新利器
文章目录 1. STEMNET工具简介2. STEMNET的安装方法3. STEMNET常用命令 1. STEMNET工具简介 在生物信息学领域,分析和处理大规模数据集是研究者们面临的日常挑战。STEMNET工具应运而生,旨在提供一个强大的平台,用于探索和分析单细胞RNA测序&a…...

GitLab Runner配置并行执行多个任务
检查并修改方法: 打开 Runner 的配置文件(通常位于 /etc/gitlab-runner/config.toml 或 ~/.gitlab-runner/config.toml)。 确保 concurrent 值大于 1,例如: concurrent 4 # 允许最多 4 个任务同时运行重启 Runner…...