【论文精读】Reformer:高效Transformer如何突破长序列处理瓶颈?
目录
- 一、引言:当Transformer遇到长序列瓶颈
- 二、核心技术解析:从暴力计算到智能优化
- 1. 局部敏感哈希注意力(LSH Attention):用“聚类筛选”替代“全量计算”
- 关键步骤:
- 数学优化:
- 2. 可逆残差网络(RevNet):让内存占用“逆生长”
- 3. 分块前馈层(Chunked FFN):细粒度内存优化
- 三、性能实测:效率与精度的双重突破
- 1. 复杂度对比
- 2. 精度验证
- 3. 速度优势
- 四、工业级应用场景:长序列处理的“刚需解法”
- 1. 超长文本理解(如法律合同、学术论文)
- 2. 实时推荐系统(用户行为序列建模)
- 3. 边缘设备部署(资源受限场景)
- 五、开源工具与落地建议
- 1. 主流框架集成
- 2. 调优关键点
- 3. 避坑指南
- 六、总结:Reformer的技术价值与未来
一、引言:当Transformer遇到长序列瓶颈
在自然语言处理领域,Transformer凭借自注意力机制在长距离依赖建模上展现出强大能力。然而,传统Transformer的注意力机制存在两个核心痛点:
- 平方级复杂度:注意力计算复杂度为 O ( L 2 ) O(L^2) O(L2),处理64K长度序列时,仅注意力矩阵就需16GB显存,直接导致长序列处理时显存溢出。
- 内存爆炸问题:深度网络中每层激活值都需存储,64层模型的内存占用随层数线性增长,训练成本呈指数级上升。
Google在ICLR 2020提出的Reformer模型,通过局部敏感哈希注意力(LSH Attention)和可逆残差网络两大核心技术,将计算复杂度降至 O ( L log L ) O(L\log L) O(LlogL),内存效率提升10倍以上,为超长序列处理(如10万+Token)打开了突破口。
二、核心技术解析:从暴力计算到智能优化

1. 局部敏感哈希注意力(LSH Attention):用“聚类筛选”替代“全量计算”
传统注意力需要计算每个Query与所有Key的相似度,而LSH Attention的核心思想是:仅关注与当前Query语义最接近的Key,通过哈希聚类快速筛选候选集合。
关键步骤:
- 向量归一化:将Key和Query归一化为单位向量,使相似度计算仅依赖方向(余弦相似度等价于点积)。
- 多轮随机投影哈希:
通过 n r o u n d s n_{rounds} nrounds 组随机投影矩阵生成哈希值,每组哈希将向量映射到不同桶中。例如,4轮哈希可将相似向量分到同一桶的概率提升至99%以上。 - 桶内局部计算:每个Query仅计算当前桶及相邻桶内的Key(通常前后各1个桶),将注意力矩阵从密集型转为稀疏型。

数学优化:
注意力公式引入掩码矩阵 M M M,仅保留同一桶内的有效位置:
Attention ( Q , K , V ) = softmax ( Q K T d k ⊙ M ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} \odot M\right)V Attention(Q,K,V)=softmax(dkQKT⊙M)V
复杂度从 O ( L 2 ) O(L^2) O(L2) 降至 O ( n r o u n d s ⋅ L ⋅ c ) O(n_{rounds} \cdot L \cdot c) O(nrounds⋅L⋅c),其中 c c c 为平均桶大小(通常 c ≈ log L c \approx \log L c≈logL)。
2. 可逆残差网络(RevNet):让内存占用“逆生长”
传统残差网络 y = x + F ( x ) y = x + F(x) y=x+F(x) 需要存储每层激活值 x x x 用于反向传播,导致内存随层数 N N N 线性增长。
Reformer采用可逆结构,将输入分为两部分交替处理:
{ y 1 = x 1 + Attention ( x 2 ) y 2 = x 2 + FeedForward ( y 1 ) \begin{cases} y_1 = x_1 + \text{Attention}(x_2) \\ y_2 = x_2 + \text{FeedForward}(y_1) \end{cases} {y1=x1+Attention(x2)y2=x2+FeedForward(y1)
反向传播时通过 x 2 = y 2 − FeedForward ( y 1 ) x_2 = y_2 - \text{FeedForward}(y_1) x2=y2−FeedForward(y1) 和 x 1 = y 1 − Attention ( x 2 ) x_1 = y_1 - \text{Attention}(x_2) x1=y1−Attention(x2) 重构输入,仅需存储单层激活值,内存复杂度从 O ( N ⋅ L ⋅ d ) O(N \cdot L \cdot d) O(N⋅L⋅d) 降至 O ( L ⋅ d ) O(L \cdot d) O(L⋅d)。
3. 分块前馈层(Chunked FFN):细粒度内存优化
前馈层中间维度 d f f d_{ff} dff 通常是模型维度的4倍(如4096),直接计算会占用大量内存。
Reformer将前馈层拆分为多个块,逐个处理每个块的计算:
Y 2 = concat ( FFN ( Y 1 ( 1 ) ) , … , FFN ( Y 1 ( c ) ) ) Y_2 = \text{concat}\left(\text{FFN}(Y_1^{(1)}), \dots, \text{FFN}(Y_1^{(c)})\right) Y2=concat(FFN(Y1(1)),…,FFN(Y1(c)))
通过调整块大小,可灵活平衡内存占用与计算速度,例如处理64K序列时内存占用减少75%。
三、性能实测:效率与精度的双重突破
1. 复杂度对比
| 指标 | 传统Transformer | Reformer | 提升幅度 |
|---|---|---|---|
| 时间复杂度 | O ( L 2 ) O(L^2) O(L2) | O ( L log L ) O(L\log L) O(LlogL) | 100倍+ |
| 内存复杂度(激活值) | O ( N L d ) O(NLd) O(NLd) | O ( L d ) O(Ld) O(Ld) | 随层数线性下降 |
| 64K序列显存占用 | 16GB+溢出 | 12GB可运行 | 显存节省50%+ |
2. 精度验证
- 合成任务:在序列复制任务中,4轮哈希的LSH Attention可达到99.9%的精度,接近全注意力(100%)。
- 文本任务:EnWiki8数据集上,Reformer困惑度2.85 vs 传统2.83,几乎无损失;翻译任务中BLEU得分28.1 vs 28.3,精度持平。
- 图像生成:ImageNet-64生成任务中,FID分数与Transformer相当,但推理速度提升4倍。
3. 速度优势
如图2所示,传统注意力耗时随序列长度呈平方级增长,而Reformer保持近似线性增长,处理16K序列时速度是传统方案的8倍。
四、工业级应用场景:长序列处理的“刚需解法”
1. 超长文本理解(如法律合同、学术论文)
- 场景:处理10万+Token的长文档,传统Transformer因显存限制无法运行。
- Reformer方案:通过LSH Attention筛选关键段落关联,可逆层节省内存,支持单卡处理64K+序列。
2. 实时推荐系统(用户行为序列建模)
- 挑战:用户历史行为序列可达10万次点击,需低延迟生成推荐。
- 优化点:哈希聚类快速匹配相似行为模式,分块计算降低在线推理延迟,显存占用减少90%,支持高并发部署。
3. 边缘设备部署(资源受限场景)
- 需求:在手机、IoT设备上运行轻量Transformer,功耗<1W。
- 方案:可逆层减少内存占用,LSH Attention降低计算量,使12层Reformer可在512MB显存设备上运行。
五、开源工具与落地建议
1. 主流框架集成
- Hugging Face:提供Reformer预训练模型及API,支持快速调用:
from transformers import ReformerModel model = ReformerModel.from_pretrained("google/reformer-crime-and-punishment") - Google Trax:官方JAX实现,支持TPU高效训练,代码库包含LSH Attention核心逻辑。
2. 调优关键点
- 哈希轮数:训练时用4轮平衡速度与精度,推理时可增至8轮提升精度(如Table 2中LSH-8达94.8%精度)。
- 块大小:根据显存大小调整,64K序列建议块大小128,内存占用降至1/512。
- 归一化策略:对Key/Query进行L2归一化,提升哈希聚类准确性。
3. 避坑指南
- 哈希冲突:极端情况下相似向量可能分至不同桶,可通过多轮哈希(≥4轮)降低概率。
- 位置编码:使用轴向位置编码(Axial Positional Embedding),避免哈希打乱序列顺序影响位置信息。
六、总结:Reformer的技术价值与未来
Reformer的核心贡献在于将Transformer从“暴力计算”转向“智能稀疏计算”,通过三大创新:
- LSH Attention:用哈希聚类实现注意力的“精准打击”,计算量下降两个数量级;
- 可逆层:颠覆传统残差结构,让内存占用不再随层数增长;
- 工程优化:分块计算、参数共享等细节设计,使理论优化落地为实际效率提升。
尽管在极端长序列(如100万Token)中仍需进一步优化哈希策略,但Reformer已为长文本处理、多模态生成等领域提供了可行方案。随着硬件加速(如TPU LSH专用单元)和动态哈希技术的发展,Transformer模型将在更长序列、更低资源消耗的场景中发挥更大价值。
参考资料
Reformer论文原文
Google Trax开源实现
Hugging Face Reformer文档
相关文章:
【论文精读】Reformer:高效Transformer如何突破长序列处理瓶颈?
目录 一、引言:当Transformer遇到长序列瓶颈二、核心技术解析:从暴力计算到智能优化1. 局部敏感哈希注意力(LSH Attention):用“聚类筛选”替代“全量计算”关键步骤:数学优化: 2. 可逆残差网络…...
jmeter中监控服务器ServerAgent
插件下载: 将ServerAgent上传至需要监控的服务器,mac/liunx启动startAgent.sh(启动命令:./startAgent.sh) 在jmeter中添加permon监控组件 配置需要监控的服务器IP地址,添加需要监控的资源 注意…...

网络结构及安全科普
文章目录 终端联网网络硬件基础网络协议示例:用户访问网页 OSI七层模型网络攻击(Hack)网络攻击的主要类别(一)按攻击目标分类(二)按攻击技术分类 网络安全防御 典型攻击案例相关名词介绍网络连接…...

JVM虚拟机-JVM调优、内存泄漏排查、CPU飙高排查
一、JVM调优的参数在哪里设置 项目开发过程中有以下两种部署项目的方式: 项目部署在tomcat中,是一个war包;项目部署在SpringBoot中,是一个jar包。 (1)war包 catalina文件在Linux系统下的tomcat是以sh结尾,在windows系…...

安全复健|windows常见取证工具
写在前面: 此博客仅用于记录个人学习内容,学识浅薄,若有错误观点欢迎评论区指出。欢迎各位前来交流。(部分材料来源网络,若有侵权,立即删除) 取证 01系统运行数据 使用工具:Live-F…...
FPGA开发流程初识
FPGA 的开发流程可知,在 FPGA 开发的过程中会产生很多不同功能的文件,为了方便随时查找到对应文件,所以在开始开发设计之前,我们第一个需要考虑的问题是工程内部各种文件的管理。如 果不进行文件分类,而是将所有文件…...

Docker 中将文件映射到 Linux 宿主机
在 Docker 中,有多种方式可以将文件映射到 Linux 宿主机,以下是常见的几种方法: 使用-v参数• 基本语法:docker run -v [宿主机文件路径]:[容器内文件路径] 容器名称• 示例:docker run -it -v /home/user/myfile.txt:…...
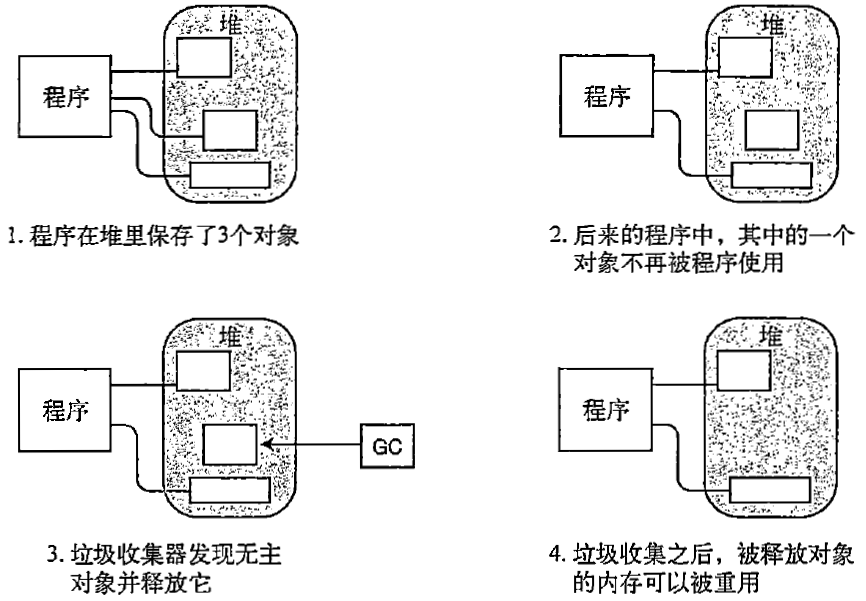
C# 类型、存储和变量(栈和堆)
本章内容 C#程序是一组类型声明 类型是一种模板 实例化类型 数据成员和函数成员 预定义类型 用户定义类型 栈和堆 值类型和引用类型 变量 静态类型和dynamic关键字 可空类型 栈和堆 程序运行时,它的数据必须存储在内存中。一个数据项需要多大的内存、存储在什么地方…...
基于深度学习Yolo8的驾驶员疲劳与分心行为检测系统
基于深度学习Yolo8的驾驶员疲劳与分心行为检测系统 【包含内容】 【一】项目提供完整源代码及详细注释 【二】系统设计思路与实现说明 【三】疲劳检测模型与行为分析统计 【技术栈】 ①:系统环境:Windows/Mac/Linux ②:开发环境:P…...

AOSP Android14 Launcher3——远程窗口动画关键类SurfaceControl详解
在 Launcher3 执行涉及其他应用窗口(即“远程窗口”)的动画时,例如“点击桌面图标启动应用”或“从应用上滑回到桌面”的过渡动画,SurfaceControl 扮演着至关重要的角色。它是实现这些跨进程、高性能、精确定制动画的核心技术。 …...

Linux系统学习----概述与目录结构
linux 是一个开源、免费的操作系统,其稳定性、安全性、处理多并发已经得到业界的认可,目前很多企业级的项目 (c/c/php/python/java/go)都会部署到 Linux/unix 系统上。 一、虚拟机系统操作 1.网络连接的三种方式(桥接模式、nat模式、主机模…...

python pdf转图片再OCR
先pdf转图片 import os from pdf2image import convert_from_path# PDF文件路径 pdf_path /Users/xxx/2022.pdf # 输出图片的文件夹 output_folder ./output_images2022 # 输出图片的命名格式 output_name page# 如果输出文件夹不存在,创建它 if not os.path.ex…...
Docker 常用命令)
(2)Docker 常用命令
文章目录 Docker 服务器Docker 镜像Docker 容器本地 RegistryRUN vs CMD vs ENTRYPOINTRUNCMDENTRYPOINT 限制容器对内存、CPU 和 IO 资源的使用内存CPUBlock IO设置权重bps 和 iops cgroup 和 namespacecgroupnamespacMount namespaceUTS namespaceIPC namespacePID namespace…...
虚拟列表技术深度解析:原理、实现与性能优化实战
虚拟列表技术深度解析:原理、实现与性能优化实战 引言 在当今数据驱动的互联网应用中,长列表渲染已成为前端开发的核心挑战。传统的一次性全量渲染方式在数据量超过千条时,往往导致页面卡顿、内存飙升等问题。虚拟列表(Virtual L…...
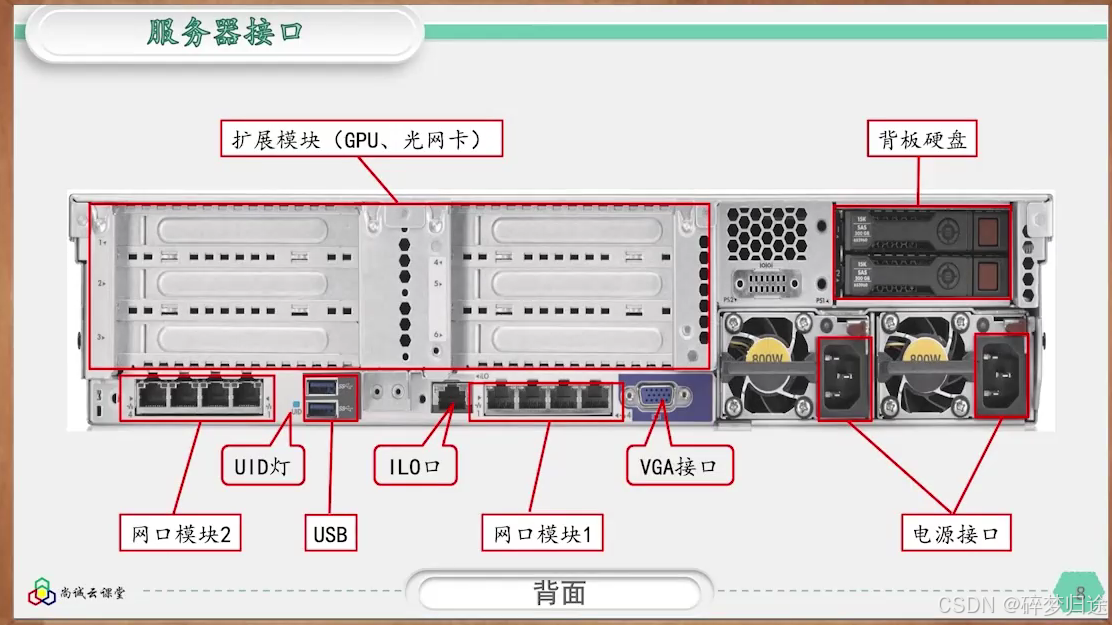
服务器简介(含硬件外观接口介绍)
服务器(Server)是指提供资源、服务、数据或应用程序的计算机系统或设备。它通常比普通的个人计算机更强大、更可靠,能够长时间无间断运行,支持多个用户或客户端的请求。简单来说,服务器就是专门用来存储、管理和提供数…...
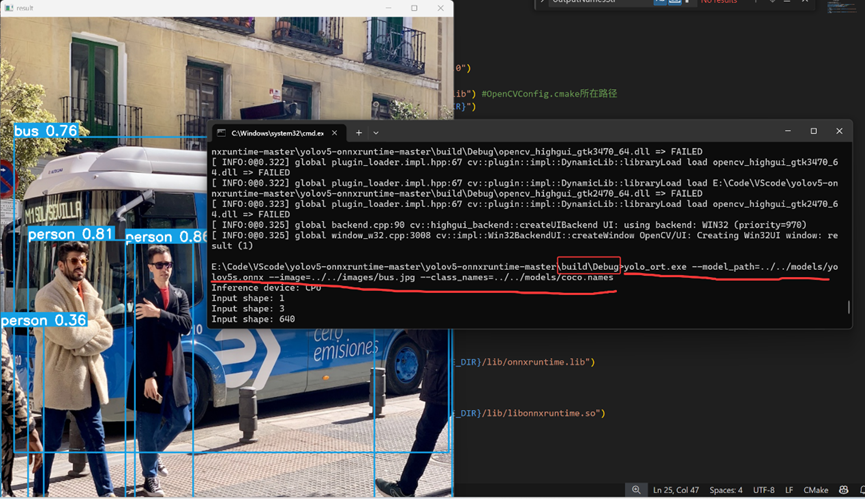
c++下的onnx推理
参考代码:https://github.com/itsnine/yolov5-onnxruntime 参考链接:https://blog.csdn.net/magic_ll/article/details/125517798 1.下载onnx 官网:https://github.com/microsoft/onnxruntime/releases/tag/v1.21.0 2.下载代码 https://g…...
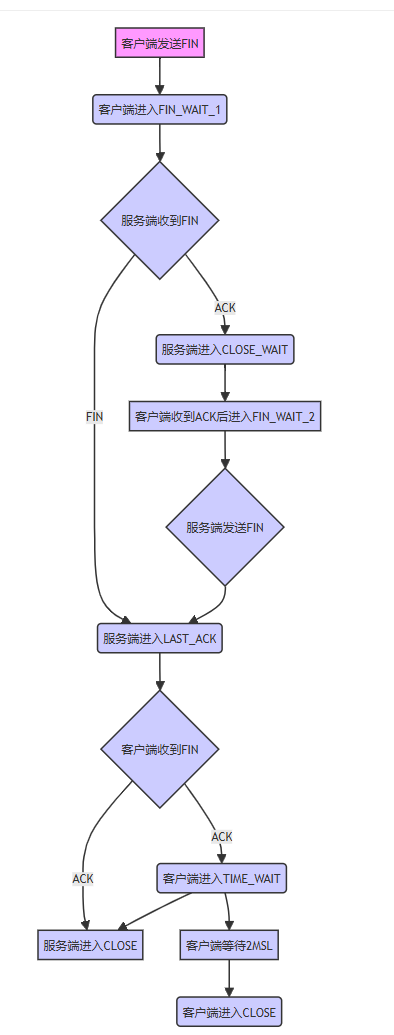
TCP三次握手与四次挥手面试回答版本
面试官:说一下TCP三次握手的过程 参考面试回答: 在第一次握手的时候、客户端会随机生成初始化序号、放到TCP报文头部的序号字段中、同时把SYN标志设置为1 这样就表示SYN报文(这里是请求报文)。客户端将报文放入 TCP 报文首部的序…...

Vue3 使用PrimeVue的面包屑组件Breadcrumb,使用JS滚动进行
做了一个自动添加的面包写导航栏,需要在添加之后自动滚动到最右边,发现常规的滚动方法不行,以下是源码,直接调用ScrollToRight方法就行,最主要的就是在value后面加一个$el: <Breadcrumb :home"hom…...

0101基础知识-区块链-web3
文章目录 1 web3学习路线2 区块链简史2.1 区块链2.2 公共账本2.3 区块链的设计哲学2.3.1 去中心化2.3.2 共识2.3.2.1 上链2.3.2.2 共识算法 3 web3面向资产的互联网3.1 安全性和去中心化的权衡 4 智能合约4.1 以太坊智能合约4.2 去中心化应用 5 小结结语 1 web3学习路线 参考下…...

工作纪实_63-Mac电脑使用brew安装软件
最近在接触kafka,想着在自己的电脑安装一套环境,docker也能行,但是还是想装一些原生的软件试试看,因此便想着整理一下brew的命令,这命令确实是方便,不需要下载tar包乱八七糟的东西,一键安装 bre…...

Cadence学习笔记之---库元件制作、元件放置
目录 01 | 引 言 02 | 环境描述 03 | 工具介绍 04 | 无源器件的制作 05 | IC芯片制作 06 | 放置元件 07 | 结 语 01 | 引 言 在上一篇小记中,讲述使用Cadence创建原理图工程和元件库; 本篇小记主要讲述如何制作常用的库元件,如电阻、…...

服务器如何修复SSL证书错误?
修复服务器上的SSL证书错误需要根据具体错误类型逐步排查和解决。以下是常见的步骤和解决方案: --- ### **1. 确认错误类型** 首先检查浏览器或工具(如OpenSSL)报错的具体信息,常见错误包括: - **证书过期**…...
图解Mysql原理:深入理解事务的特性以及它的实现机制
前言 大家好,我是程序蛇玩编程。 Mysql中事务大家不陌生吧,事务就是要保证一组数据库操作,要么全部成功,要么全部失败。那它具有哪些特性,如何实现的呢?接着往下看。 正文 事务的特性: 事务的基本特性主要为四种…...
》)
《前端面试题之 Vue 篇(第四集)》
目录 1、Vue 中实现强制刷新2、Vue3 和 Vue2 的区别解析3、 Vue3 性能优于 Vue2 的原因解析4、Vue3 使用 Proxy5、首屏优化6、组件的理解7、vue项目中合理规划文件目录8、Nuxt.js 简单了解9、单页应用10、 SEO 优化 1、Vue 中实现强制刷新 在 Vue 中实现强制刷新的分析如下&am…...
在大规模系统中的实践难点)
C++ 模块化编程(Modules)在大规模系统中的实践难点
随着项目规模的不断扩大和代码复杂性的提升,传统的 C++ 开发模式逐渐暴露出一些根深蒂固的问题,尤其是头文件和预处理器机制所带来的编译效率低下、依赖管理混乱以及代码复用性差等痛点。C++20 标准引入的模块化编程(Modules)特性,正是为了解决这些问题而设计的一项革命性…...

DasViewer主要功能流程介绍
摘要:本文主要介绍DasViewer软件本地数据、云端数据以及在线3DTiles服务模型浏览功能。 本地数据浏览功能 打开 DasViewer 浏览器;打开本地数据,包括如下几种方式: 选择工程文件(.dav、.dvp)、模型文件(…...

提交bug单时,应该说明哪些信息?
在提交 Bug 单时,为了让开发人员能够快速定位和解决问题,需要详细说明以下几方面信息: Bug 的基本信息 标题:简洁明了地概括 Bug 的主要问题,例如 “登录页面输入错误密码后提示信息不准确”。Bug 类型:明确…...

Linux[指令与权限]
Linux指令与权限 Linux环境中,打包文件有多种 tar (打包/解包) 指令 tar -czvf 文件要打包到的位置 文件(打包并压缩到) tar -xzvf 文件(在当前目录下解压) tar选项 -c创建压缩文件 -z使用gzip属性压缩 -v展现压缩过程 -f后面使用新建文档名 -x不要新建,解压 -C 文件…...

MySQL 的锁,表级锁是哪一层的锁?行锁是哪一层的锁?
MySQL 的锁层级与类型 在 MySQL 中,锁的层级和实现与存储引擎密切相关。 1. 表级锁(Table-Level Locks) (1)存储引擎层的表级锁 实现层级:存储引擎层(如 MyISAM、InnoDB)。特点&a…...

Flink介绍——实时计算核心论文之Dataflow论文总结
数据流处理的演变与 Dataflow 模型的革新 在大数据处理领域,流式数据处理系统的发展历程充满了创新与变革。从早期的 S4 到 Storm,再到 MillWheel,每一个系统都以其独特的方式推动了技术的进步。S4 以其无中心架构和 PE(Processi…...