空闲列表:回收和再利用
空闲列表:回收和再利用
手动与自动内存管理
- 手动管理:程序员需要明确地分配和释放内存。
- 自动管理:例如使用垃圾收集器(GC),它能够自动检测并回收未使用的对象,不需要程序员干预。
对于某些数据结构如B树,通过实现删除回调函数可以手动管理未使用的节点,从而可能避免使用GC。
未使用对象列表
为了有效地重复利用被释放的空间(如磁盘上的页面),通常会维护一个未使用空间的列表,称为自由列表(free list)或对象池(object pool)。这种机制简化了内存管理,因为它处理的是相同大小的块,而不是像malloc那样需要处理任意大小的请求。
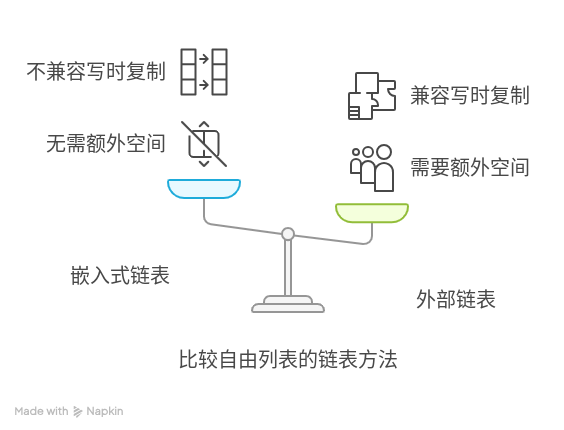
嵌入式链表
一种简单的策略是使用嵌入式(侵入式)链表,其中指向下一个对象的指针直接存放在对象内部。这种方式的优点是不需要额外的空间来存储链表结构,但是它不兼容写时复制机制,因为更新时可能会覆盖原数据。
外部链表
另一种方法是将未使用页面的指针存储在一个外部的数据结构中。虽然这种方法需要额外的空间来维持这个数据结构本身,但它避免了嵌入式链表的一些问题。
自由列表作为日志
当自由列表只是未使用页面编号的日志时,添加新项仅需追加到列表末尾。然而,如何有效移除条目以防止列表无限增长是一个挑战。
解决这个问题的一种方法可能是周期性地整理自由列表,合并连续的空闲段,或者采用更复杂的数据结构如平衡树来高效管理这些信息。这有助于确保即使频繁地分配和释放页面,系统的性能也不会受到显著影响。
在磁盘上实现链表(如自由列表)需要仔细设计,以确保其高效性、可靠性和与写时复制(copy-on-write, COW)机制的兼容性。以下是对该问题的详细分析和解决方案。
自由列表的设计要求
自由列表是一个存储未使用页面编号的日志式数据结构。由于在写时复制树中,每次更新都会生成新节点并删除旧节点,因此自由列表需要同时支持添加和移除操作:
- 从末尾移除:如果从末尾移除条目,新增加的条目会覆盖旧数据。这需要额外的崩溃恢复机制(如第3章讨论的内容)。
- 从开头移除:如果从开头移除条目,则面临如何回收这些被移除条目占用的空间的问题。
为了解决这些问题,自由列表应基于页面进行管理,这样它就可以自我维护。这种基于页面的链表本质上是一个“展开的链表”(unrolled linked list),其中每个页面可以存储多个条目。
自由列表的核心特性
-
独立的数据结构:
- 自由列表是一个基于页面的链表。
- 当需要扩展新节点时,它会尝试从自身获取一个空闲页面。
- 被移除的节点会被重新添加到自由列表中以供重用。
-
每个页面的多条目存储:
- 每个页面包含多个条目(例如页面编号)。
- 页面是原地更新的,但在页面内部仍然是追加写入(append-only)。
-
条目的追加与消费:
- 条目被追加到尾节点(tail node)。
- 条目从头节点(head node)消费。
- 这种设计使得尾节点更容易保持追加写入的特性。
自由列表的磁盘布局
每个节点的格式如下:
| next | pointers | unused |
| 8B | n*8B | ... |
next是指向下一个节点的指针,占 8 字节。pointers是存储页面编号的数组,每个编号占 8 字节。unused是未使用的空间。
定义如下常量和方法:
type LNode []byteconst FREE_LIST_HEADER = 8 // "next" 指针大小
const FREE_LIST_CAP = (BTREE_PAGE_SIZE - FREE_LIST_HEADER) / 8 // 每页能存储的条目数// 获取和设置方法
func (node LNode) getNext() uint64 { /* 返回 next 指针 */ }
func (node LNode) setNext(next uint64) { /* 设置 next 指针 */ }
func (node LNode) getPtr(idx int) uint64 { /* 获取第 idx 个条目 */ }
func (node LNode) setPtr(idx int, ptr uint64) { /* 设置第 idx 个条目 */ }
元页面(meta page)中存储了指向头节点和尾节点的指针。尾节点指针的存在是为了实现 O(1) 的插入操作。
磁盘布局示例:
first_item↓
head_page -> [ next | xxxxx ]↓[ next | xxxxxxxx ]↓
tail_page -> [ NULL | xxxxxx ]↑last_item
自由列表节点的更新
在没有自由列表的情况下,元页面是唯一需要原地更新的页面。这是写时复制机制使得崩溃恢复变得简单的原因之一。
引入自由列表后,会有两种额外的原地更新操作:
- 更新链表节点的
next指针。 - 在链表节点中追加条目。
尽管链表节点是原地更新的,但在页面内部不会覆盖已有数据。因此,即使更新中断,元页面仍然指向相同的数据,不需要额外的崩溃恢复机制。此外,与元页面不同,链表节点的原子性不是必需的。
嵌入式链表的可行性
嵌入式链表也可以工作,但前提是 B+ 树节点中需要预留 next 指针的空间。这种方法虽然可行,但会导致写放大效应加倍(write amplification doubles)。具体来说:
- 写放大效应是指为了完成一次逻辑写操作而实际写入的物理数据量。
- 如果在 B+ 树节点中嵌入
next指针,则每次更新不仅需要更新节点本身,还需要更新链表结构,从而增加了写入量。
总结
通过将自由列表设计为基于页面的链表,我们实现了以下目标:
- 高效的内存管理:自由列表能够自我维护,并且支持快速分配和释放页面。
- 与写时复制的兼容性:通过追加写入的方式避免覆盖数据,减少了崩溃恢复的复杂性。
- 灵活性:可以选择外部链表或嵌入式链表,根据性能和存储需求进行权衡。
这种设计为数据库系统中的磁盘空间管理提供了一种优雅的解决方案。
在这一节中,我们详细讨论了自由列表(Free List)的实现方法。自由列表是一种用于管理未使用页面的数据结构,它通过链表的形式组织页面编号,并支持高效的分配和回收操作。以下是对自由列表实现的逐步分析和总结。
自由列表接口设计
核心数据结构
自由列表是 KV 数据库中的一个额外组件:
type KV struct {Path string// 内部字段fd inttree BTreefree FreeList // 自由列表// ...
}
FreeList 是自由列表的核心结构,包含以下内容:
- 回调函数:用于管理磁盘上的页面。
get:读取页面。new:追加新页面。set:更新现有页面。
- 持久化数据:存储在元页面中。
headPage和tailPage:分别指向链表头节点和尾节点。headSeq和tailSeq:单调递增的序列号,用于索引头节点和尾节点中的条目。
- 内存状态:
maxSeq:保存上一次的tailSeq,以防止消费刚刚添加的条目。
type FreeList struct {// 回调函数get func(uint64) []byte // 读取页面new func([]byte) uint64 // 追加新页面set func(uint64) []byte // 更新现有页面// 持久化数据headPage uint64 // 头节点指针headSeq uint64 // 头节点序列号tailPage uint64 // 尾节点指针tailSeq uint64 // 尾节点序列号// 内存状态maxSeq uint64 // 上一次的 tailSeq
}
接口方法
PopHead():从链表头部移除一个条目。PushTail(ptr uint64):向链表尾部添加一个条目。SetMaxSeq():将maxSeq更新为当前的tailSeq,以允许消费新添加的条目。
自由列表的操作
1. 从头部消费
从自由列表中移除条目时,只需递增 headSeq。如果当前头节点为空,则移动到下一个节点,并将空节点回收到自由列表中。
func (fl *FreeList) PopHead() uint64 {ptr, head := flPop(fl)if head != 0 { // 回收空的头节点fl.PushTail(head)}return ptr
}func flPop(fl *FreeList) (ptr uint64, head uint64) {if fl.headSeq == fl.maxSeq {return 0, 0 // 无法继续消费}node := LNode(fl.get(fl.headPage))ptr = node.getPtr(seq2idx(fl.headSeq)) // 获取条目fl.headSeq++// 如果当前头节点已空,移动到下一个节点if seq2idx(fl.headSeq) == 0 {head, fl.headPage = fl.headPage, node.getNext()assert(fl.headPage != 0) // 确保链表至少有一个节点}return
}
2. 向尾部追加
向自由列表尾部添加条目时,递增 tailSeq。如果当前尾节点已满,则创建一个新的尾节点,并确保链表始终至少有一个节点。
func (fl *FreeList) PushTail(ptr uint64) {// 将条目添加到尾节点LNode(fl.set(fl.tailPage)).setPtr(seq2idx(fl.tailSeq), ptr)fl.tailSeq++// 如果尾节点已满,添加新的尾节点if seq2idx(fl.tailSeq) == 0 {next, head := flPop(fl) // 尝试从头节点回收空节点if next == 0 {// 如果没有可回收的节点,则分配新节点next = fl.new(make([]byte, BTREE_PAGE_SIZE))}// 链接到新尾节点LNode(fl.set(fl.tailPage)).setNext(next)fl.tailPage = next// 如果头节点被移除,则将其添加到新尾节点if head != 0 {LNode(fl.set(fl.tailPage)).setPtr(0, head)fl.tailSeq++}}
}
关键点分析
1. 序列号的设计
headSeq和tailSeq是单调递增的序列号,用于唯一标识链表中的位置。- 通过
seq2idx(seq)将序列号映射到节点内的索引,避免直接操作环形缓冲区的复杂性。
func seq2idx(seq uint64) int {return int(seq % FREE_LIST_CAP)
}
2. 自我管理
自由列表是自我管理的:
- 被移除的头节点会被重新添加到尾部。
- 在需要新节点时,优先尝试从头节点回收空节点,而不是直接分配新节点。
3. 崩溃恢复
由于自由列表的更新是基于追加写入的,即使中断也不会覆盖已有数据。因此,崩溃恢复机制与写时复制树一致,无需额外处理。
总结
自由列表的实现通过以下几个关键特性,确保了其高效性和可靠性:
- 基于页面的链表:每个页面可以存储多个条目,减少了节点数量,提高了空间利用率。
- 自我管理能力:被移除的节点会自动回收,避免了外部干预。
- 崩溃安全性:通过追加写入的方式,保证了崩溃后的一致性。
- 灵活性:支持动态扩展和收缩,能够适应不同的工作负载。
这种设计使得自由列表成为数据库系统中管理未使用页面的理想选择。
在这一节中,我们详细讨论了如何将自由列表(Free List)集成到键值存储(KV)数据库中,并分析了页面管理的实现细节。通过引入自由列表,数据库能够高效地重用未使用的页面,从而减少磁盘空间的浪费。
1. 页面管理
核心数据结构
为了支持页面的重用和原地更新,KV 数据库新增了一个 page 结构,用于管理页面的状态:
type KV struct {// ...page struct {flushed uint64 // 已刷新的页面数量nappend uint64 // 待追加的页面数量updates map[uint64][]byte // 待处理的页面更新,包括追加的页面}
}
updates:一个映射表,用于捕获待处理的页面更新。当页面被修改时,其新内容会先存储在这里,而不是直接写入磁盘。flushed和nappend:分别记录已刷新的页面数量和待追加的页面数量。
2. 页面分配与更新
2.1 分配新页面
BTree.new 方法现在由 KV.pageAlloc 替代。在分配页面时,优先从自由列表中获取空闲页面,只有在自由列表为空时才追加新页面。
func (db *KV) pageAlloc(node []byte) uint64 {if ptr := db.free.PopHead(); ptr != 0 { // 尝试从自由列表获取页面db.page.updates[ptr] = nodereturn ptr}return db.pageAppend(node) // 追加新页面
}
2.2 更新现有页面
KV.pageWrite 方法返回一个可写的页面副本,用于捕获原地更新。如果页面已经有待处理的更新,则直接返回该副本;否则从磁盘读取页面内容并创建一个新副本。
func (db *KV) pageWrite(ptr uint64) []byte {if node, ok := db.page.updates[ptr]; ok {return node // 返回待处理的更新}node := make([]byte, BTREE_PAGE_SIZE)copy(node, db.pageReadFile(ptr)) // 从磁盘初始化db.page.updates[ptr] = nodereturn node
}
2.3 读取页面
由于页面可能已经被更新,KV.pageRead 方法需要优先检查 updates 映射表。如果页面有未提交的更新,则直接返回更新后的内容;否则从磁盘读取。
func (db *KV) pageRead(ptr uint64) []byte {if node, ok := db.page.updates[ptr]; ok {return node // 返回待处理的更新}return db.pageReadFile(ptr) // 从磁盘读取
}
3. 元页面更新
元页面(meta page)是数据库的核心元数据,包含了树根指针、自由列表指针等信息。引入自由列表后,元页面的格式如下:
| sig | root_ptr | page_used | head_page | head_seq | tail_page | tail_seq |
| 16B | 8B | 8B | 8B | 8B | 8B | 8B |
head_page和tail_page:分别指向自由列表的头节点和尾节点。head_seq和tail_seq:用于索引自由列表中的条目。page_used:记录当前数据库中已使用的页面数量。
3.1 初始化空数据库
在初始化一个空数据库时,需要为元页面和自由列表预留至少两个页面:
- 第一页是元页面。
- 第二页是自由列表的初始节点。
func readRoot(db *KV, fileSize int64) error {if fileSize == 0 { // 空文件// 预留两个页面:元页面和自由列表节点db.page.flushed = 2// 添加一个初始节点到自由列表,确保它永远不会为空db.free.headPage = 1 // 第二个页面db.free.tailPage = 1return nil // 元页面将在第一次更新时写入}// ...
}
3.2 准备下一次更新
在每次更新之间,调用 SetMaxSeq() 方法以允许重用上一版本的页面。
func updateFile(db *KV) error {// ...// 为下一次更新准备自由列表db.free.SetMaxSeq()return nil
}
4. 关键点分析
4.1 自由列表的作用
- 自由列表使得未使用的页面可以被重用,减少了磁盘空间的浪费。
- 在分配新页面时,优先从自由列表中获取空闲页面,只有在自由列表为空时才追加新页面。
4.2 原地更新的安全性
- 页面更新被捕获在
updates映射表中,直到提交时才会写入磁盘。 - 由于页面更新是基于追加写入的,即使中断也不会覆盖已有数据,因此崩溃恢复机制仍然有效。
4.3 元页面的一致性
- 元页面包含自由列表的指针和序列号,这些信息与树根指针一起原子性地更新,确保了一致性。
5. 并发支持的展望
目前的实现假设页面访问是顺序的。在后续引入并发支持时,headSeq 的推进将受到最老的读取操作的限制,而不是简单的 maxSeq。
总结
通过引入自由列表,KV 数据库实现了以下目标:
- 高效的页面重用:通过自由列表管理未使用的页面,减少了磁盘空间的浪费。
- 安全的原地更新:通过
updates映射表捕获页面更新,确保了崩溃恢复的安全性。 - 一致的元数据管理:元页面包含自由列表的指针和序列号,与树根指针一起原子性地更新。
这种设计为数据库系统提供了一种高效且可靠的页面管理机制,同时为后续引入并发支持奠定了基础。
相关文章:
空闲列表:回收和再利用
空闲列表:回收和再利用 手动与自动内存管理 手动管理:程序员需要明确地分配和释放内存。自动管理:例如使用垃圾收集器(GC),它能够自动检测并回收未使用的对象,不需要程序员干预。 对于某些数据结构如B树,…...

504 nginx解决方案
当遇到 504 Gateway Time-out 错误时,通常是因为 Nginx 作为反向代理等待后端服务(如 PHP-FPM、Java 应用等)响应的时间超过了预设的超时阈值。以下是详细的解决方案,结合知识库中的信息整理而成: 一、核心原因分析 后…...

【消息队列RocketMQ】五、RocketMQ 实战应用与生态拓展
本篇文章主要将结合前面几篇文章的基础讲解,来演示RocketMQ的实际场景中的应用。 一、RocketMQ 实战应用场景 1.1 电商系统中的应用 在电商系统中,RocketMQ 承担着重要角色。以双十一大促活动为例,短时间内会产生海量的订单请求、库存…...
)
volatile怎么保证可见性和有序性?(个人理解)
volatile怎么保证可见性和有序性? volatile变量会在字段修饰符中显示ACC_VOLATILE。通过插入内存屏障指令,禁止指令重排序。不管前面与后面任何指令,都不能与内存屏障指令进行重排,保证前后的指令按顺序执行 。同时保证数据修改的…...
计算机组成与体系结构:直接内存映射(Direct Memory Mapping)
目录 CPU地址怎么找到真实的数据? 内存映射的基本单位和结构 1. Pages(页)——虚拟地址空间的基本单位 2. Frames(页框)——物理内存空间的基本单位 3. Blocks(块)——主存和缓存之间的数据…...

RAGFlow:构建高效检索增强生成流程的技术解析
引言 在当今信息爆炸的时代,如何从海量数据中快速准确地获取所需信息并生成高质量内容已成为人工智能领域的重要挑战。检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生,它将信息检索与大型语言模型(L…...
STM32提高篇: 蓝牙通讯
STM32提高篇: 蓝牙通讯 一.蓝牙通讯介绍1.蓝牙技术类型 二.蓝牙协议栈1.蓝牙芯片架构2.BLE低功耗蓝牙协议栈框架 三.ESP32-C3中的蓝牙功能1.广播2.扫描3.通讯 四.发送和接收 一.蓝牙通讯介绍 蓝牙,是一种利用低功率无线电,支持设备短距离通信的无线电技…...

SpringMVC处理请求映射路径和接收参数
目录 springmvc处理请求映射路径 案例:访问 OrderController类的pirntUser方法报错:java.lang.IllegalStateException:映射不明确 核心错误信息 springmvc接收参数 一 ,常见的字符串和数字类型的参数接收方式 1.1 请求路径的…...

高质量学术引言如何妙用ChatGPT?如何写提示词
目录 1、引言究竟是什么? 2、引言如何构建?? 在学术写作领域,巧妙利用人工智能来构建文章的引言和理论框架是一个尚待探索的领域。小编在这篇文章中探讨一种独特的方法,即利用 ChatGPT 作为工具来构建引言和理论框架…...

【程序员 NLP 入门】词嵌入 - 上下文中的窗口大小是什么意思? (★小白必会版★)
🌟 嗨,你好,我是 青松 ! 🌈 希望用我的经验,让“程序猿”的AI学习之路走的更容易些,若我的经验能为你前行的道路增添一丝轻松,我将倍感荣幸!共勉~ 【程序员 NLP 入门】词…...

从物理到预测:数据驱动的深度学习的结构化探索及AI推理
在当今科学探索的时代,理解的前沿不再仅仅存在于我们书写的方程式中,也存在于我们收集的数据和构建的模型中。在物理学和机器学习的交汇处,一个快速发展的领域正在兴起,它不仅观察宇宙,更是在学习宇宙。 AI推理 我们…...

各种各样的bug合集
一、连不上数据库db 1.可能是密码一大包东西不对; 2.可能是里面某个port和数据库不一样(针对于修改了数据库但是连不上的情况); 3.可能是git代码没拉对,再拉一下代码。❤ 二、没有这个包 可能是可以#注释掉。❤ …...

大模型AI的“双刃剑“:数据安全与可靠性挑战与破局之道
在数字经济蓬勃发展的浪潮中,数据要素已然成为驱动经济社会创新发展的核心引擎。从智能制造到智慧城市,从电子商务到金融科技,数据要素的深度融合与广泛应用,正以前所未有的力量重塑着产业格局与经济形态。 然而,随着…...

如何使用 CompletableFuture、Function 和 Optional 优雅地处理异步编程?
当异步遇上函数式编程,代码变得更优雅 在日常开发中,很多时候我们需要处理异步任务、函数转换和空值检查。传统的回调方式和空值判断常常让代码看起来繁琐而难以维护。幸运的是,Java 提供了 CompletableFuture、Function 和 Optional&#x…...

基于大模型的结肠癌全病程预测与诊疗方案研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 二、结肠癌概述 2.1 流行病学特征 2.2 发病机制与危险因素 2.3 临床症状与诊断方法 三、大模型技术原理与应用现状 3.1 大模型的基本原理 3.2 在医疗领域的应用情况 3.3 在结肠癌预测中的潜力分析 四、术前…...
操作系统概述与安装
主流操作系统概述 信创平台概述 虚拟机软件介绍与安装 windows server 安装 centos7 安装 银河麒麟V10 安装 一:主流服务器操作系统 (1)Windows Server 发展历程: 1993年推出第一代 WindowsNT(企业级内核&am…...
)
算法设计与分析(基础)
问题列表 一、 算法的定义与特征,算法设计的基本步骤二、 算法分析的目的是什么?如何评价算法,如何度量算法的复杂性?三、 递归算法、分治法、贪婪法、动态规划法、回溯法的基本思想方法。四、 同一个问题,如TSP&#…...
)
多线程(线程安全)
一、线程安全的风险来源 1.1 后厨的「订单撞单」现象 场景:两服务员同时录入客人点单到同一个菜单本 问题: 订单可能被覆盖菜品数量统计错误 Java中的表现: public class OrderServlet extends HttpServlet {private int totalOrders 0…...
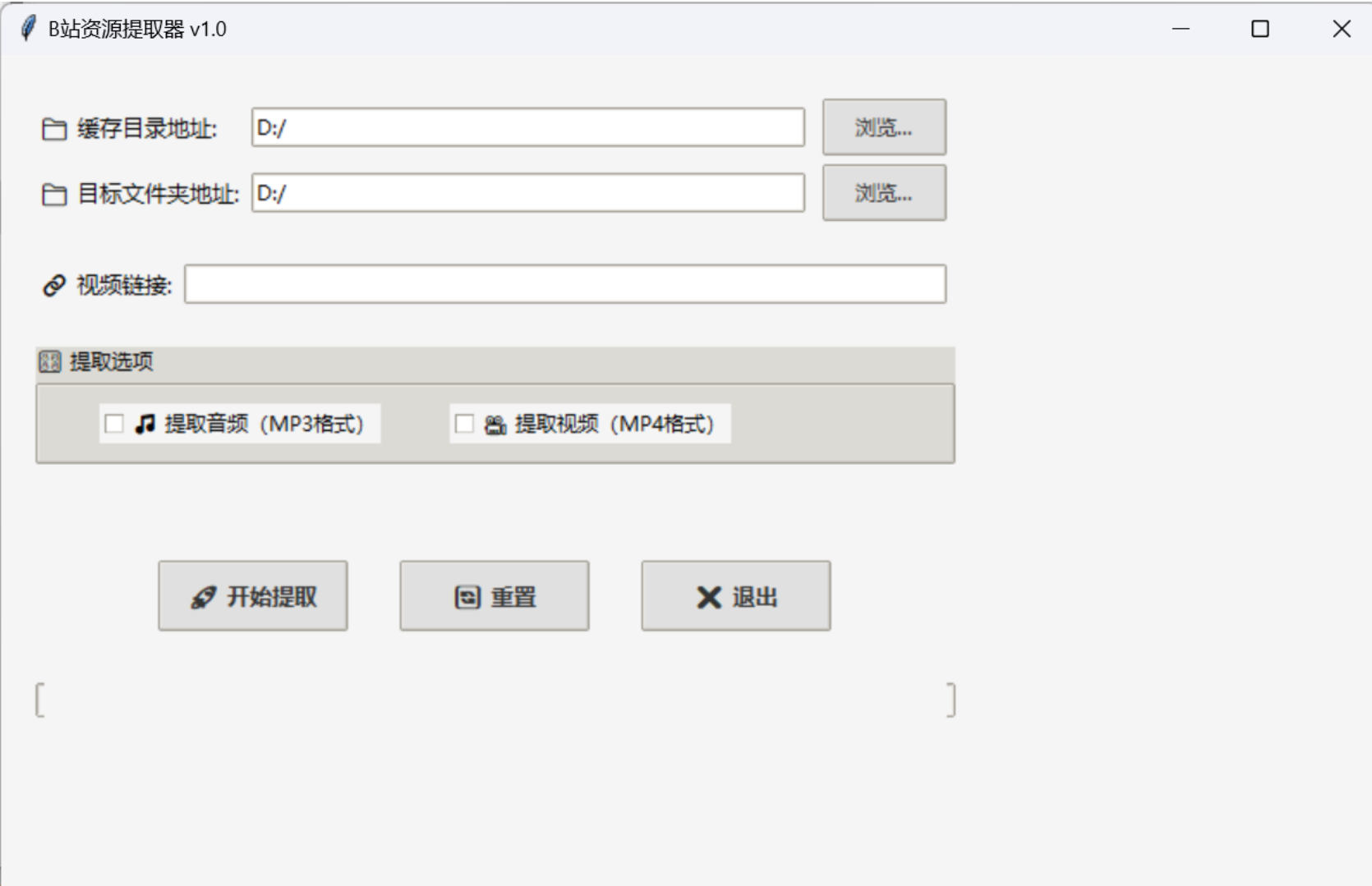
开发了一个b站视频音频提取器
B站资源提取器-说明书 一、功能说明 本程序可自动解密并提取B站客户端缓存的视频资源,支持以下功能: - 自动识别视频缓存目录 - 将加密的.m4s音频文件转换为标准MP3格式 - 将加密的.m4s视频文件转换为标准MP4格式(合并音视频流)…...
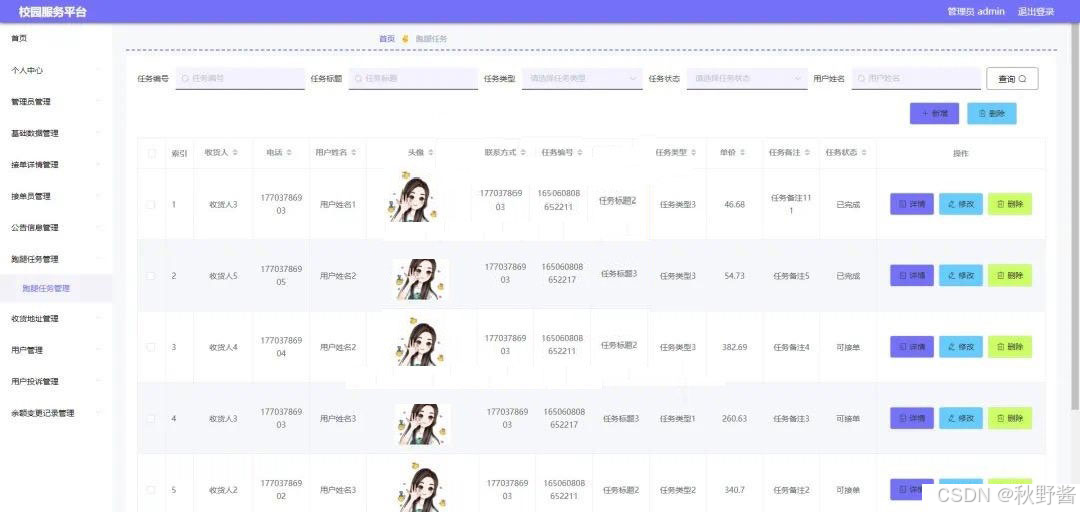
基于javaweb的SpringBoot校园服务平台系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

北京SMT贴片加工工艺优化要点
内容概要 在北京地区SMT贴片加工领域,工艺优化是实现高可靠电子组装的系统性工程。本文以精密化生产需求为导向,围绕制程关键节点展开技术剖析,从钢网印刷的锡膏成型控制到贴装环节的视觉定位精度,逐步构建全流程优化模型。通过分…...
PHYBench:首个大规模物理场景下的复杂推理能力评估基准
2025-04-23, 由北京大学物理学院和人工智能研究所等机构共同创建的 PHYBench 数据集,这是一个专门用于评估大型语言模型在物理场景下的复杂推理能力的高质量基准。该数据集包含 500 道精心策划的物理问题,覆盖力学、电磁学、热力学、光学、现代物理和高级…...

将输入帧上下文打包到下一个帧的预测模型中用于视频生成
Paper Title: Packing Input Frame Context in Next-Frame Prediction Models for Video Generation 论文发布于2025年4月17日 Abstract部分 在这篇论文中,FramePack是一种新提出的网络结构,旨在解决视频生成中的两个主要问题:遗忘和漂移。 具体来说,遗忘指的是在生成视…...

使用localStorage的方式存储数据,刷新之后,无用户消息,需要重新登录,,localStorage 与 sessionStorage 的区别
1 localStorage 与 sessionStorage 的区别: 特性localStoragesessionStorage存储时长永久存储,除非手动删除或者清空浏览器缓存会话存储,浏览器关闭后数据丢失数据生命周期持久存在,直到被明确删除(即使关闭浏览器也不会消失)当前会话结束后数据自动清空(关闭标签页或浏…...

第15章:MCP服务端项目开发实战:性能优化
第15章:MCP服务端项目开发实战:性能优化 在构建和部署 MCP(Memory, Context, Planning)驱动的 AI Agent 系统时,性能和可扩展性是关键的考量因素。随着用户量、数据量和交互复杂度的增加,系统需要能够高效地处理请求,并能够平滑地扩展以应对更高的负载。本章将探讨 MCP…...
MOA Transformer:一种基于多尺度自注意力机制的图像分类网络
MOA Transformer:一种基于多尺度自注意力机制的图像分类网络 引言 近年来,Transformer 架构在自然语言处理领域取得了巨大的成功,并逐渐扩展到计算机视觉领域。Swin Transformer 就是其中一个典型的成功案例。它通过引入“无卷积”架构&…...

Red:1靶场环境部署及其渗透测试笔记(Vulnhub )
环境介绍: 靶机下载: https://download.vulnhub.com/red/Red.ova 本次实验的环境需要用到VirtualBox(桥接网卡),VMware(桥接网卡)两台虚拟机(网段都在192.168.152.0/24࿰…...

从 Java 到 Kotlin:在现有项目中迁移的最佳实践!
全文目录: 开篇语 1. 为什么选择 Kotlin?1.1 Kotlin 与 Java 的兼容性1.2 Kotlin 的优势1.3 Kotlin 的挑战 2. Kotlin 迁移最佳实践2.1 渐进式迁移2.1.1 步骤一:将 Kotlin 集成到现有的构建工具中2.1.2 步骤二:逐步迁移2.1.3 步骤…...

Java Collections工具类指南
一、Collections工具类概述 java.util.Collections是Java集合框架中提供的工具类,包含大量静态方法用于操作和返回集合。这些方法主要分为以下几类: 排序操作查找和替换同步控制不可变集合特殊集合视图其他实用方法 二、排序操作 1. 自然排序 List&…...

深入详解人工智能数学基础——概率论中的KL散度在变分自编码器中的应用
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C++, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C++、C#等开发语言,熟悉Java常用开发技术,能熟练应用常用数据库SQL server,Oracle,mysql,postgresql等进行开发应用…...