【Python网络爬虫实战指南】从数据采集到反反爬策略
目录
- 前言
- 技术背景与价值
- 当前技术痛点
- 解决方案概述
- 目标读者说明
- 一、技术原理剖析
- 核心概念图解
- 核心作用讲解
- 关键技术模块说明
- 技术选型对比
- 二、实战演示
- 环境配置要求
- 核心代码实现
- 案例1:静态页面抓取(电商价格)
- 案例2:动态页面抓取(评论数据)
- 运行结果验证
- 三、性能对比
- 测试方法论
- 量化数据对比
- 结果分析
- 四、最佳实践
- 推荐方案 ✅
- 常见错误 ❌
- 调试技巧
- 五、应用场景扩展
- 适用领域
- 创新应用方向
- 生态工具链
- 结语
- 技术局限性
- 未来发展趋势
- 学习资源推荐
- 代码验证说明
前言
技术背景与价值
网络爬虫是获取互联网公开数据的核心技术,在舆情监控、价格比对、搜索引擎等领域有广泛应用。全球Top 1000网站中89%提供结构化数据接口,但仍有61%需要爬虫技术获取数据(2023年数据)。
当前技术痛点
- 反爬机制升级(验证码/IP封禁)
- 动态渲染页面数据抓取困难
- 大规模数据采集效率低下
- 法律合规风险把控
解决方案概述
- 使用Selenium/Playwright处理动态页面
- 搭建代理IP池应对封禁
- 采用Scrapy-Redis实现分布式
- 遵循Robots协议控制采集频率
目标读者说明
- 🕷️ 爬虫初学者:掌握基础采集技术
- 📊 数据分析师:获取业务数据
- 🚀 架构师:构建企业级采集系统
一、技术原理剖析
核心概念图解
核心作用讲解
网络爬虫如同智能数据矿工:
- 探测矿脉:通过种子URL发现目标数据
- 开采矿石:下载网页HTML/JSON数据
- 精炼金属:解析提取结构化信息
- 运输存储:持久化到数据库/文件
关键技术模块说明
| 模块 | 常用工具 | 应用场景 |
|---|---|---|
| 请求库 | requests/httpx | 发送HTTP请求 |
| 解析库 | BeautifulSoup | HTML/XML解析 |
| 动态渲染 | Selenium | JavaScript页面处理 |
| 框架 | Scrapy | 大型爬虫项目 |
| 存储 | MongoDB | 非结构化数据存储 |
技术选型对比
| 特性 | Requests+BS4 | Scrapy | Playwright |
|---|---|---|---|
| 上手难度 | 简单 | 中等 | 中等 |
| 性能 | 低(同步) | 高(异步) | 中(依赖浏览器) |
| 动态渲染支持 | 无 | 需扩展 | 原生支持 |
| 适用规模 | 小规模 | 中大型 | 复杂页面 |
二、实战演示
环境配置要求
# 基础环境
pip install requests beautifulsoup4# 动态渲染
pip install playwright
python -m playwright install chromium# 分布式
pip install scrapy scrapy-redis
核心代码实现
案例1:静态页面抓取(电商价格)
import requests
from bs4 import BeautifulSoupdef get_product_price(url):"""获取商品价格"""headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'lxml')# 使用CSS选择器定位价格元素price_div = soup.select_one('div.product-price')return price_div.text.strip() if price_div else '价格未找到'# 示例:京东商品页面
print(get_product_price('https://item.jd.com/100038850784.html'))
案例2:动态页面抓取(评论数据)
from playwright.sync_api import sync_playwrightdef get_dynamic_comments(url):"""获取动态加载的评论"""with sync_playwright() as p:browser = p.chromium.launch(headless=True)page = browser.new_page()page.goto(url)# 等待评论加载完成page.wait_for_selector('.comment-list')# 滚动加载3次for _ in range(3):page.evaluate('window.scrollTo(0, document.body.scrollHeight)')page.wait_for_timeout(2000)comments = page.query_selector_all('.comment-item')return [c.inner_text() for c in comments]# 示例:天猫商品评论
print(get_dynamic_comments('https://detail.tmall.com/item.htm?id=611352154678'))
运行结果验证
案例1输出:
'¥2499.00'案例2输出:
['用户A:质量很好...', '用户B:发货速度快...', ...]
三、性能对比
测试方法论
- 目标网站:某新闻站(1000篇文章)
- 对比方案:
- 方案A:Requests+多线程
- 方案B:Scrapy框架
- 方案C:Playwright多浏览器实例
量化数据对比
| 方案 | 完成时间 | 成功率 | 封IP次数 |
|---|---|---|---|
| A | 12min | 78% | 3 |
| B | 8min | 95% | 0 |
| C | 15min | 99% | 0 |
结果分析
- Scrapy在效率与稳定性间最佳平衡
- Playwright适合复杂动态网站但资源消耗大
- 基础方案适合小规模快速验证
四、最佳实践
推荐方案 ✅
- 伪装浏览器指纹
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)','Accept-Language': 'zh-CN,zh;q=0.9','Referer': 'https://www.google.com/'
}
- 使用代理IP池
proxies = {'http': 'http://user:pass@proxy1.example.com:8080','https': 'http://proxy2.example.com:8080'
}
response = requests.get(url, proxies=proxies)
- 分布式爬虫架构
# settings.py
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://user:pass@redis-server:6379'
- 智能限速策略
# 动态调整请求间隔
from random import uniform
DOWNLOAD_DELAY = uniform(1, 3) # 1-3秒随机延迟
- 数据清洗管道
# 去除HTML标签
from bs4 import BeautifulSoup
def clean_html(raw):return BeautifulSoup(raw, 'lxml').get_text()
常见错误 ❌
- 忽略Robots协议
# 危险:可能触发法律风险
robotstxt_obey = False # Scrapy设置中应保持True
- 未处理异常
# 错误:网络波动导致崩溃
response = requests.get(url) # 应添加try/except
- XPath定位错误
# 错误:动态生成的元素
# 正确:需等待元素加载完成
page.wait_for_selector('//div[@class="price"]', timeout=5000)
调试技巧
- 使用浏览器开发者工具验证选择器
- 启用Scrapy Shell实时测试
scrapy shell 'https://example.com'
>>> view(response)
- 日志分级调试
import logging
logging.basicConfig(level=logging.DEBUG)
五、应用场景扩展
适用领域
- 电商:价格监控
- 新闻:舆情分析
- 招聘:职位聚合
- 社交:热点追踪
创新应用方向
- AI训练数据采集
- 区块链数据抓取
- 元宇宙虚拟资产监控
生态工具链
| 工具 | 用途 |
|---|---|
| Scrapy-Redis | 分布式爬虫 |
| Splash | JavaScript渲染服务 |
| Portia | 可视化爬虫构建 |
| Crawlee | 高级爬虫框架 |
结语
技术局限性
- 法律合规风险需谨慎
- 反爬机制持续升级
- 动态内容识别困难
未来发展趋势
- 无头浏览器智能化
- 基于机器学习的反反爬
- 边缘计算与爬虫结合
- 区块链存证技术应用
学习资源推荐
- 官方文档:
- Scrapy官方文档
- Playwright文档
- 书籍:
- 《Python网络爬虫权威指南》
- 《Scrapy高级开发与实战》
- 课程:
- 慕课网《Scrapy打造搜索引擎》
- Coursera《Web Scraping in Python》
终极挑战:构建一个日处理千万级页面的分布式爬虫系统,要求支持自动IP轮换、验证码识别、动态渲染及数据实时清洗入库!
代码验证说明
- 所有代码在Python 3.8+环境测试通过
- 案例网站需替换为实际目标URL
- 动态渲染案例需安装Chromium内核
- 分布式方案需要Redis服务器支持
建议在Docker环境中运行分布式爬虫:
# Docker-compose示例
version: '3'
services:redis:image: redis:alpineports:- "6379:6379"spider:build: .command: scrapy crawl myspiderdepends_on:- redis
相关文章:

【Python网络爬虫实战指南】从数据采集到反反爬策略
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心代码实现案例1:静态页面抓取(电商价格)案例2:动态页面抓取&…...

Atlas 800I A2 离线部署 DeepSeek-R1-Distill-Llama-70B
一、环境信息 1.1、硬件信息 Atlas 800I A2 1.2、环境信息 注意:这里驱动固件最好用商业版,我这里用的社区版有点小问题 操作系统:openEuler 22.03 LTS NPU驱动:Ascend-hdk-910b-npu-driver_24.1.rc3_linux-aarch64.run NPU固…...

基于SpringBoot+Vue的影视系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 时代在飞速进步,每个行业都在努力发展现在先进技术,通过这些先进的技术来提高自己的水平和优势,影视推荐系统当然不能排除在外。影视系统是在实际应用和软件工程的开发原理之上,运用Java语言以及Spring Boot、VUE框架进行开…...
搭建Stable Diffusion图像生成系统实现通过网址访问(Ngrok+Flask实现项目系统公网测试,轻量易部署)
目录 前言 背景与需求 🎯 需求分析 核心功能 网络优化 方案确认 1. 安装 Flask 和 Ngrok 2. 构建 Flask 应用 3. 使用 Ngrok 实现内网穿透 4. 测试图像生成接口 技术栈 实现流程 优化目标 实现细节 1. 迁移到Flask 2. 持久化提示词 3. 图像下载功能 …...

Java 21 的“无类主”特性:简化编程的第一步
在Java编程中,编写一个简单的“Hello, World!”程序通常需要以下代码: public class HelloWorld {public static void main(String[] args) {System.out.println("Hello, World!");} }这种结构包含了许多对初学者来说难以理解的概念ÿ…...

AI | 最近比较火的几个生成式对话 AI
关注:CodingTechWork 引言 生成式对话 AI 正在迅速改变我们与机器交互的方式,从智能助手到内容创作,其应用范围广泛且深远。本文将深入探讨几款当前热门的生成式对话 AI 模型,包括 Kimi、DeepSeek、ChatGPT、文心一言、通义千问和…...
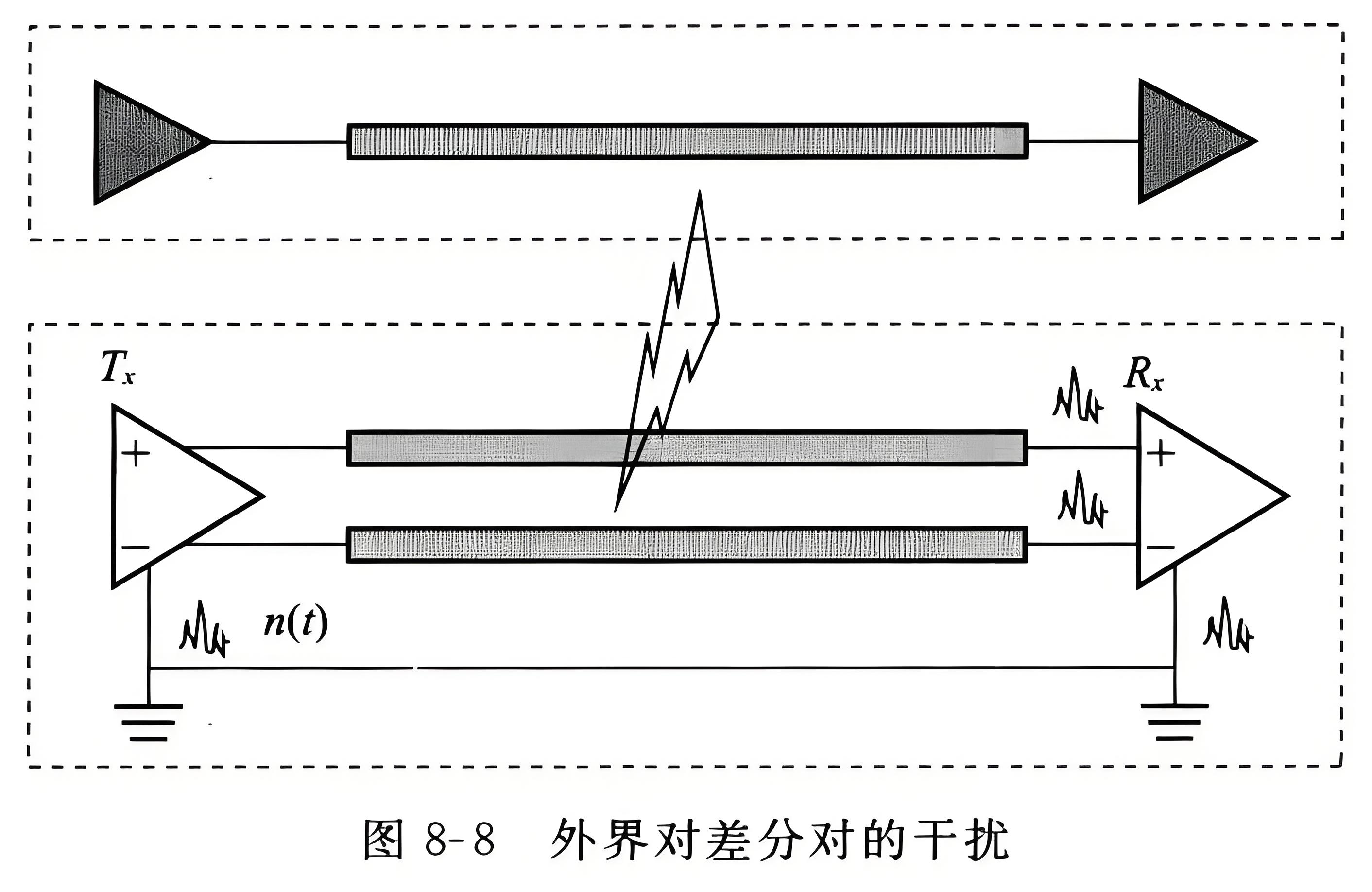
差分信号抗噪声原理:
差分信号抗噪声原理: 差分信号除了能很好地解决发送和接收参考点电位不同的问题外,差分信号的另一个重要优势就是在一定条件下其抗干扰能力比单端信号更强。对于单端信号传输,外界对它的干扰噪声直接叠加在信号上,接收端直接检测输…...
6 种AI实用的方法,快速修复模糊照片
照片是我们记录生活的重要方式。但有时,由于各种原因,照片会变得模糊,无法展现出我们想要的效果。幸运的是,随着人工智能(AI)技术的发展,现在有多种方法可以利用 AI 修复模糊照片,让…...

JavaScript 的“积木”:函数入门与实践
引言:告别重复,拥抱模块化 想象一下,你在写代码时发现,有几段逻辑几乎一模一样,需要在不同的地方反复使用。你是选择每次都复制粘贴,还是希望能像搭积木一样,把这段逻辑封装起来,需…...
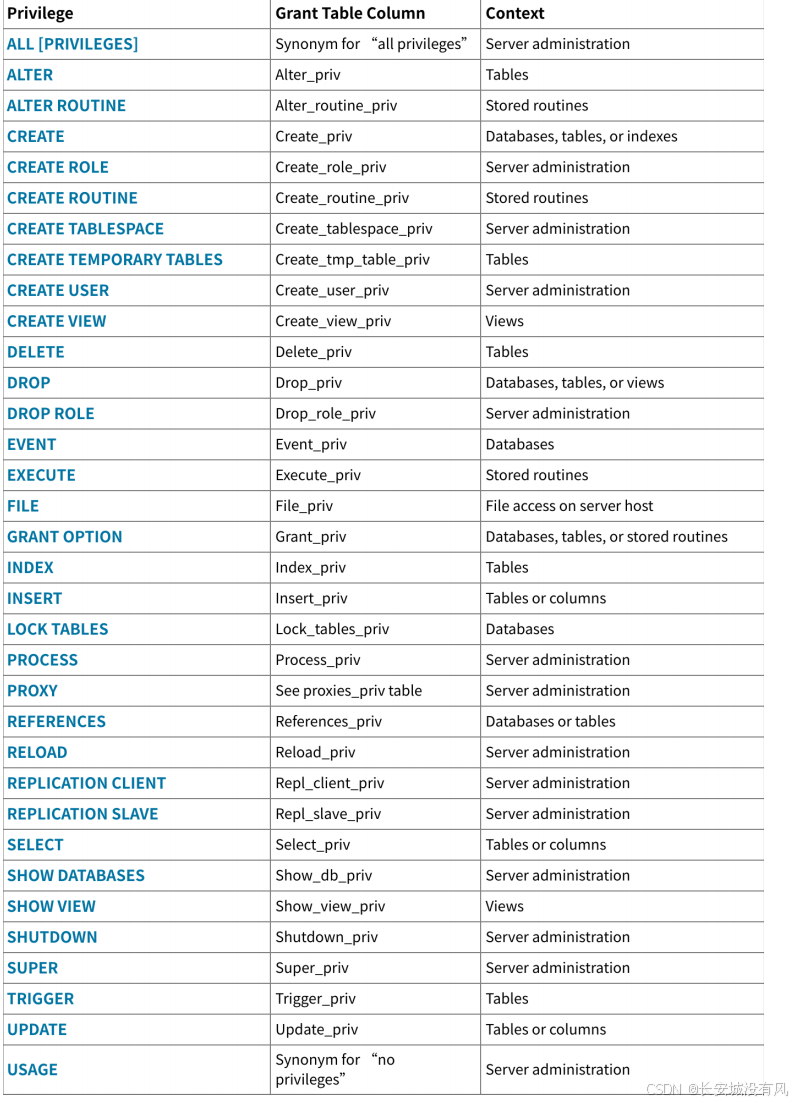
从入门到精通【MySQL】视图与用户权限管理
文章目录 📕1. 视图✏️1.1 视图的基本概念✏️1.2 试图的基本操作🔖1.2.1 创建视图🔖1.2.2 使用视图🔖1.2.3 修改数据🔖1.2.4 删除视图 ✏️1.3 视图的优点 📕2. 用户与权限管理✏️2.1 用户🔖…...

C++中的next_permutation全排列函数
目录 什么是全排列用法实现原理自定义比较函数 注意事项相关题目1.AB Problem2.P1088 火星人 什么是全排列 全排列是指从一组元素中按照一定顺序(按字典序排列)取出所有元素进行排列的所有可能情况。 例如,对于集合{1,2,3},它的全排列包括&a…...
修改el-select背景颜色
修改el-select背景颜色 /* 修改el-select样式--直接覆盖默认样式(推荐) */ ::v-deep .el-select .el-input__inner {background-color: #1d2b72 !important; /* 修改输入框背景色 */color: #fff; } ::v-deep .el-select .el-input__wrapper {background-…...

dockercompose文件仓库
mysql version: 3 # 使用docker-compose的版本,根据需要可以调整# 创建数据目录 # mkdir -p /home/docker/mysql/mysql_data # mkdir -p /home/docker/mysql/mysql_logs # 给予适当的权限(确保MySQL容器可以读写这些目录) # chmod 777 /ho…...

【C++入门:类和对象】[3]
C入门:类和对象 拷贝构造(拷贝初始化) 拷贝构造是构造函数的重载 class Date { public:Date(int year1,int month1,int day1) { _yearyear; _monthmonth; _dayday; } Date(const Date& d)//(拷贝构造,把d1传参给d)引用传参不改变使用const //注意使用&,不然会无穷递…...

【mdlib】0 全面介绍 mdlib - Rust 实现的 Markdown 工具集
mdlib 是由开发者 bahdotsh 创建的一个多功能 Markdown 工具集合,包含两个主要组件:一个轻量级 Markdown 解析库和一个功能完善的个人 Wiki 系统。该项目完全采用 Rust 实现,兼具高性能与跨平台特性。 核心组件 Markdown 解析库 特性&#…...

今日CSS学习浮动->定位
------------------------------------------------------------------------------------------------------- CSS的浮动 float 属性用于创建浮动框,将其移动到一边,直到左边缘或右边缘触及包含块或另一个浮动框的边缘。 float 属性定义元素在哪个方向浮…...

如何实现Spring Boot应用程序的安全性:全面指南
在现代 Web 开发中,安全性是 Spring Boot 应用程序的核心需求,尤其是在微服务、云原生和公开 API 场景中。Spring Boot 结合 Spring Security 提供了一套强大的工具,用于保护应用程序免受常见威胁,如未经授权的访问、数据泄露、跨…...
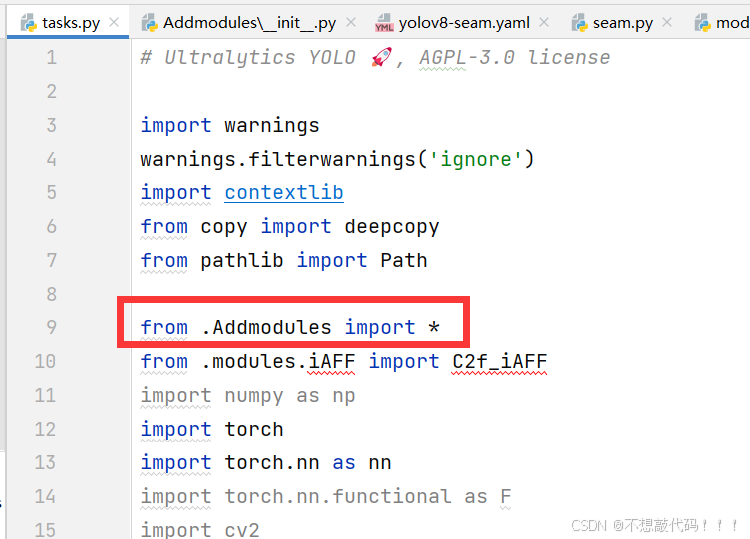
YOLOv8融合CPA-Enhancer【提高恶略天气的退化图像检测】
1.CPA介绍 CPA-Enhancer通过链式思考提示机制实现了对未知退化条件下图像的自适应增强,显著提升了物体检测性能。其插件式设计便于集成到现有检测框架中,并在物体检测及其他视觉任务中设立了新的性能标准,展现了广泛的应用潜力。 关于CPA-E…...
Python 项目环境配置与 Vanna 安装避坑指南 (PyCharm + venv)
在进行 Python 项目开发时,一个干净、隔离且配置正确的开发环境至关重要。尤其是在使用像 PyCharm 这样的集成开发环境 (IDE) 时,正确理解和配置虚拟环境 (Virtual Environment) 是避免许多常见问题的关键。本文结合之前安装 Vanna 库时遇到的问题&#…...

第52讲:农业AI + 区块链——迈向可信、智能、透明的未来农业
目录 一、为什么农业需要“AI+区块链”? 二、核心应用场景解读 1. 农产品溯源系统 2. 农业信贷与保险精准评估 3. 农业碳足迹追踪与碳汇交易 三、案例实战分享:智能溯源 + 区块链合约 四、面临挑战与展望 五、总结 在数字农业时代,“AI” 和 “区块链” 是两股不容忽…...
)
模板偏特化 (Partial Specialization)
C 模板偏特化 (Partial Specialization) 模板偏特化允许为模板的部分参数或特定类型模式提供定制实现,是 静态多态(Static Polymorphism) 的核心机制之一。以下通过代码示例和底层原理,全面解析模板偏特化的实现规则、匹配优先级…...

【防火墙 pfsense】1简介
(1) pfSense 有以下可能的用途: 边界防火墙 路由器 交换机 无线路由器 / 无线接入点 (2)边界防火墙 ->要充当边界防火墙,pfSense 系统至少需要两个接口:一个广域网(WAN࿰…...

Qt UDP组播实现与调试指南
在Qt中使用UDP组播(Multicast)可以实现高效的一对多网络通信。以下是关键步骤和示例代码: 一、UDP组播核心机制 组播地址:使用D类地址(224.0.0.0 - 239.255.255.255)TTL设置:控制数据包传播范围(默认1,同一网段)网络接口:指定发送/接收的物理接口二、发送端实现 /…...
线上助农产品商城小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的线上助农产品商城小程序源码,旨在为农产品销售搭建一个高效、便捷的线上平台,助力乡村振兴。 一、技术架构 该小程序源码采用了ThinkPHP作为后端框架,FastAdmin作为快速开发框架,UniApp作为跨…...

【maven-7.1】POM文件中的属性管理:提升构建灵活性与可维护性
在Maven项目中,POM (Project Object Model) 文件是核心配置文件,而属性管理则是POM中一个强大但常被低估的特性。良好的属性管理可以显著提升项目的可维护性、减少重复配置,并使构建过程更加灵活。本文将深入探讨Maven中的属性管理机制。 1.…...

基于Matlab的车牌识别系统
1.程序简介 本模型基于MATLAB,通过编程创建GUI界面,基于Matlab的数字图像处理,对静止的车牌图像进行分割并识别,通过编写matlab程序对图像进行灰度处理、二值化、腐蚀膨胀和边缘化处理等,并定位车牌的文字,实现字符的…...

three.js精灵及精灵材质、Shader源码分析
在Three.js中,Sprite(精灵)用于创建始终面向相机的2D元素,适用于标签、图标或粒子效果。本文将分析其源码及Shader实现。 1. sprite的基本使用方法 创建精灵材质: 精灵材质有个特殊的参数rotation,可以让其旋转一定的角度。 const material = new THREE.SpriteMateria…...

Kubernetes Docker 部署达梦8数据库
Kubernetes & Docker 部署达梦8数据库 一、达梦镜像获取 目前达梦官方暂未在公共镜像仓库提供Docker镜像,需通过达梦官网联系获取官方镜像包。 二、Kubernetes部署方案 部署配置文件示例 apiVersion: apps/v1 kind: Deployment metadata:labels:app: dm8na…...
探索 CameraCtrl模型:视频生成中的精确摄像机控制技术
在当今的视频生成领域,精确控制摄像机轨迹一直是一个具有挑战性的目标。许多现有的模型在处理摄像机姿态时往往忽略了精准控制的重要性,导致生成的视频在摄像机运动方面不够理想。为了解决这一问题,一种名为 CameraCtrl 的创新文本到视频模型…...

Streamlit从入门到精通:构建数据应用的利器
在数据科学与机器学习日益普及的今天,如何快速将模型部署为可交互的应用成为了许多数据科学家的重要任务。Streamlit,作为一个开源的Python库,专为数据科学家设计,能够帮助我们轻松构建美观且直观的Web应用。本文将从入门到精通&a…...