爬虫-oiwiki
我们将BASE_URL 设置为 "https://oi-wiki.org/" 后脚本就会自动开始抓取该url及其子页面的所有内容,并将统一子页面的放在一个文件夹中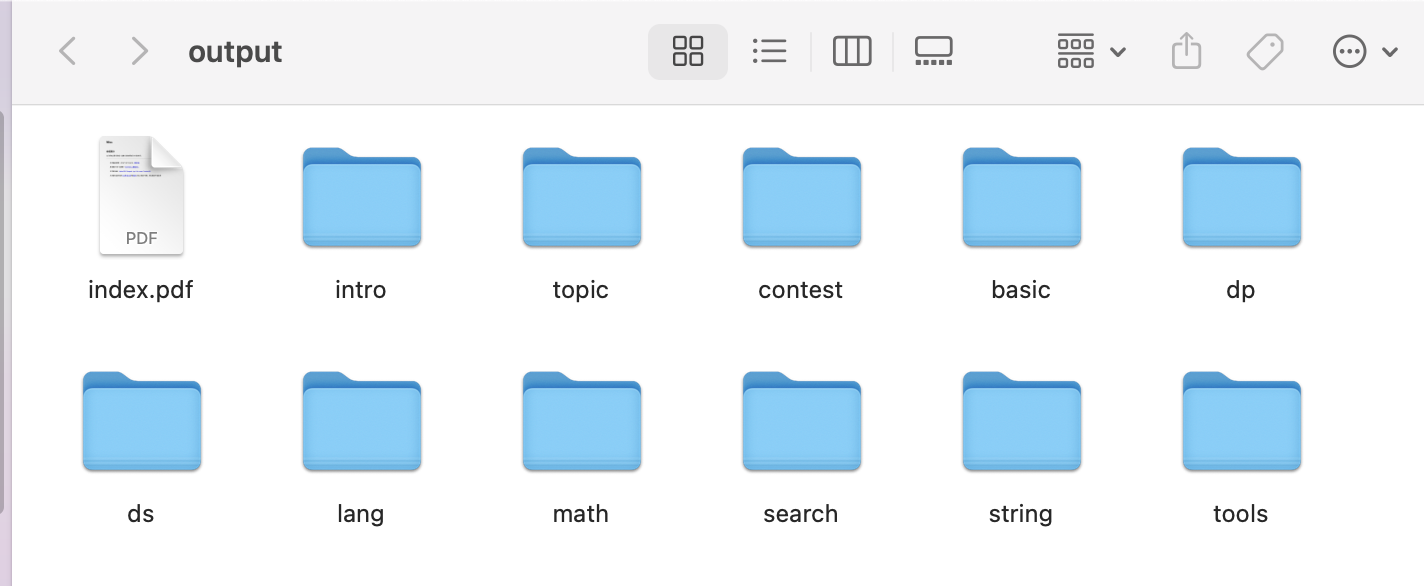
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
import os
import pdfkit
from urllib3.exceptions import InsecureRequestWarning# 禁用SSL警告
requests.packages.urllib3.disable_warnings(category=InsecureRequestWarning)# 配置wkhtmltopdf路径
config = pdfkit.configuration(wkhtmltopdf='/usr/local/bin/wkhtmltopdf')BASE_URL = "https://oi-wiki.org/"
DOMAIN = urlparse(BASE_URL).netlocheaders = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36","Accept-Language": "zh-CN,zh;q=0.9"
}visited = set()
queue = [BASE_URL]def is_valid_url(url):parsed = urlparse(url)return (parsed.netloc == DOMAIN andnot parsed.fragment andnot url.endswith(('.zip', '.pdf', '.jpg', '.png')))def extract_links(html, base_url):soup = BeautifulSoup(html, 'html.parser')links = []for a in soup.find_all('a', href=True):full_url = urljoin(base_url, a['href']).split('#')[0]if is_valid_url(full_url) and full_url not in visited:links.append(full_url)visited.add(full_url)return linksdef fetch_page(url):try:print(f"[*] 抓取中: {url}")res = requests.get(url, headers=headers, verify=False, timeout=30)res.encoding = 'utf-8'return res.textexcept Exception as e:print(f"[!] 抓取失败: {url} - {str(e)}")return Nonedef clean_html(html, url):soup = BeautifulSoup(html, 'html.parser')# 移除所有顶部导航和侧边栏相关元素for tag in soup.select('.navbar, .page-toc, .sidebar, footer, .giscus, .page-footer, .page-actions'):tag.decompose()# 仅保留主内容区域main_content = soup.select_one('main article') or soup.select_one('article') or soup# 修正资源路径for tag in main_content.find_all(['img', 'a']):for attr in ['href', 'src']:if tag.has_attr(attr):tag[attr] = urljoin(url, tag[attr])# 获取有效标题(使用最后一个有效路径段)title_parts = urlparse(url).path.strip('/').split('/')title = title_parts[-1].replace('-', ' ').title() if title_parts else "Document"return f"""<!DOCTYPE html><html><head><meta charset="utf-8"><title>{title}</title><style>body {{ font-family: 'Noto Sans CJK SC', Arial, sans-serif;line-height: 1.6;margin: 2em;}}/* 保持原有样式 */</style></head><body><h1>{title}</h1>{main_content}</body></html>"""def save_as_pdf(html, url):parsed = urlparse(url)path_segments = [seg for seg in parsed.path.strip('/').split('/') if seg]if len(path_segments) > 1:dir_path = os.path.join('output', *path_segments[:-1])filename = f"{path_segments[-1]}.pdf"else:dir_path = 'output'filename = "index.pdf"os.makedirs(dir_path, exist_ok=True)full_path = os.path.join(dir_path, filename)try:pdfkit.from_string(html, full_path, configuration=config, options={'encoding': "UTF-8",'enable-local-file-access': None,'quiet': '' # 隐藏控制台输出})print(f"[√] 已保存: {full_path}")except Exception as e:print(f"[!] PDF生成失败: {full_path} - {str(e)}")def crawl():while queue:current_url = queue.pop(0)html = fetch_page(current_url)if not html:continuenew_links = extract_links(html, current_url)queue.extend(new_links)cleaned_html = clean_html(html, current_url)save_as_pdf(cleaned_html, current_url)if __name__ == "__main__":print("🚀 启动爬虫,目标站点:", BASE_URL)visited.add(BASE_URL)crawl()print("✅ 所有内容已保存至 output/ 目录")
相关文章:
爬虫-oiwiki
我们将BASE_URL 设置为 "https://oi-wiki.org/" 后脚本就会自动开始抓取该url及其子页面的所有内容,并将统一子页面的放在一个文件夹中 import requests from bs4 import BeautifulSoup from urllib.parse import urljoin, urlparse import os import pd…...
: つもり 计划/打算)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(10): つもり 计划/打算
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(10): つもり 计划/打算 1、前言(1)情况说明(2)工程师的信仰 2、知识点(1)つもり 计划/打算(2&a…...
强化学习核心原理及数学框架
1. 定义与核心思想 强化学习(Reinforcement Learning, RL)是一种通过智能体(Agent)与环境(Environment)的持续交互来学习最优决策策略的机器学习范式。其核心特征为: 试错学习&#x…...
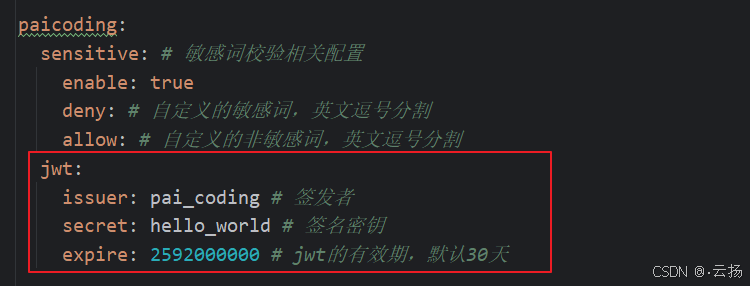
【技术派后端篇】技术派中 Session/Cookie 与 JWT 身份验证技术的应用及实现解析
在现代Web应用开发中,身份验证是保障系统安全的重要环节。技术派在身份验证领域采用了多种技术方案,其中Session/Cookie和JWT(JSON Web Token)是两种常用的实现方式。本文将详细介绍这两种身份验证技术在技术派中的应用及具体实现…...

【基础】Node.js 介绍、安装及npm 和 npx功能了解
前言 后面安装n8n要用到,做一点技术储备。主要是它的两个工具:npm 和 npx。 Node.js介绍 Node.js 是一个免费的、开源的、跨平台的 JavaScript 运行时环境,允许开发人员在浏览器之外编写命令行工具和服务器端脚本,是一个基于 C…...

第53讲 农学科研中的AI伦理与可解释性——探索SHAP值、LIME等可解释工具与科研可信性建设之道
目录 一、为什么农学科研中需要“可解释AI”? ✅ 场景示例: 二、常见可解释AI工具介绍 1. SHAP(SHapley Additive exPlanations) 2. LIME(Local Interpretable Model-agnostic Explanations) 三、AI伦理问题在农学中的体现 🧭 公平性与偏见 🔐 数据隐私 🤖…...

助力网站优化利用AI批量生成文章工具提升质量
哎,有时候觉得写东西这事儿吧,真挺玄乎的。你看着那些大网站的优质内容,会不会突然冒出个念头——这些家伙到底怎么做到日更十篇还不秃头的?前阵子我蹲在咖啡馆里盯着屏幕发呆,突然刷到个帖子说现在用AI写文章能自动纠…...

Java语言的进化:JDK的未来版本
作为一名Java开发者,我们正处在一个令人兴奋的时代!Java语言正在以前所未有的速度进化,每个新版本都带来令人惊喜的特性。让我们一起探索JDK未来版本的发展方向,看看Java将如何继续领跑编程语言界!💪 &…...
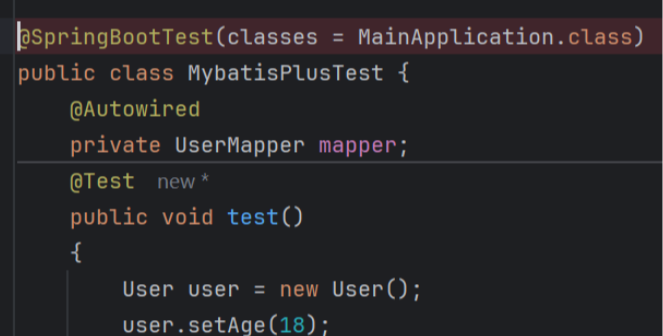
SpringBootTest报错
Unable to find a SpringBootConfiguration, you need to use ContextConfiguration or … 解决方案:在SpringTest注解中添加属性(classes )填写启动类 如我的启动类是MainApplication.class javax.websocket.server.ServerContainer no…...
--多文件上传)
Flask + ajax上传文件(二)--多文件上传
Flask多文件上传完整教程 本教程将详细介绍如何使用Flask实现多文件上传功能,并使用时间戳为上传文件自动命名,避免文件名冲突。 一、环境准备 确保已安装Python和Flask pip install flask项目结构 flask_upload/ ├── app.py ├── upload/ # 上传文…...

w~视觉~合集3
我自己的原文哦~ https://blog.51cto.com/whaosoft/12327888 #几个论文 Fast Charging of Energy-dense Lithium-ion Batteries Real-time Short Video Recommendation on Mobile Devices Semantic interpretation for convolutional neural networks: What makes a ca…...
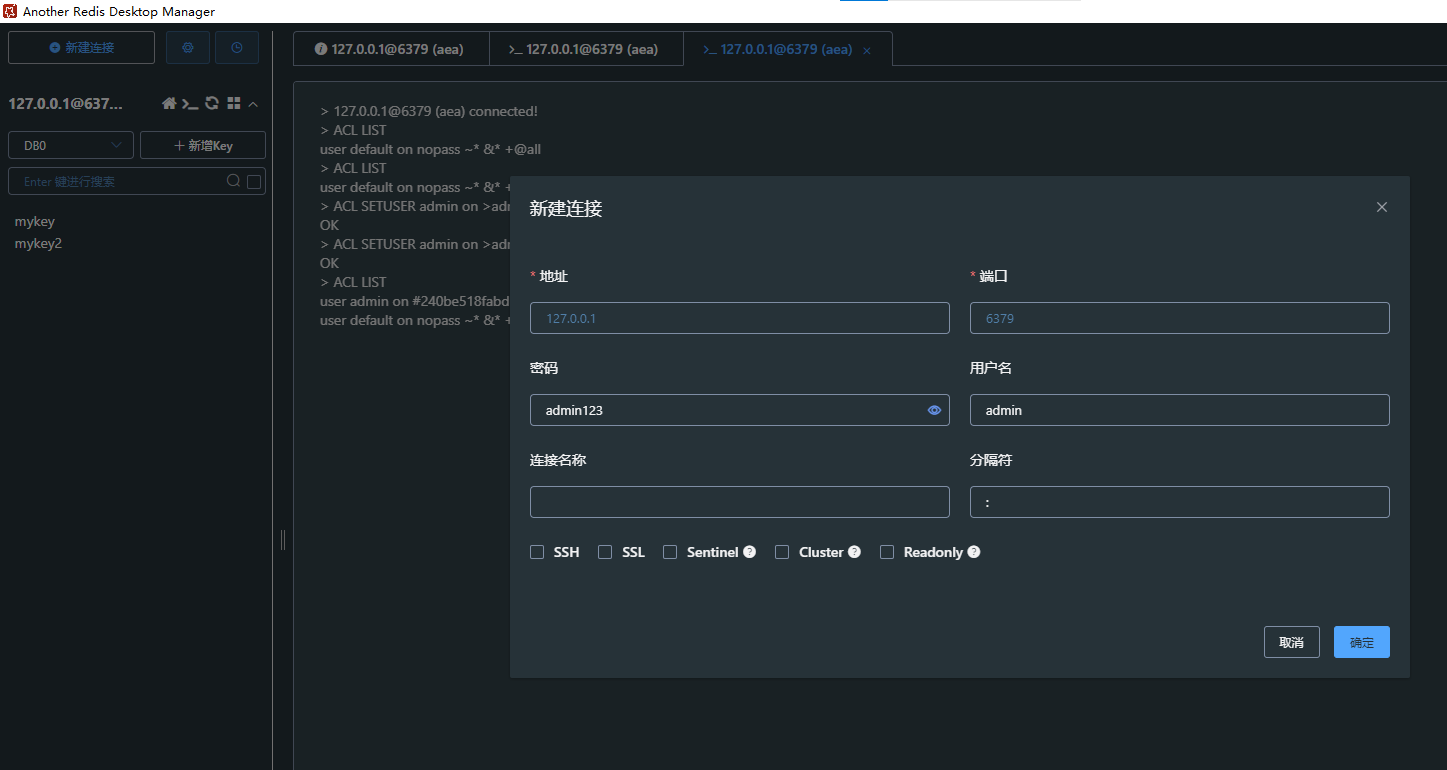
Redis安装及入门应用
应用资料:https://download.csdn.net/download/ly1h1/90685065 1.获取文件,并在该文件下执行cmd 2.输入redis-server-lucifer.exe redis.windows.conf,即可运行redis 3.安装redis客户端软件 4.安装后运行客户端软件,输入链接地址…...

NODE_OPTIONS=--openssl-legacy-provider vue-cli-service serve
//"dev": " NODE_OPTIONS--openssl-legacy-provider vue-cli-service serve" // 修改后(Windows 适用) "dev": "vue-cli-service serve --openssl-legacy-provider" 升级 Node.js 到 v14,确保依赖…...

如何在 Postman 中,自动获取 Token 并将其赋值到环境变量
在 Postman 中,你可以通过 预请求脚本(Pre-request Script) 和 测试脚本(Tests) 实现自动获取 Token 并将其赋值到环境变量,下面是完整的操作步骤: ✅ 一、创建获取 Token 的请求 通常这个请求…...
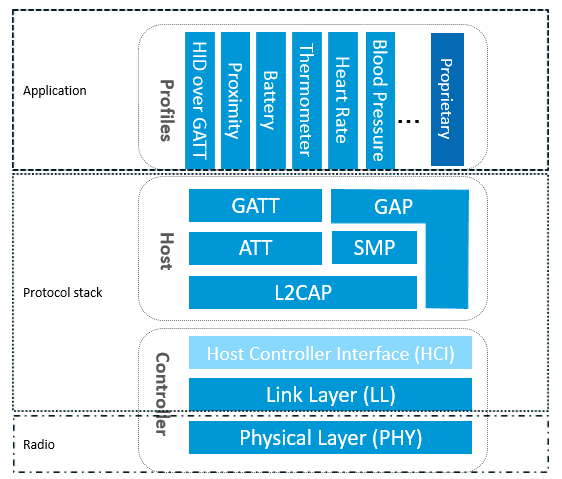
上篇:深入剖析 BLE 底层物理层与链路层(约5000字)
引言 在无线通信领域,Bluetooth Low Energy(BLE)以其超低功耗、灵活的连接模式和良好的生态支持,成为 IoT 与可穿戴设备的首选技术。要想在实际项目中优化性能、控制功耗、保证可靠通信,必须对 BLE 协议栈的底层细节有深入了解。本篇将重点围绕物理层(PHY)与链路层(Li…...

PostgreSQL 的 MVCC 机制了解
PostgreSQL 的 MVCC 机制了解 PostgreSQL 使用多版本并发控制(MVCC)作为其核心并发控制机制,这是它与许多其他数据库系统的关键区别之一。MVCC 允许读操作不阻塞写操作,写操作也不阻塞读操作,从而提供高度并发性。 一 MVCC 基本原理 1.1 M…...

【Pandas】pandas DataFrame dot
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

2025 年“泰迪杯”数据挖掘挑战赛B题——基于穿戴装备的身体活动监测问题分析
摘要 本文聚焦于基于穿戴设备采集的加速度计数据,深入研究志愿者在日常活动中的行为特征,构建了多个数学建模框架,实现从身体活动监测、能耗预测、睡眠阶段识别到久坐预警等多个目标。我们依托于多源数据融合与机器学习模型,对人体活动状态进行识别与分析,为健康管理、行…...

Vivado版本升级后AXI4-Stream Data FIFO端口变化
Vivado 2017.4版本中异步AXI4-Stream Data FIFO升级到Vivado 2018.3后,IP管脚会发生变化,2018.3版中没有m_axis_aresetn和axis_data_count。 async_axis_fifo_8_1024 async_axis_fifo_8_1024 ( .s_axis_aresetn (I_do0_rstn ), // input wire…...
Linux424 chage密码信息 gpasswd 附属组
https://chat.deepseek.com/a/chat/s/e55a5e85-de97-450d-a19e-2c48f6669234...

Git 恢复误删除的文件
由于一些操作,把项目中的大量文件删除了,还以为之前敲得代码都付之东流了,突然想起,我的项目使用git进行的版本管理,且一些更改都暂存在本地的仓库的,因此可以使用git来恢复存入仓库的文件 首先࿰…...
自定义指令简介及用法(vue3)
一介绍 防抖与节流,应用场景有很多,例如:禁止重复提交数据的场景、搜索框输入搜索条件,待输入停止后再开始搜索。 防抖 点击button按钮,设置定时器,在规定的时间内再次点击会重置定时器重新计时…...

关于Qt对Html/CSS的支持
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、原生控件二、QtWebEngine总结 前言 最近遇到了一些问题需要使用Qt加载Html发现一些特性不能使用,估计很多人也和我一样遇到这种情况。需要说明…...

海量数据笔试题--Top K 高频词汇统计
问题描述: 假设你有一个非常大的文本文件(例如,100GB),文件内容是按行存储的单词(或其他字符串,如 URL、搜索查询词等),单词之间可能由空格或换行符分隔。由于文件巨大&…...

Python函数与模块
简介 在Python编程中,函数和模块是实现代码复用、提高开发效率的核心机制。本文将结合理论与实例,解析Python函数与模块的核心知识点,帮助开发者打下基础。 一、函数 函数是一段可重复调用的代码块,通过参数传递实现灵活的逻辑…...

位运算题目:解码异或后的排列
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法思路和算法代码复杂度分析 题目 标题和出处 标题:解码异或后的排列 出处:1734. 解码异或后的排列 难度 6 级 题目描述 要求 有一个整数数组 perm \texttt{perm} perm,是前…...

【Spring Boot】深入解析:#{} 和 ${}
1.#{} 和 ${}的使用 1.1数据准备 1.1.1.MySQL数据准备 (1)创建数据库: CREATE DATABASE mybatis_study DEFAULT CHARACTER SET utf8mb4;(2)使用数据库 -- 使⽤数据数据 USE mybatis_study;(3ÿ…...

linux:启动后,ubuntu屏幕变成红色了
屏幕启动后变成 红色背景 通常说明 显卡驱动出了问题,或者是 图形界面加载失败 使用了 fallback 模式。这种现象在 NVIDIA 驱动安装失败或显卡与驱动不兼容时常见。 🎯 先给你几个快速修复选项 ✅ 1. 进入 TTY 命令行界面 按下:Ctrl Alt …...

从实验室到产业端:解码 GPU 服务器的八大核心应用场景
一、深度学习与人工智能的基石 在深度学习领域,GPU 服务器的并行计算架构成为训练大规模模型的核心引擎 —— 传统 CPU 集群训练千亿参数模型需数月,而基于某国际知名芯片厂商 H100 的 GPU 服务器可将周期缩短至数周,国内科技巨头 910B 芯…...
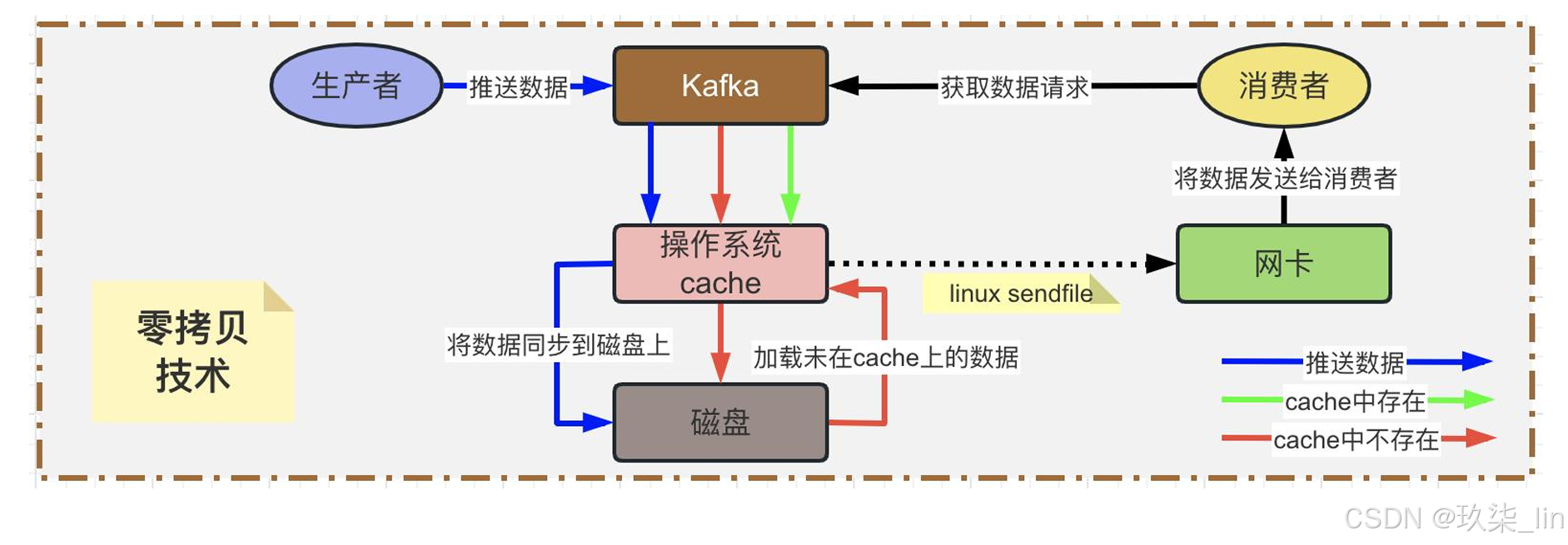
java—12 kafka
目录 一、消息队列的优缺点 二、常用MQ 1. Kafka 2. RocketMQ 3. RabbitMQ 4. ActiveMQ 5. ZeroMQ 6. MQ选型对比 适用场景——从公司基础建设力量角度出发 适用场景——从业务场景角度出发 四、基本概念和操作 1. kafka常用术语 2. kafka常用指令 3. 单播消息&a…...