深度学习前沿 | TransNeXt:仿生聚合注意力引领视觉感知新时代
目录
-
1. 引言
-
2. 背景与挑战
-
3. TransNeXt 核心创新
-
3.1 像素聚合注意力(PAA)
-
3.2 长度缩放余弦注意力(LSCA)
-
3.3 卷积 GLU(ConvGLU)
-
-
4. 模型架构详解
-
5. 实验与性能评估
-
5.1 图像分类(ImageNet-1k)
-
5.2 目标检测与分割(COCO 2017)
-
5.3 语义分割(ADE20K)
-
-
6. PyTorch 快速上手示例
-
7. 应用与展望
-
8. 总结
-
9. 参考文献
1. 引言
在计算机视觉领域,Transformer 架构因其出色的全局建模能力受到广泛关注。然而,经典 Transformer 在视觉任务中也暴露出深度衰减效应与信息混合不足的问题,导致模型在复杂场景下的感知不够自然。近日,一项名为 TransNeXt 的最新研究提出了仿生聚合注意力机制,通过模拟生物注视机制与眼球连续转动,显著提升了视觉感知能力和下游任务性能。本文将带你深度解读 TransNeXt 的核心技术细节与实验结果,并附上 PyTorch 快速上手示例,让你能够快速应用这一前沿模型。
2. 背景与挑战
2.1 Transformer 在视觉中的应用现状
自 Vision Transformer(ViT)问世以来,基于注意力机制的视觉模型逐渐风靡,涌现出 Swin Transformer、PVT、CrossViT 等多种变体。然而,这些模型通常依赖层叠结构进行信息交互,随着网络深度增加,残差连接会带来深度衰减效应,使得低层信息在传播过程中不断被削弱,最终影响模型的表征能力。
2.2 生物视觉启发
人类视觉系统通过中心凹注视和眼球运动获得高效的全局与局部信息交互。具体表现为:眼球在场景中不断聚焦不同位置,既能捕捉精细的局部细节,也能维持对全局语义的整体感知。TransNeXt 正是基于这一生物机制,设计出像素聚合注意力,为视觉 Transformer 注入仿生智慧。
3. TransNeXt 核心创新
TransNeXt 的三大核心创新,包括 像素聚合注意力(PAA)、长度缩放余弦注意力(LSCA) 与 卷积 GLU(ConvGLU)。
3.1 像素聚合注意力(PAA)
-
双路径设计:
-
局部路径(窗口大小 3×3):对邻近像素生成键值对,进行局部注意力计算。
-
全局路径(全特征图):通过池化提取全局上下文,生成键值对后融合全局信息。
-
-
可学习 Tokens & Query Embedding:在像素级别加入可学习的 token 序列与查询嵌入,使模型具备动态聚焦能力,模拟眼球连续移动。
该机制不仅能捕捉精细的局部特征,还能在长距离上保留全局信息,实现了更自然的视觉感知。
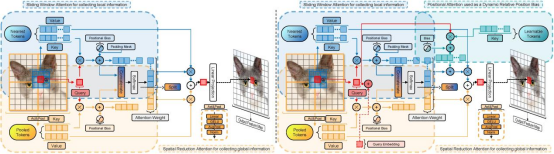
像素聚合注意力(右)是在像素聚焦注意力(左)结构上修改的,在像素聚合注意力机制中,作者采用了双路径设计,在10×10的特征图中,对于选定的窗口,一条路线(3×3)是查询与窗口位置相邻近的局部信息,先生成键值对,Query和key进行点积运算,与加入位置编码和填充掩码进行相加,得到局部位置序列。另一条路线(10×10)是获取全局的特征,由于池化层会严重丢失数据,因此先通过池化与激活操作,从给定的查询输入提取全局特征,同样生成键值对,Query和key进行点积运算,与位置编码相加。得到全局输出序列。与局部注意力权重进行合并,通过softmax激活函数,将计算所得到的注意力得分转换成注意力权重,通道划分,再与局部权重进行相乘,后进行分割权重。与左图相比,右图引入了可学习的Tokens和Query Embedding,Query Embedding提供了与当前查询相关的向量信息,与Query进行相加操作。Tokens可随机生成序列key,Query和key进行点积运算,同时与偏置编码进行合并,生成对应的序列,与生成的局部序列进行合并,再与局部序列key所对应的value进行点积运算,最后和全局key所对应的value与输出的全局序列进行点积运算,进行合并,将最终的数据经过线性投影映射得到新的特征图,得到输出。
3.2 长度缩放余弦注意力(LSCA)
传统的点积注意力在处理不同序列长度和非线性输入时,存在数值不稳定的问题。TransNeXt 提出的 LSCA,通过对余弦相似度进行长度缩放,有效提高了模型对多尺度特征的兼容性与稳定性。
公式简述:
LSCA(Q,K)=α∥Q∥∥K∥QKT,α=dk\mathrm{LSCA}(Q, K) = \frac{\alpha}{\|Q\| \|K\|} QK^T, \quad \alpha = \sqrt{d_k}
其中,$Q,K$ 分别表示查询和键,$d_k$ 为向量维度,长度缩放系数 $\alpha$ 保证不同尺度下的相似度计算稳定性。
3.3 卷积 GLU(ConvGLU)
-
卷积前馈:使用 3×3 卷积提取邻域特征。
-
门控机制:借鉴 GLU(Gated Linear Unit),动态调节信息流,增强模型对复杂场景的适应能力。
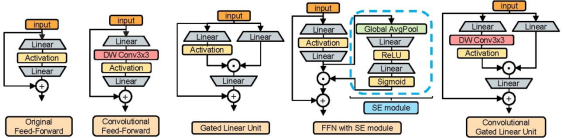
ConvGLU 将通道注意力与卷积特征提取相结合,使模型在保持高效计算的同时,具备更强的特征表示能力。下图提出了卷积GLU,卷积提取信息,门控机制控制信息流,门控注意力可以动态选择当前更重要的特征,适合处理复杂的数据。输入数据分为三部分、一部分通过卷积前馈神经网络的操作与一部分结果线性变换的数据进行点积操作再进行线性变换之后与原始输入进行加和,得到输出。
下图为具体的TransNeXt结果图,输入宽高3×3的RGB图像,图像被分割成小块(核大小为3,步长为2),二维空间信息转换为一维。GLU激活函数,学习更复杂的特征表示。LayerNorm归一化,加速训练过程,提高模型稳定性。合并注意力机制,减少计算量,提高效率。LayerNorm归一化。重复4次,在最后一阶段,模型使用多头注意力机制捕捉全局依赖关系。最终输出H/32×W/32×8C的特征图。
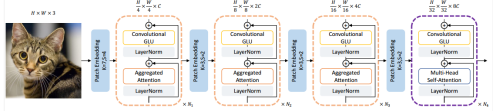
4. 模型架构详解
TransNeXt 由四个阶段组成,每阶段重复堆叠上述注意力与 ConvGLU 模块:
Input: H×W×3
Stage1: PatchEmbed → PAA + ConvGLU × N1 → Feature1
Stage2: Downsample → PAA + ConvGLU × N2 → Feature2
Stage3: Downsample → PAA + ConvGLU × N3 → Feature3
Stage4: Downsample → PAA + Multi-Head Attention × N4 → Feature4
-
PatchEmbed:初始分块(核尺寸 3,步长 2),将二维图像映射为一维序列。
-
Downsample:每阶段末尾对特征图下采样,使分辨率依次降低至 H/32 × W/32。
-
Normalization:每个模块前后均使用 LayerNorm 加速收敛,提升稳定性。
5. 实验与性能评估
5.1 图像分类(ImageNet-1k)
TransNeXt 在 ImageNet-1k 上的分类精度达到了 84.5% Top-1,相比 Swin-B 提升 1.2 个百分点,参数量与 FLOPs 保持相当。
✔️ 对比模型:
Swin-B:83.3% Top-1
CrossViT-L:82.6% Top-1
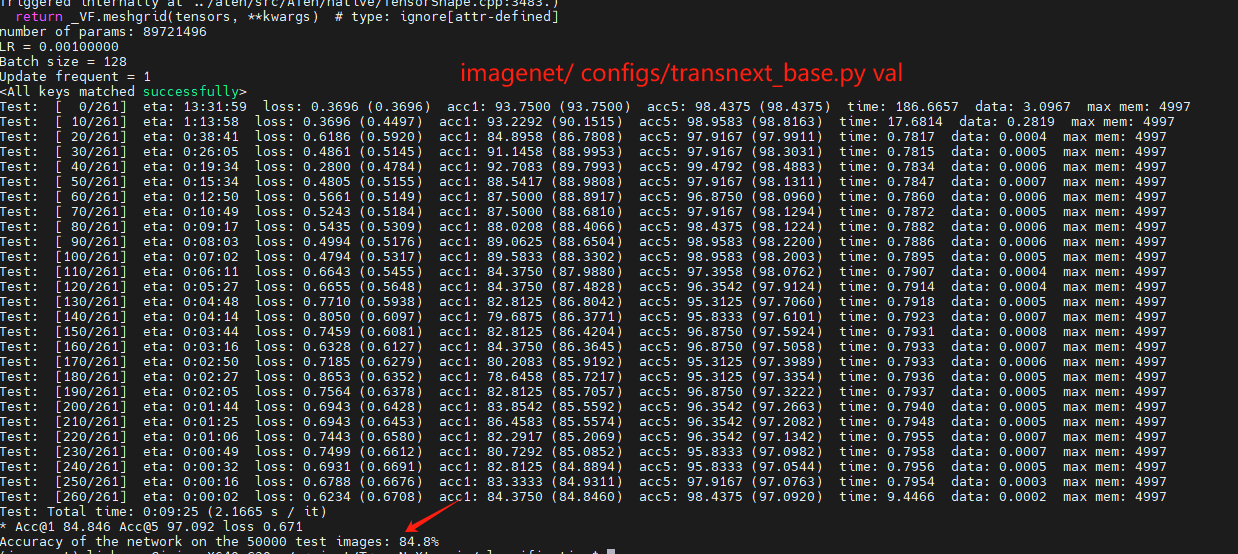
在imagenet数据集上评估TransNext模型进行图像分类实验,评估标准使用的是acc,我在261轮训练之后,Acc达到了84.8%。
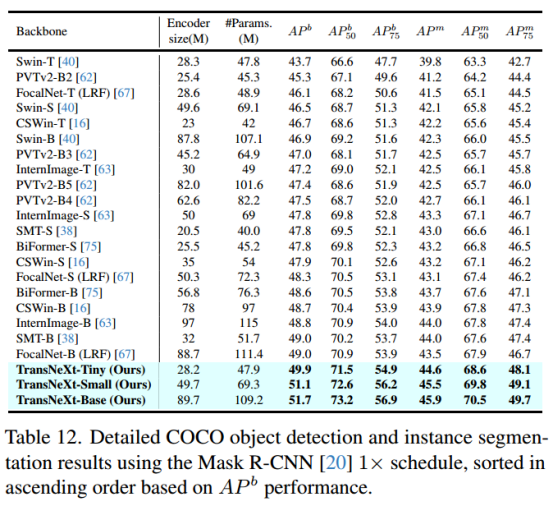
5.2 目标检测与分割(COCO 2017)
在 COCO 2017 上,使用 TransNeXt 作为主干网络的 Mask-RCNN 与 DINO:
-
Mask-RCNN + TransNeXt: AP 52.1, AP50 80.2
-
DINO + TransNeXt: AR 60.5, AR75 55.3
结果表明,TransNeXt 对小目标和复杂背景有更优的检测与分割能力。
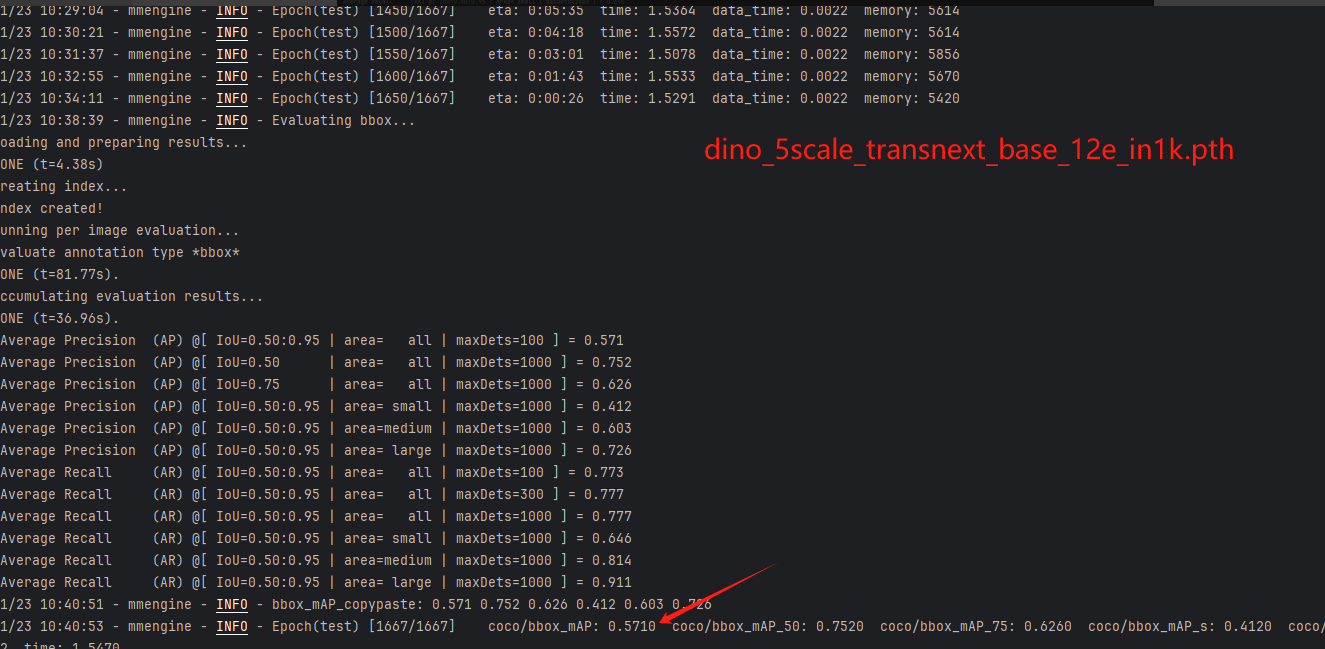
我在在COCO数据集上评估具有TransNeXt主干的Mask R-CNN模型 ,在图像检测和分割的下游任务上进行验证评估指标使用的是Average Precision(AP)、Average Recall(AR),使用了编码器大小和参数大小不同的tiny、small、base模型,在5000轮训练之后得到如下结果。
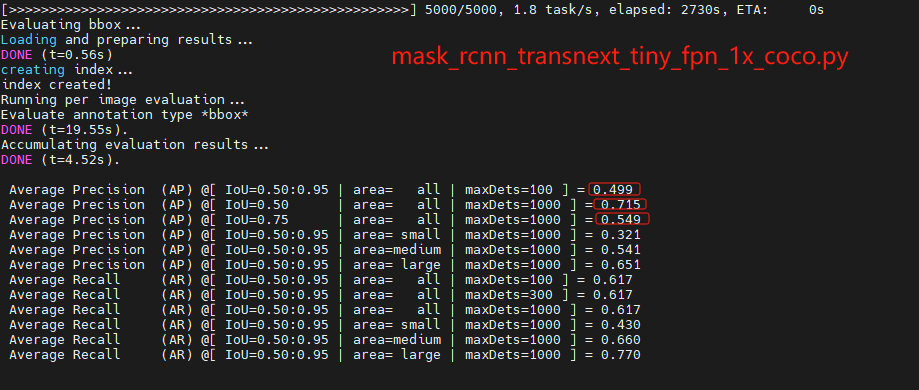
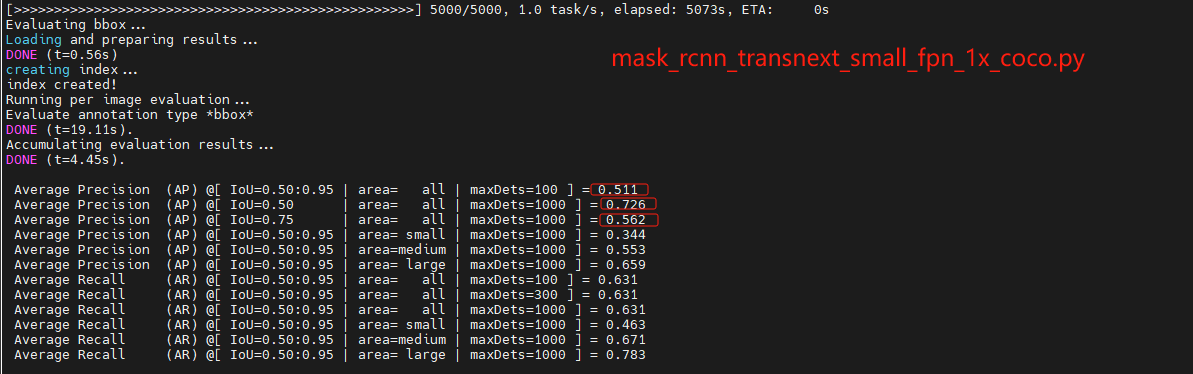
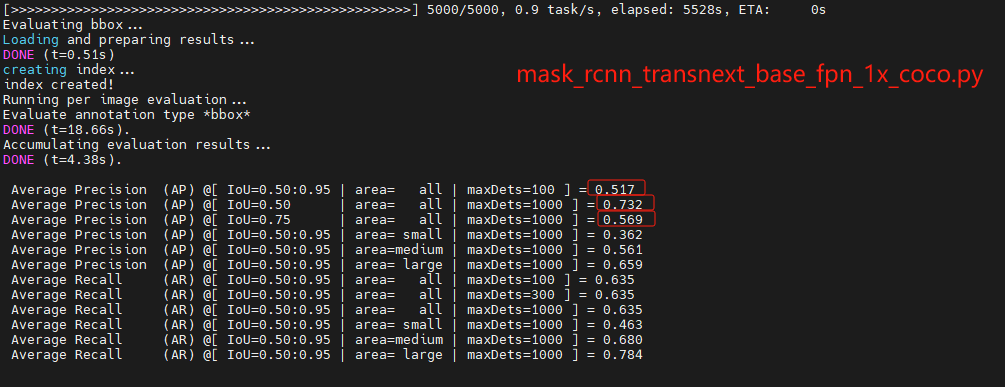
结果与该论文发表的数据一样。
DINO(这里只选取一个base版本进行验证):
5.3 语义分割(ADE20K)
在ADE20K数据集上评估具有TransNeXt主干的UperNet和mask2fomer模型 :在语义分割的下游任务上进行实验,评估指标使用的是mIOU,结果按照mIOU分数升序排序,使用了编码器大小和参数大小不同的tiny、small、base模型。
在 ADE20K 语义分割任务中,结合 UperNet 与 Mask2Former:
-
UperNet + TransNeXt: mIoU 55.8%
-
Mask2Former + TransNeXt: mIoU 57.2%
与传统 Transformer 架构相比,平均提升约 1.5 个百分点。
实验验证结果:
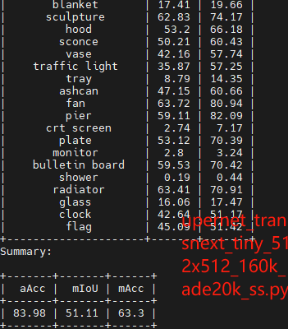
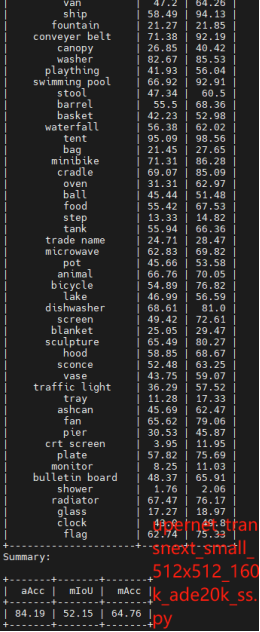
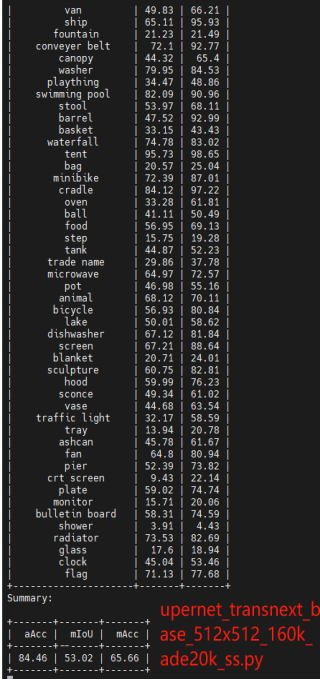
实验结果与该论文所给对应数据完全相同。
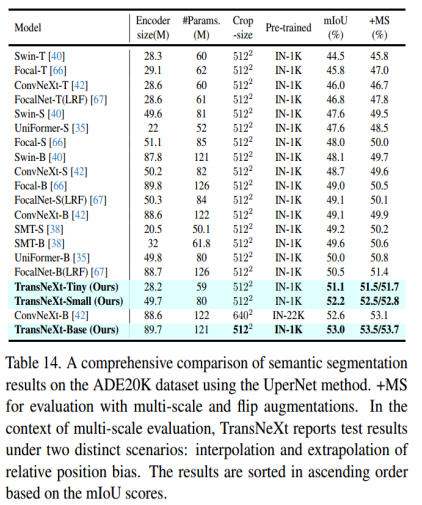
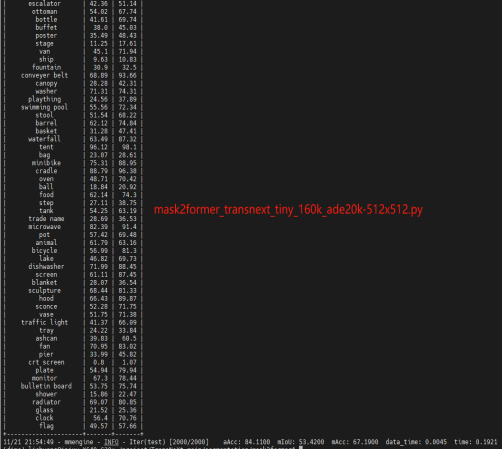
在ADE20K数据集上评估具有TransNeXt主干的mask2fomer模型 ,进行语义分割实验,评估指标使用的是mIOU,在这里仅仅选取部分实验(Tiny、small版本)验证结果,具体读者可更具需求进行实验。
6. PyTorch 快速上手示例
import torch
from transnext import TransNeXt# 模型初始化
model = TransNeXt(depths=[3, 4, 6, 3], dims=[64, 128, 256, 512])
model.cuda()
model.eval()# 测试单张图像
img = torch.randn(1, 3, 224, 224).cuda()
with torch.no_grad():logits = model(img)print(f"输出特征维度: {logits.shape}") # (1, 1000)
⚠️ 提示:实际训练时请结合
torch.utils.data.DataLoader、学习率调度器以及混合精度训练以获得最佳性能。
7. 应用与展望
-
增强现实(AR)/虚拟现实(VR):借助全局与局部特征的高效融合,可实现更流畅的交互体验。
-
智能安防:在复杂场景下的目标检测与分割能力,为视频监控提供更精准的分析。
-
医学影像:高精度的语义分割有助于病灶检测与诊断。
未来可考虑将 TransNeXt 与 NAS、量化推理相结合,进一步提升推理效率与硬件适配性。
8. 总结
TransNeXt 通过仿生聚合注意力、长度缩放余弦注意力与卷积 GLU 等创新,成功解决了深度衰减与信息混合不足的问题,在分类、检测、分割多项任务上均实现了 SOTA 水平。本文从原理剖析、架构设计到实验结果与代码示例,为你全面呈现了这一视觉新架构的魅力。欢迎在评论区与我交流更多心得。
相关文章:
深度学习前沿 | TransNeXt:仿生聚合注意力引领视觉感知新时代
目录 1. 引言 2. 背景与挑战 3. TransNeXt 核心创新 3.1 像素聚合注意力(PAA) 3.2 长度缩放余弦注意力(LSCA) 3.3 卷积 GLU(ConvGLU) 4. 模型架构详解 5. 实验与性能评估 5.1 图像分类(I…...
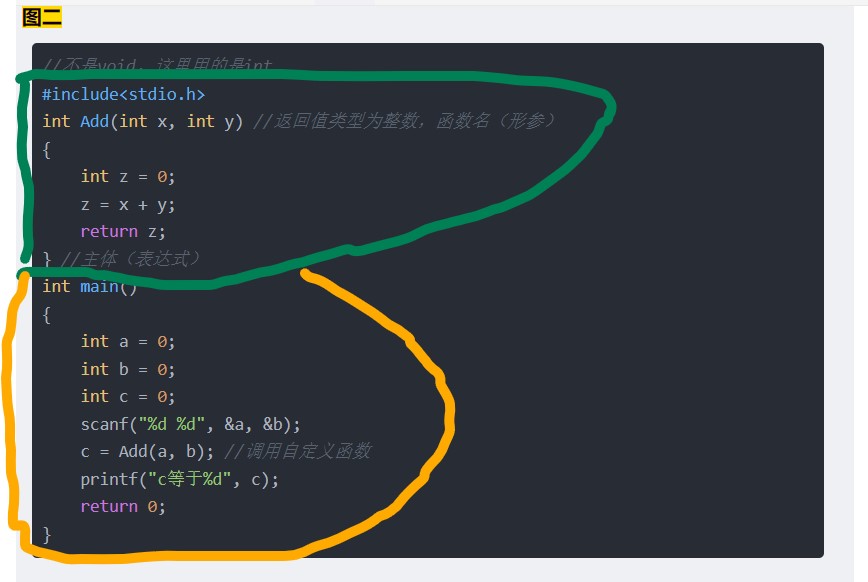
C语言-函数-1
以下是我初学C语言的笔记记录,欢迎在评论区留言补充 一,函数分为几类 * 函数分为两类: 一类是库函数;一类是自定义函数 * 库函数: 系统自己带的,在使用时候,要用到头文件; 查询库函…...

卡尔曼滤波解释及示例
卡尔曼滤波的本质是用数学方法平衡预测与观测的可信度 ,通过不断迭代逼近真实状态。其高效性和鲁棒性,通常在导航定位中,需要融合GPS、加速度计、陀螺仪、激光雷达或摄像头数据,来提高位置精度。简单讲,卡尔曼滤波就是…...
openwrt作旁路由时的几个常见问题 openwrt作为旁路由配置zerotier 图文讲解
1 先看openwrt时间,一定要保证时间和浏览器和服务器是一致的,不然无法更新 2 openwrt设置旁路由前先测试下,路由器能否ping通主路由,是否能够连接外网,好多旁路由设置完了,发现还不能远程好多就是旁路由本…...

Redis--预备知识以及String类型
目录 一、预备知识 1.1 基本全局命令 1.1.1 KEYS 1.1.2 EXISTS 1.1.3 DEL 1.1.4 EXPIRE 1.1.5 TTL 1.1.6 TYPE 1.2 数据结构以及内部编码 1.3 单线程架构 二、String字符串 2.1 常见命令 2.1.1 SET 2.1.2 GET 2.1.3 MGET 2.1.4 MSET 2.1.5 SETNX 2.2 计数命令 2.2.1 INCR 2.2.2…...
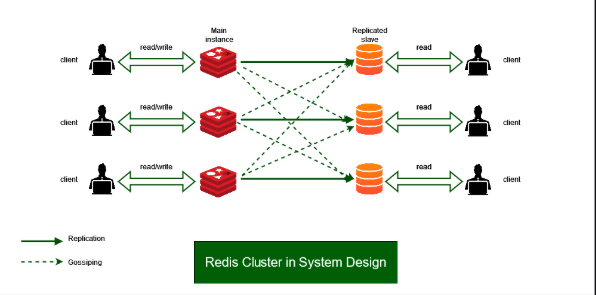
Redis 及其在系统设计中的作用
什么是Redis Redis 是一个开源的内存数据结构存储系统,可用作数据库、缓存和消息代理。它因其快速的性能、灵活性和易用性而得到广泛应用。 Redis 数据存储类型 Redis 允许开发人员以各种数据结构(例如字符串、位图、位域、哈希、列表、集合、有序集合…...

UEC++第10天|UEC++获取对象、RTTI是C++
最近在写UEC项目,这里写几个案例里的问题,还在学习阶段 1. 如何获取小鸟对象? void AFlappyBirdGameModeBase::BeginGame() { // 让管道动起来PipeActor->SetMoveSpeed();// 让小鸟开始飞行// 如何获取到小鸟对象APawn* Pawn UGameplayS…...
)
【python】一文掌握 markitdown 库的操作(用于将文件和办公文档转换为Markdown的Python工具)
更多内容请见: python3案例和总结-专栏介绍和目录 文章目录 一、markitdown概述1.1 markitdown介绍1.2 MarkItDown支持的文件1.3 为什么是Markdown?二、markitdown安装2.1 pip方式安装2.2 源码安装2.3 docker方式安装三、基本使用3.1 命令行方式3.2 可选依赖项配置3.3 插件方…...
爬虫-oiwiki
我们将BASE_URL 设置为 "https://oi-wiki.org/" 后脚本就会自动开始抓取该url及其子页面的所有内容,并将统一子页面的放在一个文件夹中 import requests from bs4 import BeautifulSoup from urllib.parse import urljoin, urlparse import os import pd…...
: つもり 计划/打算)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(10): つもり 计划/打算
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(10): つもり 计划/打算 1、前言(1)情况说明(2)工程师的信仰 2、知识点(1)つもり 计划/打算(2&a…...
强化学习核心原理及数学框架
1. 定义与核心思想 强化学习(Reinforcement Learning, RL)是一种通过智能体(Agent)与环境(Environment)的持续交互来学习最优决策策略的机器学习范式。其核心特征为: 试错学习&#x…...
【技术派后端篇】技术派中 Session/Cookie 与 JWT 身份验证技术的应用及实现解析
在现代Web应用开发中,身份验证是保障系统安全的重要环节。技术派在身份验证领域采用了多种技术方案,其中Session/Cookie和JWT(JSON Web Token)是两种常用的实现方式。本文将详细介绍这两种身份验证技术在技术派中的应用及具体实现…...

【基础】Node.js 介绍、安装及npm 和 npx功能了解
前言 后面安装n8n要用到,做一点技术储备。主要是它的两个工具:npm 和 npx。 Node.js介绍 Node.js 是一个免费的、开源的、跨平台的 JavaScript 运行时环境,允许开发人员在浏览器之外编写命令行工具和服务器端脚本,是一个基于 C…...

第53讲 农学科研中的AI伦理与可解释性——探索SHAP值、LIME等可解释工具与科研可信性建设之道
目录 一、为什么农学科研中需要“可解释AI”? ✅ 场景示例: 二、常见可解释AI工具介绍 1. SHAP(SHapley Additive exPlanations) 2. LIME(Local Interpretable Model-agnostic Explanations) 三、AI伦理问题在农学中的体现 🧭 公平性与偏见 🔐 数据隐私 🤖…...

助力网站优化利用AI批量生成文章工具提升质量
哎,有时候觉得写东西这事儿吧,真挺玄乎的。你看着那些大网站的优质内容,会不会突然冒出个念头——这些家伙到底怎么做到日更十篇还不秃头的?前阵子我蹲在咖啡馆里盯着屏幕发呆,突然刷到个帖子说现在用AI写文章能自动纠…...

Java语言的进化:JDK的未来版本
作为一名Java开发者,我们正处在一个令人兴奋的时代!Java语言正在以前所未有的速度进化,每个新版本都带来令人惊喜的特性。让我们一起探索JDK未来版本的发展方向,看看Java将如何继续领跑编程语言界!💪 &…...
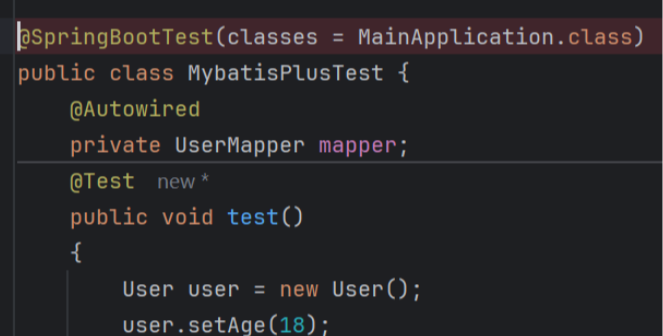
SpringBootTest报错
Unable to find a SpringBootConfiguration, you need to use ContextConfiguration or … 解决方案:在SpringTest注解中添加属性(classes )填写启动类 如我的启动类是MainApplication.class javax.websocket.server.ServerContainer no…...
--多文件上传)
Flask + ajax上传文件(二)--多文件上传
Flask多文件上传完整教程 本教程将详细介绍如何使用Flask实现多文件上传功能,并使用时间戳为上传文件自动命名,避免文件名冲突。 一、环境准备 确保已安装Python和Flask pip install flask项目结构 flask_upload/ ├── app.py ├── upload/ # 上传文…...

w~视觉~合集3
我自己的原文哦~ https://blog.51cto.com/whaosoft/12327888 #几个论文 Fast Charging of Energy-dense Lithium-ion Batteries Real-time Short Video Recommendation on Mobile Devices Semantic interpretation for convolutional neural networks: What makes a ca…...
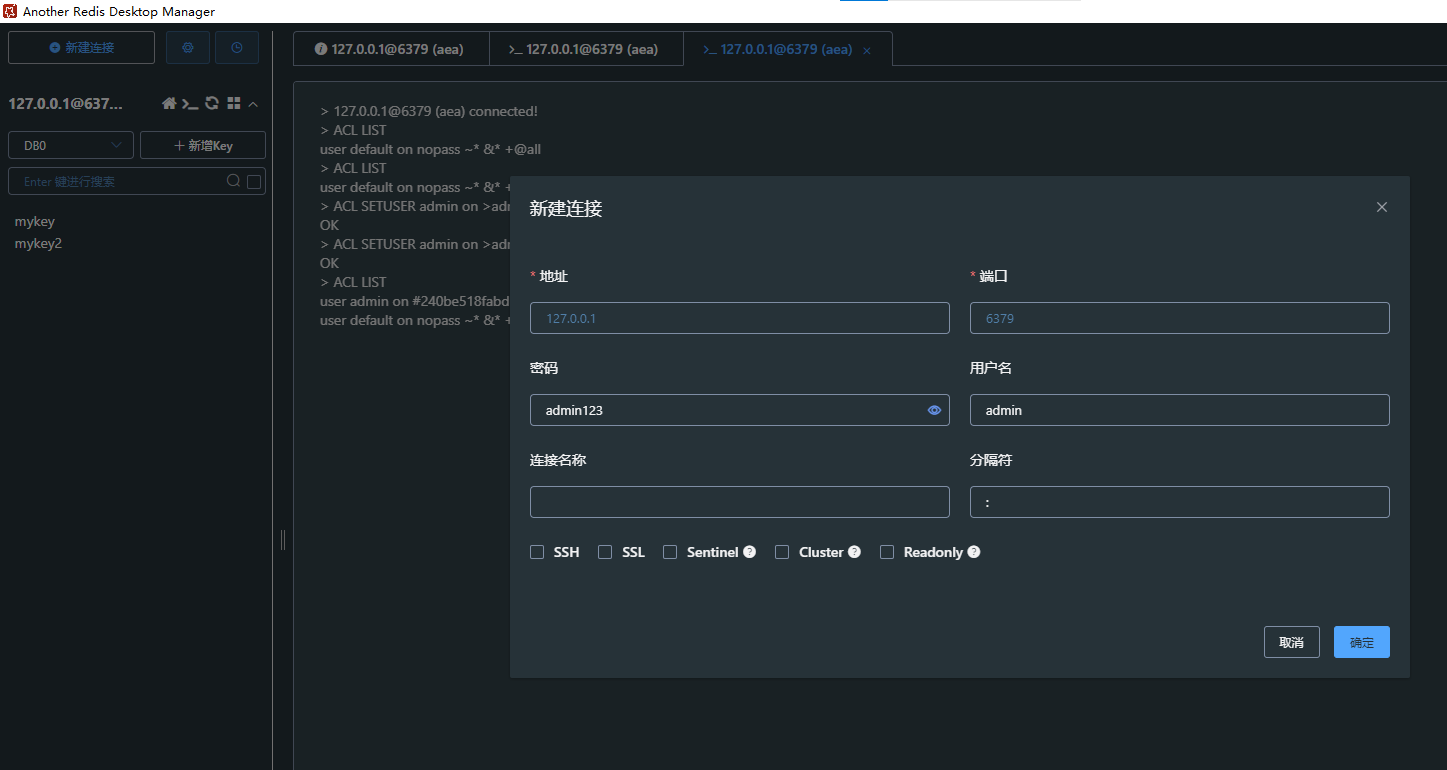
Redis安装及入门应用
应用资料:https://download.csdn.net/download/ly1h1/90685065 1.获取文件,并在该文件下执行cmd 2.输入redis-server-lucifer.exe redis.windows.conf,即可运行redis 3.安装redis客户端软件 4.安装后运行客户端软件,输入链接地址…...

NODE_OPTIONS=--openssl-legacy-provider vue-cli-service serve
//"dev": " NODE_OPTIONS--openssl-legacy-provider vue-cli-service serve" // 修改后(Windows 适用) "dev": "vue-cli-service serve --openssl-legacy-provider" 升级 Node.js 到 v14,确保依赖…...

如何在 Postman 中,自动获取 Token 并将其赋值到环境变量
在 Postman 中,你可以通过 预请求脚本(Pre-request Script) 和 测试脚本(Tests) 实现自动获取 Token 并将其赋值到环境变量,下面是完整的操作步骤: ✅ 一、创建获取 Token 的请求 通常这个请求…...
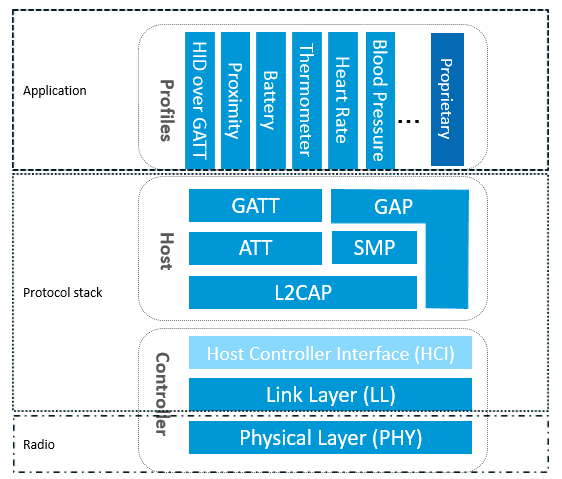
上篇:深入剖析 BLE 底层物理层与链路层(约5000字)
引言 在无线通信领域,Bluetooth Low Energy(BLE)以其超低功耗、灵活的连接模式和良好的生态支持,成为 IoT 与可穿戴设备的首选技术。要想在实际项目中优化性能、控制功耗、保证可靠通信,必须对 BLE 协议栈的底层细节有深入了解。本篇将重点围绕物理层(PHY)与链路层(Li…...

PostgreSQL 的 MVCC 机制了解
PostgreSQL 的 MVCC 机制了解 PostgreSQL 使用多版本并发控制(MVCC)作为其核心并发控制机制,这是它与许多其他数据库系统的关键区别之一。MVCC 允许读操作不阻塞写操作,写操作也不阻塞读操作,从而提供高度并发性。 一 MVCC 基本原理 1.1 M…...

【Pandas】pandas DataFrame dot
Pandas2.2 DataFrame Binary operator functions 方法描述DataFrame.add(other)用于执行 DataFrame 与另一个对象(如 DataFrame、Series 或标量)的逐元素加法操作DataFrame.add(other[, axis, level, fill_value])用于执行 DataFrame 与另一个对象&…...

2025 年“泰迪杯”数据挖掘挑战赛B题——基于穿戴装备的身体活动监测问题分析
摘要 本文聚焦于基于穿戴设备采集的加速度计数据,深入研究志愿者在日常活动中的行为特征,构建了多个数学建模框架,实现从身体活动监测、能耗预测、睡眠阶段识别到久坐预警等多个目标。我们依托于多源数据融合与机器学习模型,对人体活动状态进行识别与分析,为健康管理、行…...

Vivado版本升级后AXI4-Stream Data FIFO端口变化
Vivado 2017.4版本中异步AXI4-Stream Data FIFO升级到Vivado 2018.3后,IP管脚会发生变化,2018.3版中没有m_axis_aresetn和axis_data_count。 async_axis_fifo_8_1024 async_axis_fifo_8_1024 ( .s_axis_aresetn (I_do0_rstn ), // input wire…...
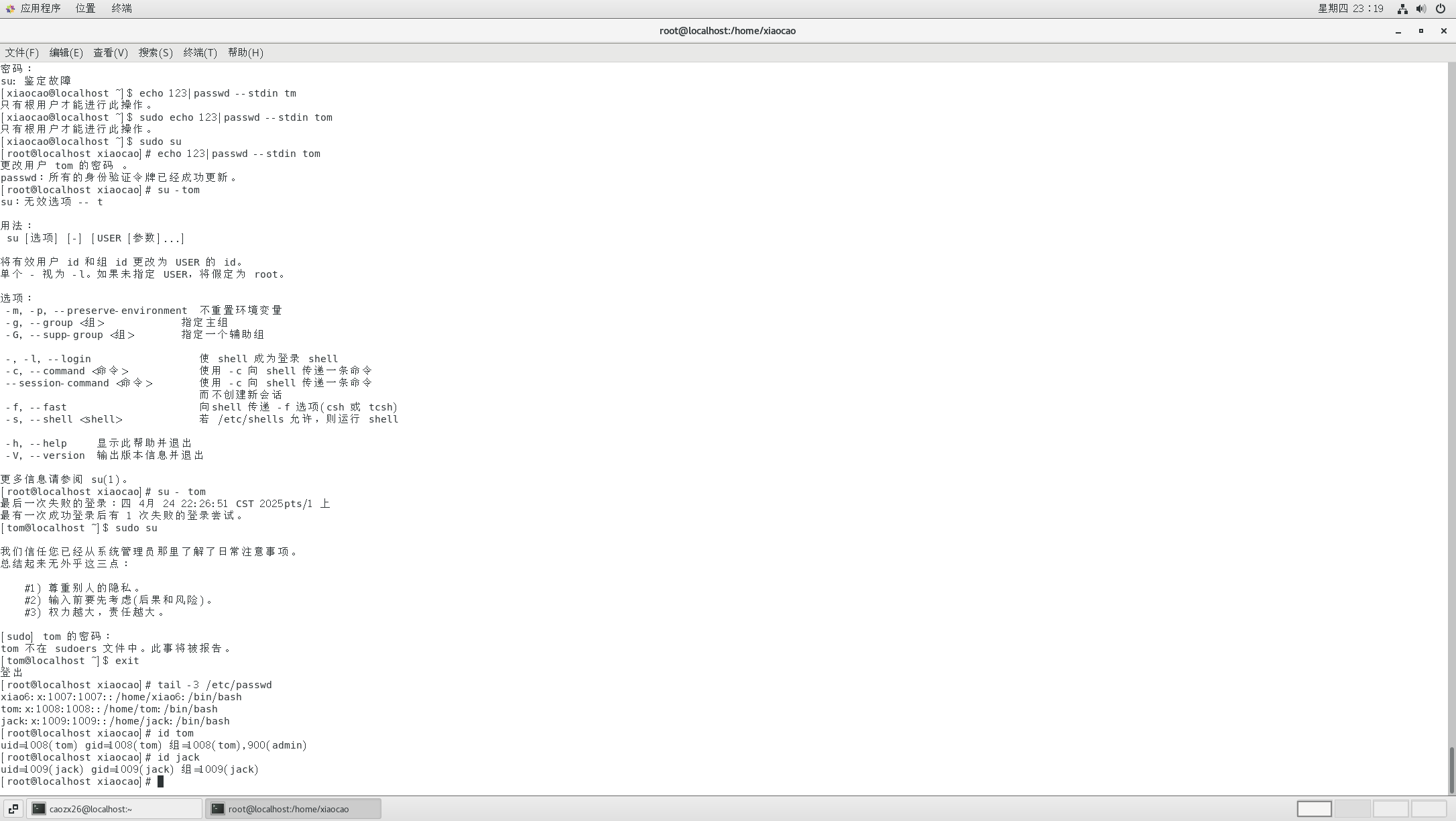
Linux424 chage密码信息 gpasswd 附属组
https://chat.deepseek.com/a/chat/s/e55a5e85-de97-450d-a19e-2c48f6669234...

Git 恢复误删除的文件
由于一些操作,把项目中的大量文件删除了,还以为之前敲得代码都付之东流了,突然想起,我的项目使用git进行的版本管理,且一些更改都暂存在本地的仓库的,因此可以使用git来恢复存入仓库的文件 首先࿰…...
自定义指令简介及用法(vue3)
一介绍 防抖与节流,应用场景有很多,例如:禁止重复提交数据的场景、搜索框输入搜索条件,待输入停止后再开始搜索。 防抖 点击button按钮,设置定时器,在规定的时间内再次点击会重置定时器重新计时…...