C++学习:六个月从基础到就业——STL算法(三)—— 数值算法(上)
C++学习:六个月从基础到就业——STL算法(三)—— 数值算法(上)
本文是我C++学习之旅系列的第二十七篇技术文章,也是第二阶段"C++进阶特性"的第五篇,主要介绍C++ STL算法库中的数值算法(上部分)。查看完整系列目录了解更多内容。
引言
在前两篇文章中,我们分别介绍了STL算法库中的基础查找算法以及排序和变序算法。本文作为系列的第三篇,将重点探讨STL中的数值算法,这些算法主要定义在<numeric>头文件中,用于执行各种数值计算操作。
数值算法是科学计算、数据分析和统计处理中不可或缺的工具。STL提供的数值算法虽然在数量上不及其他类型的算法丰富,但它们提供了基础的数学运算功能,可以方便地处理数值序列,执行累加、乘积、差分、前缀和等常见数值操作。
本文将详细介绍这些算法的用法、特性和应用场景,并通过实际的代码示例,帮助你更好地理解和应用这些算法。
STL数值算法概述
STL的数值算法主要定义在<numeric>头文件中,它们提供了一系列用于数值计算的函数模板。与其他STL算法一样,这些数值算法也是通过迭代器操作容器元素,因此可以应用于任何满足迭代器要求的容器。
主要的数值算法包括:
std::accumulate- 计算序列元素的累加值或通过指定操作的累积值std::inner_product- 计算两个序列的内积或通过指定操作的组合值std::partial_sum- 计算序列的部分和(即前缀和)std::adjacent_difference- 计算序列中相邻元素的差值std::iota- 用连续递增的值填充序列
此外,C++17新增了几个并行版本的数值算法,如std::reduce、std::transform_reduce等,它们提供了更高的性能和灵活性。
接下来,我们将逐一介绍这些算法的用法和特点。
std::accumulate - 累加与累积
std::accumulate是最常用的数值算法之一,用于计算序列元素的总和或者通过某种操作的累积结果。
基本用法
accumulate算法有两种形式:
- 使用默认的加法操作:
accumulate(first, last, init) - 使用自定义二元操作:
accumulate(first, last, init, binary_op)
其中,first和last是定义序列范围的迭代器,init是累加的初始值,binary_op是可选的二元操作函数。
让我们来看一些基本示例:
#include <iostream>
#include <vector>
#include <numeric>
#include <functional>
#include <string>int main() {// 简单整数序列的累加std::vector<int> numbers = {1, 2, 3, 4, 5};// 计算总和(初始值为0)int sum = std::accumulate(numbers.begin(), numbers.end(), 0);std::cout << "Sum: " << sum << std::endl; // 输出: 15// 计算总和(初始值为10)int sumWith10 = std::accumulate(numbers.begin(), numbers.end(), 10);std::cout << "Sum with initial value 10: " << sumWith10 << std::endl; // 输出: 25// 使用自定义操作(乘法)计算乘积int product = std::accumulate(numbers.begin(), numbers.end(), 1, std::multiplies<int>());std::cout << "Product: " << product << std::endl; // 输出: 120 (1*2*3*4*5)// 使用lambda表达式计算平方和int squareSum = std::accumulate(numbers.begin(), numbers.end(), 0,[](int acc, int val) { return acc + val * val; });std::cout << "Sum of squares: " << squareSum << std::endl; // 输出: 55 (1^2+2^2+3^2+4^2+5^2)return 0;
}
这个例子展示了如何使用accumulate计算序列的总和、乘积以及更复杂的运算如平方和。
处理不同类型的数据
accumulate不仅可以处理基本数值类型,还可以处理任意可以应用指定操作的类型。下面是一些例子:
#include <iostream>
#include <vector>
#include <numeric>
#include <string>int main() {// 字符串连接std::vector<std::string> words = {"Hello", ", ", "world", "!"};std::string concatenated = std::accumulate(words.begin(), words.end(), std::string(""));std::cout << "Concatenated string: " << concatenated << std::endl; // 输出: Hello, world!// 注意初始值类型的重要性// 如果使用const char*作为初始值,结果会不正确// 错误的做法:// std::string wrong = std::accumulate(words.begin(), words.end(), ""); // 不要这样做// 浮点数计算(注意初始值的类型)std::vector<int> values = {1, 2, 3, 4, 5};double average = std::accumulate(values.begin(), values.end(), 0.0) / values.size();std::cout << "Average: " << average << std::endl; // 输出: 3.0// 使用自定义结构struct Point {int x, y;Point(int x = 0, int y = 0) : x(x), y(y) {}};std::vector<Point> points = {{1, 2}, {3, 4}, {5, 6}, {7, 8}};// 计算所有点的x和y坐标总和Point sum = std::accumulate(points.begin(), points.end(), Point(),[](const Point& acc, const Point& p) {return Point(acc.x + p.x, acc.y + p.y);});std::cout << "Sum of points: (" << sum.x << ", " << sum.y << ")" << std::endl; // 输出: (16, 20)return 0;
}
这个例子展示了如何使用accumulate处理字符串连接、浮点数计算以及自定义结构的累积操作。
常见应用场景
accumulate在实际编程中有许多应用场景,以下是一些常见的例子:
- 计算统计指标:总和、平均值、方差等
- 字符串拼接:将多个字符串按特定格式连接
- 向量运算:计算向量的范数、点积等
- 数据转换:将一个容器的数据转换为另一种表示形式
下面是一个更复杂的例子,展示了如何使用accumulate实现一些常见的统计计算:
#include <iostream>
#include <vector>
#include <numeric>
#include <cmath>
#include <iomanip>
#include <functional>// 计算统计指标的函数
struct StatisticsResult {double sum;double mean;double variance;double stdDev;double max;double min;
};StatisticsResult calculateStatistics(const std::vector<double>& data) {StatisticsResult result{};if (data.empty()) return result;// 计算总和result.sum = std::accumulate(data.begin(), data.end(), 0.0);// 计算平均值result.mean = result.sum / data.size();// 计算方差result.variance = std::accumulate(data.begin(), data.end(), 0.0,[mean = result.mean](double acc, double val) {return acc + std::pow(val - mean, 2);}) / data.size();// 计算标准差result.stdDev = std::sqrt(result.variance);// 找出最大值result.max = *std::max_element(data.begin(), data.end());// 找出最小值result.min = *std::min_element(data.begin(), data.end());return result;
}int main() {// 一组样本数据std::vector<double> measurements = {10.2, 15.6, 9.8, 12.3, 14.5, 13.7, 11.2, 10.9, 12.8, 13.4};// 计算统计指标StatisticsResult stats = calculateStatistics(measurements);// 打印结果std::cout << std::fixed << std::setprecision(2);std::cout << "Statistical Analysis Results:" << std::endl;std::cout << "---------------------------" << std::endl;std::cout << "Sum: " << stats.sum << std::endl;std::cout << "Mean: " << stats.mean << std::endl;std::cout << "Variance: " << stats.variance << std::endl;std::cout << "Standard Deviation: " << stats.stdDev << std::endl;std::cout << "Maximum: " << stats.max << std::endl;std::cout << "Minimum: " << stats.min << std::endl;// 使用accumulate连接字符串生成格式化报告std::vector<std::pair<std::string, double>> statItems = {{"Sum", stats.sum},{"Mean", stats.mean},{"Variance", stats.variance},{"Standard Deviation", stats.stdDev},{"Maximum", stats.max},{"Minimum", stats.min}};std::string report = std::accumulate(statItems.begin(), statItems.end(), std::string("Statistical Report:\n"),[](const std::string& acc, const std::pair<std::string, double>& item) {std::stringstream ss;ss << acc << "- " << std::left << std::setw(20) << item.first << ": " << std::fixed << std::setprecision(2) << item.second << "\n";return ss.str();});std::cout << "\n" << report << std::endl;return 0;
}
这个示例展示了如何使用accumulate计算一组数据的统计指标,包括总和、平均值、方差和标准差,以及如何用accumulate生成格式化的统计报告。
std::inner_product - 内积与组合操作
std::inner_product用于计算两个序列的内积或者通过自定义操作组合两个序列的元素。
基本用法
inner_product算法有两种形式:
- 使用默认的乘法和加法操作:
inner_product(first1, last1, first2, init) - 使用自定义操作:
inner_product(first1, last1, first2, init, binary_op1, binary_op2)
其中,first1和last1定义第一个序列的范围,first2是第二个序列的开始迭代器,init是初始累积值,binary_op1和binary_op2是可选的二元操作函数。
让我们来看一些基本示例:
#include <iostream>
#include <vector>
#include <numeric>
#include <functional>int main() {// 两个整数向量std::vector<int> v1 = {1, 2, 3, 4, 5};std::vector<int> v2 = {10, 20, 30, 40, 50};// 计算内积(相应元素相乘然后相加)int dotProduct = std::inner_product(v1.begin(), v1.end(), v2.begin(), 0);std::cout << "Dot product: " << dotProduct << std::endl; // 输出: 550 (1*10 + 2*20 + 3*30 + 4*40 + 5*50)// 使用自定义操作:加法替代乘法,乘法替代加法int customResult = std::inner_product(v1.begin(), v1.end(), v2.begin(), 1,std::multiplies<int>(), std::plus<int>());std::cout << "Custom result: " << customResult << std::endl; // 输出: 65610 (1 * (1+10) * (2+20) * (3+30) * (4+40) * (5+50))// 检查两个向量是否相等std::vector<int> v3 = {1, 2, 3, 4, 5};bool areEqual = std::inner_product(v1.begin(), v1.end(), v3.begin(), true,std::logical_and<bool>(), [](int a, int b) { return a == b; });std::cout << "v1 and v3 are " << (areEqual ? "equal" : "not equal") << std::endl; // 输出: v1 and v3 are equalreturn 0;
}
这个例子展示了如何使用inner_product计算两个向量的内积以及使用自定义操作实现其他功能,如检查两个序列是否相等。
常见应用场景
inner_product在多个领域有广泛的应用,例如:
- 向量代数:计算向量的点积、余弦相似度等
- 矩阵运算:矩阵乘法的基本操作
- 信号处理:信号的相关性计算
- 相似度度量:计算两个数据集的相似度
下面是一个使用inner_product计算向量余弦相似度的例子:
#include <iostream>
#include <vector>
#include <numeric>
#include <cmath>
#include <iomanip>// 计算两个向量的余弦相似度
double cosineSimilarity(const std::vector<double>& v1, const std::vector<double>& v2) {if (v1.size() != v2.size() || v1.empty()) {return 0.0; // 无效输入}// 计算点积double dotProduct = std::inner_product(v1.begin(), v1.end(), v2.begin(), 0.0);// 计算v1的模长double magnitude1 = std::sqrt(std::inner_product(v1.begin(), v1.end(), v1.begin(), 0.0));// 计算v2的模长double magnitude2 = std::sqrt(std::inner_product(v2.begin(), v2.end(), v2.begin(), 0.0));// 计算余弦相似度if (magnitude1 == 0.0 || magnitude2 == 0.0) {return 0.0; // 避免除以零}return dotProduct / (magnitude1 * magnitude2);
}int main() {// 两个文档的词频向量(TF-IDF值)std::vector<double> doc1 = {0.5, 0.8, 0.3, 0, 0.2, 0.7, 0, 0.4};std::vector<double> doc2 = {0.9, 0.4, 0.2, 0.1, 0, 0.6, 0.3, 0.2};// 计算文档相似度double similarity = cosineSimilarity(doc1, doc2);std::cout << "Cosine similarity between two documents: " << std::fixed << std::setprecision(4) << similarity << std::endl;// 相似度解释std::cout << "Interpretation: ";if (similarity > 0.8) {std::cout << "Very similar";} else if (similarity > 0.5) {std::cout << "Moderately similar";} else if (similarity > 0.2) {std::cout << "Slightly similar";} else {std::cout << "Not similar";}std::cout << std::endl;return 0;
}
这个例子演示了如何使用inner_product计算两个文档向量的余弦相似度,这是文本挖掘和信息检索中常用的相似度度量方法。
std::partial_sum - 部分和(前缀和)
std::partial_sum用于计算序列的部分和,也称为前缀和或累积和,即输出序列的每个元素是输入序列中对应位置及之前所有元素的和。
基本用法
partial_sum算法有两种形式:
- 使用默认的加法操作:
partial_sum(first, last, d_first) - 使用自定义的二元操作:
partial_sum(first, last, d_first, binary_op)
其中,first和last定义输入序列的范围,d_first是输出序列的起始迭代器,binary_op是可选的二元操作函数。
以下是一些基本示例:
#include <iostream>
#include <vector>
#include <numeric>
#include <iterator>
#include <functional>// 辅助函数,打印向量内容
template<typename T>
void printVector(const std::vector<T>& vec, const std::string& name) {std::cout << name << ": ";for (const T& item : vec) {std::cout << item << " ";}std::cout << std::endl;
}int main() {// 整数序列std::vector<int> numbers = {1, 2, 3, 4, 5};std::vector<int> sums(numbers.size());// 计算前缀和std::partial_sum(numbers.begin(), numbers.end(), sums.begin());printVector(numbers, "Original"); // 输出: 1 2 3 4 5printVector(sums, "Prefix sums"); // 输出: 1 3 6 10 15// 使用自定义操作(乘法)计算部分积std::vector<int> products(numbers.size());std::partial_sum(numbers.begin(), numbers.end(), products.begin(), std::multiplies<int>());printVector(products, "Prefix products"); // 输出: 1 2 6 24 120// 原地计算(覆盖原始数据)std::partial_sum(numbers.begin(), numbers.end(), numbers.begin());printVector(numbers, "In-place prefix sums"); // 输出: 1 3 6 10 15return 0;
}
这个例子展示了如何使用partial_sum计算一个序列的前缀和以及如何使用自定义操作计算前缀积。
常见应用场景
partial_sum在多种场景下都非常有用,例如:
- 前缀和查询:快速计算数组任意区间的和
- 累积统计:计算随时间累积的值
- 积分近似:数值积分的梯形法则
- 概率分布:计算累积分布函数(CDF)
下面是一个使用partial_sum解决实际问题的例子:
#include <iostream>
#include <vector>
#include <numeric>
#include <algorithm>
#include <iomanip>
#include <random>// 使用前缀和快速计算区间和
class RangeSum {
private:std::vector<int> prefixSums;public:RangeSum(const std::vector<int>& arr) {// 计算前缀和数组prefixSums.resize(arr.size() + 1); // 多一个元素,使索引更直观prefixSums[0] = 0; // 前缀和的第一个元素为0std::partial_sum(arr.begin(), arr.end(), prefixSums.begin() + 1);}// 计算区间[start, end)的和int query(int start, int end) const {if (start < 0 || end > static_cast<int>(prefixSums.size()) - 1 || start >= end) {return 0; // 无效区间}return prefixSums[end] - prefixSums[start];}
};// 计算股票的移动平均价格
void calculateMovingAverage(const std::vector<double>& prices, int windowSize) {if (prices.empty() || windowSize <= 0) return;std::vector<double> movingSum(prices.size() + 1);movingSum[0] = 0.0;std::partial_sum(prices.begin(), prices.end(), movingSum.begin() + 1);std::cout << "Moving Average (window size " << windowSize << "):" << std::endl;std::cout << std::setw(10) << "Day" << std::setw(10) << "Price" << std::setw(15) << "Moving Avg" << std::endl;std::cout << std::string(35, '-') << std::endl;for (size_t i = 0; i < prices.size(); ++i) {std::cout << std::fixed << std::setprecision(2);std::cout << std::setw(10) << i + 1 << std::setw(10) << prices[i];// 计算移动平均if (i + 1 >= static_cast<size_t>(windowSize)) {int start = i + 1 - windowSize;double avg = (movingSum[i + 1] - movingSum[start]) / windowSize;std::cout << std::setw(15) << avg;} else {std::cout << std::setw(15) << "-";}std::cout << std::endl;}
}int main() {// 示例1:使用前缀和进行高效区间查询std::vector<int> data = {3, 7, 2, 5, 8, 9, 1, 6};RangeSum rangeSum(data);std::cout << "Original array: ";for (int num : data) std::cout << num << " ";std::cout << std::endl;// 查询示例std::cout << "Sum of range [1, 4): " << rangeSum.query(1, 4) << std::endl; // 7+2+5=14std::cout << "Sum of range [2, 6): " << rangeSum.query(2, 6) << std::endl; // 2+5+8+9=24std::cout << "Sum of range [0, 8): " << rangeSum.query(0, 8) << std::endl; // 整个数组的和=41// 示例2:计算股票的移动平均价格std::vector<double> stockPrices = {45.67, 46.23, 46.01, 45.89, 47.05, 46.78, 47.30, 48.15, 47.95, 48.87};calculateMovingAverage(stockPrices, 5);return 0;
}
这个例子展示了两种partial_sum的实际应用:
- 使用前缀和实现高效的区间和查询
- 计算股票价格的移动平均线
std::adjacent_difference - 相邻差值
std::adjacent_difference用于计算序列中相邻元素的差值,即输出序列的每个元素是输入序列中当前元素与前一个元素的差。
基本用法
adjacent_difference算法有两种形式:
- 使用默认的减法操作:
adjacent_difference(first, last, d_first) - 使用自定义的二元操作:
adjacent_difference(first, last, d_first, binary_op)
其中,first和last定义输入序列的范围,d_first是输出序列的起始迭代器,binary_op是可选的二元操作函数。
以下是一些基本示例:
#include <iostream>
#include <vector>
#include <numeric>
#include <functional>template<typename T>
void printVector(const std::vector<T>& vec, const std::string& name) {std::cout << name << ": ";for (const T& item : vec) {std::cout << item << " ";}std::cout << std::endl;
}int main() {// 整数序列std::vector<int> numbers = {1, 3, 6, 10, 15};std::vector<int> diffs(numbers.size());// 计算相邻差值std::adjacent_difference(numbers.begin(), numbers.end(), diffs.begin());printVector(numbers, "Original"); // 输出: 1 3 6 10 15printVector(diffs, "Differences"); // 输出: 1 2 3 4 5 (注意第一个元素保持不变)// 使用自定义操作(加法而非减法)std::vector<int> sums(numbers.size());std::adjacent_difference(numbers.begin(), numbers.end(), sums.begin(), std::plus<int>());printVector(sums, "Adjacent sums"); // 输出: 1 4 9 16 25// 原地计算std::adjacent_difference(numbers.begin(), numbers.end(), numbers.begin());printVector(numbers, "In-place differences"); // 输出: 1 2 3 4 5return 0;
}
这个例子展示了如何使用adjacent_difference计算序列的相邻元素差值,以及如何使用自定义操作代替默认的减法。
还原前缀和
有趣的是,adjacent_difference可以看作是partial_sum的逆操作。如果我们有一个前缀和序列,使用adjacent_difference可以还原原始序列:
#include <iostream>
#include <vector>
#include <numeric>template<typename T>
void printVector(const std::vector<T>& vec, const std::string& name) {std::cout << name << ": ";for (const T& item : vec) {std::cout << item << " ";}std::cout << std::endl;
}int main() {// 原始序列std::vector<int> original = {3, 1, 4, 1, 5, 9};printVector(original, "Original");// 计算前缀和std::vector<int> prefixSum(original.size());std::partial_sum(original.begin(), original.end(), prefixSum.begin());printVector(prefixSum, "Prefix sum");// 使用adjacent_difference还原原始序列std::vector<int> restored(prefixSum.size());std::adjacent_difference(prefixSum.begin(), prefixSum.end(), restored.begin());printVector(restored, "Restored");return 0;
}
输出:
Original: 3 1 4 1 5 9
Prefix sum: 3 4 8 9 14 23
Restored: 3 1 4 1 5 9
常见应用场景
adjacent_difference在多种场景下有用,例如:
- 差分数组:求解区间更新问题
- 速度计算:从位置序列计算速度
- 加速度计算:从速度序列计算加速度
- 连续变化率:计算数据的变化速率
下面是一个使用adjacent_difference解决实际问题的例子:
#include <iostream>
#include <vector>
#include <numeric>
#include <algorithm>
#include <iomanip>
#include <cmath>// 通过位置数据计算速度和加速度
void calculateKinematics(const std::vector<double>& positions, double timeStep) {if (positions.size() < 3) return;std::vector<double> velocities(positions.size());std::vector<double> accelerations(positions.size());// 计算速度(一阶差分)std::adjacent_difference(positions.begin(), positions.end(), velocities.begin());// 将速度除以时间步长std::transform(velocities.begin() + 1, velocities.end(), velocities.begin() + 1,[timeStep](double diff) { return diff / timeStep; });// 计算加速度(二阶差分)std::adjacent_difference(velocities.begin(), velocities.end(), accelerations.begin());// 将加速度除以时间步长std::transform(accelerations.begin() + 1, accelerations.end(), accelerations.begin() + 1,[timeStep](double diff) { return diff / timeStep; });std::cout << std::fixed << std::setprecision(3);std::cout << std::setw(10) << "Time" << std::setw(12) << "Position" << std::setw(12) << "Velocity" << std::setw(15) << "Acceleration" << std::endl;std::cout << std::string(49, '-') << std::endl;for (size_t i = 0; i < positions.size(); ++i) {std::cout << std::setw(10) << i * timeStep<< std::setw(12) << positions[i]<< std::setw(12) << (i > 0 ? velocities[i] : 0)<< std::setw(15) << (i > 1 ? accelerations[i] : 0)<< std::endl;}
}// 使用差分数组进行区间更新和查询
class RangeUpdateQuery {
private:std::vector<int> arr; // 原始数组std::vector<int> diff; // 差分数组public:RangeUpdateQuery(const std::vector<int>& initial) : arr(initial) {diff.resize(arr.size());std::adjacent_difference(arr.begin(), arr.end(), diff.begin());}// 区间[start, end]增加valvoid rangeUpdate(int start, int end, int val) {if (start < 0 || end >= static_cast<int>(arr.size()) || start > end) return;diff[start] += val;if (end + 1 < static_cast<int>(arr.size())) {diff[end + 1] -= val;}// 更新原始数组std::partial_sum(diff.begin(), diff.end(), arr.begin());}// 获取当前数组const std::vector<int>& getArray() const {return arr;}
};int main() {// 示例1:计算运动学参数std::cout << "Kinematics Example:" << std::endl;// 简单的抛物线运动:x = x0 + v0*t + 0.5*a*t^2double x0 = 0.0; // 初始位置double v0 = 10.0; // 初始速度double a = -9.8; // 加速度(重力)double dt = 0.5; // 时间步长std::vector<double> positions;for (int i = 0; i < 10; ++i) {double t = i * dt;double x = x0 + v0 * t + 0.5 * a * t * t;positions.push_back(x);}calculateKinematics(positions, dt);// 示例2:使用差分数组进行区间更新std::cout << "\nRange Update Example:" << std::endl;std::vector<int> initial(10, 0); // 初始全为0的数组RangeUpdateQuery ruq(initial);std::cout << "Initial array: ";for (int val : ruq.getArray()) std::cout << val << " ";std::cout << std::endl;// 进行区间更新ruq.rangeUpdate(2, 6, 3); // 区间[2,6]增加3ruq.rangeUpdate(0, 4, 2); // 区间[0,4]增加2ruq.rangeUpdate(5, 9, 1); // 区间[5,9]增加1std::cout << "After updates: ";for (int val : ruq.getArray()) std::cout << val << " ";std::cout << std::endl;return 0;
}
这个例子展示了两个adjacent_difference的实际应用:
- 根据物体位置序列计算速度和加速度
- 使用差分数组高效处理区间更新问题
std::iota - 递增序列生成
std::iota用于以递增顺序填充序列,它生成连续的递增值,从指定的起始值开始。这个算法的名称来源于APL编程语言中的一个函数,而不是英文缩写。
基本用法
iota算法的格式为:iota(first, last, value)
其中,first和last定义要填充的序列范围,value是起始值。
以下是一些基本示例:
#include <iostream>
#include <vector>
#include <list>
#include <numeric>
#include <iomanip>template<typename T>
void printContainer(const T& container, const std::string& name) {std::cout << name << ": ";for (const auto& item : container) {std::cout << item << " ";}std::cout << std::endl;
}int main() {// 填充向量std::vector<int> vec(10);std::iota(vec.begin(), vec.end(), 1); // 从1开始递增printContainer(vec, "Vector"); // 输出: 1 2 3 4 5 6 7 8 9 10// 填充列表std::list<int> lst(5);std::iota(lst.begin(), lst.end(), 100); // 从100开始递增printContainer(lst, "List"); // 输出: 100 101 102 103 104// 使用浮点数std::vector<double> doubles(8);std::iota(doubles.begin(), doubles.end(), -3.5); // 从-3.5开始递增std::cout << "Doubles: ";for (double d : doubles) {std::cout << std::fixed << std::setprecision(1) << d << " ";}std::cout << std::endl; // 输出: -3.5 -2.5 -1.5 -0.5 0.5 1.5 2.5 3.5// 使用字符std::vector<char> chars(26);std::iota(chars.begin(), chars.end(), 'a'); // 从'a'开始递增printContainer(chars, "Chars"); // 输出: a b c ... zreturn 0;
}
这个例子展示了如何使用iota填充各种容器,生成不同类型的递增序列。
常见应用场景
iota在创建索引序列、生成测试数据、初始化容器等方面非常有用,下面是一些常见的应用:
- 创建索引数组:用于间接排序或重新排列元素
- 生成测试序列:快速创建具有特定模式的测试数据
- 数值范围生成:创建特定范围内的数值序列
- 初始化循环变量:为循环或迭代准备初始值
下面是一些实际应用的例子:
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
#include <iomanip>
#include <random>// 间接排序示例
void indirectSortExample() {std::cout << "Indirect Sort Example:" << std::endl;// 原始数据std::vector<std::string> names = {"Alice", "Bob", "Charlie", "David", "Eve", "Frank"};std::vector<double> scores = {85.5, 92.0, 78.5, 95.5, 88.0, 71.5};// 创建索引数组std::vector<int> indices(scores.size());std::iota(indices.begin(), indices.end(), 0); // 填充0,1,2,...// 按分数排序索引std::sort(indices.begin(), indices.end(),[&scores](int a, int b) { return scores[a] > scores[b]; });// 打印排序结果std::cout << "Rank | Name | Score" << std::endl;std::cout << "---------------------------" << std::endl;for (size_t i = 0; i < indices.size(); ++i) {int idx = indices[i];std::cout << std::setw(4) << i + 1 << " | " << std::left << std::setw(10) << names[idx] << " | " << std::fixed << std::setprecision(1) << scores[idx]<< std::endl;}
}// 生成随机排列
std::vector<int> generateRandomPermutation(int n) {std::vector<int> perm(n);std::iota(perm.begin(), perm.end(), 0); // 填充0,1,2,...,n-1// 随机打乱std::random_device rd;std::mt19937 g(rd());std::shuffle(perm.begin(), perm.end(), g);return perm;
}// 使用iota生成离散区间
template<typename T>
std::vector<T> linearSpace(T start, T end, size_t num) {std::vector<T> result(num);T step = (end - start) / static_cast<T>(num - 1);// 使用transform和iota生成线性空间std::vector<size_t> indices(num);std::iota(indices.begin(), indices.end(), 0);std::transform(indices.begin(), indices.end(), result.begin(),[start, step](size_t i) { return start + step * static_cast<T>(i); });return result;
}int main() {// 间接排序示例indirectSortExample();// 生成随机排列std::cout << "\nRandom Permutation Example:" << std::endl;auto perm = generateRandomPermutation(10);std::cout << "Random permutation: ";for (int p : perm) std::cout << p << " ";std::cout << std::endl;// 生成线性空间std::cout << "\nLinear Space Example:" << std::endl;auto linspace = linearSpace<double>(0.0, 1.0, 11);std::cout << "Linear space [0,1] with 11 points: ";for (double x : linspace) {std::cout << std::fixed << std::setprecision(2) << x << " ";}std::cout << std::endl;return 0;
}
这个例子展示了iota的三种实际应用:
- 创建索引数组用于间接排序,保留原始数据不变
- 生成随机排列,用于洗牌或随机采样
- 结合
transform生成线性等分的数值序列
C++17的并行算法
C++17引入了并行版本的STL算法,包括数值算法,允许在多核环境中实现更高的性能。
并行版本的数值算法
C++17新增了以下并行数值算法:
std::reduce-accumulate的并行版本,允许非顺序计算std::transform_reduce- 结合transform和reduce的功能std::inclusive_scan-partial_sum的并行版本std::exclusive_scan- 类似inclusive_scan,但不包括当前元素std::transform_inclusive_scan- 结合transform和inclusive_scanstd::transform_exclusive_scan- 结合transform和exclusive_scan
下面是这些并行算法的基本使用示例:
#include <iostream>
#include <vector>
#include <numeric>
#include <execution>
#include <chrono>
#include <random>
#include <iomanip>// 计时辅助函数
template<typename Func>
long long measureTime(Func func) {auto start = std::chrono::high_resolution_clock::now();func();auto end = std::chrono::high_resolution_clock::now();return std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();
}int main() {// 创建大数组进行测试constexpr size_t size = 50'000'000;std::vector<double> data(size);// 用随机数填充std::random_device rd;std::mt19937 gen(rd());std::uniform_real_distribution<> dis(1.0, 100.0);for (auto& val : data) {val = dis(gen);}double sum1 = 0, sum2 = 0, sum3 = 0, sum4 = 0;// 使用普通accumulateauto time1 = measureTime([&] {sum1 = std::accumulate(data.begin(), data.end(), 0.0);});// 使用顺序reduce (std::execution::seq)auto time2 = measureTime([&] {sum2 = std::reduce(std::execution::seq, data.begin(), data.end(), 0.0);});// 使用并行reduce (std::execution::par)auto time3 = measureTime([&] {sum3 = std::reduce(std::execution::par, data.begin(), data.end(), 0.0);});// 使用并行向量化reduce (std::execution::par_unseq)auto time4 = measureTime([&] {sum4 = std::reduce(std::execution::par_unseq, data.begin(), data.end(), 0.0);});std::cout << std::fixed << std::setprecision(1);std::cout << "Sum (accumulate): " << sum1 << std::endl;std::cout << "Sum (seq reduce): " << sum2 << std::endl;std::cout << "Sum (par reduce): " << sum3 << std::endl;std::cout << "Sum (par_unseq): " << sum4 << std::endl;std::cout << "\nPerformance Comparison:" << std::endl;std::cout << "accumulate: " << time1 << " microseconds" << std::endl;std::cout << "sequential reduce: " << time2 << " microseconds" << std::endl;std::cout << "parallel reduce: " << time3 << " microseconds" << std::endl;std::cout << "parallel_unsequenced reduce: " << time4 << " microseconds" << std::endl;// transform_reduce示例 - 计算平方和double squareSum1 = 0, squareSum2 = 0;// 使用transform和reduce组合auto time5 = measureTime([&] {std::vector<double> squares(size);std::transform(data.begin(), data.end(), squares.begin(), [](double x) { return x * x; });squareSum1 = std::reduce(squares.begin(), squares.end(), 0.0);});// 使用transform_reduceauto time6 = measureTime([&] {squareSum2 = std::transform_reduce(std::execution::par,data.begin(), data.end(),0.0,std::plus<double>(),[](double x) { return x * x; });});std::cout << "\nSquare Sum (transform + reduce): " << squareSum1 << std::endl;std::cout << "Square Sum (transform_reduce): " << squareSum2 << std::endl;std::cout << "Time (transform + reduce): " << time5 << " microseconds" << std::endl;std::cout << "Time (transform_reduce): " << time6 << " microseconds" << std::endl;return 0;
}
注意:要使用C++17的并行算法,需要支持C++17的编译器,并根据编译器要求链接适当的并行库(如Intel TBB、OpenMP等)。
总结
在这篇文章中,我们详细探讨了STL中的数值算法,包括:
- std::accumulate - 计算序列元素的总和或通过某种操作的累积结果
- std::inner_product - 计算两个序列的内积或组合结果
- std::partial_sum - 计算序列的部分和(前缀和)
- std::adjacent_difference - 计算序列中相邻元素的差值
- std::iota - 用递增值填充序列
我们还简要介绍了C++17引入的并行版本数值算法,如std::reduce和std::transform_reduce等。
这些数值算法在科学计算、数据分析、统计处理、信号处理等领域有广泛的应用。掌握这些算法可以帮助你更高效地处理数值数据,编写更简洁、更可读的代码。
在下一篇文章中,我们将继续探讨数值算法的高级应用以及STL中的集合算法,如std::set_union、std::set_intersection等,这些算法用于对有序序列执行集合操作。
参考资源
- C++ Reference - 详细的STL数值算法文档
- 《C++标准库》by Nicolai M. Josuttis
- 《Effective STL》by Scott Meyers
- 《C++17 STL Cookbook》by Jacek Galowicz
这是我C++学习之旅系列的第二十七篇技术文章。查看完整系列目录了解更多内容。
如有任何问题或建议,欢迎在评论区留言交流!
相关文章:
—— 数值算法(上))
C++学习:六个月从基础到就业——STL算法(三)—— 数值算法(上)
C学习:六个月从基础到就业——STL算法(三)—— 数值算法(上) 本文是我C学习之旅系列的第二十七篇技术文章,也是第二阶段"C进阶特性"的第五篇,主要介绍C STL算法库中的数值算法(上部分)。查看完整系列目录了解…...

路由与路由器
路由的概念 路由是指在网络通讯中,从源设备到目标设备路径的选择过程。路由器是实现这一过程的关键设备,它通过转发数据包来实现网络的互联。路由工作在OSI参考模型的第三层,‘网络层’。 路由器的基本原理 路由器通过维护一张路由表来决定…...
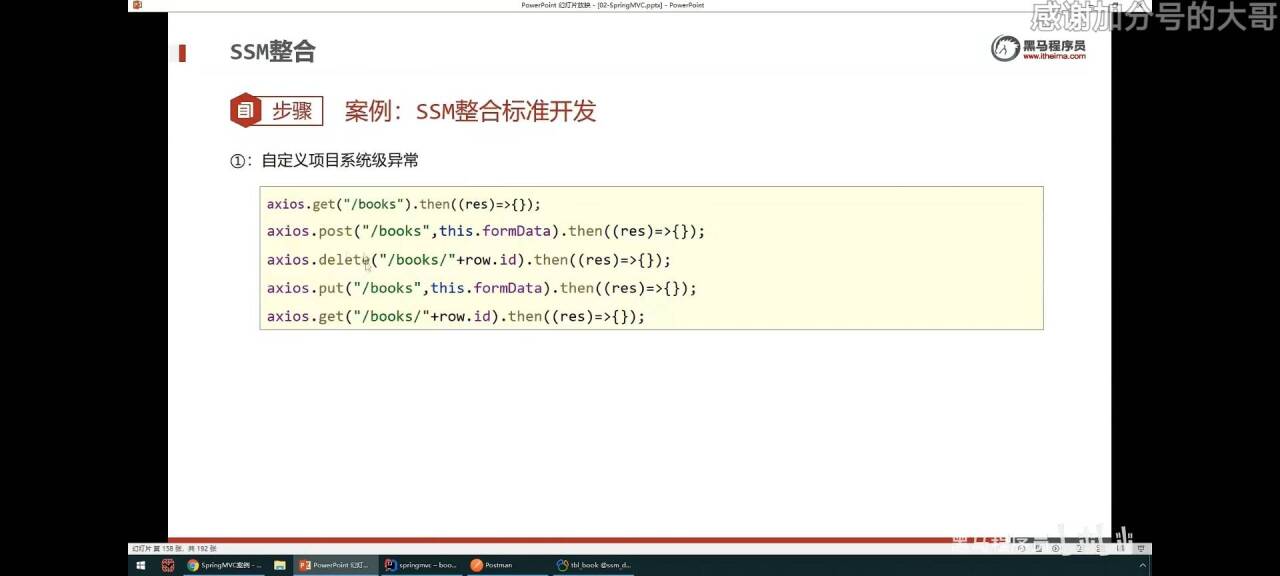
5.学习笔记-SpringMVC(P61-P70)
SpringMVC-SSM整合-接口测试 (1)业务层接口使用junit接口做测试 (2)表现层用postman做接口测试 (3)事务处理— 1)在SpringConfig.java,开启注解,是事务驱动 2)配置事务管理器(因为事务管理器是要配置数据源对象&…...

【专题刷题】二分查找(一):深度解刨二分思想和二分模板
📝前言说明: 本专栏主要记录本人的基础算法学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码;ÿ…...
硬核解析!电动汽车能耗预测与续驶里程的关键技术研究
引言 随着电动汽车的普及,续航里程和能耗表现成为用户关注的核心痛点。然而,表显续航与实际续航的差异、低温环境下的电量衰减等问题始终困扰着消费者。本文基于《电动汽车能耗预测与续驶里程研究》的实验成果,深入剖析电动汽车能耗预测的核心模型、多环境测试方法及续航里…...
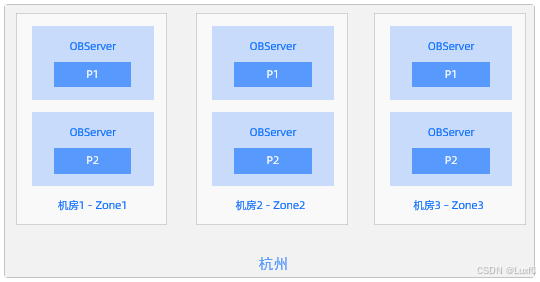
【OceanBase相关】01-OceanBase数据库部署实践
文章目录 一、前言1、介绍说明2、部署方案二、部署说明1、环境准备2、软件安装2.1、安装OAT2.2、安装OCP3、软件部署三、集群管理1、MySQL租户管理四、Q&A1、OBServer 服务器重启后 observer 进程未能自动启动1.1、问题说明1.2、解决措施2、ERROR 1235 (0A000) at line 1: …...
(C++))
【华为OD机试真题】428、连续字母长度 | 机试真题+思路参考+代码解析(E卷)(C++)
文章目录 一、题目题目描述输入输出样例1样例2 一、代码与思路🧠C语言思路✅C代码 一、题目 参考:https://sars2025.blog.csdn.net/article/details/139492358 题目描述 ◎ 给定一个字符串,只包含大写字母,求在包含同一字母的子串…...

C# 综合示例 库存管理系统4 classMod类
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的 在《库存管理系统》中使用classMod类来保存全局变量。 变量定义和含义,请详见下面的源代码: public class classMod { //数据库路径...

ZooKeeper配置优化秘籍:核心参数说明与性能优化
#作者:张桐瑞 文章目录 tickTime:Client-Server通信心跳时间initLimit:Leader-Follower初始通信时限syncLimit:Leader-Follower同步通信时限dataDir:数据文件目录clientPort:客户端连接端口服务器名称与地…...

详细讲解 QMutex 线程锁和 QMutexLocker 自动锁的区别
详细讲解 QMutex 线程锁和 QMutexLocker 自动锁的区别 下面我们详细拆解 Qt 中用于线程同步的两个核心类:QMutex 和 QMutexLocker。 🧱 一、什么是 QMutex? QMutex 是 Qt 中的互斥锁(mutex)类,用于防止多个…...
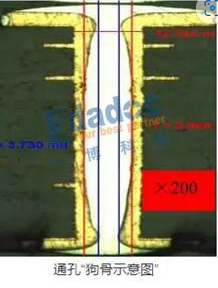
PCB 过孔铜厚的深入指南
***前言:在上一期的文章中介绍了PCB制造的工艺流程,但仍然想在过孔的铜厚和PCB的过孔厚径比两个方面再深入介绍。 PCB铜厚的定义 电路中铜的厚度以盎司(oz)**表示。那么,为什么用重量单位来表示厚度呢? 盎司(oz)的定义 将1盎司(28.35 克)的铜…...

【ES实战】Elasticsearch中模糊匹配类的查询
Elasticsearch中模糊匹配类的查询 文章目录 Elasticsearch中模糊匹配类的查询通配符查询前缀匹配查询正则匹配查询标准的正则操作特殊运算符操作 模糊化查询Fuzziness text类型同时配置keyword类型 Elasticsearch中模糊类查询主要有以下 Wildcard Query:通配符查询P…...

Spring Security认证流程
认证是Spring Security的核心功能之一,Spring Security所提供的认证可以更好地保护系统的隐私数据与资源,只有当用户的身份合法后方可访问该系统的资源。Spring Security提供了默认的认证相关配置,开发者也可以根据自己实际的环境进行自定义身…...

TXPOLARITY/RXPOLARITY设置
TXPOLARITY/RXPOLARITY:该端口用来反向输出数据的极性。 0:表示不反向。TXP是正,TXN是负; 1:标识反向。TXP是负,TXN是正; 如下图所示:...
2026届华为海思秋暑期IC实习秋招笔试真题(2025.04.23更新)
今天给大家分享下华为海思2025.04.23号最新IC笔试真题。 华为海思IC前端中后端(COT&XPU)岗位笔试机考题 更多华为海思数字IC岗秋招实习笔试真题,可以私信小编。 数字后端培训实战项目六大典型后端实现案例 秒杀数字后端实现中clock gating使能端setup viola…...
优考试V4.20机构版【可注册】
优考试V4.20机构版,可通过注册机完美激活。 优考试机构版是一个功能强大的在线考试系统,适用于各种 考试场景,包括在线考试、培训、学习等多种用途。以下是优考试机构版的主要功能和特点: 多层级管理:优考试机…...

携国家图书馆文创打造AI创意短片,阿里妈妈AIGC能力面向商家开放
在4月23日“世界读书日”之际,阿里妈妈联合国家图书馆文创正式发布了三条AI创意视频。 该系列视频以“千年文脉典籍奇谈”为主题,借助阿里妈妈的AIGC能力,以AI链接古今,打开阅读典籍新方式,引起不少人强烈兴趣。据悉&…...

Spark,配置hadoop集群2
1.建立新文件,编写脚本程序 在hadoop101中操作,在/root/bin下新建文件:myhadoop,输入如下内容: 2.分发执行权限 保存后退出,然后赋予脚本执行权限 [roothadoop101 ~]$ chmod x /root/bin/myhadoop 像下图…...

4.1 融合架构设计:LLM与Agent的协同工作模型
大型语言模型(Large Language Models, LLMs)与智能代理(Agent)的融合架构已成为人工智能领域推动企业智能化的核心技术。这种协同工作模型利用LLM的语言理解、推理和生成能力,为Agent提供强大的知识支持,而…...

MMsegmentation第一弹-(认识与安装)
前言 在刚接触MMsegmentation的时候,我是怎么看都看不明白,那个过程实在是太痛苦了,所以我当时就想着一定要把这个写成文章,希望后来者能很轻松的就上手。该系列文章不涉及框架的底层原理,仅以一个使用者的身份带领读…...

12.无线网络安全入门
无线网络安全入门 第一部分:无线网络基础与风险第二部分:Wi-Fi攻击方式第三部分:无线网络安全实践总结 目标: • 理解无线网络的基本原理和安全风险 • 掌握Wi-Fi常见的攻击方式 • 通过实践提升对无线网络安全的认识和防护能力 …...

React19源码阅读之commitRoot
commitRoot入口 在finishConcurrentRender函数,commitRootWhenReady函数,commitRoot函数。 commitRoot流程图 commitRoot函数 commitRoot 函数是 React 渲染流程中用于提交根节点的关键函数。它的主要作用是设置相关的优先级和状态,然后调…...

目标检测:视觉系统中的CNN-Transformer融合网络
一、背景 无人机(UAVs)在城市自动巡逻中发挥着重要作用,但它们在图像识别方面面临挑战,尤其是小目标检测和目标遮挡问题。此外,无人机的高速飞行要求检测系统具备实时处理能力。 为解决这些问题,我们提出…...

Turso:一个基于 libSQL的分布式数据库
Turso 是一个完全托管的数据库平台,支持在一个组织中创建高达数十万个数据库,并且可以复制到任何地点,包括你自己的服务器,以实现微秒级的访问延迟。你可以通过Turso CLI(命令行界面)管理群组、数据库和API…...
深度学习前沿 | TransNeXt:仿生聚合注意力引领视觉感知新时代
目录 1. 引言 2. 背景与挑战 3. TransNeXt 核心创新 3.1 像素聚合注意力(PAA) 3.2 长度缩放余弦注意力(LSCA) 3.3 卷积 GLU(ConvGLU) 4. 模型架构详解 5. 实验与性能评估 5.1 图像分类(I…...
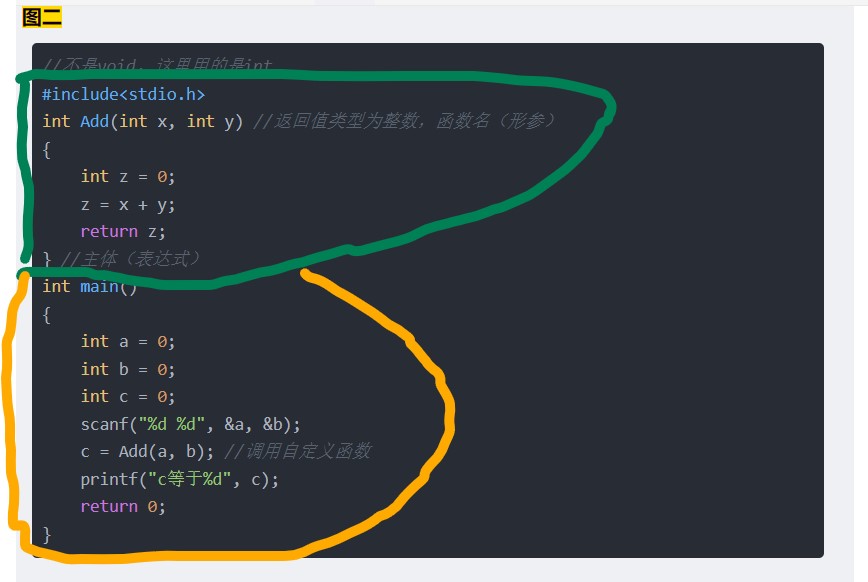
C语言-函数-1
以下是我初学C语言的笔记记录,欢迎在评论区留言补充 一,函数分为几类 * 函数分为两类: 一类是库函数;一类是自定义函数 * 库函数: 系统自己带的,在使用时候,要用到头文件; 查询库函…...

卡尔曼滤波解释及示例
卡尔曼滤波的本质是用数学方法平衡预测与观测的可信度 ,通过不断迭代逼近真实状态。其高效性和鲁棒性,通常在导航定位中,需要融合GPS、加速度计、陀螺仪、激光雷达或摄像头数据,来提高位置精度。简单讲,卡尔曼滤波就是…...
openwrt作旁路由时的几个常见问题 openwrt作为旁路由配置zerotier 图文讲解
1 先看openwrt时间,一定要保证时间和浏览器和服务器是一致的,不然无法更新 2 openwrt设置旁路由前先测试下,路由器能否ping通主路由,是否能够连接外网,好多旁路由设置完了,发现还不能远程好多就是旁路由本…...

Redis--预备知识以及String类型
目录 一、预备知识 1.1 基本全局命令 1.1.1 KEYS 1.1.2 EXISTS 1.1.3 DEL 1.1.4 EXPIRE 1.1.5 TTL 1.1.6 TYPE 1.2 数据结构以及内部编码 1.3 单线程架构 二、String字符串 2.1 常见命令 2.1.1 SET 2.1.2 GET 2.1.3 MGET 2.1.4 MSET 2.1.5 SETNX 2.2 计数命令 2.2.1 INCR 2.2.2…...
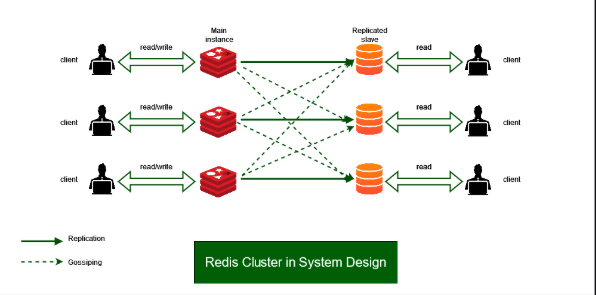
Redis 及其在系统设计中的作用
什么是Redis Redis 是一个开源的内存数据结构存储系统,可用作数据库、缓存和消息代理。它因其快速的性能、灵活性和易用性而得到广泛应用。 Redis 数据存储类型 Redis 允许开发人员以各种数据结构(例如字符串、位图、位域、哈希、列表、集合、有序集合…...