windows中kafka4.0集群搭建
参考文献
Apache Kafka
windows启动kafka4.0(不再需要zookeeper)_kafka压缩包-CSDN博客
Kafka 4.0 KRaft集群部署_kafka4.0集群部署-CSDN博客
正文
注意jdk需要17版本以上的

修改D:\software\kafka_2.13-4.0.0\node1\config\server.properties配置文件
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.############################# Server Basics ############################## The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller# The node id associated with this instance's roles
node.id=1# List of controller endpoints used connect to the controller cluster
controller.quorum.bootstrap.servers=localhost:19093############################# Socket Server Settings ############################## The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://localhost:19092,CONTROLLER://localhost:19093# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT# Listener name, hostname and port the broker or the controller will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://localhost:19092,CONTROLLER://localhost:19093# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=D:\\software\\kafka_2.13-4.0.0\\node1\\kraft-combined-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets", "__share_group_state" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
share.coordinator.state.topic.replication.factor=1
share.coordinator.state.topic.min.isr=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000controller.quorum.voters=1@127.0.0.1:19093,2@127.0.0.1:29093,3@127.0.0.1:39093修改D:\software\kafka_2.13-4.0.0\node2\config\server.properties配置文件
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.############################# Server Basics ############################## The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller# The node id associated with this instance's roles
node.id=2# List of controller endpoints used connect to the controller cluster
controller.quorum.bootstrap.servers=localhost:29093############################# Socket Server Settings ############################## The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://localhost:29092,CONTROLLER://localhost:29093# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT# Listener name, hostname and port the broker or the controller will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://localhost:29092,CONTROLLER://localhost:29093# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=D:\\software\\kafka_2.13-4.0.0\\node2\\kraft-combined-logs# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets", "__share_group_state" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
share.coordinator.state.topic.replication.factor=1
share.coordinator.state.topic.min.isr=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000controller.quorum.voters=1@127.0.0.1:19093,2@127.0.0.1:29093,3@127.0.0.1:39093修改D:\software\kafka_2.13-4.0.0\node3\config\server.properties配置文件
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.############################# Server Basics ############################## The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller# The node id associated with this instance's roles
node.id=3# List of controller endpoints used connect to the controller cluster
controller.quorum.bootstrap.servers=localhost:39093
############################# Socket Server Settings ############################## The address the socket server listens on.
# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
# with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://localhost:39092,CONTROLLER://localhost:39093# Name of listener used for communication between brokers.
inter.broker.listener.name=PLAINTEXT# Listener name, hostname and port the broker or the controller will advertise to clients.
# If not set, it uses the value for "listeners".
advertised.listeners=PLAINTEXT://localhost:39092,CONTROLLER://localhost:39093# A comma-separated list of the names of the listeners used by the controller.
# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
# This is required if running in KRaft mode.
controller.listener.names=CONTROLLER# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log files
log.dirs=D:\\software\\kafka_2.13-4.0.0\\node3\\kraft-combined-logs# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets", "__share_group_state" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
share.coordinator.state.topic.replication.factor=1
share.coordinator.state.topic.min.isr=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000controller.quorum.voters=1@127.0.0.1:19093,2@127.0.0.1:29093,3@127.0.0.1:39093会生成一个随机的cluster.id(集群id)
.\bin\windows\kafka-storage.bat random-uuid
虽然有error错误信息,但是这个不影响。我的uuid是xDd-c_vwSCOda91tgPLX2g
下面用这个uuid来作为cluster.id(集群id)来格式化日志
.\bin\windows\kafka-storage.bat format -t xDd-c_vwSCOda91tgPLX2g -c .\config\server.properties


启动kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties![]()
![]()
![]()
Create a topic to store your events
.\bin\windows\kafka-topics.bat --create --topic quickstart-events --bootstrap-server localhost:19092,localhost:29092,localhost:39092
Write some events into the topic
.\bin\windows\kafka-console-producer.bat --topic quickstart-events --bootstrap-server localhost:19092,localhost:29092,localhost:39092
Read the events
.\bin\windows\kafka-console-consumer.bat --topic quickstart-events --from-beginning --bootstrap-server localhost:19092,localhost:29092,localhost:39092
使用kafka消息可视化工具offset Explorer进行连接
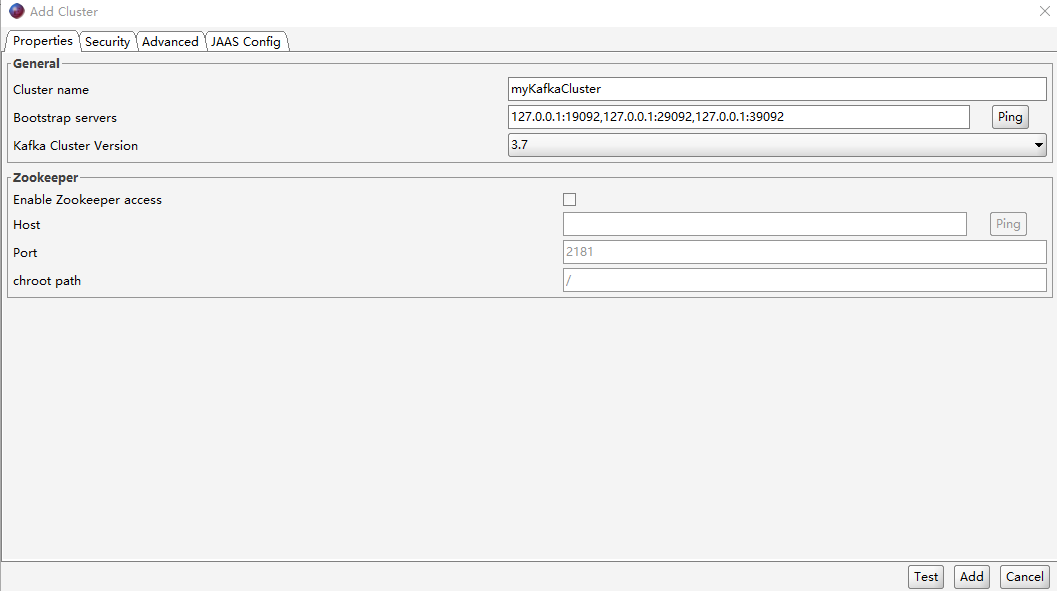
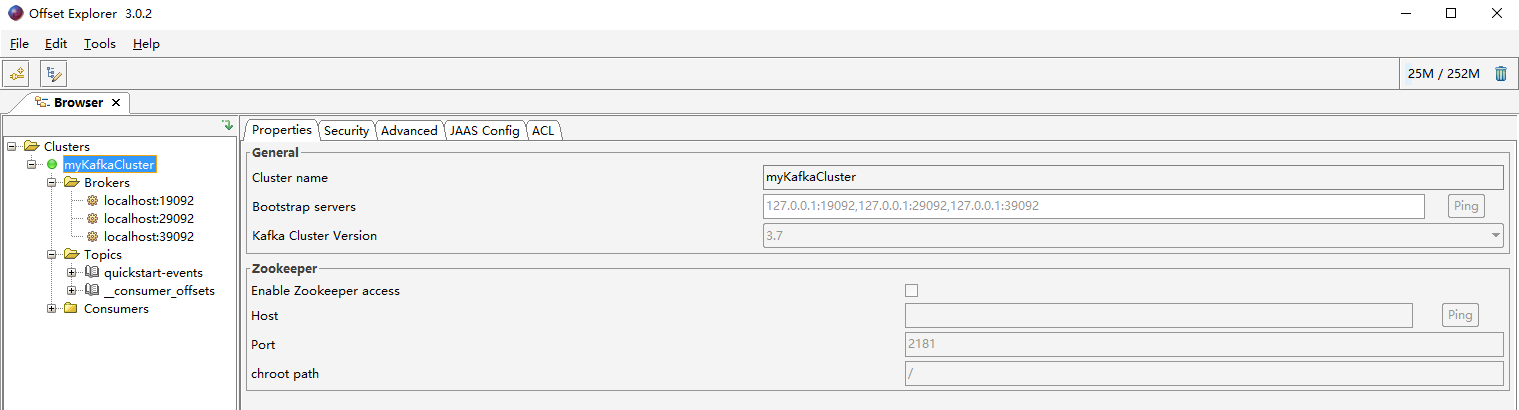
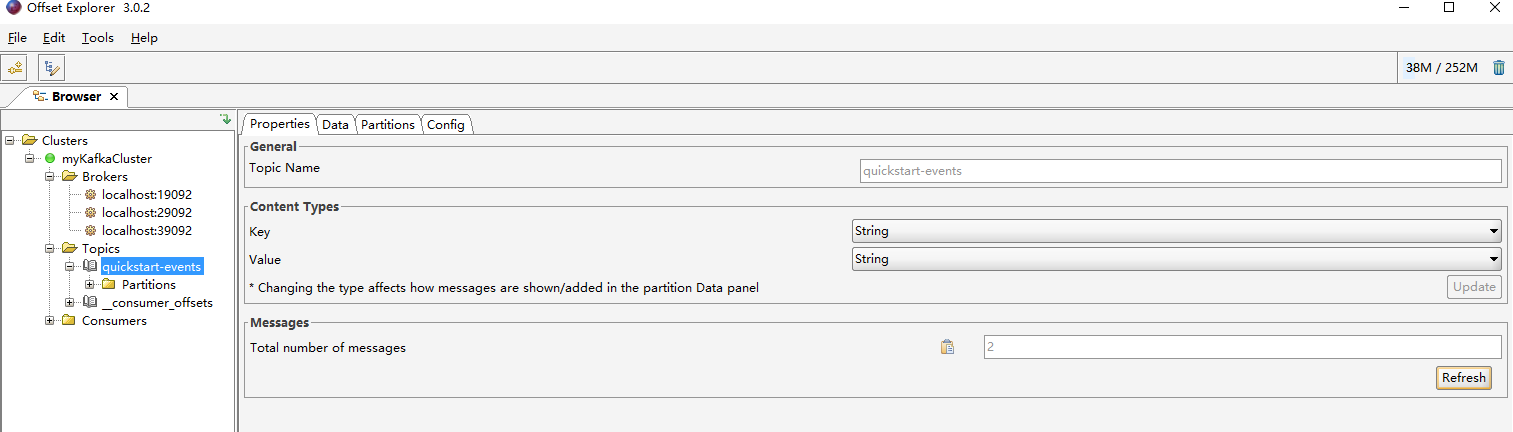
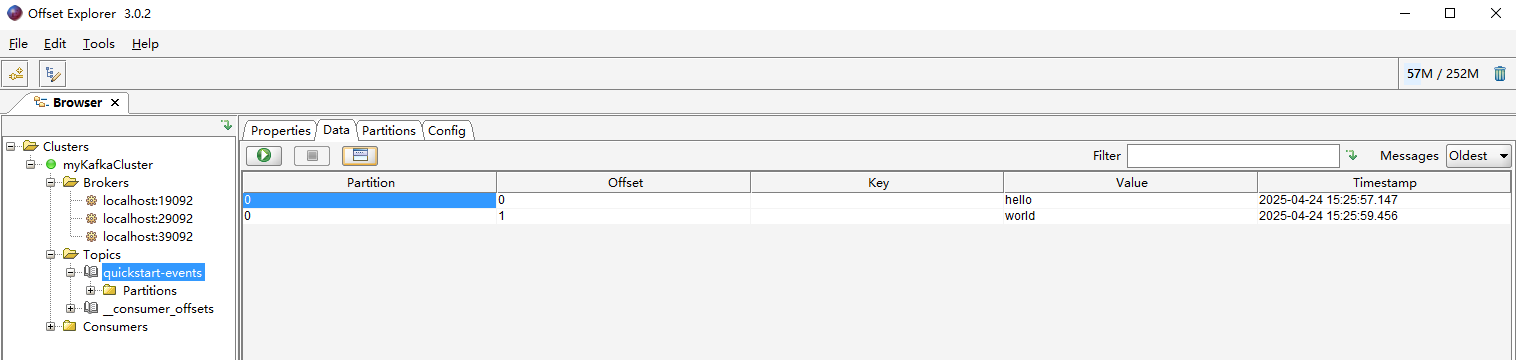
编写一个bat脚本启动kafka集群
start.bat
@echo off
start cmd /k "D:\software\kafka_2.13-4.0.0\node1\bin\windows\kafka-server-start.bat D:\software\kafka_2.13-4.0.0\node1\config\server.properties"
start cmd /k "D:\software\kafka_2.13-4.0.0\node2\bin\windows\kafka-server-start.bat D:\software\kafka_2.13-4.0.0\node2\config\server.properties"
start cmd /k "D:\software\kafka_2.13-4.0.0\node3\bin\windows\kafka-server-start.bat D:\software\kafka_2.13-4.0.0\node3\config\server.properties"相关文章:
windows中kafka4.0集群搭建
参考文献 Apache Kafka windows启动kafka4.0(不再需要zookeeper)_kafka压缩包-CSDN博客 Kafka 4.0 KRaft集群部署_kafka4.0集群部署-CSDN博客 正文 注意jdk需要17版本以上的 修改D:\software\kafka_2.13-4.0.0\node1\config\server.properties配置文…...

Oracle Linux8 安装 MySQL 8.4.3,搭建一主一从
文章目录 安装依赖获取安装包解压准备相关目录设置配置文件启动数据库连接数据库socket 文件优化同样方法准备 3307 数据库实例设置配置文件启动 3307 实例数据库连接并查看 3307 数据库实例基于 bin log 搭建主从模式 安装依赖 yum install -y numactl libaio ncurses-compat…...

【JavaWeb后端开发04】java操作数据库(JDBC + Mybatis+ yml格式)详解
文章目录 1. 前言2. JDBC2.1 介绍2.2 入门程序2.2.1 DataGrip2.2.2 在IDEA执行sql语句 2.3 查询数据案例2.3.1 需求2.3.2 准备工作2.3.3 AI代码实现2.3.4 代码剖析2.3.4.1 ResultSet2.3.4.2 预编译SQL2.3.4.2.1 SQL注入2.3.4.2.2 SQL注入解决2.3.4.2.3 性能更高 2.4 增删改数据…...
postman 删除注销账号
一、删除账号 1.右上角找到 头像,view profile https://123456-6586950.postman.co/settings/me/account 二、找回账号 1.查看日志所在位置 三、postman更新后只剩下history 在 Postman 中,如果你发现更新后只剩下 History(历史记录&…...
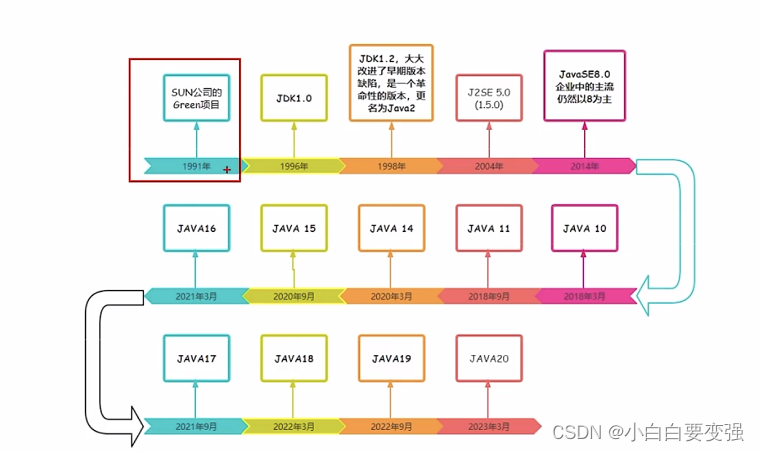
Java发展史及版本详细说明
Java发展史及版本详细说明 1. Java 1.0(1996年1月23日) 核心功能: 首个正式版本,支持面向对象编程、垃圾回收、网络编程。包含基础类库(java.lang、java.io、java.awt)。支持Applet(浏览器嵌入…...

React 5 种组件提取思路与实践
在开发时,经常遇到一些高度重复但略有差异的 UI 模式,此时我们当然会把组件提取出去,但是组件提取的方式有很多,怎么根据不同场景选取合适的方式呢?尤其时在复杂的业务场景中,组件提取的思路影响着着代码的可维护性、可读性以及扩展性。本文将以一个[详情]组件为例,探讨…...
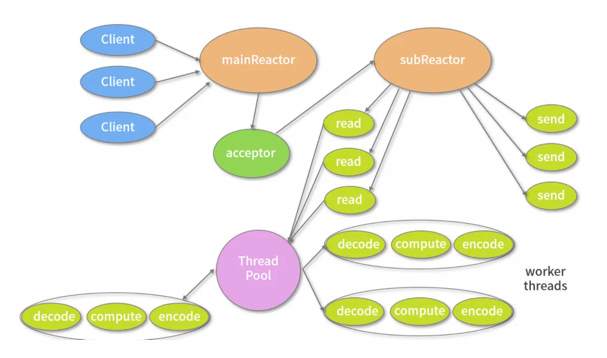
[java八股文][Java基础面试篇]I/O
Java怎么实现网络IO高并发编程? 可以用 Java NIO ,是一种同步非阻塞的I/O模型,也是I/O多路复用的基础。 传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据…...
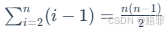
数据结构-冒泡排序(Python)
目录 冒泡排序算法思想 冒泡排序算法步骤 冒泡排序代码实现 冒泡排序算法分析 冒泡排序算法思想 冒泡排序(Bubble Sort)基本思想: 经过多次迭代,通过相邻元素之间的比较与交换,使值较小的元素逐步从后面移到前面…...

Java单例模式详解:实现线程安全的全局访问点
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、什么是单例模式? 单例模式(Singleton Pattern)是一种创建型设计模式,它保证一个类仅有一个实例ÿ…...

React-组件和props
1、类组件 import React from react; class ClassApp extends React.Component {constructor(props) {super(props);this.state{};}render() {return (<div><h1>这是一个类组件</h1><p>接收父组件传过来的值:{this.props.name}</p>&…...

Java面试:从Spring Boot到微服务的全面考核
Java面试:从Spring Boot到微服务的全面考核 场景设定: 在一家互联网大厂的面试室内,严肃的面试官正准备开始对前来面试的赵大宝进行技术考核。赵大宝是一位自称在Java开发方面经验丰富的求职者,不过却是个搞笑的水货程序员。 第…...

深入理解React高阶组件(HOC):原理、实现与应用实践
组件复用的艺术 在React应用开发中,随着项目规模的增长,组件逻辑的复用变得越来越重要。传统的组件复用方式如组件组合和props传递在某些复杂场景下显得力不从心。高阶组件(Higher-Order Component,简称HOC)作为React中…...
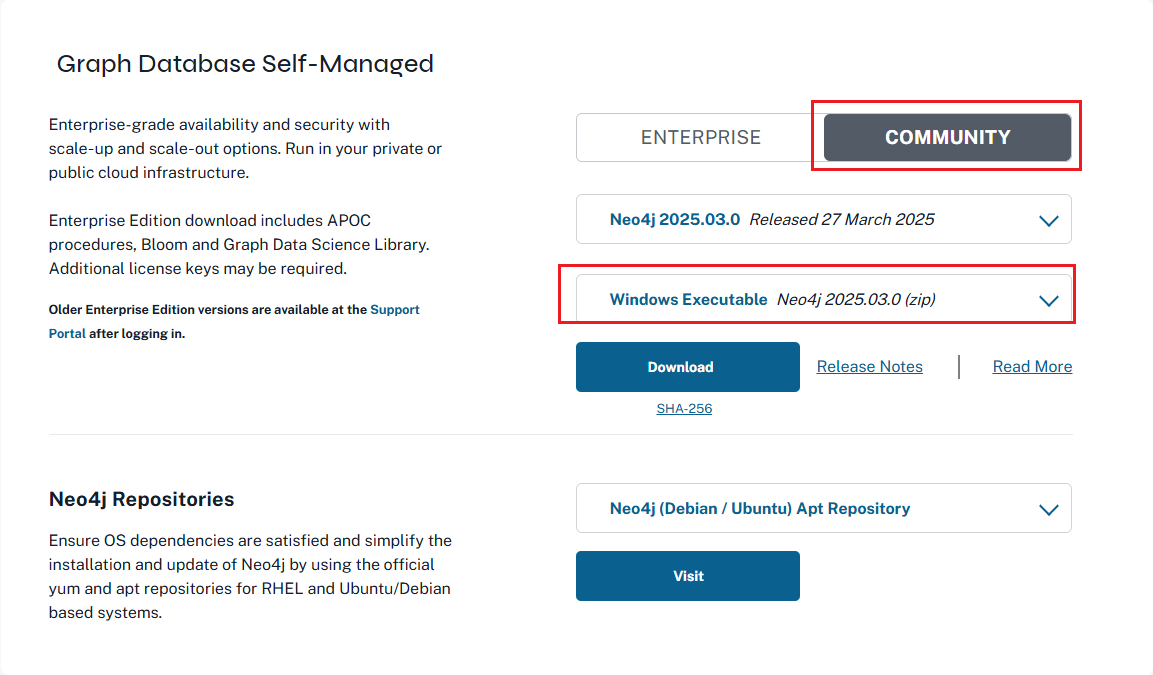
Neo4j社区版在win下安装教程(非docker环境)
要在 Windows 10 上安装 Neo4j 社区版数据库并且不使用 Docker Desktop,你可以按照以下步骤操作: 1. 安装 Java Development Kit (JDK) Neo4j 需要 Java 运行环境。推荐安装 JDK 17 或 JDK 11(请根据你下载的 Neo4j 版本查看具体的兼容性要…...
)
【AI 加持下的 Python 编程实战 2_10】DIY 拓展:从扫雷小游戏开发再探问题分解与 AI 代码调试能力(中)
文章目录 DIY 实战:从扫雷小游戏开发再探问题分解能力3 问题分解实战(自顶向下)3.2 页面渲染逻辑3.3 事件绑定逻辑 4 代码实现(自底向上)4.1 页面渲染部分4.2 事件绑定部分 写在前面 本篇将利用《Learn AI-assisted Py…...

使用PHP对接印度尼西亚股票市场
在本篇文章中,我们将介绍如何使用PHP语言与StockTV API接口对接,获取并处理印度尼西亚(Indonesia)的股票市场数据。我们将以查询IPO信息和查看涨跌排行榜为例,展示具体的操作流程。 准备工作 首先,确保您…...

如何在 Odoo 18 中配置自动化动作
如何在 Odoo 18 中配置自动化动作 Odoo是一款多功能的业务管理平台,旨在帮助各种规模的企业更高效地处理日常运营。凭借其涵盖销售、库存、客户关系管理(CRM)、会计和人力资源等领域的多样化模块,Odoo 简化了业务流程,…...
node.js 实战——(Http 知识点学习)
HTTP 又称为超文本传输协议 是一种基于TCP/IP的应用层通信协议;这个协议详细规定了 浏览器 和万维网 服务器 之间互相通信的规则。协议中主要规定了两个方面的内容: 客户端:用来向服务器发送数据,可以被称之为请求报文服务端&am…...

新市场环境下新能源汽车电流传感技术发展前瞻
新能源革命重构产业格局 在全球碳中和战略驱动下,新能源汽车产业正经历结构性变革。国际清洁交通委员会(ICCT)最新报告显示,2023年全球新能源汽车渗透率突破18%,中国市场以42%的市占率持续领跑。这种产业变革正沿着&q…...

系统重装——联想sharkbay主板电脑
上周给一台老电脑重装系统系统,型号是lenovo sharkbay主板的电脑,趁着最近固态便宜,入手了两块长城的固态,装上以后插上启动U盘,死活进不去boot系统。提示 bootmgr 缺失,上网查了许久,终于解决了…...

CentOS 7.9升级OpenSSH到9.9p2
初始版本 ssh -V OpenSSH_7.4p1, OpenSSL 1.0.2k-fips 26 Jan 2017 1.安装编译依赖 yum install -y gcc perl make zlib-devel pam-devel openssl-devel wget 2.升级OpenSSL到1.1.1版本 2.1 备份当前OpenSSL配置 sudo cp -r /usr/bin/openssl /usr/bin/openssl.bak sudo …...

fastjson使用parseObject转换成JSONObject出现将字符特殊字符解析解决
现象:将字符串的${TARGET_VALUE}转换成NULL字符串了问题代码: import com.alibaba.fastjson.JSON;JSONObject config JSON.parseObject(o.toString()); 解决方法: 1.更换fastjson版本 import com.alibaba.fastjson2.JSON;或者使用其他JS…...

37、aiomysql实操习题
练习题1:慢查询优化 题目描述 将以下低效查询优化为索引查询: # 原始低效查询 await cursor.execute("SELECT * FROM orders WHERE YEAR(created_at)2023")参考答案 # 优化后查询(使用索引范围扫描) await cursor.e…...

Rust 2025:内存安全革命与异步编程新纪元
Rust 2025 Edition通过区域内存管理、泛型关联类型和零成本异步框架三大革新,重新定义系统级编程语言的能力边界。本次升级不仅将内存安全验证效率提升80%,更通过异步执行器架构优化实现微秒级任务切换。本文从编译器原理、运行时机制、编程范式转型三个…...
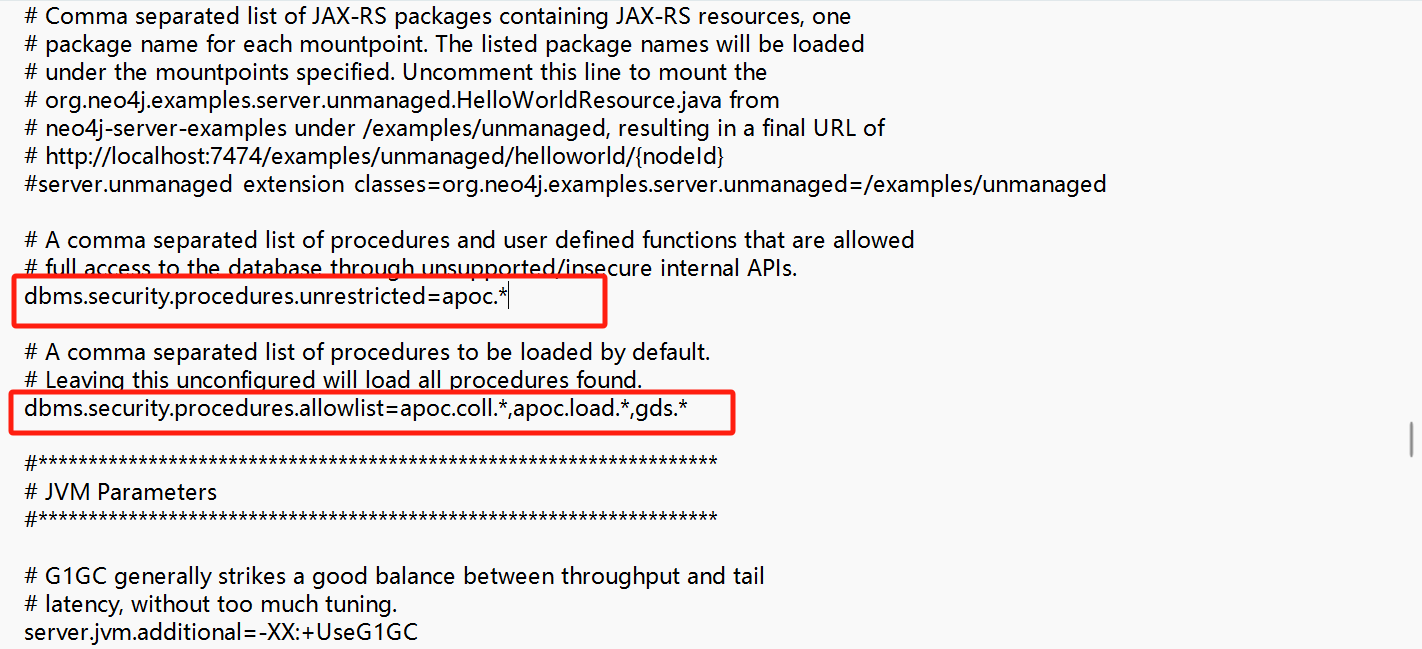
【安装neo4j-5.26.5社区版 完整过程】
1. 安装java 下载 JDK21-windows官网地址 配置环境变量 在底下的系统变量中新建系统变量,变量名为JAVA_HOME21,变量值为JDK文件夹路径,默认为: C:\Program Files\Java\jdk-21然后在用户变量的Path中,添加下面两个&am…...
STM32数控电源BuckBoost)
开关电源实战(六)STM32数控电源BuckBoost
文章目录 芯片手册详解栅极驱动器EG3112栅极驱动芯片2EDF7275K隔离式MOS栅极驱动器运放检测电流GS8558MCP6022打板测试硬件设计PID测试存在的问题参考:基于STM32的同步整流Buck-Boost数字电源 开源 芯片手册详解 栅极驱动器 EG3112栅极驱动芯片 (较低芯片,一个四五毛) …...

Vue3项目中 npm 依赖安装 --save 与 --save-dev 的区别解析
这两个命令的区别如下: bash npm install --save types/crypto-js # 安装到 dependencies(生产依赖) npm install --save-dev types/crypto-js # 安装到 devDependencies(开发依赖) 核心区别 依赖分类不同…...

Oracle 数据库中的 JSON:性能注意事项
本文为白皮书“JSON in Oracle Database: Performance Considerations”的翻译及阅读笔记。 目的 本文档概述了在 Oracle 数据库中存储和处理的 JavaScript 对象表示法 (JSON) 的性能调优最佳实践。应用这些最佳实践将使开发人员、数据库管理员和架构师能够主动避免性能问题&…...

机器人项目管理新风口:如何高效推动智能机器人研发?
在2025年政府工作报告中,“智能机器人”首次被正式纳入国家发展战略关键词。从蛇年春晚的秧歌舞机器人惊艳亮相,到全球首个人形机器人马拉松的热议,智能机器人不仅成为科技前沿的焦点,也为产业升级注入了新动能。而在热潮背后&…...
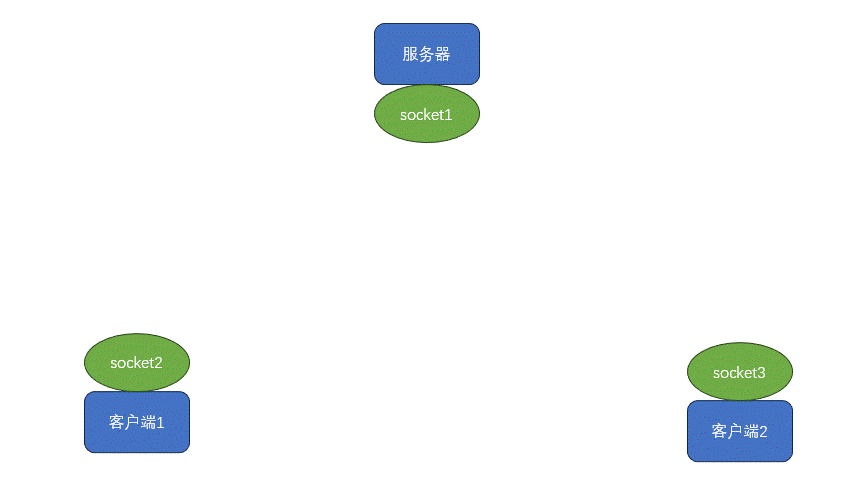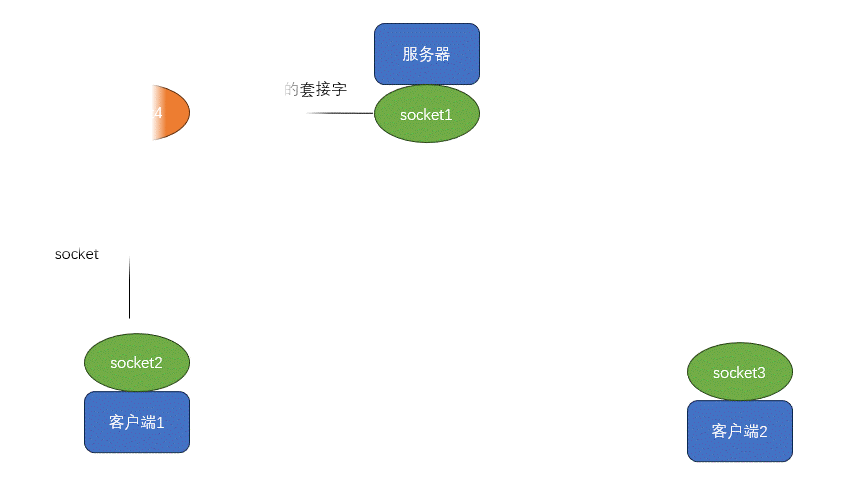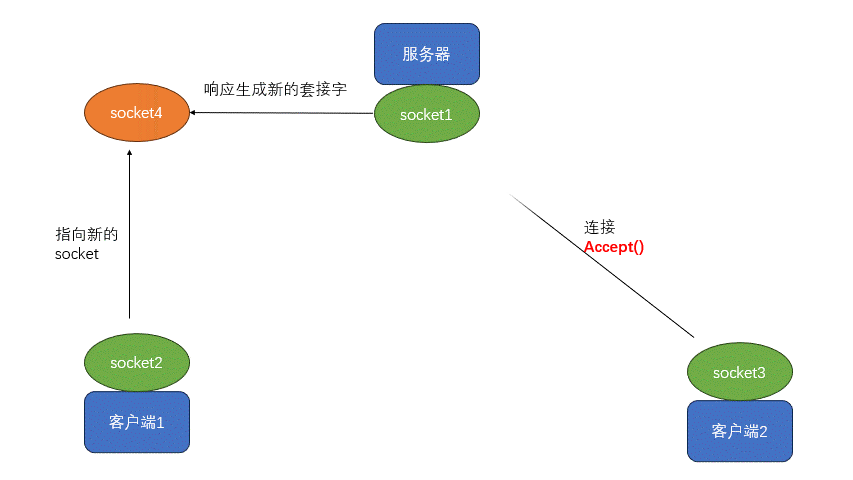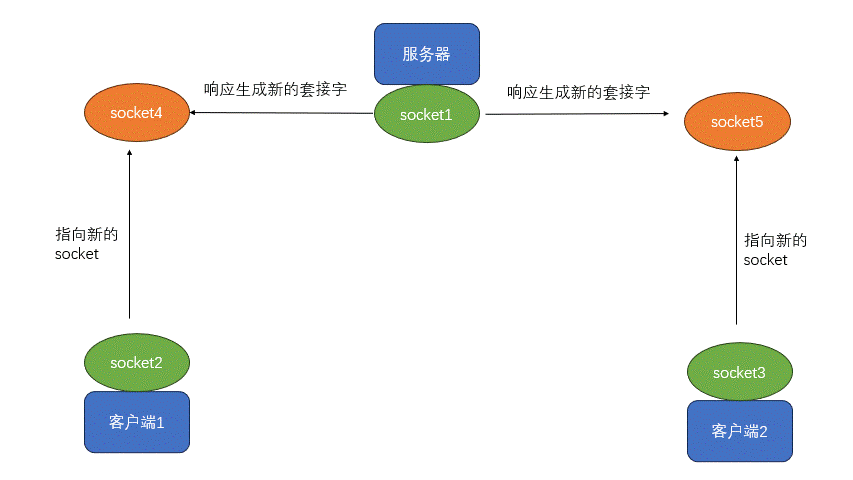
【Linux】网络基础和socket(4)
1.网络通信(app\浏览器、小程序) 2.网络通信三要素: IP:计算机在网络上唯一标识(ipv4:4个字段,每段最大255 IPV6:16进制) 端口:计算机应用或服务唯一标识 ssh提供远程安全连接…...

大数据可能出现的bug之flume
一、vi /software/flume/conf/dir_to_logger.conf配置文件 问题的关键: Dir的D写成了小写 另一个终端里面的东西一直在监听状态下无法显示 原来是vi /software/flume/conf/dir_to_logger.conf里面的配置文件写错了 所以说不是没有source参数的第三行的原因 跟这个没关系 …...