计算机视觉cv入门之答题卡自动批阅

前边我们已经讲解了使用cv2进行图像预处理与边缘检测等方面的知识,这里我们以答题卡自动批阅这一案例来实操一下。
大致思路
答题卡自动批阅的大致流程可以分为这五步:图像预处理-寻找考试信息区域与涂卡区域-考生信息区域OCR识别-涂卡区域填涂答案判断-图像中标记结果
接下来我们按照这五步来进行讲解。
图像预处理
答题卡获取首先,在网上随便找一张答题卡图片

由于这里我只需要考生信息与填途题目,所以只是截取了左上角这一部分作为我们后续的目标。

接着,我们使用图像编辑软件将考生信息填入,并将10道题目进行填涂。

读取图像
# #读取答题卡图片
import cv2
import matplotlib.pyplot as plt
src_image=cv2.imread(filename='answercard4.jpg',flags=cv2.IMREAD_COLOR_RGB)
height,width=src_image.shape[:2]
plt.xticks(range(0,width,10),minor=True)
plt.yticks(range(0,height,10),minor=True)
plt.imshow(src_image)
这里我使用matplotlib的imshow函数来显示图像,这样在jupyter环境中可以不打开任何弹窗直接显示图像,比较方便。
转为灰度图
#转为灰度图
gray_image=cv2.cvtColor(src=src_image,code=cv2.COLOR_RGB2GRAY)
plt.title('原始图像(灰度图)')
plt.imshow(gray_image,cmap='gray')
将原始图像转化为灰度图是为了后续的检测等操作,在计算机视觉任务中,基本上所有的操作都是针对灰度图来进行的,灰度图是将原始图像的多个通道按照一定权重求和叠加而来,这样一来多通道变成了单通道(),在计算量上也会比较友好。
阈值化
#阈值化
thresh,binary_image=cv2.threshold(src=gray_image,thresh=128,maxval=255,type=cv2.THRESH_OTSU+cv2.THRESH_BINARY)
plt.imshow(binary_image,cmap='gray')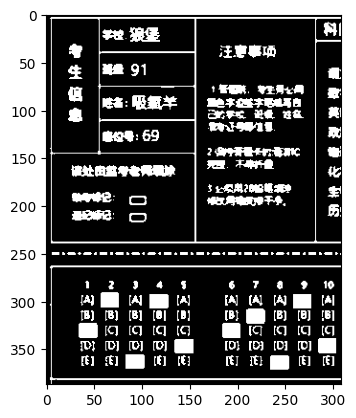
阈值化是为了更好的查找轮廓。这里阈值化我们使用cv2.THRESH+cv2.THRESH-OTSU方法来自动对图像进行二值化阈值分割。
考生信息与答题区域分割
#考生信息区域与答题区域分割
contours,hiercahy=cv2.findContours(binary_image,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
possible_rectangles=[]
answer_rectangle=[]
for points in contours:x,y,w,h=cv2.boundingRect(points)if 800<w*h<120000:possible_rectangles.append((x,y,w,h))
information_rectangles=[rect for rect in possible_rectangles if 100<rect[2]<140 and 30<rect[3]<60]#长在100~~60
answer_rectangle=sorted(possible_rectangles,key=lambda x:x[2]*x[3])[-2]
marked_img=src_image.copy()
information_images=[]
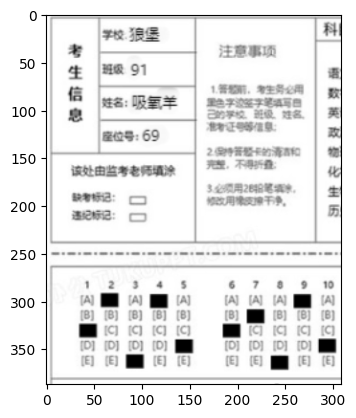
for rect in information_rectangles:x, y, w, h,=rectcv2.rectangle(marked_img, (x, y), (x+w, y+h), (0, 255, 0), 3)information_images.append(marked_img[y:y+h,x:x+w])
x,y,w,h=answer_rectangle
answer_area=marked_img[y:y+h,x:x+w]
answer_area=cv2.cvtColor(src=answer_area,code=cv2.COLOR_RGB2GRAY)
cv2.rectangle(marked_img,(x,y),(x+w,y+h),(255,0,0),3)
plt.xticks(range(0,marked_img.shape[1],10),minor=True)
plt.yticks(range(0,marked_img.shape[0],10),minor=True)
plt.imshow(marked_img)
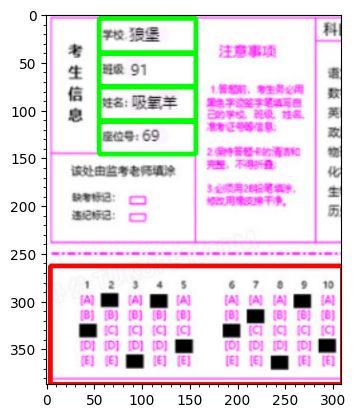
查找轮廓时我们通常使用findContours函数来进行查找(返回值为所有可能的轮廓点contours以及这些点之间的拓扑结构hierachy),考虑到要分割的区域都是矩形,因此我们可以在查找到的轮廓点中使用cv2.boundingrectangle函数来对查找到的轮廓进行矩形拟合。
然后,我们再使用cv2.drawContours函数将其在原始图像中标记出来即可。
OCR识别
这里我使用现成的OCR字符识别库,这里我使用的是paddleocr
获取方式
pip install paddlepaddle paddleocrOCR识别
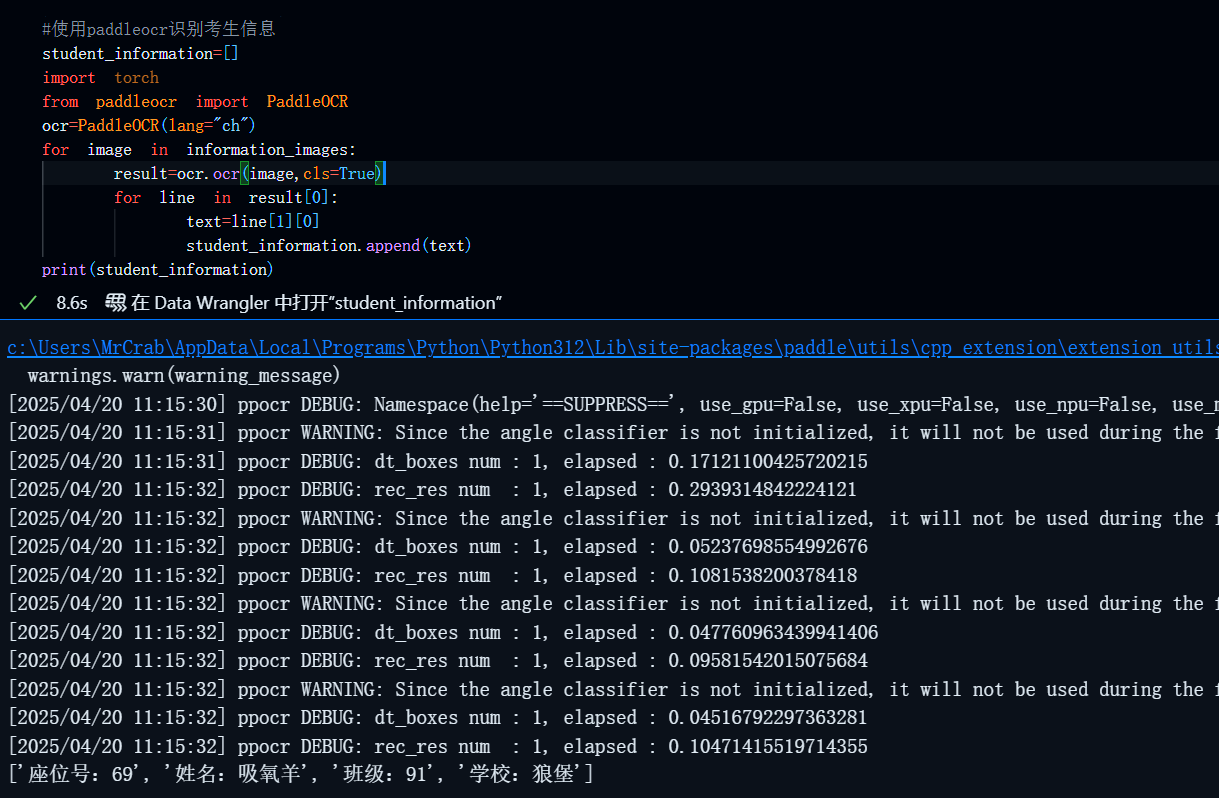
#使用paddleocr识别考生信息
student_information=[]
import torch
from paddleocr import PaddleOCR
ocr=PaddleOCR(lang="ch")
for image in information_images:result=ocr.ocr(image,cls=True)for line in result[0]:text=line[1][0]student_information.append(text)
print(student_information) 结果:
答题区域答案识别
这一步是整个任务的关键,但其实也比较简单,就是按照查找到的填涂过的黑色矩形的位置来判断,首先我们要在这个填涂答案的区域内定位所有黑色矩形的位置以及长和宽,然后根据以下的关系来判断每一列的答案是ABCDE的哪一个,其中filled_area_top是指整个填涂答案中最顶部的位置,即A的位置(我的答案中有A,倘若没有的话,也可以完全根据y坐标自行指定一个ABCDE所在的范围),filled_area_bottom是整个填入答案中最底部的位置,即E的位置。
thresh,binary_answer_area=cv2.threshold(src=answer_area,thresh=128,maxval=255,type=cv2.THRESH_BINARY+cv2.THRESH_OTSU)
contours,hiercahy=cv2.findContours(image=binary_answer_area,mode=cv2.RETR_TREE,method=cv2.CHAIN_APPROX_SIMPLE)
filled_areas=[]
answers=[]
epsilon=5
true_answers=['C','A','D','A','C','C','B','E','A','D']
for points in contours:x,y,w,h=cv2.boundingRect(points)if 300<w*h<500:filled_areas.append((x,y,w,h))
filled_areas=sorted(filled_areas,key=lambda point:point[1])
filled_area_top,filled_area_bottom=filled_areas[0][1],filled_areas[-1][1]
filled_areas=sorted(filled_areas,key=lambda point:point[0])
score=0
total_num=len(filled_areas)
avg_score=100/total_num
plt.imshow(marked_img)
for i in range(len(filled_areas)):x,y,w,h=filled_areas[i]if 0<=(y-filled_area_top)<=epsilon:answers.append('A')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='A',color='blue')if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)if epsilon<abs(y-filled_area_top)<=h+epsilon:answers.append('B')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='B',color='blue',size=15)if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)if h+epsilon<abs(y-filled_area_top)<=2*h+epsilon:answers.append('C')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='C',color='blue')if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)if 2*h+epsilon<abs(y-filled_area_top)<=3*h+epsilon:answers.append('D')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='D',color='blue')if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)if 0<=filled_area_bottom-y<=epsilon:answers.append('E')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='E',color='blue')if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)
plt.text(x=width-100,y=50,s=score,color='red',size='20')
plt.text(x=width-100,y=70,s='———',color='red',size='15')
plt.text(x=width-100,y=75,s='———',color='red',size='15')
for info in student_information:print(info)
print(f'你的答案是:{answers}')
print(f'正确答案是:{true_answers}')
print(f'考试成绩:{score}')结果:

完整代码
# #读取答题卡图片
import cv2
import matplotlib.pyplot as plt
src_image=cv2.imread(filename='answercard4.jpg',flags=cv2.IMREAD_COLOR_RGB)
height,width=src_image.shape[:2]
plt.xticks(range(0,width,10),minor=True)
plt.yticks(range(0,height,10),minor=True)
plt.imshow(src_image)
#转为灰度图
gray_image=cv2.cvtColor(src=src_image,code=cv2.COLOR_RGB2GRAY)
plt.imshow(gray_image,cmap='gray')
thresh,binary_image=cv2.threshold(src=gray_image,thresh=128,maxval=255,type=cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
plt.imshow(binary_image,cmap='gray')
#考生信息区域与答题区域分割
contours,hiercahy=cv2.findContours(binary_image,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
possible_rectangles=[]
answer_rectangle=[]
for points in contours:x,y,w,h=cv2.boundingRect(points)if 800<w*h<120000:possible_rectangles.append((x,y,w,h))
information_rectangles=[rect for rect in possible_rectangles if 100<rect[2]<140 and 30<rect[3]<60]#长在100~~60
answer_rectangle=sorted(possible_rectangles,key=lambda x:x[2]*x[3])[-2]
marked_img=src_image.copy()
information_images=[]
for rect in information_rectangles:x, y, w, h,=rectcv2.rectangle(marked_img, (x, y), (x+w, y+h), (0, 255, 0), 3)information_images.append(marked_img[y:y+h,x:x+w])
x,y,w,h=answer_rectangle
answer_area=marked_img[y:y+h,x:x+w]
answer_area=cv2.cvtColor(src=answer_area,code=cv2.COLOR_RGB2GRAY)
cv2.rectangle(marked_img,(x,y),(x+w,y+h),(255,0,0),3)
plt.xticks(range(0,marked_img.shape[1],10),minor=True)
plt.yticks(range(0,marked_img.shape[0],10),minor=True)
plt.imshow(marked_img)
#使用paddleocr识别考生信息
student_information=[]
import torch
from paddleocr import PaddleOCR
ocr=PaddleOCR(lang="ch")
for image in information_images:result=ocr.ocr(image,cls=True)for line in result[0]:text=line[1][0]student_information.append(text)
print(student_information) thresh,binary_answer_area=cv2.threshold(src=answer_area,thresh=128,maxval=255,type=cv2.THRESH_BINARY+cv2.THRESH_OTSU)
contours,hiercahy=cv2.findContours(image=binary_answer_area,mode=cv2.RETR_TREE,method=cv2.CHAIN_APPROX_SIMPLE)
filled_areas=[]
answers=[]
epsilon=5
true_answers=['C','A','D','A','C','C','B','E','A','D']
for points in contours:x,y,w,h=cv2.boundingRect(points)if 300<w*h<500:filled_areas.append((x,y,w,h))
filled_areas=sorted(filled_areas,key=lambda point:point[1])
filled_area_top,filled_area_bottom=filled_areas[0][1],filled_areas[-1][1]
filled_areas=sorted(filled_areas,key=lambda point:point[0])
score=0
total_num=len(filled_areas)
avg_score=100/total_num
plt.imshow(marked_img)
for i in range(len(filled_areas)):x,y,w,h=filled_areas[i]if 0<=(y-filled_area_top)<=epsilon:answers.append('A')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='A',color='blue')if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)if epsilon<abs(y-filled_area_top)<=h+epsilon:answers.append('B')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='B',color='blue',size=15)if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)if h+epsilon<abs(y-filled_area_top)<=2*h+epsilon:answers.append('C')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='C',color='blue')if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)if 2*h+epsilon<abs(y-filled_area_top)<=3*h+epsilon:answers.append('D')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='D',color='blue')if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)if 0<=filled_area_bottom-y<=epsilon:answers.append('E')plt.text(x=x+5,y=y+height-answer_area.shape[0],s='E',color='blue')if true_answers[i]==answers[i]:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='√',color='red',size=15)score+=avg_scoreelse:plt.text(x=x+5,y=y+h+height-answer_area.shape[0],s='X',color='red',size=15)
plt.text(x=width-100,y=50,s=score,color='red',size='20')
plt.text(x=width-100,y=70,s='———',color='red',size='15')
plt.text(x=width-100,y=75,s='———',color='red',size='15')
for info in student_information:print(info)
print(f'你的答案是:{answers}')
print(f'正确答案是:{true_answers}')
print(f'考试成绩:{score}')总结

以上便是计算机视觉cv2入门之答题卡自动批阅的所有内容,所有代码作者纯手敲无任何AI,如果本文对你有用,还劳驾各位一键三连支持一下博主。
相关文章:
计算机视觉cv入门之答题卡自动批阅
前边我们已经讲解了使用cv2进行图像预处理与边缘检测等方面的知识,这里我们以答题卡自动批阅这一案例来实操一下。 大致思路 答题卡自动批阅的大致流程可以分为这五步:图像预处理-寻找考试信息区域与涂卡区域-考生信息区域OCR识别-涂卡区域填涂答案判断…...

Java学习手册:JSON 数据格式基础知识
1. JSON 简介 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于阅读和编写,也易于机器解析和生成。它最初来源于 JavaScript,但如今已被许多语言所采用,包括 Java、Python、C 等。JSON 以…...

【Python爬虫详解】第四篇:使用解析库提取网页数据——BeautifuSoup
在前一篇文章中,我们学习了如何编写第一个爬虫程序,成功获取了网页的HTML内容。然而,原始HTML通常包含大量我们不需要的信息,真正有价值的数据往往隐藏在HTML的标签和属性中。这一篇,我们将学习如何使用Python的解析库…...
《重塑AI应用架构》系列: Serverless与MCP融合创新,构建AI应用全新智能中枢
在人工智能飞速发展的今天,数据孤岛和工具碎片化问题一直是阻碍AI应用高效发展的两大难题。由于缺乏统一的标准,AI应用难以无缝地获取和充分利用数据价值。 为了解决这些问题,2024年AI领域提出了MCP(Model Context Protocol模型上…...

深度图可视化
import cv2# 1.读取一张深度图 depth_img cv2.imread("Dataset_depth/images/train/1112_0-rgb.png", cv2.IMREAD_UNCHANGED) print(depth_img.shape) cv2.imshow("depth", depth_img) # (960, 1280) print(depth_img)# 读取一张rgb的图片做对比 input_p…...

【调优】log日志海量数据分表后查询速度调优
原始实现 使用pagehelper实现分页 // 提取开始时间的年份和月份,拼装成表名List<String> timeBetween getTimeBetween(condition);List<String> fullTableName getFullTableName(Constants.LOG_TABLE_NAME, timeBetween);PageHelperUtil.startPage(c…...

hive默认的建表格式
在 Hive 中创建表时,默认的建表语法格式如下: CREATE TABLE table_name (column1_type,column2_type,... ) ROW FORMAT DELIMITED FIELDS TERMINATED BY , STORED AS TEXTFILE;在这个语法中: CREATE TABLE table_name:指定要创建…...

sass 变量
基本使用 如果分配给变量的值后面添加了 !default 标志 ,这意味着该变量如果已经赋值,那么它不会被重新赋值,但是,如果它尚未赋值,那么它会被赋予新的给定值。 如果在此之前变量已经赋值,那就不使用默认值…...
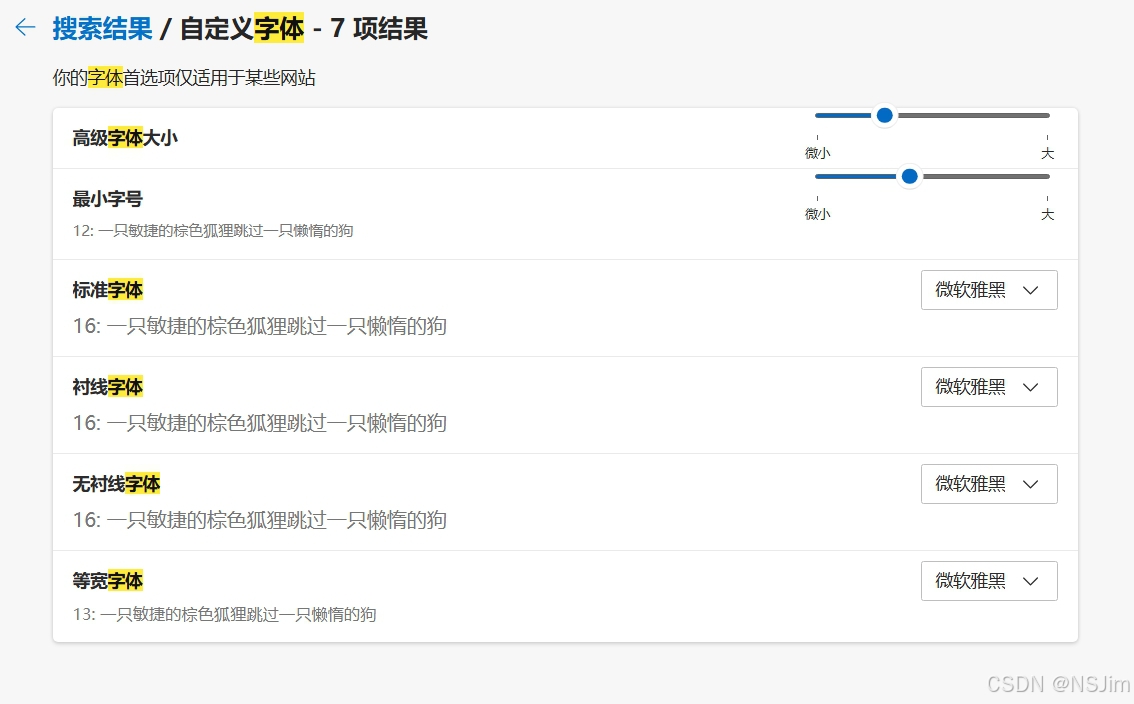
微软Edge浏览器字体设置
前言 时间:2025年4月 自2025年4月起,微软Edge浏览器的默认字体被微软从微软雅黑替换成了Noto Sans,如下图。Noto Sans字体与微软雅黑风格差不多,但在4K以下分辨率的显示器上较微软雅黑更模糊,因此低分辨率的显示器建议…...
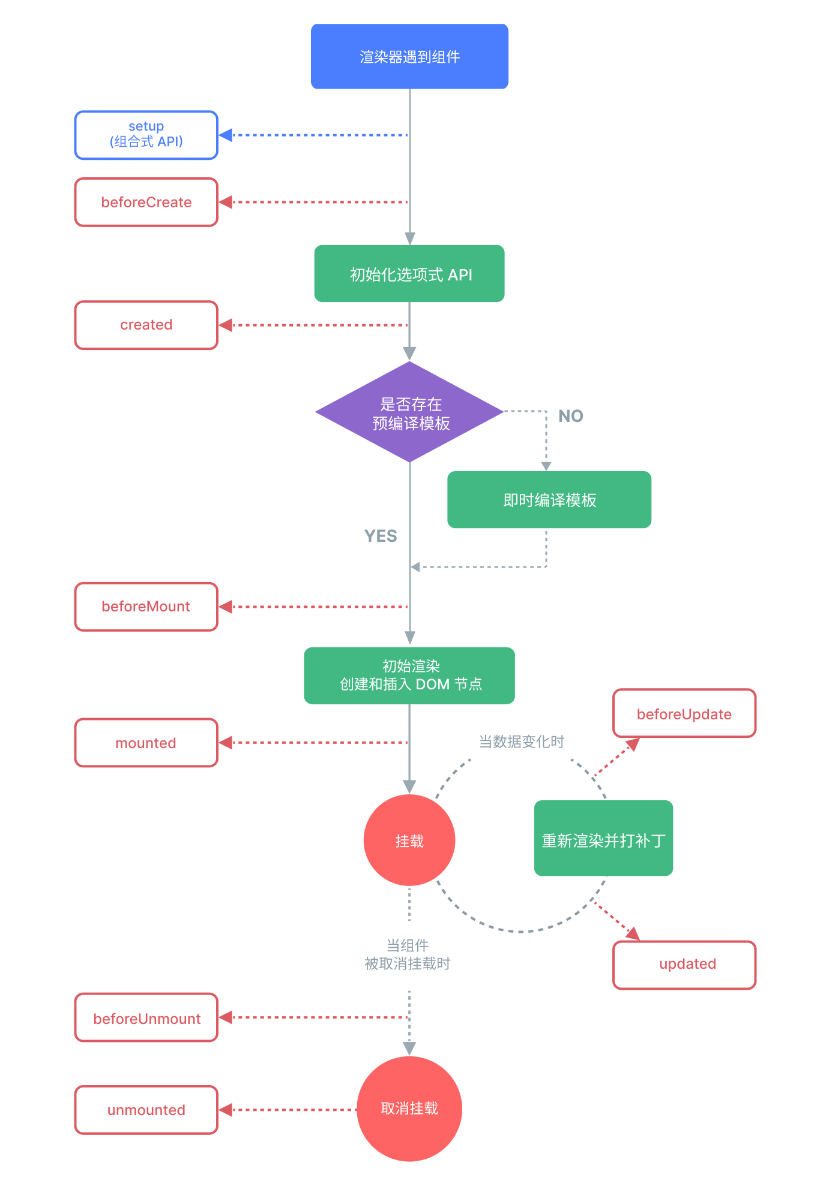
Vue生命周期详细解析
前言 Vue.js作为当前最流行的前端框架之一,其生命周期钩子函数是每个Vue开发者必须掌握的核心概念。本文将全面解析Vue的生命周期,帮助开发者更好地理解Vue实例的创建、更新和销毁过程。 一、Vue生命周期概述 Vue实例从创建到销毁的整个过程被称为Vue…...
基于c#,wpf,ef框架,sql server数据库,音乐播放器
详细视频: 【基于c#,wpf,ef框架,sql server数据库,音乐播放器。-哔哩哔哩】 https://b23.tv/ZqmOKJ5...
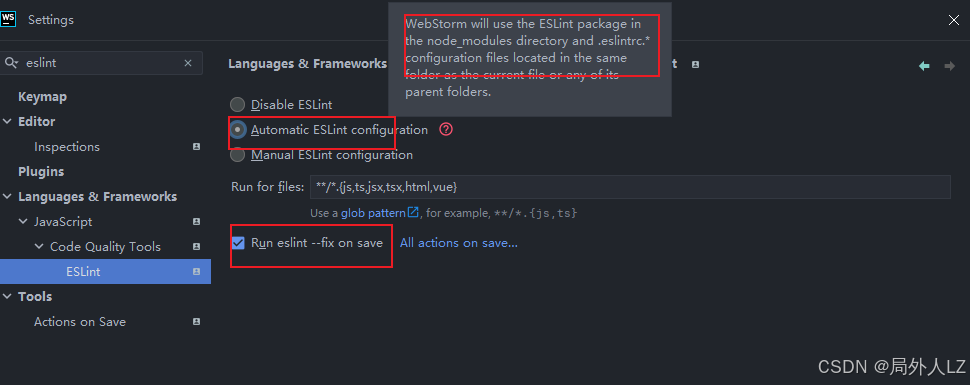
前端项目搭建集锦:vite、vue、react、antd、vant、ts、sass、eslint、prettier、浏览器扩展,开箱即用,附带项目搭建教程
前端项目搭建集锦:vite、vue、react、antd、vant、ts、sass、eslint、prettier、浏览器扩展,开箱即用,附带项目搭建教程 前言:一、Vue项目下载快速通道二、React项目下载快速通道三、BrowserPlugins项目下载快速通道四、项目搭建教…...
——统计学解构材质与光影)
【C++游戏引擎开发】第21篇:基于物理渲染(PBR)——统计学解构材质与光影
引言 宏观现象:人眼观察到的材质表面特性(如金属的高光锐利、石膏的漫反射柔和),本质上是微观结构对光线的统计平均结果。 微观真相:任何看似平整的表面在放大后都呈现崎岖的微观几何。每个微表面(Microfacet)均为完美镜面,但大量微表面以不同朝向分布时,宏观上会表…...
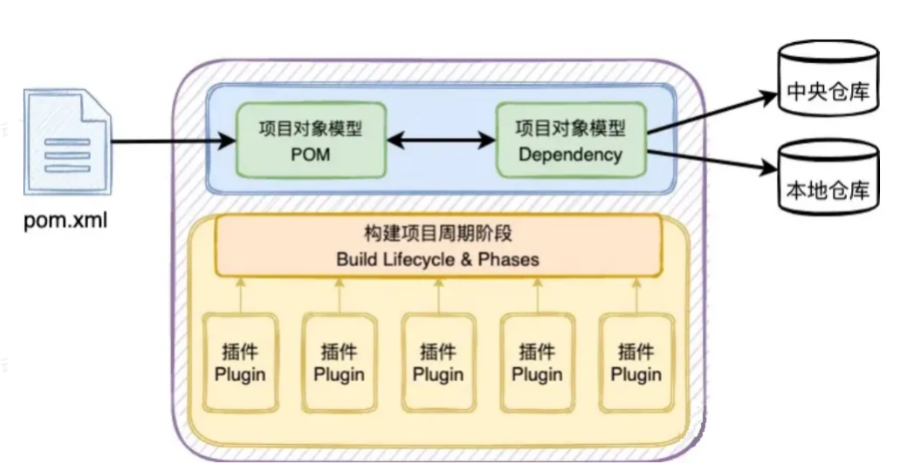
什么是Maven
Maven的概念 Maven是一个一键式的自动化的构建工具。Maven 是 Apache 软件基金会组织维护的一款自动化构建工具,专注服务于Java 平台的项目构建和依赖管理。Maven 这个单词的本意是:专家,内行。Maven 是目前最流行的自动化构建工具࿰…...
(动手学也有))
强化学习复习,价值函数的推导——北大pdf p41(ppt75)(动手学也有)
我们经常看到强化学习中有求汇报期望 E E E,转化为价值函数(value function) V V V,策略的状态价值函数(State-Value function) V π V_π Vπ和动作价值函数(action-value function) Q π Q_π Qπ。还有提到通过将期望将消除…...

neo4j中节点内的名称显示不全解决办法(如何让label在节点上自动换行)
因为节点过多而且想让节点中所有文字都显示出来而放大节点尺寸 从neo4j中导出png,再转成PDF来查看时,要看清节点里面的文字就得放大5倍才行 在网上看了很多让里面文字换行的办法都不行 然后找到一个比较靠谱的办法是在要显示的标签内加换行符 但是我的节点上显示的是…...

day 32 学习笔记
文章目录 前言一、模版匹配的概念二、模版匹配方法 前言 通过今天的学习,我掌握了OpenCV中有关模版匹配和模版匹配方法的相关原理和操作 一、模版匹配的概念 模板匹配就是用模板图(通常是一个小图)在目标图像(通常是一个比模板图…...

【GIT】github中的仓库如何删除?
你可以按照以下步骤删除 GitHub 上的仓库(repository): 🚨 注意事项: ❗️删除仓库是不可恢复的操作,所有代码、issue、pull request、release 等内容都会被永久删除。 🧭 删除 GitHub 仓库步骤…...

使用Python将YOLO的XML标注文件转换为TXT文件格式
使用Python将YOLO的XML标注文件转换为TXT文件格式,并划分数据集 import xml.etree.ElementTree as ET import os from os import listdir, getcwd from os.path import join import random from shutil import copyfile from PIL import Image# 只要改下面的CLASSE…...

docker容器监控自动恢复
关于实现对docker容器监控以及自动恢复,这里介绍两种实现方案。 方案1: 实现思路: 找到(根据正则表达式)所有待监控的docker容器,此处筛选逻辑根据docker运行状态找到已停止(Exit)类…...

【农气项目】基于适宜度的产量预报
直接上干货(复制到开发工具即可运行的代码) 1. 适宜度模型及作物適宜度计算方法 2. 产量分离 3. 基于适宜度计算产量预报 1. 适宜度模型及作物適宜度计算方法 // 三基点温度配置private final double tempMin;private final double tempOpt;private f…...

1、AI及LLM基础:Python语法入门教程
Python语法入门教程 这是一份全面的Python语法入门教程,涵盖了注释、变量类型与操作符、逻辑运算、list和字符串、变量与集合、控制流和迭代、模块、类、继承、进阶等内容,通过详细的代码示例和解释,帮助大家快速熟悉Python语法。 文章目录 Python语法入门教程一、注释二…...
3台CentOS虚拟机部署 StarRocks 1 FE+ 3 BE集群
背景:公司最近业务数据量上去了,需要做一个漏斗分析功能,实时性要求较高,mysql已经已经不在适用,做了个大数据技术栈选型调研后,决定使用StarRocks StarRocks官网:StarRocks | A High-Performa…...

服务器上安装node
1.安装 下载安装包 https://nodejs.org/en/download 解压安装包 将安装包上传到/opt/software目录下 cd /opt/software tar -xzvf node-v16.14.2-linux-x64.tar.gz 将解压的文件夹移动到安装目录(/opt/nodejs)下 mv /opt/software/node-v16.14.2-linux-x64 /opt/nodejs …...
:解析经典数据分析框架,助力创业增长)
精益数据分析(20/126):解析经典数据分析框架,助力创业增长
精益数据分析(20/126):解析经典数据分析框架,助力创业增长 在创业和数据分析的学习道路上,每一次深入探索都可能为我们带来新的启发。今天,依旧带着和大家共同进步的想法,我们一起深入研读《精…...

9.策略模式:思考与解读
原文地址:策略模式:思考与解读 更多内容请关注:7.深入思考与解读设计模式 引言 你是否曾遇到过这样的情况:在一个系统中,有许多算法或策略,每种策略的实现逻辑相似,但在某些情况下需要进行替换和扩展&am…...
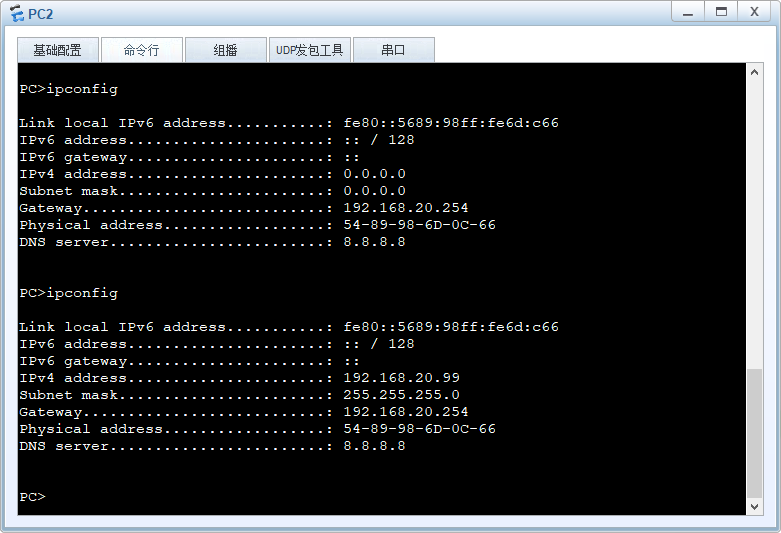
【HCIA】简易的两个VLAN分别使用DHCP分配IP
前言 之前我们通过 静态ip地址实现了Vlan间通信 ,现在我们添加一个常用的DHCP功能。 文章目录 前言1. 配置交换机2. 接口模式3. 全局模式后记修改记录 1. 配置交换机 首先,使用DHCP,需要先启动DHCP服务: [Huawei]dhcp enable I…...

【设计模式-4】深入理解设计模式:工厂模式详解
在软件开发中,对象的创建是一个基础但至关重要的环节。随着系统复杂度的增加,直接使用new关键字实例化对象会带来诸多问题,如代码耦合度高、难以扩展和维护等。工厂模式(Factory Pattern)作为一种创建型设计模式&#…...

Spring Boot 整合 JavaFX 核心知识点详解
1. 架构设计与集成模式 1.1 Spring Boot 与 JavaFX 的分层架构设计 Spring Boot 与 JavaFX 的整合需要精心设计的分层架构,以充分利用两个框架的优势。 标准分层架构 ┌────────────────────────────────────────────────…...

Spring MVC DispatcherServlet 的作用是什么? 它在整个请求处理流程中扮演了什么角色?为什么它是核心?
DispatcherServlet 是 Spring MVC 框架的绝对核心和灵魂。它扮演着前端控制器(Front Controller)的角色,是所有进入 Spring MVC 应用程序的 HTTP 请求的统一入口点和中央调度枢纽。 一、 DispatcherServlet 的核心作用和职责: 请…...