从青涩到 AI:我与评估程序的三十年 “纠缠” 与重启(参数化)
接上篇:从青涩到 AI:我与评估程序的三十年 “纠缠” 与重启
主要对参数配置和模板文件处理进行了改动,将可参数化的数据放到了config.yaml文件中,再一个将模板文件(评估模板.xlsx)分离为(7年级模板.xlsx,8年级模板.xlsx,9年级模板.xlsx),真正做到评估结果直接可以打印。对于各年级评估算法一样,只是科目名不同,所以模板大同小异,分别设置模板后,以免打印时再次重新调整,提高易用性和效率。
主要改动:
-
评估规则参数化配置:
- 核心改动: 将之前硬编码在 Python 代码 (
score_evaluator.py的_evaluate_*函数中) 的大量评估规则数值移到了config.yaml文件中。 - 具体参数: 这包括:
- 排名阈值: 如一层次评估中的 80 名、160 名界限。
- 重点评估得分: 每个项目中,符合条件的学生所得的分数(例如,一层次班团总分前 80 名得 2 分,二层次教师单科优秀且总分合格得 2 分等)。
- 全面评估权重/乘数: 在计算优秀率、平均分、合格率、非低分率等指标相对于同层次最高值的得分时,所使用的乘数(例如,一层次班团优秀率积分乘以 40)。
- 教师最终总分权重: 在计算教师最终总分时,小计1 和小计2 所占的百分比(例如,一层次教师的小计1权重为 0.3,小计2权重为 0.7)。
- 实现方式: 在
config.yaml的每个年级配置下增加了evaluation_rules部分,并细分了class_team和teacher,再按level_1和level_2组织这些参数。Python 代码中的相应评估函数被修改为从self.eval_rules读取这些配置值。
- 核心改动: 将之前硬编码在 Python 代码 (
-
模板文件按年级配置:
- 核心改动: 将原先在
config.yaml的general_settings中的全局template_file设置,移至每个年级(7, 8, 9)各自的配置块内。 - 实现方式: 每个年级配置下现在都有一个独立的
template_file键,例如7: template_file: '7年级模板.xlsx'。Python 代码 (__init__,check_required_files,save_results) 被修改为读取和使用当前评估年级对应的template_file配置。
- 核心改动: 将原先在
-
代码适应性修改:
ScoreEvaluator.__init__: 更新以加载新的evaluation_rules和年级特定的template_file。load_config: 更新以验证新的配置结构。- 评估函数 (
_evaluate_*): 更新以使用从配置加载的规则参数。 - 文件处理函数 (
check_required_files,save_results): 更新以使用年级特定的模板文件名。
-
计算逻辑修正 (附带):
- 根据您的确认,修正了
_evaluate_second_level_class函数中二层次班团的总积分计算逻辑,使其现在等于未加权的小计1与未加权的小计2之和。
- 根据您的确认,修正了
这些改动带来的好处:
-
提高灵活性和可配置性:
- 最显著的好处是,如果学校将来需要调整评估标准(例如修改排名界限、调整各项得分或权重),只需修改
config.yaml文件即可,不再需要深入 Python 代码进行修改。这大大降低了调整评估规则的难度和风险。 - 可以轻松地为不同年级设置不同的评估规则和模板文件,满足差异化需求。
- 最显著的好处是,如果学校将来需要调整评估标准(例如修改排名界限、调整各项得分或权重),只需修改
-
增强可维护性:
- 将易变的评估规则与相对稳定的计算逻辑分离。代码 (
.py) 专注于“如何计算”,配置文件 (.yaml) 则定义“计算标准是什么”。 - 规则集中存放在
config.yaml中,更易于查找、理解和管理。修改配置通常比修改代码更安全,减少了引入程序错误的可能性。
- 将易变的评估规则与相对稳定的计算逻辑分离。代码 (
-
提升代码清晰度和可读性:
- 评估函数中的代码不再充斥着各种“魔法数字”,而是引用具有明确含义的配置变量(如
rules['focus_points_rank1']),使得代码逻辑更易懂。
- 评估函数中的代码不再充斥着各种“魔法数字”,而是引用具有明确含义的配置变量(如
-
便于扩展和重用:
- 如果需要为新的年级(如六年级)添加评估,只需在
config.yaml中增加对应的配置块,并准备好相应的模板文件,代码主体基本无需改动。 - 这套程序更容易被其他需要类似评估逻辑的场景复用,只需修改配置文件即可适应新规则。
- 如果需要为新的年级(如六年级)添加评估,只需在
总而言之,这些改动将评估的核心“规则”部分从程序代码中解耦出来,放入了专门的配置文件,使得程序更加灵活、易于维护和适应未来的变化。
修改后配置文件 “config.yaml”
# === 程序配置文件 ===# --- 通用设置 ---
general_settings:# template_file: '评估模板.xlsx' # <--- 移除此行# !!! 重要:请根据实际教师分工表修改此项 !!!head_teacher_column_name: '班主任' # 教师分工表中代表"班主任"的列名 class_team_output_label: '班团' # 在最终评估结果中代表"班团"评估的标签名# --- 评分标准阈值 (百分比) ---
score_thresholds:excellent_rate: 0.8 # 优秀线比例 (满分的80%)pass_rate: 0.6 # 合格线比例 (满分的60%)low_score_rate: 0.3 # 低分线低于此比例 (满分的30%)# --- 年级特定配置 ---
grades:# --- 七年级配置 ---7: template_file: '7年级模板.xlsx' # <--- 新增七年级模板配置# 成绩表科目列名 (参与总分计算和排名)subjects: - 语文- 数学- 英语- 道法- 历史- 地理- 生物# 各科目满分full_scores: 语文: 120数学: 120英语: 90道法: 60历史: 60地理: 50生物: 100# 教师分工表科目列名 (程序将查找这些列以获取教师姓名)teacher_file_subjects: - 语文- 数学- 英语- 生物- 地理- 道法- 历史# --- 评估规则 ---evaluation_rules:class_team: # 班团评估level_1: # 一层次rank_threshold_1: 80 # 重点评估项目1排名界限rank_threshold_2: 160 # 重点评估项目2排名界限focus_points_rank1: 2 # 项目1得分/人focus_points_rank2: 1.5 # 项目2得分/人focus_points_excellent: 1 # 项目3得分/人comp_weight_excellent: 40 # 全面评估-优生率积分权重comp_weight_avg: 40 # 全面评估-平均分积分权重comp_weight_non_low: 20 # 全面评估-非低分率积分权重level_2: # 二层次focus_points_excellent: 2 # 项目1得分/人focus_points_pass: 1.5 # 项目2得分/人comp_weight_excellent: 5 # 全面评估-优生率积分权重comp_weight_pass: 30 # 全面评估-合格率积分权重comp_weight_avg: 30 # 全面评估-平均分积分权重comp_weight_non_low: 35 # 全面评估-非低分率积分权重# 注意:二层次班团总分 = 小计1 + 小计2 (直接相加)teacher: # 教师评估level_1: # 一层次rank_threshold_1: 80 # 重点评估项目1&2排名界限rank_threshold_2: 160focus_points_p1: 2 # 项目1得分/人focus_points_p2: 1.5 # 项目2得分/人focus_points_p3: 1 # 项目3得分/人focus_points_p4: 0.5 # 项目4得分/人comp_weight_excellent: 40 # 全面评估-优生率积分权重comp_weight_avg: 40 # 全面评估-平均分积分权重comp_weight_non_low: 20 # 全面评估-非低分率积分权重final_weight_sub1: 0.3 # 最终总分中小计1权重final_weight_sub2: 0.7 # 最终总分中小计2权重level_2: # 二层次focus_points_p1: 2 # 项目1得分/人focus_points_p2: 1.5 # 项目2得分/人comp_weight_excellent: 5 # 全面评估-优生率积分权重comp_weight_pass: 30 # 全面评估-合格率积分权重comp_weight_avg: 30 # 全面评估-平均分积分权重comp_weight_non_low: 35 # 全面评估-非低分率积分权重final_weight_sub1: 0.2 # 最终总分中小计1权重final_weight_sub2: 0.8 # 最终总分中小计2权重# --- 八年级配置 ---8: template_file: '8年级模板.xlsx' # <--- 新增八年级模板配置subjects: - 语文- 数学- 英语- 物理- 生物- 地理- 历史- 道法full_scores:语文: 120数学: 120英语: 120物理: 70生物: 50地理: 50历史: 60道法: 60teacher_file_subjects:- 语文- 数学- 英语- 物理- 道法- 历史- 地理- 生物# --- 评估规则 ---evaluation_rules: # (与7年级相同,如果不同请修改)class_team: level_1: rank_threshold_1: 80rank_threshold_2: 160focus_points_rank1: 2focus_points_rank2: 1.5focus_points_excellent: 1comp_weight_excellent: 40comp_weight_avg: 40comp_weight_non_low: 20level_2: focus_points_excellent: 2focus_points_pass: 1.5comp_weight_excellent: 5comp_weight_pass: 30comp_weight_avg: 30comp_weight_non_low: 35teacher: level_1: rank_threshold_1: 80rank_threshold_2: 160focus_points_p1: 2focus_points_p2: 1.5focus_points_p3: 1focus_points_p4: 0.5comp_weight_excellent: 40comp_weight_avg: 40comp_weight_non_low: 20final_weight_sub1: 0.3final_weight_sub2: 0.7level_2: focus_points_p1: 2focus_points_p2: 1.5comp_weight_excellent: 5comp_weight_pass: 30comp_weight_avg: 30comp_weight_non_low: 35final_weight_sub1: 0.2final_weight_sub2: 0.8# --- 九年级配置 ---9: template_file: '9年级模板.xlsx' # <--- 新增九年级模板配置subjects: - 语文- 数学- 英语- 物理- 化学- 历史- 道法full_scores:语文: 120数学: 120英语: 120物理: 80化学: 70历史: 50道法: 50teacher_file_subjects:- 语文- 数学- 英语- 物理- 化学- 历史- 道法# --- 评估规则 ---evaluation_rules: # (与7年级相同,如果不同请修改)class_team: level_1: rank_threshold_1: 80rank_threshold_2: 160focus_points_rank1: 2focus_points_rank2: 1.5focus_points_excellent: 1comp_weight_excellent: 40comp_weight_avg: 40comp_weight_non_low: 20level_2: focus_points_excellent: 2focus_points_pass: 1.5comp_weight_excellent: 5comp_weight_pass: 30comp_weight_avg: 30comp_weight_non_low: 35teacher: level_1: rank_threshold_1: 80rank_threshold_2: 160focus_points_p1: 2focus_points_p2: 1.5focus_points_p3: 1focus_points_p4: 0.5comp_weight_excellent: 40comp_weight_avg: 40comp_weight_non_low: 20final_weight_sub1: 0.3final_weight_sub2: 0.7level_2: focus_points_p1: 2focus_points_p2: 1.5comp_weight_excellent: 5comp_weight_pass: 30comp_weight_avg: 30comp_weight_non_low: 35final_weight_sub1: 0.2final_weight_sub2: 0.8
修改后的程序
import pandas as pd
import numpy as np
import os
import shutil
from datetime import datetime
import yaml # 新增:用于读取 YAML 配置# 尝试导入 openpyxl,如果失败则提示安装
try:from openpyxl import load_workbook
except ImportError:print("错误:缺少必需的库 'openpyxl'。请使用 'pip install openpyxl' 命令安装后再试。")raise # 重新抛出异常# --- 全局配置变量 ---
CONFIG = None # 用于存储加载的配置
CONFIG_FILE = 'config.yaml' # 配置文件名def load_config(config_path=CONFIG_FILE):"""加载 YAML 配置文件"""global CONFIGtry:with open(config_path, 'r', encoding='utf-8') as f:CONFIG = yaml.safe_load(f)if CONFIG is None:raise ValueError(f"配置文件 '{config_path}' 为空或格式不正确。")# 基本的配置验证 (可以根据需要扩展)if 'general_settings' not in CONFIG or 'score_thresholds' not in CONFIG or 'grades' not in CONFIG:raise ValueError(f"配置文件 '{config_path}' 缺少必需的顶层键 (general_settings, score_thresholds, grades)。")# !! 新增: 检查每个年级配置中是否有 template_file 和 evaluation_rulesfor grade, grade_config in CONFIG['grades'].items():if 'template_file' not in grade_config:raise ValueError(f"配置文件 '{config_path}' 中年级 {grade} 缺少必需的 'template_file' 配置。")if 'evaluation_rules' not in grade_config:raise ValueError(f"配置文件 '{config_path}' 中年级 {grade} 缺少必需的 'evaluation_rules' 配置。")# 可选:更深入地检查 evaluation_rules 内部结构if 'class_team' not in grade_config['evaluation_rules'] or 'teacher' not in grade_config['evaluation_rules']:raise ValueError(f"配置文件 '{config_path}' 中年级 {grade} 的 'evaluation_rules' 缺少 'class_team' 或 'teacher' 配置。")# ... 可根据需要添加更多层级的检查 ...print(f"配置文件 '{config_path}' 加载成功。")except FileNotFoundError:print(f"错误:配置文件 '{config_path}' 未找到。请确保它与脚本在同一目录下。")raiseexcept yaml.YAMLError as e:print(f"错误:解析配置文件 '{config_path}' 时出错:{e}")raiseexcept ValueError as e: # 捕获上面添加的 ValueErrorprint(f"错误:配置文件 '{config_path}' 内容不完整或格式错误:{e}")raiseexcept Exception as e:print(f"加载配置文件时发生未知错误:{e}")raiseclass ScoreEvaluator:def __init__(self, grade):global CONFIGif CONFIG is None:# 尝试加载配置,如果 main 函数未预先加载try:load_config()except Exception:print("在 ScoreEvaluator 初始化时加载配置失败。程序无法继续。")raise RuntimeError("无法加载配置文件") # grade 现在是整数if grade not in CONFIG['grades']: supported_grades_str = [str(k) for k in CONFIG['grades'].keys()]raise ValueError(f"不支持的年级: {grade}. 配置文件中支持的年级: {supported_grades_str}")self.grade = grade self.grade_config = CONFIG['grades'][grade] self.general_config = CONFIG['general_settings']self.threshold_config = CONFIG['score_thresholds']# --- 关键修复:确保加载评估规则 ---# 检查 evaluation_rules 是否存在,如果不存在则抛出更明确的错误if 'evaluation_rules' not in self.grade_config:raise ValueError(f"配置文件 '{CONFIG_FILE}' 中年级 {grade} 缺少必需的 'evaluation_rules' 配置。")self.eval_rules = self.grade_config['evaluation_rules'] # -------------------------------------# --- 从配置加载其他设置 ---self.SUBJECTS = self.grade_config['subjects']self.SUBJECT_FULL_SCORES = self.grade_config['full_scores']self.TEACHER_FILE_SUBJECTS = self.grade_config['teacher_file_subjects']# !! 修改: 从年级配置加载 template_fileif 'template_file' not in self.grade_config:raise ValueError(f"配置文件 '{CONFIG_FILE}' 中年级 {grade} 缺少必需的 'template_file' 配置。")self.template_file = self.grade_config['template_file'] self.head_teacher_col = self.general_config['head_teacher_column_name']self.class_team_label = self.general_config['class_team_output_label']self.SCORE_THRESHOLDS = self.threshold_config# -----------------------# --- 设置动态文件名和目录名 ---self.scores_file = f'{self.grade}年级成绩表.xlsx'self.teachers_file = f'{self.grade}年级教师分工表.xlsx'self.detailed_data_dir = f'{self.grade}年级详细数据'# ---------------------------self.subject_thresholds = self._calculate_subject_thresholds()if not os.path.exists(self.detailed_data_dir):os.makedirs(self.detailed_data_dir)def _calculate_subject_thresholds(self):"""计算各科目的优秀、合格、低分线"""thresholds = {}# 使用 self.SUBJECT_FULL_SCORES 和 self.SCORE_THRESHOLDS (从配置加载)for subject, full_score in self.SUBJECT_FULL_SCORES.items():thresholds[subject] = {'excellent': full_score * self.SCORE_THRESHOLDS['excellent_rate'],'pass': full_score * self.SCORE_THRESHOLDS['pass_rate'],'low': full_score * self.SCORE_THRESHOLDS['low_score_rate']}return thresholdsdef check_required_files(self):"""检查必需的文件是否存在"""# 使用动态和配置的文件名required_files = [self.scores_file, self.teachers_file, self.template_file]missing_files = []for file in required_files:if not os.path.exists(file):missing_files.append(file)if missing_files:# !! 修改: 明确指出哪个模板文件缺失if self.template_file in missing_files:raise FileNotFoundError(f"缺少必需文件,特别是 {self.grade} 年级的模板文件 '{self.template_file}'。其他缺失文件(如果有):{', '.join(f for f in missing_files if f != self.template_file)}")else:raise FileNotFoundError(f"缺少以下必需文件:{', '.join(missing_files)}")def prepare_data(self):"""准备评估所需的数据"""self.check_required_files()try:# 读取原始数据 (使用动态文件名)self.scores_df = pd.read_excel(self.scores_file)self.teachers_df = pd.read_excel(self.teachers_file)# self.template_df = pd.read_excel(self.template_file) # 不再需要读取模板内容# 检查必需的列 (使用配置的科目列表和班主任列名)required_scores_columns = ['评估班级', '层次', '准考证', '姓名'] + self.SUBJECTS # 确保准考证和姓名也在检查列表里# 教师表需要班号、配置的班主任列名、以及配置的所有科目教师列required_teachers_columns = ['班号', self.head_teacher_col] + self.TEACHER_FILE_SUBJECTSmissing_scores_cols = [col for col in required_scores_columns if col not in self.scores_df.columns]if missing_scores_cols:raise ValueError(f"{self.scores_file} 缺少必需的列:{', '.join(missing_scores_cols)}")missing_teachers_cols = [col for col in required_teachers_columns if col not in self.teachers_df.columns]if missing_teachers_cols:raise ValueError(f"{self.teachers_file} 缺少必需的列:{', '.join(missing_teachers_cols)}")# 验证层次数据 (保持不变)if not self.scores_df['层次'].isin(['一层次', '二层次']).all():raise ValueError(f"{self.scores_file} 中的层次列必须只包含'一层次'或'二层次'")# 将层次值映射为数字 (保持不变)self.scores_df['层次_数值'] = self.scores_df['层次'].map({'一层次': 1, '二层次': 2})# 重新组织教师数据 (使用配置的班主任列名和科目列表)teacher_data = []for _, row in self.teachers_df.iterrows():班号 = row['班号']# 添加班主任记录 (使用配置的列名)teacher_data.append({'班号': 班号,'教师姓名': row[self.head_teacher_col],'学科': '__HeadTeacher__' # 使用内部固定标识符,不暴露给配置})# 添加各科目教师记录 (使用配置的 self.TEACHER_FILE_SUBJECTS)for subject in self.TEACHER_FILE_SUBJECTS:teacher_data.append({'班号': 班号,'教师姓名': row[subject],'学科': subject})# 转换为DataFrameself.teachers_df = pd.DataFrame(teacher_data)# 创建班主任映射字典 (使用内部标识符查找)self.class_teacher_map = self.teachers_df[self.teachers_df['学科'] == '__HeadTeacher__'].set_index('班号')['教师姓名'].to_dict()# 计算总分 (使用配置的科目列表 self.SUBJECTS)self.scores_df['总分'] = self.scores_df[self.SUBJECTS].sum(axis=1)# 计算各科目排名self._calculate_rankings()except KeyError as e:# 捕获因配置错误或Excel列名不匹配导致的KeyErrorprint(f"数据准备过程中出现列名错误:找不到列 '{e}'。")print(f"请检查配置文件 ({CONFIG_FILE}) 中的科目/班主任列名是否与 Excel 文件 ({self.scores_file}, {self.teachers_file}) 完全匹配。")raise ValueError(f"列名不匹配错误: {e}")except Exception as e:print(f"数据准备过程中出错:{str(e)}") # 提供更具体的错误信息raisedef _calculate_rankings(self):"""计算各科目的排名"""# 使用配置的科目列表 self.SUBJECTSsubjects_to_rank = self.SUBJECTS + ['总分']# 计算全校排名 (保持不变)for subject in subjects_to_rank:if subject in self.scores_df.columns:self.scores_df[f'{subject}_全校名次'] = self.scores_df[subject].rank(ascending=False, method='min')# 计算班级排名 (保持不变)for subject in subjects_to_rank:if subject in self.scores_df.columns:self.scores_df[f'{subject}_班级名次'] = self.scores_df.groupby('评估班级')[subject].rank(ascending=False, method='min')def _safe_max(self, values, default=0):"""安全地计算最大值,如果列表为空则返回默认值"""try:# 过滤掉可能的NaN值或其他非数值类型numeric_values = [v for v in values if isinstance(v, (int, float)) and not np.isnan(v)]return max(numeric_values) if numeric_values else defaultexcept Exception:# 更广泛的异常捕获可能更安全return defaultdef _save_detailed_data(self, class_data, class_num, subject, level, debug_info):"""保存详细评估数据到文件"""# 检查输出的科目名是否是内部的班主任标记,如果是,则替换为配置的输出标签output_subject_name = self.class_team_label if subject == '__HeadTeacher__' else subjecttry:# 使用动态目录名和处理过的科目名filename = os.path.join(self.detailed_data_dir, f'{output_subject_name}.txt')# 以追加模式打开文件with open(filename, 'a', encoding='utf-8') as f:f.write(f"\n{'='*50}")f.write(f"\n{class_num}班({level})详细数据 - 科目: {output_subject_name}\n") # 明确指出科目# 添加所有考生基本信息f.write(f"\n--- 所有考生基本信息 (总人数: {len(class_data)}) ---\n")for _, student in class_data.iterrows():# 如果是班团评估(用内部标记判断),只显示总分相关if subject == '__HeadTeacher__': f.write(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, 总分:{student['总分']}, 总分名次:{student['总分_全校名次']}\n")else:# 对于其他科目,显示科目相关信息 (保持不变)subject_score = student.get(subject, 'N/A')subject_rank = student.get(f'{subject}_全校名次', 'N/A')total_score = student.get('总分', 'N/A')total_rank = student.get('总分_全校名次', 'N/A')f.write(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, {subject}:{subject_score}, {subject}名次:{subject_rank}, 总分:{total_score}, 总分名次:{total_rank}\n")# --- 解析和写入 debug_info 的逻辑保持不变 --- project_sections = []assessment_data = []assessment_calc = []current_section = Nonesection_type = None # 可以是 'project', 'data', 'calc'for line in debug_info:line_stripped = line.strip()# 跳过空行或不必要的行if not line_stripped:continue# 检测部分标题if line_stripped.startswith("--- 项目") and line_stripped.endswith("---"):if current_section and section_type == 'project':project_sections.append(current_section)current_section = {"title": line_stripped, "description": [], "students": [], "summary": None}section_type = 'project'continueelif line_stripped.startswith("--- 全面评估数据 ---"):if current_section and section_type == 'project': # 完成最后一个项目project_sections.append(current_section)current_section = Nonesection_type = 'data'continueelif line_stripped.startswith("--- 全面评估积分计算 ---"):section_type = 'calc'continue# 其他类型的分隔符可以视为部分的结束elif line_stripped.startswith("---"):if current_section and section_type == 'project':project_sections.append(current_section)current_section = Nonesection_type = None # 重置类型continue# 根据当前部分类型收集内容if section_type == 'project' and current_section:if "准考证" in line and "姓名" in line:current_section["students"].append(line_stripped)elif "线" in line or "范围" in line:if not ("人数" in line and "得分" in line):current_section["description"].append(line_stripped)elif "项目" in line and "人数" in line and "得分" in line:current_section["summary"] = line_strippedelif section_type == 'data':assessment_data.append(line_stripped)elif section_type == 'calc':assessment_calc.append(line_stripped)# 确保最后一个项目(如果存在)被添加if current_section and section_type == 'project':project_sections.append(current_section)# --- 结束修改后的解析逻辑 ---# 写入记分项目考生详细信息部分f.write("\n--- 记分项目考生详细信息 ---\n")if not project_sections:f.write("无记分项目信息\n")else:for section in project_sections:# 写入项目标题f.write(f"\n{section['title']}\n")# 写入项目描述for desc in section["description"]:f.write(f"{desc}\n")# 写入考生信息if section["students"]:f.write("考生详细信息:\n")for student in section["students"]:f.write(f"{student}\n")else:f.write("无符合条件的考生\n")# 写入项目汇总if section["summary"]:f.write(f"{section['summary']}\n")# 写入全面评估数据f.write("\n--- 全面评估数据 ---\n")if not assessment_data:f.write("无全面评估数据\n")else:for line in assessment_data:f.write(f"{line}\n")# 写入全面评估积分计算f.write("\n--- 全面评估积分计算 ---\n")if not assessment_calc:f.write("无全面评估积分计算数据\n")else:for line in assessment_calc:f.write(f"{line}\n")f.write('\n')except Exception as e:print(f"保存科目 '{output_subject_name}' 的详细数据时出错:{str(e)}") # 提示哪个科目出错# 不再向上抛出,避免一个科目的错误中断整个流程,但会在最后提示# raise def _evaluate_first_level_class(self, class_data, class_num):"""一层次班级评估"""total_students = len(class_data)debug_info = [] # 用于存储调试信息# 创建一个标记数组,用于记录已计分的学生counted_students = pd.Series(False, index=class_data.index)# --- 重点评估 --- # 项目1:总分1-80名(2分)top_80_mask = class_data['总分_全校名次'] <= 80top_80_students = class_data[top_80_mask]top_80_count = len(top_80_students) # 使用len确保一致性score_1 = top_80_count * 2counted_students = counted_students | top_80_maskdebug_info.append(f"\n总人数:{total_students}") # 移到项目1之前debug_info.append("\n--- 项目1:总分1-80名(2分)---")for _, student in top_80_students.iterrows():debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, 总分:{student['总分']}, 总分名次:{student['总分_全校名次']}")debug_info.append(f"项目1人数:{top_80_count}, 得分:{score_1}")# 项目2:总分81-160名(1.5分)top_81_160_mask_scored = (class_data['总分_全校名次'] > 80) & (class_data['总分_全校名次'] <= 160) & ~counted_studentstop_81_160_students_scored = class_data[top_81_160_mask_scored]top_81_160_count = len(top_81_160_students_scored)score_2 = top_81_160_count * 1.5counted_students = counted_students | top_81_160_mask_scoreddebug_info.append("\n--- 项目2:总分81-160名(1.5分)---")debug_info.append(f"总分名次范围:81-160名")for _, student in top_81_160_students_scored.iterrows():debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, 总分:{student['总分']}, 总分名次:{student['总分_全校名次']}")debug_info.append(f"项目2人数:{top_81_160_count}, 得分:{score_2}")# 项目3:总分优秀(1分)# 使用动态科目列表计算总分优秀线excellent_threshold = sum([self.subject_thresholds[s]['excellent'] for s in self.SUBJECTS if s in self.subject_thresholds])excellent_mask_base = class_data['总分'] >= excellent_thresholdexcellent_mask_scored = excellent_mask_base & ~counted_studentsexcellent_students_scored = class_data[excellent_mask_scored]excellent_count = len(excellent_students_scored)score_3 = excellent_count * 1counted_students = counted_students | excellent_mask_scoreddebug_info.append("\n--- 项目3:总分优秀(1分)---")debug_info.append(f"总分优秀线:{excellent_threshold}") # 修改名称for _, student in excellent_students_scored.iterrows():debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, 总分:{student['总分']}, 总分名次:{student['总分_全校名次']}")debug_info.append(f"项目3人数:{excellent_count}, 得分:{score_3}")# --- 全面评估 --- excellent_rate = sum(excellent_mask_base) / total_students # 使用基础优秀标记# 使用动态科目列表计算总分合格线pass_threshold = sum([self.subject_thresholds[s]['pass'] for s in self.SUBJECTS if s in self.subject_thresholds])pass_mask_base = class_data['总分'] >= pass_threshold # 使用基础合格标记pass_rate = sum(pass_mask_base) / total_students # 使用基础合格标记avg_score = class_data['总分'].mean()# 使用动态科目列表计算总分低分线low_threshold = sum([self.subject_thresholds[s]['low'] for s in self.SUBJECTS if s in self.subject_thresholds])low_score_mask = class_data['总分'] < low_thresholdnon_low_score_rate = 1 - (sum(low_score_mask) / total_students)low_score_count = sum(low_score_mask)debug_info.append("\n--- 全面评估数据 ---")debug_info.append(f"总分优秀线:{excellent_threshold}") # 修改名称debug_info.append(f"总分合格线:{pass_threshold}") # 修改名称debug_info.append(f"总分低分线:{low_threshold}") # 修改名称debug_info.append(f"优生数:{sum(excellent_mask_base)}") # 使用基础优秀标记debug_info.append(f"优生率:{excellent_rate*100:03.2f}%")debug_info.append(f"合格数:{sum(pass_mask_base)}") # 使用基础合格标记debug_info.append(f"合格率:{pass_rate*100:03.2f}%")debug_info.append(f"平均分:{avg_score:.2f}")debug_info.append(f"低分数:{low_score_count}")debug_info.append(f"非低分人数:{total_students - sum(low_score_mask)}")debug_info.append(f"非低分率:{non_low_score_rate*100:03.2f}%")# 计算相对值(与同层次班级比较)first_level_data = self.scores_df[self.scores_df['层次_数值'] == 1]if len(first_level_data) == 0:max_excellent_rate = 0max_avg_score = 0max_non_low_score_rate = 0else:# 在计算groupby后的指标时,确保分母不为0excellent_rates = [(sum(c['总分'] >= excellent_threshold) / len(c)) if len(c) > 0 else 0for _, c in first_level_data.groupby('评估班级')]max_excellent_rate = self._safe_max(excellent_rates)avg_scores = [c['总分'].mean() if len(c) > 0 else 0 for _, c in first_level_data.groupby('评估班级')]max_avg_score = self._safe_max(avg_scores)non_low_score_rates = [(1 - sum(c['总分'] < low_threshold) / len(c)) if len(c) > 0 else 0for _, c in first_level_data.groupby('评估班级')]max_non_low_score_rate = self._safe_max(non_low_score_rates)# 计算全面评估各项积分excellent_rate_score = (excellent_rate/max_excellent_rate) * 40 if max_excellent_rate > 0 else 0avg_score_score = (avg_score/max_avg_score) * 40 if max_avg_score > 0 else 0non_low_rate_score = (non_low_score_rate/max_non_low_score_rate) * 20 if max_non_low_score_rate > 0 else 0debug_info.append("\n--- 全面评估积分计算 ---")debug_info.append(f"最高优生率:{max_excellent_rate*100:03.2f}%")debug_info.append(f"最高平均分:{max_avg_score:.2f}")debug_info.append(f"最高非低分率:{max_non_low_score_rate*100:03.2f}%")debug_info.append(f"优生率积分:{excellent_rate_score if excellent_rate_score.is_integer() else excellent_rate_score:.2f}")debug_info.append(f"平均分积分:{avg_score_score if avg_score_score.is_integer() else avg_score_score:.2f}")debug_info.append(f"非低分率积分:{non_low_rate_score if non_low_rate_score.is_integer() else non_low_rate_score:.2f}")# 保存详细数据self._save_detailed_data(class_data, class_num, '__HeadTeacher__', '一层次', debug_info)return {'班号': class_num,'班级人数': total_students,'教师姓名': self.class_teacher_map.get(class_num, ''),'层次': '一层次','项目1': top_80_count,'积分1': score_1,'项目2': top_81_160_count,'积分2': score_2,'项目3': excellent_count,'积分3': score_3,'小计1': score_1 + score_2 + score_3,'优生数': sum(excellent_mask_base), # 使用基础优秀标记计数'优生率': excellent_rate,'优生积分': excellent_rate_score,'平均分': avg_score,'平均分积分': avg_score_score,'低分数': low_score_count,'非低分率': non_low_score_rate,'非低分率积分': non_low_rate_score,'小计2': excellent_rate_score + avg_score_score + non_low_rate_score,'总积分': (score_1 + score_2 + score_3) + (excellent_rate_score + avg_score_score + non_low_rate_score),'科目名': self.class_team_label # 使用配置的班团标签}def _evaluate_second_level_class(self, class_data, class_num):"""二层次班级评估"""rules = self.eval_rules['class_team']['level_2'] # 获取规则total_students = len(class_data)debug_info = []# --- 重点评估 --- # 项目1:总分优秀 (得分: focus_points_excellent)points_excellent = rules['focus_points_excellent']excellent_threshold = sum([self.subject_thresholds[s]['excellent'] for s in self.SUBJECTS if s in self.subject_thresholds])excellent_mask = class_data['总分'] >= excellent_thresholdexcellent_students = class_data[excellent_mask]excellent_count = len(excellent_students)score_1 = excellent_count * points_excellentdebug_info.append(f"\n总人数:{total_students}")debug_info.append(f"\n--- 项目1:总分优秀({points_excellent}分)---")debug_info.append(f"总分优秀线:{excellent_threshold}")for _, student in excellent_students.iterrows():debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, 总分:{student['总分']}, 总分名次:{student['总分_全校名次']}")debug_info.append(f"项目1人数:{excellent_count}, 得分:{score_1}")# 项目2:总分合格 (得分: focus_points_pass)points_pass = rules['focus_points_pass']pass_threshold = sum([self.subject_thresholds[s]['pass'] for s in self.SUBJECTS if s in self.subject_thresholds])pass_mask_base = class_data['总分'] >= pass_thresholdpass_mask_scored = pass_mask_base & ~excellent_mask # 合格且非优秀pass_students_scored = class_data[pass_mask_scored]pass_count = len(pass_students_scored)score_2 = pass_count * points_passdebug_info.append(f"\n--- 项目2:总分合格({points_pass}分)---")debug_info.append(f"总分合格线:{pass_threshold}")for _, student in pass_students_scored.iterrows():debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, 总分:{student['总分']}, 总分名次:{student['总分_全校名次']}")debug_info.append(f"项目2人数:{pass_count}, 得分:{score_2}")# 小计1 (未加权)subtotal_1 = score_1 + score_2# --- 全面评估 --- excellent_rate = sum(excellent_mask) / total_studentspass_rate = sum(pass_mask_base) / total_studentsavg_score = class_data['总分'].mean()low_threshold = sum([self.subject_thresholds[s]['low'] for s in self.SUBJECTS if s in self.subject_thresholds])low_score_mask = class_data['总分'] < low_thresholdnon_low_score_rate = 1 - (sum(low_score_mask) / total_students)low_score_count = sum(low_score_mask)debug_info.append("\n--- 全面评估数据 ---")debug_info.append(f"总分优秀线:{excellent_threshold}")debug_info.append(f"总分合格线:{pass_threshold}")debug_info.append(f"总分低分线:{low_threshold}")debug_info.append(f"优生数:{sum(excellent_mask)}")debug_info.append(f"优生率:{excellent_rate*100:03.2f}%")debug_info.append(f"合格数:{sum(pass_mask_base)}")debug_info.append(f"合格率:{pass_rate*100:03.2f}%")debug_info.append(f"平均分:{avg_score:.2f}")debug_info.append(f"低分数:{low_score_count}")debug_info.append(f"非低分人数:{total_students - sum(low_score_mask)}")debug_info.append(f"非低分率:{non_low_score_rate*100:03.2f}%")second_level_data = self.scores_df[self.scores_df['层次_数值'] == 2]if len(second_level_data) == 0:max_excellent_rate, max_pass_rate, max_avg_score, max_non_low_score_rate = 0, 0, 0, 0else:excellent_rates = [(sum(c['总分'] >= excellent_threshold)/len(c)) if len(c) > 0 else 0 for _, c in second_level_data.groupby('评估班级')]max_excellent_rate = self._safe_max(excellent_rates)pass_rates = [(sum(c['总分'] >= pass_threshold)/len(c)) if len(c) > 0 else 0 for _, c in second_level_data.groupby('评估班级')]max_pass_rate = self._safe_max(pass_rates)avg_scores = [c['总分'].mean() if len(c) > 0 else 0 for _, c in second_level_data.groupby('评估班级')]max_avg_score = self._safe_max(avg_scores)non_low_rates = [(1 - sum(c['总分'] < low_threshold)/len(c)) if len(c) > 0 else 0 for _, c in second_level_data.groupby('评估班级')]max_non_low_score_rate = self._safe_max(non_low_rates)# 计算全面评估各项积分 (使用配置权重)weight_excellent = rules['comp_weight_excellent']weight_pass = rules['comp_weight_pass']weight_avg = rules['comp_weight_avg']weight_non_low = rules['comp_weight_non_low']excellent_rate_score = (excellent_rate/max_excellent_rate) * weight_excellent if max_excellent_rate > 0 else 0pass_rate_score = (pass_rate/max_pass_rate) * weight_pass if max_pass_rate > 0 else 0avg_score_score = (avg_score/max_avg_score) * weight_avg if max_avg_score > 0 else 0non_low_rate_score = (non_low_score_rate/max_non_low_score_rate) * weight_non_low if max_non_low_score_rate > 0 else 0debug_info.append("\n--- 全面评估积分计算 ---")debug_info.append(f"最高优生率:{max_excellent_rate*100:03.2f}% (权重: {weight_excellent})")debug_info.append(f"最高合格率:{max_pass_rate*100:03.2f}% (权重: {weight_pass})")debug_info.append(f"最高平均分:{max_avg_score:.2f} (权重: {weight_avg})")debug_info.append(f"最高非低分率:{max_non_low_score_rate*100:03.2f}% (权重: {weight_non_low})")debug_info.append(f"优生率积分:{excellent_rate_score if excellent_rate_score.is_integer() else excellent_rate_score:.2f}")debug_info.append(f"合格率积分:{pass_rate_score if pass_rate_score.is_integer() else pass_rate_score:.2f}")debug_info.append(f"平均分积分:{avg_score_score if avg_score_score.is_integer() else avg_score_score:.2f}")debug_info.append(f"非低分率积分:{non_low_rate_score if non_low_rate_score.is_integer() else non_low_rate_score:.2f}")# !! 修正: 小计2直接累加,不乘以权重subtotal_2 = excellent_rate_score + pass_rate_score + avg_score_score + non_low_rate_scoreself._save_detailed_data(class_data, class_num, '__HeadTeacher__', '二层次', debug_info)# !! 修正: 总积分直接累加 小计1 和 小计2total_score_final = subtotal_1 + subtotal_2return {'班号': class_num,'班级人数': total_students,'教师姓名': self.class_teacher_map.get(class_num, ''),'层次': '二层次','项目1': excellent_count,'积分1': score_1,'项目2': pass_count,'积分2': score_2,'小计1': subtotal_1, # 未加权小计1'优生数': sum(excellent_mask),'优生率': excellent_rate,'优生积分': excellent_rate_score, # 未加权'合格数': sum(pass_mask_base), '合格率': pass_rate,'合格率积分': pass_rate_score, # 未加权'平均分': avg_score,'平均分积分': avg_score_score, # 未加权'低分数': low_score_count,'非低分率': non_low_score_rate,'非低分率积分': non_low_rate_score, # 未加权'小计2': subtotal_2, # 未加权小计2'总积分': total_score_final, # 修正后的总积分 (小计1+小计2)'科目名': self.class_team_label }def _evaluate_first_level_teacher(self, class_data, subject, teacher_row):"""一层次教师评估"""total_students = len(class_data)debug_info = [] # 用于存储调试信息debug_info.append(f"\n总人数:{total_students}") # 移到项目1之前# 检查科目是否存在于阈值配置中,如果不存在则跳过评估if subject not in self.subject_thresholds:print(f"警告:科目 '{subject}' 没有定义阈值,跳过教师 {teacher_row['教师姓名']} ({teacher_row['班号']}班) 的评估。")# 可以在这里返回一个空的或表示跳过的字典,或者根据需要处理# 为保持一致性,我们可能需要返回一个包含基本信息的字典,但评估值为0或NaNreturn {'班号': teacher_row['班号'], '班级人数': total_students, '教师姓名': teacher_row['教师姓名'], '层次': '一层次','项目1': 0, '积分1': 0, '项目2': 0, '积分2': 0, '项目3': 0, '积分3': 0, '项目4': 0, '积分4': 0,'小计1': 0, '优生数': 0, '优生率': 0, '优生积分': 0, '平均分': np.nan, '平均分积分': 0,'低分数': 0, '非低分率': 0, '非低分率积分': 0, '小计2': 0, '总积分': 0, '科目名': subject}# 创建一个标记数组,用于记录已计分的学生counted_students = pd.Series(False, index=class_data.index)# --- 重点评估 --- # 项目1:单科1-80名且总分进入1-80名(2分)subject_top_80_mask = class_data[f'{subject}_全校名次'] <= 80total_top_80_mask = class_data['总分_全校名次'] <= 80project1_mask_scored = subject_top_80_mask & total_top_80_maskproject1_students_scored = class_data[project1_mask_scored]top_80_count = len(project1_students_scored) # 统计得分人数score_1 = top_80_count * 2counted_students = counted_students | project1_mask_scored # 更新计分标记# --- 移除 DEBUG ---# print(f" DEBUG (一层次教师): T={teacher_row['教师姓名']}, C={teacher_row['班号']}, S={subject} - P1(单科<=80&总分<=80): Count={top_80_count}, Score={score_1}")# ------------------debug_info.append("\n--- 项目1:单科1-80名且总分进入1-80名(2分)---")for _, student in project1_students_scored.iterrows(): # 只记录得分学生debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, {subject}:{student[subject]}, {subject}名次:{student[f'{subject}_全校名次']}, 总分:{student['总分']}, 总分名次:{student['总分_全校名次']}")debug_info.append(f"项目1人数:{top_80_count}, 得分:{score_1}")# 项目2:单科81-160名且总分进入81-160名(1.5分)subject_81_160_mask = (class_data[f'{subject}_全校名次'] > 80) & (class_data[f'{subject}_全校名次'] <= 160)total_81_160_mask = (class_data['总分_全校名次'] > 80) & (class_data['总分_全校名次'] <= 160)project2_mask_scored = subject_81_160_mask & total_81_160_mask & ~counted_studentsproject2_students_scored = class_data[project2_mask_scored]top_160_count = len(project2_students_scored)score_2 = top_160_count * 1.5counted_students = counted_students | project2_mask_scored# --- 移除 DEBUG ---# print(f" DEBUG (一层次教师): T={teacher_row['教师姓名']}, C={teacher_row['班号']}, S={subject} - P2(单科81-160&总分81-160): Count={top_160_count}, Score={score_2}")# ------------------debug_info.append("\n--- 项目2:单科81-160名且总分进入81-160名(1.5分)---")debug_info.append(f"{subject}名次范围:81-160名")debug_info.append(f"总分名次范围:81-160名")for _, student in project2_students_scored.iterrows(): # 只记录得分学生debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, {subject}:{student[subject]}, {subject}名次:{student[f'{subject}_全校名次']}, 总分:{student['总分']}, 总分名次:{student['总分_全校名次']}")debug_info.append(f"项目2人数:{top_160_count}, 得分:{score_2}")# 项目3:单科优秀且总分优秀(1分)subject_excellent_mask_base = class_data[subject] >= self.subject_thresholds[subject]['excellent']# 使用动态科目列表计算总分优秀线total_excellent_threshold = sum([self.subject_thresholds[s]['excellent'] for s in self.SUBJECTS if s in self.subject_thresholds])total_excellent_mask = class_data['总分'] >= total_excellent_thresholdproject3_mask_scored = subject_excellent_mask_base & total_excellent_mask & ~counted_studentsproject3_students_scored = class_data[project3_mask_scored]excellent_count = len(project3_students_scored)score_3 = excellent_count * 1counted_students = counted_students | project3_mask_scored# --- 移除 DEBUG ---# print(f" DEBUG (一层次教师): T={teacher_row['教师姓名']}, C={teacher_row['班号']}, S={subject} - P3(单科优&总分优): Count={excellent_count}, Score={score_3}")# ------------------debug_info.append("\n--- 项目3:单科优秀且总分优秀(1分)---")debug_info.append(f"{subject}优秀线:{self.subject_thresholds[subject]['excellent']}")debug_info.append(f"总分优秀线:{total_excellent_threshold}")for _, student in project3_students_scored.iterrows(): # 只记录得分学生debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, {subject}:{student[subject]}, 总分:{student['总分']}, {subject}名次:{student[f'{subject}_全校名次']}, 总分名次:{student['总分_全校名次']}")debug_info.append(f"项目3人数:{excellent_count}, 得分:{score_3}")# 项目4:单科优秀且总分合格(0.5分)# 使用动态科目列表计算总分合格线total_pass_threshold = sum([self.subject_thresholds[s]['pass'] for s in self.SUBJECTS if s in self.subject_thresholds])total_pass_mask = class_data['总分'] >= total_pass_thresholdproject4_mask_scored = subject_excellent_mask_base & total_pass_mask & ~counted_studentsproject4_students_scored = class_data[project4_mask_scored]excellent_pass_count = len(project4_students_scored)score_4 = excellent_pass_count * 0.5counted_students = counted_students | project4_mask_scored# --- 移除 DEBUG ---# print(f" DEBUG (一层次教师): T={teacher_row['教师姓名']}, C={teacher_row['班号']}, S={subject} - P4(单科优&总分合格): Count={excellent_pass_count}, Score={score_4}")# ------------------debug_info.append("\n--- 项目4:单科优秀且总分合格(0.5分)---")debug_info.append(f"{subject}优秀线:{self.subject_thresholds[subject]['excellent']}")debug_info.append(f"总分合格线:{total_pass_threshold}")for _, student in project4_students_scored.iterrows(): # 只记录得分学生debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, {subject}:{student[subject]}, 总分:{student['总分']}, {subject}名次:{student[f'{subject}_全校名次']}, 总分名次:{student['总分_全校名次']}")debug_info.append(f"项目4人数:{excellent_pass_count}, 得分:{score_4}")# 修正:小计1 = 以上四项得分之和 (不加权)subtotal_1 = score_1 + score_2 + score_3 + score_4# --- 全面评估 --- subject_excellent_rate = sum(subject_excellent_mask_base) / total_students # 使用基础优秀标记subject_avg_score = class_data[subject].mean()subject_low_mask = class_data[subject] < self.subject_thresholds[subject]['low']subject_non_low_rate = 1 - (sum(subject_low_mask) / total_students)subject_low_count = sum(subject_low_mask)debug_info.append("\n--- 全面评估数据 ---")debug_info.append(f"{subject}优秀线:{self.subject_thresholds[subject]['excellent']}")debug_info.append(f"{subject}合格线:{self.subject_thresholds[subject]['pass']}")debug_info.append(f"{subject}低分线:{self.subject_thresholds[subject]['low']}")debug_info.append(f"优生数:{sum(subject_excellent_mask_base)}") # 使用基础优秀标记计数debug_info.append(f"优生率:{subject_excellent_rate*100:03.2f}%")debug_info.append(f"平均分:{subject_avg_score:.2f}")debug_info.append(f"低分数:{subject_low_count}")debug_info.append(f"非低分人数:{total_students - sum(subject_low_mask)}")debug_info.append(f"非低分率:{subject_non_low_rate*100:03.2f}%")# 计算相对值(与同层次班级比较)first_level_data = self.scores_df[self.scores_df['层次_数值'] == 1]if len(first_level_data) == 0:max_excellent_rate = 0max_avg_score = 0max_non_low_rate = 0else:excellent_rates = [(sum(c[subject] >= self.subject_thresholds[subject]['excellent'])/len(c)) if len(c) > 0 else 0for _, c in first_level_data.groupby('评估班级')]max_excellent_rate = self._safe_max(excellent_rates)avg_scores = [c[subject].mean() if len(c) > 0 else 0 for _, c in first_level_data.groupby('评估班级')]max_avg_score = self._safe_max(avg_scores)non_low_rates = [(1 - sum(c[subject] < self.subject_thresholds[subject]['low'])/len(c)) if len(c) > 0 else 0for _, c in first_level_data.groupby('评估班级')]max_non_low_rate = self._safe_max(non_low_rates)# 计算全面评估各项积分excellent_rate_score = (subject_excellent_rate/max_excellent_rate) * 40 if max_excellent_rate > 0 else 0avg_score_score = (subject_avg_score/max_avg_score) * 40 if max_avg_score > 0 else 0non_low_rate_score = (subject_non_low_rate/max_non_low_rate) * 20 if max_non_low_rate > 0 else 0debug_info.append("\n--- 全面评估积分计算 ---")debug_info.append(f"最高优生率:{max_excellent_rate*100:03.2f}%")debug_info.append(f"最高平均分:{max_avg_score:.2f}")debug_info.append(f"最高非低分率:{max_non_low_rate*100:03.2f}%")debug_info.append(f"优生率积分:{excellent_rate_score if excellent_rate_score.is_integer() else excellent_rate_score:.2f}")debug_info.append(f"平均分积分:{avg_score_score if avg_score_score.is_integer() else avg_score_score:.2f}")debug_info.append(f"非低分率积分:{non_low_rate_score if non_low_rate_score.is_integer() else non_low_rate_score:.2f}")# 修正:小计2 = 以上三项得分之和 (不加权)subtotal_2 = excellent_rate_score + avg_score_score + non_low_rate_score# 保存详细数据self._save_detailed_data(class_data, teacher_row['班号'], subject, '一层次', debug_info)# 修正:总分 = (小计1 * 0.3) + (小计2 * 0.7)total_score_final = (subtotal_1 * 0.3) + (subtotal_2 * 0.7)return {'班号': teacher_row['班号'],'班级人数': total_students,'教师姓名': teacher_row['教师姓名'],'层次': '一层次','项目1': top_80_count,'积分1': score_1,'项目2': top_160_count,'积分2': score_2,'项目3': excellent_count,'积分3': score_3,'项目4': excellent_pass_count,'积分4': score_4,'小计1': subtotal_1, # 返回未加权的小计1'优生数': sum(subject_excellent_mask_base), '优生率': subject_excellent_rate,'优生积分': excellent_rate_score,'平均分': subject_avg_score,'平均分积分': avg_score_score,'低分数': subject_low_count,'非低分率': subject_non_low_rate,'非低分率积分': non_low_rate_score,'小计2': subtotal_2, # 返回未加权的小计2'总积分': total_score_final, # 返回最终加权总分'科目名': subject}def _evaluate_second_level_teacher(self, class_data, subject, teacher_row):"""二层次教师评估"""total_students = len(class_data)debug_info = [] # 用于存储调试信息debug_info.append(f"\n总人数:{total_students}") # 移到项目1之前# 检查科目是否存在于阈值配置中if subject not in self.subject_thresholds:print(f"警告:科目 '{subject}' 没有定义阈值,跳过教师 {teacher_row['教师姓名']} ({teacher_row['班号']}班) 的评估。")return {'班号': teacher_row['班号'], '班级人数': total_students, '教师姓名': teacher_row['教师姓名'], '层次': '二层次','项目1': 0, '积分1': 0, '项目2': 0, '积分2': 0, '小计1': 0,'优生数': 0, '优生率': 0, '优生积分': 0, '合格数': 0, '合格率': 0, '合格率积分': 0,'平均分': np.nan, '平均分积分': 0, '低分数': 0, '非低分率': 0, '非低分率积分': 0,'小计2': 0, '总积分': 0, '科目名': subject}# --- 重点评估 --- # 项目1:单科优秀且总分合格subject_excellent_mask_base = class_data[subject] >= self.subject_thresholds[subject]['excellent']# 使用动态科目列表计算总分合格线total_pass_threshold = sum([self.subject_thresholds[s]['pass'] for s in self.SUBJECTS if s in self.subject_thresholds])total_pass_mask = class_data['总分'] >= total_pass_thresholdproject1_mask_scored = subject_excellent_mask_base & total_pass_maskproject1_students_scored = class_data[project1_mask_scored]excellent_pass_count = len(project1_students_scored) # 统计得分人数score_1 = excellent_pass_count * 2# --- 移除 DEBUG ---# if teacher_row['班号'] == 10 and subject == '历史':# print(f" DEBUG (二层次教师): T={teacher_row['教师姓名']}, C={teacher_row['班号']}, S={subject} - P1(单科优&总分合格): Count={excellent_pass_count}, Score={score_1}")# # ---------------------------debug_info.append("\n--- 项目1:单科优秀且总分合格(2分)---")debug_info.append(f"{subject}优秀线:{self.subject_thresholds[subject]['excellent']}")debug_info.append(f"总分合格线:{total_pass_threshold}")for _, student in project1_students_scored.iterrows(): # 只记录得分学生debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, {subject}:{student[subject]}, 总分:{student['总分']}")debug_info.append(f"项目1人数:{excellent_pass_count}, 得分:{score_1}")# 项目2:单科合格且总分合格subject_pass_mask_base = class_data[subject] >= self.subject_thresholds[subject]['pass']# 计算实际得分的学生 (合格且非优秀)project2_mask_scored = subject_pass_mask_base & total_pass_mask & ~subject_excellent_mask_base project2_students_scored = class_data[project2_mask_scored]pass_count = len(project2_students_scored) # 统计得分人数score_2 = pass_count * 1.5# --- 移除 DEBUG ---# if teacher_row['班号'] == 10 and subject == '历史':# print(f" DEBUG (二层次教师): T={teacher_row['教师姓名']}, C={teacher_row['班号']}, S={subject} - P2(单科合格&总分合格): Count={pass_count}, Score={score_2}")# # ---------------------------debug_info.append("\n--- 项目2:单科合格且总分合格(1.5分)---")debug_info.append(f"{subject}合格线:{self.subject_thresholds[subject]['pass']}")debug_info.append(f"总分合格线:{total_pass_threshold}")for _, student in project2_students_scored.iterrows(): # 只记录得分学生debug_info.append(f"准考证:{student['准考证']}, 姓名:{student['姓名']}, {subject}:{student[subject]}, 总分:{student['总分']}")debug_info.append(f"项目2人数:{pass_count}, 得分:{score_2}")# 修正:计算未加权的小计1unweighted_subtotal_1 = score_1 + score_2# --- 全面评估 --- subject_excellent_rate = sum(subject_excellent_mask_base) / total_students # 使用基础优秀标记subject_pass_rate = sum(subject_pass_mask_base) / total_students # 使用基础合格标记subject_avg_score = class_data[subject].mean()subject_low_mask = class_data[subject] < self.subject_thresholds[subject]['low']subject_non_low_rate = 1 - (sum(subject_low_mask) / total_students)subject_low_count = sum(subject_low_mask)debug_info.append("\n--- 全面评估数据 ---")debug_info.append(f"{subject}优秀线:{self.subject_thresholds[subject]['excellent']}")debug_info.append(f"{subject}合格线:{self.subject_thresholds[subject]['pass']}")debug_info.append(f"{subject}低分线:{self.subject_thresholds[subject]['low']}")debug_info.append(f"优生数:{sum(subject_excellent_mask_base)}") # 使用基础优秀标记计数debug_info.append(f"优生率:{subject_excellent_rate*100:03.2f}%")debug_info.append(f"合格数:{sum(subject_pass_mask_base)}") # 使用基础合格标记计数debug_info.append(f"合格率:{subject_pass_rate*100:03.2f}%")debug_info.append(f"平均分:{subject_avg_score:.2f}")debug_info.append(f"低分数:{subject_low_count}")debug_info.append(f"非低分人数:{total_students - sum(subject_low_mask)}")debug_info.append(f"非低分率:{subject_non_low_rate*100:03.2f}%")# 计算相对值(与同层次班级比较)second_level_data = self.scores_df[self.scores_df['层次_数值'] == 2]if len(second_level_data) == 0:max_excellent_rate = 0max_pass_rate = 0max_avg_score = 0max_non_low_rate = 0else:excellent_rates = [(sum(c[subject] >= self.subject_thresholds[subject]['excellent'])/len(c)) if len(c) > 0 else 0for _, c in second_level_data.groupby('评估班级')]max_excellent_rate = self._safe_max(excellent_rates)pass_rates = [(sum(c[subject] >= self.subject_thresholds[subject]['pass'])/len(c)) if len(c) > 0 else 0for _, c in second_level_data.groupby('评估班级')]max_pass_rate = self._safe_max(pass_rates)avg_scores = [c[subject].mean() if len(c) > 0 else 0 for _, c in second_level_data.groupby('评估班级')]max_avg_score = self._safe_max(avg_scores)non_low_rates = [(1 - sum(c[subject] < self.subject_thresholds[subject]['low'])/len(c)) if len(c) > 0 else 0for _, c in second_level_data.groupby('评估班级')]max_non_low_rate = self._safe_max(non_low_rates)# 计算全面评估各项积分excellent_rate_score = (subject_excellent_rate/max_excellent_rate) * 5 if max_excellent_rate > 0 else 0pass_rate_score = (subject_pass_rate/max_pass_rate) * 30 if max_pass_rate > 0 else 0avg_score_score = (subject_avg_score/max_avg_score) * 30 if max_avg_score > 0 else 0non_low_rate_score = (subject_non_low_rate/max_non_low_rate) * 35 if max_non_low_rate > 0 else 0debug_info.append("\n--- 全面评估积分计算 ---")debug_info.append(f"最高优生率:{max_excellent_rate*100:03.2f}%")debug_info.append(f"最高合格率:{max_pass_rate*100:03.2f}%")debug_info.append(f"最高平均分:{max_avg_score:.2f}")debug_info.append(f"最高非低分率:{max_non_low_rate*100:03.2f}%")debug_info.append(f"优生率积分:{excellent_rate_score if excellent_rate_score.is_integer() else excellent_rate_score:.2f}")debug_info.append(f"合格率积分:{pass_rate_score if pass_rate_score.is_integer() else pass_rate_score:.2f}")debug_info.append(f"平均分积分:{avg_score_score if avg_score_score.is_integer() else avg_score_score:.2f}")debug_info.append(f"非低分率积分:{non_low_rate_score if non_low_rate_score.is_integer() else non_low_rate_score:.2f}")# 修正:计算未加权的小计2unweighted_subtotal_2 = excellent_rate_score + pass_rate_score + avg_score_score + non_low_rate_score# 保存详细数据self._save_detailed_data(class_data, teacher_row['班号'], subject, '二层次', debug_info)# 修正:总分 = (未加权小计1 * 0.2) + (未加权小计2 * 0.8)total_score_final = (unweighted_subtotal_1 * 0.2) + (unweighted_subtotal_2 * 0.8)# --- 移除临时调试打印 --- # if teacher_row['班号'] == 10 and subject == '历史':# # 打印未加权的小计和最终总分# print(f"DEBUG (二层次教师): 10班 历史 - 返回前的值: 未加权小计1={unweighted_subtotal_1}, 未加权小计2={unweighted_subtotal_2}, 总积分={total_score_final}") # # --- 结束临时调试 --- return {'班号': teacher_row['班号'],'班级人数': total_students,'教师姓名': teacher_row['教师姓名'],'层次': '二层次','项目1': excellent_pass_count,'积分1': score_1,'项目2': pass_count,'积分2': score_2,'小计1': unweighted_subtotal_1, # 返回未加权的小计1'优生数': sum(subject_excellent_mask_base), # 使用基础优秀标记计数'优生率': subject_excellent_rate,'优生积分': excellent_rate_score,'合格数': sum(subject_pass_mask_base), # 使用基础合格标记计数'合格率': subject_pass_rate,'合格率积分': pass_rate_score,'平均分': subject_avg_score,'平均分积分': avg_score_score,'低分数': subject_low_count,'非低分率': subject_non_low_rate,'非低分率积分': non_low_rate_score,'小计2': unweighted_subtotal_2, # 返回未加权的小计2'总积分': total_score_final, # 最终加权总分'科目名': subject}def evaluate_class_team(self):"""班团评估"""results = []for class_num in sorted(self.scores_df['评估班级'].unique()):class_data = self.scores_df[self.scores_df['评估班级'] == class_num].copy()if class_data.empty:continuelevel = class_data['层次_数值'].iloc[0]if level == 1:# 调用班级评估函数,它内部会使用配置的标签返回结果result = self._evaluate_first_level_class(class_data, class_num)else:result = self._evaluate_second_level_class(class_data, class_num)results.append(result)return pd.DataFrame(results)def evaluate_teachers(self):"""教师评估"""results = []# 过滤掉班主任记录 (使用内部标记),只评估学科教师subject_teachers = self.teachers_df[self.teachers_df['学科'] != '__HeadTeacher__']for _, teacher_row in subject_teachers.iterrows():subject = teacher_row['学科']class_num = teacher_row['班号']teacher_class_data = self.scores_df[self.scores_df['评估班级'] == class_num].copy()if teacher_class_data.empty:print(f"警告:班级 {class_num} 在成绩表中没有数据,跳过教师 {teacher_row['教师姓名']} ({subject}) 的评估。")continuelevel = teacher_class_data['层次_数值'].iloc[0]if subject not in teacher_class_data.columns:print(f"警告:科目 '{subject}' 不在班级 {class_num} 的成绩数据中,跳过教师 {teacher_row['教师姓名']} 的评估。")continue# 检查科目阈值是否存在 (教师评估函数内部已有此检查)# if subject not in self.subject_thresholds: ...if level == 1:result = self._evaluate_first_level_teacher(teacher_class_data, subject, teacher_row)else:result = self._evaluate_second_level_teacher(teacher_class_data, subject, teacher_row)if result: results.append(result)return pd.DataFrame(results)def save_results(self, exam_name):"""保存评估结果"""output_path = Nonetry:# 清空详细数据目录下的 .txt 文件if os.path.exists(self.detailed_data_dir):print(f"清空目录:{self.detailed_data_dir}")for filename in os.listdir(self.detailed_data_dir):if filename.endswith(".txt"):file_path = os.path.join(self.detailed_data_dir, filename)try:os.remove(file_path)print(f" 已删除: {filename}")except Exception as e:print(f"无法删除文件 {file_path}: {e}")else:# 如果目录不存在,则创建它print(f"创建目录:{self.detailed_data_dir}")os.makedirs(self.detailed_data_dir)# --- 计算评估 --- print("正在进行班团评估...")class_results = self.evaluate_class_team()print("正在进行教师评估...")teacher_results = self.evaluate_teachers()# ------------------# 检查是否有评估结果if class_results.empty and teacher_results.empty:print("警告:没有生成任何评估结果。请检查输入文件和配置。")return None # 如果都没有结果,则不继续执行保存elif class_results.empty:print("警告:班团评估未生成结果。")elif teacher_results.empty:print("警告:教师评估未生成结果。")# --- 合并和处理结果 --- # 移除错误的总积分重新计算# if not class_results.empty:# class_results['总积分'] = class_results.apply(lambda row: row.get('小计1', 0) + row.get('小计2', 0), axis=1)# if not teacher_results.empty:# teacher_results['总积分'] = teacher_results.apply(lambda row: row.get('小计1', 0) + row.get('小计2', 0), axis=1)# 合并结果 (处理可能为空的DataFrame)results_list = []if not class_results.empty:results_list.append(class_results)if not teacher_results.empty:results_list.append(teacher_results)if not results_list:print("错误:无法合并结果,因为两个评估结果都为空。")return Noneresults = pd.concat(results_list, ignore_index=True)# 添加名次列 (基于 '总积分' 列)if '总积分' in results.columns:results['名次'] = results.groupby(['科目名', '层次'])['总积分'].rank(method='min', ascending=False).astype(int)else:results['名次'] = np.nan # 如果没有总积分,名次无意义# 创建科目名的排序顺序 (使用配置的班团标签和科目列表)# 注意:这里使用 self.class_team_labelsubject_order = [self.class_team_label] + sorted(list(self.SUBJECTS))present_subjects = results['科目名'].unique()final_subject_order = [s for s in subject_order if s in present_subjects]for s in present_subjects:if s not in final_subject_order:final_subject_order.append(s)results['科目名排序'] = pd.Categorical(results['科目名'], categories=final_subject_order, ordered=True)# --- 格式化 --- def format_number(x):if pd.isna(x):return xif isinstance(x, (int, float)):# 检查是否非常接近整数if np.isclose(x, round(x)):return int(round(x))# 修改:保留一位小数return round(x, 1) return xdef format_percentage(x):if pd.isna(x):return xif isinstance(x, (int, float)):# 确保百分比格式为048.39%return f"{x*100:03.2f}%"return x # 如果不是数字,直接返回# 应用格式化format_cols = results.select_dtypes(include=[np.number]).columnspercent_cols = ['优生率', '合格率', '非低分率']for col in format_cols:if col in percent_cols:results[col] = results[col].apply(format_percentage)elif col not in ['班号', '班级人数', '名次']: # 这些通常是整数results[col] = results[col].apply(format_number)# ----------------# --- 排序 --- # 按要求排序:科目名、层次、班号 (逻辑保持不变)sort_columns = ['科目名排序', '层次']if '班号' in results.columns: sort_columns.append('班号')results = results.sort_values(by=sort_columns, ascending=[True] * len(sort_columns))results = results.drop('科目名排序', axis=1)# -------------# --- 重新排列列顺序 (使用 '总积分' 替换 '总分') --- expected_columns_order = ['班号', '班级人数', '名次', '教师姓名','总积分', # 使用正确的 '总积分' 列'项目1', '积分1', '项目2', '积分2', '项目3', '积分3', '项目4', '积分4', '小计1', # 未加权'优生数', '优生率', '优生积分','合格数', '合格率', '合格率积分','平均分', '平均分积分','低分数', '非低分率', '非低分率积分', '小计2', # 未加权'科目名', '层次']# 获取实际存在的列,并按期望顺序排列available_columns = [col for col in expected_columns_order if col in results.columns]results = results[available_columns]# ---------------------# --- 新增:文件复制、命名、写入标题和数据 ---# 检查合并后的 results 是否为空if results.empty:print("警告:评估结果为空,无法生成输出文件。")return None# 1. 生成时间戳和输出文件名timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")output_filename = f"{exam_name}_{timestamp}.xlsx"# 将输出文件路径设置在详细数据目录内output_path = os.path.join(self.detailed_data_dir, output_filename)# 2. 复制模板文件 (保持不变)print(f"复制 {self.grade} 年级模板文件 '{self.template_file}' 到 '{output_path}'")shutil.copy(self.template_file, output_path)# 3. 使用 openpyxl 将结果 DataFrame 数据写入复制的模板(从第4行开始,保留模板原有内容)print(f"将评估结果数据写入文件 '{output_path}' (从第4行开始,保留模板表头)...")workbook = load_workbook(output_path)sheet = workbook.active# 新增:在第一行A1单元格写入考试名称print(f"在 A1 单元格写入考试名称: {exam_name}")sheet['A1'] = exam_name + " 评估结果"# 定义数据写入的起始行 (Excel行号,1-based)start_excel_row = 4 # 将格式化后的 DataFrame 数据转换为适合 openpyxl 写入的列表# 注意:此时 results DataFrame 中的数据已经是格式化过的字符串或数字data_to_write = results.values.tolist()# 逐行逐单元格写入数据for r_idx, row_data in enumerate(data_to_write):# 计算当前要写入的 Excel 行号current_excel_row = start_excel_row + r_idxfor c_idx, value in enumerate(row_data):# 计算当前要写入的 Excel 列号 (1-based)current_excel_col = c_idx + 1# 直接写入值 (因为之前已经格式化过)sheet.cell(row=current_excel_row, column=current_excel_col, value=value)# 保存对工作簿的修改workbook.save(output_path)# --------------------------------------------------print(f"评估结果已成功写入复制的模板: {output_path}")return output_path # 返回成功生成的文件路径except FileNotFoundError as e: # 特别处理文件复制时的错误print(f"文件操作错误:{str(e)}")print(f"请确保 {self.grade} 年级的模板文件 '{self.template_file}' (来自配置) 存在。")return None # 返回 None 表示失败except KeyError as e:print(f"保存结果时出现配置或列名错误:'{e}'。可能是科目名排序或列重排时出错。")print(f"请检查配置文件 ({CONFIG_FILE}) 和评估结果 DataFrame 的列名。")return Noneexcept Exception as e:print(f"保存结果到复制模板时出错:{str(e)}")import tracebacktraceback.print_exc()# 可以在这里决定是否需要回退到旧的保存方式,或者直接返回失败# print(f"尝试保存到默认位置...") # 移除旧的回退逻辑return None # 返回 None 表示失败def main():global CONFIG # 声明要修改全局 CONFIG 变量try:# --- 程序启动时首先加载配置 --- load_config()# -----------------------------# 获取配置文件中支持的年级列表 (并确保是字符串)supported_grades = [str(k) for k in CONFIG['grades'].keys()]# 获取用户输入的年级while True:try:grade_input = input(f"请输入要评估的年级 ({', '.join(supported_grades)}):")# 不需要转换成 int,因为配置查找使用字符串 <- 旧注释,现在需要转换if grade_input in supported_grades:grade = int(grade_input) # 转换回整数breakelse:print(f"错误:不支持的年级 '{grade_input}'。请输入 {', '.join(supported_grades)} 中的一个。")except ValueError: # 添加对 int 转换失败的处理print(f"错误:输入的 '{grade_input}' 不是有效的数字年级。")except Exception as e: print(f"输入年级时发生错误: {e}")# 获取考试名称 (保持不变)exam_name = input("请输入本次考试的名称:")if not exam_name: # 注意:grade 现在是整数,如果需要拼接,需要转回字符串exam_name = f"{str(grade)}年级评估" print(f"未输入考试名称,将使用默认名称:'{exam_name}'")print(f"开始 {grade} 年级 '{exam_name}' 评估程序...")# 使用整数年级初始化evaluator = ScoreEvaluator(grade)print("正在准备数据...")evaluator.prepare_data()print("正在保存评估结果...")output_file_path = evaluator.save_results(exam_name)# 结果处理和输出 (保持不变)if output_file_path:print("-" * 30)print(f"{grade} 年级 '{exam_name}' 评估完成!")print(f"评估结果已保存到文件: {output_file_path}") print(f"详细数据日志已保存到目录: {evaluator.detailed_data_dir}")print("-" * 30)else:print("-" * 30)print(f"{grade} 年级 '{exam_name}' 评估过程中发生错误,未能成功生成结果文件。")print("请检查上面的错误信息。")print("-" * 30)except (FileNotFoundError, ValueError, yaml.YAMLError, RuntimeError, ImportError) as e:# 捕获配置文件加载、数据准备、库缺失等特定错误print(f"程序运行失败:{str(e)}")# 可以在这里添加更详细的指引,例如检查配置文件路径、内容、Excel文件等print("程序终止")except Exception as e:print(f"发生未知错误:{str(e)}")import tracebacktraceback.print_exc()print("程序终止")if __name__ == '__main__':main()
相关文章:
)
从青涩到 AI:我与评估程序的三十年 “纠缠” 与重启(参数化)
接上篇:从青涩到 AI:我与评估程序的三十年 “纠缠” 与重启 主要对参数配置和模板文件处理进行了改动,将可参数化的数据放到了config.yaml文件中,再一个将模板文件(评估模板.xlsx)分离为(7年级模板.xls…...
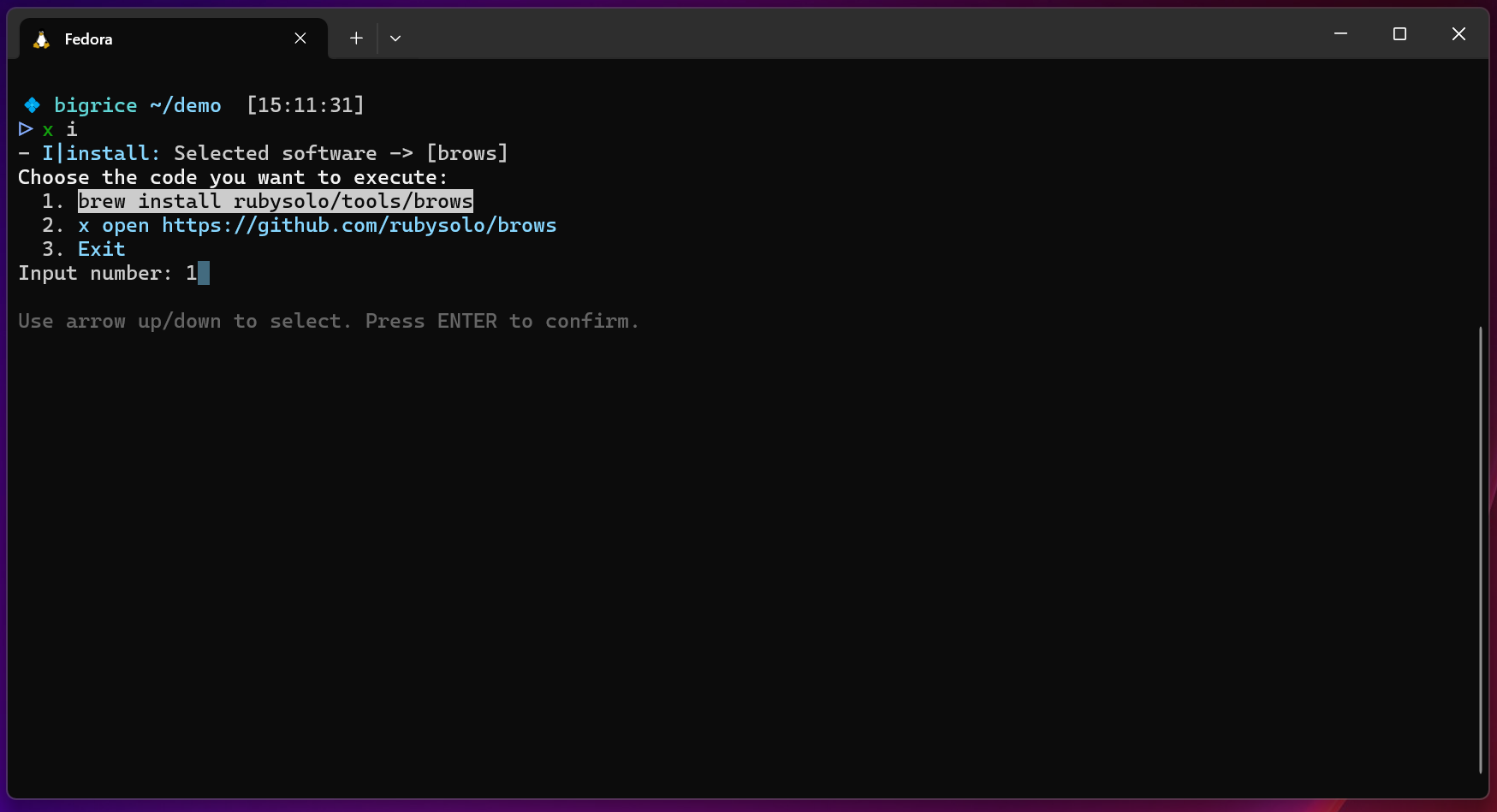
x-cmd install | brows - 终端里的 GitHub Releases 浏览器,告别繁琐下载!
目录 核心功能与优势安装适用场景 还在为寻找 GitHub 项目的特定 Release 版本而苦恼吗?还在网页上翻来覆去地查找下载链接吗?现在,有了 brows,一切都将变得简单高效! brows 是一款专为终端设计的 GitHub Releases 浏览…...

【python】如何将文件夹及其子文件夹下的所有word文件汇总导出到一个excel文件里?
根据你的需求,这里提供一套完整的Python解决方案,支持递归遍历子文件夹、提取Word文档内容(段落+表格),并整合到Excel中。以下是代码实现及详细说明: 一个单元格一个word的全部内容 完整代码 # -*- coding: utf-8 -*- import os from docx import Document import pand…...

C++ 封装成DLL,C#调用
目录 前言 一、C DLL 封装 二、C# 调用 DLL 1、创建 C# 控制台项目,调用 三、注意事项 前言 在实际工程开发中,跨语言调用是常见的需求,尤其是在性能要求较高的模块中,常常采用 C 实现核心算法逻辑,并通过封装为 D…...
多模态知识图谱:重构大模型RAG效能新边界
当前企业级RAG(Retrieval-Augmented Generation)系统在非结构化数据处理中面临四大核心问题: 数据孤岛效应:异构数据源(文档/表格/图像/视频)独立存储,缺乏跨模态语义关联,导致知识检…...
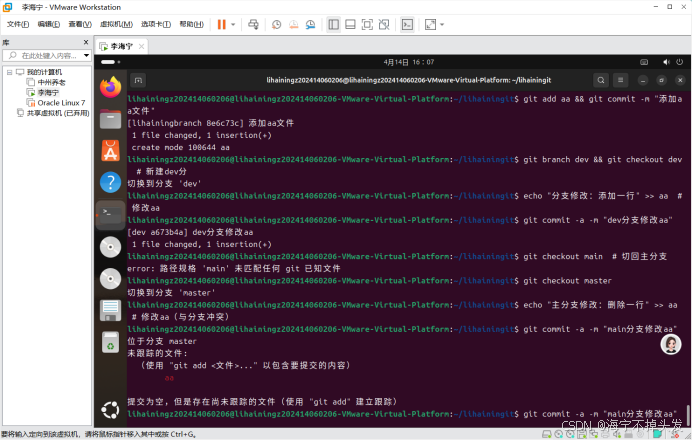
实验八 版本控制
实验八 版本控制 一、实验目的 掌握Git基本命令的使用。 二、实验内容 1.理解版本控制工具的意义。 2.安装Windows和Linux下的git工具。 3.利用git bash结合常用Linux命令管理文件和目录。 4.利用git创建本地仓库并进行简单的版本控制实验。 三、主要实验步骤 1.下载并安…...

微服务相比传统服务的优势
这是一道面试题,咱们先来分析这道题考察的是什么。 如果分析面试官主要考察以下几个方面: 技术理解深度 你是否清楚微服务架构(Microservices)和传统单体架构(Monolithic)的本质区别。能否从设计理念、技术…...
JavaWeb:Web介绍
Web开篇 什么是web? Web网站工作流程 网站开发模式 Web前端开发 初识web Web标准 HtmlCss 什么是Html? 什么是CSS?...

教育行业网络安全:守护学校终端安全,筑牢教育行业网络安全防线!
教育行业面临的终端安全问题日益突出,主要源于教育信息化进程的加速、终端设备多样化以及网络环境的开放性。 以下是教育行业终端安全面临的主要挑战: 1、设备类型复杂化 问题:教育机构使用的终端设备包括PC、服务器等,操作系统…...
)
【论文速递】2025年04周 (Robotics/Embodied AI/LLM)
目录 DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning摘要 Evolving Deeper LLM Thinking摘要 Kimi k1.5: Scaling Reinforcement Learning with LLMs摘要 Agent-R: Training Language Model Agents to Reflect via Iterative Self-Train…...
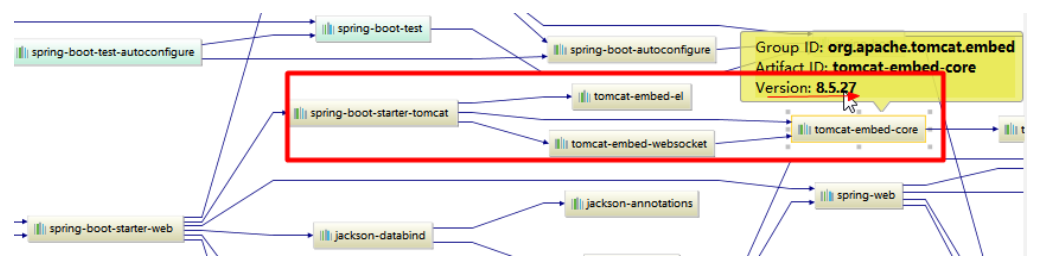
Spring Boot知识点详解
打包部署 <!‐‐ 这个插件,可以将应用打包成一个可执行的jar包;‐‐> <build><plugins> <plugin> <groupId>org.springframework.boot</groupId><artifactId>spring‐boot‐maven‐plugin</artifactId&g…...
LangChain与图数据库Neo4j LLMGraphTransformer融合:医疗辅助诊断、金融风控领域垂直领域、法律咨询场景问答系统的技术实践
LangChain与图数据库融合:垂直领域问答系统的技术实践 一、技术背景与核心价值 在垂直领域(如金融、医疗、法律)的问答场景中,传统RAG系统常面临实体关系推理不足和专业术语理解偏差的痛点。LangChain通过集成图数据库与知识图谱…...
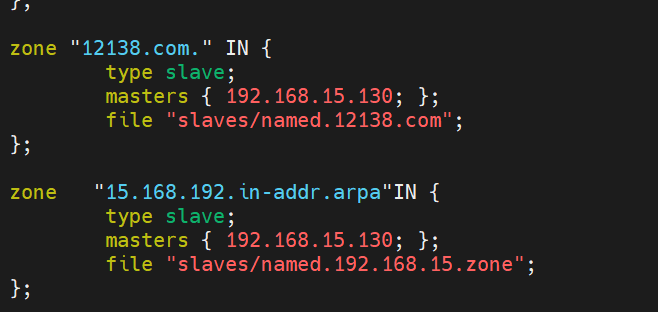
DNS主从同步及解析
DNS 域名解析原理 域名系统的层次结构 :DNS 采用分层树状结构,顶级域名(如.com、.org、.net 等)位于顶层,下面是二级域名、三级域名等。例如,在域名 “www.example.com” 中,“com” 是顶级域名…...
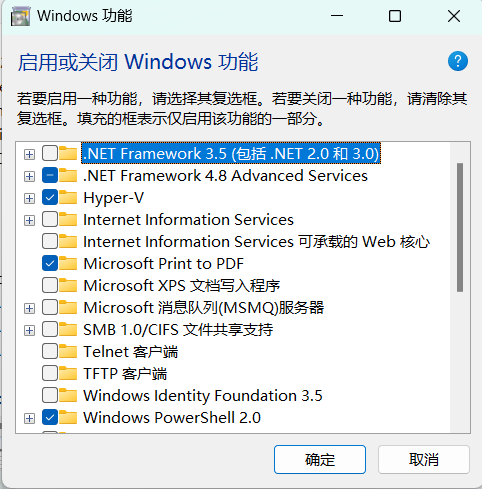
在Windows11上用wsl配置docker register 镜像地址
一、下载软件 1、下载wsl:安装 WSL | Microsoft Learn,先按照旧版 WSL 的手动安装步骤 | Microsoft Learn的步骤走 注:如果wsl2怎么都安装不下来,可能是Hyper-V没有打开,打开控制面板->程序和功能->启用或关闭Windows功能,勾选Hyper-V 如果Windows功能里面没有Hyp…...

Spring—循环依赖与三级缓存
Spring中存在三级缓存: 第一层缓存(singletonObjects):单例对象缓存池,已经实例化并且属性赋值,这里的对象是成熟对象;第二层缓存(earlySingletonObjects):单…...
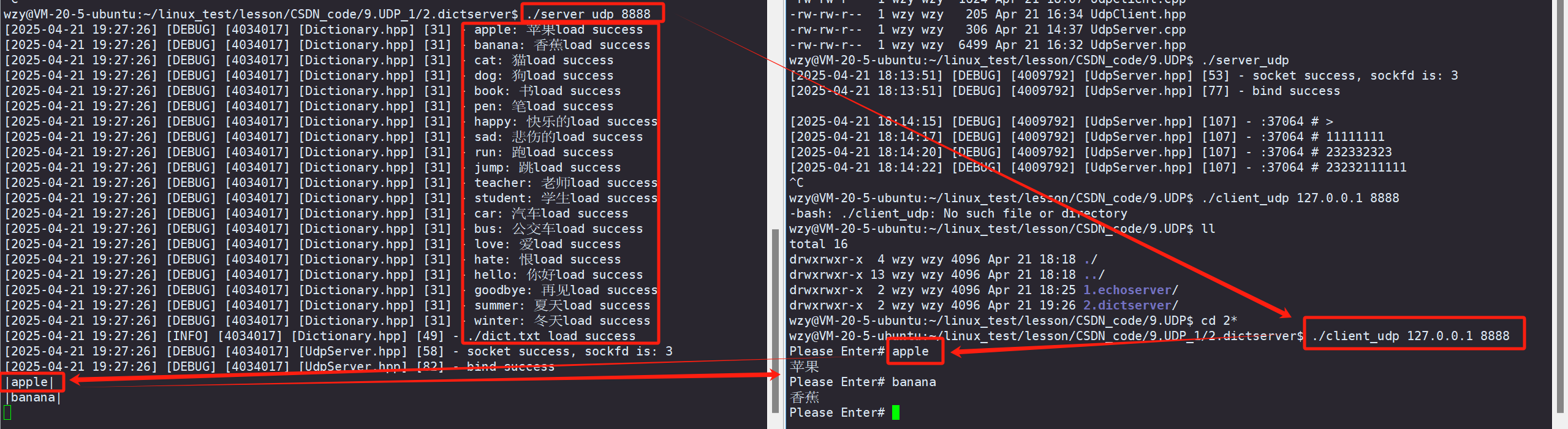
【Linux网络】构建UDP服务器与字典翻译系统
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

【PGCCC】Postgres 故障排除:修复重复的主键行
如何从表中删除不需要的重复行。这些重复行之所以“不需要”,是因为同一个值在指定为主键的列中出现多次。自从 glibc 好心地改变了排序方式后,我们发现这个问题有所增加。当用户升级操作系统并修改底层 glibc 库时,这可能会导致无效索引。 唯…...

DeepSeek+Cursor+Devbox+Sealos项目实战
黑马程序员DeepSeekCursorDevboxSealos带你零代码搞定实战项目开发部署视频教程,基于AI完成项目的设计、开发、测试、联调、部署全流程 原视频地址视频选的项目非常基础,基本就是过了个web开发流程,但我在实际跟着操作时,ai依然会…...
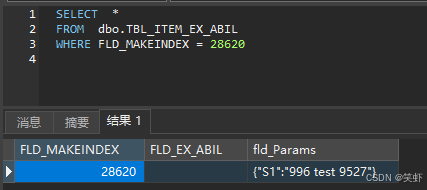
996引擎-拓展变量:物品变量
996引擎-拓展变量:物品变量 测试代码参考资料对于Lua来说,只有能保存数据库的变量才有意义。 至于临时变量,不像TXT那么束手束脚,通常使用Lua变量就能完成。 SELECT * FROM dbo.TBL_ITEM_EX_ABIL WHERE FLD_MAKEINDEX = 28620 <...

Java 设计模式心法之第3篇 - 总纲:三大流派与导航地图
前两章,我们修炼了 SOLID 这套强大的“内功心法”,为构建高质量软件打下了坚实根基。现在,是时候鸟瞰整个设计模式的“武林”了!本文将为您展开一幅由 GoF 四人帮精心绘制的 23 种经典设计模式的“全景导航地图”。我们将探索这些…...

【OpenCV图像处理实战】从基础操作到工业级应用
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明 一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比 二、实战演示环境配置要求核心代码实现(6个案例)案例1:图像基本操作案例2:边缘检测案例3&…...

如何识别金融欺诈行为并进行分析预警
金融行业以其高效便捷的服务深刻改变了人们的生活方式。然而,伴随技术进步而来的,是金融欺诈行为的日益猖獗。从信用卡盗刷到复杂的庞氏骗局,再到网络钓鱼和洗钱活动,金融欺诈的形式层出不穷,其规模和影响也在不断扩大。根据全球反欺诈组织(ACFE)的最新报告,仅2022年,…...
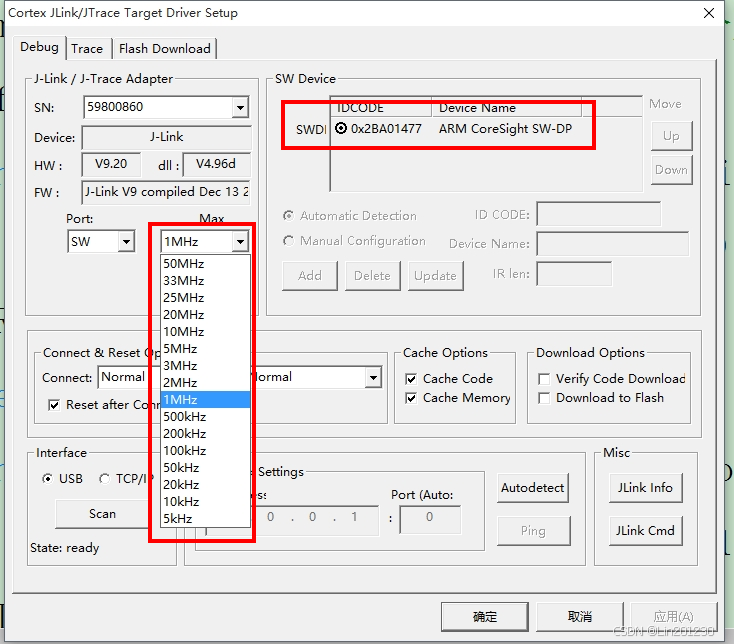
【踩坑记录】stm32 jlink程序烧录不进去
最近通过Jlink给STM32烧写程序时一直报错,但是换一个其他工程就可以烧录,对比了一下jink配置,发现是速率选太高了“SW Device”,将烧录速率调整到10MHz以下就可以了...

SpringSecurity源码解读AbstractAuthenticationProcessingFilter
一、介绍 AbstractAuthenticationProcessingFilter 是 Spring Security 框架里的一个抽象过滤器,它在处理基于表单的认证等认证流程时起着关键作用。它继承自 GenericFilterBean,并实现了 javax.servlet.Filter 接口。此过滤器的主要功能是拦截客户端发送的认证请求,对请求…...

RISC-V低功耗MCU动态时钟门控技术详解
我来分享一下RISC-V核低功耗MCU的动态时钟门控技术实现: 这款MCU通过硬件级时钟门控电路实现了模块级的功耗管理。当外设(如UART、SPI)处于闲置状态时,系统会自动切断其时钟信号,减少无效翻转功耗。同时支持多电压域协…...

网络设备配置实战:交换机与路由器的入门到精通
引言:网络设备——构建数字世界的基石 想象一下走进一个现代化的数据中心,成千上万的线缆如同神经网络般连接着各种设备,而交换机和路由器就是这些网络连接的智能枢纽。作为网络工程师,熟练掌握这些核心网络设备的配置与管理,就如同建筑师精通各种建筑工具和材料一样重要…...

移动通信行业术语
英文缩写英文全称中文名称解释/上下文举例IMSIP Multimedia SubsystemIP多媒体子系统SIPSession Initiation Protocol会话初始化协议常见小写sip同。ePDG/EPDGEvolved Packet Data Gateway演进分组数据网关 EPDG是LTE(4G)和后续蜂窝网络架构(…...
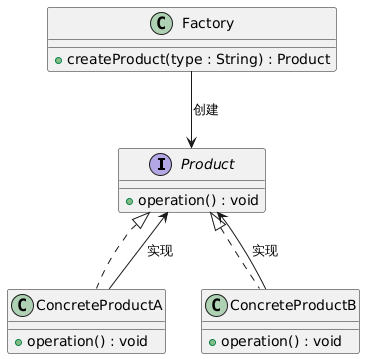
工厂模式:解耦对象创建与使用的设计模式
工厂模式:解耦对象创建与使用的设计模式 一、模式核心:封装对象创建逻辑,客户端无需关心具体实现 在软件开发中,当创建对象的逻辑复杂或频繁变化时,直接在客户端代码中 new 对象会导致耦合度高、难以维护。例如&…...
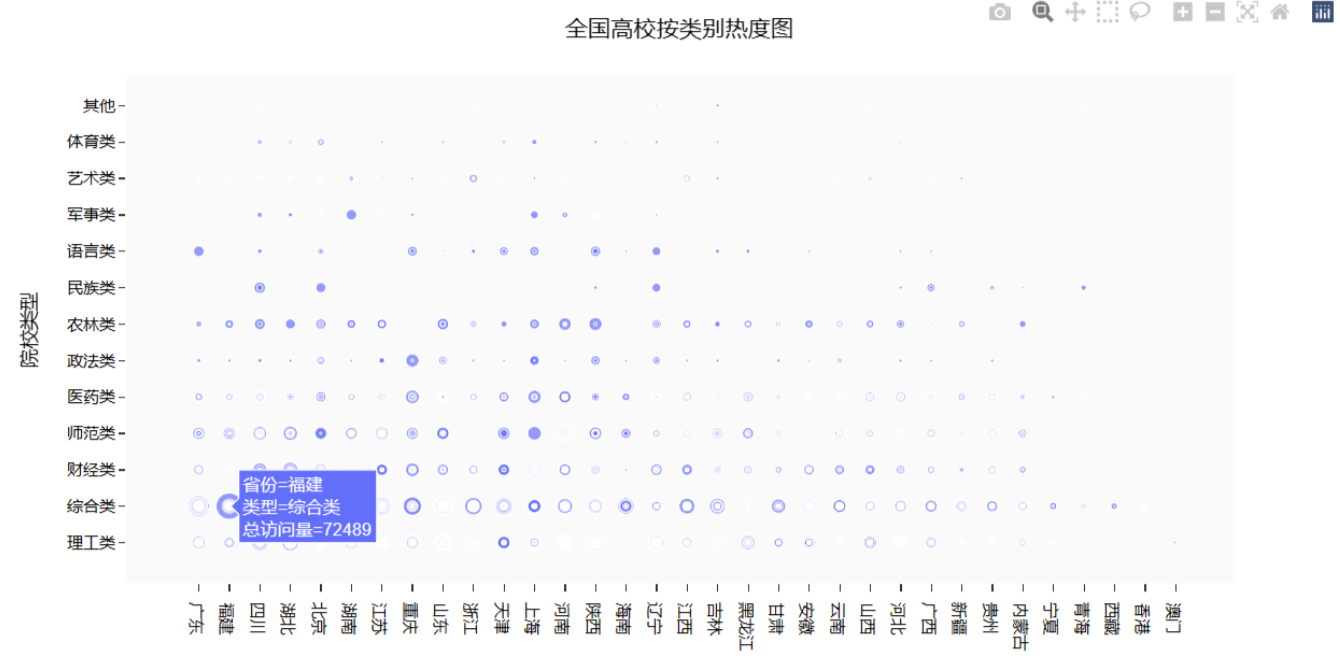
Python爬虫学习:高校数据爬取与可视化
本项目实现了从中国教育在线(eol.cn)的公开 API 接口爬取高校相关数据,并对数据进行清洗、分析与可视化展示。主要包括以下功能: 爬取高校基础信息及访问量数据数据清洗与格式转换多维度数据分析与可视化,如高校数量分…...

linux 手动触发崩溃
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、如何手动触发linux崩溃?二、内核相关panic和oops的cmdline(启动参数)总结 前言 提示:这里可以添加本文要记…...