Python爬虫学习:高校数据爬取与可视化
本项目实现了从中国教育在线(eol.cn)的公开 API 接口爬取高校相关数据,并对数据进行清洗、分析与可视化展示。主要包括以下功能:
- 爬取高校基础信息及访问量数据
- 数据清洗与格式转换
- 多维度数据分析与可视化,如高校数量分布、热度排名、地理分布等
Part1: 爬取所查学校里面院校库的网页数据并保存为“全国大学数据.csv”文件

代码如下:
import os
import json
import time
import random
import numpy as np
import pandas as pd
import plotly as py
from time import sleep
import plotly.express as px
from bs4 import BeautifulSoup
from requests_html import HTMLSession, UserAgent# 定义获取随机请求头的函数
def get_header():from fake_useragent import UserAgentlocation = os.getcwd() + '/fake_useragent.json'try:ua = UserAgent(path=location)return ua.randomexcept:# 如果无法加载配置文件,使用默认的UserAgentreturn UserAgent().random# 高校数据
def get_size(page=1):url = 'https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&keyword=&nature=&page={0}&province_id=&ranktype=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&top_school_id=[2941]&type=&uri=apidata/api/gk/school/lists'.format(page)session = HTMLSession()user_agent = UserAgent().randomheader = {"User-Agent": user_agent}try:res = session.post(url, headers=header)res.raise_for_status() # 如果响应状态码不是200,引发HTTPErrordata = json.loads(res.text)size = 0if data["message"] == '成功---success':size = data["data"]["numFound"]return sizeexcept:print(f"请求第 {page} 页数据时出错,返回 None")return Nonedef get_university_info(size, page_size=20):page_cnt = int(size / page_size) if size % page_size == 0 else int(size / page_size) + 1print(f'一共{page_cnt}页数据,即将开始爬取...')session2 = HTMLSession()df_result = pd.DataFrame()for index in range(1, page_cnt + 1):print(f'正在爬取第 {index}/{page_cnt} 页数据')url = 'https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&keyword=&nature=&page={0}&province_id=&ranktype=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&top_school_id=[2941]&type=&uri=apidata/api/gk/school/lists'.format(index)user_agent = UserAgent().randomheader = {"User-Agent": user_agent}try:res = session2.post(url, headers=header)res.raise_for_status()with open("res.text", "a+", encoding="utf-8") as file:file.write(res.text)data = json.loads(res.text)if data["message"] == '成功---success':df_data = pd.DataFrame(data["data"]["item"])df_result = pd.concat([df_result, df_data], ignore_index=True)time.sleep(random.randint(5, 7))except:print(f"处理第 {index} 页数据时出错,跳过该页")continuereturn df_resultsize = get_size()
if size is not None:df_result = get_university_info(size)df_result.to_csv('全国大学数据.csv', encoding='gbk', index=False)
else:print("获取数据总数量时出错,程序终止。")Part2: 用访问量排序来查询保存下来的“全国大学数据.csv”文件
效果图如下:

代码如下:
# 对数据进行处理
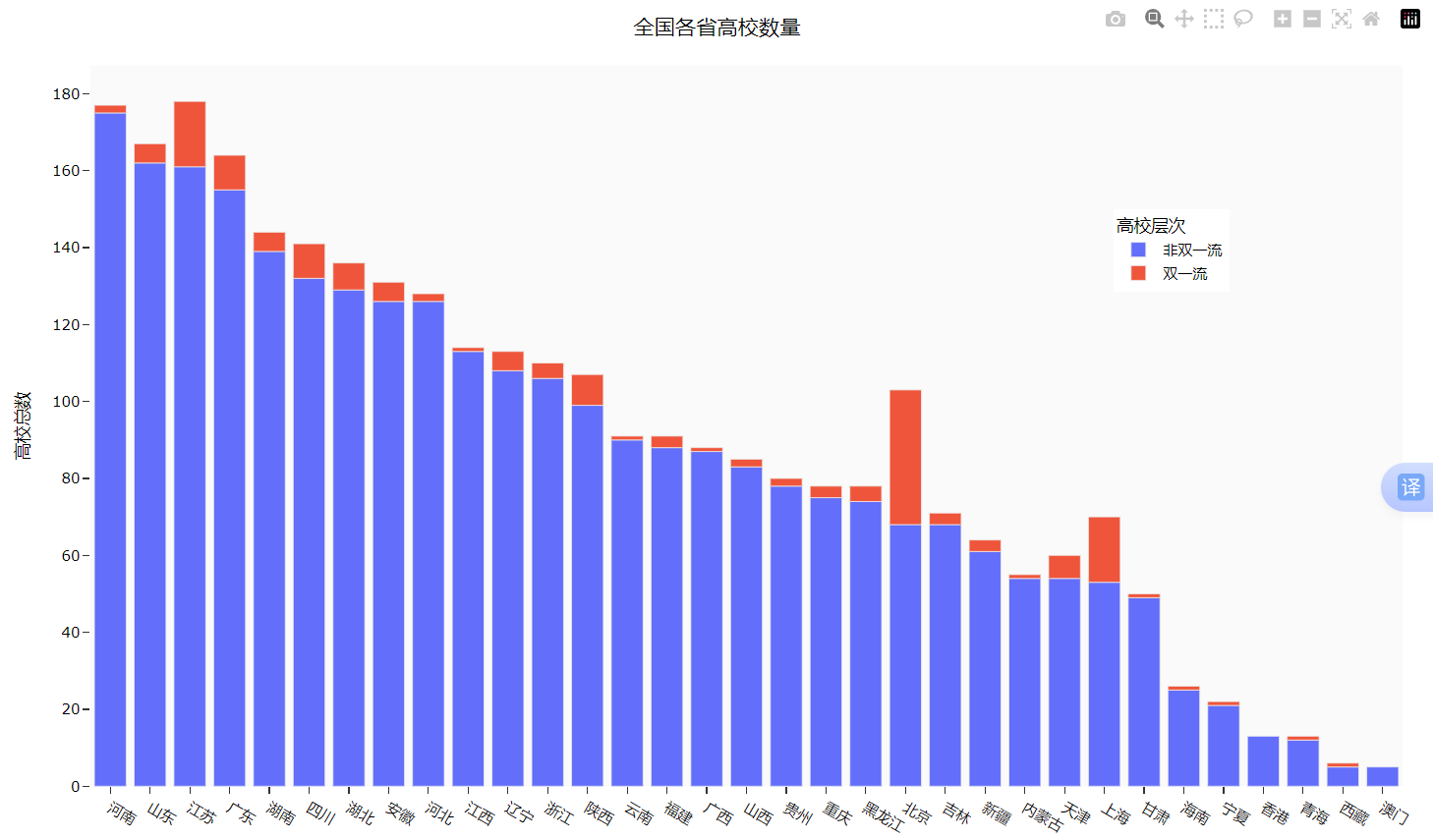
if not university.empty:university = university.loc[:, ['name', 'nature_name', 'province_name', 'belong','city_name', 'dual_class_name', 'f211', 'f985', 'level_name','type_name', 'view_month_number', 'view_total_number','view_week_number', 'rank']]c_name = ['大学名称', '办学性质', '省份', '隶属', '城市', '高校层次','211院校', '985院校', '级别', '类型', '月访问量', '总访问量', '周访问量', '排名']university.columns = c_name# 访问量排序print(university.sort_values(by='总访问量', ascending=False).head())Part3: 用条形图显示全国各省的 “双一流” 和 “非双一流” 高校数量
效果图如下:
代码如下:
# 显示全国双一流和非双一流的高校数量university['高校总数'] = 1university.fillna({'高校层次': '非双一流'}, inplace=True)university_by_province = university.pivot_table(index=['省份', '高校层次'],values='高校总数', aggfunc='count')university_by_province.reset_index(inplace=True)university_by_province.sort_values(by=['高校总数'], ascending=False, inplace=True)# 查询全国各省高校数量fig = px.bar(university_by_province,x="省份",y="高校总数",color="高校层次")fig.update_layout(title='全国各省高校数量',xaxis_title="省份",yaxis_title="高校总数",template='ggplot2',font=dict(size=12,color="Black",),margin=dict(l=40, r=20, t=50, b=40),xaxis=dict(showgrid=False),yaxis=dict(showgrid=False),plot_bgcolor="#fafafa",legend=dict(yanchor="top",y=0.8,xanchor="left",x=0.78))fig.show()Part4: 根据 “全国省市区行政区划.xlsx” 文件结合 “全国大学数据.csv” 中的经纬度生成全国高校地理分布图
# 生成全国高校地理分布图try:df = pd.read_excel('./data/全国省市区行政区划.xlsx', header=1)df_l = df.query("层级==2").loc[:, ['全称', '经度', '纬度']]df_l = df_l.reset_index(drop=True).rename(columns={'全称': '城市'})df7 = university.pivot_table('大学名称', '城市', aggfunc='count')df7 = df7.merge(df_l, on='城市', how='left')df7.sort_values(by='大学名称', ascending=False)df7['text'] = df7['城市'] + '<br>大学总数 ' + (df7['大学名称']).astype(str) + '个'limits = [(0, 10), (11, 20), (21, 50), (51, 100), (101, 200)]colors = ["royalblue", "crimson", "lightseagreen", "orange", "red"]import plotly.graph_objects as gofig = go.Figure()for i in range(len(limits)):lim = limits[i]df_sub = df7[df7['大学名称'].map(lambda x: lim[0] <= x <= lim[1])]fig.add_trace(go.Scattergeo(locationmode='ISO-3',lon=df_sub['经度'],lat=df_sub['纬度'],text=df_sub['text'],marker=dict(size=df_sub['大学名称'],color=colors[i],line_color='rgb(40, 40, 40)',line_width=0.5,sizemode='area'),name='{0} - {1}'.format(lim[0], lim[1])))fig.update_layout(title_text='全国高校地理分布图',showlegend=True,geo=dict(scope='asia',landcolor='rgb(217, 217, 217)',),template='ggplot2',font=dict(size=12,color="Black",),legend=dict(yanchor="top",y=1.,xanchor="left",x=1))fig.show()
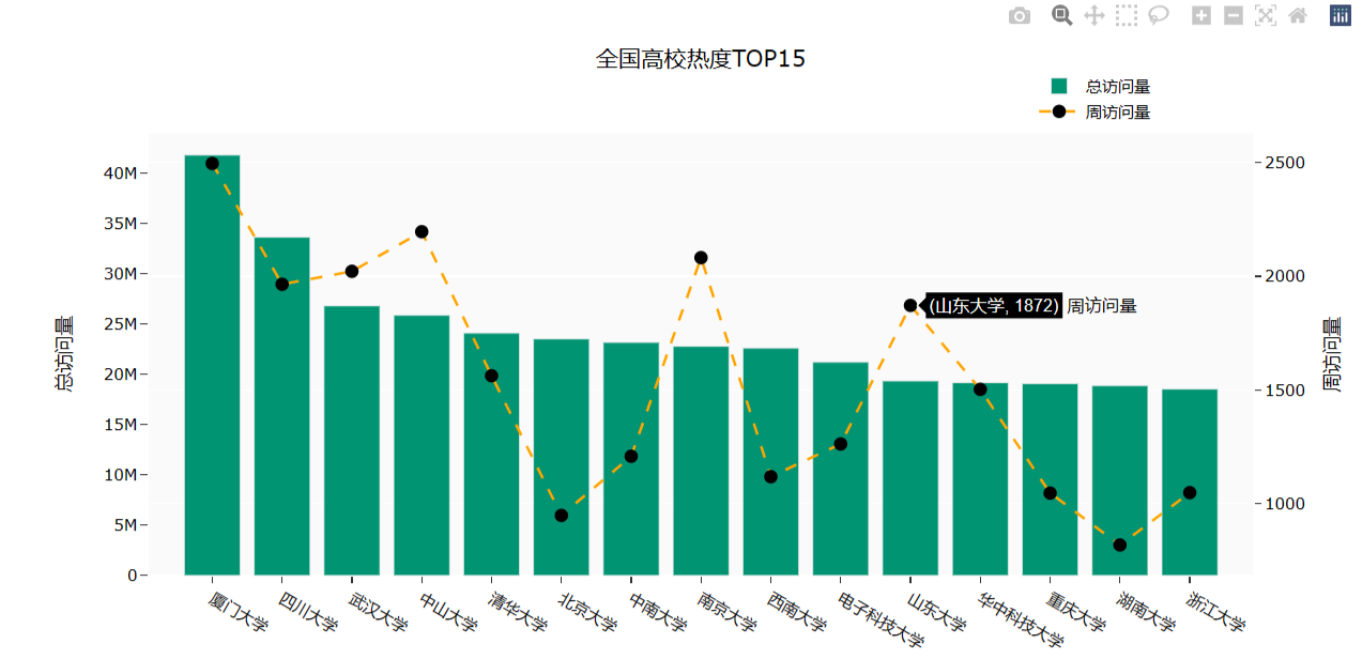
Part5: 针对全国高校的热度排行创建一个柱状图,并在其中创建一个散点图用来显示高校名称和周访问量。
效果图如下:
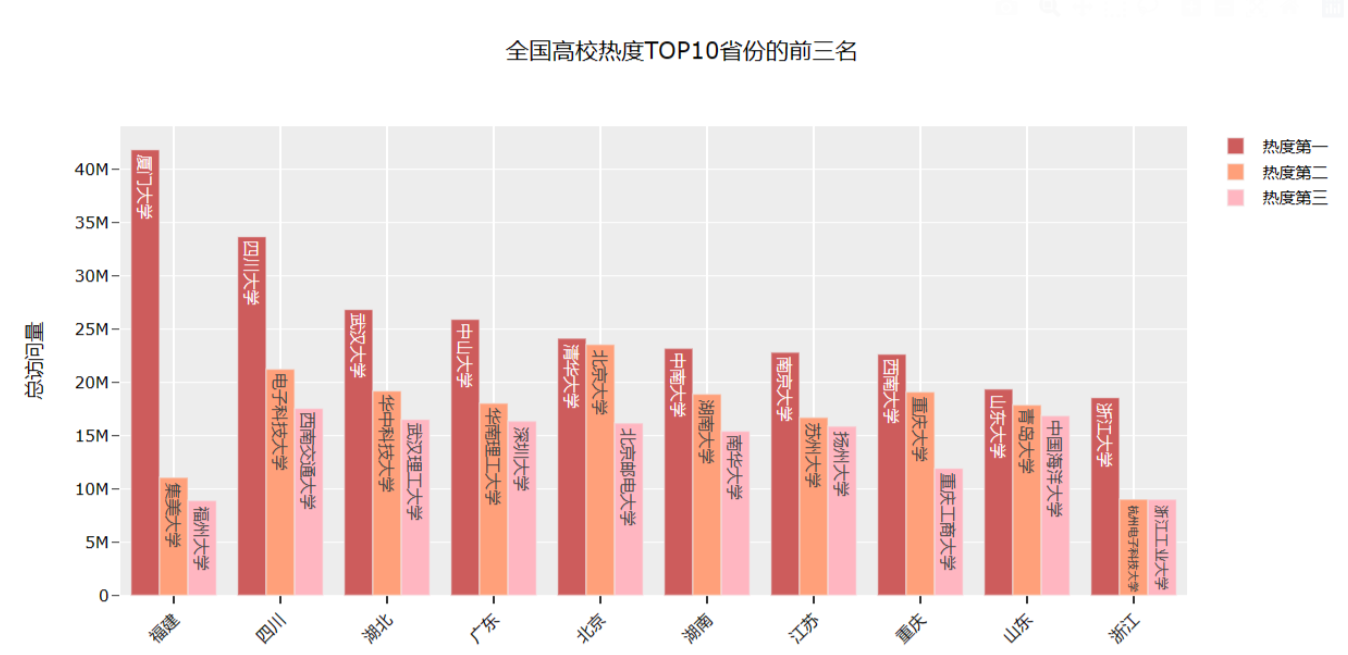
# 全国高校热度TOP15import plotly.graph_objects as gofig = go.Figure()df3 = university.sort_values(by='总访问量', ascending=False)fig.add_trace(go.Bar(x=df3.loc[:15, '大学名称'],y=df3.loc[:15, '总访问量'],name='总访问量',marker_color='#009473',textposition='inside',yaxis='y1'))fig.add_trace(go.Scatter(x=df3.loc[:15, '大学名称'],y=df3.loc[:15, '周访问量'],name='周访问量',mode='markers+text+lines',marker_color='black',marker_size=10,textposition='top center',line=dict(color='orange', dash='dash'),yaxis='y2'))fig.update_layout(title='全国高校热度TOP15',xaxis_title="大学名称",yaxis_title="总访问量",template='ggplot2',font=dict(size=12,color="Black",),xaxis=dict(showgrid=False),yaxis=dict(showgrid=False),plot_bgcolor="#fafafa",yaxis2=dict(showgrid=True, overlaying='y', side='right', title='周访问量'),legend=dict(yanchor="top",y=1.15,xanchor="left",x=0.8))fig.show()Part6: 查询热度排名前十的省份内前三的学校
效果图如下:
代码如下:
# 全国高校热度TOP10省份的前三名df9 = university.loc[:, ['省份', '大学名称', '总访问量']]df9['前三'] = df9.drop_duplicates()['总访问量'].groupby(by=df9['省份']).rank(method='first',ascending=False)df_10 = df9[df9['前三'].map(lambda x: True if x < 4 else False)]df_10['前三'] = df_10['前三'].astype(int)df_pt = df_10.pivot_table(values='总访问量', index='省份', columns='前三')df_pt_2 = df_pt.sort_values(by=1, ascending=False)[:10]df_labels_1 = df9[df9['前三'] == 1].set_index('省份').loc[df_pt_2.index, '大学名称'][:10]df_labels_2 = df9[df9['前三'] == 2].set_index('省份').loc[df_pt_2.index, '大学名称'][:10]df_labels_3 = df9[df9['前三'] == 3].set_index('省份').loc[df_pt_2.index, '大学名称'][:10]x = df_pt_2.indexfig = go.Figure()fig.add_trace(go.Bar(x=x,y=df_pt_2[1],name='热度第一',marker_color='indianred',textposition='inside',text=df_labels_1.values,textangle=90))fig.add_trace(go.Bar(x=x,y=df_pt_2[2],name='热度第二',marker_color='lightsalmon',textposition='inside',text=df_labels_2.values,textangle=90))fig.add_trace(go.Bar(x=x,y=df_pt_2[3],name='热度第三',marker_color='lightpink',textposition='inside',text=df_labels_3.values,textangle=90))fig.update_layout(barmode='group', xaxis_tickangle=-45)fig.update_layout(title='全国高校热度TOP10省份的前三名',xaxis_title="省份",yaxis_title="总访问量",template='ggplot2',font=dict(size=12,color="Black",),barmode='group', xaxis_tickangle=-45)fig.show()Part7: 查询北京市热度排名前十五的学校
效果图如下:
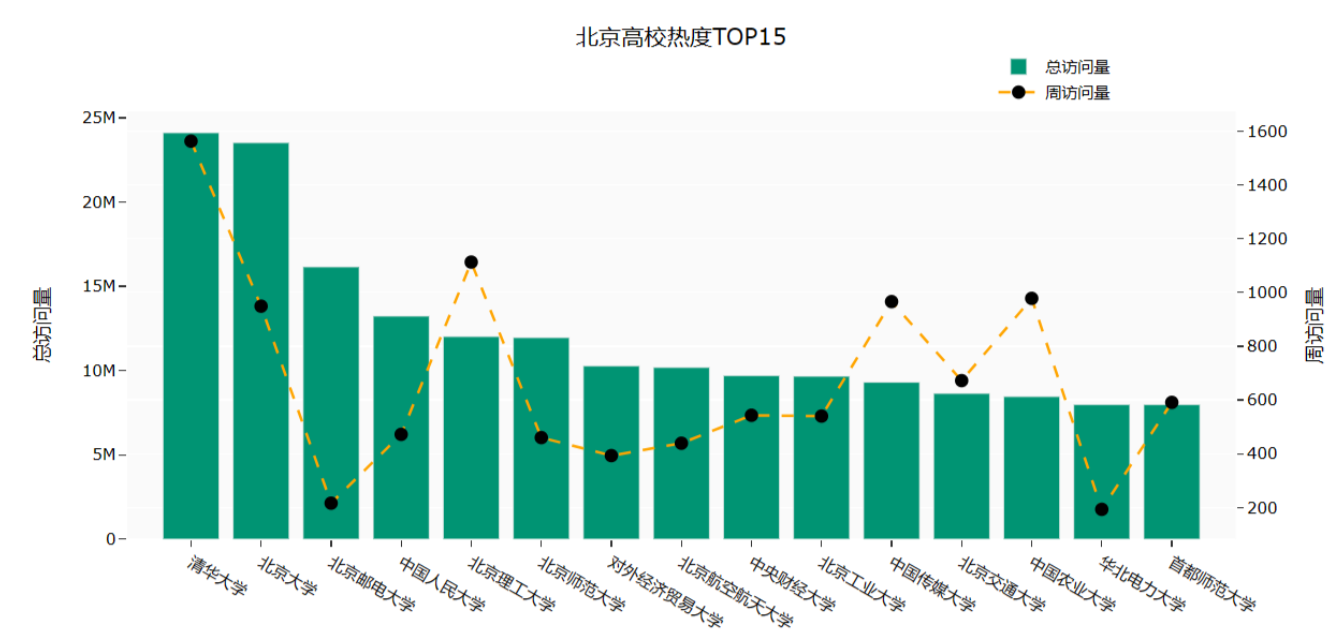
代码如下:
# 查询北京市热度排名前十五的学校df_bj = university.query("高校层次 == '双一流' and 城市== '北京市'").iloc[:15, :]fig = go.Figure()df3 = university.sort_values(by='总访问量', ascending=False)fig.add_trace(go.Bar(x=df_bj['大学名称'],y=df_bj['总访问量'],name='总访问量',marker_color='#009473',textposition='inside',yaxis='y1'))fig.add_trace(go.Scatter(x=df_bj['大学名称'],y=df_bj['周访问量'],name='周访问量',mode='markers+text+lines',marker_color='black',marker_size=10,textposition='top center',line=dict(color='orange', dash='dash'),yaxis='y2'))fig.update_layout(title='北京高校热度TOP15',xaxis_title="大学名称",yaxis_title="总访问量",template='ggplot2',font=dict(size=12, color="Black", ),xaxis=dict(showgrid=False),yaxis=dict(showgrid=False),plot_bgcolor="#fafafa",yaxis2=dict(showgrid=True, overlaying='y', side='right', title='周访问量'),legend=dict(yanchor="top",y=1.15,xanchor="left",x=0.78))fig.show()
Part8: 查询全国高校按类别划分的热度图
效果图如下:
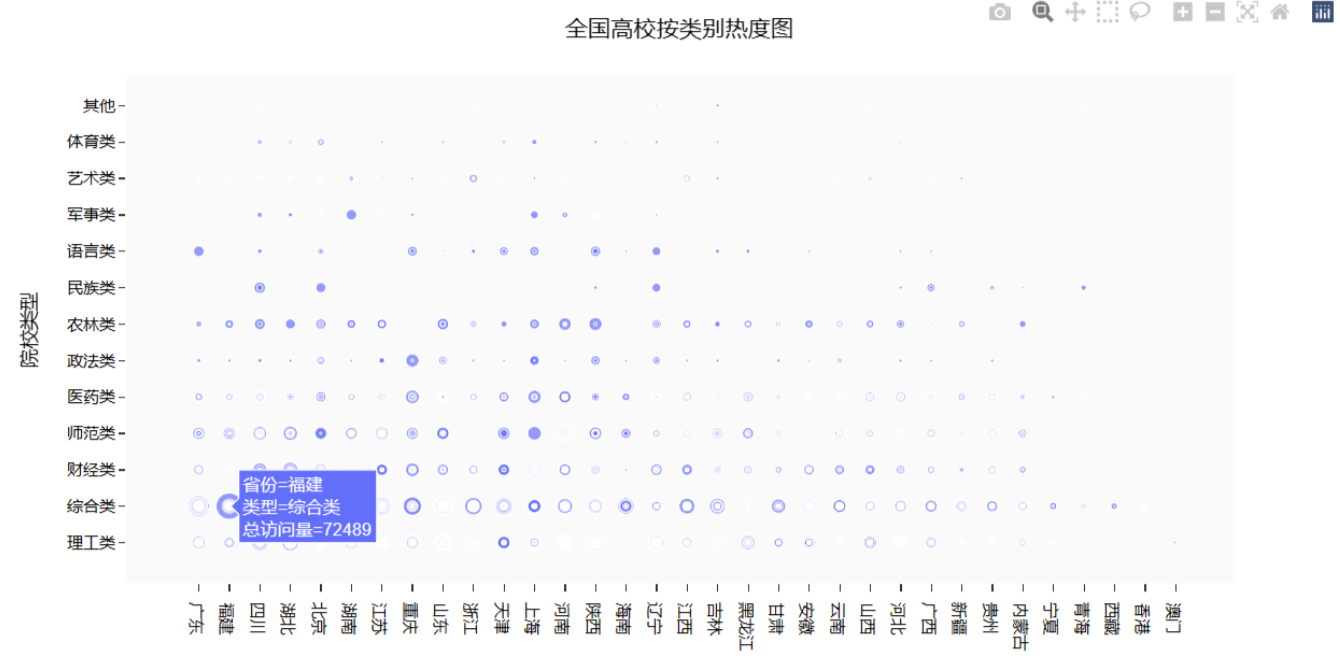 代妈如下:
代妈如下:
# 查询全国高校按类别划分的热度图df5 = university.loc[:, ['城市', '高校层次', '211院校', '985院校']]df5['总数'] = 1df5['211院校'] = df5['211院校'].map(lambda x: '是' if x == 1 else '否')df5['985院校'] = df5['985院校'].map(lambda x: '是' if x == 1 else '否')df6 = df5.pivot_table(index=['城市', '985院校'], values='总数').reset_index()fig = px.scatter(university,x="省份", y="类型",size="总访问量")fig.update_layout(title='全国高校按类别热度图',xaxis_title="省份",yaxis_title="院校类型",template='ggplot2',font=dict(size=12,color="Black",),xaxis=dict(showgrid=False),yaxis=dict(showgrid=False),plot_bgcolor="#fafafa",)fig.show()except FileNotFoundError:print("行政区划数据文件未找到,请检查文件路径和文件名。")
else:print("数据读取失败,无法进行后续操作。")爬虫全部代码如下:
import os
import json
import time
import random
import numpy as np
import pandas as pd
import plotly as py
from time import sleep
import plotly.express as px
from bs4 import BeautifulSoup
from requests_html import HTMLSession, UserAgent# 定义获取随机请求头的函数
def get_header():from fake_useragent import UserAgentlocation = os.getcwd() + '/fake_useragent.json'try:ua = UserAgent(path=location)return ua.randomexcept:# 如果无法加载配置文件,使用默认的UserAgentreturn UserAgent().random# 高校数据
def get_size(page=1):url = 'https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&keyword=&nature=&page={0}&province_id=&ranktype=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&top_school_id=[2941]&type=&uri=apidata/api/gk/school/lists'.format(page)session = HTMLSession()user_agent = UserAgent().randomheader = {"User-Agent": user_agent}try:res = session.post(url, headers=header)res.raise_for_status() # 如果响应状态码不是200,引发HTTPErrordata = json.loads(res.text)size = 0if data["message"] == '成功---success':size = data["data"]["numFound"]return sizeexcept:print(f"请求第 {page} 页数据时出错,返回 None")return Nonedef get_university_info(size, page_size=20):page_cnt = int(size / page_size) if size % page_size == 0 else int(size / page_size) + 1print(f'一共{page_cnt}页数据,即将开始爬取...')session2 = HTMLSession()df_result = pd.DataFrame()for index in range(1, page_cnt + 1):print(f'正在爬取第 {index}/{page_cnt} 页数据')url = 'https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&keyword=&nature=&page={0}&province_id=&ranktype=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&top_school_id=[2941]&type=&uri=apidata/api/gk/school/lists'.format(index)user_agent = UserAgent().randomheader = {"User-Agent": user_agent}try:res = session2.post(url, headers=header)res.raise_for_status()with open("res.text", "a+", encoding="utf-8") as file:file.write(res.text)data = json.loads(res.text)if data["message"] == '成功---success':df_data = pd.DataFrame(data["data"]["item"])df_result = pd.concat([df_result, df_data], ignore_index=True)time.sleep(random.randint(5, 7))except:print(f"处理第 {index} 页数据时出错,跳过该页")continuereturn df_resultsize = get_size()
if size is not None:df_result = get_university_info(size)df_result.to_csv('全国大学数据.csv', encoding='gbk', index=False)
else:print("获取数据总数量时出错,程序终止。")# 查询总访问量排序下的全国大学数据文件
# 读取数据
try:university = pd.read_csv('D:/E盘文件/课程/大三下课程/Python/课堂练习/全国大学数据.csv', encoding='gbk')
except FileNotFoundError:print("数据文件未找到,请检查文件路径和文件名。")university = pd.DataFrame()# 对数据进行处理
if not university.empty:university = university.loc[:, ['name', 'nature_name', 'province_name', 'belong','city_name', 'dual_class_name', 'f211', 'f985', 'level_name','type_name', 'view_month_number', 'view_total_number','view_week_number', 'rank']]c_name = ['大学名称', '办学性质', '省份', '隶属', '城市', '高校层次','211院校', '985院校', '级别', '类型', '月访问量', '总访问量', '周访问量', '排名']university.columns = c_name# 访问量排序print(university.sort_values(by='总访问量', ascending=False).head())# 显示全国双一流和非双一流的高校数量university['高校总数'] = 1university.fillna({'高校层次': '非双一流'}, inplace=True)university_by_province = university.pivot_table(index=['省份', '高校层次'],values='高校总数', aggfunc='count')university_by_province.reset_index(inplace=True)university_by_province.sort_values(by=['高校总数'], ascending=False, inplace=True)# 查询全国各省高校数量fig = px.bar(university_by_province,x="省份",y="高校总数",color="高校层次")fig.update_layout(title='全国各省高校数量',xaxis_title="省份",yaxis_title="高校总数",template='ggplot2',font=dict(size=12,color="Black",),margin=dict(l=40, r=20, t=50, b=40),xaxis=dict(showgrid=False),yaxis=dict(showgrid=False),plot_bgcolor="#fafafa",legend=dict(yanchor="top",y=0.8,xanchor="left",x=0.78))fig.show()# 生成全国高校地理分布图try:df = pd.read_excel('D:/E盘文件/课程/大三下课程/Python/课堂练习/全国省市区行政区划.xlsx', header=1)df_l = df.query("层级==2").loc[:, ['全称', '经度', '纬度']]df_l = df_l.reset_index(drop=True).rename(columns={'全称': '城市'})df7 = university.pivot_table('大学名称', '城市', aggfunc='count')df7 = df7.merge(df_l, on='城市', how='left')df7.sort_values(by='大学名称', ascending=False)df7['text'] = df7['城市'] + '<br>大学总数 ' + (df7['大学名称']).astype(str) + '个'limits = [(0, 10), (11, 20), (21, 50), (51, 100), (101, 200)]colors = ["royalblue", "crimson", "lightseagreen", "orange", "red"]import plotly.graph_objects as gofig = go.Figure()for i in range(len(limits)):lim = limits[i]df_sub = df7[df7['大学名称'].map(lambda x: lim[0] <= x <= lim[1])]fig.add_trace(go.Scattergeo(locationmode='ISO-3',lon=df_sub['经度'],lat=df_sub['纬度'],text=df_sub['text'],marker=dict(size=df_sub['大学名称'],color=colors[i],line_color='rgb(40, 40, 40)',line_width=0.5,sizemode='area'),name='{0} - {1}'.format(lim[0], lim[1])))fig.update_layout(title_text='全国高校地理分布图',showlegend=True,geo=dict(scope='asia',landcolor='rgb(217, 217, 217)',),template='ggplot2',font=dict(size=12,color="Black",),legend=dict(yanchor="top",y=1.,xanchor="left",x=1))fig.show()# 全国高校热度TOP15import plotly.graph_objects as gofig = go.Figure()df3 = university.sort_values(by='总访问量', ascending=False)fig.add_trace(go.Bar(x=df3.loc[:15, '大学名称'],y=df3.loc[:15, '总访问量'],name='总访问量',marker_color='#009473',textposition='inside',yaxis='y1'))fig.add_trace(go.Scatter(x=df3.loc[:15, '大学名称'],y=df3.loc[:15, '周访问量'],name='周访问量',mode='markers+text+lines',marker_color='black',marker_size=10,textposition='top center',line=dict(color='orange', dash='dash'),yaxis='y2'))fig.update_layout(title='全国高校热度TOP15',xaxis_title="大学名称",yaxis_title="总访问量",template='ggplot2',font=dict(size=12,color="Black",),xaxis=dict(showgrid=False),yaxis=dict(showgrid=False),plot_bgcolor="#fafafa",yaxis2=dict(showgrid=True, overlaying='y', side='right', title='周访问量'),legend=dict(yanchor="top",y=1.15,xanchor="left",x=0.8))fig.show()# 全国高校热度TOP10省份的前三名df9 = university.loc[:, ['省份', '大学名称', '总访问量']]df9['前三'] = df9.drop_duplicates()['总访问量'].groupby(by=df9['省份']).rank(method='first',ascending=False)df_10 = df9[df9['前三'].map(lambda x: True if x < 4 else False)]df_10['前三'] = df_10['前三'].astype(int)df_pt = df_10.pivot_table(values='总访问量', index='省份', columns='前三')df_pt_2 = df_pt.sort_values(by=1, ascending=False)[:10]df_labels_1 = df9[df9['前三'] == 1].set_index('省份').loc[df_pt_2.index, '大学名称'][:10]df_labels_2 = df9[df9['前三'] == 2].set_index('省份').loc[df_pt_2.index, '大学名称'][:10]df_labels_3 = df9[df9['前三'] == 3].set_index('省份').loc[df_pt_2.index, '大学名称'][:10]x = df_pt_2.indexfig = go.Figure()fig.add_trace(go.Bar(x=x,y=df_pt_2[1],name='热度第一',marker_color='indianred',textposition='inside',text=df_labels_1.values,textangle=90))fig.add_trace(go.Bar(x=x,y=df_pt_2[2],name='热度第二',marker_color='lightsalmon',textposition='inside',text=df_labels_2.values,textangle=90))fig.add_trace(go.Bar(x=x,y=df_pt_2[3],name='热度第三',marker_color='lightpink',textposition='inside',text=df_labels_3.values,textangle=90))fig.update_layout(barmode='group', xaxis_tickangle=-45)fig.update_layout(title='全国高校热度TOP10省份的前三名',xaxis_title="省份",yaxis_title="总访问量",template='ggplot2',font=dict(size=12,color="Black",),barmode='group', xaxis_tickangle=-45)fig.show()# 查询北京市热度排名前十五的学校df_bj = university.query("高校层次 == '双一流' and 城市== '北京市'").iloc[:15, :]fig = go.Figure()df3 = university.sort_values(by='总访问量', ascending=False)fig.add_trace(go.Bar(x=df_bj['大学名称'],y=df_bj['总访问量'],name='总访问量',marker_color='#009473',textposition='inside',yaxis='y1'))fig.add_trace(go.Scatter(x=df_bj['大学名称'],y=df_bj['周访问量'],name='周访问量',mode='markers+text+lines',marker_color='black',marker_size=10,textposition='top center',line=dict(color='orange', dash='dash'),yaxis='y2'))fig.update_layout(title='北京高校热度TOP15',xaxis_title="大学名称",yaxis_title="总访问量",template='ggplot2',font=dict(size=12, color="Black", ),xaxis=dict(showgrid=False),yaxis=dict(showgrid=False),plot_bgcolor="#fafafa",yaxis2=dict(showgrid=True, overlaying='y', side='right', title='周访问量'),legend=dict(yanchor="top",y=1.15,xanchor="left",x=0.78))fig.show()# 查询全国高校按类别划分的热度图df5 = university.loc[:, ['城市', '高校层次', '211院校', '985院校']]df5['总数'] = 1df5['211院校'] = df5['211院校'].map(lambda x: '是' if x == 1 else '否')df5['985院校'] = df5['985院校'].map(lambda x: '是' if x == 1 else '否')df6 = df5.pivot_table(index=['城市', '985院校'], values='总数').reset_index()fig = px.scatter(university,x="省份", y="类型",size="总访问量")fig.update_layout(title='全国高校按类别热度图',xaxis_title="省份",yaxis_title="院校类型",template='ggplot2',font=dict(size=12,color="Black",),xaxis=dict(showgrid=False),yaxis=dict(showgrid=False),plot_bgcolor="#fafafa",)fig.show()except FileNotFoundError:print("行政区划数据文件未找到,请检查文件路径和文件名。")
else:print("数据读取失败,无法进行后续操作。")
相关文章:
Python爬虫学习:高校数据爬取与可视化
本项目实现了从中国教育在线(eol.cn)的公开 API 接口爬取高校相关数据,并对数据进行清洗、分析与可视化展示。主要包括以下功能: 爬取高校基础信息及访问量数据数据清洗与格式转换多维度数据分析与可视化,如高校数量分…...

linux 手动触发崩溃
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、如何手动触发linux崩溃?二、内核相关panic和oops的cmdline(启动参数)总结 前言 提示:这里可以添加本文要记…...

触觉智能RK3506核心板,工业应用之RK3506 RT-Linux实时性测试
在工业自动化、机械臂控制等高实时性场景中,系统响应速度与稳定性直接决定设备效能。触觉智能RK3506核心板基于瑞芯微三核Cortex-A7架构深度优化,搭载Linux 6.1内核并支持Linux-RT实时系统,提供实时性能的高性价比解决方案。 RK3506与RT-Linu…...

AI日报 - 2025年04月21日
🌟 今日概览(60秒速览) ▎🤖 AGI突破 | O3模型性能引热议,Rich Sutton提出「体验时代」新范式,自递归AI构建仍存挑战。 新模型如O3展示高IQ,但AGI定义与实现路径讨论加剧,强调自主生成数据与体验学习。 ▎&…...

基于SpringBoot的高校体育馆场地预约管理系统-项目分享
基于SpringBoot的高校体育馆场地预约管理系统-项目分享 项目介绍项目摘要目录总体功能图用户实体图赛事实体图项目预览用户个人中心医生信息管理用户管理场地信息管理登录 最后 项目介绍 使用者:管理员 开发技术:MySQLJavaSpringBootVue 项目摘要 随着…...
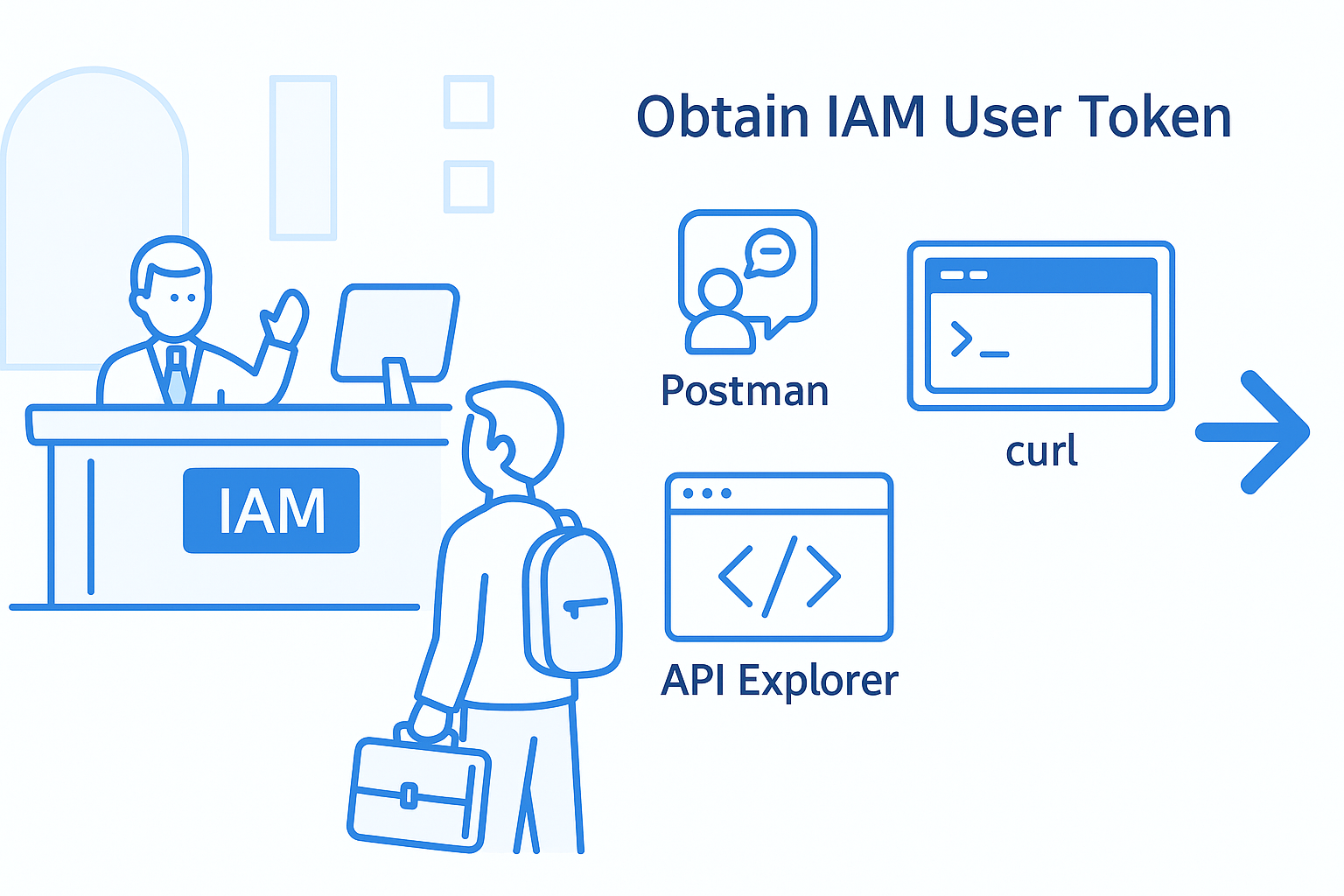
华为云获取IAM用户Token的方式及适用分析
🧠 一、为什么要获取 IAM 用户 Token? 我们用一个生活中的比喻来解释👇: 🏢 比喻场景: 你要去一个 高级写字楼(华为云物联网平台) 办事(调用接口管理设备)&…...

如何利用快照与备份快速恢复服务器的数据
在服务器上利用**快照(Snapshot)**和**备份(Backup)**快速恢复数据,可显著减少停机时间并确保业务连续性。以下是具体操作步骤和最佳实践: --- ### **1. 快照(Snapshot)恢复** **适…...

Git 详细使用说明文档(适合小白)
Git 详细使用说明文档(适合小白) 1. 什么是 Git? Git 是一个版本控制系统,帮助你管理和跟踪代码的变更。无论是个人项目还是团队协作,Git 都能帮助你记录代码的历史版本,方便回溯和协作。 2. 安装 Git …...
)
Spring JDBC 的开发步骤(非注解方式)
以下是使用 非注解方式(纯 XML 配置)实现 Spring JDBC 的完整示例: 1. 项目依赖(不变) <!-- pom.xml --> <dependencies><!-- Spring JDBC --><dependency><groupId>org.springframewo…...
Graph Database Self-Managed Neo4j 知识图谱存储实践1:安装和基础知识学习
Neo4j 是一个原生图数据库,这意味着它在存储层实现了真正的图模型。它不是在其他技术之上使用“图抽象”,而是以您在白板上绘制想法的相同方式在Neo4j中存储数据。 自2007年以来,Neo4j已经发展成为一个丰富的工具、应用程序和库的生态系统。…...

一天学完Servlet!!!(万字总结)
文章目录 前言Servlet打印Hello ServletServlet生命周期 HttpServletRequest对象常用api方法请求乱码问题请求转发request域对象 HttpServletResponse对象响应数据响应乱码问题请求重定向请求转发与重定向区别 Cookie对象Cookie的创建与获取Cookie设置到期时间Cookie注意点Cook…...

E3650工具链生态再增强,IAR全面支持芯驰科技新一代旗舰智控MCU
近日,全球嵌入式软件开发解决方案领导者IAR与全场景智能车芯引领者芯驰科技正式宣布,IAR Embedded Workbench for Arm已全面支持芯驰E3650,为这一旗舰智控MCU提供开发和调试一站式服务,进一步丰富芯驰E3系列智控芯片工具链生态&am…...

Spring Boot Controller 单元测试撰写
文章目录 引言标准用法必需依赖项核心注解说明代码示例 当涉及静态方法时的测试策略必需依赖项核心注解说明代码示例 引言 之前在编写 Controller 层的单元测试时,我一直使用 SpringBootTest 注解,但它会加载整个 Spring 应用上下文,资源开销…...
--- 如何定义泛型?)
TypeScripts前端基础篇(4)--- 如何定义泛型?
在 TypeScript 中,泛型(Generics)是语言内置的功能,不需要额外下载或安装任何东西;泛型(Generics)允许你创建可重用的组件,这些组件可以支持多种类型。现在给出的两个例子展示了不同的用法&…...

在深度学习中FLOPs和GFLOPs的含义及区别
在深度学习中,FLOPs和GFLOPs是衡量计算性能的关键指标,但两者的定义和应用场景不同: 1. 定义与区别 • FLOPs(Floating-point Operations) 表示模型或算法执行时所需的浮点运算总次数,用于衡量模型的计算复…...
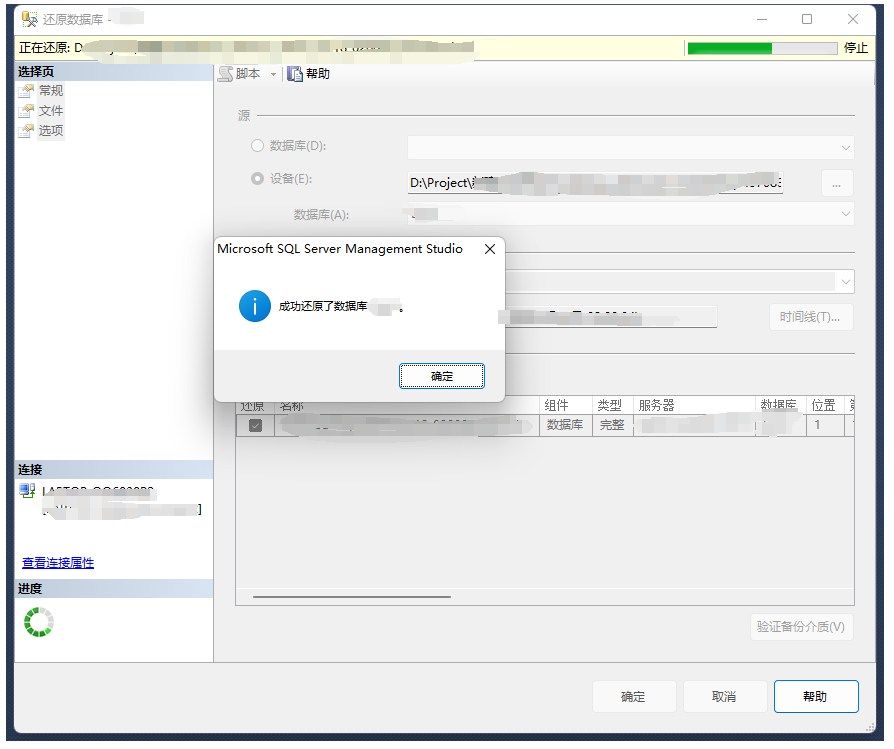
MSSQL-数据库还原报错-‘32(另一个程序正在使用此文件,进程无法访问。)‘
这里是引用 标题: Microsoft SQL Server Management Studio 还原 对于 服务器“<<服务器名称>>”失败。 (Microsoft.SqlServer.SmoExtended) 有关帮助信息,请单击: http://go.microsoft.com/fwlink?ProdNameMicrosoftSQLServer&ProdVer12.0.2000.8…...

卷积神经网络:视觉炼金术士的数学魔法
引言:当数学遇见视觉炼金术 在人工智能的奇幻世界里,卷积神经网络(CNN)犹如掌握视觉奥秘的炼金术士,将原始像素的"铅块"淬炼成认知的"黄金"。这种融合数学严谨性与生物灵感的算法架构,…...

立马耀:通过阿里云 Serverless Spark 和 Milvus 构建高效向量检索系统,驱动个性化推荐业务
作者:厦门立马耀网络科技有限公司大数据开发工程师 陈宏毅 背景介绍 行业 蝉选是蝉妈妈出品的达人选品服务平台。蝉选秉持“陪伴达人赚到钱”的品牌使命,致力于洞悉达人变现需求和痛点,提供达人选高佣、稳变现、速响应的选品服务。 业务特…...

青少年编程与数学 02-018 C++数据结构与算法 07课题、堆
青少年编程与数学 02-018 C数据结构与算法 07课题、堆 一、堆1. 定义2. 堆的存储方式3. 堆的常见操作4. 堆的应用 二、最大堆的实现1. 堆的存储2. 基本操作3. C代码实现4. 代码说明5. 示例输出 三、最小堆的实现四、建堆操作1. 建堆操作的原理2. 为什么从最后一个非叶子节点开始…...

机器学习特征工程中的数值分箱技术:原理、方法与实例解析
标题:机器学习特征工程中的数值分箱技术:原理、方法与实例解析 摘要: 分箱技术作为机器学习特征工程中的关键环节,通过将数值数据划分为离散区间,能够有效提升模型对非线性关系的捕捉能力,同时增强模型对异…...

安装Github软件详细流程,win10系统从配置git到安装软件详解,以及github软件整合包制作方法(
win10系统部署安装开源ai必备 一、安装git应用程序(用来下来github软件) 官网下载git的exe可执行文件,Git - Downloads 或者这里下夸克网盘分享 运行git应用程序,一路’Next’到底即可。 配置安装路径 此时如果直接运行git命…...

专业热度低,25西电光电工程学院(考研录取情况)
1、光电工程学院各个方向 2、光电工程学院近三年复试分数线对比 学长、学姐分析 由表可看出: 1、光学工程25年相较于24年下降20分, 2、光电信息与工程(专硕)25年相较于24年上升15分 3、25vs24推免/统招人数对比 学长、学姐分析…...
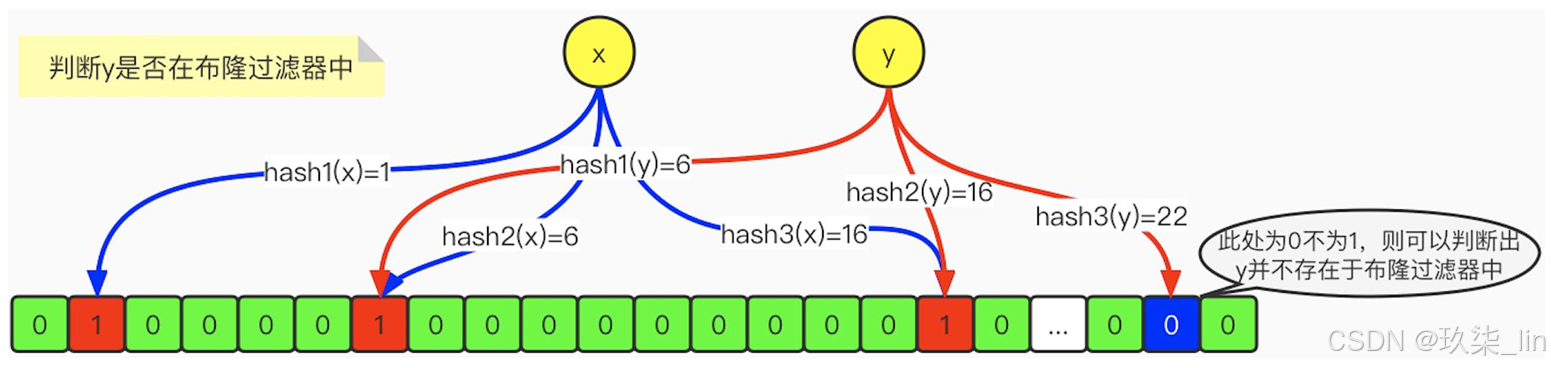
java—11 Redis
目录 一、Redis概述 二、Redis类型及编码 三、Redis对象的编码 1. 类型&编码的对应关系 2. string类型常用命令 (1)string类型内部实现——int编码 (2)string类型内部实现——embstr编码 编辑 (3&#x…...

C语言编程--14.电话号码的字母组合
题目: 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。 给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。 示例 1: 输入:digits “23” …...

热门算法面试题第19天|Leetcode39. 组合总和40.组合总和II131.分割回文串
39. 组合总和 力扣题目链接(opens new window) 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的数字可以无限制重复被选取。 说明: 所有数字(包括 ta…...
——物体跟踪)
OpenCv高阶(十一)——物体跟踪
文章目录 前言一、OpenCV 中的物体跟踪算法1、均值漂移(Mean Shift):2、CamShift:3、KCF(Kernelized Correlation Filters):4、MIL(Multiple Instance Learning)…...
2194出差-节点开销Bellman-ford/图论
题目网址: 蓝桥账户中心 我先用Floyd跑了一遍,不出所料TLE了 n,mmap(int,input().split())clist(map(int,input().split()))INFfloat(inf) ma[[INF]*n for i in range(n)]for i in range(m):u,v,wmap(int,input().split())ma[u-1][v-1]wma[v-1][u-1]w#“…...
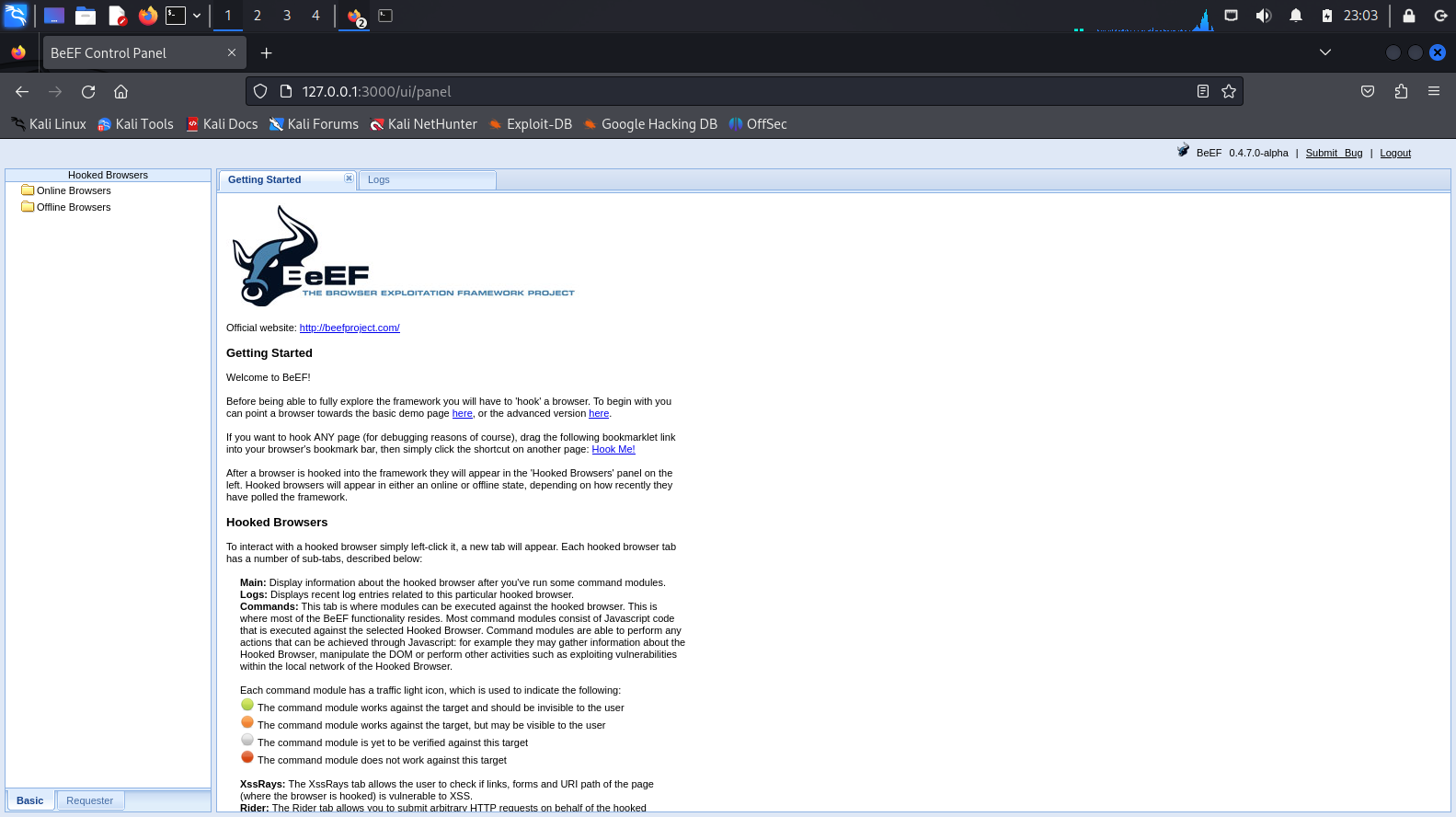
Docker安装beef-xss
新版的kali系统中安装了beef-xss会因为环境问题而无法启动,可以使用Docker来安装beef-xss,节省很多时间。 安装步骤 1.启动kali虚拟机,打开终端,切换到root用户,然后执行下面的命令下载beef的docker镜像 wget https:…...

产品经理学习过程
一:扫盲篇(初始产品经理) 阶段1:了解产品经理 了解产品经理是做什么的、产品经理的分类、产品经理在实际工作中都会接触什么样的岗位、以及产品经理在实际工作中具体要做什么事情。 二:准备篇 阶段2:工…...
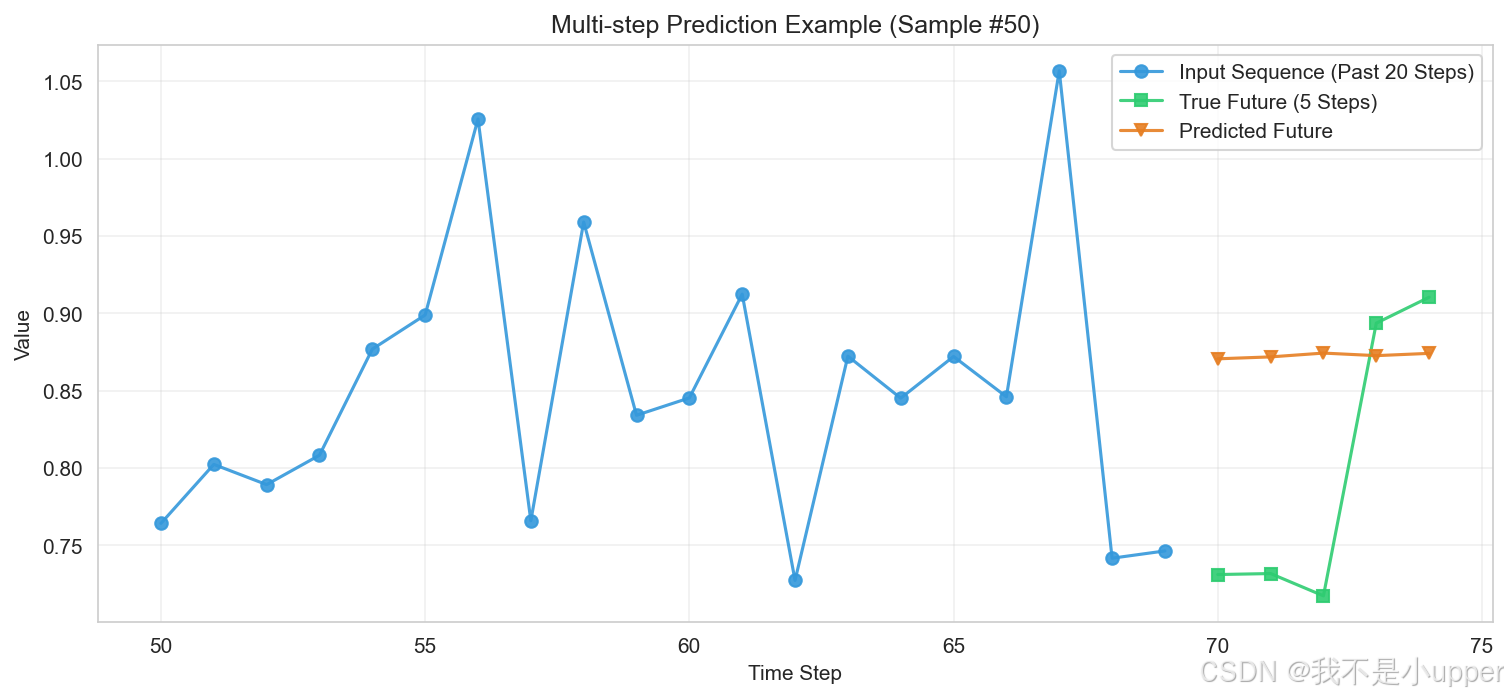
时间序列-数据窗口进行多步预测
在时间序列预测领域,多步预测旨在基于历史数据预测未来多个时间点的值,而创建数据窗口是实现这一目标的常用且高效的技术手段。数据窗口技术的核心是通过滑动窗口机制构建训练数据集,其核心逻辑可概括为:利用历史时间步的序列模式…...