热门算法面试题第19天|Leetcode39. 组合总和40.组合总和II131.分割回文串
39. 组合总和
力扣题目链接(opens new window)
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
- 所有数字(包括 target)都是正整数。
- 解集不能包含重复的组合。
示例 1:
- 输入:candidates = [2,3,6,7], target = 7,
- 所求解集为: [ [7], [2,2,3] ]
示例 2:
- 输入:candidates = [2,3,5], target = 8,
- 所求解集为: [ [2,2,2,2], [2,3,3], [3,5] ]
思路:
在我们之前做过的组合总和中,取法都是不能重复的,现在给出的数组元素可以重复
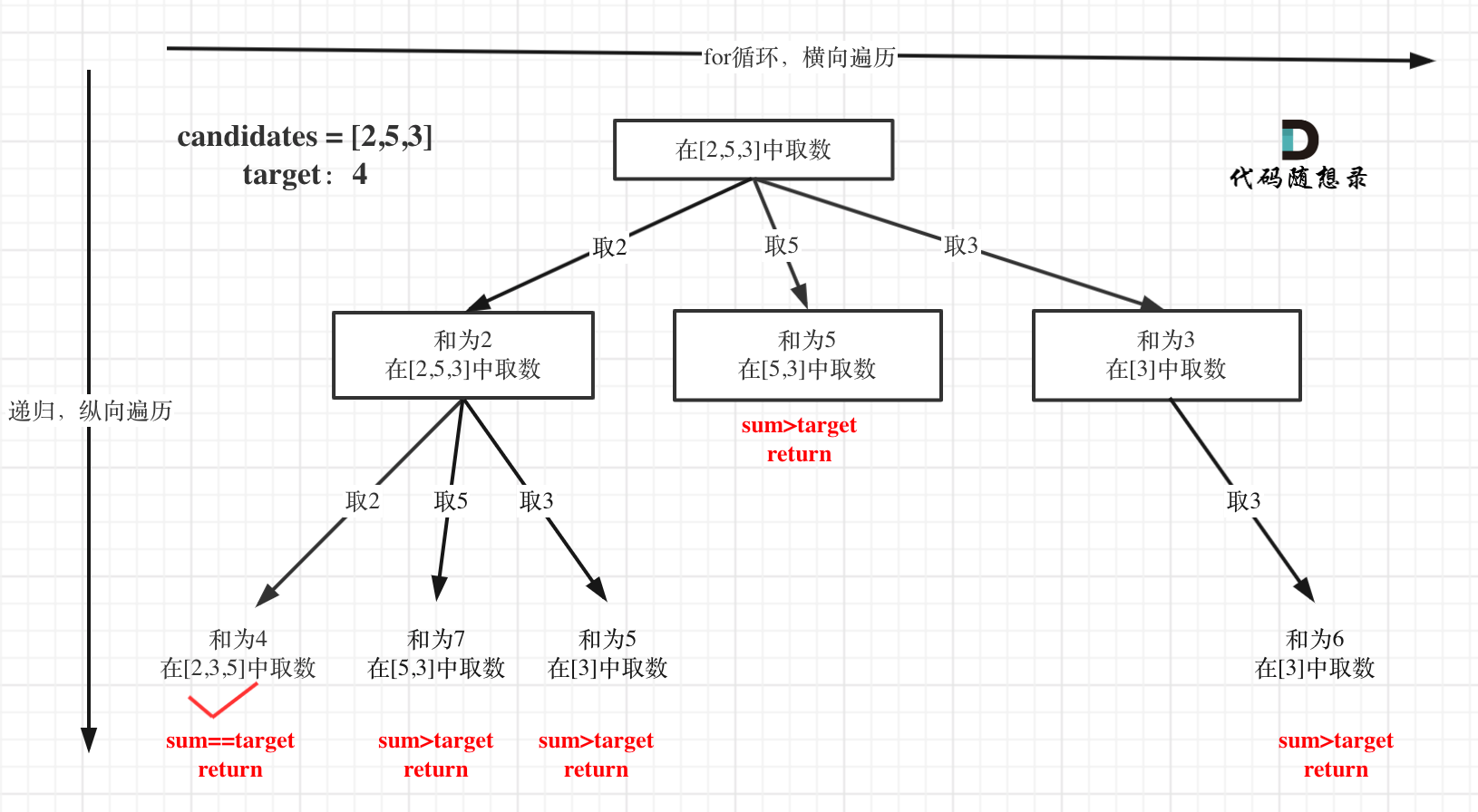
本题搜索的过程抽象成树形结构如下:
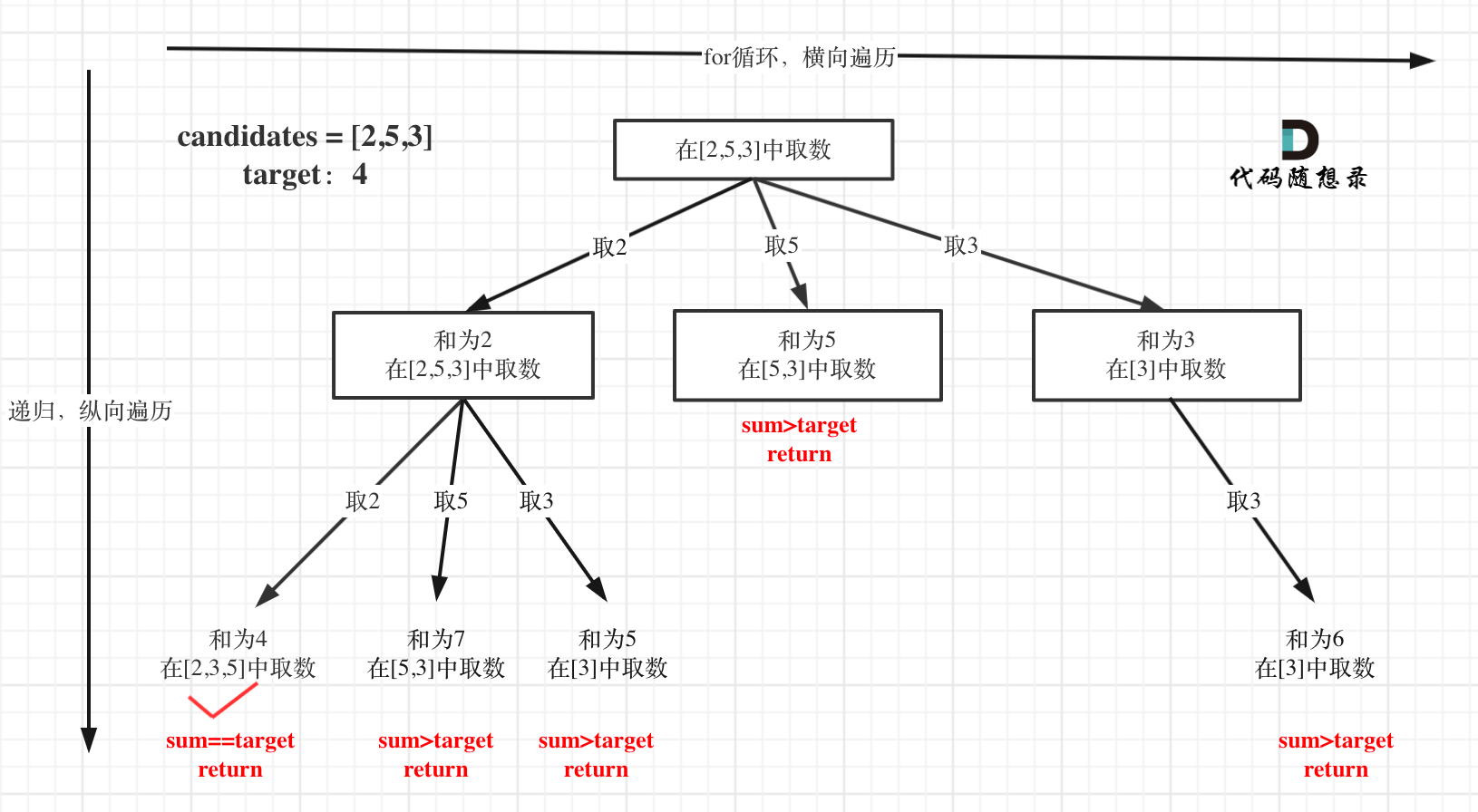
注意图中叶子节点的返回条件,因为本题没有组合数量要求,仅仅是总和的限制,所以递归没有层数的限制,只要选取的元素总和超过target,就返回!
确定递归函数及其参数
这里依然是定义两个全局变量,二维数组result存放结果集,数组path存放符合条件的结果。(这两个变量可以作为函数参数传入)
首先是题目中给出的参数,集合candidates, 和目标值target。
此外我还定义了int型的sum变量来统计单一结果path里的总和,其实这个sum也可以不用,用target做相应的减法就可以了,最后如何target==0就说明找到符合的结果了,但为了代码逻辑清晰,我依然用了sum。
本题还需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?
如果是一个集合来求组合的话,就需要startIndex
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex
代码如下:
// 存储所有符合条件的组合private List<List<Integer>> result = new ArrayList<>();// 当前路径(当前组合)private List<Integer> path = new ArrayList<>();// 回溯算法核心private void backtracking(int[] candidates, int target, int sum, int startIndex) {递归终止条件:
终止情况就两种,要么sum==target,要么sum>target
// 当前和超过目标值,直接返回if (sum > target) {return;}// 找到符合条件的组合if (sum == target) {result.add(new ArrayList<>(path)); // 注意创建新列表return;}
sum等于result直接add,大于return吊
确定单层递归逻辑
单层for循环依然是从startIndex开始,搜索candidates集合。
// 从startIndex开始遍历候选数字for (int i = startIndex; i < candidates.length; i++) {sum += candidates[i]; // 尝试选择当前数字path.add(candidates[i]);backtracking(candidates, target, sum, i); // 关键点:允许重复使用同一数字sum -= candidates[i]; // 撤销选择path.remove(path.size() - 1); // 移除最后添加的数字}}但与之前也有不同,我们在循环里面的递归的时候不用更新startindex
因为可以无限制重复选取
我们来看完整代码
import java.util.ArrayList;
import java.util.List;class Solution {// 存储所有符合条件的组合private List<List<Integer>> result = new ArrayList<>();// 当前路径(当前组合)private List<Integer> path = new ArrayList<>();// 回溯算法核心private void backtracking(int[] candidates, int target, int sum, int startIndex) {// 当前和超过目标值,直接返回if (sum > target) {return;}// 找到符合条件的组合if (sum == target) {result.add(new ArrayList<>(path)); // 注意创建新列表return;}// 从startIndex开始遍历候选数字for (int i = startIndex; i < candidates.length; i++) {sum += candidates[i]; // 尝试选择当前数字path.add(candidates[i]);backtracking(candidates, target, sum, i); // 关键点:允许重复使用同一数字sum -= candidates[i]; // 撤销选择path.remove(path.size() - 1); // 移除最后添加的数字}}// 主方法public List<List<Integer>> combinationSum(int[] candidates, int target) {result.clear(); // 清空结果集path.clear(); // 清空当前路径backtracking(candidates, target, 0, 0); // 从和为0,索引0开始回溯return result;}
}
剪枝优化
在这个树形结构中:
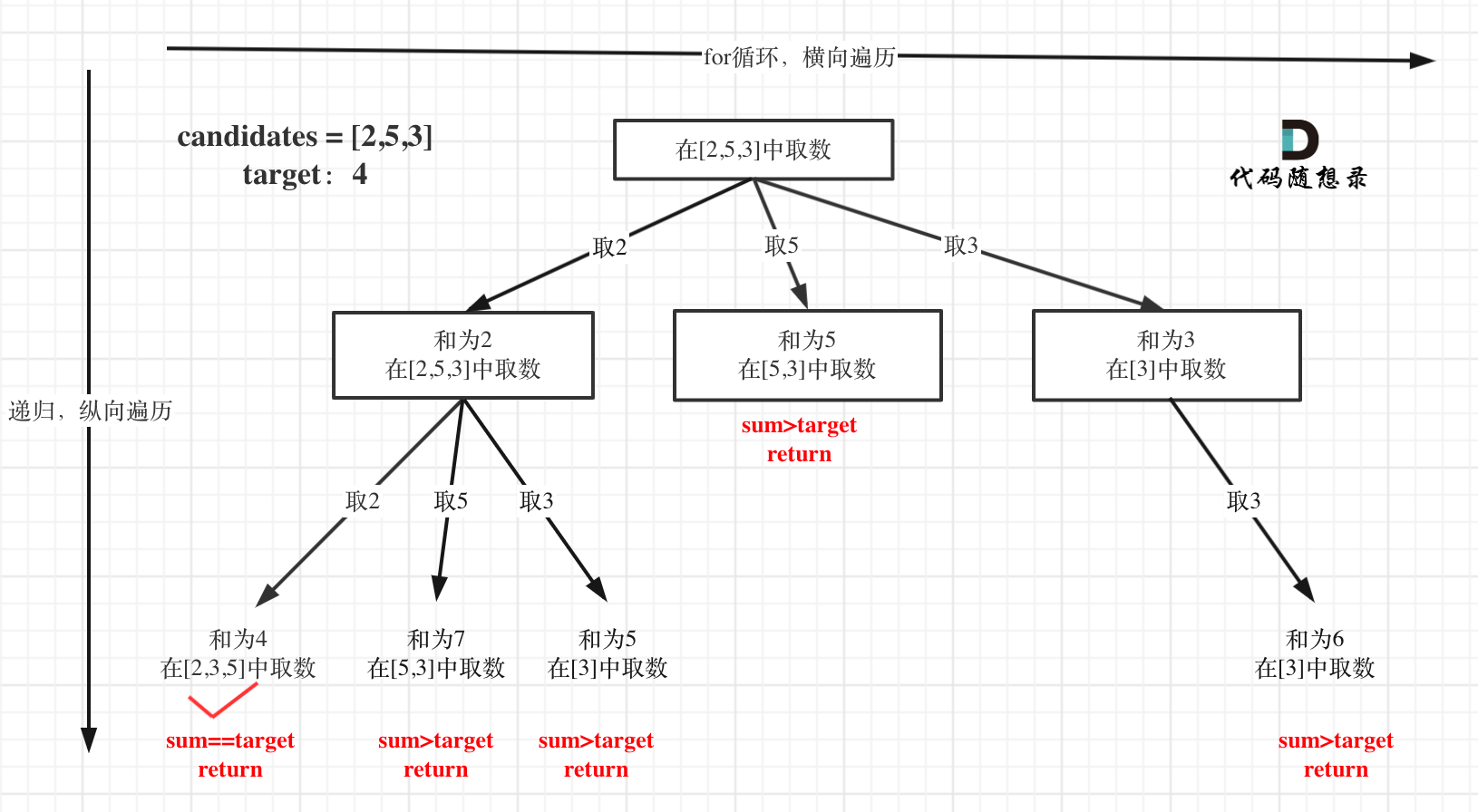
以及上面的版本一的代码大家可以看到,对于sum已经大于target的情况,其实是依然进入了下一层递归,只是下一层递归结束判断的时候,会判断sum > target的话就返回。
其实如果已经知道下一层的sum会大于target,就没有必要进入下一层递归了。
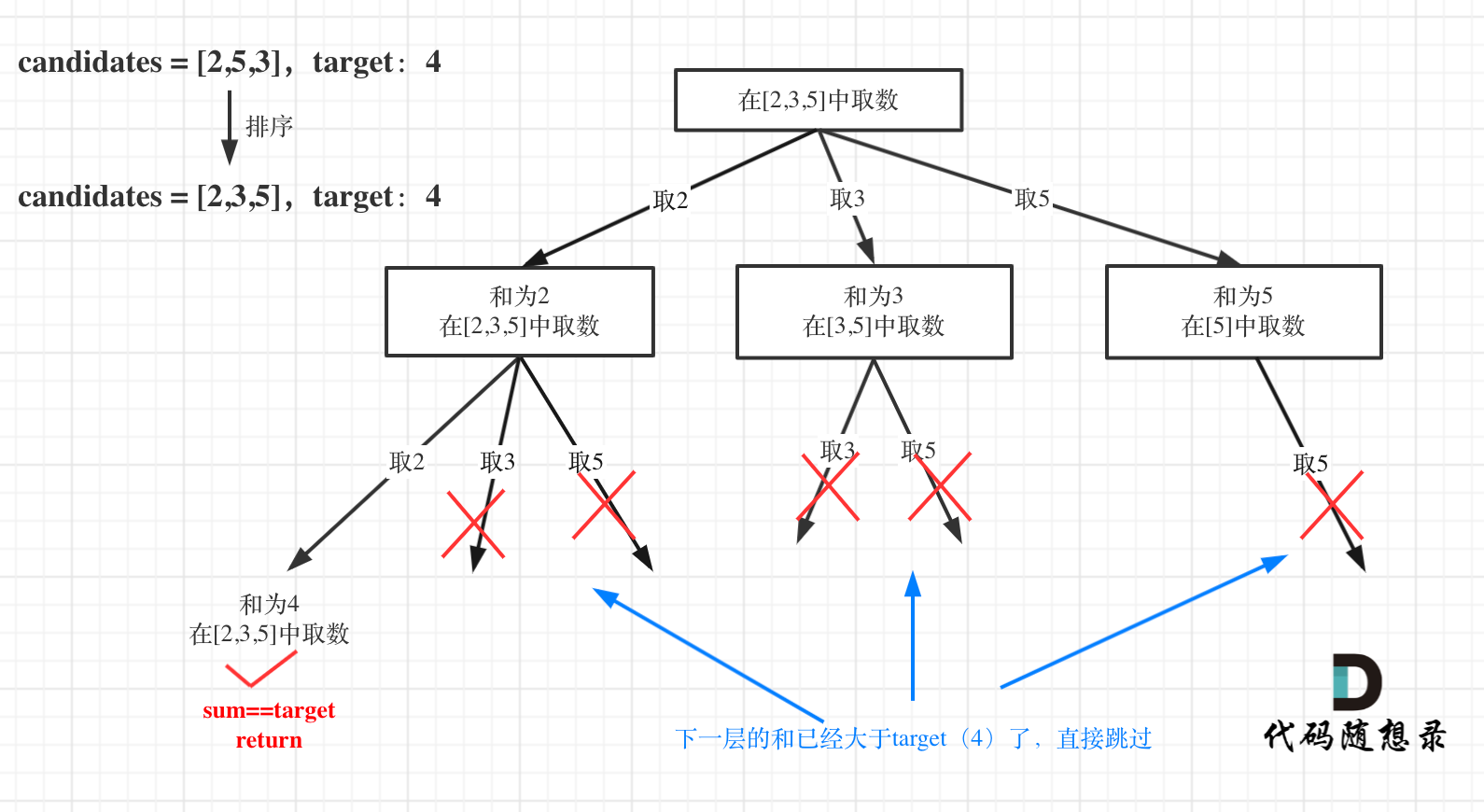
那么可以在for循环的搜索范围上做做文章了。
对总集合排序之后,如果下一层的sum(就是本层的 sum + candidates[i])已经大于target,就可以结束本轮for循环的遍历。
如图:
最终代码
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;class Solution {private List<List<Integer>> result = new ArrayList<>();private List<Integer> path = new ArrayList<>();private void backtracking(int[] candidates, int target, int sum, int startIndex) {if (sum == target) {result.add(new ArrayList<>(path));return;}// 剪枝优化:sum + candidates[i] <= targetfor (int i = startIndex; i < candidates.length && sum + candidates[i] <= target; i++) {sum += candidates[i];path.add(candidates[i]);backtracking(candidates, target, sum, i); // 允许重复使用sum -= candidates[i];path.remove(path.size() - 1);}}public List<List<Integer>> combinationSum(int[] candidates, int target) {result.clear();path.clear();Arrays.sort(candidates); // 关键:排序后才能剪枝backtracking(candidates, target, 0, 0);return result;}
}
40.组合总和II
力扣题目链接(opens new window)
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次。
说明: 所有数字(包括目标数)都是正整数。解集不能包含重复的组合。
- 示例 1:
- 输入: candidates = [10,1,2,7,6,1,5], target = 8,
- 所求解集为:
[[1, 7],[1, 2, 5],[2, 6],[1, 1, 6]
]
- 示例 2:
- 输入: candidates = [2,5,2,1,2], target = 5,
- 所求解集为:
[[1,2,2],[5]
]思路:
这道题目和39.组合总和 (opens new window)如下区别:
本题candidates 中的每个数字在每个组合中只能使用一次。
本题数组candidates的元素是有重复的,而39.组合总和 (opens new window)是无重复元素的数组candidates
最后本题和39.组合总和 (opens new window)要求一样,解集不能包含重复的组合。
本题的难点在于区别2中:集合(数组candidates)有重复元素,但还不能有重复的组合。
那么问题来了,我们是要同一树层上使用过,还是同一树枝上使用过呢?
回看一下题目,元素在同一个组合内是可以重复的,怎么重复都没事,但两个组合不能相同。
所以我们要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重。
为了理解去重我们来举一个例子,candidates = [1, 1, 2], target = 3,(方便起见candidates已经排序了)
强调一下,树层去重的话,需要对数组排序!
选择过程树形结构如图所示:
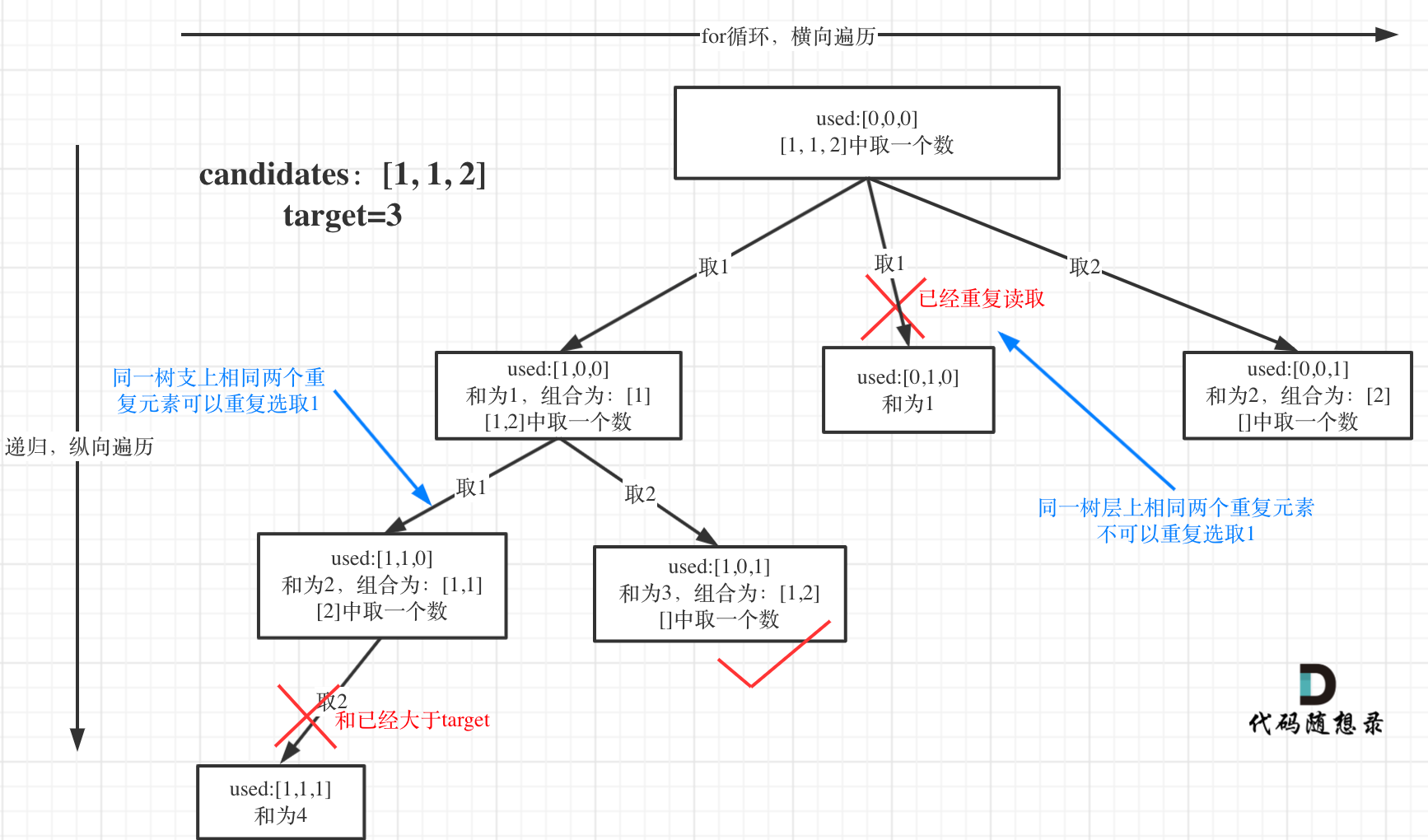
确定递归函数及其参数
与上一题的套路相同,此题还需要加一个bool型数组used,用来记录同一树枝上的元素是否使用过。
这个集合去重的重任就是used来完成的。
private List<List<Integer>> result = new ArrayList<>();private List<Integer> path = new ArrayList<>();private void backtracking(int[] candidates, int target, int sum, int startIndex, boolean[] used) {确定终止条件:
和上一题相同
if (sum > target) { // 这个条件其实可以省略return;
}
if (sum == target) {result.push_back(path);return;
}确定单层递归逻辑
for (int i = startIndex; i < candidates.length && sum + candidates[i] <= target; i++) {// 去重逻辑:当前元素和前一个相同,且前一个未被使用if (i > 0 && candidates[i] == candidates[i - 1] && !used[i - 1]) {continue;}sum += candidates[i];path.add(candidates[i]);used[i] = true;backtracking(candidates, target, sum, i + 1, used); // i+1 表示每个数字只能用一次used[i] = false;sum -= candidates[i];path.remove(path.size() - 1);}前面我们提到:要去重的是“同一树层上的使用过”,如何判断同一树层上元素(相同的元素)是否使用过了呢。
如果candidates[i] == candidates[i - 1] 并且 used[i - 1] == false,就说明:前一个树枝,使用了candidates[i - 1],也就是说同一树层使用过candidates[i - 1]。
不然会重复,比如第一个树枝的取1取我,和第二个树枝取1取2重复
此时for循环里就应该做continue的操作。
这块比较抽象,如图:
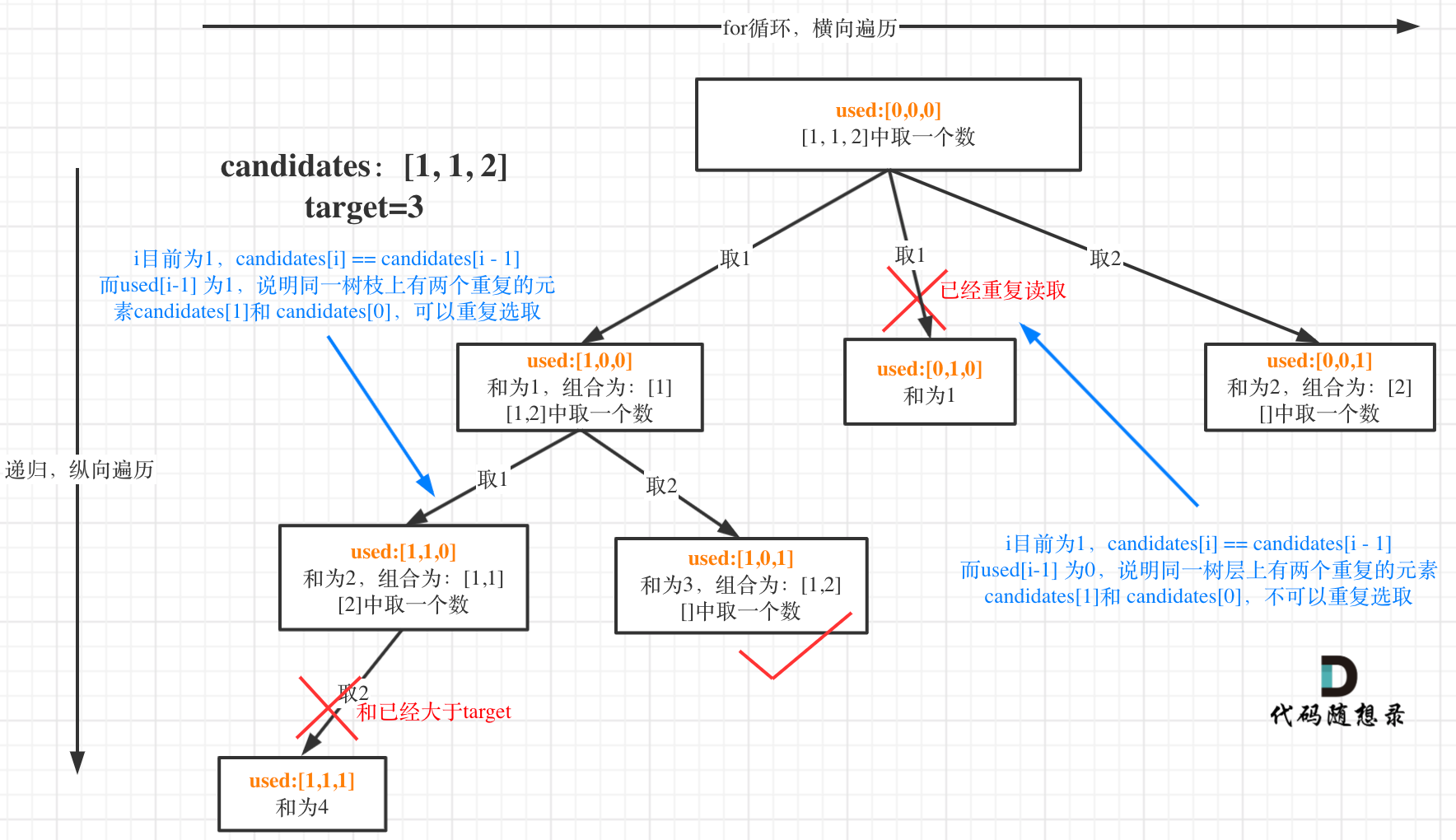
我在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
- used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
- used[i - 1] == false,说明同一树层candidates[i - 1]使用过
为什么 used[i - 1] == false 就是同一树层呢,因为同一树层,used[i - 1] == false 才能表示,当前取的 candidates[i] 是从 candidates[i - 1] 回溯而来的。
而 used[i - 1] == true,说明是进入下一层递归,去下一个数,所以是树枝上,如图所示:
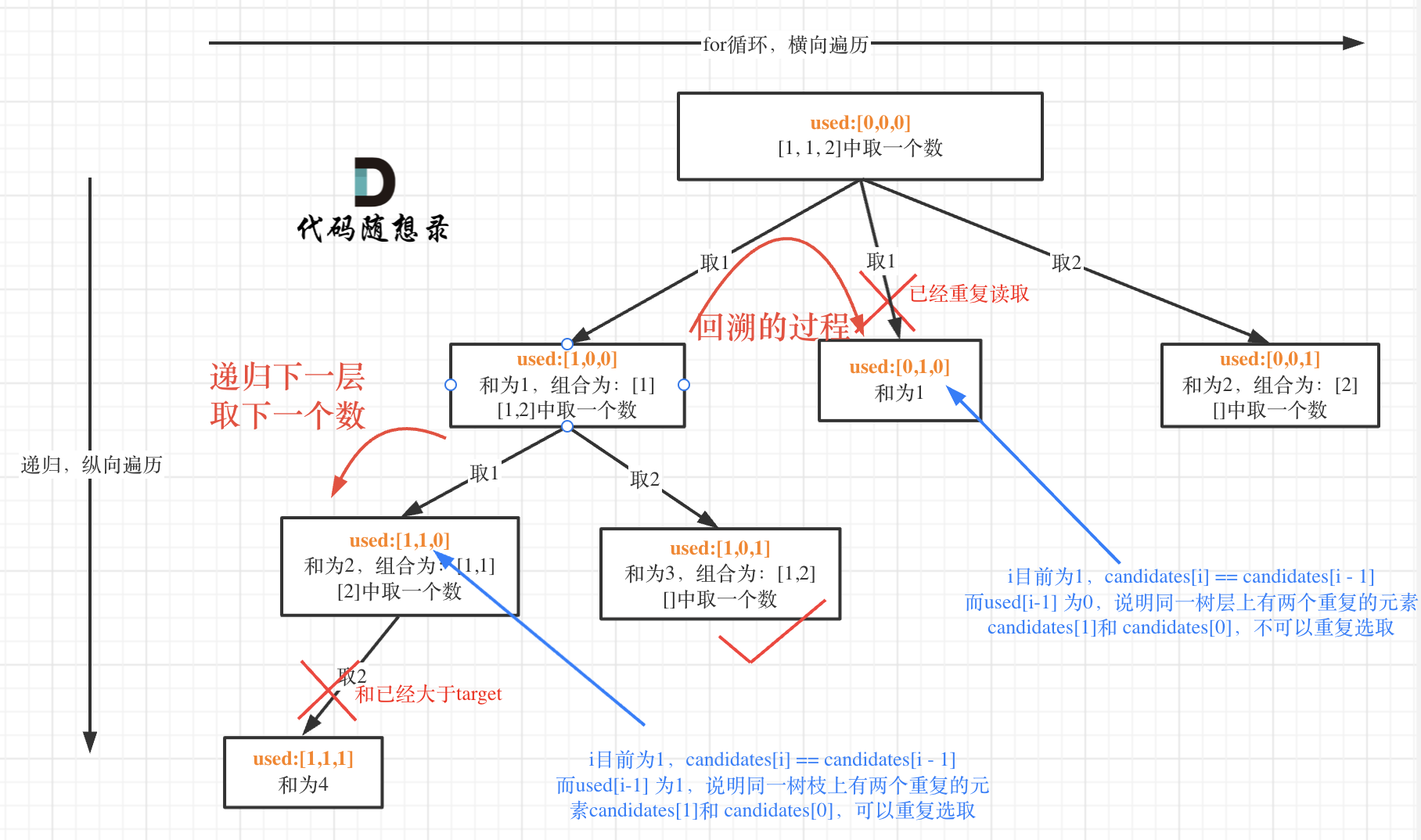
剪枝优化总体和之前相同
我们来看完整的代码
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;class Solution {private List<List<Integer>> result = new ArrayList<>();private List<Integer> path = new ArrayList<>();private void backtracking(int[] candidates, int target, int sum, int startIndex, boolean[] used) {if (sum == target) {result.add(new ArrayList<>(path));return;}for (int i = startIndex; i < candidates.length && sum + candidates[i] <= target; i++) {// 去重逻辑:当前元素和前一个相同,且前一个未被使用if (i > 0 && candidates[i] == candidates[i - 1] && !used[i - 1]) {continue;}sum += candidates[i];path.add(candidates[i]);used[i] = true;backtracking(candidates, target, sum, i + 1, used); // i+1 表示每个数字只能用一次used[i] = false;sum -= candidates[i];path.remove(path.size() - 1);}}public List<List<Integer>> combinationSum2(int[] candidates, int target) {result.clear();path.clear();Arrays.sort(candidates); // 必须先排序boolean[] used = new boolean[candidates.length];backtracking(candidates, target, 0, 0, used);return result;}
}
131.分割回文串
力扣题目链接(opens new window)
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回 s 所有可能的分割方案。
示例: 输入: "aab" 输出: [ ["aa","b"], ["a","a","b"] ]
思路:
其实切割问题类似组合问题。
例如对于字符串abcdef:
- 组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中再选取第三个.....。
- 切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中再切割第三段.....。
感受出来了不?
所以切割问题,也可以抽象为一棵树形结构,如图:
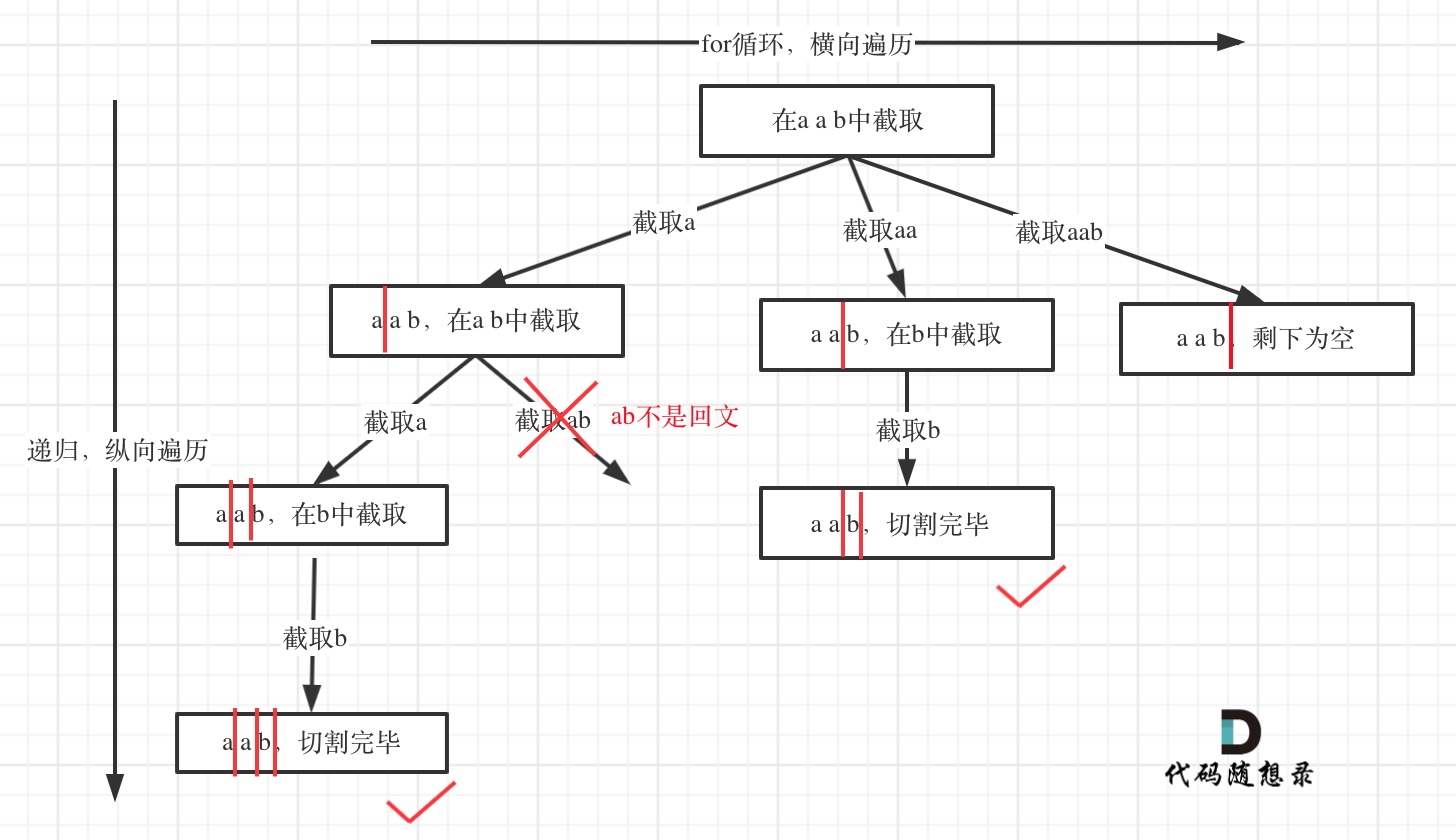
递归用来纵向遍历,for循环用来横向遍历,切割线(就是图中的红线)切割到字符串的结尾位置,说明找到了一个切割方法。
此时可以发现,切割问题的回溯搜索的过程和组合问题的回溯搜索的过程是差不多的。
确定递归函数及其参数
全局变量数组path存放切割后回文的子串,二维数组result存放结果集。 (这两个参数可以放到函数参数里)
本题递归函数参数还需要startIndex,因为切割过的地方,不能重复切割,和组合问题也是保持一致的。
private List<List<String>> result = new ArrayList<>();private List<String> path = new ArrayList<>();private void backtracking(String s, int startIndex) {确定递归终止条件
从树形结构的图中可以看出:切割线切到了字符串最后面,说明找到了一种切割方法,此时就是本层递归的终止条件。
在处理组合问题的时候,递归参数需要传入startIndex,表示下一轮递归遍历的起始位置,这个startIndex就是切割线。
// 如果起始位置已经大于等于字符串长度,说明找到一组分割方案if (startIndex >= s.length()) {result.add(new ArrayList<>(path));return;}确定单层递归逻辑
在for (int i = startIndex; i < s.size(); i++)循环中,我们 定义了起始位置startIndex,那么 [startIndex, i] 就是要截取的子串。
首先判断这个子串是不是回文,如果是回文,就加入在vector<string> path中,path用来记录切割过的回文子串。
代码如下:
for (int i = startIndex; i < s.length(); i++) {// 如果是回文子串if (isPalindrome(s, startIndex, i)) {// 获取当前回文子串String str = s.substring(startIndex, i + 1);path.add(str);// 递归处理剩余部分backtracking(s, i + 1);// 回溯path.remove(path.size() - 1);}// 不是回文则跳过}
判断回文子串
就是之前的双指针,从前后选两个指针,然后分别遍历就行
// 判断是否是回文串private boolean isPalindrome(String s, int start, int end) {for (int i = start, j = end; i < j; i++, j--) {if (s.charAt(i) != s.charAt(j)) {return false;}}return true;}完整代码
import java.util.ArrayList;
import java.util.List;class Solution {private List<List<String>> result = new ArrayList<>();private List<String> path = new ArrayList<>();private void backtracking(String s, int startIndex) {// 如果起始位置已经大于等于字符串长度,说明找到一组分割方案if (startIndex >= s.length()) {result.add(new ArrayList<>(path));return;}for (int i = startIndex; i < s.length(); i++) {// 如果是回文子串if (isPalindrome(s, startIndex, i)) {// 获取当前回文子串String str = s.substring(startIndex, i + 1);path.add(str);// 递归处理剩余部分backtracking(s, i + 1);// 回溯path.remove(path.size() - 1);}// 不是回文则跳过}}// 判断是否是回文串private boolean isPalindrome(String s, int start, int end) {for (int i = start, j = end; i < j; i++, j--) {if (s.charAt(i) != s.charAt(j)) {return false;}}return true;}public List<List<String>> partition(String s) {result.clear();path.clear();backtracking(s, 0);return result;}
}
相关文章:
热门算法面试题第19天|Leetcode39. 组合总和40.组合总和II131.分割回文串
39. 组合总和 力扣题目链接(opens new window) 给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的数字可以无限制重复被选取。 说明: 所有数字(包括 ta…...
——物体跟踪)
OpenCv高阶(十一)——物体跟踪
文章目录 前言一、OpenCV 中的物体跟踪算法1、均值漂移(Mean Shift):2、CamShift:3、KCF(Kernelized Correlation Filters):4、MIL(Multiple Instance Learning)…...
2194出差-节点开销Bellman-ford/图论
题目网址: 蓝桥账户中心 我先用Floyd跑了一遍,不出所料TLE了 n,mmap(int,input().split())clist(map(int,input().split()))INFfloat(inf) ma[[INF]*n for i in range(n)]for i in range(m):u,v,wmap(int,input().split())ma[u-1][v-1]wma[v-1][u-1]w#“…...
Docker安装beef-xss
新版的kali系统中安装了beef-xss会因为环境问题而无法启动,可以使用Docker来安装beef-xss,节省很多时间。 安装步骤 1.启动kali虚拟机,打开终端,切换到root用户,然后执行下面的命令下载beef的docker镜像 wget https:…...

产品经理学习过程
一:扫盲篇(初始产品经理) 阶段1:了解产品经理 了解产品经理是做什么的、产品经理的分类、产品经理在实际工作中都会接触什么样的岗位、以及产品经理在实际工作中具体要做什么事情。 二:准备篇 阶段2:工…...
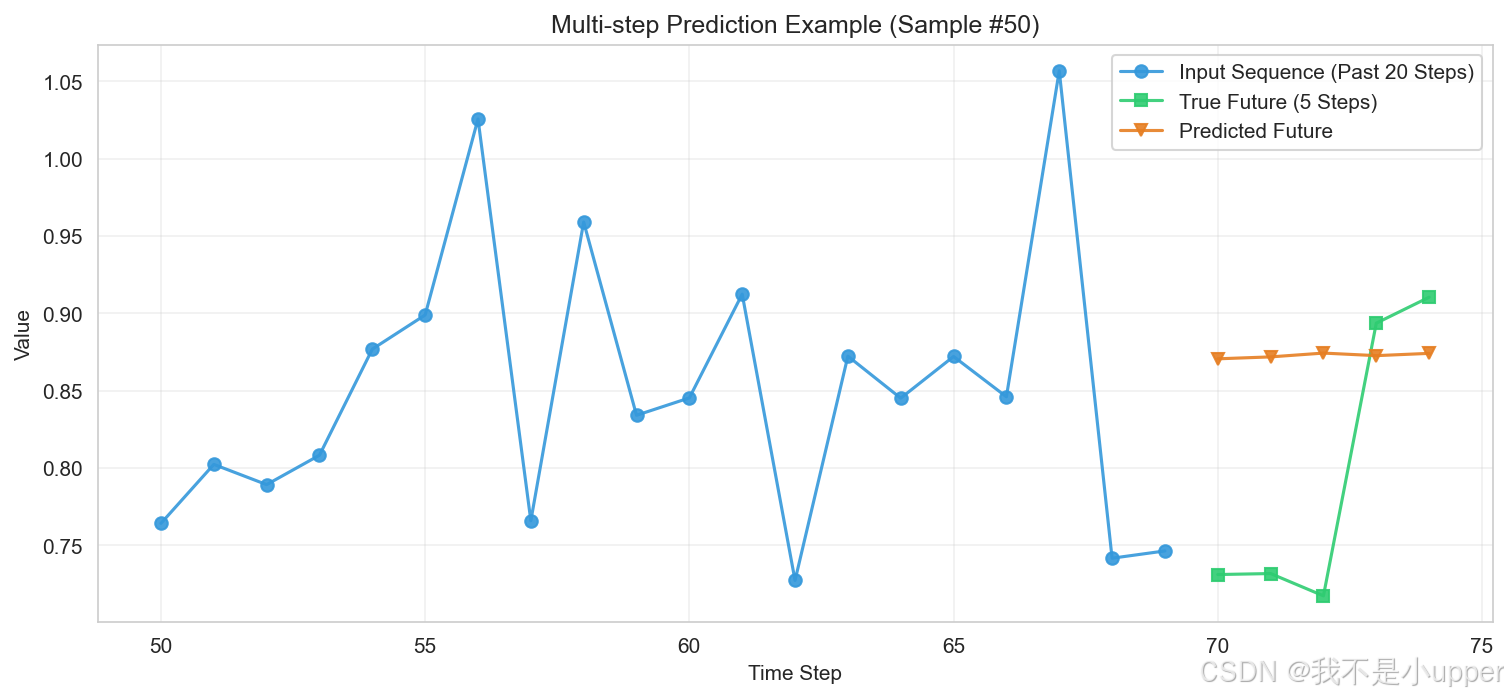
时间序列-数据窗口进行多步预测
在时间序列预测领域,多步预测旨在基于历史数据预测未来多个时间点的值,而创建数据窗口是实现这一目标的常用且高效的技术手段。数据窗口技术的核心是通过滑动窗口机制构建训练数据集,其核心逻辑可概括为:利用历史时间步的序列模式…...

【系统架构设计师】嵌入式微处理器
目录 1. 说明2. 微处理器(MPU)3. 微控制器(MCU)4. 信号处理器(DSP)5. 图形处理器(GPU)6. 片上系统(SoC)7. 例题7.1 例题1 1. 说明 1.嵌入式微处理器主要用于处理相关任务。2.由于嵌入式系统通常都在室外使用,可能处于不同环境,因此,选择处理…...

Oracle创建触发器实例
一 创建DML 触发器 DML触发器基本要点: 触发时机:指定触发器的触发时间。如果指定为BEFORE,则表示在执行DML操作之前触发,以便防止某些错误操作发生或实现某些业务规则;如果指定为AFTER,则表示在执行DML操作…...
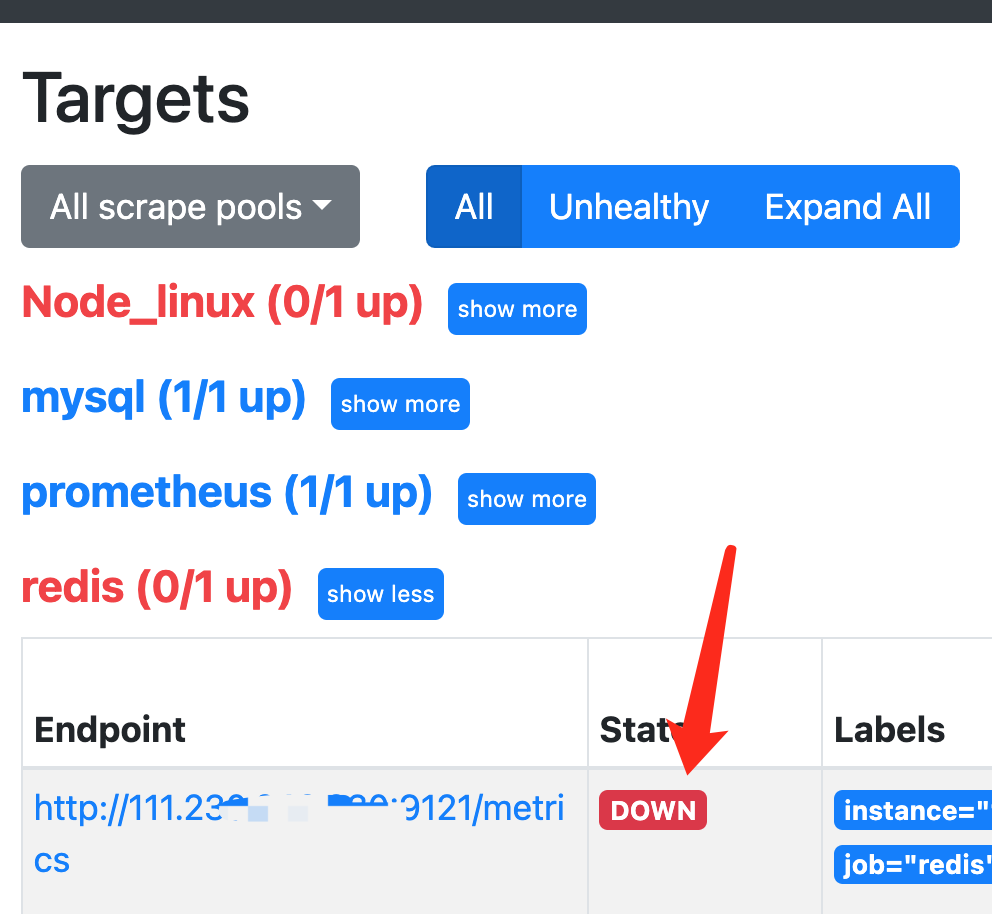
(三)mac中Grafana监控Linux上的Redis(Redis_exporter安装使用)
框架:GrafanaPrometheusRedis_exporter Grafana安装-CSDN博客 普罗米修斯Prometheus监控安装(mac)-CSDN博客 1.Redis_exporter安装 直接下载 wget https://github.com/oliver006/redis_exporter/releases/download/v1.0.3/redis_expor…...

Linux Sed 深度解析:从日志清洗到 K8s 等12个高频场景
看图猜诗,你有任何想法都可以在评论区留言哦~ 摘要:Sed(Stream Editor)作为 Linux 三剑客之一,凭借其流式处理与正则表达式能力,成为运维场景中文本批处理的核心工具。本文聚焦生产环境高频需求ÿ…...
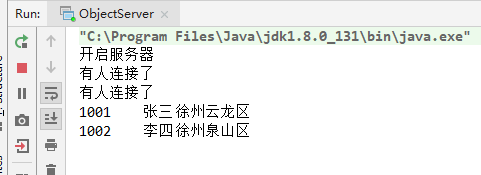
基于java的网络编程入门
1. 什么是IP地址 由此可见,32位最大为255.255.255.255 打开cmd查询自己电脑的ip地址:ipconfig 测试网络是否通畅:ping 目标ip地址 2. IP地址的组成 注意:127.0.0.1是回送地址,指本地机,一般用来测试使用 …...

CV和NLP领域常见模型列表
图像分类(Image Classification) 模型名特点备注ConvNeXt V2卷积改进,媲美 Transformer强于 ResNet、EfficientNetVision Transformer (ViT)全 Transformer 架构开创图像 transformer 浪潮Swin Transformer V2局部注意力 金字塔结构更强的多…...
Git简介与入门
Git的发明 Git由著名的Linux创始人linus于2005年发明(所以git的界面、使用方式与Linux挺像的,即命令行方式) 经过发展,现在广泛应用于代码管理与团队协作。 Git特性 Git是分布式版本控制系统 分布式 每个开发者拥有完整仓库&…...
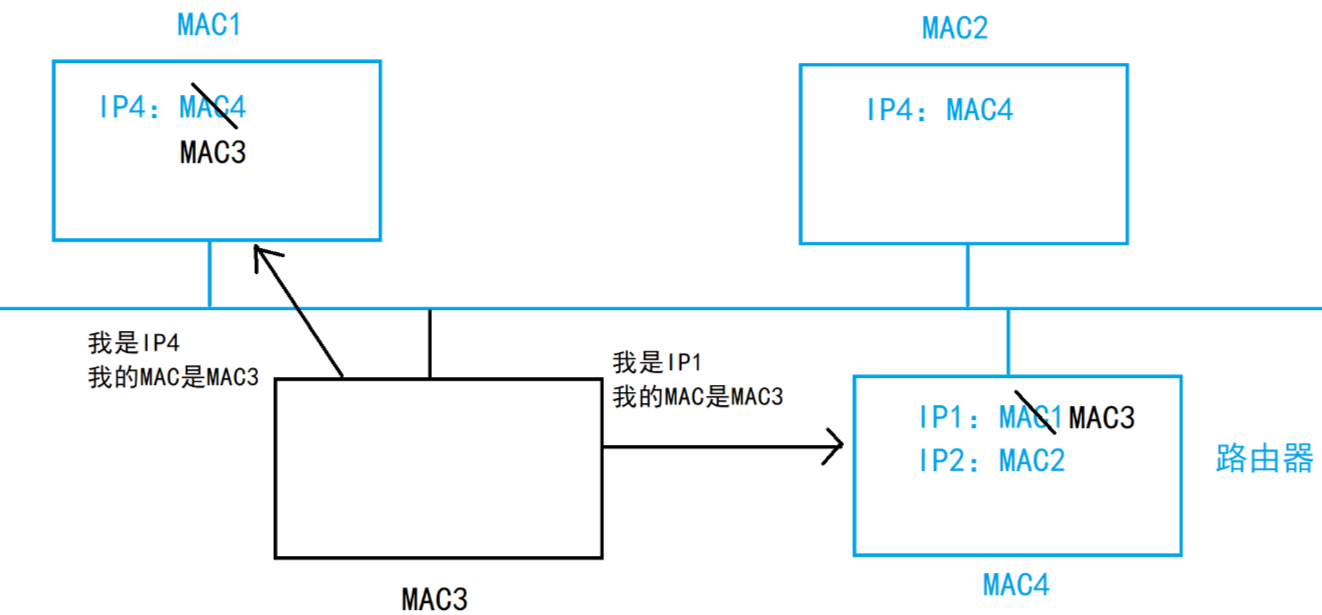
Linux 网络基础三 (数据链路层协议:以太网协议、ARP 协议)
一、以太网 两个不同局域网的主机传递数据并不是直接传递的,而是通过路由器 “一跳一跳” 的传递过去。 跨网络传输的本质:由无数个局域网(子网)转发的结果。 所以,要理解数据跨网络转发原理就要先理解一个局域网中数…...

16.QT-Qt窗口-菜单栏|创建菜单栏|添加菜单|创建菜单项|添加分割线|添加快捷键|子菜单|图标|内存泄漏(C++)
Qt窗⼝是通过QMainWindow类来实现的。 QMainWindow是⼀个为⽤⼾提供主窗⼝程序的类,继承⾃QWidget类,并且提供了⼀个预定义的布局。QMainWindow包含⼀个菜单栏(menu bar)、多个⼯具栏(tool bars)、多个浮动窗⼝(铆接部…...
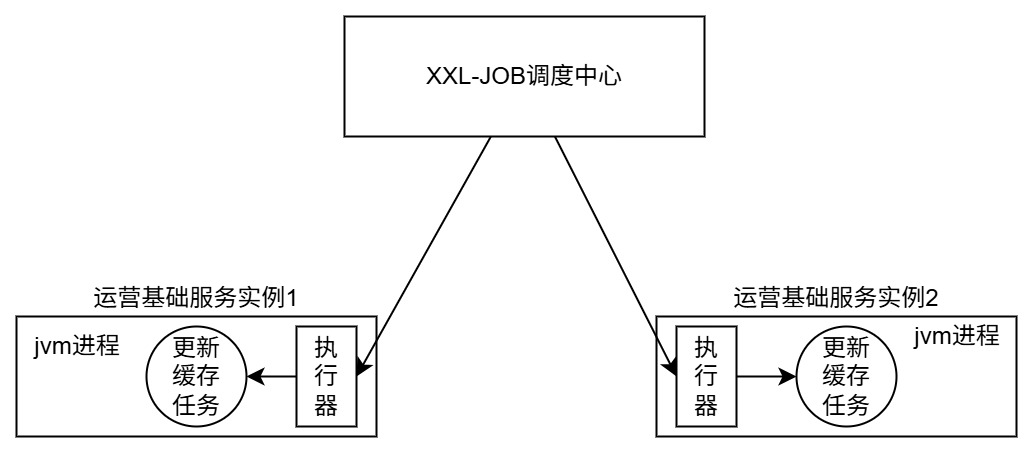
[特殊字符] 分布式定时任务调度实战:XXL-JOB工作原理与路由策略详解
在微服务架构中,定时任务往往面临多实例重复执行、任务冲突等挑战。为了解决这一问题,企业级调度框架 XXL-JOB 提供了强大的任务统一调度与执行机制,特别适合在分布式系统中使用。 本文将从 XXL-JOB 的核心架构入手,详细讲解其调…...

java面试题及答案2020,java最新面试题(四十四)
java面试题及答案2020 二面-2020/3/18 1、自我介绍项目比赛 2、java集合框架全部介绍。。从list set queue到map 3、hashmap底层扩容线程安全问题 4、如果-一个对象要作为hashmap的key需要做什么 5、Threadlocal类以及 内存泄漏 6、线程同步方式,具体每一个怎么做的 7、jvm类加…...

Spring Boot 中处理 JSON 数值溢出问题:从报错到优雅解决
一、问题背景:为什么我的接口突然报错了? 假设你正在开发一个 Spring Boot 接口,接收类似这样的 JSON 请求: {"size": 111111111111111111111 }然后突然收到用户的反馈:请求报错啦! 查看日志&a…...

oracle 锁的添加方式和死锁的解决
DML锁添加方式 DML 锁可由一个用户进程以显式的方式加锁,也可通过某些 SQL 语句隐含方式实现。 DML 锁有三种加锁方式:共享锁方式、独占锁方式、共享更新。 共享锁,独占锁用于 TM 锁,共享锁用于 TX 锁。 1)共享方式的表级锁 共享方…...
基于Hadoop的音乐推荐系统(源码+lw+部署文档+讲解),源码可白嫖!
摘要 本毕业生数据分析与可视化系统采用B/S架构,数据库是MySQL,网站的搭建与开发采用了先进的Java语言、爬虫技术进行编写,使用了Spring Boot框架。该系统从两个对象:由管理员和用户来对系统进行设计构建。主要功能包括ÿ…...
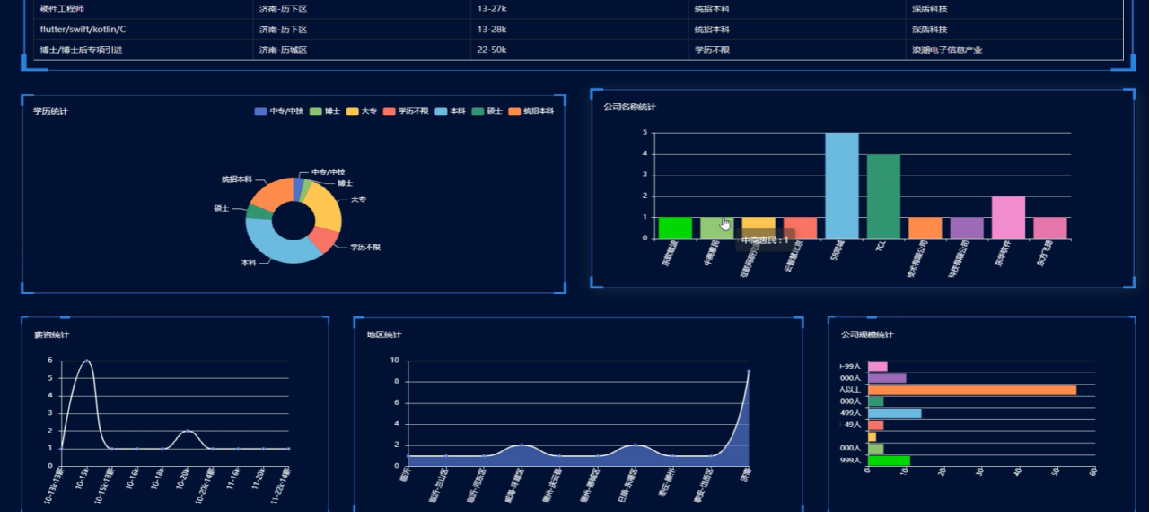
Java查询数据库表信息导出Word
参考: POI生成Word多级标题格式_poi设置word标题-CSDN博客 1.概述 使用jdbc查询数据库把表信息导出为word文档, 导出为word时需要下载word模板文件。 已实现数据库: KingbaseES, 实现代码: 点击跳转 2.效果图 2.1.生成word内容 所有数据库合并 数据库不合并 2.2.生成文件…...

DAY9:Oracle数据库安全管理深度解析
引言 在当今数据泄露事件频发的时代,数据库安全管理已成为DBA和开发者的必修课。本文将深入探讨Oracle数据库安全管理的四大核心领域:用户权限管理、数据库审计、透明数据加密(TDE)和虚拟私有数据库(VPD)&…...

RK3588平台用v4l工具调试USB摄像头实践(亮度,饱和度,对比度,色相等)
目录 前言:v4l-utils简介 一:查找当前的摄像头设备 二:查看当前摄像头支持的v4l2-ctl调试参数 三根据提示设置对应参数,在提示范围内设置 四:常用调试命令 五:应用内执行命令方法 前言:v4l-utils简介 v4l-utils工具是由Linu…...

Dart Flutter数据类型详解 int double String bool list Map
目录 字符串的几种方式 bool值的判断 List的定义方式 Map的定义方式 Dart判断数据类型 (is 关键词来判断类型) Dart的数据类型详解 int double String bool list Map 常用数据类型: Numbers(数值): int double Strings(字符串) String Booleans(布尔…...

LainChain技术解析:基于RAG架构的下一代语言模型增强框架
摘要 随着大语言模型(LLM)在自然语言处理领域的突破性进展,如何突破其知识时效性限制、提升事实准确性成为关键挑战。LainChain通过整合检索增强生成(RAG)技术,构建起动态知识接入框架,为LLM提供实时外部知识支持。本文从技术原理、架构设计、应用场景三个维度,深入解…...
:虚拟列表-VirtualList)
组件是怎样写的(1):虚拟列表-VirtualList
本篇文章是《组件是怎样写的》系列文章的第一篇,该系列文章主要说一下各组件实现的具体逻辑,组件种类取自 element-plus 和 antd 组件库。 每个组件都会有 vue 和 react 两种实现方式,可以点击 https://hhk-png.github.io/components-show/ …...
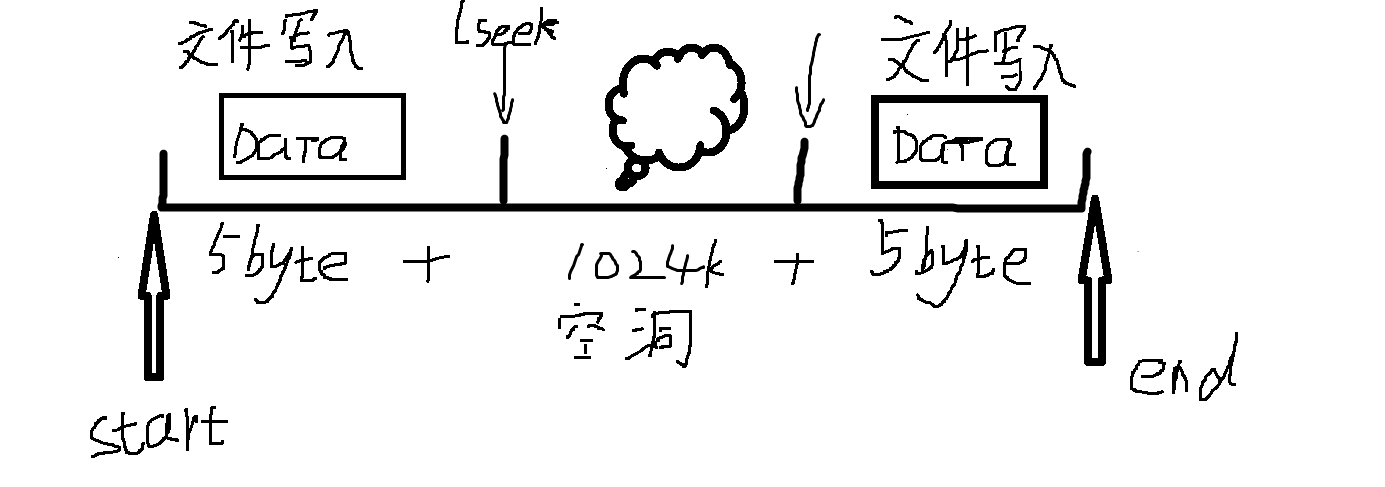
在Linux中,使用read函数去读取写入文件空洞部分时,读取出来的内容是什么?为什么这样操作,以及应用场景?
使用 read 函数读取文件空洞(hole)部分时,读取到的内容会被系统填充为 \0(即零字节)。文件空洞是稀疏文件中未实际分配磁盘空间的区域,但逻辑上表现为连续的零字节。 1.在指定空洞部分后,写入数…...
Qt6笔记-对Qt6中对CMakeLists.txt的解析
首先,新建Qt Console Application项目。 下面对CMakeLists.txt进行次理解。新建好后,Qt Creator会生成CMakeLists.txt,具体内容如下: cmake_minimum_required(VERSION 3.16)project(EasyCppMain LANGUAGES CXX)set(CMAKE_AUTOUIC…...

CIFAR10图像分类学习笔记(三)---数据加载load_cifar10
新创建一个load_cifar10源文件 需要导入的包 import glob from torchvision import transforms from torch.utils.data import DataLoader ,Dataset import os #读取工具 from PIL import Image import numpy as np 01同样定义10个类别的标签名数组 label_name ["airpl…...

计算机视觉cv入门之答题卡自动批阅
前边我们已经讲解了使用cv2进行图像预处理与边缘检测等方面的知识,这里我们以答题卡自动批阅这一案例来实操一下。 大致思路 答题卡自动批阅的大致流程可以分为这五步:图像预处理-寻找考试信息区域与涂卡区域-考生信息区域OCR识别-涂卡区域填涂答案判断…...